
Automation of Basketball Match Data Management


Abstract
:1. Introduction
- -
- Examination of market position and requirements for game scoresheet processing system;
- -
- The proposition of the game scoresheet processing method, which includes basketball rules;
- -
- Experimental verification of proposed method.
2. Related Work
- -
- Convolutional layers—in such a layer, the relationship between the current pixel and its threshold of a specific size is considered.
- -
- Pooling layers are used to reduce the size of the data (down-sampling). Typical operations are selecting the average or maximum value.
- -
- Flattening layers—these are used to convert data to a single feature tensor, which is to be passed to the next layer. As a rule, the exit from the flattening layer is the entry into the layers responsible for classification.
- -
- Dense layers—each neuron of such a layer is connected to each neuron in the previous layer
3. Requirements Details
- -
- Project goal, target group and competition assessment;
- -
- Functional requirements and business rules.
3.1. Project on the Market
- -
- Specific (states the outcome);
- -
- Measurable (it specifies how to measure the outcome);
- -
- Attainable (it states the desired value of the indicator);
- -
- Realistic (achievable with available resources);
- -
- Time-bound (specifies time frames).
- -
- Competition in the industry;
- -
- Potential of new entrants into the industry;
- -
- Power of suppliers;
- -
- Power of customers;
- -
- Threat of substitute products.
3.2. Functional Requirements
- As a user, I want to be able to analyze a protocol photo taken while using the application or selected from the photo gallery;
- As a user, I want to be able to rotate the photo and correct the perspective;
- As a user, I want to be able to complete the names and numbers of players;
- As a user, I want to send a photo for analysis;
- As a user, I want to pick up the photo and see the obtained data.
- Player numbers cannot be repeated within one team;
- Exactly five players are starting the match for each team;
- The number of the scoring or foul player must match the players’ names assigned to them;
- After a successful throw, the score may change by two or three points;
- After free throws, the score may change by zero, one, two or three points;
- The points scored in the flow chart are stored in chronological order.
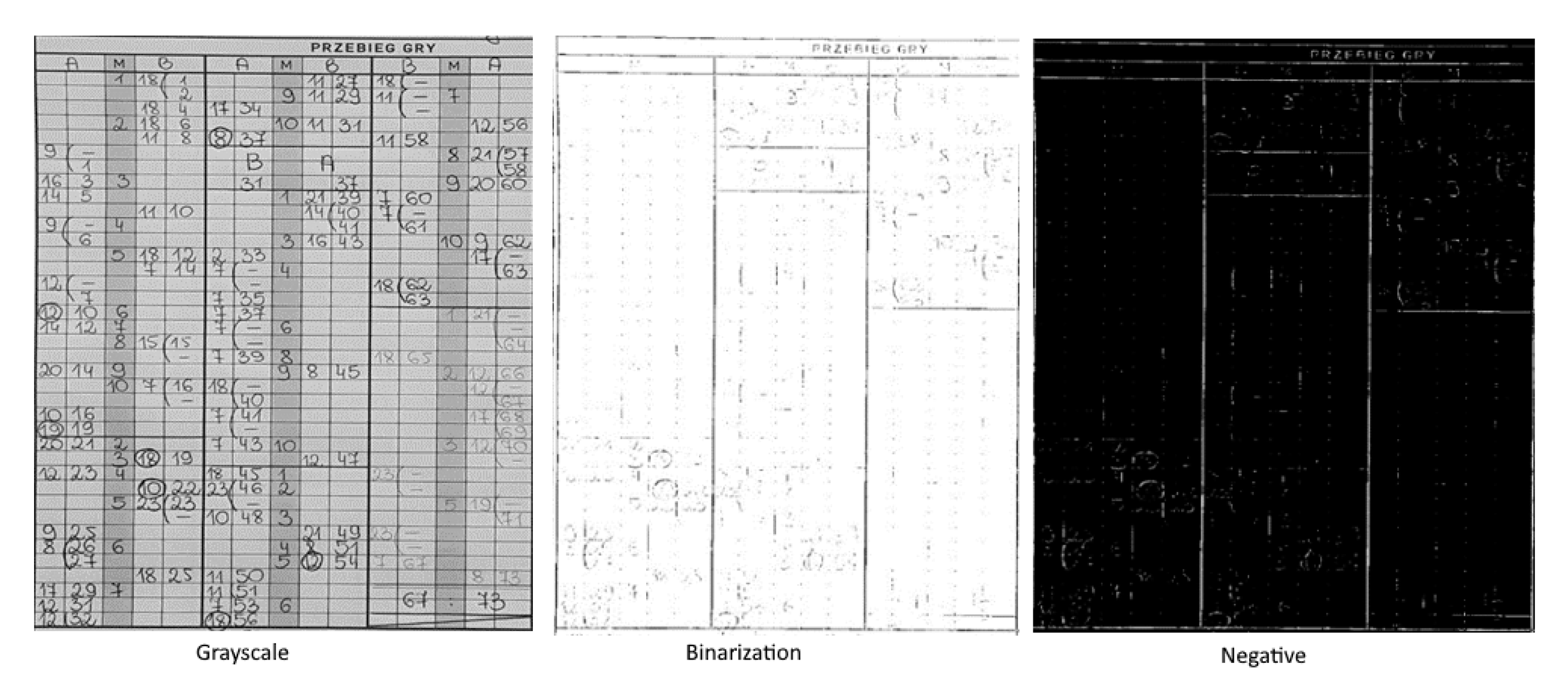
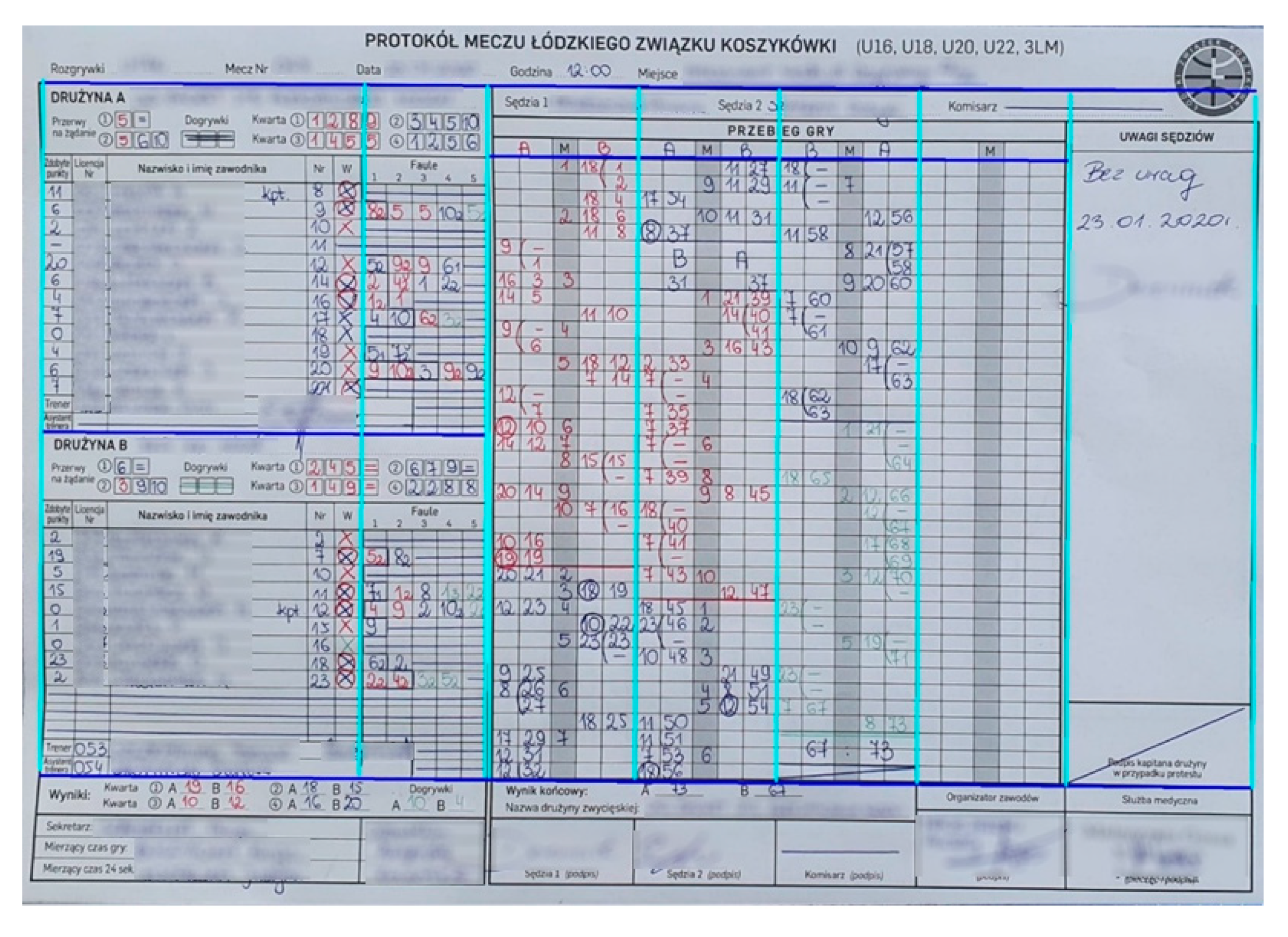
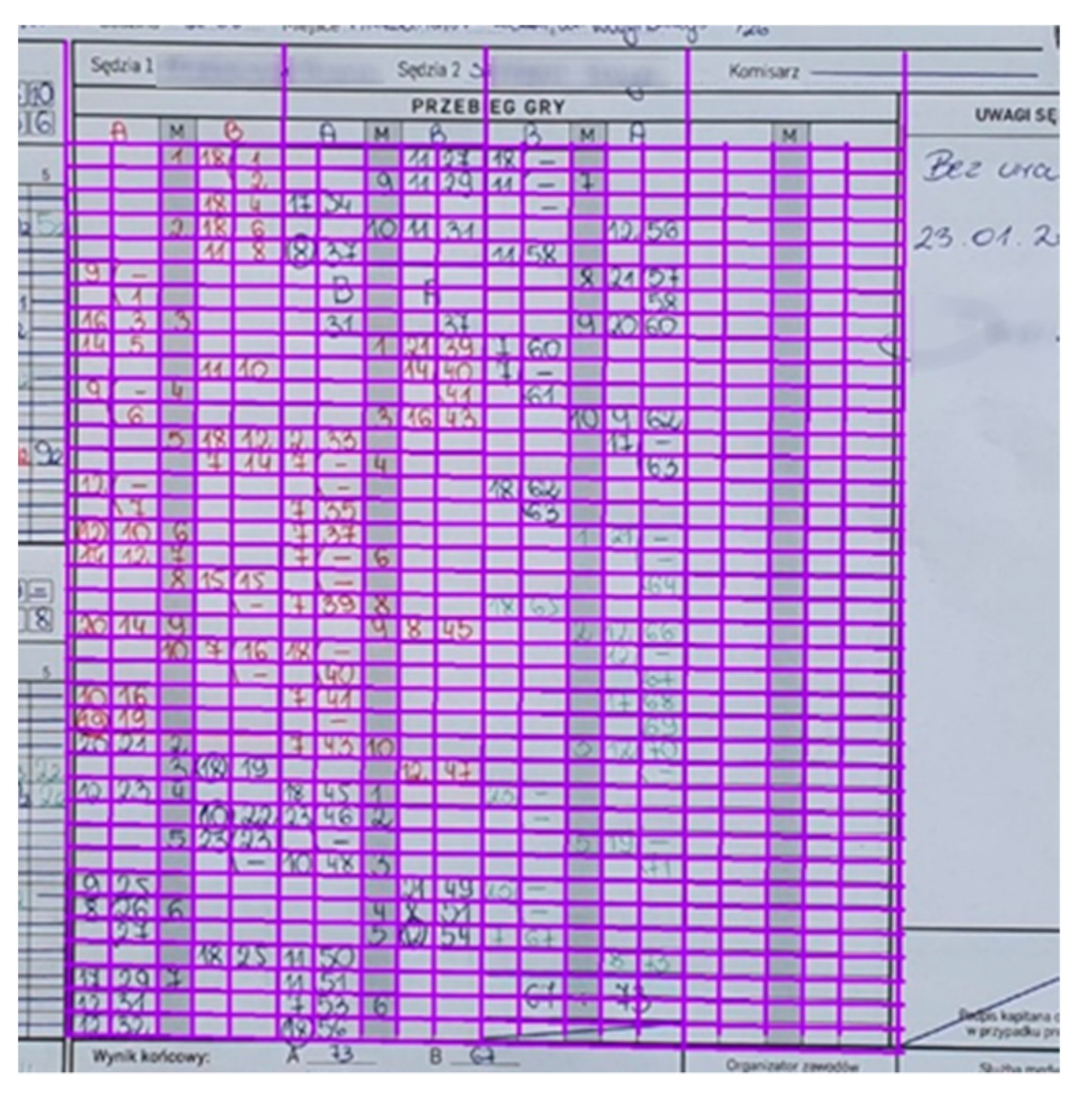
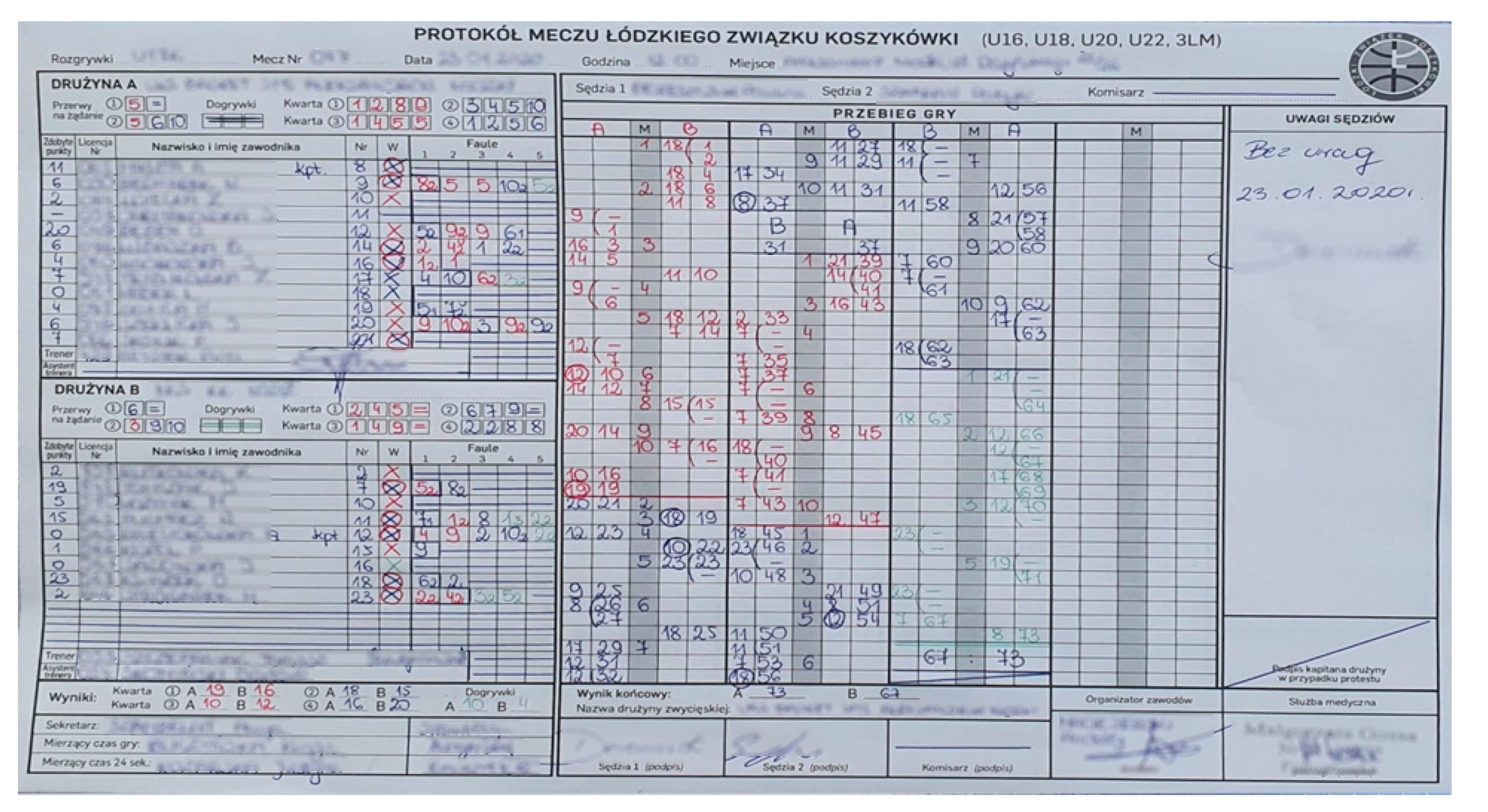
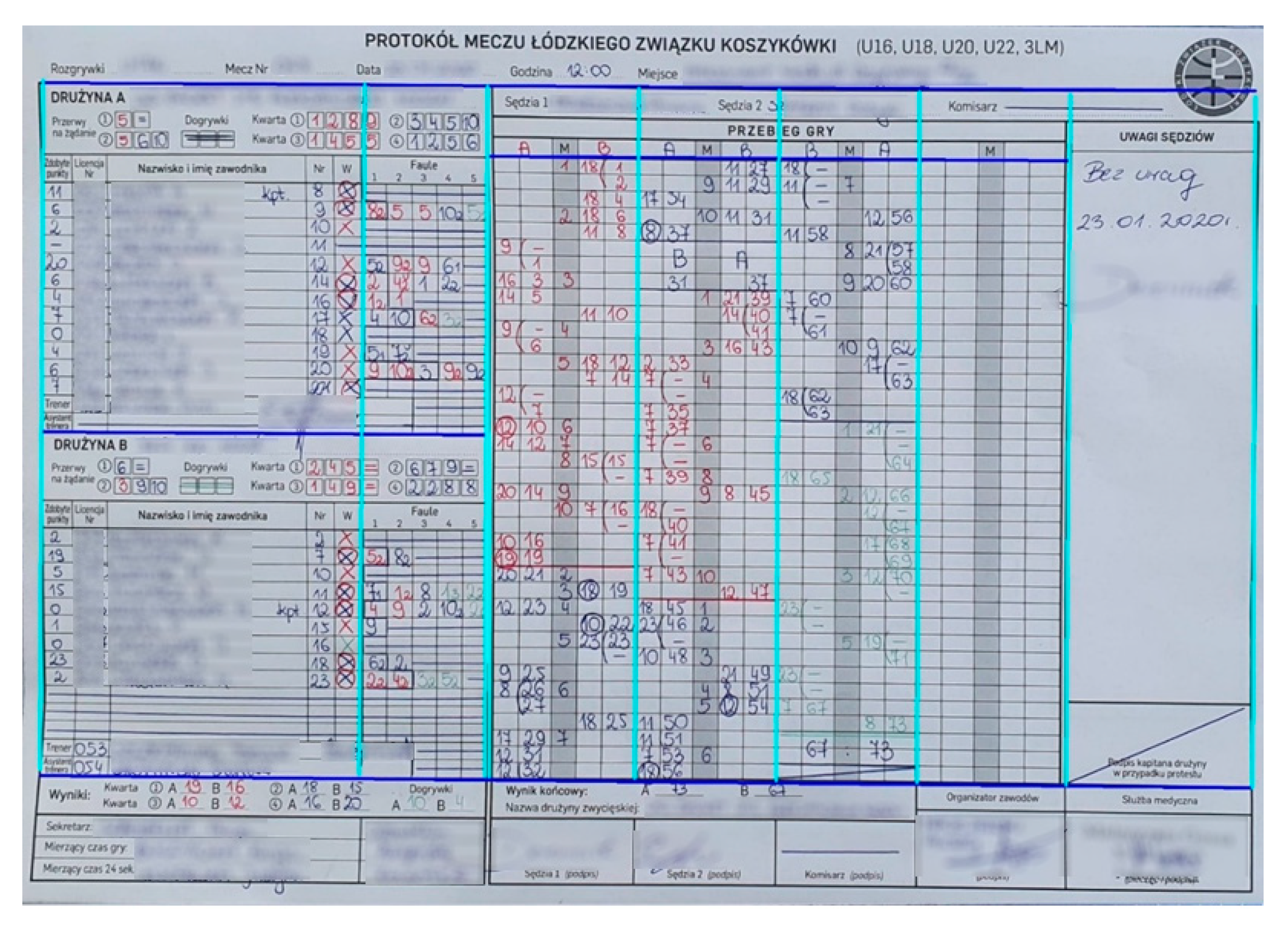
4. Data Extraction Method
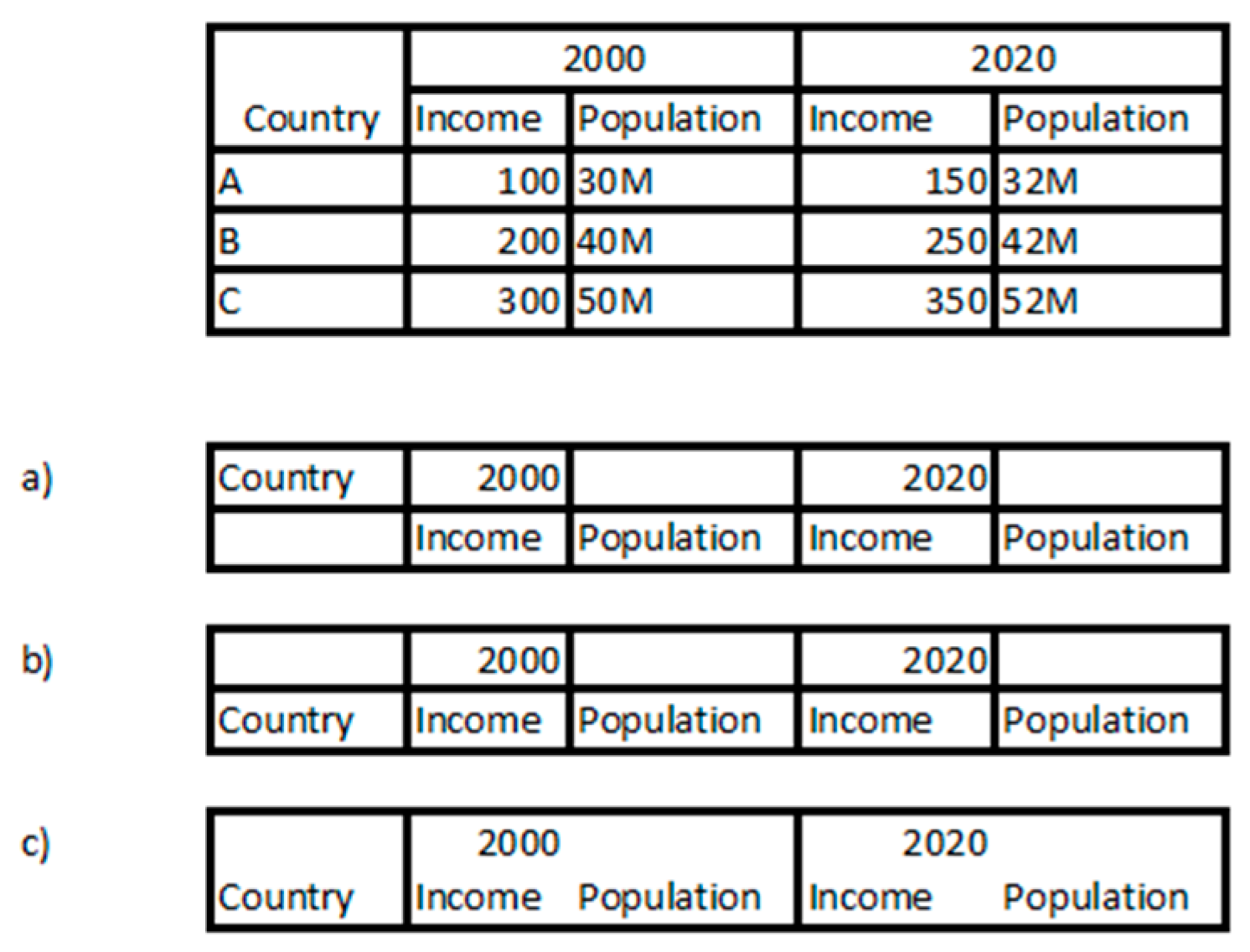
4.1. Table Extraction
- The protocol header that delimits at the bottom (being the top line of the section describing the course of the game and Team A);
- Separating the data of Team A and Team B;
- Separating the A Team data of Team B and the section containing a summary of the result and signatures.
- For each line:
- Get the distance to the other lines.
- If angle and distance criteria are satisfied, put lines in the same group.
- Merge lines in the same group into one line:
- Order lines by x and y coordinates.
- hoose the minimum and maximum coordinates of the merged line based on the ordering.
4.2. Preparation of Numbers for Recognition
- Cutting in the middle of the picture-ineffective in handwriting, the second digit can take up much more places than the first digit, and the writer could simply write the number closer to the left or right edge.
- Intersecting the image with no black pixels—where two digits do not touch—is not adequate for handwriting because people often combine two digits, making it impossible to find a space between the digits.
- Combining the above two methods—finding the smallest number of black pixels between 35% and 65% of the image gives the following effect for one and two-digit numbers (the green vertical line shows where the algorithm split the image—Figure 4):
4.3. Identification of Numbers
5. Results
6. Discussion
7. Conclusions
- Basketball protocol scanning;
- Sending an image to the server (application written in Python);
- Discovery of tables in the log using the OpenCV library;
- Recognition of scoring data from an image using a neural network model;
- Sending data to a mobile application for final verification.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Appendix A


{kind=link}
{kind=link}
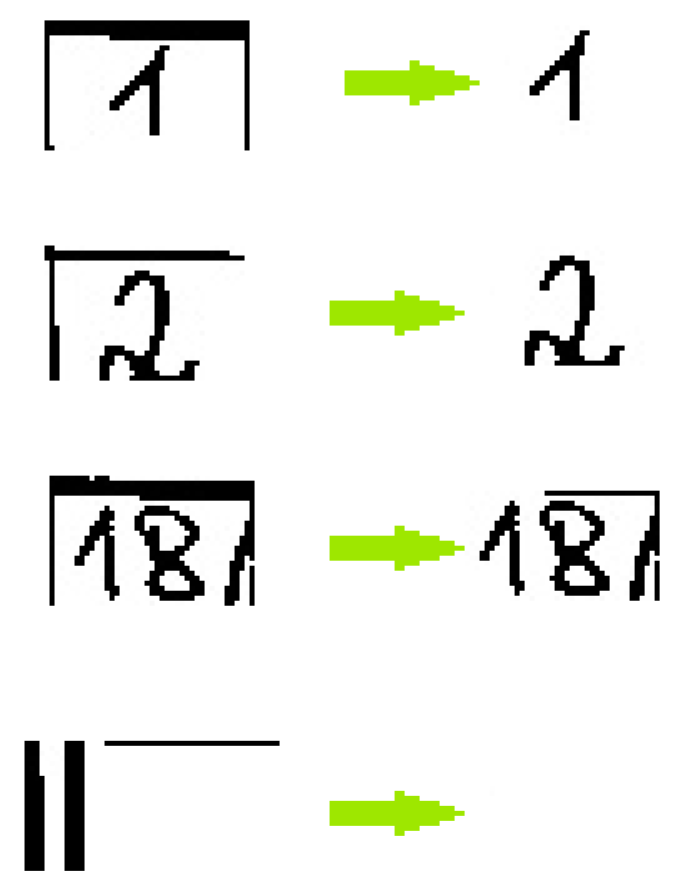{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
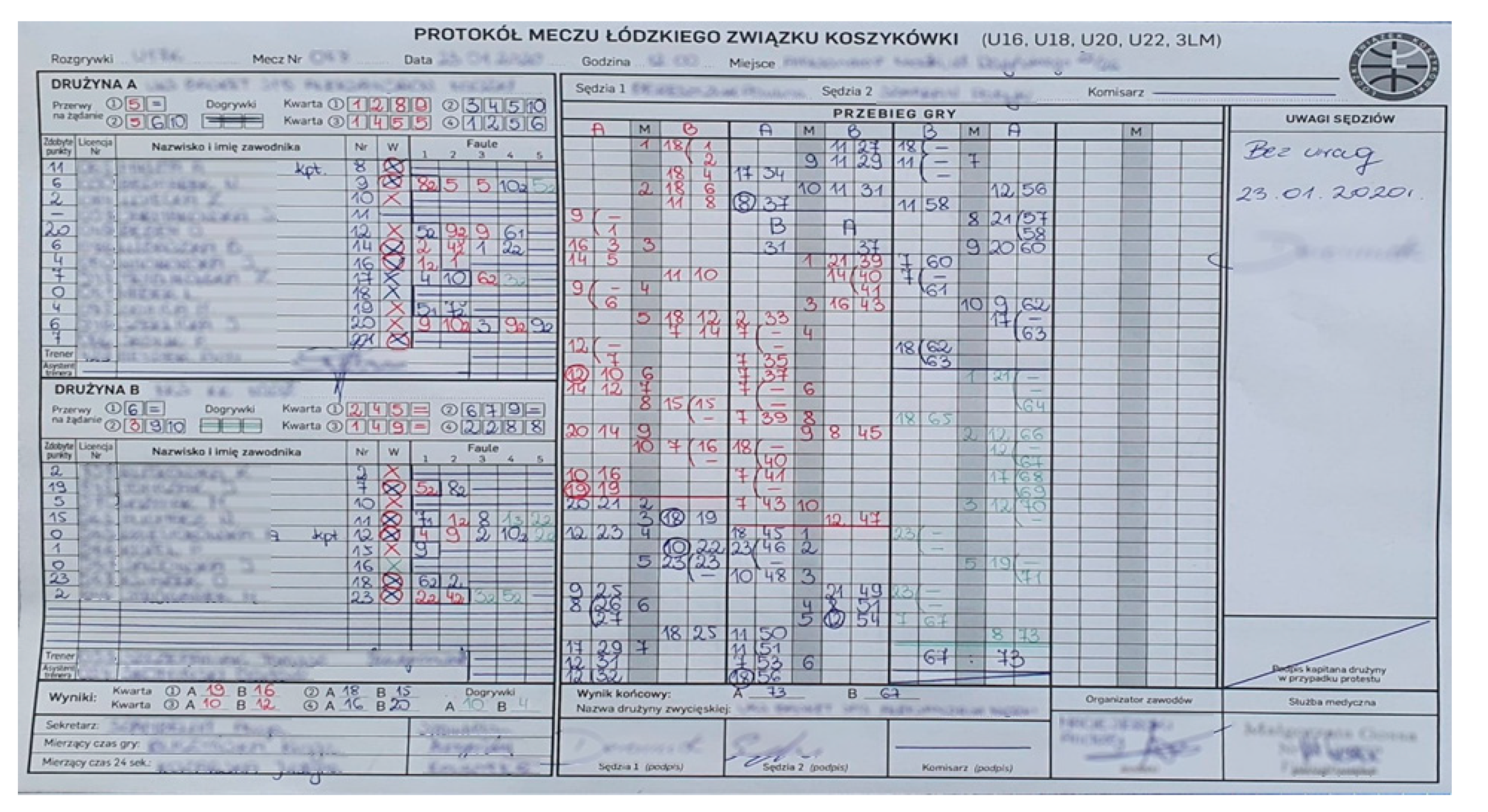
| Points Gained | License Number | Name | Number | 1st Squad | Fouls | ||||
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | |||||
| 10 | 0001 | John Smith | 7 | X | 6 | ||||
| 3 | 0002 | Edmund High | 10 | 2 | 5 | 72 | |||
- A given minute is entered only once, even if there are several baskets in it.
- If a three-point throw was hit, circle the player’s number
- If there are free throws (one, two or three), then in the right-hand column in the “A” or “B” column, we enter the left-hand bracket in the height of one, two or three boxes, depending on the number of throws. We only enter the player’s number once during the first throw. An accurate throw is marked by entering the next point in a given box. The missed throw is marked with “-”.


- An ordinary foul is marked with a minute next to the name of the fouling player.
- The foul with free throws is marked with the minute with the free throws number in the subscript, next to the name of the fouling player.
- Intentional/unsportsmanlike, technical and disqualifying fouls are marked as foul with personal throws, but additionally, in the superscript, we enter a letter denoting the type of foul.
References
- FIBA. Regulations for European Club Competitions. Available online: https://www.fiba.basketball/europe/RegulationsforEuropeanClubCompetitions2020-21.pdf (accessed on 31 October 2021).
- Itonori, K. Table structure recognition based on textblock arrangement and ruled line position. In Proceedings of the 2nd International Conference on Document Analysis and Recognition (ICDAR 93), Tsukuba Science City, Japan, 20–22 October 1993. [Google Scholar]
- Nazir, D.; Hashmi, K.A.; Pagani, A.; Liwicki, M.; Stricker, D.; Afzal, M.Z. HybridTabNet: Towards better table detection in scanned document images. Appl. Sci. 2021, 11, 8396. [Google Scholar] [CrossRef]
- Green, E.; Krishnamoorthy, M. Recognition of tables using table grammars. In Proceedings of the Fourth Annual Symposium on Document Analysis and Information Retrieval, Las Vegas, Nevada, 24–26 April 1995. [Google Scholar]
- Zucker, A.; Belkada, Y.; Vu, H.; Nguyen, V.N. ClusTi: Clustering method for table structure recognition in scanned images. Mob. Networks Appl. 2021, 26, 1765–1776. [Google Scholar] [CrossRef]
- Adiga, D.; Bhat, S.A.; Shah, M.B.; Vyeth, V. Table Structure Recognition Based on Cell Relationship, a Bottom-Up Approach. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 5–6 September 2019. [Google Scholar]
- Chi, Z.; Huang, H.; Xu, H.-D.; Yu, H.; Yin, W.; Mao, X.-L. Complicated table structure recognition. arXiv 2019, arXiv:1908.04729. [Google Scholar]
- Ahlawat, S.; Choudhary, A.; Nayyar, A.; Singh, S.; Yoon, B. Improved handwritten digit recognition using convolutional neural networks (CNN). Sensors 2020, 20, 3344. [Google Scholar] [CrossRef] [PubMed]
- Albahli, S.; Alhassan, F.; Albattah, W.; Khan, R.U. Handwritten digit recognition: Hyperparameters-based analysis. Appl. Sci. 2020, 10, 5988. [Google Scholar] [CrossRef]
- Ali, S.; Li, J.; Pei, Y.; Aslam, M.S.; Shaukat, Z.; Azeem, M. An effective and improved CNN-ELM classifier for handwritten digits recognition and classification. Symmetry 2020, 12, 1742. [Google Scholar] [CrossRef]
- Matan, O.; Burges, C.J.; LeCun, Y.; Denker, J.S. Multi-digit recognition using a space displacement neural network. In Advances in Neural Information Processing Systems; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 1992. [Google Scholar]
- Yang, X.; Pu, J. MDig: Multi-Digit Recognition Using Convolutional Neural Network on Mobile. 2015. Available online: https://web.stanford.edu/class/cs231m/projects/final-report-yang-pu.pdf (accessed on 20 September 2021).
- Ciresan, D. Avoiding segmentation in multi-digit numeral string recognition by combining single and two-digit classifiers trained without negative examples. In Proceedings of the 2008 10th International Symposium on Symbolic and Numeric Algorithms for Scientific Computing, Timisoara, Romania, 26–29 September 2008. [Google Scholar]
- Goodfellow, J.; Bulatov, Y.; Ibarz, J.; Arnoud, S.; Shet, V. Multi-digit number recognition from street view imagery using deep convolutional neural networks. arXiv 2013, arXiv:1312.6082. [Google Scholar]
- Ogbeiwi, O. Why written objectives need to be really SMART. Br. J. Healthc. Manag. 2017, 23, 324–336. [Google Scholar] [CrossRef]
- Valenzuela, F. Marketing: A Snapshot; Pearson Higher Education AU: London, UK, 2013. [Google Scholar]
- Hailes, J. Business Analysis Based on BABOK® Guide Version 2—A Pocket Guide; Van Haren: Hertogenbosch, The Netherlands, 2014. [Google Scholar]
- Dobbs, M.E. Guidelines for applying Porter’s five forces framework: A set of industry analysis templates. Compet. Rev. 2014, 24, 32–45. [Google Scholar] [CrossRef]







Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chomątek, Ł.; Sierakowska, K. Automation of Basketball Match Data Management. Information 2021, 12, 461. https://doi.org/10.3390/info12110461
Chomątek Ł, Sierakowska K. Automation of Basketball Match Data Management. Information. 2021; 12(11):461. https://doi.org/10.3390/info12110461
Chicago/Turabian StyleChomątek, Łukasz, and Kinga Sierakowska. 2021. "Automation of Basketball Match Data Management" Information 12, no. 11: 461. https://doi.org/10.3390/info12110461
APA StyleChomątek, Ł., & Sierakowska, K. (2021). Automation of Basketball Match Data Management. Information, 12(11), 461. https://doi.org/10.3390/info12110461