1. Introduction
Cloud computing comes with significant benefits. These benefits include increased agility and reliability; better scalability and elasticity; improved maintenance; device and location independence; and reduced cost [
1]. Thus, it is understandable that the popularity of cloud infrastructures is rapidly rising both when considering small and larger companies.
Whereas the benefits of cloud computing are well known, there are drawbacks or challenges which need to be taken into account by stakeholders considering a move to the cloud. This paper focuses on incident response, which is the process of dealing with an incident from detection, through analysis, containment, eradication and recovery, and preparation [
2]. These activities have increased in complexity since the time when servers were physical machines running a single system for one organization, possibly at their own physical premises. A set of security issues related to incident-handling in the cloud were examined by Grobauer & Schreck [
2] back in 2010, who called for more research in several areas. In the years which have passed since, surprisingly little research addressing those challenges has been published [
3]. Most of this research, however, is mainly concerned with digital forensics in the cloud, or more traditional incident-response scenarios.
Traditionally, exchanging incident information has been conducted based on personal trust relationships. The actual exchange of incident information normally happens by means of email, phone, incident trackers, help desk systems, conference calls, and face to face meetings. With the advent of cloud computing, however, the human element is much less prominent. A cloud service can be made up of a chain of providers where none of the Computer Security Incident Response Team (CSIRT) members have ever communicated directly with a representative from any of the other providers. In addition, an incident in the cloud may need to involve different parts of the provider chain, potentially even in an automated, real-time fashion, to minimize business disruption [
4]. This poses new requirements to the way incident response needs to be managed and supported by tools which can communicate effectively across rapidly changing constellations of organizations.
An essential challenge is that there is no single part of the supply chain which has access to all events and all areas to monitor, thus nobody can immediately see the full picture. In a survey conducted by Torres [
5],
little visibility into system/endpoint configurations/vulnerabilities as such was considered one of the top hindrances to effective incident response in the participants’ organizations. The cloud actors therefore need to be able to communicate efficiently to provide each other with information to ease detection or assist responding to an incident. It has also been claimed that attackers are better at handling information sharing than those protecting services and systems [
6]. This adds to the importance of providing good tools and solutions to incident handlers [
7].
“Our adversaries are amazingly coordinated. They do a far better job-sharing information than we do. it is becoming clear that the good guys need to find ways to share actionable information in real time to counter this threat.”
The terms provider and subscriber are used in the following way throughout this paper:
A CSP can be both provider and subscriber, if it relies on services from other providers when offering their services to cloud customers.
In this paper, we extend our previous contribution [
7] through the Incident Information Sharing Tool (IIST) tool and provide an overview of technical challenges (
Section 2) and non-technical aspects (
Section 3), that directly impact incident-response abilities for cloud-computing scenarios. The overall concept is introduced in
Section 4 before going into details on the incident message format in
Section 5. Moreover, the Application Programming Interface (API) for managing and exchanging incident notifications is presented in
Section 6. A prototype implementation is presented in
Section 7, while
Section 8 presents the result of two focused interviews. An overall discussion of the approach is provided in
Section 9, while
Section 10 concludes the paper.
2. Functional Considerations
As a basis for our proposed specification, we have investigated functional aspects of how incident information should be represented and shared. The following provides an overview of how these aspects relate to cloud-computing scenarios in particular.
2.1. Notification
If an incident occurs at a CSP, he will eventually need to inform his customers. Customers includes both end users and other providers in the supply chain which relies on services from the CSP. Service Level Agreements (SLAs) and applicable law (e.g., the General Data Protection Regulation (GDPR) [
8]) will regulate which notifications to give the end users. In [
7] we discussed the different models for sharing incident information between provider and subscriber. These include a-priori agreements, provider decides it all and a hybrid where the subscriber may choose to receive incident information from categories predefined by the provider.
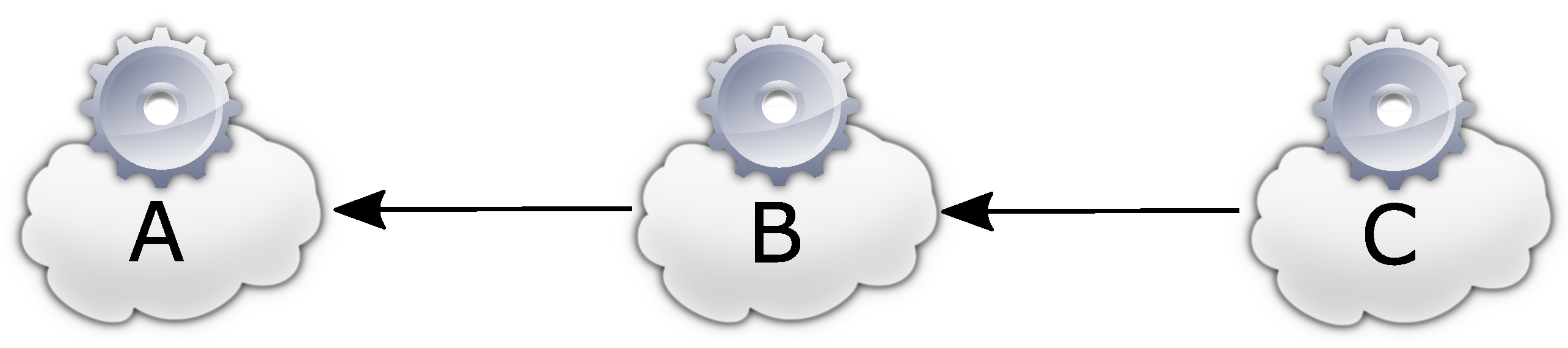
Figure 1 shows an example of the relationship between service providers and services used, and thus provides an example of the amount of unneeded or unwanted incident information a subscriber could receive if he is notified for all incidents in the entire service.
2.2. Propagation of Incidents
Incidents which affect one CSP could in turn affect other CSPs, and the incident message should hence be propagated. In [
7], we discussed two approaches to representing propagated incident messages. First, we discarded including the entire parent incident message as leaking too much information down the chain.
An alternate approach would be to allow the incident message sender to be more in control of his incident information, by only referencing the parent incident when propagating down to a subscriber of a subscriber. In this way, only relevant information would propagate directly, through the actions of an entity, while there would still be a hard link to follow to establish exactly what happened during the incident-handling. This could, e.g., be useful when auditing a provider or during criminal investigations.
While referencing the parent incident message is a better solution than embedding the entire incident message, it still has noteworthy flaws. The referencing system first designed as part of IIST was leaking vital information about the value chain of a cloud provider. If a cloud provider received an incident notification from e.g., Amazon and notified their customers about the incident, all their customers would know that the provider uses Amazon for some part of their offering. Given enough time, a customer could map not only the external services used by a provider, but also their internal incident detection tools connected to the IIST since these would be the parent of some received incidents. Some providers would consider this trade secrets vital in differentiating their service offering from the competition. For this reason, the parent incident message is currently not referenced or included in the incident format.
The lack of information about the parent incident message does not affect the traceability of an incident, as the provider would need to store information about which incident message a subsequent incident message is derived from. This will still allow an auditor to follow the trail of an incident message, going from provider to provider collecting the relevant information. Furthermore, it removes the possibility to short-circuit the cloud service provisioning chain and maintains the proper communication channels. If company A buys a service from company B, they would have a contract in place. This contract would regulate the relationship between A and B, not A and C in the event B buys services from company C. Thus, even though the root cause of the incident originates at company C, the incident report to company A should be properly abstracted according to the service delivered and originate from company B.
2.3. Security
Security incident messages might contain vital information about a computer system and potentially personally identifiable information (PII). This makes it important to secure the incident information both in transit and at rest. This includes compliance with GDPR such as making sure to either anonymize any PII or avoiding its inclusion in the incident message. Given that incident information can be used to decide which changes to apply to a production system, it is also important to know that an incident message was received from the correct CSP. This makes it important that the subscriber has a way to validate the providers he subscribes to notifications from.
Transportation of incidents should only be allowed over a secure channel such as Transport Layer Security (TLS). To ensure that the only valid cloud customers or CSPs receive/provide incident information from/to another entity, authentication should be performed. While securing the incident information during incident exchange is important, the amount of information an attacker can obtain by eavesdropping is dependent on time—unless e.g., system credentials are transferred as part of an incident message. Hence, it is equally important to secure the incident information in the backend system, since an attacker would gain access to all incidents messages the entity has sent and received if having access to the incident system just once. The incident information must thus be protected using access control mechanisms and cryptographic protection in line with current good practice [
9], the details of which are outside the scope of this article.
3. Non-Technical Aspects
For this solution to be useful, it needs to be adopted by businesses and CSPs. Given how most businesses strive to improve their financial results, it is likely that for the system to be adopted, one of the following criteria must be fulfilled:
A
Level 1 implementation, that is exchange of security incident information without any automation in incident-handling, is unlikely to result in significantly reduced costs, if reduced costs at all. However, the solution has been designed with implementation cost in mind, so the cost of adopting the solution should be quite low. The CSP could integrate the interface with their existing incident management tool and use an incident format adapter or translator to convert between their local format and the format used by the solution outlined in this document. If the solution was separated into microservices, one could further decrease the implementation cost by offering them as open source. The incremental nature of the solution allows the implementer to gradually introduce more formats and automation. As the implementation progresses into a
Level 2 implementation, with an increasing amount of automation, the reduced costs are expected to become noticeable. Metzger et al. [
9] claim that more than 85% of abuse cases can be partly or fully automated, which in turn would free up resources allowing for reduced costs or for the incident handlers and the security team to focus more energy on improving security and handling the more difficult cases where full automation is not desired. Some incidents might require inspection and decisions to be made by a human before any information could be passed on to subscribers.
This solution is unlikely to contribute directly to a higher revenue stream, but might contribute indirectly e.g., by making it easier to notify affected parties and thus be more in compliance with the GDPR. If a CSP, or any other organization adopting this solution, is diligent in sharing information about incidents, this could contribute to building an image of trustworthiness and professionalism. Such an image could in turn result in more customers, and thus increased revenue. This would, however, require the organization to be careful to explain incidents and their process in an understandable manner, so the customer is reassured rather than unnecessarily alarmed. CSPs could even offer incident management dashboards for customers, so the customer would not need to administer their own instance of such a system. If the organization fails to appear trustworthy, it is likely to lose customers which in turn would affect the organization’s revenue. It is, therefore, important to have competent incident handlers operating the system and any automation put in place, to ensure quality in both incident-handling and communication.
In [
7], we discuss how more efficient incident response can result in financial benefits and improve the provider’s reputation. Furthermore, there is a need to move the trust relationship from a personal level to an organizational level.
In [
7], based on the findings of Bandyophyay et al. [
10], it is argued that reporting an incident might increase its cost due to it becoming publicly known and causing secondary losses. Thus, the provider might be reluctant to share incident information. Additionally, the problem of having to share incident information before the incident is fully understood arises. The worst case would be to provide an attacker with information about how his attack is progressing. Technological solutions that provide secure means to distribute incident information can to some extent reduce the risk of sharing such information, as providers can have an improved overview of who has received what information regarding the incident. Terms regarding sharing and receiving incident information can also be covered in contracts.
Many other problems can be defined as sub-problems of trust. Legal worries about sharing incident information comes from the fear of legal action as a result of information sharing, but this can be traced back to not trusting how the recipient uses the received information. Public relations worries related to public perception of the company being damaged as a result of sharing information can also be traced back to lack of trust in how the recipient uses the information received. While our solution does not automatically make service providers trust each other, it could make a way for communication to happen in a flexible fashion between distinct and already known organizations, through a secure channel and in an environment controlled by the sender of incident information. It is expected that most non-technical problems, such as trust and who can forward what information to whom, can be solved by adding terms to the respective SLAs and adopt and enforce the Traffic Light Protocol (TLP) [
11,
12]. Use of sanctions for breach of contracts and trust might also assist in making it easier for organizations to share incident information, as they would know that any misbehavior would have consequences.
Laws are powerful incentives for changing behaviors in entire industries within a country. When large entities such as the United States or the European Union introduce similar laws, this affects the entire western world and, to some degree, the rest of the world [
13]. Due to the substantial fines mandated by the GDPR [
14], service providers are given an incentive to ensure accurate and timely notification about breaches relating to personal information.
Laws are not only an incentive, but sometimes also an obstacle. The difference between laws covering PII could complicate information exchange. The organization wishing to send incident information needs to make sure that no PII is included. It has been claimed that information disclosure is the biggest potential contributor to CSIRT liability ([
15], p. 57). To mitigate the fear of being sued for sharing incident information, the US introduced a bill to protect companies that share information with the government from liability [
16].
4. Concept
To allow cloud providers and cloud customers to exchange security incident information, we propose an agreed-upon subscription-based API following the Publish-Subscribe pattern [
17]. An agreed-upon API, and potentially format, allows for increased automation of incident-response tasks, yet it does not require automation to be implemented anywhere. The goal is not to define how every aspect of the system should be design and implemented, but rather define the interactions and formats for exchanging information. The underlying system is left to the implementers of each incident-handling system.
5. Incident Format
We use the small base format presented in [
7], with the ability to represent the most common information in a simple way, while providing a structured way of attaching other incident formats such as Incident Object Description Exchange Format (IODEF) and Structured Threat Information eXpression (STIX). In addition, the format supports custom fields, which allow the provider and the subscriber to agree upon extra information to be included in the base format without altering its base structure. This allows for three levels of implementation. If an implementation is at Level 1 (
Figure 2), the base format would be the only implemented artifact, thus only being usable with humans as the primary actor.To reach Level 2 (
Figure 3), various attachment formats would be added, allowing for some automation while reusing existing incident formats as well as remaining open to new formats. Level 3 (
Figure 4) would be a fully automated incident information exchange tool.
The fields included in the core format are inspired by IODEF [
18], the Federal Incident Notification Guidelines [
19], the EU Commission Regulation No 611/2013 [
20], STIX [
21], and a shared mental model for incident-response teams described by Flodeen et al. [
22]. In
Table 1 each data field is explained further.
Custom Fields and Attachments
Having a defined set of incident formats, agreed upon between the provider and subscriber through SLAs, simplifies the implementation as a cloud customer would only have to support the attachment formats agreed upon with the cloud provider, and the cloud provider only provides the formats agreed upon with its customers. Thus, not all cloud providers and customers have to support all incident formats, but our scheme still gives flexibility to the provider and the subscriber in identifying the formats most suitable for their use case and applying those. The attachments are not attached to the incident notification in the same way as email attachments are attached to an email, but is rather a reference to where the receiver can fetch the files if he desires.
Custom fields represent an easy way of exchanging a few extra values that the subscriber wants, but without the overhead of another incident representation format. There are multiple ways custom fields could be implemented, including allowing any values to be included in any format, allowing only a predefined set of basic data values, and providing data building blocks that allow representation of anything in a structured way.
Custom fields are related to incident types; thus, incident types can be viewed as a template for incidents by providing a customized set of fields to be completed by the incident handler. This reduces the mental burden of having to browse through large amounts of unrelated fields; only the fields needed for the incident type in question are made available to the incident handler.
6. Exchange Interface
The API is implemented through Representational State Transfer (REST), which acts as an
adapter pattern [
23]. Reducing coupling to a minimum increases flexibility, modifiability, and portability, and makes it easier to adopt the solution also for established systems and solutions. A list of all endpoints along with their HTTPS method can be found in [
7]. The specifics of each method are presented later in this section, but
Figure 5 provides a high-level overview of how the content of the methods relate.
Given a chain of CSP and cloud customers, a cloud customer can subscribe to incident information from a CSP. The CSP controls which kind of incident information each subscriber can subscribe to.
6.1. Incident Type
This endpoint gives the subscriber an overview of the incident types available for notification. The incident types are specified by the provider, and the provider would need to have conducted an assessment on how and when incidents of each type can be shared. This is specified by the provided trigger types. The provider also needs to decide whether an incident of the given type can be automatically pushed to subscribers or if humans needs to manually approve the notification. If the incident handler decides not to send an incident, to which cloud customers have subscribed, this needs to be logged so that the necessary information will be available for an eventual audit of the provider. This could be achieved by using dedicated logging utilities such as Transparency Log as defined by Pulls et al. [
24].
Table 2 describes the parameters and their types relating to the incident type payload.
6.2. Trigger Type
This endpoint gives the subscriber an overview of the available types of triggers for the incident type in question. The provider creates trigger types matching its infrastructure and the conditions upon which it has assessed the need to share incident information. The cloud customer uses these trigger types to manage under which conditions he wants to receive notifications. This will help the provider stay in control of when different types of data are shared with subscribers, while still allowing the subscribers to choose when to receive notifications.
Table 3 describes the parameters and their types relating to the payload of a trigger type.
6.3. Notification Trigger
Notification Triggers define when a cloud customer is to be notified. The subscriber creates notification triggers, which is instantiations of trigger types, for each incident type he subscribes to. A notification trigger consists of a trigger_type and a threshold.
Table 4 describes the parameters and their types related to the payload of a notification trigger.
6.4. Subscription Incident
When the subscriber adds an incident type to his subscription, he creates a subscription incident. This is a combination of an incident type and incident triggers with the accompanying threshold values defined by the subscriber. A subscription can hold one or more subscription incidents.
Table 5 describes the parameters and their types related to the payload of the subscription incident.
6.5. Subscription
A subscription is a set of incident types and triggers specified by the cloud customer. A subscription holds at least one incident type and one incident type holds at least one trigger, but each could hold an infinite number of incident types or trigger types. The triggers can be assigned methods on how they relate to the other triggers as AND, OR, or NONE. The trigger method operates on the current trigger and the next trigger in the list. The none operator can only be used for the last or only trigger in a list.
Incident → Trigger 1 AND Trigger 2 OR Trigger 3
AND has higher precedence than OR, so the above statement is interpreted as (Trigger 1 AND Trigger 2) OR Trigger 3.
Table 6 describes the parameters and their types related to the payload of a subscription.
6.6. Notification Validation
This is an endpoint the subscriber can use to validate that a received incident notification is correct and was actually sent by the claimed sender.
The payload is the notification the subscriber wants to validate. He receives either 200 OK or an error:
{
“error”: ERRORCODE,
“error_msg”: STRING_DESCRIBING_ERROR
}
6.7. Sent Incident Notification
When the provider pushes an incident notification to the endpoint defined by the subscriber, he uses the format described in
Table 7.
7. Prototype
The customers of a cloud provider may have varying preferences when it comes to which systems, services, and incident types they are interested in notifications for, as well as which thresholds of severity these should operate in relation to. Supporting such individual preferences can be accommodated by publishers e.g., through offering customers a subscription mechanism. The individual provider will need to have the final say as to what information their customers are allowed to receive, regardless of preferences. To avoid data leakage and enforce the principle of least privilege, access to the API is only provided through a secure channel, over HTTPS. Both senders and receivers should be authenticated using established methods of authentication.
Figure 6 shows a screen-shot from a prototype built around the concept and specification outlined in this paper. The prototyped graphical user interface presents a minimal way to manage the basic part of the incident format which is meant to be easy to understand for human incident handlers. As a subscriber, the dashboard allows you to browse through the received incident notifications. Currently the functionality to subscribe to incidents is not implemented in the user interface, but supported through the API. As a provider, the prototype has functionality for defining possible incident types which others can subscribe to, as well as composing new incident notifications and updates related to these. For those who are both a subscriber and a provider, the interface contains functionality for deriving a new message from a received notification, which must retain internal links to the origin of the notification. The source code of the prototype can be obtained from our Github repository [
25].
As the message format indicates, the user interface supports an indication of the message’s origin, its status, impact, type, language, description, and timestamps for occurrence and detection time. In addition, there is information to add about the company’s liaison with relation to this incident, and any custom fields which the incident type supports. The message composer also supports uploading attachments, allowing for extra data to be transferred in a deterministic and parsable way upon agreement between two parties. As mentioned earlier, standardized event exchange formats such as IODEF and STIX could be uploaded here for organizations wishing to represent their incidents in this level of detail. While incident notification theoretically could be fully automated, this particular prototype requires a human-in-the-loop to decide whether to notify subscribers or not. Attachments could increase the flexibility of incident information exchange while still maintaining a simple common base format. This will also contribute to reducing the coupling of information in incident reporting compared to having one large common format to represent everything.
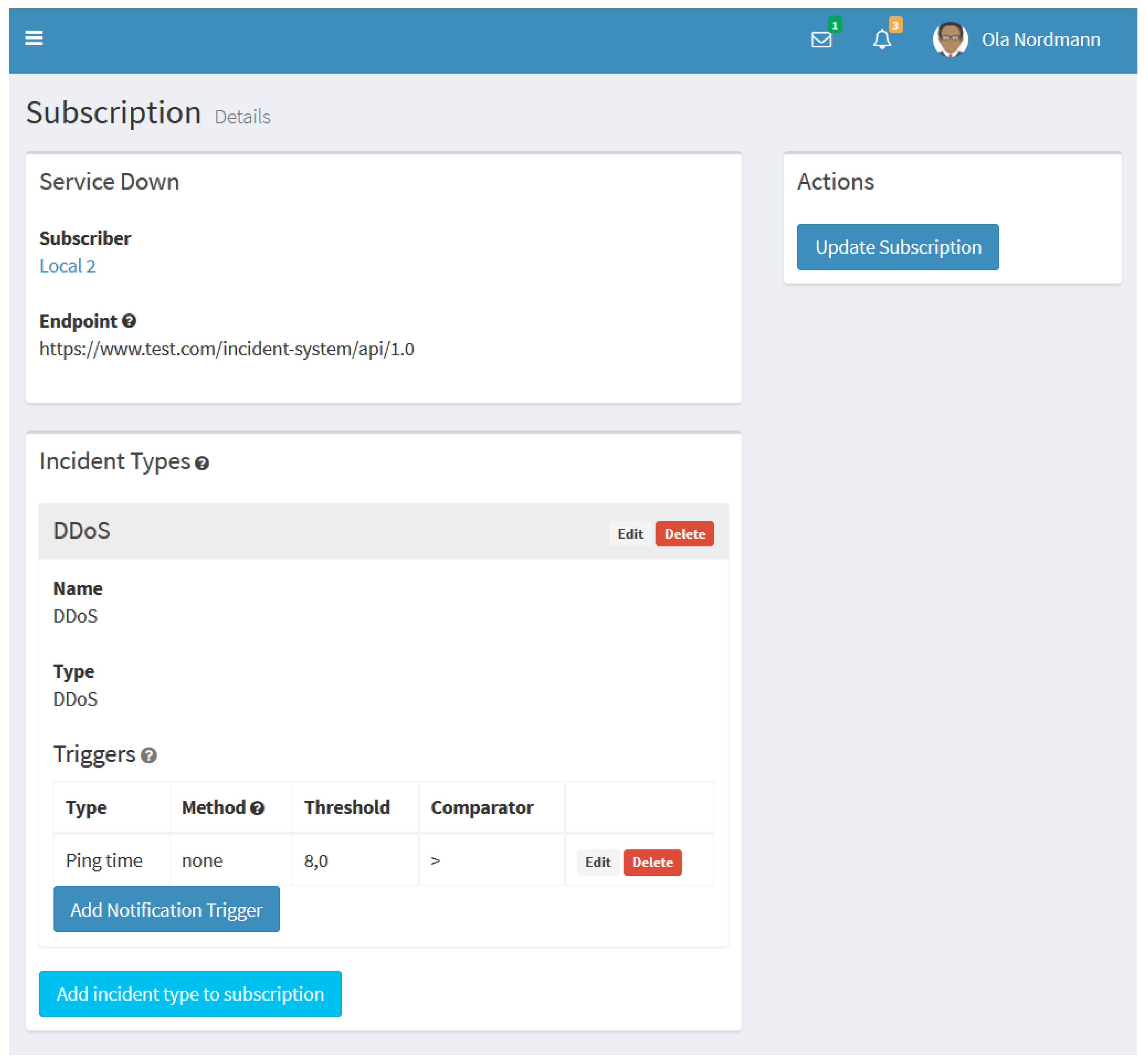
Figure 7 gives an example of a simple notification subscription with the incident types and triggers the subscriber is interested in.
8. Interviews
In connection with a demo of the dashboard prototype, we have conducted two focused interviews with experienced incident handlers from two organizations to evaluate our approach. Due to the early stage of the development, the number of participants was limited to two experienced incident handlers—the interviews were used as an initial test of the concept.
The interviewees noted that if most providers supported the exchange interface and the base incident format, it would be most useful in assisting notification to subscribers, customers, and users. There is also a potential added value in this increasing the amount and quality of the incident reports to the national Computer Emergency Response Teams (CERTs). Both interviewees wanted a simple way of requesting additional information regarding an incident. One of them suggested using a comment section visible to all recipients of the incident, thus giving the sender the option to reply once for every question rather than once for every recipient. Additionally, this could foster collaboration between receiving incident handlers to work around the issue before a final solution is released.
9. Discussion
Our main contribution is a simplified method of incident-sharing, making it available for organizations of all sizes, while still allowing for implementing a large ecosystem with automation if so desired. While the approach does not guarantee that all participants of the chain understand and correctly act upon the information, it gives all participants in the chain the possibility to receive any information they are eligible to receive by setting up subscriptions with its adjacent links. The approach also supports preserving traceability for incidents propagating through the Cloud Provision Chain. Finally, this facilitates the notification of end users, since the last provider in the chain is in the best position to know who to notify.
9.1. Adoption
It was strongly suggested to us, in response to presenting our approach at the A4Cloud [
26] Advisory Board 2015, that the entire process should be completely automated and the incident handler or privacy officer should not have any say in whether incidents are provided to cloud customers or not—this would be a
level 3 implementation. Still, we have decided to make the prototype with a human-in-the-loop. Please note that there is nothing in the API or incident format that hinders removing the human from the loop. The reason for using an approach with a human-in-the-loop, boils down to incident handlers claiming that they would not adopt a system in which the customer and potentially end users were notified without them being allowed to ensure the correctness and quality of the notification [
27]. The proponents of complete automation use the GDPR [
20] and its 72 h notification rule as the main argument. The rationale is that if you have a chain of cloud service providers relying upon each other, a small delay in notification from each of them would soon amount to more than 72 h. This raises the question of who is responsible for the incident in the first place and when an incident is detected. Given a cloud service provider chain A-B-C-D and, for example, say A only has a relationship with B, B with C and C with D. As far as A is concerned, B is his only supplier and should therefore be responsible for any incident occurring further down the chain. Thus, A could sue B, but B could in turn sue C for not upholding his responsibilities. If this is the case, then the incident would be detected by A at the time of B revealing the incident, not when the root cause occurred at D. We have not been able to obtain a definitive answer to when the incident occurs for A in such a case, but our approach supports both full automation and human-in-the-loop. However, while full automation could help with timely notifications, it would require solid ground work to ensure not to violate other regulations by blindly passing on any information.
A
Level 1 implementation, i.e., exchange of security incident information without any automation in incident-handling as illustrated in
Figure 2, is unlikely to result in significantly reduced costs. However, the solution has been designed with implementation cost in mind, so the cost of adopting the solution should be quite low. The incremental nature of the solution allows implementers to gradually introduce more formats and also automation. As the implementation progresses into a
Level 2 implementation, with an increasing amount of automation as illustrated in
Figure 3, the reduced costs are expected to become noticeable. Metzger et al. [
9] claim that more than 85% of abuse cases can be partly or fully automated, which in turn would free up resources allowing for reduced costs. Finally, a
Level 3 implementation would not need a human-in-the-loop but rely solely on automated services for sharing of incident information as illustrated in
Figure 4.
“Even the smallest organizations need to be able to share incident information with peers and partners to deal with many incidents effectively” [
28]. Large and small organizations are different in many ways, particularly in resources available to implement and adhere to new standards and systems. The solution presented here, was designed from the ground up to reduce the cost of initial adoption while facilitating added value as the complexity of the implementation increases—e.g., full automation.
9.2. Early Decision Making
Cichonski et al. [
28] state that
“The incident-response team should discuss information sharing with the organization’s public affairs office, legal department, and management before an incident occurs to establish policies and procedures regarding information sharing.” Our proposed solution facilitates such decisions to be taken before incidents occur, as subscribers can subscribe to incident types made available to them by the CSP. Thus, the CSP needs to have decided beforehand which incident types each subscriber can subscribe to. In addition, each organization is free to decide how to implement the backend and can thus require a human-in-the-loop, allowing for a second screening of incidents before they are sent to subscribers.
9.3. Prior Research and Industry Efforts
Cusick and Ma [
29] describe a solution conceptually similar to the one proposed here, but for internal use in the organization. Users might subscribe to be notified when events are created or changed, which has led to improved communication around the incidents. The authors state that this feature alone made it worth their while to create a new process and implement new tools. Our proposal takes this one step further and allows other entities to be notified just as easily as the human subscribers.
Metzger et al. [
9] describe a system that notifies subscribers about malware and other unwanted programs running on their systems, and is able to handle 85% of all incidents in a fully or partially automated manner. While our proposal does not provide any assistance with detection, it might be of assistance in notifying subscribers. It does also offer more fine-grained control over which notifications they wish to receive. The proposed solution could also be used as a communication channel for sensors submitting incidents to the central incident database. However, it would probably not replace email and phone as reporting channels for all users. For collaborating organizations, the solution could replace such means of communication, but for single individuals a simpler way of reporting would probably be needed, such as a web interface or email and phone as described in the article.
9.4. Further Work
There are multiple important challenges to tackle for sharing of security incident information to become common. However, further work should spring out of industry needs and evolve during use. Therefore, there is a need for a larger test and demonstration of the different approaches to incident and threat sharing to find the most practical approach for organizations of all sizes.
10. Conclusions
In this paper, we have presented a solution for propagating security incident information along Cloud Service Provisioning Chains. We have defined a format and an API which has been successfully tested in a lab environment. The solution would ease the propagation of incident information along the Cloud Service Provisioning Chain, which in turn can facilitate more accurate and timely information for CSIRTs and eventually improve overall security. Finally, the solution must be tested in a large real environment before more firm conclusions are made.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}