1. Introduction
Surveillance systems have been used immensely in various public and private areas such as airports, universities, schools, streets, houses, etc. These surveillance systems provide massive data, including images and videos, which are helpful in the investigation of criminal activities [
1]. However, processing and analyzing these images and videos to track and monitor a person over non-overlapping cameras is a time-consuming and challenging task [
2]. Several factors can significantly affect the performance of the person ReID system in practical applications, such as pose variations, illumination changes, occlusions, different camera settings, and background clutter [
3]. All these factors cause the appearance of the same person to look extremely different. This leads to a heavy burden on investigators to identify the wanted person from many surveillance videos in a short time. Therefore, the person Re-ID task is still an unsolved problem that is worth further research. However, the ethical and privacy implications of surveillance biometric-based systems (e.g., person ReID) have become significantly critical, and have attracted increasingly critical attention [
4]. Some direct questions have been raised concerning whether biometric systems offer society significant advantages over traditional methods of personal identification (e.g., passwords, ID cards, etc.), or whether it constitutes a threat to people’s privacy. For instance, CCTVs are used in car parks and cities, and X-ray machines at airports to detect and prevent potential crimes against people or property. However, the dilemma facing the surveillance systems is data collection, and ensuring that collected data will not be used for purposes that are unethical or impinge upon human rights. Thus, the collected information should be protected by ethics and laws, except in specific circumstances (e.g., in a court of law) [
5].
In general, the person ReID system is mainly based on three critical steps: automatic pedestrian detection, features extraction, and classification step. Most of the previously published works directly learn the feature representations from the whole pedestrian image, that contains background clutter. Quite recently, several person ReID deep learning-based systems have suggested learning effective feature representations from the detected pedestrian body to reduce the background clutter and improve the robustness of the person ReID system [
6,
7,
8]. This motivates us to develop an automated image segmentation algorithm to eliminate background noise interference issues and enhance the discriminability of the extracted feature representations, even for an incomplete person, which may contain information that is discriminatory and deserves attention.
In the features extraction step, person ReID systems can be divided into either handcrafted-based systems or deep learning-based systems. Handcrafted-based systems are designed to extract invariant features (e.g., color and texture) for pedestrian description [
9]. For instance, Zheng et al. [
10] applied the SIFT descriptor to extract a feature vector of 128 values for pedestrian description and employed the bag of words (BOW) for person ReID. Klaser et al. [
11] proposed the integration of the histograms oriented gradient (HOG) and histograms of optical flow (HOF) to introduce a 3D pedestrian descriptor, named HOG3D. Although the handcrafted-based descriptors have further improved the performance of person ReID systems, the massive amount of captured data using multiple cameras has made extracting common feature representations from the same pedestrian very hard due to these descriptors lacking a self-learning process. This promotes the appearance of deep learning-based systems for person ReID.
Recently, deep learning methods, for example, convolutional neural networks (CNN), have played an essential role in addressing person re-identification problems due to their ability to jointly handle occlusions, geometric transforms, illumination changes, and background clutter in a unified framework [
12]. CNNs can extract discriminative and robust feature representations for either the whole or part body of a pedestrian’s image. However, a tremendous amount of data is required to train ReID deep learning-based systems and achieve a satisfactory performance. Some examples of ReID deep learning-based systems can be found in [
3,
13,
14]. Another critical step of person ReID is learning a robust distance or similarity function to address the problems of the matching pedestrian (e.g., heterogeneous face recognition). In this regard, metric learning methods have been developed to solve matching person problems, such as cross-view quadratic discriminant analysis (XQDA) [
15], distance metric [
16], etc.
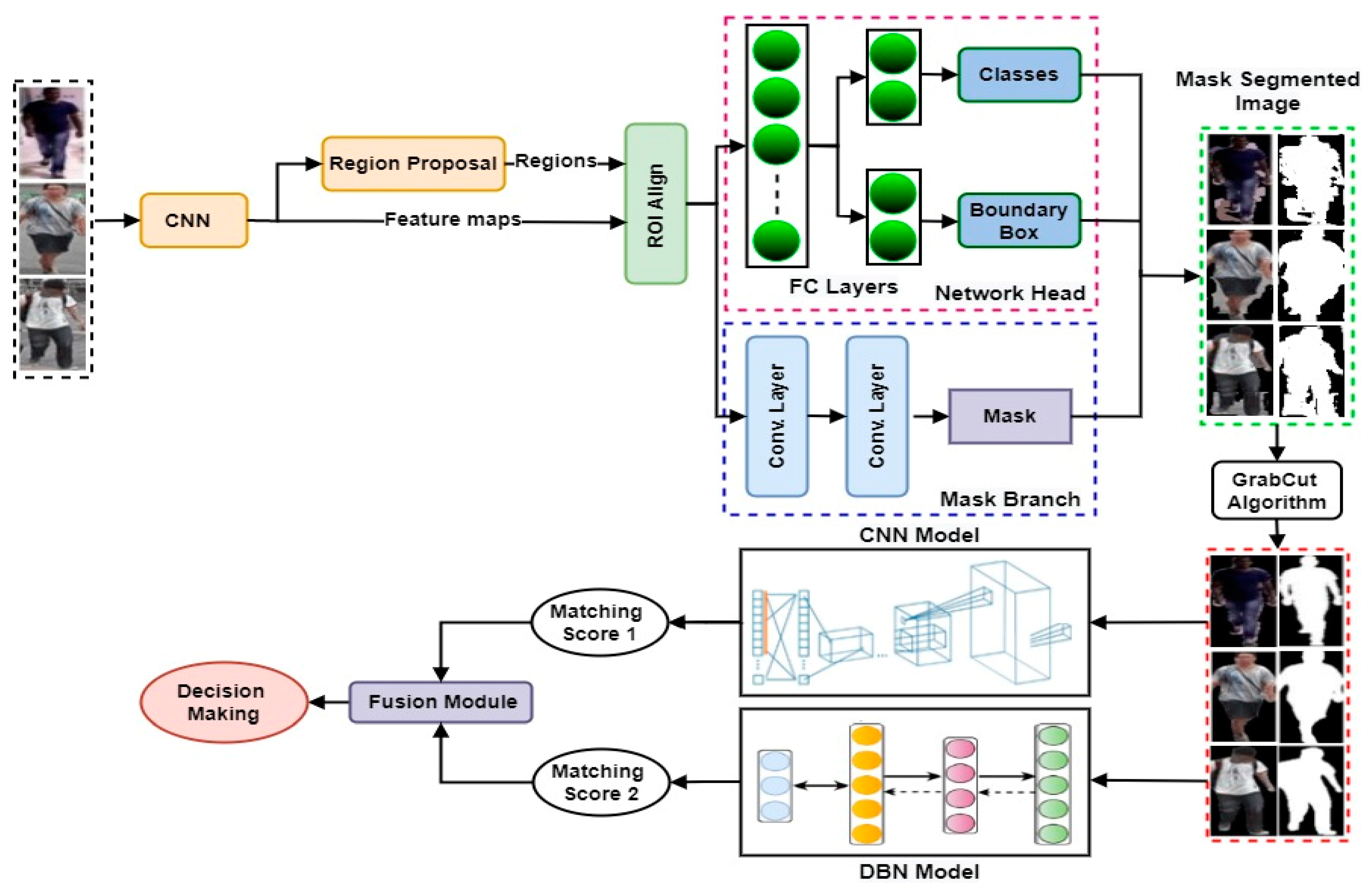
In this paper, an automatic hybrid deep learning system is developed and named ReID-DeePNet system, to identify a person in real life using multiple CCTVs/street camera views. Initially, an efficient and reliable image segmentation procedure was developed based on integrating the advantages of the Mask R-CNN and GrabCut algorithm to tackle the adverse effects caused by background clutter. Then, the matching scores from two distinctive deep learning models based on CNN and deep belief network (DBN) models were obtained to establish the person’s identity across multiple cameras.
An automated and fast image segmentation algorithm was proposed to eliminate background noise interference issues and enhance the feature representations’ discriminability in the subsequent steps of the proposed ReID-DeePNet system. Herein, the MASK region-based CNN (Mask R-CNN) algorithm was applied to automatically extract the pixel-wise mask for foreground objects “pedestrians” out of the complex background. However, Mask R-CNN could not ideally detect the object of interest, such as the dynamic pedestrian body, and some parts of the background still appeared in the final segmented image. This could negatively affect the accuracy of the proposed system. Thus, the GrabCut algorithm was applied using the mask generated by Mask R-CNN as the initial seed to reduce the effects of background noise interference and enhance the person’s body segmentation accuracy;
An effective and real-time person ReID system was developed based on integrating the matching scores generated from two different deep learning approaches, such as CNN and DBN, to extract discriminative feature representations from the pedestrian image. To the best of our knowledge, this was the first attempt to investigate the possibility of training a CNN and DBN from scratch, to address the person ReID problem in a unified system;
A parallel architecture for integrating the matching scores generated from the CNN and DBN model was considered that could give end users a high degree of flexibility in establishing a person’s identity using the result obtained from one or both adopted models, based on the desired security level and the user’s satisfaction. The performance of the proposed system was assessed using different fusion rules at the score level (e.g., sum rule (SR), weighted sum rule (WSR), product rule (PR), max rule, and min rule) and rank level (e.g., highest rank (HR), Borda count (BC), and logistic regression (LR));
The accuracy of the proposed ReID-DeePNet system was assessed by carrying out several comprehensive experiments on three large-scale and challenging ReID datasets, including the Market-1501, CUHK03, and P-DESTRE datasets. A new advanced Rank-1 identification rate and mAP were achieved using the ReID-DeePNet system on all the employed datasets.
The rest of this article is organized as follows: A review of the previous works is presented in
Section 2, and the proposed framework of ReID-DeePNet in
Section 3. The employed ReID datasets and the empirical results are discussed and explained in
Section 4. Finally, conclusions and future work guidelines are outlined in the last section.
2. Related Work
Recently, many researchers have focused on addressing the person re-identification problem by developing ideal solutions that can help in recognizing the person’s identity across multiple cameras. Many researchers have employed deep learning approaches to address the person ReID task by combining the feature extraction and classification stages in a unified system. For instance, Weilin et al. [
17] developed a hybrid framework combining multilevel feature extraction and a multi-loss learning approach to obtain a high description of the pedestrian. The multilevel feature extraction process was achieved using a feature aggregation network (FAN) to extract multilevel attributes from different layers. The multi-loss learning process included two actions: verification and recognition, where the verification aimed to verify that the two images belonged to the same identity, and where the recognition aimed to specify the identity within each image. This was accomplished using recurrent comparative network (RCN) and global average pooling (GAP) algorithms. Their experiments were conducted using four datasets, including CUHK03, CUHK01, Market1501, and DukeMTMC-reID. The best Rank-1 rate of 84.7% and mAP of 65.8% were obtained on Market1501dataset.
Yutian et al. [
18] proposed a Bayesian query expansion (BQE) algorithm to produce a new query from the initial ranking list. They suggested dividing the dataset into three mutually exclusive sets of data: a training set, gallery set, and testing set. Once the algorithm was trained on the training data, the algorithm calculated the probability of images within the initial gallery, producing actual matches. The images of actual matches were used to predict a single vector used to generate a new list as a query expansion process. Extensive experiments on four different datasets were carried out, including Market-1501, DukeMTMC-reID, CUHK03, and MARS. The highest Rank-1 rate of 85.24% and mAP of 69.79% were achieved on the Market-1501 dataset.
Yichao et al. [
19] proposed a feature attention block to generate part-level representations for pedestrians. Their method provided a weight for each part of the pedestrian’s body by finding various horizontal features. A deep CNN model was utilized in the method to learn discriminative feature representations to compute the distance between pairs of query images in the gallery set and generate a ranking list for each query person. The authors evaluated their method using three datasets, Market-1501, DukeMTMC-ReID, and CUHK03. The experiments showed that the best results were obtained on the Market-1501 dataset by achieving a Rank-1 rate of 93.5% and mAP of 81.8%. Li et al. [
20] proposed two branches of CNN network architecture for person feature extraction purposes. These branches considered the global and local features based on loss functions that are commonly used in person re-ID. The highest Rank-1 rate of 93.8% and mAP of 84.6% were achieved on the Market1501 dataset. In the context of multi-modules methods, Xin et al. [
21] developed a semi-supervised feature representation approach to obtain discriminative feature representations from pedestrian images across disjoined cameras. They suggested using various CNN models to generate different feature representations from a single labeled image within a dataset. A finely-tuned process was applied to each CNN’s feature representation to simultaneously decrease the identification loss and verification loss. Afterward, a multi-view clustering process was utilized to classify the CNN’s features into similar groups and dissimilar to different groups, thereby integrating the features into the proper representations. The multi-view clustering process also estimated pseudo labels for unlabeled images to produce a label for each image within the dataset. Two benchmark datasets, including Market1501 and the DukeMCMT-reID dataset, were employed in the conducted experiments. The best performance on the Market1501 dataset was obtained by achieving a Rank-1 rate of 75.2% and mAP of 52.6%.
Isobe et al. [
22] investigated the ability to learn discriminative feature representations within the person image. They proposed a framework to reduce the noise with unlabelled images, transfer the knowledge that could be learned from the source to the target image, and add extra training constraints. Therefore, the cluster-wise contrastive learning algorithm (CCL) was utilized with progressive domain adaptation (PDA) followed by Fourier augmentation (FA). Their experiments were performed on various datasets, including Market-1501, Duke, and MSMT. Their results outperformed current state- of-the-art works by achieving a mAP of 8.1%, 9.9%, 11.4%, and 11.1%, on the Market-to-Duke, Duke-to-Market, Market-to-MSMT, and Duke-to-MSMT tasks, respectively. In terms of using low-resolution images, Xia et al. [
23] developed a semi-supervised method based on the mixed-space super-resolution model (MSSR) to enhance a person’s resolution. Then, a part-based graph convolutional network (PGCN) was performed to obtain discriminative feature representations from the pedestrian images. Their experiments were carried out on the Market1501, CUHK03, and MSMT17 datasets to evaluate the performance of the proposed methods. The results showed that they were able to identify the person with good accuracy compared with many semi-supervised methods, by achieving the highest Rank-1 rate of 73.2% and mAP of 49.8 on the Market-1501 dataset.
Recently, Wu et al. [
24] suggested learning more distinctive features for person ReID by jointly optimizing the appearance feature and the information of the ranking context. The authors proposed a hybrid ranking framework composed of two streams for addressing the person ReID problems. In the first stream, the external ranking information was obtained by generating the ranking list for each probe image to learn visible changes among the top ranks of the gallery set. On the other hand, the internal ranking information was obtained using the fine-grained feature in the second stream. The performance of the proposed hybrid ranking framework was assessed using four ReID datasets, including the Market-1501, DukeMTMC-ReID, CUHK03 and MSMT17 datasets. The best performance was achieved on Market-1501 with 94.7 and 86.8, of Rank-1 and mAP respectively. Tang et al. [
25] developed a novel harmonious multi-branch network (HMBN) with various stripes on different branches to learn more discriminative feature representations for person ReID. The authors replaced the uniform partition procedure with a horizontal overlapped partition to avoid losing important information within the local regions. The performance of the HMBN was assessed on three different ReID datasets, including DukeMTMC-ReID, CUHK03, and Market-1501. The highest Rank-1 rate of 95.58% and mAP of 94.21% were achieved on the Market1501 dataset.
Gu et al. [
26] considered extracting clothes’ irrelevant feature representation from the original RGB images of pedestrians. The performance of the developed clothes-based adversarial loss (CAL) was tested on a private ReID dataset, named CCVID dataset. The CAL achieved a Rank-1 rate of 82.6% and mAP of 81.3%. Yang et al. [
27] addressed the problem of twin noise labels (TNL) in visible infrared person re-identification (VI-ReID), which refers to noisy annotation and correspondence. The authors developed a new approach for reliable VI-ReID, named DuAlly robust training (DART). DART is mainly based on computing the clean confidence of noisy annotations and rectifying the noisy correspondence with the estimated confidence. The performance of DART has outperformed five state-of-the-art methods using two ReID datasets: SYSU-MM01 and RegDB datasets.
Throughout this review, one can see that several studies in the literature were developed to tackle the person re-identification problem using different deep learning architectures. In general, the models trained in a supervised manner showed better performance than semi-supervised and unsupervised approaches, due to the labeled images playing a substantial role in improving the learning ability of the developed models in recognizing a person’s identity across multiple cameras. Although most of the developed approaches have significantly reduced the effects of lighting and pose changes and achieved good performance, the discriminative power of the extracted feature representations may still be affected by background clutter. Thus, the generalization abilities of currently developed approaches are still far from being at an acceptable level in handling real person ReID issues. In this study, several advanced deep learning approaches are integrated to develop a competitive person ReID system.
3. The Proposed ReID-DeePNet System
This section describes the proposed ReID-DeePNet system for person ReID. As depicted in
Figure 1, the overall structure of the proposed ReID-DeePNet system is composed of two modules: The background suppression module and the person Re-ID module. In the background suppression module, the issues of background noise interference are solved to enhance the discriminability of feature representations in the subsequent steps of the proposed system. Mask R-CNN is employed to automatically extract the pixel-wise mask for foreground objects “pedestrians” out of the complex background. Nevertheless, the Mask R-CNN algorithm cannot perfectly distinguish between the foreground and background in the input image during the segmentation process. Thus, the output of the Mask R-CNN algorithm is further enhanced using the GrabCut method to reduce the effects of the background noise interference and enhance the person’s body segmentation accuracy. This is followed by identifying a pedestrian’s identity by integrating the advantages of two distinctive deep learning models (CNN and DBN) to address the person ReID problem.
3.1. The Background Suppression Module
It was proved that using the pixel-wise mask of pedestrians can significantly reduce background clutter and improve the robustness of person ReID models under various background conditions. Furthermore, the generated pixel-wise masks have body shape information which is considered an important gait feature and useful for identifying a person, thus, boosting the identification accuracy [
28,
29]. The Mask R-CNN is an extension to the Fast R-CNN model that works on detecting objects in the input image and produces a binary mask for each object. Mask R-CNN aims to detect various objects in an image or video to produce the bounding box of an object along with its class label and binary mask. In other words, the Mask R-CNN consists of two stages including proposal generation of the potential objects within the input image, and prediction of the object’s class then refinement of the surrounding box to generate the binary mask of the presented object within the first stage [
30].
In addition, these two stages are connected using a backbone model to predict the person’s class. In this study, the backbone component, based on a pre-trained ResNet101 model, is employed to extract more discriminative feature maps of the person from the input image. Then, the generated feature maps are transferred on to the feature pyramid network (FPN) to efficiently extract useful feature representations of different scales in the input image. The FPN uses the feature maps and semantic information to localize the region of object. The FPN also takes the benefits of the inherent and multiple scale nature of CNNs to gain a better detection of the person’s object and to perform the semantic segmentation with various scales. This is achieved using the sliding window that applies on the generated feature maps to generate regions of persons within the image in the form of a bounding box. However, these proposals of bonding boxes come with different sizes, causing various issues in generating the segmented person within its mask. Therefore, the ROIAlign is employed to produce fixed feature maps with a unique form. Afterward, these fixed maps are passed into two fully connected layers within the network head component to produce the class of person and the boundary box of that person. In addition, the features maps will also pass into multi-convolutional layers within a mask component to obtain the mask of the segmented person. As a result, the output from the Mask R-CNN is represented by three components including the class of person, the boundary box, and the binary mask. However, the Mask R-CNN cannot perfectly separate the foreground objects from the complicated background during the segmentation process. In this study, the accuracy of the Mask R-CNN algorithm has been further improved using the predicted mask from Mask R-CNN as an initial seed to the GrabCut algorithm to reduce the effects of the background noise interference and enhance the person’s body segmentation accuracy.
The GrabCut algorithm is an effective segmentation method used to remove undesired and heterogeneous edges of background from the segmented image of the person, and retain the foreground which is represented as a person’s body [
31]. Herein, the GrabCut algorithm utilizes the graph cuts method by drawing a boundary box around the foreground object of a person within the input image produced from the Mask R-CNN. Then, the Gaussian Mixture Model (GMM) is applied for estimating the color distribution of the foreground and background. The GMM then learns and predicts class labels for the unknown pixels based on the data from the input image, where each pixel is classified either as a foreground or background depending on its color statistics [
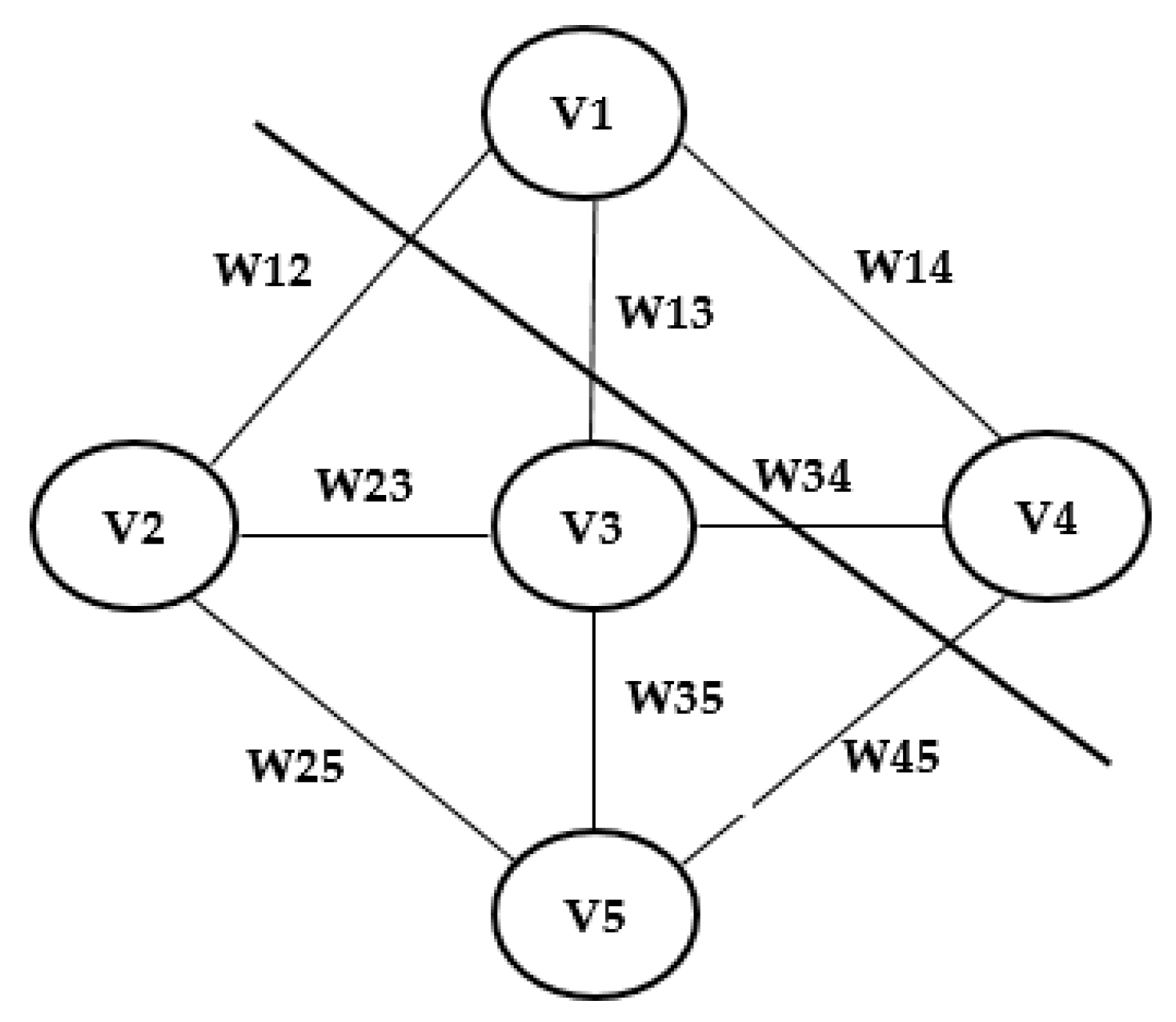
32]. The GrabCut algorithm represents the input image as a graph by considering its pixels as vertices and the feature connection between these pixels as the edges (see
Figure 2). The GrabCut algorithm loops on all the pixels within an image and breaks the weak connections between them, and then assigns each pixel to either the foreground or background. The implementation of the GrabCut algorithm on the top of the Mask R-CNN has significantly reduced the effects of the image’s background and enhanced the segmentation accuracy and contour extraction of the person’s body.
3.2. The Person Re-ID Module
The output of proposed image segmentation procedure in the background suppression module is the targeted person who should be classified in order to be tracked, based on his appearance. In this study, the person’s identity is recognized using two powerful deep learning models (CNN and DBN) trained from scratch to address the person ReID problem. To the best of our knowledge, this is the first study that explores the possible use of CNN and DBN models in a unified person ReID system to extract distinctive local feature representations from pedestrian images. In the next sub-sections, the main architecture and the training methodology of the adopted deep learning models (CNN and DBN) are explained in detail.
3.2.1. CNN for Person ReID
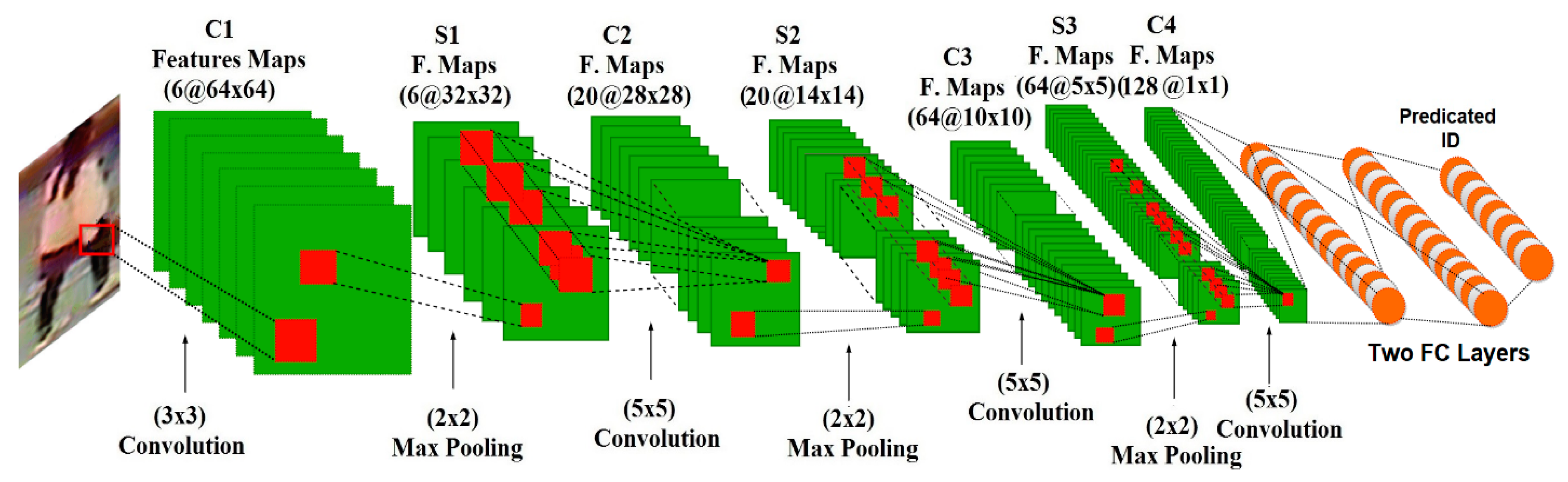
As shown in
Figure 3, the main structure of the employed CNN model comprises a combination of four locally-connected convolutional layers, each one followed by (2 × 2) sub-sampling max-pooling layer. Each convolutional layer has an assigned number of trainable filters to learn high-level feature representations from the pedestrian image. Herein, the number of trainable filters are set as 6, 20, 64, and 128, for the employed convolutional layer. In this work, two fully connected layers are employed on top of the proposed CNN model for the multi-class classification tasks. The output of the last fully connected layer is fed into the Softmax classifier, which computes the probability distribution over all of the class labels in the dataset being used to produce the predicted class label. Finally, a suitable loss function based on a cross-entropy is employed to measure the correspondence between the predicted and the target labels and compute the cost value for the proposed CNN model.
Following the same training procedure described [
33], we start training a specific CNN model with a particular structure by splitting the training set into four sets. The CNN model is trained using the first three sets, and the last set is used as a validation set to assess the CNN model’s generalization capacity during the learning process. The last trained CNN model with minimum validation error on the validation set is stored to report the real performance using the testing set. To prevent the overfitting problem, an early stopping procedure is applied by stopping the training process when the value of validation error on the validation set starts to increase again, for few times. Furthermore, some of the most widely used data augmentation techniques are implemented to reduce overfitting and enhance the generalization capability of the last trained CNN model during the learning process. In this work, five image regions are randomly cropped from each image in the training set along with their horizontally flipped versions. The main steps of the implemented training procedure can be defined as follows:
Divide the dataset into three sets (e.g., training set, validation set, and testing set);
Select a particular CNN structure and initialize the value of the hyper-parameters (e.g., number of epochs, learning rate, etc.);
Train the selected CNN model with the training set;
Assess the performance of the selected CNN model using the validation set during the learning process;
Repeat steps 3 through 4 using 300 epochs;
Save the weights of the best trained CNN model with less validation error on the validation set;
Report the actual performance of the saved CNN model using the testing set.
3.2.2. DBN for Person ReID
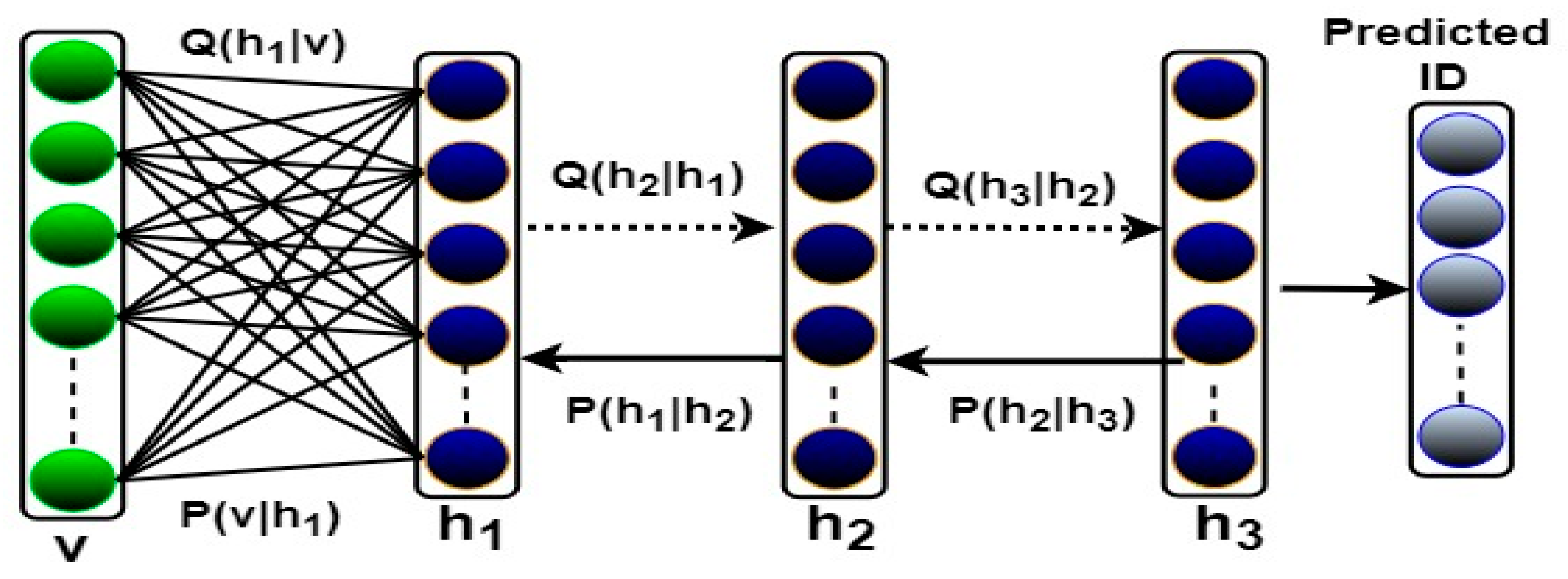
On the other hand, the DBN model consists of a single visible layer and multiple hidden layers connected with each other in a strong relationship to learn high-level feature representations from input data [
34]. These layers are also utilized to learn the statistical associations between units of a previous layer where each unit within the proceeding layer is connected to all units of the earlier layer, as illustrated in
Figure 4. The DBN is a stack of multiple layers of restricted Boltzmann machines (RBMs). RBM is a generative stochastic neural network consisting of two fully-connected layers using symmetric undirected edges with no links between nodes of the same layer. As shown in
Figure 4, the employed DBN model for a person ReID is composed of stacking three RBMs as hidden layers. The first two hidden layers are trained one at a time as feature descriptors in a bottom-up fashion utilizing an unsupervised greedy layer wised (GLW) algorithm. Herein, the CD learning algorithm is employed. The applied DBN model’s final hidden layer is trained as a discriminative model in combination with a Softmax classifier to perform the classification task. Herein, the suggested training procedure to train the employed DBN model can be outlined into three steps as follows:
As per the training procedure described in [
35,
36], the first two RBMs are trained one at a time using an unsupervised learning algorithm based on the CD learning algorithm. After the training process of the first RBM is finished, its activation outputs can be seen as features learned from the input image. Then, these feature representations are used as input data to train the next RBM in the stack. This unsupervised learning process enables us to train the network with massive amounts of unlabeled data to advance the generalization capability of the proposed DBN model. After finishing the training process of the first two RBMs, they can be seen as feature descriptors that can extract the most discriminative features from the raw images automatically;
The training and validation sets, together with their associated class labels, are used to train the last hidden layer in the proposed DBN as a non-linear classifier, which is used to monitor the learning process;
To improve classification accuracy, the weights of the whole network are fine-tuned in a top-down fashion using the back-propagation algorithm.
4. Experimental Results
This section provides a description of the three large-scale and challenging ReID datasets that were employed to evaluate the effectiveness of the proposed ReID-DeePNet system. Then, implementation details of the proposed approaches in the background suppression and person Re-ID module are introduced. Next, the hyper-parameters analysis and visualization of the employed deep learning models are also presented to verify their effectiveness. Finally, we compare the performance of the proposed ReID-DeePNet system with advanced systems on these three datasets. The code of the ReID-DeePNet system was coded in Python programming language and all the experiments were conducted on the Google Colab server platform with 69K GPU graphics card, and 16 GB of RAM on the Windows 10 operating system, Intel(R) Core (TM) i7-4510U GHz CPU.
4.1. Datasets Description
The robustness of the proposed ReID-DeePNet system was tested on three large-scale and challenging Re-ID datasets, including the Market-1501 [
10], CUHK03 [
37], and P-DESTRE datasets [
38]. These three employed Re-ID datasets reflected the main issues that influence person Re-ID in a real-world application, such as perspectives, changes of illumination, occasions, poses of pedestrians, etc. All the conducted experiments followed the standard evaluation protocol and data split setting of these three datasets. The performance evaluation metrics, such as the Rank-1 identification rate and mean average precision (mAP) were computed.
Table 1 shows the statistics of the adopted three Re-ID datasets, and some samples from these datasets are shown in
Figure 5.
Market-1501 dataset [
10] is a public benchmark dataset containing 1501 identities that were collected by six cameras from different viewpoints. The total number of pedestrian images was 32,688, with approximately 3.6 images on average for each identity from different viewpoints. In addition, all images were in .jpg format. A deformable part models (DPM) pedestrian detector was used to extract and detect the pedestrian within the collected images. Following the standard evaluation protocol, the Market-1501 dataset was divided into two sets, with 750 for training set (e.g., 17.2 images per identity) and 751 for testing set. Thus, all the 12,936 images were used to train the proposed ReID-DeePNet system;
CUHK03 dataset [
37] is also a public dataset composed of 1360 identities with 13,164 images in .jpg format. Six surveillance cameras were utilized to capture these images and each two disjoined cameras produced 4.8 images on average for each identity. The captured images within the CUHK03 dataset contained various variations, such as illumination, direction of pedestrians, different cameras settings, etc. Following the training and testing splits described in [
37], the dataset was divided into two sets: the training set had 767 IDs, while the testing set contained the remaining 700 identities;
P-DESTRE dataset [
38] contained a total of 75 videos and individual tracks sequences with a resolution of (3840 × 2160) pixels. The cameras used to capture these videos were attached to several UAVs. The dataset included videos acquired at altitudes of 5.5 and 6.7 m over many days in crowded outdoor settings. Although most of the bounding boxes included humans with an acceptable resolution, this was not always the case when people were caught from a distance (distances exceeding 40 m), which resulted in low resolution and blur in some situations. Some of the frames had motion blur problems because of the UAVs’ fast movements and low altitude. The proposed ReID-DeePNet system’s effectiveness on this dataset was evaluated by computing the mean and standard deviation of the results across all five splits, which had five predefined splits of test data and training data. A 10-fold cross validation strategy was employed for the P-DESTRE set, with the data in each split being randomly split into 60% for the training set (45 videos), 20% for the validation set (15 videos), and 20% for the testing set (15 videos).
4.2. The Background Suppression Module Evaluation
The experimental hypothesis of image segmentation was to locate and segment a person in the image among various objects, such as vehicles, trees, animals, etc. In addition, the person could appear in a small part of the image, such as their upper/lower body. Therefore, an automated segmentation step was desperately required to locate the person within the image and apply accurate classification. Herein, the Mask R-CNN was applied as an effective and reliable approach to detect a person’s body across multiple cameras. Although the Mask R-CNN has shown encouraging results, it still had some parts of the image’s background appearing in the final segmented image that could significantly degrade the accuracy of the developed system. Therefore, the effects of the background noise interference were eliminated by employing the Mask R-CNN as an initial seed to the GrabCut algorithm as a post-process step of the person segmentation procedure. Several experiments were conducted based on different network backbones within the Mask R-CNN, such as ResNet34, ResNet5o, ResNet101, and VGG19. These experiments were repeated with the same network backbones based on merging the advantages of the Mask R-CNN and GrabCut methods to prove the effectiveness of the proposed background suppression module, as illustrated in
Table 2. In these experiments, two common evaluation metrics were calculated, including cumulative match characteristic (CMC) which denoted as Rank-1 accuracy, and mAP. All the experiments were carried out using the pre-trained ResNet50 model in the classification stage.
From
Table 2, one can see that using only the Mask R-CNN method with ResNet34 and ResNet50 as network backbones demonstrated a varying accuracy among the other network backbones. In terms of the Rank-1 rate, the Mask R-CNN method provided a higher accuracy using ResNet50 on the CUHK03 and P-DESTRE datasets, compared with the ResNet34 model, by achieving a Rank-1 rate of 66.24% and 45.67%, respectively. In contrast, the ResNet34 presented a better accuracy on the Market-1501 dataset by achieving a Rank-1 rate of 69.61%. Moreover, it was obvious that using ResNet34 model obtained higher mAP values on Market-1501 and CUHK03 datasets by achieving a mAP of 59.22% and 63.31, respectively. However, using Mask R-CNN along with the ResNet101 model, better segmentation accuracy was obtained, compared with the other three models across all the employed datasets. However, a slightly higher mAP value was obtained using the VGG19 model as a network backbone on the CUHK03 dataset. In general, the best segmentation accuracy was obtained using the ResNet101 model as a network backbone by producing a Rank-1 rate of 84.24%, 72.56%, and 80.89% on the Market-1501, CUHK03 and P-DESTRE datasets, respectively.
Although higher results were obtained on the CUHK0 dataset using the VGG19 model by achieving a Rank-1 rate of 70.74% and mAP of 72.24%, inferior results were obtained on the other two datasets compared with the ResNet101 model. On the other hand, one can see that the overall results in terms of Rank-1 rate, and mAP were further improved by merging the advantages of the Mask R-CNN and GrabCut algorithm. However, a slightly lower Rank-1 rate of 69.99% and mAP of 68.49% were obtained using the VGG19 model as a network backbone on the CUHK03 dataset. Generally, the highest Rank-1 rates of 84.51%, 79.11%, and 85.67% were acquired using the ResNet101 model as a network backbone on the Market-1501, CUHK03 and P-DESTRE datasets, respectively. However, a slightly higher mAP value of 81.02% was acquired using the ResNet50 model on the Market-1501 dataset compared with inferior results on the other two datasets by achieving a mAP of 63.31% and 45.65% on the CUHK03 and P-DESTRE datasets, respectively.
Figure 6 shows some results of applying the proposed person’s body segmentation procedure using Mask R-CNN (e.g., using the ResNet101 model as a network backbone) and the GrabCut algorithm on the Market-1501dataset. Furthermore, some examples of the created attention masks using the proposed background suppression module are shown in
Figure 7. The proposed background suppression module could effectively focus on several unique parts of the human body and eliminated background noise interference to significantly improve the accuracy of the subsequence steps of the proposed system.
4.3. Person Re-ID Module Evaluation
This section seeks to validate the automated approach of classification in finding the person of interest based on the given query image. In this study, we examine two powerful deep learning models, including the CNN model and the DBN model trained from scratch, on top of the output of the proposed segmentation procedure. All experiments were carried out on the three ReID datasets described above to finely-tune all the hyper-parameters of each model.
4.3.1. The Evaluation of the CNN Model
In this section, a set of comprehensive experiments conducted to find the optimal CNN model for the person Re-ID system, are presented. In these experiments, the effects of some hyper-parameters and a set of CNN architectures were assessed to find the optimal CNN model with optimal values of hyper-parameters to address the person Re-ID problem. Initially, the influence of the learning rate values was assessed using the AdaGrad optimization method. Using the suggested training methodology for the CNN model, an initial value of learning rate was set as 0.001. However, it was noticed that the CNN model took a long time to converge during the learning process due to the value of the learning rate being too small, and it was continuously reduced after each epoch using the AdaGrad optimization method. Thus, an initial value of the learning rate of 0.01 was set for all the remaining experiments. At the same time, the first number of epochs was set as 100, and using the same training methodology, the performance of larger numbers was also tested, including 200, 300, and 400 epochs. It was observed that if the CNN model was trained with a larger number of epochs than 100 epochs, its performance improved on the validation set. However, the CNN model started overfiting the training data and its performance on the validation set started to decline when it trained 400 epochs. As a result, the number of epochs was set as 300 epochs for all remaining experiments as the last trained CNN model had a good generalization ability without overfitting the training data.
Table 3 shows the values of the employed hyper-parameters for the best obtained CNN model.
In addition, image size plays an important role in the training speed and accuracy of the CNN model. Herein, the image size was set as 64 × 64 pixels, as the quality of the image becomes very poor for a lower image size, while a larger image size can require higher memory requirements and higher computational costs. A zero-padding of 1 pixel was applied only to the input layer of the proposed CNN to avoid a rapid decline in the amount of input data. On the other hand, to prevent the proposed CNN model from overfitting the training set, a dropout method was employed by ignoring the individual nodes within each training iteration. The dropout probability within each iteration was set to 0.5 to reduce the complexity of nodes co-adaptation by avoiding interdependency emerging between the nodes. The ReLU was employed as an activation function on the top of the convolutional and fully connected layers. The aim of the ReLU activation function was to increase the non-linearity of the CNN model. Based on knowledge from previous works the values of the weight decay, momentum, and batch size, were set to 0.0002, 0.9, and 64, respectively.
Table 3 illustrates hyper-parameters that were employed in the best CNN model.
As shown in
Table 4, several comprehensive experiments were conducted using various network architectures on Market-1501, CUHK03, and P-DESTRE datasets to obtain the best CNN architecture for personal Re-ID purposes. Initially, the CNN model used three layers with a different number of filters of each layer, such as 6, 20, and 32. The proposed model presented poor results across all the employed datasets for the Rank-1 rate and mAP accuracy. Afterward, the filter configuration of the third layer was duplicated to become 64 filters instead of 32. It was observed that the Rank-1 rate and mAP were enhanced by roughly 15%, compared with the previous setting. As a result, it was obvious that the number of filters in each convolutional layer had a strong impact on the accuracy of the CNN model. Thus, the number of filters within the second layer was also increased to become 32 filters instead of 20. One can see that the overall performance of the CNN model improved on the Market-1501 and P-DESTRE datasets. However, slightly lower values of Rank-1 rate and mAP on the CUHK03 dataset were obtained, by achieving 72.91% and 68.98%, respectively. Furthermore, it was also noticed that the accuracy of the CNN model was enhanced as we added more layers and increased the number of filters within the convolutional layer. From
Table 4, the overall results in terms of Rank-1 rate and mAP were significantly improved for all adopted ReID datasets by adding a new convolutional layer on the top of the CNN model. As shown in
Figure 3, we chose the last CNN architecture (6, 20, 64, and 128) in
Table 4 as the adopted CNN architecture for recognizing a person’s identity due to it providing the highest Rank-1 rate and mAP values for all the three datasets. As shown in
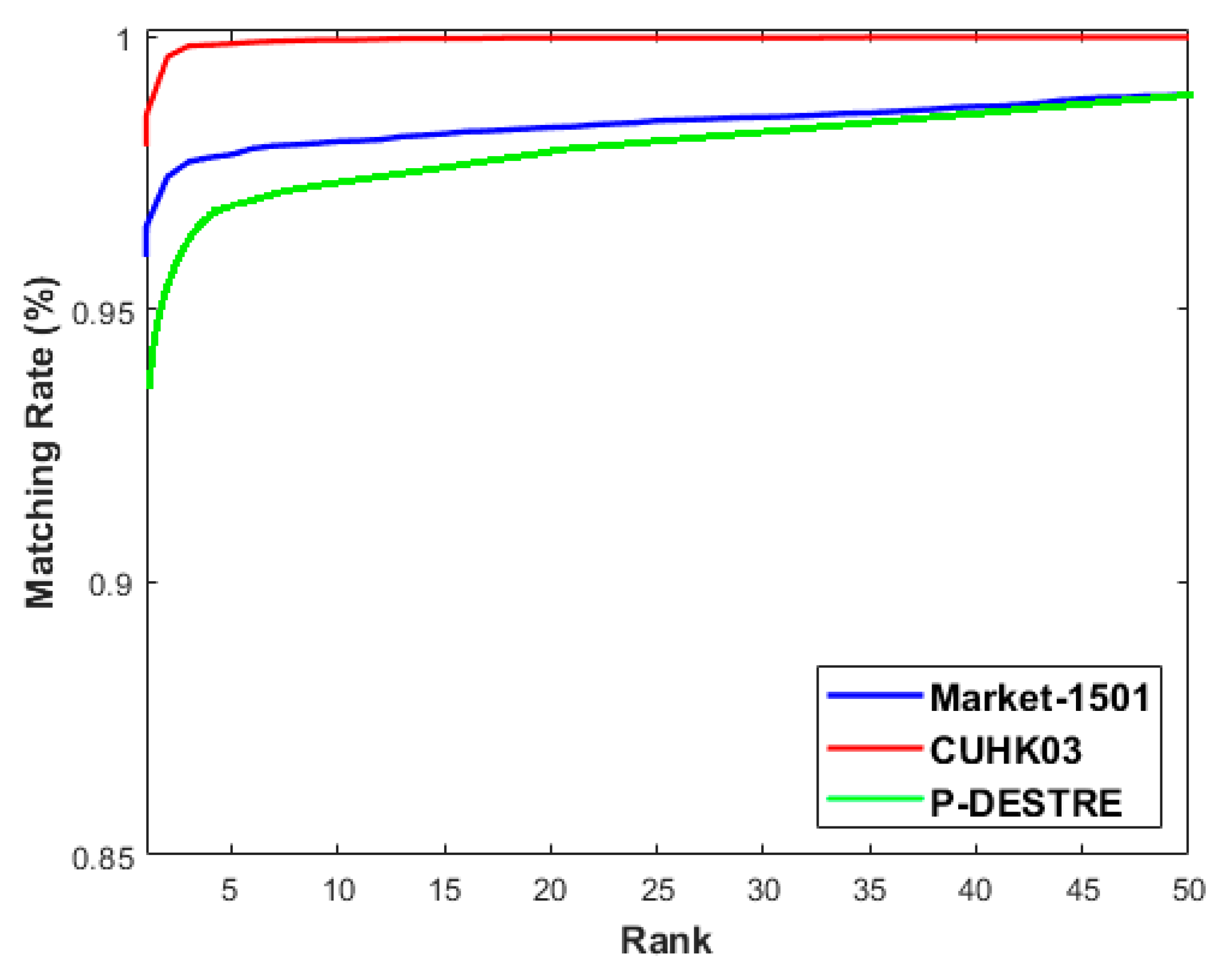
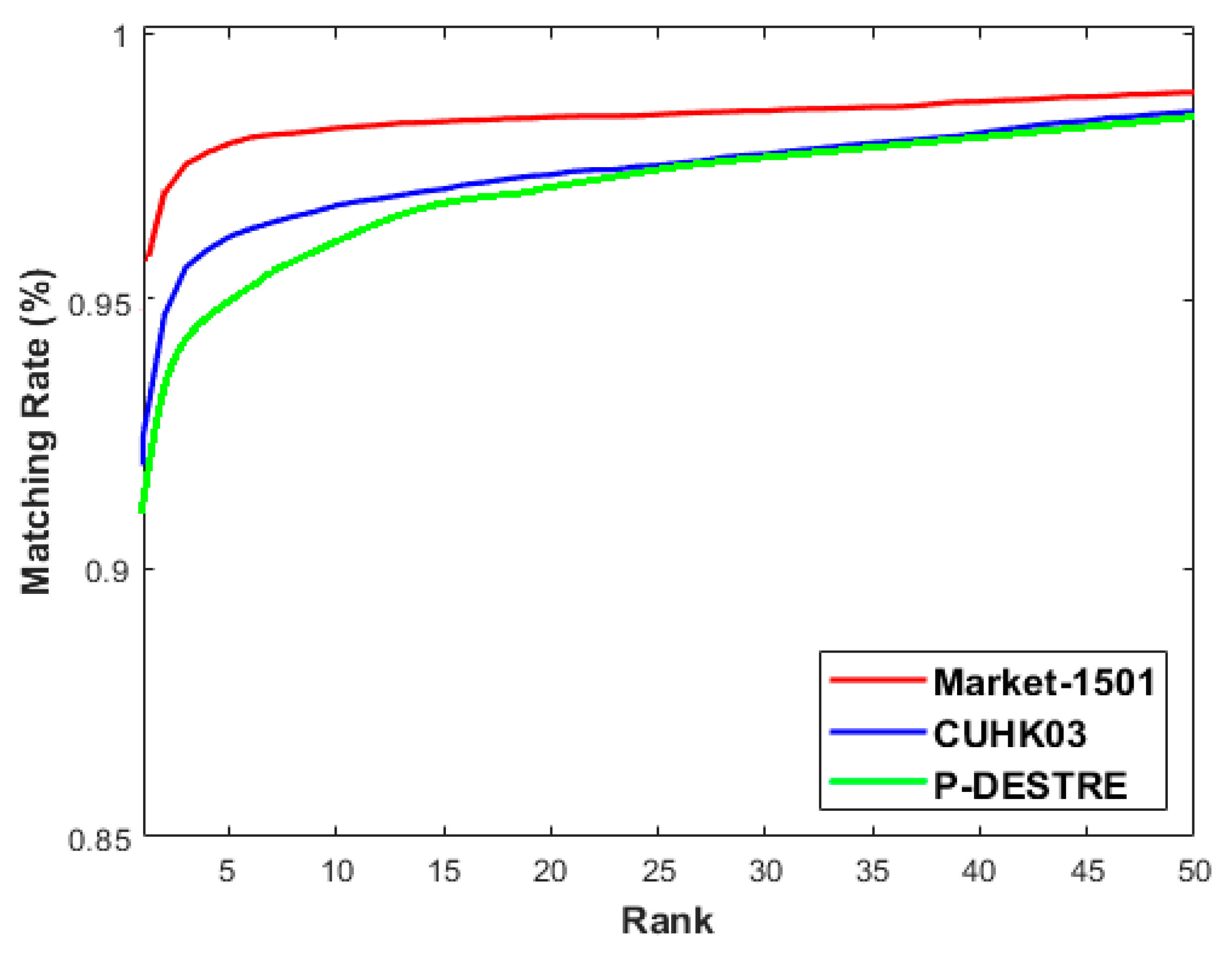
Figure 8, the performance of the best CNN model for person Re-ID tasking on three different datasets is expressed via the CMC curves.
4.3.2. The Evaluation of the DBN Model
The number of DBN architectures and hyper-parameters that need to be verified, such as the number of RBMs and the number of units per RBM, the number of epochs, the learning rate, etc., make the process of training a DBN model from scratch a challenging and difficult task. In training process of a DBN model, the value of a particular parameter could be affected by the values set for other hyper-parameters, which could be affected by the values set for other hyper-parameters. Additionally, the hyper-parameter values set in one RBM may depend on the values set in other RBMs in the stack. Consequently, the fine-tuning process of the hyper-parameter in a DBN model is quite expensive. Herein, a coarse search for all possible values was employed to carry out the fine-tuning procedure to identify the optimal hyper-parameter values. Using the training methodology described before, the DBN model was trained from scratch in a greedy manner using different numbers of hidden units per each RBM. After the training process of a specific RBM was finished, its weights matrix was preserved, and its activations were utilized as input to train the following RBM in the stack.
In this work, an initial DBN model composed of three hidden layers with a different number of hidden units (e.g., 1024-1024-1024) was greedily trained in a bottom-up fashion to assess the different values of the hyper-parameters. The first two hidden layers (RBMs) were trained separately in an unsupervised manner utilizing the CD learning algorithm using one-step Gibbs sampling (CD-1). The first two hidden layers were trained for 200 epochs, a weight decay of 0.0005, a momentum of 0.91, and mini-batch size of 64. The value of the learning rate was set to 0.001 for each RBM model, but it was noticed that the RBMs models needed a long time to converge because the learning rate value was very small. Thus, the learning rate value was set as 0.01 for all the remaining experiments. Next, the discriminative performance of the last RBM model was assessed by training it in supervised manner as a non-linear classifier. The last RBM model was trained using the same hyper-parameter values as the first two RBM models, with the exception that it was trained for 300 epochs. Finally, to minimize overfitting issues and improve the generalizability of the last trained DBN model, the complete network was trained in a top-down fashion using the back-propagation algorithm supported by the dropout technique. The dropout ratio was set to 0.5. The early stopping procedure was employed to determine the number of epochs during the fine-tuning phase, which was around 500 epochs. The values of the hyper-parameters for the best obtained DBN model are listed in
Table 5.
Using the hyper-parameters shown in
Table 5, different experiments were conducted by training a DBN model composed of three layers, but with a different number of hidden units per layer on the top of the segmented images generated from three different datasets. As shown in
Table 6, four DBNs models were trained using a different number of hidden units per layer, ranging from 1024 to 3048 units. These models received the input image size of 64 × 64 pixels for all datasets. The first DBN model was composed of three hidden layers with the same number of hidden units (e.g., 1024). This DBN model presented the lowest accuracy among the other models, in terms of Rank-1 rate and mAP on all the employed datasets. Therefore, the number of hidden units within the second hidden layer was increased (to become, e.g., 2024). Notably, better results were obtained compared with the previous one, by achieving Rank-1 rates of over 80% on the Market-1501 and P-DESTRE datasets. Another experiment was also conducted using the DBN model, composed of three hidden layers with the number of hidden units set to 3048, 2024, and 1024, respectively. One can see that the overall performance of the last trained DBN model was significantly improved, by achieving the highest Rank-1 rates of 96.86%, 93.97%, and 91.81%, and mAP of 97.85%, 92.04%, and 87.94%, on the Market-1501, CUHK03 and P-DESTRE datasets, respectively. However, by increasing the number of the hidden units in last layer to 2024 units, it was observed that the values of the Rank-1 rate and mAP were reduced by approximately 10% compared with the third DBN model in
Table 6. Therefore, the third DBN model was adopted in all the remaining experiments to identify the person’s identity using the proposed ReID-DeePNet system (See
Figure 4). As shown in
Figure 9, the performance of the best DBN model for person Re-ID task on three different datasets is expressed via the CMC curves.
4.4. The Evaluation of Fusion Rules
Using the proposed ReID-DeePNet system as a personal Re-ID system each time a query image is presented,
N matching scores were generated from two different deep learning models (CNN and DBN models). These matching scores were either fused directly using one of matching scores rules (e.g., SR, WSR, PR, max, and min rule) or sorted in descending order to generate the ranking list of matching identities, which was fused using one of the ranking rules (e.g., HR, BC, and LR) to make the final decision. As can be seen from
Table 7 and
Table 8, that the best results were obtained using the WSR rule in the matching score level by achieving Rank-1 rates of 99.91%, 98.92%, and 99.69%, and mAP of 99.67%, 98.34%, and 94.79%, on the Market-1501, CUHK03 and P-DESTRE datasets, respectively. In this work, using the WSR rule, a highest weight was given to the CNN model in making the final decision, due to its better performance compared with the performance of the DBN model on all the employed datasets. On the other hand, the BC rule in the ranking level achieved the highest mAP of 98.56% on the CUHK03 dataset. However, as shown in
Table 9 and
Table 10, the HR rule produced the highest results compared with other ranking rules by achieving Rank-1 rates of 99.54%, 98.67%, and 94.85%, and mAP of 98.01%, 97.89%, and 93.95%, on the Market-1501, CUHK03 and P-DESTRE datasets, respectively.
4.5. Comparison Study and Discussion
The performance of the proposed ReID-DeePNet system was compared against other existing state-of-the-art personal Re-ID systems. For a fair comparison, Rank-1 and mAP values on all three datasets were reported. As shown in
Table 11, the proposed ReID-DeePNet system outperformed all state-of-the-art personal Re-ID systems in terms of Rank-1 rates and mAP, using WSR and HR, on all the employed datasets. It is worthwhile noting that the accuracy of the proposed ReID-DeePNet system using WSR on all three ReID datasets, was higher than its performance using HR. Another observation was that the accuracy of the proposed ReID-DeePNet system on the P-DESTRE dataset was lower compared with the other datasets.
In general, the obtained results indicate that learning effective feature representations from the detected pedestrian body can significantly reduce background clutter and improve accuracy of the proposed ReID-DeePNet system. However, despite good preparation of the employed ReID datasets, the accuracy of detecting pedestrians’ bodies cannot reach an optimal level, since it depends on image contrast, pose variations, illumination changes, occlusions, different camera settings, the location of the objects within the image, and the effect of the overlapped objects. Thus, pedestrian detection accuracy may be further improved by investigating the possibility of applying many methods, such as single shot multibox detector (SSD) [
39], YOLO [
40], and fast R-CNN [
41] along with the GrabCut algorithm to obtain an accurate segmentation of individuals within the image.
Table 11.
Performance comparison with state-of-the-art approaches on three large-scale and challenging ReID datasets.
Table 11.
Performance comparison with state-of-the-art approaches on three large-scale and challenging ReID datasets.
| Methods | Market-1501 | CUHK03 | P-DESTRE |
|---|
| Rank-1 | mAP | Rank-1 | mAP | Rank-1 | mAP |
|---|
| DPA [6] | 94.14 | 90.31 | 63.04 | 61.73 | --- | --- |
| SegHAN [8] | 92.3 | 76.1 | 88.3 | --- | --- | --- |
| RANGEv2 [24] | 94.7 | 86.8 | 64.3 | 67.4 | --- | --- |
| HMBN (RK)[25] | 95.58 | 94.21 | 84.16 | 82.64 | --- | --- |
| Siamese [28] | 83.79 | 74.33 | 50.14 | 50.21 | --- | --- |
| PAP-S-PS [42] | 94.6 | 85.6 | 72.5 | 66.8 | --- | --- |
| GoogLeNet [43] | 81.0 | 63.4 | 85.4 | --- | --- | --- |
| HPM [44] | 94.2 | 82.7 | 63.9 | 57.5 | --- | --- |
| EDAAN [45] | 95.3 | 86.8 | 94.7 | 83.4 | --- | --- |
| DSA-reID [46] | 95.7 | 87.6 | 78.9 | 75.2 | --- | --- |
| M3L (IBN-Net50) [47] | 75.9 | 50.2 | 33.1 | 32.1 | --- | --- |
| +NFormer [48] | 95.7 | 93.0 | 80.6 | 79.1 | --- | --- |
| COSAM [38] | --- | --- | --- | --- | 80.2 ± 12.9 | 80.6 ± 11.9 |
| GLTR [38] | --- | --- | --- | --- | 81.0 ± 12.5 | 79.7 ± 12.0 |
| OSNet [49] | --- | --- | --- | --- | 82.9 ± 7.7 | 84.0 ± 7.4 |
Deep SORT +
OSNet [50] | --- | --- | --- | --- | 77.9 ± 5.1 | 70.5 ± 4.8 |
| ReID-DeePNet (WSR) | 99.91 | 99.67 | 98.92 | 98.34 | 94.79 ± 4.3 | 94.15 ± 4.4 |
| ReID-DeePNet (HR) | 99.54 | 98.01 | 98.67 | 97.89 | 94.85 ± 5.2 | 93.95 ± 4.6 |
In this study, the processes of learning discriminative feature representations and producing the final matching scores were jointly optimized using two powerful deep learning models, the CNN and the DBN models. These two deep learning models were trained from scratch, using the top of the detected pedestrian body instead of the whole raw pedestrian image. Herein, a parallel architecture was used to combine the matching scores acquired from the adopted models, providing a high degree of flexibility in establishing the person’s identity. The results from the proposed ReID-DeePNet system are encouraging, especially given that they were derived from three different ReID datasets made up of more than 1000 IDs and a significant number of pedestrian images, which is relevant to real-world applications. Therefore, we believe that the proposed ReID-DeePNet system can be readily used for real-time application. Nevertheless, it should be pointed out that at the current stage of work, the proposed ReID-DeePNet system has not yet been applied in any real commercial application.
5. Conclusions and Future Work
In this paper, an efficient and real-time ReID-DeePNet system was proposed to match a person across non-overlapping cameras by various viewpoints. This system combined the Mask R-CNN followed by the GrabCut algorithm to obtain an accurate segmentation of individuals within the image. The developed segmentation approach worked in an automated method to obtain the person from among other objects. Afterward, a fusion module based on CNN and DBN was also developed to extract discriminative and robust features, thereby obtaining a correct classification. The effectiveness and robustness of the ReID-DeePNet system was tested on three challenging ReID datasets, namely, Market-1501, CUHK03, and P-DESTRE datasets. It produced higher results than existing state-of-the-art personal Re-ID systems, by achieving Rank-1 rates of 99.91%, 98.92%, and 94.79%, and mAP of 99.67%, 98.34%, and 94.15%, on the Market-1501, CUHK03 and P-DESTRE datasets, respectively. Based on the experimental results, it is obvious that the proposed system has illustrated its ability to segment and identify individuals using various fusion approaches at the score and rank levels.
The focus of future research will be on evaluating the effectiveness of the proposed ReID-DeePNet system using more difficult ReID datasets. We are also working on expanding the current background suppression module by combining person masks and key points to match body parts accurately, eliminate undesired information (e.g., background clutter) and achieve higher accuracy. Another important factor to investigate is the size of deep learning models, since large trained models require more storage space, which makes them difficult to store on small embedded devices. Therefore, models with fewer hyper-parameters and equal or better matching accuracy should be considered.



 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}








