The experimental and evaluative components of our study are organized into two distinct sections. The first section delves into the relevant parameters involved in computing urban delay features. The second section provides an overview of the fundamental aspects of the reference database CDCDB, accompanied by a discussion on the validity of the CDCDB. Then, we evaluate the reliability of four experimental IP geolocation libraries utilizing the reference database CDCDB as a benchmark.
5.1. Discussion of Parameter a
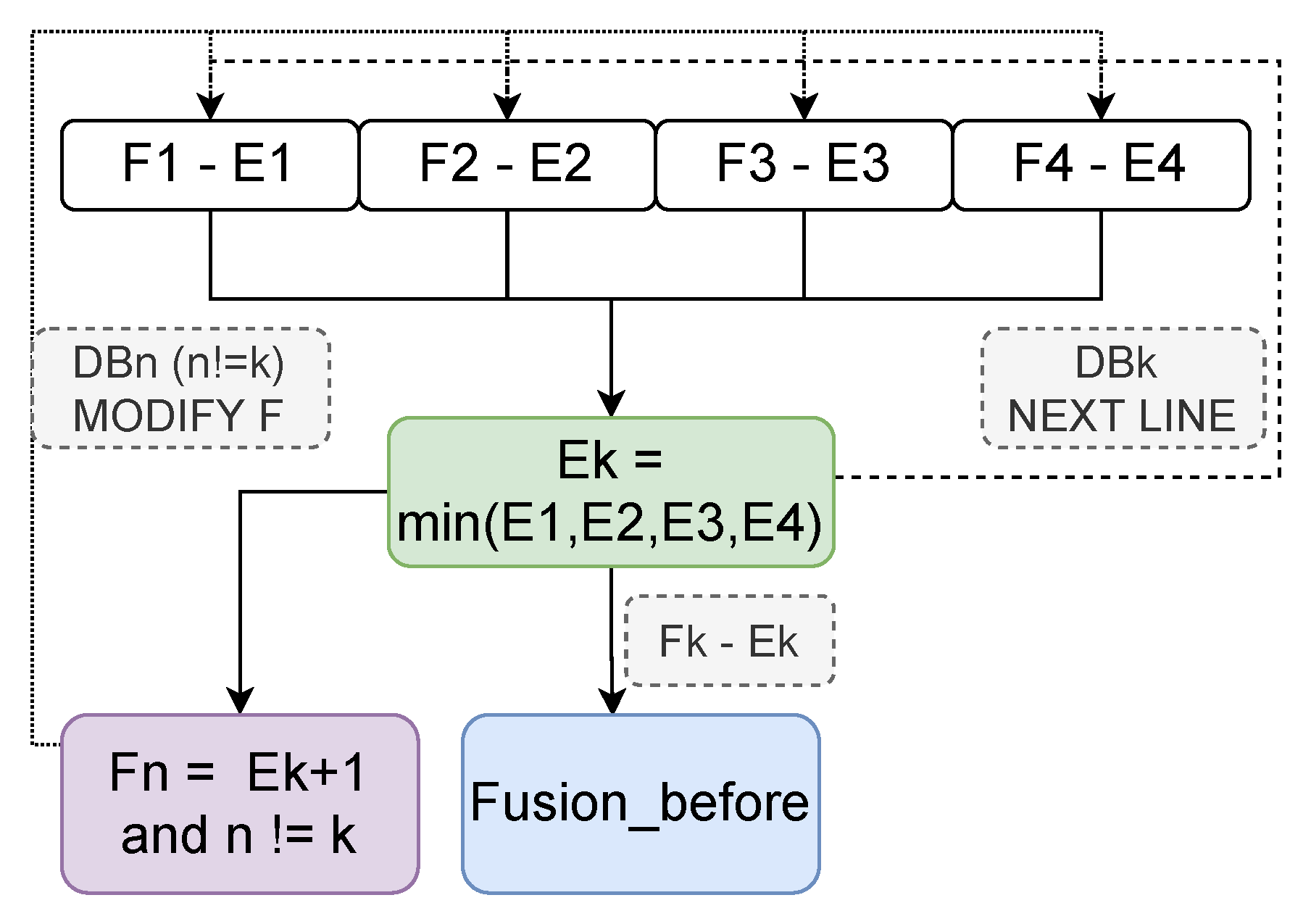
In order to enhance the reliability of urban delay features, we introduced the “Low-frequency rejection” data cleaning method in
Section 4.3. In this section, we explore the parameter
a in “Low-frequency rejection” to determine the optimal cleaning scheme.
Reliable city boundary delay ranges are typically characterized by a high frequency of RTTs and a highly concentrated distribution of RTTs. The more concentrated the distribution range of city delay, the more pronounced the characteristics of delay distribution in the city. Our objective is to eliminate as much distorted RTT information as possible, while retaining as many original delay data points as possible, in order to discover the delay characteristics of the city as comprehensively and accurately as possible. Therefore, we take the data retention rate as the primary measurement index for the selection of parameter a. the smaller the range of delay distribution of the city, the more pronounced the delay characteristics of the city; the higher the retention rate of raw data, the more comprehensive the delay characteristics of the city.
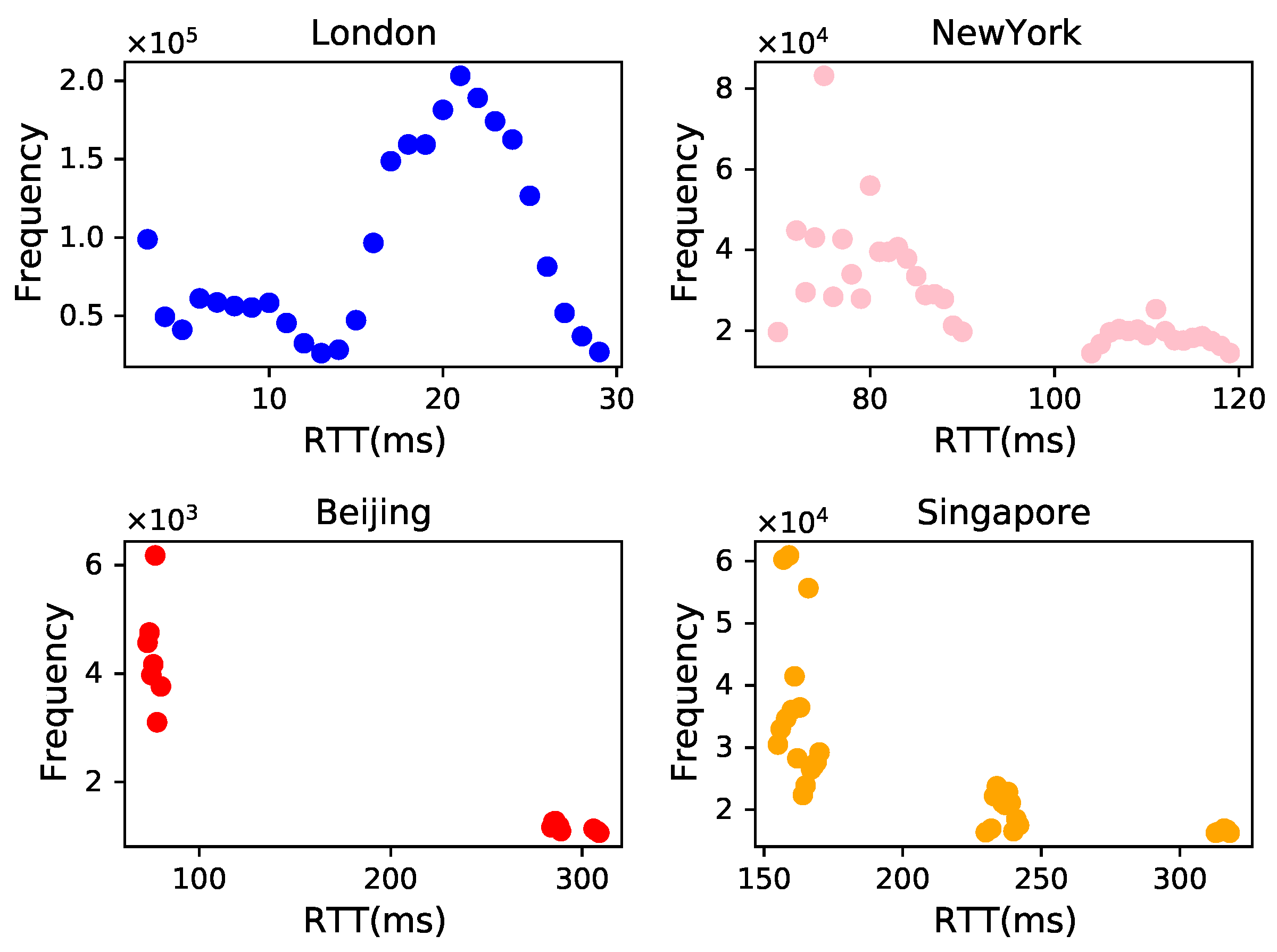
Table 2 presents the results of the experiments conducted in Shanghai following several data cleansing sessions. Prior to data cleaning, the latency data distribution range for Shanghai was 112,672 milliseconds. However, after applying the “Low-frequency rejection” method, the delay range for Shanghai was significantly reduced. When
, the delay range is reduced to 49 milliseconds (ms), with a retention rate of 66%; when
, the delay range expands to 79 ms, but the retention rate increases to 90%. When we set the parameter
a to 1000, the distribution range of delay increases to 101 ms, but the data retention rate reaches 95%. The experimental results demonstrate that the data cleaning method based on “Low-frequency rejection” can effectively reduce the delay distribution range of the city, minimize the impact of distorted RTT information on the delay characteristics of the city, and enhance the reliability of the delay range of the city boundary.
We further analyzed the experimental results of data cleaning based on “Low-frequency rejection” for 42 large cities, as detailed in
Table 3. The average latency ranges for the 42 cities are 26.78 ms, 40.21 ms, and 72.57 ms, while the data retention rates are 74.5%, 83.8%, and 91.4% for the values of parameter
a of 100, 200, and 1000, respectively. The overall delay distribution and data retention ratio are similar to that of Shanghai. Therefore, we posit that when the delay distribution of a city ranges around 100 ms and the data retention ratio exceeds 90%, the remaining RTT data can effectively reflect the delay characteristics of the city. Consequently, we ultimately choose to make parameter
.
5.2. Analysis and Evaluation
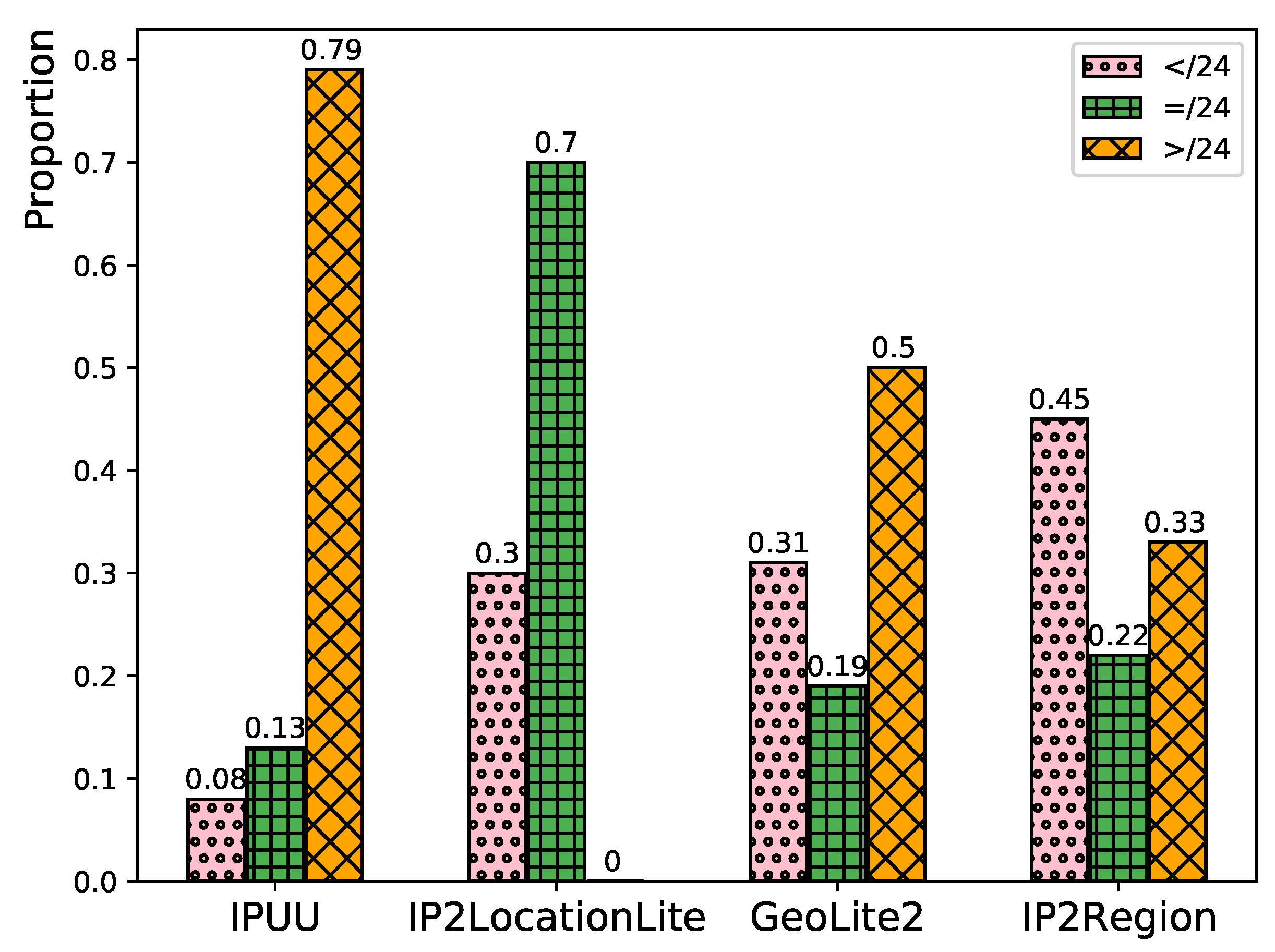
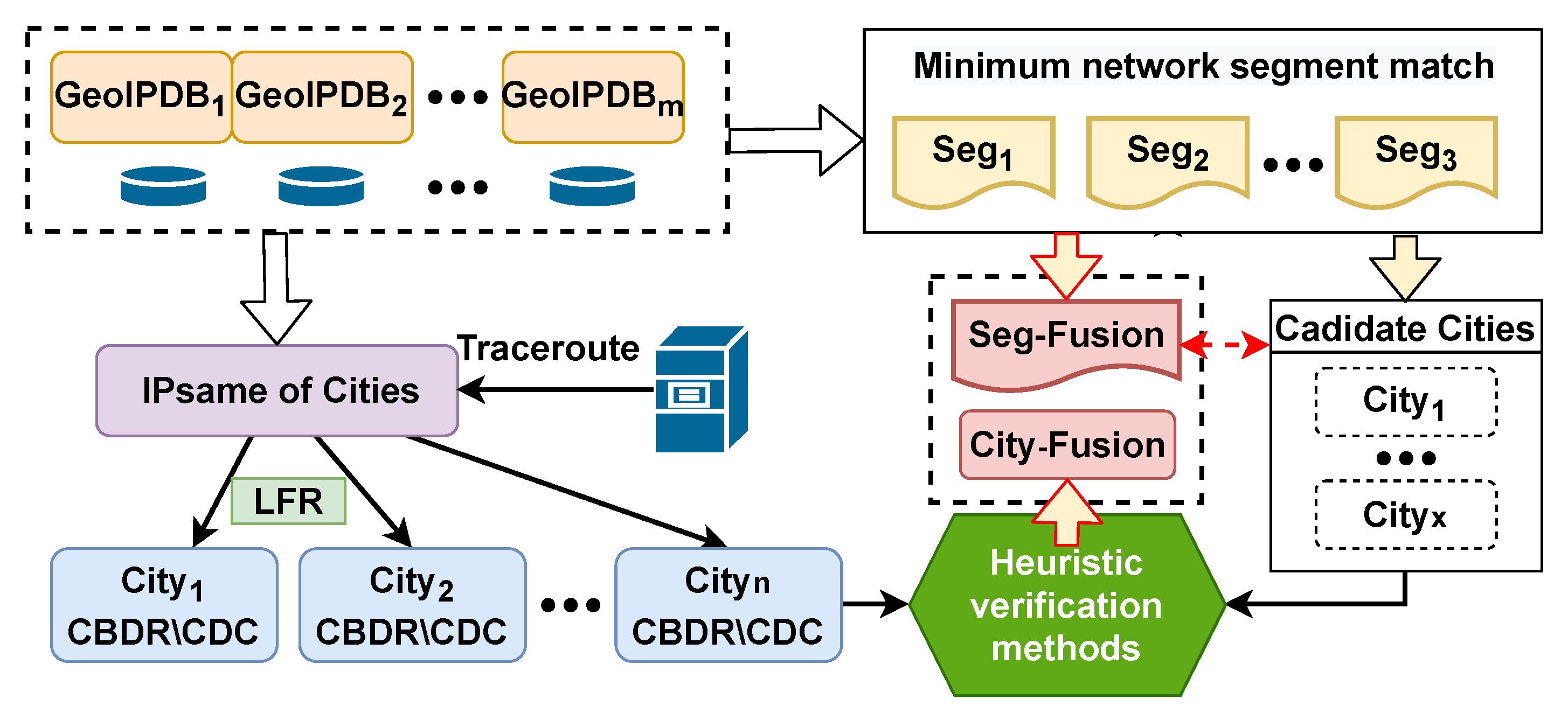
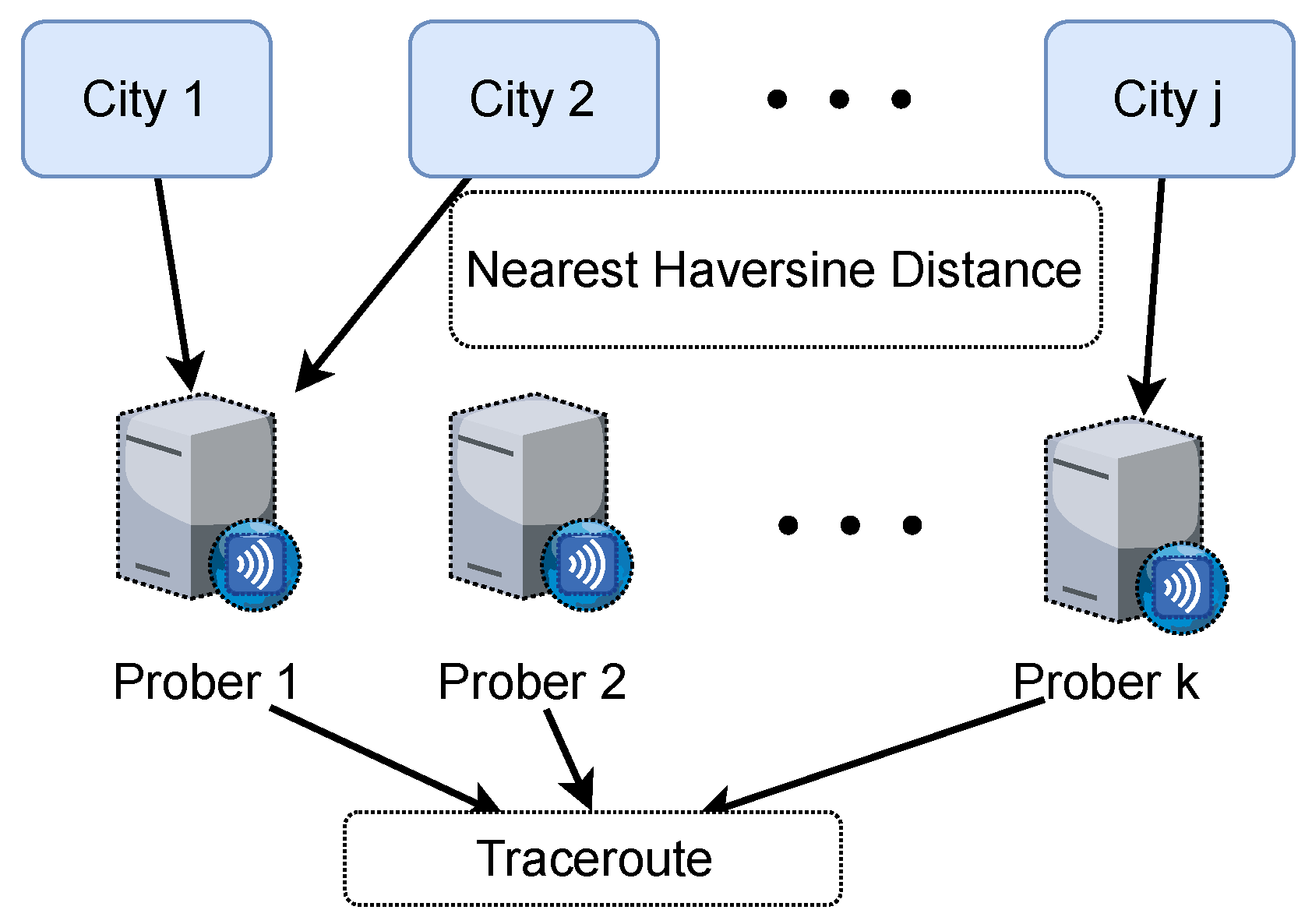
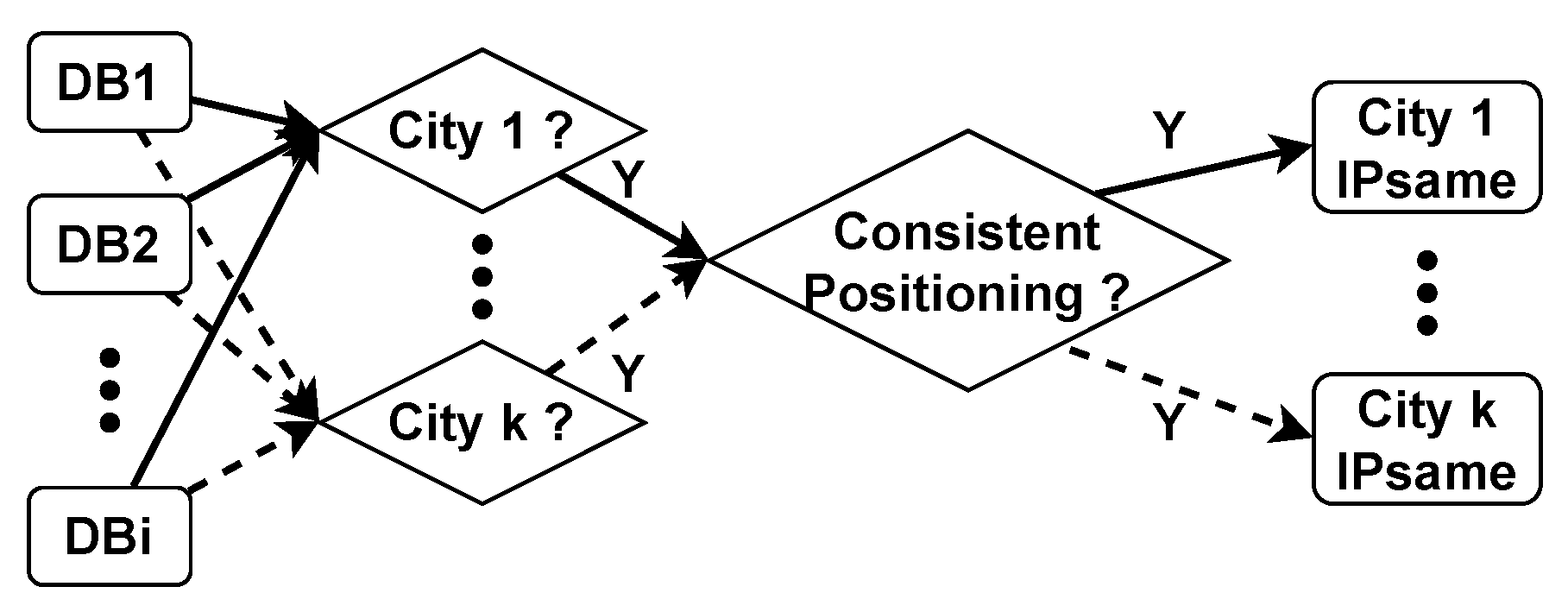
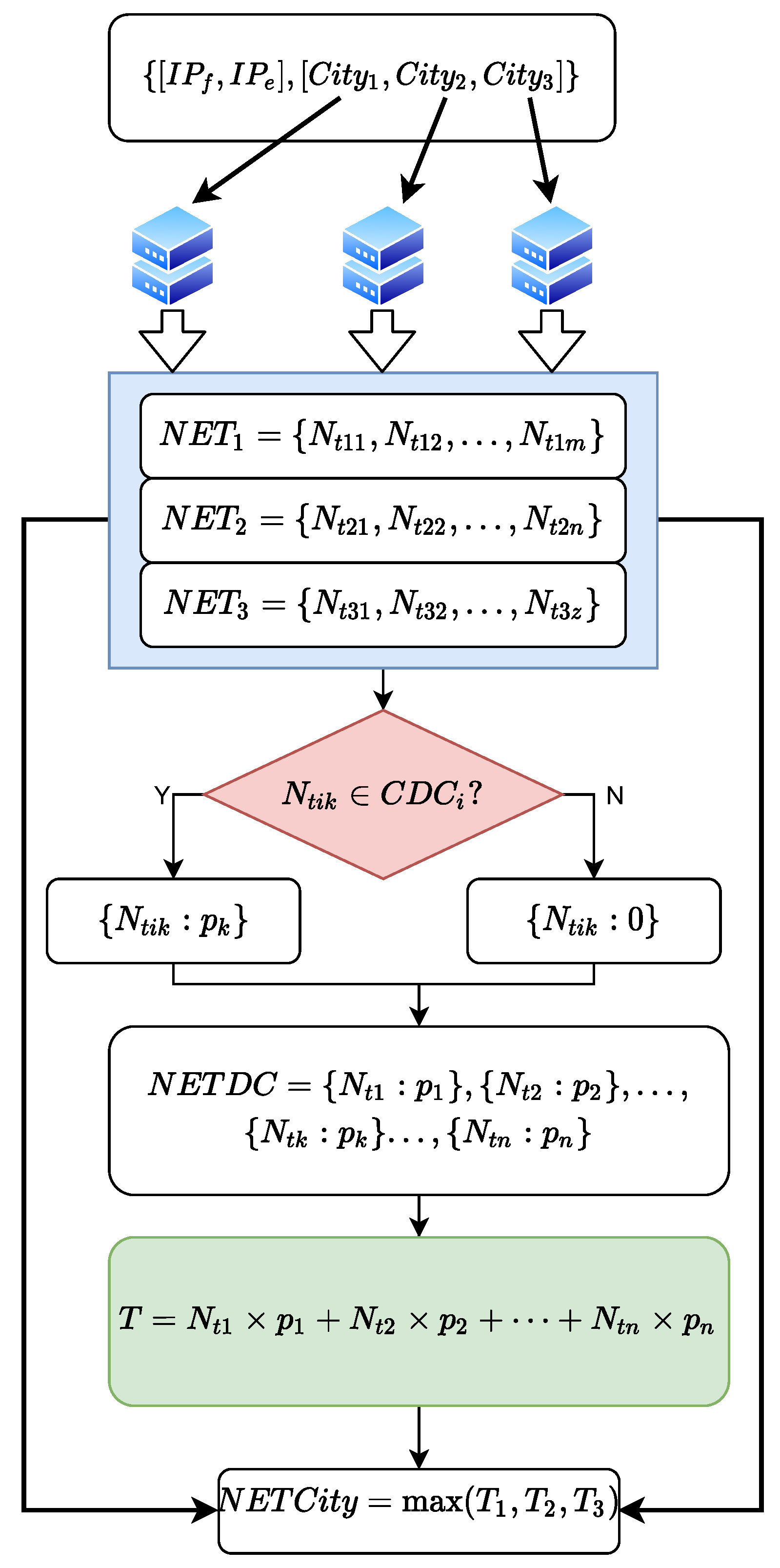
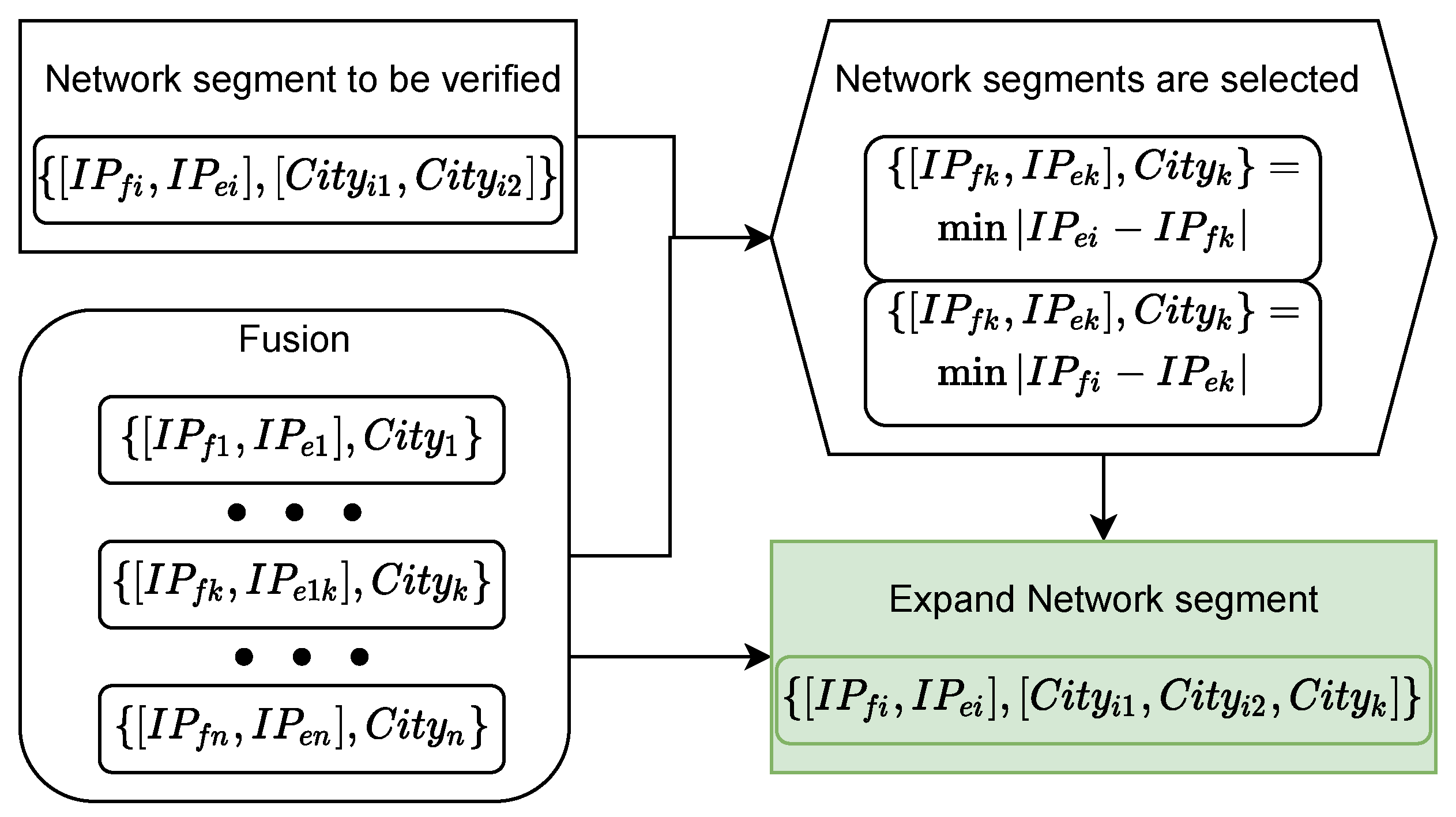
Leveraging the minimum segment matching mechanism and the city delay characteristics, we construct the reference database CDCDB for evaluating the IP geolocation repository. CDCDB comprises 16.27 million network segments, of which 6.38 million segments with unique candidate cities account for 39.1% of all segments in the database. Consequently, we only need to verify the location of 9.89 million network segments where multiple candidate addresses exist. Compared with the traditional IP address-based method to construct the reference database, our proposed method improves computational efficiency nearly a hundredfold.
In the CDCDB database, there are a mere total of 1.269 million non-high-quality network segments with prefix length no greater than /24, constituting 7.8% of the number of all network segments, and the coverage of city-level network segments reaches 99.99%. Compared with IPUU, the number of network segments in CDCDB increases by 18.7%, the number of high-quality network segments increases by 13.2%, and the coverage of city-level network segments increases by 20.92%, as shown in
Table 4. This demonstrates that our proposed minimum segment matching mechanism indeed expands the number of segments, improves segment quality and city-level coverage, and is crucial for enhancing city-level localization accuracy of IP addresses.
We evaluated the accuracy of CDCDB in 42 cities using the macro Internet Topology Data Kit (ITDK) provided by CAIDA [
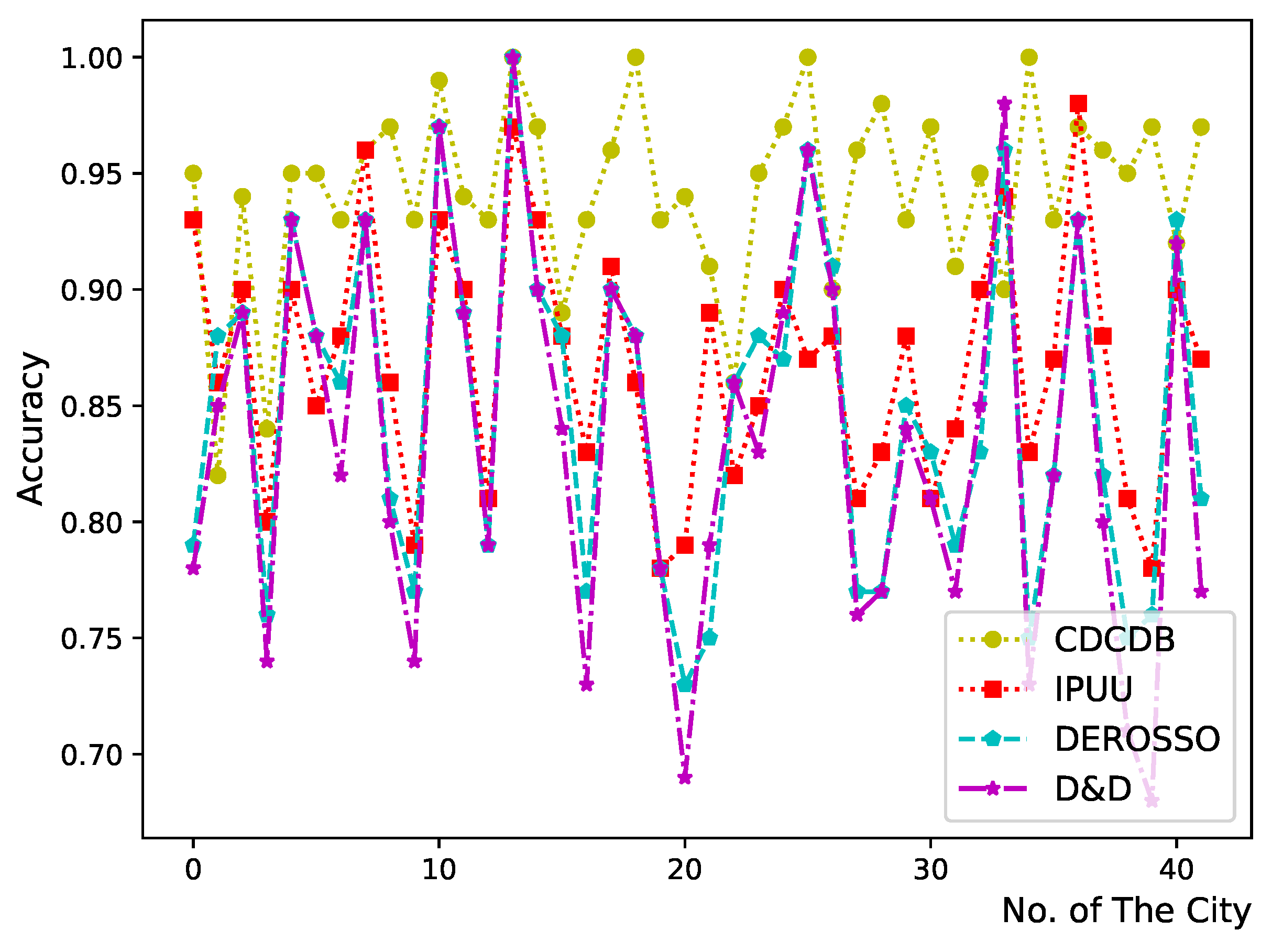
38]. This kit amalgamates well-known Internet exchange point information, Hoiho hostname mapping, and city granularity GeoLite2 geolocation data freely available from MaxMind. After filtering out the location information provided by MaxMind, we verified the geolocation accuracy of the IP addresses of the 42 cities in the CDCDB. We found that the average accuracy is as high as 94%. The results are depicted in
Figure 12.
We also evaluated the geolocation accuracy of the DEROSSO model proposed by H Li et al. [
18] and the D&D model proposed by X Bo et al. [
19], as well as IPUU, in 42 experimental cities. As depicted in
Figure 12, we find that the overall accuracy of both DEROSSO and D&D is lower compared to CDCDB, indicating that our proposed evaluation method effectively enhances the accuracy of the reference database. We also observe that the accuracy curves of DEROSSO and D&D models follow almost the same trend as that of IPUU, and do not demonstrate any superiority over the original IP geolocation database IPUU. This suggests that the reference databases constructed by DEROSSO and D&D models are highly dependent on the IP geolocation database IPUU and do not significantly improve geolocation accuracy. Conversely, the overall accuracy of CDCDB is significantly improved compared to that of IPUU, indicating that our constructed reference database effectively improves city-level geolocalization results of IP addresses and is less dependent on the original IP geolocation database.
The results depicted in
Figure 12 suggest that we conclude that the reference database CDCDB, constructed through the minimum segment matching mechanism and city delay characteristics, has highly reliability in evaluating IP geolocation databases. Furthermore, this reliability increases as the number of integrated IP geolocation databases increases.
Lastly, we assessed the reliability of the four experimental IP geolocation libraries utilizing the reference database CDCDB. As identified in
Section 3.1, IP geolocation libraries exhibit varying preferences for different cities, implying that the reliability of geolocation information provided by IP geolocation libraries differs across cities. Next, we validated this finding through the reference database.
We assess the reliability of the IP geolocation database in a specific city by selecting the city to be evaluated. We then compared the IP geolocation database under evaluation with the reference database, CDCDB, and calculated the data similarity to gauge the reliability of the IP geolocation database in that city. Specifically, we evaluated the reliability of the IP geolocation repository in a given city using three metrics: Database Accuracy (), Database Recall (), and Database Reliability Score (). The definitions for these three metrics are as follows:
Consider a scenario where the quantity of IP addresses, which share the same localization between the IP geolocation database and the reference database CDCDB within a specific city, is denoted as . The total number of IP addresses localized in that city by the IP geolocation database is represented as , and the quantity of IP addresses localized in that city by the CDCDB is symbolized as .
- 1.
Database Accuracy (): This metric represents the proportion of IP addresses whose geolocation aligns with both the IP geolocation database and the reference database CDCDB, relative to the total number of IPs assigned to the IP geolocation database in that city. Mathematically, it can be expressed as:
- 2.
Database Recall (): This measure signifies the ratio of the number of IPs with consistent geolocation between the IP geolocation repository and the reference database CDCDB, to the total number of IPs assigned to the reference repository in that city. It can be formulated as:
- 3.
Database Reliability Score (): This score is a weighted reconciled average of both the database accuracy (
) and database recall (
) of the IP geolocation repository. Mathematically, it can be expressed as:
Database Accuracy () serves as a reflection of the reliability of IP addresses provided by IP geolocation databases that are situated in a specific city. A higher signifies a greater degree of reliability of the IP information furnished by the database for that city. On the other hand, Database Recall () mirrors the comprehensiveness of the IP addresses provided by the IP geolocation database in a particular city. A higher indicates a more extensive coverage of IP addresses by the IP geolocation database in that city. and encapsulate the accuracy and comprehensiveness of IP information provided by IP geolocation databases separately. Yet, we lack a comprehensive assessment indicator. Therefore we proposed the Database Reliability Score () as a comprehensive analytical indicator, which amalgamates and . This score provides a holistic measure of the performance of the database, thereby facilitating more informed decision-making for users leveraging these databases. In this study, we introduce a parameter, , which serves as a measure of the relative importance of database accuracy () versus database recall (). The value of influences the balance between these two metrics in the following manner:
When , it signifies that and hold equal importance.
When , it indicates a greater emphasis on .
Conversely, when , is given more weight.
In the context of this paper, we assign a higher priority to database accuracy. This decision is driven by the expectations of IP geolocation database users, who generally anticipate that the positioning information provided by these databases will be highly accurate. Consequently, we set the parameter to 0.5, thereby giving more influence to in our analysis.
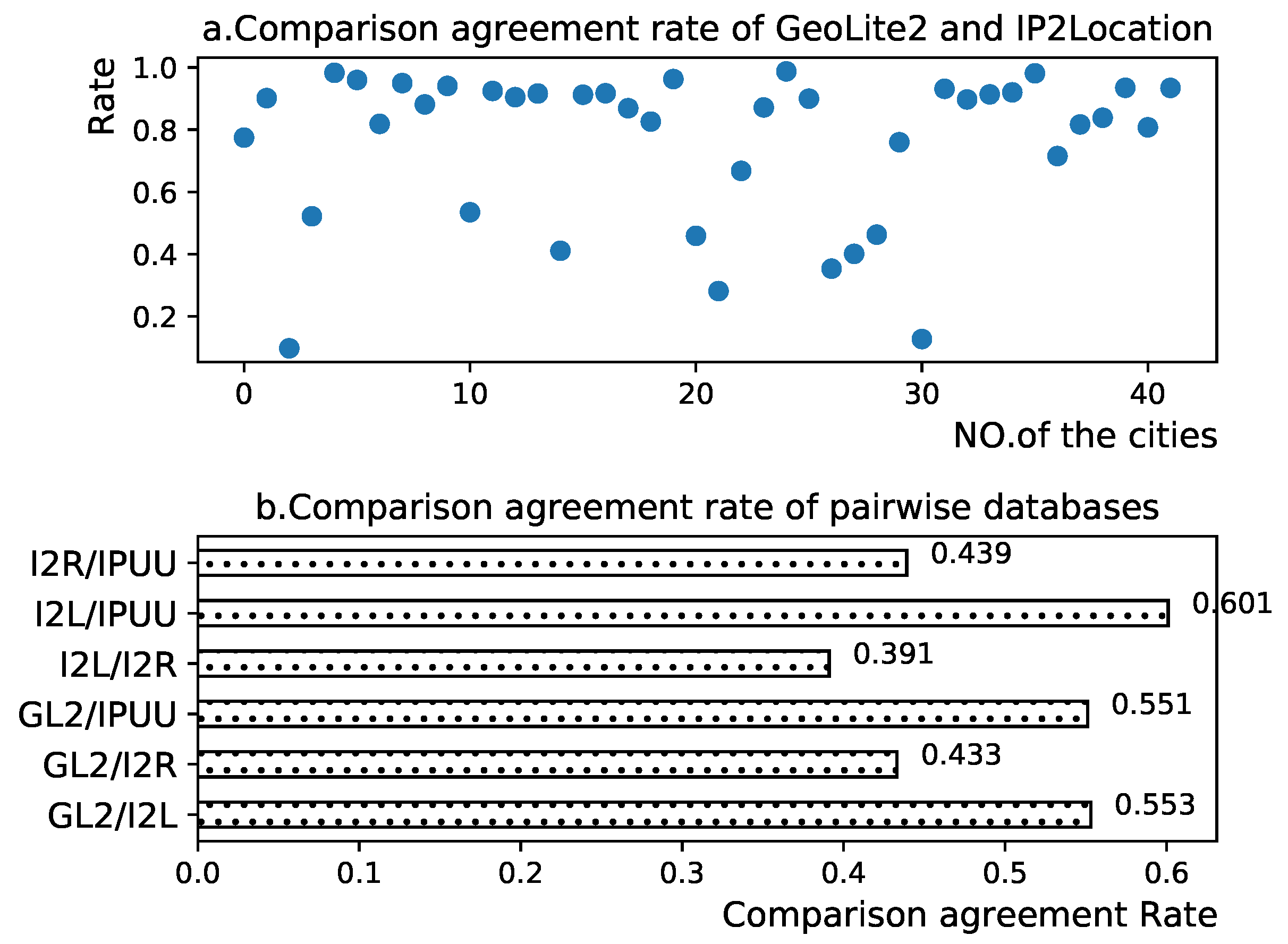
In this study, we selected 12 cities across China, Europe, and the United States to evaluate the city-specific performance of the IP geolocation repository.
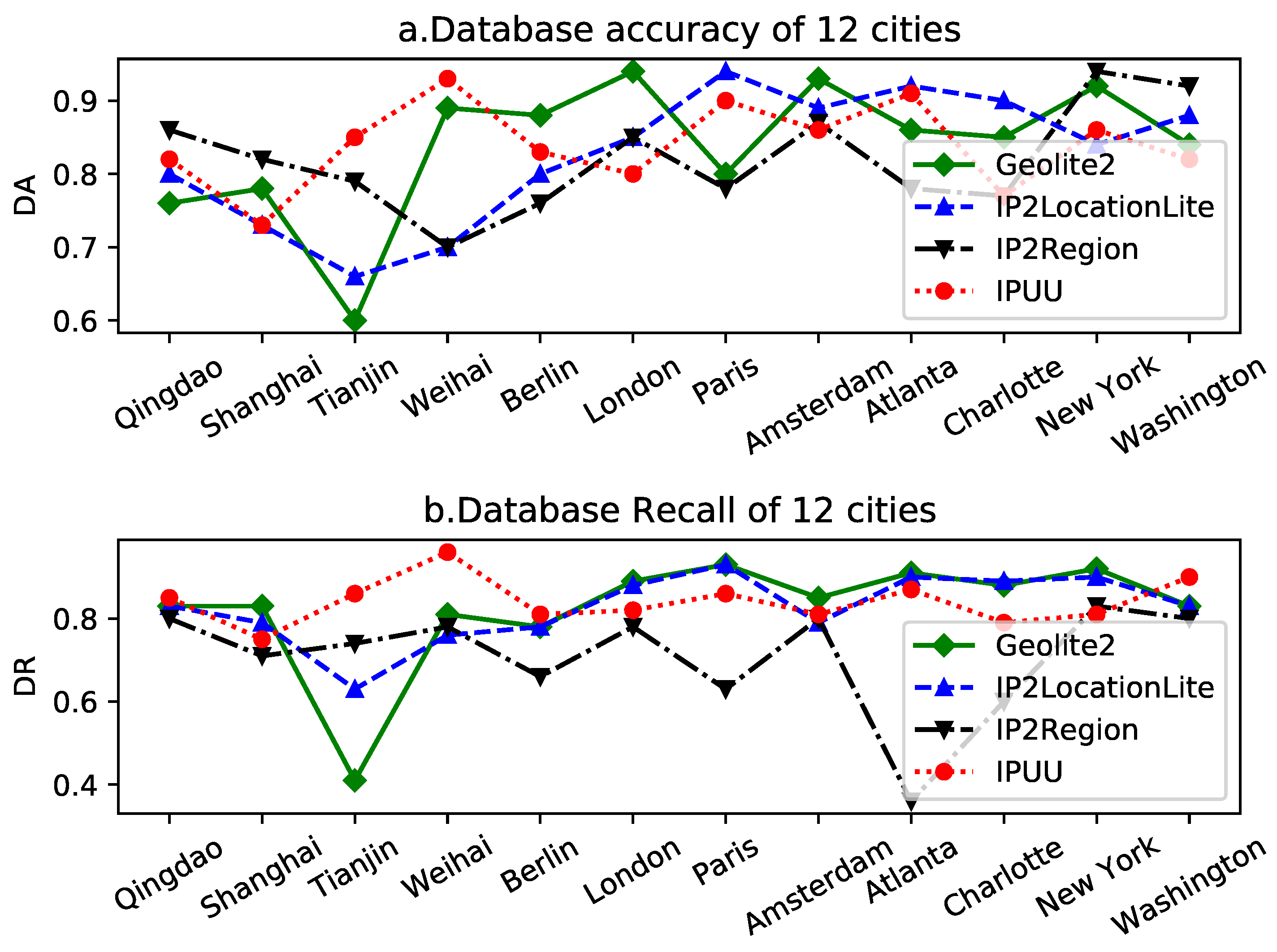
Figure 13 presents a schematic representation of the database accuracy and database recall results for four experimental IP geolocation libraries across these 12 cities.
The results delineated in
Figure 13 illustrate that all IP geolocation libraries exhibit exemplary performance in the majority of cities, with high scores for both data accuracy and data recall. This indicates that these four experimental IP geolocation libraries can confidently localize IP addresses in most cities. Interestingly, we observed that the database accuracy and database recall curves of the IP geolocation database generally follow similar trends in most cities, underscoring the impressive results achieved by this IP geolocation database in city-level geolocation endeavors.
However, in a select few cities, the and of the IP geolocation database do not exhibit congruence. For instance, in Atlanta, the IP2Region database boasts a of 78% and a of 36%. This significant difference implies that in Atlanta, there is a substantial discrepancy between the IP information provided by IP2Region and that provided by the CDCDB: IP2Region provides only a limited number of IP addresses located in Atlanta, but the vast majority of these IP addresses are locationally accurate IPs. While there is a similar trend observed between the database accuracy curve and the database recall curve, a closer examination reveals distinct differences. The data recall curve clearly indicates that the IP2Region database is less proficient at geolocating cities in Europe and the US. However, this conclusion is not as evident when examining the database accuracy curve. This discrepancy underscores the existence of differences between the reference database CDCDB constructed based on the minimum segment matching mechanism and city delay features and the original IP geolocation database. The reference database improves the original IP geolocation database, and the degree of reliance on the original database varies depending on the city of location.
The close alignment between database accuracy and database recall for the IP geolocation database signifies a high degree of congruence between the IP geolocation database and the reference database. This observation underscores the broad reliability of current IP geolocation databases for city-level geolocation endeavors. However, there are also instances where the and of the IP geolocation repository diverge significantly in a few cities. This situation validates the reference databases we constructed on one hand, and on the other hand, it also reveals that the same IP geolocation database may perform differently in different cities.
We further scrutinize the performance of different IP geolocation databases in the same city. From
Figure 13, it can be discerned that the performance of different IP geolocation databases does not differ significantly in most cities, and the major differences are confined to a few cities. For instance, in Tianjin, the database recall and database accuracy of GeoLite2 are significantly lower than other databases. The results of this experiment demonstrate that the performance of different IP geolocation databases in the same city varies; though, in most cities, the differences between different IP geolocation databases are marginal. Combined with our previous finding that the same IP geolocation database also has reliability differences in different cities, we can draw a potential conclusion that IP geolocation databases exhibit a certain degree of city bias, and that the reliability of IP information provided by different IP geolocation databases varies according to the city in which they are located.
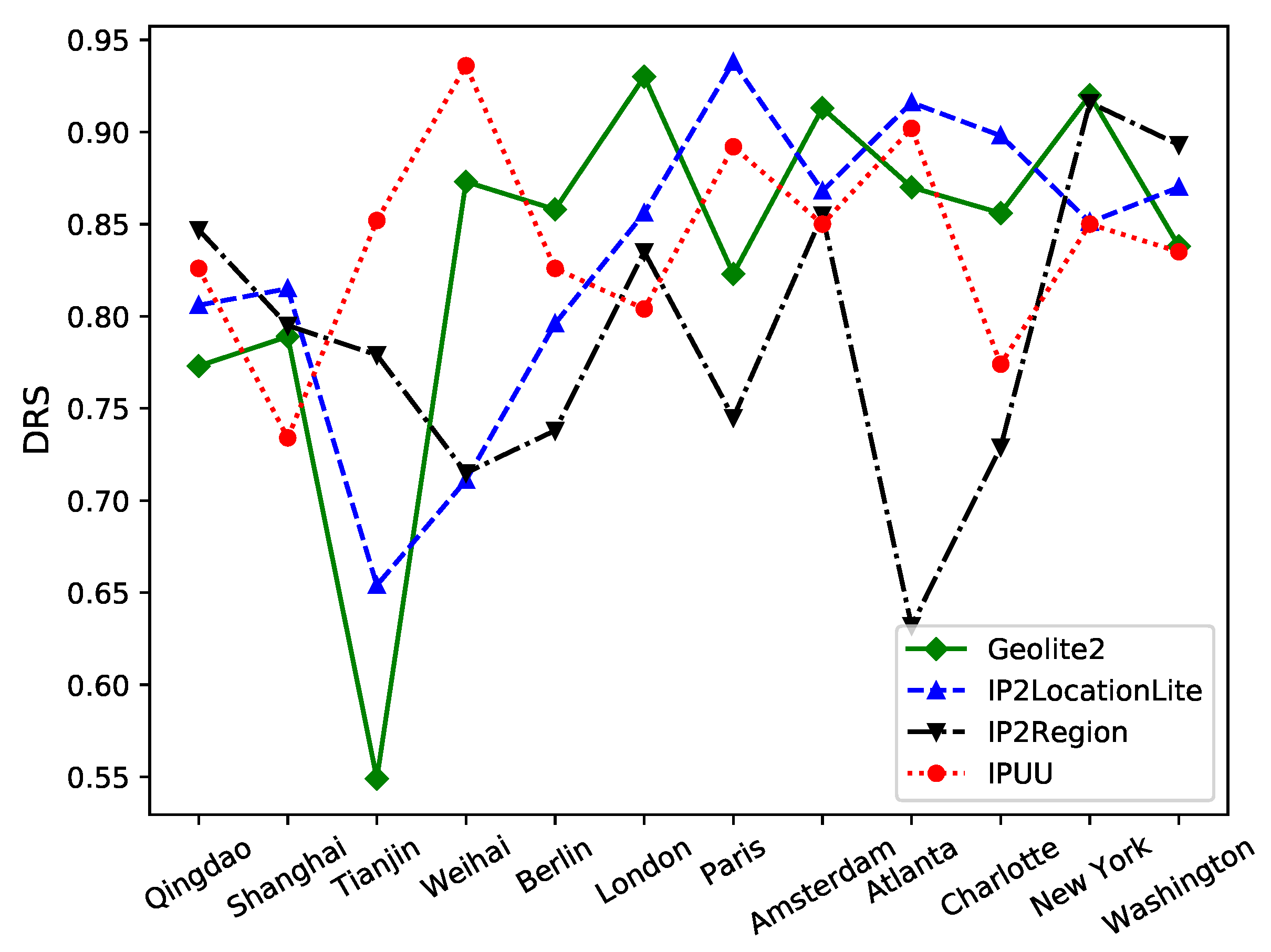
Figure 14 presents the database reliability scores of the four experimental IP geolocation libraries across 12 specific cities. A significant observation from
Figure 14 is that different IP geolocation libraries exhibit different reliability in locating different cities. Overall, IPUU outperforms the others, demonstrating a high overall database reliability score with minimal fluctuations. IP2LocationLite follows, leading in cities such as Qingdao, Shanghai, Paris, Atlanta, and Charlotte, despite its subpar performance in Tianjin and Weihai. GeoLite2 experiences considerable fluctuations in its database reliability score due to its poor performance in Tianjin. The least effective overall is IP2Region, with a score significantly lower than the other three databases. Interestingly,
Figure 14 does not reveal any specific country characteristics for the cities that the IP geolocation databases excel at locating. Instead, their strengths and weaknesses appear to be more city-specific.
We computed the mean and variance of the database reliability scores of the four experimental IP geolocation databases, as delineated in
Table 5. In
Table 5, we observe that IPUU, GeoLite2, and IP2LocationLite exhibit similar average
scores, with IPUU achieving the optimal result with a
score of 84%. This suggests that, on the whole, the performance of each IP geolocation database is comparable for city-level geolocation work, with the exception of IP2Region, which performs slightly subpar.
However, the variances of the four databases exhibit noticeable differences. GeoLite2, which has the largest variance, is 3.2 times larger than IPUU, which has the smallest variance. The variance of IP2LocationLite is akin to that of IP2Region, with a minor difference of 0.0003 only. In terms of variance, IPUU’s location results are more stable, indicating that it is a database that can provide stable location results more independent of the city where it is located. Conversely, GeoLite2 exhibits more city preference, and in some of the “bad” cities, the positioning information provided by it may be suboptimal.
Of course, since IPUU is a paid database, we cannot ascertain whether the variance difference is due to the difference between free and paid databases, so we refrain from evaluating the overall quality of the databases. However, from the performance of the three free databases, the generally high mean and generally small variance demonstrate that the IP geolocation database has been relatively perfected in city-level geolocation, but there are still a few “bad” regions. Such regional geolocation weaknesses will be the main reason for IPUU’s success in city-level geolocation. This kind of regional geolocalization weakness will be the focus of IP geolocalization database in city-level geolocalization work.
Figure 13 and
Figure 14 collectively indicate that different IP geolocation repositories do indeed exhibit city preferences. While the reliability of different IP geolocation databases within the same city is often similar, significant performance differences emerge in a few cities. This suggests that the primary distinctions between IP geolocation databases lie at the city level. In certain specific cities, different IP geolocation databases provide markedly different services. Therefore, we recommend online service providers to select an appropriate IP geolocation database based on the cities they serve to enhance service quality.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}