1. Introduction
Reliability-based design optimisation (RBDO) has attracted increasing attention in the field of structural-acoustic reliability. Structural-acoustic systems refer to complex systems comprising structures, coupled interfaces, and acoustic cavities [
1]. In engineering practice, unavoidable uncertainties, such as initial conditions, external excitation, material characteristics, boundary conditions, and external environment, exist [
2]. Accordingly, the RBDO of structural-acoustic systems with uncertain parameters has recently garnered extensive attention.
Reliability optimisation requires an appropriate uncertain model to quantify the uncertainty parameters. Recently, reliability optimisation models for structural-acoustic systems have been built to handle uncertain information, including probability models, interval models, and hybrid probabilistic and interval models. In the case of probability models, the uncertainty should be represented by a precise probability distribution of an uncertain parameter made available from many samples. In the case of interval models, it is not necessary to obtain the exact distribution function; instead, it is sufficient to represent the uncertainty of an uncertain parameter by its upper and lower bounds [
3]. In engineering practice, both uncertain models that mentioned above are common. This study mainly investigates reliability analysis and optimisation problems under hybrid probabilistic and interval models.
RBDO with hybrid probabilistic and interval parameters is comparatively complex and can be considered a three-loop optimisation problem. The inner and middle loops help evaluate the objective function and limit state function, respectively, and analyse their probabilistic statistics in extreme cases. The computational burden in each iteration is considerable due to the large number of uncertainty analyses of the inner and middle loops [
4]. Two common methods have been employed to increase the computational efficiency of RBDO with probabilistic and interval variables. One of them is decoupling, which converts a nested optimisation problem into a single-loop optimisation problem. Du et al. [
5] made an early attempt to convert a hybrid RBDO problem of the inner loop into a single-loop optimisation problem. This method was further extended to a hybrid RBDO problem with dependent interval variables [
6]. Subsequently, Kang and Luo et al. [
7,
8] developed a valid single-loop decoupling method based on linearisation and optimality conditions for performance functions. Torii and Lopez et al. [
9] proposed a decoupling sum method that can be applied to different reliability analysis methods based on the sequence optimisation and reliability evaluation method. Wang C et al. [
10] proposed a novel reliability-based optimization method for thermal structure with hybrid random, interval, and fuzzy parameters.
The computational burden in uncertain optimisation can also be reduced by increasing the computational efficiency of probabilistic interval analyses. The efficiency problem in an uncertain analysis with probabilistic and interval variables is typically solved using the perturbation method and polynomial chaos expansion (PCE) method. Xia et al. [
1] utilised an uncertain analysis method based on the perturbation method to solve the objective function and reliability constraint, effectively reducing the computational burden in the RBDO of structural-acoustic systems. Although the perturbation method is computationally efficient, it has limitations in the case of structural-acoustic problems with less uncertainty [
11]. Generally, the polynomial expansion method can be divided into the Kriging model expansion, gPC expansion, Chebyshev expansion, and arbitrary PCE methods. Yang and Liu et al. [
12] proposed a combined Monte Carlo simulation (RS-MCS) method, and a novel optimisation method for Karush–Kuhn–Tucker conditions was proposed to increase the efficiency of the reliability analysis. Wu et al. [
13,
14] used the gPC expansion and Chebyshev expansion methods to construct a polynomial basis with probabilistic and interval parameters, respectively, and calculated the response of a hybrid uncertain structural-acoustic system. However, because of the limitations of the gPC expansion method itself, a hybrid uncertain problem with an arbitrary probability density function (PDF) cannot be solved. Yin et al. [
15] integrated the aPC expansion with the Chebyshev expansion method to improve the computational accuracy when solving a hybrid uncertainty problem with arbitrary PDFs. Hamdia K M et al. [
16] operate the application of PCEs in sensitivity analysis for the mechanics of tendons and ligaments. Compared with the perturbation method and other surrogate model methods, the arbitrary PCE method has the following advantages. First, the statistical characteristics of a system’s response can be acquired using its expansion coefficient, avoiding complex probability integration; second, surrogate models with different fidelity requirements can be established through polynomial optimisation.
The calculation efficiency in solving uncertain engineering problems using the arbitrary PCE method mainly depends on the solution efficiency of the expansion coefficient. The original approach to solving the expansion coefficient involves applying the total-order expansion method, in which the polynomial expansion orders are identical for different variables. The novel Legendre polynomial expansion method developed by Wang et al. [
17] utilises the full-order expansion method and Latin hypercube sampling to compute the expansion coefficients. However, this approach has a comparatively higher computational cost than the Taylor-based approach. A sequential sampling strategy has been developed to increase the efficiency of PCE sampling. Wu et al. [
13] used the total-order expansion method and sequential sampling to propose a novel high-order polynomial surrogate model, which would be unstable if other sampling methods were used instead of the Chebyshev sampling method. Zhu et al. [
18] used the total-order expansion method and sparse-grid sequential sampling to develop a novel sparse-polynomial expansion method. The computational efficiency was significantly improved without compromising the precision using this method. However, none of these methods are suitable for cases where the number of variables is extremely large, and the expansion orders vary significantly for different variables. In a structural-acoustic system, the sensitivity of the system response to different parameters varies significantly. For a structural-acoustic problem, Yin et al. [
19] adopted a tensor-product method to calculate the expansion coefficients; this method can retain different polynomial expansion orders for different variables. However, with an increase in the number of input parameters, the computational cost quickly increases, making it unsuitable for multivariate cases. To further reduce the computational cost, Thapa et al. [
20] proposed a novel method to obtain stochastic models of responses based on an adaptive algorithm. This method firstly constructs the initial surrogate model
by first-order expansion, then constructs the high-order surrogate model
by adaptive convergence criterion. The advantages of the adaptive PCE include the following: (1) The surrogate model of the adaptive PCE method is simple and convenient for optimization; (2) less sampling points are required to construct the surrogate model, which means higher computational efficiency can be obtained. Meanwhile, owing to its substantial computational savings, the adaptive PCE has been widely implemented in many applications, such as nonlinear random vibration analysis [
21], nonintrusive projection [
21,
22,
23,
24,
25], stochastic finite element analysis [
26,
27], and benchmark problems [
20].
Clearly, many uncertainty analysis algorithms have been proposed to increase the calculation efficiency of uncertain optimisation [
28,
29], particularly the adaptive PCE method, which has a high calculation accuracy and efficiency. However, when constructing a surrogate model for a system with high-dimension variables and strong nonlinearity, the conventional adaptive PCE will be also inefficient. The main reason is that lots of polynomial update iterations are required from the construction of initial surrogate model
to the final high-order surrogate model
, while the computational burden of each iteration is relatively large for uncertainty problem with high-dimension variables. It should be noted that strong nonlinearity usually exhibits between the system response of the actual structural-acoustic problem and part of variables. Therefore, it is eagerly to develop a method for uncertainty analysis and reliability-based optimization for structural-acoustic problems.
In this paper, a novel anisotropy-based adaptive PCE method, called ABAPC, was developed to address the computational cost and accuracy problems in the reliability optimisation of structural-acoustic systems. Based on this method, hybrid uncertainty quantification and RBDO were performed on a structural-acoustic system. First, an adaptive PCE was suggested to reduce unnecessary computations in the polynomial expansion mode. Subsequently, an anisotropy-based initial surrogate model was proposed to handle the anisotropy of structural-acoustic systems and further reduce the computational burden. Thus, to decrease the number of polynomial basis terms and effectively increase the computational efficiency in the reliability optimisation of structural-acoustic systems, a novel adaptive algorithm was implemented.
The remainder of this paper is organised as follows. In
Section 2, a moment-based arbitrary polynomial chaos (MAPC) approach for hybrid uncertainty quantification is described. In
Section 3, we propose an anisotropy-based adaptive PCE method, and in
Section 4, we discuss the application of this method to the RBDO of a structural-acoustic system. In
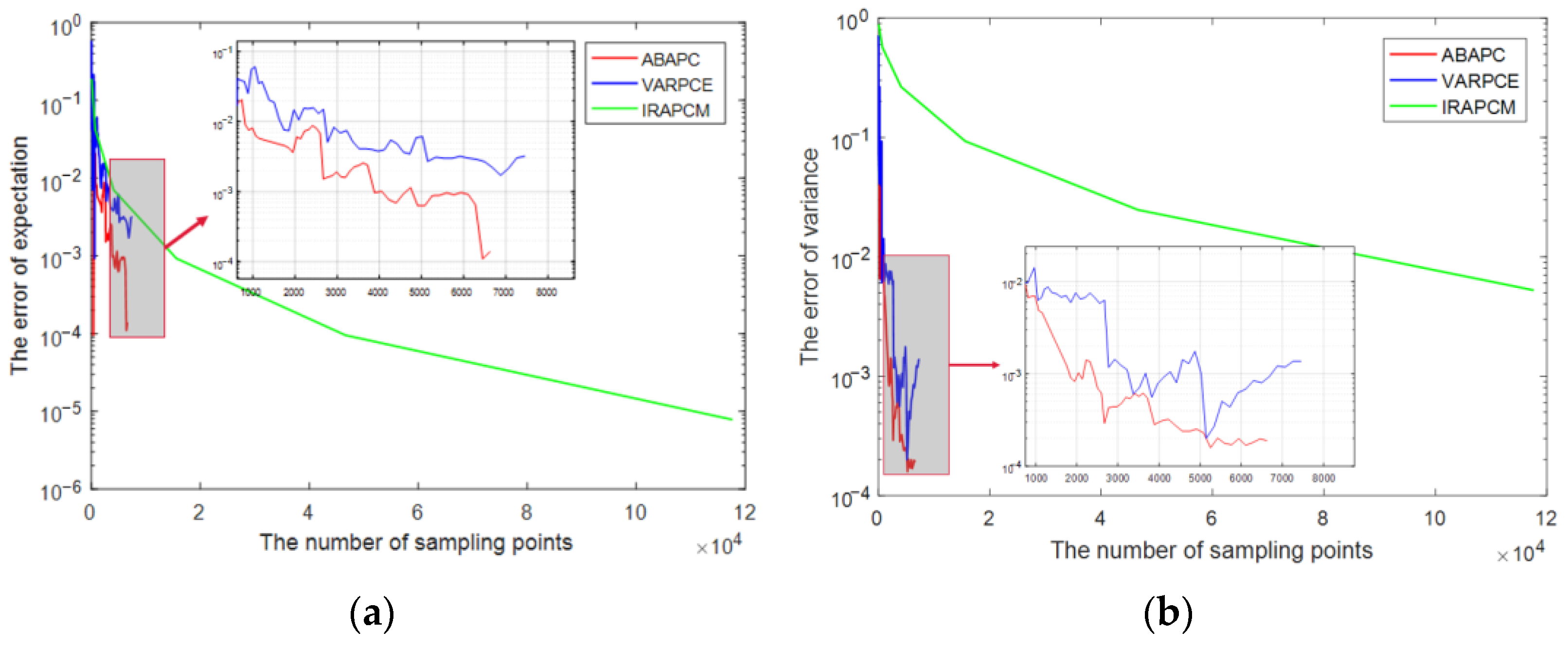
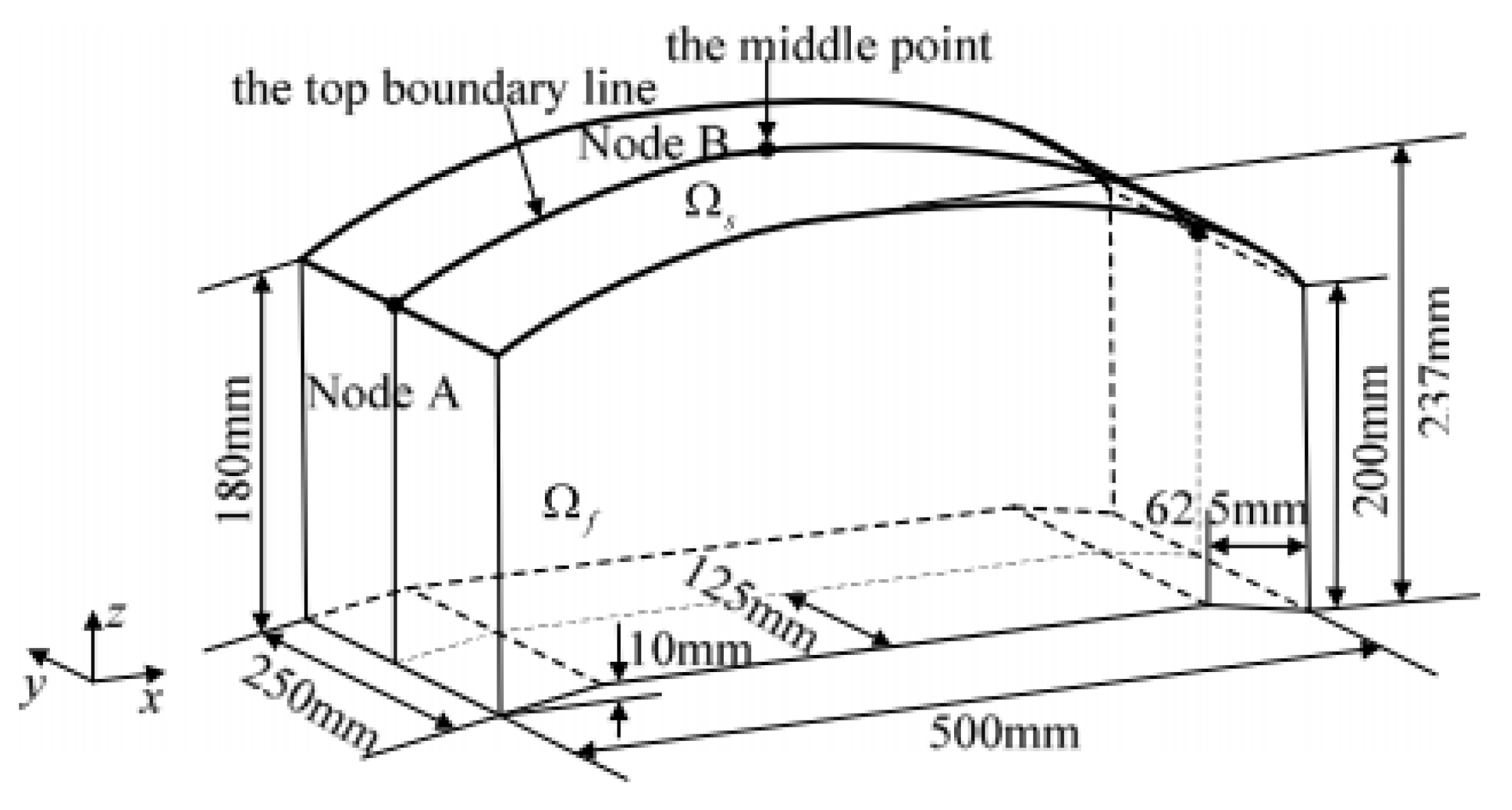
Section 5, the efficiency and effectiveness of the ABAPC are demonstrated by solving two numerical examples and optimisation problems of a structural-acoustic system. Finally, the conclusions are presented in
Section 6.
3. Anisotropy-Based Adaptive Polynomial Chaos Expansion Method
The response of an uncertain structural-acoustic system exhibits anisotropy, and the complexity of each dimension varies significantly. Existing expansion methods are inefficient in solving multi-dimensional and strongly anisotropic problems. Moreover, an excessive number of polynomial basis terms can increase the computational burden of optimisation when using a surrogate model. To solve the above problems, the proposed method employs the following steps. First, the anisotropy-based polynomial chaos expansion is used to construct the initial surrogate model in high-order and multi-dimensional problems. Second, an anisotropy-based adaptive basis growth strategy is proposed based on the adaptive strategy to reduce the estimation for the coefficients of the PCE method and improve the computational efficiency of the PCE method. Finally, an adaptive basis truncation strategy based on the contribution of the variance was introduced and implemented to solve problems with probabilistic and interval parameters. The specific steps of the ABAPC method proposed in this section are as follows.
3.1. Anisotropy-Based Initial Surrogate Model
Treating each dimension isotropically means that each dimension is treated in the same manner. However, this assumption only applies to problems in which there is little difference in the complexity of each dimension. In other words, if the problem exhibits significant differences between dimensions, the method requires a large number of polynomial update iterations to converge. Thus, it is desirable to consider the anisotropy in the PCE-based adaptive basis truncation strategy [
33,
34]. Therefore, an anisotropy-based initial surrogate model was proposed in this section to address this problem.
The anisotropy-based initial surrogate model can be built by obtaining an initial expansion-order vector that considers the complexity of each dimension, which can be defined as follows:
where the initial expansion order of the
rth variable in the anisotropy-based initial surrogate model is defined as
, and
denotes the
l-dimensional initial expansion order vector. Therefore, based on the idea that transforms a multi-dimensional problem into a one-dimensional problem, the main steps for obtaining the initial expansion order of each dimension in the PCE method are as follows:
Step 1: Input dimension r of the PCE and treat the other dimensions as constants;
Step 2: Obtain the response of the PCE by the method described in
Section 2.2.;
Step 3: Calculate the relative errors in the expectation and variance by Equations (20) and (21);
Step 4: If the maximum value of the errors is less than the given tolerance , stop
Otherwise, the order is increased to , and Steps 3 and 4 are repeated until the error is satisfied;
Step 5: Steps 1–4 are repeated until all the initial expansion orders for l dimensions are obtained. Output the initial expansion-order vector .
Here, the relative errors in the expectation and variance can be determined as follows:
In Equations (20) and (21), and represent the reference results obtained using the Monte Carlo method (MCM). The number of sampling points for the random (interval) variables of the MCM was set to 10,000. The number of sampling points for obtaining is determined by the expansion order. The precision of the PCE method was obtained by iteratively increasing the order of the PCE until the maximum value of and is less than the given tolerance , which was set as 10−2 in this study. Further applications of the anisotropy-based initial surrogate model are presented in the next section.
3.2. Anisotropy-Based Adaptive Basis Growth
The adaptive enrichment of the polynomial basis proposed in [
20] treats each dimension isotropically, leading to unnecessary computations for problems with strong anisotropy. To reduce the estimation of the coefficients of the PCE method and increase its efficiency, a weight vector based on the anisotropy-based initial surrogate model was proposed. A new basis set was obtained by adaptively adding a new polynomial basis based on the weight vector.
Iteratively increasing the order of the PCE is the conventional method for enhancing the precision of the PCE approach with a given number of samples. Therefore, a PCE model with order
can be constructed based on existing available information of the PCE method with the order
. Subsequently, the number of additional polynomial basis terms added can be represented by
and is expressed in Equation (22).
Here, Num.() represents the cardinality of the set. increases exponentially with increasing retained order of the PCE, which significantly increases the computational amount for obtaining the response of an uncertain structural-acoustic system/(multi-dimensional problems). To mitigate this effect, a polynomial basis can be selected a priori by implementing specific strategies. However, because the rank and sparsity of solutions are typically not known in advance, the importance of the polynomial basis cannot be realized in advance. Therefore, an adaptive enrichment basis polynomial is required to extract the maximum amount of information from a given number of samples.
The adaptive enrichment of the old basis set of order
is achieved by adaptively adding a new polynomial basis in blocks to obtain new basis sets of order
, instead of adding all the polynomials of
. The number of polynomial basis terms in each block
is given by Equation (19). Each chunk is assigned an equal number of polynomial basis terms. However, the last one contains leftover basis polynomials if this requirement cannot be satisfied. The total number of chunks of
represented by
is given by Equation (24).
Here, ⌈ ⌉ represents the real part of the number. The basis set of the early adaptive selection algorithm, proposed by A at al. [
20], was gradually enriched by adding
new polynomials at a time. In this study, the basis set of the PCE method was updated by adding a group of polynomial basis
to the old basis set
, obtaining a new set
, which is expressed as follows:
In the adaptive enrichment of a polynomial basis based on the adaptive basis truncation strategy, each dimension is treated isotropically. The expansion order of each variable in each iteration is increased by one level. To consider the anisotropy in the operation of adaptive enrichment,
can be defined as an
l-dimensional weight vector for each variable. The anisotropy-based adaptive enrichment of the existing basis set, which includes a polynomial basis with the initial expansion order
, is to obtain new basis set with an updated order
by adaptively adding a new polynomial basis based on
. After anisotropy-based adaptive enrichment of the existing expansion-order vector, the updated expansion-order vector is defined as follows:
where
denotes the updated
l-dimensional expansion-order vector. The term
m represents the expansion order to be increased for each variable,
represents the integral part of the value in Equation (26), and the weight vector
can be obtained from Equation (27).
As mentioned above, the anisotropic method can account for problems in which each dimension is not equally important by appropriately setting the weight vector. This can be explained by the fact that, the higher the weight value in the anisotropic formula, the higher the importance. For example, the isotropic adaptive basis truncation strategy is a special case for the anisotropic method. The initial expansion orders of each dimension and components of the weight vectors are equal. This implies . In other words, the anisotropic method can be treated as a more generalised version of the isotropic adaptive-basis truncation strategy.
For instance, a four-dimensional problem is considered as in Equation (28):
where
represents the independent uncertain parameters, which can be assumed as a linear function of the random variable.
Table 1 presents the uncertainty information and deformed function of each uncertain parameter. In this case, each random variable is uniformly distributed in the range [−1, 1].
From
Table 1, the order vector of the initial expansion order can be set to
. The weight vector
can be calculated using Equation (23).
Table 2 presents the order vectors of the proposed approach and the isotropic adaptive polynomial chaos expansion (IAPCE) approach updated as an increase in
m. The number of sampling points can be set as 1.5 times the number of basis terms before the basis truncation operation.
As shown in
Table 2, the sampling points in the ABAPC method are fewer than those in the IAPCE method. The advantages of the proposed method become increasingly evident with increasing number of variables.
Traditional arbitrary PCE method requires extensive calculation of the expansion coefficients. However, the adaptive expansion method can require a smaller number of estimates for the coefficients of the PCE method because it adaptively adds a new polynomial basis in chunks. This improves the computational efficiency of the polynomial expansion method. In addition, the computational cost of the PCE method is expected to be reduced further, as described in the next section.
3.3. Basis Discarded Based on Variance Contribution
Adaptive basis enrichment can help reduce the computational cost; however, it is inapplicable when the basis set already contains many basis terms. The contribution to the precision of the response varies with respect to the basis terms. Thus, only a few basis items are significant for the influence of the response analysis, and the others can be discarded. Consequently, to refine the basis terms, an adaptive basis truncation strategy was developed in [
20]. However, this strategy is applicable only to problems with random parameters. Therefore, it is introduced in this study and implemented to solve problems with probabilistic and interval parameters.
For a hybrid probabilistic and interval method, the interval variables can be considered constant to determine the bounds of the expectation and variance. The variance of a response can be expanded through the sum of the variances of the polynomial basis terms, which is defined as follows:
where
represents the variance of the basis term with the
th (
) interval variable in the basis set
. The sensitivity of the basis term for each random variable is given by Equation (31).
where
denotes the variance of the basis term with the
th (
) interval variable in the basis set
. Here,
denotes the variance contribution vector of the basis term of each interval variable, and
denotes the variance contribution vector of all the basis terms. Different interval variable polynomial basis terms correspond to different numbers of random-variable polynomial basis terms. Meanwhile, with different
, the number of vectors
varies.
The tolerance is given by Equation (36). The polynomial basis will be preserved if its sensitivity is above the given tolerance
, whereas the unimportant polynomial basis
can be ignored. The new refined basis set
is given in Equation (38). The basis terms are retained when the sensitivity of the basis term is greater than a given tolerance; otherwise, they are discarded when the basis term is less sensitive than the given tolerance.
The choice of
significantly influences the precision and efficiency of the PCE method.
and
represent the variance of the PCE method used to determine whether to perform basis refinement.
denotes the absolute percentage difference between
and
. The optimal value of
is selected as follows. If the absolute percentage difference
is less than the reference value
,
is divided by a factor of 10 until
is less than
, which is expressed in Equation (40).
where
t is the iterations of
.
3.4. Adaptive Sampling Scheme
The adaptive sequence sampling scheme proposed in [
20], which combines growth strategies and a sequence sampling scheme, can deal with many function evaluations with a large number of random input parameters. Hence, an adaptive sequence sampling scheme was introduced in this study to calculate the expansion coefficient.
3.4.1. Initial Sampled Set
In this section, the candidate set, represented by
, is generated using the Gaussian integration sampling scheme. The sampled set can be represented using
. The elements of the initial sampled set were determined using the maximin metric from the candidate set. The scalar-valued criterion function of the maximin metric [
35], as expressed in Equaiton (41), is primarily used to sort the competing sampling sets.
where
denotes the number of integration points for the candidate set.
represents a comparatively large integer that can be set to 100.
represents the
ith integration point in the
space.
represents the Euclidean distance, which is expressed as follows [
36]:
where
represents the
i-th sampling point of the
-th variable,
q represents the number of variables, and 2 represents the Euclidean norm.
The uniformity of the sampled set is greater if the value of
decreases. According to 35,
is recalculated to select a new sampling point each time, and the new sampling point with the minimum
is placed in the sampling set
to update the sampling set. This process is repeated until all the elements are identified.
can be rewritten as follows:
where
denotes a new sampling set that includes both the original sampling point
and the recalculated sampling point
. The number of sampling points in
is represented by
.
3.4.2. Sampling Technique for Sampling Point Selection
The specific procedure for sampling point selection for adaptive growth strategies is as follows. First, new sampling points in
can be acquired using the minimum value of the maximin metric
, which can be calculated using Equaiton (42). The previously obtained sampled set
can then be reutilised as a subset of the expansion, and the variance is recalculated by
. The relationship between
,
, and
can be expressed by Equation (44).
The adaptive strategy considers both the original and updated basis sets; thus, the accuracy and computational cost are significantly affected. Additionally, the calculation of the sampling point was based on the LSM. Thus, A denotes the matrix of the polynomial basis used in this approach, which needs to be a full-column rank matrix. The rank of matrix A can be determined using singular value decomposition.
When the rank of A equals n, it is determined to be a full-column rank matrix. The rank of A was calculated for each sampling point. If the rank is not equal to n, the sampling point is deleted, and both the sampling and candidate sets are updated. The above steps are repeated until the number of sampling points retained in the sampling set is 1.0–1.3 times the number of expansion coefficients.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}