
Deep Siamese Neural Network-Driven Model for Robotic Multiple Peg-in-Hole Assembly System
Abstract
:1. Introduction
2. Related Work
2.1. Peg-in-Hole Assembly
2.1.1. Traditional Control Methods
2.1.2. Deep Learning Methods
2.2. Object Detection
2.3. Deep Siamese Neural Network
2.4. Motion Control for Robot
2.4.1. Robot Acquisition of MPCC Assembly State
2.4.2. Reward Design
3. Methodology
3.1. MPCC Initial Assembly
3.1.1. Detection and Localization of the MPCC
3.1.2. Yaw Angle Estimation for the MPCC Female
3.2. DSNN-Driven Alignment for MPCC
3.2.1. Visual Perception
3.2.2. Feature Extraction
3.2.3. Regression for Position Identification
3.3. Robot Assembly Online Control
| Algorithm 1 Control |
|
1: While 2: 3: transfer to 4: 5: 6: if 7: return; 8: Else 9: Control |
4. Experiments and Results
4.1. Experiment Platform
4.2. Calibration Errors
4.3. Performance Evaluation
4.3.1. Data Collection
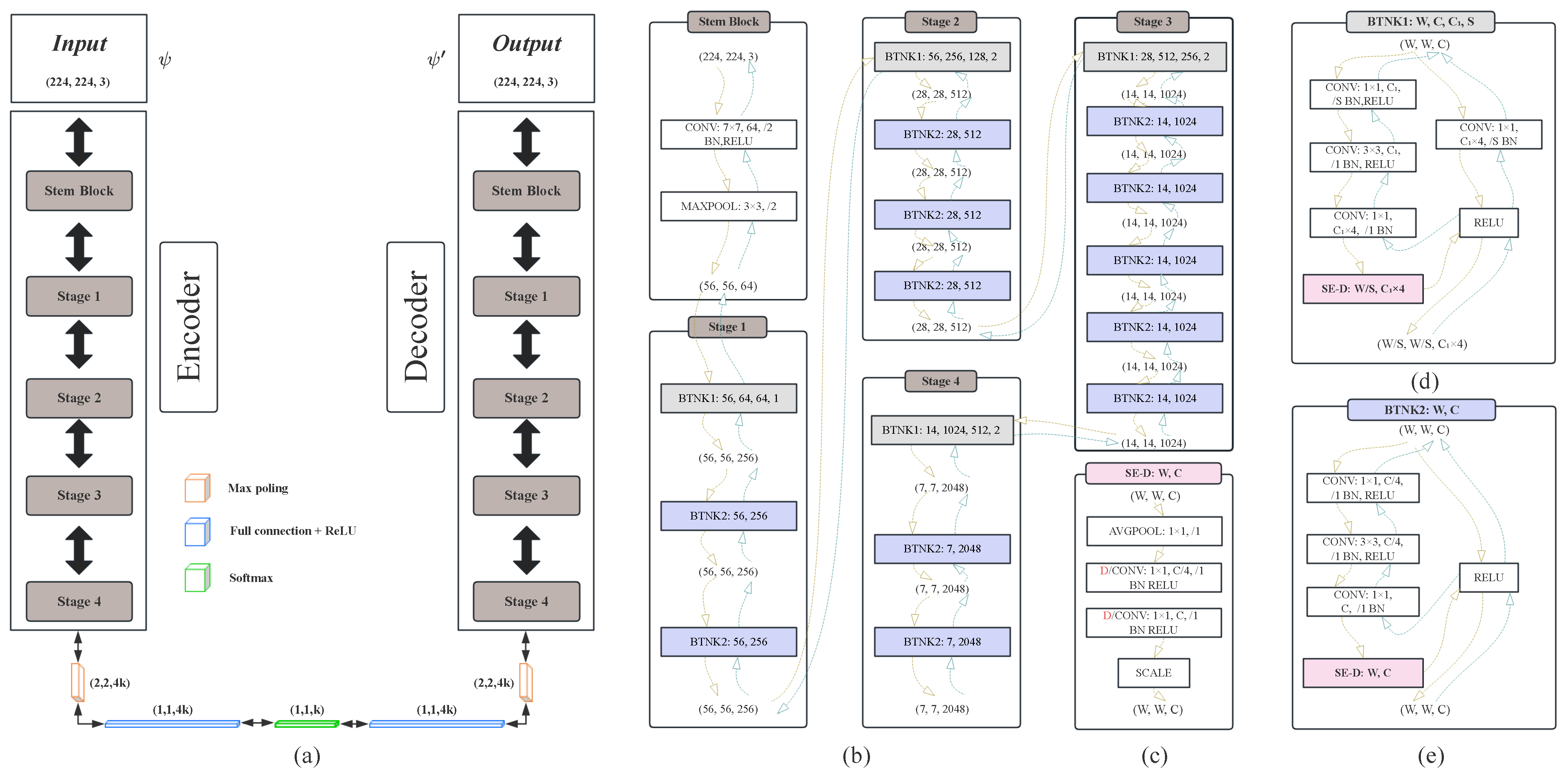
4.3.2. Autoencoder
4.3.3. DSNN Structures
4.3.4. Performance in Practical Assembly
4.3.5. Ablation Study
4.4. Discussions
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| MPCC | Multi-Pin Circular Connector |
| DSNN | Deep Siamese Neural Network |
| SE-D | Squeeze-and-Excitation with Depthwise separable convolutions |
| ResNetSED-50 | ResNet50 integrated with SE-D module. |
| RT18 | RT-DETR-18 |
| AE | AutoEncoder |
References
- Arents, J.; Greitans, M. Smart industrial robot control trends, challenges and opportunities within manufacturing. Appl. Sci. 2022, 12, 937. [Google Scholar] [CrossRef]
- Yang, M.; Huang, Z.; Sun, Y.; Zhao, Y.; Sun, R.; Sun, Q.; Chen, J.; Qiang, B.; Wang, J.; Sun, F. Digital twin driven measurement in robotic flexible printed circuit assembly. IEEE Trans. Instrum. Meas. 2023, 72, 5007812. [Google Scholar] [CrossRef]
- Kyrarini, M.; Haseeb, M.A.; Ristić-Durrant, D.; Gräser, A. Robot learning of industrial assembly task via human demonstrations. Auton. Robot. 2019, 43, 239–257. [Google Scholar] [CrossRef]
- Lee, Y.; Hu, E.S.; Lim, J.J. IKEA furniture assembly environment for long-horizon complex manipulation tasks. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xian, China, 30 May–5 June 2021; pp. 6343–6349. [Google Scholar]
- Zhang, K.; Wang, C.; Chen, H.; Pan, J.; Wang, M.Y.; Zhang, W. Vision-based six-dimensional peg-in-hole for practical connector insertion. In Proceedings of the 2023 IEEE International Conference on Robotics and Automation (ICRA), London, UK, 29 May–2 June 2023; pp. 1771–1777. [Google Scholar]
- Schoettler, G.; Nair, A.; Luo, J.; Bahl, S.; Ojea, J.A.; Solowjow, E.; Levine, S. Deep reinforcement learning for industrial insertion tasks with visual inputs and natural rewards. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24–29 October 2020; pp. 5548–5555. [Google Scholar]
- Park, H.; Park, J.; Lee, D.-H.; Park, J.-H.; Baeg, M.-H.; Bae, J.-H. Compliance-based robotic peg-in-hole assembly strategy without force feedback. IEEE Trans. Ind. Electron. 2017, 64, 6299–6309. [Google Scholar] [CrossRef]
- Triyonoputro, J.C.; Wan, W.; Harada, K. Quickly inserting pegs into uncertain holes using multi-view images and deep network trained on synthetic data. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 5792–5799. [Google Scholar]
- Xu, J.; Hou, Z.; Wang, W.; Xu, B.; Zhang, K.; Chen, K. Feedback deep deterministic policy gradient with fuzzy reward for robotic multiple peg-in-hole assembly tasks. IEEE Trans. Ind. Inform. 2018, 15, 1658–1667. [Google Scholar] [CrossRef]
- Chen, W.; Zeng, C.; Liang, H.; Sun, F.; Zhang, J. Multimodality driven impedance-based sim2real transfer learning for robotic multiple peg-in-hole assembly. IEEE Trans. Cybern. 2023, 99, 1–14. [Google Scholar] [CrossRef]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. 1–9. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–15. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 213–229. [Google Scholar]
- Zhao, Y.; Lv, W.; Xu, S.; Wei, J.; Wang, G.; Dang, Q.; Liu, Y.; Chen, J. Detrs beat yolos on real-time object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 16965–16974. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese neural networks for one-shot image recognition. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 7–9 July 2015; Volume 2, Number 1. pp. 1–30. [Google Scholar]
- Zhang, Y.; Wang, L.; Qi, J.; Wang, D.; Feng, M.; Lu, H. Structured siamese network for real-time visual tracking. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 351–366. [Google Scholar]
- Groth, O.; Hung, C.-M.; Vedaldi, A.; Posner, I. Goal-conditioned end-to-end visuomotor control for versatile skill primitives. In Proceedings of the 2021 IEEE International Conference on Robotics and Automation (ICRA), Xian, China, 30 May–5 June 2021; pp. 1319–1325. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Higgins, I.; Matthey, L.; Pal, A.; Burgess, C.P.; Glorot, X.; Botvinick, M.M.; Mohamed, S.; Lerchner, A. beta-VAE: Learning basic visual concepts with a constrained variational framework. In Proceedings of the 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, 24–26 April 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Pérez-Dattari, R.; Celemin, C.; Franzese, G.; Ruiz-del-Solar, J.; Kober, J. Interactive learning of temporal features for control: Shaping policies and state representations from human feedback. IEEE Robot. Autom. Mag. 2020, 27, 46–54. [Google Scholar] [CrossRef]
- Kang, H.; Zang, Y.; Wang, X.; Chen, Y. Uncertainty-driven spiral trajectory for robotic peg-in-hole assembly. IEEE Robot. Autom. Lett. 2022, 7, 6661–6668. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Evaluation Set | Test Set | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Model Architecture | X | Y | X | Y | ||||||||
| VGG-16+FC [25] | 2.85 | 0.46 | 1.32 | 2.09 | 0.32 | 0.91 | 1.26 | 0.34 | 1.06 | 1.32 | 0.22 | 0.97 |
| DT+VGG-16+LSTM [2] | 1.67 | 0.27 | 0.76 | 1.49 | 0.19 | 0.53 | 0.93 | 0.42 | 0.81 | 0.85 | 0.29 | 0.66 |
| DSNN+ResNet-50+FC | 0.87 | 0.12 | 0.41 | 0.65 | 0.00 | 0.38 | 0.59 | 0.21 | 0.45 | 0.53 | 0.19 | 0.42 |
| DSNN+ResNet-50+LSTM | 0.63 | 0.00 | 0.31 | 0.77 | 0.00 | 0.23 | 0.65 | 0.16 | 0.39 | 0.58 | 0.12 | 0.36 |
| DSNN+ResNetSED-50+LSTM | 0.42 | 0.00 | 0.16 | 0.35 | 0.00 | 0.14 | 0.45 | 0.11 | 0.28 | 0.35 | 0.00 | 0.27 |
| Model Architecture | Params (M) | Response (ms) | X (mm) | Y (mm) | Success (%) |
|---|---|---|---|---|---|
| VGG16+FC [25] | 145 | 63 | 1.06 | 0.97 | 49.3 |
| DT+VGG-16+LSTM [2] | 184 | 88 | 0.81 | 0.66 | 69.2 |
| DSNN+AE(ResNetSED-50)+LSTM | 98 | 43 | 0.28 | 0.27 | 83.1 |
| Model Architecture | Assembly Times | Ave | ||
|---|---|---|---|---|
| 1 | 5 | 10 | ||
| RT18 | 34.1 | 53.9 | 69.3 | 52.4 |
| RT18 + DSNN + ResNet-50 | 67.6 | 79.2 | 88.4 | 78.4 |
| RT18 + DSNN + ResNetSED-50 | 74.8 | 85.5 | 93.2 | 84.5 |
| RT18+DSNN+AE(ResNetSED-50) | 81.6 | 88.7 | 95.7 | 88.7 |
| RT18+DSNN+AE(ResNetSED-50)+LSTM | 83.1 | 91.3 | 97.4 | 90.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, J.; Tang, W.; Yang, M. Deep Siamese Neural Network-Driven Model for Robotic Multiple Peg-in-Hole Assembly System. Electronics 2024, 13, 3453. https://doi.org/10.3390/electronics13173453
Chen J, Tang W, Yang M. Deep Siamese Neural Network-Driven Model for Robotic Multiple Peg-in-Hole Assembly System. Electronics. 2024; 13(17):3453. https://doi.org/10.3390/electronics13173453
Chicago/Turabian StyleChen, Jinlong, Wei Tang, and Minghao Yang. 2024. "Deep Siamese Neural Network-Driven Model for Robotic Multiple Peg-in-Hole Assembly System" Electronics 13, no. 17: 3453. https://doi.org/10.3390/electronics13173453