1. Introduction
The amount and diversity of data that is being created, collected, stored and processed in enterprises is growing at an unprecedented pace. However, sophisticated data processing demands for predictable performance guarantees, as a potential degradation in performance introduces a risk where the time needed to complete the processing and analysis exceeds the window of opportunity to exploit the results by the application. This is for example the case in an online payment processing application that processes historical and contextual data to improve risk assessment without introducing unacceptable delays for customers and merchants.
Application architects are adopting NoSQL storage technologies that have been designed to provide good horizontal scalability for data-intensive computing and analytics applications. Not only are architects faced with the curse of choosing the technology [
1] that best matches their data model, consistency and availability requirements, yet it is far from trivial to compare the relative impact and trade-offs between different performance and scalability tactics that must be applied when configuring the chosen storage technology [
2,
3]. Standard benchmarks can help evaluators in testing different storage systems and in facilitating performance comparisons. For example, the Yahoo! Cloud Serving Benchmark (YCSB) [
4] is a well-known standard benchmark that tests storage systems with different mixes of read (single-record gets and range scans) and write (single-record inserts and updates) workloads. However, YCSB benchmark reports do not always paint the required accurate picture on a distributed system’s performance and scalability because the amount of stored data and the generated artificial workload is typically not representative for the workload imposed by today’s real world applications. Indeed, application architects are faced with the following challenges:
There is no one-size-fits-all solution to select and configure storage technology for supporting data-intensive applications, because (1) different applications may impose workloads (e.g., in terms of mixing read and write operations, in terms of data aggregation and querying) that are better serviced by a particular type of data storage, (2) the suitability of storage technologies for adaptation may vary, and (3) they come with specific configuration options that are not (and cannot be) represented in standard benchmarks.
The run-time environment and conditions of a specific data-intensive application may not allow for a statically optimal configuration, for example because of unpredictable deployment settings in a cloud-based deployment, but also because of the dynamics of the application itself, as workloads evolve at run-time. This may jeopardize the effectiveness of performance enhancing tactics (e.g., performance hits of secondary indices for write-heavy workloads).
Yet dynamic reconfiguration may not pay off: applying a performance tactic at run-time may trigger a temporary overhead and a delay before the tactic becomes effective, and the cost of run-time adaptation may not outweigh the benefit if the window of opportunity is short lived.
Selecting the best performing technology and configuring the deployment for scalability and tuning parameters for an optimal service delivery are challenging tasks that should not be re-executed from scratch by knowledgeable application architects. This task should be addressed and facilitated by special purpose middleware.
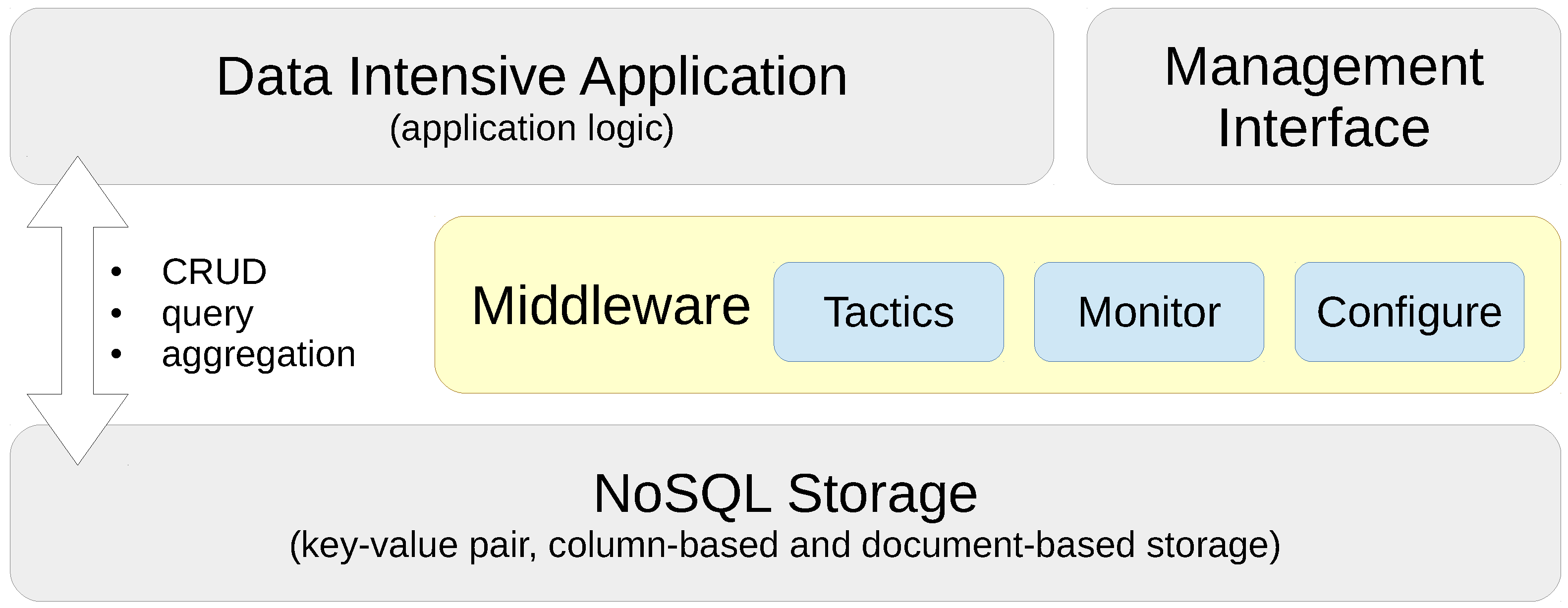
In this paper, we present a Performance and Scalability Tactics Architecture (PaSTA) and implementation (see
Figure 1 for a conceptual view) of a configuration (deployment time) and a dynamic re-configuration (run-time) middleware layer for data-intensive applications that select and map performance and scalability tactics in terms of application specific characteristics and needs by monitoring create, read, update and delete (CRUD) as well as query and aggregation operations. Our middleware design absorbs the know-how through supervised machine learning based on data gathered in performance and scalability experiments in two real-world, industrial application cases that impose complementary Quality of Service (QoS) requirements. The contributions of this paper are threefold:
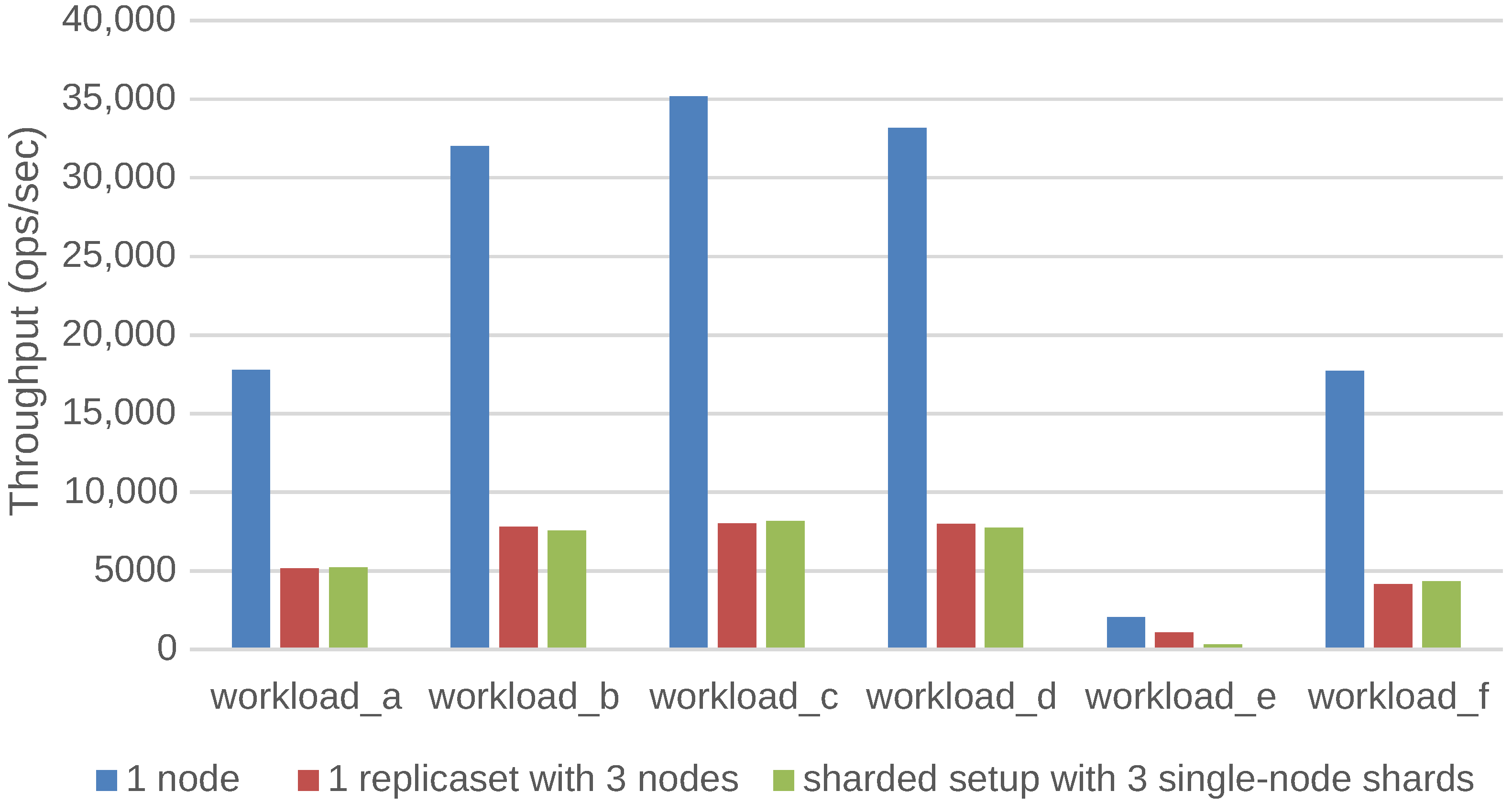
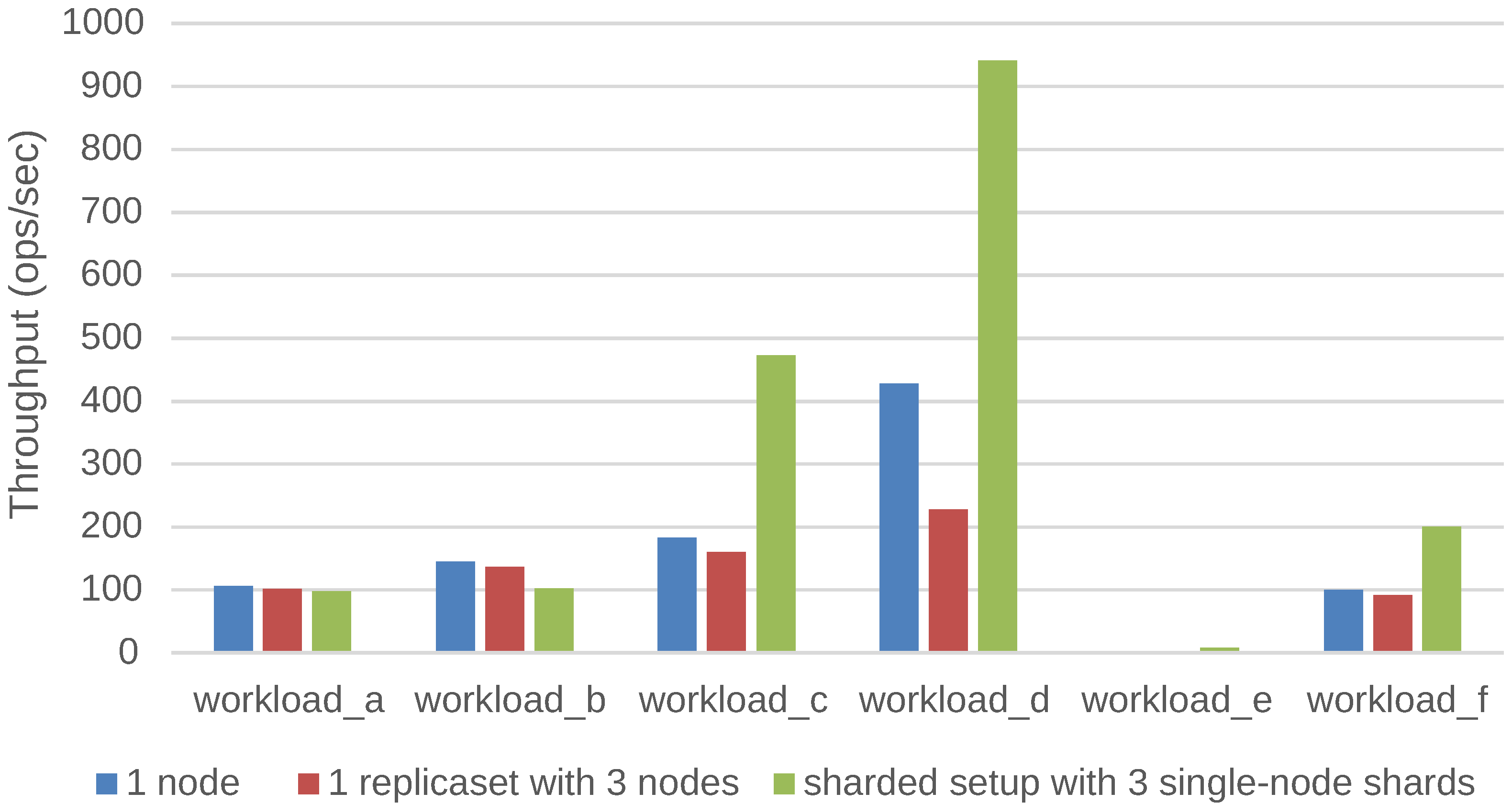
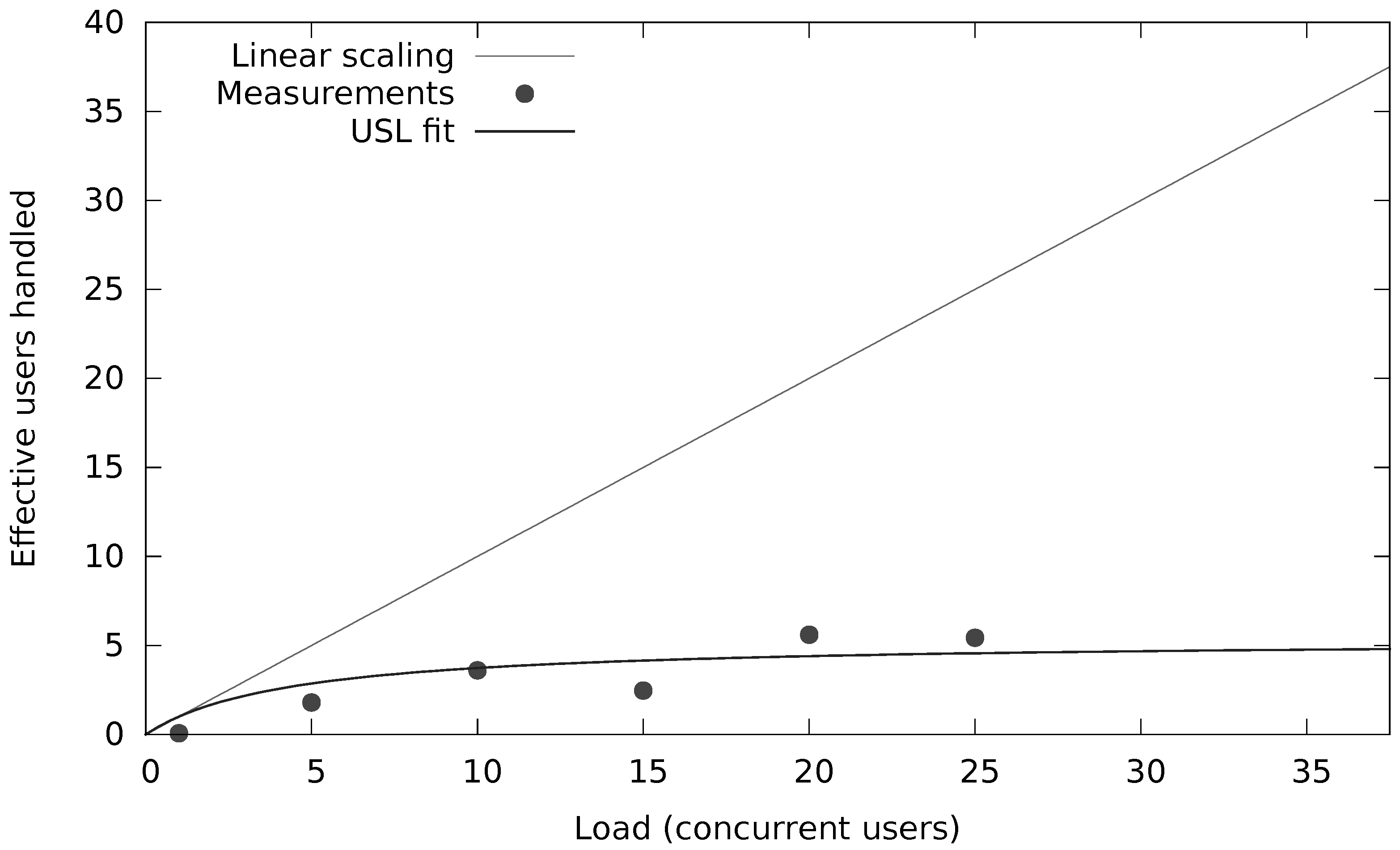
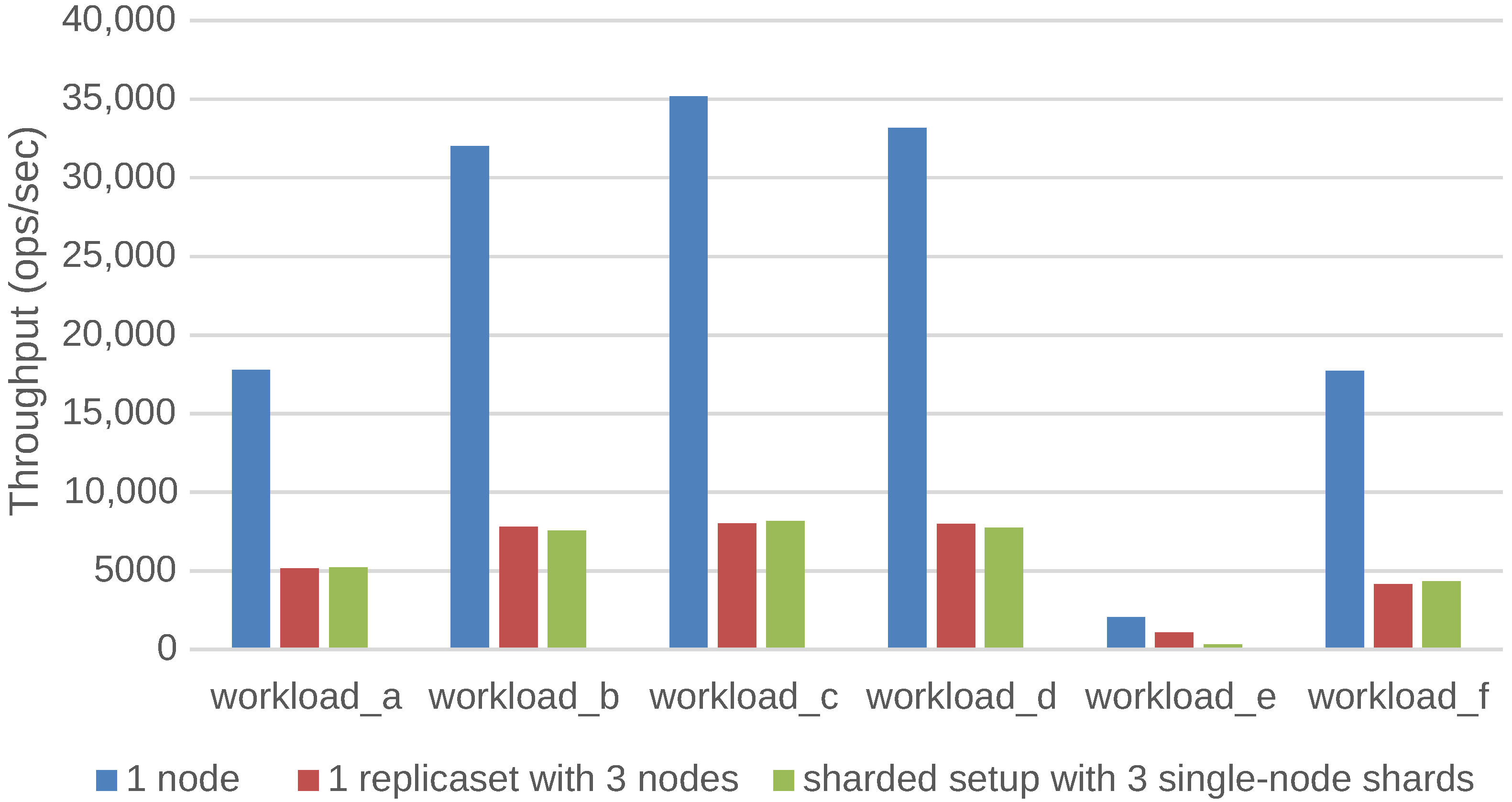
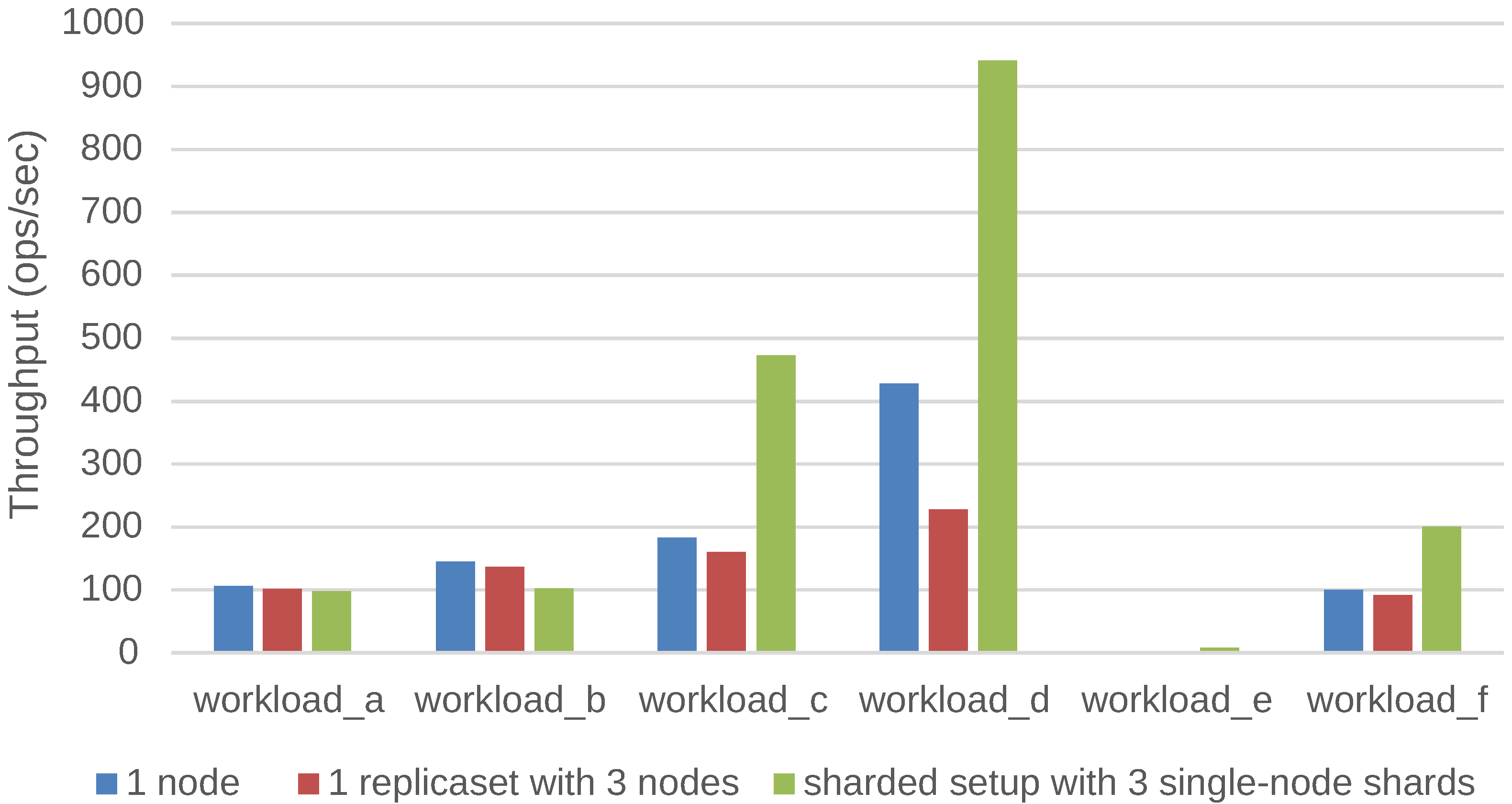
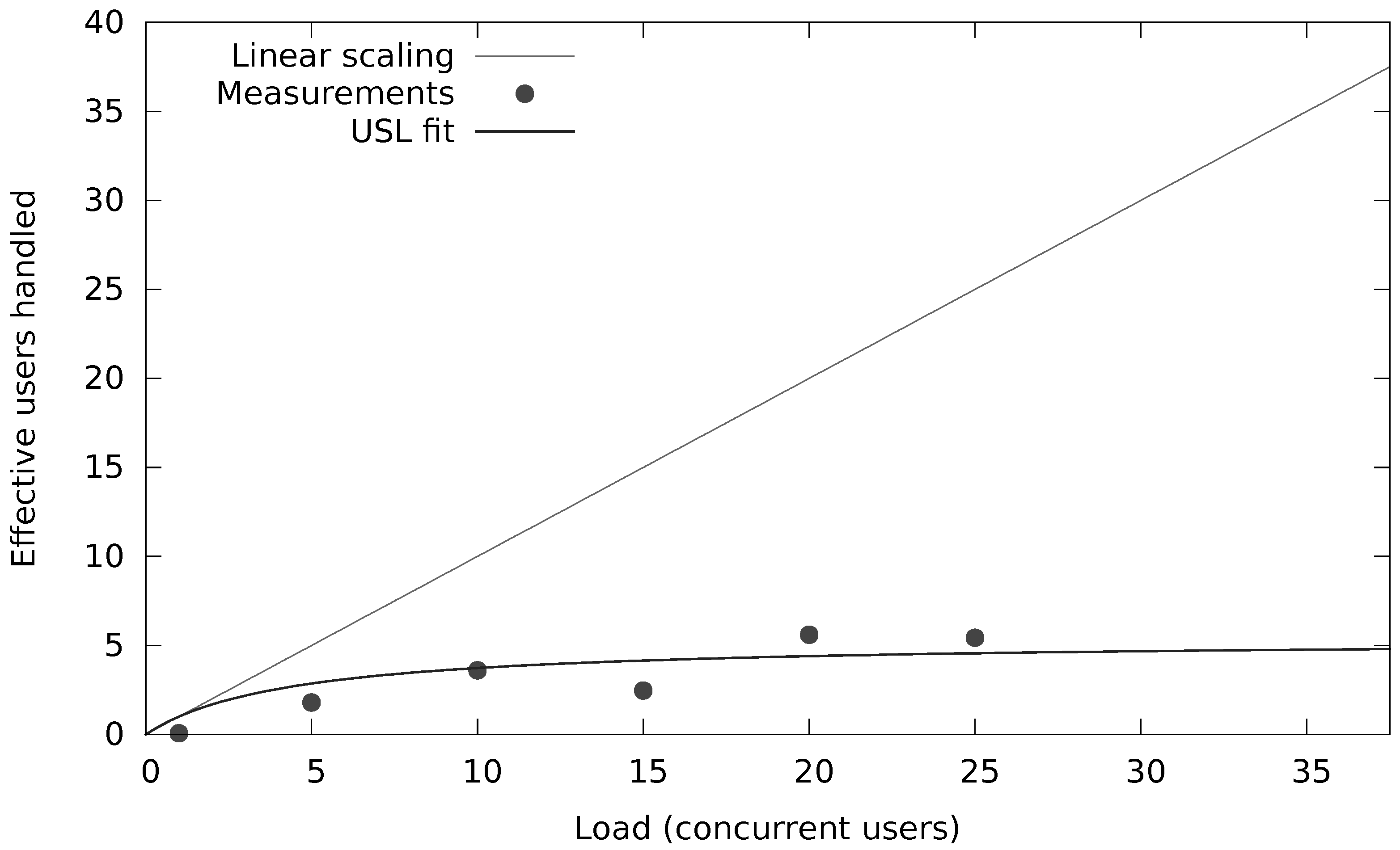
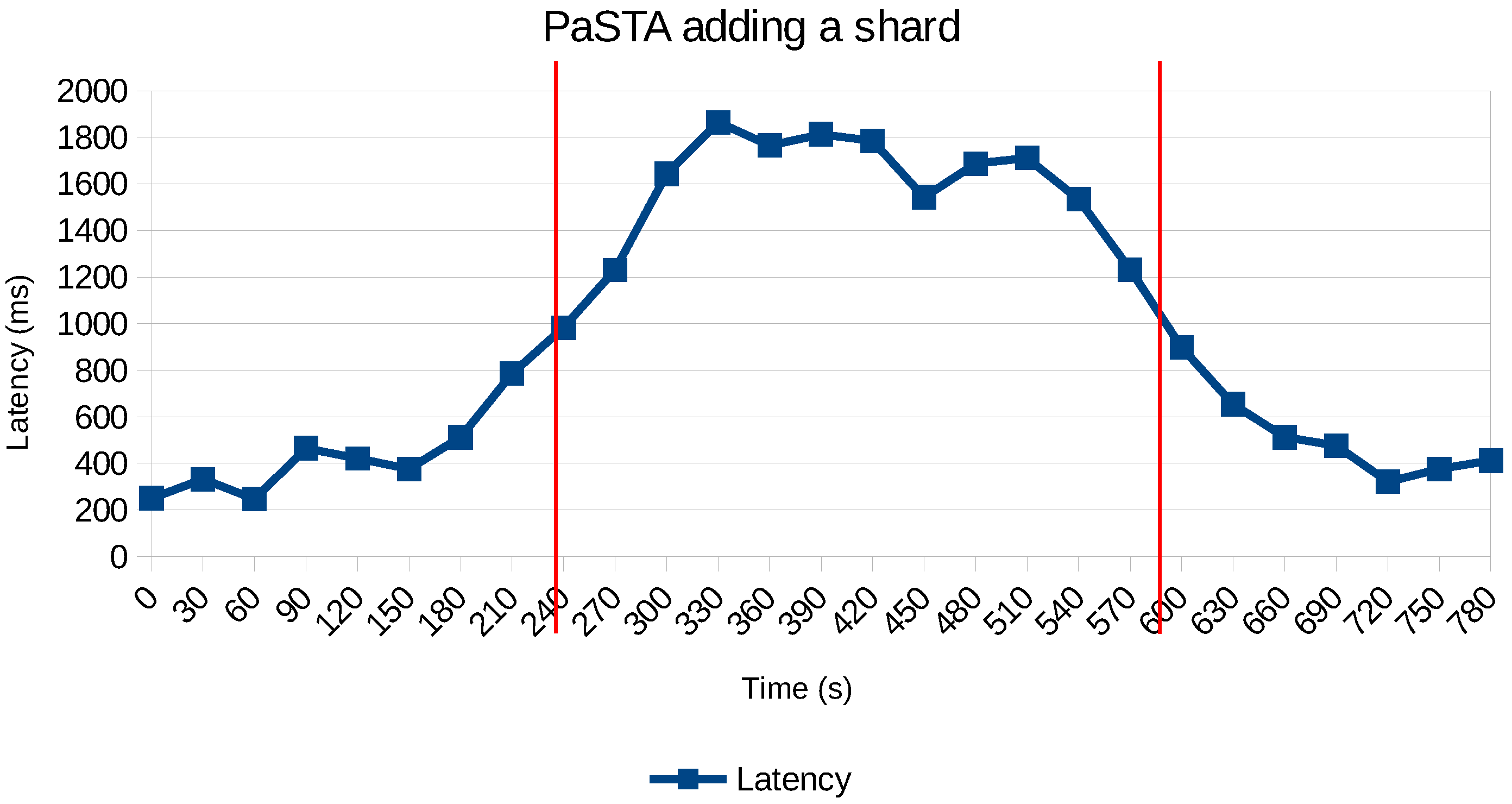
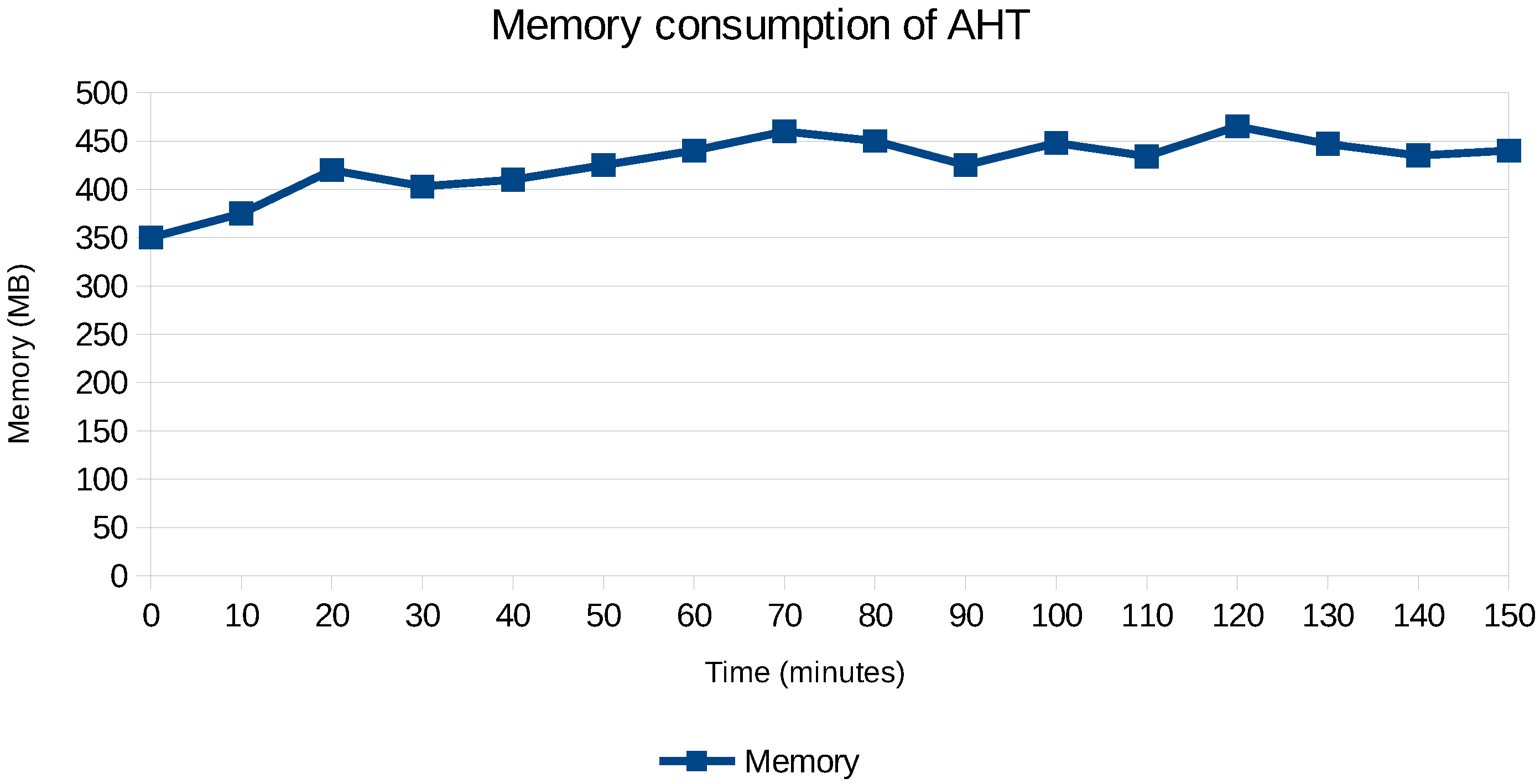
We have investigated and quantified the impact of different performance and scalability tactics, including vertical and horizontal scaling, sharding, caching, replication, in-memory stores and secondary indices. These benchmarking results and newly collected monitoring information is used to automatically tune at runtime the configuration of NoSQL systems through supervised machine learning on streaming monitoring data with Adaptive Hoeffding Trees.
The impact analysis sketched above is at the basis of a middleware support layer that offers mapping capabilities to associate these high-level tactics, evolving application workloads, and preferences of the architect with the configuration interfaces of a range of underlying NoSQL technologies, with representative platforms for key-value pair, column-based and document-based stores, as depicted in
Table 1.
We have validated and applied our solution in the context of industry-level case studies of data-intensive applications where performance and scalability are key. The acquired insights have been embedded into the design of our PaSTA middleware. The evaluation demonstrates that the machine learning based mapping by our middleware can adapt NoSQL systems to unseen workloads of data-intensive applications.
Ultimately, the role of our PaSTA middleware is to identify and apply NoSQL system configurations for multiple concurrent optimization objectives (e.g., throughput, latency, cost) based on a quantitative assessment of various performance and scalability tactics. Our middleware solves this problem at runtime by monitoring the data growth, changes in the read/write/query mix at run-time, as well as other system metrics that are indicative of sub-optimal performance. Our middleware employs supervised machine learning on historic and current monitoring information and corresponding configurations to select the best combinations of high-level tactics and adapt NoSQL systems to evolving workloads.
Related work on autonomic computing contains point solutions that optimize some of the presented configuration tactics in a more finely grained and sometimes more sophisticated way. The presented middleware in this paper services the comprehensive goal of statically and dynamically managing and tuning the configuration of distributed storage systems that support data-intensive applications that utilize distributed NoSQL technology.
The remainder of the paper is structured as follows. We discuss two real world case studies and the corresponding QoS requirements in
Section 2. In
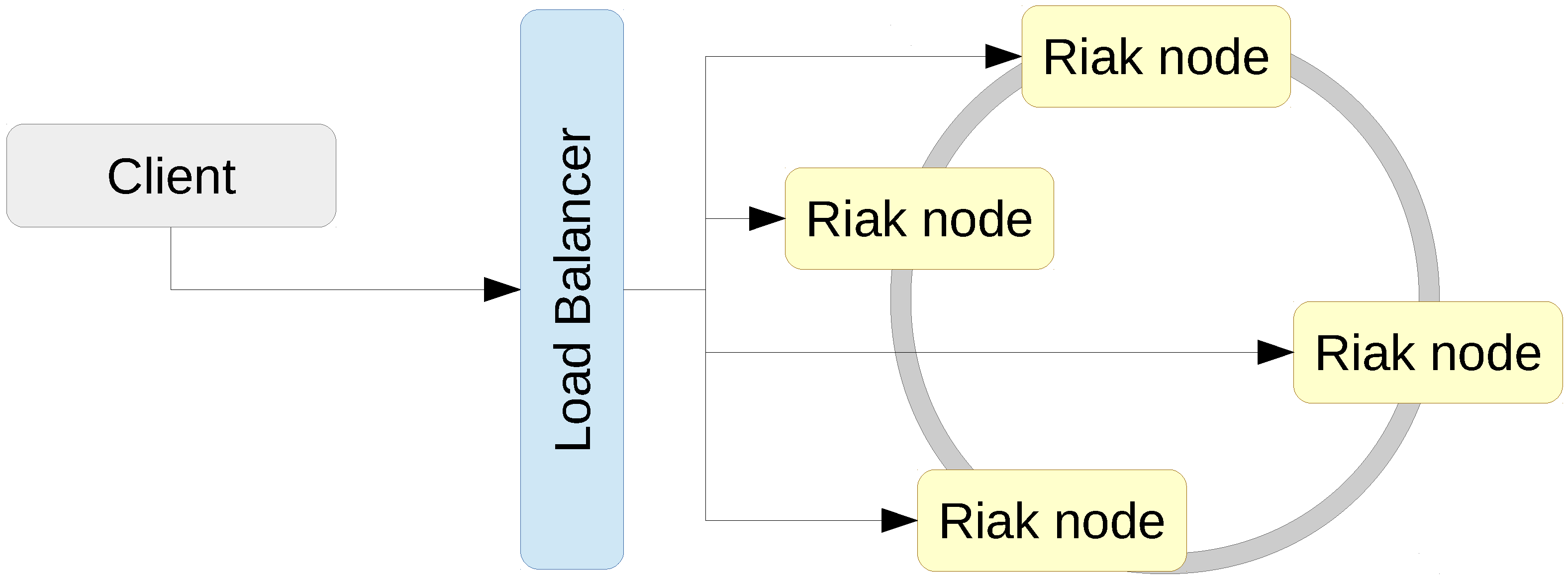
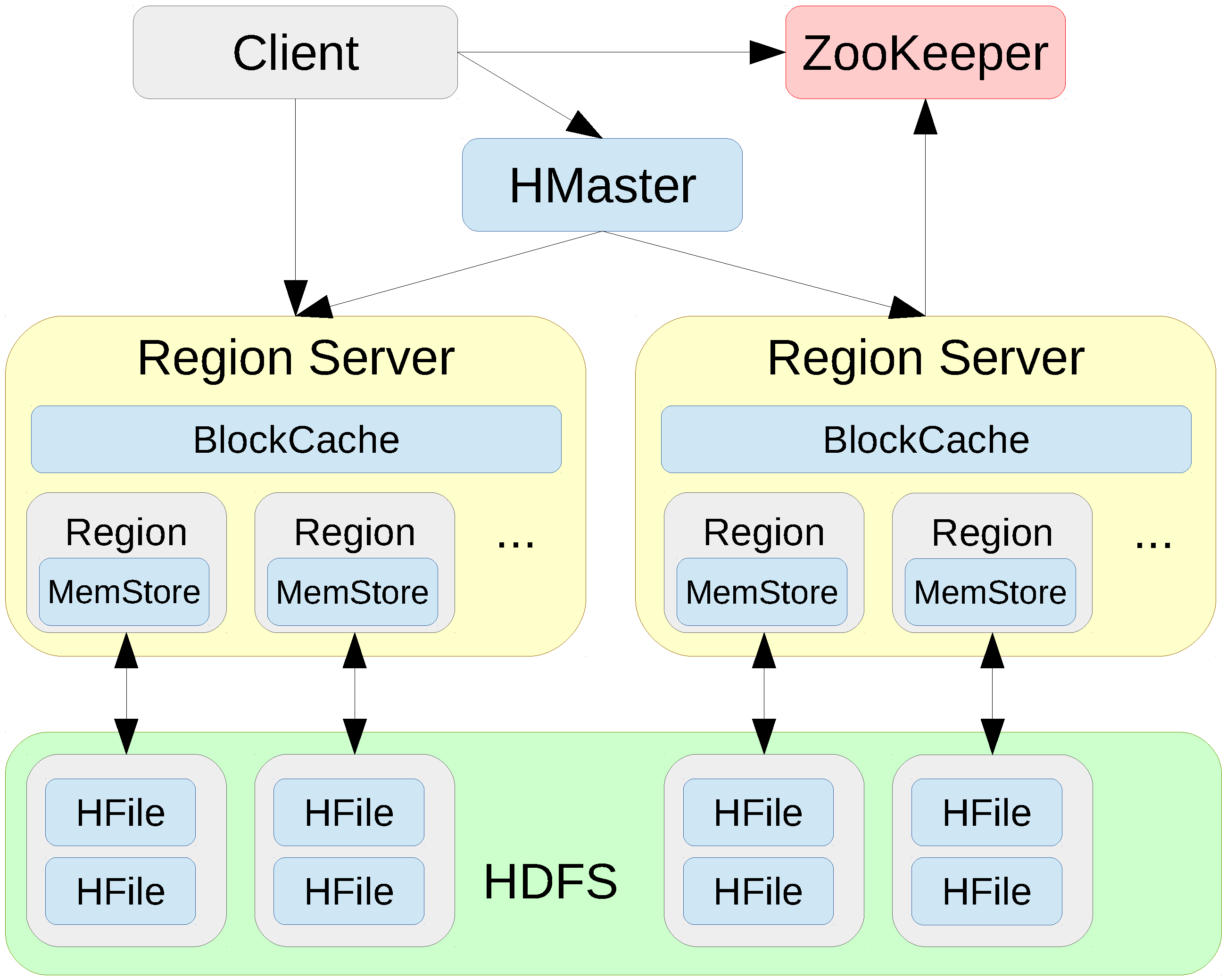
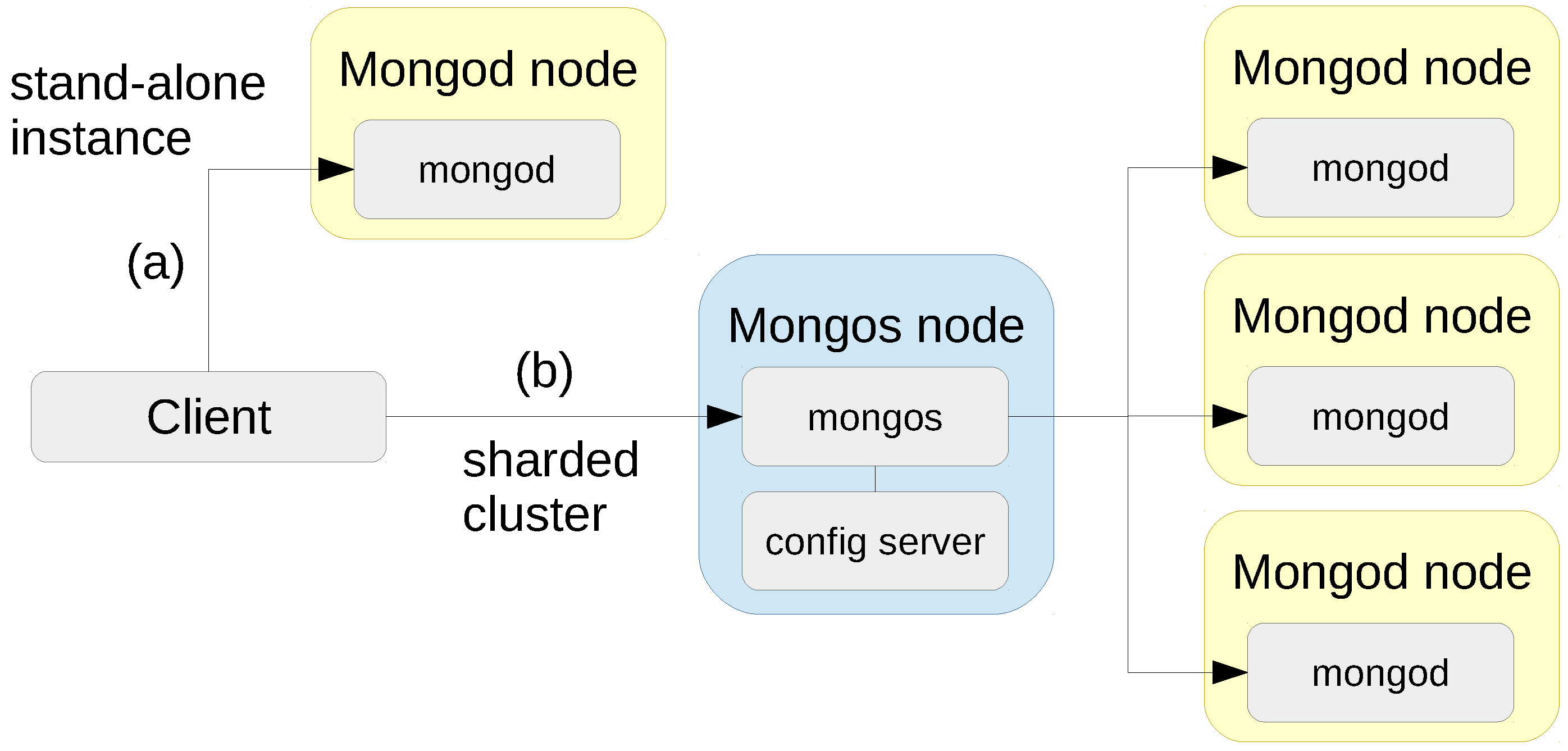
Section 3 we review representative NoSQL storage systems and the distributed deployment infrastructures.
Section 4 elaborates on the characterization of workloads and the mapping of system configurations. In
Section 5, we explain how the acquired insights have been embedded in the design of our middleware and how our prototype configures NoSQL technology based on high-level tactics and preferences imposed by the application architect. We illustrate the feasibility and performance of our solution in
Section 6. In
Section 7, we discuss and compare with related work. We conclude in
Section 8.
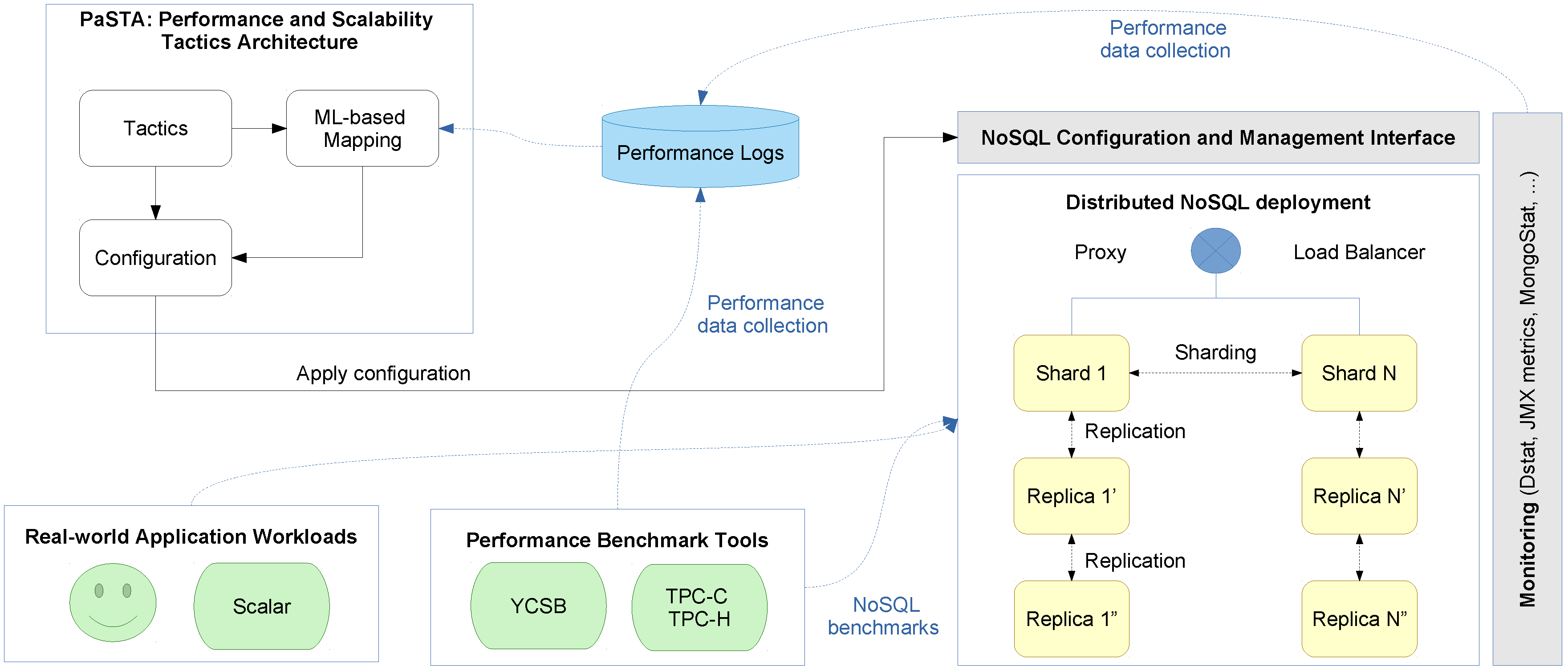
5. The PaSTA Middleware Implementation
The PaSTA middleware in
Figure 6 includes three layers; At the top level, the middleware offers a management dashboard to the application owner, supporting (a) the observation of performance and QoS/SLA compliance that is achieved, and (b) potentially the approval of configuration changes that are proposed by the core of the middleware. The
Performance Monitoring component of our middleware collects resource consumption metrics for the nodes in the cluster using off-the-shelf performance monitoring tools. Additionally, NoSQL database specific performance monitoring tools (e.g.,
mongostat for MongoDB) collect run-time statistics and metrics about the transactions itself (e.g., latency and throughput, cache usage, read vs. write mix). The
Unified Runtime Metrics collects, aggregates, normalizes and interprets metrics, and signals events regarding saturated resources (i.e., above a
capacity threshold for cpu, memory, network and hard drive). The normalized metrics are computed with Esper (
http://www.espertech.com/), a Complex Event Processing (CEP) engine. The raw measurements and normalized metrics are fed into the
SLA Policy Monitoring component which verifies compliance with QoS/SLA goals configured by the application architect in the
SLA Policy Administration component through the
Management Dashboard. The
SLA Policy Monitoring component autonomously triggers the
Configuration Selection and Mapping component that leverages knowledge and input from the
Tactics Knowledge Base and the
Configuration Repository of current and previous configurations.
At the bottom level, the middleware includes monitoring support to feed the core functionality with online measurements to actually quantify the performance and scalability characteristics of the running applications. This essential monitoring support is not tightly integrated with the core of the middleware, in order to flexibly leverage upon existing and emerging third part monitoring components.
At the heart of the middleware architecture is a core that can, in principle, autonomously configure and reconfigure the storage layer to optimize performance characteristics of the data-intensive application at run-time. The
Tactic Knowledge Base component maintains generic knowledge about the benchmarks and a list of tactics that have a positive or negative impact on the
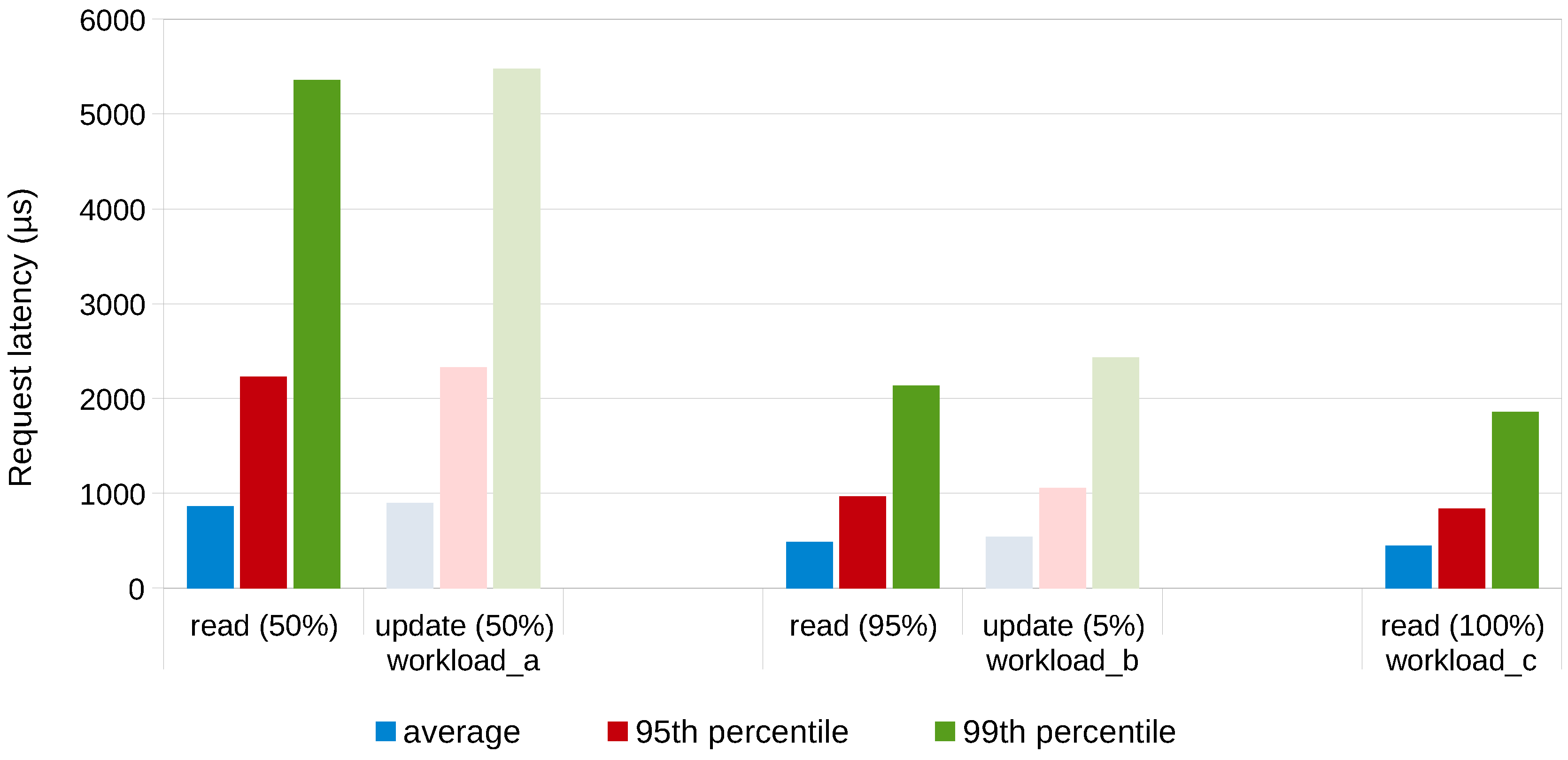
throughput in terms of NoSQL operations per second, the
latency distribution of these NoSQL operations, resource consumption and type of operation. Last but not least, the
Deployment Automation component provisions and configures replication or shard nodes in the NoSQL cluster using the Chef [
12] deployment and configuration management tool.
The remainder of this section will elaborate in more detail on the Configuration Selection and Mapping component that embeds the machine learning logic, and more specifically the Adaptive Hoeffding Trees algorithms for streaming data classification, to map application workloads and operational conditions on NoSQL system configurations.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}