
Digital Forensics Readiness in Big Data Networks: A Novel Framework and Incident Response Script for Linux–Hadoop Environments




Abstract
:1. Introduction
2. Research Focus
- RQ1: How can DFR be effectively implemented in an existing Linux–Hadoop big data network without disrupting its operations?
- RQ2: Can digital forensics investigations within a Linux–Hadoop cluster be simplified for both experienced and inexperienced investigators, considering the various configurations of different Hadoop environments?
3. Literature Review
3.1. Background
3.2. Review of Related Work
- Supporting evidential information: This includes data that aid in identifying evidence or provide context regarding the operations and configurations of the Hadoop cluster.
- Record evidence: This encompasses any data that are processed within Hadoop, such as HBase data, sequence files, text files used in MapReduce jobs, or output generated by Pig scripts.
- User and application evidence: Comprises log and configuration files, analysis scripts, MapReduce logic, metadata, and other customisations or logic applied to the data. It is particularly valuable in investigations where there are questions about how the data were analysed or generated.
3.3. Conclusion
4. Research Methodology
- Prototype development.
- Prototype evaluation.
4.1. Prototype Development
4.2. Prototype Testing and Evaluation
5. Proposed Framework
5.1. Requirements Analysis
- Architecture: Research on DFR and big data frameworks informed the identification of necessary system components and their functionalities.
- Operational needs: The practical needs of digital forensics investigations, such as data collection, secure storage, efficient processing, and access control, were key drivers in defining the system requirements.
- Technological capabilities: Leveraging existing technologies like Hadoop and Apache Spark ensured that the system could meet the performance and efficiency demands of both BI and forensics analytics.
- Compliance and security: Ensuring compliance with legal standards and maintaining robust security measures were paramount in defining the system requirements.
- Data Collection and Storage: The system must be capable of capturing and securely storing network access logs, firewall logs, IDS logs, SIEM logs, and Hadoop cluster data. It should centralise the storage of all relevant forensic data to facilitate easy management and analysis.
- Network Segmentation and Security: Network segmentation and security of both the big data network and its DFR segment must be implemented.
- Efficient Data Processing: The system must leverage technologies that effectively enforce both BI and forensics analytics, ensuring efficient processing and analysis of large data volumes.
- Metadata Management: The system should provide efficient metadata management through secure centralised nodes, crucial for precise and efficient forensic analysis.
- Access Control and Compliance: Strict access control measures must be enforced to ensure that only authorised personnel can interact with the forensic data. Furthermore, the system should log all security policies and maintain an up-to-date terms and conditions big data collection policy.
- Time Synchronisation: Effective synchronisation with the network’s network time protocol (NTP) server is essential to adhere to digital forensics admissibility requirements.
- Resource Allocation: The forensic nodes must have sufficient storage and processing capabilities to handle the volume of data collected.
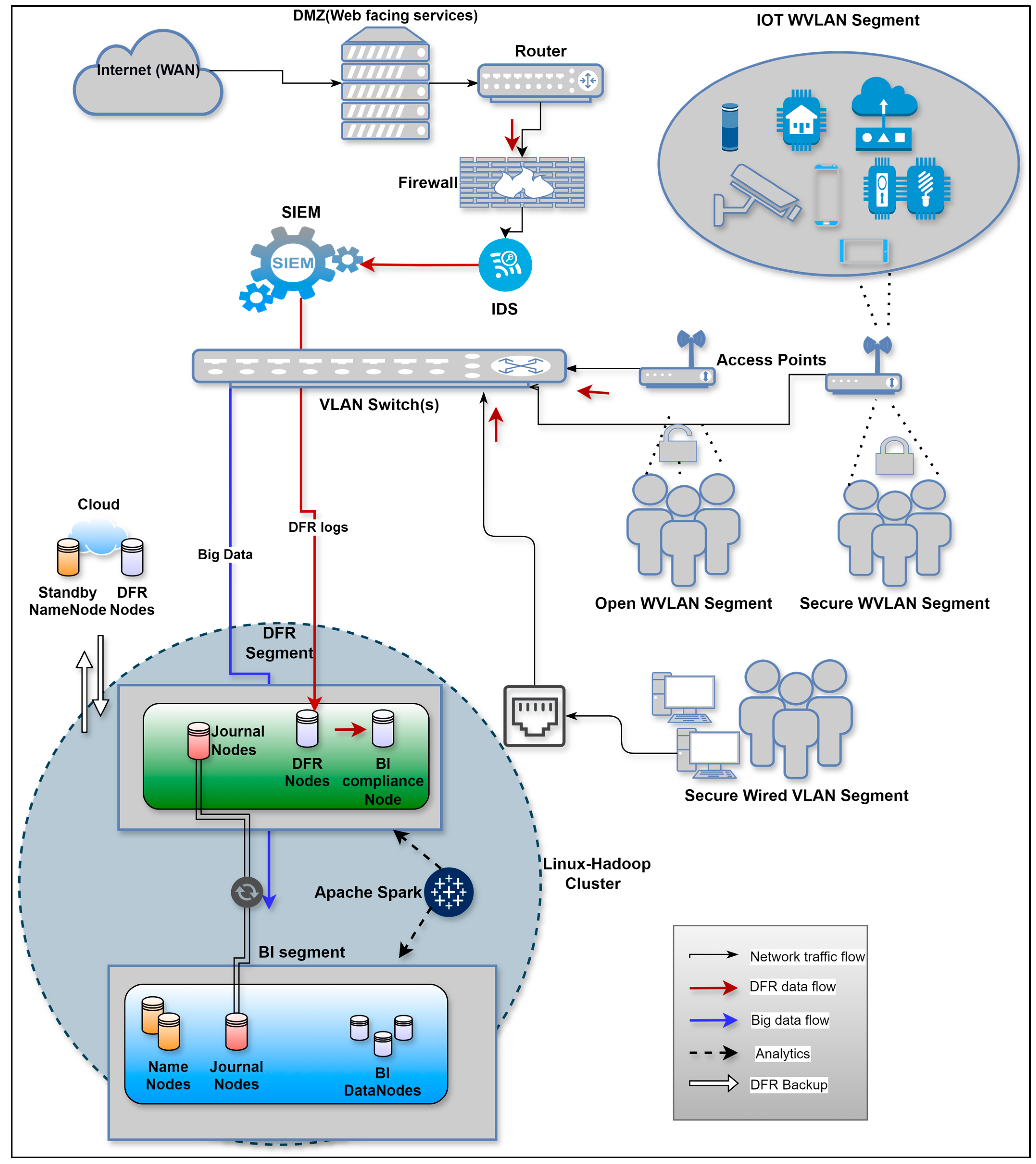
5.2. Framework Overview
5.3. Research Question 1 Insights
- Begin by configuring a standby NameNode in the cloud to ensure redundancy and immediate backup capabilities.
- Use VLANs or SDN (Software Defined Networking) to segment the network, creating separate segments for BI (BI segment) and DFR (DFR segment) operations. Ensure that the forensic nodes are placed on their own segment, which can securely communicate with the BI segment’s NameNode and the cloud-based standby NameNode.
- Equip the forensic nodes with dedicated network interfaces that connect them directly to the BI segment. This ensures that forensic operations are prioritised within their dedicated segment and can communicate efficiently with the NameNode in the BI segment and the standby NameNode in the cloud.
- Install Linux OS, Java, and Hadoop on the forensic nodes, set up SSH (Secure Shell) access, and update host resolution. Use automation tools like Ansible or Chef to standardise and automate the installation process, reducing configuration errors.
- Synchronise all nodes (BI segment, DFR segment, and cloud-based standby NameNode) to a reliable NTP server to ensure consistent time settings across the cluster. This is crucial for accurate timestamping and coordination of distributed processes. Configure the NTP service on all nodes to point to the network’s NTP server.
- Implement an active–passive NameNode setup with the primary NameNode located in the BI segment and the standby NameNode in the cloud. Configure a quorum-based JournalNode cluster spanning both the BI and DFR segments. This setup ensures that all updates to the NameNode’s metadata are immediately synchronised across all relevant nodes, maintaining consistency and reliability in both BI and forensic operations.
- Set up a backup of the DFR nodes in the cloud to ensure that all forensic data are securely stored and can be recovered in case of a failure or disaster.
- Start Hadoop services on the forensic nodes, such as DataNode and any additional services related to forensic readiness. Ensure these services are properly configured to interact with the primary NameNode in the BI segment and the cloud-based standby NameNode.
- Conduct simulated failover tests to ensure that the forensic nodes maintain synchronisation with the BI segment’s NameNode and the standby NameNode in the cloud during a failover. This verifies the resilience and reliability of the forensic setup.
- Reconfigure Apache Spark to extend its capabilities from BI analytics to also support forensics analytics, ensuring that Spark can handle both BI and forensic data processing requirements effectively.
- Implement end-to-end data integrity checks, including checksum validations and consistency checks across the HDFS. This step ensures that forensic data can be accurately retrieved and analysed without any discrepancies.
- Implement MFA (multifactor authentication) for SSH access to the forensic nodes, adding an extra layer of security to prevent unauthorised access. This should be integrated into the network’s existing security protocols.
- Configure RBAC (Role-Based Access Control) to restrict access to forensic data and tools based on user roles, ensuring that only authorised personnel can access sensitive forensic data.
- Set up a continuous monitoring solution using tools like Prometheus and Grafana to track the performance and health of the forensic nodes, as well as the BI segment. This ensures that any issues are quickly identified and resolved.
- Finally, verify the integration by ensuring that the forensic nodes are recognised by the NameNode in the BI segment and can communicate efficiently with it and the cloud-based standby NameNode. Test data retrieval and forensic tool operations to confirm the setup functions as intended.
5.4. Research Question 2 Insights
6. Prototype Configuration and Evaluation
6.1. Prototype Testbeds
- AWS with Ubuntu Linux: This environment consisted of one NameNode, one secondary NameNode, and two DataNodes.
- Oracle VB with CentOS Linux: This setup included one NameNode and two DataNodes.
- Hortonworks Data Platform (HDP) Sandbox using CentOS: The testbed consisted of a single-node cluster running in a Docker container on a virtual machine. HDP comes with a suite of applications such as Apache Hive, Apache HBase, Apache Spark, and Apache Pig, providing a comprehensive platform for managing, processing, and analysing big data within a CentOS-based environment.
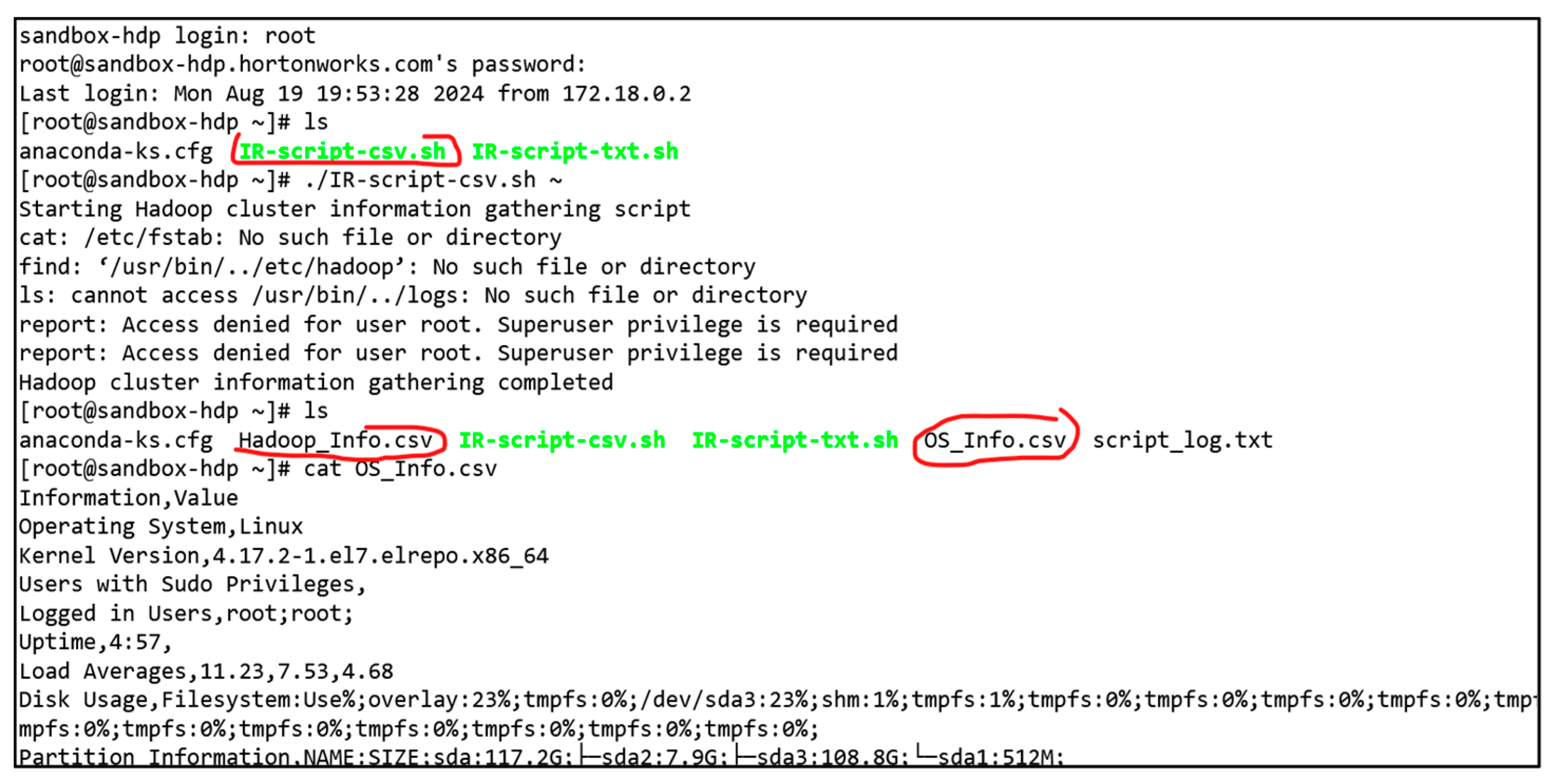
6.2. IR-Script Overview
- OS Information Collection: The script gathers detailed information about the operating system, including OS version, kernel details, users with sudo privileges, currently logged-in users, system uptime, load averages, disc usage, partition information, network configuration, and Linux log files. These comprehensive data are essential for understanding the system’s state and configuration.
- Hadoop Cluster Information: This collects specific details about the Hadoop cluster, such as Hadoop configuration files, the HDFS version, Namenodes, secondary Namenodes, Hadoop log files, cluster environment variables, detailed Hadoop metrics, running Hadoop and Java processes, and information about cluster nodes. This ensures thorough coverage of critical Hadoop-specific information relevant to forensic analysis.
- Intrusion Detection Systems (IDS): The script checks the status and logs of various IDS tools, including Snort, Suricata, and OSSEC, if they are present on the system. This provides an overview of the security monitoring tools and their current operational status.
- Rootkit Detection: The script incorporates rootkit detection capabilities using tools such as chkrootkit, rkhunter, and unhide. These scans help in identifying potential rootkit infections, which is crucial for security investigations.
- usage(): Displays usage instructions for the script.
- handle_error(): Manages errors by displaying an error message and exiting the script.
- command_exists(): Checks for the presence of required commands.
- get_os_info(): Retrieves and records OS-specific information.
- get_hadoop_info(): Gathers Hadoop cluster-related data.
- get_ids_info(): Provides information about installed IDS tools.
- get_rootkit_info(): Performs rootkit scans and records results.
- add_Section_header(), add_command_output(), add_csv_header(), and add_csv_row(): Functions to format and add data to output files, either as text or CSV.
6.3. IR-Script Evaluation
- Successful Retrieval: In total, 57 out of 63 artefacts were fully retrieved, indicating successful extraction and validation across the testbeds (marked as “Yes”).
- Partial Retrieval: Three artefacts were only partially retrieved, reflecting incomplete or partial extraction (marked as “Partial”).
- Failed Retrieval: Three artefacts could not be retrieved at all, denoting a failure in the extraction process (marked as “No”).
- HDP Sandbox Testbed: Out of the three artefacts that were not retrieved (“No”), all were associated with the HDP sandbox. Additionally, one artefact was only partially retrieved on this testbed.
- Oracle VB Testbed: One artefact experienced partial retrieval in the Oracle VB environment.
- AWS Testbed: Similarly, one artefact was partially retrieved in the AWS testbed environment.
7. Conclusions
- Extended Testing: A prototype and evaluation of the proposed conceptual DFR framework for big data networks. Additionally, the further evaluation of IR-script on additional Linux distributions to ensure its robustness and adaptability across a wider range of environments.
- AI Integration: Incorporating AI to enhance the script’s capabilities, potentially improving its adaptability and accuracy in diverse scenarios.
- User-Friendly Interface: The development of a Python-based graphical user interface to make the script more accessible and user-friendly for a broader range of investigators and administrators.
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ahmed, H.; Ismail, M.A.; Hyder, M.F. Performance optimization of hadoop cluster using linux services. In Proceedings of the 17th IEEE International Multi Topic Conference 2014, Karachi, Pakistan, 8–10 December 2014; IEEE: New York City, NY, USA, 2014; pp. 167–172. [Google Scholar]
- Asim, M.; McKinnel, D.R.; Dehghantanha, A.; Parizi, R.M.; Hammoudeh, M.; Epiphaniou, G. Big data forensics: Hadoop distributed file systems as a case study. In Handbook of Big Data and IoT Security; Springer: Cham, Switzerland, 2019; pp. 179–210. [Google Scholar]
- Taylor, R.C. An overview of the Hadoop/MapReduce/HBase framework and its current applications in bioinformatics. BMC Bioinform. 2010, 11, S1. [Google Scholar] [CrossRef] [PubMed]
- Singh, D.; Reddy, C.K. A survey on platforms for big data analytics. J. Big Data 2015, 2, 8. [Google Scholar] [CrossRef] [PubMed]
- Sremack, J. Big Data Forensics—Learning Hadoop Investigations: Perform Forensic Investigations on Hadoop Clusters with Cutting-Edge Tools and Techniques; Mumbai Packt Publishing: Birmingham, UK, 2015. [Google Scholar]
- Russom, P. Big data analytics. TDWI Best Pract. Rep. Fourth Quart. 2011, 19, 1–34. [Google Scholar]
- Thakur, M. Cyber security threats and countermeasures in digital age. J. Appl. Sci. Educ. (JASE) 2024, 4, 1–20. [Google Scholar]
- Sarker, I.H. AI-Driven Cybersecurity and Threat Intelligence: Cyber Automation, Intelligent Decision-Making and Explainability; Springer Nature: Berlin/Heidelberg, Germany, 2024. [Google Scholar]
- Beloume, A. The Problems of Internet Privacy and Big Tech Companies. The Science Survey. 2023. Available online: https://thesciencesurvey.com/news/2023/02/28/the-problems-of-internet-privacy-and-big-tech-companies/ (accessed on 12 March 2024).
- Olabanji, s.o.; Oladoyinbo, O.B.; Asonze, C.U.; Oladoyinbo, T.O.; Ajayi, S.A.; Olaniyi, O.O. Effect of Adopting AI to Explore Big Data on Personally Identifiable Information (PII) for Financial and Economic Data Transformation. 2024. Available online: https://ssrn.com/abstract=4739227 (accessed on 3 March 2024).
- Harshany, E.; Benton, R.; Bourrie, D.; Glisson, W. Big Data Forensics: Hadoop 3.2.0 Reconstruction. Forensic Sci. Int. Digit. Investig. 2020, 32, 300909. [Google Scholar] [CrossRef]
- Akinbi, A.O. Digital forensics challenges and readiness for 6G Internet of Things (IoT) networks. Wiley Interdiscip. Rev. Forensic Sci. 2023, 5, e1496. [Google Scholar] [CrossRef]
- Shoderu, G.; Baror, S.; Venter, H. A Privacy-Compliant Process for Digital Forensics Readiness. Int. Conf. Cyber Warf. Secur. 2024, 19, 337–347. [Google Scholar] [CrossRef]
- Elgendy, N.; Elragal, A. Big data analytics: A literature review paper. In Advances in Data Mining. Applications and Theoretical Aspects, Proceedings of the 14th Industrial Conference, ICDM 2014, St. Petersburg, Russia, 16–20 July 2014; Proceedings 14; Springer International Publishing: Berlin/Heidelberg, Germany, 2014; pp. 214–227. [Google Scholar]
- Kumar, Y.; Kumar, V. A Systematic Review on Intrusion Detection System in Wireless Networks: Variants, Attacks, and Applications. Wirel. Pers. Commun. 2023, 133, 395–452. [Google Scholar] [CrossRef]
- Mpungu, C.; George, C.; Mapp, G. Developing a novel digital forensics readiness framework for wireless medical networks using specialised logging. In Cybersecurity in the Age of Smart Societies, Proceedings of the 14th International Conference on Global Security, Safety and Sustainability, London, 7-8 September 2022; Springer International Publishing: Cham, Switzerland, 2023; pp. 203–226. [Google Scholar]
- Yaman, O.; Ayav, T.; Erten, Y.M. A Lightweight Self-Organized Friendly Jamming. Int. J. Inf. Secur. Sci. 2023, 12, 13–20. [Google Scholar] [CrossRef]
- Sachowski, J. Implementing Digital Forensic Readiness: From Reactive to Proactive Process, 2nd ed.; CRC Press: Boca Raton, FL, USA; Taylor & Francis Group: Abingdon On Thames, UK, 2019. [Google Scholar]
- Oo, M.N. Forensic Investigation on Hadoop Big Data Platform. Ph.D. Thesis, University of Computer Studies, Yangon, Myanmar, 2019. [Google Scholar]
- Thanekar, S.A.; Subrahmanyam, K.; Bagwan, A.B. A study on digital forensics in Hadoop. Indones. J. Electr. Eng. Comput. Sci. 2016, 4, 473–478. [Google Scholar] [CrossRef]
- Joshi, P. Analyzing big data tools and deployment platforms. Int. J. Multidiscip. Approach Stud. 2015, 2, 45–56. [Google Scholar]
- Messier, R.; Jang, M. Security Strategies in Linux Platforms and Applications; Jones & Bartlett Learning: Burlington, MA, USA, 2022. [Google Scholar]
- Nazeer, S.; Bahadur, F.; Iqbal, A.; Ashraf, G.; Hussain, S. A Comparison of Window 8 and Linux Operating System (Android) Security for Mobile Computing. Int. J. Comput. (IJC) 2015, 17, 21–29. [Google Scholar]
- Evaluating Prototypes. Available online: https://www.tamarackcommunity.ca/hubfs/Resources/Tools/Aid4Action%20Evaluating%20Prototypes%20Mark%20Cabaj.pdf (accessed on 20 May 2024).
- Häggman, A.; Honda, T.; Yang, M.C. The influence of timing in exploratory prototyping and other activities in design projects. In Proceedings of the ASME 2013 International Design Engineering Technical Conferences and Computers and Information in Engineering Conference, Portland, OR, USA, 4–7 August 2013; American Society of Mechanical Engineers: New York, NY, USA, 2013; Volume 55928, p. V005T06A023. [Google Scholar]
- Sadia, H. 10 Prototype Testing Questions a Well-Experienced Designer Need to Ask. Webful Creations. 2022. Available online: https://www.webfulcreations.com/10-prototype-testing-questions-a-well-experienced-designer-need-to-ask/ (accessed on 18 February 2024).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| IR-Script Generated Files | Forensics Artefacts | AWS | Oracle VB | HDP Sandbox | Results Summary |
|---|---|---|---|---|---|
| OS_Info.txt OS_Info.csv |
| 1. Yes 2. Yes 3. Yes 4. Yes 5. Yes 6. Yes 7. Yes 8. Yes 9. Yes 10. Partial 11. Yes | 1. Yes 2. Yes 3. Yes 4. Yes 5. Yes 6. Yes 7. Yes 8. Yes 9. Yes 10. Partial 11. Yes | 1. Yes 2. Yes 3. Yes 4. Yes 5. Yes 6. Yes 7. Yes 8. Yes 9. Yes 10. No 11. Yes | In total, 10/11 instances of the supporting OS information in both the txt and CSV formats were retrieved for all three testbeds. More details in conclusion Section. |
| Hadoop_Info.txt Hadoop_Info.csv |
| 1. Yes 2. Yes 3. Yes 4. Yes 5. Yes 6. Yes 7. Yes 8. Yes 9. Yes | 1. Yes 2. Yes 3. Yes 4. Yes 5. Yes 6. Yes 7. Yes 8. Yes 9. Yes | 1. No 2. Yes 3. Yes 4. No 5. Yes 6. Yes 7. Yes 8. Yes 9. Partial | All of the artefacts were retrieved for AWS and Oracle VB. However, 7/9 were retrieved for HDP sandbox. |
| Script_Log.txt | Time-Stamped Script Operations Account | Yes | Yes | Yes | Time-stamped log files for all testbeds were generated. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Published by MDPI on behalf of the International Institute of Knowledge Innovation and Invention. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mpungu, C.; George, C.; Mapp, G. Digital Forensics Readiness in Big Data Networks: A Novel Framework and Incident Response Script for Linux–Hadoop Environments. Appl. Syst. Innov. 2024, 7, 90. https://doi.org/10.3390/asi7050090
Mpungu C, George C, Mapp G. Digital Forensics Readiness in Big Data Networks: A Novel Framework and Incident Response Script for Linux–Hadoop Environments. Applied System Innovation. 2024; 7(5):90. https://doi.org/10.3390/asi7050090
Chicago/Turabian StyleMpungu, Cephas, Carlisle George, and Glenford Mapp. 2024. "Digital Forensics Readiness in Big Data Networks: A Novel Framework and Incident Response Script for Linux–Hadoop Environments" Applied System Innovation 7, no. 5: 90. https://doi.org/10.3390/asi7050090