1. Introduction
Polycystic Ovary Syndrome (PCOS) consists of symptoms occurring because of abnormally elevated androgen levels [
1]. Androgens are widely categorized as male sex hormones. However, when produced in smaller amounts play a vital role in the effective functioning of the female reproductive system. Most patients of PCOS are women of reproductive age experiencing weight gain, irregular menstrual cycles, excessive body hair, hair thinning or male-pattern balding, acne or oily skin, and at times infertility [
2]. The hormone imbalance can hinder ovarian follicle development, inhibiting a normal ovulation cycle. 8.2% to 22.5% of women in India, suffer from PCOS [
3]. This endocrinopathy can significantly impact the patient’s lifestyle, wherein the patient may face depression, anxiety, eating disorders, and sleep apnea. Further, metabolic syndromes can put them at risk of cardiovascular disorders, endometrial cancer, and diabetes mellitus [
4,
5].
The exact cause of PCOS is still unknown. However, researchers have discovered That cells become resistant to insulin, thereby increasing blood sugar levels. The external manifestation of insulin resistance is usually skin darkening around the neck and armpits [
6]. A sedentary, inactive lifestyle and an improper diet can also contribute to a woman getting PCOS.
Artificial Intelligence (AI) is a vast domain characterized by a machine having the ability and intelligence to perceive, infer, process, synthesis, and forecast information without much human interference. AI has been deployed in various sectors, such as banking, finance, agriculture, education, business, engineering, sociology, forensics, and medicine [
7]. AI is extensively used for processing and providing insights to improve patient health outcomes [
8]. Machine learning and deep learning can efficiently process medical data such as bio-signal and medical images [
9] Another rapidly expanding branch of AI with extensive research is fuzzy systems. [
10,
11] Further, with efficient networks, researchers can scale their machine learning and deep learning architecture [
12,
13]. Automated diagnosis, patient-triaging, severity prediction, drug discovery, treatments such as computerized drug delivery, precision medicine, prognosis, and decision-making assistance are all possible today owing to the virtue of AI technology [
14,
15,
16,
17].
Explainable AI (XAI) can be characterized by system transparency and interpretability. In recent years, XAI has helped solve issues of biases, unfairness, safety, and causality [
18]. Integrating XAI with AI-based systems for diagnostic, prognostic, and treatment purposes could aid in achieving accountability and increase trust in the medical decision made by the system [
19]. Clinical validation of ML and DL models can be made possible with XAI. This study focuses on applications of SHapley Additive exPlanations (SHAP), Local Interpretable Model-agnostic Explanations (LIME), ELI5, Qlattice and Feature importance with Random Forest for screening PCOS. SHAP uses a game theory approach and provides mathematical values for accuracy and explanation consistency. SHAP provides a feature-importance-based ranking. LIME helps in hypothesis verification and gives insights on potential overfitting to noise. This technique explains local predictions made for each data sample [
20]. ELI5 deploys a feature-based weight assignment technique to create a tree map explaining holistic and individual predictions [
21]. Qlattice produces a classification model trained on raw data and produces QGraphs followed by a simplified expression to describe the graph [
22]. Researchers have established a pathophysiological link between increased LH, insulin resistance, increased estrogen, and decreased FSH levels to PCOS, which is the most common cause of reduced fertility [
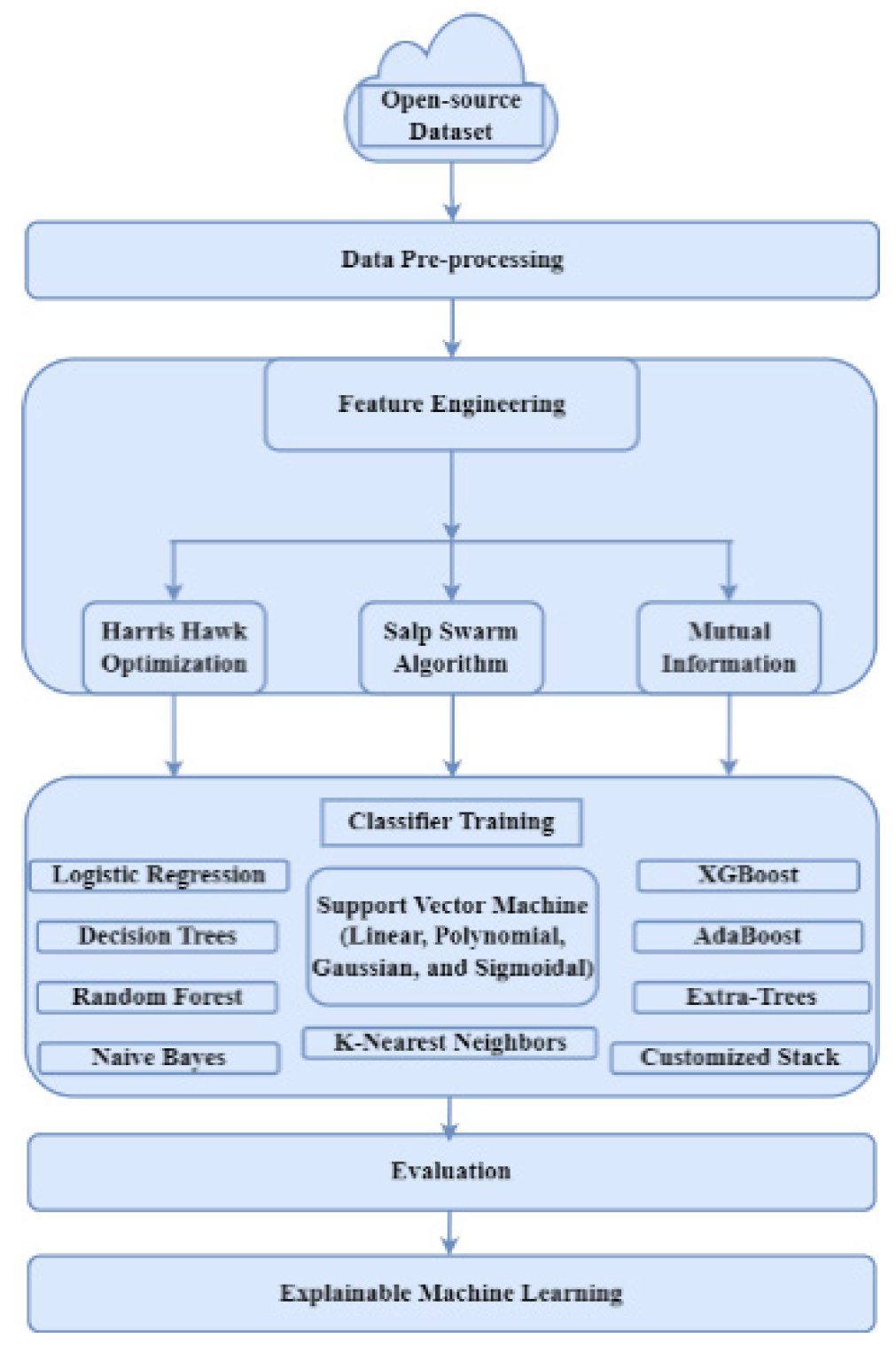
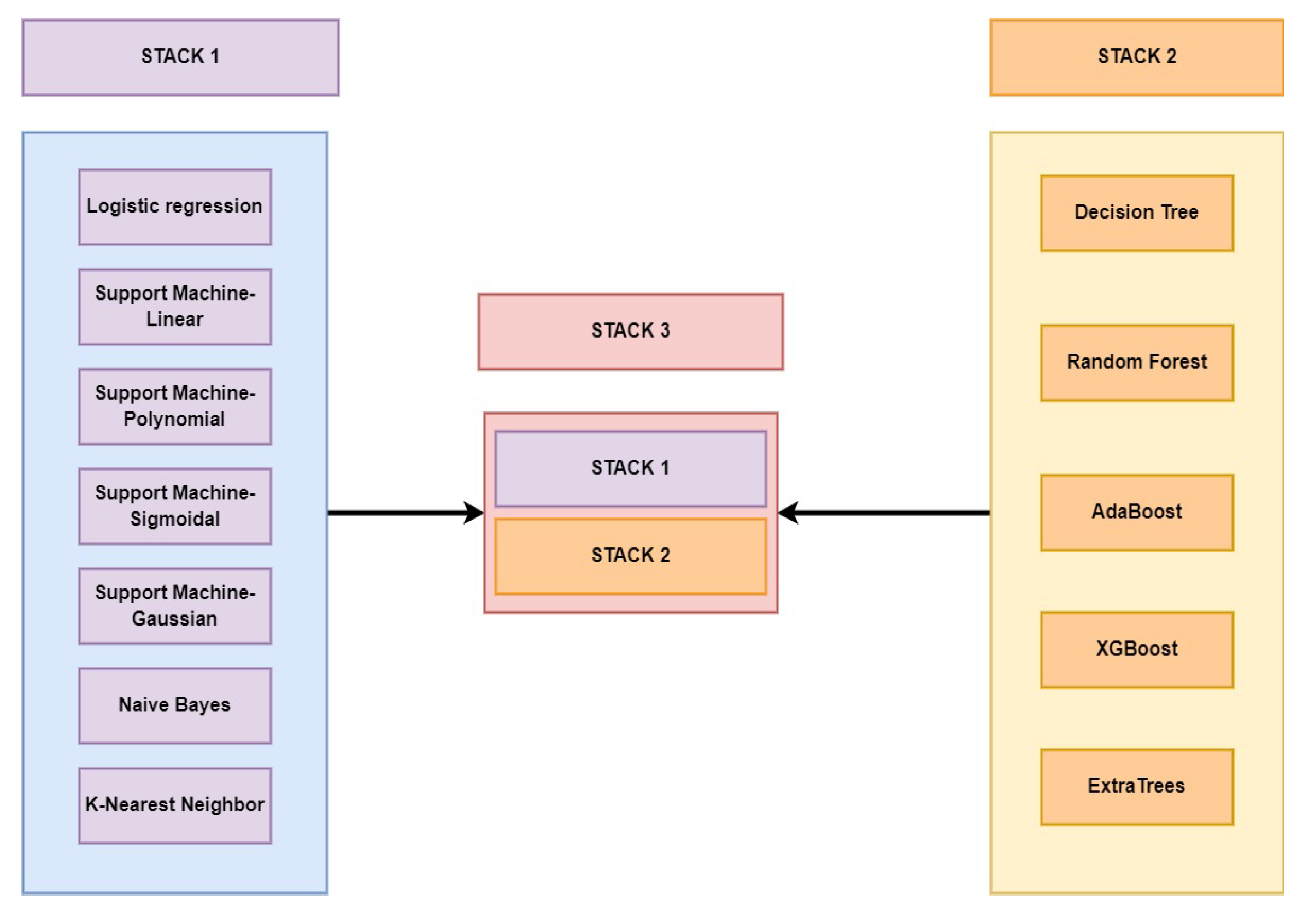
23]. In this study, we have explored an open-source dataset of fertile PCOS patients and proposed a Machine learning-based multi-level stack to create a PCOS screening decision support. The contributions of this article are as follows: (1) Assessment of the significant PCOS features extracted by three feature selection methods: Salp swarm optimization, Harris hawk optimization, and mutual information. (2) Evaluation of the performance of ML classifiers such as LR, SVM (Kernel: linear, polynomial, Gaussian, Sigmoid), DT, RT, XGBoost, AdaBoost, and ExtraTrees classifiers and creating an improved and reliable classifier by an ensemble stacking of meta-learners. (3) Analysis of our customized multi-level stack against Deep Neural Networks and 1-D CNN models for screening PCOS. (4) Analysis of an XAI layer of our tree-based framework with SHAP, LIME, ELI5, and Qlattice, and feature importance with Random Forest. The rest of the article follows:
Section 2 discusses various related work,
Section 3 highlights the materials and methods. An in-depth result analysis is conducted in
Section 4.
Section 5 provides a comparison finding with existing research. The last section comprises of conclusion and future scope.
2. Literature Review
In recent years, many researchers have proposed AI models for PCOS diagnosis, with datasets consisting of clinical parameters and vital signs. Bharadwaj et al. [
24] provided a detailed analysis of various clinical features and their contribution to a patient having PCOS. They used an open-source Kaggle PCOS dataset [
25], with records of 541 patients and 44 features whose target label was PCOS diagnosis. The dataset is multicentric and was collected from 10 different hospitals in Kerala. The architecture consisted of machine learning classifiers and the Pearson correlation technique for feature selection. They concluded, the most critical features were: the average left and right follicle size, number of follicles in the left, hair growth, and prolactin levels. The SVM Radial Basis Function (RBF) kernel, and Multilayer Perceptron (MLP) obtained an accuracy of 93%. Zigarelli et al. [
26] used the same dataset, adopting the CatBoost classifier with K-fold validation evaluating the classifier performance, achieving 82.5% for the invasive methods and 90.1% accuracy for the non-invasive clinical parameters. Bharati et al. [
27] suggested a CatBoost model and a voting hard and voting soft classifier. They extracted the top 13 features by univariate feature selection followed by a hold-out and cross-validation for the data splitting. The soft voting classifier performed with an accuracy of 91.12%. Tiwari et al. [
28] developed an ML based Smart PCOS diagnostic system. The architecture compared the performance of various classifiers such as SVM, LR, RF, AdaBoost, DT, KNN, Gradient Boosting, XgBoost, CatBoost, Linear Discriminant Analysis, and Quadratic Discriminant Analysis. They used an open-source dataset and obtained an overall accuracy of 93.25%. Danaei et al. [
29] developed an ensemble random forest classifier model and trained features selected by embedded feature selection methods. The model performed with accuracy and sensitivity of 98.89% and 100%, respectively. Bharati et al. [
30] proposed an ML model architecture with classifiers such as RF, LR, Hybrid Random Forest- Logistic regression (RFLR), and gradient boosting. RFLR gave the best performance with an accuracy of 91%. Silva et al. [
31] proposed a BorutaShap method and sequentially trained a random forest model to identify the most relevant and significant clinical markers. A dataset comprised 72 PCOS patients and 73 healthy women. Fifty-eight features were ranked according to their relevance and significance. The model was able to obtain an overall accuracy of 86%.
5. Discussion
Polycystic Ovary Syndrome (PCOS) is a hormonal disorder that causes ovary enlargement and symptoms such as obesity, acne, hirsutism, oligomenorrhea, acanthosis nigricans, and male-pattern baldness. It is often underdiagnosed or misdiagnosed, leading to the risk of severe health conditions such as type 2 diabetes, hypertension, cardiovascular disorders, infertility, and uterine and endometrial cancer. We created multiple ML and DL pipelines in this study and evaluated their performance to find the best-performing classifier.
The ML frameworks were created by considering all combinations of two data split ratios, three feature extraction methods, and 10 classifiers. Models trained with 80% (80:20 split) of data samples performed significantly better than the ones trained on 70% of samples, regardless of the feature selection technique. As seen in
Table 5, the impact of various feature selection techniques gives insights into the training of the classifiers. Interestingly, all tree-based classifiers such as DT, RF, AdaBoost, XGBoost, and Extra-trees had comparable performances irrespective of the features selected. However, Classifiers trained on MI-extracted features achieved the highest performance metrics among other deployed feature selection techniques. These models had higher sensitivity, assuring a significant reduction in false negatives.
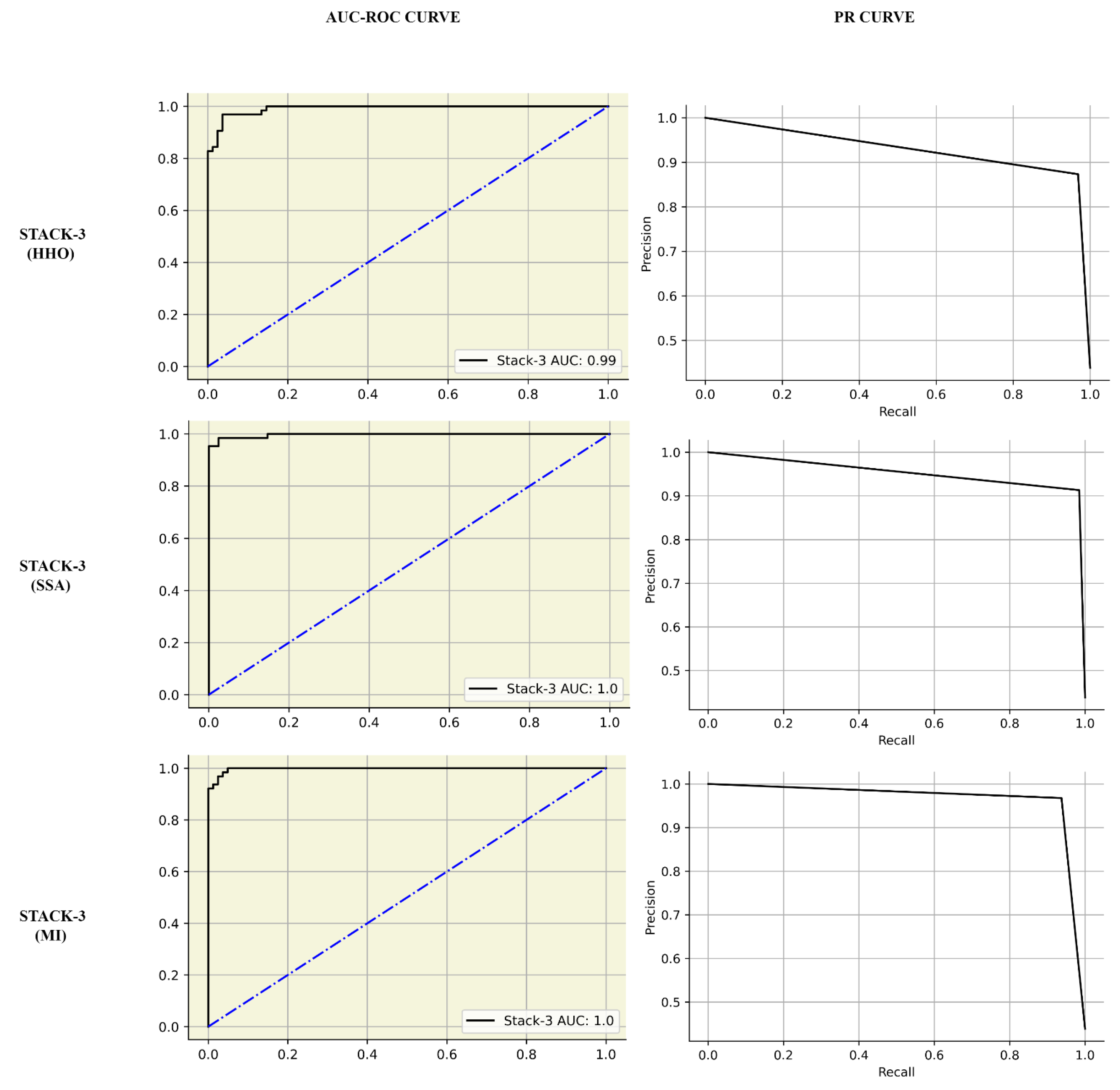
Further, the accuracies of most models trained on the HHO and SSA methods provided a similar performance, except for the NB classifier, whose accuracy significantly worsened with SSA data. Stack models, a blend of individual meta-learners based on how they get trained, would define how they work in an ensemble. This can be observed in the STACK-3 performance under each feature selection technique. HHO features trained the poorest STACK-3 classifier with an accuracy of 92%, and MI features trained the best stack achieving 98% accuracy.
Figure 4 depicts the improvement in the AUC-ROC score and PR curve for STACK-3 from HHO to MI-trained stack.
Different feature-selection pipelines had different ‘best-performing’ classifiers. With HHO, the stochastic-based method for feature selection, XGBoost outperformed all other models with prediction accuracy, recall, and AUC score of 97%, 100%, and 99%, respectively. When considering the model performance on data feature engineering with SSA, STACK-2 achieved the best accuracy, recall, and AUC score of 98%, 98%, and 99%, respectively. Classifiers trained on MI-extracted features achieved the highest performance metrics among other deployed feature selection techniques. Out of all combinations of classifiers and feature extraction techniques, STACK-3 trained with an 80:20 split on MI-engineered data had the highest performance, achieving accuracy, precision, recall, f1-score, AUC score, and Precision-Recall scores of 98%, 97%, 98%, 98%, 1, and 1, respectively. As indicated in
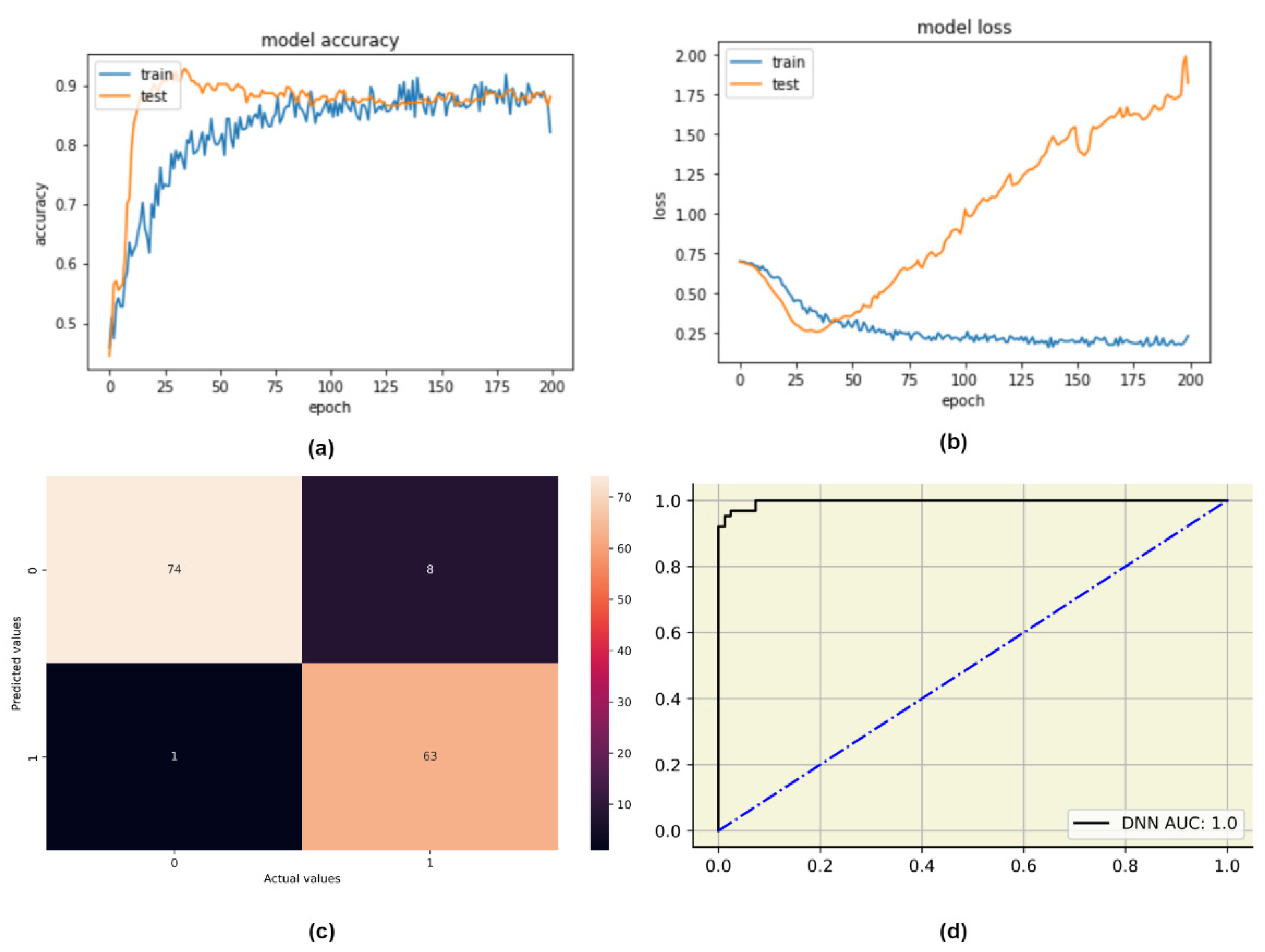
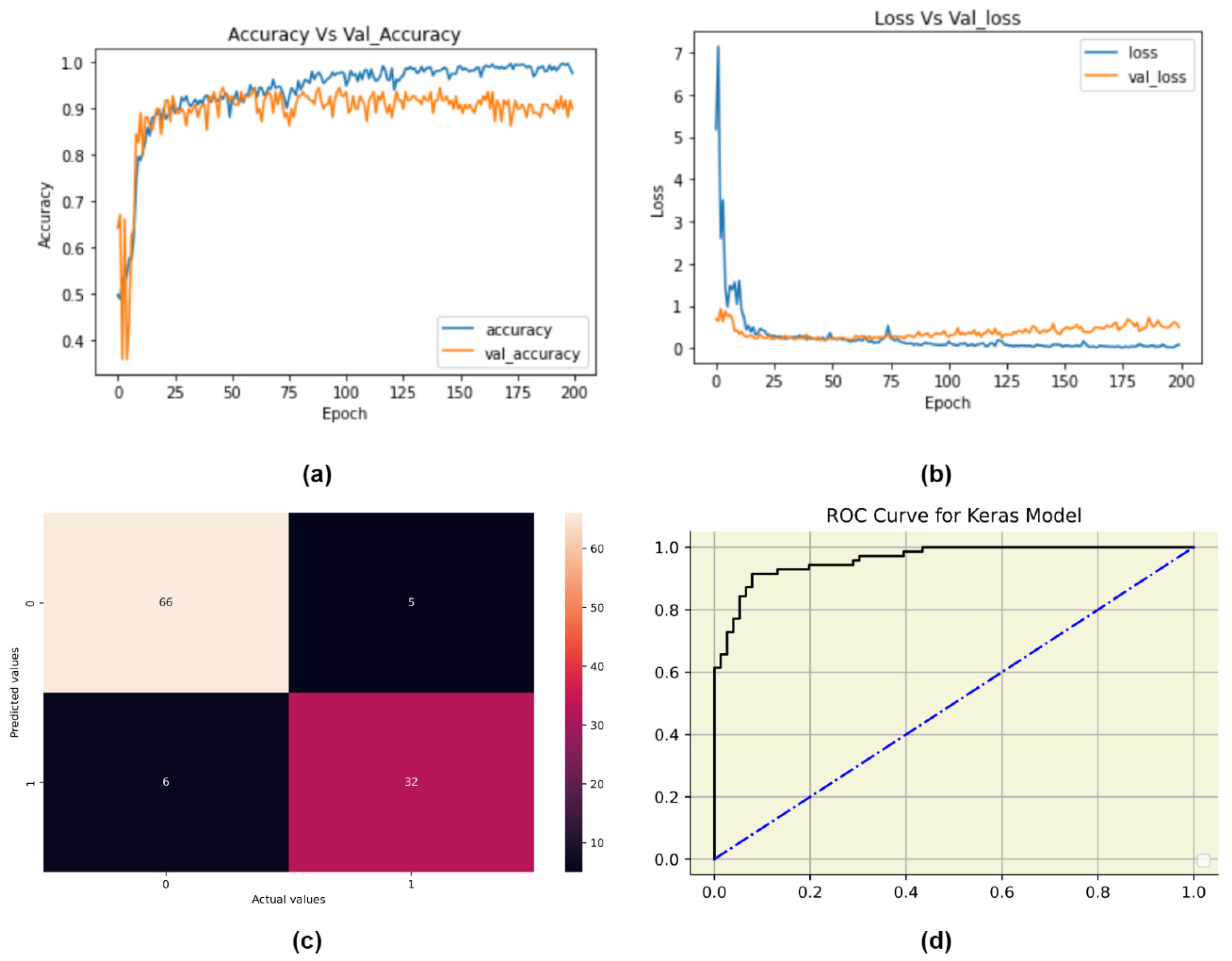
Table 6, it should be noted meta-learners like RF, SVM-RBF, and XGBoost trained on an 80:20 split on MI-engineered data have performed significantly better than other models, with close to 100% sensitivity. These meta-learners could be the ideal choice when designing individual PCOS classifiers. The ML-based pipelines were compared with customized DL architectures. DNN obtaining accuracy and recall of 94% and 98%, respectively. 1-D CNN performed comparatively poor with an accuracy and recall of 90% and 94%. Both the tree-based meta-learner (MI) pipelines such as RF, XGBoost and STACK-3 have outperformed these complex deep learning architectures. Our proposed best-performing multi-level stack drastically lowered the number of false negatives PCOS-predictions (with only 3 out of the processed 146 samples).
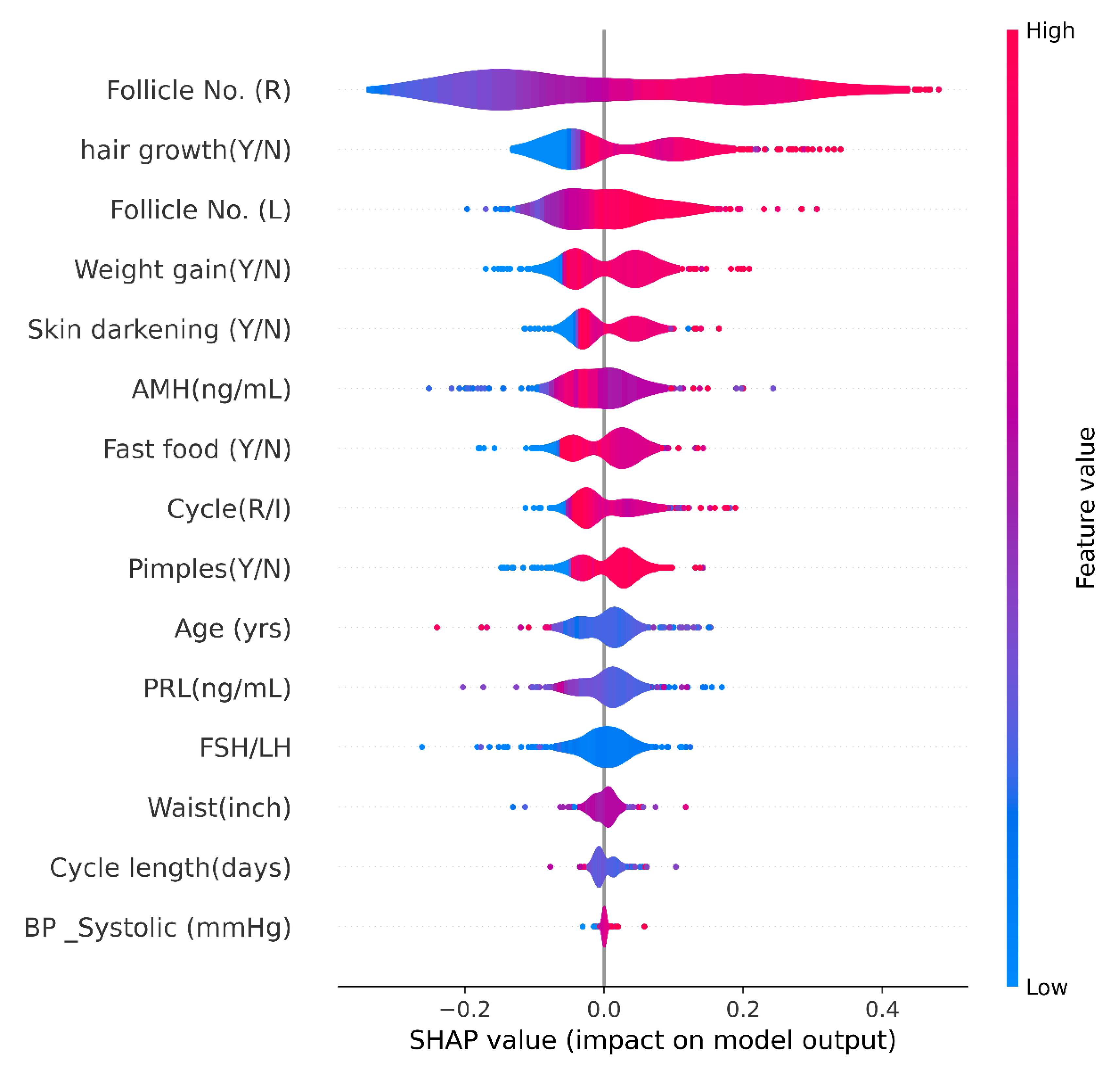
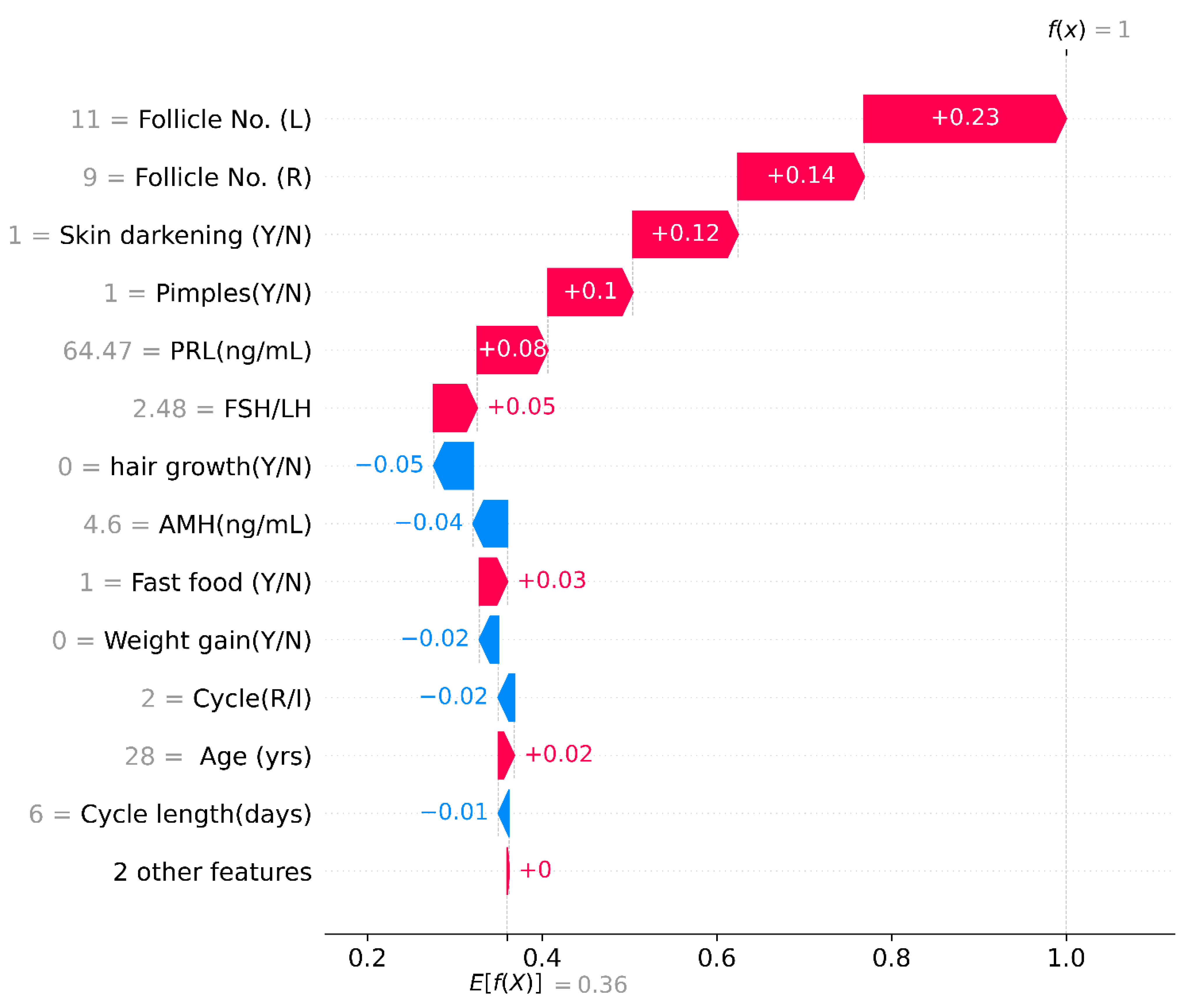
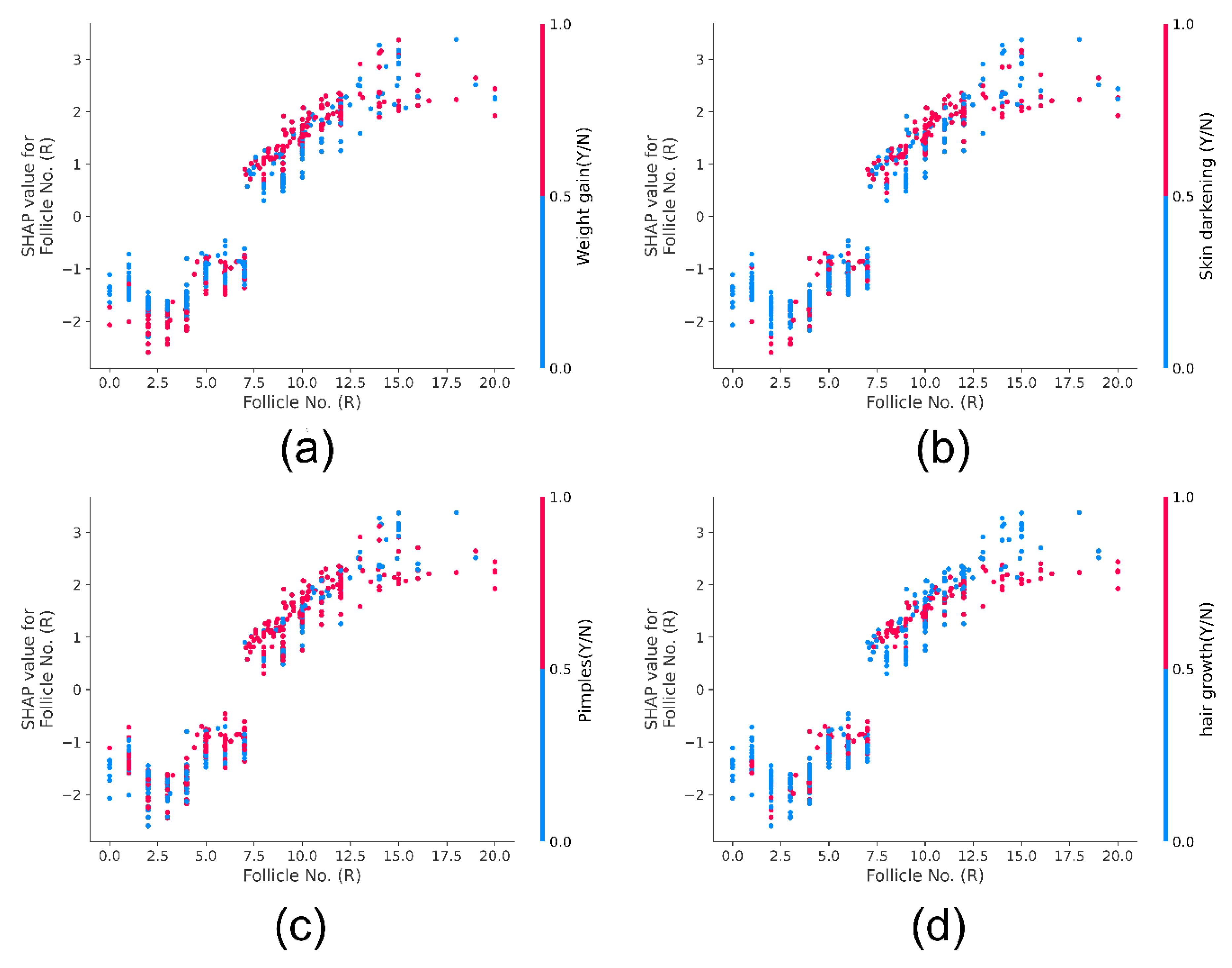
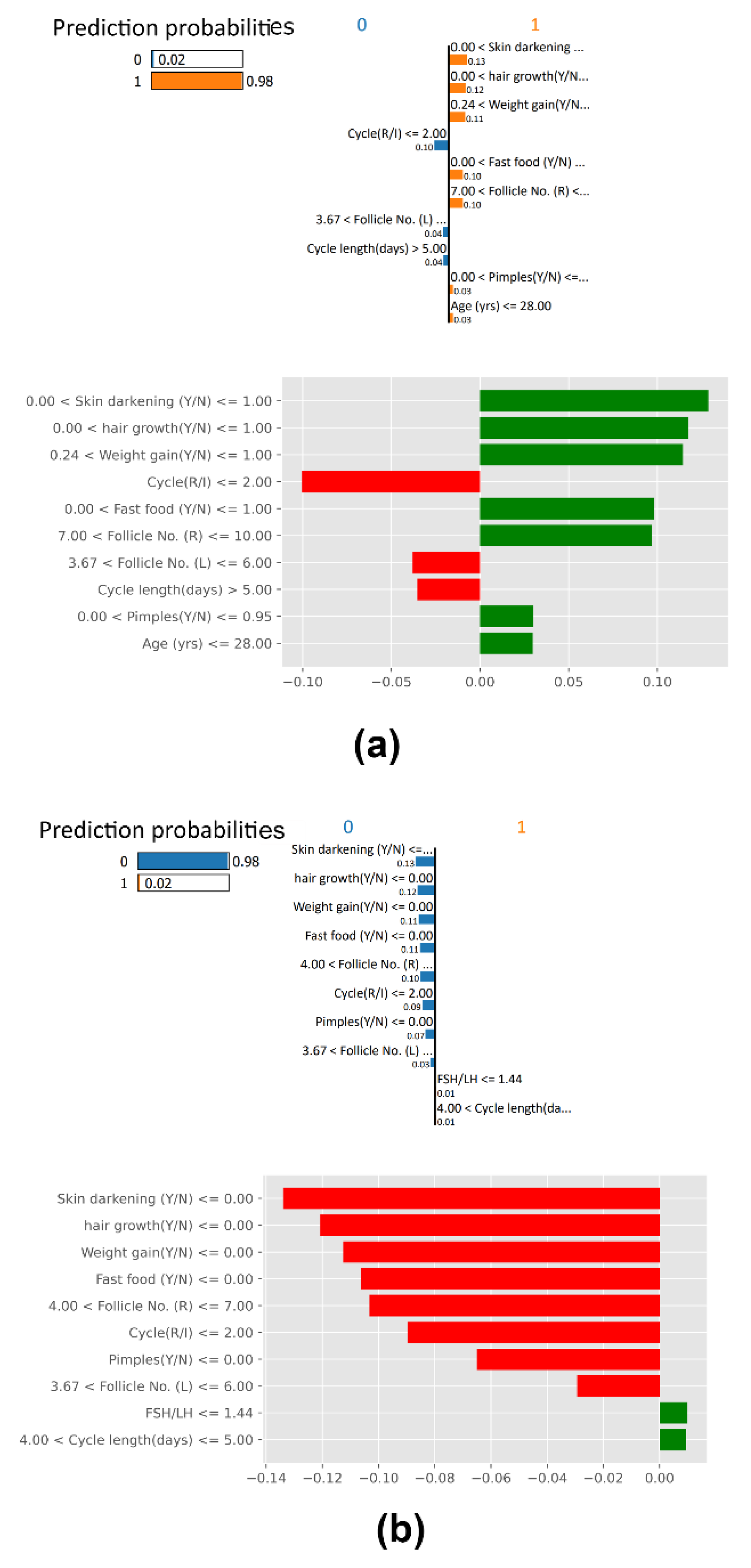
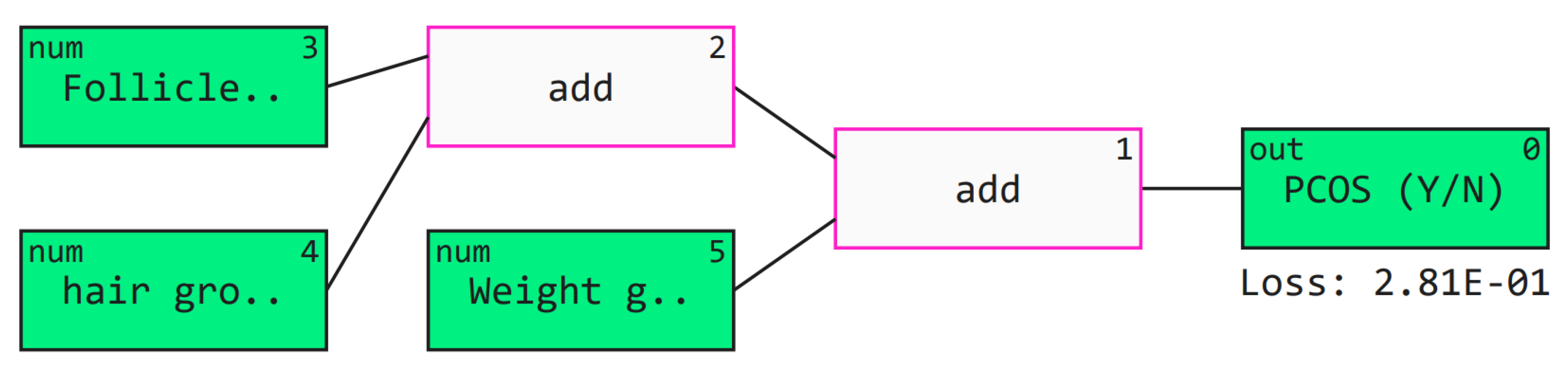
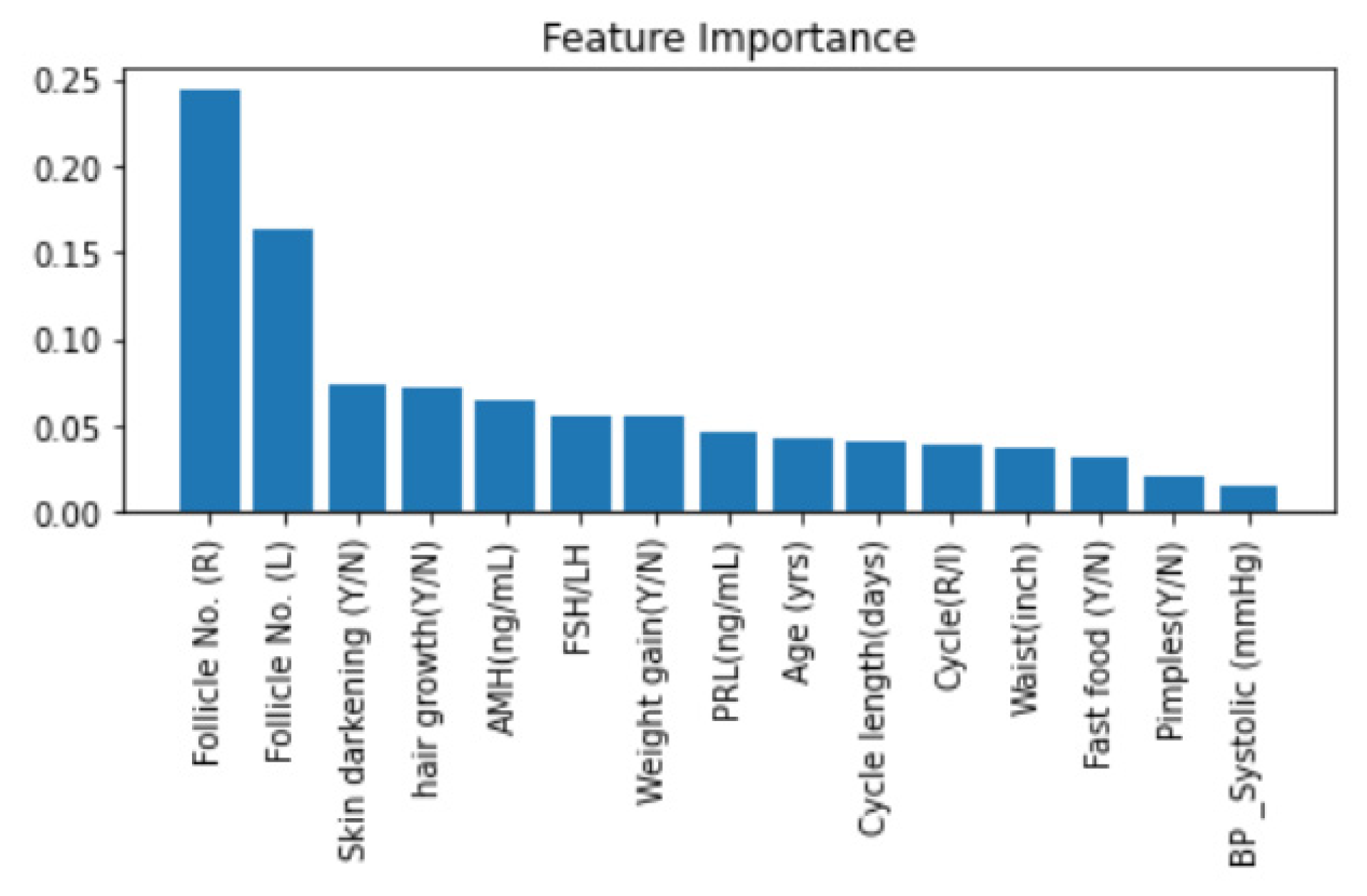
Further, we added a layer of Explainable machine learning to the high-performing tree-based meta-learner frameworks. We explored multiple SHAP with visualizations to explain global and local XGBoost predictions based on feature importance. LIME created an intuitive and interpretable probability-based visual for local predictions of Random Forest. ELI5 ranked and assigned weights based on feature importance and created a tree map for debugging the decision tree classifier. Further, we deployed a Qlattice algorithm that automatically created a predictive model along with a Qgraph to explain the classifier. Feature Importance with Random Forest helped get insights into global predictions made by RF. Notably most tools explained the predictions based having the following features with highest significance: Follicle No. (L), Follicle No. (R), Skin darkening (Y/N), Weight gain (Y/N), hair growth(Y/N), Pimples (Y/N). Research has indicated the significance of these features in diagnosis [
4]. XAI tools hence help visualize and interpret local predictions just as practitioners would consider during primary detection of PCOS.
Multiple articles proposed machine learning models for screening PCOS using the same open-source Kaggle dataset used in this study. Neto et al. [
58] published a study for detecting PCOS patients with data mining tools. Classifiers such as SVM, MLP, RF, LR, and NB, along with Cross Industry Standard Process for Data Mining (CRISP-DM) methodology, were adopted. RF, along with data sampling techniques, performed the best with accuracy, sensitivity, and precision of 95%, 94%, and 96%, respectively. Nandipati et al. [
59] This study compared Python (Spyder IDE) and Rapid Miner for diagnosis. Spyder IDE used a correlation matrix and recursive feature elimination with a logistic regression model, while RapidMiner used forward selection (with NB) and backward elimination (with DT) with a cross-validation operator. The engineered data trained seven ML models, KNN, SVM, RF, NB, Auto-MLP, AdaBoost, and Bagging with DT. Ten features were selected, with RapidMiner obtaining the highest average accuracies of the ML models at 85.97%. Vedpathak et al. [
60] proposed an ML PCOS detection architecture named ‘PCOcare’. Out of the 42 features, 30 were selected by the Chi-square method. They deployed RF, SVM (with Linear kernel and radial basis function kernel), NB, LR, and KNN. RF performed the best with accuracy, sensitivity, and precision metric scores at 91%, 94%, and 88%. Hdaib et al. [
61] trained multiple classifiers, KNN, NN, NB, SVM, LR, classification tree, and Linear discriminant (LD). After feature engineering, they selected 43 features, and LD performed the best with 92.60% accuracy. ÇİÇEK et al. [
62] proposed a LIME PCOS diagnostic model, which used RF as its classifier. A chi-square test was deployed, and features with a
p-value greater than 0.05 were considered statistically significant. RF obtained an accuracy of 86.03%. LIME described local predictions for the first five patients. We have tabulated the remaining model performance comparison in
Table 8.
Multiple studies mentioned above have RF as the best-performing classifier. However, our RF meta-learner pipeline outperforms these architectures with accuracy, precision, and recall of 97%, 97%, and 97%, respectively. Overall, the proposed customized multilevel stack is superior to most studies conducted on this dataset. Our ensemble, where various models work towards the same problem of screening PCOS among fertile women, provides improved performance, reduction in false negatives, and reliability compared to all other models. At the time of writing this manuscript, no other authors had used SHAP, ELI5, Qlattice and feature importance with Random Forest. on this dataset. Rather than a mystified ‘black box’, we believe a meaningful and interpretable model would be of more practical use in clinical settings. With this motivation, we created this architecture to contribute towards de-mystifying artificial intelligence in healthcare.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}