3.1. Non-Linear Time-Series System Identification via Recurrent Neural Networks
ANNs serve as a potential source of models that capture the dynamics of highly non-linear systems sufficiently well while being relatively easy to obtain and evaluate online, and RNNs are a sub-class of ANNs that are structured to better capture temporal dependencies in the system. RNNs are particularly useful for making p-step ahead predictions of state variables for predictive control, because the prediction for time-step p depends on the present state and all control actions in time-step . The prediction for time-step used in the above prediction for time-step p depends similarly on the present state and all control actions in time-step , and so on.
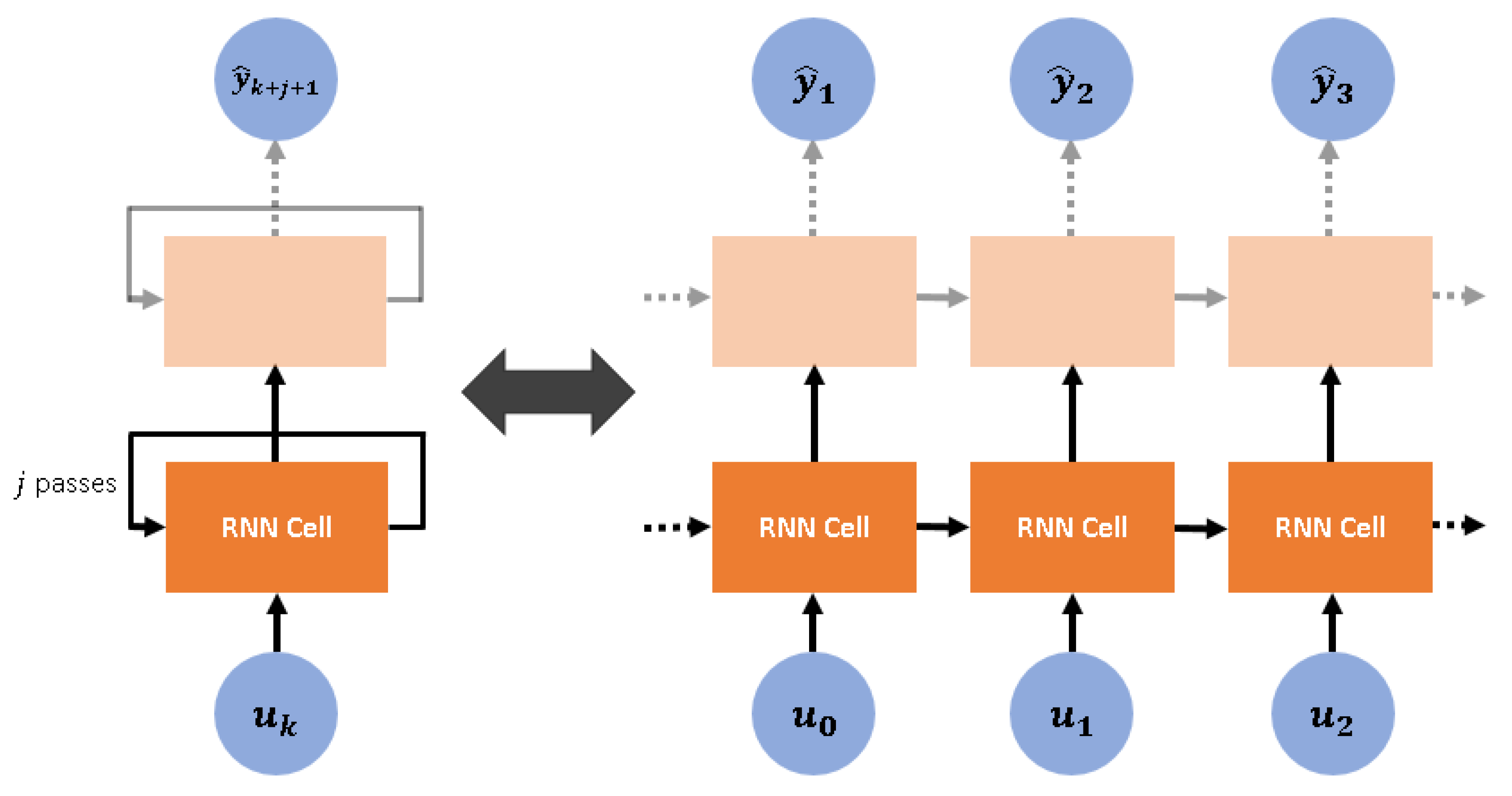
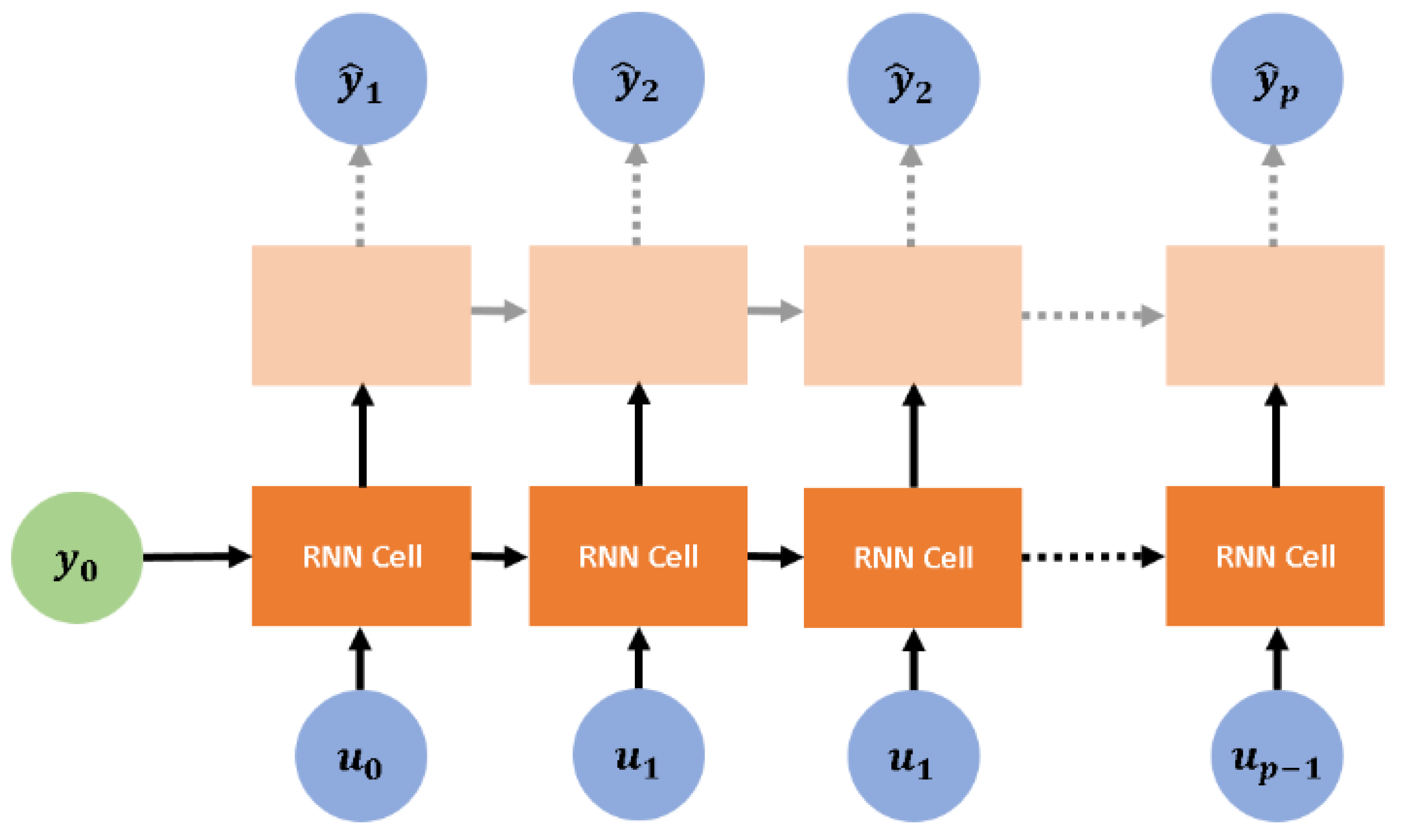
Figure 3 illustrates the structure of an RNN layer in its compact and unfolded forms. The unfolded form reveals the repeating cells forming each layer, and each cell is taken in this study to represent a time-step, such that the state of the cell representing time-step
serves as the input for a cell representing time-step
. Each cell contains
N number of hidden nodes that encode the state representation, where
N is user-specifiable. The equations that mathematically characterise a single RNN cell in a single-layer RNN are as shown in Equations (
7) and (8) below:
where
is the discrete-time index with
p the prediction horizon,
the (hidden) state of the cell representing time-step
k,
the cell input,
the cell output which corresponds to the state vector prediction for time-step
k,
the offset vectors,
and
the input-to-hidden-state weight matrix and the hidden-state-to-hidden-state weight matrix respectively, and
an activation function that is applied element-wise.
is initialised in this study by using
.
Equations (
7) and (8) are generalisable to deep RNNs containing more than one layer. For an
l-layer RNN, the activation functions for layers
take the form
, and the input-to-hidden-state weight matrices have dimensions
instead. Deep RNNs may be preferred to single-layer RNNs for their enhanced ability to learn features of the dynamical system that occur “hierarchically”, but this comes at the expense of longer RNN training times stemming from more parameters to train.
The regressors required to predict
are henceforth represented by
, and they are introduced into the RNN in a fashion illustrated in
Figure 4. Equation (
9) below serves as a shorthand to describe the RNN:
An RNN is characterised by the values of
,
,
and
for all layers, and these values constitute the set of parameters. These parameters are learnt from training data by minimising the predictive error of the model on the training set as determined through a user-specified loss function. The learning process is performed through the back-propagation through time (BPTT) algorithm that estimates the gradient of the loss function as a function of the weights, and an optimisation algorithm that uses the calculated gradient to adjust the existing weights. The adaptive moment estimation algorithm (Adam) [
33] is an example of an optimisation algorithm that is widely used.
The RNN parameters may be difficult to train in some cases due to problems with vanishing and exploding gradients, and RNN cells with different structures can be used to circumvent this issue. Long Short-Term Memory cells (LSTMs) were developed to address these problems, and they are used as the repeating cell in this study. Further details on LSTM cells may be found in the
Appendix B.
To generate the data set for training the RNNs in this study, a numerical model of the CSTR system based on Equations (
2)–(4) is needed, because this data consists precisely of this system’s response to MV perturbations. This numerical model was implemented in Python version 3.6.5, and its temporal evolution between sampling points was simulated using the explicit Runge-Kutta method of order 5(4) through the
scipy.integrate.solve_ivp function.
MV perturbations are then introduced into the system to obtain its dynamic response. This procedure mimics the manual perturbation of the system through experiments, which become necessary in more complicated reaction systems whose reaction kinetics and overall dynamics resist expression in neat analytical forms. These perturbations take the form of pre-defined sequences of control actions, , where the “exp” subscript refers to “experiment” and represents the final time-step for the experiment. These control actions are separated by .
To simulate the system’s dynamic response to the experimental sequence, the control actions associated to the element in this sequence, , , are applied at time-step k for a period of , during which the system’s evolution with this MV is simulated using the Runge-Kutta method of order 5(4). Once elapses, is applied with the system evolution proceeding in the same manner. This procedure repeats until the final time-step, , is completed.
A history of the system’s experimental dynamic response is associated to each experimental sequence, which takes the form of
.
is the measured system output at time-step
k after
has been applied to the system for a period of
. This history corresponds to the labels in machine learning terminology, and the data set is thereafter constructed from both the experimental sequences and their associated labels. For the
p-step ahead prediction problem, each data point thus takes the form
with the associated label
,
.
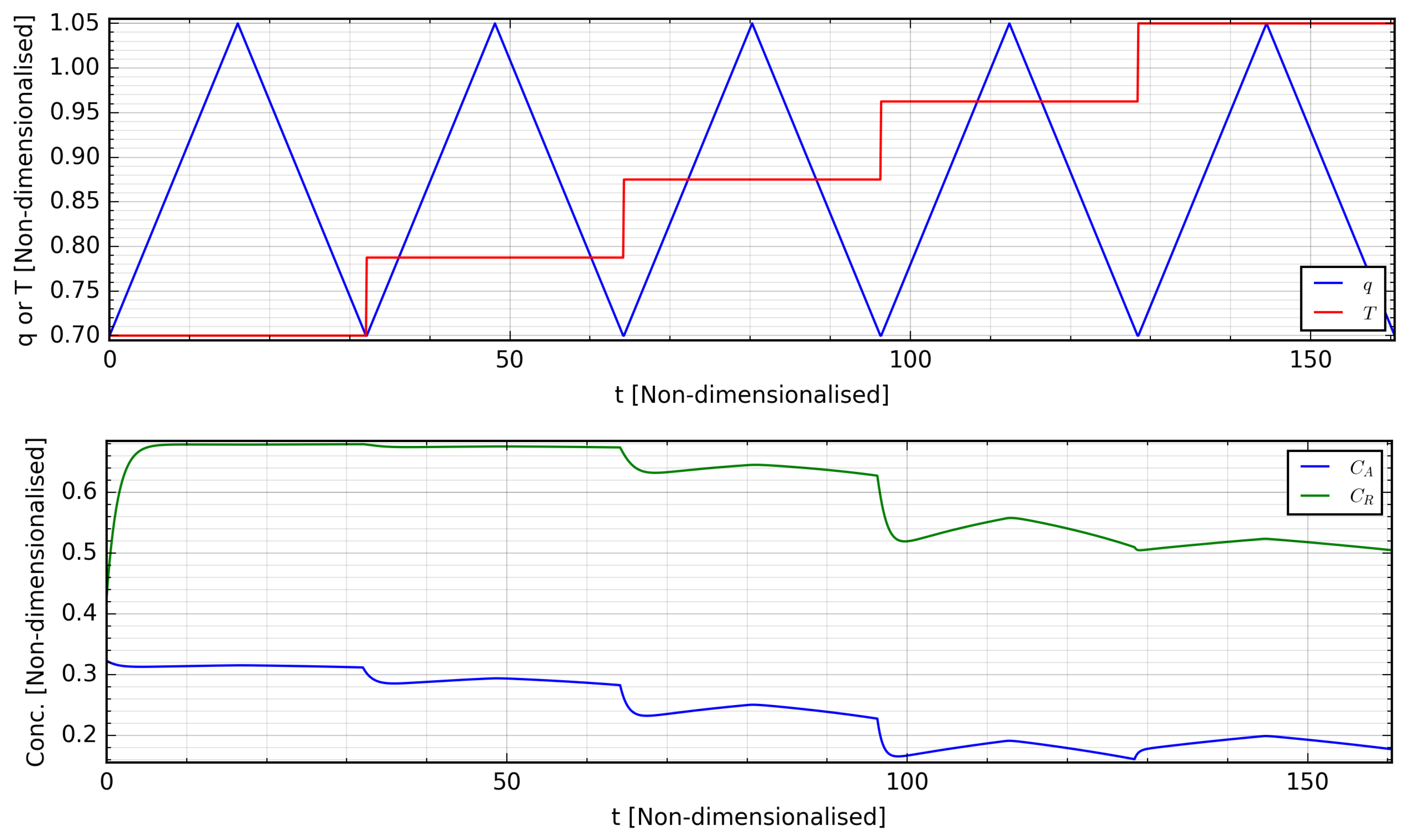
data points can thus be extracted from each experimental sequence. Multiple experimental sequences can be constructed by perturbing the MVs in different ways, and such a sequence is shown in
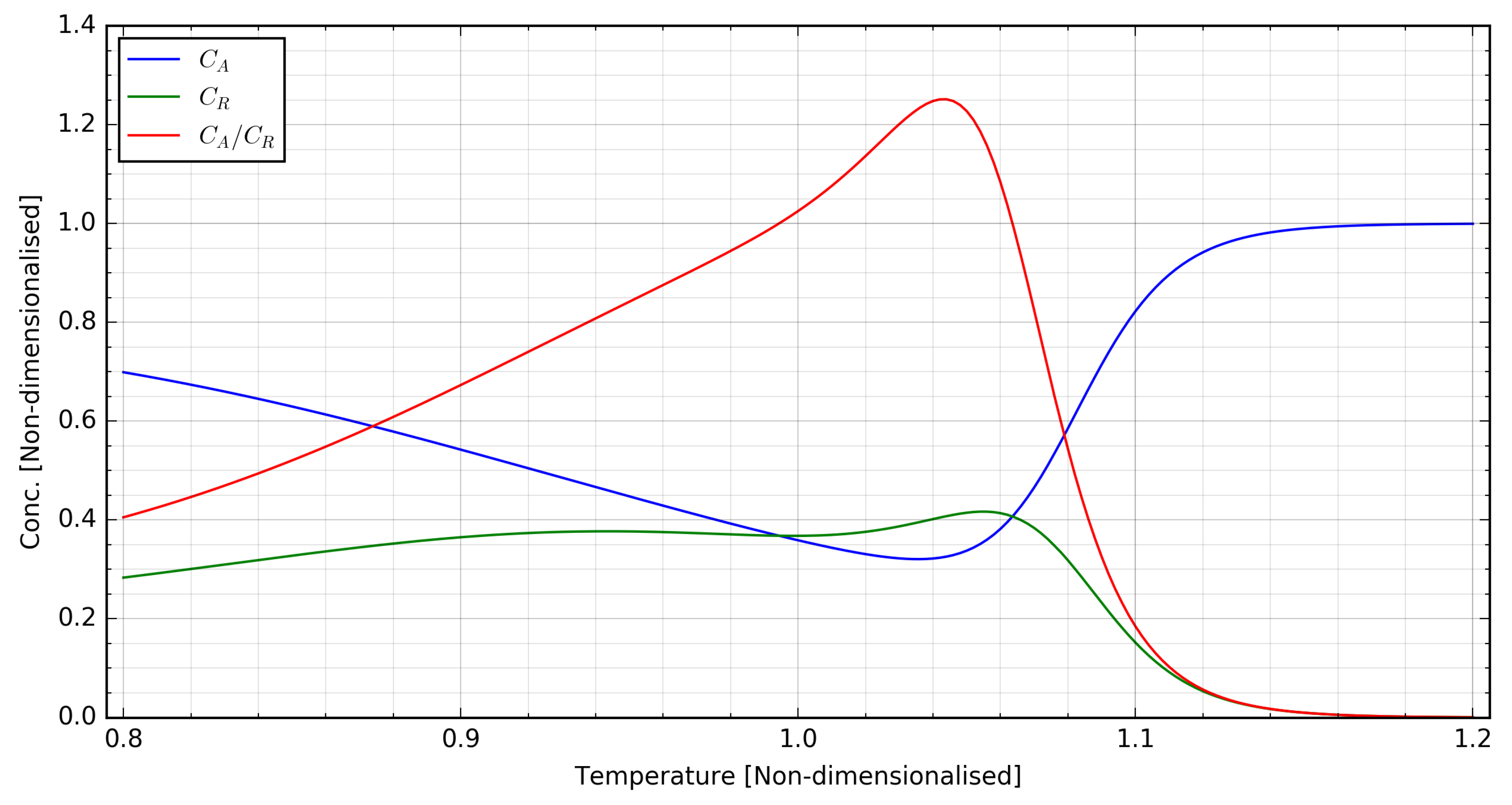
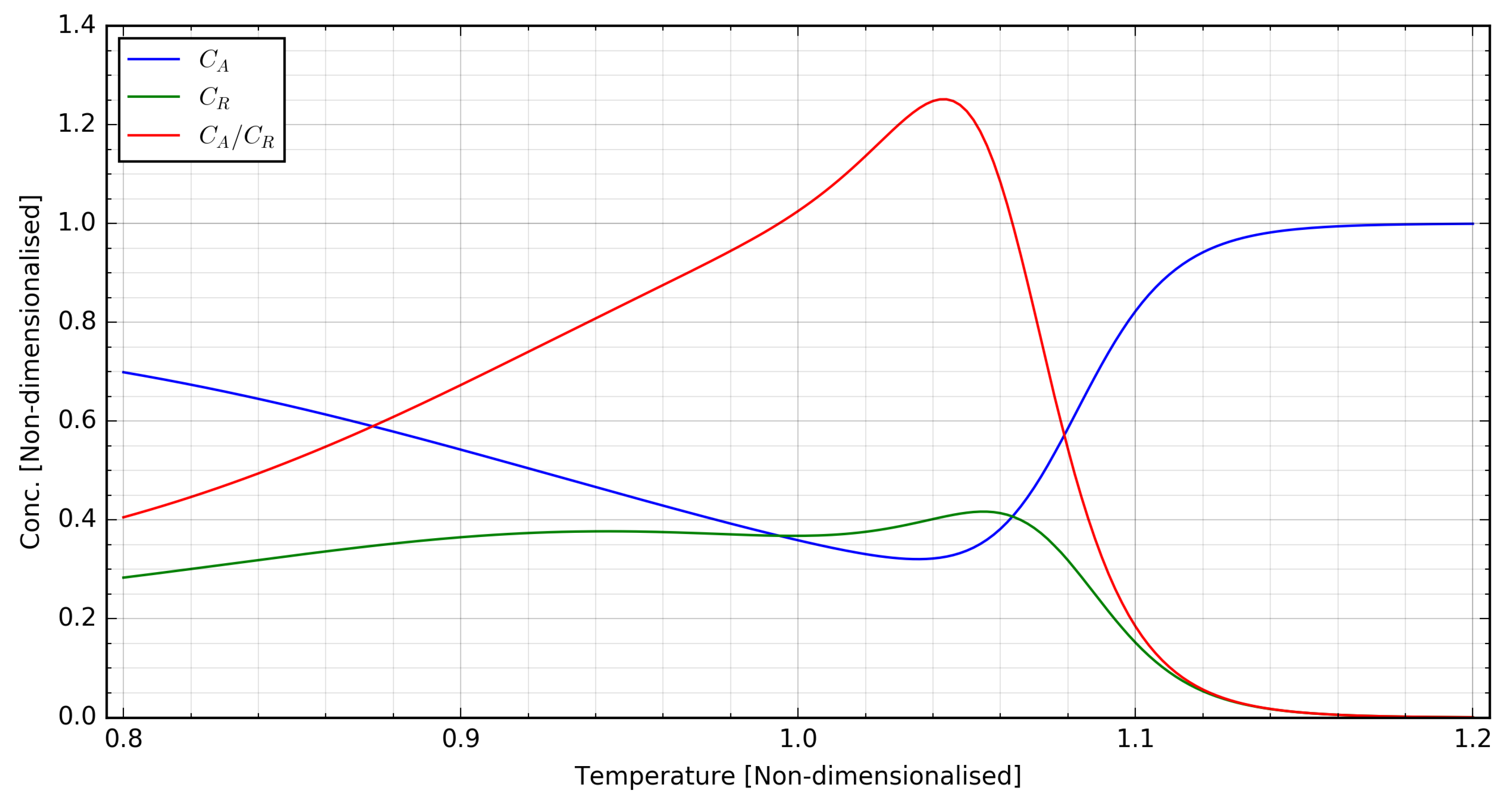
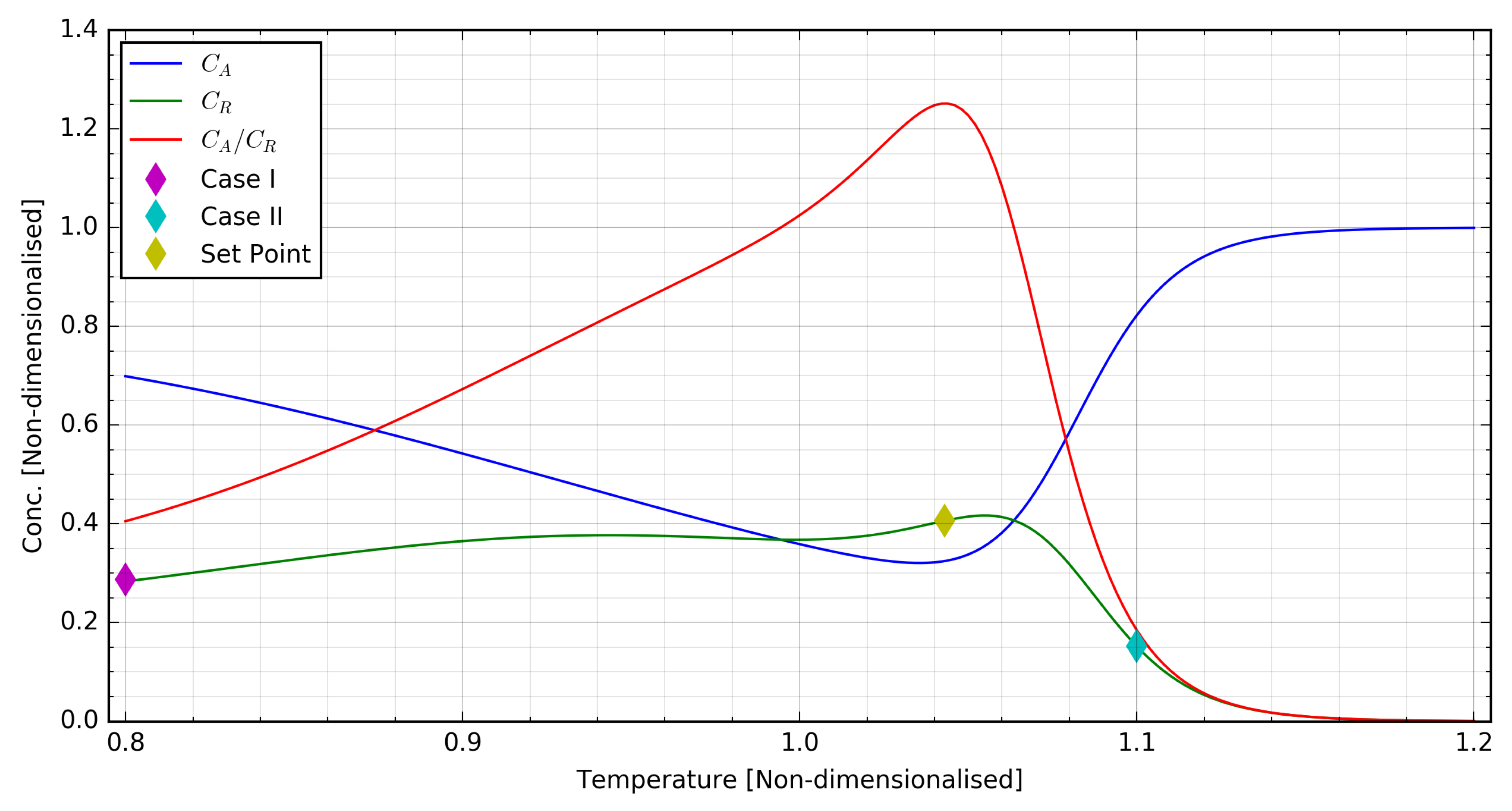
Figure 5 with its associated system dynamical response, with this sequence showing variations of
q in the range
for fixed values of
T. For this study, these sequences were generated in a fashion similar to
Figure 5, by introducing linear changes of different frequencies to one component of the MV spanning its experimental range while keeping the other MV component constant.
Before training the RNNs, it is necessary to split the data set into the training set and the test set. The training set contains the data with which the RNN trains its weight matrices, and the test set will be used to determine the models with the best hyperparameters. The two hyperparameters considered in this study are the number of hidden nodes, which also correspond to the dimensionality of the hidden states, and the number of hidden layers.
The experimental simulations and the extraction of training data were performed using Python version 3.6.5 for this study. Keras version 2.1.5, an open-source neural network library written in Python, was used for RNN training with TensorFlow version 1.7.0 as its backend.
3.2. Control Problem Formulation
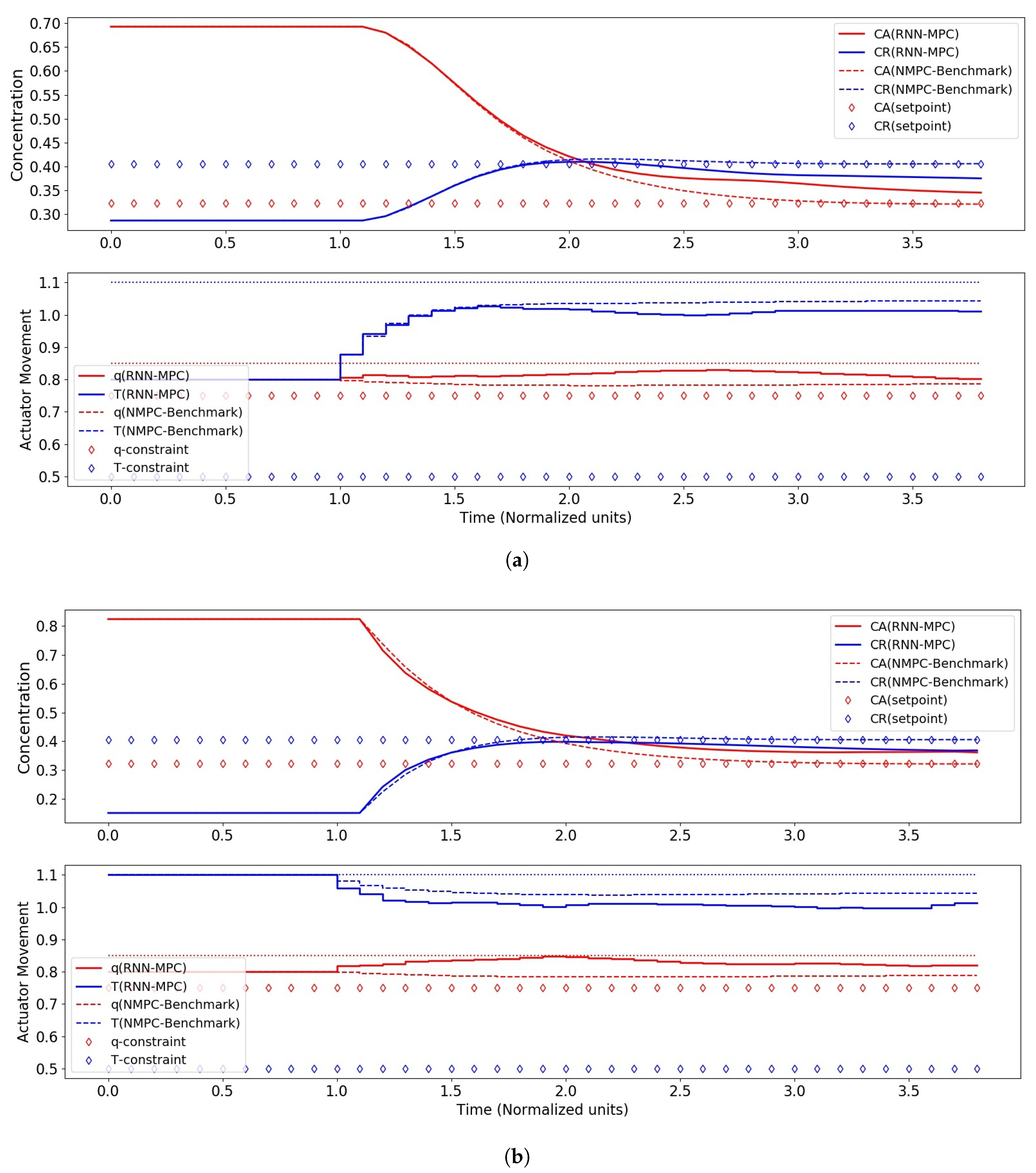
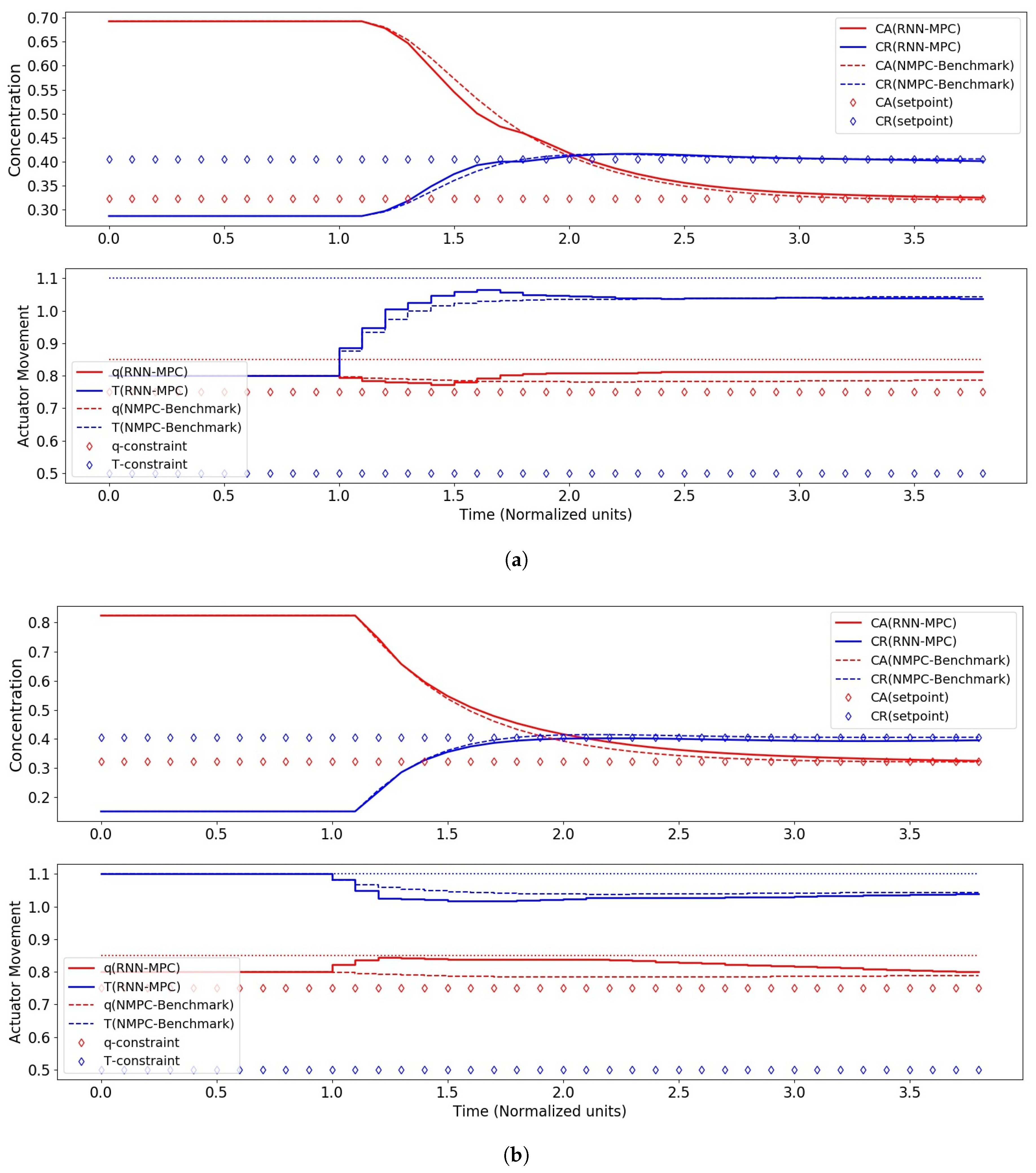
MPC is a control strategy that selects a set of m future control moves, , that minimises a cost function over a prediction of p steps by incorporating predictions of the dynamical system for these p steps, . The cost function is typically chosen to punish large control actions, which implies greater actuator power consumption, and differences between the state vector and the set-point at each time-step. Input and output constraints can also be factored into the MPC formulation. Since MPC performance depends on the quality of the predictions of the system, obtaining a reasonably accurate model through system identification is crucial.
The MPC problem can be formulated as shown in Equations (
10)–(13) below:
where
is the prediction horizon,
the control horizon,
the prediction of the state vector for the discrete-time step
k obtained from the RNN,
described in Equation (
9),
the set-point at time-step
k,
the MV for time-step
k,
the discrete-time rate of change of the MV which corresponds to the control action size at time-step
k,
symmetric positive semi-definite weight matrices, and
the lower and upper bounds for the control action and the rate of change of the control action at time-step
k. In the above formulation, it is assumed that there are no changes in actuator position beyond time-step
, i.e.,
.
This optimization problem is not convex in general and thus does not possess special structures amenable to global optimality. This is therefore a Non-Linear Programming (NLP) problem, and modern off-the-shelf solvers can be used to solve it. This problem is solved at every time-step to yield the optimal control sequence for that time-step, . The first element, , is then applied to the system until the next sampling instant, where the problem is solved again to yield another optimal control sequence. This procedure is then repeated in a moving horizon fashion.
The MPC controller in this study was implemented in Python version 3.6.5 through the scipy.optimize.minimize function, and the sequential least squares quadratic programming (SLSQP) algorithm was selected as the option for this solver.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}