
A Fault Diagnosis Method for Electric Check Valve Based on ResNet-ELM with Adaptive Focal Loss

Abstract
:1. Introduction
1.1. Background
1.2. Status of the Research on Fault Diagnosis of Check Valves
1.3. Contributions and Structure
- (a)
- Addressing the health monitoring requirements of check valves, we propose a check valve condition monitoring model that combines residual networks and ELMs. This model extracts features using the residual network and employs ELMs for feature identification, achieving high-precision monitoring of the operational status of check valves.
- (b)
- To tackle the issue of extreme imbalance in the check valve dataset, we introduce the Adaptive Weighted FL. This method improves the accuracy of identifying check valve faults or other abnormal states, mitigates the impact of data imbalance, and ensures the core objectives of this study.
2. Methods
2.1. Proposed of the ResNet and ELM Model
2.1.1. Proposed of the ResNet
2.1.2. Brief Introduction of ELM
2.1.3. The Development of ResNet-ELM Model
2.2. Improved ResNet-ELM with AFL
2.2.1. Brief Introduction of FL
2.2.2. AFL for Data Class Imbalance
2.2.3. Improved ResNet-ELM Model
2.3. Check Valve Conditions Monitoring Method Based on AFL-ResNet-ELM
3. Experimental Testing
3.1. Data Collection Schemes
3.2. Vibration Signal Analysis of Check Valves
- (1)
- Normal operation: in this state, both the diaphragm pump and the check valve function properly, and the vibration signal from the valve body appears as a periodic random signal.
- (2)
- Early degradation: while the diaphragm pump continues to operate reliably, the check valve experiences minor wear, resulting in a pulsed vibration signal indicative of the valve’s reciprocating motion.
- (3)
- Fault warning: This condition is typically characterized by severe scratching on the valve due to the presence of high-hardness particles in the slurry or continuous impact on the valve sealing surface. The vibration signal in this state is often represented by a multi-peak strong pulse signal or a pronounced noise signal.
- (4)
- Equipment failure: This state indicates significant breakdown or deformation of the valve body at the sealing surface. The corresponding vibration signal is a high-intensity, multi-peak periodic pulse signal.
3.3. Dataset Analysis
4. Analysis of Results and Discussions
4.1. Data Preprocessing
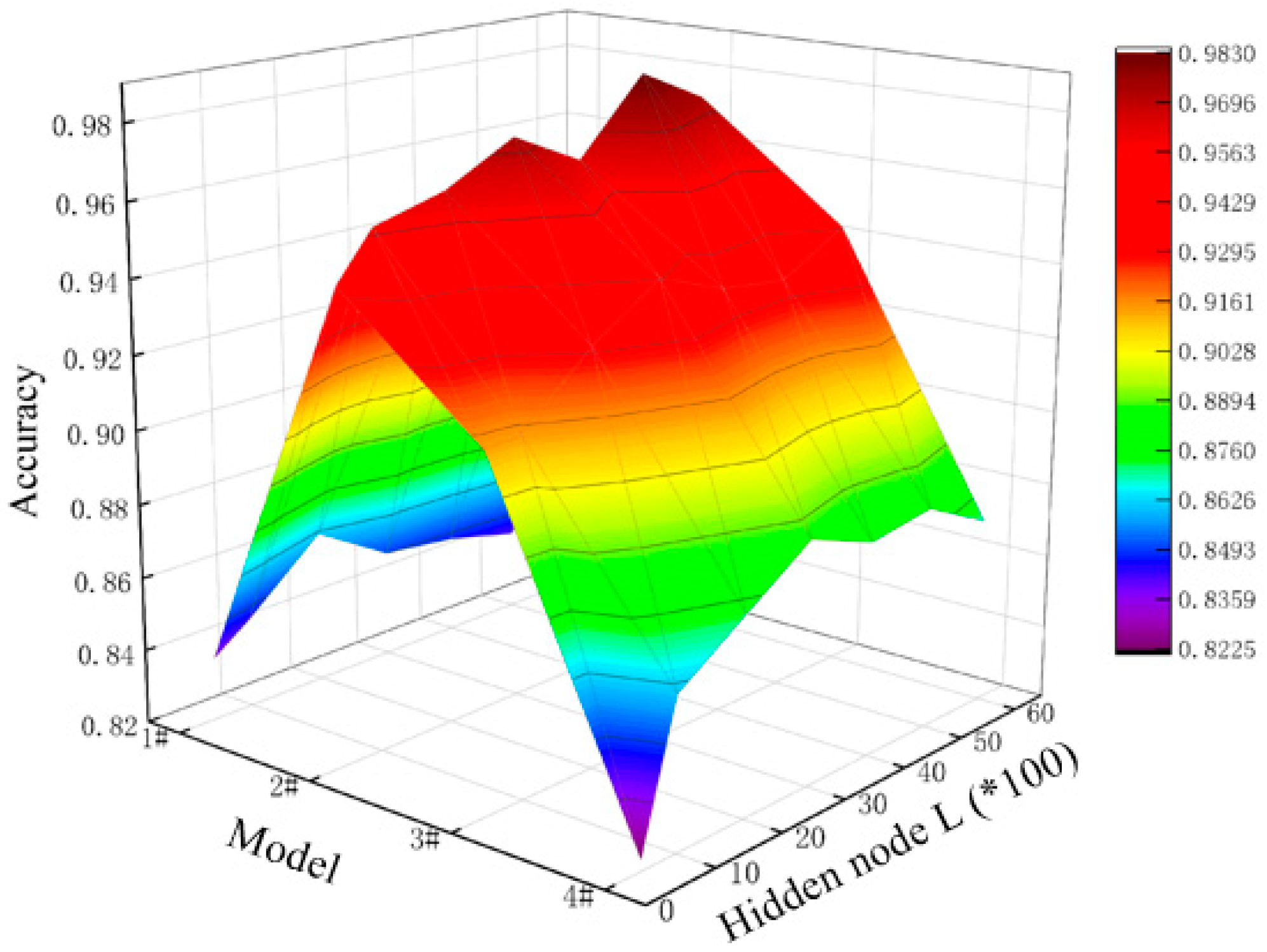
4.2. Establishment of the ResNet-ELM Model
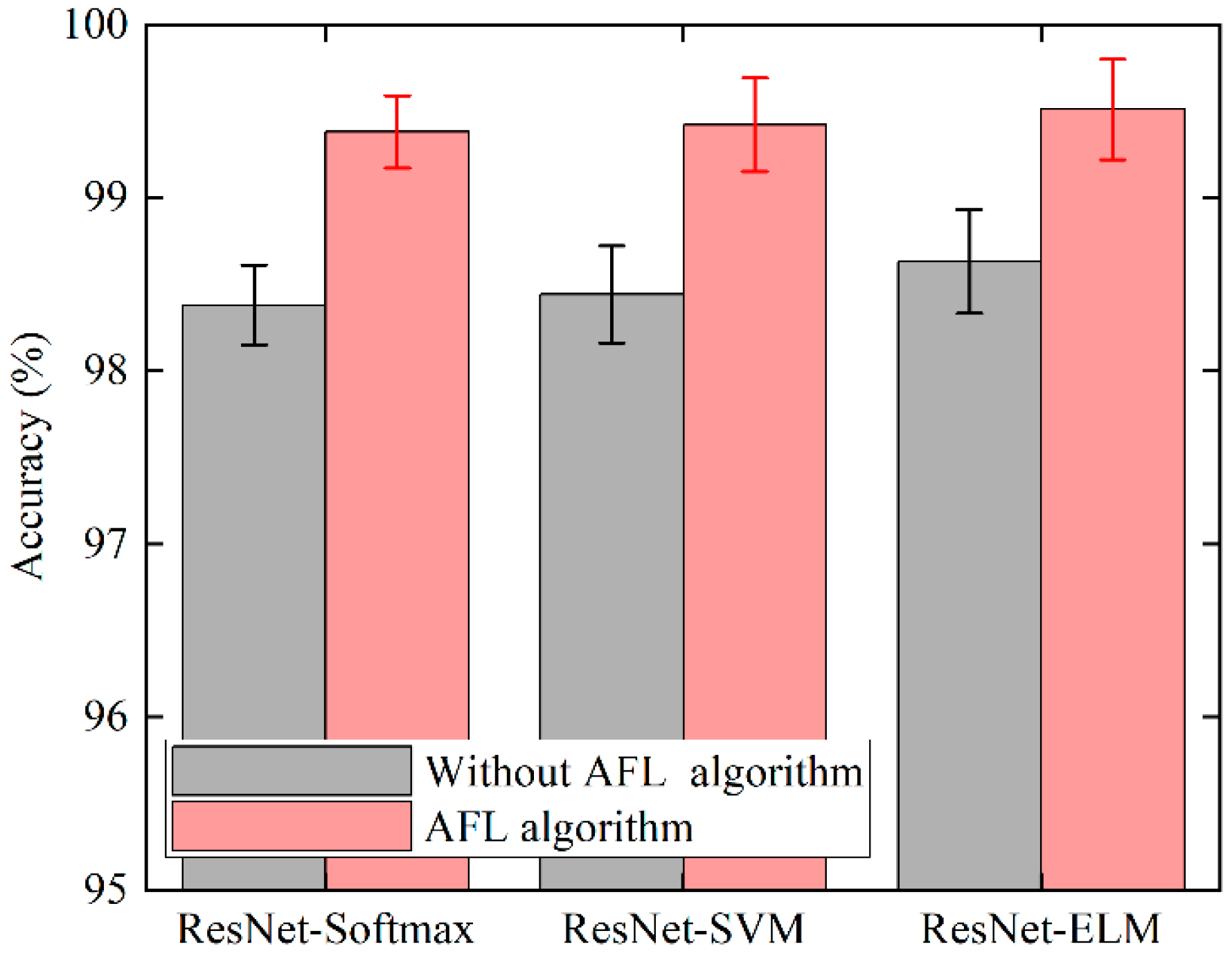
4.3. Results and Discussion
5. Conclusions
- (1)
- In the future, data analysis and other means can be used to automatically isolate the interference of “noise” signals, so as to improve the accuracy of diagnosis.
- (2)
- Only one method is used to solve the problem of data imbalance in this paper, and a variety of methods (data augmentation/resampling) can be used for verification in subsequent studies.
- (3)
- Future data-driven fault diagnosis algorithms should be based on online system testing rather than offline datasets. Fault diagnosis research should be aimed at practical and online monitoring.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Glossary
| The convolution operations | |
| The feature mapping of the th channel in the layer | |
| The convolution kernels | |
| The biases corresponding to the th channel | |
| A feature map of the th channel of the th layer | |
| A nonlinear activation function | |
| A pooling function or a dimensionality reduction sampling method | |
| The normalized output of the matrix | |
| The stability factor | |
| The backpropagation adjustment coefficients | |
| The backpropagation adjustment coefficients | |
| The penalty coefficient | |
| The target matrix of the training samples used | |
| The output weight matrix connecting the nodes of the output layer and the nodes of the hidden layer | |
| An input | |
| The hidden nodes | |
| The hidden layer input | |
| The output of the ELM | |
| The identity matrix of the L dimension | |
| The full rank of the column | |
| An invertible matrix | |
| The only solution of the optimization function | |
| The probability that the predicted sample is true | |
| The tag value | |
| The focus parameter | |
| The initial value of the | |
| The initial learning rate of model training | |
| The attenuation learning rate generated with the model training iteration | |
| A modulation factor | |
| The weighted factor modulation factor | |
| The initial weight | |
| The proportion of class t in the overall data | |
| The attenuation coefficient of the learning rate | |
| The decay rate | |
| The number of iterations required for a model to complete a full dataset training | |
| The pointer function | |
| A partial derivative of the parameter | |
| The number of discrete information points | |
| The discrete information value | |
| The integer operation | |
| The harmonic coefficient |
References
- Mu, Z.; Huang, G.; Wu, J.; Fan, Y. Early Fault Diagnosis of Check Valve of High-pressure Diaphragm Pump Based on DEMM. Vibration. Test. Diagn. 2018, 38, 758–764+873. [Google Scholar]
- Hou, C.J.; Ma, J.; Wu, J.D. Research on fault diagnosis of check valve based on CEEMD compound screening and improved SECPSO. J. Comput. 2019, 30, 128–144. [Google Scholar]
- Yuan, J.; Han, T.; Tang, J.; An, L. Intelligent fault diagnosis method for rolling bearings based on wavelet time-frequency diagram and CNN. Mech. Des. Res. 2017, 33, 93–97. [Google Scholar] [CrossRef]
- Huang, H.; Huang, X.; Ding, W.; Yang, M.; Yu, X.; Pang, J. Vehicle vibro-acoustical comfort optimization using a multi-objective interval analysis method. Expert Syst. Appl. 2023, 213, 119001. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, C.; Guo, X. Research on fault diagnosis of rolling bearing based on MCKD-EWT. Bearing 2020, 5, 43–48. [Google Scholar] [CrossRef]
- Zhou, C.; Ma, J.; Wu, J. Fault Diagnosis of Check Valve Based on CEEMD Compound Screening, BSE and FCM. IFAC-Pap. OnLine 2018, 51, 323–328. [Google Scholar] [CrossRef]
- Pan, Z.; Huang, G.; Fan, Y. A Check Valve Fault Diagnosis Method Based on Variational Mode Decomposition and Permutation Entropy. In Proceedings of the 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; pp. 650–655. [Google Scholar] [CrossRef]
- Chen, Y.; Huang, G.; Feng, Z. Early Fault Diagnosis of High Pressure Diaphragm Pump Check Valve Based on VMD-HMM. In Proceedings of the 2019 IEEE 8th Data Driven Control and Learning Systems Conference (DDCLS), Dali, China, 24–27 May 2019; pp. 808–813. [Google Scholar] [CrossRef]
- Zhao, N.; Zhang, J.; Ma, W.; Jiang, Z.; Mao, Z. Variational time-domain decomposition of reciprocating machine multi-impact vibration signals. Mech. Syst. Signal Process. 2022, 172, 108977. [Google Scholar] [CrossRef]
- Xia, S.; Xia, Y.; Wang, J. Piston Wear Detection and Feature Selection Based on Vibration Signals Using the Improved Spare Support Vector Machine for Axial Piston Pumps. Materials 2022, 15, 8504. [Google Scholar] [CrossRef] [PubMed]
- Wasim, Z.; Zahoor, A.; Muhammad, F.; Niamat, U.; Kim, K. Centrifugal Pump Fault Diagnosis Based on a Novel SobelEdge Scalogram and CNN. Sensors 2023, 23, 5255. [Google Scholar] [CrossRef] [PubMed]
- Ma, M.; Sun, C.; Zhang, C.; Chen, X. Subspace-based MVE for performance degradation assessment of aero-engine bearings with multimodal features. Mech. Syst. Signal Process. 2019, 124, 298–312. [Google Scholar] [CrossRef]
- Huang, H.; Lim, T.C.; Wu, J.; Ding, W.; Pang, J. Multitarget prediction and optimization of pure electric vehicle tire/road airborne noise sound quality based on a knowledge-and data-driven method. Mech. Syst. Signal Process. 2023, 197, 110361. [Google Scholar] [CrossRef]
- Li, K.; Gao, X.; Tian, Z.; Qiu, Z. Using the curve moment and the PSO-SVM method to diagnose downhole conditions of a sucker rod pumping unit. Pet. Sci. 2013, 10, 73–80. [Google Scholar] [CrossRef]
- Li, R.; Fan, Y. Fault Diagnosis of Check Valve of High-pressure Diaphragm Pump Based on CEEMDAN Multi-scale Arrangement Entropy and SO-RELM. Vib. Shock 2023, 42, 127–135. [Google Scholar]
- Ma, J.; Wu, J.; Wang, X. Fault Diagnosis Method of Check Valve Based on Multikernel Cost-Sensitive Extreme Learning Machine. Complexity 2017, 2017, 8395252. [Google Scholar] [CrossRef]
- Xu, W.H.; Fu, K. An intelligent diagnostic system for reciprocating machine. In Proceedings of the 1997 IEEE International Conference on Intelligent Processing Systems, Beijing, China, 28–31 October 1997; pp. 1520–1522. [Google Scholar] [CrossRef]
- Chen, Z.; Mauricio, A.; Li, W.; Gryllias, K. A deep learning method for bearing fault diagnosis based on Cyclic Spectral Coherence and Convolutional Neural Networks. Mech. Syst. Signal Process. 2020, 140, 106683. [Google Scholar] [CrossRef]
- Bie, F.; Du, T.; Lyu, F. An integrated approach based on improved CEEMDAN and LSTM deep learning neural network for fault diagnosis of reciprocating pump. IEEE Access 2021, 9, 23301–23310. [Google Scholar] [CrossRef]
- Wei, X.L.; Chao, Q.; Tao, J.F. Cavitation fault diagnosis method for high-speed plunger pumps based on LSTM and CNN. Acta Aeronaut. Astronaut. Sin. 2021, 42, 423876. [Google Scholar] [CrossRef]
- Chen, Z.; Chen, S.; Chen, X.; Li, C.; Sanchez, R.V.; Qin, H. Deep neural networks-based rolling bearing fault diagnosis. Microelectron. Reliab. 2017, 75, 327–333. [Google Scholar] [CrossRef]
- Li, G.; Hu, J.; Shan, D.; Ao, J.; Huang, B.; Huang, Z. A CNN model based on innovative expansion operation improving the fault diagnosis accuracy of drilling pump fluid end. Mech. Syst. Signal Process. 2023, 187, 109974. [Google Scholar] [CrossRef]
- Tamilselvan, P.; Wang, P. Failure diagnosis using deep belief learning based health state classification. Reliab. Eng. Syst. Saf. 2013, 115, 124–135. [Google Scholar] [CrossRef]
- Muhammad, F.; Zahoor, A.; Kim, J. Pipeline leak diagnosis based on leak-augmented scalograms and deep learning. Eng. Appl. Comput. Fluid Mech. 2023, 17, 1. [Google Scholar] [CrossRef]
- Prosvirin, A.; Ahmad, Z.; Kim, J. Global and Local Feature Extraction Using a Convolutional Autoencoder and Neural Networks for Diagnosing Centrifugal Pump Mechanical Faults. IEEE Access 2021, 9, 65838–65854. [Google Scholar] [CrossRef]
- Mao, W.; He, L.; Yan, L.; Wang, J. Online sequential prediction of bearings imbalanced fault diagnosis by extreme learning machine. Mech. Syst. Signal Process. 2017, 83, 450–473. [Google Scholar] [CrossRef]
- Huang, H.; Wu, J.; Lim, T.; Yang, M.; Ding, W. Pure electric vehicle nonstationary interior sound quality prediction based on deep CNNs with an adaptable learning rate tree. Mech. Syst. Signal Process. 2021, 148, 107170. [Google Scholar] [CrossRef]
- Tang, Y.; Zhang, Y.Q.; Chawla, N.V.; Krasser, S. SVMs modeling for highly imbalanced classification. IEEE Trans. Syst. Man Cybern. 2009, 9, 281–288. [Google Scholar] [CrossRef]
- Haixiang, G.; Yijing, L.i.; Shang, J.; Mingyun, G.u.; Yuanyue, H.; Bing, G. Learning from class-imbalanced data: Review of methods and applications. Exp. Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Zhang, C.; Tan, K.C.; Li, H.; Hong, G.S. A cost-sensitive deep belief network for imbalanced classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 109–122. [Google Scholar] [CrossRef]
- Chawla, V.; Nitesh, W.; Kevin, W.; Bowyer, O.; Lawrence, W.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. Artif. Intell. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristicoversampling method based on k-means and SMOTE. Inf. Sci. 2018, 456, 1–20. [Google Scholar] [CrossRef]
- Qian, M.; Li, Y. A weakly supervised learning-based oversampling framework for classimbalanced fault diagnosis. LEEE Trans. Reliab. 2022, 71, 429–442. [Google Scholar] [CrossRef]
- Qin, Z.; Yu, D.; Chen, L.; Chao, W.; Liang, M.; Tao, L.; Ma, J. An adaptive fault diagnosis framework under class-imbalanced conditions based on contrastive augmented deep reinforcement learning. Expert Systems with Applications. 2023, 234, 121001. [Google Scholar] [CrossRef]
- Lin, T.; Goyal, P.; Girshick, R. Focal loss for dense object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 318–327. [Google Scholar] [CrossRef] [PubMed]
- Zhou, W.; Li, X.; Yi, J. A novel UKF-RBF method based on adaptive noise factor for fault diagnosis in pumping unit. IEEE Trans. Ind. Inform. 2019, 15, 1415–1424. [Google Scholar] [CrossRef]
- Li, C.; Sanchez, R.; Zurita, G.; Cerrada, V.; Cabrera, D.; Vasquez, R. Multimodal deep support vector classification with homologous features and its application to gearbox fault diagnosis. Neurocomputing 2015, 168, 119–127. [Google Scholar] [CrossRef]
- Wang, B.; Guo, J.; Zhang, Y. Application of learning receptive field algorithm based on deep networkin image classification. Control Theory Appl. 2015, 32, 1114–1119. [Google Scholar] [CrossRef]
- Jia, F.; Lei, Y.; Lin, J.; Zhou, X.; Lu, N. Deep neural networks:a promising tool forfault characteristic mining and intelligent diagnosis of rotating machinerywith massive data. Mech. Syst. Signal Process. 2016, 7273, 303–315. [Google Scholar] [CrossRef]
- Huang, H.; Huang, X.; Ding, W.; Zhang, S.; Pang, J. Optimization of electric vehicle sound package based on LSTM with an adaptive learning rate forest and multiple-level multiple-object method. Mech. Syst. Signal Process. 2023, 187, 109932. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F. Effective data generation for imbalanced learning using conditional generative adversarial networks. Exp. Syst. 2018, 91, 464–471. [Google Scholar] [CrossRef]
- Malik, J.; Mishra, S. Proximal support vector machine (PSVM) based imbalance fault diagnosis of wind turbine using generator current signals. Energy Proc. 2016, 90, 593–603. [Google Scholar] [CrossRef]
- Sun, P.; Dai, R.; Li, H.; Zheng, Z.; Wu, Y.; Huang, H. Multi-Objective Prediction of the Sound Insulation Performance of a Vehicle Body System Using Multiple Kernel Learning–Support Vector Regression. Electronics 2024, 13, 538. [Google Scholar] [CrossRef]
- Jiao, J.; Zhao, M.; Lin, J.; Ding, C. Deep coupled dense convolutional network with complementary data for intelligent fault diagnosis. IEEE Trans. Ind. Electron. 2019, 66, 9858–9867. [Google Scholar] [CrossRef]
- Huang, H.; Huang, X.; Li, R.; Lim, T.; Ding, W. Sound quality prediction of vehicle interior noise using deep belief networks. Applied Acoustics. 2016, 113, 149–161. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: A new learning scheme of feedforward neural networks. In Proceedings of the 2004 IEEE International Joint Conference on Neural Networks, Budapest, Hungary, 25–29 July 2004; pp. 985–990. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Identity Mappings in Deep Residual Networks; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 630–645. [Google Scholar] [CrossRef]
- Huang, G.; Zhu, Q.; Siew, C. Extreme learning machine: Theory and applications. Neurocomputing 2006, 70, 489–501. [Google Scholar] [CrossRef]
- Wu, Y.; Liu, X.; Huang, H.; Wu, Y.; Ding, W. Multi-Objective Prediction and Optimization of Vehicle Acoustic Package Based on ResNet Neural Network. Sound Vib. 2023, 57, 73–95. [Google Scholar] [CrossRef]
- Zhao, H.; Wang, J.; Lee, J.; Li, Y. A compound interpolation envelope local mean decomposition and its application for fault diagnosis of reciprocating compressors. Mech. Syst. Signal Process. 2018, 110, 273–295. [Google Scholar] [CrossRef]
- Fröhlingsdorf, K.; Dreßen, M.; Pischinger, S.; Steffens, C. Analysis of the Influence of Image Processing, Feature Selection, and Decision Tree Classification on Noise Separation of Electric Vehicle Powertrains. SAE Int. J. Veh. Dyn. Stab. NVH 2023, 7, 23–33. [Google Scholar] [CrossRef]
- Li, X.; Lv, C.; Wang, W.; Li, G.; Yang, L.; Yang, J. Generalized Focal Loss: Towards Efficient Representation Learning for Dense Object Detection. IEEE Trans Pattern Anal Mach Intell. 2023, 3139–3153. [Google Scholar] [CrossRef]
- Chong, U. Signal model-based fault detection and diagnosis for induction motors using features of vibration signal in two-dimension domain. Stroj. Vestn. Mech. Eng. 2011, 57, 655–666. [Google Scholar] [CrossRef]
- Liu, Z.; Li, S.; Wang, R.; Jia, X. Research on Fault Feature Extraction Method of Rolling Bearing Based on SSA–VMD–MCKD. Electronics 2022, 11, 3404. [Google Scholar] [CrossRef]
- Huang, H.; Li, R.X.; Yang, M.L.; Lim, T.C.; Ding, W. Evaluation of vehicle interior sound quality using a continuous restricted Boltzmann machine-based DBN. Mech. Syst. Signal Process. 2017, 84, 245–267. [Google Scholar] [CrossRef]
- Xu, Q.; Lu, S.; Jia, W.; Jiang, C. Imbalanced fault diagnosis of rotating machinery via multi-domain feature extraction and cost-sensitive learning. Intell. Manuf. 2020, 31, 1467–1481. [Google Scholar] [CrossRef]
- Yuan, W.; Yang, Q. A Novel Method for Pavement Transverse Crack Detection Based on 2D Reconstruction of Vehicle Vibration Signal. KSCE J. Civ. Eng. 2023, 27, 2868–2881. [Google Scholar] [CrossRef]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Label | Normal | Early Degradation | Warning | Fault |
|---|---|---|---|---|
| Class label | 1 | 2 | 3 | 4 |
| The proportion of data | 66.0% | 17.0% | 7.0% | 10.0% |
| Total Population | Condition Positive | Condition Negative |
|---|---|---|
| Predicted condition positive | True positive (TP) | False positive (FP) |
| Predicted condition negative | False negative (FN) | True negative (TN) |
| Model | Model 1# | Model 2# | Model 3# | Model 4# |
|---|---|---|---|---|
| Conv1 | Stage 1 × 8 | Stage 1 × 16 | Stage 1 × 32 | Stage 1 × 64 |
| Conv2 | Stage 2 × 8 | Stage 2 × 16 | Stage 2 × 32 | Stage 2 × 64 |
| Stage 2 × 8 | Stage 2 × 16 | Stage 2 × 32 | Stage 2 × 64 | |
| Conv3 | Stage 3 × 16 | Stage 3 × 32 | Stage 3 × 64 | Stage 3 × 128 |
| Stage 2 × 16 | Stage 2 × 32 | Stage 2 × 64 | Stage 2 × 128 | |
| Conv4 | Stage 3 × 32 | Stage 3 × 64 | Stage 3 × 128 | Stage 3 × 256 |
| Stage 2 × 32 | Stage 2 × 64 | Stage 2 × 128 | Stage 2 × 256 | |
| Conv5 | Stage 3 × 64 | Stage 3 × 128 | Stage 3 × 256 | Stage 3 × 512 |
| Stage 2 × 64 | Stage 2 × 128 | Stage 2 × 256 | Stage 2 × 512 | |
| Average pool: dimensionality reduction to 512 data points ELM: the network predicts the results | ||||
| Optimizer = ‘Adam’ Initial LR = 0.001 Final LR = 0.0001 batch-size = 128, epochs = 30 | ||||
| The Network Module’ Name | Parameters of Residual Block | ||
|---|---|---|---|
| Block 1 | Block 2 | Block 3 | |
| Conv layer 1 | Conv: 1 × 1; s: 1 | Conv: 3 × 3; s: 1 | Conv: 3 × 3; s: 1 |
| Conv layer 2 | Conv: 3 × 3; s: 2 | Conv: 3 × 3; s: 2 | Conv: 3 × 3; s: 1 |
| Conv layer 3 | Conv: 1 × 1; s: 1 | Conv: 3 × 3; s: 1 | --- |
| Pooling layer | Avgpool: 2 × 2; s: 1 | --- | --- |
| Conv layer 4 | Conv: 1 × 1; s: 1 | --- | --- |
| Method | Parameters | Values or Guidelines |
|---|---|---|
| ResNet | Stage 1 | As shown in Figure 4a |
| Stage 2 | As shown in Figure 4b | |
| Stage 3 | As shown in Figure 4c | |
| ELM | Penalty coefficient C | 0.1 |
| Number of hidden nodes L | 4000 | |
| Optimizer = ‘Adam’, initial LR = 0.001, final LR = 0.0001, batch-size = 128, epochs = 30, activation function = ‘relu’ | ||
| Methods | Loss Function | F2-Score | ||
|---|---|---|---|---|
| Without AFL | AFL | Without AFL | AFL | |
| ResNet-Softmax | 96.88% ± 0.23 | 99.22% ± 0.21 | 97.07% ± 0.22 | 98.43% ± 0.24 |
| ResNet-SVM | 98.44% ± 0.28 | 99.41% ± 0.21 | 96.77% ± 0.18 | 97.11% ± 0.23 |
| ResNet-ELM | 98.63% ± 0.31 | 99.60% ± 0.29 | 98.79% ± 0.28 | 99.20% ± 0.21 |
| Methods | Diagnostic Time/s | |
|---|---|---|
| Without AFL | AFL | |
| ResNet-Softmax | 0.4830 | 0.4312 |
| ResNet-SVM | 0.7651 | 0.7120 |
| ResNet-ELM | 0.6349 | 0.6034 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xiang, W.; Wu, Y.; Peng, C.; Cai, K.; Ren, H.; Peng, Y. A Fault Diagnosis Method for Electric Check Valve Based on ResNet-ELM with Adaptive Focal Loss. Electronics 2024, 13, 3426. https://doi.org/10.3390/electronics13173426
Xiang W, Wu Y, Peng C, Cai K, Ren H, Peng Y. A Fault Diagnosis Method for Electric Check Valve Based on ResNet-ELM with Adaptive Focal Loss. Electronics. 2024; 13(17):3426. https://doi.org/10.3390/electronics13173426
Chicago/Turabian StyleXiang, Weijia, Yunru Wu, Cheng Peng, Kaicheng Cai, Hongbing Ren, and Yuming Peng. 2024. "A Fault Diagnosis Method for Electric Check Valve Based on ResNet-ELM with Adaptive Focal Loss" Electronics 13, no. 17: 3426. https://doi.org/10.3390/electronics13173426