1. Introduction
Recent developments in mobile communication and location-acquisition technologies have motivated mobile users to share information about their location [
1]. Online content is increasingly enhanced by geographic information, which represents a new context layer and is used for organizing and displaying data. These developments have led to convergence of GIS (Geographic Information System) and social media, resulting in augmentation of the existing social network sites with new location-based capabilities; e.g., Facebook or Twitter, and the development of new ones exclusively around the location-based data, such as Foursquare [
2]. In location-based social networks (LSBNs), the available check-in data provide useful knowledge of the user’s interests and behavior, and therefore are suitable for a broad variety of applications such as location, friend, and activity recommendations [
3].
The recommendation system is an information filtering system subclass that retrieves interesting items for users based on their preference, historical activities, and friend suggestions [
4]. Standard recommendation approaches concentrate often on a single user. However, the user interacts socially with other individuals in many cases, and therefore, recommendations to a group of users with diverse interests are required. For example, a group of friends would like to go someplace, or a group of individuals would like to watch a movie. Group recommendation systems identify items that obtain the greatest satisfaction among the users, for which they face several challenges [
5]. Due to the different priorities and preferences of group members, it is important to provide relevant recommendations that meet their needs. Therefore, finding effective factors that contribute to user satisfaction is of interest in this field. In addition, cold-start and data sparsity problems are other challenges that need to be addressed. Difficulties in assessing the effectiveness of group recommendations are another issue for which effective evaluation metrics need to be developed. User preferences are likely to change in different contexts such as time, location, surrounding people, emotion, devices, weather, etc. Therefore, ignoring these contextual variables would lead to a reduction in the efficacy of recommendations. The crucial impact of contextual information on user preferences has led to the development of Context-Aware Recommender Systems (CARSs), which produce more relevant recommendations by considering the particular contextual situation of the user [
6].
Spatial group recommender systems supply recommendations about locations where more than one individual participates in the recommendation procedure. Groups are made up of participants with similar preferences that are best suited for similar recommendations. In order to reduce decision complexity and provide recommendations that can increase satisfaction levels among members, the group members should have the maximum possible common preferences. A possible scenario to use spatial group recommendation is when a user intends to spend his or her leisure time. In this scenario, it is relatively hard and time-consuming to coordinate group members and find a favorite place, taking into consideration their distinct interests and priorities. In addition, the suitability of locations would change as a function of weather conditions, days of the week, and times of the day. So, for effective location recommendation in a spatial group recommender system, a procedure must be developed that takes into account both the preferences of group members and the environmental context.
In this research, a Context-aware Location Recommendation for Groups with Random Walk (CLGRW in short) is introduced. The CLGRW system has the least interactions with the user and provides the required data from the user’s location history and environmental context. This system utilizes the Random Walk with Restart (RWR) algorithm [
7] for ranking locations. The proposed approach considers some contexts such as user preference (personal context), social relationships (social context), user’s location history (personal spatial context), and the popularity and category of venues (location context) for scoring the locations. In addition, the CLGRW system employs context related to the weather, day of the week, and capacity of venues at different time intervals to recommend locations to groups. In this research, various group recommendation strategies and group decision policies are implemented. Furthermore, multiple group sizes are regarded to investigate the effects of group size on the reliability of the recommended locations.
The main contributions of this study are as follows. (1) Group location recommendations are made according to the user’s preferences, social relationships, location history, and the neighborhood of locations and users. In addition, environmental context such as weather conditions, day of the week, and the capacity of venues in different time intervals are used as contextual post-filtering to contribute to recommendation efficacy. (2) Content similarity and location popularity are used to enhance the performance of recommendations for groups. (3) A new metric is introduced to complement the existing metrics for the evaluation of recommendations in the recommender systems. In contrast to the other existing methods, this metric does not limit the evaluation to exact correspondence between the test and recommended locations, and uses the similarity between the recommended locations and the test data to assess the quality of these recommendations.
The rest of the paper is structured as follows. In
Section 2, a review of the literature with a brief description of the group recommendation and random walk is discussed.
Section 3 describes the two main phases of the proposed system: the offline modeling and context-aware group recommendations. Experimental evaluation based on a real dataset is outlined in
Section 4. Conclusions are summarized in
Section 5.
2. Preliminaries and Related Work
In this section, firstly, the context-aware recommender system along with a brief description of the recommender algorithm, as the main part of a group recommender system, are described. Secondly, a definition and research literatures on group-based recommendations are outlined.
2.1. Context-Aware Recommender System
Traditional recommender systems (RSs) neglect the contextual conditions when providing recommendations. Context-aware recommender systems (CARs) are normally developed to recommend items that are relevant to altering user needs by incorporating contextual data into RSs [
8,
9]. The term “context” is commonly defined as “any information useful to characterize the situation of an entity (e.g., a user or an item) that can affect the way users interact with systems” [
10]. Extracting contexts is an important stage in the development process of CARS. Depending on the nature of the context, contextual information can be extracted explicitly, implicitly, or through using a machine learning approach [
11]. The major challenge for CARSs is to determine
when and
how context information should be incorporated. There are three distinct paradigms for integrating contextual data into recommender systems based on the phase in which context is analyzed: contextual pre-filtering, contextual post-filtering and contextual modeling [
8,
9].
The current application domains in CARS could be classified into travel and tourism, places, e-documents, multimedia, e-commerce, and others. Incorporated contexts can be different according to the application domain. Incorporated contexts in the places domain can be personal preferences, current time, location, distance to the point of interest, intent, nationality, current activity, weather, and the user’s mood and social relationships [
11].
Savage et al. [
12] proposed a location-based context-aware recommendation system named “I’m feeling LoCo”, which uses user preferences, time, geography, and similarity measurements. Physical limitations are defined by the place and mode of transportation of the user. The collaborative filtering algorithm is used for the recommendation of locations to users. Huang [
13] used Flickr (social media photo dataset) to create location recommendations based on the tourist preferences and environmental contexts (i.e., weather, season, and daytime). Collaborative filtering techniques were utilized to make location recommendations. Majid et al. [
14] designed a context-aware personalized tourist recommendation framework that obtains the traveling preferences of the users from their contributed photos. The photo’s spatial and temporal contexts in conjunction with the weather context are used in the proposed approach to support context-aware recommendation. Xu et al. [
15] proposed an approach to travel location recommendations in a city, based on topic distribution of the user’s travel histories in other cities, as well as season and weather context information. A topic model is used to mine the user’s interest. Contextual data is regarded during the mining and recommendation procedures. Bao et al. [
16] introduced a location-based and preference-aware recommender system. The proposed system recommends a set of locations within the geospatial range taking into account both the user preferences and social opinions. Christopher et al. [
17] developed a context-aware recommender system for tourist trip routes composed of the sequential points of interest. In this work, in addition to the usual context information such as the location, weather, and opening hours, additional contextual data such as the time of the day and previously visited places were utilized for recommendation. These studies verified that the inclusion of contextual data in the recommendation process could improve the quality of recommendations, particularly in providing satisfactory recommendations for the location. They also show that contextual data is very diverse, and the selection of a relevant contextual data for a particular application is very important for the usefulness of the recommendations.
2.2. Recommending Algorithm
The main part of group recommendation is the algorithms used to generate recommendations. Major recommendation methodologies can be classified into three categories, including: (1) content-based recommendation, (2) link analysis-based recommendation, and (3) collaborative filtering (CF) recommendation [
1].
Each of the recommendation methodologies has specific drawbacks and benefits. For instance, data sparsity and cold starts are major problems in collaborative filtering-based recommender systems, while these issues are avoided in link analysis-based recommender systems [
1]. RWR is a subclass of the algorithms used in link analysis-based recommendation and has a key role in identifying the missing relations among different nodes in graph mining. It has been found that this algorithm obtains an acceptable relevance score between two nodes in a weighted graph [
18]. Due to its advantages, RWR has recently gained considerable attention in many distinct fields such as the recommendation systems.
Noulas et al. [
19] suggested a new model based on random walk over a user-location graph that incorporates location data and social relationships in order to recommend unvisited locations to users. To estimate the recommendation probabilities of the nodes, a random walk algorithm is conducted. Bagci et al. [
20] proposed a context-aware recommender system using a random walk algorithm that recommends locations in LBSNs. In this method, a graph is constructed to model the relationships between users, locations, and experts. Then, RWR is performed on this graph to combine personal, social, and spatial information automatically. According to experimental results, the proposed model outperformed popularity-based, friend-based, and expert-based baselines, as well as a user-based collaborative filtering approach.
Random Walk with Restart
RWR is a version of random walk that is widely used in graphs with several nodes. If there are an excessive number of nodes, moving out of the context during the random walk is feasible. This can lead to visiting less relevant nodes. RWR would not permit moving out of context by a constant probability of jumping back to the starting node in each move. Due to this limitation, nodes nearer to the starting node are likely to have more visits [
21,
22].
In the recommendation graph
G = (
V;
E),
indicates the number of nodes on the graph.
θ is a v × 1
personalized probability vector:
where
e1,
e2,…
ev are the standard basis of column vectors.
β is a
restarting probability. The rank score
s is obtained by the following equation:
where W is the transition matrix. It is determined by the link weights.
The vector of RWR score
s is updated iteratively as follows:
where
s(t) is the vector of the RWR score at the
t-th iteration. The iteration begins with the initial RWR score vector
s(0) and continues until convergence (i.e., the iteration will stop when
|s(t) −
s(t−1)| <
ε where
ε is the error tolerance) [
7]. In this paper,
s(0) is initialized as
, where
is the number of nodes, and
is an all-ones vector.
2.3. Group Recommendation
A group recommender system suggests items, such as web videos, movies, music, etc., that might be of concern to a group of individuals. Group recommender systems consist of two main processes: the recommendation strategies and group decision policies [
23].
Two different strategies are generally used to generate recommendation in group recommendation systems: one is recommendations based on an aggregated models strategy, and the other is recommendations based on an aggregated predictions strategy [
18,
24,
25]. The aggregated models strategy originally merges the individual ratings of group members with a specified policy to calculate a group rating for the venues. Then recommender algorithm is applied to this group model in order to generate recommendations for the group. The aggregated predictions strategy initially generates an individual prediction for a user and an unvisited venue using the recommender algorithm. In order to estimate prediction for a group, the individual predictions for group members are combined by a specified policy [
18,
25]. Many group decision policies exist; least misery and weighted aggregation policies are two common ones that have been extensively used in traditional group recommender systems [
18,
26].
Group recommendations have been suggested in various fields including: music [
27,
28], TV programs [
29], web/news pages [
30], and tourism [
31,
32]. Baltrunas et al. [
33] evaluated the efficacy of group recommendations by applying different rank aggregation techniques. The results showed that the group size has no influence on the recommendation performance for homogeneous groups. Meanwhile, in a group, as the members are more similar to each other, they are more satisfied with recommendations. Berkovsky and Freyne [
25] used different strategies to assess food recipe recommendations. Furthermore, considering the influence of the members, different weighted models were investigated for aggregating individual preferences. According to the results, the aggregated models strategy generates more effective recommendations than the aggregated predictions strategy.
Liao et al. [
34] proposed the companion recommendation task in LBSNs to identify who is most interested in joining the suggested activity among the friends of a specified user. This task is distinct from the group recommendation task, which also includes multiple users, but the aim of group recommendation is to recommend the most satisfactory locations to a group.
Pera et al. [
35] suggested a model using content-based filtering. The proposed model generates movie recommendations for groups by estimating the similarity of content among movies, creating a group profile, and considering the popularity of movies. Kim et al. [
36] proposed an approach that creates a graph from items and users and then utilizes the RWR to calculate the positive and negative preferences of the users. Then, a consensus function is applied to combine obtained preferences. Feng et al. [
18] introduced an approach based on RWR that used a tripartite graph to represent the relationships among users, groups, and items. Two common group recommendation strategies are implemented to estimate the relevance scores between groups and unrated items. The main goal of this work is to predict the preferences of groups by discovering the relevance scores among users, groups, and items, aiming at reducing the data sparsity.
Purushotham et al. [
4] studied group behavior and recommending locations to groups in LBSNs. They proposed a hierarchical Bayesian model that learns activities and group preferences by using topic models; and performs group recommendation using matrix factorization in a collaborative filtering framework. Ayala-Gómez et al. [
37] proposed Geo Group Recommender (GGR) to recommend locations to a group of users in the areas with the most frequent group presence. GGR is a class of hybrid recommender systems that combines the group geographical preferences, category and location features, and group check-ins. They used group information in LBSNs without using specific assumptions and heuristics to detect the groups. The results showed that GGR outperforms most other recommender systems in providing relevant recommendations.
Most of the literature on the group recommendation field is implemented on non-spatial datasets, and the location recommendation for groups has received less attention so far. In this study, due to the advantages of RWR, it is used as the main algorithm for recommendations in our proposed approach. Two methods are applied for group recommendation, including aggregating individual recommendations and extending RWR to predict group preferences. Furthermore, the results of these methods are investigated on different graphs.
Group Decision Policies
In traditional group recommender approaches, two decision policies of least misery and weighted aggregation have been widely used, which are introduced briefly as follows [
18,
26].
The Least Misery Policy
The main hypothesis in this method is that a group as a whole is as happy as its least satisfied member [
26,
38,
39]. Therefore, if
is a rating of user
ua on item
mj, the group rating is calculated as Equation (4):
The Weighted Aggregation Policy
In this policy, the group rating is calculated as follows:
where
is the weight of user
ua in group g
i. The active degrees of members can be considered as users’ weights, which is estimated by the number of venues that they visited. If a member visited more locations than the other group members, this member would have the highest weight among the group members [
25].
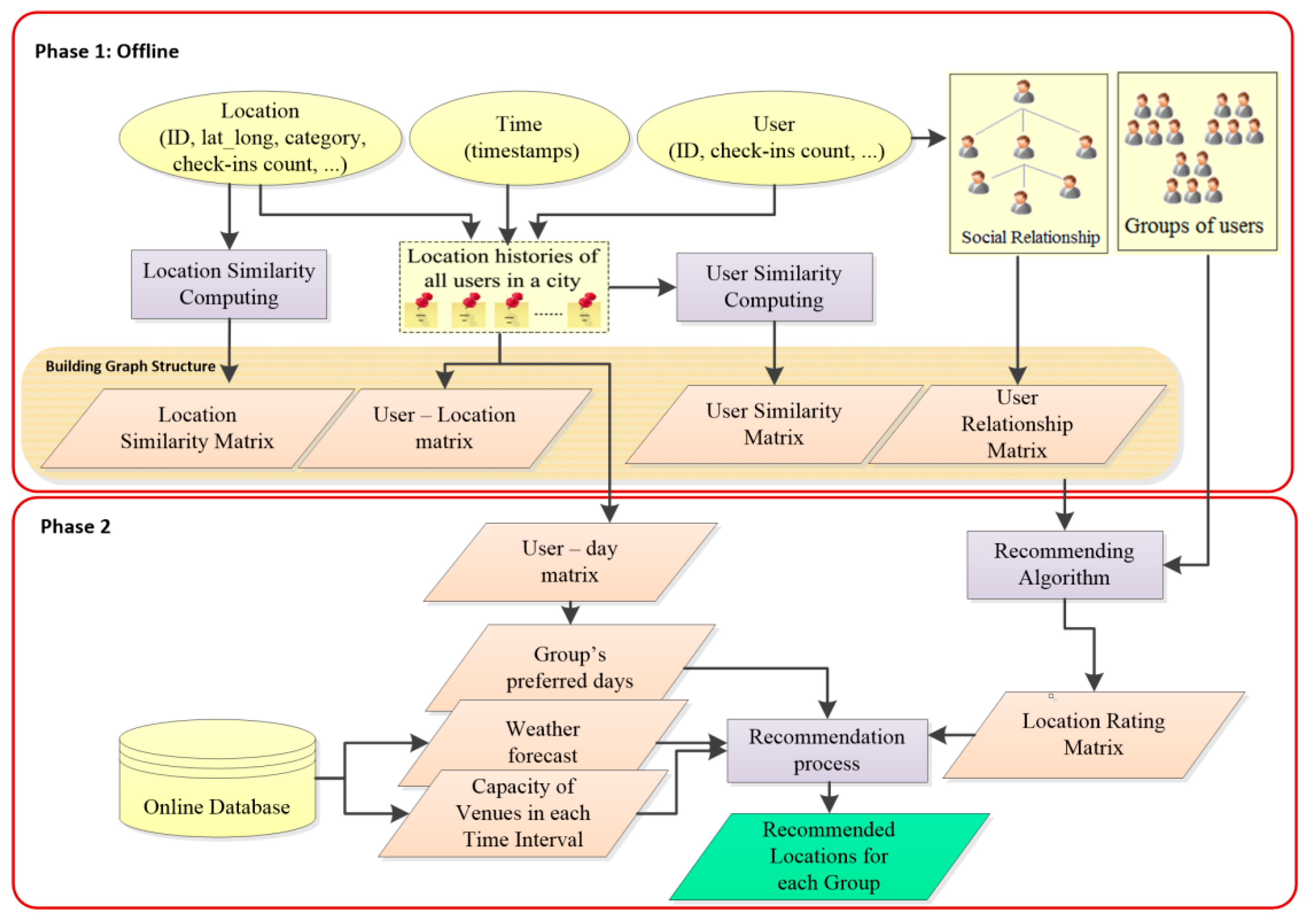
3. System Framework
The architecture of our context-aware group recommendation system, CLGRW, is outlined in
Figure 1. CLGRW consists of two major phases: offline modeling and group recommendation.
Offline modeling. The offline modeling phase comprises two major components: building a graph structure and group formation. The former builds the graph structure used in the recommender algorithm. Users and locations are considered as nodes, and the edges of the graph are formed by connecting users to locations, users to users, and locations to locations. These connections and their weights are obtained from the user’s location history, the social relationships among users, the similarity of users, and the similarity of locations. Several graphs are constructed based on different relationships. The second component is group formation, which will be used for location recommendations.
Context-aware group recommendation. This phase provides a list of locations for each group, considering the group member preferences, social relationships, locations similarities, and environmental contexts. This part consists of two main components: a locations rating and recommending locations to groups.
The former component calculates the rank of locations for each group. For this, the RWR algorithm estimates the scores of locations; then, the group profile is applied to improve the recommendations. Finally, by considering the popularity of locations as another criterion for ranking locations, they are aggregated. The latter component uses a group-location rating matrix along with online information about the capacity of locations in each time interval, as well as the weather forecast, to recommend locations for each group.
3.1. Offline Modeling
This subsection describes how to model graphs based on user location histories, social relationships, location similarities, and similarities among users, and also outlines how to classify users into groups.
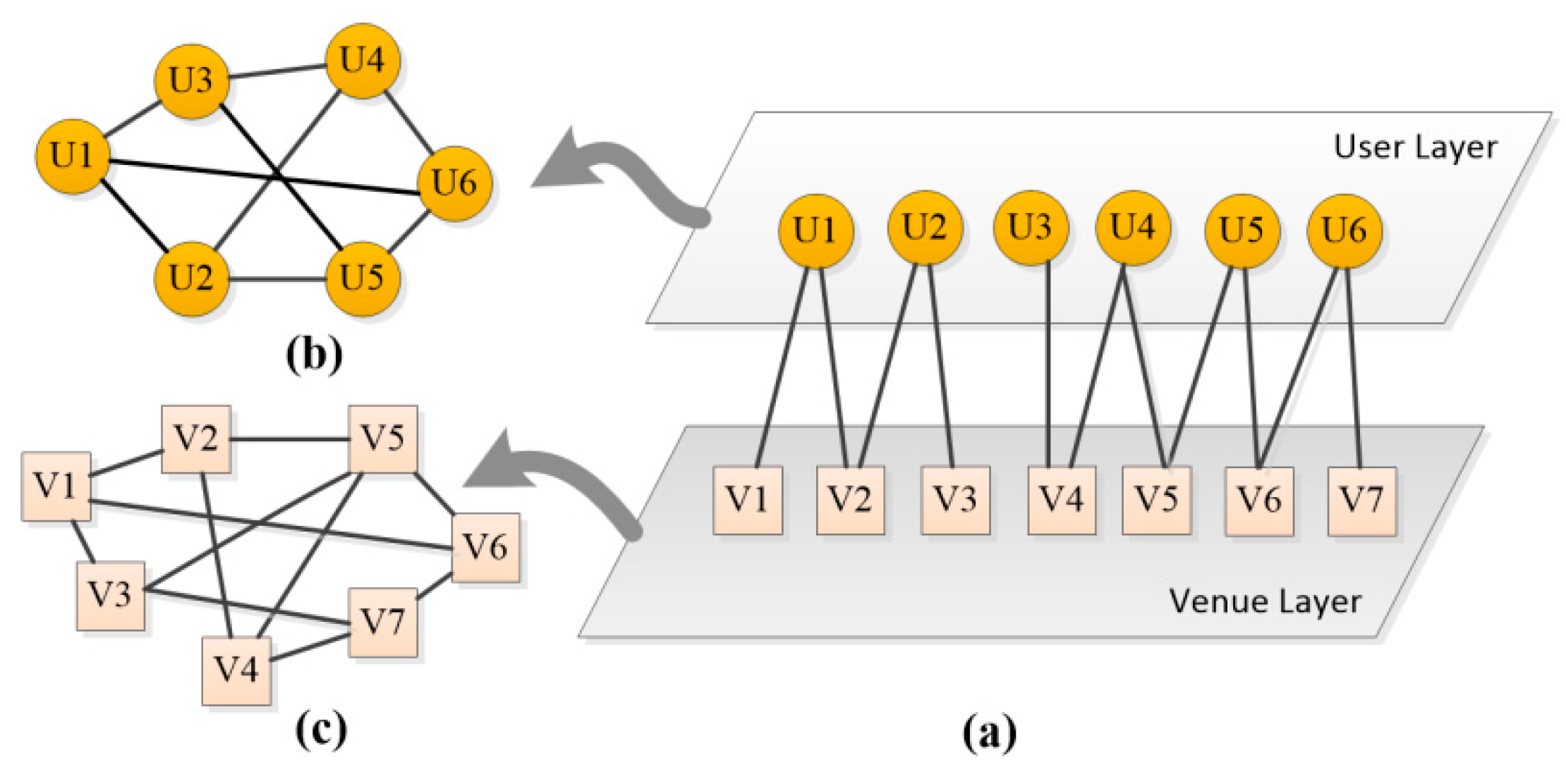
3.1.1. Building Graph Structure
In this study, a graph-based approach is introduced to rank and recommend locations to a group. Each user and venue is depicted as a node in a graph. The link-structures between users and locations are derived from the users’ location history. To use social wisdom, neighborhood-based links can be incorporated into a graph. Furthermore, user and venue similarities can be used to create a neighborhood-based link. On such link-structures (graphs), random walk is performed from specific nodes belonging to group members. Based on the results of the random walks, the algorithm recommends a set of ranked locations that the group would find interesting.
In this study, three types of graph structures are set up and used separately to create a transition matrix in the RWR algorithm. The first graph is built based on the user-location link, and this graph is used as the basis for two other graphs. In the second graph, in addition to the user-location link, the user relationship is considered. Finally, the third graph is constructed based on user and venue neighborhood graphs. The results of group recommendation on these different graphs are compared with each other.
User-Location Graph
A user-location graph is constructed based on the user’s location history. If the user visits a venue, an edge is constructed between them. Although the LBSN-based check-in dataset does not contain the user’s visiting rate to the location, it may be assumed that the more often a user check-ins at the same location, the more the user is interested in that place. All of the users do not have the same number of check-ins, and there may be a huge difference between the check-in times of different users. Thus, it is impractical to use the number of check-ins directly as a place rating. The term frequency-inverse document frequency (TF-IDF) technique is used to express user preference at the point P
i as follows [
40]:
where |{u.v
i : v
i = p
i}| is the number of times that user u visits point P
i, u.V is the sum of the user’s visits, and |{u
j: p
i ∈ u
j.V}| is the number of users who have visited the point P
i among all the users
. Then, TF-IDF is normalized with a Euclidean norm and used as the weight of edge in a user-location graph. This graph is shown in
Figure 2a.
User Relationship Graph
In this graph, the edge connects users who have social relationships with each other. However, the social relationship among LSBN users does not directly contribute to the accuracy of recommendations, because the preferences and interests of the user affect the recommendation of locations. Therefore, considering both user similarities and social relationships may be more helpful in addressing the above challenge. The weight of edge is calculated as follows [
41]:
where
is the similarity between users u
i and u
j, and
is the degree of trust of user u
i to user u
j. The degree of trust between the users is usually estimated using the historical interactions of the users. Due to the lack of historical interactions between users in this research, social relationships have been used to model the interpersonal trust. So, if there is a social relationship between users u
i and u
j,
is considered as 1. Thus, a user relationship graph G
U = (U, E
U) is defined where E
U contains an edge e(
) if there is a social relationship between user
and user
. In this graph, the edge weight is considered user similarities.
User Neighborhood Graph
For a given user, the user neighborhood comprises those users who prefer similar location categories; this group is referred to as
k-nearest neighbors [
36]. In this study, the similarity between users is calculated by the cosine distance. A vector is generated for each user in which each element’s value indicates the number of user visits in a category. The cosine distance is calculated as follows:
where
and
are the similarity vectors of user
and user
, respectively. The
k-nearest neighbor of each user is derived from user similarities. A user neighborhood graph G
U = (U, E
U) is defined where E
U contains an edge (
) if user
is in user
’s neighborhood. The edge weight considers the similarity of users. For each user, 30 nearest neighbors are regarded in this study. This graph is shown in
Figure 2b.
Location Neighborhood Graph
For a given location, the location neighborhood consists of locations that are in the same category and in close proximity to each other. To obtain the
k-nearest neighbors for each location, a location–location matrix is computed where the arrays of this matrix are distances between locations. Then, this matrix is normalized. The shorter the distance between the two locations, the more similar they are assumed to be. Therefore, a similarity matrix is obtained from (1-distance). This matrix is simplified using category data in which, if the category of two locations is the same, the array of the matrix is kept; otherwise, the value of the array is considered to be zero.
k-nearest neighbors are selected for each location. A location neighborhood graph G
V = (V, E
V) is defined where E
V contains an edge e(
) if location
is a neighbor of location
. In this study, 30 nearest neighbors are considered for each location. This graph is depicted in
Figure 2c.
3.1.2. Group Formation
In a group recommender system, users can set group members, or the system creates groups automatically. In automatic user grouping, users are divided into groups that are most similar to group members. In this study, the proposed approach in [
42] is used for automatic group formation. In this approach, similar preferences, spatial proximity, free days, and social relationships are used for computing user similarity. After that, user similarity is used in a modified k-medoids clustering algorithm, which creates groups with a given size. This approach is used in this study, because it considers important factors to determine the similarity between users.
Groups are generated with two, four, six, eight, and 12 members to investigate the impact of group size on location recommendations. The proposed group recommender system provides the location recommendations for these generated groups.
3.2. Context-Aware Group Recommendation
This section explains how the group’s scores are estimated for unvisited locations and how the environmental contexts affect the location recommendations.
3.2.1. Locations Rating for Each Group
In this study, two group recommendation strategies are implemented, and their results are compared. One is an aggregated predictions strategy, and the other is the strategy derived from extending the RWR algorithm to a group. The aggregation model strategy was not used here, because the group’s members do not usually share a large number of visited locations. A brief explanation of the used strategies to predict the group rating of an unrated location is as follows.
Group Recommendations by the RWR under Aggregated Predictions Strategy (RWR-P)
In the aggregated prediction strategy, first, the relevance scores are estimated using the RWR algorithm between users and locations. Then, these relevance scores are aggregated to obtain the group’s location preferences by a specified policy. The weighted aggregation policy and the least misery are used in this study.
In RWR-P, Equation (2) should be executed in an iteration process until it converges. For each user, this procedure must be performed. The transition matrix is defined based on the used graph structure. The value of restarting probability (β) is considered to be 0.2 [
43]. For each user
ua, the relevance scores of unvisited locations
mj,
j = 1, 2, ...,
M are obtained as:
Considering all the members of group gi, the relevance scores between group gi and all locations mj, j = 1, 2, ..., M can be calculated by a specific aggregation policy.
Group Recommendations via RWR (RWR-G)
Due to the special structure of the rank graph, recommendations for individual users can naturally be extended to groups. This method can calculate the integrated scores of group members at locations concurrently by analyzing link structures that reflect the location histories of users. In the RWR algorithm, the
personal vector θ can be set as [
44]:
where
is the number of members in the group. The rest of the predictions are the same as the individuals. For each group
gi, the relevance scores of unvisited locations
mj,
j = 1, 2, ...,
M can be obtained as:
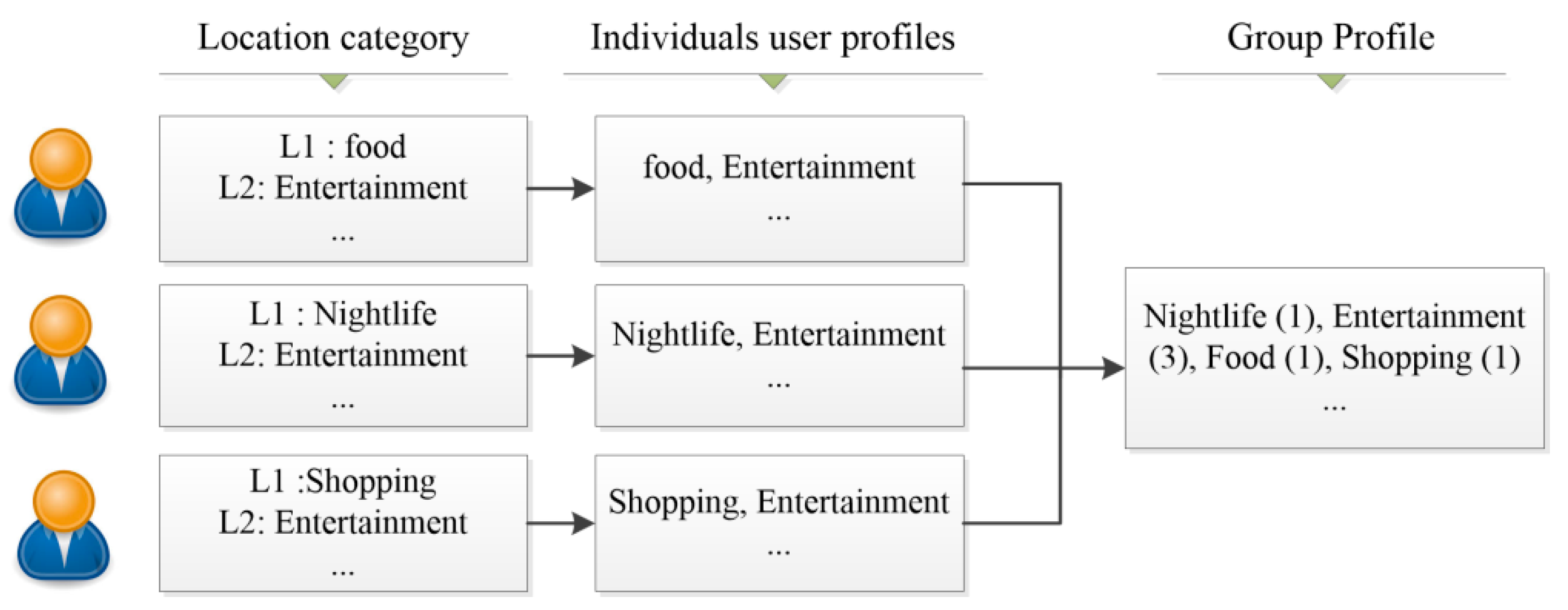
3.2.2. Building a Group Profile
Since the aim of group recommenders is to recommend a list of locations that are interesting for a group, the proposed system analyzes the preference of each group member within a location category and builds a group profile that represents the types of categories preferred by the group as a whole [
24,
35,
41]. The personal location category of each member represents the interests of the user to the locations. Then, the CLGRW system constructs a group profile that includes the common location categories among the individual profiles of the group members. In the group profile, the location category with higher repetition reflects that the members’ preferences show an interest in that location category. Therefore, this location category has more effect on the location recommendations than the other location categories with lower repetition.
Figure 3 demonstrates the creation of a group profile by taking into account the categories of the visited locations on the individual user profiles.
3.2.3. Score of Locations Considering Group Profile
After calculating the relevance score of each location using the RWR algorithm, the CLGRW system utilizes the group profile for generating more relevant location recommendations that the group’s members might find interesting. For this purpose,
is defined, which considers the location categories within the group profile. If location
belongs to category c, the score of this location for group (
is calculated as:
where
is the relevance score of group
to location
obtained from the RWR algorithm,
is the repetition of category c in the group profile,
is the maximum of repetition categories,
is the number of group members that have category c in their personal profiles, and
is the number of group members.
3.2.4. Popularity Score of Locations
Popularity is also a factor that affects users’ behavior. Users are influenced by public opinion in addition to those with whom they have direct interactions. People will make decisions based on reputation, so they will also take into account popularity and ratings [
23]. Popularity is computed as shown in Equation (13):
3.2.5. Rank Aggregation
With the group and popularity scores of each location, the system estimates the general location ranking using the popular linear combination metric called CombMNZ [
45]. CombMNZ estimates a combined ranking of an item I with considering multiple ranked lists. It calculates the new score as follows:
where
is the normalized score of I in list c, N is the number of lists to be merged, and
is the number of non-zero scores of I in the lists.
Before aggregating the ranked lists, it is essential to calculate the normalized score in each list by applying Equation (15) [
35,
45]:
where
is the score of item I in the ranked list c.
and
are the maximum and minimum score in c, respectively.
After rank aggregation, the unvisited locations are ranked for each group on the basis of their scores. Then, the top-k ranked locations can be recommended to groups. The output of this step is the group-location matrix where the value of array is the score of a group to a location.
3.2.6. Recommending Location to a Group
In this part, it is assumed that the system will have access to online information of the location capacity and weather forecasts at different time intervals. The capacity of locations varies during the day as well as depending on the day of the week; therefore, these parameters can influence the recommendation of a location. In addition, the location recommendation may be different for rainy or sunny weather. In rainy weather, the system will only recommend indoor locations for groups. Knowledge of location capacity becomes more critical when group sizes are large, and date and time intervals are predefined. In other words, location capacity is required when time-based recommendations are the main objective. However, the applicability of the proposed system is not limited to the availability of these data. Recommended locations may be used with temporal flexibility by the relevant groups, which means going to locations whenever they want and free capacity is available in the recommended places.
It is possible to identify a preferred day for group members from days of visiting the locations in the history of check-ins. To find the user preference for each day of the week, a user-day matrix is extracted from the day of the visit. Then, the TF-IDF is calculated to normalize the user-day matrix, where the user’s location history is considered as a document, and the day is regarded as a term in the document. Finally, the least misery policy is used for aggregating group member preferences.
Based on the group-location matrix, which demonstrates the group-to-location scoring, the capacity of locations on a group’s preferred day, and the weather forecast, the system recommends the top-K ranked venues for each group at different time intervals. If the location lacks capacity, the next alternative location in the ranked location list is recommended. In this paper, three time intervals of 07:00–12:00, 12:00–18:00, and 18:00–01:00 are used for recommendation. As required, the number of time intervals can be increased or decreased. The output of this phase is the top-K ranked locations for each group, and the capacity of recommended locations at each time interval. The capacity of the locations may change over time; consequently, group recommendations also need to be changed.
3.3. Application Scenario
The main purpose of the proposed group-oriented location recommender system is to suggest the best locations such as cinemas, restaurants, and parks for a relatively large number of users with various interests. This is performed by dividing the users into groups and providing specific recommendations for each group. In the proposed spatial group recommender system, users can either set group members, or the system generates groups automatically. The proposed system can be applied in two main scenarios as follows:
Groups are automatically generated, and the system, based on the preferred day for group members, recommends locations to each group at each time interval. All of this process is done automatically. The system performs this process continuously and users receive requests to join groups for particular activities. In this situation, preferred group activity is derived from the group profile.
Users can define group members, and the system, based on the personal profiles of the group members, recommends locations on the preferred day of group members at each time interval.
In these two scenarios, the system has the least interactions with the users. The proposed system can be adapted in many different situations, such as planning specific group activities (e.g., going to the movie theater, a park for a picnic, or a restaurant) or scheduling an activity on a particular day (e.g., Saturday) or both (e.g., going to a restaurant on Saturday). In all situations, the system can recommend suitable locations for groups based on group preferences.
4. Experiments and Results
In this section, first, the experiment settings, including the dataset and the evaluation metrics, are expressed. Then, the assessment results of the proposed approach are provided.
4.1. Dataset
The experimental data used in this study was gathered from a popular LBSN, Gowalla. The dataset consisted of 36,001,959 check-ins made by 319,063 users over 2,844,076 locations [
3]. Each check-in included: user id, location id, longitude, latitude, and timestamp.
In order to assess the performance of the proposed approach, the check-in data generated in a popular city, London, is extracted from the Gowalla dataset. Then, users with equal or more than seven check-ins at different locations are chosen. These data of users and corresponding check-ins are used to create the new dataset for use in this research. The detailed statistics of dataset are summarized in
Table 1.
Locations in Gowalla are classified into seven major categories, i.e., community, entertainment, food, nightlife, outdoors, shopping, and travel. Each category is classified into distinct subcategories [
46].
Free weather forecasts are now available on the different websites of meteorological organizations. Due to the lack of location capacity in the Gowalla dataset and the need to demonstrate the usefulness of the proposed system for real-time recommendations, synthetic data is used for the location capacity at each time interval. First, a random total capacity is assigned to each location; then, the actual capacity of each location is generated randomly at each time interval.
4.2. Evaluation Metrics
To evaluate the proposed CLGRW, a fivefold cross validation is performed. For this purpose, the dataset is randomly divided into five equal parts, and one part is used as the test data, while the other four parts are applied as the training data in five test rounds. For each user, 20% of their check-ins are picked randomly in each part. Finally, the average performance of the five runs is reported. A training dataset is used to construct a graph and implement the recommended algorithm.
In the following, the individual and group recommendations are evaluated. For individual recommendations, many metrics are developed; however, there is no standard approach for evaluating group recommendation methods, because the real group ratings are needed for all items [
5]. Therefore, for group recommendation assessment, the recommendations are provided for the whole group, and then results are compared with the test set of each group member. In this section, the metrics used to evaluate each recommendation are described.
To assess the quality of point of interest (POI) recommendations, it is essential to discover how many POI recommendations are actually visited by a user in the test set. For this purpose,
F-measure is used at different cut-offs K (i.e., 5, 10, 20, 30, 40, and 50). The F-measure is the harmonic average of the precision and recall, where an F-measure reaches its best value at 1 and worst score at 0 (Equation (16)).
where Precision is defined as the ratio of the number of relevant locations in the top-K recommended locations to K, and Recall is the ratio of the number of relevant locations in the top-K recommended location to the total number of relevant locations [
47].
Mean average precision (MAP) is a fairer metric compared to Precision-Recall due to considering the order of a hit in the recommendation list. Since the system recommends a top-K list of locations to a user, the order of the presented locations in this list should be considered. The system has a better performance if the positions of correct guesses are in the first places of the recommendation list [
48]. The MAP of the top-K recommendations is defined as Equation (17).
where
is the number of users,
indicates the size of the test set for user u, r is a cut-off rank, and
indicates the precision of u at a cut-off rank r. rel(r) denotes whether that r
th item was relevant (rel(r) = 1) or not (rel(r) = 0).
Another metric used to evaluate recommendation quality is
hit rate (HR). The hit rate was developed to indicate the proportion of users who have the target item in their top-K list of recommendations (Equation (18)).
where #users is the number of users, and #hits is the number of users who have a relevant item in the top-k recommendation list (i.e., a hit) [
49]. An HR value of 1.0 denotes that the recommending approach could always recommend the relevant item, whereas an HR value of 0.0 denotes that the approach could not recommend any of the relevant items. One drawback of the hit rate is that it does not consider where hits occur in the top-K list of recommendations [
50].
Normalized Discounted Cumulative Gain (nDCG) is another metric used to assess the accuracy of group recommendation approaches. nDCG is prevalent to assess the graded relevance of the recommended items. Discounted Cumulative Gain (DCG) and nDCG are obtained at rank K as Equations (19) and (20):
where rel
i is the binary function. If the i
th recommended item is relevant, it is considered to be 1; otherwise, it is considered to be 0. IDCG is the highest possible gain value that can be acquired for user u with the best order of K items. A greater nDCG score denotes that the provided recommendations are more relevant, and thus are top-listed in the recommendation list [
33].
The base of the metrics expressed so far is hits in the recommended list. In other words, these metrics consider common locations in the test set and the top-K recommended locations. In the recommended list, some of the recommended POIs may be suitable and very similar to the visited POIs by each user, but these POIs are not considered for evaluation in expressed metrics. Therefore, another metric is designed and introduced that considers the similarity of the recommended POI with the visited POI in order to evaluate the results. This metric is called Sim-MAP, which is defined in Equation (21):
where m indicates the size of test set for the user u, r is the cut-off rank, and
is the binary function that is assigned 1 if the r
th recommended item is similar to a test data (i); otherwise, it is assigned 0.
is defined based on the similarity of a test data (i) with the recommended list at cut-off r. This definition is shown in Equation (22):
where
is the number of POIs in a given cut-off r that has more similarity than the threshold with a test data (i). In this study, the threshold for similarity is considered 0.7. The issue that can be mentioned here is the definition of similarity between locations. In this study, location category and spatial proximity are the parameters that are used to calculate similarity.
4.3. Evaluation
The performance of the proposed CLGRW system is assessed in two parts. First, the RWR algorithm is evaluated for the individual recommender system. Second, the effect of different recommendation strategies and aggregation policies on the performance of the group recommender system is investigated at different cut-offs. In addition, the effect of group size on the accuracy of the system is examined. The results of the evaluations are described in the following subsections.
4.3.1. Evaluation of Individual Recommender System
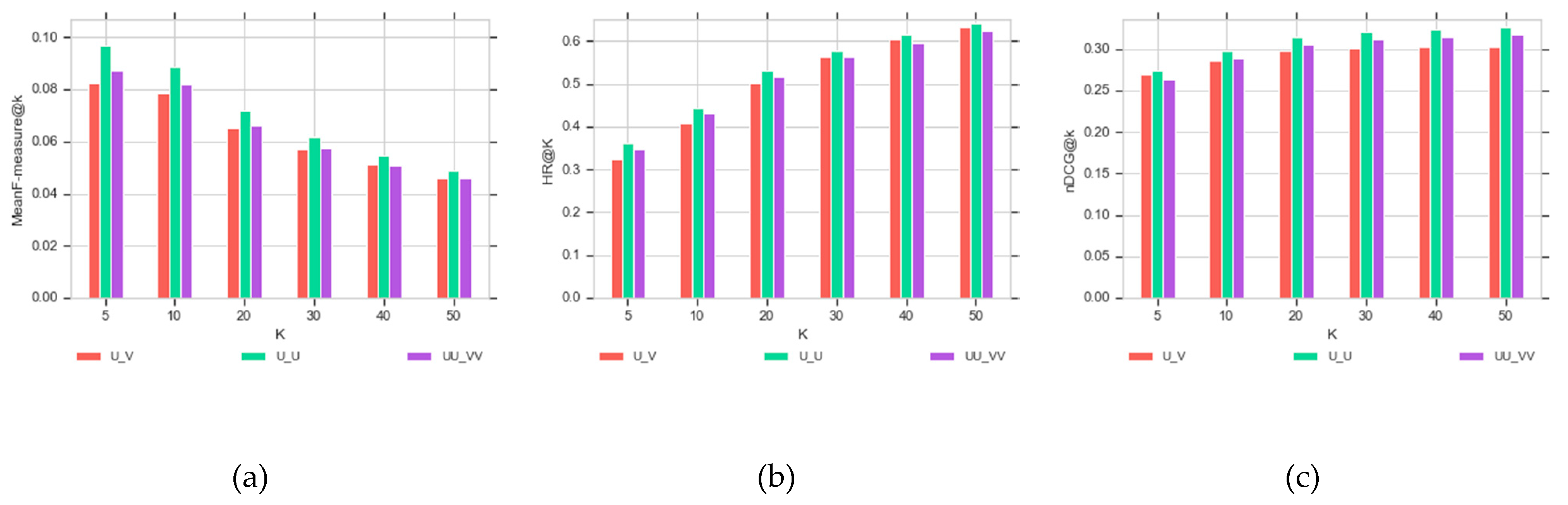
As stated earlier, three different graphs are constructed to evaluate the effect of side information on recommended locations.
Figure 4 shows the results of applying the RWR algorithm for recommendation to individuals on different cut-off and different graph models. In this figure, U-V is the abbreviation for the user-location graph; UU-VV implies that the user and location neighborhood graphs are added to the user-location graph. Finally, U-U indicates that the user relationship graph is added to the user-location graph.
As shown in
Figure 4, by increasing the number of recommendations, the F-measure values of all three graph models decrease (4a), and the HR values rise on all graph models (4b). Increasing HR values imply that the proportion of users who have a hit rises by increasing the number of recommendations.
Figure 4c indicates the values of the nDCG. It is noted that there is a comparatively tiny ascending slope with the growing number of recommendations. The ascending slope indicates that the relevant recommendations are at the top of the recommendation list with the rise in the number of recommendations.
Figure 4a-d shows that implementation of the RWR algorithm on the U-U graph is slightly better than on the other graph models in terms of matching the recommendation with test data. However,
Figure 4e shows that the UU-VV graph recommended more locations similar to the test data.
In addition, the performance of the RWR algorithm is compared with other recommending algorithms such as matrix factorization with Implicit Alternating Least Squares (iALS) optimization [
51], Item-based collaborative filtering (ITEM-ITEM), and content-based recommender (CB), as well as ones based on item popularity (pop). Turi’s GraphLab Create (
https://turi.com/) is used to implement the recommender systems listed above. As shown in
Figure 5, the RWR algorithm has better performance than other algorithms for recommending new locations to individuals.
4.3.2. Evaluation of Group Recommender Systems
Two group recommendation strategies are implemented, including an aggregated prediction strategy with weighted aggregation and least misery policies, and extension of the RWR to group (RWR-G). RAP_W_AVG and RAP_LM, respectively, are abbreviations for the use of aggregated prediction strategy with weighted aggregation and least misery policies. In order to represent the effect of applying group profile and location popularity on recommendation, the results of the proposed CLGRW system are compared with group recommendations that only use RWR for scoring locations.
Table 2,
Table 3 and
Table 4 present the performance of group recommendation in different methods and strategies on graph models for groups with two members.
As can be seen in
Table 2,
Table 3 and
Table 4, recommendations based on the UU-VV graph have better performance than those of the other graph models before applying group profile and location popularity. Furthermore,
Table 2 and
Table 3 show that the evaluation metrics value of the RAP-LM strategy are lower than that of the other two strategies on U-U and U-V graphs. In addition, in U-U and U-V graphs, Sim-MAP values indicate that recommended locations have less similarity to test data compared to recommendations based on the UU-VV graph.
A consideration of group profile and location popularity leads to an increase of the values of evaluation metrics of group recommendation (CLGRW) on U-V and U-U graphs. In addition, some values of evaluation metrics are raised on UU-VV graphs. For U-V, U-U, and UU-VV graphs, the average proportion of users with recommendations that match test data (HR) increases by 1.18, 1.14, and 1.02 times, respectively, while the precision of generating relevant recommendations (sim-MAP) is increased by 3.4, 2.89, and 1.55 times, respectively. From
Table 2,
Table 3 and
Table 4, it can be seen that the CLGRW system leads the values of evaluation metrics to be close to each other on the three graph models.
For assessment of the impact of the number of recommendations on the performance of the CLGRW system, evaluation metrics are computed for different cut-offs.
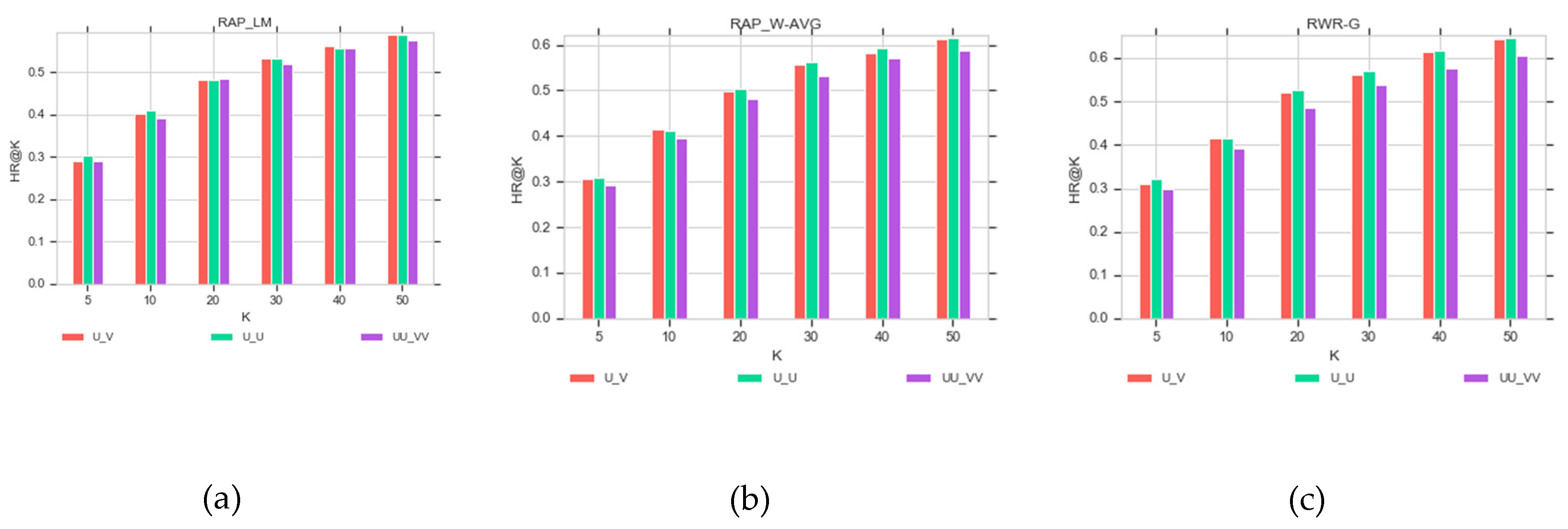
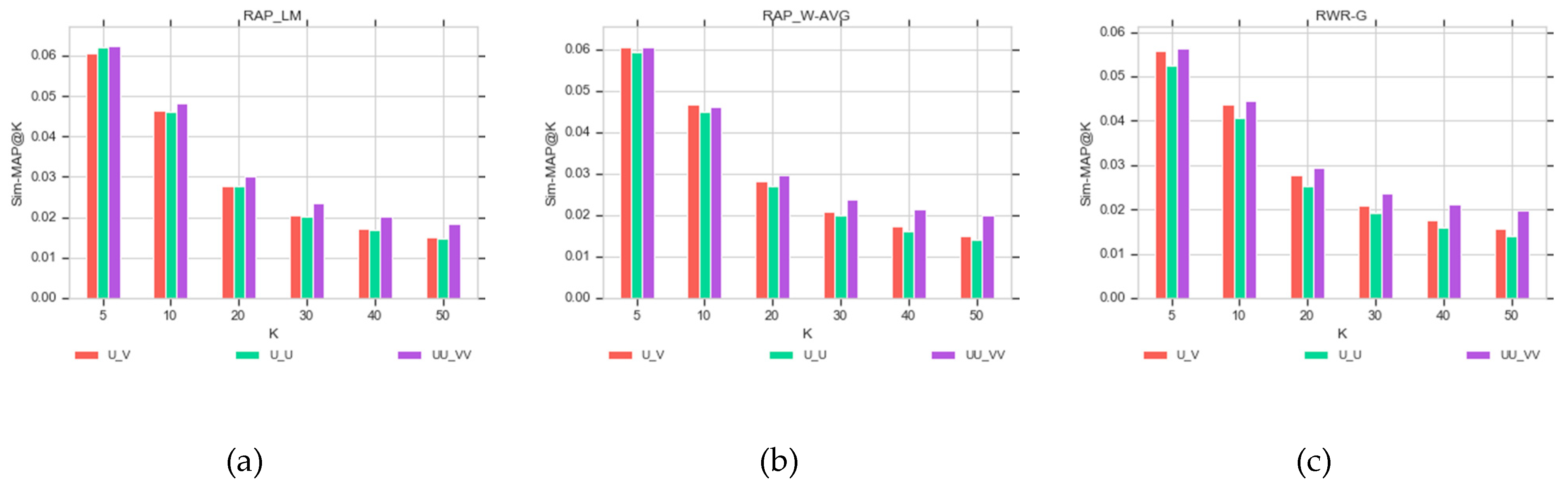
Figure 6 and
Figure 7 indicate HR@K and sim-MAP@K values for different strategies and policies on different graph models for groups with two members. The value of HR increases in all approaches following an increase in the number of recommendations.
Figure 6a indicates that by applying the RAP-LM strategy, HR values on different graphs are almost equal. As compared to the other two methods, this strategy has fewer hits following an increment in the number of recommendations.
Figure 6b,c shows that the RAP_W-AVG and RWR-G strategies have fewer hits on the UU-VV graph. When the number of recommendations is increased, the number of hits of the RWR-G strategy is more than the other two methods.
Figure 7a–c depicts that the Sim-MAP values are reduced when the number of recommendations is increased. In addition, Sim-MAP has higher values in the UU-VV graph than the other two graph models. This indicates that the use of the UU-VV graph creates more relevant recommendations. As shown in
Figure 7c, the RWR-G strategy for five and 10 recommendations creates less relevant recommendations than the other two methods.
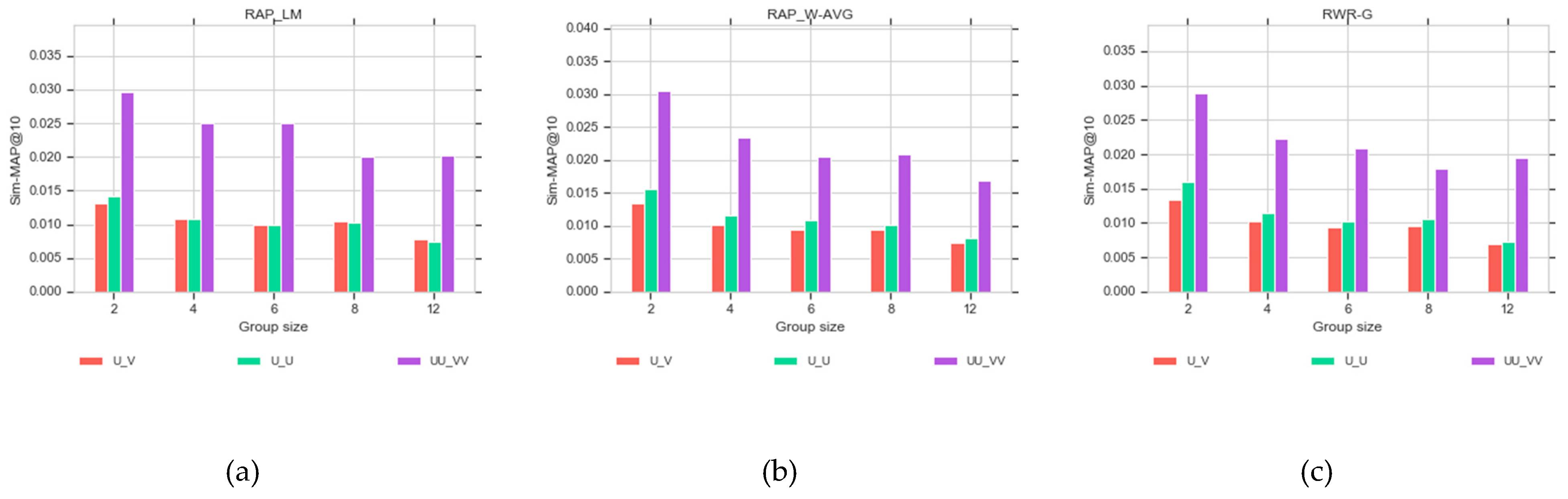
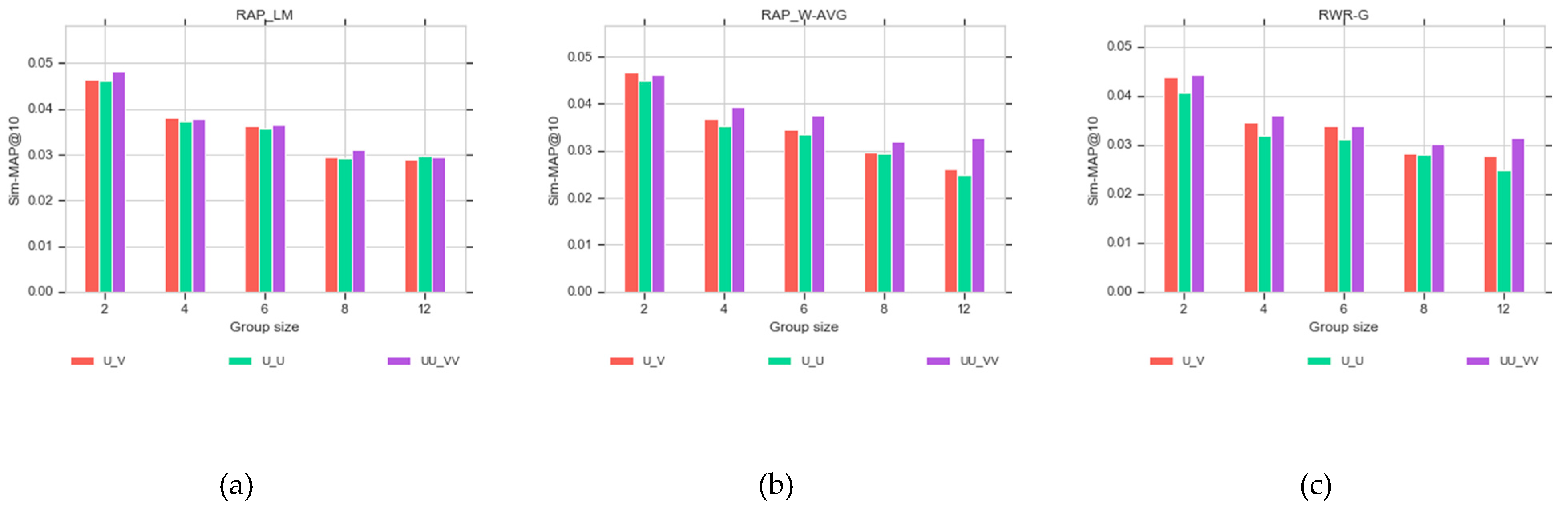
Different group sizes are considered to assess the effect of group size on the group recommendation results.
Figure 8,
Figure 9,
Figure 10 and
Figure 11 show the results of different group sizes for different models at specific cut-off points. The results show that HR decreases with increasing group size for all approaches. This can be related to increasing the complexity and difficulties of making effective group recommendations as a function of increasing the group size. In addition, by comparing
Figure 8 and
Figure 9, it can be concluded that CLGRW increases the number of hits in the U-U and U-V graphs. As shown in
Figure 9, the RWR-G for a large group has more hits than the other two methods.
Figure 10 and
Figure 11 show that CLGRW leads to significant increases in sim-MAP values on the U-U and U-V graphs in different group sizes, which are approximately equal on three graph models. Increasing sim-MAP values reflects an increase in relevant recommendations.
The displayed results are obtained from the group-location rating matrix, which is created from the recommending algorithm. However, the location capacity, weather, time, and days of week are not considered. The effects of using the mentioned context on the performance of the system cannot be evaluated unless users use the system, and their satisfaction levels are assessed. Due to user privacy, there is no data or link to contact users in the Gowalla dataset, so it was not possible to evaluate the user satisfaction of the proposed system with weather and location capacity.
5. Conclusions
In this research, a context-aware group-oriented location recommendation system, called CLGRW, is developed based on the random walk algorithm. The proposed approach considers some contexts for scoring the locations such as the user’s preferences, social relationships, location history, and the popularity and category of venues. In addition, context related to the weather, day of the week, and capacity of venues in different time intervals are used to recommend locations to groups. The proposed system is applied in various graph models. In addition, two group recommendation strategies are used. One is the aggregated prediction strategy, and the other is derived from extending the RWR to a group.
The RWR algorithm performance is compared with popularity-based, collaborative filtering and content-based filtering for individual recommendations. The results of evaluation with test data show that the RWR algorithm outperforms these approaches. Since groups are composed of members, the performance of the RWR algorithm is better than the mentioned algorithms for group recommendations as well. Application of the RWR algorithm without using the group profile or location popularity on the UU-VV (user and location neighborhood) graph resulted in more accurate recommendations than when this algorithm was applied to the U-V (user-location) and U-U (social relationship) graphs. As the UU-VV graph has more links between nodes, computational expense increases for a large dataset. CLGRW utilizes the group profile and location popularity to enhance the recommendations. The results show that using these factors improves the accuracy of recommendations on three graph models, and the values of the evaluation metrics on the user-location graph (U_V) and the user relationship graph (U_U) are almost close to those of the UU_VV graph. Furthermore, the RWR-G strategy for large group sizes has more hits than the aggregated prediction strategy. However, the aggregated prediction strategy with a least misery policy on the U_U and U_V graphs and with a weighted aggregation policy on the UU-VV graph creates more relevant recommendations. In addition, the results indicate that an increase in group size leads to a decrease of the accuracy of all the approaches. This can be related to the complexity of making group recommendations, due to an increase in the diversity of interests and priorities of individuals in larger groups.
The proposed system uses different contexts to recommend more accurate and useful recommendations. The availability of the residence or work locations of users can lead to more effective user similarity modeling and grouping as well as consideration of travel times for location recommendations. Moreover, knowledge of the locations of group members facilitates filtering locations to recommend closer ones to each member.
The size of the constructed graph and computation time vary depending on the size of the users’ and locations’ datasets. Therefore, we suggest creating an ideal subgraph for individuals or groups to make computations more time-efficient.
In this research, the location category and spatial proximity are considered in order to assess the similarity of locations. In fact, location similarities can be estimated with many other factors such as facilities, accessibility, and location size. The availability of additional location data can lead to more efficient location recommendations.
The issue in the proposed evaluation metric is to define the similarity between items. In contrast to the other existing methods, this metric does not limit the evaluation to exact correspondence between the test and the recommended locations, and uses the similarity between the recommended locations and the test data to assess the quality of these recommendations. So, because of its complementary role for other metrics, it can be used more widely in other individual or group recommender systems.
In this study, the Gowalla dataset was used to assess the performance of the proposed model. Due to a lack of information about the quality of the user-generated content, reliability of the existing datasets has not been considered in this research. Therefore, it has been assumed that users’ checks-ins at a place are correct and reflect their true preferences. The impact of the quality of the user-generated content on the performance of the group recommender system is an important subject in our next research. In addition, the proposed approach for location recommendation is applicable for wider use in other LBSNs (e.g., Foursquare, Facebook Places) and group-based activity programing problems.
In this study, the dataset of London city was considered for evaluation of the proposed approach. The results of proposed approach are mainly based on data-driven knowledge. Due to many differences such as the size of cities, environmental, socioeconomic, and cultural aspects, knowledge of the behaviors and the resulting recommendations cannot be extended and applied to other users. Special analysis and recommendations would be required for different populations, users, and geographic locations.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}