1. Introduction
Question answering (QA), or reading comprehension, has long been the holy grail of machine intelligence. In pursuit of it, efforts are dedicated to enabling machines to automatically retrieve information and perform inference over texts, just like the human cognitive reasoning process. Pioneering research focuses on single-document QA, using benchmarks including
CNN&Dailymail [
1],
SQuAD [
2] and
RACE [
3]. The progressive development of human cognition and reasoning follows a rule of “creep-before-you-walk”. We begin with some straightforward questions which can be simply answered by referring to a single document. Then, we proceed to more challenging questions which might need to be inferred from different information sources. The same applies for the machine. Starting from single-document QA, it enhances its reasoning ability step by step and eventually addresses multiple-document problems. There are some works exploring multiple-document scenarios [
4], but they basically still fall into the single-document QA category, as only one document contains the supporting evidence to answer the question, while others are noises to confuse the model. To the best of our knowledge,
QAngaroo [
5] is among the first to concentrate on predicting answers from several documents. However, questions in
QAngaroo are in the form of knowledge triplets, and the task fails to capture the explicit reasoning path of the documents since the metric does not contain the part about the reasoning path.
During the growth of the logic inference ability of people, people only need one document for a single question in senior schools, while many references are required in junior schools. Inspired by the development, machines are also supposed to enhance cognitive reasoning ability to address multiple-documents problems. The latest effort was focused on multi-hop QA (MH-QA) within multiple documents [
6,
7,
8,
9], among which
HotpotQA is one of the representative works. In
HotpotQA, questions are in the natural language form, and answers need to be inferred from several pieces of similar texts without candidate answers. In comparison with previous tasks, the aim of MH-QA is to infer answers by exploiting the interaction between relevant documents and the given question.
MH-QA is difficult due to the fact that there exists a reasoning chain hidden behind the QA process, through which multiple documents are connected and interact. The challenges lie in the need to explicitly sort out a reasoning path through multiple content-related and logically connected documents. Previous works tried to put several subtasks, such as candidate sentence selection, answer prediction, and answer type prediction, under a unified multi-task learning framework [
6,
8], aiming to capture the interactions among various parts of several texts. To handle the unique challenge, graph neural network (GNNs) methods have been widely explored to understand the inter-relations among texts [
7,
9]. Specifically, they construct an interaction graph by extracting entities in text as nodes and treating all possible connections between those nodes as relations. GNN is then incorporated to learn the intrinsic interactions among entities.
Nevertheless, the current methods tend to fall short in the following aspects. First, the construction of an interaction graph is highly reliant on the entities extracted from questions and candidate texts, but the entities are too fuzzy to express a concrete meaning in most cases. Hence, it may not be easy for the reasoning process to figure out which entity to follow successively in order to arrive at the correct answer. For example (as depicted in
Figure 1), when “Soviet statesman” is used as the reasoning starting point, there are three viable subsequent entities to follow, namely, “Mikhail Gorbachev”, “Nikolai Viktorovich Podgorny” and “Andrei Pavlovich Kirilenko”. It can be non-trivial to choose from the three candidates to ensure that the reasoning process will eventually lead to the right answer.In contrast, if we choose “former Soviet statesman” as the starting point, it will be much easier to locate the right subsequent entity “Mikhail Gorbachev” to update the query. Therefore, we hypothesize that the phrase, rather than entities, is better at fulfilling the task of connecting reasoning chains.
Second, combining all possible information from the texts results in an information overload, which is likely to overwhelm the model. Statistics show that there can be as many as 111 entities in a context in HotpotQA (based on our data processing). If they are all fed into a GNN, irrelevant information inevitably becomes involved, which undermines the performance. For instance, besides “Mikhail Gorbachev”, the existence of the other irrelevant entities “Nikolai Viktorovich Podgorny” and “Andrei Pavlovich Kirilenko” inevitably introduces noise. In this connection, it is beneficial to clarify the corresponding part of the question, using “Mikhail Gorbachev” in the first place.Therefore, it can be beneficial to refine the contextual information for fusion before conducting MH-QA.
To investigate the ideas, we implement them in a novel framework inspired by the classic query reformulation technique in information retrieval. Specifically, we propose to incorporate phrases to latently reformulate the questions such that the answer prediction can better perform. For the first challenge, we employ phrases as the basic units of our model to construct a reasoning chain in which information from different documents is transferred. To obtain quality phrases, we first filter out relevant documents and then extract phrases under the guidance of certain grammar rules. To tackle the second challenge, we introduce a phrase-level latent query reformulation method by using semantic information to latently update the question representations, without changing the original literal texts. It is realized by (1) constructing a similarity graph, in which phrases are treated as nodes, and pair-wise similarity as edges; and (2) learning a semantic-augmenting model to update the representations of phrases and hence, latently reformulating the question. The process helps our model to accurately locate the significant words, which avoids information overload.
To summarize, the key contributions of the paper is at least two-fold:
We propose to incorporate phrases in the latent query reformulation method (IP-LQR) for the multi-hop QA problem. IP-LQR utilizes information from relevant contexts to reformulate the question in the semantic space. Then the updated query representations interact with contexts within which the answer hides.
We design a semantic-augmented fusion method based on the phrase graph. Phrases in the question are regarded as central nodes in the graph, and then phrases from relevant contexts are connected with them based on both literal and semantic relevance. The graph is finally used to propagate the information.
2. Related Work
The related work can be divided into three categories: pseudo-multi-document QA, MH-QA and dialogue QA.
Pseudo-multi-document QA. The research about pseudo-multi-document QA was pioneered by the information retrieval community and dates back to the 1980s. START [
10] is the first work in this field. It uses two databases to retrieve the query by default. If the question is not covered by them, START executes a matching process between words from questions and documents from the external knowledge base, and then returns relevant results. The following works focused on expanding the search space or improving retrieval efficiency, such as [
11]. However, these works are more like designing search engines rather than QA systems, as they all return the whole document that might contain the answer, instead of directly giving the answer. Recently, DrQA [
4] first introduced the neural networks into a pseudo-multi-document QA. It utilizes questions to retrieves the top 5 relevant paragraphs based on TF-IDF from Wikipedia and uses a QA model to extract the answer span from these paragraphs. Then, a rerank component is added to generate the final answer. The retrieve-read framework significantly outperforms the former methods in the pseudo-multi-document question and has quickly drawn wide attention. There are numerous studies that apply a similar method to construct their models and try to improve the performance in QA [
12,
13] or retrieve components [
14,
15,
16]. However, the retrieve–read framework cannot handle MH-QA since in many situations, golden contexts containing the answer are not readily retrievable with the question. Moreover, the framework uses the QA model on each paragraph separately, which fails to build the context-level interactions among documents.
MH-QA. To address the MH-QA problem, many works focus on applying GNN to represent the multiple relations between different documents. Ref. [
9] proposes a knowledge-enhanced graph neural network (KGNN) to build the connections of different entities. They firstly extract entities from documents as nodes to build an entity graph. Then, if there is a relation between two entities, they will set an edge between them in the corresponding place of an entity graph. However, it excessively depends on the knowledge graph. Once the knowledge graph is incomplete, the edges are missing as well. Ref. [
7] introduces a dynamically fused graph network (DFGN), concentrating on the dynamic update of graphs and documents. Similar to the former work, an entity graph is constructed firstly and a graph attention method is utilized to achieve information aggregation. After that, they update the representation of original sentences, questions, and documents based on the entity graph. Though the dynamic fusion layer has good performance, DFGN ignores some important information from explicitly irrelevant but implicitly relevant entities. Besides the graph-based method, some other works explore MH-QA from different perspectives. Ref. [
8] proposed a multi-task learning framework containing prediction, extraction, and explainability. The authors combined cascade models from the pipeline to strengthen the connections of different parts and obtained the final result, step by step. Ref. [
6] utilized a query-focused extractor (QFE) to capture the relevance between questions and documents. Inspired by the text summarization model, they extract the summary of documents with the participant of questions to ensure the coverage of target information. Intuitively, these models cannot build the relations between nodes well because they ignore the deep interactions between information. The above methods select entities as primary units, which might increase ambiguity in the information aggregation process. Moreover, in order to add explainability, they all select a single sentence as evidence of QA to obtain the answer, which means that the information of the remaining document is abandoned directly. To overcome these shortcomings, IP-LQR is developed in our research and proven to obtain promising performance.
Multi-hop KBQA. Multi-hop knowledge-based question answering (KBQA) is the complementary line of the research relevant to the complicated question answering. The task’s novelty lies in the supporting corpus (i.e., knowledge graph) of the question. Existing methods mainly fall into two approaches: information retrieval (IR), which retrieves answers from KG by learning representations of question and graph; and semantic parsing (SP), which queries answers by parsing the question into a logical form. In the IR-based category, Ref. [
17] applied manually defined and extracted features to capture the relevance between questions and KG, which are time consuming and cannot efficiently exploit question semantics. Regarding these issues, the following methods convert questions and related entities into representations and treat KGQA tasks as semantic matching between embeddings of questions and candidate answers [
18,
19,
20]. Typically, EmbedKGQA relaxes the requirement of answer selection from a pre-specified local neighborhood and first introduces KG embeddings into the task. After that, the similarity score is calculated as the clue to determine the final answer [
21]. SP-based approaches follow a parse-then-execute procedure. These methods [
22,
23,
24] can be briefly summarized into the following steps: (1) parsing relations and subjects involved in complex questions; (2) decoding the subgraph into an executable logic form, such as high-level programming languages, or structured queries, such as SPARQL; and (3) searching from KGs using the query language and providing query results as the final answer.
Dialogue QA. There is another branch of MH-QA, called dialogue QA [
25]. One big challenge of this task is effectively exploiting the conversation history. Choi et al. [
26] proposed a feature vector embedding and an answer vector embedding to respectively store the previous question features and answers. However, these methods ignore the previous reasoning history performed by the model when reasoning at the current turn. Huang et al. [
27] introduced the idea of integration flow (IF) to allow rich information in the reasoning process to flow through a conversation. Another challenge of dialogue QA is generating abstractive answers. Reddy et al. [
28] combined an extractive reading comprehension model and a text generator to tackle the problem. Yatskar [
29] designed a model which firstly makes a three classification prediction (yes/no/span) and outputs an answer span only if Yes/No is not selected. On top of that, there are also many studies concentrating on the conversational sentiment analysis area [
30] and dialogue systems with commonsense [
31] or audio contexts [
32]. Though these branches also lay on the multi-document, the goal is to generate conversational situations between humans and machines. Thus, we do not further discuss these topics in our paper.
3. Materials and Methods
This section introduces the framework of our method, namely, IP-LQR, which fuses high-quality phrases via a similarity graph and then reformulates the question representation for answer prediction. We first formally define the task and introduce the overall framework, the relevant graph construction in
Section 3.2 and latent reformulation in
Section 3.3.
3.1. Task Definition and Framework
Given a collection of paragraphs, the task of multi-hop question answering is to provide an answer to a question and also justify these answers with supporting facts (which are the facts that are necessary for reasoning to derive the answer). We refer to the sentences containing supporting facts as supporting sentences. The HotpotQA is under the distractor setting, which is also followed in this paper, and the number of paragraphs is limited to 10. The performance of such systems is measured by F1 scores of predicting answers (denoted as “Ans”) and supporting facts (denoted as “Sup”), as well as jointly (denoted as “Joint”).
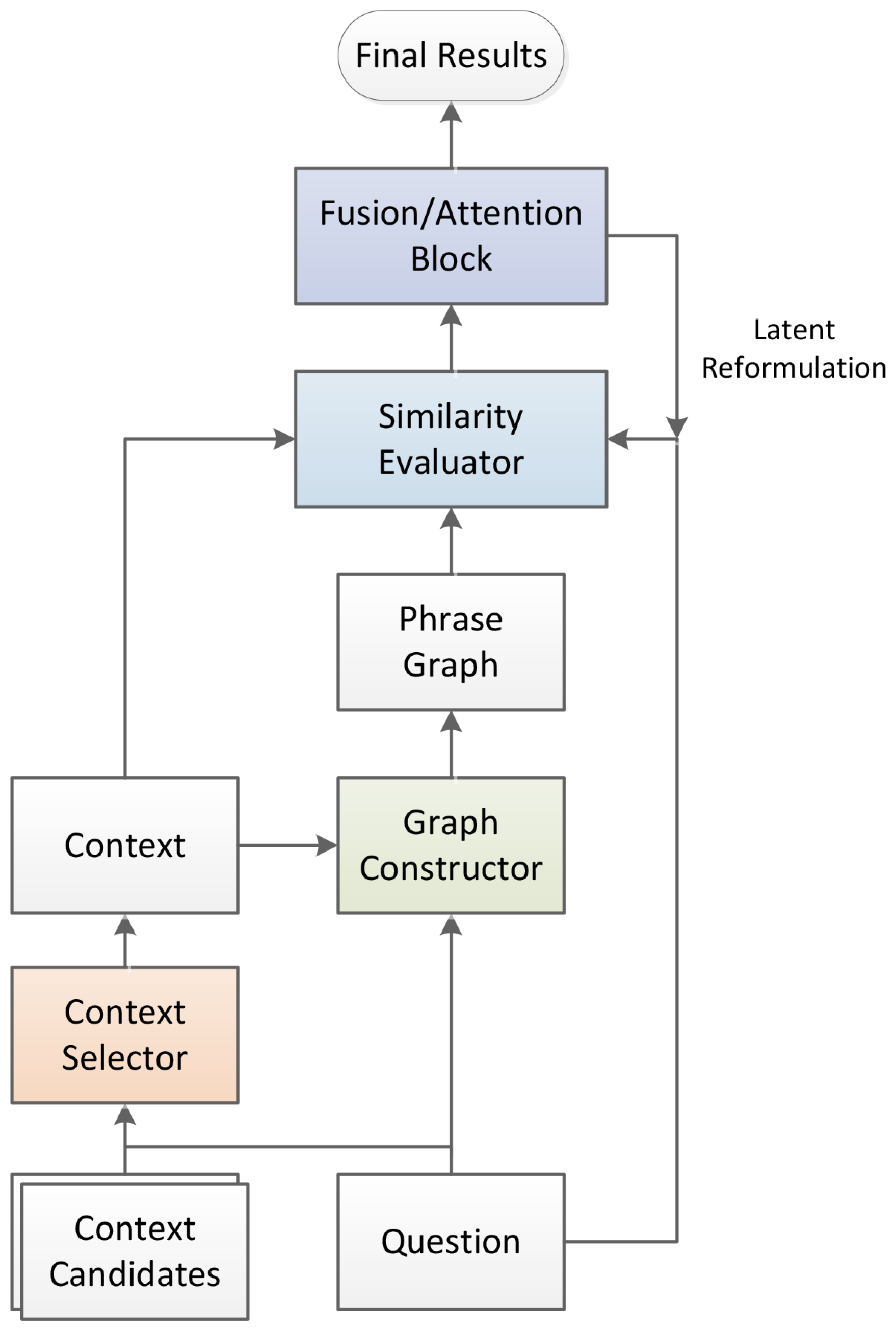
An illustration of the framework is given in
Figure 2. Our method starts with a context selector to filter irrelevant contexts with the question. Then, selected contexts and the question are put into the graph constructor to build a phrase graph. Based on the phrase graph, our model evaluates the similarities between phrases and the question to construct the input of the fusion block. After fusing, the final results are generated by the model. More details about these modules are discussed below.
3.2. Relevance Graph Construction
Constructing the phrase graph involves two steps: (1) context selection, to identify the context that is truly relevant to the answer; and (2) graph construction, where phrases are extracted and connected with each other. Based on these procedures, more high-quality phrases are captured, which also facilitates the following parts of the model.
3.2.1. Context Selection
Since phrases play a pivotal role in our model, it is of great importance to filter the irrelevant context in order to help us locate relevant ones, where quality phrases usually appear. We regard the task as a binary classification problem and design a selection network to achieve it.
The encoding layer of the network is based on pre-trained BERT [
33]. Denoting the
j-th paragraph as “context
”, we concatenate it with a question to form a latent representation,
where
is the class label produced by BERT,
Q is for the question, and
is for context
. Then, a binary classifier
is used to calculate a relevance score
between
Q and
based on the representation
of
token, and a sigmoid function follows.
where
serves as the evidence to determine the relevance between
Q and
.
In training, the label of the question–paragraph pair
(following Equation (
1)) is tagged as 1 if context
contains a supporting sentence, and 0 otherwise. The training sample is shown in
Figure 3. These annotated samples fine-tune pre-trained BERT to approach the downstream task in the high vector space. In inference, we follow the form above and use fine-tuned BERT to acquire the prediction score of each sample. The top
n-ranked paragraphs by relevance scores are chosen as the question-related context of
Q.
3.2.2. Graph Construction
As there is not a complete external phrase base, we apply the Stanford CoreNLP toolkit [
34] to recognize phrases from texts. In order to extract high-quality phrases, we design 3 grammar rules to refine the output: (1) the part of speech (POS) of the last word in the phrase is a noun, as key phrases in MH-QA are usually nominal phrases; (2) the POS of the start word in the phrase cannot be a verb, as phrases in the form of “verb + noun” are verbal phrases; and (3) two sequential phrases in one sentence are combined into a single phrase, as it is common that in domain applications, infrequent phrases are made of some frequently used phrases. Some examples of the refinement are given in
Table 1.
Afterward, all phrases are classified into two categories, according to whether or not they appear in the question. The phrases appearing in the question are called core nodes, and the others peripheral nodes. In addition, we supplement the graph with sentences in the question as core nodes and the context paragraphs and sentences thereof as peripheral nodes. For edges in the graph, we connect all peripheral nodes to every core node. In this way, we expect the semantic structure of relevant context with respect to the question can be sufficiently captured.
3.3. Latent Reformulation
In the information retrieval area, the query reformulation applies a set of techniques to (explicitly) rewrite the queries so that better search results can be returned. Inspired by this, we propose to incorporate reformulation into MH-QA and employ information from relevant parts of texts to augment the question via latent reformulation. The updated question can avoid the model taking irrelevant words into the fusion block and avoid invalid information passing.
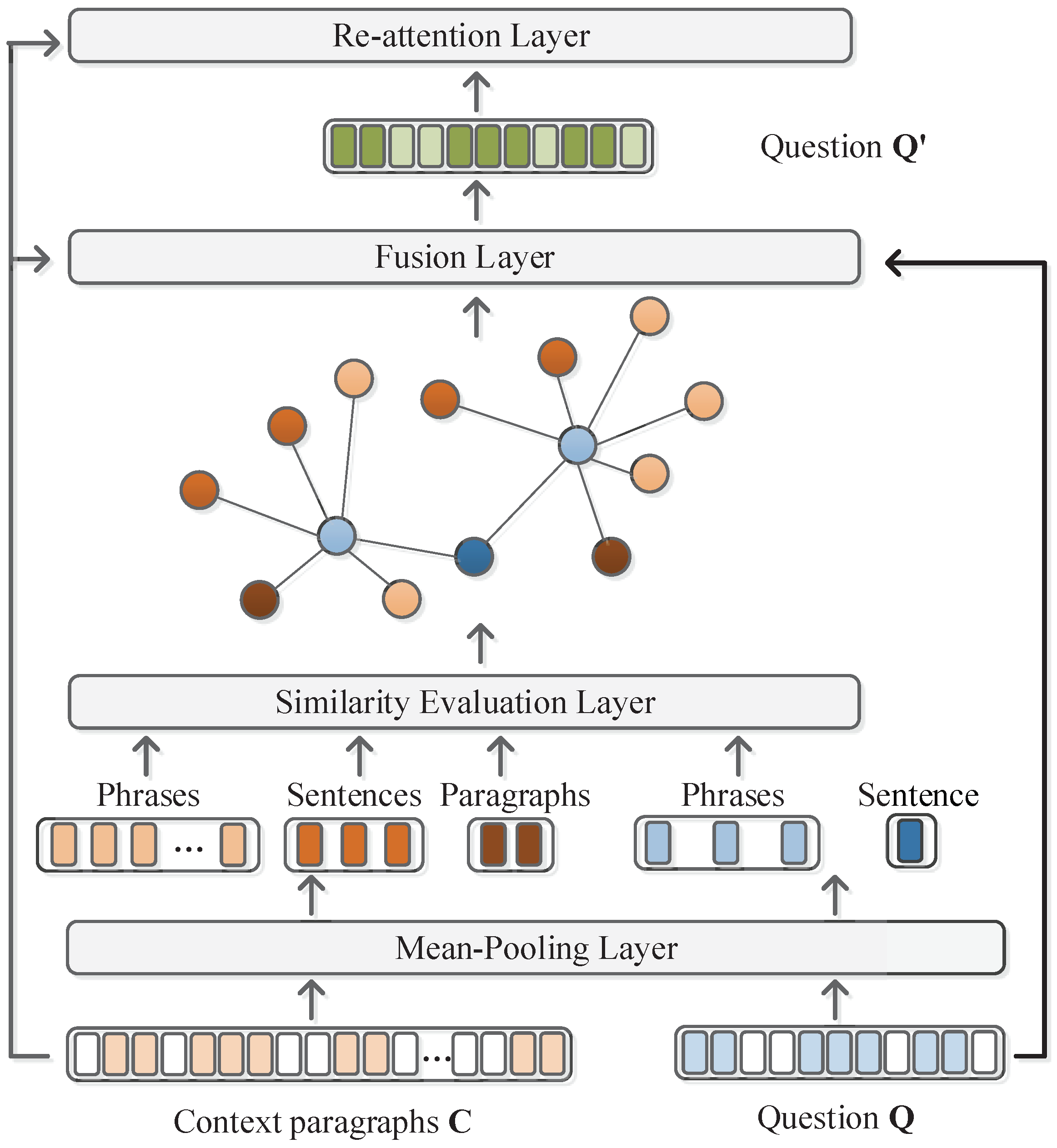
The reformulation framework is illustrated in
Figure 4. Given a context and the corresponding question, we first encode them into the high vector space and acquire the representations of phrases, sentences, and paragraphs via the
mean-pooling layer. Then, a similarity evaluation strategy is designed to calculate the weights of edges in the graph (cf.
Section 3.3.1). The fusion layer works as an information aggregation to latently update the original question’s representation (cf.
Section 3.3.2). Finally, we propose a re-attention mechanism to help locate the gold answer based on the new representation.
3.3.1. Similarity Evaluation
In the information retrieval community, studies usually locate the most relevant part in contexts with the question based on the max string similarity. The part is then employed to replace the confusing part in the question, which is named literal reformulation. Intuitively, the process tends to increase the irrelevant information of the question. The problem with literal similarity is that it sometimes introduces false negatives. Take the phrases “town plaza” and “city square” as an example. The two phrases imply the same annotation but have no literal overlapping. Obviously, underestimates the connection between synonyms. As a remedy, we further incorporate over embeddings to make up for the deficiency, which exploits the semantic relevance between phrases. Different from conventional methods, we reformulate the question on its representation, namely latent reformulation, based on and .
As
Figure 1 shows, many phrases have word overlaps or even are identical in MH-QA. Thus, we take a phrase “Soviet statesman” from questions as the start of reasoning. Then we use the character-level Levenshtein distance to measure the connection between two nodes,
a and
b. That is,
where
is the Levenshtein distance, and
is the string length.
Given that we already have word embeddings by using BERT in context selection, sentence embeddings are simply the average of the embeddings of words in a sentence. The output
is used to represent the paragraph embedding. Following Equation (
1), we can obtain representations
and
of phrases
a and
b from the representations of the question and the context, respectively. With the embeddings of phrases, an attention network is applied to calculate the semantic similarity. Mathematically,
where
and
are learnable linear projection matrices, and
and
are biases. So far, the edges in the relevance graph were weighted by
and
.
In addition, we employ a post-processing procedure over the similarity results. Considering the MH-QA’s core, the directly relevant phrases to the answer can hardly be identified via one hop. Intuitively, these phrases tend to exist in the sentences containing core nodes (i.e., phrases in the question). Thus, we emphasize that the phrases co-appear with the core node to concentrate on the true relevant phrases. To be more specific, a max-pooling strategy is leveraged to intensify the signal from highly relevant phrases. For each phrase t in the question and each supporting sentence, we obtain the maximum similarity score between t and every phrase of the sentence and use this value to update all the others’ values. Moreover, such post-processing can also prevent less relevant information from influencing the aggregation of important signals.
3.3.2. Reformulation via Fusion
After deriving the weighted relevance in the graph, we are ready to fuse them with the question representation. The information to be fused can be described by
where
denotes one of the
n core nodes.
m are the peripheral nodes’ set of core node
i.
denotes the character string of phrase
.
denotes the representation of nodes smoothed by
mean-pooling.
and
define transformations on the literal and semantic level representations, implemented with a multi-layer perceptron.
Then, we design a fusion layer to propagate the information over the graph. Using weighting by literal similarity,
where
is the combination of the computed update and the original representation,
are transformations on the representation, ⊙ is element-wise multiplication, and
is a balancing parameter. Similarly, the computation via weighting by semantic similarity can be conducted.
Finally, we obtain two globally aggregated representations as
Consequently, we define
,
as an information
clue to update the question. To latently reformulate the question, we compute the attention between questions and clues. We use the fusion layer to combine the information by
where
is the representation of the question, and
is the same layer as in Equations (9)–(11). Finally, we derive the new representation of the question, denoted by
. Additionally, we utilize re-attention mechanism [
35] to update context paragraphs. This post-processing is to help the model locate the correct span of the answer.
3.4. Multi-Task Prediction
Distinct from the popular structure of the prediction layer [
8], we conceive a revised prediction method via multi-task learning. It learns to infer (1) supporting context paragraph; (2) answer paragraph; (3) supporting sentences; (4) starting position of the answer; (5) ending position of the answer; and (6) answer type.
The intuition to incorporate two additional prediction tasks (i.e., supporting context paragraph and answer paragraph) is that in many situations, a single supporting sentence is insufficient to obtain the complete and accurate reason path. The task of predicting supporting context paragraphs is expected to help further reduce the number of context paragraphs from n (5 in our experiment) to what we really need (2 in our experiment). In this way, the information is filtered for effective answer prediction. Akin to that, the task of predicting the answer paragraph further helps to locate the selected golden context paragraph from the predicted context paragraphs.
Merging the tasks into a global optimization framework, we have
where
is a hyperparameter, and each component is defined by cross-entropy loss corresponding to the six tasks, respectively.








{kind=link}
{kind=link}
{kind=link}
{kind=link}