1. Introduction
Autonomous underwater vehicles (AUVs) have assumed indispensable roles in various underwater operations, such as ocean exploration and hydrologic surveys [
1]. They can autonomously perform appropriate maneuvers to achieve predefined objectives. Compared with the operational capability of a single AUV, collaborative AUVs can respond more reliably and flexibly to complex missions and extended operational ranges, thereby improving the efficiency and robustness of undersea operations. Given this backdrop, numerous application cases about AUV coordinated formation have been triggered in both civilian and industrial fields for decades [
2,
3]. Irrespective of the specific collaborative missions undertaken by AUVs, the core challenge lies in ensuring motion stability of AUV formations within complex underwater environments and the constraints of their own models. To tackle this problem, several mainstream methodologies have been proposed by engineers and academics. Studies by Chen et al. [
4] and Zhen et al. [
5] proposed AUV formation control schemes combined with the virtual structure method. However, this approach suffers from limited flexibility and applicability. Wang et al. [
6] utilized the leader–follower method to address the AUV formation tracking problem, but this approach relies on the state of the leader, reducing the robustness and fault tolerance of the formation. Conversely, leaderless formations have been proposed promisingly and have received more considerable attention [
7]. Munir et al. [
8] proposed a new arbitrary-order distributed control strategy based on the novel sliding surfaces of error dynamics, which addresses the cooperative tracking control of uncertain higher-order nonlinear systems. The strategies to mitigate the chattering issue caused by sliding surfaces are discussed in [
9]. Despite the abundance of existing research, multiple-AUV formation tracking control remains a significantly challenging project.
One of the main challenges is the various disturbances resulting from the underwater environment and the motion model of the AUVs themselves [
10]. On the one hand, unknown disturbances such as waves, tides, and currents, are inevitable in practical marine environments. On the other hand, AUVs exhibit highly nonlinear and coupled dynamics, leading to model uncertainties. These uncertainties are often induced by modeling errors and deviations in hydrodynamic coefficient measurement. According to the research by Cui et al. [
11], these external disturbances and model uncertainties that degrade the system performance negatively are referred to as compound disturbances. In response to these challenges, researchers have developed diverse schemes, such as disturbance observers [
12], fuzzy logic theory [
13], and neural networks [
14]. Among these, the extended state observer (ESO) initially proposed by Han [
15] is an attractive option to estimate compound disturbances, as it does not rely on an accurate model. Lei et al. [
16] designed a high-gain ESO to solve AUV horizontal trajectory tracking problems under the time-varying disturbances. Although many ESOs have been established for different platforms, most only guarantee asymptotic convergence of estimation errors, implying a potentially infinite convergence time. Some research works also lack a rigorous analysis of convergence. Considering the impact of severe underwater environments on estimation accuracy, the concept of finite-time ESO proves more beneficial for improving control performance [
17]. Wang et al. [
18] implemented a FTESO-based nonsingular terminal sliding mode controller to address unmanned surface vehicle (USV) trajectory tracking in disturbed environments. This approach ensured that the disturbance estimation errors converge within a finite time. However, there remains room for improvement and optimization of the design structure to further enhance observation performance.
AUV formation navigation also presents significant technical challenges due to various complex constraints. For instance, the AUV attitude has a certain desired range and navigation velocities are inherently limited. These intrinsic input and state constraints pose substantial challenges to control performance [
19]. In practical applications, actuators often have input saturation constraints due to physical structure limitations. This results in a limitation of the actual active control force of the AUV. If a control signal exceeds this boundary, it may lead to system instability. However, most previous work assumes that the actuators can tolerate any level of control signals. To avoid actuator saturation, a nonlinear auxiliary system for filtering saturation errors was proposed [
20]. Additionally, collisions between AUVs are undesirable during the formation configuration phase. Thus, the ability to avoid collisions is vital for AUV formation control. A wealth of solutions have been developed to this end, with Li and Wang [
21] proposing a collision-free position consensus algorithm for AUVs based on potential function. Moreover, Xu et al. [
22] presented an event-triggered algorithm based on deep reinforcement learning to avoid AUV collisions. However, the above studies disregard the physical constraints of AUVs. From the perspective of safe navigation, it is essential to integrate factors such as input, state restrictions, and collision avoidance into the design scheme.
Model predictive control (MPC) has garnered considerable attention due to its ability to simultaneously handle multiple composite constraints and offer superior dynamic performance. This is widely applied to MIMO systems affected by model distortions and complex constraints. Several MPC-based applications have been integrated into AUV control systems. Zhang et al. [
23] proposed an MPC-based AUV trajectory tracking strategy under random disturbances. In [
24], a robust model-predictive control scheme based on the active disturbance rejection control approach was developed for the AUV tracking task. The challenge of extending these systems to multi-AUV systems involves coordinating the control behavior of each subsystem and ensuring the closed-loop stability of the local MPC optimization problem under system constraints. This coordination aims to maximize the overall control performance. Hence, DMPC came into being. Zheng et al. [
25] proposed a DMPC method based on local state information for MAS formation tracking. To the best of our knowledge, there are few studies that apply DMPC to multi-AUV formations. Wei et al. [
26] developed a Lyapunov-based distributed predictive controller for AUV formation tracking, subject to current disturbances. The auxiliary controller was utilized to establish stability constraints to ensure the closed-loop stability of the system. However, this method only considers horizontal formations without uncertainties and state constraints. Furthermore, many works that design predictive controllers result in additional computational loads, which could impair the real-time execution capability of the controller. Shen and Shi [
27] managed to reduce the MPC computational burden by decomposing the original AUV trajectory tracking optimization problem into smaller subproblems and then solving them in a distributed manner. Despite these efforts, there has been no research to address the heavy computation of DMPC applied to AUV formations. In order to improve the dynamic response and control accuracy of AUV formation tracking in three-dimensional (3-D) space, we adopt the Laguerre orthogonal function to reduce the computational load. In response to these discussions, it is imperative to develop a safe and efficient formation control scheme to solve the problems of disturbances, parameter uncertainties, and complicated constraints.
Motivated by the above observations, this paper investigates the collision-free formation tracking of multi-AUVs with compound disturbances under complicated constraints. A novel FTESO-based distributed dual closed-loop model predictive control scheme is proposed. This method satisfies the formation constraints and collision avoidance requirements while compensating for model uncertainties and external disturbances. We incorporate the Laguerre function to alleviate the computational burden of the DMPC optimization problem, also giving corresponding stability analysis. Based on the connected directed topology, comparative simulations under different schemes demonstrate the effectiveness and robustness of our proposed scheme. The main contributions of this paper are as follows:
Compared with the FTESO-based controllers presented in works [
16,
28], the proposed third-order fast FTESO can estimate the compound disturbances and their first derivatives, which effectively suppress the amplification and fluctuation of the generalized uncertainties. It has better estimation accuracy and convergence speed. Hence, the active disturbance rejection capability of AUV formation is enhanced;
Unlike the existing DMPC schemes depicted in works [
29,
30], a dual closed-loop structure is utilized to enhance the response speed of the DMPC system and the controllability of the AUV speed. The outer-loop controller sets the desired velocity and the inner-loop controller generates the driving force. By solving the constrained quadratic programming (QP) problems, the risks of actuator saturation and collision are reduced. The safety and robustness of formation tracking are improved;
In order to solve the issue of heavy computational burden in traditional predictive control, the Laguerre orthogonal function is incorporated to reconstruct the input matrices, which automatically trades off control performance and computational complexity, thus avoiding possible formation deviation due to slow computational speed. The stability of the closed-loop system is proved by exerting terminal state constraints.
The rest of this paper is organized as follows:
Section 2 introduces some notations, lemmas, and graph theory, and describes the AUV model and control objective.
Section 3 presents the methodology, including the design of the FTESO and dual closed-loop DMPC scheme, the application of the Laguerre function, and the corresponding stability analysis.
Section 4 and
Section 5, respectively, provide simulation results and conclusions.
3. Methodology
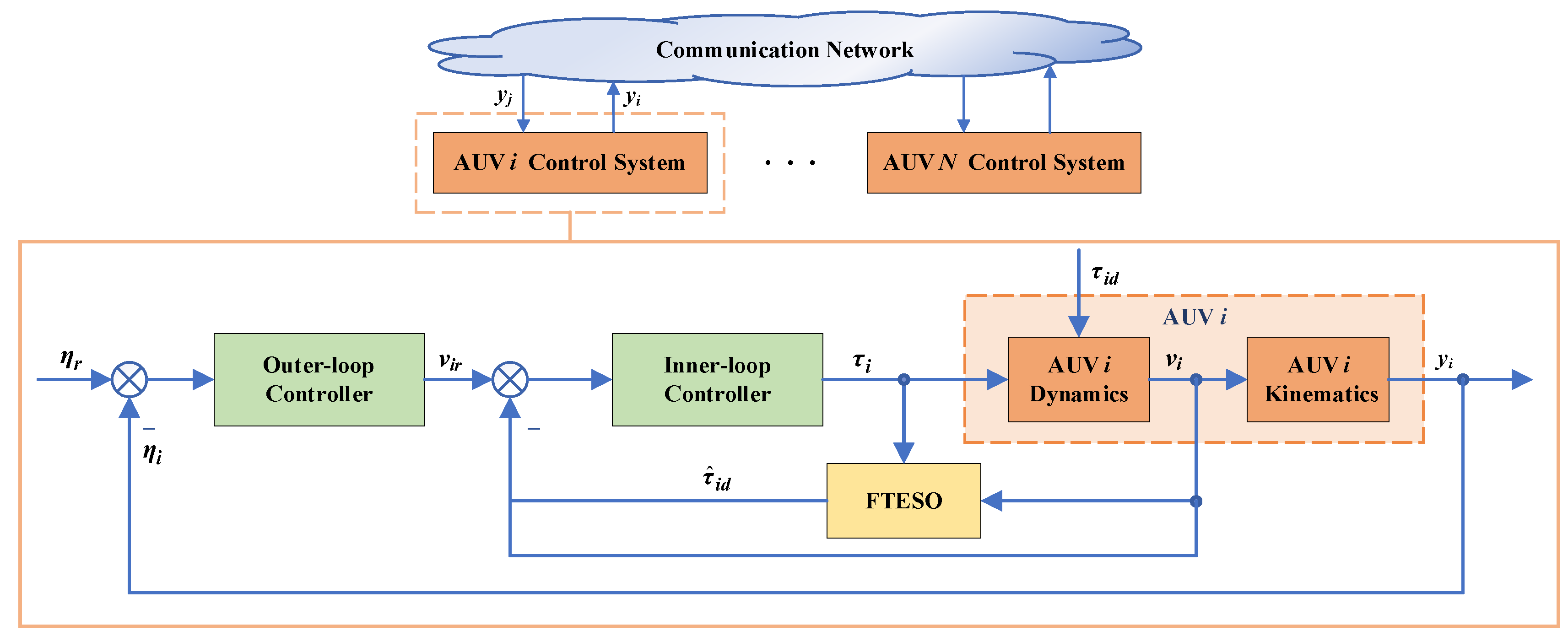
This section develops the FTESO-based distributed dual closed-loop model predictive control scheme for the AUV formation to perform trajectory tracking. A novel FTESO is designed to compensate the compound disturbances. Based on the model information reconstructed by FTESO, the DMPC optimization problems are formulated for the outer and inner loops under constraints such as actuator saturation and collision avoidance, respectively. The Laguerre function is applied to alleviate the computational load. The block diagram of proposed control scheme is depicted in
Figure 2.
3.1. FTESO Design and Convergence Analysis
The AUV model is fundamental to controller design, but obtaining an accurate model in practice is challenging. Considering the superiority and effectiveness of the ESO technique in estimating and compensating for synthetic uncertainty, a novel fast FTESO is designed to simultaneously reconstruct the external disturbance and model uncertainties of multiple AUVs.
First, define the auxiliary velocity variable as
, the derivative of
with respect to time can be obtained from (4)
For simplicity, denote
. Then, a new variable is defined as
, and the order of the system is extended by additional state variables,
and
, defined as
and
with
. It should be noted that the compound disturbances
are assumed to be bounded and continuously differentiable, and the components of its second derivative satisfies
,
. where
is an unknown positive constant. Afterward, the dynamic model of the
ith AUV can be extended as follows:
Denote
,
, and
as the observation values of states
,
, and
in the above extended system, and
,
, and
as the observation errors of the velocity, the compound disturbances, and its first derivatives, respectively. Then, a third-order fast FTESO is proposed as follows:
where the observer gains satisfy
,
and
, and
. Although the actual value of
is probably unavailable, its observed value
can be obtained by the above FTESO. The analysis and proof that
tracks the actual value are described below.
According to the extended system (6) and the proposed FTESO (7), we can obtain the observation error dynamics as follows:
The stability and convergence of the proposed FTESO are stated in the following theorem:
Theorem 1. Consider the AUV formation control system with the dynamic model (4) under Assumption 1. If the FTESO is proposed in the form of (9), with appropriate observer gains satisfying the prescribed constraints, then the observation errors will converge to the small region in finite time . This implies that the error dynamics system (8) is finite-time uniformly ultimately bounded stable.
Proof of Theorem 1. Consider a Lyapunov candidate function as
, where
is a positive definite symmetric matrix and
is introduced as an auxiliary error variable. It should be noted that
,
, and
will converge to origin in finite time, if the new state
is finite-time stable. The time derivative of
, invoking (8), yields:
where
and the coefficient matrices
and
are expressed as:
with
. From the characteristic polynomials of
and
that all their eigenvalues have negative real parts if the observer gains are set as
, indicating that
and
are Hurwitz matrices. Thus, symmetric and positive definite matrices
and
exist that satisfy the following Lyapunov equations:
Differentiating
with respect to time yields the following:
where
and
. Given the fact that
and
, we can obtain the following:
Since
is assumed to be bounded reasonably by
, we have
, by using the inequality
Then, inequality (13) becomes the following:
where
,
, and
.
It can be seen that (15) has the same form as the sufficient condition in Lemma 1 2. Thus, the error trajectories of the proposed FTESO (7) are fast finite-time uniformly ultimately bounded stable. The state observation errors
will converge to a small region
in the finite time
. Moreover, the settling time
is subject to the constraint:
And the stable region
is denoted as
where
and
are arbitrary constants that meet the conditions
and
. This completes the proof. □
Remark 1. Contrasting our proposed FTESO (7) with the FTESO in [
37], our approach factors in the dynamics of disturbances and uncertainties to achieve a higher degree of estimation accuracy. Our usage of fractional powers within the FTESO allows for a quick finite-time convergence. It can be noted that the size of the attraction region
hinges upon the selection of the observer gains
and
. By increasing
or decreasing
, the attraction region of the observation error system can be expanded and the convergence speed can be improved, but excessive tuning will lead to undesired overshoot and oscillation. As a result, a trade-off should be taken for
and
.
3.2. Outer-Loop Formation Prediction Control Law
In this subsection, we design a DMPC-based outer-loop formation controller. This controller, which draws on the information interaction with neighbors, facilitates the positional tracking of the ith AUV. The controller operates under composite constraints and ensures the avoidance of collisions. Then, we formulate a constrained QP problem in accordance with the control objective to obtain the optimal driving speed.
To facilitate the recursive model prediction and the implementation of the control law, the kinematic model (1) is discretized by using the Forward-Euler method with a sampling period
, resulting in following discrete model:
To smoothen the speed change of the AUV, the velocity increment
is taken as the control input.
is denoted as the state variable of the prediction model. The augmented state-space model of the outer-loop subsystem can be derived as:
where
,
, and
.
According to the state prediction model (19) and (20), we can calculate the predicted state sequence of the system when given an input sequence. Let
and
denote the prediction and control horizon of the outer-loop controller, respectively. The predicted state sequence and the input incremental sequence are usually represented by compact vectors:
where
and
are the output vector
and state vector
predicted at time
k, respectively.
denotes the input increment
predicted at the same time
k. Then, we characterize the relationship between the predicted output vector sequence and the control increment sequence through the following prediction equation based on the recurrence relations:
where
is the initial state,
and
.
Considering the control objective, the constraints within the outer-loop subsystem are considered. First, we set upper and lower boundaries for the amplitude of the control input
and the input increment
:
where
and
represent the predefined lower bounds, and
and
represent the predefined upper bounds.
Next, to assure safe navigation throughout the formation construction stage, we need to consider the collision avoidance constraints between AUVs. The primitive collision avoidance constraints of the
ith AUV can be transformed into a convex constraint, as follows:
where
and
is the preset minimum allowable distance between the
ith AUV and the
jth AUV.
denotes a scaling matrix. Let
be the radius of the safe detection zone for the
ith AUV.
is the set of those AUVs that contain within
. Let the nominal value
represent an initial guess of the actual value
for convexifying the collision avoidance constraint. It follows from (26) that a sufficient condition for upholding the collision avoidance constraint is the following:
where
. In order to express the constraints in a compact matrix form, define
,
and
, and
. Then, (27) can be rewritten as
. Substitute (23) to derive the collision avoidance constraint as follows:
The input amplitude constraint (24) can be converted to the input incremental constraint, associating (25) and (28), expressed in the compact linear constraint form as follows:
where
,
,
, and
.
In order to achieve the control objective of formation positional tracking with low energy requirements, we define the local distributed cost function in the outer-loop subsystem of the
ith AUV in a discretized form:
where
,
, and
are the weight matrices.
with
represents the formation configuration.
with
represents the predefined relative distance between the
ith AUV and its neighbor
jth AUV.
indicates the degree of prediction of future tracking errors. The larger it is, the better the tracking accuracy and stability. The smaller
is, the worse the dynamic response is, and conversely the more maneuverable the control is.
is the position tracking matrix, the larger it is, the better the tracking accuracy and dynamic response.
is the relative position matrix, the larger it is, the better the ability of the formation to maintain the preset configuration.
is the control increment weight matrix, mainly to limit the drastic change of
.
Based on the above derivations, we can formulate the optimization problem for the outer-loop subsystem of the
ith AUV at the sampling instant
k within the receding-horizon framework:
To simplify the computation of (31), it can be transformed into a convex QP problem. This problem is solved over a finite receding horizon using a QP solver. The standard convex QP form of the DMPC problem (31) can be derived:
where
,
, with , , , , and are similar to , both corresponding compact matrices.
By solving the QP optimization problem in (32) online, we obtain the optimal control input increment sequence
. Of this sequence, we only utilize the first element
for receding optimization. Once
is determined, we obtain
which serves as the desired driving speed for the inner-loop controller of the
ith AUV, i.e.,
3.3. Inner-Loop Formation Prediction Control Law
In this subsection, with the aid of the proposed FTESO, we design a DMPC-based formation controller for the inner-loop subsystem to obtain the optimal driving force and moment for the ith AUV to track the desired speed.
The dynamic model (4) is discretized with a sampling period
, yielding the following discretized model:
where
represents the compound disturbance compensated by FTESO (7), which is supposed to be invariant over a short period. It should be noted that we assume the center of gravity and buoyancy of the
ith AUV to coincide, which allows
to approximate to zero. We select
as the state variable and take the increment
as the control input. This allows us to reformulate the inner-loop predictive model as follows:
where
,
,
, and
. Similar to our previous approach, we can characterize the relationship between the predicted output vector sequence and the control increment sequence using the following prediction equation:
where
,
,
,
, and
. and denote the prediction and control horizon of the inner-loop controller, respectively.
According to the control objective, we assess the constraints on the control input increment and the actuator saturation in the inner-loop subsystem, as follows:
where
and
represent predefined lower bounds, while
and
denote predefined upper bounds. The actuator saturation constraint (39) can be transformed into an input incremental constraint, and we can express the above constraints in a compact linear constraint form:
where
,
, with
and
.
To achieve the convergence of the formation tracking velocity to the desired value, we define the local distributed cost function of the inner-loop subsystem as follows:
where
and
denote the predicted value of
and
at time
k, respectively.
and
are given weight matrices.
By substituting (37) into (41), we can formulate the DMPC optimization problem for the inner-loop subsystem of the
ith AUV at sampling instant
k as the following QP form:
where
and
, with
,
, and
.
The solution of the QP optimization problem (42) yields the optimal control input increment sequence at time k. However, only the first element of the sequence is used for the ith AUV to obtain the optimal control force and moment . The is recalculated at each sampling instant, the ith AUV repeatedly calculates and executes to achieve receding optimization. The predicted state and the optimal input are both determined solely by the current state .
With the parallel optimization of N AUV subsystems, all local optimization problems are solved simultaneously at each sampling moment. One or more information interactions occur between local controllers to obtain the optimal input sequence for that moment. Thus, the proposed control law can compensate well for the compound disturbances, which consist of model uncertainties and external disturbances. This occurs throughout the iterative optimization process, while simultaneously ensuring collision avoidance and formation tracking control tasks under complex constraints.
3.4. Use of Laguerre Functions in the DMPC Design
This subsection introduces a strategy to handle the computational burden caused by a longer control horizon and dual closed-loop structure. This is the main difficulty in our theoretical analysis. The Laguerre orthogonal functions are leveraged in the DMPC design to decrease the order of the input incremental matrices. This approach permits a reduction in input variables during each control cycle, thereby reducing the computational burden in the time interval and improving real-time performance.
The Laguerre functions are a set of discrete orthogonal polynomial functions, let it be
, the z-transfer of the
mth Laguerre function is expressed as follows:
where
denotes the pole of the Laguerre function, also known as the scaling factor. It can be verified that
satisfies the following orthogonality:
where
denotes complex conjugate of
.
The discrete Laguerre functions are defined by taking the inverse Z-transform of (43), i.e.,
. Given the network structure of
and the recurrence relation, the set of discrete Laguerre functions satisfies the following difference equation:
where
and
, with
and initial condition
. Note that at
, the Laguerre functions are converted to impulse functions.
Assuming the current moment is
k, the input increment of the single-input system at the next time
l, represented by the Laguerre function, is:
where
. When we extend this to the multi-AUV system, each AUV has five independent control inputs, and the input increment of the
ith AUV is as follows:
where
and
, with
, and
. Note that within a multi-input structure, the scaling factor
and the number of polynomial terms
can be selected independently for each input signal.
For illustrative purposes, the inner-loop predictive controller of the
ith AUV is taken as an example. If we partition the input matrix into
, the prediction of the system output in the next
l steps can be derived as follows:
For a compact notation, we denote (48) by the following:
where
and
.
as the parameter vector that is to be optimized.
First, we employ the Laguerre function to optimize the constraint terms (38) and (39), leading to the following constraint form:
where
and
.
Given that the Laguerre functions are orthonormal for a sufficiently large control horizon
. Substituting (47) into (41) and using the orthogonality (44) of the Laguerre function (i.e., the inner product of different terms is 0 and the same term is 1), the following derivation can be performed to obtain the reconstructed form of the cost function (41):
By substituting (49) into (52), we can rewrite the DMPC optimization problem (42) for the inner-loop subsystem of the
ith AUV as:
where
and
.
The QP optimization Equation (53), with constraints, can be solved to obtain the optimal parameter vector . This vector replaces the conventional DMPC method calculation of . Thus, the optimal input increment of the inner-loop subsystem is indirectly obtained by the rolling optimized control law, , until the control variables at the next moment are calculated. This iterative process ensures the achievement of receding horizon optimization. The use of the Laguerre function in the design of the outer-loop predictive controller is not included here, as its analysis parallels that of the inner-loop controller described above.
Remark 2. By parameterizing the input increment sequence using the Laguerre function, the input matrix order in the prediction horizon can be lowered, thereby reducing the computational load online. This property enables its application in large-scale and real-time AUV control systems. With the employment of the Laguerre function, the coefficients
and
can also be served as tuning parameters, in addition to the control and prediction horizon and weighting matrices. Larger
and
lead to faster closed-loop responses [
38].
3.5. Stability Analysis
A notable attribute of the MPC is the potential for establishing the stability of a closed-loop system under certain conditions. Extending this to cases using Laguerre polynomials, a terminal state constraint is utilized to analyze the stability of the closed-loop system. Specifically, for the inner-loop subsystem, an additional constraint is attached to the final state of the receding optimization problem: , where is the terminal state produced under the effect of the control sequence, .
Theorem 2. Consider the inner-loop subsystem (35) and (36) of the ith AUV in the formation control system, which has a local cost function (41) with constraints (38) and (39). The inner-loop predictive control subsystem is asymptotically stable if for each sampling instant k, there exists a solution such that the performance index is minimized subject to the terminal state constraint.
Proof of Theorem 2. Constructing an appropriate Lyapunov function is key to ensuring the stability of the DMPC system. Select the cost function
as the Lyapunov function
:
where
and
,
is the parameter vector solution of the cost function (41) under the original and terminal constraints at moment
k, and input increment
. It is clear that
is positive definite and tends to infinity as
tends to infinity. Similarly, the Lyapunov function at moment
can be derived as:
where
,
is the parameter vector solution at time
, and
. Given that
is the response one step ahead of
and
, the feasible solution of
corresponding to the initial output
in the receding horizon is
. Therefore, the feasible solution sequence at moment
is to move the elements in
,
, …,
one step forward and substitute the last element with
0, i.e.,
,
, …,
,
. Due to the optimality of the solution
at
, it follows that
where
is identical to (55) except that the parameter vector solution
in the control sequence is replaced by the feasible solution
. The difference between
and
is then bounded by the following:
Eliminate the same terms in the control sequence and output sequence of
and
at moments
,
,…,
, and we can derive the following equation:
Given the terminal constraint
is applied, equivalent to
, we have the following:
This allows inequality (57) to be converted into:
Namely, ; the Lyapunov function is monotonically decreasing. This proves that the inner loop subsystem is asymptotically stable. □
Next, we analyze the stability of the entire closed-loop system. Analogous to the proof of Theorem 2, we select
as the Lyapunov function
of the outer-loop subsystem:
According to the idea of the proof of Theorem 2, the following inequality can be obtained:
Next, we set the Lyapunov function of the entire closed-loop system as follows:
From inequalities (60) and (62), we have the following:
As a result, the entire closed-loop system is asymptotically stable.
4. Simulation
In this section, some simulation analyses are conducted to verify the effectiveness and robustness of the proposed control scheme. A formation system consisting of four AUVs
with a virtual leader (AUV0) is considered. The directed communication topology for the simulation is depicted in
Figure 3, the meaning of the arrows is the direction of the communication or information flow between the nodes in the formation network. Initial values for
,
, and
are randomly distributed within the intervals
,
, and
, respectively, while the attitude angles
and
lie within the intervals
and
, respectively. The parameters related to the AUVs are based on previous research [
39]. A diamond formation was predefined to facilitate omnidirectional exploration, with the desired formation configuration preset to
,
,
, and
.
,
,
,
,
and
. The safety distance during the formation construction stage is set as
, while the detection distance measured using sonar is set as
. To reflect model uncertainties, 20% of the nominal values were taken as model errors, meaning that the parameters for the AUVs in the simulation represented only 80% of the nominal system dynamics. External disturbances were applied to each AUV to evaluate the formation robustness, modeled as follows [
34]:
Each control parameter has its settings guidelines: Given the low driving speed of the AUV in this paper, smaller
and
are intended to be used. During debugging, reduce it if the rapidity is not enough, and increase it if the stability is not good; the selection of
and
is based on a trade-off between performance and computation [
40]; since we value the position tracking performance more than the velocity tracking performance,
is set slightly larger than
; to weaken the interaction of angles between AUVs, the orientation weight in
is set slightly smaller; when tuning
and
, it can be set very small first, and then increase it slightly if the system is stable and the control variable does not change too drastically [
41]. By solving the Lyapunov Equation (11), the relationship between the observer gains
and
, such that
and
are Hurwitz matrices, can be obtained, and tuned to select the appropriate values [
42]; the Laguerre parameter
is adjusted within the constraint interval, and a smaller
is selected to coordinate the number of constraints in the optimization problem, and to make a trade-off between response speed and control complexity [
38]. Following the above guidelines, we dealt with the main difficulties in the simulation and selected the parameters that produced the optimal simulation results and listed them in
Table 1.
Moreover, based on the actual speed limit of the thruster, we provide the state and input constraints as follows:
,
, and
. To avoid actuator saturation for each AUV, the bounds of force and moment are set as
and
.The reference trajectory generated by the virtual leader is a 3-D spiral curve, defined as follows:
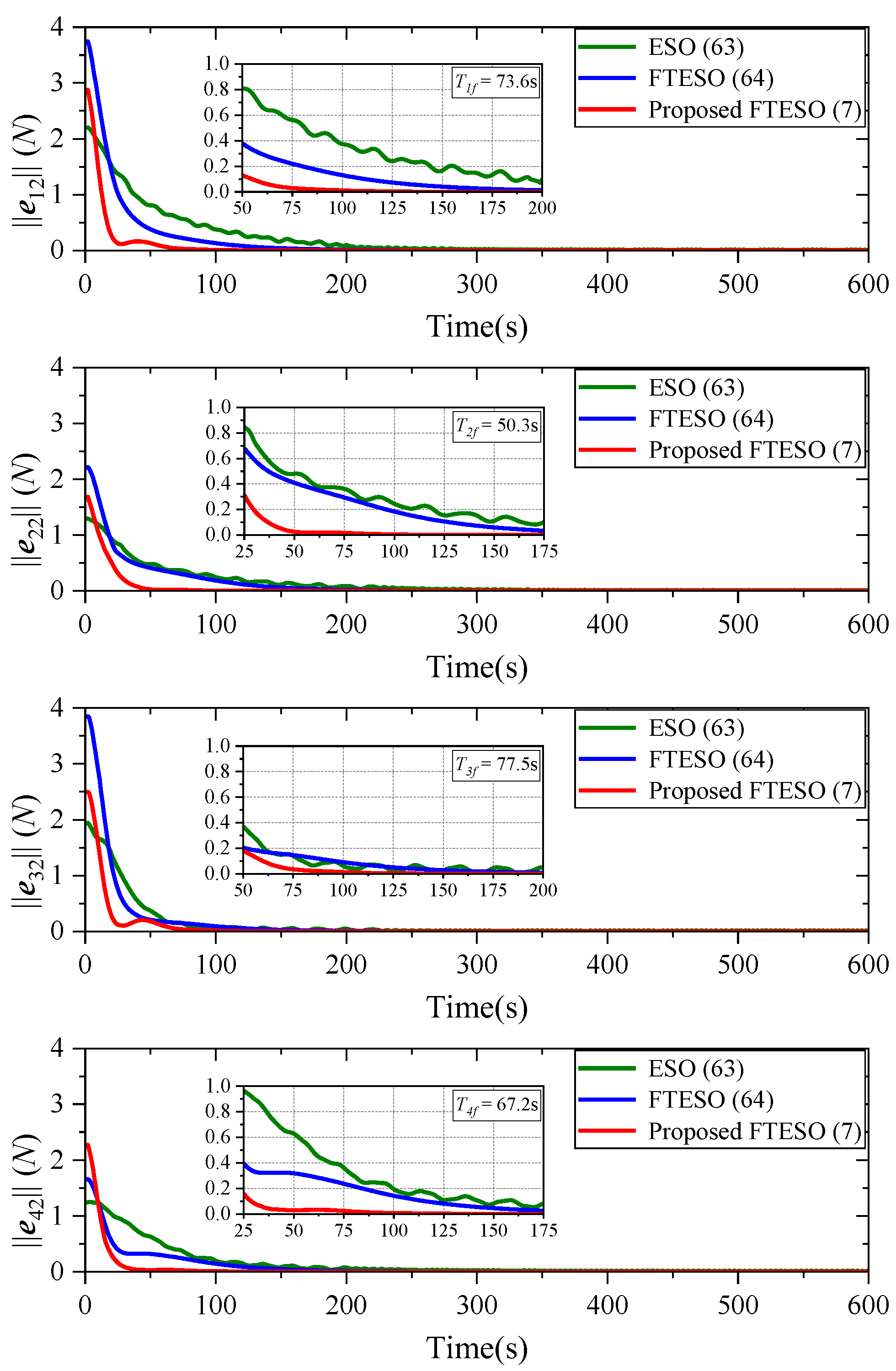
To verify the disturbance compensation performance of the proposed FTESO (7), we conducted comparative simulations with the ESO (67) from [
43] and the FTESO (68) from [
18].
Figure 4 shows the norms of the compound disturbance estimation errors
for the four AUVs under the three observers, characterizing insights into transient and steady-state responses. We calculated the settling time of the designed FTESO in the simulation and highlighted it on the plots. It is clear from
Figure 4 that our proposed third-order fast FTESO can achieve finite-time stabilization, with the estimation errors converging to a small neighborhood of the origin. And the dynamic convergence speed and estimation accuracy of the proposed FTESO are better than ESO (67) and FTESO (68) with less chattering. This shows the advantages of our approach. Thus, each AUV can accurately compensate for model uncertainties and external disturbances of its corresponding subsystem in finite time.
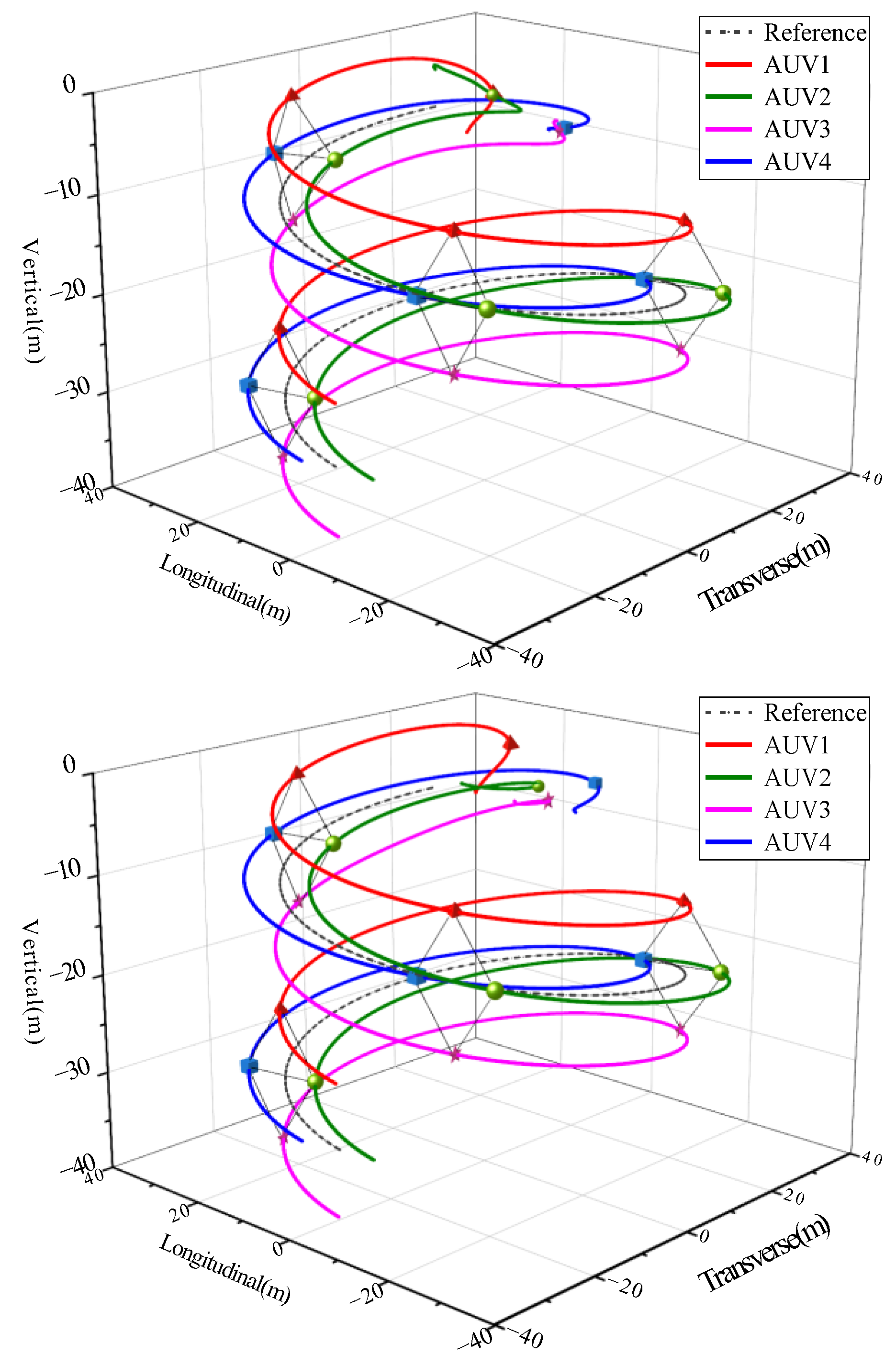
The collision avoidance performance of the AUV formation was tested via a set of comparison experiments with and without collision avoidance constraints based on our proposed scheme. Since the initial positions of the four AUVs are randomly distributed, the risk of collision is increased. The formation trajectory without collision avoidance constraints is shown in
Figure 5 (top). Here, the four AUVs track the reference trajectory while keeping the preset shape, but AUV3 and AUV4 collide at 10 s, followed by a collision between AUV1 and AUV2 at 20 s. Specifically, as presented in
Figure 6 (top), the relative distance between AUV1 and AUV2 during the formation configuration stage exceeds the safe distance, resulting in a collision. The same situation occurs with AUV3 and AUV4. However, when collision avoidance constraints are considered, the formation trajectory (shown in
Figure 5 (bottom)) indicates that the four AUVs can perform the formation tracking task while avoiding collision during the configuration stage. The collision avoidance performance is visualized in
Figure 6 (bottom), where the distances among AUVs within the detection zone are always greater than the safe distance, indicating that inter-vehicle collision avoidance can be achieved. Therefore, the proposed control scheme can provide real-time collision avoidance capability for AUV formation maneuvers.
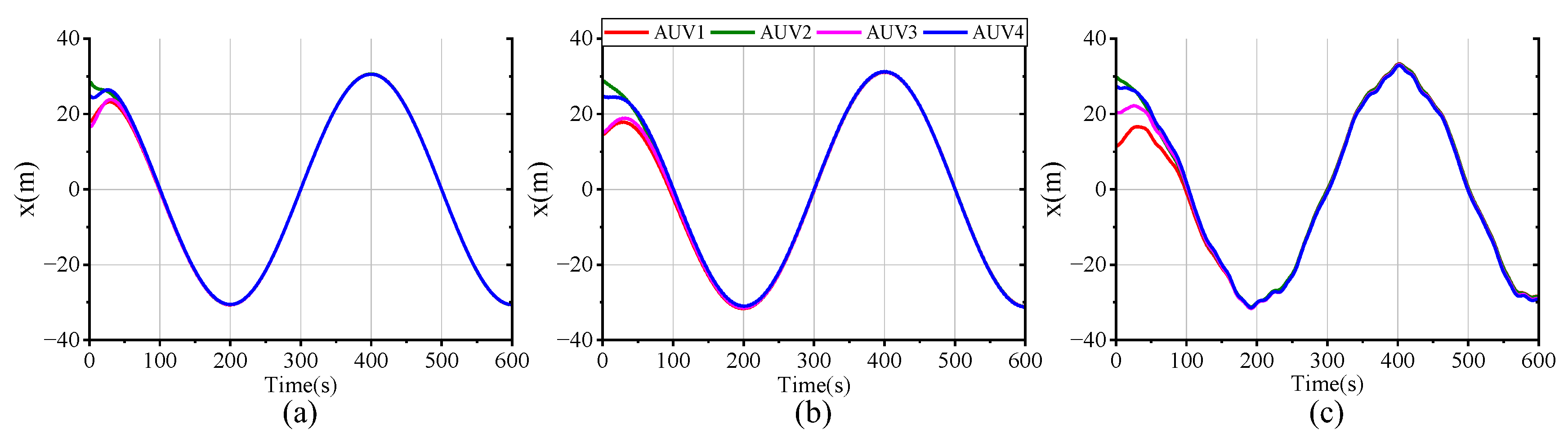
In order to assess the feasibility and superiority of the proposed scheme, we conducted three sets of comparative simulations with the same parameters, constraints, and disturbance settings: (a) the proposed FTESO-based dual closed-loop DMPC with Laguerre function; (b) a FTESO-based dual closed-loop DMPC without Laguerre function; (c) a standard DMPC without FTESO.
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
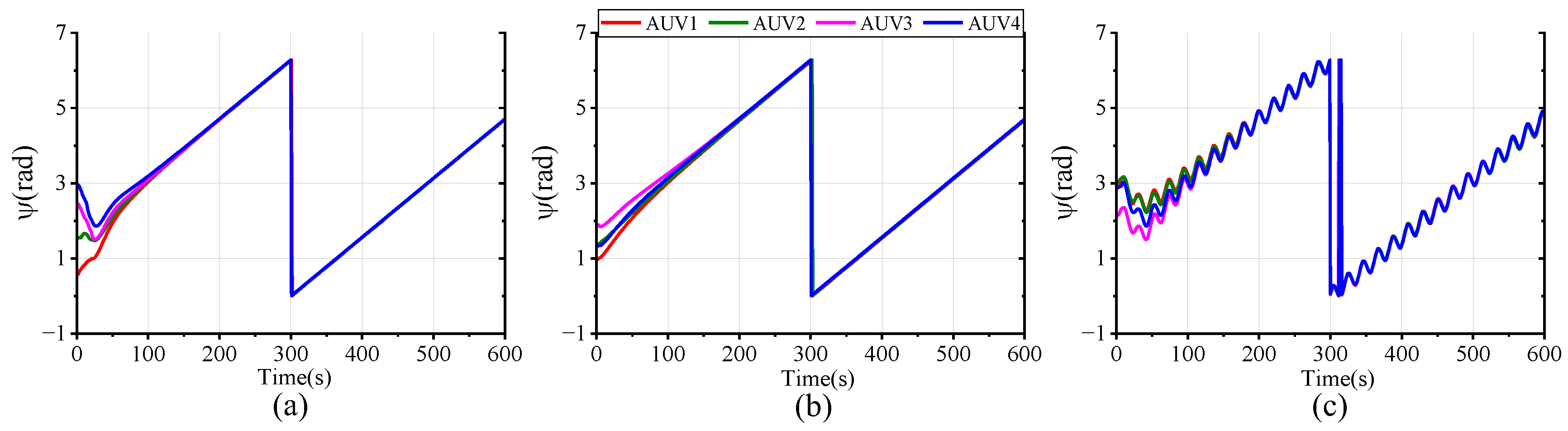
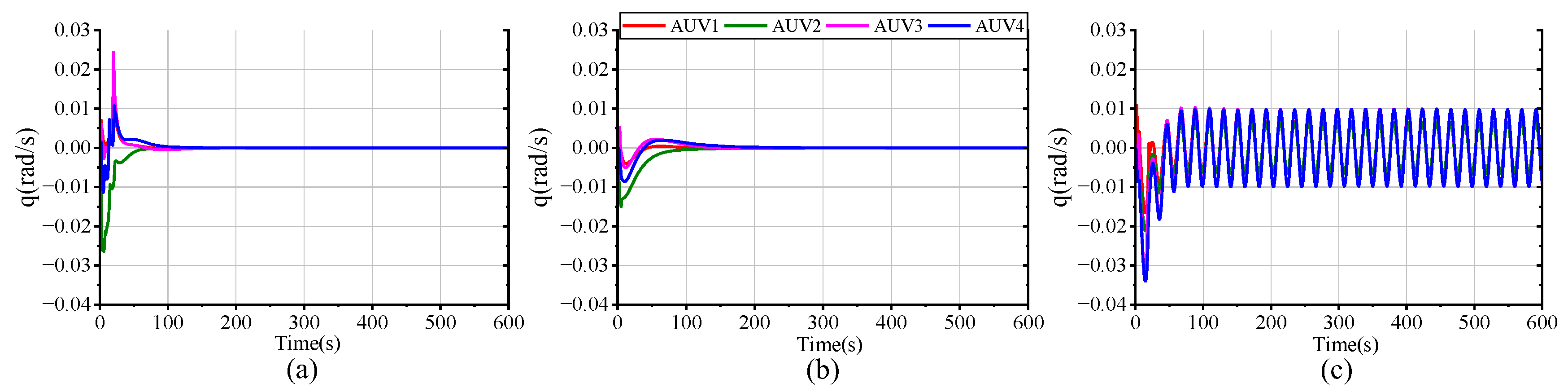
Figure 16 plot the tracking performance curves of AUV positional and velocity states under the three schemes. It can be easily observed that, in all scenarios, the four AUVs are able to successfully track the desired state despite the differing tracking errors. In scheme (a), full-state stable tracking is achieved within 200 s. Meanwhile, in scheme (b), the process takes about 300 s, which suggests that the use of the Laguerre function improves both the response speed and control accuracy. Although the standard DMPC scheme (c) can also achieve formation tracking, the settling time of the state variables is longer and accompanied by oscillations due to the uncompensated compound disturbance effects. Compared with the other schemes, our proposed method delivers superior formation tracking control performance.
Figure 17 intuitively presents a 3-D formation trajectory tracking. Combined with
Figure 7,
Figure 8,
Figure 9,
Figure 10,
Figure 11,
Figure 12,
Figure 13,
Figure 14,
Figure 15 and
Figure 16, it implies that all three schemes can successfully accomplish formation spiral tracking under the specified input and state constraints. However, when the formation faces harsh compound disturbances, the tracking performance of the controller without disturbance compensation performs poorly, demonstrating a tracking error significantly larger than that of the FTESO-based controller. This is because the compound disturbances cause the AUV to deviate from the desired trajectory. By comparing the results of (a,b), it can be further observed that the proposed control scheme with Laguerre function allows the AUV to form the preset formation more quickly and converge to the desired trajectory more smoothly. This implies a faster response at the onset of the task. Thus, the dual closed-loop structure and Laguerre function enable the AUV formation to track the reference trajectory with better speed and accuracy.
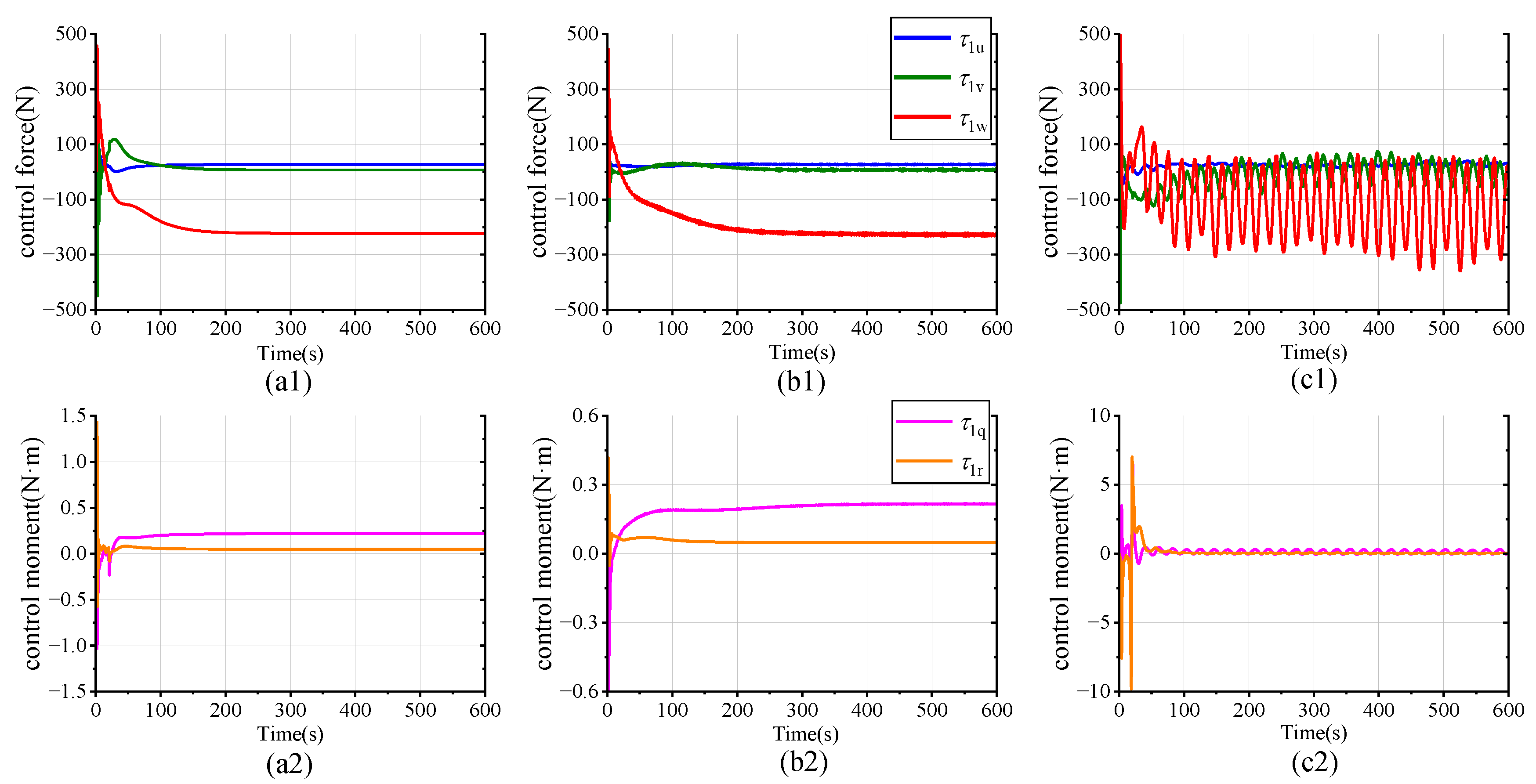
Without loss of generality,
Figure 18 shows the actual control forces and moments versus time for AUV1 under the three schemes. Without the benefit of FTESO to compensate for compound disturbances, the fluctuations of the control force and moment are relatively drastic and unstable (
Figure 18(c1,c2)). This is attributed to the need for the AUV to significantly rectify the driving forces and moments to more rapidly approach the deviated reference trajectory. Under the proposed scheme, as shown in
Figure 18(a1,a2), the AUV forces and moments vary relatively smoothly, which makes the AUV track the trajectory steadily when disturbed. Comparing
Figure 18(a1,a2) and
Figure 18(b1,b2), the Laguerre-based controller has the fastest control signal response with the smallest amplitude when the disturbances are accurately compensated. This confirms that our proposed scheme (a) provides superior control performance. It is worth noting that the variation of control forces and moments always remains within the prescribed limits. This reflects the ability of the DMPC to handle the actuator saturation effectively, ensuring that the control input for each DOF does not exceed the maximum force provided by the actuator, thus reducing actuator losses.
To differentiate between the computational demands among the three schemes, we recorded the emulator execution times under the same configurations. The detailed simulation times corresponding to
Figure 17 are given in
Table 2. It can be observed that the actual running time of the standard DMPC system is approximately 43.62 s. In contrast, the system with a dual closed-loop DMPC requires 57.91 s, which is about 32.8% longer than the standard DMPC. This increase is due to the greater complexity of the dual closed-loop structure as opposed to the simpler DMPC structure. Although there is improvement in control efficacy, the execution of the dual closed-loop structure is sacrificed to some extent. However, the proposed system, which employs a Laguerre-based dual closed-loop DMPC, the computation time only requires 11.75 s. This suggests that, despite the inclusion of both the dual closed-loop structure and FTESO, the use of the Laguerre function makes the system solution faster. Thus, the proposed scheme can simultaneously improve the computational speed and control performance.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}