1. Introduction
Mobile robots must possess a basic skill: the ability to plan and follow a path through the environment in an optimal way, while avoiding obstacles and computing its location within the map. In order to solve this problem, mobile robots require the existence of a precise map. In consequence, map building is an important task for autonomous mobile robots. This task is especially complex when no external measure of the robot location is available (e.g., no GPS signal is available). In such cases, the robot must face the situation in which it moves through an unknown space and incrementally builds a map of this environment, while simultaneously uses this map to compute its absolute location. In consequence, this problem has been designated as Simultaneous Localization and Mapping (SLAM) and has received great attention during the last decade. The SLAM problem is considered difficult, since an error in the estimation of the robot’s pose leads to an error in the map and
vice versa. In this paper we consider the case in which the map building task is carried out simultaneously by a group of mobile robots that perform different trajectories in the environment. When multiple vehicles build the map simultaneously, this task will be finished more quickly and robustly than a single one [
1], since the whole environment will be covered in less time. Also, at the same time more measurements can be obtained from the environment, thus giving the possibility to estimate a more precise map. However, in the multi-robot case, the SLAM problem becomes harder, since the trajectories of several robots need to be estimated and the dimensionality of the problem is increased.
SLAM techniques differ mainly in the kind of sensor used by the robot to obtain information from the environment. To date, typical SLAM approaches have used laser range sensors to build maps in two and three dimensions (e.g., [
2–
6]). Typically, these applications use directly the laser measurements to build 2D occupancy grid maps [
2,
5], or they extract features from the laser measurements [
4,
7] to build 2D landmark-based maps. Nevertheless, recently the interest on using cameras as sensors in SLAM has increased and researchers focus on the creation of three dimensional maps based on the measurements provided by vision sensors. These approaches are usually denoted as visual SLAM. Compared to laser ranging systems, stereo vision systems are typically less expensive. In addition, typical laser range systems allow to collect distance measurements on a 2D plane, whereas the information provided by stereo vision systems can be processed to provide a more complete 3D representation of the space. On the contrary, stereo systems are usually less precise than laser sensors. In common configurations, the camera is installed at a fixed height and orientation with respect to the robot reference system and the movement of the camera and robot is restricted to a plane [
8,
9].
The research in visual SLAM has many similarities with the rich research in the Structure from Motion (SFM) field, carried out in the computer vision community. The approach taken in SFM, however, has generally been very different from visual SLAM solutions because the applications did not require real-time operation, and the trajectory of the camera and the structure of the environment could be computed offline. Some real-time SFM systems have been produced by efficient implementation of frame-to-frame SFM steps (e.g., [
10]), in which repeatable localisation is possible and motion uncertainty does not grow without bound over time. Visual SLAM approaches typically deal with large camera trajectories and significant uncertainties in order to compute a visual map online.
Stereo vision systems provide a huge quantity of raw information from the environment stored in both images. In consequence, the images are normally processed in order to reduce the information to be used for mapping. As a result, most approaches to visual SLAM are feature-based. In this case, a set of points extracted from the images are used as visual landmarks. Features, such as image edges were used in [
11] to build maps using a single camera. However, the localization of the camera with respect to the segments is difficult. For example, in [
12] regions of interest are extracted using a visual attention system. The regions are extracted from images at different scales in a similar manner as the human perceptual system does. The main drawback with this kind of landmarks is that it may be difficult to obtain an accurate measurement of a region using a stereo camera, since regions can be arbitrarily large, thus providing inaccurate results.
In this paper we extract salient points from images and use them as visual landmarks in the environment. In a stereo system, corresponding points can be found in both images, thus obtaining a camera relative distance measurement. Mainly, two steps are distinguished in the selection of point-like visual landmarks. The first step involves the detection of interest points in the images that can be used as reliable landmarks. The points should be detected robustly at different distances and viewing angles, since they will be observed by the robot from different locations in the environment. At a second step the interest points are described by a feature vector, computed using local image information.
In the past, other authors have proposed different combinations of image detectors and descriptors in the context of mapping and localization. A summary of detection and description methods used in visual SLAM is included in Section 4. In order to compare the available methods, in a previous work [
13] we evaluated the behavior of different interest point detectors and descriptors under the conditions needed to be used as landmarks in vision-based SLAM. To do this, we evaluated the repeatability of the detectors, as well as the invariance and distinctiveness of the descriptors under different perceptual conditions using sequences of images representing planar objects as well as 3D scenes. The results presented suggested that the Harris corner detector [
14] in combination with the SURF (Speeded Up Robust Features [
15]) descriptor outperformed other existing methods in terms of stability and discriminating power. In this sense, this paper can be understood as a prolongation of [
13]. Thus, the real experiments presented here demonstrate the suitability of the selected detector and descriptor to compute 3D visual maps with a team of mobile robots in a real scenario.
In this paper we concentrate on the problem of cooperative visual SLAM and we propose a solution that allows to build a map using a set of visual observations provided by the sensors installed on every mobile robot. To date, most of the approaches to multi-robot SLAM are based on laser range sensors [
2,
16]. However, in our opinion, little effort has been done until now in the field of multi-robot visual SLAM, which considers the case where several robots are equipped with vision sensors and are distributed in a robot network with the purpose of building a visual map. In addition, the suggested application requires the extraction of stable points from images in combination with a descriptor that uniquely describes each visual landmark. For example, consider the case in which two different robots use their sensors to observe the same visual landmark from two locations in the environment. In order to construct an accurate map both observations have to be associated with the same landmark in the map and this implies that the descriptor should be invariant to scale and general viewpoint transformations. In consequence, the difficulty of this problem suggested the evaluation of the existing point extraction methods and visual descriptors in order to find the most suitable to be used in visual SLAM [
13].
As we said before, each observation obtained by the robot, has to be associated to one of the landmarks in the map. In this sense, the robot has to decide whether the observation corresponds to one of the landmarks previously integrated in the map, or, on the contrary, it is a new one. This situation is commonly referred as the data association problem, which is in close relation with the SLAM problem. We propose to use the visual description associated to the landmark along with the distance measurement obtained by the robot to solve the data association. Typically, when the robot moves along places already explored, it detects previously observed landmarks. In this case, if the current observations are correctly associated with the visual landmarks in the map, the robot will be able to find its location with respect to these landmarks, thus reducing the uncertainty in its pose. If the observations cannot be correctly associated to the landmarks in the map, the map will become inconsistent. Moreover, when several robots are exploring, the same landmark may be viewed simultaneously by the sensors of different robots from separate distances and angles. Still all the observations should be associated with the same landmark in the map. To sum up, the data association is a fundamental part of the SLAM process, since wrong data associations will produce incorrect maps and an inconsistent estimation of the paths.
Finally, it is worth noting that SLAM algorithms focus on the incremental construction of a map, given a set of movements carried out by the robots and the set of observations obtained from different locations, and they do not consider the computation of the movements that need to be performed by the robots. This is generally considered as a different problem, denoted as exploration. In this paper we concentrate on the visual SLAM problem and assume that the robots are able to explore the environment in an efficient way.
The main contribution of this paper consists in an approach that allows to solve the multi-robot SLAM problem using visual information by means of a Rao-Blackwellized particle filter (RBPF). In order to do this, we consider that each robot is equipped with a stereo camera sensor and is able to obtain 3D relative measurements to visual landmarks, each one accompanied by a descriptor. We also propose a method to solve the data association based on visual information that is well suited for the visual SLAM algorithm presented here.
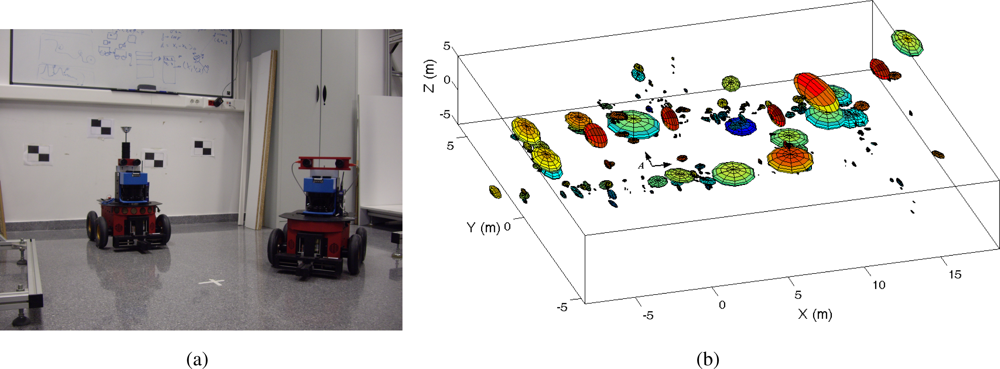
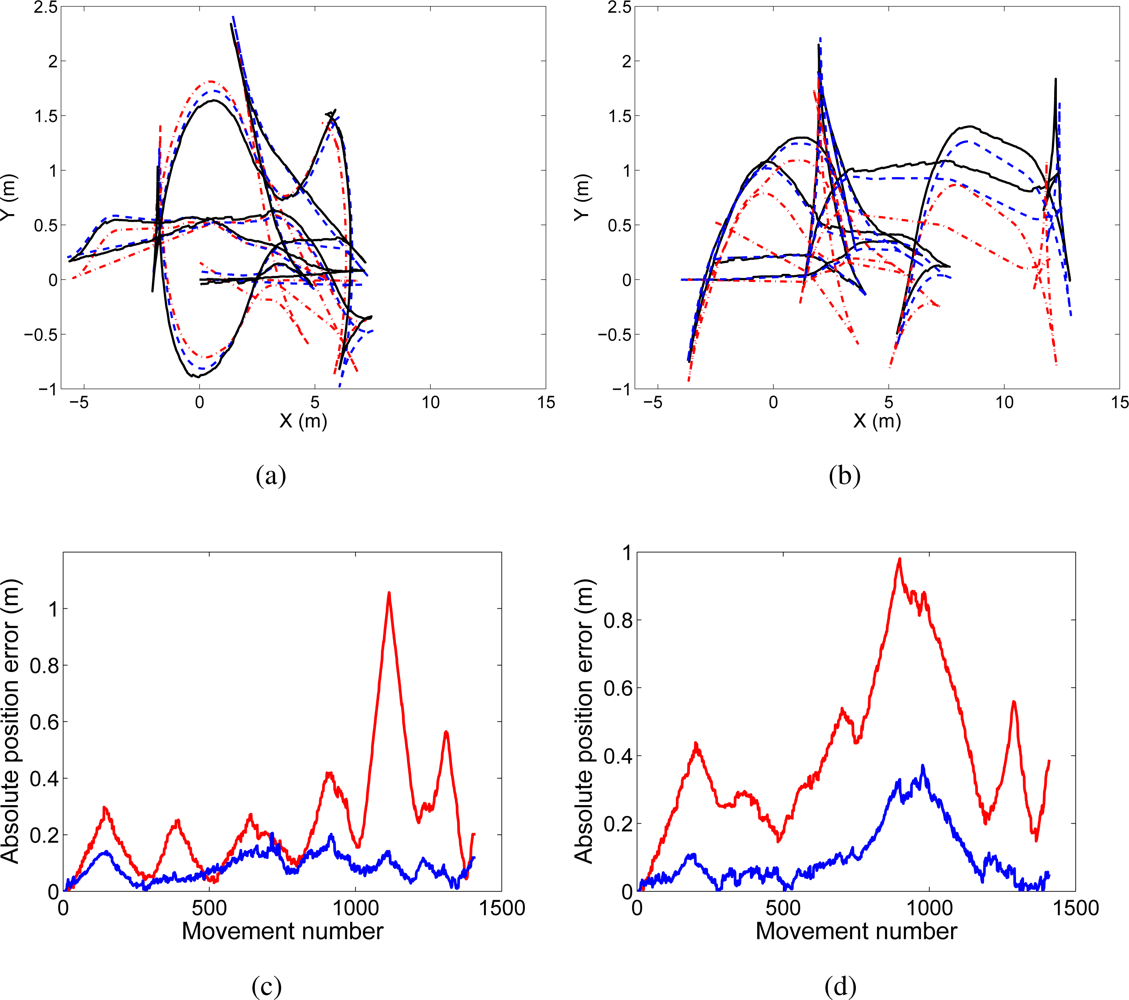
This algorithm has been validated in indoor environments using real data obtained by a network of vision sensors installed on mobile robots. In addition, the SLAM algorithm has been tested under different conditions by changing the parameters in the filter. Evaluating the results of visual SLAM using real data is complex. The true path followed by the robots is not known, and the map cannot be known precisely, since the exact location of the landmarks cannot be established in advance. In consequence, we have compared the paths estimated by the visual SLAM algorithm with the paths estimated using laser range data. In this case, the ground truth is obtained using the laser-based approach described in [
5], which has been shown to be very precise. The results demonstrate that our visual approach is suitable to build visual maps using small robot teams. In addition, the algorithm is suitable to be used in real time, that is, it can be used to build a map online while the robots explore the environment. We show results of two robots that explore the environment and simultaneously build a map of it.
The remainder of the paper is structured as follows. First, Section 2 presents related work in this field. Next, Section 3 presents the approach to multi-robot visual SLAM. Following, Section 4 introduces visual landmarks and deals with their utility in SLAM. Our approach to the data association problem in the context of visual features will be exposed in Section 5. Then, in Section 6 we present the experimental results obtained. Finally, Section 7 summarizes the most important conclusions.
3. 3D Visual SLAM for a Team of Mobile Robots
In this section, the approach to multi-robot 3D visual SLAM is described. We consider the case in which a team of mobile robots explore the environment, and simultaneously build a map using visual information obtained from cameras.
The complexity of the SLAM problem stems from the fact that the estimation of the map robot poses are in close relation. As a result, if we make an error in the estimation of the pose, this induces an error in the estimation of the map and viceversa. On the other hand, the problem is made harder when more robots take part in the exploration, since the number of observations increases, as well as the dimensions of the state to estimate.
In the solution presented here we propose the use of a Rao-Blackwellized particle filter (RBPF), commonly referred as FastSLAM in the literature [
4]. In our case, a Rao-Blackwellized particle filter represents the robot trajectories by means of a set of particles, combined with a closed estimation of the map conditioned to the trajectories.
We assume that every robot in the team has a stereo camera installed onboard, enabling them to compute the relative distance from the robot to visual landmarks found in the surroundings. In addition, each relative distance measurement is associated with a visual descriptor, computed using local information of the detected point in the images. In order to build the map, we also consider that the robots can exchange their information with a central agent in the system, sharing their observations performed over the landmarks to create a common map of the environment. We assume that, at the beginning of the exploration, the relative position of the robots is known.
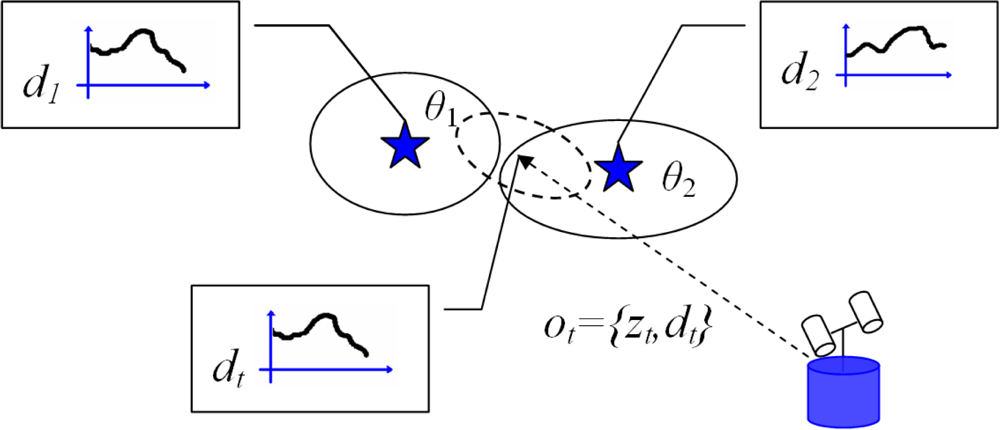
Next, we explain the algorithm for the case where a single robot explores the environment and constructs a map with the 3D position of the observed landmarks. At time t the robot obtains an observation ot. The observation consists of two parts, ot = (zt, dt), where zt = (Xc, Yc, Zc) is a three dimensional distance vector relative to the left camera reference frame and dt is the visual descriptor associated to the landmark. The map L is represented by a collection of N landmarks L = {l1, l2, ..., lN }. Each landmark is described as: lk = {μk, ∑k, dk}, where μk = (Xk, Yk, Zk) is the mean vector that describes the 3D position of the landmark k in coordinates of a global reference frame. The mean vector is associated with the covariance matrix ∑k that describes the uncertainty in the position of the landmark. Also, the landmark lk is associated with a descriptor dk that was computed using the visual appearance of the point in the space.
Next, we define the most usual nomenclature in Rao-Blackwellized SLAM. We denote the robot pose at time
t as
xt and the movement of the robot at time
t as
ut. On the other hand, the robot path until
t is referred as
x1:t = {
x1,
x2, . . . ,
xt}, the set of observations made by the robot until time
t will be designated
z1:t = {
z1,
z2, . . . ,
zt} and the set of actions
u1:t = {
u1,
u2, . . . ,
ut}. The SLAM problem tries to determine the location of every landmark in the map
L and robot path
x1:t using a set of sensor measurements
z1:t and considering that the robot performed the movements
u1:t. Thus, the SLAM problem attempts to estimate the following probability function defined over the map and path:
where
c1:t designates the set of data associations performed until time
t,
c1:t = {
c1,
c2, . . . ,
ct}. The data association is represented with the variable
ct and can be explained in the following manner: while the robot explores the map, it has to decide whether the observation
ot = (
zt,
dt) corresponds to a landmark observed before or it is a new one. Considering that, at time
t, the map is formed by
N landmarks, this correspondence is represented by
ct, where
ct ∈ [1
. . . N]. The notation
zt,ct means that the measurement
zt corresponds to the landmark
ct in the map. If none of the landmarks in the map until the moment correspond to the current measurement, we indicate it as
ct =
N + 1, since a new landmark is added to the map. For the moment, we consider this correspondence as known. In Section 5 we present an algorithm to compute the data association using the data provided by the vision sensors.
We can find two different parts in the problem of SLAM: (i) the estimation of the trajectory of the robot. (ii) The estimation of the map. Both parts are closely related, since, the absolute position of a landmark in the map depends on the estimation of the location of the robot. Nevertheless, we can separate the two parts. For example, imagine that we could know the whole trajectory followed by the robot. In that case, it may be easy to build the map using the sensor measurements. We refer to this fact as the conditional independence property of SLAM problem. According to this property, the probability function defined in (1) can be written in the following manner [
4]:
that implies that the probability over the path
x1:t and the map
L, given the observations
z1:t, movements
u1:t and data associations
c1:t can be separated into two parts: the estimation of the probability over robot paths
p(
x1:t|z1:t,
u1:t,
c1:t), and the product of
N independent estimators
p(
lk|x1:t,
z1:t,
u1:t,
c1:t) over landmark positions, each conditioned to the path estimate . The first part
p(
x1:t|z1:t,
u1:t,
c1:t) is approximated using a set of
M particles. Each particle stores
N independent landmark estimations implemented as EKFs. Thus, we define each particle as:
where
represents the mean value for the position of landmark
lk conditioned to the path of the particle
m and the observations until time
t. On the other hand,
refers to the covariance matrix associated to the uncertainty in the position. Finally,
represents the visual descriptor associated to the landmark
j. When a landmark is first sensed and initialized in the map a visual descriptor is computed in base of the image information nearby the projected point.
Whenever the robot moves, a new particle set
is computed using the prior particle set
St−1 at time
t−1 and the robot control
ut. This, process represents the increase in uncertainty when the robot carries out a movement using the probability function
p(
xt|xt−1,
ut). The estimation process follows a prediction and update fashion, as described in [
22]. Each particle is assigned a weight that accounts for the probability of the estimated map and path.
Next, we present the algorithm that allows us to build a feature-based map while a team of K robots explores the environment equipped with vision sensors. We show the algorithm to estimate the map formed by the position of all the visual landmarks detected, as well as the trajectories followed by the robots during the exploration. In order to do so, we assume that, at time t the robot 〈i〉 is located at pose xt,〈i〉 and uses its vision sensor to obtain the observation ot,〈i〉 = {zt,〈i〉, dt,〈i〉}, where, again zt,〈i〉 is a relative measurement distance from the location of the robot to the observed landmark. Also, dt,〈i〉 denotes the visual descriptor associated with the landmark. The trajectory that the robot 〈i〉 followed until time t will be referred as x1:t,〈i〉 = {x1,〈i〉, x2,〈i〉, . . . , xt,〈i〉}.
Next, we need to represent the trajectories of all the robots in the team. In consequence, x1:t,〈1:K〉 = {x1:t,〈1〉, x1:t,〈2〉, . . . , x1:t,〈K〉} will represent all the trajectories of the robots until time t. In addition, u1:t,〈1:K〉 = {u1:t,〈1〉, u1:t,〈2〉, . . . , u1:t,〈K〉} denotes the movements performed by the robots and the observations will be referred as z1:t,〈1:K〉 = {z1:t,〈1〉, z1:t,〈2〉, . . . , z1:t,〈K〉}. In a similar way to the case where a single robot explores the environment, we express the data association with the variable ct, which indicates that the observation zt,〈i〉 was produced when the robot observed the landmark ct of the map. It is important to highlight that we propose to estimate a single map common to all the robots, thus each observation will have a correspondence to a landmark in the map with independence of the robot that observed it. At each time step, the robot obtains an observation and computes the data association. We refer to the set of data associations until time t as c1:t = {c1, c2, . . . , ct}.
Using the previous notation, we can define the multi-robot SLAM problem as that of estimating the probability density function:
that poses the estimation of a set of
K trajectories
x1:t,〈1:K〉 and the map
L, considering that the robots have performed a number of movements
u1:t,〈1:K〉 and observations
z1:t,〈1:K〉 with data association
c1:t in the map.
Equation (4) is analogous to
Equation (2) and indicates that the estimation of the map and the
K trajectories can be separated into two parts: the first function
p(
x1:t,〈1:K〉|z1:t,〈1:K〉,
u1:t,〈1:K〉,
c1:t) suggests the estimation of the robot trajectories, conditioned to all the measurements, movements and data associations, whereas the map is estimated using
N independent estimations conditioned to the paths
x1:t,〈1:K〉. In consequence,
Equation (4) divides the SLAM problem in two different parts: the localization of
K robots in the map and a number of independent landmark estimations, each one conditioned to the trajectories
x1:t,〈1:K〉 of all the robots. The estimation of both parts is carried out by means of a particle filter. Each of the
M particles is associated with a map
L, formed by
N independent estimations for each of the landmarks. The computation of each landmark position is implemented by means of an Extended Kalman Filter (EKF). In our case, each of the Kalman Filters will be conditioned to the
K paths of the robot team. Each particle in the filter is represented as:
If we compare this definition with the particle defined in (3), we may observe that, in this case, the state to estimate is formed with the pose (x, y,
θ) of each of the
K robots in the team, being (x, y) the position of the robot in cartesian coordinates and
θ the orientation of the robot. We denote the set of robot poses of the whole team as
xt,〈1:K〉 = {
xt,〈1〉,
xt,〈2〉, ⋯,
xt,〈K〉}. To sum up, the algorithm proposes the estimation of a path state of dimension 3
K using jointly the information provided by all the sensors in the robot network. In order to clarify,
Table 1 presents the structure of the particle defined in (5).
In the algorithm proposed here, a common map is shared by all the robots. This fact means that, when a robot changes the estimation of a landmark using its sensor measurement, this change affects the map of the whole robot team. The main advantage of this solution is that one member of the team may sense a landmark previously seen by a different robot and update its estimate, thus fusing the measurements obtained by both robot sensors. Also, another advantage is that a robot can reduce the uncertainty in its pose by observing landmarks previously mapped by other robots. As a consequence, the robots fuse all the information provided by its sensors in the estimation of the map and all the observations of every robot are used in the estimation of the map and paths.
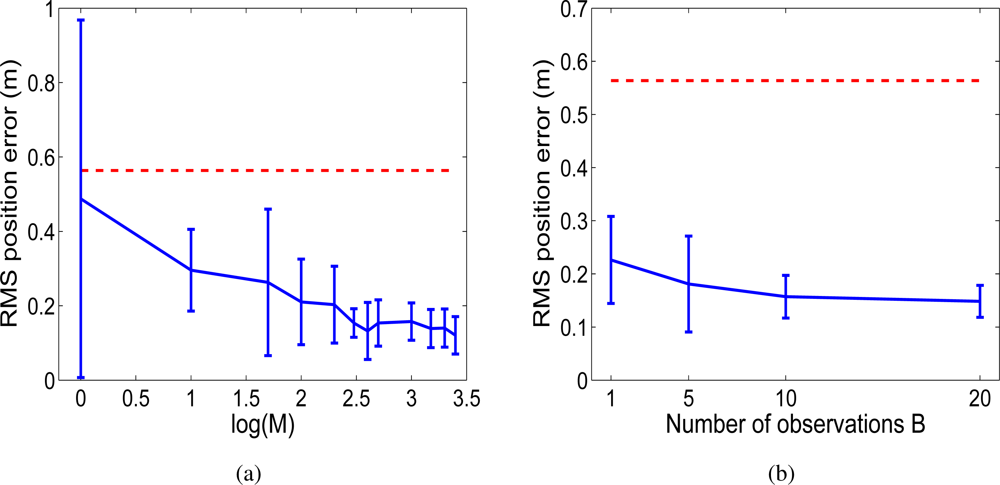
In principle, in order to obtain a good estimation, the number of particles required increases exponentially with the dimension of the state [
23]. Nevertheless, we present here results that show that the approach is suitable for robot teams of 2–3 members using a reasonable number of particles.
Next, we summarize the proposed algorithm. In order to clarify the ideas, the algorithm is separated in four different steps:
New particles generation (Section 3.1).
Updating each landmark with new sensor measurements (Section 3.2).
Compute a weight for each particle (Section 3.3).
Resampling based on the weight (Section 3.4).
We provide a detailed explanation of each step in the following subsections. In addition, in
Algorithm 1 we describe the complete process, assuming that there exist three robots that explore simultaneously the environment.
3.1. New Particles Generation
In the beginning of the exploration, we assume that each robot knows its location with precision. Next, the robot moves and uses its odometry to estimate the new location in the map. Since the odometry is noisy, the robot is no longer certain of its position, thus the uncertainty over its pose has to be reproduced. In the proposed algorithm the particle set St represents the possible locations of the robot in the environment. When the robot moves, the uncertainty grows, and this fact is translated in a wider spread of the particles associated to each robot. In order to do this, we generate a new set of hypotheses St based on the previous set St−1 by adding some noise according to a probabilistic motion model p(xt|xt−1, ut). We compute a new pose
for each one of the robots independently using the motion model, by applying the movement model to each of the K poses of the particle separately using ut,〈i〉, the movement performed by the robot 〈i〉.
3.2. Updating Each Landmark with New Sensor Measurements
We update the 3D position of each landmark using the pose of the robot 〈i〉 that used its sensor to obtain the observation ot,〈i〉 = {zt,〈i〉, dt,〈i〉}. For the moment we assume that this measurement belongs to the landmark ct. Later, in Section 5 we deal with this problem in more detail.
The computation of a new estimation for each landmark
lk is performed independently, using the standard EKF equations:
being
ẑt,〈i〉 the prediction for the current sensor measurement
zt,〈i〉 that assumes that it has been associated with the landmark
ct in the map. The observation model
g(
xt,
lct) is linearly approximated by the Jacobian matrix
Glct, considering that the noise in the sensor is Gaussian and can be represented with the covariance matrix
Rt. Next,
Equation (10) updates the prior estimate
of the landmark using the difference between the current and predicted observation
v = (
zt,〈i〉 − ẑt,〈i〉). Following,
Equation (11) represents the updated covariance matrix
, that defines the uncertainty in the landmark
ct associated to the particle
m. In this case the covariance matrix is of dimensions 3
× 3, since
is a three dimensional vector representing the 3D position of the landmark
ct.
Following, we define the matrix
Rt associated with the noise in the sensor. In our case, we consider the equations of a standard stereo pair of cameras, assuming pin-hole cameras and parallel optical axes of both cameras. In a standard stereo pair of cameras, we can compute the 3D coordinates of a point in space relative to the left camera reference system as:
where, (
r,
c) are the coordinates in pixels (row and column) of the 3D point projected in the left image. The 3D point projects in the pixel (
r,
c +
d) in the right image. The variable
d denotes the disparity associated to that point. The parameter
I is named baseline, and corresponds to the horizontal separation of both cameras and the parameters
Cx and
Cy refer to the intersection of the optical axis with the image plane in both cameras. Also, the parameter
f is the focal distance of the cameras. Given that we assume an error in the estimation of the projected points (
r,
c), we can compute the propagation of this error to the relative measurement (
Xr,
Yr,
Zr), assuming a first order linear error propagation law. In consequence, the covariance matrix
Rt associated to
zt,〈i〉 = (
Xr,
Yr,
Zr) can be computed as:
Rt =
JRspJT, where
J = ▿
r,c,d zt,〈i,i〉 is the Jacobian matrix and
Rsp is the error matrix associated with the errors in the computation of
d,
r and
c. We assume typical errors in cameras that take into account the uncertainty in the camera calibration parameters:
σd = 1 pixel,
σr = σc = 10 pixel. Thus
. This model has been previously used in a visual SLAM context in [
24].
3.3. Compute a Weight for Each Particle
As described in [
22], we assign a weight to each particle based on the quality of the matching between the current observation. Then, the sampling process generates a new set of particles
St by choosing particles from the set
St−1. In the case of
K robots, and considering that each one obtains a single measurement from its sensor
zt,〈i〉 with data association
ct, the weight
associated with the particle
m and the robot 〈
i〉 is computed as:
Since, as defined in
Equation (5), each particle
represents the trajectories of
K robots, we compute
K weights
ωt,〈i〉={
ωt,〈1〉 ⋯
ωt,〈K〉}. In order to estimate the joint probability over the robot paths, the total weight associated to the particle
is calculated by the product of the prior
K weights:
. Finally, the weights are normalized to approximate a probability density function, so that
.
3.4. Resampling Based on the Weight
During the resampling process, a particle from the set St−1 will be included in the set St or not with probability proportional to its weight
. If the weight assigned to the particle is high, the particle will be included in St with high probability. Often, particles with low weight are discarded and are not integrated in St. After resampling, the resulting particle set St is distributed according to p(x1:t,〈1:K〉, L|z1:t,〈1:K〉, u1:t,〈1:K〉, c1:t,〈1:K〉).
3.5. Path and Map Estimation
As described so far, the SLAM filter stores a set of particles that represent a set of hypothesis over the possible trajectories of every robot in the team. A number of 3D landmark positions is associated to each particle, being each landmark represented with an extended Kalman Filter. Since different trajectories and maps exist in the particle set, we need to choose the path and the map that best represent the true trajectories and map. In order to do this, we choose the most probable particle as the one that maximizes the sum:
being
A the total number of steps performed by the robot along the path.
4. Visual Landmarks
In our case, our vision sensor provides the robot with a huge amount of information, generally encoded in the gray-level images. This quantity of information has to be reduced in order to accelerate the map building process. A common approach considers the use of visual landmarks. Thus, the construction of the map considers the estimation of the position of all the visual landmarks detected by the robots. A visual landmark can be defined as a point in space that can be easily detected using images obtained by the camera at different distances and viewing angles. We focus on natural visual landmarks, that is: any point that exists in the environment that can be extracted from images by means of a detection algorithm.
Algorithm 1.
Summary of the algorithm.
Algorithm 1.
Summary of the algorithm.
| 1: S = ∅ |
| 2: [Imaget,〈1〉, Imaget,〈2〉, Imaget,〈3〉] = AcquireImages () |
| 3: [ot,〈1〉, ot,〈2〉, ot,〈3〉] = ObtainObservations(Imaget,〈1〉, Imaget,〈2〉, Imaget,〈3〉) |
| 4: InitialiseMap(S, x0,〈1:3〉, ot,〈1:3〉) |
| 5: for t = 1 to numMovements do |
| 6: [Imaget,〈1〉, Imaget,〈2〉, Imaget,〈3〉] = AcquireImages () |
| 7: [ot,〈1〉, ot,〈2〉, ot,〈3〉] = ObtainObservations(Imaget,〈1〉, Imaget,〈2〉, Imaget,〈3〉) |
| 8: [S, ωt,〈1〉] = MRSLAM(S, ot,〈1〉, Rt, ut,〈1〉) |
| 9: [S, ωt,〈2〉] = MRSLAM(S, ot,〈2〉, Rt, ut,〈2〉) |
| 10: [S, ωt,〈3〉] = MRSLAM(S, ot,〈3〉, Rt, ut,〈3〉) |
| 11: ωt = ωt,〈1〉ωt,〈2〉ωt,〈3〉 |
| 12: [Neff] = ComputeNeff(ωt) |
| 13: if Neff < 0.5 // resample when the number of effective particles is low? then |
| 14: S = ImportanceResampling(S, ωt) // Sample randomly from S |
| 15: end if |
| 16: end for |
| function [St] = MRSLAM(St−1, ot,〈i〉, Rt, ut,〈i〉) |
| 17: St = ∅ |
| 18: for m = 1 to M {repeat for every particle} do |
| 19:
// generate a new particle using the movement model p(xt,〈i〉|xt−1,〈i〉, ut,〈i〉) |
| 20: for // find data associations do |
| 21:
|
| 22:
|
| 23:
|
| 24: D(n) = (zt,〈i〉 − ẑt,〈i〉)T [Zn,t]−1(zt,〈i〉 − ẑt,〈i〉) |
| 25: E(n) = (dt,〈i〉 − dn)T (dt,〈i〉 − dn) |
| 26: end for |
| 27:
|
| 28: j = find(D ≤ D0) {Find candidates below D0} |
| 29: ct = argminj E(j) {Find minimum among candidates} |
| 30: if E(ct) > E0 // Is this a new landmark? then |
| 31:
|
| 32: end if |
| 33: if / / New landmark then |
| 34:
|
| 35:
|
| 36:
|
| 37:
|
| 38: else |
| 39:
|
| 40:
|
| 41:
|
| 42:
|
| 43: end if |
| 44:
|
| 45: add
to St |
| 46: end for |
| 47: return St |
Two main processes can be found in the observation of a visual landmark: the detection phase and the description phase. The detection considers the extraction of a set of points from images of the environment. In the case of visual landmarks, we aim at detecting some points in the images that are highly salient, and can be easily detected at different distances and viewing angles. The description of the landmark aims at representing the landmark based on its visual appearance. The descriptor enables the robot to recognize a particular landmark in the map, thus, it is in close relation with the data association problem. The description of the visual landmarks is based on a sub-image centered at the detected point.
In the context of mapping and localization different combinations of detectors and descriptors have been used. For example, in the context of monocular SLAM, in [
25] the Harris corner detector was used to find salient points in images and describe them using a window patch centered at the detected points. In [
26] the SIFT transform was presented, which combines an interest point detector and a description method, initially applied to object recognition applications [
27]. Later, in [
24] SIFT features were used as visual landmarks in the 3D space in a map building applications. In [
8] the detected SIFT points were tracked to keep the most robust ones. Other authors [
28] used a rotationally variant version of SIFT in combination with a Harris-Laplace detector for monocular SLAM. The SIFT transform has been used widely, for example [
29] presents the applications of the SIFT transform to photogrammetric applications, where the extracted points are used to match aerial images.
Recently, the SURF features were presented [
15], which also proposes an interest point detector in combination with a descriptor. Lately, in [
30] the SURF features were used in localization tasks using omnidirectional images.
In the context of matching and recognition, many authors have presented their works evaluating several interest point detectors and descriptors. For example, in [
31] a collection of detectors is evaluated by measuring the quality of these features for tasks like image matching, object recognition and 3D reconstruction. However, the mentioned work does not consider the interest point detectors that are most frequently used nowadays in visual SLAM.
Several comparative studies of local region detectors and descriptors have been presented so far. For instance, [
32] present a comparison of several local affine region detectors. On the other hand, in [
33] different detectors are used to extract affine invariant regions, but they focus on the comparison of different description methods. A set of local descriptors are evaluated using a criterion based on the number of correct and false matches between pairs of images. All these previous approaches perform the evaluation of detection and description methods using pairs of images and analyze different imaging conditions.
The case of visual SLAM is particularly difficult, since some point extractors fail at detecting the same point when viewed from different distances or angles. In consequence, it is difficult to detect again previously mapped landmarks, for example, when the robot observes the scene from a different pose. Moreover, the description of the points must be invariant to changes in viewing distance (scale) and viewing angle. In the case of visual landmarks it is difficult to compute a visual description that is totally invariant, since the appearance of a point in space varies largely with viewpoint changes. In consequence, the data association problem becomes hard to solve. For this reason, in a prior work [
13], a comparison of point detectors and descriptors was carried out. The study focuses on the comparison of different interest points detectors and descriptors under the conditions needed to be used as landmarks in vision-based SLAM. The repeatability of different interest point detectors, as well as the invariance and distinctiveness of several description methods is evaluated. The evaluation is made in conditions similar to the case of visual SLAM. In order to do this, sequences of images representing planar objects as well as 3D scenes were used. It is worth noting that in this study the Harris corner detector obtained the best results for the kind of indoor images used. Moreover, the U-SURF descriptor showed good properties to be used as a descriptor for visual SLAM. The U-SURF descriptor is a particular version of the SURF descriptor. In consequence, this fact justifies the combination of descriptor and detector used in the experiments presented here.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






