
Smart Visualization of Mixed Data



Abstract
:1. Introduction
2. Materials and Methods
2.1. FS-DB Algorithm
2.2. A Protocol to Visualize Mixed Data
- Exploratory step.
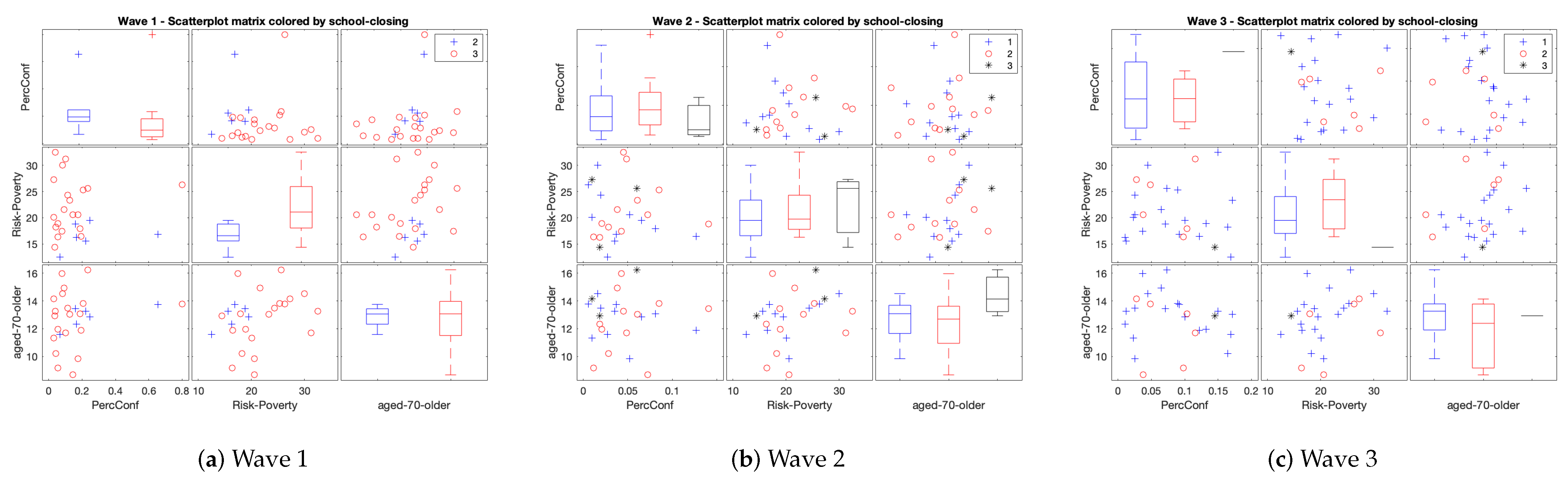
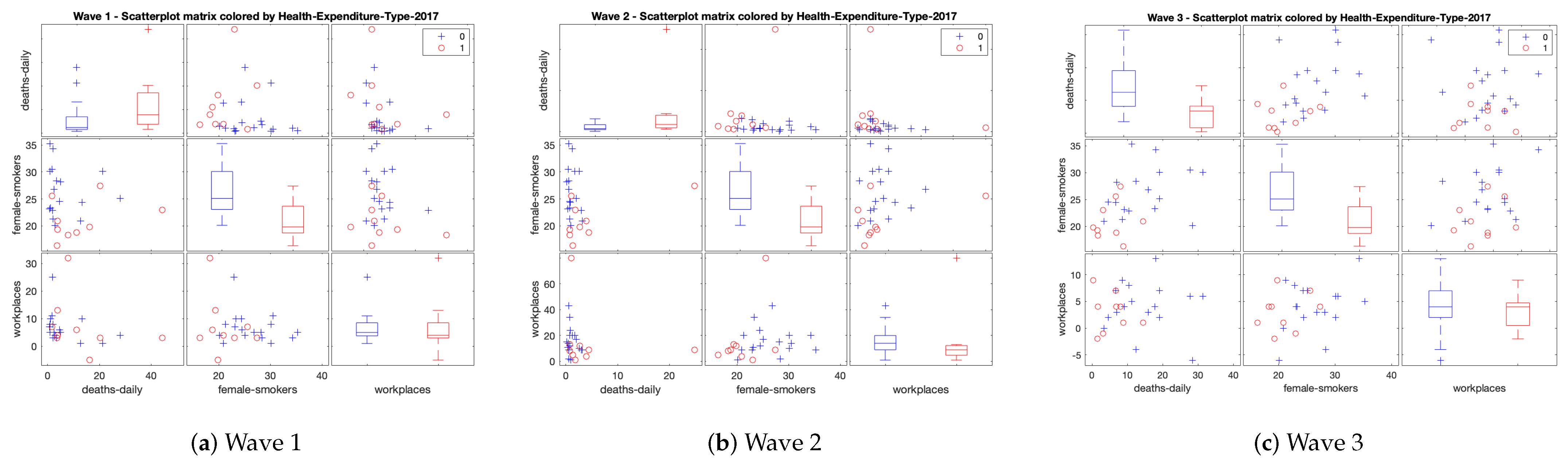
- Multiple scatter-plots and box-plots of quantitative variables by categorical ones. Due to the mixture nature of the data, we represent the individuals in the original variable space and color them according to the categories of the categorical variables in order to better understand the complexity of the data.
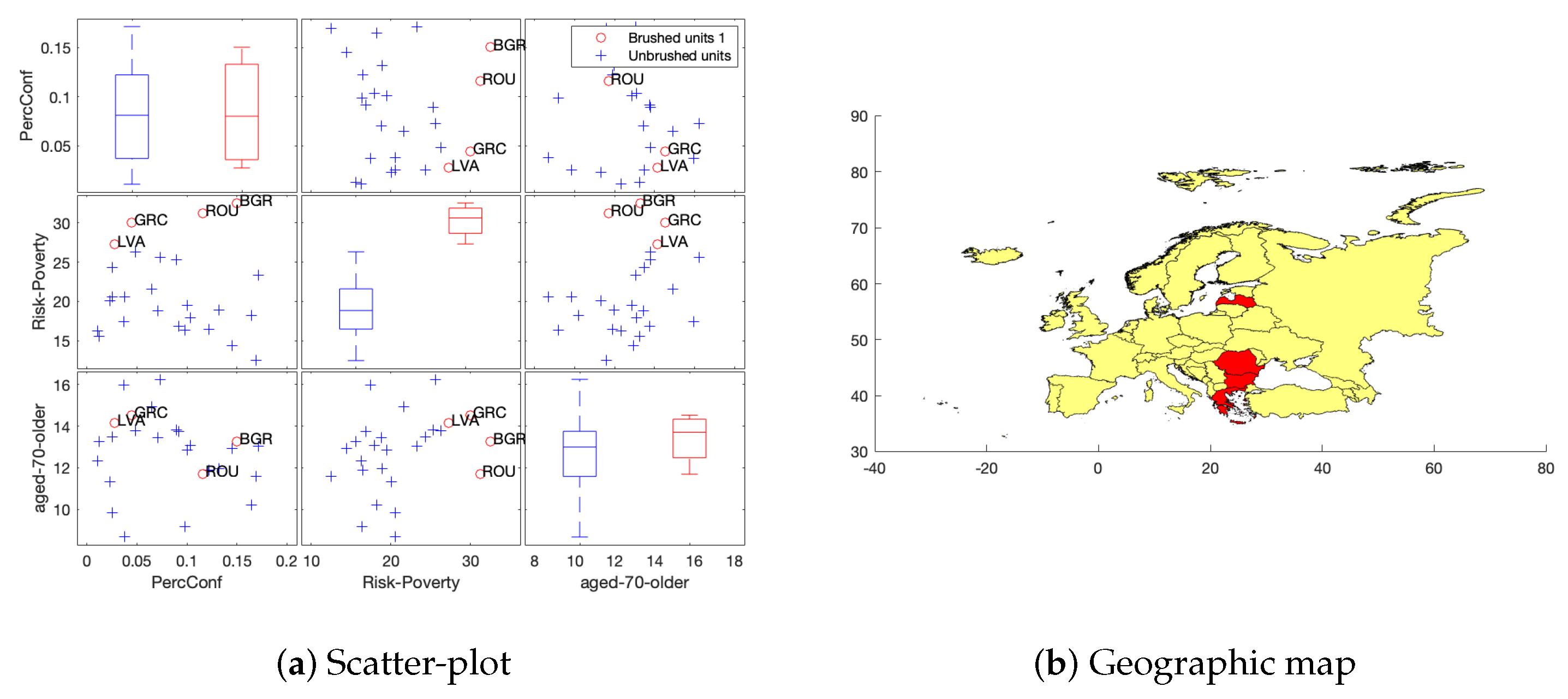
- Spatial data tool. In multiple scatter-plots the user can select which data points wants to be highlight in a geographical map. The code allows the possibility to link the data to a shape-file (when available), inspired by the GeoDa user friendly tool for spatial data analysis (https://geodacenter.github.io, accessed on 1 February 2021).
- Data analysis step.
- Starting point: A data matrix of mixed data .
- Metric construction: Robustification of Gower index. Gower’s similarly coefficient [12] is one of the most popular similarity measures for mixed data. This well-known similarity coefficient is the Pythagorean sum of three similarity coefficients for quantitative, binary and multi-state categorical variables. For quantitative variables, the similarity is related to range-standardized city-block distance and for binary and multi-state categorical ones, respectively, simple matching and Jaccard’s similarity coefficients are computed. One of the main drawbacks of Gower’s coefficient is its lack of robustness which yields to non-stable MDS configurations [5,8]. Inspired by Gower’s idea, we construct a robust distance by adding three distance measures: robust Mahalanobis distance for quantitative variables, Hamming distance for binary ones and for multi-state categorical variables we calculate the distance associated to Jaccard’s similarity coefficient. We denote this new distance measure by . Note that, first, our robust proposal only concerns quantitative variables, since distance measures for binary and multi-sate categorical are left unchanged, and second, by considering (robust) Mahalanobis distance, we also take into account the redundant information within quantitative variables, which is not taken into account by Euclidean or Minkowski distances, since these well-known distances always increase despite the added statistical information is not relevant. Thus, the choice of the distance measure is a key point. Here we are not interested in a general distance measure but in a statistical distance measure, that is, we want to see close those individuals that share the same kind of information and we want to see distant those with very different characteristics.
- Data analysis: FS-DB algorithm is applied to the distance matrix obtained from metric .
- Visualization step.
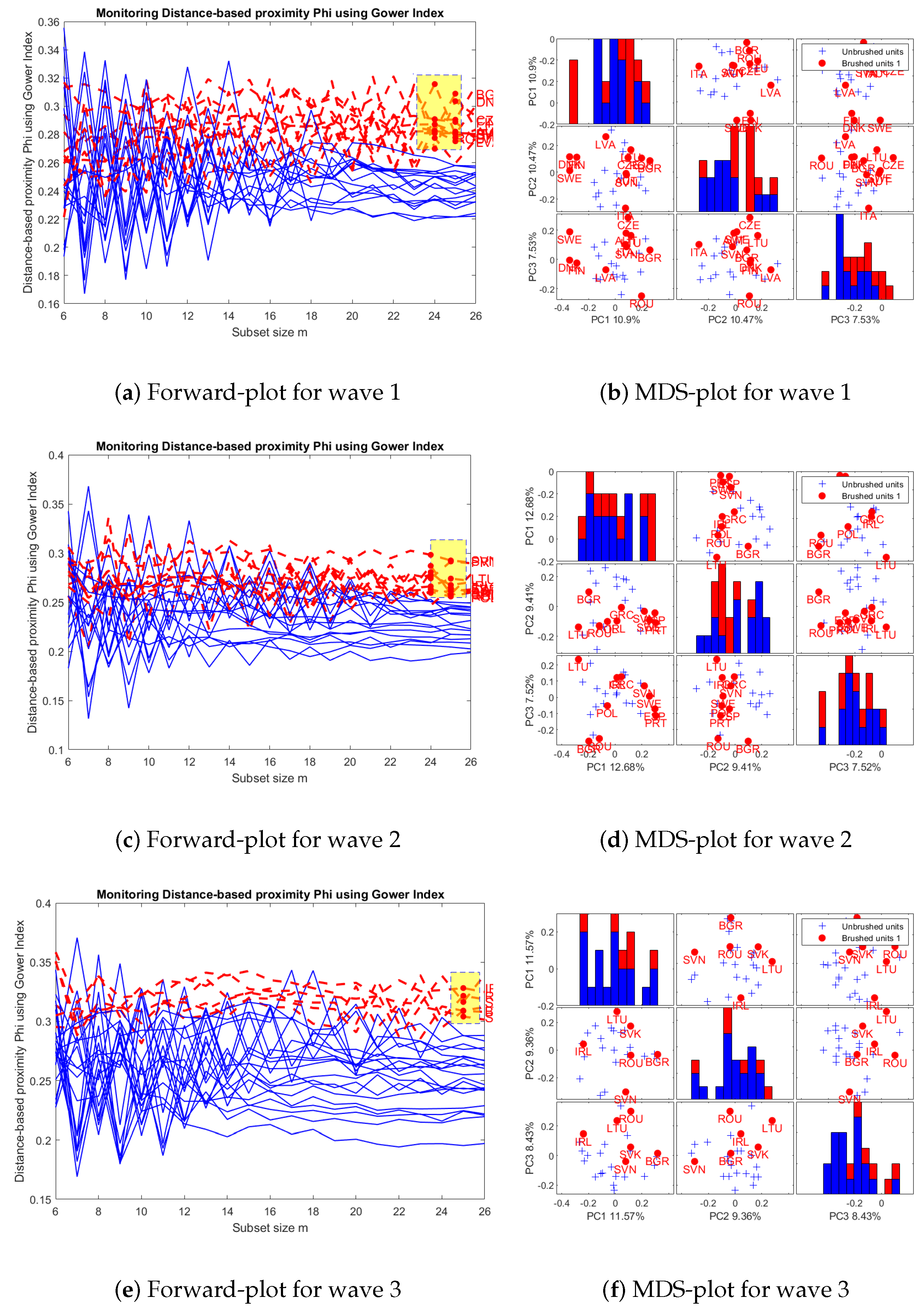
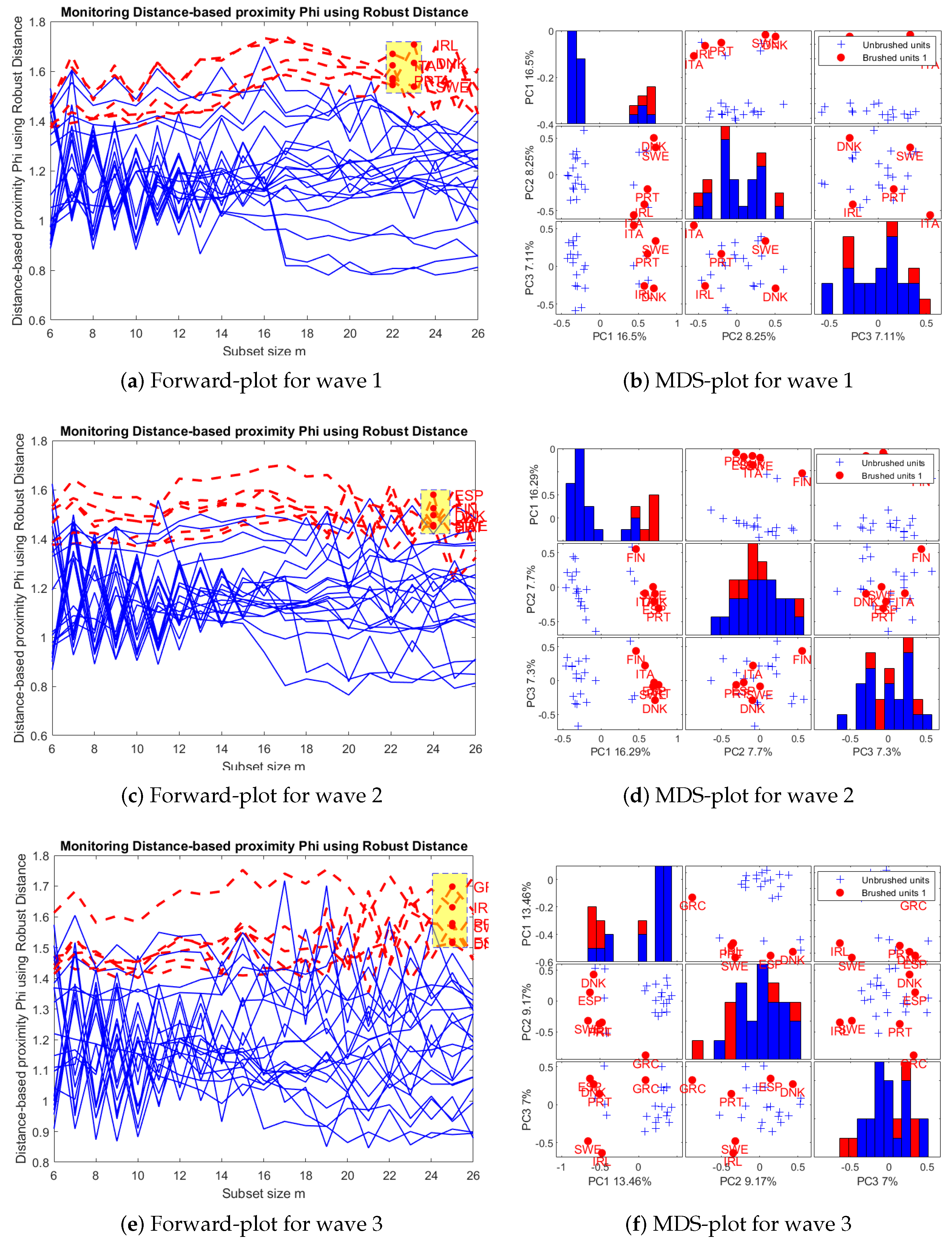
- Outliers. We use FS-DB algorithm to visualize the most inner and most outer observations in the dataset, according to . The Forward-plot is an interactive plot, where the user can select a group of individuals to explore.
- Multiple scatter-plots with MDS-maps. We produce MDS maps to visualize the proximities among individuals, according to . Groups of user-selected individuals are subsequently highlighted with colors.
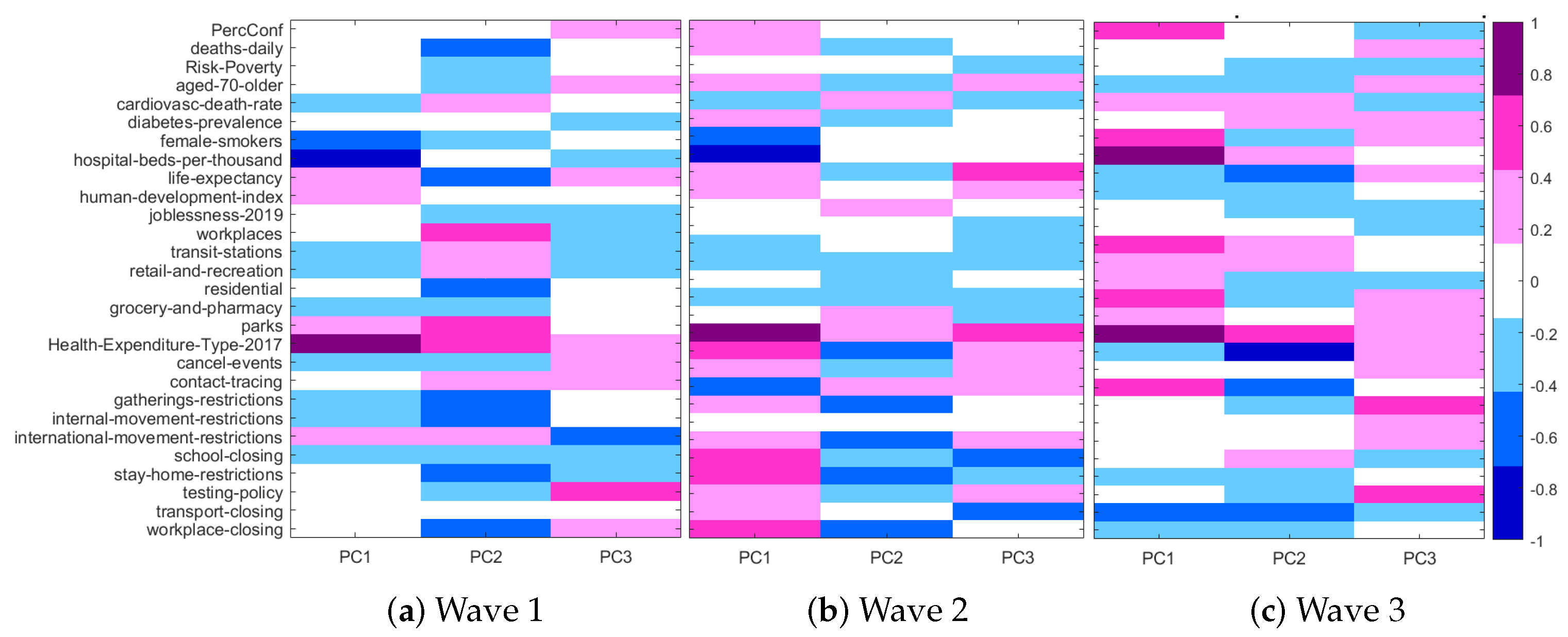
- Relationship between original mixed-type variables and MDS coordinates. A way to see the influence of each original variable in the principal coordinates is to compute a correlation coefficient or a association measure between the original variables and the axes. We use Pearson’s correlation coefficient for quantitative variables, Cramer’s V for nominal ones and Spearman’s correlation coefficient for ordinal ones. Other measures of association (Kendall’s and , , etc.) can be implemented. We visualize these relationships through a heat map.
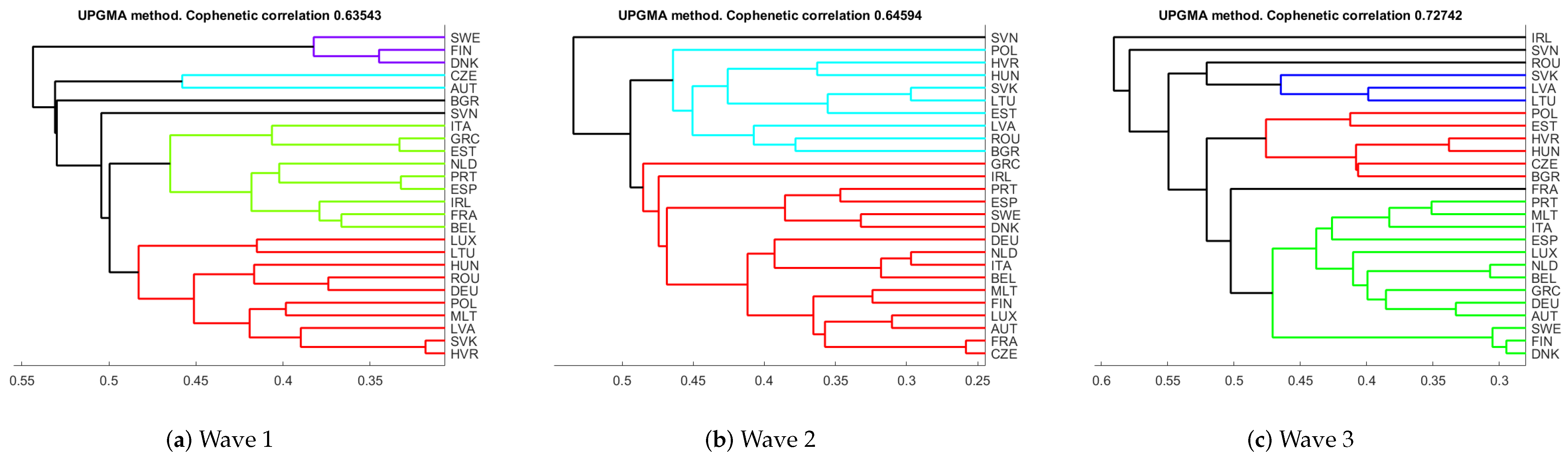
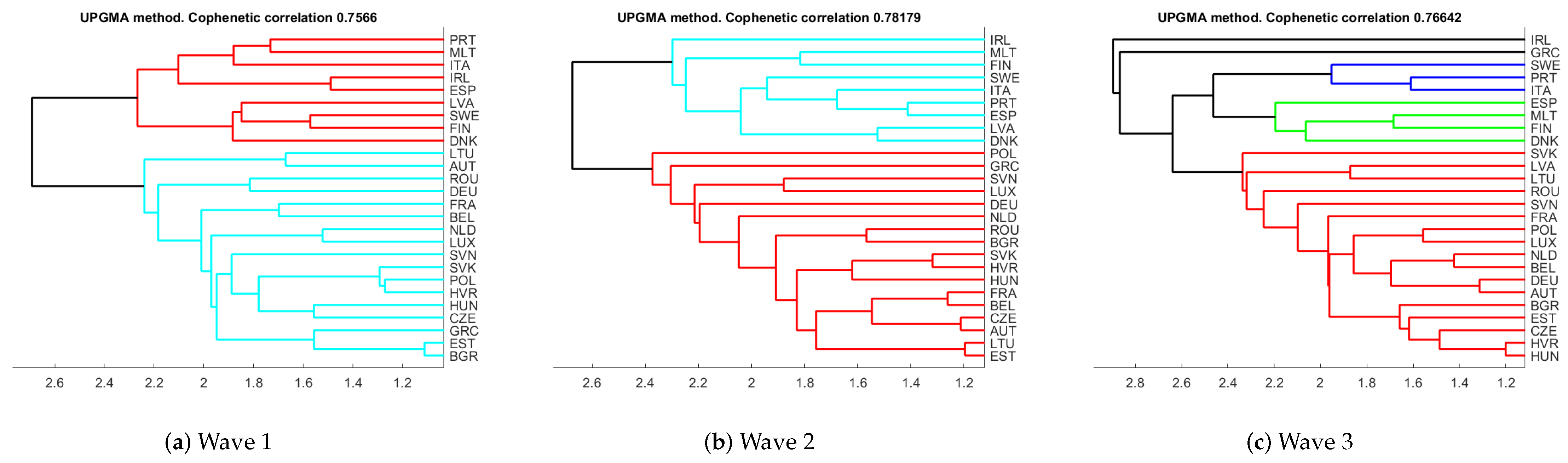
- Clustering. We give hierarchical clustering representations of the individuals based on distance . We also give cophenetic correlation coefficient as a measure of discrepancy between and the corresponding ultrametric distance. This analysis allows to check the coherence with the previous clusterings observed in the Forward-plot and the MDS-maps.
3. Results
3.1. Data Description
3.2. Visual Exploratory Data Analysis
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Results Concerning Gowers’ Distance
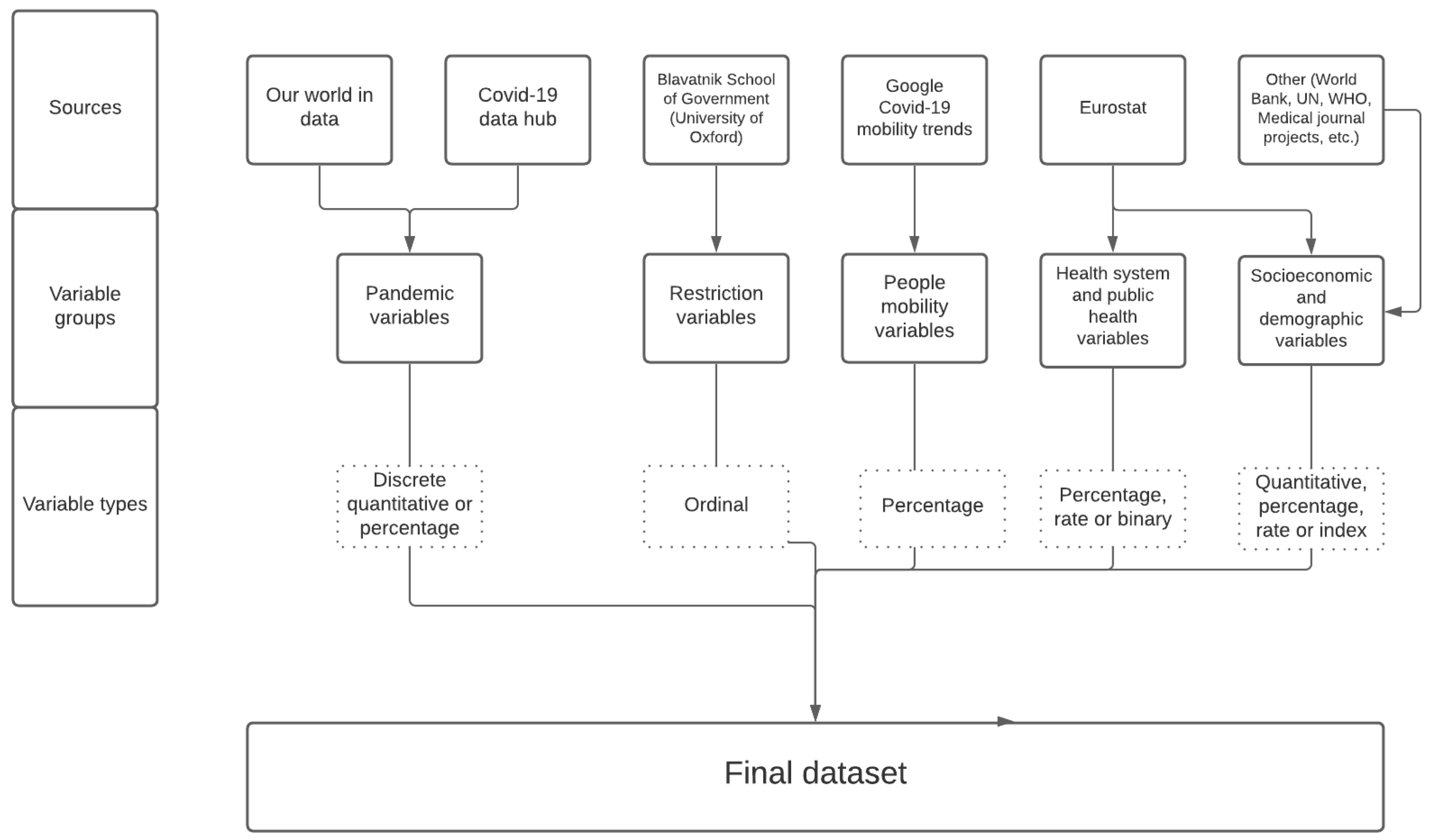
Appendix B. Variable Description and Sources

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable Name | Variable Group | Variable Type | Description | Periodicity | Source; Accessed on 1 January 2021 |
|---|---|---|---|---|---|
| Tests | Pandemic | Discrete quantitative | Cumul. no. of SARS-CoV-2 tests | Daily | github.com/owid |
| confirmed | Pandemic | Discrete quantitative | Cumul. no. of new COVID-19 cases | Daily | github.com/owid |
| recovered | Pandemic | Discrete quantitative | Cumul. no. of recovered | Daily | github.com/covid19datahub/COVID19 |
| people from COVID-19 | |||||
| deaths_accumulated | Pandemic | Discrete quantitative | Cumul. no. of COVID-19 deaths | Daily | github.com/owid |
| deaths_daily | Pandemic | Discrete quantitative | No. of daily COVID-19 deaths per 1000 inhab. | Daily | github.com/owid |
| PercConf | Pandemic | % rate | No. of tested positive over No. of tests (×100) | Daily | github.com/owid |
| hosp | Pandemic | Discrete quantitative | No. of people currently | Daily | github.com/owid; github.com/covid19datahub |
| hospitalized for COVID-19 | |||||
| icu | Pandemic | Discrete quantitative | No. of people currently in | Daily | github.com/owid; github.com/covid19datahub |
| intensive care for COVID-19 | |||||
| school_closing | Restriction | Ordinal | Record closings of schools and universities | Daily | www.bsg.ox.ac.uk |
| workplace_closing | Restriction | Ordinal | Record closings of working places | Daily | www.bsg.ox.ac.uk |
| cancel_events | Restriction | Ordinal | Record canceling public events | Daily | www.bsg.ox.ac.uk |
| gatherings_restrictions | Restriction | Ordinal | Record bans on private gatherings | Daily | www.bsg.ox.ac.uk |
| transport_closing | Restriction | Ordinal | Record closing of public transport | Daily | www.bsg.ox.ac.uk |
| stay_home_restrictions | Restriction | Ordinal | Record confinement to home. | Daily | www.bsg.ox.ac.uk |
| internal_movement_restrictions | Restriction | Ordinal | Record restrictions on internal movement | Daily | www.bsg.ox.ac.uk |
| international_movement_restrictions | Restriction | Ordinal | Record restrictions on international travel | Daily | www.bsg.ox.ac.uk |
| information_campaigns | Restriction | Ordinal | Record presence of public info campaigns | Daily | www.bsg.ox.ac.uk |
| testing_policy | Restriction | Ordinal | Record testing policy | Daily | www.bsg.ox.ac.uk |
| contact_tracing | Restriction | Ordinal | Record government contact tracing | Daily | www.bsg.ox.ac.uk |
| stringency_index | Restriction | Index | Weighted average of closures variables (×100) | Daily | www.bsg.ox.ac.uk |
| retail_and_recreation_mobility | Mobility | % change | % change in mobility for retail and recreation | Daily | www.google.com/covid19/mobility |
| grocery_and_pharmacy_mobility | Mobility | % change | % change in mobility for grocery and pharmacy | Daily | www.google.com/covid19/mobility |
| parks_mobility | Mobility | % change | % change in mobility for parks | Daily | www.google.com/covid19/mobility |
| transit_stations_mobility | Mobility | % change | % change in mobility in stations | Daily | www.google.com/covid19/mobility |
| workplaces_mobility | Mobility | % change | % change in mobility for workplaces | Daily | www.google.com/covid19/mobility |
| residential_mobility | Mobility | % change | % change in mobility for residential places | Daily | www.google.com/covid19/mobility |
| 2019_Risk_Poverty | Socioeconomic | % rate | % of population at risk of poverty | Annual (2019) | www.ec.europe.eu |
| Population | Socioeconomic | Discrete quantitative | Estimated country’s population | Quarterly | ec.europa.eu/eurostat/data/database |
| excess_mortality | Socioeconomic | % change | Estimated country’s excess mortality | Monthly | ec.europa.eu/eurostat/data/database |
| per_capita_gdp | Socioeconomic | Discrete quantitative | Quarterly per-capita GDP | Quarterly | ec.europa.eu/eurostat/data/database |
| gdp_per_capita | Socioeconomic | Discrete quantitative | Annual per-capita GDP | Annual | ec.europa.eu/eurostat/data/database |
| population_density | Socioeconomic | Rate | Population density | Annual | www.ec.europe.eu |
| median_age | Socioeconomic | Quantitative | Population median age | Annual | www.ec.europe.eu |
| median_age | Socioeconomic | Quantitative | Population median age | Annual | www.ec.europe.eu |
| aged_65_older | Socioeconomic | % | % of population aged 65 or older | Annual | www.ec.europe.eu |
| aged_70_older | Socioeconomic | Quantitative | Population median age | Annual | www.ec.europe.eu |
| extreme_poverty | Socioeconomic | % | % of people living in extreme poverty | Annual | data.worldbank.org |
| cardiovasc_death_rate | Public health | Rate | Death rate from cardiovascular disease | Annual (2017) | www.thelancet.com/gbd |
| diabetes_prevalence | Public health | % | % of people aged 20–79 diagnosed with diabetes | Annual (2017) | idf.org |
| female_smokers | Public health | % | % of women who smoke | Annual | apps.who.int/gho |
| male_smokers | Public health | % | % of men who smoke | Annual | apps.who.int/gho |
| hospital_beds | Public health | Rate | No. of hosp. beds per 1 K inhabitants | Annual | www.ec.europe.eu |
| life_expectancy | Public health | Quantitative | Life expectancy at birth | Annual (2019) | population.un.org/wpp |
| human_development_index | Socioeconomic | Index | Composite index measuring basic develop. | Annual (2019) | hdr.undp.org |
| joblessness | Socioeconomic | % | % of people living in jobless households | Annual | www.ec.europe.eu |
| gps_per_100k_inhab | Socioeconomic | Rate | No. of GPs per 100 K inhabitants | Annual (2018) | gateway.euro.who.int/en/indicators |
| Health_Expenditure_Type | Public health | Binary | Prevalent health system (private or public) | Annual | www.ec.europe.eu |
References
- Van Rijmenam, M.; Erekhinskaya, T.; Schweitzer, J.; Williams, M.-A. Avoid being the Turkey: How big data analytics changes the game of strategy in times of ambiguity and uncertainty. Long Range Plan. 2019, 52, 1–21. [Google Scholar] [CrossRef]
- Bar-Hillel, A.; Hertz, T.; Shental, N.; Weinshall, D. Learning a mahalanobis metric from equivalence constraints. J. Mach. Learn. Res. 2005, 6, 937–965. [Google Scholar]
- Jian, S.; Hu, L.; Cao, L.; Lu, K. Metric-Based Auto-Instructor for Learning Mixed Data Representation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York Hilton Midtown, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Wang, D.; Tan, X. Robust Distance Metric Learning via Bayesian Inference. IEEE Trans. Image Process. 2018, 27, 1542–1553. [Google Scholar] [CrossRef] [PubMed]
- Grané, A.; Romera, R. On visualizing mixed-type data: A joint metric approach to profile construction and outlier detection. Sociol. Methods Res. 2018, 47, 207–239. [Google Scholar] [CrossRef]
- Cuadras, C.M. Multidimensional dependencies in classification and ordination. In Analyses Multidimensionelles des Données; CISIA-CERESTA: Saint-Mandé, France, 1998; pp. 15–25. [Google Scholar]
- Cuadras, C.M.; Fortiana, J. Visualizing categorical data with related metric scaling. In Visualization of Categorical Data; Elsevier: Amsterdam, The Netherlands, 1998; pp. 365–376. [Google Scholar]
- Grané, A.; Salini, S.; Verdolini, E. Robust multivariate analysis for mixed-type data: Novel algorithm and its practical application in socio-economic research. Socio Econ. Plan. Sci. 2020, 73, 100907. [Google Scholar] [CrossRef]
- Atkinson, A.; Riani, M. The forward search and data visualization. Comput. Stat. 2004, 19, 29–54. [Google Scholar] [CrossRef]
- Atkinson, A.C.; Riani, M.; Cerioli, A. The forward search: Theory and data analysis. J. Korean Stat. Soc. 2010, 39, 117–134. [Google Scholar] [CrossRef]
- Riani, M.; Perrotta, D.; Torti, F. FSDA: A matlab toolbox for robust analysis and interactive data exploration. Chemom. Intell. Lab. Syst. 2012, 116, 17–32. [Google Scholar] [CrossRef]
- Gower, J.C. A General Coefficient of Similarity and Some of its Properties. Biometrics 1971, 27, 857–874. [Google Scholar] [CrossRef]
- Guidotti, E.; Ardia, D. COVID-19 Data Hub. J. Open Source Softw. 2020, 5, 2376. [Google Scholar] [CrossRef]
- Roser, M.; Ritchie, H.; Ortiz-Ospina, E.; Hasell, J. Coronavirus Pandemic (COVID-19). 2020. Available online: OurWorldInData.org (accessed on 1 December 2020).
- Hale, T.; Angrist, N.; Goldszmidt, R.; Kira, B.; Petherick, A.; Phillips, T.; Webster, S.; Cameron-Blake, E.; Hallas, L.; Majumdar, S.; et al. A global panel database of pandemic policies (Oxford COVID-19 Government Response Tracker). Nat. Hum. Behav. 2021, 5, 529–538. [Google Scholar] [CrossRef] [PubMed]
- The Lancet Global Burden Desease Editorial. Global health: Time for radical change? Lancet 2020, 396, 1129. [Google Scholar] [CrossRef]
- Chang, S.; Pierson, E.; Koh, P.W.; Gerardin, J.; Redbird, B.; Grusky, D.; Leskovec, J. Mobility network models of COVID-19 explain inequities and inform reopening. Nature 2021, 589, 82–87. [Google Scholar] [CrossRef] [PubMed]
- Nouvellet, P.; Bhatia, S.; Cori, A.; Ainslie, K.E.; Baguelin, M.; Bhatt, S.; Boonyasiri, A.; Brazeau, N.F.; Cattarino, L.; Cooper, L.V.; et al. Reduction in mobility and COVID-19 transmission. Nat. Commun. 2021, 12, 1090. [Google Scholar] [CrossRef] [PubMed]
- Savaris, R.F.; Pumi, G.; Dalzochio, J.; Kunst, R. Stay-at-home policy is a case of exception fallacy: An internet-based ecological study. Sci. Rep. 2021, 11, 5313. [Google Scholar] [CrossRef] [PubMed]
- Williams, D.W.; Yung, K.C.; Grépin, K.A. The failure of private health services: COVID-19 induced crises in low- and middle-income country (LMIC) health systems. Glob. Public Health 2021, 1–14. [Google Scholar] [CrossRef] [PubMed]
- Grané, A.; Sow-Barry, A.A. Visualizing profiles of large datasets of weighted and mixed data. Mathematics 2021, 9, 891. [Google Scholar] [CrossRef]


Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Grané, A.; Manzi, G.; Salini, S. Smart Visualization of Mixed Data. Stats 2021, 4, 472-485. https://doi.org/10.3390/stats4020029
Grané A, Manzi G, Salini S. Smart Visualization of Mixed Data. Stats. 2021; 4(2):472-485. https://doi.org/10.3390/stats4020029
Chicago/Turabian StyleGrané, Aurea, Giancarlo Manzi, and Silvia Salini. 2021. "Smart Visualization of Mixed Data" Stats 4, no. 2: 472-485. https://doi.org/10.3390/stats4020029