1. Introduction
On 31 December 2019, China reported several cases of pneumonia related to a novel coronavirus in Wuhan, mainland China. Twelve weeks later, on 11 March 2020, the World Health Organization (WHO) declared a global pandemic originating from
severe acute respiratory syndrome coronavirus 2 (SARS-CoV-2), also known as the
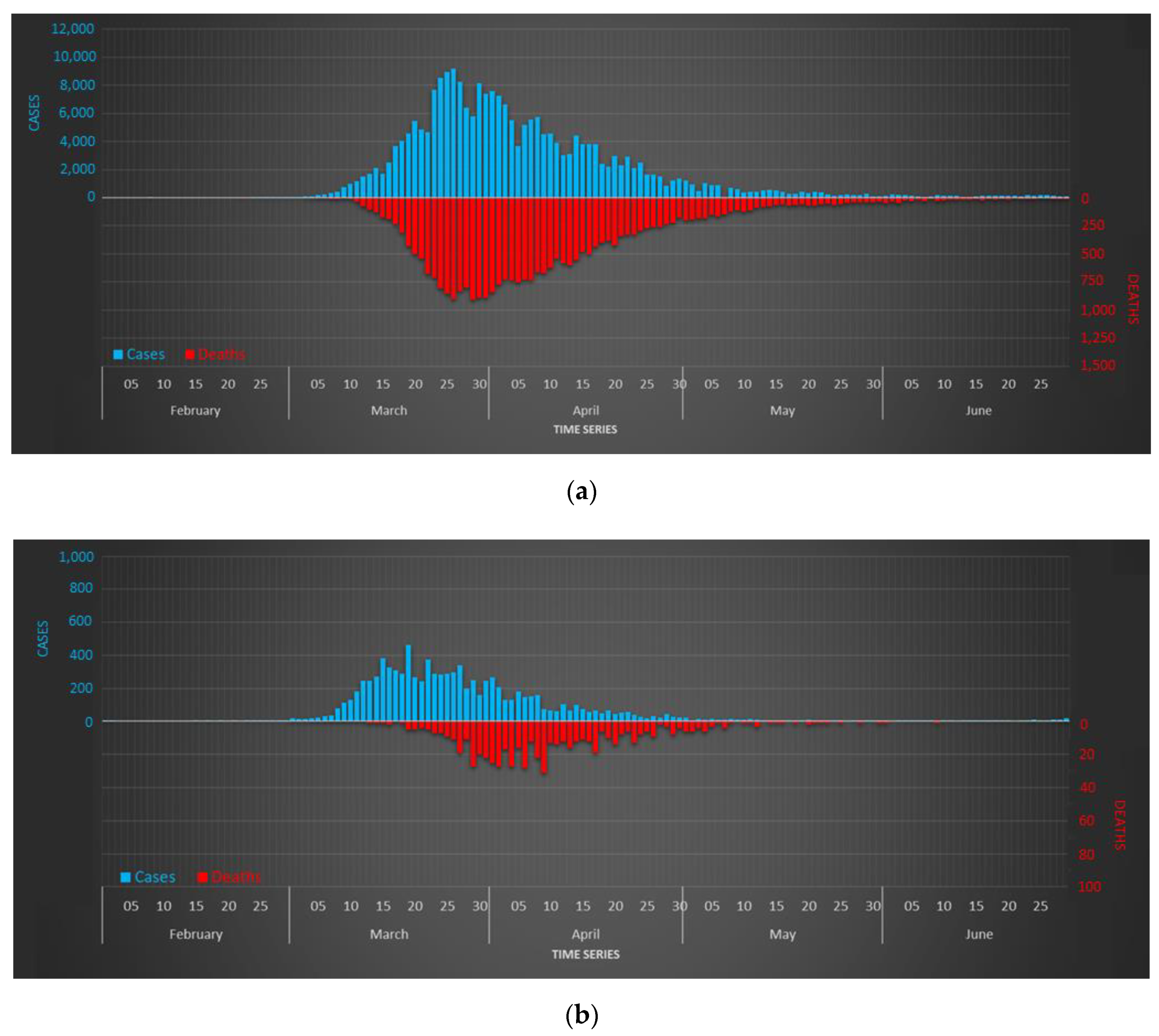
novel coronavirus 2019-nCoV. In just a few weeks, the virus spread uncontrollably across the world, despite all the mitigation interventions adopted. As of 22 June 2021, 177.6 million cases and 3.8 million deaths had been reported. In addition, the impact of the pandemic foreshadows difficult economic scenarios [
1], including impoverishment of large sections of communities and a substantial increase in social inequalities across multiple scales [
2,
3]. Social behavior is the major factor behind the virus spread. Most of the world, especially western countries, had shown serious difficulties in containing the virus along the pandemic. Different national strategies were implemented that ranged from a coexistence with the virus to its total suppression (i.e., Zero COVID), being a referent in both extremes the policies initially adopted by Sweden and China.
Since people who are pre-symptomatic or asymptomatic may spread the virus, substantial undetected transmission is very likely to appear before cases are officially reported. Before the vaccine was approved, the most effective strategy against the virus was to massively reduce mobility flows in order to reduce the virus spread. The struggle against the virus requires understanding its spatial behavior over time to avoid and anticipate outbreaks. In the event of new cases, fast tracking of their movements and contact tracing is required. This process requires fast and effective data management, taking into account the incubation period of the virus and the fact that the rate of asymptomatic patients is relatively high.
For addressing this emergency, many authorities in health management from western countries have decided to share sensitive data with the scientific community. The aim was to contribute in understanding the virus and to support their interventions based on scientific criteria. In the particular case of geo-information, it plays a key role for a better understanding of the virus spread across the globe. Geographic Information Systems (GIS) and geospatial analysis not only became essential tools for modelling the virus spread but also in subsequent steps related with contact tracing of cases, testing, and/or vaccine distribution according with the territorial particularities of a region.
Geospatial technologies have captured great attention during the pandemic. The proliferation of web-mapping applications and dashboards was a pivotal source of information by combining advanced computer graphics and technologically innovative imaging solutions [
4]. Geospatial tools have not only helped to inform people but also have raised social awareness in society by contributing in managing the uncertainty associated with the virus. In addition, these tools had facilitated a transparent communication by policy authorities.
Mapping COVID-19 data in real time (or near-real time) allows classifying areas depending on risks and supports decision-making process. Globally, the most popular dashboards were the published by the Center for Systems Science and Engineering at Johns Hopkins University [
5] and the World Health Organization [
6]. Both dashboards represent official data by countries/regions in near-real time and are updated every 15 min approximately. Another popular dashboard, HealthMap [
7] uses online media data sources for real time surveillance, showing better spatial resolution in some particular regions.
The range of application of geospatial technologies within this context is much more extensive, including the optimal location of emergency treatment units, basic resources and medical supplies in critical situations, and the centers for vaccination and/or testing, among others [
8]. In addition, China and other countries have used unmanned aerial vehicles (UAV) during the pandemic, especially at the most critical times. The integration between UAV vehicles and GIS technologies contributes in terms of optimizing efforts for controlling the virus, especially in vulnerable regions. Thus, the combined use of both technologies can be used for tracing the most optimal flying routes, delivering basic goods or medical supplies to quarantined individuals and people living in remote areas, surveillance tasks, and search and rescue operations, among others [
9,
10]. The adoption of these technologies underlines the need for accurate and updated three-dimensional models of the intervention areas [
11,
12]. On the other hand, geospatial technologies were also implemented for tracing potential cases and close contacts. The use of web app/platforms for tracing allows inferring spatial patterns over time and allows checking the actual transmissibility of the virus. With different successes, many countries developed their own web app/platforms such as the
Close Contact Detector in China [
13],
Trace Together in Singapore [
14],
COCOA in Japan [
15],
SwissCoVID in Switzerland [
16], and
RadarCoVID in Spain [
17].
All of these applications and examples demonstrate the importance of geospatial analysis during this pandemic. Paradoxically, COVID-19 became a great opportunity for the development and implementation of geospatial analysis in emergencies [
18]. The exponential growth of computational capacity of GIS tools has increased our ability for dealing with big datasets and extended our analytical skills by raising more questions that can be replied to more accurately than ever. However, in the face of an unprecedented boom related with geo-information, there are some shortcomings related to the adoption of the most appropriate mapping strategies that should be discussed.
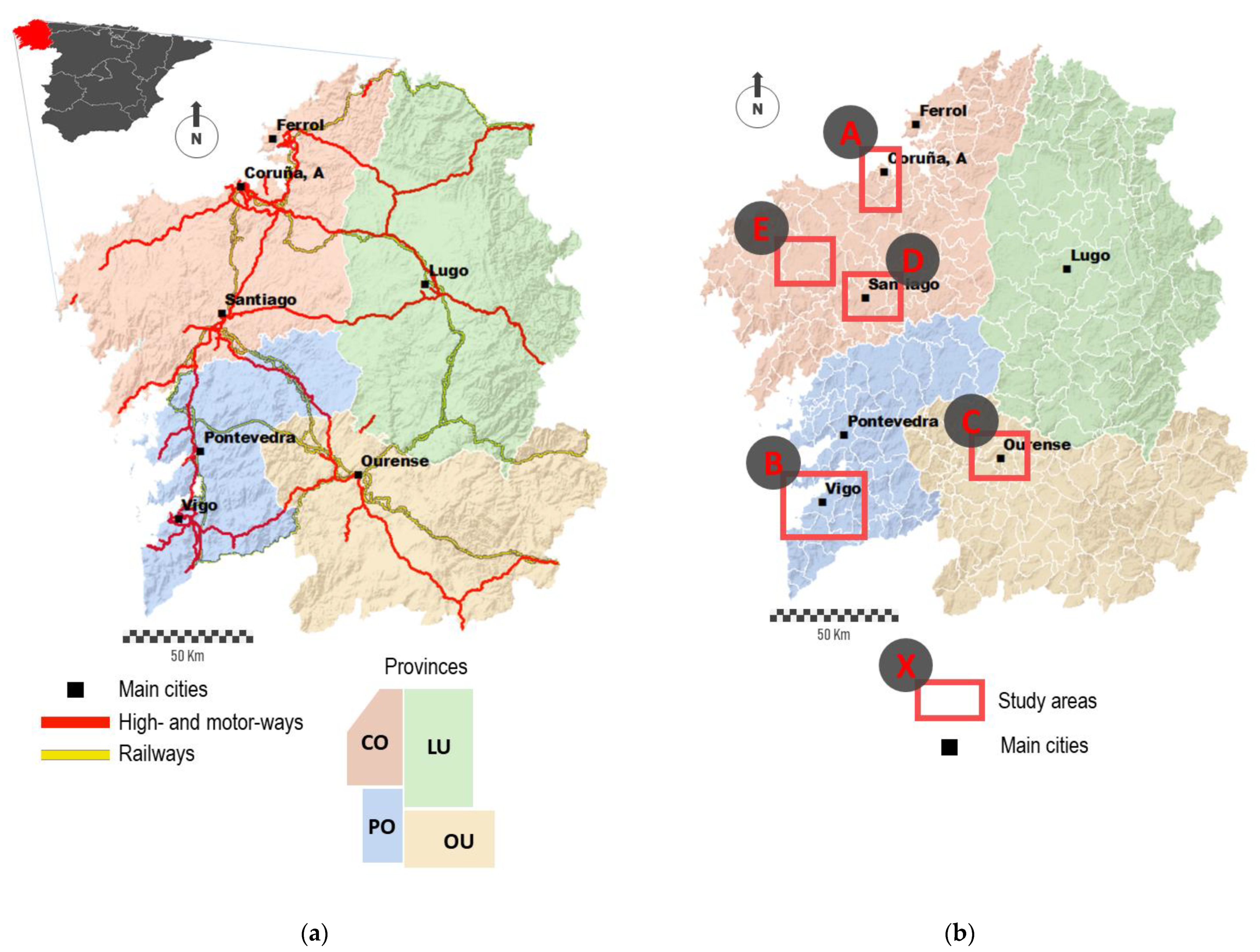
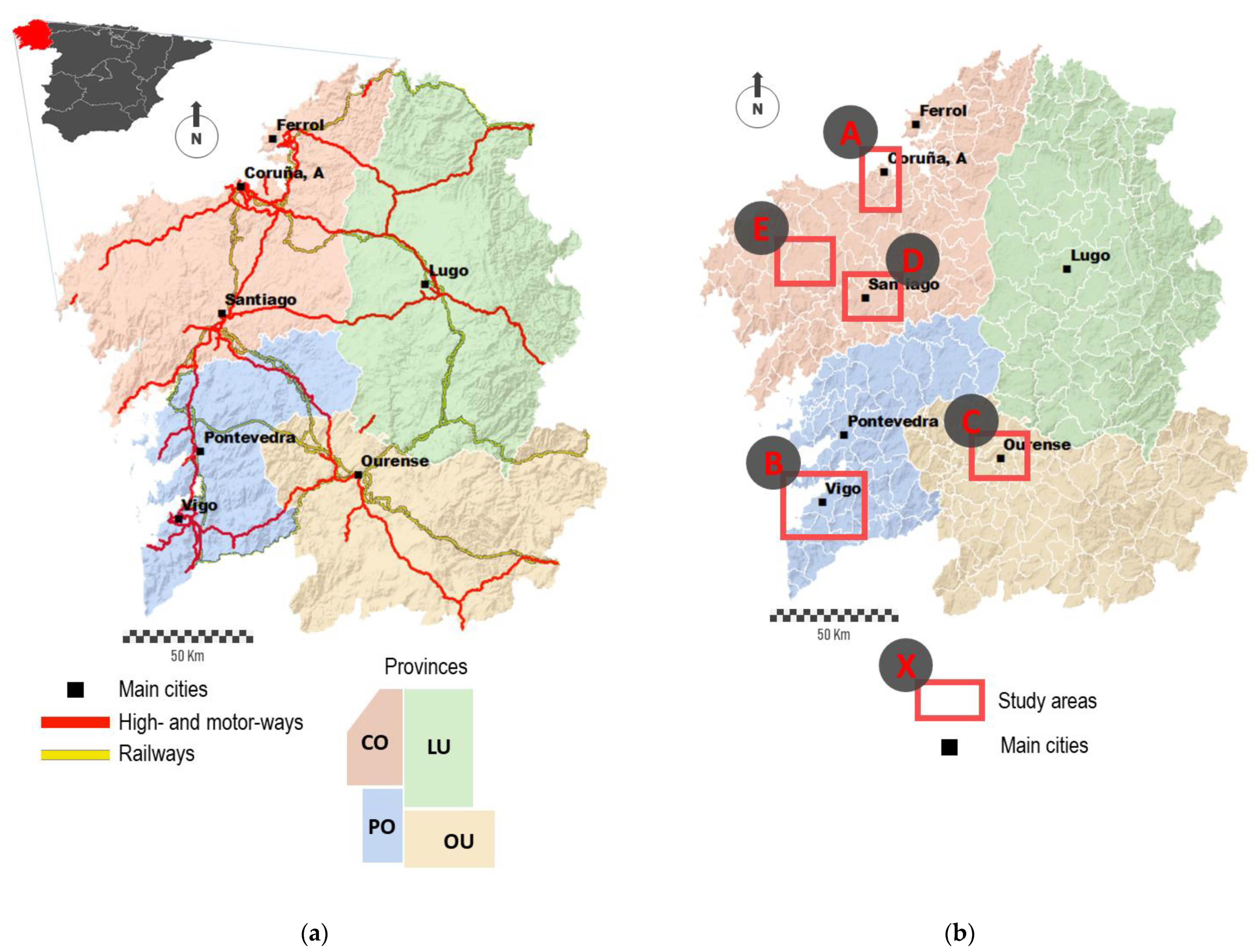
The case study presented here is conducted in the region of Galicia, Northwestern Spain. We count the accurate and detailed fine-grained dataset related with all the cases officially reported during the first wave of the pandemic. Among other data, this dataset includes the personal address of each patient. The aim presented here is to propose valid mapping strategies for this dataset for enhancing the value of these data while avoiding conflicts associated with them.
It is also worth highlighting the spatial context where this study is conducted. Spain was one of the worst severely affected countries by the COVID-19 during the first months (see
Section 4.1). The suboptimal national response to the pandemic has been widely criticized [
19]. In subsequent editorials of
The Lancet, a group of experts referred to the weakness of the so-called
test-trace-isolate tryptic for explaining the tremendous impact of the virus in this country. For that, they made a desperate appeal to authorities to make public fine-grained and detailed data related to the incidence of the virus [
20,
21], which would help in responding adequately to new outbreaks. The study presented here is consistent with their approach, showing the great potential of these data for better understanding the virus impact in a particular region.
This paper is structured as follows.
Section 2 provides a comprehensive literature review on how mapping has been used in disease mapping before the emergence of COVID-19.
Section 3 presents the aim and methodology of this research.
Section 4 introduces the study area and describes the entire dataset.
Section 5 introduces some visual results in the form of maps that show the incidence of the virus across the region of Galicia.
Section 6 discusses the previous results and the most relevant aspects that must be considered. Finally, the most relevant ideas shown in this paper are summarized in the Conclusions section.
2. Literature Review
Throughout history, emerging and re-emerging infectious diseases have threatened humanity. Some of these diseases became epidemics affecting a large number of people in a short time lapses. Disease spreading depends on the intrinsic mechanism, human mobility, and control strategy [
22]. A complete understanding of these diseases requires identifying their spatial patterns, which are explained by a complex set of interactions between human and environmental factors [
23].
Health geography studies the spatial factors behind the impact of diseases. According to Kearns and Moon [
24], this subdiscipline not only presents a predominantly utilitarian and technical perspective of the territory but also considers cultural and anthropological factors.
Mapping tools can plot the spatial impact of any disease and its spatial spread. The Atlas of Cancer Mortality in China [
25] and in the United States [
26] are two very representative examples of disease mapping. These studies mostly depict incidence data related to cancer disease, but they also estimate risk levels by region and identity spatial patterns across multiple scales [
27]. Similarly with other diseases, Castronovo, Chui, and Naumova [
28] analyzed the spatio-temporal dynamics of salmonella infections for 2002 in elderly people in the United States, while Mohd, Jacobsen, and Wiersma [
29] established risk maps of hepatitis A virus across the world.
One of the first maps about infectious disease was carried out in 1694 on plague containment in Southern Italy [
30]. Sure enough, the John Snow’s map on the 1854 cholera outbreak in London is the most paradigmatic example of the importance of disease mapping [
31]. In recent years, a relevant number of recent studies on disease mapping were published. In 2014, a review paper about
geo-health found that 248 research papers (out of 865) were focused on disease mapping [
32]. Wahid et al. [
33] analyzed the spread of Chikungunya virus, a mosquito-transmitted alphavirus, since the first case was reported in Tanzania in 1952. It spread across the entire globe, causing large numbers of epidemics infecting millions of people in Asia, India, Europe, the Americas, and Pacific Islands. Pigott et al. [
34] assembled location data on all recorded zoonotic transmission relative to humans and Ebola virus infection in bats and primates since 1976 to 2014, predicting transmission niches in Central Africa and West Africa. Their study showed, despite 22 million people inhabiting regions at risk, that the rarity of human outbreaks emphasizes the very low probability of transmission between humans. Cattarino et al. [
35] implemented a high-resolution global map about dengue spread by adapting geospatial models based on the environment. Samy et al. [
36] reported recent outbreaks of Zika, a new virus discovered in Uganda in 1947 and transmitted by aedes mosquitoes. They analyzed Zika virus spread in South America, addressing urgent knowledge gaps regarding transmission’s drivers. Messina et al. [
37] showed how large portions of tropical and subtropical regions, where around 2.17 billion inhabitants live, developed suitable environmental conditions for the Zika virus. Some other studies focused on the regional impact of other viruses. Reeves, Samy, and Peterson [
38] carried out a first detailed study of MERS-CoV cases across the Middle East. Deka and Morshed [
39] analyzed the spatial spread of the Nipah virus in South Asia and Southeast Asia, while Sánchez-Gomez et al. [
40] conducted the same analysis with West Nile virus in Spain.
Interactions between social and environmental factors explain the impact of pandemics. Geospatial approaches help mitigate this impact through spatial statistics, finding spatial correlations with other parameters, and identifying transmission dynamics [
41,
42]. GIS systems favors a dynamic mapping based on simultaneous visualization of temporal and spatial information, enabling evaluation of complex interactions between humans and their surrounding environment [
28]. In this context, Grantz et al. [
43] showed how living in US census tracts with higher illiteracy rates increased the risk of influenza and pneumonia mortality during the influenza pandemic of 1918 in Chicago. Allcott et al. [
44] evaluated the relationship between COVID-19 reported cases and the compliance level relative to containment measures against the virus in the United States.
The use of GIS for tracking and mapping infectious diseases was recently analyzed. Parks, MacDonald, and Beiko [
45] used an automated pipeline to collect data for analysis with the geospatial package
GenGIS, which allows spatio-temporal tracking of new sequence types and polymorphisms related to the
2009 swine-origin strain of influenza A-H1N1. Giyonko et al. [
46] analyzed the epidemiological role of camels in the transmission of
MERS-CoV virus by implementing an iterative empirical process in GIS to identify potential hotspots. Fuller et al. [
47] identified those areas where assortment events might occur and how high pathogenicity
avian influenza virus might travel if it would affect wild bird populations.
Similarly, these geospatial tools are already playing a key role in the current COVID-19 pandemic. These serve for integrating big data from multiple sources, displaying intuitive visualizations, tracking reported cases, predicting risk transmission levels, managing supply and demand of material resources, and formulating new interventions, etc. [
48]. Some recent studies adopt a traditional approach based on evaluating the territorial impact of the virus across multiple scales [
49,
50]. A cross-sectional research shows an association between the accelerated virus spread and the high levels of air pollution combined with mild winds [
51]. Oto-Peralías [
52] conducted a multifaceted study by combining geographical and socio-economic variables to explain the large disparity of cases across Spain. He found interesting correlations between COVID-19 incidences with temperature and distance from the city of Madrid during the first wave.
The relevance of the spatial component suggests reviewing the cartographic management of these data. Cicalò and Valentino [
4] introduced new approaches for visualizing spatial patterns related to different diseases. One of the most critical issues for their study was to define the most appropriate mapping unit for visualizing health data [
53]. In
analytical geography, this problem is often referred to the
modifiable areal unit problem (MAUP), which is ever present although not always appreciated. MAUP refers to the cartographic representation of data for which its attributes are significantly influenced by spatial scale and level of data aggregation [
54]. Some scholars limited their study areas to nearby regions where they had sufficient data. For example, Tuckel et al. [
55] analyzed the diffusion of the influenza pandemic of 1918 in Hartford, United States, while Smallman-Raynor, Johnson, and Cliff [
56] conducted the same analysis in London and the county boroughs of England and Wales. More recently, Rodriguez-Morales et al. [
57] studied a recent Zika virus outbreak in Valle de Cauca, Colombia.
Nowadays, the availability of much more information, in addition to the high computational capacity of GIS tools, makes covering much larger areas feasible. This is the framework for the COVID-19 pandemic, where the first studies were mostly conducted for mapping the incidence at country-wide scales. Some studies were carried out in countries such as Iran [
58], Afghanistan [
59], Italy [
60], United States [
61], or India [
62] in order to determine what local drivers were behind the particular transmissibility of the virus across these countries. These studies not only allow understanding the virus mechanisms much better but also consider the particularities of each spatial unit, including the internal inequalities.
Mappings of cases allow identifying spatial patterns associated with COVID-19. These patterns are the first step towards other studies addressing the complexity behind the virus spread, the response capacity against it, and the application of predictive risk modeling. Verhagen et al. [
63] analyzed how the health system capacity matched spatial variation in the underlying population risk in England and Wales. They found fine-grained local differences in hospitalization capacity supply versus demand, which anticipated needs for shifting capacity and rapid redistribution of resources. In India, Roy et al. [
64] predicted the epidemiologic risk using weighted overlay analysis in GIS, while Khan et al. [
65] predicted the criticality of COVID-19 transmission using GIS and machine learning methods.
Related to mapping spatial patterns during COVID-19, Fatima et al. [
66] provided a synthesis of the most used GIS techniques and approaches, which were separately classified into three categories: disease mapping, exposure mapping, and spatial epidemiological modeling. The most common spatial methods used were clustering, hotspot analysis, space-time scan statistic, and regression modeling. According to their study, the use of these spatial techniques is limited by the unavailability and bias of COVID-19 data that restrained most of the researchers from exploring causal relationships of potential influencing factors of COVID-19. By precisely possessing this type of data, we can substantially increase the possibilities of geospatial analysis, but it raises other types of concerns and conflicts that we must take into account in the future where we will have more fine-grained and detailed data. For this purpose, we will review some aspects to take into account within the new data paradigm for geographical information.
3. Aim and Methodology
We represent fine-grained data associated with COVID-19 in the Spanish region of Galicia. The original raw dataset was provided by the regional health authorities with the goal of achieving a better understanding of the transmission of the virus in this region. This dataset contains individual and precise information, including biographical data and indicators such as the recognition of early symptoms, test results, and other information related to the follow-up of the disease for each patient. Some of these indicators were based on questionnaires and personal surveys, while testing data were officially registered by medical services.
This dataset also includes the address of each patient, which allows a very detailed spatio-temporal follow-up of all the cases. By considering that Spain decreed a hard lockdown on 14 March 2020 and Galicia was one of the regions where the virus entered later, the authorities could perform quite reliable tracing for most of the cases. Based on the addresses, we could geolocate each case across the region.
The lack of a clear catalog of appropriate practices of map-making motivated us to develop our own strategies for mapping these fine-grained data and addressing our concerns [
67]. Different solutions were proposed across multiple scales using different criteria. Our proposals were based on a heuristic experience with health authorities for the identification of outbreaks, classification of risk levels, identification of spatial patterns, and subsequent decision making. In addition, the fact that some maps could be publicly published required taking special care with certain privacy concerns by reaching the optimal trade-off between public entitlement to being informed and the right to personal privacy. The results presented attempt to provide an answer to the major concerning issues that we found relevant.
Given that, the primary objective is to raise optimal mapping strategies for helping regional authorities in decision making. At the same time, we discuss about the appropriate processing, management, and representation of this kind of data. Maps are not only crucial for identifying and extracting common or anomalous spatial patterns related with the virus but also other aspects relating to the adequacy and success of the policies adopted. Aspects related to data aggregation, multiscale approach, and other issues related to data privacy are reviewed and later discussed.
Our findings are shown in the maps shown along the paper, which show the incidence of the virus. For mapping, we used the ESRI’s GIS mapping software ArcGIS, in the version 10.8. The geographic coordinate system used was the European Terrestrial Reference System 1989 (ETRS-89), and all the maps were projected in the
UTM Zone 29N. Map representation of cases is based on very simple set of geometric features: points, lines, and polygons. Fine disaggregated data are represented with points, whereas aggregated data are represented with lines and polygons in choropleth data. The extraction of spatial patterns is carried out in heat maps. For the computation of raster values in these heat maps, we conducted an interpolation procedure with a function of the number of points per area unit, i.e., the point density. The density value (
) in a location (
) is determined by using a kernel function based on Equation (1):
for
with
are the entry points located in distance lower than the radius considered with regard to the origin point (
); this means
.
is the value of the population of the point
.
is the distance between the point
and the origin point (
).
ArcGIS software counts with a specific tool for estimating the density of points around each output raster cell according to the
quartic kernel function described in Silverman [
68]. Conceptually, a smoothly curved surface is fitted over each point. The surface value is highest at the location of the point and diminishes with increasing distance from the point, reaching zero at any radius distance previously considered by the operator. Only a circular neighborhood is possible. The density at each output raster cell is calculated by adding the values of all the kernel surfaces where they overlay the raster cell center. For all the heat maps shown in the paper, we considered a cell raster size of 1000 × 1000 and
. The radius is computed specifically to the input dataset using a spatial variant of
Silverman’s rule of thumb that is robust to spatial outliers, neglecting the influence of the points that are located far away from the rest of the points. This radius is estimated by using the shortest path on a flat earth (planar) method. Visualization of heat maps is conducted by stretching values along a color ramp. We applied a linear stretch between the values defined by the standard deviation (
) value with
. This means that all the pixel values out of the range
are equivalent to 0 at the low end and 255 at the high end. The remaining values within the range
are stretched in between 0 and 255. Moreover, for visualization purposes, we added some vertical exaggeration to the raster (
hillshade effect) by applying a scaling factor
.
5. Results
Data of patients were collected by a decentralized administrative service where different operators had access. The supervision of the raw dataset showed the existence of certain inconsistencies related to the presence of duplicate fields, errors in numbering or street names, and typing errors. For this reason, we conducted a pre-processing phase in order to eliminate duplicates and to standardize the structure of the complete dataset. After that, we carry out a semi-automatic process of geo-referencing the data by using the API tool implemented in ArcGIS. Each record was spatially represented as a point for which its location was determined according to the address and municipality values included in the database. Typing errors in some names or inconsistencies between the address and the municipality hampered the location of some records. In short, 10,853 records were successfully geolocated, which corresponds to 98 percent of the total cases.
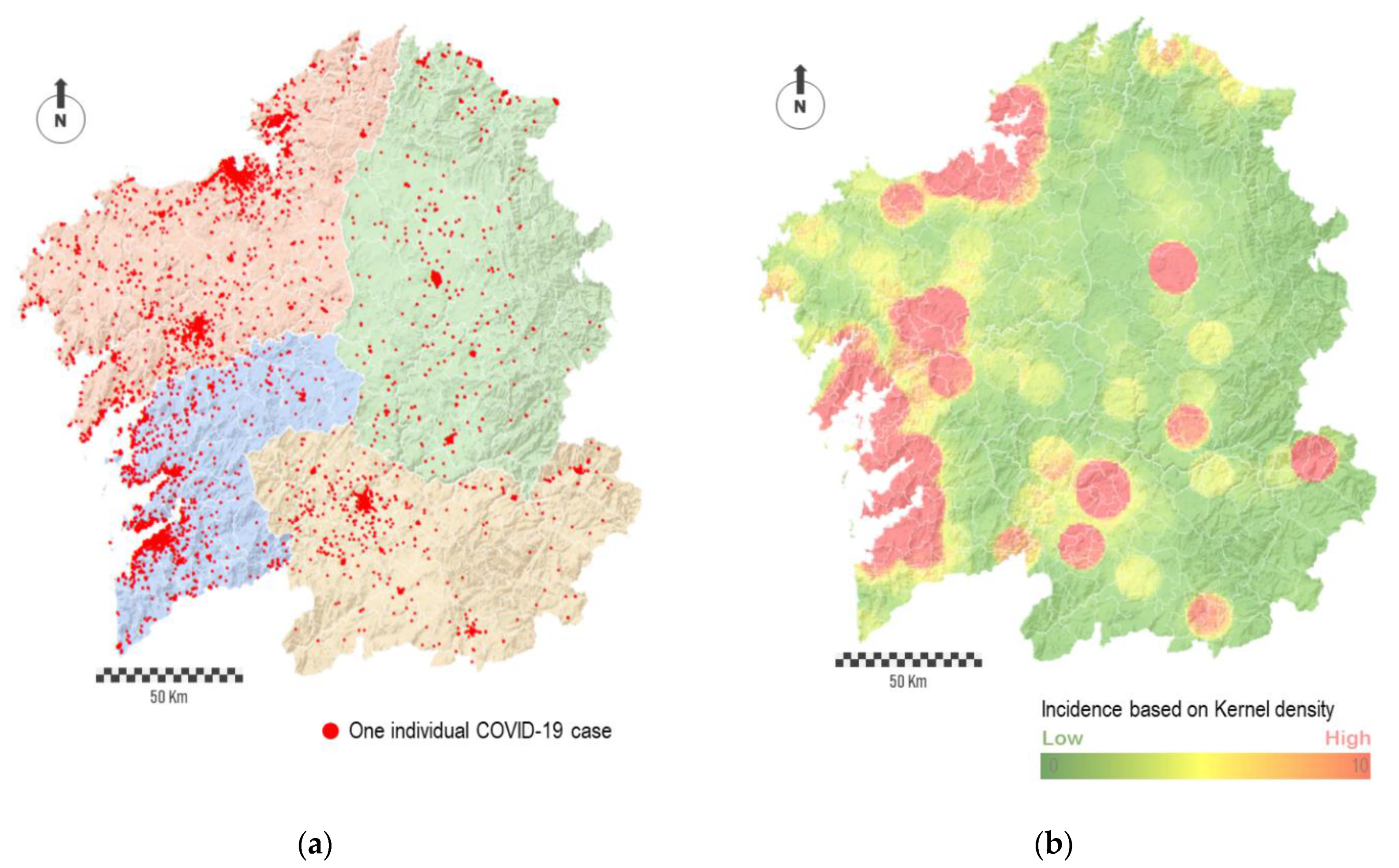
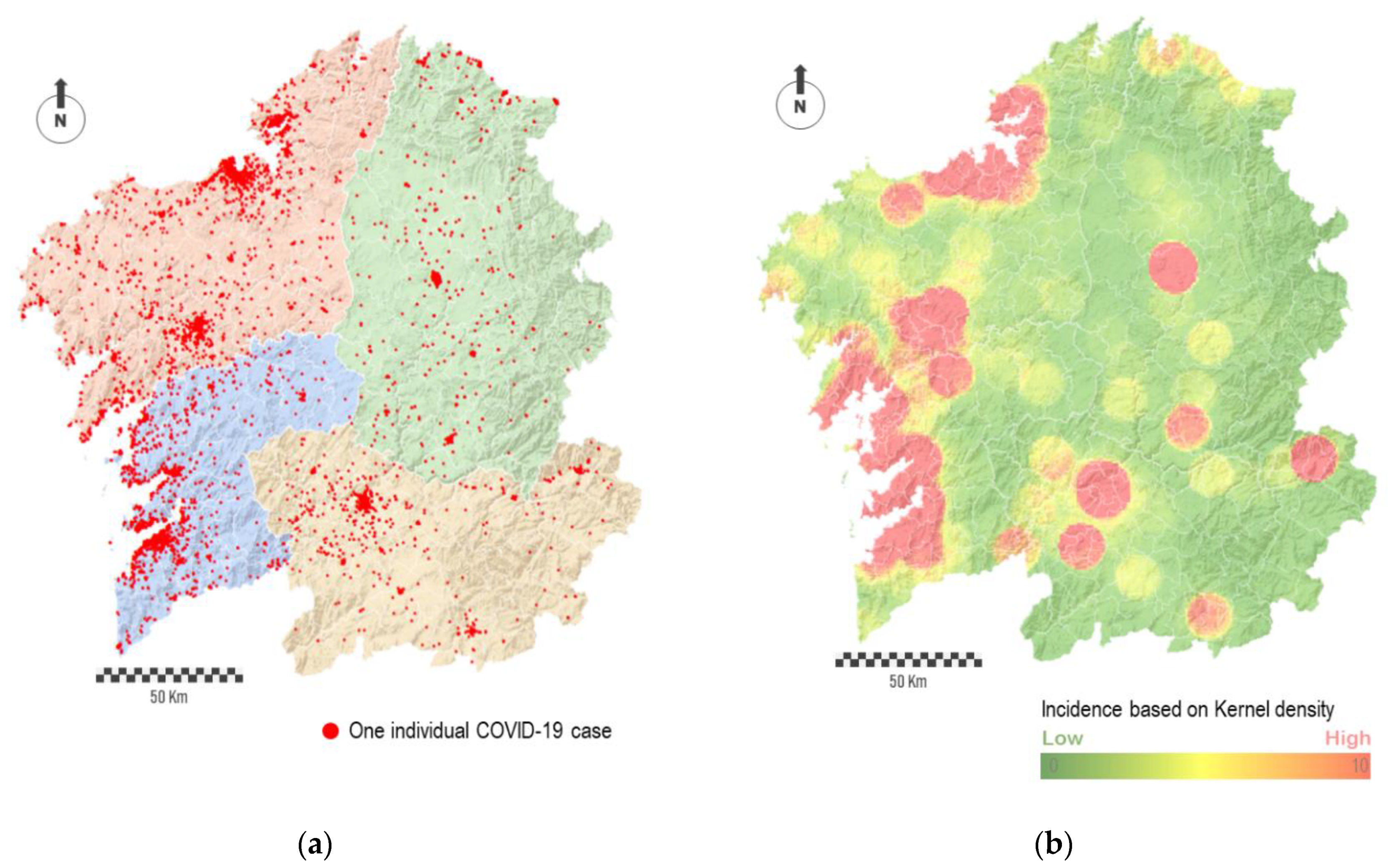
The individual geolocation of cases shows how the most populated cities concentrated clusters of cases (
Figure 3a). Apart from this, a relatively large number of points is spatially disseminated across the region. In some way, the noise behind the complete point cloud traced by cases hides the prevailing and relevant spatial patterns, both in absolute or relative terms. Thus, depending on the spatial scale, the interpolation of points into a raster map allow identifying spatial patterns behind the virus. For this purpose, we conducted an interpolation procedure based on the number of points per area unit, i.e., point density.
Figure 3b shows the result in the form of a heat map. The red-colored areas represent the most affected regions, while the green-colored areas represent the least affected ones. The degradation between these colors, which means areas in yellow, corresponds to regions with average impact.
The aggregation of data in combination with the estimation of some significant rates allows reaching a more insightful perspective of these spatial patterns. For this purpose, we elaborate choropleth maps where each polygon is color-shaded according to a distribution in value intervals. In our study, we show virus spread in relation to the total population and the surface area of each municipality.
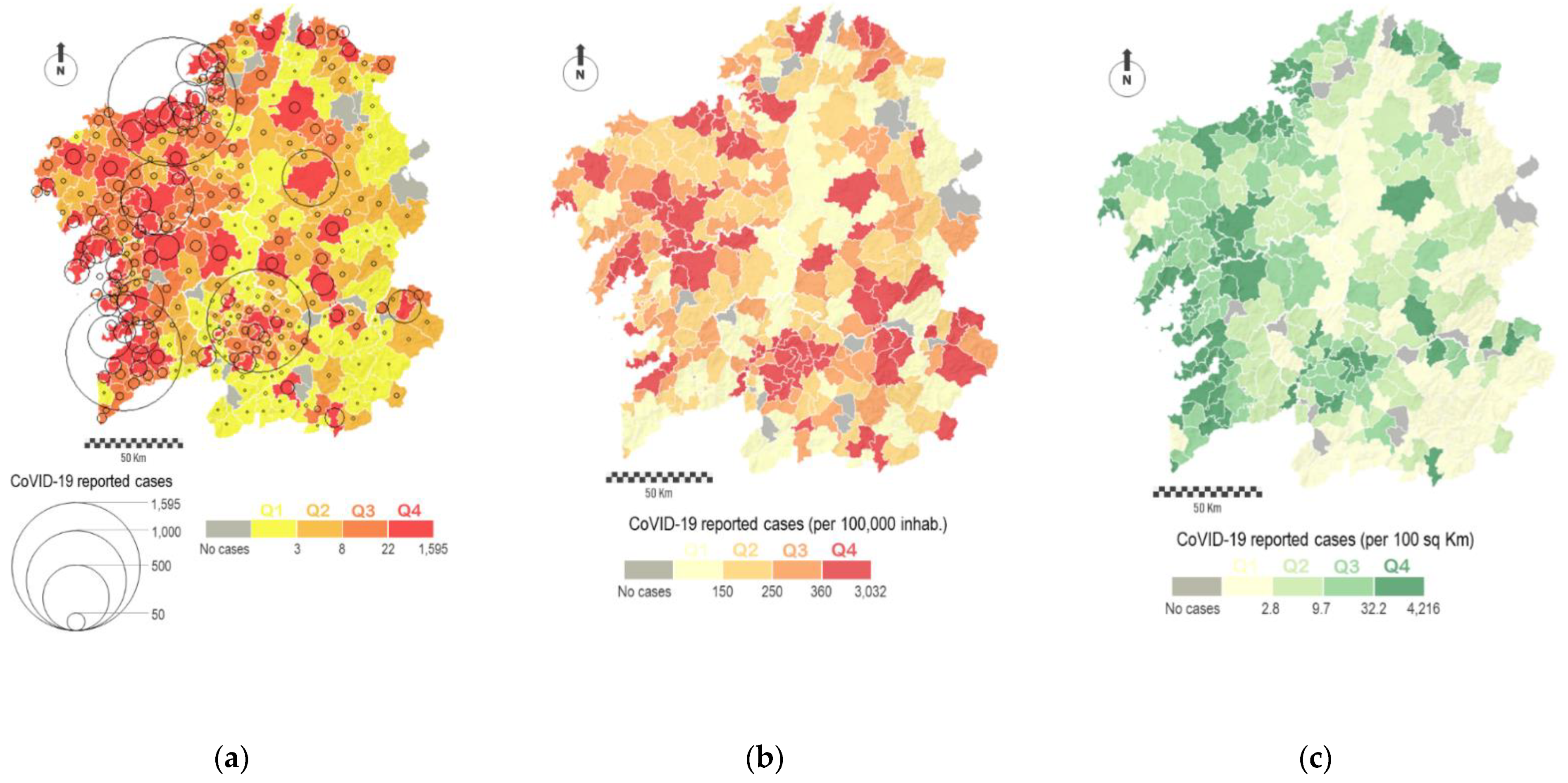
Figure 4a represents the total number of cases by municipalities by using two strategies: total number of cases (circle size) and the level of incidence classified in four different intervals (color). The spatial distribution of cases corresponds to the expected according to the population pattern with most of the cases concentrated in the western sector.
Figure 4b shows the number of cases per 100,000 people, while
Figure 4c represents the number of cases per 100 square kilometers. The value intervals in these choropleth maps are classified in regular intervals, where each interval encompasses the same number of cases. These maps demonstrate the spatial heterogeneity of the virus across the region, not only showing new patterns with continuity in certain sectors but also some relevant differences in the incidence of the virus in neighboring municipalities, which demonstrates the effect of the aggregation of data in the results.
The map of cases by square kilometer presents a similar spatial pattern in comparison with previous figures, where most of municipalities along the Atlantic Axis present major incidences. However, the map of cases by population presents additional analysis such as the emergence of some municipalities located outside of the most populated axis showing high incidence rates. In any case, it must be said that some of the municipalities, colored in grey in the successive maps, were not affected at all by the virus, at least during the first wave. In total, these group counts with 18 municipalities (5.7 percent of the total), and these were mostly located in the eastern sector of the region.
The study of spatial patterns can be conducted from a temporal perspective. In
Figure 5, we represent the impact of the virus during the first two months of the pandemic. In order to perform this, we represent the number of new COVID-19 cases officially reported every 15 days per 100,000 inhabitants. This representation is carried out on
mobility areas, and it allows observing the emergence of the virus in the most populated urban areas and the prompt spreading across the whole region. The sequential representation of data makes it possible to evaluate the general impact of the pandemic and to determine the largest territorial outbreaks, as well as the effectiveness of containment measures for the virus. These maps show a great heterogeneity in the spatial incidence of the virus across the region.
The complexity of the territory explains the spatial heterogeneity of the virus. For this reason, we must analyze the spatial incidence across multiple scales.
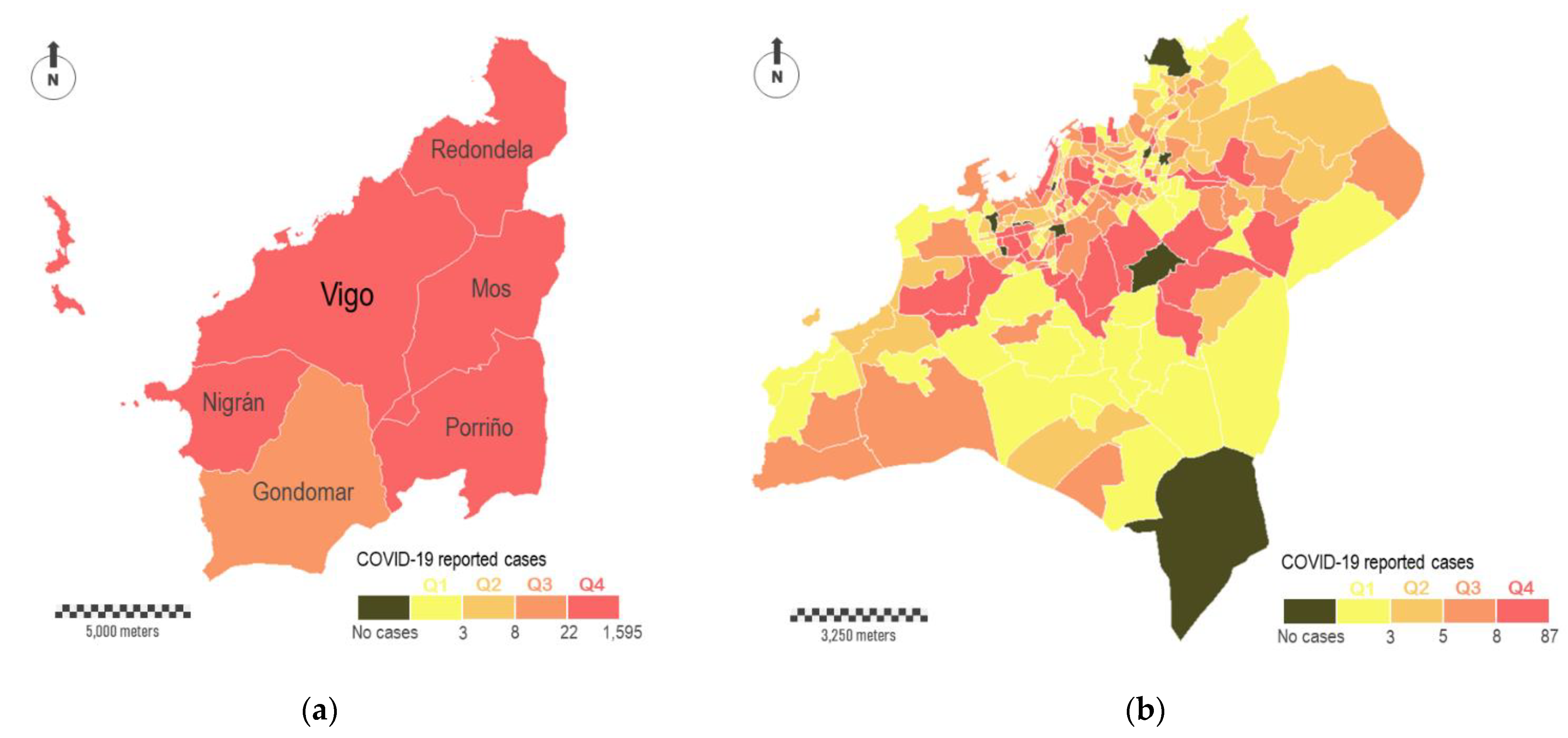
Figure 6a shows the total number of cases surrounding Vigo, the most populated city with about 300,000 inhabitants. A group of six municipalities comprises this study area, with Vigo occupying the central position (study area A in
Figure 1b). The color legend is the same used in
Figure 4a, where the four intervals of virus incidence were fixed for the complete region. According to this, the six municipalities showed the highest levels of incidence (five in Q4 and one in Q3). Data disaggregation at major scales reveals a great heterogeneity in the incidence of the virus across this particular study area. In
Figure 6b, we aggregate COVID-19 cases in census districts within Vigo municipality. In short, this municipality is fragmented in 250 polygons that correspond with census districts. These polygons differ in their surface areas, which vary substantially depending on the resident population. The smallest census districts are located in the consolidated urban area, while the largest ones are located on the city surroundings. According with the distribution of cases, some relevant aspects can be outlined. The most affected districts (Q4) are located in the central part, although not all of them are located downtown, where theoretically the economic diversity and social interactions are higher. A relevant number of red-colored polygons correspond to residential areas, where the virus is spread mostly in familiar circles. The dichotomy between downtown and periphery seems evident depending on the scale. Ten census districts did not report any COVID-19 cases, and some of them are located downtown. Areas located downtown are supposed to be a hotspot of transmission, but the people affected usually do not live there. A zoomed in view of the internal distribution of cases downtown is shown in
Figure 6c,d. In the first of these sub-figures, cases are aggregately represented by census districts (polygons), whereas in the second one the cases are individually represented (points).
Data aggregation can be carried out with different geometries, such linear features.
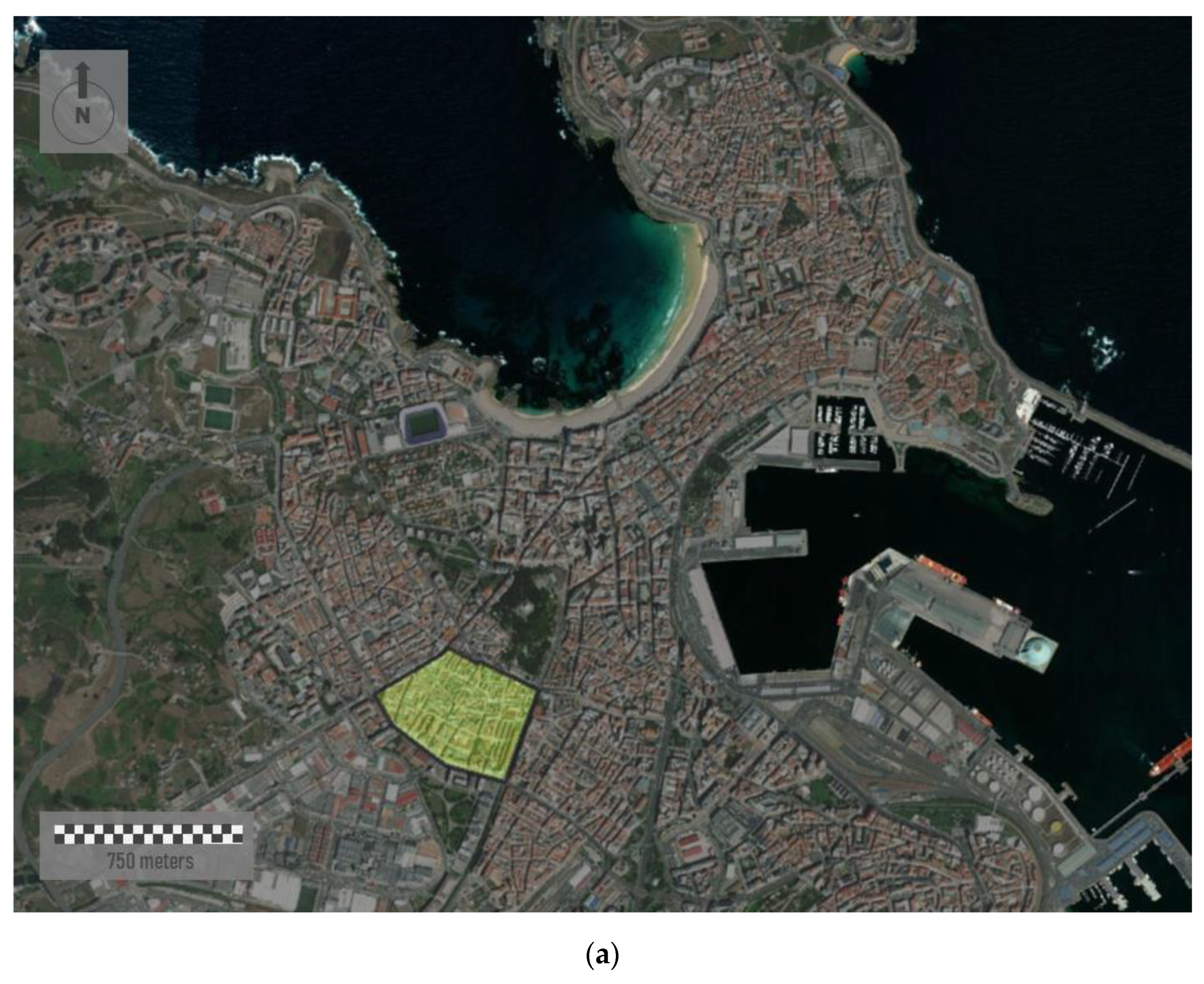
Figure 7 represents the density of cases in a specific area of A Coruña, the second most populated city with about 250,000 inhabitants (study area B in
Figure 1b). The sample area shown is located in the south of the city, covering an area of 0.21 square Kilometers (
Figure 7a). We aggregate all the individual cases registered by road sections. To perform this, we apply a spatial join between points (cases) and linear features (road sections) in ArcGIS. It is important consider that the same road is partitioned in different linear segments. Each road section corresponds to an individual segment inserted between two vertexes.
The urban morphology of the study area shows a dense street network where most of the buildings are around eight floors high. Although the urban street layout draws mostly rectilinear road sections, urban fabric is irregular and lacking in orthogonality. In addition, a lack of green spaces is observed. Visualization of cases along streets shows a close perspective of the incidence of the virus for residents, favoring the adoption of more scalable interventions in each city region by health authorities. Here, the incidence rate is classified on four levels. These levels are represented based on differences in both color and magnitude. Thus, wider linear features in red represent the road sections with more incidence. In short, 51 cases were reported in this area, showing a very unequal distribution over the study area. According to
Figure 7b, two short street sections in red showed the highest incidence rates. In 91 of 130 road sections, represented in white and with a lower thickness, no cases were registered.
The representation of all the individual cases allows reaching the maximum amount of detail and highest spatial resolution. However, this sort of representation has certain disadvantages, especially when we manage sensitive data due to privacy concerns.
Figure 8 represents three sample areas with different typologies: urban, semi-urban, and rural. The first panel,
Figure 8a, represents a random sample area located downtown of Santiago de Compostela, the capital of the region (study area C in
Figure 1b). This city area presents an urban structure of open blocks with large patios. It comprises narrow streets with a rectilinear layout and tall buildings over eight floors high.
Figure 8b corresponds to the center of a middle town, Santa Comba (study area D in
Figure 1b). This town has about 3000 inhabitants, and it is the most important urban reference across a large rural area. This town is characterized by an orthogonal layout and a dense occupation of the urban space, with buildings of variable height from one to six floors high [
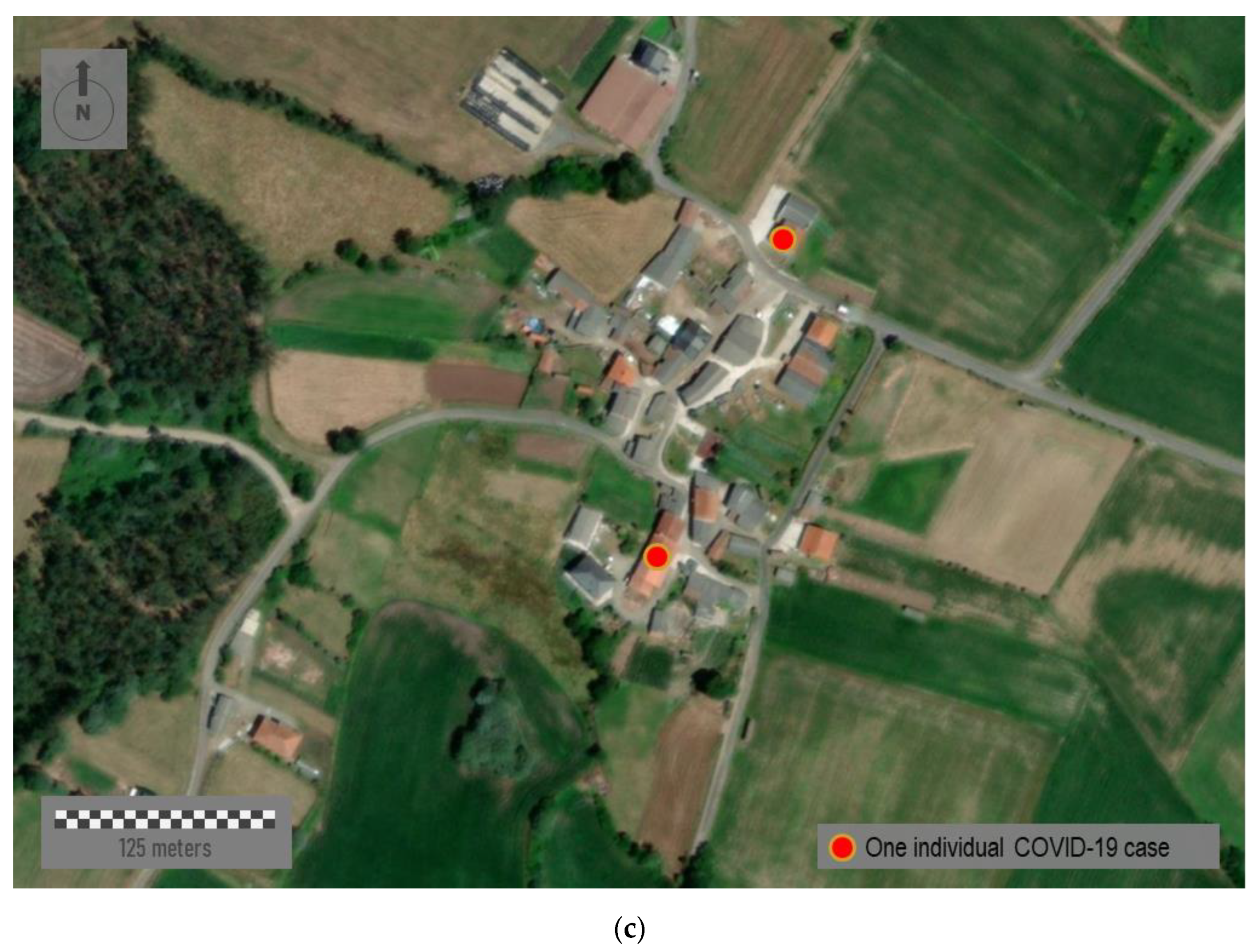
75]. Finally,
Figure 8c corresponds to a distinctly rural area located somewhere in the north of the region. This small village shows a rural nucleus with a few ground-floor houses. Mapping individual cases must never be carried out in eminently rural environments nor, in many cases, in semi-urban ones where the anonymity and privacy of patients cannot be guaranteed. Therefore, mapping strategies must be scalable and adapted to the zoom factor and spatial scale in each case.
Mapping individual cases may mislead the identification of spatial patterns across multiple scales. The next figures show the temporal evolution of cases in Ourense, the third most populated city with about 105,000 inhabitants (study area E in
Figure 1b).
Figure 9a,b show the cases reported with 12 weeks in between. The first figure represents a total of 254 points and the second one 546, which is more than the double. Even though it is a substantial difference in the density of points shown, it results in difficulty in terms of identifying risk patterns and checking how these patterns evolve over time.
Figure 9c,d represent the same data in the form of a heat map where the cases’ density is shown by colors. Both maps allow understanding the infection risk over time. The incorporation of aerial images in the background facilitates establishing a hypothesis that correlates spatial risk patterns and the emergence of potential outbreaks based on the existing risk levels.
A more efficient and realistic strategy for decision making is to reduce the mapping area to specific intervention areas, that is, the public space.
Figure 10a corresponds to a sample area located downtown of this same city. This area presents a medium-high urban density, with different types of city blocks and a limited presence of green spaces. The urban layout, although mostly rectilinear, is characterized by its lack of orthogonality.
Figure 10b shows the accumulated incidence of COVID-19 of 15 July 2020. Over this figure, we place a relevant number of different socio-community centers and public facilities—such as educational centers, hospitals, pharmacies, and health centers—which could have influences on the virus spread at a very first instance. The simultaneous visualization of potential risk elements allows spatially constraining the infection area by analyzing the spatial correlation between facilities and potential outbreaks. Among other relevant aspects, we can observe how some outbreaks are suspiciously close to educational centers.
In addition, it is important to point out that location of individual cases is based on their residential addresses, whereas patients could be infected in distant locations, e.g., industrial areas surrounding cities. However, a high percentage of the virus spread took place in familiar events and home addresses. After the hard lockdown adopted on 15 March 2020 where mobility was massively reduced to very short distances from resident addresses, these maps could help in identifying potential hotspots and infection sources.
6. Discussion
The COVID-19 pandemic has generated great uncertainty from social, health, and economic perspectives. This emergence has forced health authorities and policy makers to adopt unusual decisions in terms of joining forces and finding answers. Some of them have understood the size of the challenge we face by opting to share fine-grained and sensitive data with the scientific community. These data made it possible to conduct complex analyses across multiple scales, allowing us to reach a better understanding of the spatial behavior of the virus.
In this paper, we have not only discussed the importance of geospatial analysis for understanding the spatial patterns of the virus but also some relevant issues related to implement adequate mapping strategies for this kind of data. Geospatial tools can simplify complex and often abstract realities, turning them into graphical translations by using arbitrary symbols. In the current pandemic, geospatial tools have made feasible to evaluate a great number of hypothesis by analyzing the actual influence of a great number of environmental and social factors on the virus spread.
Spatial analysts must respond to questions related to what issue to represent, how to represent the issue, and for what purpose. The first point determines the type and amount of information to show. The second point determines what symbols to use or how classify and organize visually the data. The last point determines the final objective of the map. Although there are fundamental principles of good and easy-to-read mapping, the output must be adapted to the audience [
78]. The message must be clear, unambiguous, and self-explanatory. A clear visualization can enormously facilitate subsequent steps related to the analysis and interpretation of data.
During the pandemic, numerous institutions and governments have implemented web-dashboards based on GIS tools. Although most of them were implemented for informative purposes, web-maps could be built for decision making. However, it would have some additional requirements related to the use of trusted, detailed, accurate, and reliable information. The second one relates to the need of implementing appropriate mapping strategies for each particular objective [
79]. GIS tools allow synthesizing the complex abstraction of reality into a specific number of data layers. The operator can control, organize, and adapt these data layers [
80]. Beyond the value of these geospatial tools, the cartographic treatment of data by some dashboards has been widely criticized [
81], especially in a context with the ease and speed of map-making [
67]. In fact, the following are common issues: an excess of tools that take a long time to load and that do not work correctly; the predominance of complex and counter-intuitive designs; and/or some platforms with limited effectiveness. The same happens with the design of maps, with a tendency to both over-represent and under-represent information, in addition to an inappropriate uses of choropleth maps and different cartographic features such as datum, projection systems, and scales [
81]. In any case, these web-dashboards demonstrate the importance of integrating mapping with other charts. Cartography adds a new dimension of insight into data, but it does not replace all other visualizations.
With regard to results, we show different mapping strategies presented using fine-grained and detailed COVID-19 data that include personal information. We use simple features (points, lines, and polygons) depending on fundamental aspects such as the level of aggregation of the data or the spatial scale. Data aggregation requires implementing choropleth maps. These maps help to classify complete regions, but sharp boundaries between polygons do not totally fit with to reality [
82]. Thus, risk delimitation per area may arbitrarily shift depending on scale and the data aggregation, which reaffirms the existence of the MAUP issue. Two aspects are fundamental in the appearance, readability, and credibility of these maps: color scheme and classification method [
83]. Both factors affect the visual perception of spatial patterns and determine the final output. For the color legend, we applied a sequential color scheme in most of the maps. With regard to the classification method, we opted for a regular distribution of values in regular intervals (quartiles) with the same number of cases for each one. In this manner, we present a very general and balanced classification of the risk levels that is appropriate for the purposes of this paper. However, it is also worth noting there is an open discussion about the methods for classifying epidemiological data on choropleth maps, with some of these methods presenting advantages in function of the aims [
84]. An inappropriate or biased implementation of these map elements can result in a manipulated output [
67].
Additionally, all the map elements must be adjusted according to the privacy and sensitivity of data. Health data mapping must pursue objectives while preserving aspects such as the data integrity, user privacy, self-sovereign data ownership, as well as the legislation on data protection. Consequently, this requires implementing strategies and approaches to data governance for ensuring that data are appropriately managed. That is particularly important for visualization of socially vulnerable people such COVID-19 patients. Kim et al. [
85] indicated that perceived disclosure risk increases as the amount of locational information displayed on a map increases, and it depends on factors as the map scale and the presence of information of other people. Compared to point-based maps, the perceived disclosure risk is significantly lower for kernel density maps, convex hull maps, and standard deviational ellipse maps. Data aggregation is the most effective method in preventing the re-identification of individuals, but it must be considered depending on the spatial scale and the complexity of the phenomenon. Our study demonstrates the emergence of a complex trade-off between the transparency to provide accurate information to society and to avoid the shortcomings derived from it. A very detailed representation of COVID-19 cases can be counterproductive, creating an unjustified state of general alarm or resulting in a rejection of certain individuals or communities. The same occurs with mapping strategies, which require adopting certain arbitrary criteria (quantitative or visual) for preserving the anonymity of users. As an example, mapping individual cases can guarantee the identity of an infected individual in an urban environment but probably not in a rural environment. In the particular case of this region, this is even more complicated in areas with an apparently urban morphology such as in head towns, where data privacy is not guaranteed when the individual cases are shown. This requires the need to know the territory and to implement data aggregation strategies according with the particular characteristics of each region.
The use of geospatial tools in this pandemic is just one more example of the potential of GIS tools for health data management [
86], but this potential spans much further. In the last few years, the volume of health datasets has exponentially grown due to the enhanced capacity of portable devices such as wearables, which have favored the explosion of personal health data [
87]. It explains the progressive shift of data and services towards the cloud, partly due to convenience (availability of complete patient medical history in real time) and cost savings [
88]. This paradigm favors the creation of multidisciplinary working teams in order to reach more creative and efficient solutions in order to face a multifaceted issue such as the health management. It is here where maps must adopt a crucial role due to their capacity for integrating experts with different backgrounds within the same working team. The most optimal map is the one that facilitates a comprehensive interpretation of the spatial behavior of the virus, enriching the discussion between experts.
The importance of GIS systems goes far beyond traditional maps. These tools can be used as centralized systems for managing data in near-real time. It not only presupposes great benefits for tracing reported cases but also people at risk. The success of interventions adopted by some countries is mostly based on these technologies, which contribute to mitigating the impact on health, society, and economy.
Several aspects must be considered in our research study. We use structured datasets, which were arranged before mapping. However, future health management anticipates a boom of unstructured datasets stemming from personal devices, home sensors, and wearables. This requires implementing more advanced strategies and methodologies for handling, managing, and mapping these data. According to Fornace et al. [
89], efforts will be focused on developing real time and high-resolution mapping strategies ready to be used with mobile technology-based applications.
Our proposal is framed in a very exceptional context related with the current pandemic, which had encouraged many public administrations to share sensitive information. However, this experience must go beyond. Nowadays, many governments are trying to implement open data platforms with public data available in non-proprietary formats, available free of charge, and available without distribution rights [
90]. This, together with the ongoing digital transformation process in health management, requires developing strategies to improve population health, enhancing the quality of care services, and reducing cost growth (i.e., the so-called
triple aim) [
91].
Finally, maps presented help identifying spatial patterns but always within a particular geographical context. We can not only infer some of the most relevant spatial patterns of the virus in this region but also the effectiveness of the containment policies. This region was one of the least severely affected in Spain by COVID-19 in the first wave. This was largely due to the adoption of the hard lockdown in Spain when the presence of the virus was still quite residual in this region. The virus traced a spatial pattern very similar to the urban structure of the region with most of the cases being concentrated in the most populated areas, close to the Atlantic Axis. In future studies, the authors will conduct a more comprehensive analysis of the internal differences in the incidence rate of the virus across the study area.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}