Comparison between Random Forests, Artificial Neural Networks and Gradient Boosted Machines Methods of On-Line Vis-NIR Spectroscopy Measurements of Soil Total Nitrogen and Total Carbon


Abstract
:1. Introduction
2. Materials and Methods
2.1. Experimental Sites
2.2. On-Line Soil Measurement and Collection of Soil Samples
2.3. Laboratory Chemical and Optical Measurements
2.4. Spectra Pretreatment
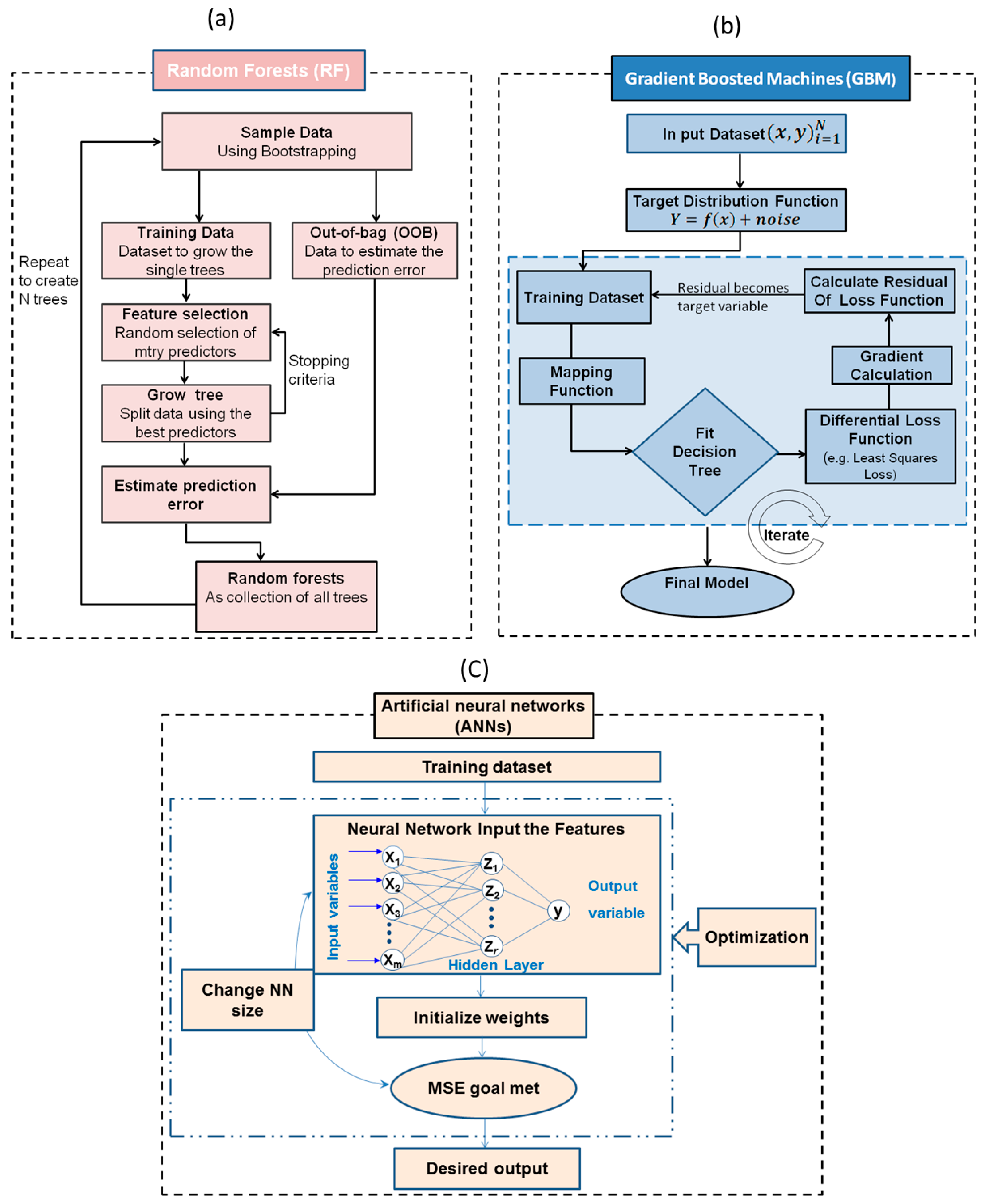
2.5. Dataset Set Selection and Modelling Techniques
- Local dataset: where samples collected from two fields (Hessleskew, n = 122; Hagg, n = 149),
- European dataset (n = 528), where a total of 528 samples collected from five European countries, namely, Germany (150 samples from two fields), Denmark (147 samples from five fields), the Netherlands (43 samples from one field), Czech Republic (99 samples from four fields), and the UK (89 samples from four fields) were collected.
2.5.1. Random Forests Regression
- (1)
- Sample the calibration set with replacement to generate bootstrap resamples
- (2)
- For each resample , grow a regression tree .
- (3)
- For predicting the test case with covariate , the predicted value by the whole RF is obtained by combining the results given by individual trees. Let denote the prediction of by mth tree, the RF prediction for regression problems can then be written [33] as:
2.5.2. Gradient Boosted Machines (GBM)
- (a)
- For computeThe components of the negative gradient are referred to the generalized residuals of the current model on the th observation evaluated at f = fm−1.
- (b)
- Fit a regression tree to the targets giving terminal regions
- (c)
- For
2.5.3. Artificial Neural Networks (ANNs)
2.6. Evaluation of Model Accuracy
3. Results
3.1. Laboratory Measured Soil Properties
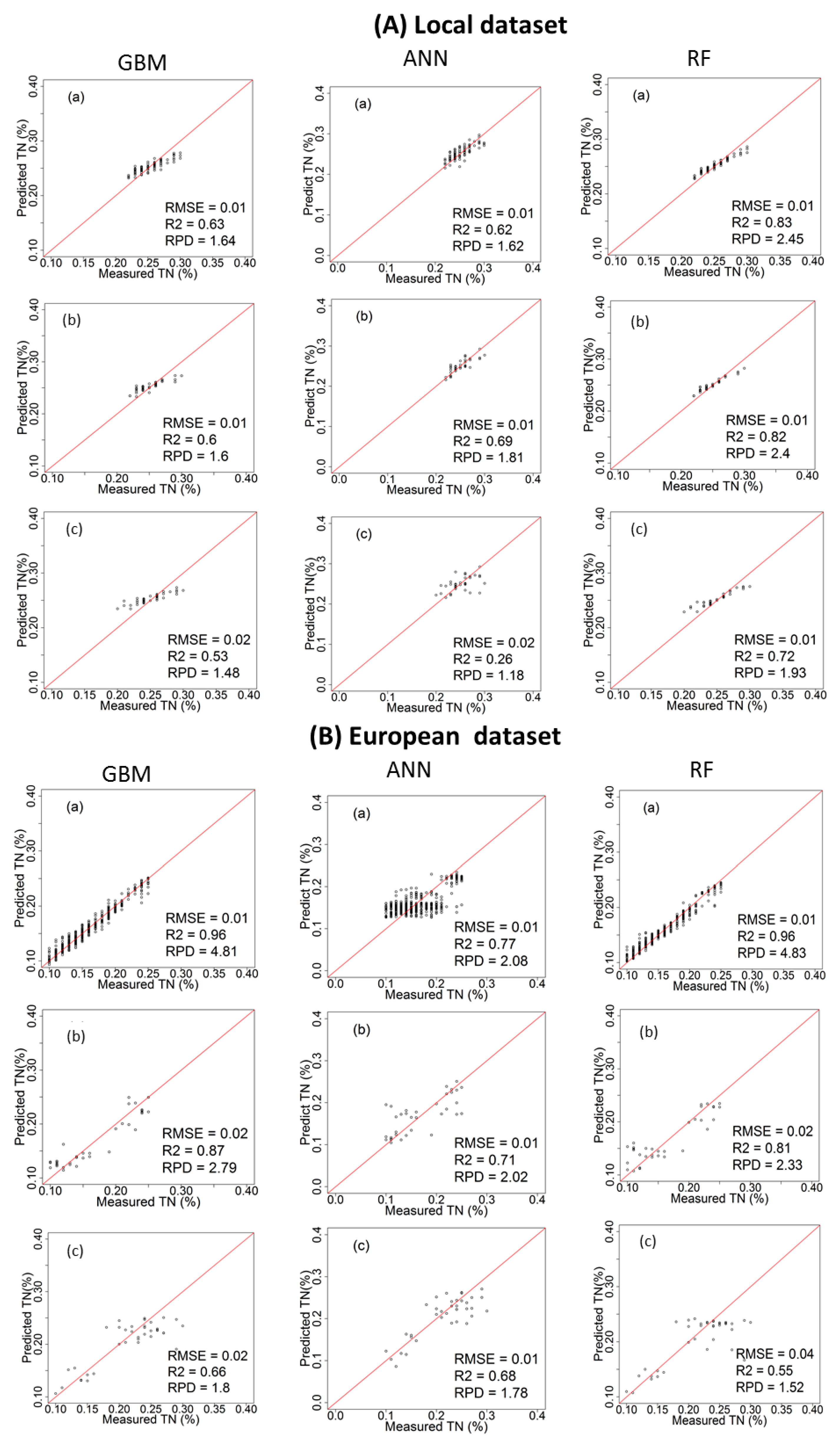
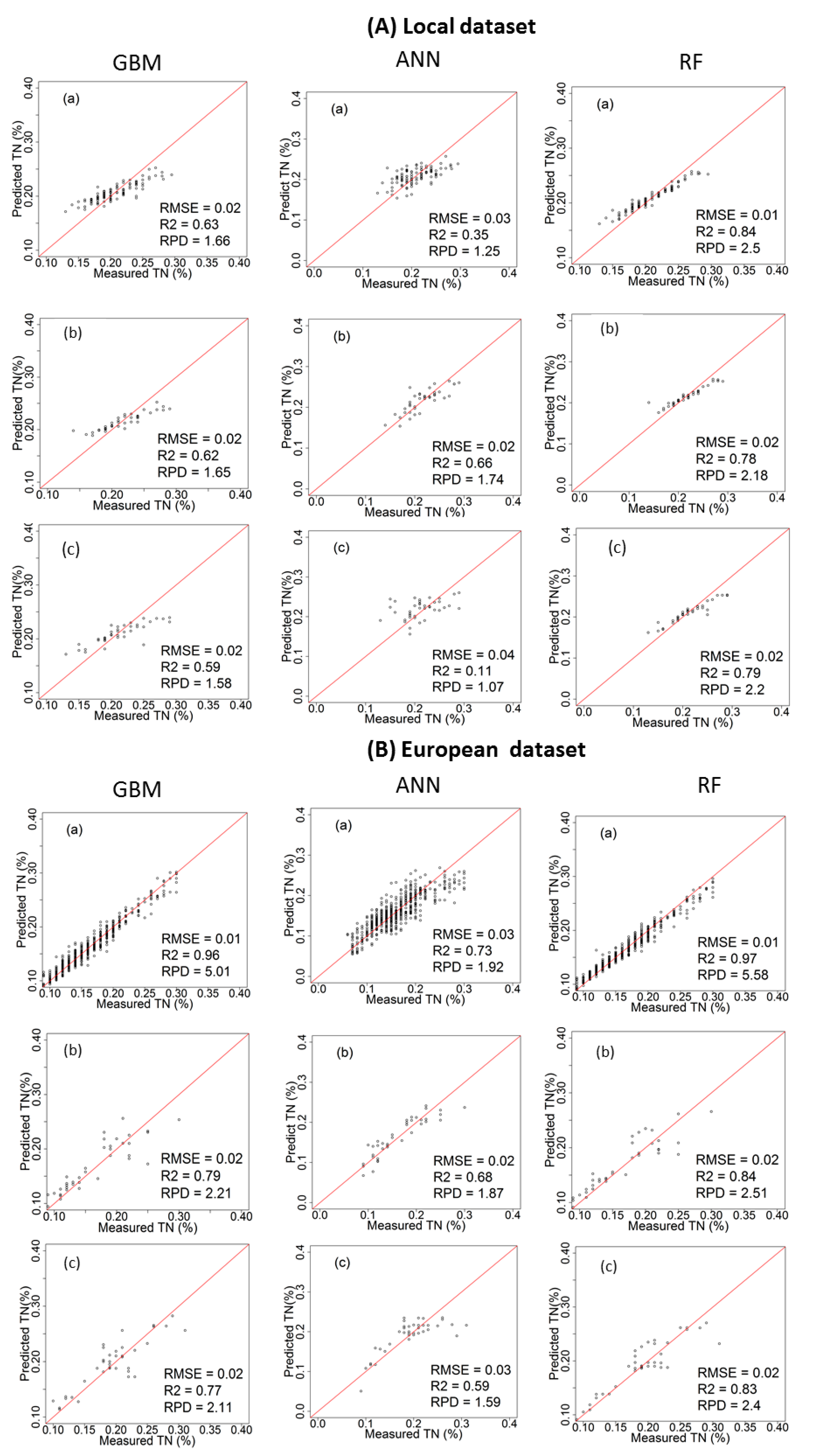
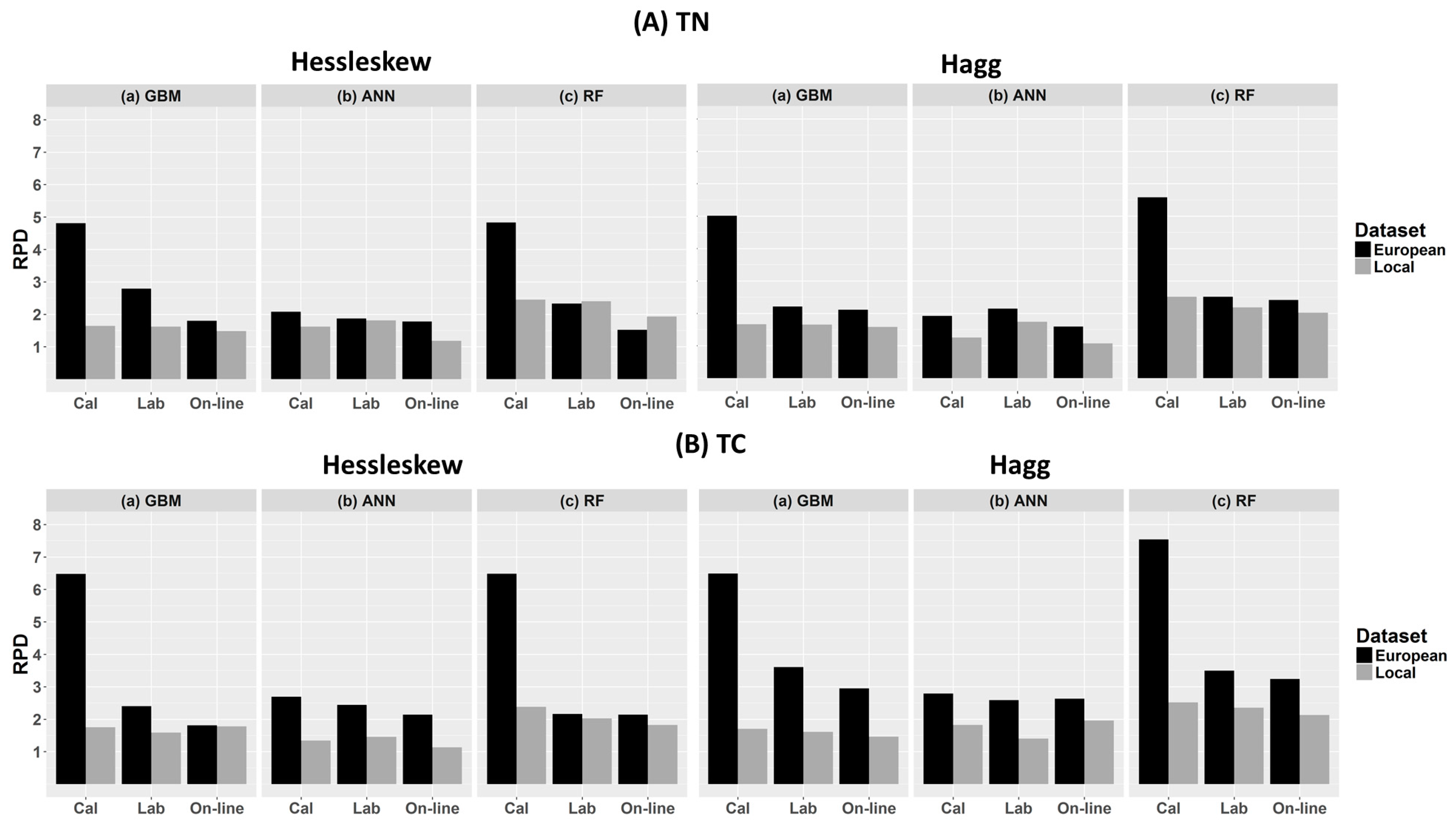
3.2. Performance of the Calibration Models for Predicting TN
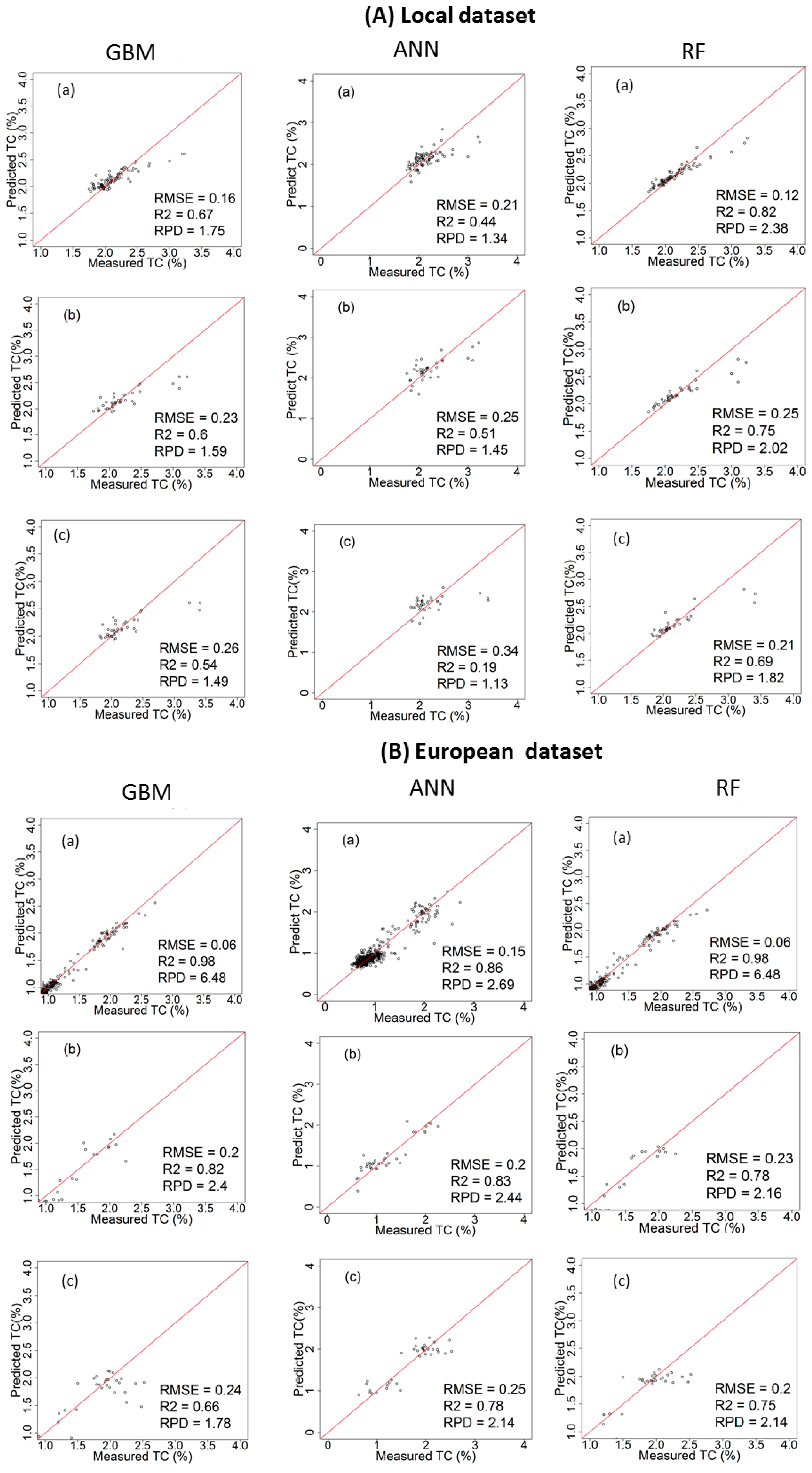
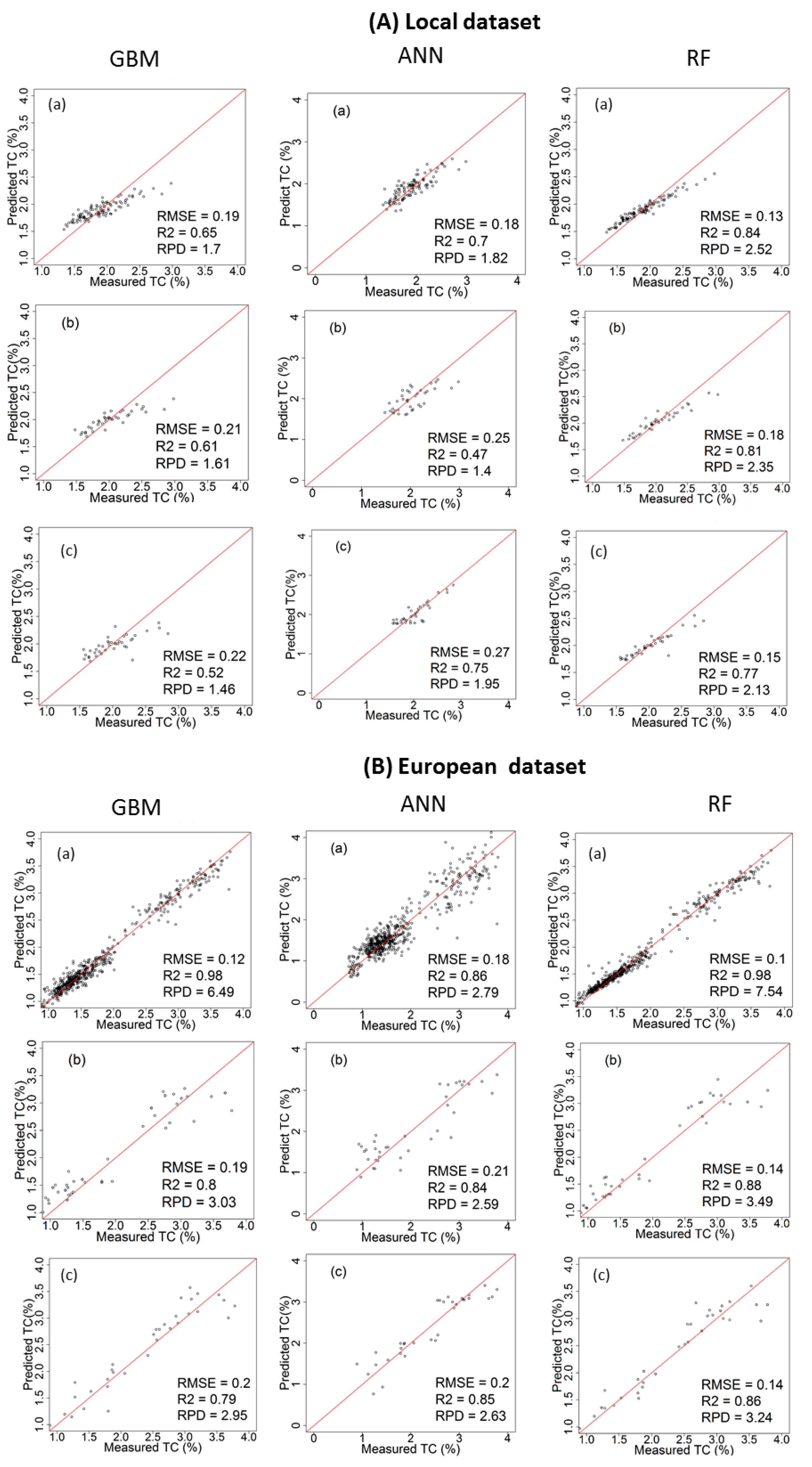
3.3. Performance of the Calibration Models for Predicting TC
4. Discussion
4.1. Comparison of Model Performance
4.2. Influence of Dataset on Models’ Performance
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Kucharik, C.J.; Brye, K.R.; Norman, J.M.; Foley, J.A.; Gower, S.T.; Bundy, L.G. Measurements and Modeling of Carbon and Nitrogen Cycling in Agroecosystems of Southern Wisconsin: Potential for SOC Sequestration during the Next 50 Years. Ecosystems 2001, 4, 237–258. [Google Scholar] [CrossRef]
- Muñoz, J.D.; Kravchenko, A. Soil carbon mapping using on-the-go near infrared spectroscopy, topography and aerial photographs. Geoderma 2011, 166, 102–110. [Google Scholar] [CrossRef]
- McDowell, M.L.; Bruland, G.L.; Deenik, J.L.; Grunwald, S.; Knox, N.M. Soil total carbon analysis in Hawaiian soils with visible, near-infrared and mid-infrared diffuse reflectance spectroscopy. Geoderma 2012, 189, 312–320. [Google Scholar] [CrossRef]
- Wang, D.; Chakraborty, S.; Weindorf, D.C.; Li, B.; Sharma, A.; Paul, S.; Ali, M.N. Synthesized use of VisNIR DRS and PXRF for soil characterization: Total carbon and total nitrogen. Geoderma 2015, 243–244, 157–167. [Google Scholar] [CrossRef]
- Nawar, S.; Mouazen, A.M. Predictive performance of mobile vis-near infrared spectroscopy for key soil properties at different geographical scales by using spiking and data mining techniques. Catena 2017, 151, 118–129. [Google Scholar] [CrossRef]
- Kuang, B.; Mouazen, A.M. Calibration of visible and near infrared spectroscopy for soil analysis at the field scale on three European farms. Eur. J. Soil Sci. 2011, 62, 629–636. [Google Scholar] [CrossRef]
- Martens, H.; Naes, T. Multivariate Calibration; Wiley: Hoboken, NJ, USA, 1991; ISBN 0471930474. [Google Scholar]
- Morellos, A.; Pantazi, X.-E.; Moshou, D.; Alexandridis, T.; Whetton, R.; Tziotzios, G.; Wiebensohn, J.; Bill, R.; Mouazen, A.M. Machine learning based prediction of soil total nitrogen, organic carbon and moisture content by using VIS-NIR spectroscopy. Biosyst. Eng. 2016, 152, 1–13. [Google Scholar] [CrossRef]
- Nawar, S.; Buddenbaum, H.; Hill, J.; Kozak, J.; Mouazen, A.M. Estimating the soil clay content and organic matter by means of different calibration methods of vis-NIR diffuse reflectance spectroscopy. Soil Tillage Res. 2016, 155, 510–522. [Google Scholar] [CrossRef]
- Mouazen, A.M.; Kuang, B.; De Baerdemaeker, J.; Ramon, H. Comparison among principal component, partial least squares and back propagation neural network analyses for accuracy of measurement of selected soil properties with visible and near infrared spectroscopy. Geoderma 2010, 158, 23–31. [Google Scholar] [CrossRef]
- Kuang, B.; Tekin, Y.; Mouazen, A.M. Comparison between artificial neural network and partial least squares for on-line visible and near infrared spectroscopy measurement of soil organic carbon, pH and clay content. Soil Tillage Res. 2015, 146, 243–252. [Google Scholar] [CrossRef]
- Brown, D.J.; Shepherd, K.D.; Walsh, M.G.; Dewayne Mays, M.; Reinsch, T.G. Global soil characterization with VNIR diffuse reflectance spectroscopy. Geoderma 2006, 132, 273–290. [Google Scholar] [CrossRef]
- Shepherd, K.D.; Walsh, M.G. Development of Reflectance Spectral Libraries for Characterization of Soil Properties. Soil Sci. Soc. Am. J. 2002, 66, 988–998. [Google Scholar] [CrossRef]
- Rossel Viscarra, R.A.; Behrens, T. Using data mining to model and interpret soil diffuse reflectance spectra. Geoderma 2010, 158, 46–54. [Google Scholar] [CrossRef]
- Sorenson, P.T.; Small, C.; Tappert, M.C.; Quideau, S.A.; Drozdowski, B.; Underwood, A.; Janz, A. Monitoring organic carbon, total nitrogen, and pH for reclaimed soils using field reflectance spectroscopy. Can. J. Soil Sci. 2017, 97, 241–248. [Google Scholar] [CrossRef]
- Marini, F. Neural Networks. In Comprehensive Chemometrics; Elsevier: Amsterdam, The Netherlands, 2010; Volume 3, pp. 477–505. [Google Scholar]
- Long, J.R.; Gregoriou, V.G.; Gemperline, P.J. Spectroscopic calibration and quantitation using artificial neural networks. Anal. Chem. 1990, 62, 1791–1797. [Google Scholar] [CrossRef]
- Diamantaras, K.; Duch, W.; Iliadis, L.S. Artificial Neural Networks. In Proceedings of the ICANN 2010: 20th International Conference, Thessaloniki, Greece, 15–18 September 2010; pp. 31–32. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Prasad, A.M.; Iverson, L.R.; Liaw, A. Newer classification and regression tree techniques: Bagging and random forests for ecological prediction. Ecosystems 2006, 9, 181–199. [Google Scholar] [CrossRef]
- Ishwaran, H. Variable importance in binary regression trees and forests. Electron. J. Stat. 2007, 1, 519–537. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- Forkuor, G.; Hounkpatin, O.K.L.; Welp, G.; Thiel, M. High Resolution Mapping of Soil Properties Using Remote Sensing Variables in South-Western Burkina Faso: A Comparison of Machine Learning and Multiple Linear Regression Models. PLoS ONE 2017, 12, e0170478. [Google Scholar] [CrossRef] [PubMed]
- Martin, M.P.; Wattenbach, M.; Smith, P.; Meersmans, J.; Jolivet, C.; Boulonne, L.; Arrouays, D. Spatial distribution of soil organic carbon stocks in France. Biogeosciences 2011, 8, 1053–1065. [Google Scholar] [CrossRef] [Green Version]
- Martin, M.P.; Orton, T.G.; Lacarce, E.; Meersmans, J.; Saby, N.P.A.; Paroissien, J.B.; Jolivet, C.; Boulonne, L.; Arrouays, D. Evaluation of modelling approaches for predicting the spatial distribution of soil organic carbon stocks at the national scale. Geoderma 2014, 223–225, 97–107. [Google Scholar] [CrossRef] [Green Version]
- Natural Resources Conservation Service, USDA. Soil Taxonomy: A Basic System of Soil Classification for Making and Interpreting Soil Surveys; Agricultural Handbook 436; Natural Resources Conservation Service, USDA: Washington, DC, USA, 1999.
- Mouazen, A.M. Soil Sensing Device. International Publication, Published under the Patent Cooperation Treaty (PCT); World Intellectual Property Organization, International Bureau: Brussels, Belgium, 2006. [Google Scholar]
- British Standards Institution. BS 7755-3.8:1995 ISO 10694:1995 Part 3: Chemical Methods—Section 3.8 Determination of Organic and Total Carbon after Dry Combustion (Elementary Analysis); British Standards Institution: London, UK, 1995. [Google Scholar]
- British Standards Institute. BS EN 13654-2:2001: Soil Improvers and Growing Media. Determination of Nitrogen. Dumas Method; British Standards Institution: London, UK, 2001. [Google Scholar]
- Stevens, A.; Ramirez Lopez, L. An Introduction to the Prospectr Package. 2014. Available online: https://cran.r-project.org/web/packages/prospectr/vignettes/prospectr-intro.pdf (accessed on 22 April 2016).
- Norris, K. Applying Norris Derivatives. Understanding and correcting the factors which affect diffuse transmittance spectra. NIR News 2001, 12, 6–9. [Google Scholar] [CrossRef]
- Kennard, R.W.; Stone, L.A. Computer Aided Design of Experiments. Technometrics 1969, 11, 137–148. [Google Scholar] [CrossRef]
- Segal, M.; Xiao, Y. Multivariate random forests. WIREs Data Mining Knowl Discov. 2011, 1, 80–87. [Google Scholar] [CrossRef]
- Cutler, A.; Cutler, D.R.; Stevens, J.R. Random Forests. In Ensemble Machine Learning; Springer: Boston, MA, USA, 2012; pp. 157–175. [Google Scholar]
- Abdel Rahman, A.M.; Pawling, J.; Ryczko, M.; Caudy, A.A.; Dennis, J.W. Targeted metabolomics in cultured cells and tissues by mass spectrometry: Method development and validation. Anal. Chim. Acta 2014, 845, 53–61. [Google Scholar] [CrossRef] [PubMed]
- Peters, J.; De Baets, B.; Verhoest, N.E.C.; Samson, R.; Degroeve, S.; De Becker, P.; Huybrechts, W. Random forests as a tool for ecohydrological distribution modelling. Ecol. Modell. 2007, 207, 304–318. [Google Scholar] [CrossRef]
- Caruana, R.; Niculescu-Mizil, A. An Empirical Comparison of Supervised Learning Algorithms | Machine Learning | Support Vector Machine. Available online: https://www.scribd.com/document/113006633/2006-An-Empirical-Comparison-of-Supervised-Learning-Algorithms# (accessed on 17 September 2017).
- Liaw, A.; Wiener, M. Breiman and Cutler’s Random Forests for Classification and Regression. 2015. Available online: https://cran.r-project.org/web/packages/randomForest/randomForest.pdf (accessed on 28 April 2016).
- Schapire, R.E. The Boosting Approach to Machine Learning: An Overview. In Nonlinear Estimation and Classification; Springer: New York, NY, USA, 2003; pp. 149–171. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning; Springer Series in Statistics; Springer New York: New York, NY, USA, 2009; Volume 20, ISBN 978-0-387-84857-0. [Google Scholar]
- Dormann, C.F.; McPherson, J.M.; Araújo, M.B.; Bivand, R.; Bolliger, J.; Carl, G.; Davies, R.G.; Hirzel, A.; Jetz, W.; Kissling, W.D.; et al. Methods to account for spatial autocorrelation in the analysis of species distributional data: A review. Ecography 2007, 30, 609–628. [Google Scholar] [CrossRef]
- Elith, J.; Leathwick, J.R.; Hastie, T. A working guide to boosted regression trees. J. Anim. Ecol. 2008, 77, 802–813. [Google Scholar] [CrossRef] [PubMed]
- Varmuza, K.; Filzmoser, P. Introduction to Multivariate Statistical Analysis in Chemometrics; CRC Press: Boca Raton, FL, USA, 2009; ISBN 9781420059472. [Google Scholar]
- Kuhn, M.; Wing, J.; Weston, S.; Williams, A.; Keefer, C.; Engelhardt, A.; Cooper, T.; Mayer, Z.; Benesty, M.; Lescarbeau, R.; et al. Package “Caret” Title Classification and Regression Training Description Misc Functions for Training and Plotting Classification and Regression Models. Available online: https://cran.r-project.org/web/packages/caret/caret.pdf (accessed on 9 August 2017).
- R Core Team. R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing: Vienna, Austria, 2016. Available online: https://www.r-project.org/ (accessed on 9 August 2017).
- Viscarra Rossel, R.A.; Walvoort, D.J.J.; McBratney, A.B.; Janik, L.J.; Skjemstad, J.O. Visible, near infrared, mid infrared or combined diffuse reflectance spectroscopy for simultaneous assessment of various soil properties. Geoderma 2006, 131, 59–75. [Google Scholar] [CrossRef]
- Yu, C.; Grunwald, S.; Xiong, X. Transferability and Scaling of VNIR Prediction Models for Soil Total Carbon in Florida; Springer: Singapore, 2016; pp. 259–273. [Google Scholar]
- Kuang, B.; Mouazen, A.M. Effect of spiking strategy and ratio on calibration of on-line visible and near infrared soil sensor for measurement in European farms. Soil Tillage Res. 2013, 128, 125–136. [Google Scholar] [CrossRef] [Green Version]
- Brown, D.J. Using a global VNIR soil-spectral library for local soil characterization and landscape modeling in a 2nd-order Uganda watershed. Geoderma 2007, 140, 444–453. [Google Scholar] [CrossRef]
- Sankey, J.B.; Brown, D.J.; Bernard, M.L.; Lawrence, R.L. Comparing local vs. global visible and near-infrared (VisNIR) diffuse reflectance spectroscopy (DRS) calibrations for the prediction of soil clay, organic C and inorganic C. Geoderma 2008, 148, 149–158. [Google Scholar] [CrossRef]
- Wetterlind, J.; Stenberg, B. Near-infrared spectroscopy for within-field soil characterization: Small local calibrations compared with national libraries spiked with local samples. Eur. J. Soil Sci. 2010, 61, 823–843. [Google Scholar] [CrossRef]
- Guerrero, C.; Zornoza, R.; Gómez, I.; Mataix-Beneyto, J. Spiking of NIR regional models using samples from target sites: Effect of model size on prediction accuracy. Geoderma 2010, 158, 66–77. [Google Scholar] [CrossRef]
- Stenberg, B.; Viscarra Rossel, R.A.; Mouazen, A.M.; Wetterlind, J. Visible and Near Infrared Spectroscopy in Soil Science; Sparks, D.L., Ed.; Academic Press: Burlington, VT, USA, 2010; Volume 107, pp. 163–215. [Google Scholar]
- Bonett, J.P.; Camacho-Tamayo, J.H.; Ramírez-López, L. Mid-infrared spectroscopy for the estimation of some soil properties. Agron. Colomb. 2015, 33, 99–106. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Min | 1st Qu. | Median | Mean | 3rd Qu. | Max | St.dev | |
|---|---|---|---|---|---|---|---|
| Hessleskew | (n = 122) | ||||||
| TN (%) | 0.19 | 0.23 | 0.25 | 0.25 | 0.26 | 0.34 | 0.02 |
| TC (%) | 1.72 | 1.94 | 2.05 | 2.12 | 2.22 | 3.67 | 0.30 |
| Hagg | (n = 149) | ||||||
| TN (%) | 0.13 | 0.19 | 0.21 | 0.21 | 0.24 | 0.35 | 0.04 |
| TC (%) | 1.34 | 1.68 | 1.90 | 1.92 | 2.08 | 3.18 | 0.31 |
| European | (n = 528) | ||||||
| TN (%) | 0.03 | 0.11 | 0.14 | 0.15 | 0.17 | 0.30 | 0.04 |
| TC (%) | 0.45 | 1.22 | 1.45 | 1.67 | 1.70 | 3.76 | 0.77 |
| Hessleskew | Hagg | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Local | European | Local | European | |||||||||||||
| RMSE | R2 | RPD | RMSE | R2 | RPD | RMSE | R2 | RPD | RMSE | R2 | RPD | |||||
| GBM | n.trees | n.trees | ||||||||||||||
| Cross- | 100 | TN | 0.01 | 0.63 | 1.64 | 0.01 | 0.96 | 4.81 | 100 | TN | 0.02 | 0.63 | 1.66 | 0.01 | 0.96 | 5.01 |
| 100 | TC | 0.16 | 0.67 | 1.75 | 0.06 | 0.98 | 6.48 | 100 | TC | 0.19 | 0.65 | 1.70 | 0.12 | 0.98 | 6.49 | |
| Lab Prediction | 100 | TN | 0.01 | 0.60 | 1.60 | 0.02 | 0.87 | 2.79 | 100 | TN | 0.02 | 0.62 | 1.65 | 0.02 | 0.79 | 2.21 |
| 100 | TC | 0.23 | 0.60 | 1.59 | 0.20 | 0.82 | 2.40 | 100 | TC | 0.21 | 0.61 | 1.61 | 0.19 | 0.83 | 3.03 | |
| On-line Prediction | 100 | TN | 0.02 | 0.53 | 1.48 | 0.02 | 0.66 | 1.80 | 100 | TN | 0.02 | 0.59 | 1.58 | 0.02 | 0.77 | 2.11 |
| 100 | TC | 0.26 | 0.54 | 1.49 | 0.24 | 0.66 | 1.78 | 100 | TC | 0.22 | 0.52 | 1.46 | 0.20 | 0.79 | 2.95 | |
| ANN | size | size | ||||||||||||||
| Cross- validation | 2 | TN | 0.01 | 0.62 | 1.62 | 0.01 | 0.77 | 2.08 | 2 | TN | 0.03 | 0.35 | 1.25 | 0.03 | 0.73 | 1.92 |
| 2 | TC | 0.21 | 0.44 | 1.34 | 0.15 | 0.86 | 2.69 | 2 | TC | 0.18 | 0.70 | 1.82 | 0.18 | 0.86 | 2.79 | |
| Lab Prediction | 2 | TN | 0.01 | 0.69 | 1.81 | 0.01 | 0.71 | 2.02 | 2 | TN | 0.02 | 0.66 | 1.74 | 0.02 | 0.68 | 1.87 |
| 2 | TC | 0.25 | 0.51 | 1.45 | 0.20 | 0.83 | 2.44 | 2 | TC | 0.25 | 0.47 | 1.40 | 0.21 | 0.84 | 2.59 | |
| On-line Prediction | 2 | TN | 0.02 | 0.26 | 1.18 | 0.01 | 0.68 | 1.78 | 2 | TN | 0.04 | 0.11 | 1.07 | 0.03 | 0.59 | 1.59 |
| 2 | TC | 0.34 | 0.19 | 1.13 | 0.25 | 0.78 | 2.14 | 2 | TC | 0.27 | 0.75 | 1. 95 | 0.20 | 0.85 | 2.63 | |
| RF | ntree | ntree | ||||||||||||||
| Cross- validation | 100 | TN | 0.01 | 0.83 | 2.45 | 0.01 | 0.96 | 4.83 | 100 | TN | 0.01 | 0.84 | 2.50 | 0.01 | 0.97 | 5.58 |
| 100 | TC | 0.12 | 0.82 | 2.38 | 0.06 | 0.98 | 6.48 | 100 | TC | 0.13 | 0.84 | 2.52 | 0.10 | 0.98 | 7.54 | |
| Lab Prediction | 100 | TN | 0.01 | 0.82 | 2.40 | 0.02 | 0.81 | 2.33 | 100 | TN | 0.02 | 0.78 | 2.18 | 0.02 | 0.84 | 2.51 |
| 100 | TC | 0.25 | 0.75 | 2.02 | 0.23 | 0.78 | 2.16 | 100 | TC | 0.18 | 0.81 | 2.35 | 0.14 | 0.88 | 3.49 | |
| On-line Prediction | 100 | TN | 0.01 | 0.72 | 1.93 | 0.04 | 0.55 | 1.52 | 100 | TN | 0.02 | 0.79 | 2. 20 | 0.02 | 0.83 | 2.40 |
| 100 | TC | 0.21 | 0.69 | 1.82 | 0.20 | 0.75 | 2.13 | 100 | TC | 0.15 | 0.77 | 2.13 | 0.14 | 0.86 | 3.24 | |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nawar, S.; Mouazen, A.M. Comparison between Random Forests, Artificial Neural Networks and Gradient Boosted Machines Methods of On-Line Vis-NIR Spectroscopy Measurements of Soil Total Nitrogen and Total Carbon. Sensors 2017, 17, 2428. https://doi.org/10.3390/s17102428
Nawar S, Mouazen AM. Comparison between Random Forests, Artificial Neural Networks and Gradient Boosted Machines Methods of On-Line Vis-NIR Spectroscopy Measurements of Soil Total Nitrogen and Total Carbon. Sensors. 2017; 17(10):2428. https://doi.org/10.3390/s17102428
Chicago/Turabian StyleNawar, Said, and Abdul M. Mouazen. 2017. "Comparison between Random Forests, Artificial Neural Networks and Gradient Boosted Machines Methods of On-Line Vis-NIR Spectroscopy Measurements of Soil Total Nitrogen and Total Carbon" Sensors 17, no. 10: 2428. https://doi.org/10.3390/s17102428