1. Introduction
According to the statistics of 2019, over 2.2 billion people suffer from different eye diseases that result in serious vision impairment and partial or full blindness [
1]. One of the main reasons for vision impairment is age-related macular degeneration (AMD). Several categories of AMD are found at present that individually contains unique characteristics and effect. Among these, the most well-known categories of AMD are the wet and dry classes. The dry class of AMD also happens in three stages named early, intermediate, and late [
2]. From the wet class of AMD, choroidal neovascularization (CNV) causes severe vision impairment and hemorrhage. Consequently, the macula and photoreceptor-dense area are affected, which may cause blindness as this area is responsible for high-resolution vision. Every year in the USA, about 2 million people are detected with CNV [
3]. On the contrary, diabetic macular edema (DME) is a type of disease that affects patients with diabetes and is related to the thickening of muscle which can be considered a complication of diabetic retinopathy. A study showed that 7.5 million people aged 40 years or older suffer from DME [
4]. Another class of AMD called DRUSEN is a type of intermediate-age-related macular degeneration that affects 125 μm or more diameter of the macula, which is a region of 3000 μm centered on the foveolar in either or both eyes. From the statistical evaluation, every year, more than 7 million people in the USA are affected by the DRUSEN class [
5]. If AMD can be detected earlier, complications can be avoided. For this reason, faster and more accurate detection of types of AMD plays a significant role in terms of preventing complications [
2]. One of the most common approaches to detect types of AMD is doing a test called optical coherence tomography (OCT), which is a medical imaging technique where a special machine takes photos of the inside of the eye that detects back reflection from different levels of biological tissue which later forms a two or three-dimensional structural images [
6]. The clinician usages OCT images to detect the types of AMD and their severity. The detection of types of AMD from these pictures is based on an algorithmic approach where handcrafted segmentation is followed by the classification of each segmented object using a statistical classifier, including a machine learning algorithm, and finally, classifying the images. This approach is not only suspected of error but also requires many skilled people. Moreover, refining and tuning a machine-learning model with handcrafted segmentation is a time-consuming and computationally expensive task [
7]. For this reason, with the advancement of computer vision technology, the detection process has evolved a lot. Instead of a handcrafted feature extraction method, the automated detection process is developed to reduce error, time, and human intervention in performing the task.
In this case, several research works have been conducted to perform retinal eye disease classification based on deep learning (DL) methods. For instance, Khan et al. [
8] proposed an ensemble model of ResNet50 and InceptionResNetV2 to detect ocular diseases from enhanced fundus images, and before training the model, the adaptive equalization technique was utilized to improve local contrast by modifying the intensity distribution adaptive with an object. The model achieved an accuracy of 82.05% by extracting only texture-based information from the pre-trained ensemble model. In another study, an ensemble of three models, including Inception-V3, InceptionResNetV2, and Xception, was proposed by Zhang et al. [
9]. The model training was initiated by performing six preprocessing techniques, such as histogram equalization (HE), adaptive histogram equalization (AHE), intensity rescaling, gamma correction, sigmoid adjustment, and limited contrast AHE (CLAHE). After that, two types of classifiers, named deep convolutional neural network (DCNN) and deep full connection network (DFNN), were used for the final classification with an accuracy of 95.42%, which is also a result of texture-based information processing. Moreover, Wijesinghe et al. [
10] proposed a transfer learning-based ensemble model consisting of DenseNet-201, ResNet-18, and VGG-16. The background removal, resolution optimization, and resizing were performed as image preprocessing to make the dataset more optimized for training. Then, techniques called global average pooling (GAP) and singular value decomposition (SVD) were used to predict a single class that combined the prediction from all the models. The extraction of only texture-based information results in an accuracy of 98.69% for the transfer learning-based ensemble model. In one of the studies, Gordon et al. [
11] designed an ensemble model with the combination of two customized convolutional neural networks (CNN) to reduce variance. Moreover, the inclusion of a median filter reduces the sparkle noise. After noise removal, data augmentation is employed for training the model. The work demonstrated the trade-off between training time and classification performance and the effect of batch size on it. For model evaluation, different ensemble techniques such as majority voting, weighted averaging, and stacking were implemented with an accuracy of 99.48%, 99.47%, and 99.51%, respectively.
In contrast, Hendria et al. [
12] proposed a model combining transformer and CNN models to detect objects in unmanned aerial vehicles (UAV) imagery. The Swin and DectectoRS with ResNet backbone were combined to extract the performance of the transformer as shaped-based information and CNN as texture-based information. For image preprocessing, augmentation techniques like random horizontal flip with a probability of 0.5 were used. The individual models were trained separately using identical training sets, and later, the predictions were combined to obtain the final prediction. The precision of this implemented system varied from 38.30% to 63.29%, and the recall varied from 1.42% to 56.43%. In one study, Shen et al. [
13] implemented a stacked ensemble model called ‘CviT’ with a combination of convolution and transformer networks to detect movement classification. Before feeding to the CviT model, the sliding window-based preprocessing technique was utilized to divide the image into patches. For better generalization of model classification, a convolution layer was deployed, followed by the transformer model, which resulted in a classification accuracy of 83.47% and 84.09% on two different datasets. In a separate study, Aldahoul et al. [
14] proposed an ensemble model with a combination of transformers to encode the retinal image. Several augmentation techniques, such as random flipping of horizontal and vertical and 360° rotation, were performed to improve the training process. The images were also rescaled between (0, 1) and cropped to remove the black border. Finally, to combine the prediction, bagging (boot-strap aggregating) was implemented, which used “majority voting”. The performance of the model was optimized using early stopping, dropout, and learning rate schedules. This ensemble of transformers processed shape-based information that achieved an f1 score of 42%. Gupta et al. [
15] proposed an ensemble model to perform person Re-ID. In this paper, a triple stream of ensemble model was observed. The models used in this model were DeIT as a vision transformer, ResNet-50, and Densenet-101, where the vision transformer interprets the pixel dependency by focusing on every specific patch of images. This model achieved an accuracy of 90.05% and 80.45% on two separate datasets, respectively.
In another study, Ullah et al. [
16] proposed a stacked model in which a convolutional neural network was stacked upon a vision transformer. The whole model was then deployed to detect anomalies in video surveillance, where the convolutional neural network detected spatial features and the vision transformer detected long-term temporal relations, which later extracted a spatiotemporal feature. The proposed model achieved an accuracy of 94.6%, 98.4%, and 89.6% in SanghiTech, UCUD Ped2, and CUHK avenue datasets, respectively. In another scholarly inquiry, Ullah et al. [
17] implemented a Vision Transformer Anomaly Recognition (ViT-ARN) framework to identify and categorize anomalies in a surveillance camera. This framework had two phases; in the first phase, the anomalies were identified using a tailored, compact, and single-class deep neural network. In the second stage, the anomaly was categorized based on the feature extracted by the vision transformer, which was improved using a bottleneck attention mechanism to improve representation. This ViT-ARN was trained using a total of 858 and 1600 videos from two datasets and was evaluated based on two datasets- LAD-2000 and UCF- Crime datasets where the proposed framework outperformed other state-of-the-art approaches with an increased accuracy of 10.14% and 3% in these two datasets, respectively. In a separate study, Yao et al. [
18] proposed a fusion of transformers and CNN for salient object detection (SOD) where the transformer captured the long-distance pixel relationship, and later, a CNN was applied, which extracted the fine-grained local details. This incorporation resolved the problem of using a CNN-based network and showed equal effectivity for both RGB and RGB-D (RGB and depth) SOD. In a different study, Yang et al. [
19] presented a novel approach designed for Hyperspectral Image Classification where classification of each pixel was necessary. However, CNN could interpret those local regions quite efficiently but failed to capture the global meaning. On the other hand, the transformer could interpret the global meaning of an image but failed to capture the local region correlation. For this reason, they proposed a fusion of CNN and transformer known as FusionNet, which incorporates the strength of CNN and transformer together.
In a separate study, Nanni et al. [
20] demonstrated how the combined power of CNN and transformer could generate a robust performance in segmentation. In this specific research, the authors combined DeepLabv3+, HarDNet-MSEG, and Pyramid Vision Transformers, which resulted in a dice score of 0.875. In another research, Zhang et al. [
21] implemented a novel architecture TransFuse which was designed for both 2D and 3D medical image segmentation. In this architecture, the researcher introduced a new fusion technique called “BiFusion” and achieved an accuracy of 94.4% in the ISIC dataset. In another scholarly inquiry, Wang et al. [
22] tried to solve the limitation of the U-Net framework in medical segmentation as it could not learn global information. They incorporated the capability of the transformer and CNN to make a new framework known as O-Net, where in the encoder and decoder part, CNN, and swin transformer were used and achieved an accuracy of 80.61%.
All the above-mentioned works generally focused on either convolution or transformer-based classification models or an ensemble of transformer and convolution-based classification models. In the case of ensemble models, the importance of extracted features from every model does not obtain the proper significance because, at the decision level, the class is already classified by a CNN or transformer network. On the other hand, in stacking, the image goes through the model sequentially, which means the extracted feature from CNN or transformer goes through another model where the feature extraction process continues. In this way, the extracted feature is changed by the latter model, which is why the extracted feature in every model does not have the same significance in the final classification. Concerning these findings [
12,
13,
14,
15,
16,
17,
18,
19,
20,
21,
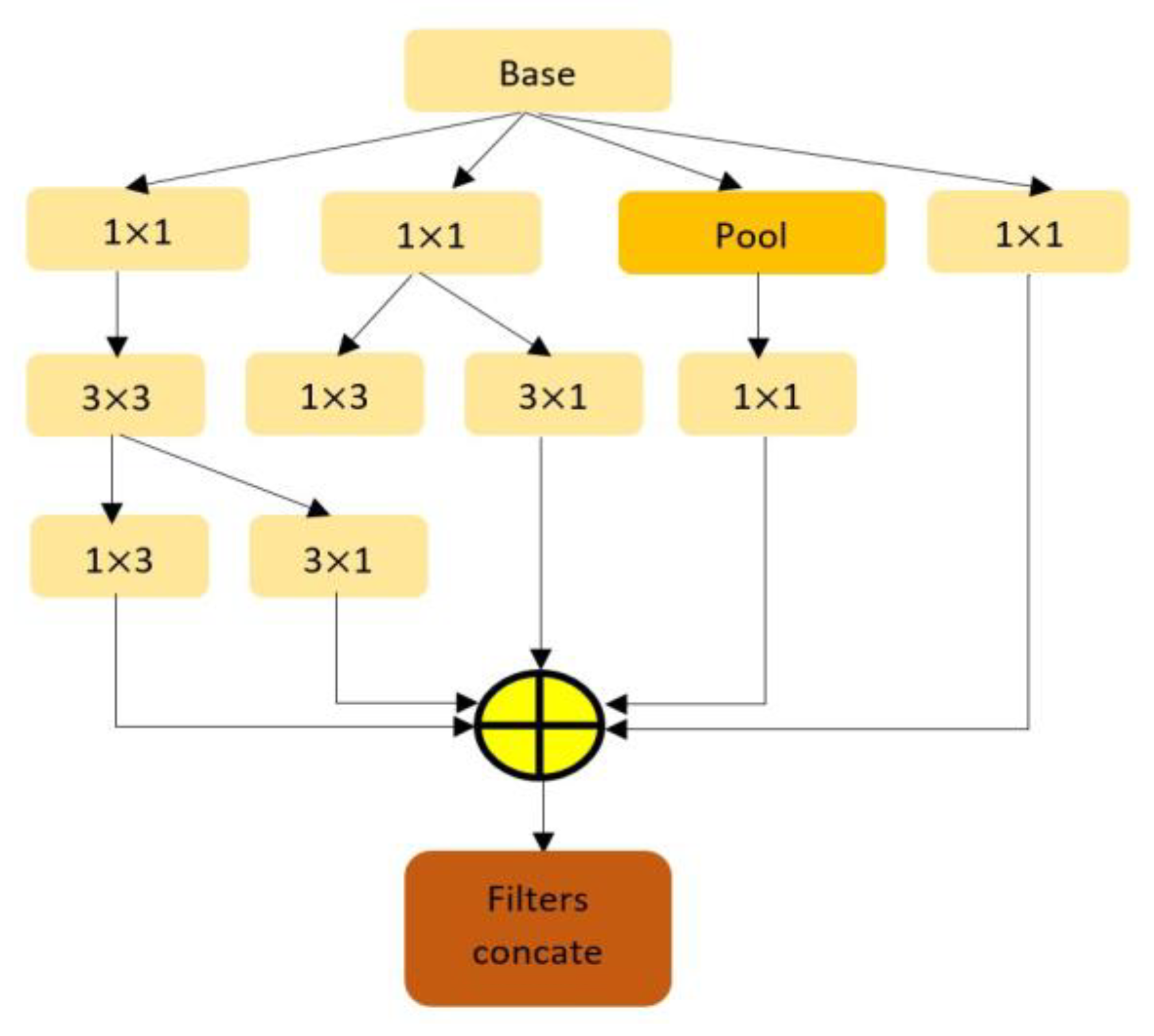
22], instead of ensembling or stacking the models, this work proposes a hybrid feature extraction method by fusing conventional pre-trained CNN models such as Inception-V3 and ResNet-50 and a transformer model. In this framework, the individual model extracts the feature individually, and later, the extracted features become fused. In this arrangement, extracted features from every individual model obtain the same significance, which provides the framework with superior performance. This triple-stream Conv-ViT consists of three individual models- Inception-V3, ResNet-50, and Vision Transformer. Inception-V3 and ResNet-50 are CNN-assisted networks where convolution is performed for feature extraction. The network uses kernels to extract texture information by correlating between nearby pixels. The Inception-V3 is a large convolutional network that works solely based on convolution. The main advantage of inception-V3 is the usage of several filters, i.e., 277 filters, to detect deep texture features by building correlations between consecutive and nearby pixels [
23]. Though Inception-V3 is computationally efficient, it is a very large and complex model which is suspected of vanishing gradient problems. For this reason, the ResNet-50 model is fused to resolve the vanishing gradient problem and extract deep features by building residual connections to nearby pixels. The residual function helps to optimize parameters that enable this model to avoid vanishing or exploding gradients [
24]. On the contrary, the vision transformer is focused on building long-distance pixel relationships rather than nearby pixel relationships resulting in shape-based features [
25]. Consequently, a transformer model is fused with the Inception-V3 and ResNet-50 models to generate a shape-based texture feature for processing through the deep neural network, which provides the classifier an upper hand in final detection. The major contribution of this research includes:
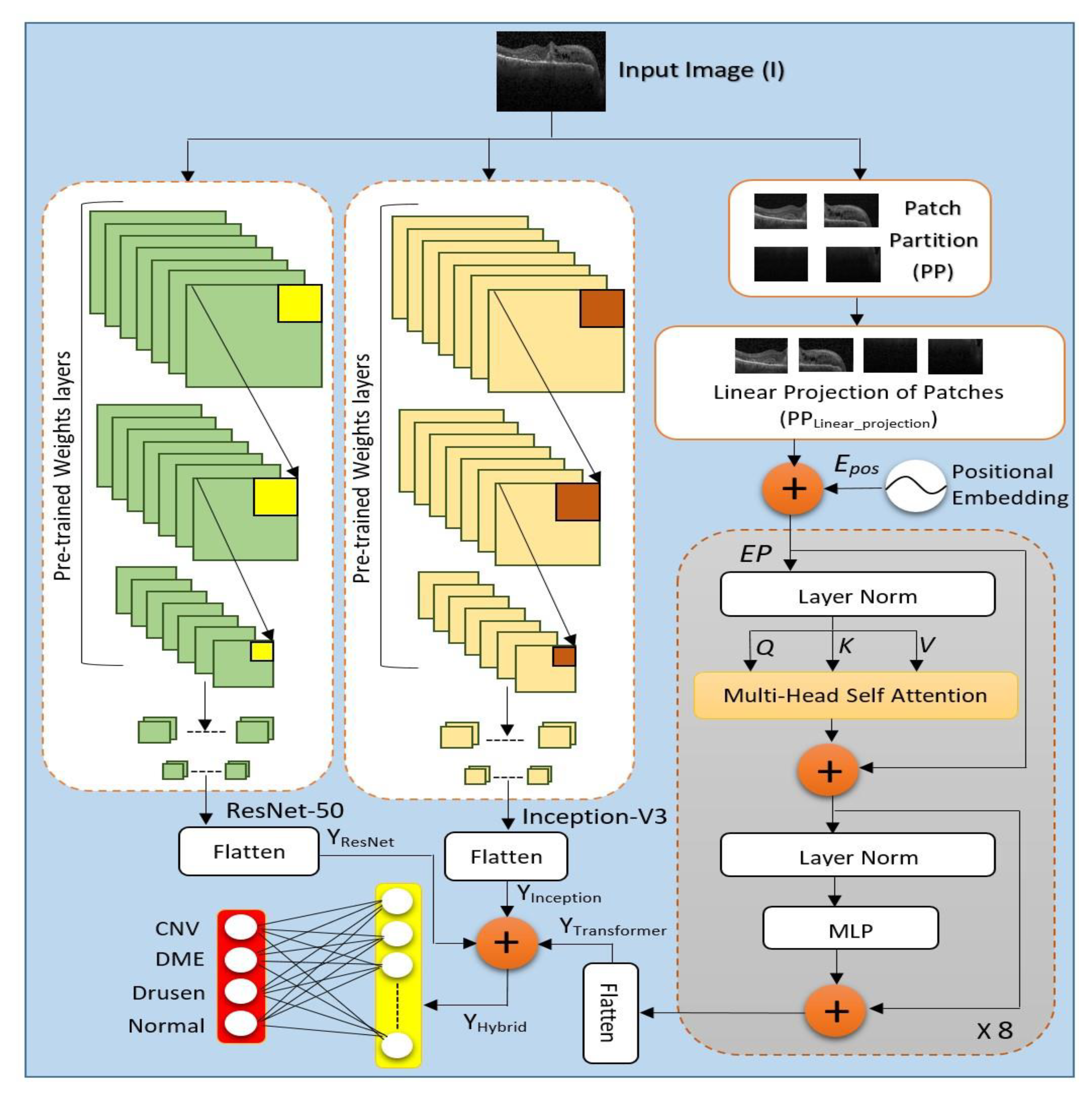
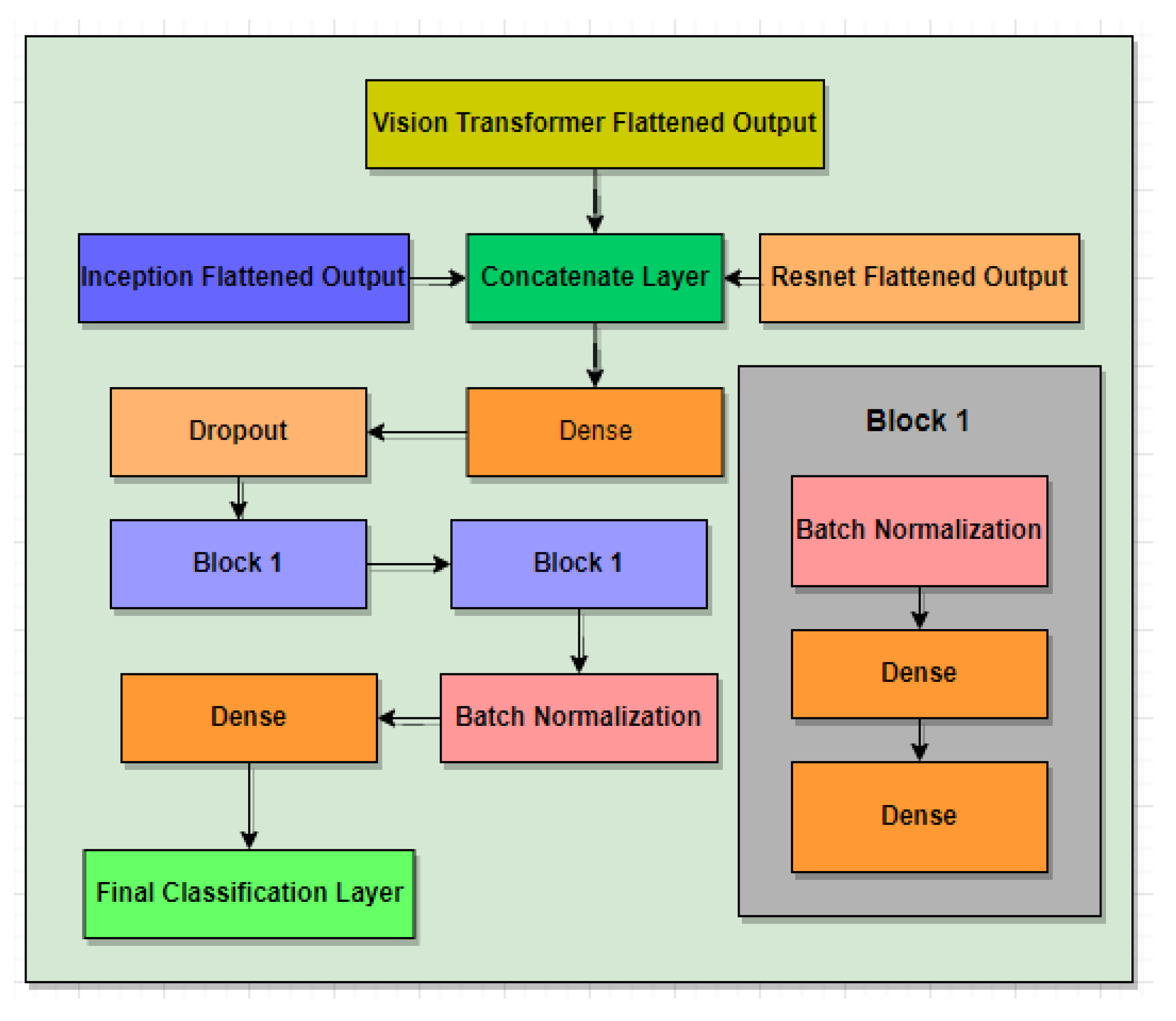
Building a three-stream fusion model called Conv-ViT for retinal disease detection by concerning both texture and feature-based information of each class of retinal images.
Using pre-trained models such as Inception-V3 and ResNet-50, as well as the transformer model, results in a hybrid feature followed by a DNN model to improve model detection performance.
Conducting laborious experiments for performance analysis, including quantitative, qualitative, and ablation, to signify the model’s effectiveness.
The rest of the paper is organized as follows:
Section 2 contains a detailed description of the materials and methods of the proposed Conv-ViT framework with a detailed analysis of all the models.
Section 3 represents the performance evaluation of the proposed system, including quantitative study, qualitative study, ablation study, and comparison with previous work in this field.
Section 4 and
Section 5 contain the discussion and conclusion, respectively.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



