Understanding the Role of Visualizations on Decision Making: A Study on Working Memory

Abstract
:1. Introduction
- We provided quantitative empirical evidence showing that the interactive visualization, SimulSort, amplifies cognition, more specifically unburdening working memory on the phonological loop; and
- We suggest an experimental method to vary the burden on working memory with a phonological suppression task in a crowdsourcing-based study in which controlling participants’ behaviors is challenging.
2. Background
2.1. Multi-Attribute Decision Making
2.2. Visualization Techniques
2.3. Visual Representation in Decision Making
2.4. Working Memory
2.5. Visualization and Human Cognition
3. Hypotheses
4. Experiment
4.1. Data Sets
4.2. Design of Primary and Secondary Tasks
4.2.1. Primary Task
4.2.2. Secondary Task
4.3. Experimental Design
4.4. Participants
4.5. Procedure
4.6. Measurements
4.6.1. Decision Quality
4.6.2. Individual Working Memory Span
4.7. Rewards
5. Results
5.1. Secondary Task Performance
5.2. Decision Quality
5.3. Individual Difference of Working Memory Span
5.3.1. Individual OSPAN Score
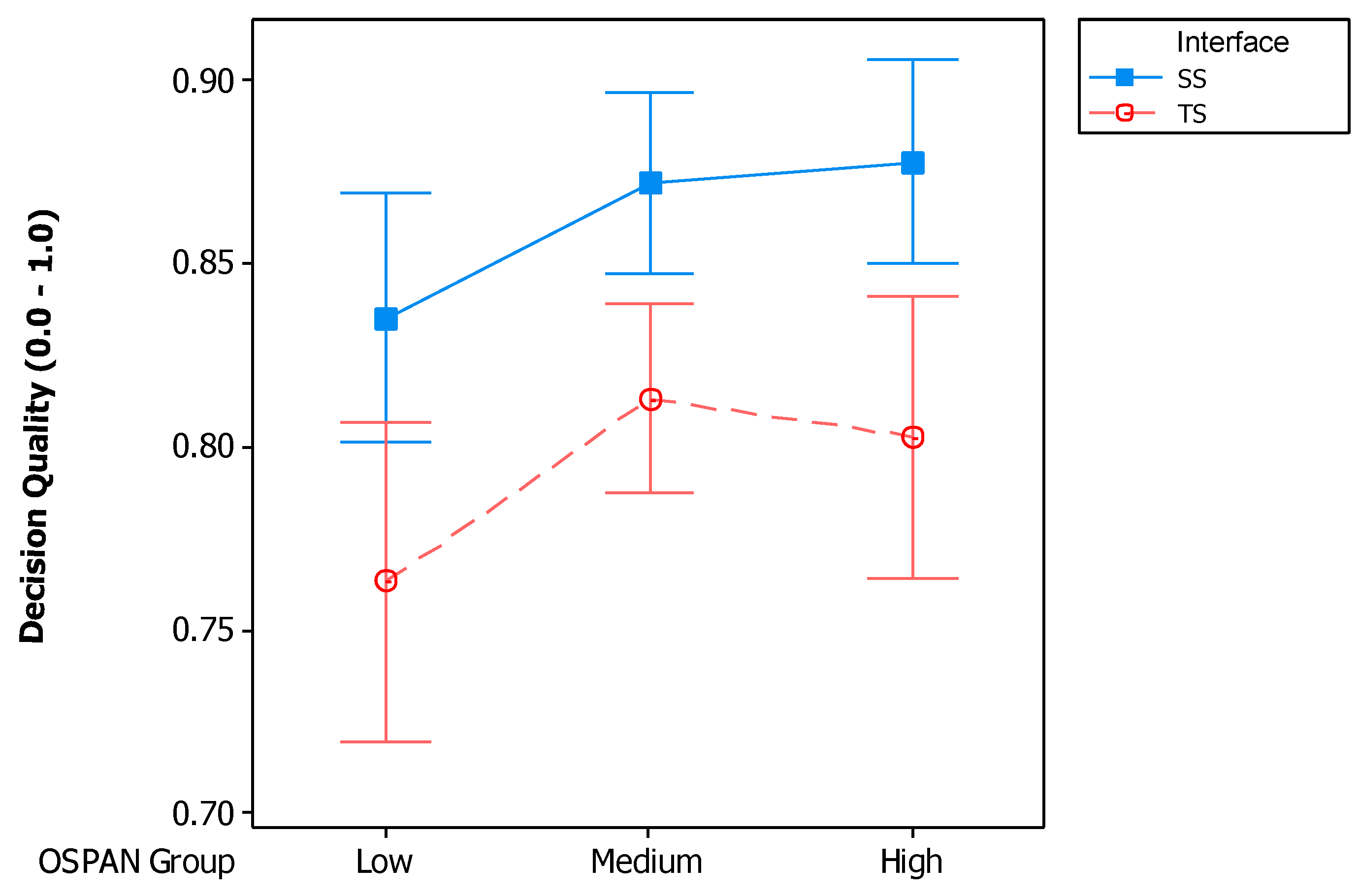
5.3.2. Decision Quality by OSPAN Groups
6. Discussion
6.1. Unburdening Working Memory
6.2. Individual Difference on Decision Quality
6.3. Conducting Online Working Memory Experiments
7. Conclusions
Funding
Conflicts of Interest
References
- Berry, I.; Soucy, J.P.R.; Tuite, A.; Fisman, D. Open access epidemiologic data and an interactive dashboard to monitor the COVID-19 outbreak in Canada. CMAJ 2020, 192, 420. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eberhardt, A.; Silveira, M.S. Show me the data! A systematic mapping on open government data visualization. In Proceedings of the 19th Annual International Conference on Digital Government Research: Governance in the Data Age, Delft, The Netherlands, 30 May–1 June 2018; pp. 1–10. [Google Scholar]
- Matheus, R.; Janssen, M.; Maheshwari, D. Data science empowering the public: Data-driven dashboards for transparent and accountable decision-making in smart cities. Gov. Inf. Q. 2018, 2018, 101284. [Google Scholar] [CrossRef]
- Cabitza, F.; Locoro, A.; Fogli, D.; Giacomin, M. Valuable visualization of healthcare information: From the quantified self data to conversations. In Proceedings of the International Working Conference on Advanced Visual Interfaces, Bari, Italy, 7–10 June 2016; pp. 376–380. [Google Scholar]
- Rapp, A.; Cena, F. Personal informatics for everyday life: How users without prior self-tracking experience engage with personal data. Int. J. Hum. Comput. Stud. 2016, 94, 1–17. [Google Scholar] [CrossRef]
- Lacefield, W.E.; Applegate, E.B. Data Visualization in Public Education: Longitudinal Student-, Intervention-, School-, and District-Level Performance Modeling. In Proceedings of the Annual Meeting of the American Educational Research Association, New York, NY, USA, 13–17 April 2018. [Google Scholar]
- Shreiner, T.L. Data literacy for social studies: Examining the role of data visualizations in K–12 textbooks. Theory Res. Soc. Educ. 2018, 46, 194–231. [Google Scholar] [CrossRef]
- Card, S.K.; Mackinlay, J.D.; Shneiderman, B. Readings in Information Visualization: Using Vision to Think; Morgan Kaufmann: San Francisco, CA, USA, 1999. [Google Scholar]
- Fekete, J.D.; Van Wijk, J.J.; Stasko, J.T.; North, C. The value of information visualization. In Information Visualization; Springer: Berlin/Heidelberg, Germany, 2008; pp. 1–18. [Google Scholar]
- Cleveland, W.S.; McGill, R. Graphical perception: Theory, experimentation, and application to the development of graphical methods. J. Am. Stat. Assoc. 1984, 79, 531–554. [Google Scholar] [CrossRef]
- Fuchs, J.; Fischer, F.; Mansmann, F.; Bertini, E.; Isenberg, P. Evaluation of alternative glyph designs for time series data in a small multiple setting. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Paris, France, 27 April–2 May 2013; pp. 3237–3246. [Google Scholar]
- Heer, J.; Bostock, M. Crowdsourcing graphical perception: Using mechanical turk to assess visualization design. In Proceedings of the 28th International Conference on Human Factors in Computing Systems, Atlanta, GA, USA, 10–15 April 2010; pp. 203–212. [Google Scholar]
- Heer, J.; Kong, N.; Agrawala, M. Sizing the horizon: The effects of chart size and layering on the graphical perception of time series visualizations. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Boston, MA, USA, 4–9 April 2009; pp. 1303–1312. [Google Scholar]
- Ondov, B.; Jardine, N.; Elmqvist, N.; Franconeri, S. Face to face: Evaluating visual comparison. IEEE Trans. Vis. Comput. Graph. 2018, 25, 861–871. [Google Scholar] [CrossRef]
- Wolfe, J.M.; Horowitz, T.S. Five factors that guide attention in visual search. Nat. Hum. Behav. 2017, 1, 0058. [Google Scholar] [CrossRef]
- Plaisant, C. The challenge of information visualization evaluation. In Proceedings of the Working Conference on Advanced Visual Interfaces, Gallipoli, Italy, 25–28 May 2004; pp. 109–116. [Google Scholar]
- Borkin, M.A.; Bylinskii, Z.; Kim, N.W.; Bainbridge, C.M.; Yeh, C.S.; Borkin, D.; Pfister, H.; Oliva, A. Beyond memorability: Visualization recognition and recall. IEEE Trans. Vis. Comput. Graph. 2015, 22, 519–528. [Google Scholar] [CrossRef]
- Haroz, S.; Kosara, R.; Franconeri, S.L. Isotype visualization: Working memory, performance, and engagement with pictographs. In Proceedings of the 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Korea, 18–23 April 2015; pp. 1191–1200. [Google Scholar]
- Liu, Z.; Stasko, J. Mental models, visual reasoning and interaction in information visualization: A top-down perspective. IEEE Trans. Vis. Comput. Graph. 2010, 16, 999–1008. [Google Scholar]
- Padilla, L.M.; Castro, S.C.; Quinan, P.S.; Ruginski, I.T.; Creem-Regehr, S.H. Toward Objective Evaluation of Working Memory in Visualizations: A Case Study Using Pupillometry and a Dual-Task Paradigm. IEEE Trans. Vis. Comput. Graph. 2019, 26, 332–342. [Google Scholar] [CrossRef]
- Cowan, N. The many faces of working memory and short-term storage. Psychon. Bull. Rev. 2017, 24, 1158–1170. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Baddeley, A.D.; Hitch, G.J. Working memory. Psychol. Learn. Motiv. 1974, 8, 47–89. [Google Scholar]
- DeStefano, D.; LeFevre, J.A. The role of working memory in mental arithmetic. Eur. J. Cogn. Psychol. 2004, 16, 353–386. [Google Scholar] [CrossRef]
- Lurie, N.H. Decision Making in Information-Rich Environments: The Role of Information Structure. J. Consum. Res. 2004, 30, 473–486. [Google Scholar] [CrossRef] [Green Version]
- Lurie, N.H.; Mason, C.H. Visual representation: Implications for decision making. J. Mark. 2007, 71, 160–177. [Google Scholar] [CrossRef]
- Hur, I.; Yi, J.S. SimulSort: Multivariate Data Exploration Through An Enhanced Sorting Technique. In Human-Computer Interaction. Novel Interaction Methods and Techniques; Jacko, J., Ed.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5611, pp. 684–693. [Google Scholar]
- Hur, I.; Kim, S.H.; Samak, A.; Yi, J.S. A Comparative Study of Three Sorting Techniques in Performing Cognitive Tasks on a Tabular Representation. Int. J. Hum. Comput. Interact. 2013, 29, 379–390. [Google Scholar] [CrossRef] [Green Version]
- Kim, S.H.; Dong, Z.; Xian, H.; Upatising, B.; Yi, J.S. Does an eye tracker tell the truth about visualizations? Findings while investigating visualizations for decision making. IEEE Trans. Vis. Comput. Graph. 2012, 18, 2421–2430. [Google Scholar] [CrossRef] [Green Version]
- Samek, A.; Hur, I.; Kim, S.H.; Yi, J.S. An experimental study of the decision process with interactive technology. J. Econ. Behav. Organ. 2016, 130, 20–32. [Google Scholar] [CrossRef] [Green Version]
- Hwang, C.; Yoon, K. Multiple Attribute Decision Making: Methods And Applications: A State-of-the-Art Survey; Springer: Berlin/Heidelberg, Germany, 1981. [Google Scholar]
- Yoon, K.; Hwang, C. Multiple Attribute Decision Making: An Introduction; Sage: Thousand Oaks, CA, USA, 1995. [Google Scholar]
- Simon, H.A. A behavioral model of rational choice. Q. J. Econ. 1955, 69, 99–118. [Google Scholar] [CrossRef]
- Payne, J.W.; Bettman, J.R.; Johnson, E.J. The Adaptive Decision Maker; Cambridge University Press: Cambridge, UK, 1993. [Google Scholar]
- Shah, A.; Oppenheimer, D. Heuristics Made Easy: An Effort-reduction Framework. Psychol. Bull. 2008, 134, 207–222. [Google Scholar] [CrossRef] [Green Version]
- Bettman, J.R. Issues in Designing Consumer Information Environments. J. Consum. Res. 1975, 2, 169–177. [Google Scholar] [CrossRef]
- Rao, R.; Card, S.K. The Table Lens: Merging Graphical and Symbolic Representations in An Interactive Focus+ Context Visualization for Tabular Information. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems: Celebrating Interdependence, Boston, MA, USA, 24–28 April 1994; pp. 318–322. [Google Scholar]
- Gratzl, S.; Lex, A.; Gehlenborg, N.; Pfister, H.; Streit, M. Lineup: Visual analysis of multi-attribute rankings. IEEE Trans. Vis. Comput. Graph. 2013, 19, 2277–2286. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wegman, E.J. Hyperdimensional data analysis using parallel coordinates. J. Am. Stat. Assoc. 1990, 85, 664–675. [Google Scholar] [CrossRef]
- Zhang, P.; Whinston, A.B. Business Information Visualization for Decision-Making Support-A Research Strategy. In Proceedings of the First Americas Conference on Information Systems, San Francisco, CA, USA, 12–14 June 1995. [Google Scholar]
- Tegarden, D.P. Business information visualization. Commun. AIS 1999, 1, 4. [Google Scholar] [CrossRef]
- Treisman, A. Preattentive processing in vision. Comput. Vis. Graph. Image Process. 1985, 31, 156–177. [Google Scholar] [CrossRef]
- Hsee, C.K. The evaluability hypothesis: An explanation for preference reversals between joint and separate evaluations of alternatives. Organ. Behav. Hum. Decis. Process. 1996, 67, 247–257. [Google Scholar] [CrossRef]
- Schkade, D.A.; Kleinmuntz, D.N. Information displays and choice processes: Differential effects of organization, form, and sequence. Organ. Behav. Hum. Decis. Process. 1994, 57, 319–337. [Google Scholar] [CrossRef]
- Sloman, S.A. The empirical case for two systems of reasoning. Psychol. Bull. 1996, 119, 3–22. [Google Scholar] [CrossRef]
- Logie, R.H.; Gilhooly, K.J.; Wynn, V. Counting on working memory in arithmetic problem solving. Mem. Cogn. 1994, 22, 395–410. [Google Scholar] [CrossRef]
- Widaman, K.F.; Geary, D.C.; Cormier, P.; Little, T.D. A componential model for mental addition. J. Exp. Psychol. Learn. Mem. Cogn. 1989, 15, 898–919. [Google Scholar] [CrossRef]
- Borkin, M.A.; Vo, A.A.; Bylinskii, Z.; Isola, P.; Sunkavalli, S.; Oliva, A.; Pfister, H. What makes a visualization memorable? IEEE Trans. Vis. Comput. Graph. 2013, 19, 2306–2315. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lohse, G.L. The role of working memory on graphical information processing. Behav. Inf. Technol. 1997, 16, 297–308. [Google Scholar] [CrossRef]
- Wickens, C.D.; Carswell, C.M. The proximity compatibility principle: Its psychological foundation and relevance to display design. Hum. Factors J. Hum. Factors Ergon. Soc. 1995, 37, 473–494. [Google Scholar] [CrossRef]
- Wickens, C.D. Engineering Psychology and Human Performance; Prentice-Hall: Englewood Cliffs, NJ, USA, 2000. [Google Scholar]
- Johnson, E.J.; Payne, J.W. Effort and Accuracy in Choice. Manag. Sci. 1985, 31, 395–414. [Google Scholar] [CrossRef] [Green Version]
- Trbovich, P.L.; LeFevre, J.A. Phonological and visual working memory in mental addition. Mem. Cogn. 2003, 31, 738–745. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Fasolo, B.; McClelland, G.H.; Todd, P.M. Escaping the Tyranny of Choice: When Fewer Attributes Make Choice Easier. Mark. Theory 2007, 7, 13–26. [Google Scholar] [CrossRef]
- Seidl, C.; Traub, S. Testing Decision Rules for Multiattribute Decision Making. In Current Trends in Economics; Springer: Berlin/Heidelberg, Germany, 1999; Volume 8, pp. 413–454. [Google Scholar]
- Kim, S.H.; Yun, H.; Yi, J.S. How to filter out random clickers in a crowdsourcing-based study? In Proceedings of the 2012 BELIV Workshop: Beyond Time and Errors-Novel Evaluation Methods for Visualization, Seattle, WA, USA, 14–15 October 2012; p. 15. [Google Scholar]
- Conway, A.R.; Cowan, N.; Bunting, M.F.; Therriault, D.J.; Minkoff, S.R. A latent variable analysis of working memory capacity, short-term memory capacity, processing speed, and general fluid intelligence. Intelligence 2002, 30, 163–183. [Google Scholar] [CrossRef]
- Engle, R.W.; Tuholski, S.W.; Laughlin, J.E.; Conway, A.R. Working memory, short-term memory, and general fluid intelligence: A latent-variable approach. J. Exp. Psychol. Gen. 1999, 128, 309–331. [Google Scholar] [CrossRef]
- Unsworth, N.; Heitz, R.P.; Schrock, J.C.; Engle, R.W. An automated version of the operation span task. Behav. Res. Methods 2005, 37, 498–505. [Google Scholar] [CrossRef] [Green Version]
- Bengson, J.J.; Mangun, G.R. Individual working memory capacity is uniquely correlated with feature-based attention when combined with spatial attention. Atten. Percept. Psychophys. 2011, 73, 86–102. [Google Scholar] [CrossRef] [Green Version]
- Hutchison, K.A. Attentional control and the relatedness proportion effect in semantic priming. J. Exp. Psychol. Learn. Mem. Cogn. 2007, 33, 645–662. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Norman, D.A. Things That Make Us Smart: Defending Human Attributes in the Age of the Machine; Basic Books: New York, NY, USA, 1993. [Google Scholar]
- Burnham, B.R.; Sabia, M.; Langan, C. Components of working memory and visual selective attention. J. Exp. Psychol. Hum. Percept. Perform. 2014, 40, 391–403. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interface | Performance | |
|---|---|---|
| Incorrect | Correct | |
| SimulSort (SS) | 159 | 385 |
| Typical Sorting (TS) | 173 | 379 |
| Interface | OSPAN Group | ||
|---|---|---|---|
| Low | Medium | High | |
| SS | 19 | 30 | 17 |
| TS | 15 | 32 | 16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, S.-H. Understanding the Role of Visualizations on Decision Making: A Study on Working Memory. Informatics 2020, 7, 53. https://doi.org/10.3390/informatics7040053
Kim S-H. Understanding the Role of Visualizations on Decision Making: A Study on Working Memory. Informatics. 2020; 7(4):53. https://doi.org/10.3390/informatics7040053
Chicago/Turabian StyleKim, Sung-Hee. 2020. "Understanding the Role of Visualizations on Decision Making: A Study on Working Memory" Informatics 7, no. 4: 53. https://doi.org/10.3390/informatics7040053
APA StyleKim, S. -H. (2020). Understanding the Role of Visualizations on Decision Making: A Study on Working Memory. Informatics, 7(4), 53. https://doi.org/10.3390/informatics7040053