1. Introduction
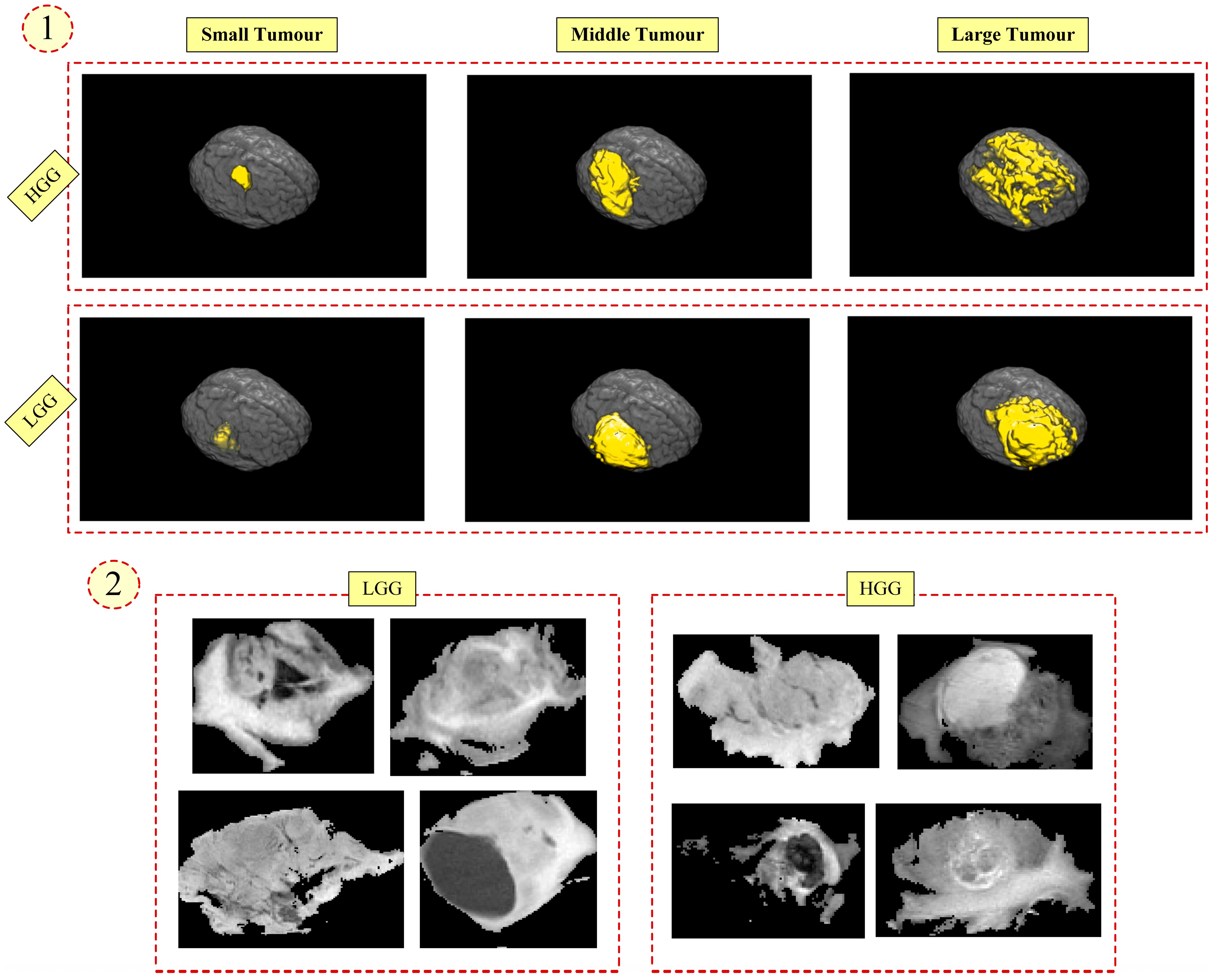
Glioma is the most frequent and one of the fastest growing brain tumors according to the grading system of the World Health Organization (WHO). Regarding this assessment, glioma is divided into four groups that are degree-I (pilocytic astrocytoma), degree-II (low-grade glioma), degree-III (malign glioma), and degree-IV (glioblastoma multiforme). Herein, the distinction of these tumors as high-grade glioma (HGG) and low-grade glioma (LGG) provides a significant opportunity to arrange treatment procedures and to make an estimation of the survival time of patients [
1,
2]. The survival time of patients with HGG-type tumors is almost two years, and this type of glioma requires rapid intervention. In contrast with HGG-type tumors, the growth rate of LGG-type tumors stays at low levels, and the survival time of patients with LGG can be kept as long as possible [
3].
Magnetic resonance imaging (MRI) is often preferred to detect brain tumors in terms of revealing different abnormalities in tissue examinations [
4]. In other words, MRI comes to the forefront on account of identifying even small tissue changes in comparison with the other imaging modalities [
5]. However, the exploration of MRI slices involving both necessary information (tumor region) and irrelevant information (non-tumor region) can make the detection process hard. Regarding this, a computer-aided diagnosis (CAD) system can help medical experts, especially radiologists, to adjust the therapeutic initiatives [
4].
In the literature studies, brain-based analyses (segmentation, classification, etc.) are handled and examined many times by using 2D- or 3D-based evaluations [
6,
7,
8,
9,
10,
11,
12]. However, the accurate classification of brain tumors is evaluated less than the segmentation issue. At this stage, the classification process is nearly always realized using two-dimensional (2D) analyses instead of three-dimensional (3D) examinations of tumors.
Latif et al. [
1] offered a system operating all phase information (T1, T2, T1c, and FLAIR), discrete wavelet transform (DWT), first- and second-order statistics, and multilayer perceptron (MLP) so as to perform the classification of tumor vs. non-tumor samples in 2D MRI images (BraTS 2015). In analyses, 39 HGG/26 LGG instances were utilized for training, and 110 HGG/LGG samples were considered for testing. In other words, a training-test split was considered to evaluate the system. Consequently, the proposed system achieved 96.73% accuracy and 99.3% AUC scores for the 2D-based classification of tumor availability. However, all training samples of BraTS 2015 were not considered in the study, and the semi-automated system was not appropriate to work with a segmentation method. Kumar et al. [
2] presented a model including stationary wavelet transform (SWT), textural features including first-order statistics (FOS), recursive feature elimination (RFE), and random forest (RF) in order to classify the HGG vs. LGG samples in 2D MRI images (BraTS 2017/2018). In the experiments, all phase information was utilized, and five-fold cross validation was chosen to evaluate the performance. As a result, the proposed model attained 97.54% accuracy and 97.48% AUC scores for the 2D-based classification of brain tumors. However, the whole brain and region of interest (ROI) including the tumor area were utilized together for feature extraction, meaning that the proposed model constituted a semi-automated classification structure requiring both the choice of slice and ROI. In other words, the proposed model was functional with a 2D-based segmentation algorithm and with an expert to choose the slice. Saba et al. [
3] designed a framework involving histogram orientation gradient (HOG), local binary patterns (LBP), deep features, and a classifier so as to discriminate 2D images that are labeled as HGG vs. LGG and as normal vs. tumor. In trials, a 50%-50% training-test split was preferred as the test method, and ensemble classifier (EC) was the best algorithm on average classification performance for three datasets. The proposed framework obtained accuracies of 91.30%, 91.47%, and 98.39% on the BraTS 2015, BraTS 2016, and BraTS 2017 datasets, respectively. Moreover, the framework was proposed as a semi-automated algorithm concerning slice selection. Gupta et al. [
4] proposed a three-level classification system utilizing a T2 + FLAIR phase combination, morphological operations, inherent characteristics, and majority voting-based EC for HGG vs. LGG categorization. Moreover, the proposed system included a T2 + FLAIR phase combination, grey level co-occurrence matrix (GLCM), grey level run length matrix (GLRLM), LBP, and majority voting-based EC for normal vs. tumor discrimination. In the experiments, two datasets containing BraTS 2012 were used, and ten-fold cross-validation was considered for evaluation. Consequently, an average accuracy of 96.75% was observed in the HGG vs. LGG classification of 2D MRI images by the system presenting a semi-automated structure. Sharif et al. [
5] suggested a pipeline comprising a T2 + FLAIR phase combination, HOG, LBP, geometric features, and support vector machines (SVM) for the categorization of healthy vs. unhealthy samples in 2D MRI images. To evaluate the pipeline, three datasets involving BraTS 2013 and BraTS 2015 were handled, and a 50%-50% training-test split was chosen as the test method. The suggested pipeline acquired 98% and 100% accuracy scores for the BraTS 2013 and 2015 datasets, respectively. Consequently, a semi-automated pipeline achieving promising scores was presented to the literature for 2D-based classification of healthy vs. unhealthy images. Bodapati et al. [
13] presented a two-channel classification model based on deep neural network (DNN) algorithms: InceptionResNetV2 and Xception. To fulfill the performance assessment, five-fold cross-validation was preferred, and two datasets including BraTS 2018 were considered. According to the results, it was revealed that the proposed two-channel DNN outperformed other deep learning approaches by attaining 93.69% accuracy on the BraTS 2018 dataset. In [
13], the input data of the model was defined as 2D MRI images, meaning that the operating condition of the model was proposed on a semi-automated basis. Koyuncu et al. [
14] proposed a detailed framework handling a T1 + T2 + FLAIR phase combination, FOS features, Wilcoxon feature ranking, and an optimized classifier named GM-CPSO-NN for discrimination of HGG/LGG samples in 3D MRI images. In experiments, two-fold cross-validation was considered to assess the performance, and the BraTS 2017/2018 dataset was considered to perform the classification. As a result, the proposed framework obtained 90.18% accuracy and 85.62% AUC scores for the 3D-based classification of brain tumors.
Concerning the literature results, it can be seen that 3D-based classification reveals a more complicated issue in comparison with 2D-based classification due to the success scores and the information amount to be processed. In addition, 3D-based information requires comprehensive analyses to accurately perform the classification task. Beyond this, a fully-automated CAD system classifying the degree of brain tumors independently with the help of an expert can only be realized using the 3D tumor obtained from a segmentation method. Herein, the motivation of this paper arises which is the design of a model handling the 3D-based classification of HGG/LGG data in 3D MRI images. This paper is formed considering the requirements stated in the literature and contributes to the literature on the following subjects:
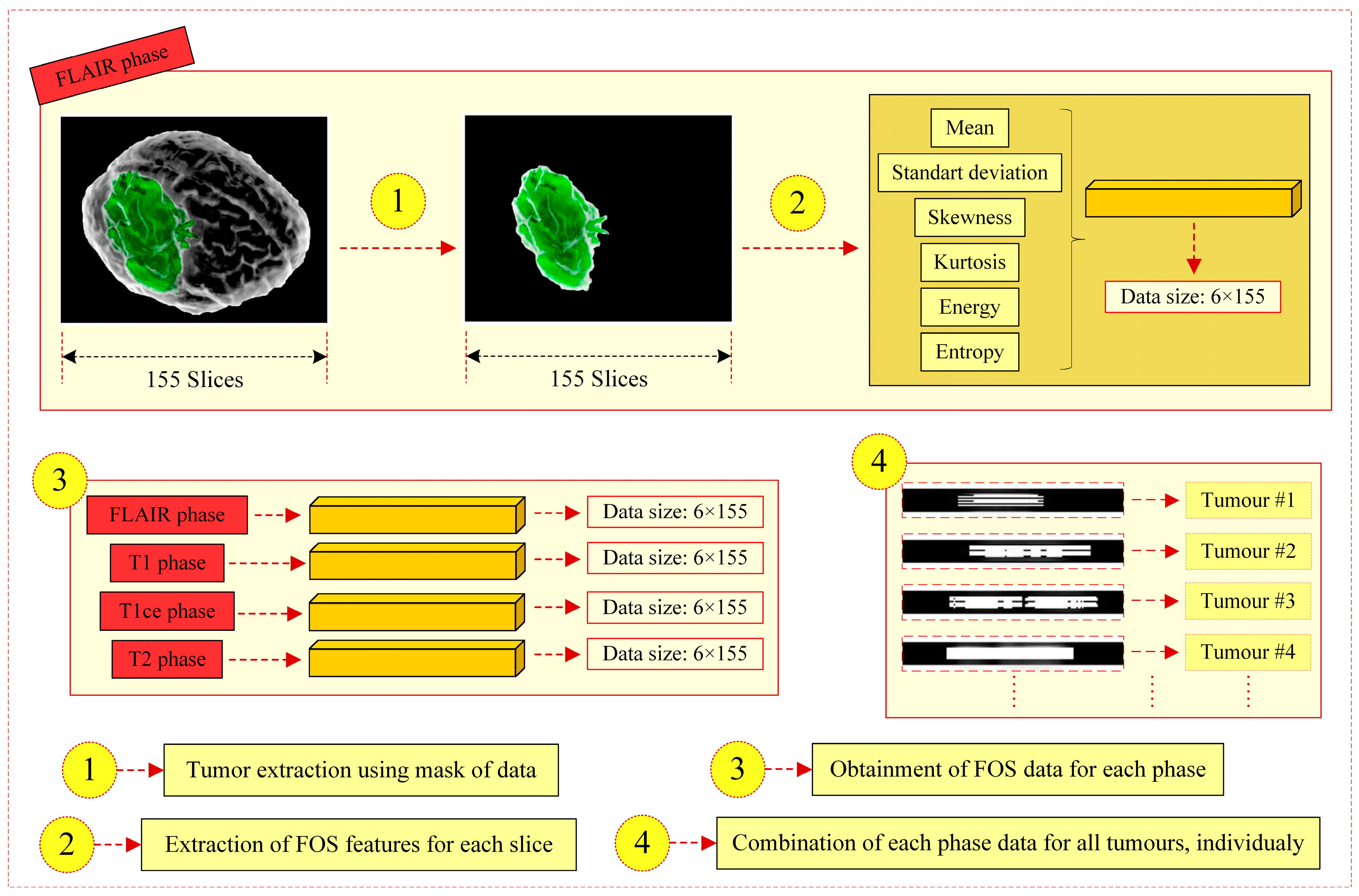
A novel 3D to 2D feature transform strategy (3t2FTS) that can be utilized to classify tumors in 3D MRI images;
A detailed application analyzing the information of a 3D voxel by transforming the space from 3D to 2D;
A comprehensive study considering the comparison of eight qualified transfer learning architectures on tumor grading;
An efficient framework to be determined for guiding 3D MRI-based classification tasks.
The organization of this paper is as follows.
Section 2 briefly explains the utilized FOS features in-depth, describes the proposed 3D to 2D feature transform strategy, gives the dataset information with its handicaps, and briefly declares the transfer learning algorithms.
Section 3 presents the experimental analyses and interpretations of the comparison of transfer learning methods for two-fold cross-validation-based evaluations.
Section 4 reveals the discussions about the results extracted. The concluding remarks are given in
Section 5.
3. Experimental Analyses and Interpretations
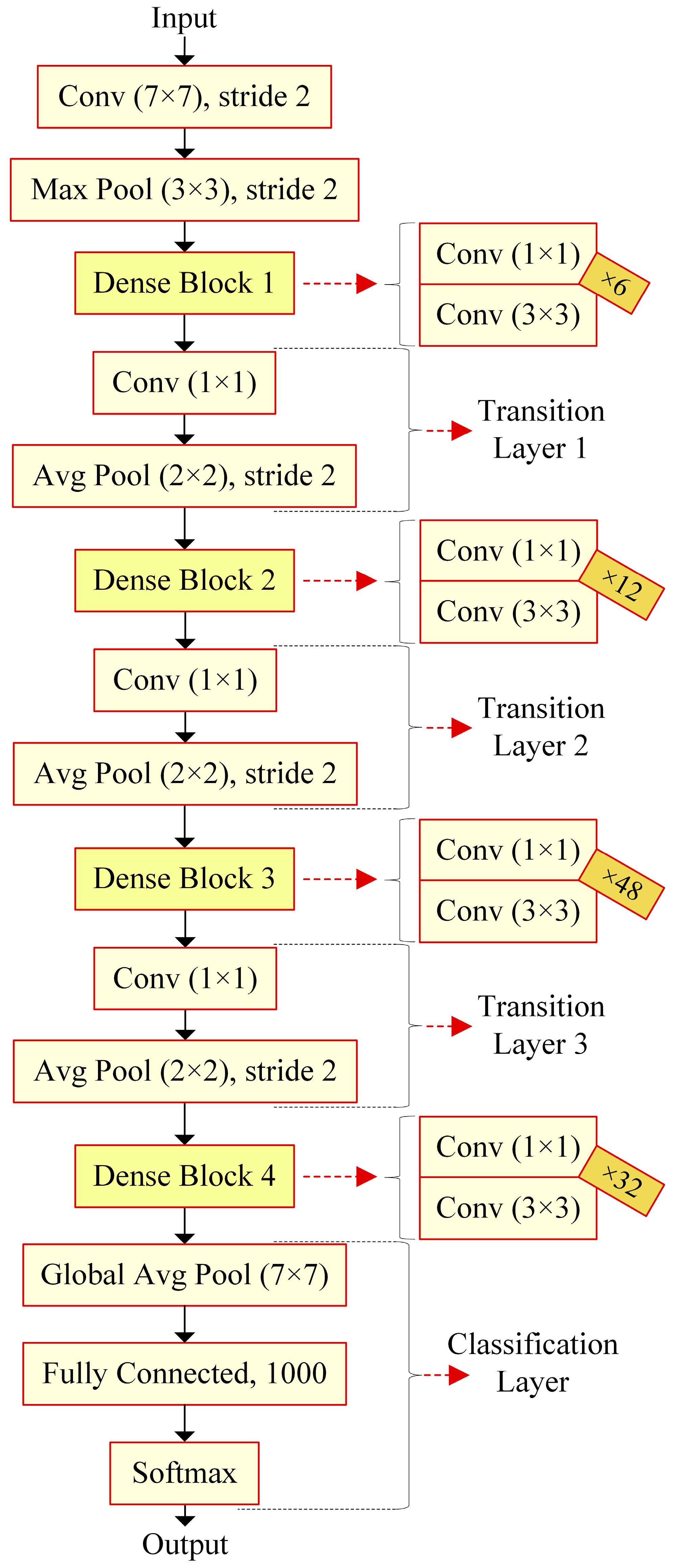
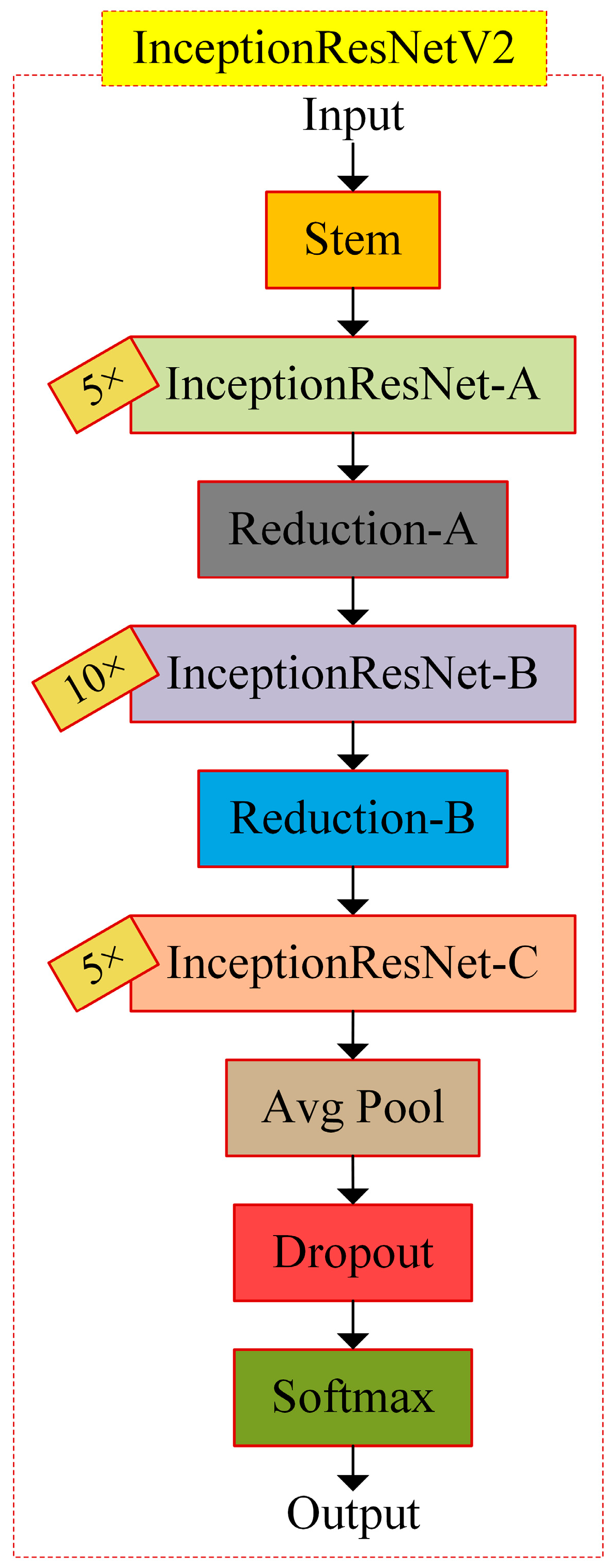
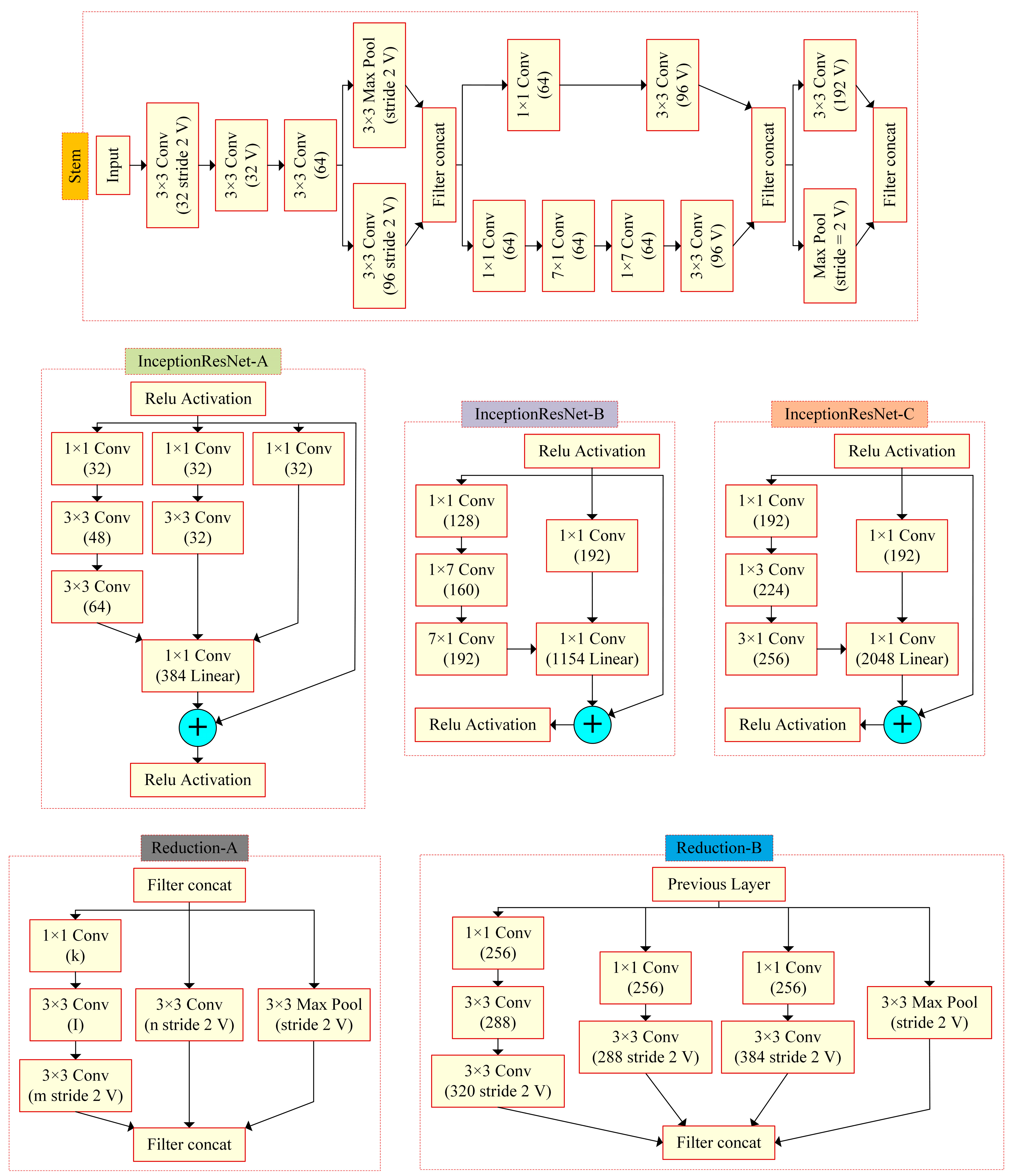
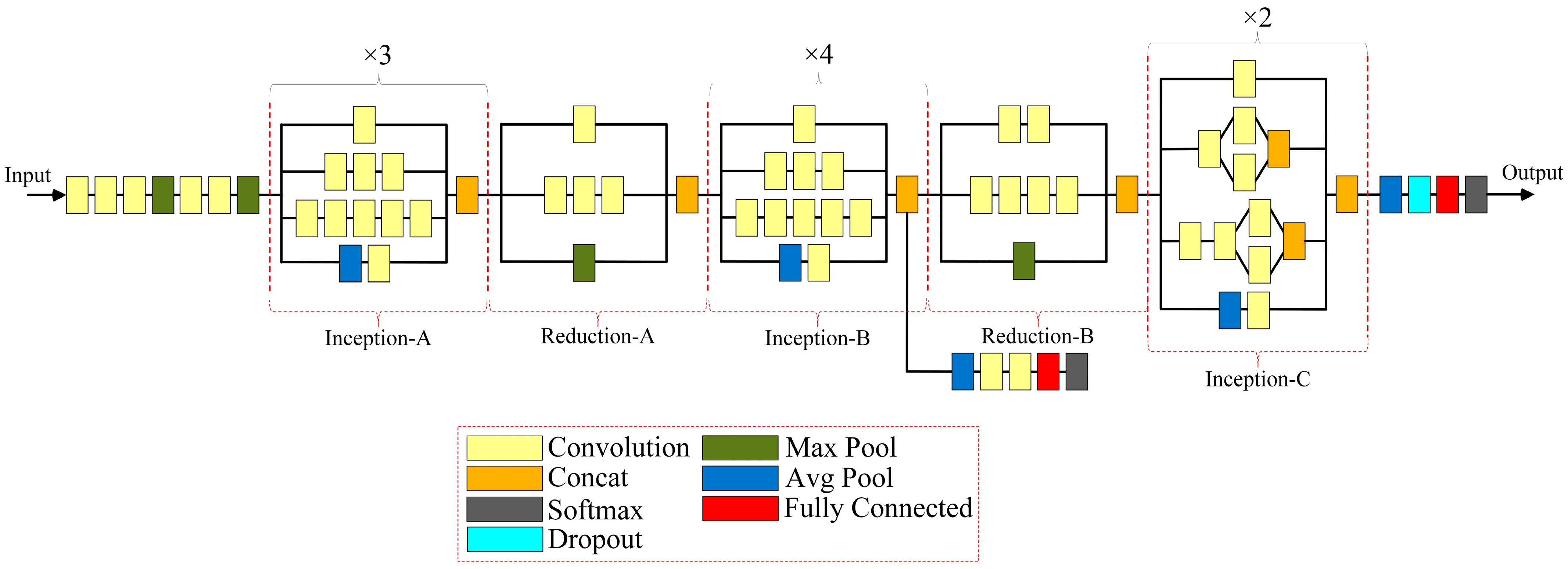
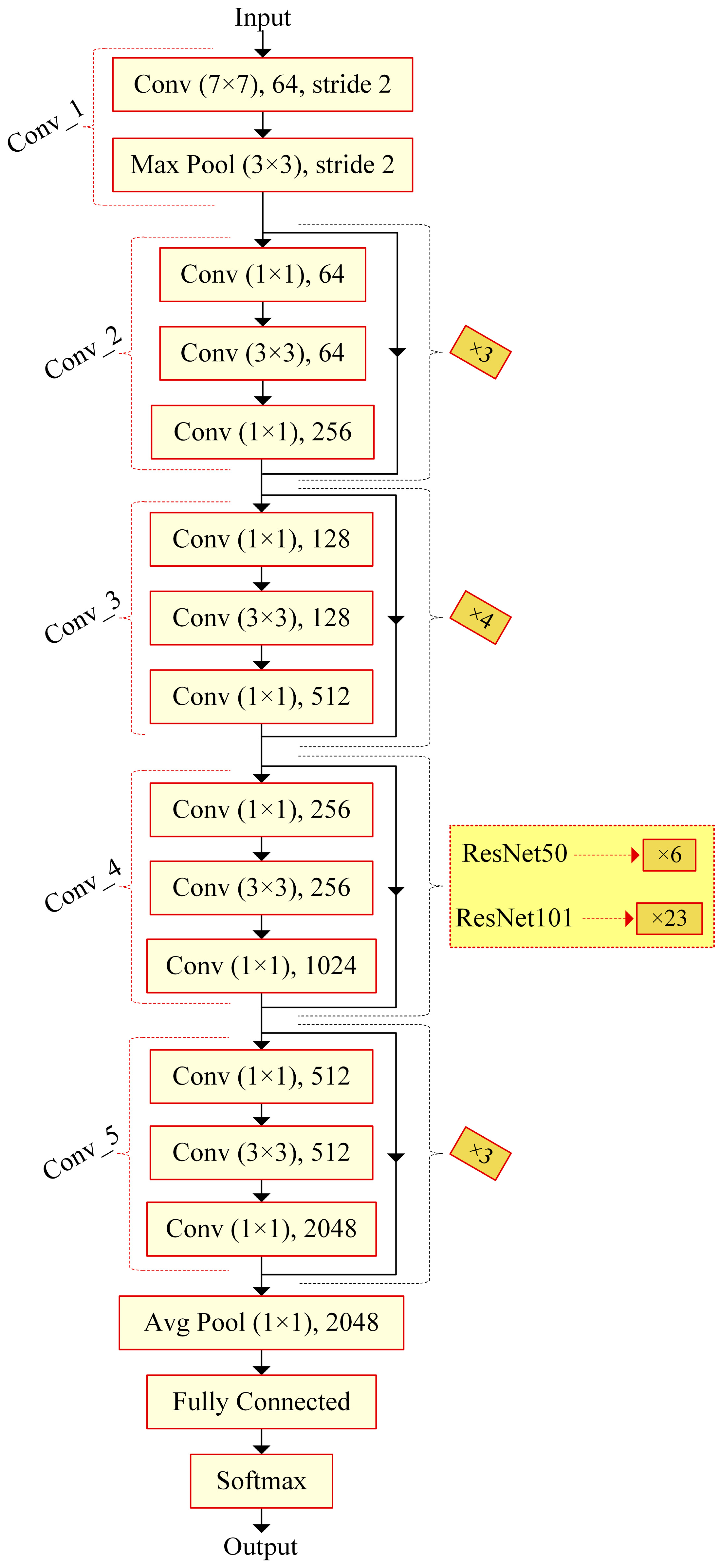
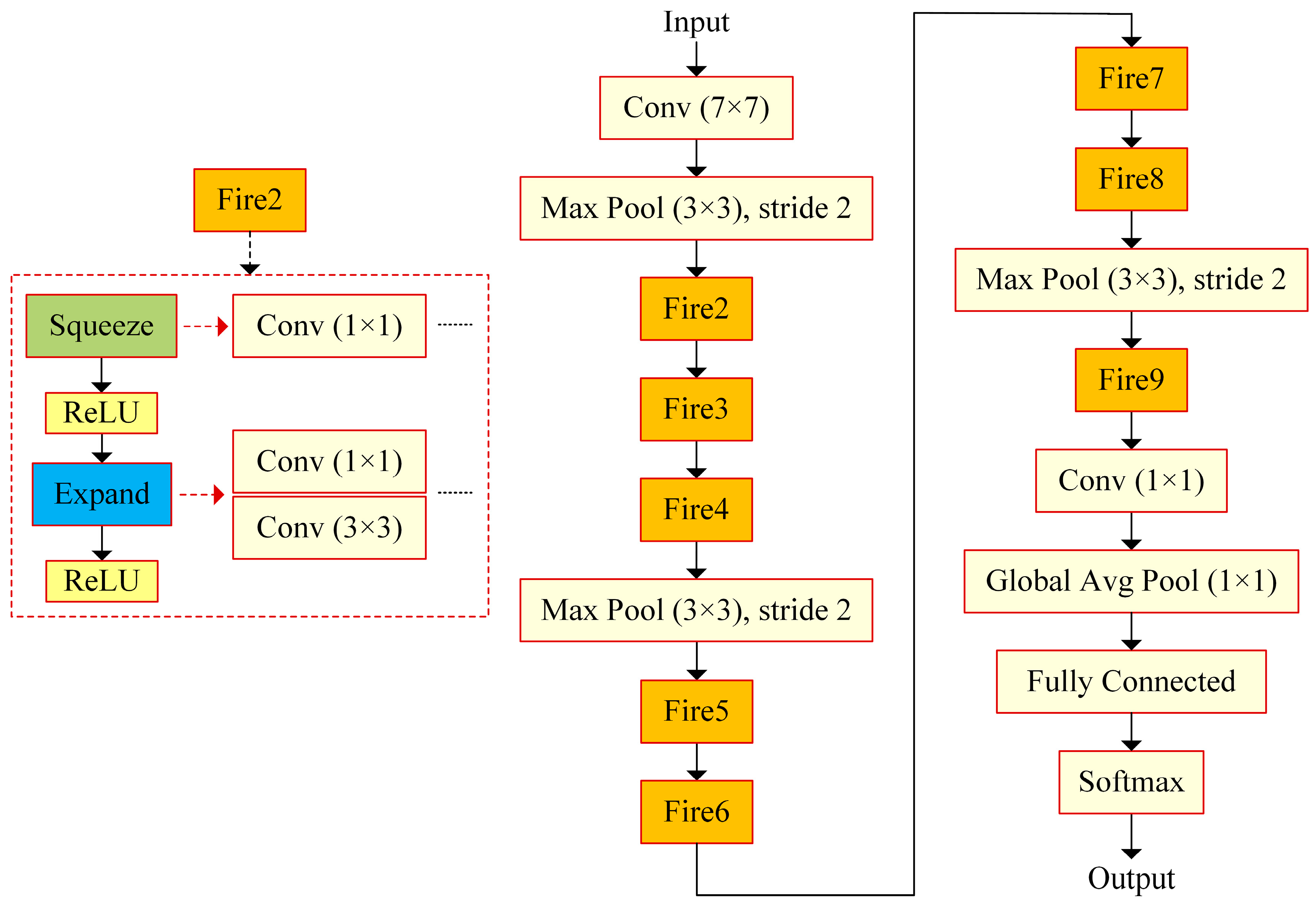
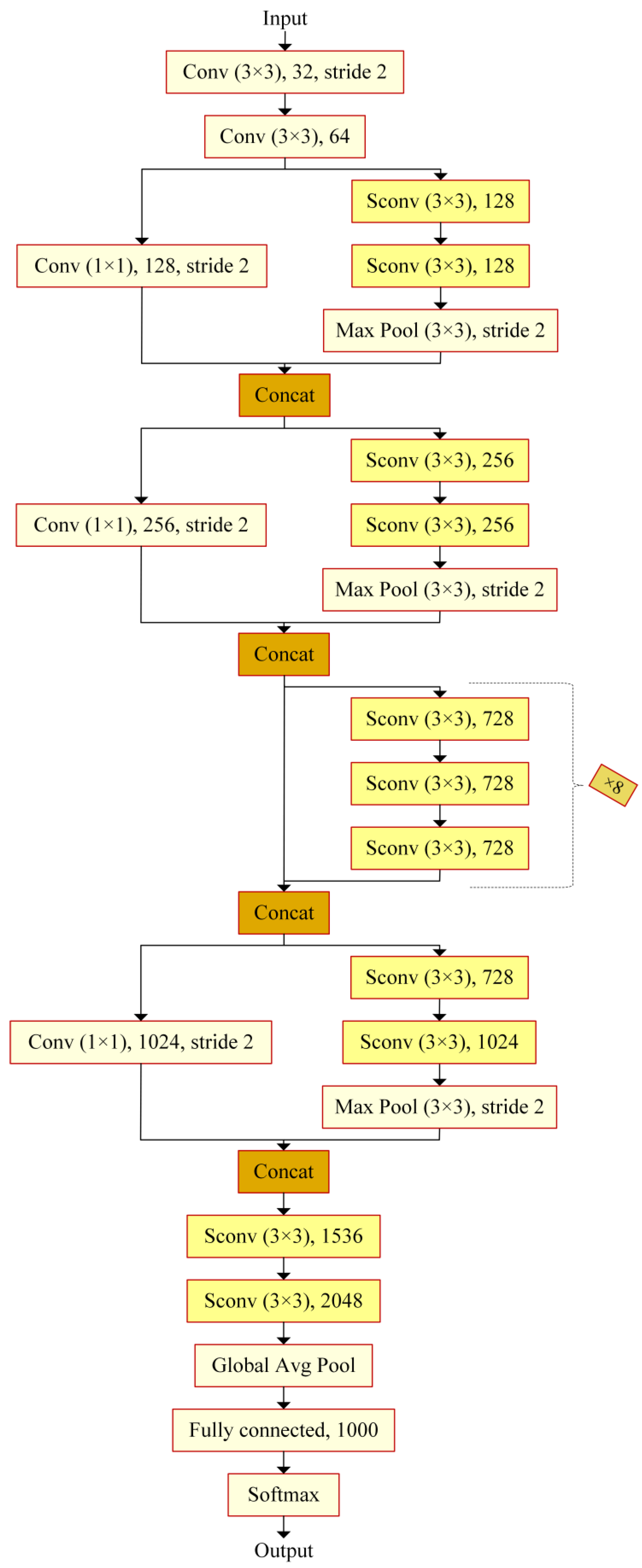
In this paper, eight transfer learning architectures, DenseNet201, InceptionResNetV2, InceptionV3, ResNet50, ResNet101, SqueezeNet, VGG19, and Xception, are examined in detail with their hyperparameters and are compared with each other to detect the most appropriate one with the data utilized. The data obtained as the result of the 3t2FTS approach were directly fed to the input of deep learning models. In this way, a novel framework handling HGG/LGG classification is presented. The experiments were performed using a two-fold cross-validation test method so as to evaluate the models in a comprehensive manner. All analyses were performed in the Deep Network Designer toolbox of MATLAB software on a personal computer with a 2.60 GHz CPU, 8 GB RAM, and Intel(R) Core(TM) i5-7200U graphic card.
Table 1 shows the hyperparameter evaluations of the utilized models. In
Table 1, only significant parameters are considered to prevent the information loss of models that are already pre-trained with effective datasets. Regarding this, four parameters are alternated to achieve the highest performance of transfer learning architectures on the classification of HGG/LGG tumors.
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7,
Table 8 and
Table 9 show the model results concerning the adjustments of hyperparameters for DenseNet201, InceptionResNetV2, InceptionV3, ResNet50, ResNet101, SqueezeNet, VGG19, and Xception respectively.
According to the results in
Table 2, the average accuracy of
sgdm in 24 trials (75.61%) is better in comparison with the scores of the
adam (74.94%) and
rmsprop (72.67%) optimizers. The LRDF of ‘0.2’ seems reliable and outperforms other preferences by achieving a 75.53% average accuracy among 18 trials. Furthermore, the learning rate of ‘0.0001’ arises as being more appropriate to use by obtaining a 75.24% average accuracy among 24 trials. The mini-batch size of ‘32’ overcomes the choice of ‘16’ by achieving a 1.45% better average accuracy and by obtaining a 75.20% average accuracy among 36 trials. By means of the average accuracy-based trials, DenseNet201 presents a 74.47% success score in 72 trials. In terms of the highest accuracy observed (79.30%), DenseNet201 operates the
sgdm optimizer, an LRDF of ‘0.8’, a learning rate of ‘0.001’, and a mini-batch size of ‘32’.
In experiments of
Table 3, it can be seen that the average accuracy of
sgdm in 24 trials (75.37%) is higher in comparison with the scores of the
adam (72.38%) and
rmsprop (72.09%) optimizers. The LRDF of ‘0.4’ seems reliable and outperforms other preferences by achieving 73.65% average accuracy among 18 trials. Furthermore, the learning rate of ‘0.0001’ arises as being more appropriate to utilize by obtaining a 74.39% average accuracy among 24 trials. The mini-batch size of ‘32’ overcomes the choice of ‘16’ by achieving a 0.04% better average accuracy and by obtaining a 73.30% average accuracy among 36 trials. By means of the average-accuracy-based trials, InceptionResNetV2 presents a 73.28% success score in 72 trials. In terms of the highest accuracy observed (77.90%), InceptionResNetV2 generally operates the
sgdm optimizer, an LRDF of ‘0.8, 0.6, 0.4, or 0.2’, a learning rate of ‘0.0001’, and a mini-batch size of ‘16’.
Concerning the trials in
Table 4, it was revealed that the average accuracy of
sgdm in 24 trials (75.16%) is better in comparison with the scores of the
adam (72.65%) and
rmsprop (71.64%) optimizers. The LRDF of ‘0.2’ seems reliable and outperforms other preferences by achieving 74.11% average accuracy among 18 trials. Furthermore, the learning rate of ‘0.001’ arises as being more appropriate to use by obtaining a 73.96% average accuracy among 24 trials. The mini-batch size of ‘32’ overcomes the choice of ‘16’ by achieving a 0.08% better average accuracy and by obtaining a 73.19% average accuracy among 36 trials. By means of the average accuracy-based trials, InceptionV3 presents a 73.15% success score in 72 trials. In terms of the highest accuracy observed (78.60%), InceptionV3 operates the
sgdm optimizer, an LRDF of ‘0.6’, a learning rate of ‘0.001’, and a mini-batch size of ‘32’.
Regarding the trials in
Table 5, the average accuracy of
sgdm in 24 trials (74.88%) is higher in comparison with the scores of the
adam (74.02%) and
rmsprop (71.52%) optimizers. The LRDF of ‘0.4’ seems reliable and outperforms other preferences by achieving 74.68% average accuracy among 18 trials. Furthermore, the learning rate of ‘0.0001’ arises as being more appropriate to utilize by obtaining a 75.64% average accuracy among 24 trials. The mini-batch size of ‘32’ overcomes the choice of ‘16’ by achieving 0.09% better average accuracy and by obtaining a 73.52% average accuracy among 36 trials. By means of the average accuracy-based trials, ResNet50 presents a 73.47% success score in 72 trials. In terms of the highest accuracy observed (80%), ResNet50 operates the
sgdm optimizer, an LRDF of ‘0.8 or 0.4’, a learning rate of ‘0.0001’, and a mini-batch size of ‘32’.
According to the results in
Table 6, the average accuracy of
sgdm in 24 trials (75.39%) is better in comparison with the scores of the
adam (73.46%) and
rmsprop (71.34%) optimizers. The LRDF of ‘0.4’ seems reliable and outperforms other preferences by achieving 73.87% average accuracy among 18 trials. Furthermore, the learning rate of ‘0.0001’ arises as being more appropriate to use by obtaining a 74.39% average accuracy among 24 trials. The mini-batch size of ‘16’ overcomes the choice of ‘32’ by achieving a 0.31% better average accuracy and by obtaining a 73.52% average accuracy among 36 trials. By means of the average accuracy-based trials, ResNet101 presents a 73.37% success score in 72 trials. In terms of the highest accuracy observed (77.89%), ResNet101 operates a learning rate of ‘0.0001’, a mini-batch size of ‘32’,
sgdm optimizer and a LRDF of ‘0.4’ or an
rmsprop optimizer and an LRDF of ‘0.6’.
In experiments of
Table 7, it can be seen that the average accuracy of
sgdm in 24 trials (73.94%) is higher in comparison with the scores of the
adam (70.99%) and
rmsprop (72.03%) optimizers. The LRDF of ‘0.6’ seems reliable and outperforms other preferences by achieving 73.78% average accuracy among 18 trials. Furthermore, the learning rate of ‘0.001’ arises as being more appropriate to utilize by obtaining a 73.90% average accuracy among 24 trials. The mini-batch size of ‘16’ overcomes the choice of ‘32’ by achieving a 1.59% better average accuracy and by obtaining a 73.12% average accuracy among 36 trials. By means of the average-accuracy-based trials, SqueezeNet presents a 72.32% success score in 72 trials. In terms of the highest accuracy observed (75.44%), SqueezeNet operates
the sgdm optimizer, an LRDF of ‘0.2’, a learning rate of ‘0.001’, a mini-batch size of ‘16’ or an
sgdm optimizer, an LRDF of ‘0.8’, a learning rate of ‘0.001’, a mini-batch size of ‘32’ or an
adam optimizer, an LRDF of 0.4’, a learning rate of ‘0.0001’, a mini-batch size of ‘32’.
Concerning the trials in
Table 8, it can be seen that the average accuracy of
sgdm in 24 trials (74.85%) is better in comparison with the scores of the
adam (73.67%) and
rmsprop (72.62%) optimizers. The LRDF of ‘0.2’ seems reliable and outperforms other preferences by achieving 73.88% average accuracy among 18 trials. Furthermore, the learning rate of ‘0.0001’ arises as being more appropriate to use by obtaining a 74.21% average accuracy among 24 trials. The mini-batch size of ‘32’ overcomes the choice of ‘16’ by achieving a 0.08% better average accuracy and by obtaining a 73.75% average accuracy among 36 trials. By means of the average-accuracy-based trials, VGG19 presents a 73.71% success score in 72 trials. In terms of the highest accuracy observed (78.25%), VGG19 operates the
sgdm optimizer, an LRDF of ‘0.2’, a learning rate of ‘0.0001’, and a mini-batch size of ‘32’.
Regarding the trials in
Table 9, the average accuracy of
adam in 24 trials (73.95%) is higher in comparison with the scores of the
sgdm (73.45%) and
rmsprop (71.20%) optimizers. The LRDF of ‘0.2’ seems reliable and outperforms other preferences by achieving 73.68% average accuracy among 18 trials. Furthermore, the learning rate of ‘0.001’ arises as being more appropriate to utilize by obtaining a 73.35% average accuracy among 24 trials. The mini-batch size of ‘16’ overcomes the choice of ‘32’ by achieving a 1.61% better average accuracy and by obtaining a 73.67% average accuracy among 36 trials. By means of the average-accuracy-based trials, Xception presents a 72.87% success score in 72 trials. In terms of the highest accuracy observed (76.49%), Xception operates the
sgdm optimizer, a mini-batch size of ‘16’, an LRDF of ‘0.2’, and a learning rate of ‘0.01’ or the
sgdm optimizer, an LRDF of ‘0.4’, a learning rate of ‘0.001’, and a mini-batch size of ‘16’ or the
rmsprop optimizer, an LRDF of ‘0.8’, a learning rate of ‘0.0001’, and a mini-batch size of ‘16’.
4. Discussion
As seen in the evaluations of
Section 3, it can be seen that all deep learning models obtain very close results that reveal the necessity of an in-depth analysis of the observed scores. Among experiments, a two-fold cross-validation is operated as the test method, and other test methods (50%-50% or 70%-30% training-test split, etc.) are not considered. Concerning the literature studies that utilize deep learning methods, data augmentation is often preferred which cannot be handled in our research. In other words, our aim is to enforce the frameworks operating 3t2FTS and a transfer learning model without data augmentation but with sufficient training data. In addition, 2D-ID input images are not appropriate to apply data augmentation.
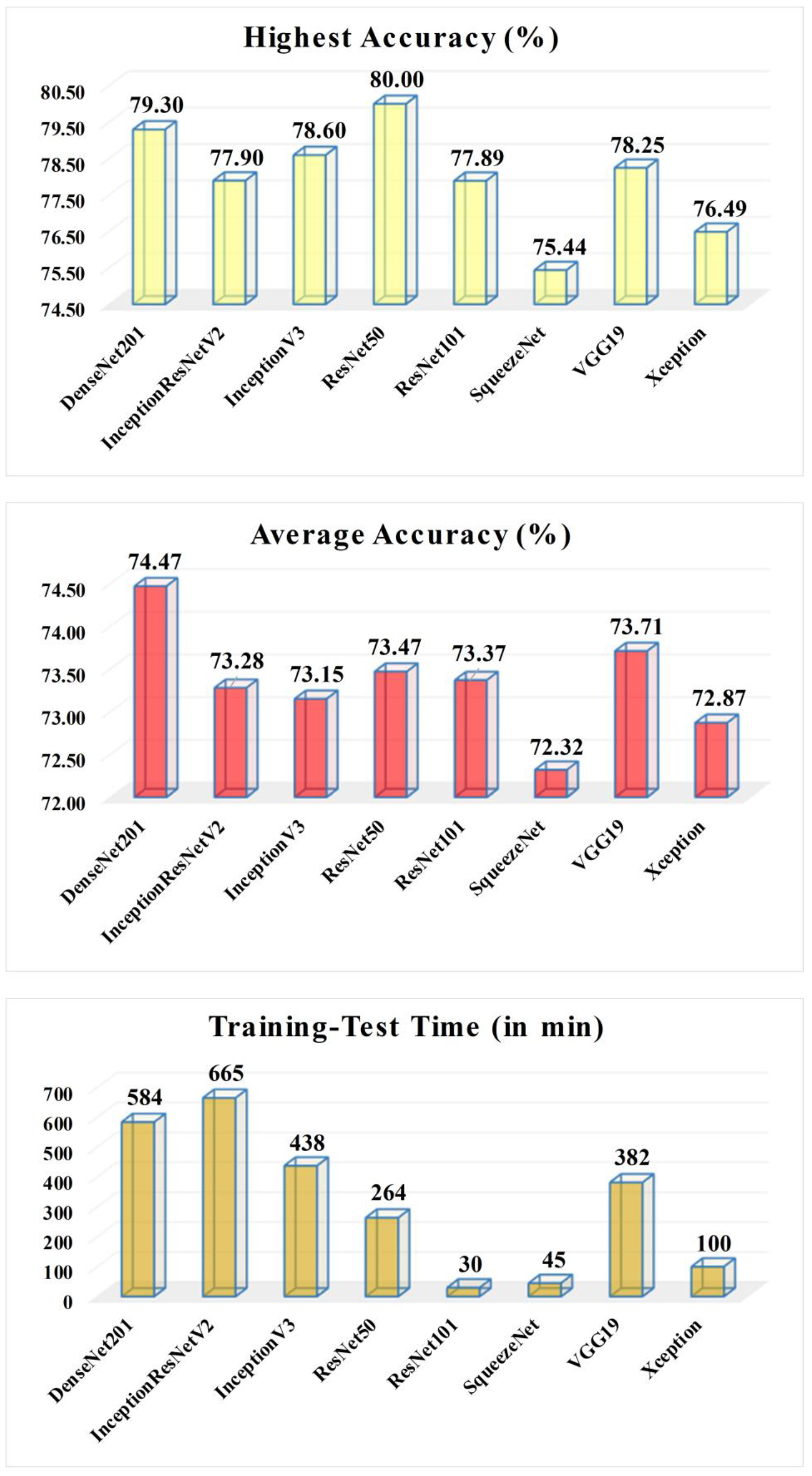
To reveal an in-depth analysis of the frameworks involving 3t2FTS and deep learning models,
Figure 11 shows the comparison of transfer learning architectures by means of the highest accuracy-, average accuracy-, and computation-time-based evaluations.
The transfer learning models generally tend to produce higher performance by operating lower learning rates and the sgdm optimizer. Regarding the LRDF rate and mini-batch size, there is no distinct assignment to be defined and these parameters can change from one model to another.
The highest accuracy is achieved by the ResNet50 model, whilst DenseNet201 and InceptionV3 obtain the second- and third-best accuracies, respectively.
The highest average accuracy is recorded by DenseNet201 architecture, while in the meantime, VGG19 and ResNet50 acquire the second- and third-best scores, respectively. In other words, these models are seen as the most robust architectures among others.
The least computation time is attained by ResNet101, while the SqueezeNet and Xception models have the second- and third-best operation times, respectively. In addition, ResNet50 comes to the forefront by resulting in 264min and by having the fourth-best performance.
Concerning the aforementioned discussions and deductions, it was revealed that DenseNet201 comes as the second-best preference regarding the highest average accuracy and the second-best highest accuracy scores. However, its computation time is the second worst one which is about 584min for the training-test time.
As one of the three robust models, by achieving the highest classification accuracy and resulting in less time in particular than the DenseNet201, InceptionV3, and VGG19 models, ResNet50 comes forward due to the operation time- and accuracy-based in-depth evaluations.
The ResNet50 architecture arises as the most appropriate one to utilize with the 3t2FTS approach by recording the highest accuracy, a robust average performance, and less operation time in comparison with the robust models (DenseNet201 and VGG19) so as to perform the HGG vs. LGG categorization.
In the literature, there exists the study of Koyuncu et al. [
14] directly classifying the HGG- vs. LGG-type tumors in 3D. In [
14], there exists an efficient, statistical, and experimental framework, and a deep learning-based system is not available in the literature which proves and motivates the importance of our study.
In summary, our framework including 3t2FTS and ResNet50 achieves good performance, and this performance is open to being enhanced. In other words, 3t2FTS can be inferred as a novel strategy and different deep learning architectures can be applicable to the output of the 3t2FTS which will guide the literature on various research areas. In addition, a novel deep learning model can be produced to operate with only 3t2FTS output which will constitute another research area. Herein, concerning our results, ResNet50-based various frameworks can yield better performance too.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}