
Perspective Transformer and MobileNets-Based 3D Lane Detection from Single 2D Image


Abstract
:1. Introduction
2. Related Works
3. Proposed Methods
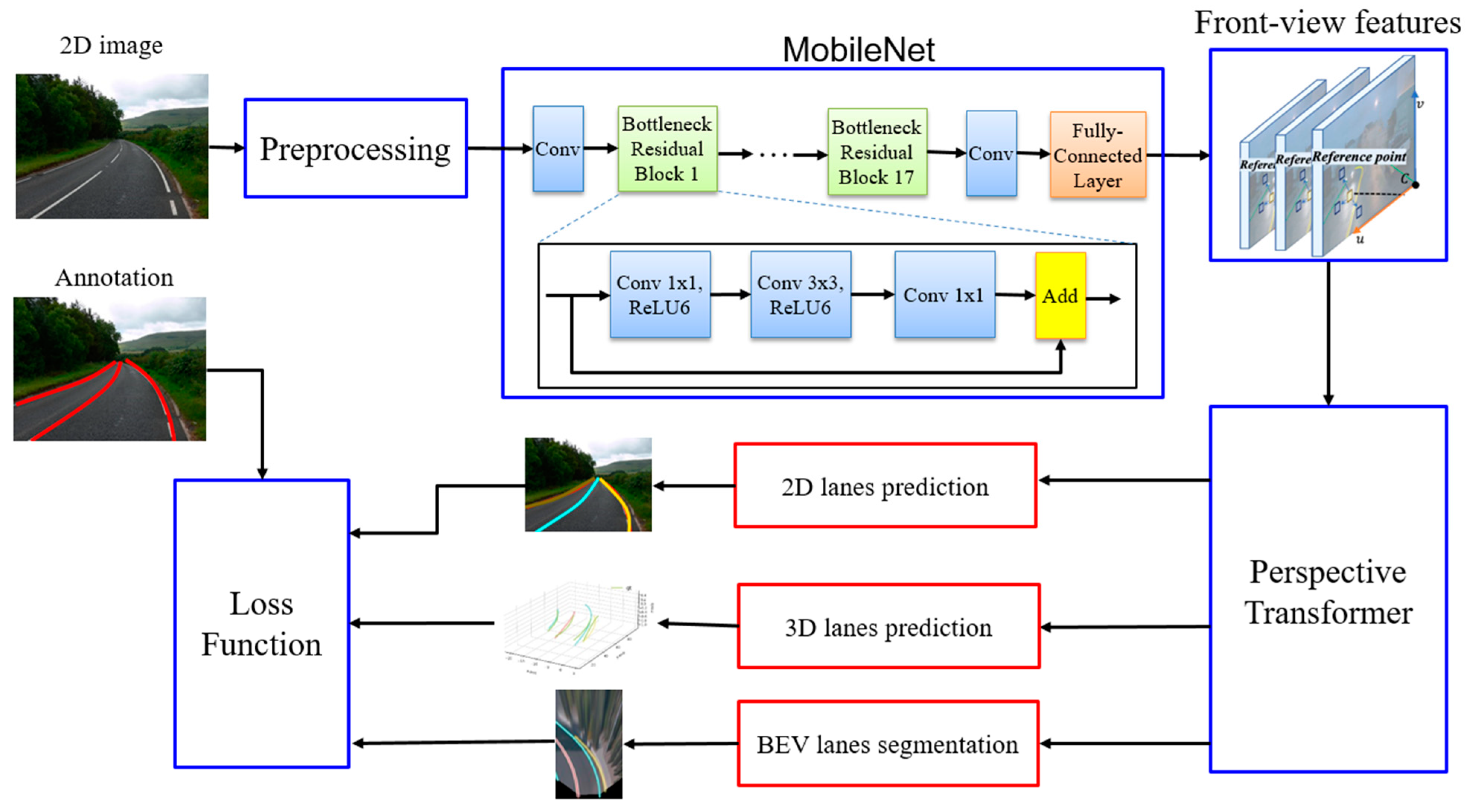
3.1. System Overview
3.2. Feature Extraction
3.3. Three-Dimensional Lane Detection
3.4. Loss Function
4. Experiments
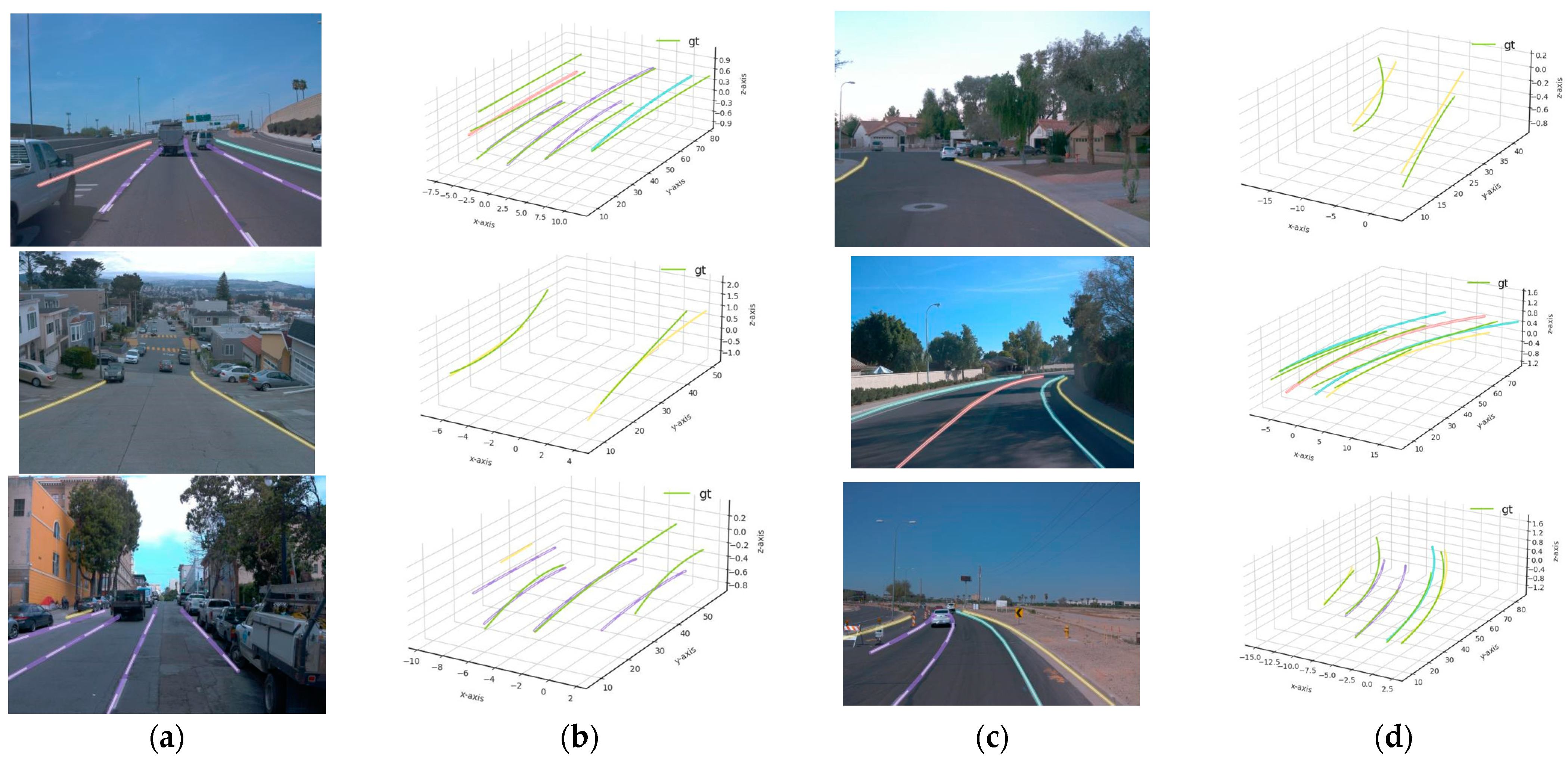
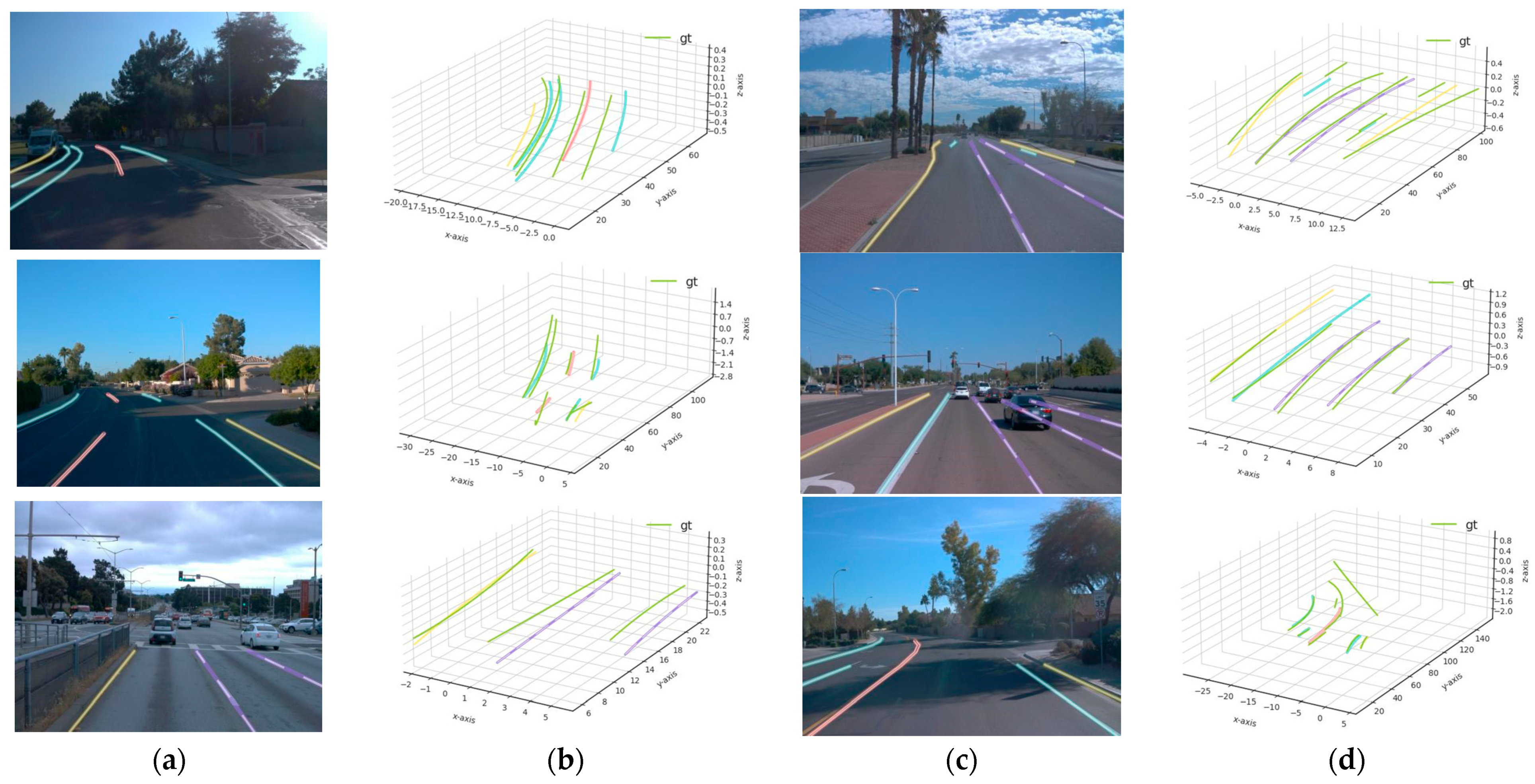
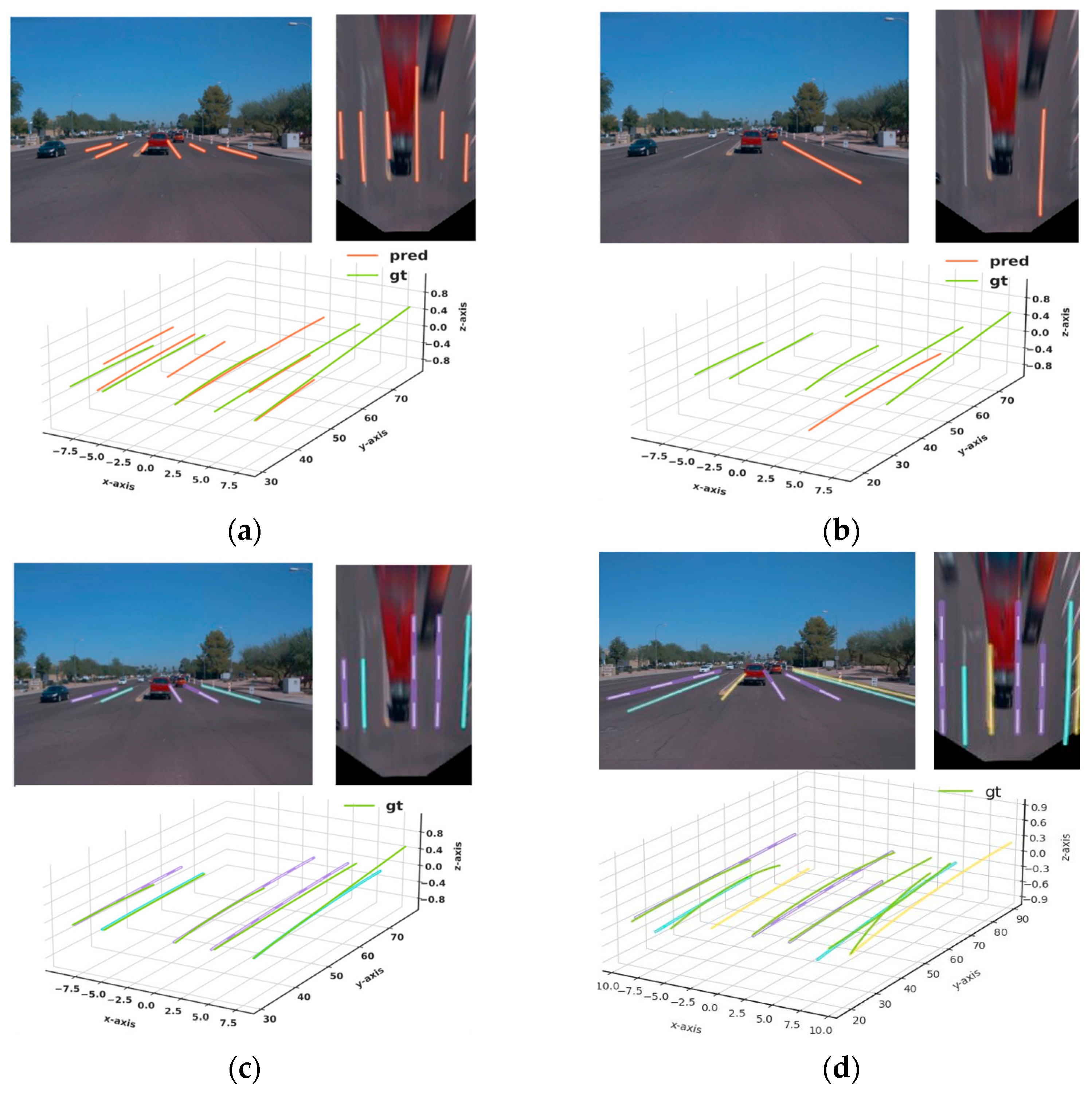
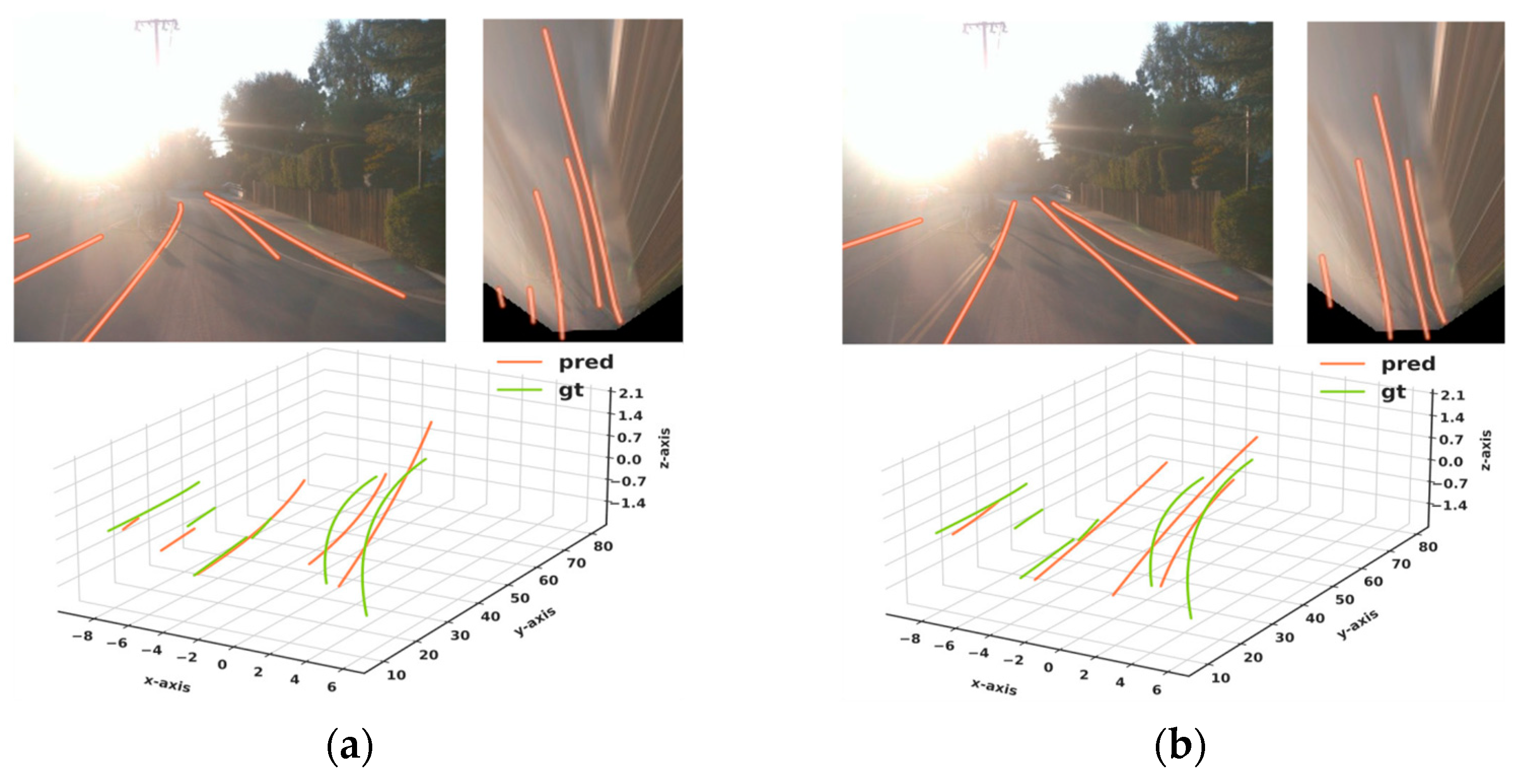
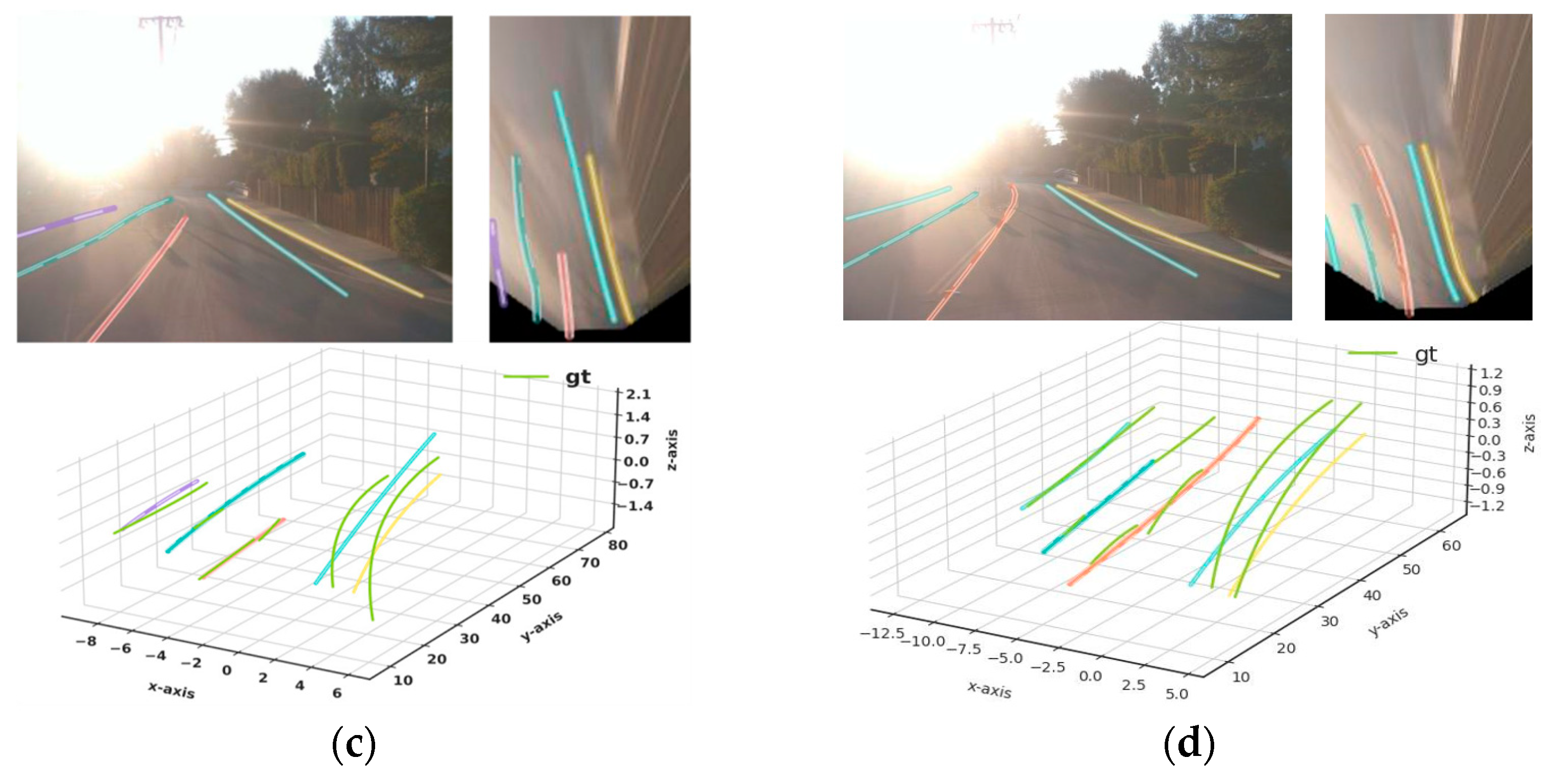
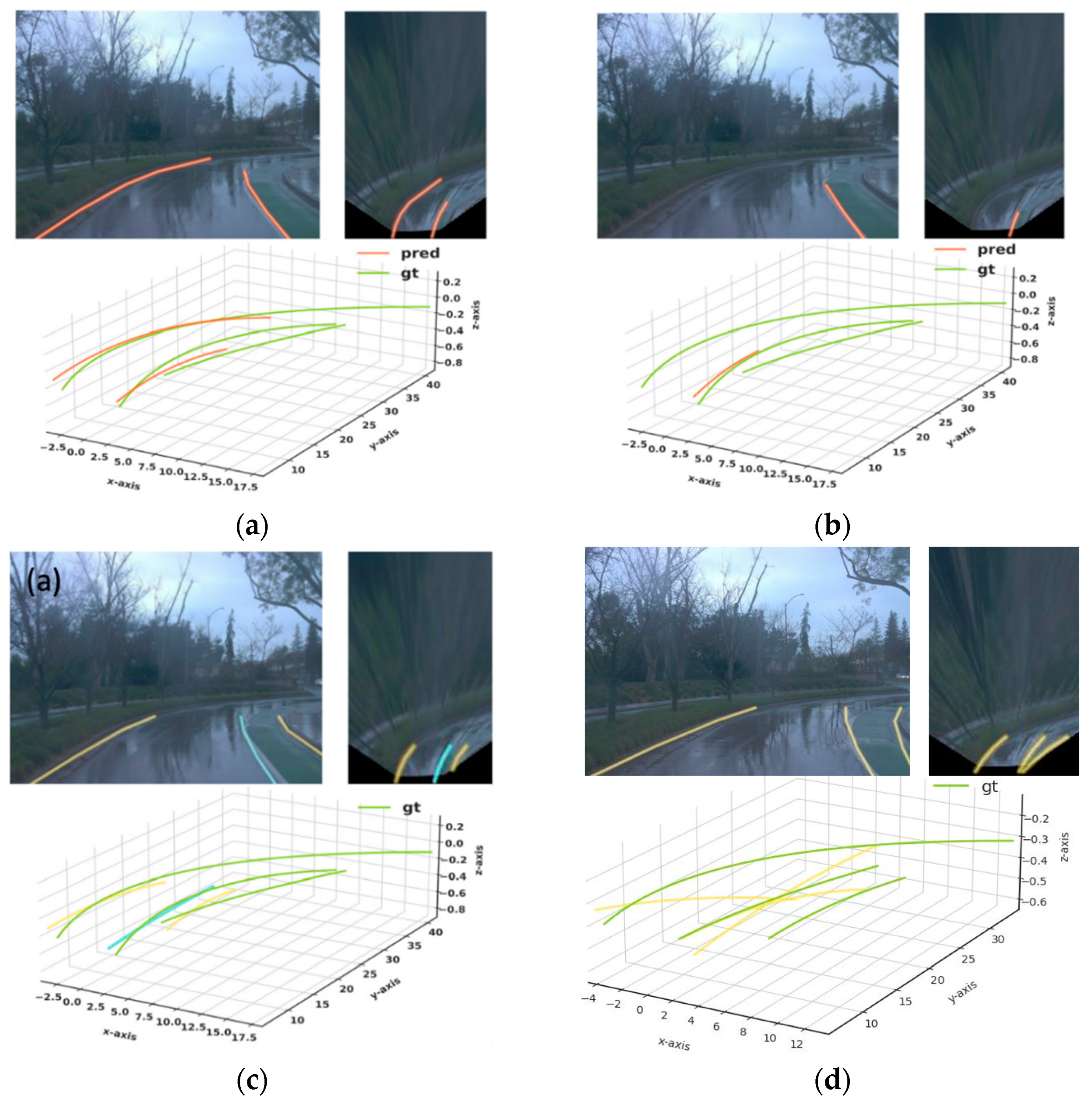
4.1. Qualitative Results
4.2. Quantitative Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Chu, P.M.; Cho, S.; Fong, S.; Park, Y.W.; Cho, K. 3D Reconstruction Framework for Multiple Remote Robots on Cloud System. Symmetry 2017, 9, 55. [Google Scholar] [CrossRef] [Green Version]
- Chu, P.; Cho, S.; Sim, S.; Kwak, K.; Cho, K. A Fast Ground Segmentation Method for 3D Point Cloud. J. Inf. Process. Syst. 2017, 13, 491–499. [Google Scholar]
- Chu, P.M.; Cho, S.; Sim, S.; Kwak, K.; Cho, K. Multimedia System for Real-Time Photorealistic Nonground Modeling of 3D Dynamic Environment for Remote Control System. Symmetry 2018, 10, 83. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Ibanez-Guzman, J. Lidar for autonomous driving: The principles, challenges, and trends for automotive lidar and perception systems. IEEE Signal Process. Mag. 2020, 37, 50–61. [Google Scholar] [CrossRef]
- Vargas, J.; Alsweiss, S.; Toker, O.; Razdan, R.; Santos, J. An overview of autonomous vehicles sensors and their vulnerability to weather conditions. Sensors 2021, 21, 5397. [Google Scholar] [CrossRef] [PubMed]
- Ravindran, R.; Santora, M.J.; Jamali, M.M. Multi-object detection and tracking, based on DNN, for autonomous vehicles: A review. IEEE Sens. J. 2020, 21, 5668–5677. [Google Scholar] [CrossRef]
- Chu, P.M.; Sung, Y.; Cho, K. Generative Adversarial Network-Based Method for Transforming Single RGB Image Into 3D Point Cloud. IEEE Access 2019, 7, 1021–1029. [Google Scholar] [CrossRef]
- Kuramoto, A.; Aldibaja, M.A.; Yanase, R.; Kameyama, J.; Yoneda, K.; Suganuma, N. Mono-camera based 3D object tracking strategy for autonomous vehicles. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 459–464. [Google Scholar]
- Zhang, H.; Ji, H.; Zheng, A.; Hwang, J.N.; Hwang, R.H. Monocular 3D localization of vehicles in road scenes. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, Canada, 11–17 October 2021; pp. 2855–2864. [Google Scholar]
- Efrat, N.; Bluvstein, M.; Oron, S.; Levi, D.; Garnett, N.; Shlomo, B.E. 3D-Lanenet+: Anchor free lane detection using a semi-local representation. arXiv 2020, arXiv:2011.01535. [Google Scholar]
- Minaee, S.; Liang, X.; Yan, S. Modern Augmented Reality: Applications, Trends, and Future Directions. arXiv 2022, arXiv:2202.09450. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Chen, L.; Sima, C.; Li, Y.; Zheng, Z.; Xu, J.; Geng, X.; Li, H.; He, C.; Shi, J.; Qiao, Y.; et al. PersFormer: 3D Lane Detection via Perspective Transformer and the OpenLane Benchmark. arXiv 2022, arXiv:2203.11089. [Google Scholar]
- Aly, M. Real time detection of lane markers in urban streets. In Proceedings of the 2008 IEEE Intelligent Vehicles Symposium (IV), Eindhoven, The Netherlands, 4–6 June 2008; pp. 7–12. [Google Scholar]
- Li, Z.Q.; Ma, H.M.; Liu, Z.Y. Road lane detection with gabor filters. In Proceedings of the 2016 International Conference on Information System and Artificial Intelligence, Hong Kong, China, 24–26 June 2016; pp. 436–440. [Google Scholar]
- Wang, J.; Mei, T.; Kong, B.; Wei, H. An approach of lane detection based on inverse perspective mapping. In Proceedings of the 17th International IEEE Conference on Intelligent Transportation Systems, Qingdao, China, 8–11 October 2014; pp. 35–38. [Google Scholar]
- Lee, S.; Kim, J.; Yoon, J.S.; Shin, S.; Bailo, O.; Kim, N.; Lee, T.H.; Hong, H.S.; Han, S.H.; Kweon, I.S. Vpgnet: Vanishing point guided network for lane and road marking detection and recognition. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1947–1955. [Google Scholar]
- Pan, X.; Shi, J.; Luo, P.; Wang, X.; Tang, X. Spatial as deep: Spatial cnn for traffic scene understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 7276–7283. [Google Scholar]
- Neven, D.; Brabandere, B.D.; Georgoulis, S.; Proesmans, M.; Gool, L.V. Towards end-to-end lane detection: An instance segmentation approach. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium(IV), Suzhou, China, 26–30 June 2018; pp. 286–291. [Google Scholar]
- Hou, Y.; Ma, Z.; Liu, C.; Loy, C.C. Learning lightweight lane detection CNNs by self attention distillation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 1013–1021. [Google Scholar]
- Abualsaud, H.; Liu, S.; Lu, D.B.; Situ, K.; Rangesh, A.; Trivedi, M.M. Laneaf: Robust multi-lane detection with affinity fields. IEEE Robot. Autom. Lett. 2021, 6, 7477–7484. [Google Scholar] [CrossRef]
- Qin, Z.; Wang, H.; Li, X. Ultra fast structure-aware deep lane detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 276–291. [Google Scholar]
- Liu, L.; Chen, X.; Zhu, S.; Tan, P. Condlanenet: A top-to-down lane detection framework based on conditional convolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 3773–3782. [Google Scholar]
- Jayasinghe, O.; Anhettigama, D.; Hemachandra, S.; Kariyawasam, S.; Rodrigo, R.; Jayasekara, P. Swiftlane: Towards fast and efficient lane detection. In Proceedings of the 2021 20th IEEE International Conference on Machine Learning and Applications, Pasadena, CA, USA, 13–15 December 2021; pp. 859–864. [Google Scholar]
- Qu, Z.; Jin, H.; Zhou, Y.; Yang, Z.; Zhang, W. Focus on local: Detecting lane marker from bottom up via key point. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 14122–14130. [Google Scholar]
- Chen, Z.; Liu, Q.; Lian, C. Pointlanenet: Efficient end-to-end CNNs for accurate real-time lane detection. In Proceedings of the 2019 IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2563–2568. [Google Scholar]
- Li, X.; Li, j.; Hu, X.; Yang, J. Line-cnn: End-to-end traffic line detection with line proposal unit. IEEE Trans. Intell. Transp. Syst. 2019, 21, 248–258. [Google Scholar] [CrossRef]
- Xu, H.; Wang, S.; Cai, X.; Zhang, W.; Liang, X.; Li, Z. Curvelane-nas: Unifying lane-sensitive architecture search and adaptive point blending. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 689–704. [Google Scholar]
- Su, J.; Chen, C.; Zhang, K.; Luo, J.; Wei, X.; Wei, X. Structure guided lane detection. In Proceedings of the Thirtieth International Joint Conference on Artificial Intelligence, Montreal, QC, Canada, 19–26 August 2021; pp. 997–1003. [Google Scholar]
- Tabelini, L.; Berriel, R.; Paixao, T.M.; Badue, C.; Souza, A.F.D.; Oliveira-Santos, T. Keep your eyes on the lane: Real-time attention-guided lane detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11–17 October 2021; pp. 294–302. [Google Scholar]
- Nedevschi, S.; Schmidt, R.; Graf, T.; Danescu, R.; Frentiu, D.; Marita, T.; Oniga, F.; Pocol, C. 3D lane detection system based on stereovision. In Proceedings of the 7th International IEEE Conference on Intelligent Transportation Systems (IEEE Cat. No. 04TH8749), Washington, DC, USA, 3–6 October 2004; pp. 161–166. [Google Scholar]
- Benmansour, N.; Labayrade, R.; Aubert, D.; Glaser, S. Stereovision-based 3D lane detection system: A model driven approach. In Proceedings of the 2008 11th International IEEE Conference on Intelligent Transportation Systems, Beijing, China, 12–15 October 2008; pp. 182–188. [Google Scholar]
- Bai, M.; Mattyus, G.; Homayounfar, N.; Wang, S.; Lakshmikanth, S.K.; Urtasun, R. Deep multi-sensor lane detection. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems, Madrid, Spain, 1–5 October 2018; pp. 3102–3109. [Google Scholar]
- Garnett, N.; Cohen, R.; Pe’er, T.; Lahav, R.; Levi, D. 3D-Lanenet: End-to-end 3D multiple lane detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 2921–2930. [Google Scholar]
- Guo, Y.; Chen, G.; Zhao, P.; Zhang, W.; Miao, J.; Wang, J.; Choe, T.E. Gen-Lanenet: A generalized and scalable approach for 3d lane detection. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 666–681. [Google Scholar]
- Jin, Y.; Ren, X.; Chen, F.; Zhang, W. Robust monocular 3D lane detection with dual attention. In Proceedings of the 2021 IEEE International Conference on Image Processing, Anchorage, AK, USA, 19–22 September 2021; pp. 3348–3352. [Google Scholar]
- Liu, R.; Chen, D.; Liu, T.; Xiong, Z.; Yuan, Z. Learning to predict 3D lane shape and camera pose from a single image via geometry constraints. In Proceedings of the AAAI Conference on Artificial Intelligence, Vancouver, BC, Canada, 22 February–1 March 2022; pp. 1765–1772. [Google Scholar]
- Jaderberg, M.; Simonyan, K.; Zisserman, A.; Kavukcuoglu, K. Spatial transformer networks. Adv. Neural Inf. Process. Syst. 2015, 28, 2017–2025. [Google Scholar]
- Sun, P.; Kretzschmar, H.; Dotiwalla, X.; Chouard, A.; Patnaik, V.; Tsui, P.; Guo, J.; Zhou, Y.; Chai, Y.; Caine, B.; et al. Scalability in perception for autonomous driving: Waymo open dataset. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 2446–2454. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Measure | Up and Down | Curve | Extreme Weather | Night | Intersection | Merge and Split | |
|---|---|---|---|---|---|---|---|
| Accuracy (higher is better) | F-score (%) | 42.8 | 53.6 | 49.8 | 45.0 | 37.6 | 45.4 |
| Recall (%) | 45.5 | 54.2 | 46.6 | 40.2 | 38.2 | 38.8 | |
| Precision (%) | 40.5 | 53.0 | 53.5 | 51.2 | 37.0 | 54.7 | |
| Category accuracy (%) | 86.6 | 93.2 | 89.6 | 85.1 | 85.0 | 87.0 | |
| Error (lower is better) | x error near (m) | 0.299 | 0.315 | 0.275 | 0.303 | 0.446 | 0.408 |
| z error near (m) | 0.161 | 0.172 | 0.141 | 0.210 | 0.336 | 0.307 | |
| x error far (m) | 1.094 | 0.851 | 0.805 | 0.742 | 0.828 | 0.733 | |
| z error far (m) | 1.010 | 0.695 | 0.723 | 0.660 | 0.742 | 0.620 | |
| Method | Accuracy Measures (Higher is Better) | Error Measures (Lower is Better) | ||||
|---|---|---|---|---|---|---|
| F-Score | Category Accuracy | X Error Near | Z Error Near | X Error Far | Z Error Far | |
| 3D-LaneNet [34] | 40.2 | - | 0.278 | 0.159 | 0.823 | 0.714 |
| Gen-LaneNet [35] | 29.7 | - | 0.309 | 0.160 | 0.877 | 0.750 |
| PersFormer [13] | 47.8 | 92.3 | 0.322 | 0.213 | 0.778 | 0.681 |
| Proposed method | 47.9 | 89.1 | 0.341 | 0.224 | 0.789 | 0.694 |
| Method | F-Score | |||||
|---|---|---|---|---|---|---|
| Up and Down | Curve | Extreme Weather | Night | Intersection | Merge and Split | |
| 3D-LaneNet [34] | 37.7 | 43.2 | 43.0 | 39.3 | 29.3 | 36.5 |
| Gen-LaneNet [35] | 24.2 | 31.1 | 26.4 | 17.5 | 19.7 | 27.4 |
| PersFormer [13] | 42.4 | 52.8 | 48.7 | 46.0 | 37.9 | 44.6 |
| Proposed method | 42.8 | 53.6 | 49.8 | 45.0 | 37.6 | 45.4 |
| Method | Number of GPUs | GPU Type | CUDA Cores | Tensor Cores | Memory |
|---|---|---|---|---|---|
| PersFormer [13] | 8 | Nvidia TeslaV100 | 5120 | 640 | 32 GB |
| Proposed method | 4 | Nvidia TitanX | 3584 | 0 | 12 GB |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, M.; Chu, P.M.; Cho, K. Perspective Transformer and MobileNets-Based 3D Lane Detection from Single 2D Image. Mathematics 2022, 10, 3697. https://doi.org/10.3390/math10193697
Li M, Chu PM, Cho K. Perspective Transformer and MobileNets-Based 3D Lane Detection from Single 2D Image. Mathematics. 2022; 10(19):3697. https://doi.org/10.3390/math10193697
Chicago/Turabian StyleLi, Mengyu, Phuong Minh Chu, and Kyungeun Cho. 2022. "Perspective Transformer and MobileNets-Based 3D Lane Detection from Single 2D Image" Mathematics 10, no. 19: 3697. https://doi.org/10.3390/math10193697
APA StyleLi, M., Chu, P. M., & Cho, K. (2022). Perspective Transformer and MobileNets-Based 3D Lane Detection from Single 2D Image. Mathematics, 10(19), 3697. https://doi.org/10.3390/math10193697