1. Introduction
The incidence of bone fractures is affected by many factors including age, gender, biology, physiology, and access to treatment and prevention programs [
1,
2,
3]. Impairment-related bone fractures contribute to an increase in morbidity and mortality across the age span [
3]. The leading causes of bone fractures include osteoporosis [
2,
4,
5] and trauma [
6]. Osteoporosis is a chronic bone disease related to the loss of bone density. Bone trauma can be defined as an injury caused to the bone by a force external to the body. When applied to clinical practice, a systematic study of bone fracture data can allow clinicians to compare affected and unaffected patient groups, determine definable and preventable characteristics that predispose patients to skeletal fractures and ensure the provision of appropriate prevention and treatment strategies [
7,
8,
9].
Deep learning is a subfield of artificial intelligence that has gained much attention due to its robust results in many challenging domains, such as machine translation, natural language processing, and computer vision, among others [
10]. Convolutional neural networks (CNNs) are part of deep learning domains where at least one layer of the neural network is a convolution layer. Many state-of-the-art results were achieved by using CNNs, especially in the computer vision domain. However, one of the main drawbacks of using CNNs to classify images is the dataset size needed to train them accurately: thousands of images are usually required. This issue limits the usage of CNNs in classifying images in the medical field. However, two main techniques can be used to get over the issue of dataset size: transfer learning and ensemble learning. Transfer learning was introduced to get over the dataset size challenge by training a CNN on a sizeable nonmedical dataset, then fine-tuning the weights to a medical dataset. Ensemble learning is a technique based on the principle of the crowd’s wisdom. In ensemble learning, multiple classifiers are trained, and then their results are combined. There are different methods of combining the outputs of different classifiers, such as taking the average of their outputs or using a machine learning algorithm over their predictions—that is, creating a classifier to sort different models’ outputs.
The classification of fracture images using CNNs was investigated in many studies. Chung et al. [
11] used a private dataset to investigate shoulder image usage to classify humerus fractures using ResNet CNN. In particular, they used a dataset with 256 × 256-pixel images. After fine-tuning the CNN, they applied the CNN model to reach an accuracy of 96%, a performance higher than that of human experts. Rajpurkar et al. [
12] investigated CNN’s performance in classifying bone fractures using a novel dataset called MURA. The images were rescaled to 320 × 320 pixels, and they compared the performance of their networks to three different radiologists’ assessments. The radiologists’ performance was more accurate than their results.
Olczak et al. [
13] tested CNN on a private dataset with 256,000 images split among wrist, hand, and ankle images. The X-ray images were rescaled to 256 × 256 pixels, and VGG16 achieved the best performance. Additionally, CNN’s performance was comparable to two senior orthopedic surgeons. Lindsey et al. [
14] studied the effect of having a CNN to classify wrist fractures in the ER to help in fracture diagnosis. They used a private dataset to train a CNN by relying on an extension of U-Net architecture as a classifier. Subsequently, they did a controlled experiment to evaluate the importance of having a CNN to aid doctors’ diagnoses. Olczak et al. [
13] found a significant decrease of 47% in the misinterpretation rate when using CNN.
Uysal et al. [
15] studied the effect of different SOTA CNN architectures on the MURA dataset’s shoulder images. The images were scaled to 320 × 320 pixels. The Adam optimizer was chosen, with a learning rate of 0.0001 with 40 epochs for training. The best kappa score was 0.6942, resulting from taking an ensemble of ResNet34, DenseNet169, DenseNet201, and a sub-ensemble of different CNNs.
Guan et al. [
16] used 3392 positive images (images with fractures) of the humerus, elbows, finger, hand, and forearm fracture from the MURA dataset to detect bone fractures. The image size was scaled to be 800 pixels for the shorter side and 1333 pixels for the longer side. Subsequently, an improved two-stage RCNN detection method was proposed. However, the original MURA dataset did not contain annotations of exact fracture locations. For this reason, the locations were annotated using the help of three radiological experts with more than 20 years of experience. To mitigate the small dataset’s effect, two main geometric augmentation techniques were considered: horizontal flipping and random rotation. The authors used 4 GPU NVIDIA GeForce GTX 1080Ti graphic cards to train the model. The average precision reported in the study was 62.04% [
16].
Huynh et al. [
17] used the humerus images from the MURA dataset. The images were rescaled to 150 × 150 pixels, and a novel CNN architecture with two convolution layers and one max pooling layer was presented. The learning rate of 0.0001 achieved the best results compared to three different learning rates. Moreover, the proposed model achieved a validation accuracy of 0.684 compared to a kappa score of 0.600 for the MURA dataset. Urinbayev et al. [
18] used the MURA dataset as a preprocessing step to determine the organ type before further classification. Thus, the dataset was used in the context of organ type classification and not for fracture classifications. The main aim was to classify chest X-ray images.
Kitamura et al. [
19] investigated the performance of three SOTA CNN models on a private dataset. The dataset used was composed of 596 ankle images. The image size was 300 × 300 pixels. Four different geometric augmentation techniques were used to increase the size of the training dataset and to make the models more invariant. The techniques used were random rotation, flipping, brightness variation, and contrast alteration. An NVIDIA GeForce 1080 GTX graphics card was used to perform the experiments, in which the performance of each of the three CNNs and an ensemble composed of the three models were investigated. The performance of the ensemble methods was better than any single model’s performance, and the best accuracy recorded was 81%.
Many studies have investigated the effects of ensemble techniques, especially their impacts on CNNs. Chouhan et al. [
20] proposed a study to classify pneumonia images and used five different CNNs. By taking the average of the five CNNs instead of using them individually, it was possible to increase the final model’s accuracy. A 2% increase in accuracy was achieved by using the average instead of using the best-performing CNN. Even with the robust model introduced by He et al. [
21] in 2016, the authors used the ensemble technique to win the ImageNet challenge [
22]. Whereas their top model scored a 4.49% error rate, using ensemble techniques allowed them to reduce the error rate to 3.57%. Rajaraman et al. [
23] investigated four different approaches to accurately classify tuberculosis from X-ray images. They reported that stacking achieved the best results. Cha et al. [
24] studied different techniques for classifying ear diseases by using otoendoscopic images. They compared the performance of nine CNNs and then selected the best two CNNs to build an ensemble model. The ensemble model achieved the best result compared to the other CNNs taken into account. Kandel and Castelli [
25] investigated the impact of transfer learning, i.e., using the weights of ImageNet instead of training the network from scratch on X-ray classification to detect fractures. They used the seven MURA datasets [
12], and investigated six state-of-the-art CNN architectures: VGG19 [
26], InceptionV3 [
27], ResNet50 [
21], DenseNet [
28], Xception [
29], and InceptionResNet [
30]. Experimental results show that the weights of ImageNet had an impact other than training the CNN from scratch. Moreover, sometimes, by training the networks from scratch, it did not converge at all, given the MURA dataset’s limited size [
12].
Joshi et al. [
31] reviewed several contributions that apply artificial intelligence techniques to fracture detection. Among techniques, they pointed out that only a few works use CNNs for fracture detection. They cited five papers in which CNNs were used with data augmentation for fracture detection. While their work suggests that stacking was used in the past with traditional (fully connected) neural networks, random forests, and support vector machines, no study was cited on the use of stacking with CNNs. Thus, we believe our contribution is timely and provides an interesting contribution to this field.
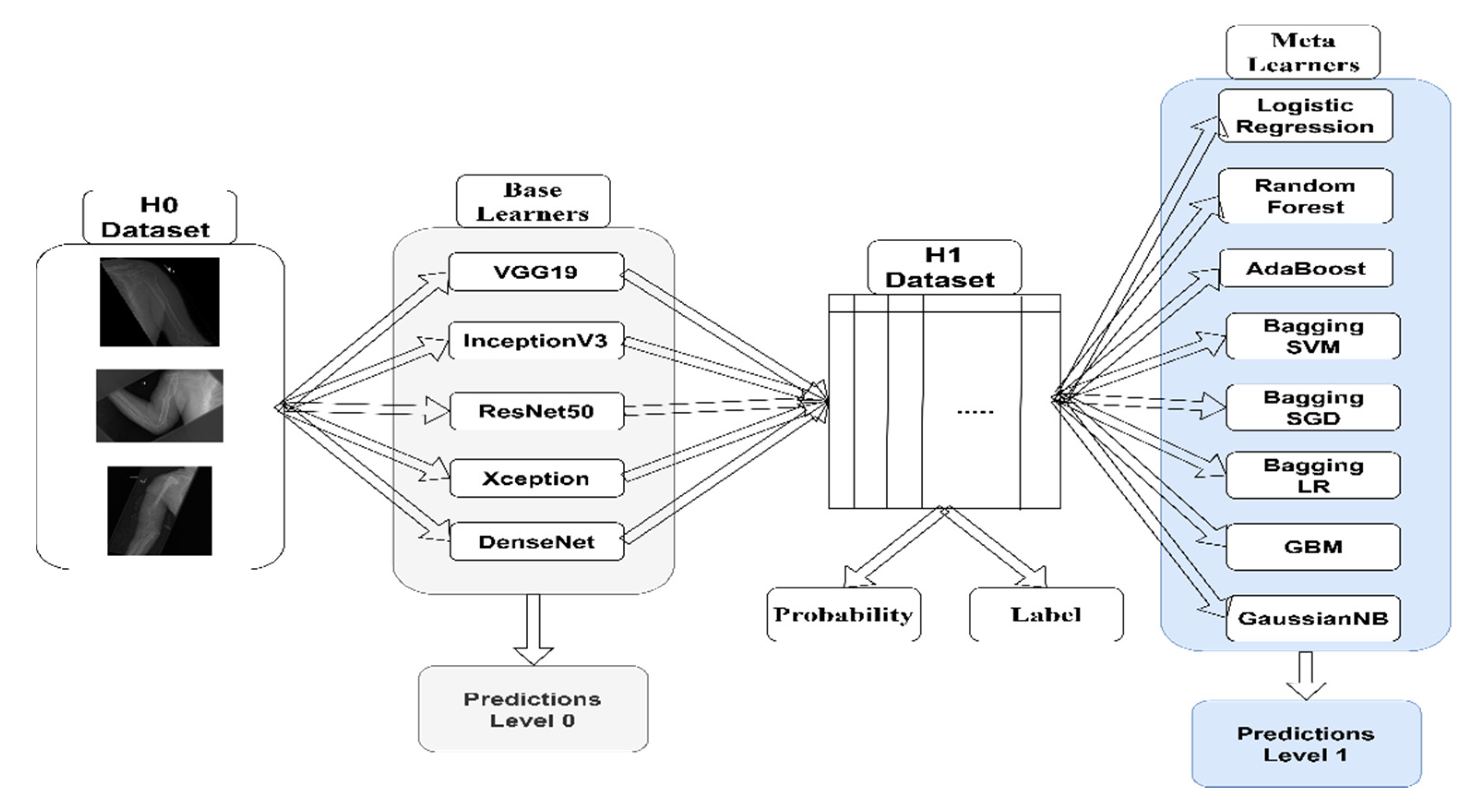
Our primary goal is to develop a classification framework for bone fracture detection using X-ray images. To reach our goal, we compared different stacking techniques to improve the classification of fractures using X-ray images.
The main contributions of this work are as follows:
- (1)
We evaluate different state-of-the-art CNNs. We also assess their combinations’ performance, either in averaging, weighted average, or majority vote.
- (2)
We investigate the usage of the stacking ensemble along with CNN outputs. To do so, we tested the performance of eight different machine learning meta-classifiers. Two main methods are considered: using probability outputs to construct the level-1 ensemble, or using label outputs.
The rest of this paper is organized as follows: In the second section, we describe our methodology. The third section presents our results obtained. The fourth section discusses the main findings of this study. Finally, the fifth section concludes the paper.
3. Results
As pointed out by [
19,
41], fine-tuning the CNN architectures will yield better results and converge faster than training a CNN from scratch. In this paper, we fine-tuned all CNN layers using the ImageNet dataset. All hyperparameters were fixed for all CNNs during the training process. We used the Adam optimizer [
42] with a learning rate of 0.0001 for all CNNs. The batch size was 64. All images were rescaled to 96 × 96 pixels. An early stopping criterion was used to stop the training if no progress occurred for 50 epochs. Four image augmentation techniques were considered to increase the model performance: zooming, 180° rotations, and horizontal and vertical flips. We relied on data augmentation to balance the numbers of images in the different classes. All machine learning algorithms’ hyperparameters were kept at the default settings of the Scikit-learn Python package. An NVIDIA RTX 2060 graphics card and an Intel i7-10750H CPU were used for training.
Due to the dataset’s size, we did not use point estimates. Instead, each base-learner classifier was trained 10 times, then average scores were calculated. To determine the statistical significance of the results, we followed the methods of [
43,
44], in which a small confidence interval implies statistical significance [
45]. For the sake of readability, we provided a summary of the results for all images in
Table 1. Full tables may be found in the annex.
In the first experiment, we tested different techniques on the humerus images. The first set of experiments tested the performance of various state-of-the-art CNNs on the humerus dataset, which considered level-0 classifiers. The VGG19 architecture achieved the highest score among the five CNNs, κ = 0.6299. This was the greatest kappa value and the smallest confidence interval compared to other level-0 classifiers. The ResNet50 network achieved the lowest score, κ = 0.5349 but had the greatest confidence interval. Subsequently, to assess the performance of statistical metrics, we averaged the predictions of the five CNNs. A majority vote was taken, and the weighted average based on kappa scores was calculated. The three scores were approximately the same, with the average score being slightly higher than the others. The second set of experiments aimed at training a machine learning classifier over the probability outputs of the CNN. The NB classifier achieved the highest score, with a score slightly lower than the one achieved in the first set of experiments. The third set of experiments was similar to the second but considered the label outputs of the CNN. The scores achieved in the third experiment were smaller than the ones achieved in the first and the second sets of experiments. Overall, the highest score was achieved by taking the average of the level-0 classifiers for the humerus images.
We tested the different techniques on the finger fracture images, as we had with the humerus images. The first set of experiments considered the level-0 classifiers. The best CNN was the DenseNet network, κ = 0.4168; while the InceptionV3 network achieved the lowest score, κ = 0.3566. To assess the performance of simple statistical metrics, we averaged the predictions of the five CNNs. A majority vote was taken, and the weighted average based on kappa scores was calculated. The kappa score of the average vote and the weighted vote were the same and were higher than the majority vote and the DenseNet score from level 0. Overall, in the first set of experiments, the highest score was achieved by considering the CNNs’ average vote. In the second set of experiments, each CNN’s probability score was used to train a machine learning classifier. The highest score was achieved by the NB classifier, κ = 0.4862. The score achieved by the NB classifier was greater than all previous scores. For the third set of experiments, the NB classifier also achieved the highest score; however, it was less than that achieved by using the probability score. Overall, the second set of experiments’ performance was better than both the first and the third sets of experiments.
In the first set of experiments for elbow images, the greatest kappa scores were achieved by the VGG19 network, κ = 0.6436and the Xception network, κ = 0.6433 . The VGG19 network’s kappa value was slightly high; however, the Xception network’s confidence interval was less than that of the VGG19 network. To assess the performance of simple statistical metrics, the predictions of the five CNNs were averaged, the majority vote was taken, and the weighted average based on kappa scores was calculated. All three kappa scores were similar to the weighted average score (0.6970 ± 0.67%), which was slightly greater than the others with the smallest confidence interval. In the second set of experiments, the probabilities of the CNNs were used to train eight machine-learning classifiers. All scores were approximately similar, with the LR bagging classifier being the highest, κ = . Overall, the scores of the second set of experiments were lesser than those of the first set of experiments. The third set of experiments’ results were lesser than those achieved in the first and second experimental sets. AdaBoost classifier scored the highest, κ = 0.6720. Overall, the best kappa score achieved for the elbow images was achieved by taking the weighted average vote of level-0 classifiers.
For wrist images, the best score achieved by a level-0 classifier was by the Xception network, κ = 0.6127%. To assess the performance of simple statistical metrics, the predictions of the five CNNs were averaged, the majority vote was taken, and the weighted average based on kappa scores was calculated. The highest score was achieved by the weighted average of the level-0 classifiers, κ = 0.6556 , which was greater than the Xception network’s score. In the second set of experiments, the best performer was the logistic regression classifier, κ = 0.6510 . While this score was greater than the level-0 classifiers’ scores, it was still less than the weighted average vote of the level-0 classifiers. The results of the third set of experiments were lesser than both the first and second sets. Overall, in all experiments, the weighted average vote of the level-0 classifiers yielded the best results for wrist images.
For forearm images, the best CNN was DenseNet, κ = 0.5592 . To assess the performance of simple statistical metrics, the predictions of the five CNNs were averaged, the majority vote was taken, and the weighted average based on kappa scores was calculated. The weighted average votes achieved the highest score, κ = 0.5765 1.85%. The results achieved in the second set of experiments were better than those of the first set, with the NB classifier achieving the highest kappa score, κ = 0.6195 . The results achieved in the third set of experiments were as high as the second set, with the NB classifier achieving the highest kappa score as well, κ = 0.6201. Overall, the NB classifier using label predictions achieved the best results for forearm images.
For hand images, the VGG19 network achieved the highest score among all CNNs, κ = 0.4358 . To assess the performance of simple statistical metrics, the predictions of the five CNNs were averaged, the majority vote was taken, and the weighted average based on kappa scores was calculated. The weighted average votes achieved the highest score, κ = 0.4260 . However, this score was less than the score achieved by the VGG19 network. The results achieved in the second set of experiments were better than those of the first set, with the NB classifier achieving the highest kappa score, κ = 0.5029 . The results achieved in the third set of experiments were slightly lesser than the second set, with the NB classifier achieving the highest kappa score, κ = 0.4962 ). Overall, the best result was achieved by an NB classifier using probabilities.
For shoulder images, the best performing CNN was the VGG19 network, κ = 0.4638
. To assess the performance of simple statistical metrics, the predictions of the five CNNs were averaged, the majority vote was taken, and the weighted average based on kappa scores was calculated. The weighted average votes achieved the highest score, κ = 0.4908
. For the second set of experiments, the highest score was achieved by the GBM classifier, κ =
. The GBM kappa score was greater than both the level-0 classifiers and their average weight score. For the third set of experiments, the bagging classifier achieved the highest score using logistic regression, κ = 0.4882
. Overall, the best classifier for shoulder images was the GBM classifier trained using probability scores.
Appendix A contains all the results for the expriments we performed.
4. Discussion
In this study, rather than relying on a single CNN classification, we investigated different methods to combine the results of individual CNN networks (level-0 classifiers) in order to classify musculoskeletal X-ray images. We first trained five different CNN networks, then assessed their performance. Afterward, we combined their predictions by taking an average of their votes, a weighted average of their votes, or by taking their majority votes. We called this last step a meta-learner using statistics. Afterward, we examined the eight different machine learning algorithms’ performance on top of the predictions made by level-0 classifiers. Two different inputs were used to train the machine learning algorithms—either the probability output of the level-0 classifiers or their label output. In
Table 2, we present the differences between the kappa scores of the best performing level-0 classifiers (CNNs) and those of the level-1 classifiers (machine learning algorithms).
By comparing the meta-learners using statistics (MLUSs) across the seven different datasets, we observed that their performance was usually better than any single CNN, except for in the hand dataset, whose best-performing CNN (VGG19) achieved a better score than the three combination methods. Across the three methods, the weighted average achieved the best results. Even in the case of the hand dataset, it yielded a better score. It is worth noting that the weights were measured based on kappa scores. The greatest difference between the meta-learners using statistics and the best CNN occurred in the elbow dataset, with an average difference of 8.30%. The least difference occurred in the hand dataset, where the best CNN achieved better results than the combinations by an average of 5.06%.
Comparing the meta-learners using probability (MLUPs) to level 0, we observed that the MLUP classifiers achieved better results than the level-0 CNNs. The most significant difference was spotted in the finger dataset, where the average increase was 12.36% compared to level 0. The least difference occurred in the humerus dataset, in which the average increase was 2.68% compared to level 0. Additionally, across the eight machine learning algorithms, all achieved more accurate results than the best level-0 classifier. The best achieving meta-classifier was NB for four datasets. Comparing MLUPs to MLUSs, MLUPs achieved higher results than MLUSs for four datasets, and MLUSs achieved the best results for the remaining three datasets. However, it is worth noting that for the hand dataset, where the score of the best level-0 classifier achieved better results than all the MLUSs, MLUPs achieved significantly better results than the MLUSs, with an average 9.59% increase in accuracy.
Comparing the meta-learners using labels (MLULs) to level-0 CNNs, we observed that the MLUL meta-classifiers achieved better results than all level-0 CNNs. The most significant difference was in the finger dataset, where the average increase was 8.78% compared to level 0. The least difference occurred in the humerus dataset, where the average increase was 0.61% compared to level 0. However, across the eight machine learning algorithms, some scored lower than the highest level-0 classifiers, such as the SGD bagging classifier for the humerus and shoulder datasets and the SVC bagging classifier for the humerus dataset. The best meta-classifier was the NB classifier, as it achieved the best results five times. Comparing MLULs to MLUSs, MLUSs achieved higher results than MLULs for four datasets. The MLUSs achieved the best results for the remaining three datasets. However, it is worth noting that for the hand dataset, where the score of the best level-0 classifier achieved better results than all MLUSs, MLULs achieved significantly better results than the MLUSs, with an average increase of 7.66%. Comparing MLUPs to MLULs, MLUPs achieved better results than MLULs for all seven datasets.
From our results, it is clear that using stacking achieves better results than using any single classifier on its own. This conclusion matches the results obtained by several works presented in the literature [
46]. One of the leading hypotheses for why stacking achieves better results than any single classifier is that combining the outputs of different classifiers can decrease each classifier’s error. This diversity is what makes stacking work [
47,
48], whereas the underlying level-0 classifiers must be different from each other and must make different errors. In our case, each CNN was different from the others both in its number of parameters and its underlying architecture, so each CNN made different errors.
Regarding the computational power needed for each MLUS, MLUP, and MLUL, the least was needed for the MLUSs. Here, no high computational power was needed since the method is all about taking the average or the majority vote. However, for MLUPs and MLULs, greater computational power was needed to train the machine learning algorithms. Nevertheless, it is worth noting that the computational power needed for the machine learning algorithm is less than the power needed to train CNNs by order of magnitude. Full tables on computational requirements can be found in the annex.
Our choice of dataset was successful for two reasons. First, the dataset has seven different types of images. Second, each of the seven datasets has a different size. Thus, it was possible to compare our results across different types of images and different dataset sizes. Based on our results, we conclude that stacking algorithms achieve higher results than level-0 algorithms alone. MLUPs achieved better results than MLULs in all datasets. Thus, we recommend using MLUPs over MLULs. However, further studies are needed to compare MLUSs to MLUPs and determine which method is better.
Concerning other results presented in the literature, Kitamura et al. [
19] investigated an ensemble method’s performance built on three CNNs: InceptionV3, ResNet, and Xception. They reported that using an ensemble (where the voting method was used to combine the different CNNs’ outputs) achieved better results than using a single model. Moreover, they investigated combining all the models versus combining only the best-achieving models. The performance of the ensemble using all models was better than that of the ensemble built on the best models only [
19]. Both our study and Kitamura et al.’s [
19] concluded that an ensemble of different CNNs would yield better results than using a single CNN.
Chung et al. [
11] used a single model (ResNet) to classify humerus fracture images. They compared the performance of the single model to human experts. However, they neither compared their model to other CNN models nor examined any ensemble models’ performance. Olczak et al. [
13] compared five different CNN architectures and selected the best model, which was the VGG16 network. They did not examine the performance of any ensemble models. Similarly, Lindsey et al. [
14] did not investigate the role of ensemble learning and instead relied on simple learners.
The main difference between our study and Uysal et al.’s [
15] is that we used all seven different MURA datasets. Uysal et al. [
15] used only the shoulder dataset. Thus, their results cannot be generalized over the different types of fracture images. Additionally, compared to Uysal et al. [
15], we repeated each experiment 10 times to increase the significance of our findings. On the other hand, Uysal et al. [
15] provided no average results and only presented their findings on a single model. They reported a kappa score exceeding our highest score for the shoulder dataset; we might speculate that this is due to the fact that they considered high-resolution images. All in all, considering the different experimental settings between our work and Uysal et al.’s work, the results obtained for the shoulder dataset are comparable.
The main difference between our study and Huynh et al.’s [
17] is that we used all seven MURA datasets, while Huynh et al. [
17] used only the humerus dataset. Thus, in this case as well, it is difficult to generalize their findings on all the different types of fracture images. The authors compared their model’s validation accuracy score to the MURA study’s kappa score [
12]. Our score was comparable to that reported by Huynh et al. [
17], even if our image sizes were smaller than the sizes they considered. Our score for the humerus dataset was κ = 0.6662 ± 1.60%, compared to κ = 0.684 reported by [
17].





{kind=link}
{kind=link}
{kind=link}


