Fuzzy Reinforcement Learning and Curriculum Transfer Learning for Micromanagement in Multi-Robot Confrontation

Abstract
:1. Introduction
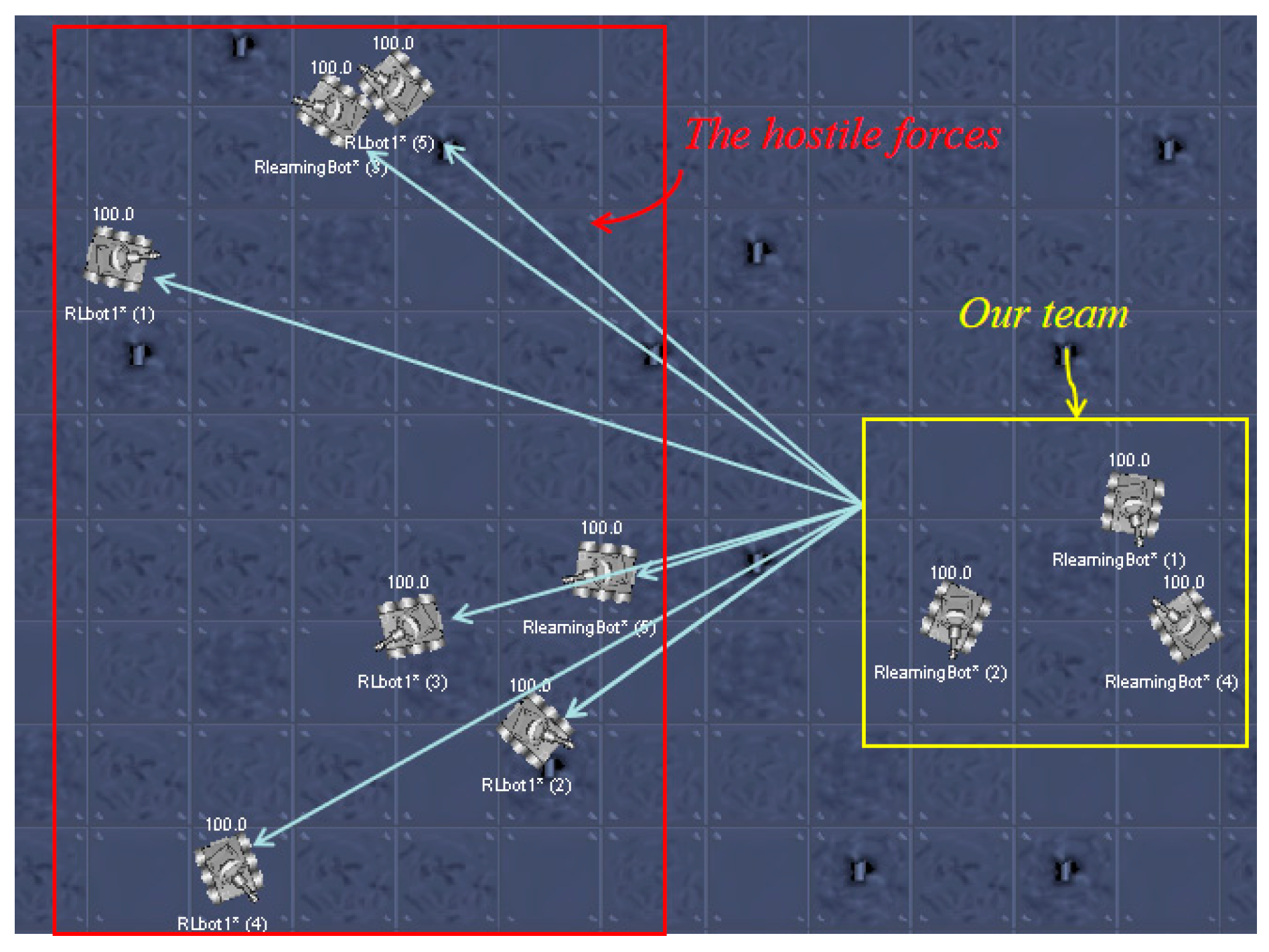
1.1. The Robot Confrontation System
1.2. Machine Learning Algorithms
1.3. Research Motivation in This Work
1.4. Contributions in This Work
1.5. Paper Structure
2. Background
2.1. Reinforcement Learning
2.2. Softmax Function Based on Simulated Annealing
3. An RL Model for a Single Agent
3.1. An Improved Q-Learning Method in Semi-Markov Decision Processes
| Algorithm 1: SSAQ algorithm for micromanagement |
| Definition : = Current temperature parameters : = Next temperature parameters : = Current reward : = Minimum temperature parameter : = Maximum temperature parameter : = Learning rate : = Discount factor : = The number of actions in t time : = Updating state-action function in SMDP Initialization Initialize each value of Q matrix arbitrarily value; Repeat (for each step) Choose an initial state ;; Repeat (for each step of the episode) Observe , after learning cycles by the same actions Obtain reward until is terminal. Until Q matrix is convergence. |
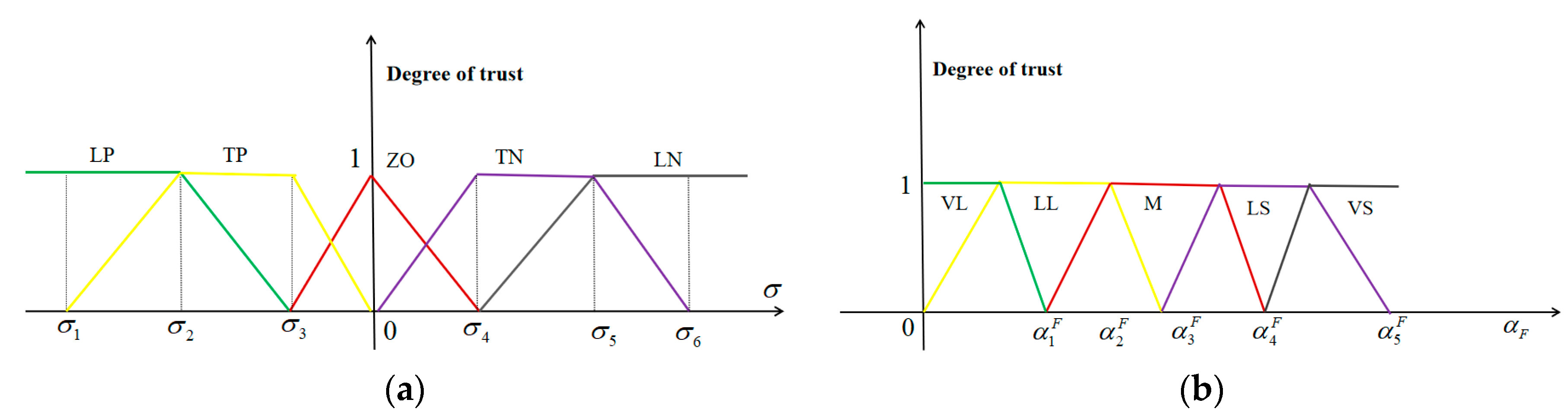
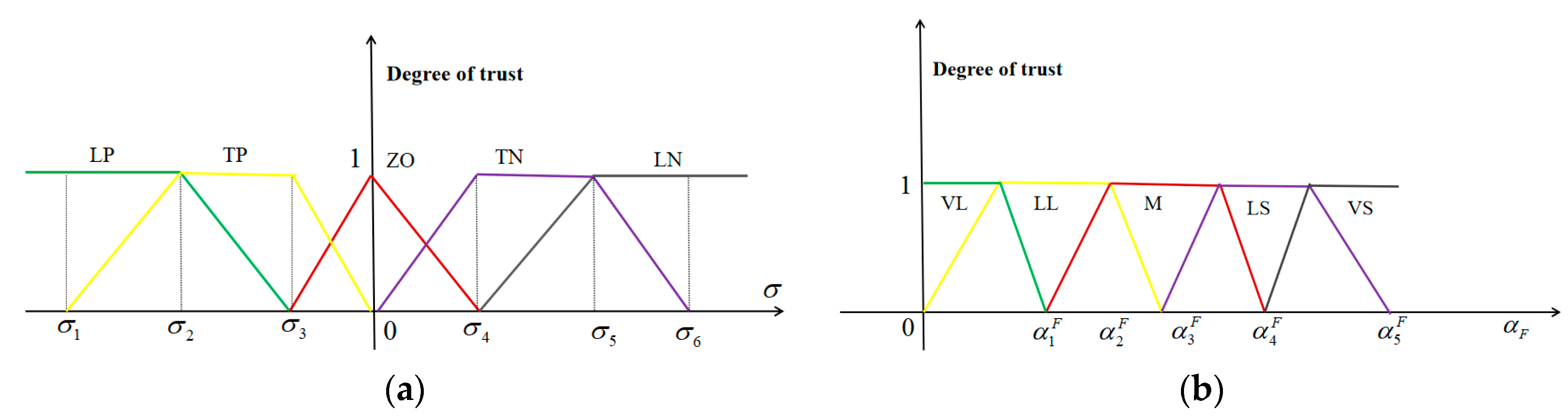
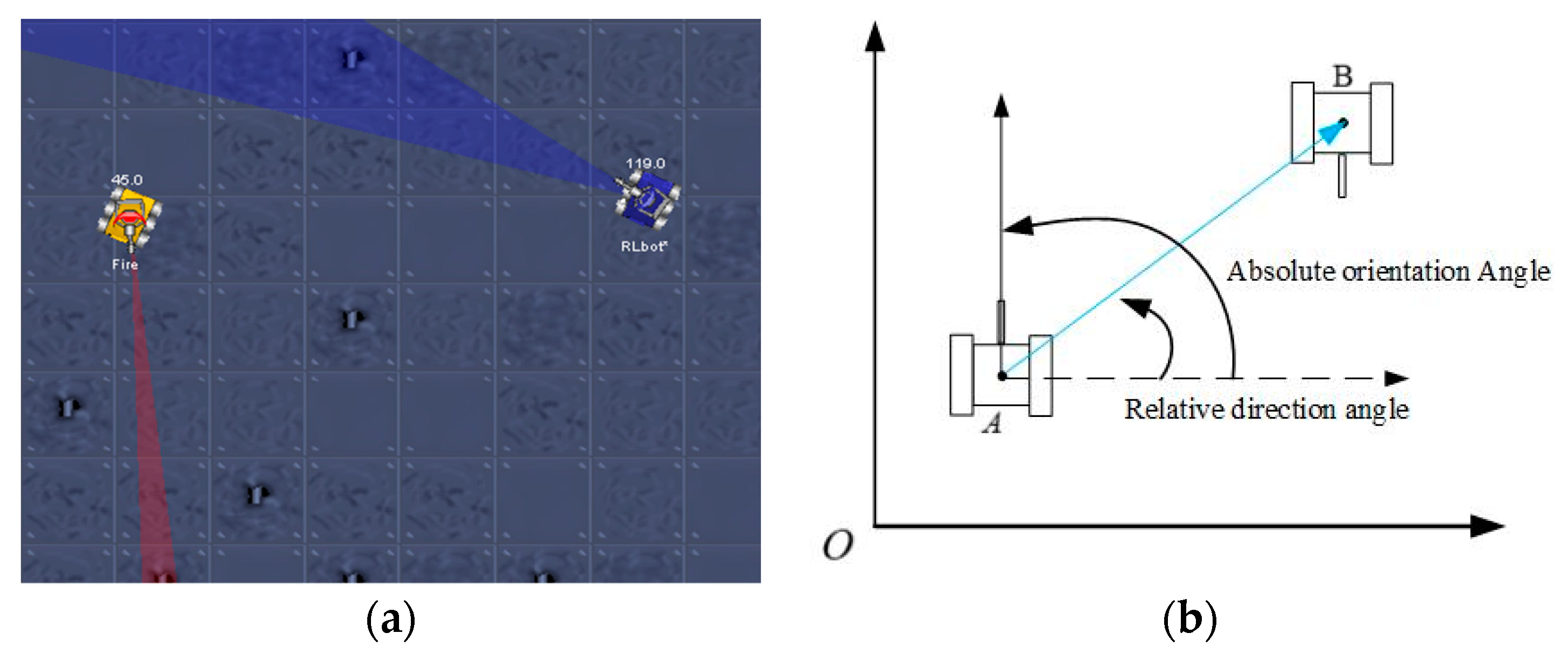
3.2. A Reinforcement Learning Method using a Fuzzy System
4. A Proposed Learning Model for Multi-Robot Confrontation
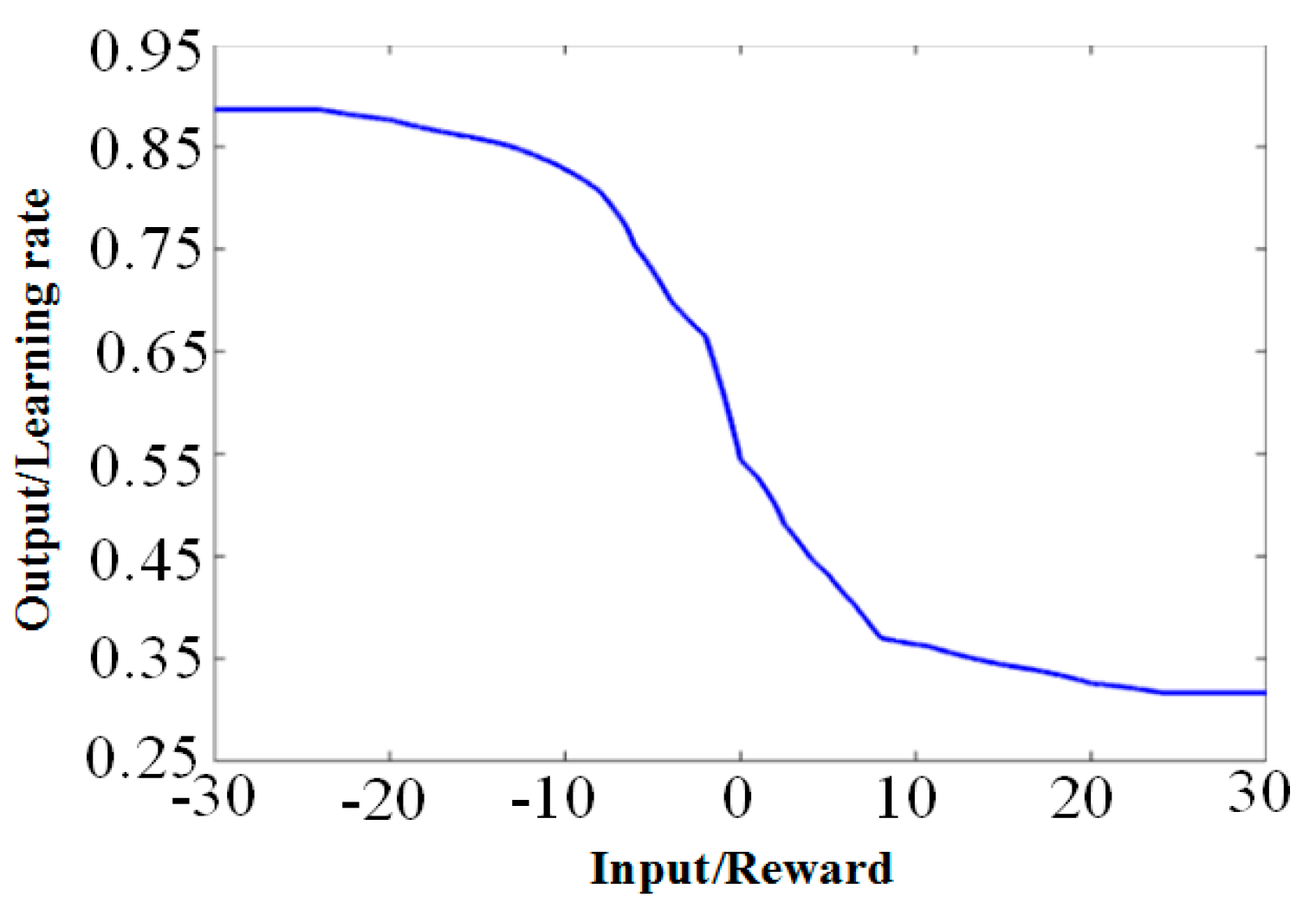
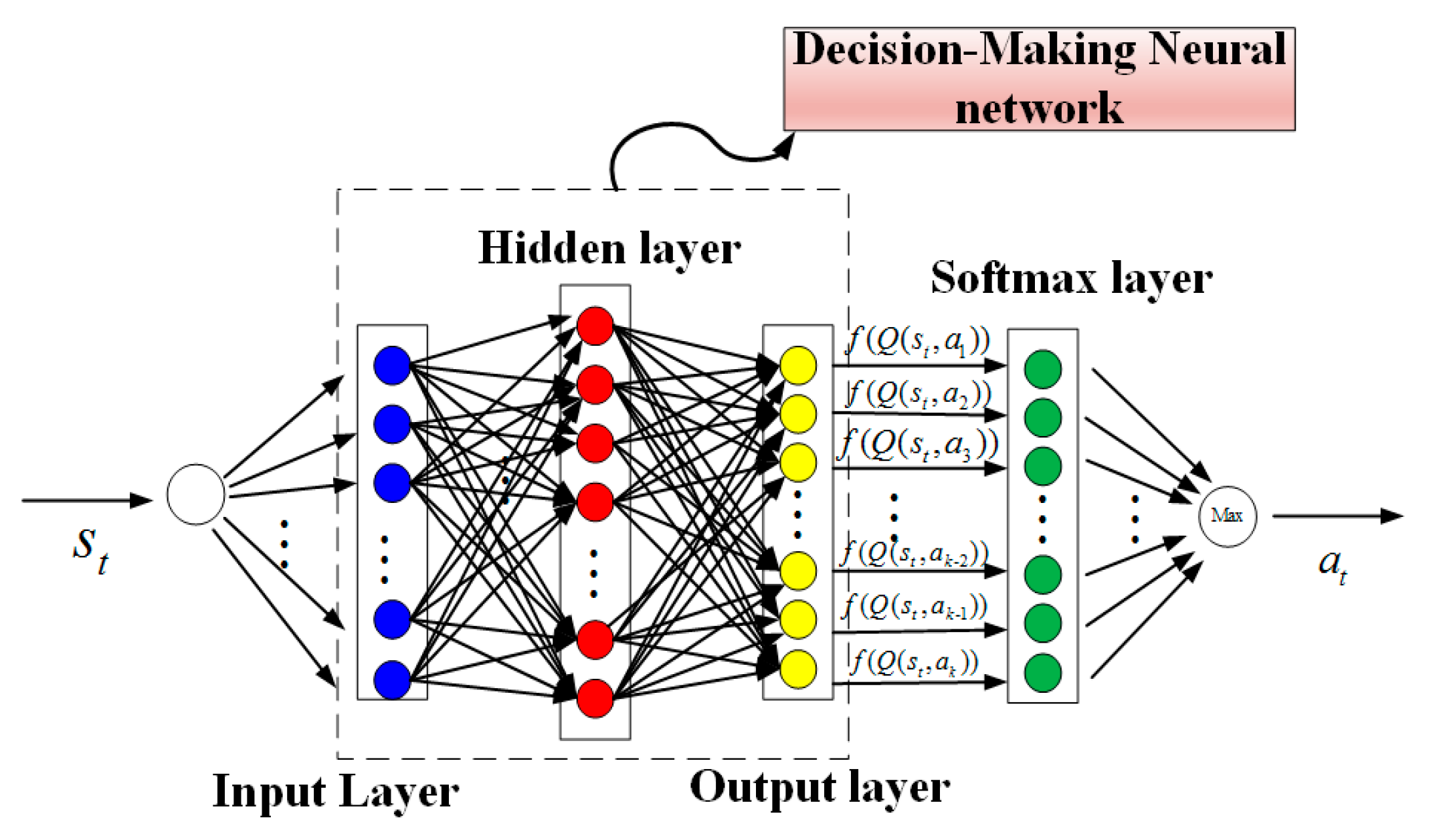
4.1. Neural Network Model with Adaptive Momentum
4.2. Multi-Agent RL Algorithm Based on Decision-Making Neural Network with Parameter Sharing
| Algorithm 2: Multi-agent SSAQ algorithm |
| Definition : = Current temperature parameters : = Next temperature parameters : = Minimum temperature parameter : = Maximum temperature parameter : = Adaptive learning rate of the neural network : = Discount factor : = The number of actions in t time : = Updating state-action function in SMDP Initialization Initialize Repeat (for each step) Choose an initial state ;; Repeat (for each step of the episode) Observe , after learning cycles by the same actions Obtain reward Update TD error and weights: ; until is terminal. |
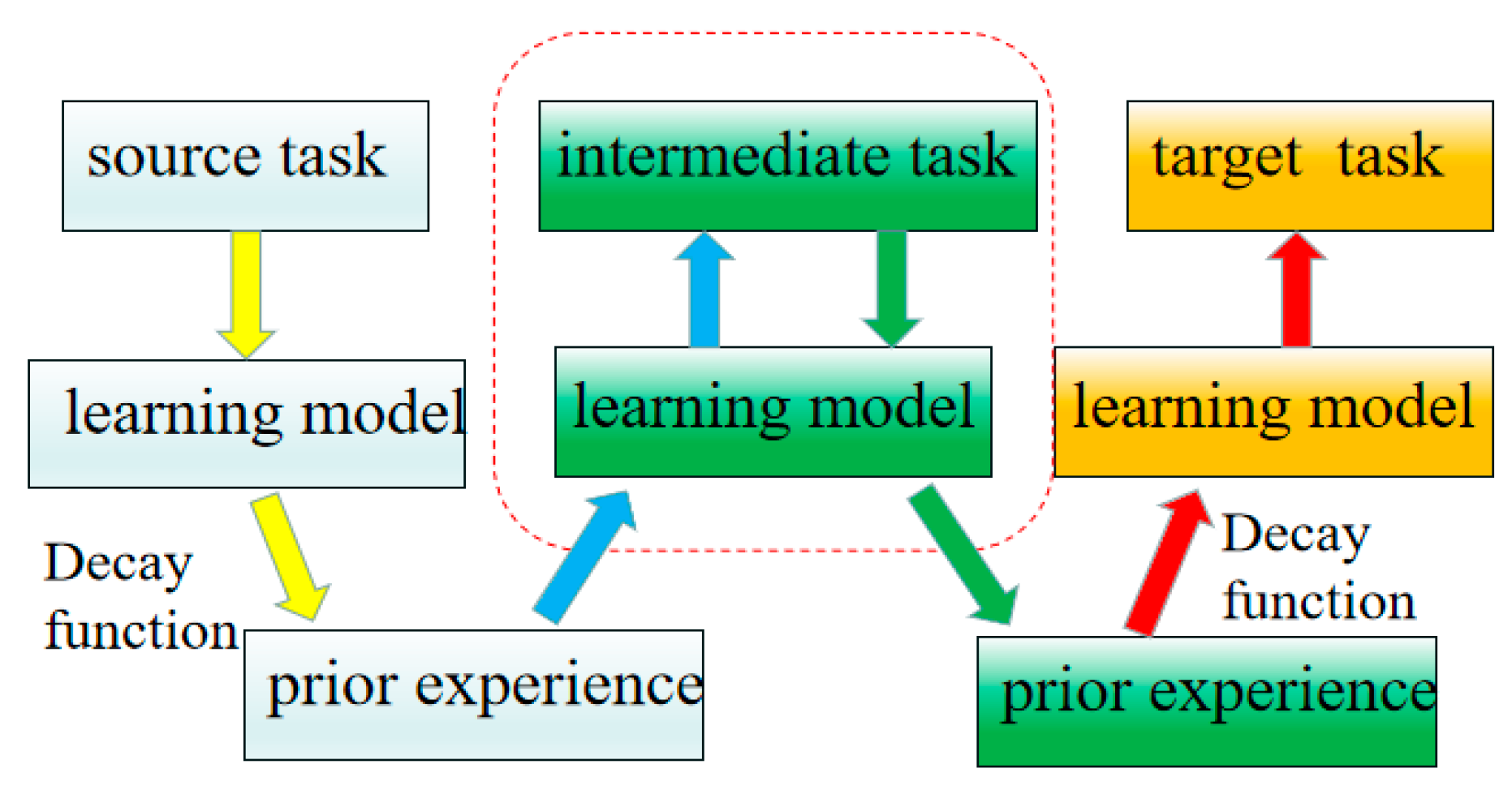
5. Curriculum Transfer Learning
Curriculum Transfer Learning for Different Micromanagement Scenarios
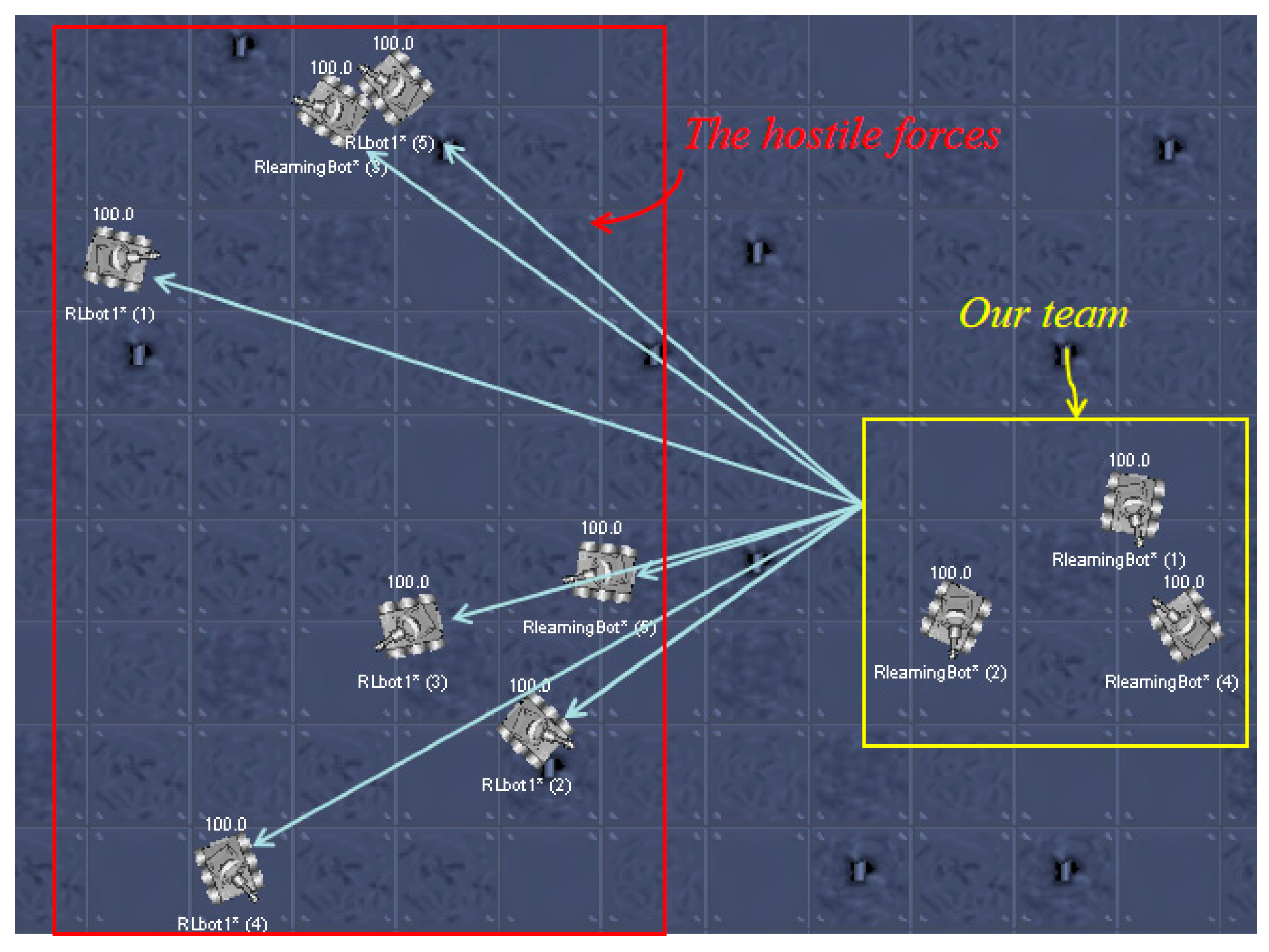
6. Experiment and Analysis
6.1. RL Model for a Confrontation Decision-Making System
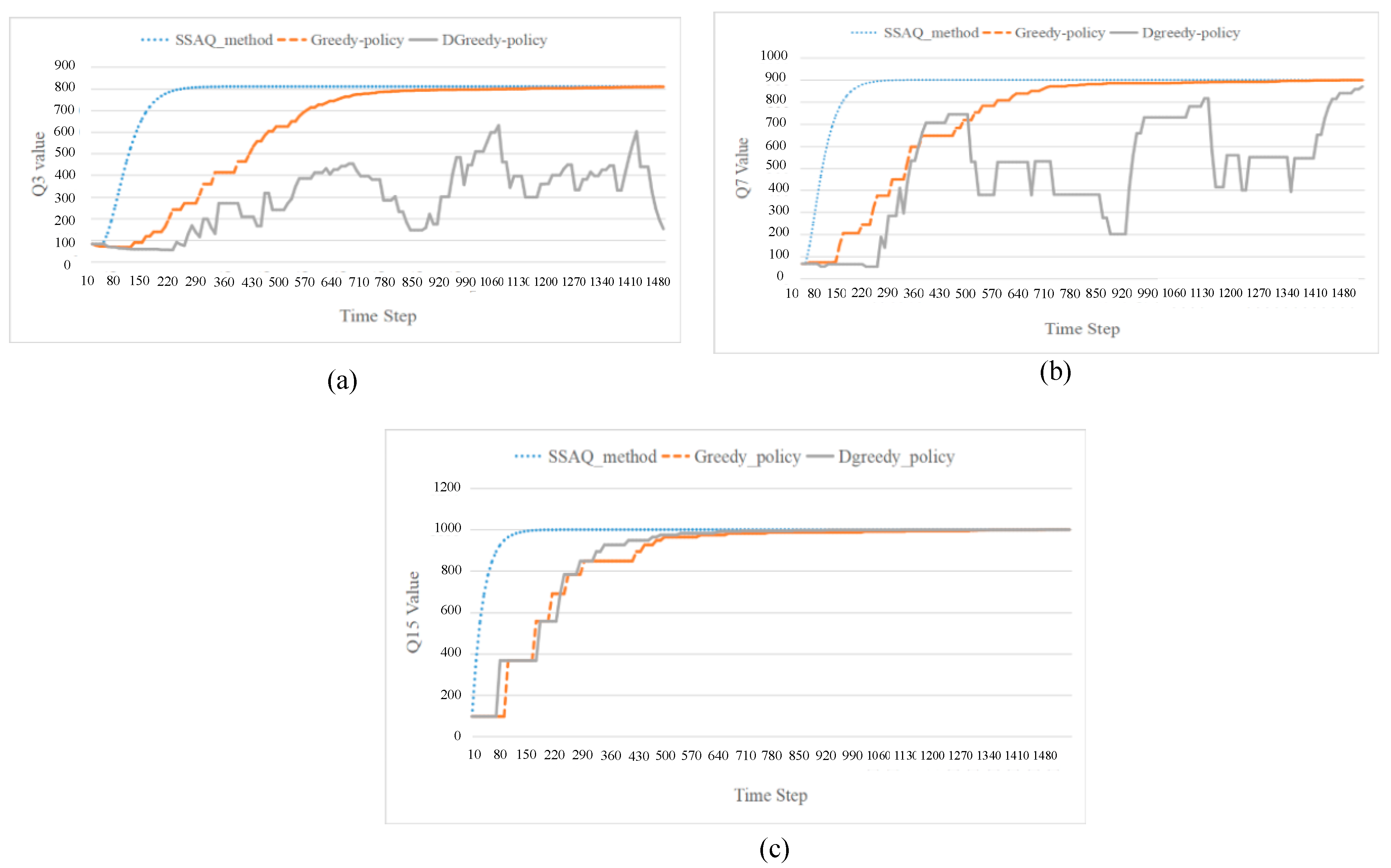
6.2. Proposed RL Algorithm Test
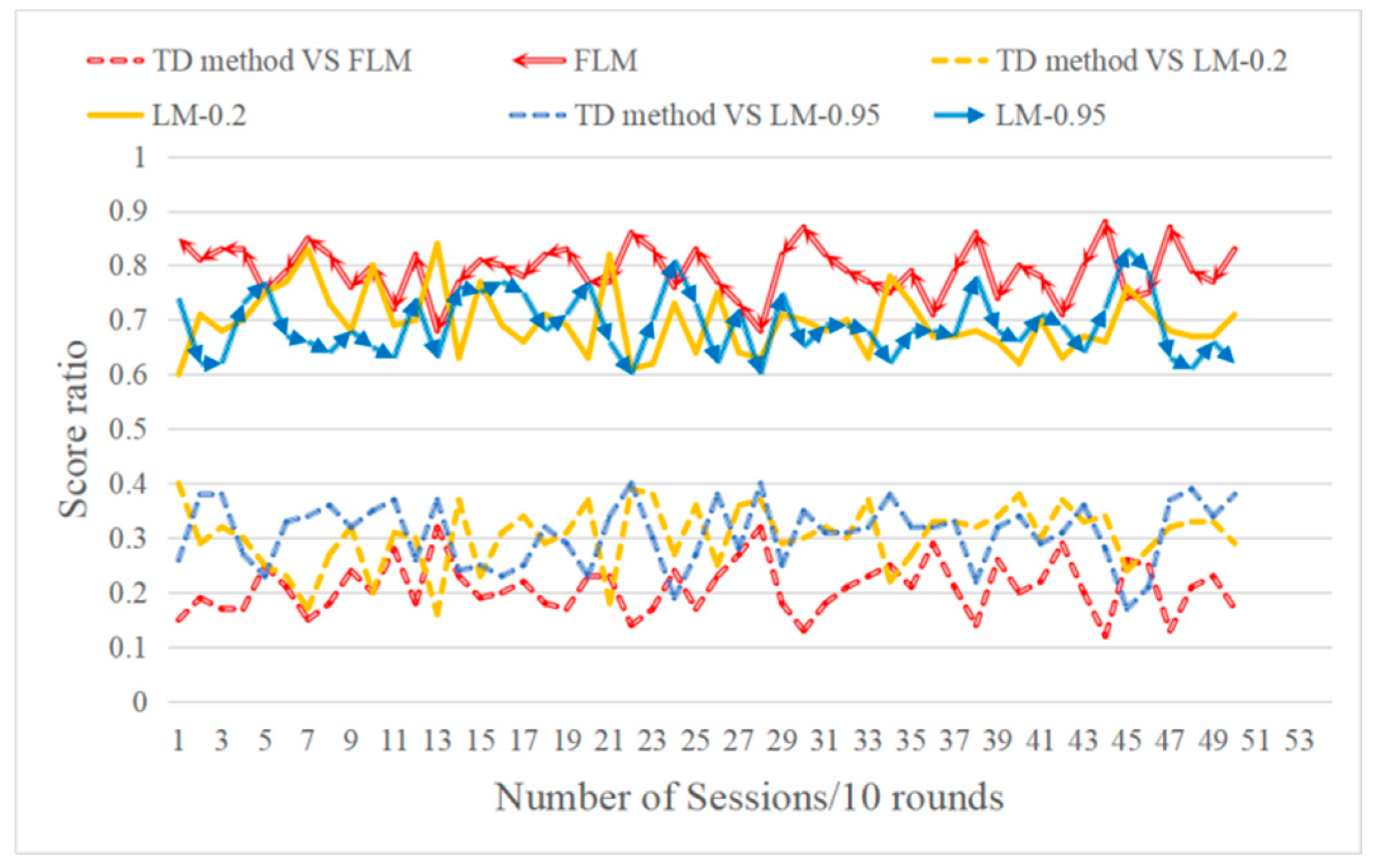
6.3. Effect Test for Multi-Agent RL Based on DMNN and Fuzzy Method
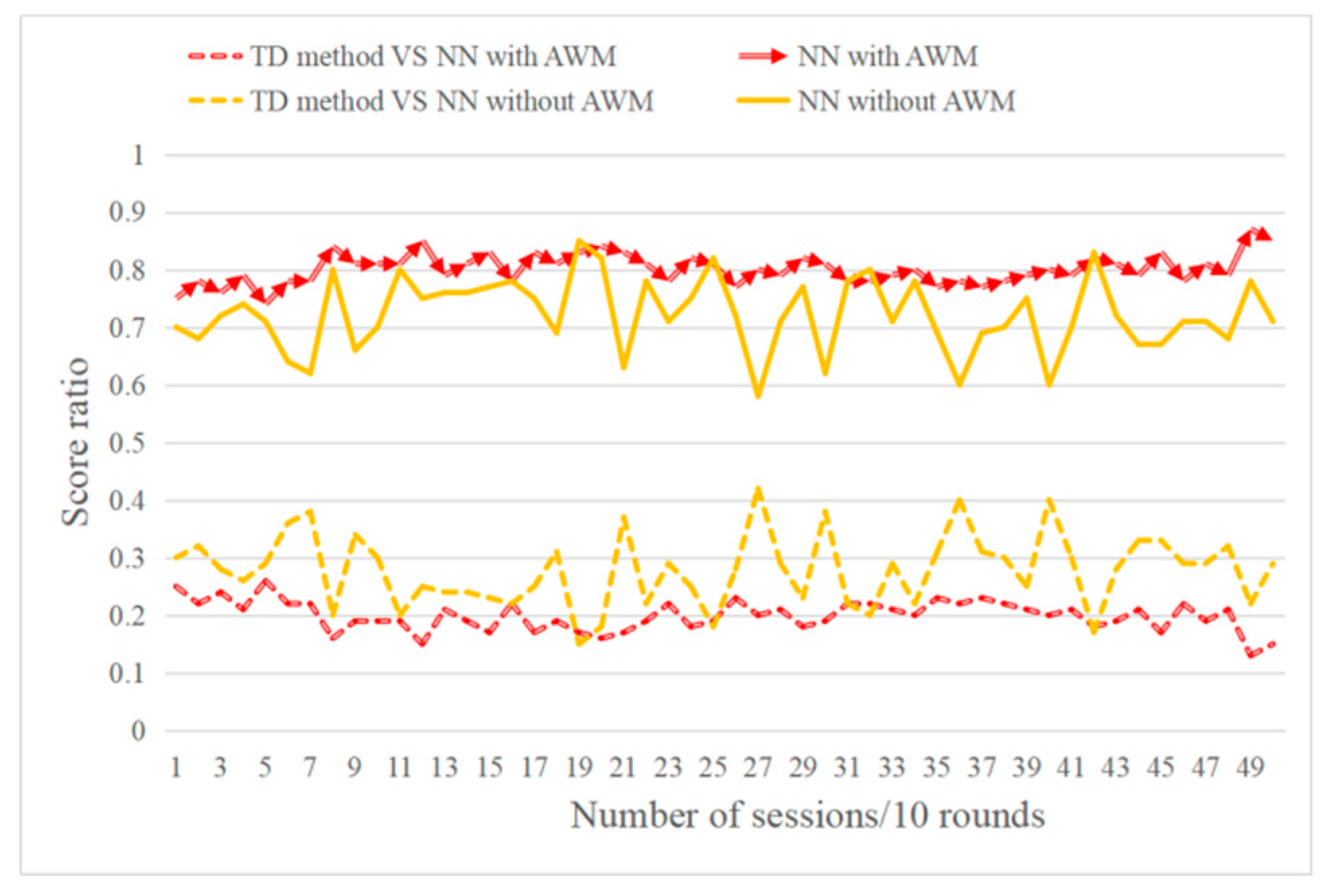
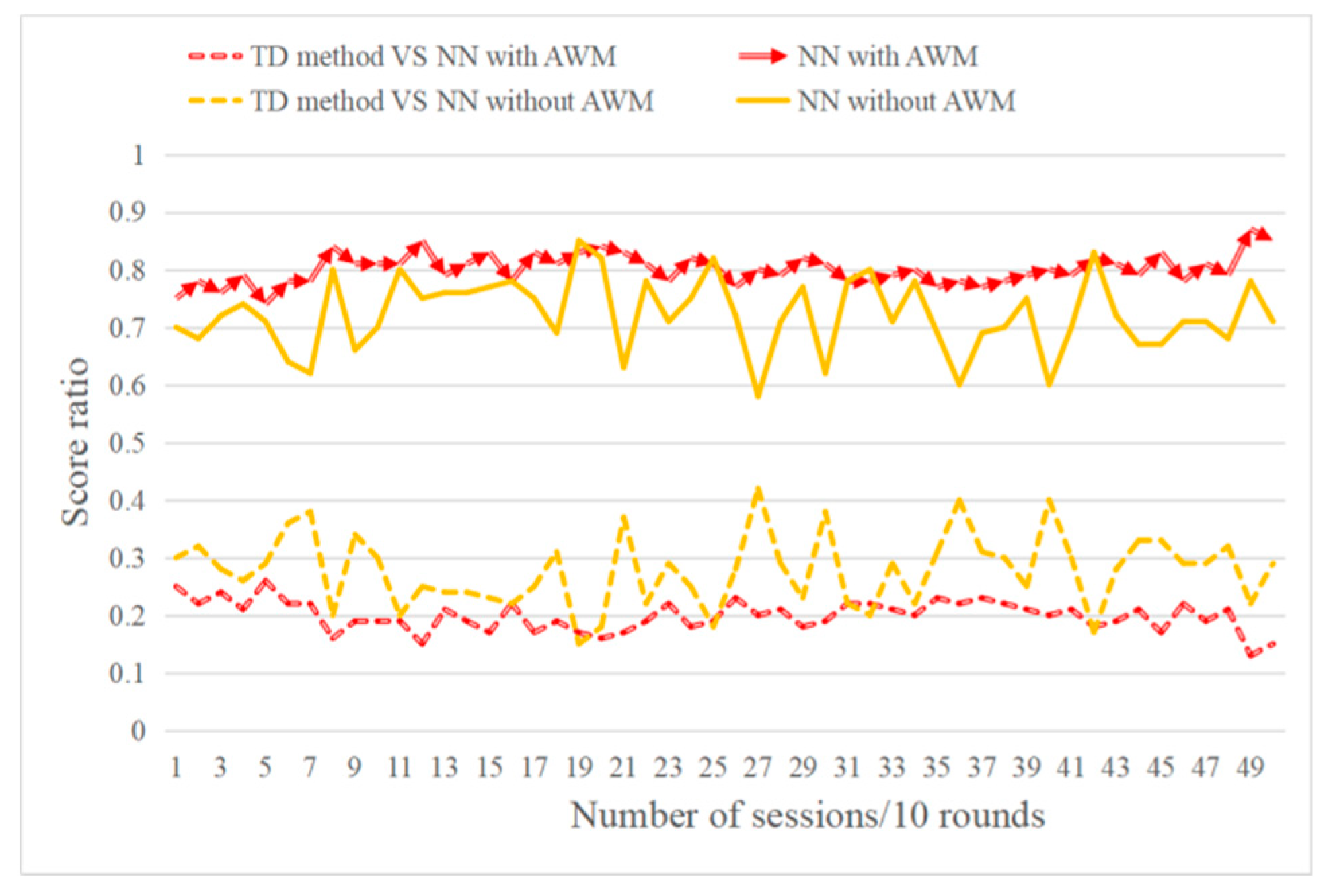
6.4. Effect Test for Curriculum Transfer Learning (TF)
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Weron, R. Electricity price forecasting: A review of the state-of-the-art with a look into the future. Int. J. Forecast. 2014, 4, 1030–1081. [Google Scholar] [CrossRef]
- Ferreira, L.N.; Toledo, C.; Tanager, A. Generator of Feasible and Engaging Levels for Angry Birds. IEEE Trans. Games 2017, 10, 304–316. [Google Scholar] [CrossRef]
- Hiller, J.; Reindl, L.M. A computer simulation platform for the estimation of measurement uncertainties in dimensional X-ray computed tomography. Measurement 2012, 45, 2166–2182. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Moravik, M.; Schmid, M.; Burch, N.; Lisy, V.; Morrill, D.; Bard, N.; Davis, T.; Waugh, K.; Johanson, M.; Bowling, M. Deepstack: Expert level artificial intelligence in heads-up no-limit poker. Science 2017, 356, 508–513. [Google Scholar] [CrossRef]
- Yao, W.; Lu, H.; Zeng, Z.; Xiao, J.; Zheng, Z. Distributed Static and Dynamic Circumnavigation Control with Arbitrary Spacings for a Heterogeneous Multi-robot System. J. Intell. Robot. Syst. 2018, 4, 1–23. [Google Scholar] [CrossRef]
- Ontanon, S.; Synnaeve, G.; Uriarte, A.; Richoux, F.; Churchill, D.; Preuss, M.A. Survey of Real-Time Strategy Game AI Research and Competition in StarCraft. IEEE Trans. Comput. Intell. AI Games 2013, 5, 293–311. [Google Scholar] [CrossRef]
- Synnaeve, G.; Bessiere, P. Multiscale Bayesian Modeling for RTS Games: An Application to StarCraft AI. IEEE Trans. Comput. Intell. AI Games 2016, 8, 338–350. [Google Scholar] [CrossRef]
- Thrun, S.; Littman, M.L. Reinforcement Learning: An Introduction. IEEE Trans. Neural Netw. 2005, 16, 285–286. [Google Scholar]
- Shi, H.; Li, X.; Hwang, K.S.; Pan, W.; Xu, G. Decoupled Visual Servoing With Fuzzy Q-Learning. IEEE Trans. Ind. Inform. 2018, 14, 241–252. [Google Scholar] [CrossRef]
- Shi, H.; Lin, Z.; Zhang, S.; Li, X.; Hwang, K.S. An adaptive Decision-making Method with Fuzzy Bayesian Reinforcement Learning for Robot Soccer. Inform. Sci. 2018, 436, 268–281. [Google Scholar] [CrossRef]
- Xu, M.; Shi, H.; Wang, Y. Play games using Reinforcement Learning and Artificial Neural Networks with Experience Replay. In Proceedings of the 2018 IEEE/ACIS 17th International Conference on Computer and Information Science (ICIS), Singapore, 6–8 June 2018; pp. 855–859. [Google Scholar]
- Cincotti, S.; Gallo, G.; Ponta, L.; Raberto, M. Modeling and forecasting of electricity spot-prices: Computational intelligence vs. classical econometrics. AI Commun. 2014, 3, 301–314. [Google Scholar]
- Geramifard, A.; Dann, C.; Klein, R.H.; Dabney, W.; How, J.P. RLPy. A value-function-based reinforcement learning framework for education and research. J. Mach. Learn. Res. 2015, 16, 1573–1578. [Google Scholar]
- Modares, H.; Lewis, F.L.; Jiang, Z.P. Optimal Output-Feedback Control of Unknown Continuous-Time Linear Systems Using Off-policy Reinforcement Learning. IEEE Trans. Cybern. 2016, 46, 2401–2410. [Google Scholar] [CrossRef] [PubMed]
- Konda, V. Actor-critic algorithms. Siam J. Control Optim. 2003, 42, 1143–1166. [Google Scholar] [CrossRef]
- Patel, P.G.; Carver, N.; Rahimi, S. Tuning computer gaming agents using Q-learning. In Proceedings of the Computer Science and Information Systems (FedCSIS), Szczecin, Poland, 18–21 September 2011; pp. 581–588. [Google Scholar]
- Shao, K.; Zhu, Y.; Zhao, D. StarCraft Micromanagement with Reinforcement Learning and Curriculum Transfer Learning. IEEE Trans. Emerg. Top. Comput. Intell. 2018, 3, 73–84. [Google Scholar] [CrossRef]
- Xu, D.; Shao, H.; Zhang, H.A. New adaptive momentum algorithm for split-complex recurrent neural networks. Neurocomputing 2012, 93, 133–136. [Google Scholar] [CrossRef]
- Lecun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436. [Google Scholar] [CrossRef]
- Peng, P.; Yuan, Q.; Wen, Y.; Yang, Y.; Tang, Z.; Long, H.; Wang, J. Multi-agent bidirectionally-coordinated nets for learning to play StarCraft combat games. arXiv 2017, arXiv:1703.10069. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Gil, P.; Rez, M.; Mez, M.; Gómez, A.F.S. Building a reputation-based bootstrapping mechanism for newcomers in collaborative alert systems. J. Comput. Syst. Sci. 2014, 80, 571–590. [Google Scholar]
- Bertsimas, D.; Tsitsiklis, J. Simulated Annealing. Stat. Sci. 1993, 8, 10–15. [Google Scholar] [CrossRef]
- Shi, H.; Yang, S.; Hwang, K.; Chen, J.; Hu, M.; Zhang, H. A Sample Aggregation Approach to Experiences Replay of Dyna-Q Learning. IEEE Access 2018, 6, 37173–37184. [Google Scholar] [CrossRef]
- Shi, H.; Xu, M.; Hwang, K. A Fuzzy Adaptive Approach to Decoupled Visual Servoing for a Wheeled Mobile Robot. IEEE Trans. Fuzzy Syst. 2019. [Google Scholar] [CrossRef]
- Shi, H.; Lin, Z.; Hwang, K.S.; Yang, S.; Chen, J. An Adaptive Strategy Selection Method with Reinforcement Learning for Robotic Soccer Games. IEEE Access 2018, 6, 8376–8386. [Google Scholar] [CrossRef]
- Choi, S.Y.; Le, T.; Nguyen, Q.; Layek, M.A.; Lee, S.; Chung, T. Toward Self-Driving Bicycles Using State-of-the-Art Deep Reinforcement Learning Algorithms. Symmetry 2019, 11, 290. [Google Scholar] [CrossRef]
- Zhao, G.; Tatsumi, S.; Sun, R. RTP-Q: A Reinforcement Learning System with Time Constraints Exploration Planning for Accelerating the Learning Rate. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 1999, 82, 2266–2273. [Google Scholar]
- Basyigit, A.I.; Ulu, C.; Guzelkaya, M. A New Fuzzy Time Series Model Using Triangular and Trapezoidal Membership Functions. In Proceedings of the International Work-Conference On Time Series, Granada, Spain, 25–27 June 2014; pp. 25–27. [Google Scholar]
- Zhou, Q.; Shi, P.; Xu, S.; Li, H. Observer-based adaptive neural network control for nonlinear stochastic systems with time delay. IEEE Trans. Neural Netw. Learn. Syst. 2012, 24, 71–80. [Google Scholar] [CrossRef]
- Harper, R. Evolving Robocode tanks for Evo Robocode. Genet. Program. Evol. Mach. 2014, 15, 403–431. [Google Scholar] [CrossRef]
- Woolley, B.G.; Peterson, G.L. Unified Behavior Framework for Reactive Robot Control. J. Intell. Robot. Syst. 2009, 55, 155–176. [Google Scholar] [CrossRef]
- Auer, P.; Cesabianchi, N.; Fischer, P. Finite-time Analysis of the Multiarmed Bandit Problem. Mach. Learn. 2002, 47, 235–256. [Google Scholar] [CrossRef]
- Shi, H.; Xu, M. A Multiple Attribute Decision-Making Approach to Reinforcement Learning. IEEE Trans. Cogn. Dev. Syst. 2019. [Google Scholar] [CrossRef]
- Shi, H.; Xu, M. A Data Classification Method Using Genetic Algorithm and K-Means Algorithm with Optimizing Initial Cluster Center. In Proceedings of the 2018 IEEE International Conference on Computer and Communication Engineering Technology (CCET), Beijing, China, 18–20 August 2018; pp. 224–228. [Google Scholar]
- Xu, M.; Shi, H.; Jiang, K.; Wang, L.; Li, X.A. Fuzzy Approach to Visual Servoing with A Bagging Method for Wheeled Mobile Robot. In Proceedings of the 2019 IEEE International Conference on Mechatronics and Automation, Tianjin, China, 4–7 August 2019; pp. 444–449. [Google Scholar]
- Shi, H.; Xu, M.; Hwang, K.; Cai, B.Y. Behavior Fusion for Deep Reinforcement Learning. ISA Trans. 2019. [Google Scholar] [CrossRef] [PubMed]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Learning rate | 0.3 |
| Discount rate | 0.9 |
| Exploring rate | 0.9 |
| Annealing factor | 0.9 |
| Maximum temperature parameter | 0.1 |
| Minimum temperature parameter | 0.01 |
| Layers of the map | 10 |
| Parameter | Value |
|---|---|
| Learning rate of RL | 0.1 |
| Discount rate | 0.9 |
| Exploring rate | 0.95 |
| Annealing factor | 0.9 |
| Maximum temperature parameter | 0.1 |
| Minimum temperature parameter | 0.01 |
| Learning rate of Neural network | 0.9 |
| Momentum constant | 0.95 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, C.; Xu, M. Fuzzy Reinforcement Learning and Curriculum Transfer Learning for Micromanagement in Multi-Robot Confrontation. Information 2019, 10, 341. https://doi.org/10.3390/info10110341
Hu C, Xu M. Fuzzy Reinforcement Learning and Curriculum Transfer Learning for Micromanagement in Multi-Robot Confrontation. Information. 2019; 10(11):341. https://doi.org/10.3390/info10110341
Chicago/Turabian StyleHu, Chunyang, and Meng Xu. 2019. "Fuzzy Reinforcement Learning and Curriculum Transfer Learning for Micromanagement in Multi-Robot Confrontation" Information 10, no. 11: 341. https://doi.org/10.3390/info10110341
APA StyleHu, C., & Xu, M. (2019). Fuzzy Reinforcement Learning and Curriculum Transfer Learning for Micromanagement in Multi-Robot Confrontation. Information, 10(11), 341. https://doi.org/10.3390/info10110341