1. Introduction
With the increasing application of cloud computing, a vast amount of data is stored in the cloud for processing. However, a significant portion of this data is sensitive and requires encryption to ensure its security. Traditional symmetric encryption methods, when applied to share encrypted files with multiple parties, necessitate the use of different symmetric keys for each encryption and decryption instance. This lack of flexibility in sharing and the complexity of key management pose challenges.
Attribute-based encryption (ABE) [
1] emerges as a flexible solution that supports one-to-many encryption, providing an effective means to address the aforementioned challenges. The fundamental concept of ABE involves associating ciphertext and keys with attribute sets and access structures. ABE is generally categorized into Key Policy Attribute-Based Encryption (KP-ABE) [
2] and Ciphertext Policy Attribute-Based Encryption (CP-ABE) [
3]. KP-ABE involves the user’s key incorporating an access structure (access policy), and the ciphertext aligns with a series of attribute sets. The user can correctly decrypt the ciphertext only if the attribute set of the ciphertext satisfies the access structure (access policy) of the user key. This approach is suitable for static scenarios where users are the principal entities and only specific ciphertexts matching their access policies can be decrypted. On the other hand, CP-ABE associates the user’s key with a set of attributes, and the ciphertext contains an access structure (access policy). The user can correctly decrypt the ciphertext only if their attribute set aligns with the access structure (access policy) of the ciphertext. This design is more applicable to real-world scenarios where each user acquires keys from the Key Generation Center (KGC) based on their own attributes. Subsequently, the data owner encrypts the data with an access structure (access policy).
Therefore, CP-ABE is highly compatible with cloud computing. When implementing CP-ABE in cloud computing scenarios, users in possession of data can define an access structure (access policy) for the encrypted data. Only unique users whose attributes satisfy the access structure (access policy) can accurately decrypt the ciphertext. Consequently, there is no need for the user to replicate the encryption of the data when sharing it. This not only eliminates redundancy but also enhances flexibility for data owners in sharing data, thanks to the customizable access structure (access policy) settings.
While CP-ABE presents an algorithm based on public key cryptography capable of achieving precise access control functions, it encounters key escrow issues in practical applications. In traditional CP-ABE [
4,
5,
6], users transmit their attribute sets to the KGC, which then generates the corresponding private key based on the user’s attributes. Subsequently, the user encrypts and shares files using this private key. It is evident in this process that KGC gains knowledge of the specific attributes of the user. In real-world usage scenarios, KGC acts as an honest but curious entity. The attributes involved are personal and private information for users who are understandably reluctant to disclose it. Consequently, users express concerns about the potential compromise of their privacy. To address this issue, some solutions currently implemented involve concealing the access structure [
7,
8,
9]. However, this hidden access structure primarily addresses privacy protection against malicious access by unauthorized users. Another approach is the joint generation of private keys by multiple KGCs [
10,
11]. While this solution prevents attributes from being exclusively known by a single KGC, it does not entirely resolve the problem of user privacy exposure to any KGC. The pursuit of a robust solution to diminish the risk of privacy leakage in CP-ABE continues to be a formidable challenge.
Addressing the aforementioned concerns, we propose that the -out-of- oblivious transfer protocol emerge as a potent solution. Fundamentally, the KGC maintains a set comprising attributes. Users are allowed to selectively choose attributes (where < ) that resonate with their individual sets from these attributes. Following this, users encrypt the chosen attributes and convey them to the KGC. Consequently, the KGC, leveraging these attributes, formulates the corresponding private key and allocates it to the users. A crucial aspect of this procedure is the KGC’s lack of awareness concerning the specific attributes chosen by the users, ensuring that the particulars used in the private key’s generation remain concealed. This method significantly bolsters user privacy safeguards in cloud computing contexts. Thus, the application of the -out-of- oblivious transfer protocol is elucidated as a proficient approach, augmenting privacy safeguards while preserving the intrinsic functionality of attribute-based encryption.
2. Related Work
Originally, ABE was limited to executing threshold operations, and its policy expression lacked the necessary versatility. Subsequently, researchers proposed ABE mechanisms based on ciphertext policy and key policy. These advancements broadened the scope of attribute operations and facilitated the implementation of flexible access control policies.
In CP-ABE, the user’s key is identified by an attribute set, and the ciphertext is associated with the access structure. Before data is encrypted, the data owner is aware of the type of user permitted to access it. In the majority of CP-ABE scenarios, the access structure is made public. To protect the privacy of the data owner’s private attributes contained in the access structure, various research works on hiding access structures have been proposed. These works are primarily categorized into two groups: CP-ABE schemes that partially hide the access structure and CP-ABE schemes that fully hide the access structure. Kapadia [
12] proposed a CP-ABE scheme capable of hiding the access policy. This method achieves policy hiding by re-encrypting the ciphertext for each user, introducing an online semi-trusted server. However, this method makes the server the bottleneck of the entire system in terms of efficiency and security.
To enhance the access structure’s flexibility in access control capabilities, Xu [
13] utilized the tree access structure to implement a CP-ABE scheme capable of hiding the access policy. This scheme not only protects policies but also offers flexible access control capabilities. Zhang [
14] introduced a CP-ABE scheme supporting partially hidden access structures (PHAS). Since attribute values are concealed in the ciphertext, users cannot directly judge the equivalence between their attributes and those in the access structure. They designed a DeJudge algorithm that uses linear algebra operations and LSSS monotonicity to help users calculate attributes, determining whether the set satisfies the access structure. However, a limitation is that the DeJudge algorithm imposes a significant computational burden on users. Chase [
15] considered a distributed ABE scheme using the multi-authority model to address key escrow issues. They resolved challenges by involving multiple attribute authorities in the key generation process. However, the scheme’s performance is influenced by the number of attributes, and its access structure has limited expressiveness, supporting only AND gates, restricting data owners’ ability to formulate access policies. Zhao [
16] designed a scheme combining multiple attribute authorities and a central authority structure. In this scheme, each attribute authority controls a distinct attribute set and sends the attribute private key to the user. To enhance performance, their scheme employs online/offline encryption to improve online computing efficiency. It is evident that existing approaches for hiding access policies often involve increased computing overhead or the incorporation of outsourced computing servers in the calculation process.
In addition to hiding the access structure, some ABE solutions achieve privacy protection through user key tracking. Liu [
17] proposed a CP-ABE scheme equipped with black-box traceability. In this scheme, the user’s key accompanies all supersets of the attribute set, making it identifiable to multiple users for decryption. Subsequently, ABE with black-box traceability [
18,
19,
20] has seen ongoing research on efficient tracking and revocation. Sethi [
21] introduced a multi-authority CP-ABE scheme with white-box traceability, policy updates, and outsourced decryption. This scheme supports distributed authority management and accommodates monotonic access structures.
Preserving user privacy is of utmost importance, especially in sensitive application contexts like electronic health records and personal data sharing. In these situations, safeguarding the confidentiality of user attributes is imperative to mitigate the risks associated with unauthorized disclosures. In instances where the KGC acts as an honest-but-curious entity, existing methods fall short of achieving optimal outcomes—they are proficient at safeguarding against post-leakage tracking but ineffective at preempting the leakage of user privacy. Therefore, our primary focus is to investigate strategies that prevent the leakage of users’ privacy to the KGC during the key generation phase, particularly when the KGC operates as an honest-but-curious entity. This approach is also aimed at safeguarding the KGC from malicious users who might attempt to traverse the entire attribute set controlled by the KGC through continuous registration and access, thereby ensuring the privacy of both parties.
Through our research, we have discovered that the oblivious transfer protocol presents a promising approach to addressing this issue. Oblivious transfer (OT) is a vital cryptographic protocol fundamental in the realm of secure multi-party computations, serving as a cornerstone for enhancing privacy and security across various cryptographic endeavors. In an oblivious transfer, two primary entities are involved: a sender possessing certain information and a receiver who wishes to acquire a segment of this information. Unique in its operation, the protocol allows the receiver to select a specific piece of information from the sender without revealing the choice. This attribute ensures the sanctity of the receiver’s privacy, maintaining the confidentiality of the selected information segment. Below, we will introduce the development of oblivious transfer protocols.
Oblivious transfer is frequently employed as a crucial primitive in the design of security protocols. The OT primitive was proposed by Rabin [
22]. In this scheme, the receiver can successfully decrypt the information sent by the sender with a probability of 1/2. After that, they even proposed a new 1-out-of-2 OT (
). In this scheme, the sender sends two encrypted messages to the receiver, and the receiver can only choose one of them to successfully decrypt. Brassard [
23] designed a 1-out-of-
OT (
) based on the former, and the receiver can choose one of the n messages from the sender to decrypt. Tzeng [
24] improved the efficiency of the
by combining distributed ideas and secret sharing techniques. Moreover,
-out-
OT (
) is a further extension of
, where
. Naor proposed the
protocol [
25] for the first time by using PRF. Under the premise of semi-honest receivers, the scheme mainly guarantees system security through onerous computation and communication expenses. In order to solve the above problems of high computational overhead and high communication costs, Chu [
26] proposed a
-out-
OT protocol, but it does not really solve the problem or minimize these costs. Tzeng [
27] proposed a
protocol that uses two different ROMs under the Computational Diffie-Hellman Problem (CDH) assumption to keep the system secure in the presence of malicious receivers.
Compared to the solutions previously discussed, hidden access structures can mitigate attribute leakage due to unauthorized user access, but they fail to shield user privacy from the KGC. Additionally, schemes involving multiple authorization centers are susceptible to collusion attacks, providing only partial attribute concealment from the KGC without completely obscuring individual attributes. In the context of key tracking solutions, their effectiveness is predominantly in post-event accountability, falling short of proactive user privacy protection. In contrast, our proposed method leverages the oblivious transfer protocol, safeguarding user attributes during the key generation phase. This approach ensures that an honest-but-curious KGC remains unaware of the specific attributes associated with a user’s private key during the key distribution process. The evolution of OT has inspired us, leading us to consider the utilization of for generating private keys in ABE. In simple terms, the KGC possesses attributes. When a user requests a private key from the KGC, the user selects attributes from the KGC. Consequently, the KGC remains unaware of the specific attributes selected by the user, thereby achieving privacy protection for the user.
4. Our Construction
In this area, we give the details of how to construct our scheme. We begin by explaining the system model and introducing its main algorithms and functions. Afterwards, we provide a description of our attribute-based encryption scheme with protocol. Finally, we will discuss the security analysis and experimentation of this scheme.
4.1. Notions
The notions utilized in this paper are enumerated in
Table 1.
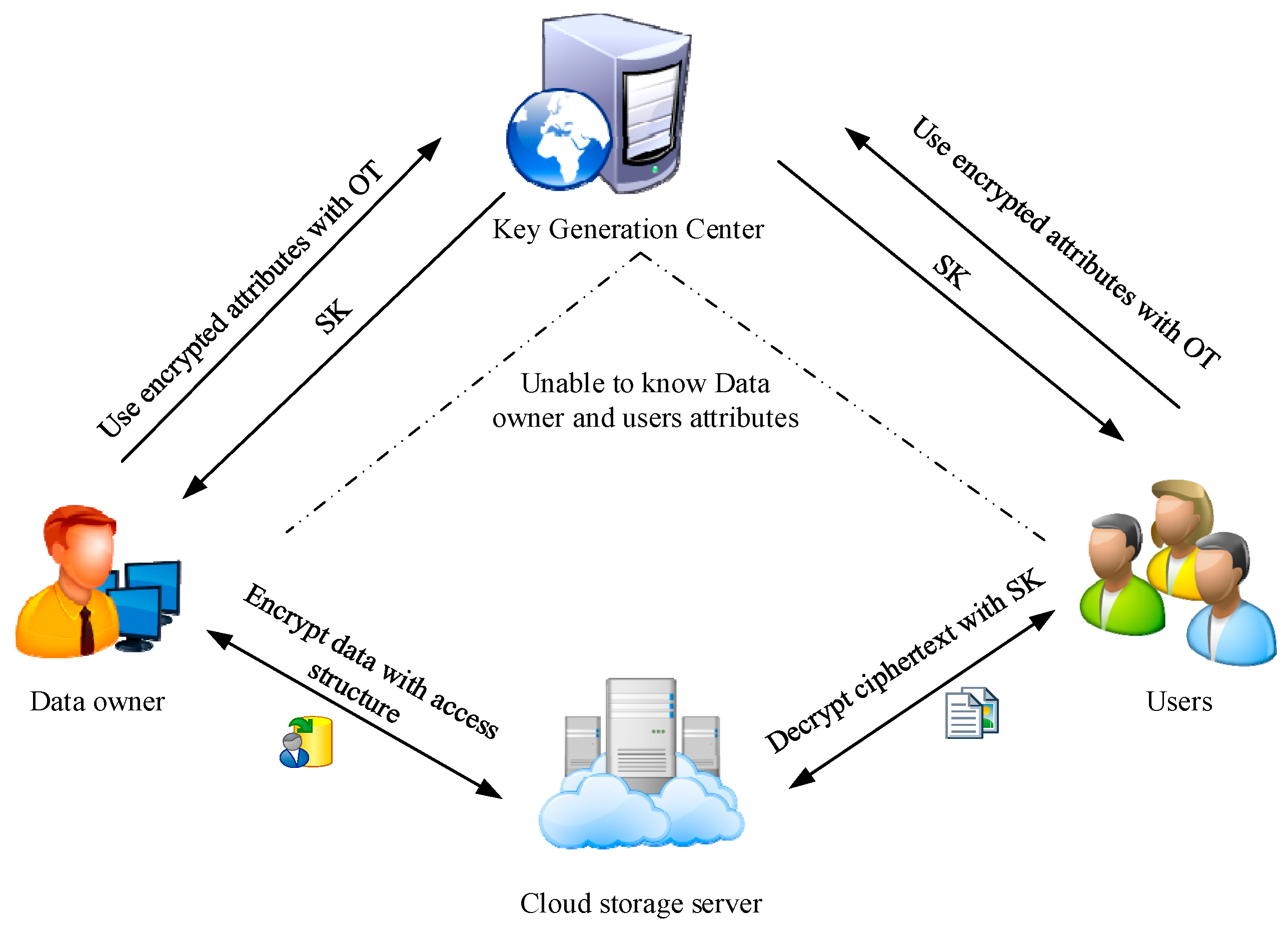
4.2. System Model
This paper proposes an attribute-based encryption with an oblivious transfer protocol, which mainly includes four parts: KGC, cloud storage server, data owner, and user. This scheme alleviates the problem of attribute privacy protection between the KGC and the user through the
protocol. The system model of CP-ABE with
is shown in
Figure 1. The scheme proposed in this paper includes the following four stages:
Setup ()(): The Setup algorithm is run by KGC. Input the security parameter λ, and the algorithm outputs the system public parameter and master private key . KGC publicizes and keeps secret.
Encrypt (): The encryption algorithm is run by the data owner. Input a system public parameter , a message , and the tree access structure , and the algorithm outputs ciphertext .
KeyGen (): The KeyGen algorithm is run by KGC and the user. Input a system public parameter and the user’s attributes and the algorithm outputs the user’s private key .
Decrypt (): The decryption algorithm is run by the user. Input ciphertext and the user’s private key , and the algorithm outputs the message .
4.3. Proposed Scheme
Setup ()(): The setup algorithm is run by KGC. Let be a cyclic additive group of prime order , and let be a generator of . In addition, let : denote the bilinear map, and let be a multiplicative group. Taking as input a security parameter and an attribute set and supposing the attribute is mapped to index for all . We will employ the hash functions H: that we would model as a random oracle. The construction is as follows:
- (1)
Choose a random and calculate . Pick two random exponents , and compute .
- (2)
The public parameters are published as , where and .
Encrypt (
)
: The algorithm of encryption is run by the data owner. Our encryption is based on the Bethencourt approach [
2]. It uses the tree access structure
to encrypt the message
. The details are as follows:
- (1)
Choose a polynomial for each node or leaf in the tree . For each node in the , set the degree of the polynomial to be one less than the threshold value of that node, that is, . We use a top-down approach to pick these polynomials, and it begins with the root node . First, the algorithm randomly chooses a and initializes . Then, it chooses other points of the polynomial randomly to define it entirely. For another node , it sets and chooses other points randomly to entirely define .
- (2)
On input the set of leaf nodes , then compute , , . Inputting a message , compute .
The data owner outputs ciphertext .
KeyGen(). The algorithm for key generation is run by the user and KGC. Users give the attribute to KGC, and KGC outputs the key associated with that . To prevent KGC from learning the key consistent with a set of attributes , we combine the idea of k-out-of-n oblivious transfer protocol. The details are as follows:
- (1)
KGC uses its to compute , . Then, on input user , compute , reply for the user.
- (2)
The user sets to denote the number of these attributes according to , and randomly chooses . Then computes , where and . Afterwards, the user randomly chooses and computes . Then the user computes a signature , where , and . Finally, user output .
- (3)
When KGC receives the , it first computes , verifying . If it is false, output ; otherwise, randomly chooses and computes .
- (4)
Afterwards, KGC randomly chooses a , and then randomly chooses for each attribute . Then it computes the key message as , where , . Moreover, , , and is a number from to in order.
- (5)
KGC randomly chooses and computes and outputs signature , where and . Finally, KGC outputs .
- (6)
When the user receives the , it first computes , verifying . If it is false, output ; otherwise, compute . Finally, the user obtains .
Decrypt (): The decryption procedure is run by the user. We define the following recursive algorithm:
- (1)
If the node is a leaf node, we can let and define it as follows: If , the user executes the recursive algorithm , otherwise output
- (2)
If the node
is a non-leaf node, for all nodes
that are children of
, it calls
and stores the output as
. Let
be an arbitrary
-sized set of child nodes
such that
. If no such set exists, then the node was not satisfied, and the function returned
. Otherwise, the user computes:
- (3)
If the tree is satisfied by , user set , and computes . If it is false, output ; otherwise, output as the decryption of the ciphertext.
Figure 2 is a schematic diagram of the algorithm steps and data flow of our solution.
5. Security Analysis
In this area, we analyze the security of this protocol and prove that the protocol can achieve KGC’s privacy and the user’s privacy protection.
Security Assumptions. For our attribute-based encryption scheme with the protocol against malicious users, we will use two hardness problem assumptions: one is the Decisional Diffie-Hellman (DDH) problem, and the other is the Chosen-Target Computational Diffie-Hellman (CT-CDH) problem.
Assumption 1. Decisional Diffie-Hellman assumption. Let , where are two primes, and let be the subgroup of with order . The following two distribution ensembles are computationally indistinguishable:
, where is a generator of and randomly chooses .
, where is a generator of and randomly chooses .
Assumption 2. Chosen-Target Computational Diffie-Hellman assumption. Let be a group of prime order , be a generator of , and randomly choose . Let be a cryptographic hash function. The adversary is given input and two oracles: the target oracle that returns a random element at the -th query and the helper oracle that returns . Let and be the number of queries made to the target oracle and helper oracle, respectively. The probability that outputs pairs , where for , , is negligible.
Theorem 1. The proposed protocol can realize the protection of users’ privacy.
Proof. During the key distribution process, the user selected the number of some attributes from the all attribute collection . First, the user hashed and randomized by and , and output . We maintain that the choice can only be known by the user themselves and not by anyone else. Due to the computational difficulty of the DDH problem, even if the adversary has the ability to obtain the user’s private key , they would still be unable to obtain from . In other words, it is impossible for adversary to determine as they are unable to compute and therefore cannot obtain any information about it. Let ; that is to say, all the possible pairs satisfying the equation together constitute . Given a value and a fixed value of , there exists only one unique value of that satisfies the equation. From the definition of a hash function, we know that if a specific value of is given, then it is possible to uniquely determine the corresponding value of and . There is a one-to-one correspondence between and . Given this fact, we can observe that there are pairs in , with the dimension of being . Specifically, ; this means that, upon seeing a particular , there is no way to reveal the user’s choice other than guesswork. Therefore, the proposed protocol has the ability to protect users’ privacy. □
Theorem 2. The proposed protocol can realize the protection of KGC’s privacy.
Proof. We can prove that under Arguments 1 and 2, it is computationally impossible for the malicious user to obtain the th message. Specifically, for argument (1), should pursue the scheme steps to generate the values of and ; on the contrary, fails to get the selected messages that it intended. In arguments (2), we will prove that cannot obtain the th messages other than his choice, because when he tries to obtain the th messages, he is actually solving the difficult problem of the CT-CDH problem. □
Argument 1. must comply with the scheme to calculate the values of and , for to ; if not, cannot receive the messages that it has chosen.
Next, we will discuss in detail three cases: (a) fakes but makes honest; (b) counterfeits but honestly generates ; and (c) forges the values of and .
(a) fakes but makes honestly. Suppose is dishonest in calculating , but honestly calculating as given in the scheme. Let us suppose the computes and chooses an at random to replace . Then, the KGC will compute and return them to . In consequence, is unable to decrypt to receive the messages since is certainly not equal to . For obtaining the messages, the can only compute equal to by obtaining KGC’s private key and one-time secrecy . However, this is computationally infeasible because extracting from is a DDH problem.
(b) fakes but forms honestly. Suppose is dishonest in calculating , and honestly generates as given in the scheme. Let us suppose, the computes , and chooses at random to replace . Then, the KGC will compute , , for , and return them to . In consequence, unable decrypt since = is certainly not equal to . For obtaining the messages, the can only compute equal to by obtaining KGC’s private key and one-time secrecy . However, this is computationally infeasible because extracting from is a DDH problem.
(c) fakes both the values of and . Let us suppose the chooses at random to replace and fakes as . Under the assumption, the value of is calculated by the sender as well as the ciphertexts for . Although is aware of the value of (because it is exactly equal to the obtained from KGC), it still cannot calculate in the absence of knowledge of . According to the above description, we know that when is and is , cannot get . In addition, probably sets as , where is a random value in . In conclusion, under the violation of calculating the values of and , was unable to acquire the chosen messages.
Argument 2. If accompanies the scheme truthfully to get messages, though it wants to process the message, afterwards it would confront the tough CT-CDH problem with the assumption of a random oracle.
The intends to get messages means would possess the awareness of , in fact, according to argument (1), an honest user should have knowledge of values, where , for , whereas , for and j . Let suppose and . In consonance with argument (1), for acquiring the selected message, is unable to modify the structures of and . In these conditions can only be decomposed into = since and . Furthermore, under the assumption of random oracle and the fact that is able to learn the and , could be expressed as , where = and is a random element. Thereafter, the malicious actually encounters the determination of the pair with the awareness of pairs of , where , but without the awareness of KGC’s secrecy (because it is DDH difficult problem for calculating from ). Consequently, the user was unable to get the th message.
In accordance with Arguments 1 and 2, we have proven Theorem 2 that our scheme is able to realize the protection of KGC’s privacy.
6. Experiment and Evaluation
In this part, we will verify the effectiveness of this scheme with respect to theoretical examination and experimental verification.
Theoretical examination: To be fair, we only consider the adopt tree structure CP-ABE scheme.
Table 2 shows the comparison of the properties between the schemes. From
Table 2, we can know that our solution is aimed at protecting the user’s attribute privacy from being known by KGC under the condition that KGC is honest and curious. At the same time, our solution does not require multiple authorization centers or additional outsourced calculations. In
Table 3 and
Table 4, we conduct theoretical analysis from two aspects of computing overhead and storage overhead for the preferred scheme and our scheme. The storage overhead is mainly for the amount of PK, SK, and CT, and the computing overhead is basically for the time cost of KeyGen, encryption, and decryption. The PK refers to the size of the user’s public key. The SK means the size of the user’s private key. The CT means the size of the ciphertext. Expand in detail; suppose the access structure
contains
-level nodes. Let |
| and |
| express the complete amount of the leaf nodes in
as well as in the subtree rooted at level node
in
individually. The
and
mean the length of one element in
,
; the |
| means the groups of attributes; and the
means the number of attributes. The
means an exponentiation operation time expense in
,
; the
means a pairing computation time expense.
Experimental verification: In order to verify the results of our above theoretical analysis, based on the PBC library [
31], we simulated and implemented the schemes in [
28,
29,
30] and our system, respectively. Specifically, we experimented on our MacBook Air, whose CPU has an Intel Core i5 (1.1 GHz), 8 GB of RAM, and runs Ventura 13.3. For the purpose of the 80-bit security level target, our scheme adopted the super-singular curve
over a 512-bit finite field to design a 160-bit elliptic curve group to simulate running these schemes. In these figures, the units of computation cost are milliseconds, while the total of the execution times of all algorithms is considered the total execution time. The experimental verification is conducted using the PBC library to implement the cryptographic computation code. The experimental process mainly entails implementing the cryptographic formulas and computations involved in the discussed schemes through the C program.
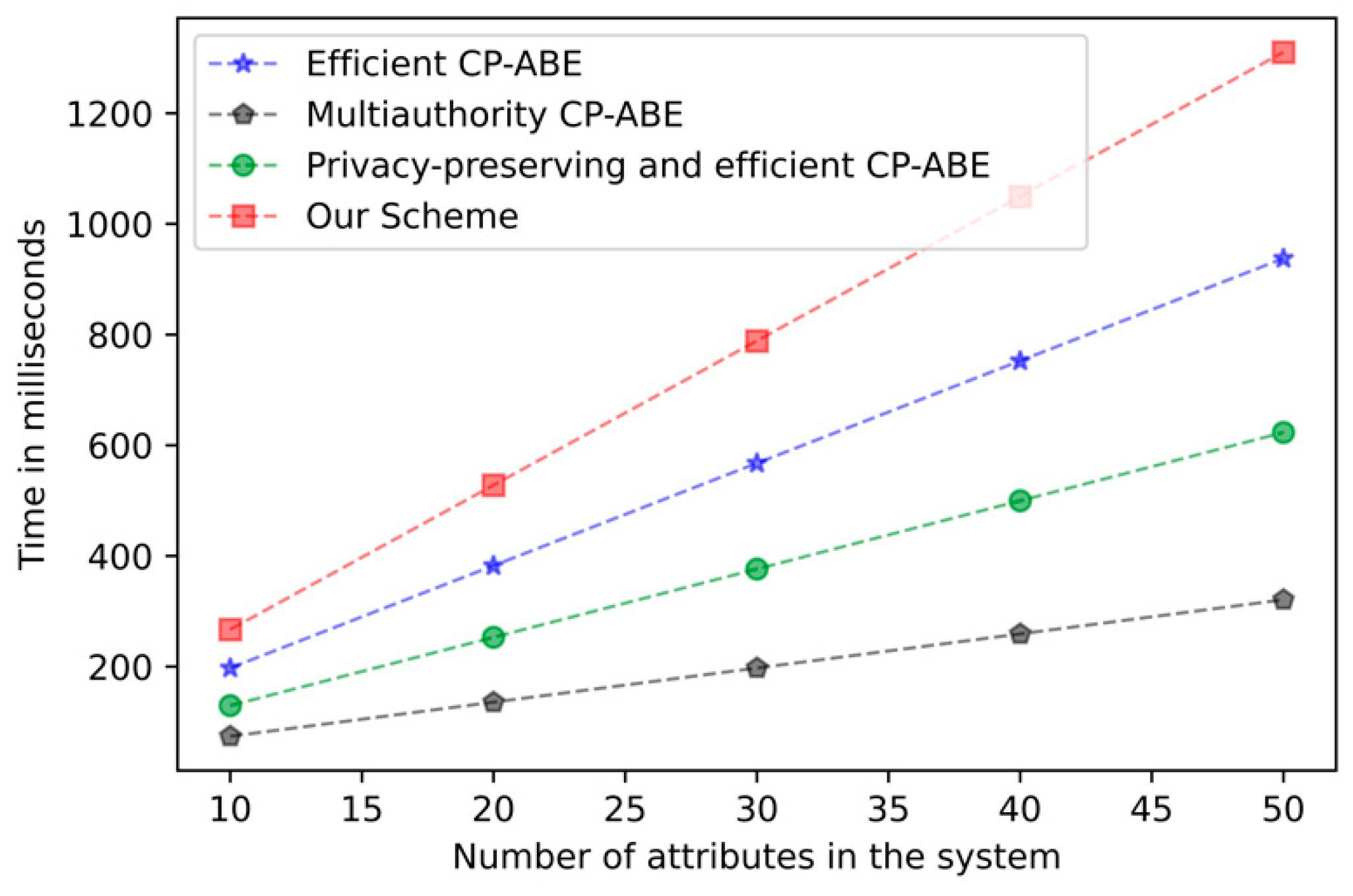
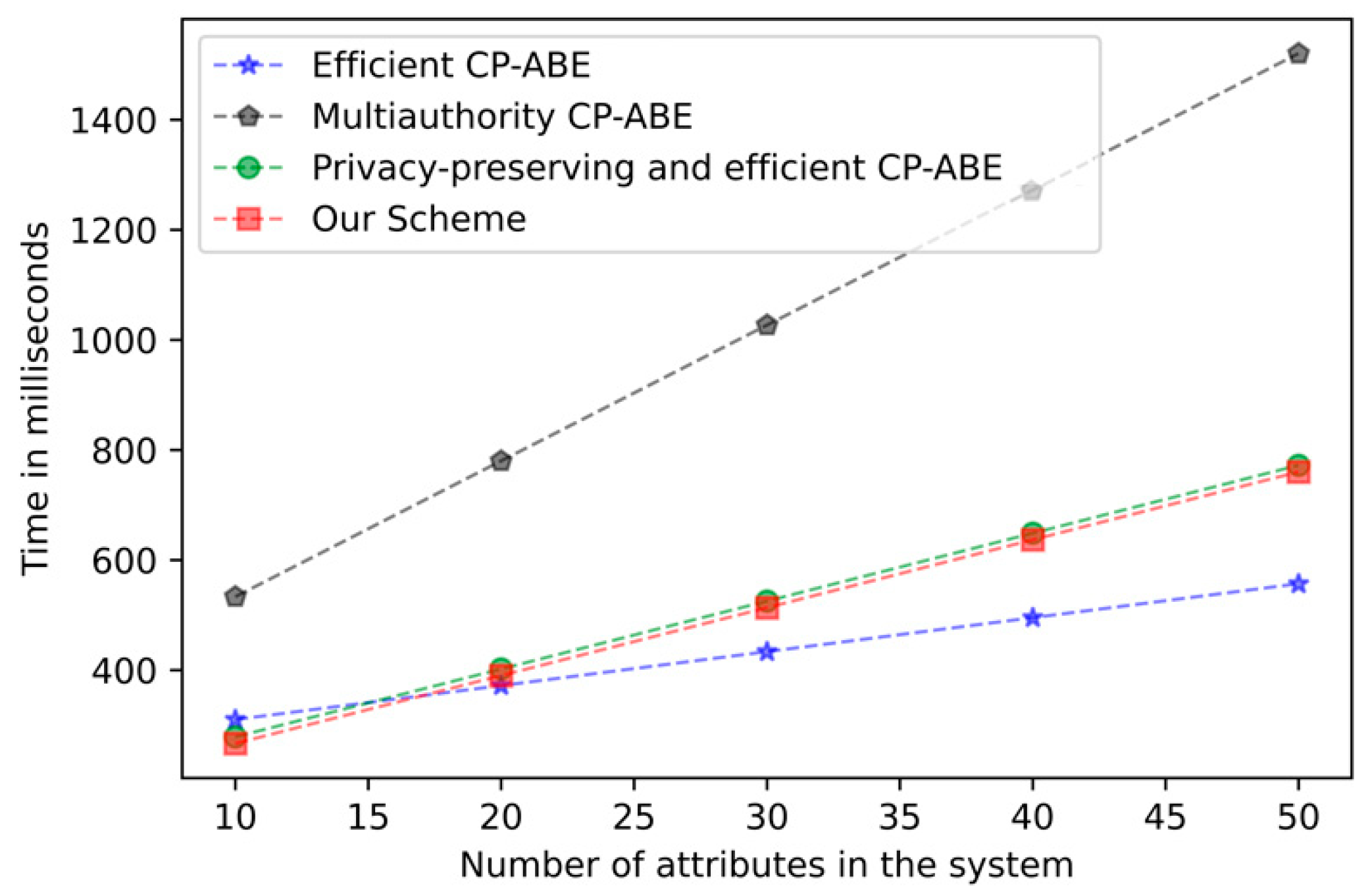
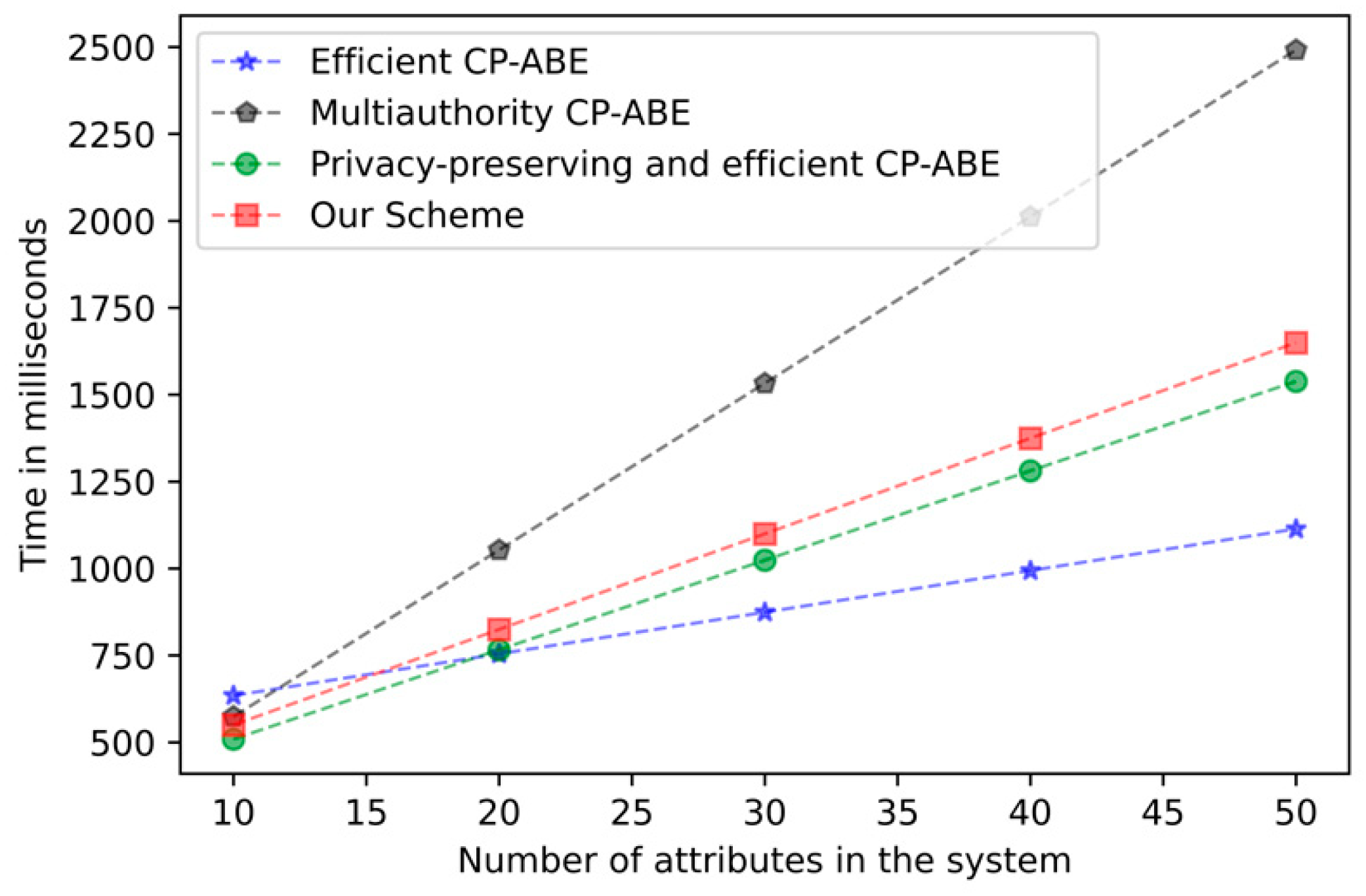
Figure 3 below depicts the actual computation time derived from running the code on our computer. We precisely conducted the experimental verification of our scheme and the selected comparative schemes on the same platform and library.
Figure 4 mainly presents the trend of computing time for key generation as the attribute increases. Due to the oblivious transfer protocol, our scheme has additional overhead in the key generation stage, but the added overhead is still acceptable.
Figure 5 shows the computation time required for encryption as the attribute increases. In the encryption stage, our overhead is basically the same as other tree structures in the CP-ABE scheme.
Figure 6 demonstrates the relationship between the computation time of decrypting overhead and the number of attributes. As with other schemes, the computational overhead in the decryption stage increases with the number of attributes. It has been proven by experiments that the addition of the
k-out-of-
n oblivious transfer protocol will not significantly affect the performance of the scheme under the condition of protecting user privacy.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}