From Geoportals to Geographic Knowledge Portals

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
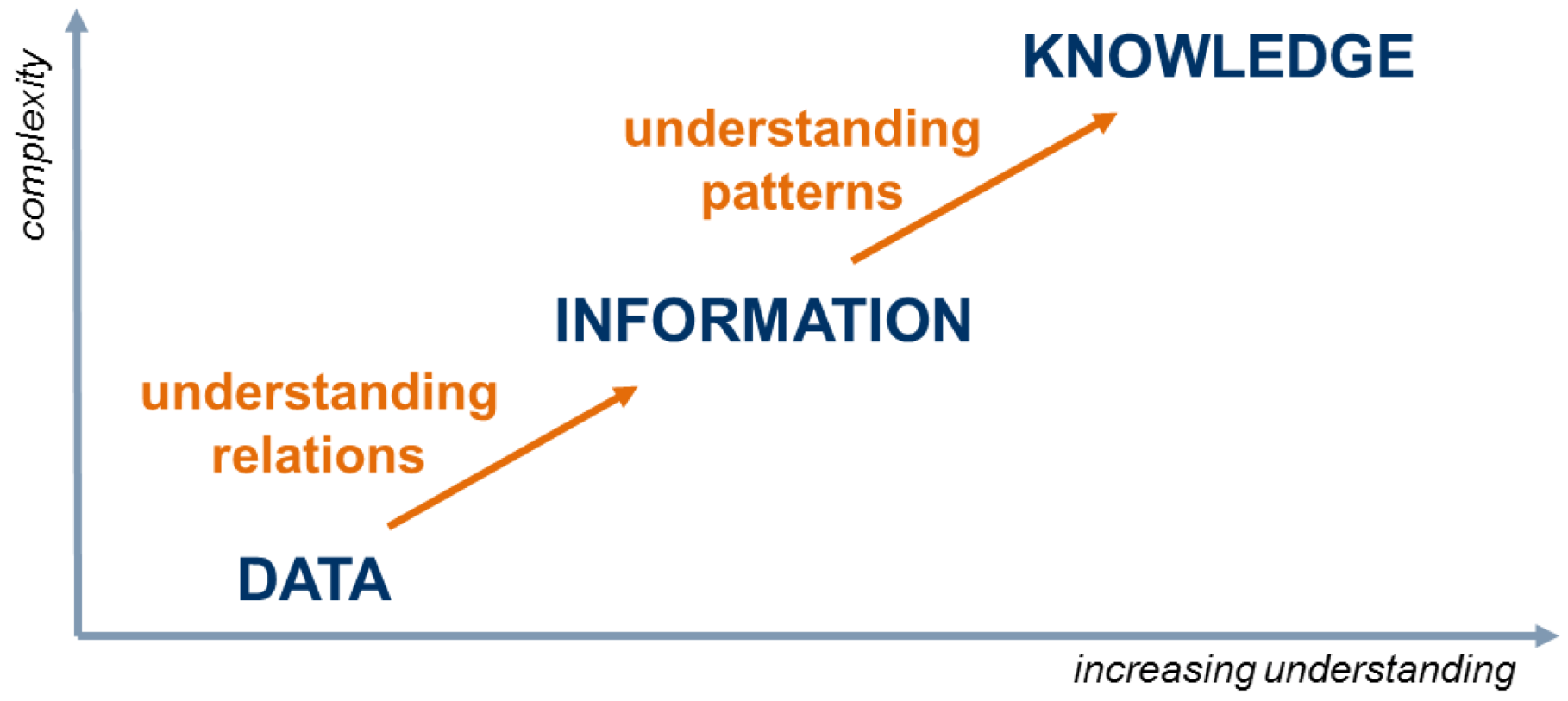
:1. Introduction

2. Spatial Portals

3. Methods of Semantic Text Matching
3.1. Method Overview
3.2. Comparison of Methods for Semantic Text Matching
4. Recommendation Approaches


5. Implementation
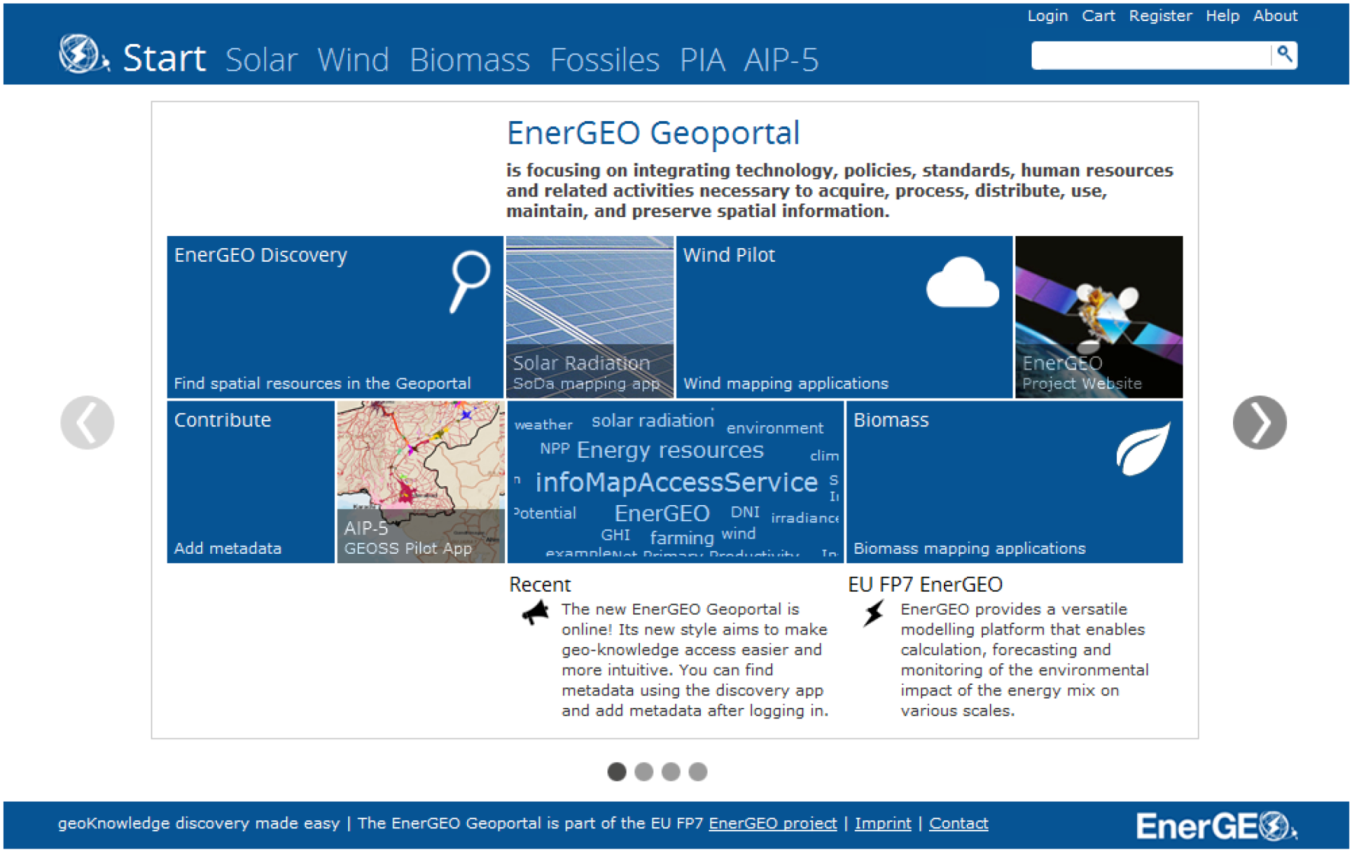
5.1. Geoportal Framework
5.2. (Semi-)Automatic Metadata Extraction Tool


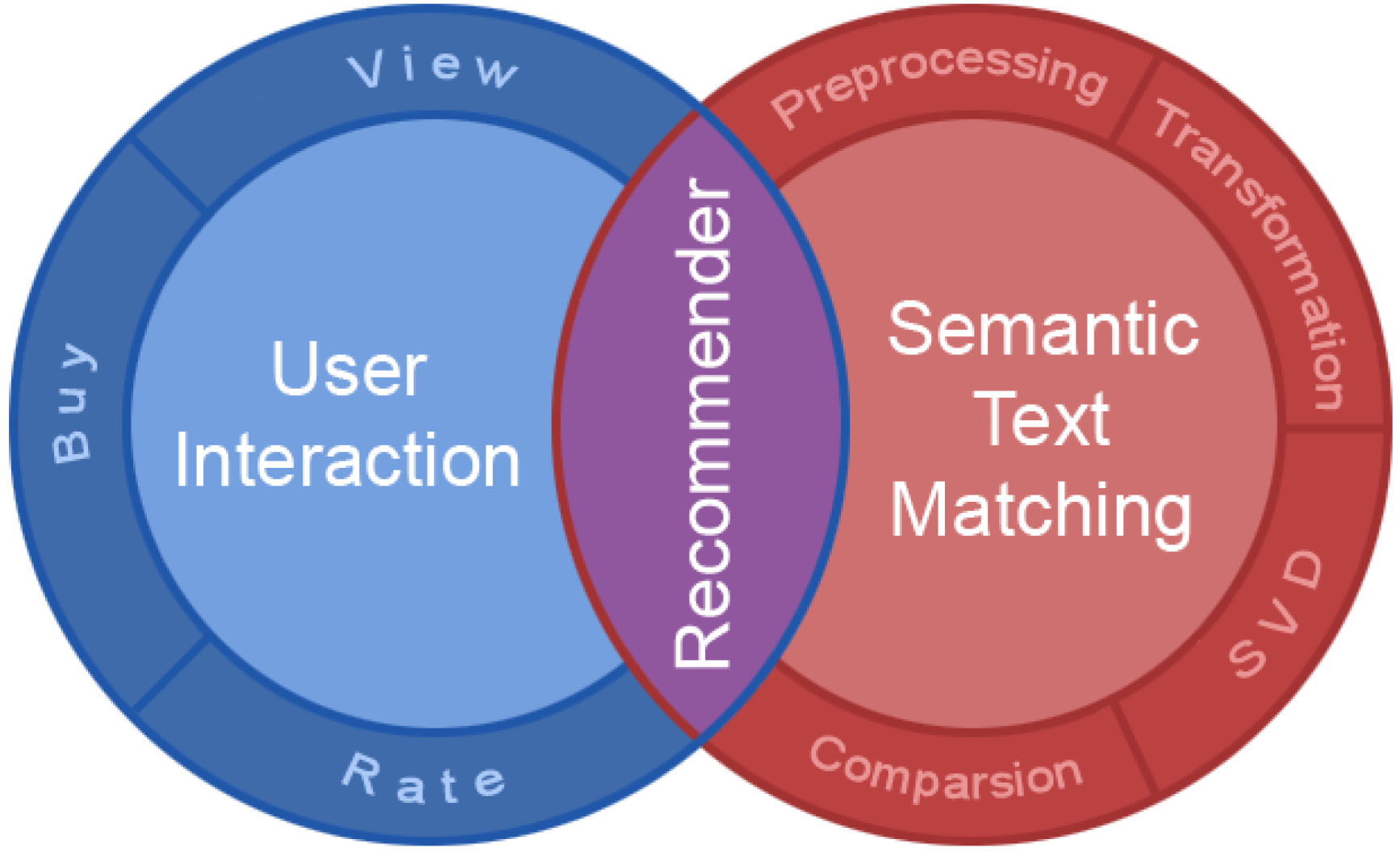
5.3. Semantic Text Matching Tool

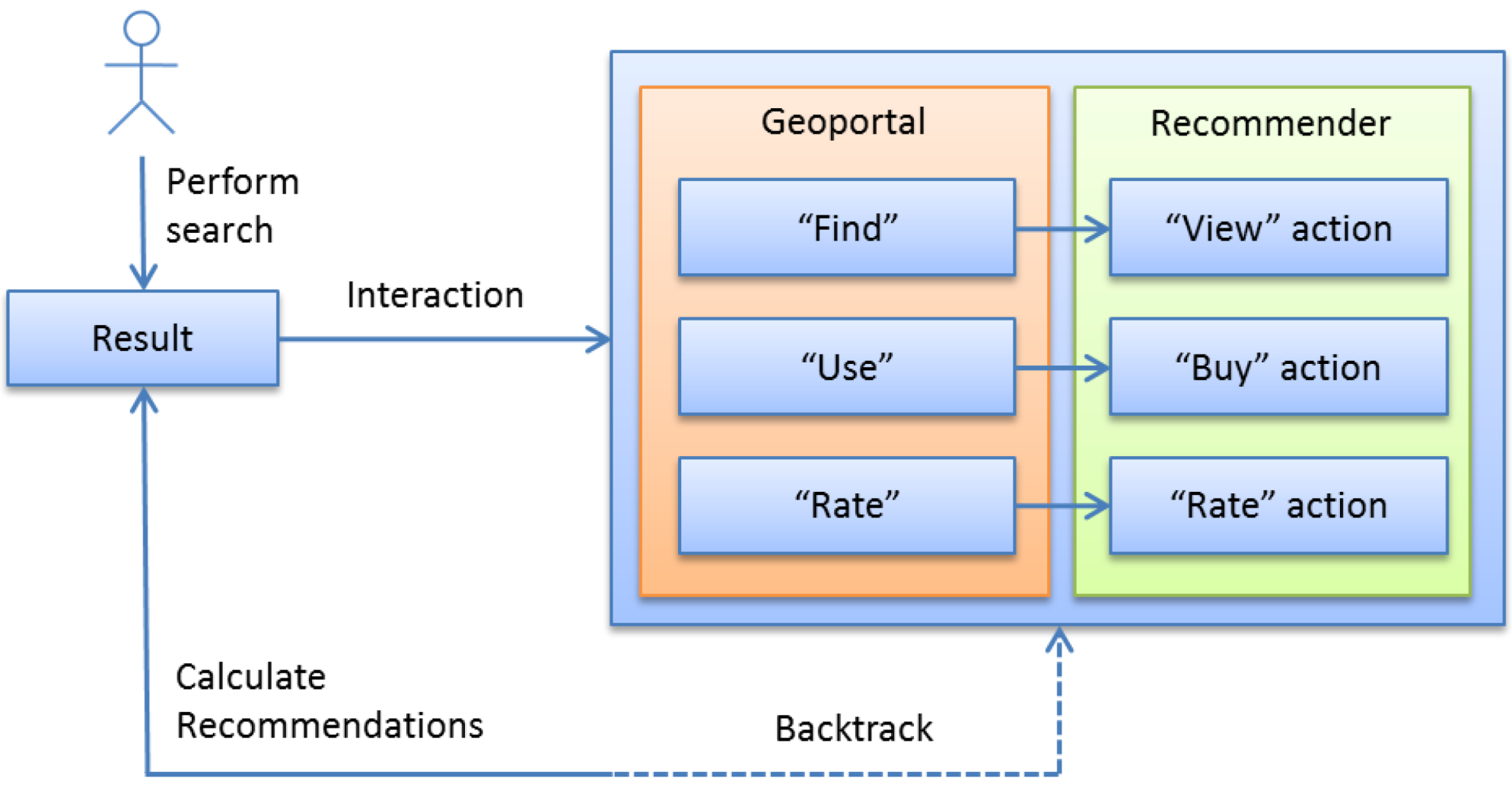
5.4. Recommender System
6. Results

7. Outlook and Discussion
8. Conclusion
Acknowledgments
References
- Rouse, M. Information Society. IT Standards and Organizations Glossary. Available online: http://whatis.techtarget.com/definition/Information-Society (accessed on 19 January 2013).
- Gantz, J.; Reinsel, D. Extracting Value from Chaos. Available online: http://www.emc.com/collateral/analyst-reports/idc-extracting-value-from-chaos-ar.pdf (accessed on 17 January 2011).
- Bellinger, G. Knowledge Management—Emerging Perspectives. Available online: http://www.systems-thinking.org/kmgmt/kmgmt.htm (accessed on 11 January 2013).
- Richter, A. Enterprise Spatial Information & Knowledge Infrastructures—Concepts and Technologies for the Oil & Gas Business Using the Example of OMV. M.S. Thesis, University of Salzburg, Salzburg, Austria, 2012. [Google Scholar]
- SAS. Text Analytics—Contextual Intelligence. Available online: http://www.eu.gov.hk/sc_chi/cmps/files/cmps_20100125_1210_sas.pdf (accessed on 1 May 2012).
- Croisier, S. The Rise of Semantic-Aware Applications. In Semantic Technologies in Content Management Systems; Maass, W., Kowatsch, T., Eds.; Springer: Berlin, Germany, 2012; pp. 23–33. [Google Scholar]
- Tang, W.; Selwood, J. Spatial Portals. Gateways to Geographic Information; ESRI Press: Redlands, CA, USA, 2005. [Google Scholar]
- Tang, W.; Selwood, J. Spatial Portals. Adding Value to Spatial Data Infrastructures. Available online: http://www.isprs.org/proceedings/XXXVI/4-W6/papers/35-40WinnieTang-A022.pdf (accessed on 21 July 2012).
- Fugazza, C.; Luraschi, G. Semantics-aware indexing of geospatial resources based on multilingual thesauri: Methodology and preliminary results. Int. J. Spat. Data Infrastruct. Res. 2012, 7, 16–37. [Google Scholar]
- Smits, P.C.; Friis-Christensen, A. Resource discovery in a European spatial data infrastructure. IEEE Trans. Knowl. Data Eng. 2007, 19, 85–95. [Google Scholar] [CrossRef]
- Vockner, B.; Belgiu, M.; Mittlböck, M. Recommender-based enhancement of discovery in Geoportals. Int. J. Spat. Data Infrastruct. Res. 2012, 7, 441–463. [Google Scholar]
- Latre, M.A.; Hofer, B.; Lacasta, J.; Nogueras-Iso, J. The Development and interlinkage of a drought vocabulary in the EuroGEOSS interoperable catalogue infrastructure. Int. J. Spat. Data Infrastruct. Res. 2012, 7, 225–248. [Google Scholar]
- Janowicz, K.; Schwarz, M.; Wilkes, M. Implementation and Evaluation of a Semantics-Based User Interface for Web Gazetteers. In Proceedings of Visual Interfaces to the Social and the Semantic Web (VISSW 2009) Workshop in Conjunction with the International Conference on Intelligent User Interfaces (IUI 2009), Sanibel Island, FL, USA, 8–11 February 2009.
- Scholz, J.; Mittlböck, M. Spatio-Temporal Visualization of Simulation Results Using a Task-Oriented Tile-Based Design-Metaphor. In Service Oriented Mapping 2012; Jobst, M., Ed.; Jobsstmedia Management Verlag: Vienna, Austria, 2012; pp. 369–382. [Google Scholar]
- Islam, A.; Inkpen, D. Semantic text similarity using corpus-based word similarity and string similarity. ACM Trans. Knowl. Discov. Data 2008, 2, 1–25. [Google Scholar] [CrossRef]
- Mihalcea, R.; Corley, C.; Strapparava, C. Corpus-Based and Knowledge-Based Measures of Text Semantic Similarity. In Proceedings of the 21st National Conference on Artificial Intelligence, Boston, MA, USA, 16–20 July 2006; Volume 1, pp. 775–780.
- Turney, P.D.; Pantel, P. From frequency to meaning: Vector space models of semantics. J. Artif. Int. Res. 2010, 37, 141–188. [Google Scholar]
- Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Deerwester, S.; Harshman, R. Using Latent Semantic Analysis to Improve Access to Textual Information. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Washington, DC, USA, 15–19 May 1988; pp. 281–285.
- Deerwester, S.; Dumais, S.; Landauer, T.; Furnas, G.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Maas, A.; Daly, R.; Pham, P.; Huang, D.; Ng, A.; Potts, C. Learning Word Vectors for Sentiment Analysis. In Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics: Human Language Technologies, Portland, OR, USA, 19–24 June 2011; pp. 142–150.
- Wiemer-Hastings, P. How Latent is Latent Semantic Analysis? In Proceedings of the 16th International Joint Conference on Artificial Intelligence, Stockholm, Sweden, 31 July–6 August 1999; Volume 2, pp. 932–937.
- Landauer, T.; Laham, D.; Rehder, B.; Schreiner, M.E. How Well can Passage Meaning be Derived without Using Word Order. In Proceedings of the 19th Annual Meeting of the Cognitive Science Society, Palo Alto, CA, USA, 7–10 August 1997.
- Dumais, S. Latent semantic analysis. Annu. Rev. Inf. Sci. Technol. 2004, 38, 188–230. [Google Scholar] [CrossRef]
- Wicijowski, J.; Ziolko, B. Extracting Semantic Knowledge from Wikipedia. In Intelligent Information Systems: New Approaches; Klopotek, M.A., Ed.; Publishing House of University of Podlasie: Podlasie, Poland, 2011; pp. 91–98. [Google Scholar]
- Nakov, P.; Popova, A.; Mateev, P. Weight Functions Impact on LSA Performance. In Proceedings of the EuroConference Recent Advances in Natural Language Processing (RANLP’01), Tzigov Chark, Bulgaria, 5–7 September 2001; pp. 187–193.
- Terzi, M.; Ferrario, M.-A.; Whittle, J. Free Text in User Reviews: Their Role in Recommender Systems. In Proceedings of the 3rd ACM RecSys’10 Workshop on Recommender Systems and the Social Web, Chicago, IL, USA, 23–27 October 2011; pp. 45–48.
- Li, Y.; McLean, D.; Bandar, Z.; O’Shea, J.; Crockett, K. Sentence similarity based on semantic nets and corpus statistics. IEEE Trans. Knowl. Data Eng. 2006, 18, 1138–1150. [Google Scholar] [CrossRef]
- Turney, P.D. Mining the Web for Synonyms: PMI-IR versus LSA on TOEFL. In Proceedings of the 12th European Conference on Machine Learning, Freiburg, Germany, 5–7 September 2001; pp. 491–502.
- Gabrilovich, E.; Markovitch, S. Computing Semantic Relatedness Using Wikipedia-Based Explicit Semantic Analysis. In Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hydrabad, India, 6–12 January 2007; pp. 1606–1611.
- Sorg, P.; Cimiano, P. Cross-Lingual Information Retrieval with Explicit Semantic Analysis. In Proceedings of Working Notes for the CLEF 2008 Workshop, Aarhus, Denmark, 17–19 September 2008.
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- L’Huillier, G.; Hevia, A.; Weber, R.; Ríos, S.A. Latent Semantic Analysis and Keyword Extraction for Phishing Classification. In Proceedings of 2010 IEEE International Conference on Intelligence and Security Informatics (ISI), Vancouver, BC, Canada, 23–26 May 2010; pp. 129–131.
- Cimiano, P.; Schultz, A.; Sizov, S.; Sorg, P.; Staab, S. Explicit Versus Latent Concept Models for Cross-Language Information Retrieval. In Proceedings of the 21st International Joint Conference on Artifical Intelligence, Pasadena, CA, USA, 11–17 July 2009; pp. 1513–1518.
- Tsatsaronis, G.; Varlamis, I.; Vazirgiannis, M.; Norvag, K. Omiotis: A Thesaurus-Based Measure of Text Relatedness. In Proceedings of the European Conference on Machine Learning and Knowledge Discovery in Databases: Part II, Bled, Slovenia, 7–11 September 2009; pp. 742–745.
- Tsatsaronis, G.; Varlamis, I.; Vazirgiannis, M. Text relatedness based on a word thesaurus. J. Artif. Int. Res. 2010, 37, 1–40. [Google Scholar]
- Lee, M.D.; Pincombe, B.M.; Welsh, M.B. An Empirical Evaluation of Models of Text Document Similarity. In Proceedings of the XXVII Annual Conference of the Cognitive Science Society, Stresa, Italy, 21–23 July 2005; pp. 1254–1259.
- Ramage, D.; Rafferty, A.N.; Manning, C.D. Random Walks for Text Semantic Similarity. In Proceedings of the 2009 Workshop on Graph-Based Methods for Natural Language Processing, Suntec, Singapore, 7 August 2009; pp. 23–31.
- Dolan, B.; Quirk, C.; Brockett, C. Unsupervised Construction of Large Paraphrase Corpora: Exploiting Massively Parallel News Sources. In Proceedings of the 20th International Conference on Computational Linguistics, Geneva, Switzerland, 23–27 August 2004; p. 350.
- Mohler, M.; Mihalcea, R. Text-to-Text Semantic Similarity for Automatic Short Answer Grading. In Proceedings of the 12th Conference of the European Chapter of the Association for Computational Linguistics, Athens, Greece, 20 March–3 April 2009; pp. 567–575.
- Resnick, P.; Iacovou, N.; Suchak, M.; Bergstrom, P.; Riedl, J. GroupLens: An Open Architecture for Collaborative Filtering of Netnews. In Proceedings of the 1994 ACM Conference on Computer Supported Cooperative Work, Chapel Hill, NC, USA, 22–26 October 1994; pp. 175–186.
- Pazzani, M.J. A framework for collaborative, content-based and demographic filtering. Artif. Intell. Rev. 1999, 13, 393–408. [Google Scholar] [CrossRef]
- ESRI Geoportal Server. Available online: http://www.esri.com/software/arcgis/geoportal (accessed on 16 March 2013).
- Apache Software Foundation. Apache Tiles. Available online: http://tiles.apache.org (accessed on 20 August 2012).
- gfx. Available online: http://www.swftools.org/gfx_tutorial.html (accessed on 10 September 2012).
- Win32com. Available online: http://starship.python.net/~skippy/win32/Downloads.html (accessed on 10 September 2012).
- Topia Termextract. Available online: http://pypi.python.org/pypi/topia.termextract/ (accessed on 12 September 2012).
- Rehurek, R.; Sojka, P. Software Framework for Topic Modelling with Large Corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 17–23 May 2010; pp. 45–50.
- Rehurek, R. Experiments with the English Wikipedia. Available online: http://radimrehurek.com/gensim/wiki.html (accessed on 15 February 2013).
- easyrec. Available online: http://www.easyrec.org (accessed on 15 March 2012).
- Agrawal, R.; Srikant, R. Fast Algorithms for Mining Association Rules in Large Databases. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago de Chile, Chile, 12–15 September 1994; pp. 487–499.
- Lemire, D.; Maclachlan, A. Slope One Predictors for Online Rating-Based Collaborative Filtering. In Proceedings of the 2005 SIAM International Conference on Data Mining (SDM’05), Newport Beach, CA, USA, 21–23 April 2007.
- Abargues, C.; Granell, C.; Díaz, L.; Huerta, J.; Beltran, A. Discovery of User-Generated Geographic Data Using Web Search Engines. In Advances in Geoscience and Remote Sensing; Jedlovec, G., Ed.; InTech: Rijeka, Croatia, 2009. [Google Scholar]
- Pearlman, J.; Craglia, M.; Bertrand, F.; Nativi, S.; Gaigalas, G.; Dubois, G.; Niemeyer, S.; Fritz, S. EuroGEOSS: An Interdisciplinary Approach to Research and Applications for Forestry, Biodiversity and Drought. In Proceedings of the 34th International Symposium on Remote Sensing of Environment, Sydney, Australia, 10–15 April 2011; pp. 1–4.
- Ankolekar, A.; Seo, Y.W.; Sycara, K. Investigating Semantic Knowledge for Text Learning. In Proceedings of ACM SIGIR Workshop on Semantic Web, Toronto, ON, Canada, 28 July–1 August 2003.
- Piwik. Available online: http://piwik.org/ (accessed on 10 February 2013).
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Vockner, B.; Richter, A.; Mittlböck, M. From Geoportals to Geographic Knowledge Portals. ISPRS Int. J. Geo-Inf. 2013, 2, 256-275. https://doi.org/10.3390/ijgi2020256
Vockner B, Richter A, Mittlböck M. From Geoportals to Geographic Knowledge Portals. ISPRS International Journal of Geo-Information. 2013; 2(2):256-275. https://doi.org/10.3390/ijgi2020256
Chicago/Turabian StyleVockner, Bernhard, Andreas Richter, and Manfred Mittlböck. 2013. "From Geoportals to Geographic Knowledge Portals" ISPRS International Journal of Geo-Information 2, no. 2: 256-275. https://doi.org/10.3390/ijgi2020256