Author Contributions
Conceptualization, D.-J.L.; Methodology, A.H., B.O. and E.P.; Software, A.H.; Validation, B.O., E.P. and D.-J.L.; Formal analysis, A.H., B.O. and E.P.; Resources, D.-J.L.; Data curation, A.H.; Writing—original draft, A.H.; Writing—review & editing, B.O., E.P. and D.-J.L.; Supervision, D.-J.L.; Project administration, D.-J.L. All authors have read and agreed to the published version of the manuscript.
Figure 1.
A demonstration of using yard lines and side lines as key features for the purpose of converting player locations to bird’s-eye view.
Figure 1.
A demonstration of using yard lines and side lines as key features for the purpose of converting player locations to bird’s-eye view.
Figure 2.
Past work of our player detection, player position, and offensive play formation recognition (from top to bottom) algorithms using images from a football video game (Madden 2020) with 90.3%, 98.8%, and 99.2% accuracy, respectively.
Figure 2.
Past work of our player detection, player position, and offensive play formation recognition (from top to bottom) algorithms using images from a football video game (Madden 2020) with 90.3%, 98.8%, and 99.2% accuracy, respectively.
Figure 3.
A visual example of the variation of camera zoom and pan angle present in real-world football footage (2022 Football Game: Troup County High School, Georgia.
Figure 3.
A visual example of the variation of camera zoom and pan angle present in real-world football footage (2022 Football Game: Troup County High School, Georgia.
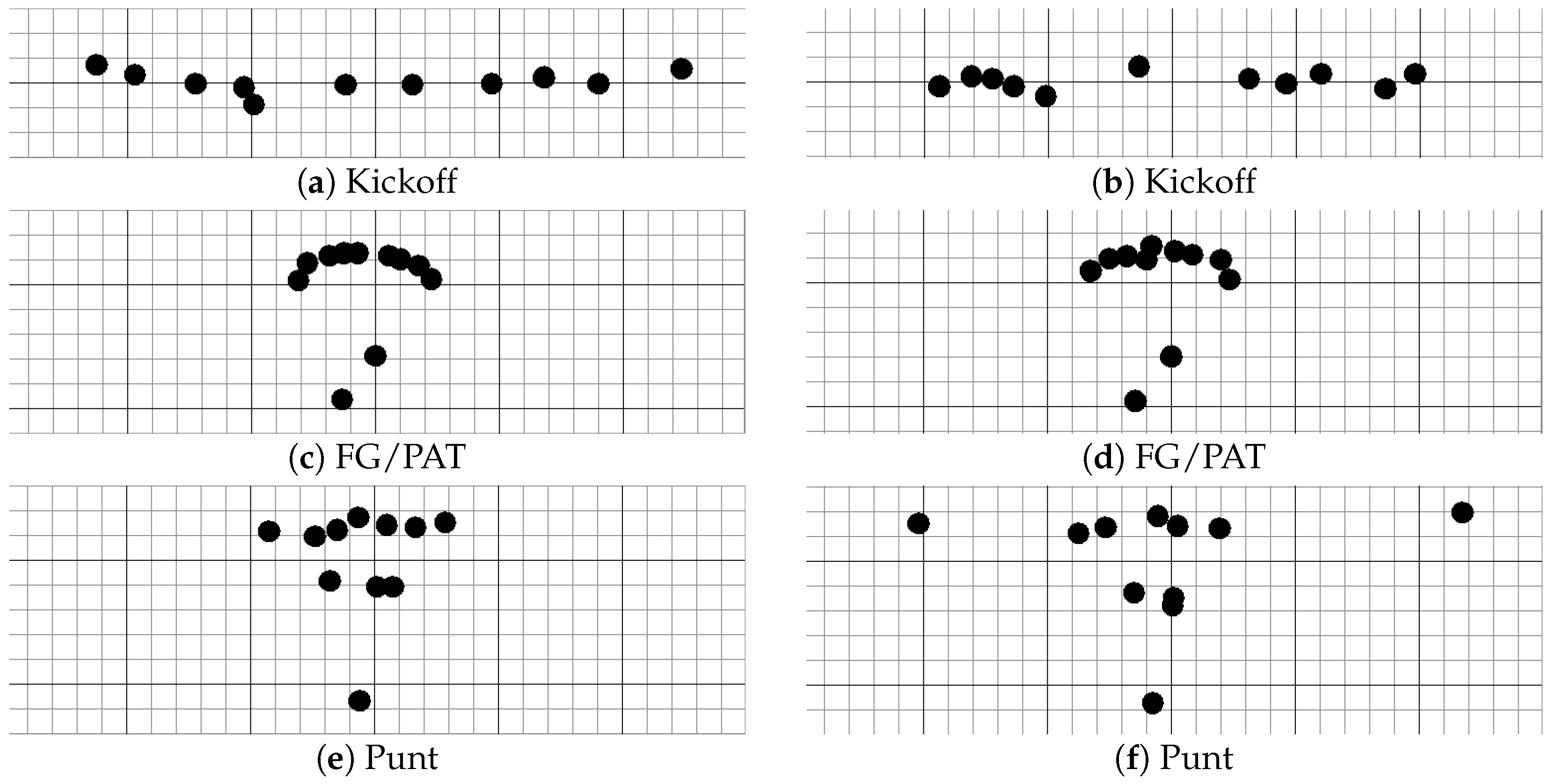
Figure 4.
Two examples of each special team play type present in the real-world dataset. Each black dot represents one player’s location in the x- and y-coordinates. (a,b) Kickoff, (c,d) FG/PAT, and (e,f) Punt.
Figure 4.
Two examples of each special team play type present in the real-world dataset. Each black dot represents one player’s location in the x- and y-coordinates. (a,b) Kickoff, (c,d) FG/PAT, and (e,f) Punt.
Figure 5.
Two examples of real offensive play formations with the zones of each player position type transposed on top. Our data augmentation was achieved by randomly placing players into these zones depending on their position type according to the requirements outlined in
Section 3.1.
Figure 5.
Two examples of real offensive play formations with the zones of each player position type transposed on top. Our data augmentation was achieved by randomly placing players into these zones depending on their position type according to the requirements outlined in
Section 3.1.
Figure 6.
(a) A play formation from the Completed Dataset with colored zones indicating the possible range of variation of each player. (b) An example of the same formation after augmentation.
Figure 6.
(a) A play formation from the Completed Dataset with colored zones indicating the possible range of variation of each player. (b) An example of the same formation after augmentation.
Figure 7.
(a) A play formation from the Completed Dataset with colored zones indicating the possible range of variation of each player. (b) An example of the same formation after augmentation with one player (right tackle) removed.
Figure 7.
(a) A play formation from the Completed Dataset with colored zones indicating the possible range of variation of each player. (b) An example of the same formation after augmentation with one player (right tackle) removed.
Figure 8.
Architecture of the MLP network. Between the input and output layers are two hidden layers with ReLU activations.
Figure 8.
Architecture of the MLP network. Between the input and output layers are two hidden layers with ReLU activations.
Figure 9.
The architecture of the play type recognition network, which takes in the x- and y-coordinates of the players to recognize the play type.
Figure 9.
The architecture of the play type recognition network, which takes in the x- and y-coordinates of the players to recognize the play type.
Figure 10.
The architecture of the player position recognition network, which takes in the x- and y-coordinates of the players and determines the position (role) of each player.
Figure 10.
The architecture of the player position recognition network, which takes in the x- and y-coordinates of the players and determines the position (role) of each player.
Figure 11.
Confusion matrix of the player position recognition accuracy when trained on the synthetic data and tested on the Original Dataset.
Figure 11.
Confusion matrix of the player position recognition accuracy when trained on the synthetic data and tested on the Original Dataset.
Figure 12.
Three example offensive play formations from the test dataset containing difficult-to-recognize wide receivers.
Figure 12.
Three example offensive play formations from the test dataset containing difficult-to-recognize wide receivers.
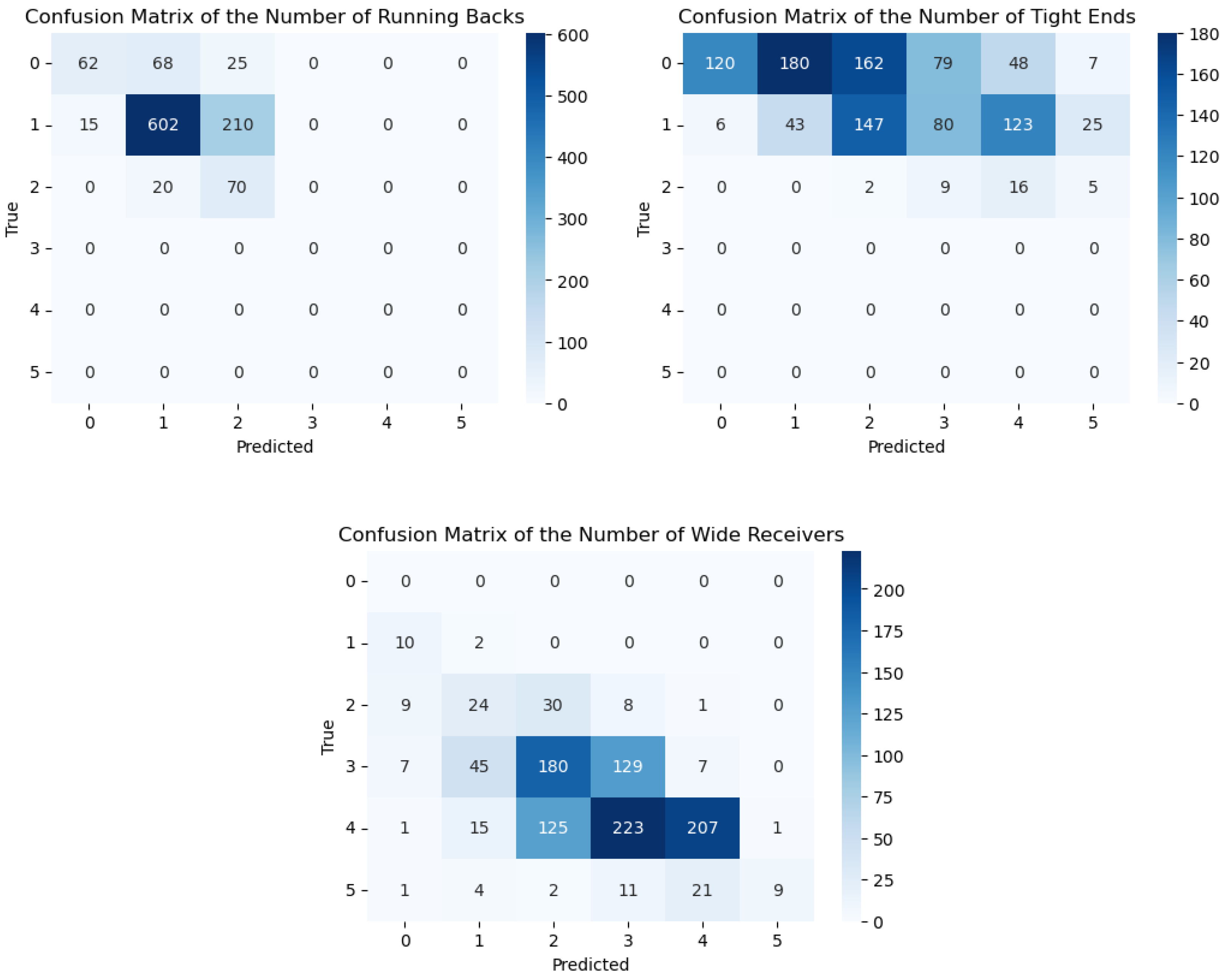
Figure 13.
Confusion matrices for the predicted number of running backs, tight ends, and wide receivers when trained with the Synthetic Dataset and tested on the Original Dataset.
Figure 13.
Confusion matrices for the predicted number of running backs, tight ends, and wide receivers when trained with the Synthetic Dataset and tested on the Original Dataset.
Figure 14.
Confusion matrix of the play type recognition accuracy, when trained on the augmented 75% of the Completed Data, with the players shifted and tested on the 25% of the remaining Completed Dataset.
Figure 14.
Confusion matrix of the play type recognition accuracy, when trained on the augmented 75% of the Completed Data, with the players shifted and tested on the 25% of the remaining Completed Dataset.
Figure 15.
Confusion matrix of the player position recognition model trained on the augmented 75% of the Completed Data with the player locations shifted. It was evaluated on the remaining 25% of the Completed Dataset.
Figure 15.
Confusion matrix of the player position recognition model trained on the augmented 75% of the Completed Data with the player locations shifted. It was evaluated on the remaining 25% of the Completed Dataset.
Figure 16.
Confusion matrices for the predicted number of running backs, tight ends, and wide receivers with the model when trained on the augmented 75% of the Completed Data with the players shifted and tested on the remaining 25% of the Completed Dataset.
Figure 16.
Confusion matrices for the predicted number of running backs, tight ends, and wide receivers with the model when trained on the augmented 75% of the Completed Data with the players shifted and tested on the remaining 25% of the Completed Dataset.
Figure 17.
Confusion matrix of the play type recognition accuracy when trained on the augmented 75% of the Completed Data with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
Figure 17.
Confusion matrix of the play type recognition accuracy when trained on the augmented 75% of the Completed Data with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
Figure 18.
Confusion matrix of the player position recognition accuracy when trained on the augmented 75% of the Completed Dataset with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
Figure 18.
Confusion matrix of the player position recognition accuracy when trained on the augmented 75% of the Completed Dataset with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
Figure 19.
Confusion matrices for the predicted number of running backs, tight ends, and wide receivers when trained on the augmented 75% of the Completed Dataset with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
Figure 19.
Confusion matrices for the predicted number of running backs, tight ends, and wide receivers when trained on the augmented 75% of the Completed Dataset with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
Figure 20.
Camera view angle from 45 degrees and 75 degrees above the football field and the bird’s-eye view captured from Madden 2020 video game.
Figure 20.
Camera view angle from 45 degrees and 75 degrees above the football field and the bird’s-eye view captured from Madden 2020 video game.
Table 1.
Training and testing data and whether Play Type or Player Position Recognition was performed for each of the three tests.
Table 1.
Training and testing data and whether Play Type or Player Position Recognition was performed for each of the three tests.
| Test | Training Data | Test Data | Play | Position |
|---|
| 1 | 20,000 Synthetic Data | 100% Original Data | No | Yes |
| 2 | 75% Augmented Completed Data | 25% Completed Data | Yes | Yes |
| 3 | 75% Augmented Completed Data | 25% Original Data | Yes | Yes |
Table 2.
Player position recognition accuracies when trained on the synthetic data and tested on the Original Dataset.
Table 2.
Player position recognition accuracies when trained on the synthetic data and tested on the Original Dataset.
| Player Position | Recognition Accuracy |
|---|
| Missing | 99.86% |
| Offensive Lineman | 84.33% |
| Quarterback/Running Back | 95.71% |
| Tight End | 25.15% |
| Left Wide Receiver | 79.76% |
| Right Wide Receiver | 68.53% |
Table 3.
Play Type recognition accuracies, when trained on the augmented 75% of the Completed Data with the players, shifted and tested on the 25% of the remaining Completed Dataset.
Table 3.
Play Type recognition accuracies, when trained on the augmented 75% of the Completed Data with the players, shifted and tested on the 25% of the remaining Completed Dataset.
| Play Type | Recognition Accuracy |
|---|
| Offensive Play | 98.42% |
| Kickoff | 98.80% |
| FG/PAT | 100.00% |
| Punt | 98.31% |
Table 4.
Player position recognition accuracies when trained on the augmented 75% of the Completed Data with the players shifted and tested on the 25% of the remaining Completed Dataset.
Table 4.
Player position recognition accuracies when trained on the augmented 75% of the Completed Data with the players shifted and tested on the 25% of the remaining Completed Dataset.
| Position | Recognition Accuracy |
|---|
| Missing | 81.82% |
| Offensive Linemen | 98.92% |
| Quarterback/Running Back | 94.33% |
| Tight End | 0.38% |
| Left Wide Receiver | 95.55% |
| Right Wide Receiver | 94.68% |
Table 5.
Play type recognition accuracies when trained on the augmented 75% of the Completed Data with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
Table 5.
Play type recognition accuracies when trained on the augmented 75% of the Completed Data with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
| Play Type | Recognition Accuracy |
|---|
| Offensive Play | 98.88% |
| Kickoff | 60.71% |
| FG/PAT | 100.00% |
| Punt | 88.71% |
Table 6.
Player position recognition accuracies when trained on the augmented 75% of the Completed Dataset with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
Table 6.
Player position recognition accuracies when trained on the augmented 75% of the Completed Dataset with players shifted and up to two players removed and tested on the 25% of the Original Dataset that were not used to create the Completed Dataset.
| Player Position | Recognition Accuracy |
|---|
| Missing | 96.94% |
| Offensive Linemen | 98.33% |
| Quarterback/Running Back | 94.25% |
| Tight End | 2.38% |
| Left Wide Receiver | 93.00% |
| Right Wide Receiver | 91.64% |






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}