1. Introduction
Reliability describes the probability that the object realizes its functions under given conditions for a specified time period [
1]. As a way to improve the quality of products, reliability assessment is carried out by companies such that they can make product planning and implement preventive maintenance. For a mechanical structure subjected to stochastic excitation, an important task is to evaluate the risk of structure failures, in other words, the failure probability of the structure. Mathematically, the failure probability is determined by a multi-dimension integral over the spaces of all possible variables (factors) involved, i.e., [
2]
where
is a vector that consists of the variables involved in the excitation.
is a defined performance function used to identify structural failures, that is to say,
when
falls into failure region.
is the uncertainty space of
;
is an indicator function that equals 1 when
and 0, otherwise;
denotes the mathematical expectation. In fact, due to various factors (manufacturing, environment, fatigue …), the structural properties become uncertain. Hence, the assessment of failure probability involves the uncertainties in both structural parameters and the excitation. Considering the relative independence between the uncertainties of the structural properties and those of the excitation, the conditional failure probability can be defined and formulated as [
3]
where
is a vector that consists of the uncertain properties of the object structure.
is a ’conditional’ indicator function of
in terms of
. Generally, in the analysis of structural dynamic responses, the stochastic excitation process is discretized so that a discrete response process is achieved. Then, the characterization of the integrals in Equations (1) and (2) may involve hundreds of random variables in the context of stochastic loading. Therefore, the current reliability problem forms actually a high dimensional problem.
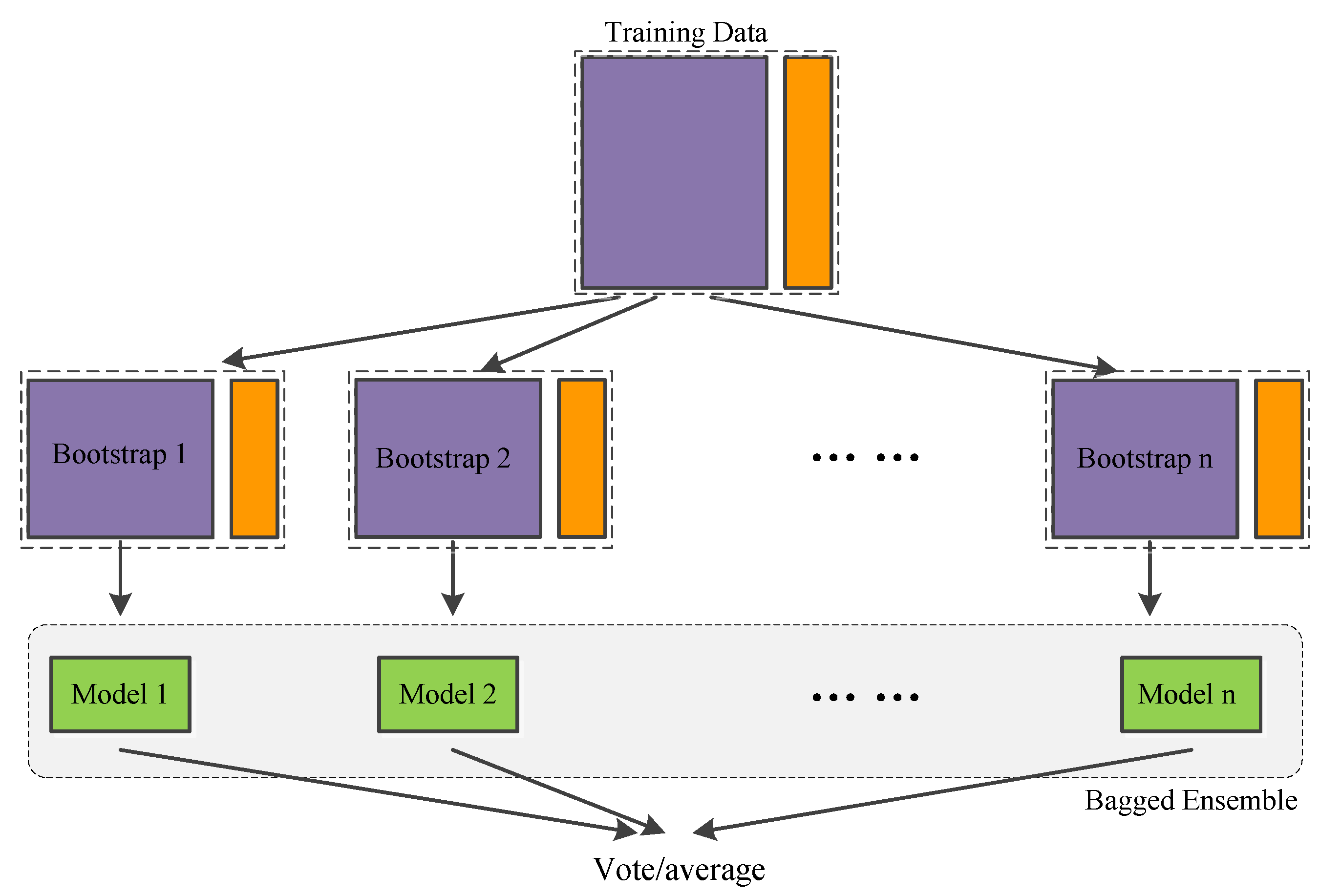
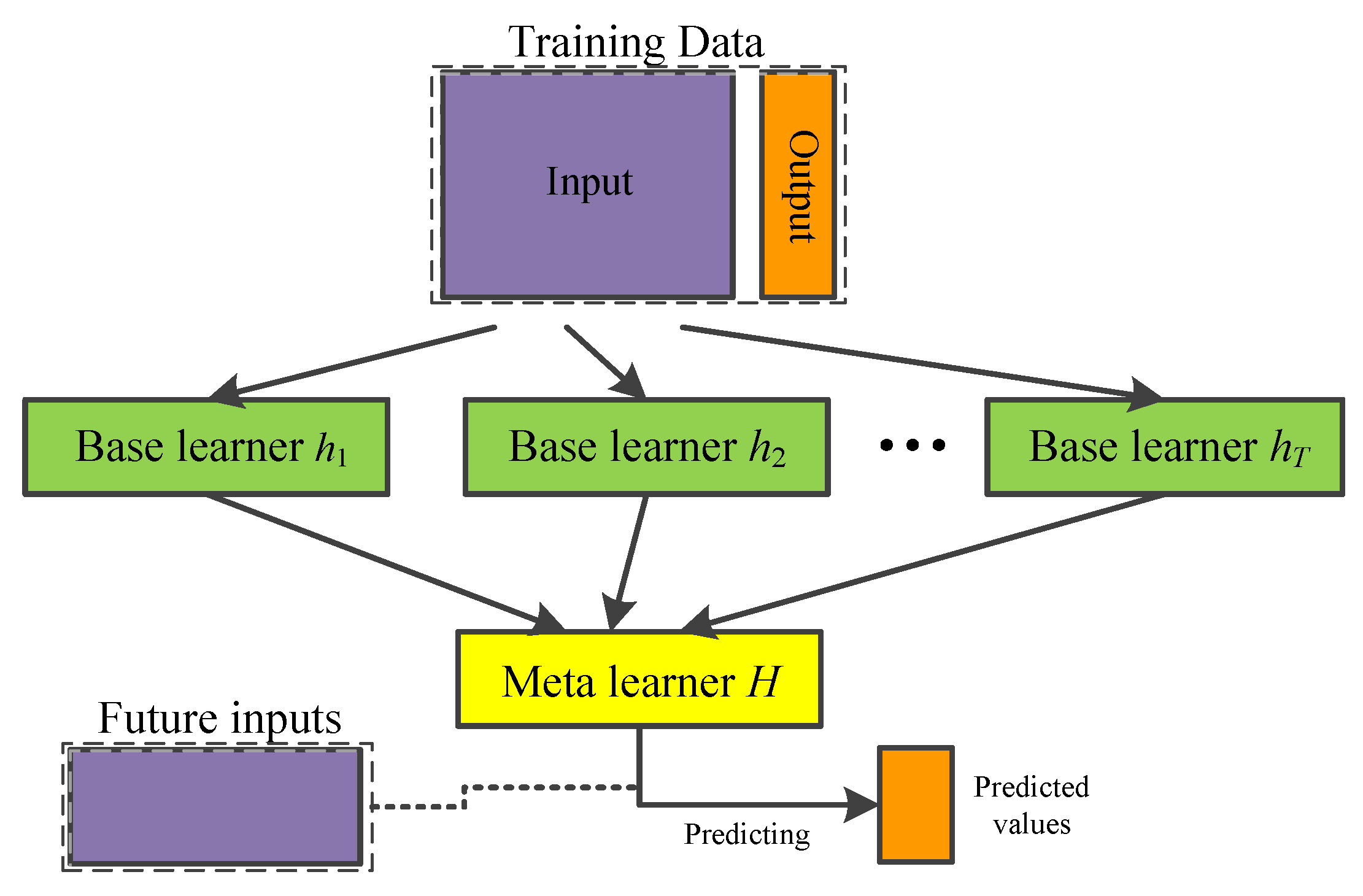
Compared with the dimension of structural properties, the dimension of the excitation is always very high. Direct MCS demands a huge number of samples to ensure a high accuracy of the estimated CFP, but this will be very time-consuming. In this aspect, surrogate models become a good alternative. Surrogate models are developed to deal with highly nonlinear or implicit performance functions. They are introduced to reduce computational burden in reliability analysis. Assuming
is a
n-dimension input vector,
y is the output. For a data set with
N samples,
, the corresponding responses are
. Assume that the function between the input variables and output response takes the following form
, where
is the unknown response function,
is a certain surrogate function seen as an approximation of the real function.
is the error induced by the surrogate function. A surrogate model technique mainly consists of three parts. Firstly, a number of samples are taken from the input space
; secondly, the output responses
of these samples are determined through numerical models such as finite element analysis (FEA), resulting in a training data set
for the surrogate model; finally, the training data are employed to train a surrogate model. See the illustration in
Figure 1.
Response surface method (RSM) [
4] is among the most popular surrogate models. Some researchers combine RSM with other approaches to refine the model parameters so that the model becomes more efficient [
5]. Support vector machine (SVM) has also gained much attention recently. Pan and Dias [
6] combined an adaptive SVM and MCS to solve nonlinear and high-dimensional problems in reliability analysis. Other surrogate models such as metamodel, ANNs, and Kriging have been proposed by other researchers [
7,
8,
9]. However, they cannot avoid shortcomings in all situations. The disadvantages in ANNs mainly include the complex architecture optimization, low robustness, and enormous training time [
10]. SVM is time-consuming for large-scale applications and sometimes shows a large error in sensitivity calculation of reliability index. RSM has been popular; however, it may be time-consuming to use the polynomial function when the components are complex and the number of random variables is large [
11]. Moreover, the approximate performance function is lack of adaptivity and flexibility, and we cannot guarantee that it is sufficiently accurate for the true one.
In the authors’ viewpoint, the evaluation of CFP in Equation (
3) can be seen as a regression problem that takes a realization of the structural uncertain properties as input and the CFP as output. To improve reliability assessment considering structural uncertainties, more attention should be paid to the non-parametric statistical learning methods, such as RF [
12] and GB [
13] et al. According to the current research state, we believe that the explorations of ML methods are far from enough. The rest of the paper is organized as follows. In
Section 2, the theories pertaining to CFP and its estimation are presented. In
Section 3, the framework of failure probability estimation based on ML models is introduced. In
Section 4, the principles of ensemble learning methods are presented. In
Section 5, numerical simulations on different structures are applied, and discussion of the results are made.
Section 6 makes some concluding remarks.
2. Failure Probability Estimation: ML-Based Framework
As mentioned before, the calculation of the overall failure probability considers both uncertainties of the stochastic excitation and those of the structural properties. In this aspect, the target failure probability is estimated according to the formula below:
which means that the target failure probability can be seen as the expectation of CFP over the uncertainty space of structural properties. From an ML perspective, training data are firstly prepared to train a model, then this model is employed to make predictions on a new data. The training data consist of several samples of the input vector and the output values while the new data only contain the samples of the input vector. When the CFPs are available for a few samples of the uncertain structural properties, an ML model is trained that takes the samples of
as inputs and the corresponding CFPs as outputs. Then, this model is employed to predict the outputs on the new data. Machine learning is a very powerful tool to find potential relationships within the data and make predictions. In this research, only a few hundred samples are needed to train an accurate ML model, then the model can be used to make immediate predictions on the new samples.
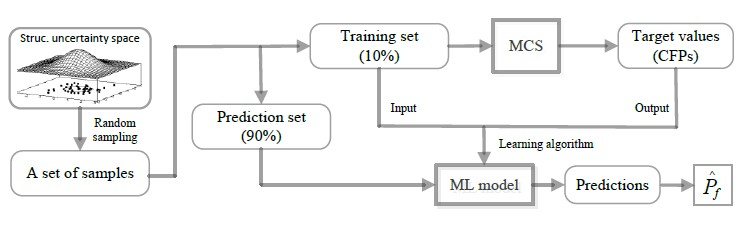
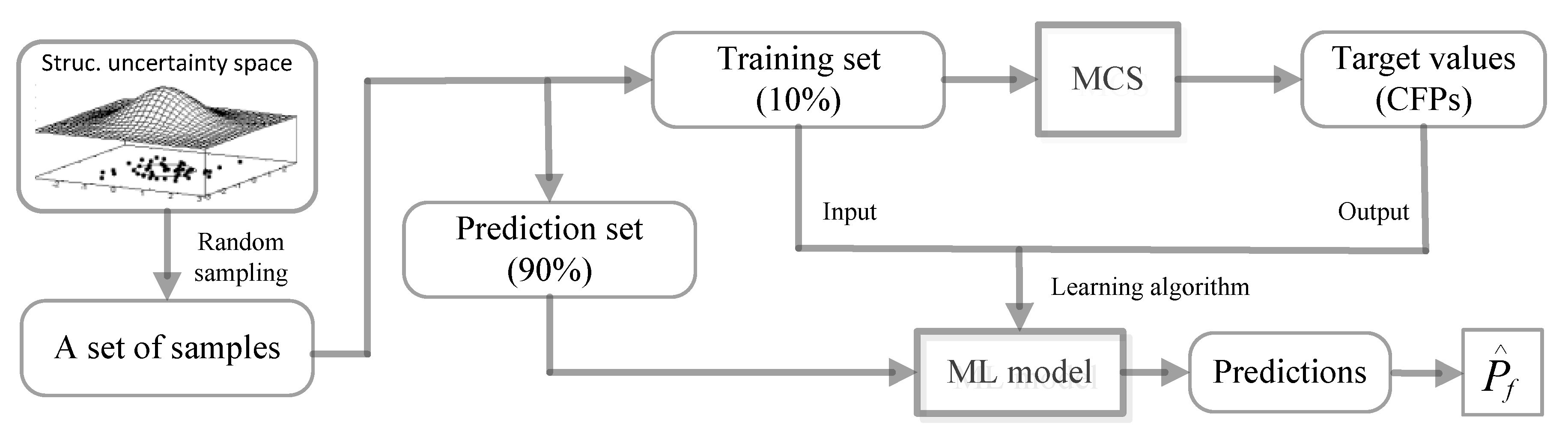
Figure 2 shows the framework of the proposed method. Firstly, a set of random samples are generated from the structural uncertainty space; secondly, the samples are split into two subsets, one for training (10%) and the other (90%) for making predictions; thirdly, MCS is employed to estimate target values (CFPs) of the training set; fourthly, an ML model is trained from the training data; fifthly, the ML model is used to make predictions on the prediction set. Finally, the predictions are averaged to obtain the estimation of overall failure probability. It is noticed that the pre-processing of the random samples of the structure is necessary. In this research, the samples are adjusted so that they follow truncated distributions. In
Figure 2, the samples to train the ML model are different from the samples for making predictions.
6. Conclusions
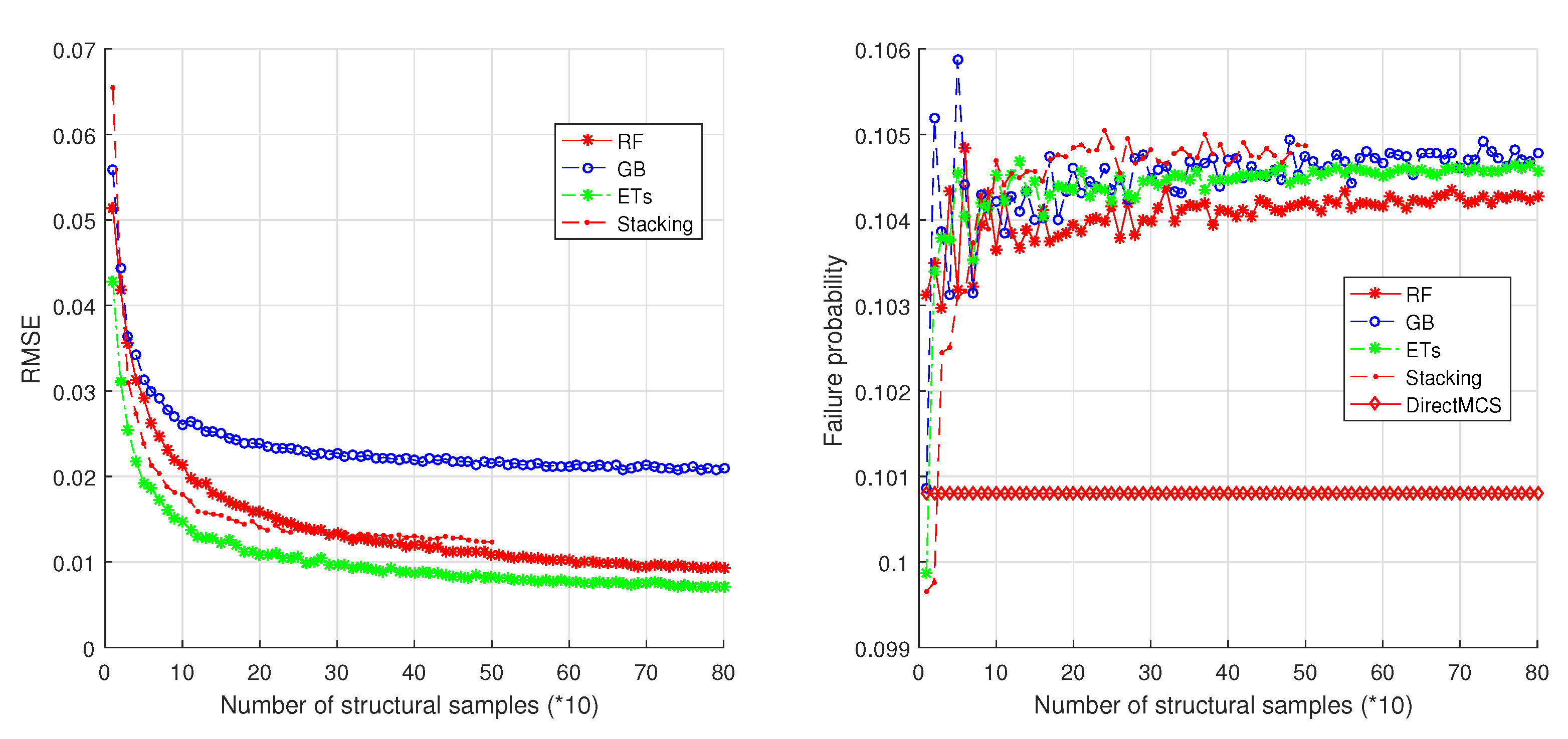
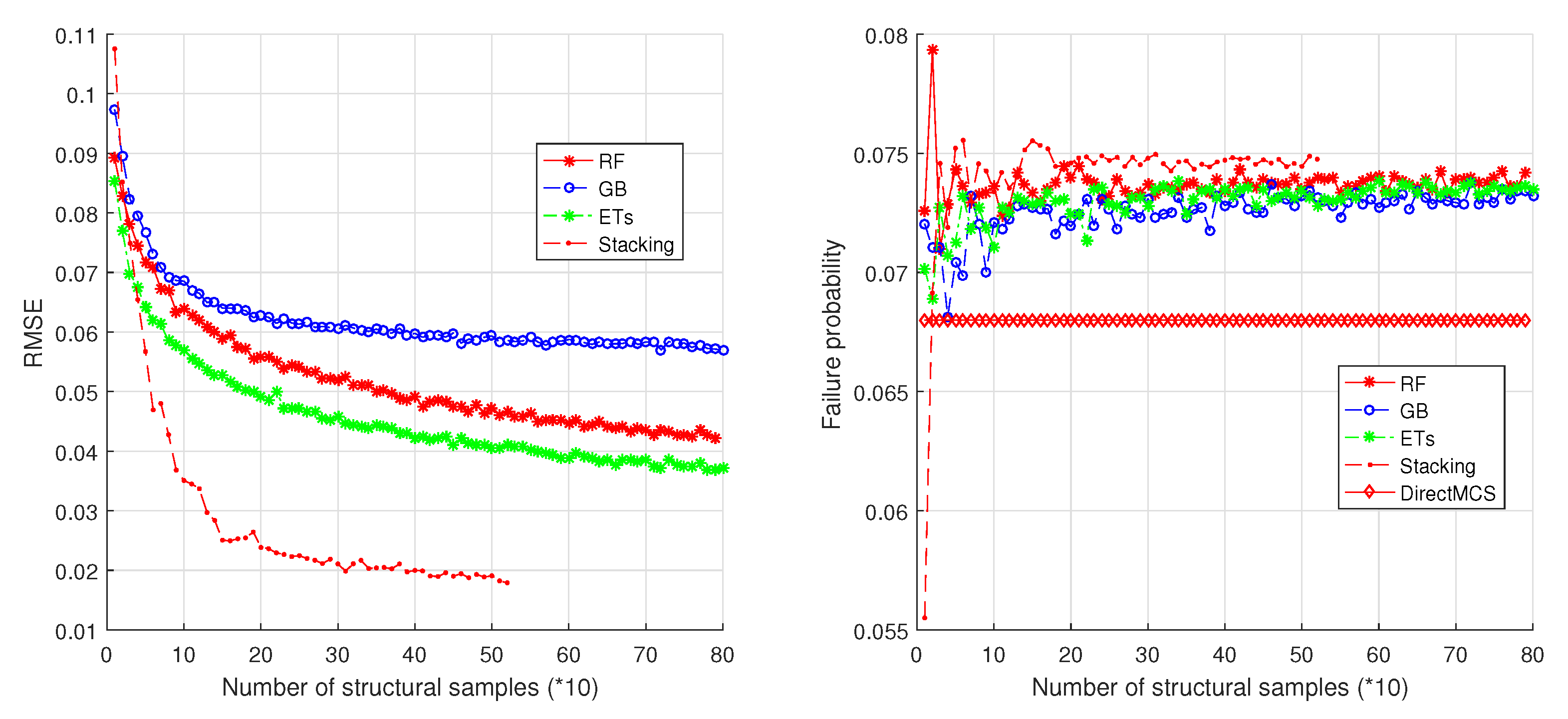
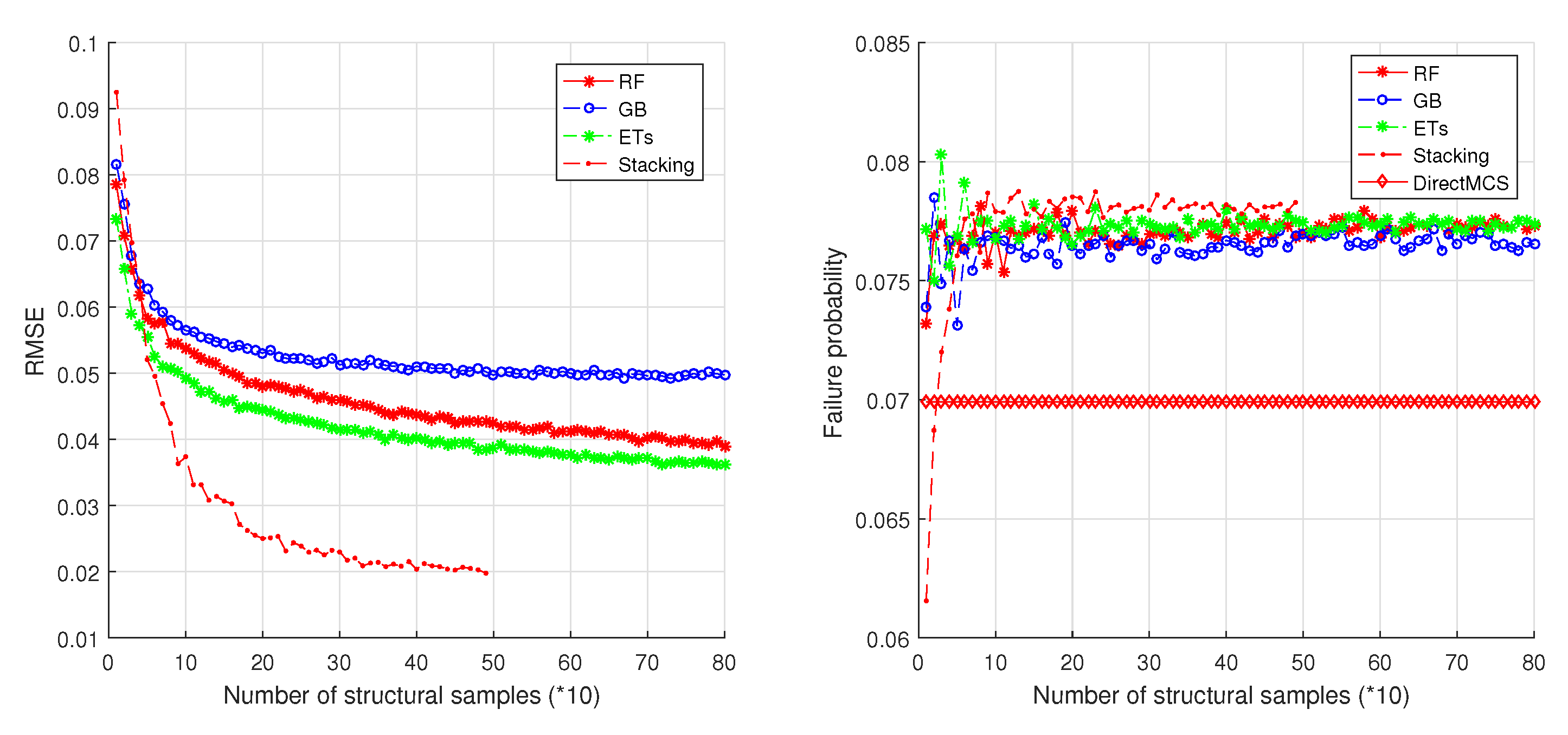
In this study, an ensemble learning based method is proposed for mechanical reliability assessment. The ensemble learning methods are treated as surrogate models that can be employed to fit the CFPs of the structure. For very small failure probabilities for which direct MCS is practically impossible to realize, an importance sampling technique is employed that constructs the importance sampling density function based on the basic failure events of the mechanical structure. Once the surrogate model is built, the predictions of CFPs can be made on new samples of the structural properties, so that the overall failure probability can be directly estimated. The representative ensemble methods RF, GB, ETs, and Stacking are considered in the proposed method. Numerical simulations are performed on a different number of DOFs structures to examine the performance of the proposed methodology. For low-dimension uncertain structures, i.e., 1-DOF, 2-DOF, and 3-DOF, the four ensemble methods are considered respectively to build the estimation models, and the results reveal that all these models achieve very high accuracies. For high-dimension uncertain structural properties, a benchmark example is introduced from the famous work of G.I. Schueller where different representative reliability methods are introduced and compared. These representative methods are further compared with the proposed method that considers different ensemble models. The simulation results show that, with a very small number of structural samples analyzed, the ensemble leaning based method obtains a significant advantage over direct MCS in terms of efficiency, meanwhile keeping a high accuracy. The comparisons with other published methods make the proposed method highly competitive.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}