1. Introduction
Handwritten digit recognition is a challenging problem in computer vision and pattern recognition; this problem has been studied intensively for many years, and numerous techniques and methods, such as K nearest neighbors (KNNs) [
1], support vector machines (SVMs) [
2], neural networks (NNs) [
3], and convolutional NNs (CNNs) [
2,
4] have been proposed. Reasonable results have been obtained using datasets with different languages.
Arabic is the main language in the Middle East and the North of Africa, and is spoken widely in many other countries. Statistically, Arabic is one of the top five spoken languages in the present world [
5,
6]. Arabic numbers are widely important in the regions that write in Arabic. Digit handwritten recognition has received much attention recently because of its wide applications in different fields, such as criminal evidence, office computerization, check verification, and data entry applications. The wide use of those numbers makes the recognition process of these numbers an important field of interest [
1]. However, most research has been focused on English digits related to the English language and some other European languages; apparently, English handwriting datasets are widely available, and significant results have been achieved [
2,
7]. By contrast, little work has been proposed for Arabic handwriting digit recognition due to the complexity of the Arabic language and the lack of public Arabic handwriting digit datasets. Arabic handwritten digit recognition suffers from many challenges, such as writing style, size, shape, and slant variations, as well as image noise, thereby leading to changes in numeral topology [
8].To address these challenges, we consider a solution that focuses on the design of an efficient method that can recognize Arabic handwritten digits that are submitted by users via digital devices.
Three main techniques—namely, preprocessing, feature extraction, and classification [
7]—are usually used to design an efficient method in pattern recognition. Preprocessing is used to enhance data quality and extract the relevant textual parts and prepare for the recognition process. The main objectives of preprocessing are dimensional reduction, feature extraction, and compression in the amount of information to be retained, among others [
9]. The output of the preprocessing produces clean data that can be used directly and efficiently in the feature extraction stage. Meanwhile, feature extraction is the main key factor that affects the success of any recognition method. However, traditional hand-designed feature extraction techniques are tedious and time consuming, and cannot process raw images, in comparison to automatic feature extraction methods by which useful features can be retrieved directly from images. Szarvas, et al. [
10] showed that the CNN–SVM combination exhibits good performance in pedestrian detection by use of the automatically optimized features learned by the CNN. Mori et al. [
11] used the time domain encoding schemes by modules with different parts of images to train the convolutional spiking NN. In their method, the output of each layer is fed as features to the SVM and 100% face recognition accuracy is obtained on the 600 images of 20 people. Furthermore, the authors in [
12] presented an automatic feature extraction method based on CNN. By using the trainable feature extractor plus affine distortions and elastic distortions, the proposed method obtains low error rates of 0.54% and 0.56% for the handwritten digit recognition problem. Therefore, the feature extraction techniques consider the most important steps to increase classification performance; several feature extraction methods are available in [
13,
14,
15,
16,
17,
18].
The final step in handwritten digit recognition application is image classification, which is a branch of computer vision, and has been extensively applied in many real-world contexts, such as handwriting image classification [
1,
19], facial recognition [
20], remote sensing [
21], and hyperspectral image [
22]. Image classification aims to classify sets of images into specified classes. Two types of classification methods in computer vision—namely, the appearance-based method and the feature-based method—are used to classify images. The most commonly used method in literature is the feature-based method, which extracts features from the images and then uses these features directly to improve the classification results [
23]. In recent years, finding an effective algorithm for feature extraction has become an important issue in object recognition and image classification. Recent developments in graphic processing unit (GPU) technology and artificial intelligence, such as deep learning algorithms, present promising results in image classification and feature extraction. Therefore, in this study, we emphasize the use of deep learning algorithms for the handwritten digit recognition context.
Deep learning algorithms comprise a subset of machine learning techniques that use multiple levels of distributed representations to learn high-level abstractions in data. At present, numerous traditional artificial intelligence problems, such as semantic parsing, transfer learning, and natural language processing [
2,
5,
24], have been solved using deep learning algorithm techniques. The main properties of deep learning methods are that they learn the effect and perform high-level feature extraction by use of the deep architectures in an unsupervised manner without considering the label data [
25]. To achieve this goal, layers of network are arranged hierarchically to form a deep architecture. Each layer in the network learns a new representation from its previous layer with the goal of modeling different explanatory factors of variation behind the data [
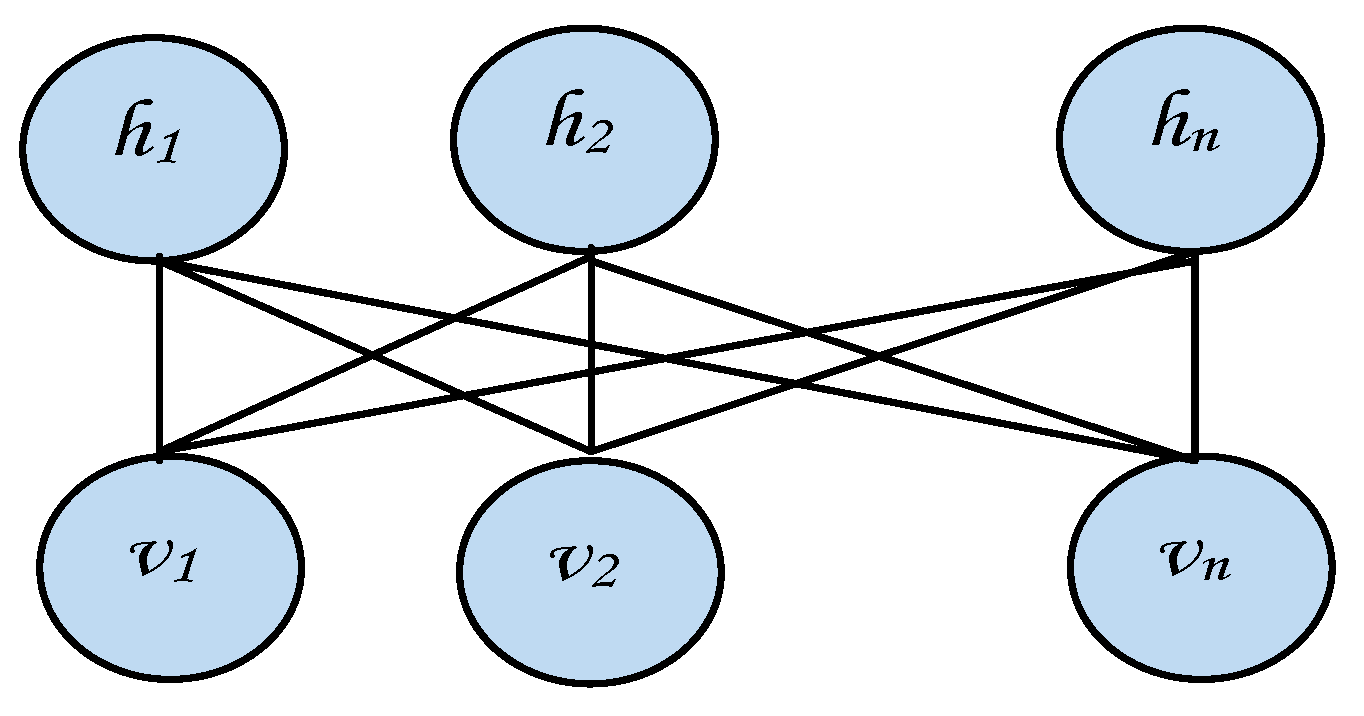
26]. Deep learning algorithms, such as the restricted Boltzmann machine (RBM), involve a powerful feature learning technique using hierarchical deep architectures in an unsupervised manner. RBM is a generative algorithm with a high capability to extract discriminative features from complex datasets in an unsupervised manner, and has been applied in numerous learning domains, including text, speech, and images [
27]. CNN is a multilayer NN that can be viewed as the combination of an automatic feature extractor and a trainable classifier. The past few years have borne witness to the increasing popularity of CNN in many different domains such as image classification [
28,
29] and object and face detection [
20,
30] over many benchmark datasets.
Numerous digit handwritten recognition methods based on different feature extraction and classifier techniques have been developed. In the last few years, the Latin digit recognition problem has been extensively researched, and a novel CNN–SVM model for handwritten Latin digit recognition was proposed in [
2]. The proposed model uses the power of the CNN algorithm to extract the features from the images, and these features are fed to the SVM to generate the predictions. Furthermore, the authors in this work used non-saturating neurons with the efficient GPU implementation of the convolution operation to reduce overfitting in fully connected layers. Ouafae et al. [
31] presented a new handwritten digit recognition system using characteristic loci (CL). In their method, each numeral image is divided into four portions, and then the CL is derived from each portion of the image. This work adopted two types of classifiers in the classification stage: multilayer perception and KNN classifiers. Nibaran Das et al. [
5] presented a handwritten digit recognition technique using a novel method that utilizes an MLP in which a set of 88 features is used. The feature set is divided into 72 shadow features and 16 octant features. The authors in [
4] proposed a CNN deep learning algorithm that uses an appropriate activation function and a regularization layer for Arabic handwritten digit recognition, thereby resulting in significantly improved accuracy compared to that of existing Arabic digit recognition methods. The authors in [
32] proposed a handwritten digit recognition method using the perceptual shape decomposition (PSD) algorithm. The proposed approach represents the deformed digits with four salient visual primitives—namely, closure, smooth curve, protrusion, and straight segment—by defining a set of external symmetry axes. The primitives are derived using an efficient set of external symmetry axes based on parallel external chords. The performance of the proposed recognition system was evaluated on five-digit datasets that involve the CMATERDB 3.3.1 Arabic digit dataset. The recognition accuracy on Arabic CMATERDB 3.3.1 was found to be 97.96. Finally, the authors in [
33] presented and compared the RBM model along with SVM and sparse RBM-SVM using the MNIST dataset, and the results were 96.9 and 97.5, respectively. The classification results showed the advantage of RBM models compared with other variants and that all RBM methods perform well in terms of classification accuracy.
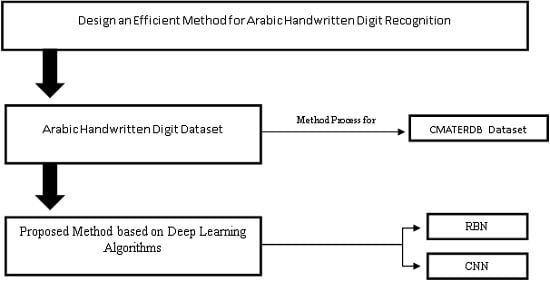
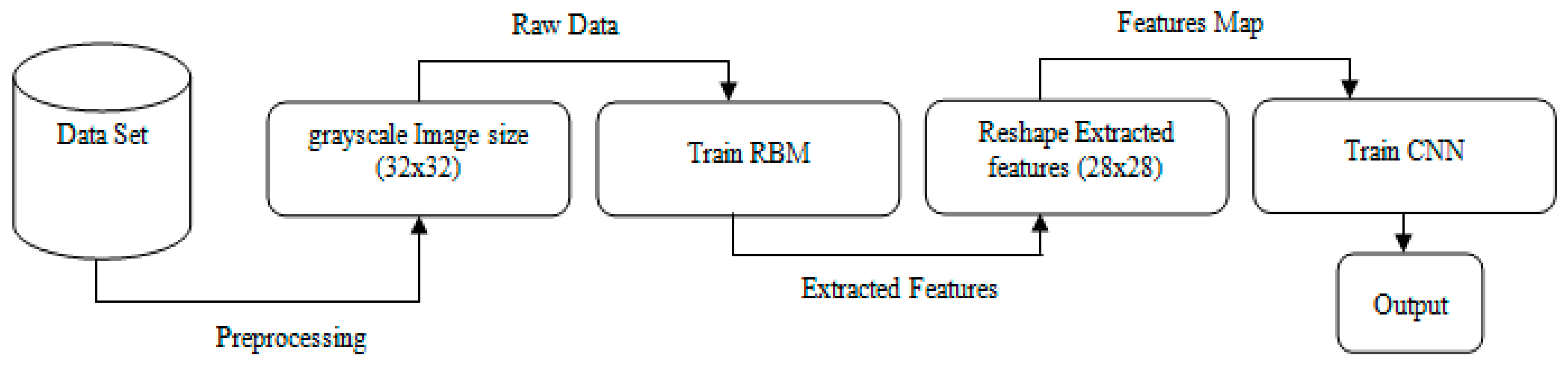
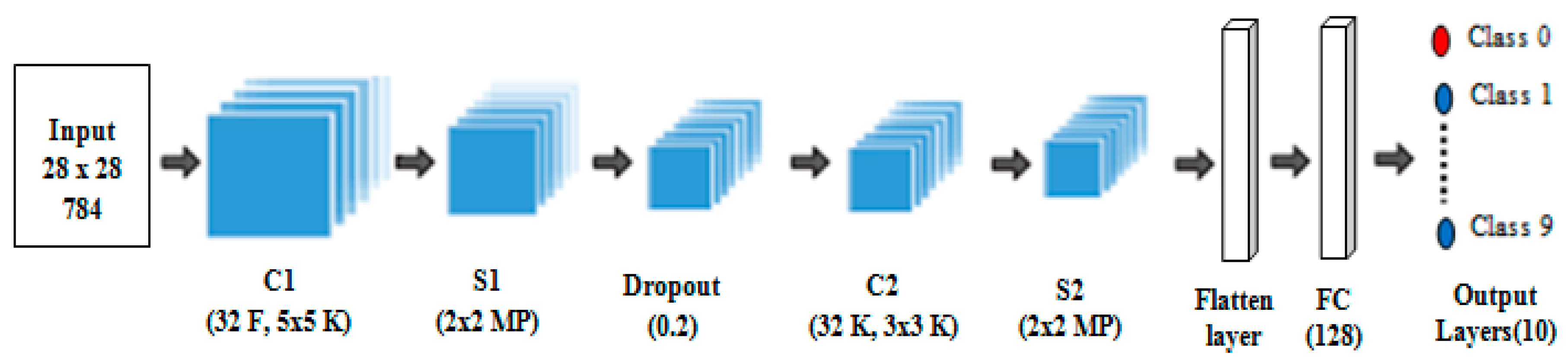
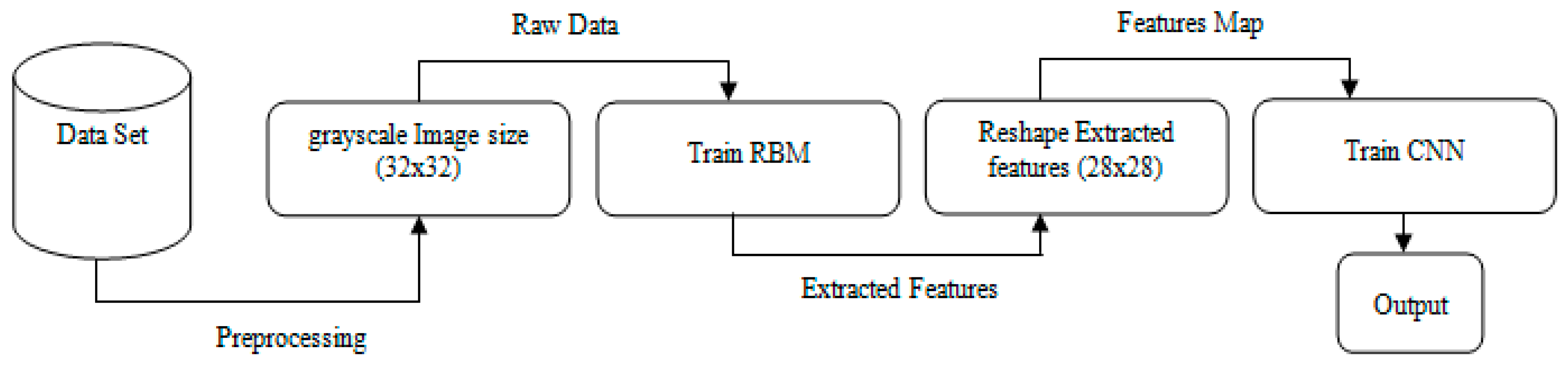
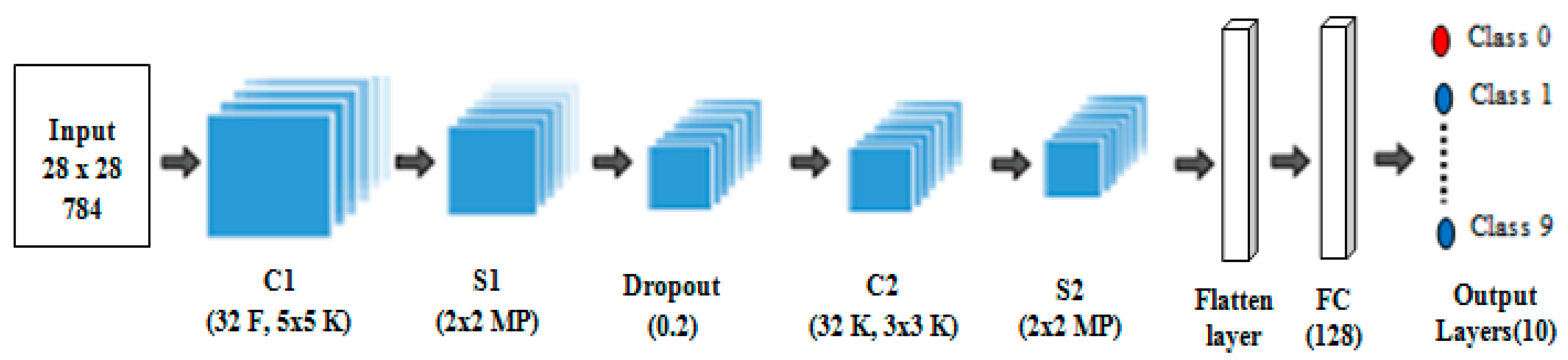
The main challenges in the handwritten recognition process are the distortions and enormous variability patterns. Therefore, any successful recognition system and image classification require an active and accurate feature extraction technique that can provide distinct features that can be used to distinguish between different numeral handwritten images effectively. Furthermore, an accurate classifier is required to compute the exact distance between the feature vectors of the test and dataset numeral handwritten images. However, most previously proposed methods select only a small number of features as the input, and thus produce insufficient information for correctly predicting the object in the classification process. By contrast, a large number of input features will cause the generalization performance of the model to deteriorate, owing to the problems of dimensionality and increased run time for the training process. Hence, we propose the hybrid RBM–CNN model to address the aforementioned problems, and to introduce a novel method that uses strong feature extraction techniques. In our proposed method, we use the RBM deep learning algorithm, a popular feature extraction technique, to learn and extract features that are optimized and used for classification. Then, the extracted features are fed to the CNN after reshaping for classification. The performance of the proposed method is evaluated using the CMATERDB 3.3.1 Arabic handwritten digit dataset [
32,
34]. The rest of this article is structured as follows.
Section 2 presents the proposed method and provides the basic concept for the used algorithms.
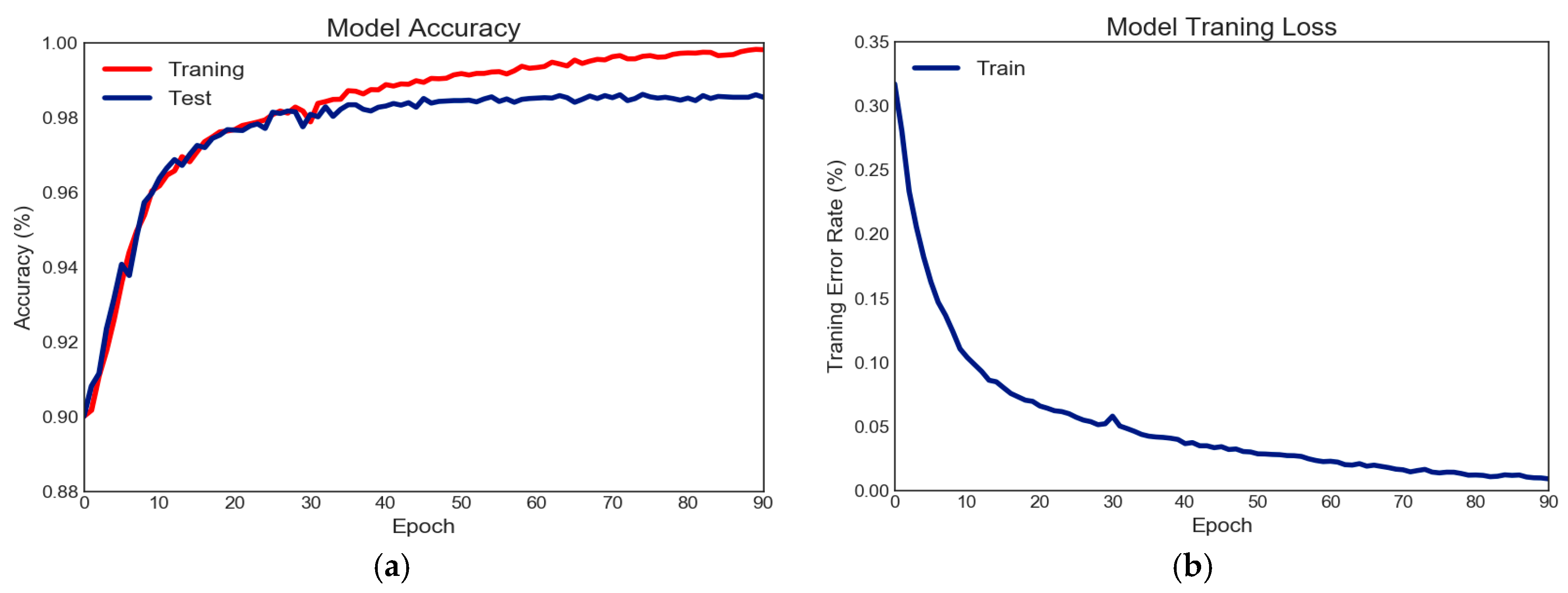
Section 3 presents the analysis of the experiment results.
Section 4 discusses the results of the proposed method with a relevant literature comparison.
Section 5 elaborates the conclusion of the study with a summary.


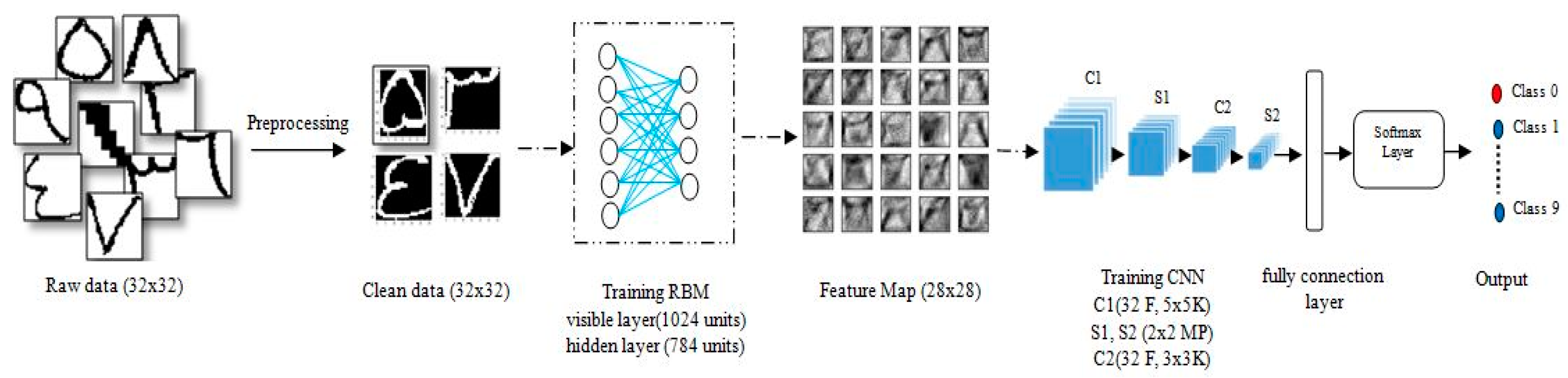
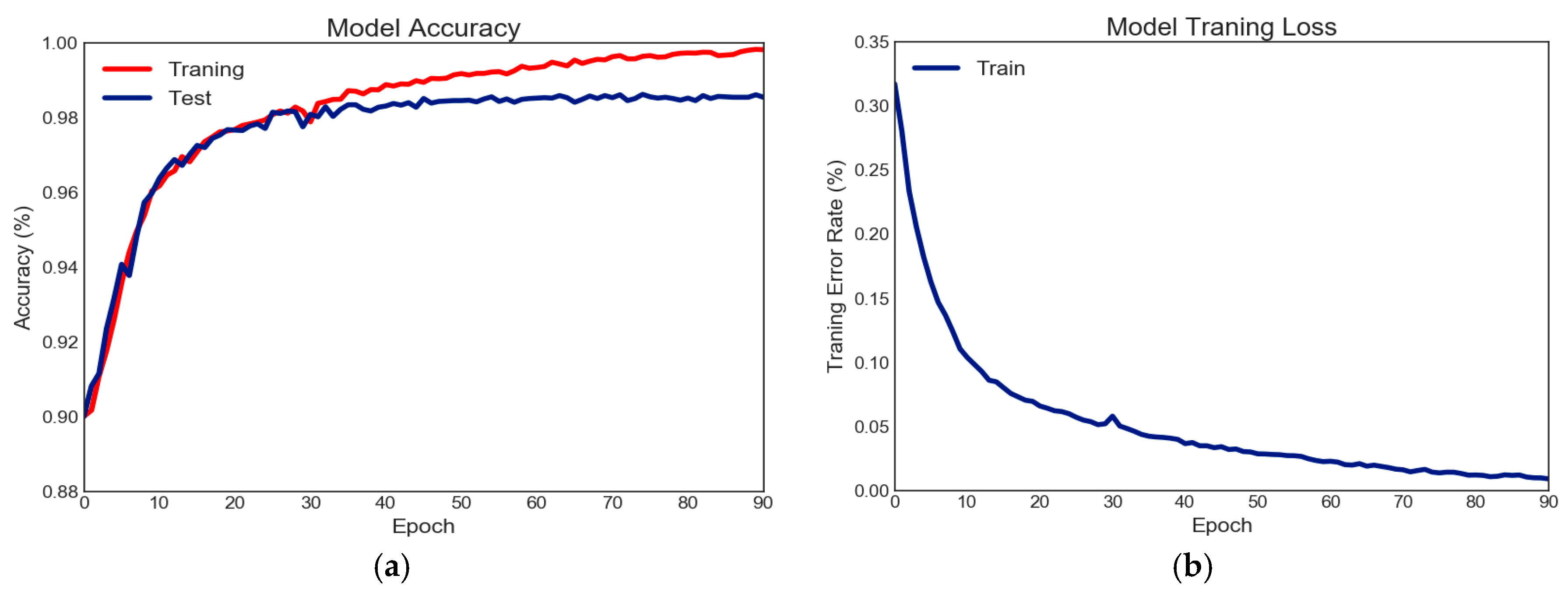
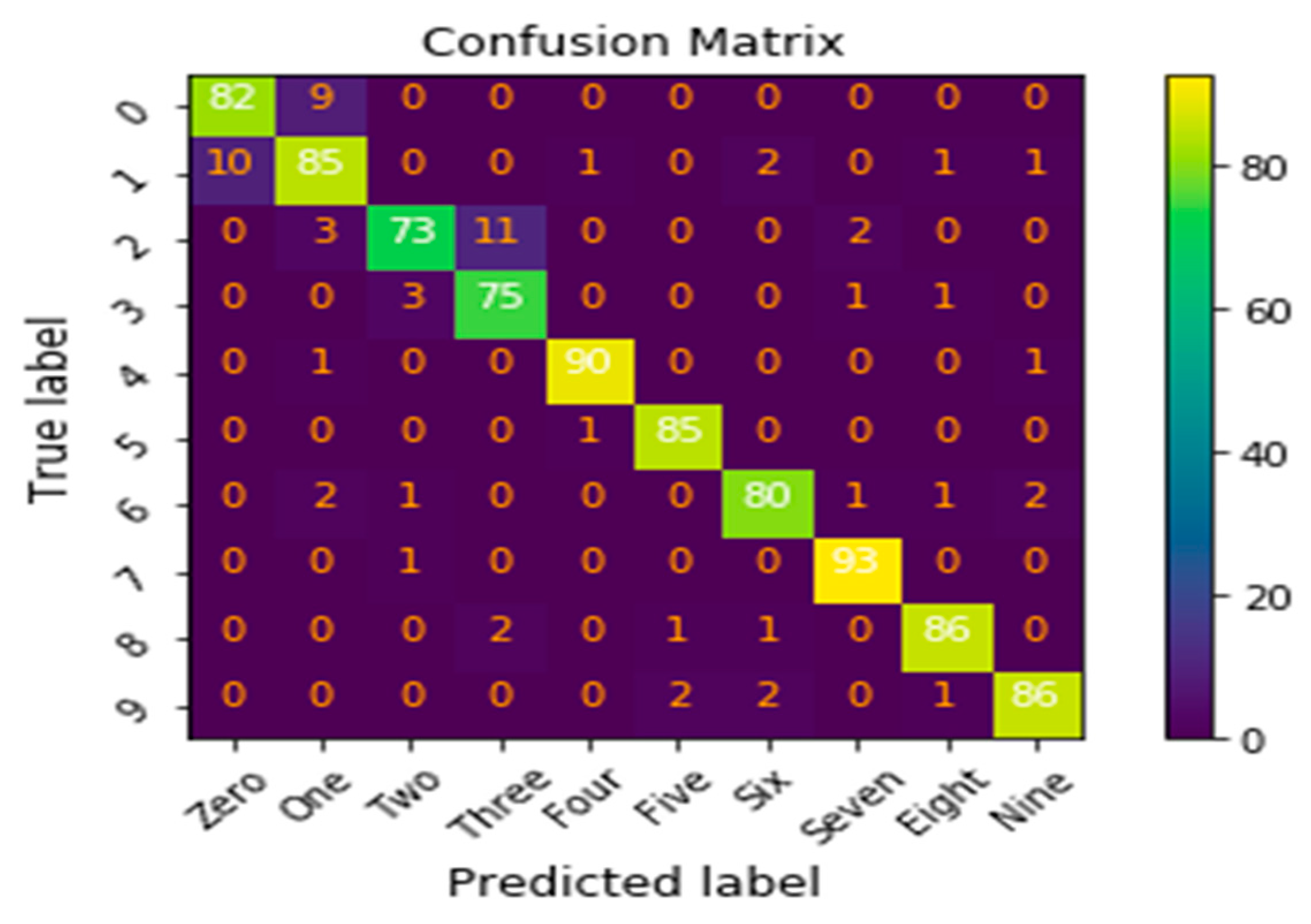

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}