
ComPipe: A Novel Flow Placement and Measurement Algorithm for Programmable Composite Pipelines

Abstract
:1. Introduction
- We present ComPipe, an innovative flow placement and measurement algorithm designed for the composite pipeline architecture. While its potential applications span numerous critical domains, this field has traditionally been underexplored in research.
- We have implemented the heavy-hitter detection algorithm entirely in the data plane, ensuring its full compatibility with the RMT architecture. This enhancement provides a more reliable and efficient mechanism for real-time identification of large traffic flows at the hardware.
- In the software pipeline, we have implemented the recording of less heavy flows, employing a multi-core approach to expedite this process. This strategy is aimed at significantly enhancing the overall measurement throughput of the software data plane.
- We conducted extensive experiments in both testbed environments and simulations to verify the high performance and precision of ComPipe. These experiments demonstrate the feasibility and effectiveness of ComPipe in practical applications.
2. Related Work
3. Design
3.1. Design Overview
3.2. Data Structure and Algorithm Design of ComPipe
3.2.1. Data Structure of ComPipe
3.2.2. Insertion of ComPipe
| Algorithm 1: Insertion of ComPipe. | |||||
| Input: Incoming packet p with flow ID f | |||||
| 1 | Function Insert(p): | ||||
| 2 | ; ; | ||||
| 3 | for to d do | ||||
| 4 | if is an empty slot then | ||||
| 5 | ; | ||||
| 6 | return | ||||
| 7 | else if then | ||||
| 8 | ; | ||||
| 9 | return | ||||
| 10 | else if then | ||||
| 11 | if then | ||||
| 12 | ; | ||||
| 13 | end | ||||
| 14 | end | ||||
| 15 | end | ||||
| 16 | if Query(f) + 1 > Query () + then | ||||
| 17 | ▹ See Section 3.2.3 for Query procedure | ||||
| 18 | Evict , replace with | ||||
| 19 | Insert to | ||||
| 20 | else | ||||
| 21 | Insert to | ||||
| 22 | end | ||||
| 23 | return | ||||
3.2.3. Query of ComPipe
3.3. Mathematical Analysis
3.4. Discussion
4. Multiple Measurement Application
4.1. Flow Size Estimation
4.2. Heavy-Hitter Detection
4.3. Flow Size Distribution
4.4. Heavy Change Detection Estimation
4.5. Cardinality Estimation
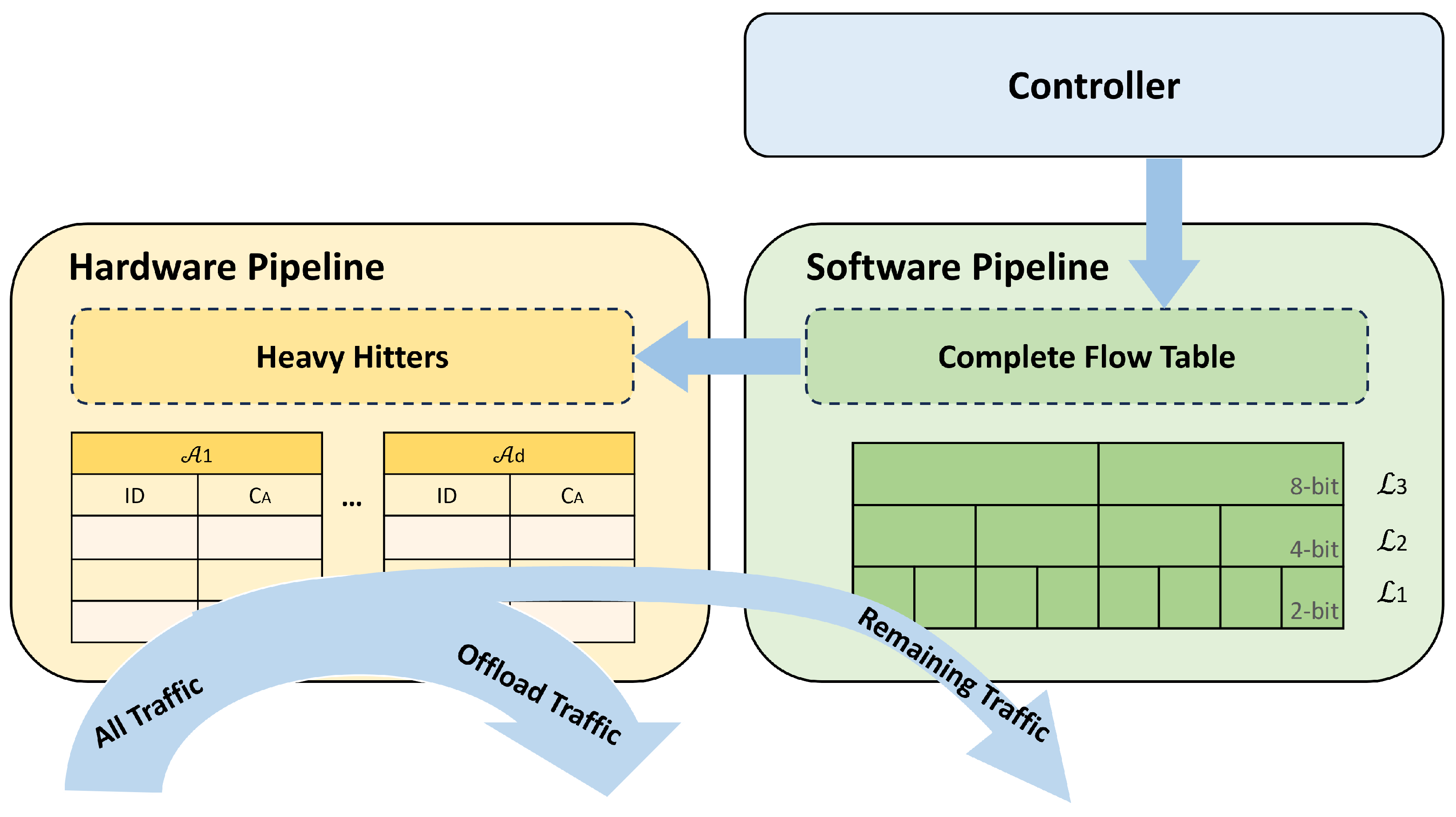
5. Implementations
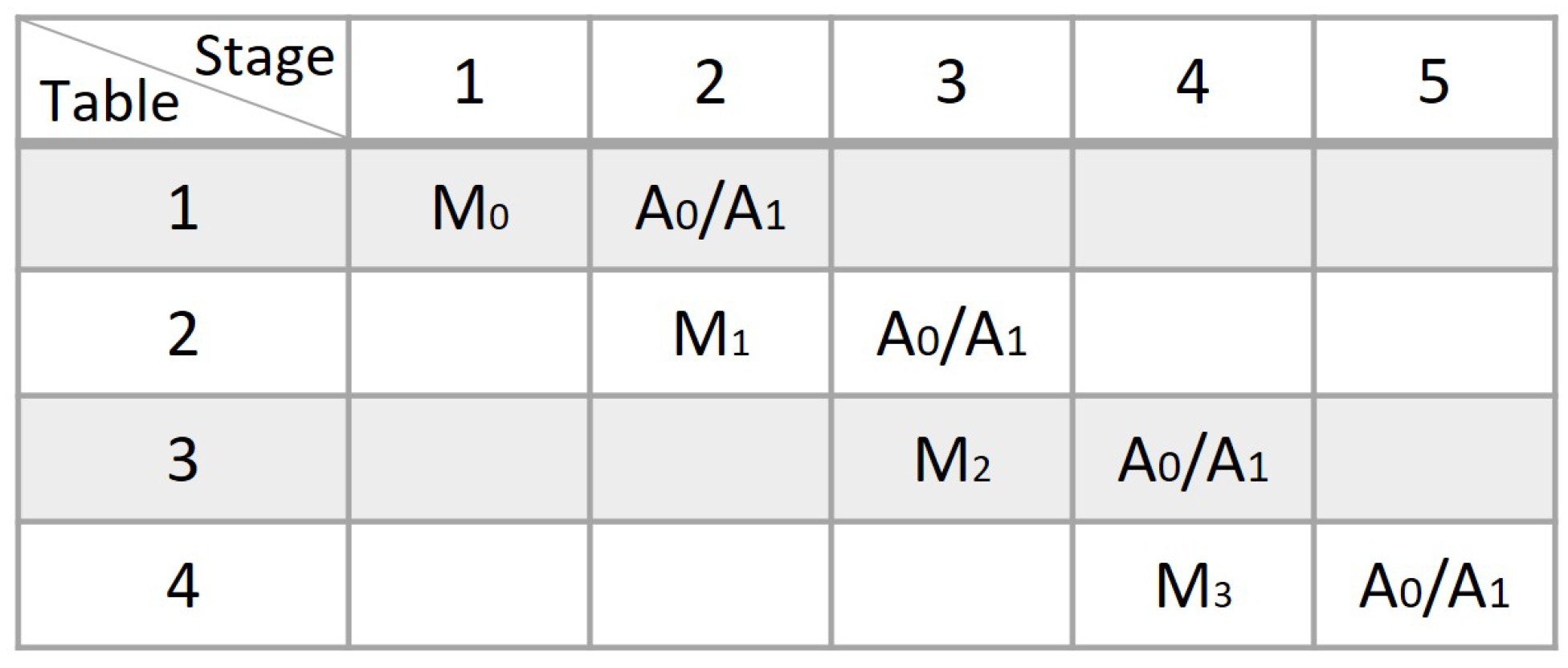
5.1. Hardware Pipeline Implementations
5.2. Software Pipeline Implementations
6. Evaluation
6.1. Experimental Setup
6.1.1. Datasets
6.1.2. Evaluation Metrics
6.1.3. Simulation Setup
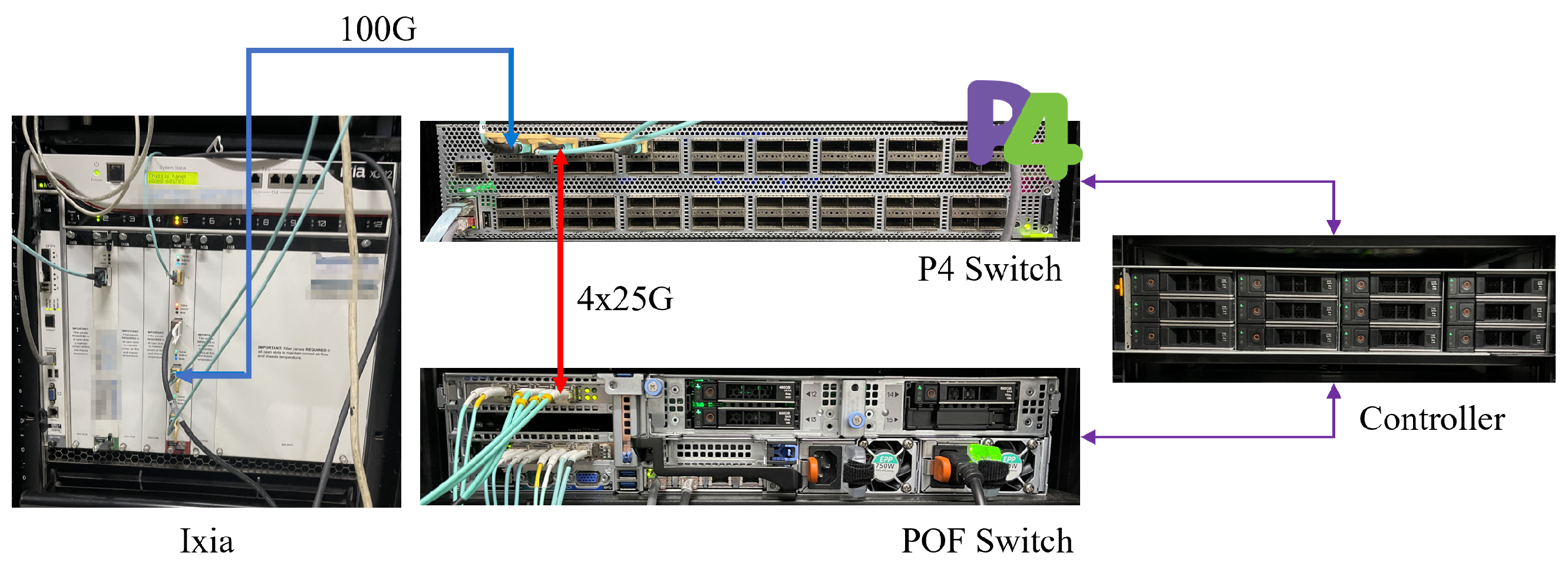
6.1.4. Testbed Setup
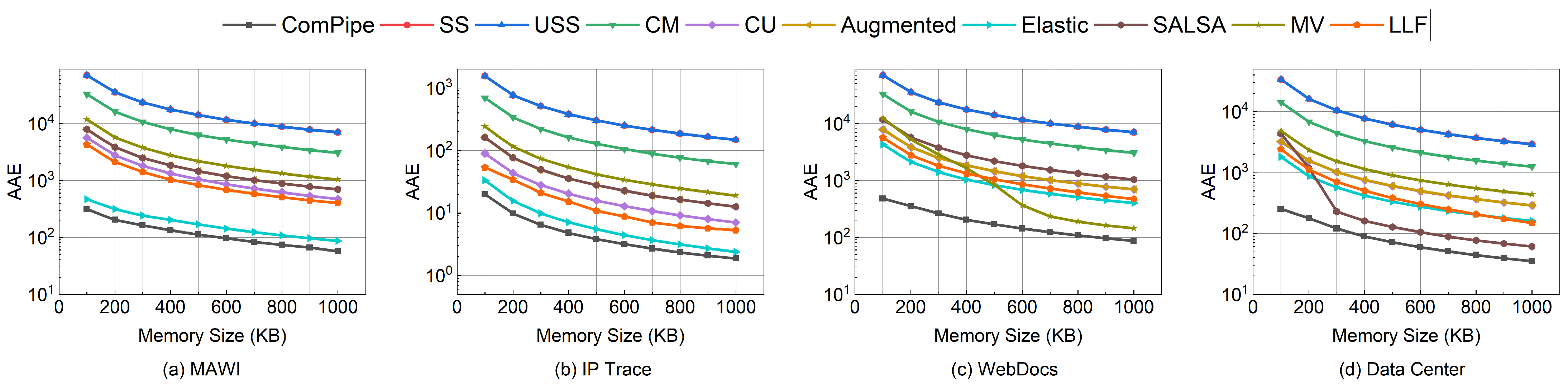
6.2. Experiments on Measurement Tasks
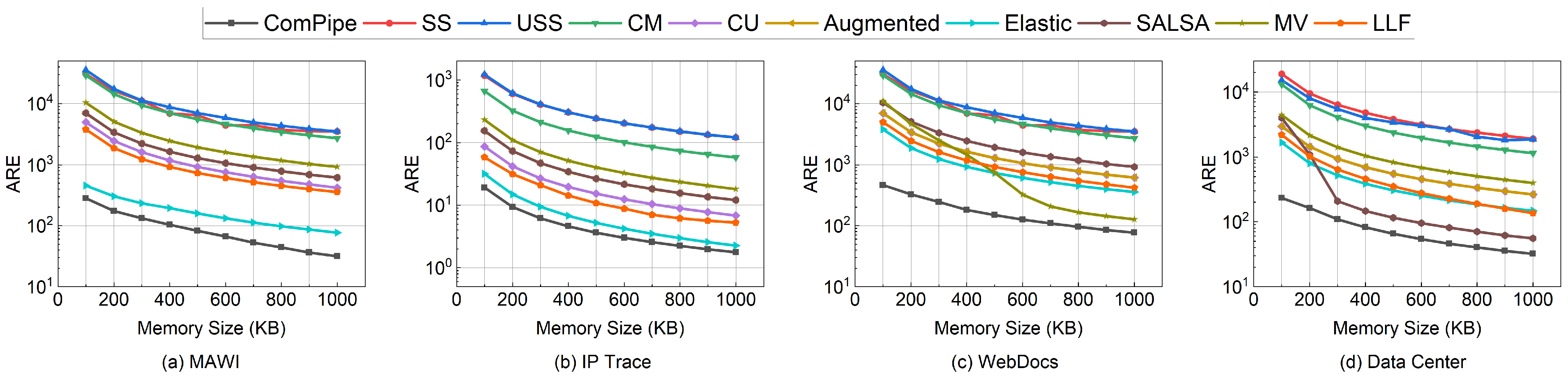
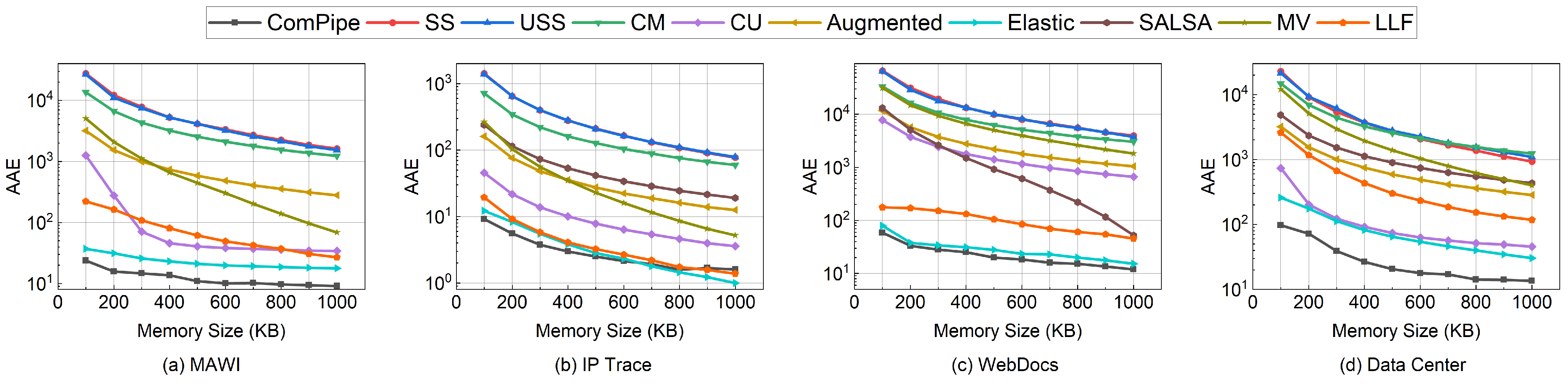
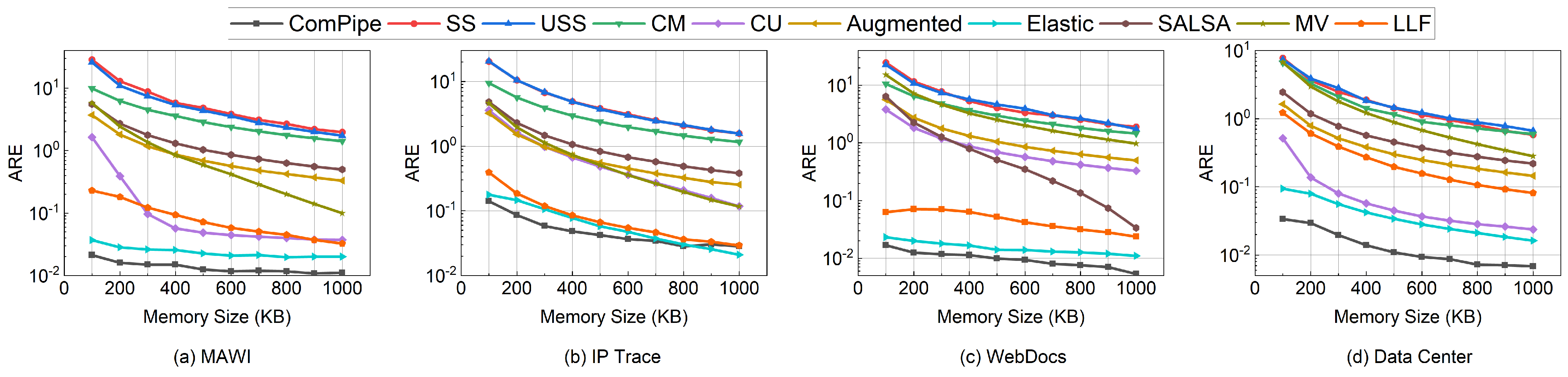
6.2.1. Flow Size Estimation
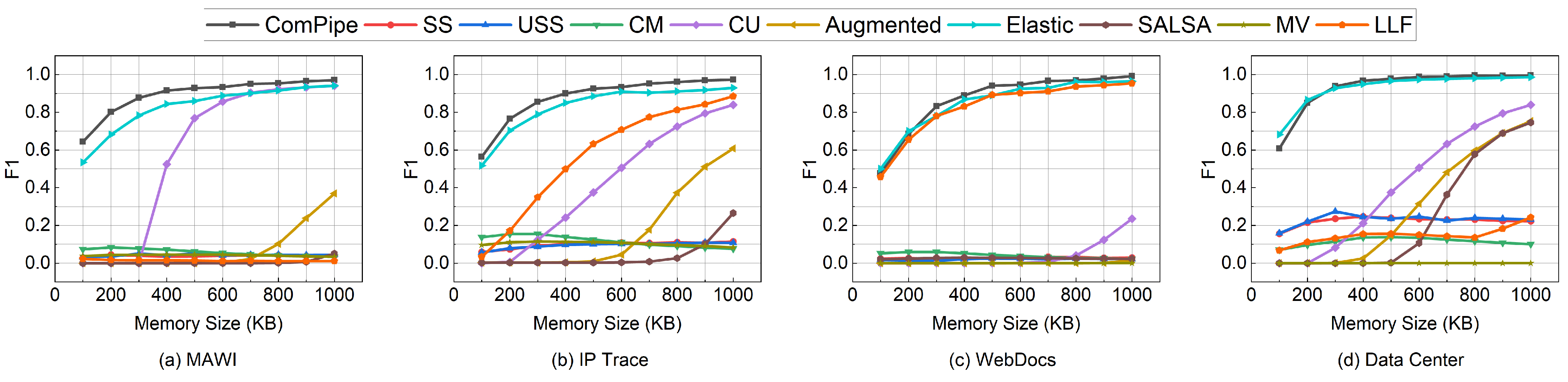
6.2.2. Heavy-Hitters Detection
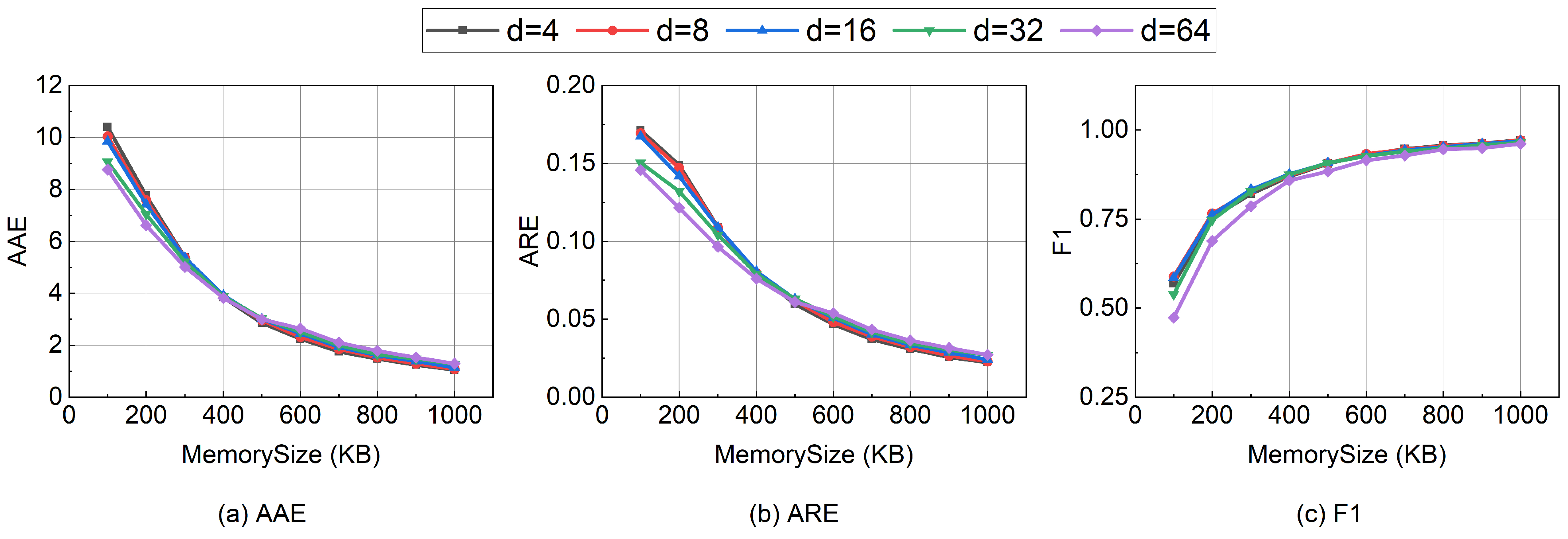
6.3. Experiments on Parameter Settings
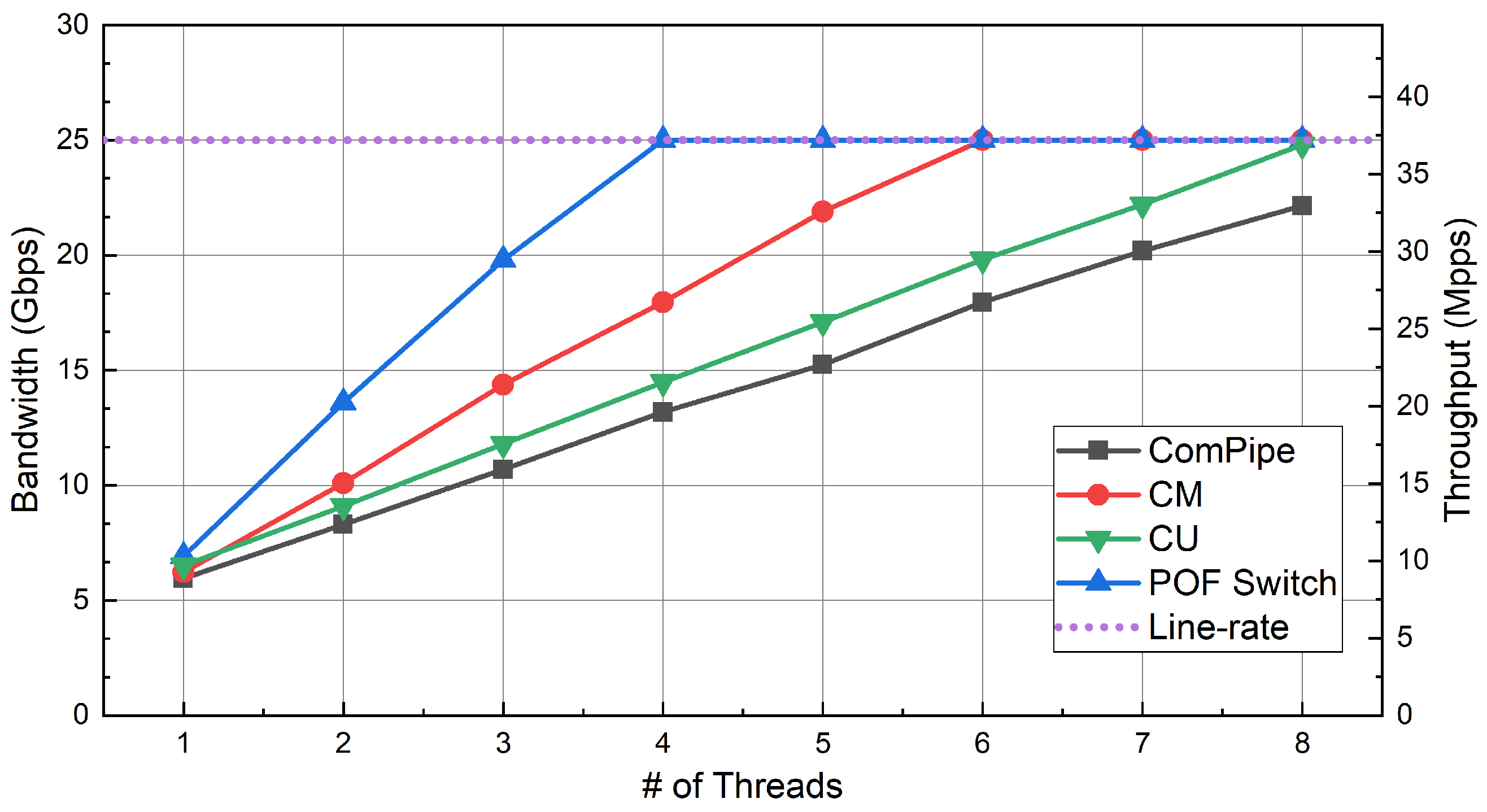
6.4. Experiments on Throughput
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HP | Hardware Pipeline |
| SP | Software Pipeline |
| VXLAN | Virtual eXtensible Local-Area Network |
| VM | Virtual Machine |
| FSE | Flow Size Estimation |
| HHD | Heavy-Hitter Detection |
| RMT | Reconfigurable Match-Action Table |
| ASIC | Application Specific Integrated Circuit |
| P4 | Programming Protocol-Independent Packet Processors |
| POF | Protocol Oblivious |
| SRAM | Static Random Access memory |
| TCAM | Ternary Content Addressable Memory |
| VLIW | Very Long Instruction Word |
| ALUs | Arithmetic Logic Units |
| ISP | Internet Service Provider |
References
- Bosshart, P.; Gibb, G.; Kim, H.S.; Varghese, G.; McKeown, N.; Izzard, M.; Mujica, F.; Horowitz, M. Forwarding metamorphosis: Fast programmable match-action processing in hardware for SDN. ACM SIGCOMM Comput. Commun. Rev. 2013, 43, 99–110. [Google Scholar] [CrossRef]
- Pfaff, B.; Pettit, J.; Koponen, T.; Jackson, E.; Zhou, A.; Rajahalme, J.; Gross, J.; Wang, A.; Stringer, J.; Shelar, P. The Design and Implementation of Open vSwitch. In Proceedings of the 12th USENIX Symposium on Networked Systems Design and Implementation (NSDI 15), Oakland, CA, USA, 4–6 May 2015; pp. 117–130. [Google Scholar]
- Pan, T.; Yu, N.; Jia, C.; Pi, J.; Xu, L.; Qiao, Y.; Li, Z.; Liu, K.; Lu, J.; Lu, J. Sailfish: Accelerating cloud-scale multi-tenant multi-service gateways with programmable switches. In Proceedings of the 2021 ACM SIGCOMM 2021 Conference, New York, NY, USA, 23–27 August 2021; pp. 194–206. [Google Scholar] [CrossRef]
- Qian, K.; Ma, S.; Miao, M.; Lu, J.; Zhang, T.; Wang, P.; Sun, C.; Ren, F. Flexgate: High-performance heterogeneous gateway in data centers. In Proceedings of the 3rd Asia-Pacific Workshop on Networking 2019, New York, NY, USA, 17–18 August 2019; pp. 36–42. [Google Scholar] [CrossRef]
- Wang, Y.; Li, D.; Lu, Y.; Wu, J.; Shao, H.; Wang, Y. Elixir: A High-performance and Low-cost Approach to Managing Hardware/Software Hybrid Flow Tables Considering Flow Burstiness. In Proceedings of the 19th USENIX Symposium on Networked Systems Design and Implementation (NSDI 22), Renton, WA, USA, 4–6 April 2022; pp. 535–550. [Google Scholar]
- Radhakrishnan, S.; Geng, Y.; Jeyakumar, V.; Kabbani, A.; Porter, G.; Vahdat, A. SENIC: Scalable NIC for end-host rate limiting. In Proceedings of the 11th USENIX Symposium on Networked Systems Design and Implementation (NSDI 14), Seattle, WA, USA, 2–4 April 2014; pp. 475–488. [Google Scholar]
- Gao, P.; Xu, Y.; Chao, H.J. OVS-CAB: Efficient rule-caching for Open vSwitch hardware offloading. Comput. Netw. 2021, 188, 107844. [Google Scholar] [CrossRef]
- Mimidis-Kentis, A.; Pilimon, A.; Soler, J.; Berger, M.; Ruepp, S. A Novel Algorithm for Flow-Rule Placement in SDN Switches. In Proceedings of the 2018 4th IEEE Conference on Network Softwarization and Workshops (NetSoft), Montreal, QC, Canada, 25–29 June 2018. [Google Scholar] [CrossRef]
- Estan, C.; Varghese, G. New directions in traffic measurement and accounting: Focusing on the elephants, ignoring the mice. ACM Trans. Comput. Syst. (TOCS) 2003, 21, 270–313. [Google Scholar] [CrossRef]
- Yang, T.; Jiang, J.; Liu, P.; Huang, Q.; Gong, J.; Zhou, Y.; Miao, R.; Li, X.; Uhlig, S. Elastic sketch: Adaptive and Fast Network-wide Measurements. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication, Budapest, Hungary, 20–25 August 2018. [Google Scholar] [CrossRef]
- Yang, T.; Zhang, H.; Li, J.; Gong, J.; Uhlig, S.; Chen, S.; Li, X. HeavyKeeper: An Accurate Algorithm for Finding Top-k Elephant Flows. IEEE/ACM Trans. Netw. 2019, 27, 1845–1858. [Google Scholar] [CrossRef]
- McKeown, N.; Anderson, T.; Balakrishnan, H.; Parulkar, G.; Peterson, L.; Rexford, J.; Shenker, S.; Turner, J. OpenFlow: Enabling Innovation in Campus Networks. ACM SIGCOMM Comput. Commun. Rev. 2008, 38, 69–74. [Google Scholar] [CrossRef]
- Li, S.; Hu, D.; Fang, W.; Ma, S.; Chen, C.; Huang, H.; Zhu, Z. Protocol Oblivious Forwarding (POF): Software-Defined Networking with Enhanced Programmability. IEEE Netw. 2017, 31, 58–66. [Google Scholar] [CrossRef]
- P4Runtime Specification. Available online: https://p4.org/p4-spec/p4runtime/main/P4Runtime-Spec.html (accessed on 23 February 2024).
- POFSwitch v1.0. Available online: https://github.com/ProtocolObliviousForwarding/pofswitch (accessed on 23 February 2024).
- Sarrar, N.; Uhlig, S.; Feldmann, A.; Sherwood, R.; Huang, X. Leveraging Zipf’s law for traffic offloading. ACM SIGCOMM Comput. Commun. Rev. 2012, 42, 16–22. [Google Scholar] [CrossRef]
- Katta, N.; Alipourfard, O.; Rexford, J.; Walker, D. CacheFlow: Dependency-Aware Rule-Caching for Software-Defined Networks. In Proceedings of the Symposium on Software Defined Networking (Sdn) Research (Sosr’16), Santa Clara, CA, USA, 14–15 March 2016. [Google Scholar] [CrossRef]
- Durner, R.; Kellerer, W. Network function offloading through classification of elephant flows. IEEE Trans. Netw. Serv. Manag. 2020, 17, 807–820. [Google Scholar] [CrossRef]
- Sivaraman, V.; Narayana, S.; Rottenstreich, O.; Muthukrishnan, S.; Rexford, J. Heavy-hitter detection entirely in the data plane. In Proceedings of the Symposium on SDN Research, Santa Clara, CA, USA, 3–4 April 2017; pp. 164–176. [Google Scholar] [CrossRef]
- Metwally, A.; Agrawal, D.; El Abbadi, A. Efficient computation of frequent and top-k elements in data streams. In Proceedings of the International Conference on Database Theory, Edinburgh, UK, 5–7 January 2005; pp. 398–412. [Google Scholar] [CrossRef]
- Ben Basat, R.; Chen, X.; Einziger, G.; Rottenstreich, O. Designing Heavy-Hitter Detection Algorithms for Programmable Switches. IEEE/ACM Trans. Netw. 2020, 28, 1172–1185. [Google Scholar] [CrossRef]
- Li, Y.; Miao, R.; Kim, C.; Yu, M. FlowRadar: A Better NetFlow for Data Centers. In Proceedings of the 13th USENIX Symposium on Networked Systems Design and Implementation (NSDI 16), Santa Clara, CA, USA, 16–18 March 2016; pp. 311–324. [Google Scholar]
- Karp, R.M.; Shenker, S.; Papadimitriou, C.H. A simple algorithm for finding frequent elements in streams and bags. ACM Trans. Database Syst. (TODS) 2003, 28, 51–55. [Google Scholar] [CrossRef]
- Manku, G.S.; Motwani, R. Approximate frequency counts over data streams. In Proceedings of the VLDB’02: Proceedings of the 28th International Conference on Very Large Databases, Hong Kong SAR, China, 20–23 August 2007; pp. 346–357. [Google Scholar] [CrossRef]
- Ting, D. Data sketches for disaggregated subset sum and frequent item estimation. In Proceedings of the 2018 International Conference on Management of Data, Houston, TX, USA, 10–15 June 2018; pp. 1129–1140. [Google Scholar] [CrossRef]
- Roy, P.; Khan, A.; Alonso, G. Augmented sketch: Faster and more accurate stream processing. In Proceedings of the 2016 International Conference on Management of Data, San Francisco, CA, USA, 26 June 2016; pp. 1449–1463. [Google Scholar] [CrossRef]
- Charikar, M.; Chen, K.; Farach-Colton, M. Finding frequent items in data streams. In Proceedings of the International Colloquium on Automata, Languages, and Programming, Malaga, Spain, 8–13 July 2002; pp. 693–703. [Google Scholar] [CrossRef]
- Cormode, G.; Muthukrishnan, S. An improved data stream summary: The count-min sketch and its applications. J. Algorithms 2005, 55, 58–75. [Google Scholar] [CrossRef]
- Basat, R.B.; Einziger, G.; Mitzenmacher, M.; Vargaftik, S. SALSA: Self-adjusting lean streaming analytics. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 864–875. [Google Scholar] [CrossRef]
- Yang, K.; Long, S.; Shi, Q.; Li, Y.; Liu, Z.; Wu, Y.; Yang, T.; Jia, Z. Sketchint: Empowering int with towersketch for per-flow per-switch measurement. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2876–2894. [Google Scholar] [CrossRef]
- Jia, P.; Wang, P.; Zhao, J.; Yuan, Y.; Tao, J.; Guan, X. LogLog Filter: Filtering Cold Items within a Large Range over High Speed Data Streams. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021. [Google Scholar] [CrossRef]
- Tang, L.; Huang, Q.; Lee, P.P.C. MV-Sketch: A Fast and Compact Invertible Sketch for Heavy Flow Detection in Network Data Streams. In Proceedings of the IEEE INFOCOM 2019—IEEE Conference on Computer Communications, Paris, France, 29 April–2 May 2019. [Google Scholar] [CrossRef]
- Yang, T.; Zhou, Y.; Jin, H.; Chen, S.; Li, X. Pyramid Sketch: A Sketch Framework for Frequency Estimation of Data Streams. Proc. VLDB Endow. 2017, 10, 1442–1453. [Google Scholar] [CrossRef]
- Fan, Z.; Wang, R.; Cai, Y.; Zhang, R.; Yang, T.; Wu, Y.; Cui, B.; Uhlig, S. OneSketch: A Generic and Accurate Sketch for Data Streams. IEEE Trans. Knowl. Data Eng. 2023, 35, 12887–12901. [Google Scholar] [CrossRef]
- Yoon, M.; Li, T.; Chen, S.; Peir, J.K. Fit a spread estimator in small memory. In Proceedings of the IEEE INFOCOM 2009, Rio de Janeiro, Brazil, 15–25 April 2009; pp. 504–512. [Google Scholar] [CrossRef]
- Whang, K.Y.; Vander-Zanden, B.T.; Taylor, H.M. A linear-time probabilistic counting algorithm for database applications. ACM Trans. Database Syst. (TODS) 1990, 15, 208–229. [Google Scholar] [CrossRef]
- Tofino Programmable Ethernet Switch ASIC. Available online: https://www.intel.com/content/www/us/en/products/network-io/programmable-ethernet-switch/tofino-series.html (accessed on 23 February 2024).
- Open-Source p4 Implementation of Features Typical of an Advanced l2/l3 Switch. Available online: https://github.com/p4lang/switch (accessed on 23 February 2024).
- Data Plane Development Kit. Available online: http://doc.dpdk.org/ (accessed on 23 February 2024).
- MAWI Working Group Traffic Archive. Available online: http://mawi.wide.ad.jp/mawi/ (accessed on 23 February 2024).
- The Caida Anonymized Internet Traces. Available online: http://www.caida.org/data/overview/ (accessed on 23 February 2024).
- Frequent Itemset Mining Dataset Repository. Available online: http://fimi.uantwerpen.be/data/ (accessed on 23 February 2024).
- Benson, T.; Akella, A.; Maltz, D.A. Network traffic characteristics of data centers in the wild. In Proceedings of the 10th ACM SIGCOMM Conference on Internet Measurement, New York, NY, USA, 1–30 November 2010; pp. 267–280. [Google Scholar] [CrossRef]
- The Source Code of Bob Hash. Available online: http://burtleburtle.net/bob/hash/evahash.html (accessed on 23 February 2024).
- Goyal, A.; Daumé, H., III; Cormode, G. Sketch algorithms for estimating point queries in nlp. In Proceedings of the 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning, Jeju Island, Republic of Korea, 12–14 July 2012; pp. 1093–1103. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Implementation | Flow Table Capacity | Lookup Speed | Update Speed | Complexity |
|---|---|---|---|---|
| Hardware Pipeline | low | high | high | low |
| Software Pipeline | high | low | low | low |
| Composite Pipeline | high | high | high | high |
| Notation | Description |
|---|---|
| p, f | packet p with flow ID f |
| d | number of hash tables in hardware pipeline |
| K | Number of concurrent flows that can be accommodated in the hardware pipeline |
| hash function of the jth table in hardware pipeline | |
| the ith bucket in the jth table of a hardware pipeline | |
| the two fields recorded in each bucket of hardware pipeline | |
| w | number of 8-bit counters in software pipeline |
| hash function of the kth array in software pipeline, where | |
| the tth counter in the kth array of software pipeline, where |
| Resource 1 | Percentage | ||
|---|---|---|---|
| switch.p4 | ComPipe | switch.p4 + ComPipe | |
| Hash Bits | 30.5% | 8.9% | 34.3% |
| SRAM | 66.7% | 15.0% | 78.5% |
| Map RAM | 23.1% | 6.7% | 25.5% |
| TCAM | 45.5% | 3.3% | 46.5% |
| Match Crossbar | 39.9% | 15.2% | 42.3% |
| Stateful ALUs | 37.5% | 40.0% | 65.4% |
| VLIW Actions | 22.7% | 6.25% | 24.0% |
| Stages | 100.0% | 50% | 100.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ran, D.; Chen, X.; Song, L. ComPipe: A Novel Flow Placement and Measurement Algorithm for Programmable Composite Pipelines. Electronics 2024, 13, 1022. https://doi.org/10.3390/electronics13061022
Ran D, Chen X, Song L. ComPipe: A Novel Flow Placement and Measurement Algorithm for Programmable Composite Pipelines. Electronics. 2024; 13(6):1022. https://doi.org/10.3390/electronics13061022
Chicago/Turabian StyleRan, Dengyu, Xiao Chen, and Lei Song. 2024. "ComPipe: A Novel Flow Placement and Measurement Algorithm for Programmable Composite Pipelines" Electronics 13, no. 6: 1022. https://doi.org/10.3390/electronics13061022