Day-Ahead PM2.5 Concentration Forecasting Using WT-VMD Based Decomposition Method and Back Propagation Neural Network Improved by Differential Evolution

Abstract
:1. Introduction
2. Methodology
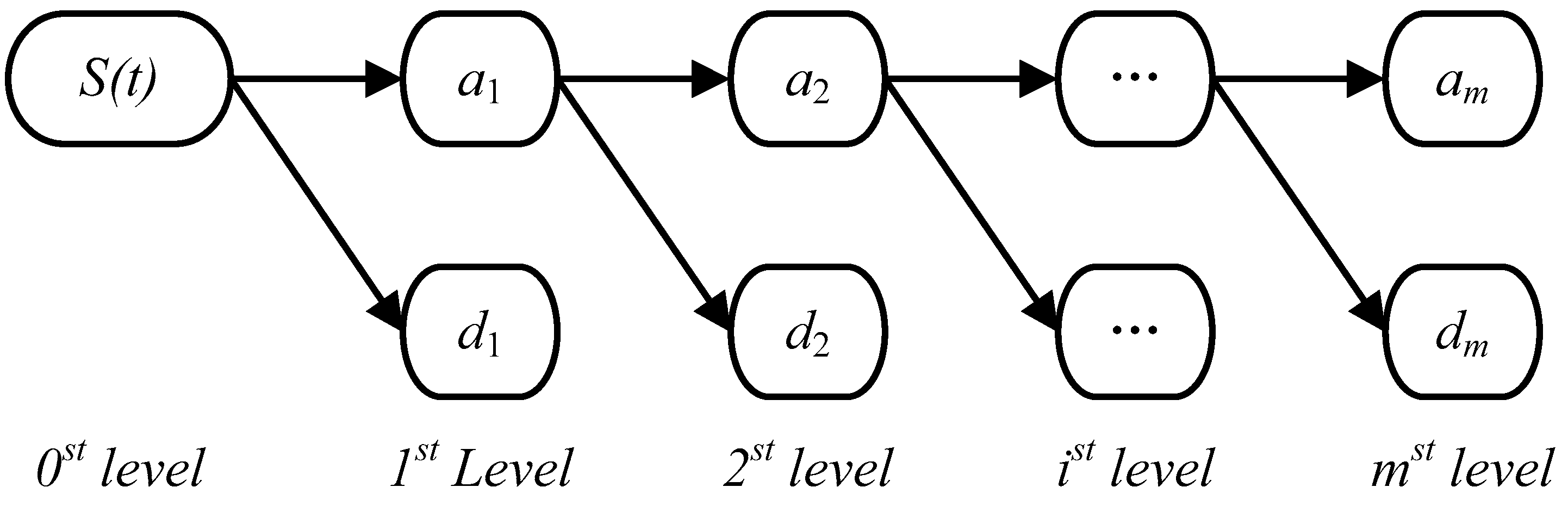
2.1. Wavelet Transform (WT)
2.2. Variational Mode Decomposition (VMD)
2.3. The DE-BP Model
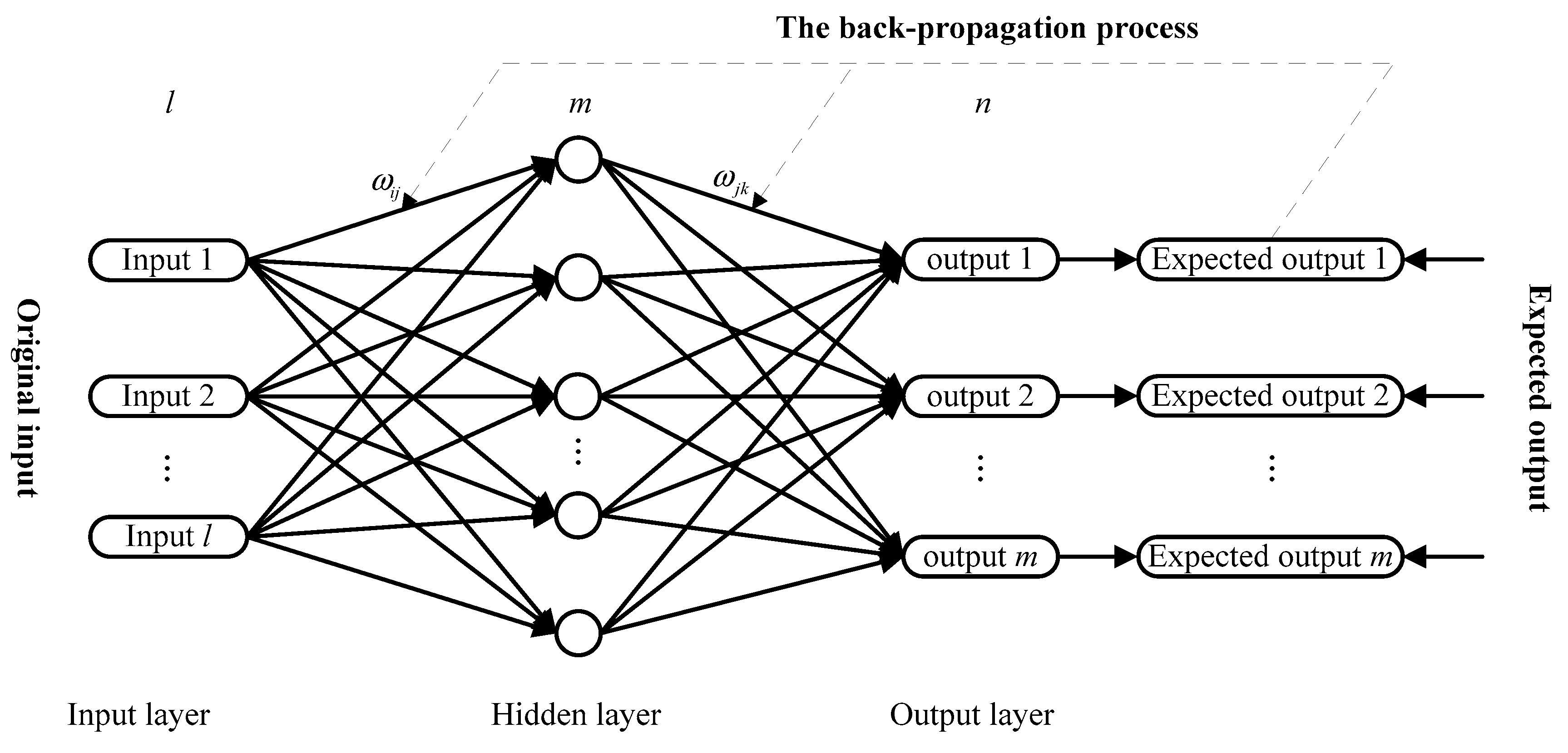
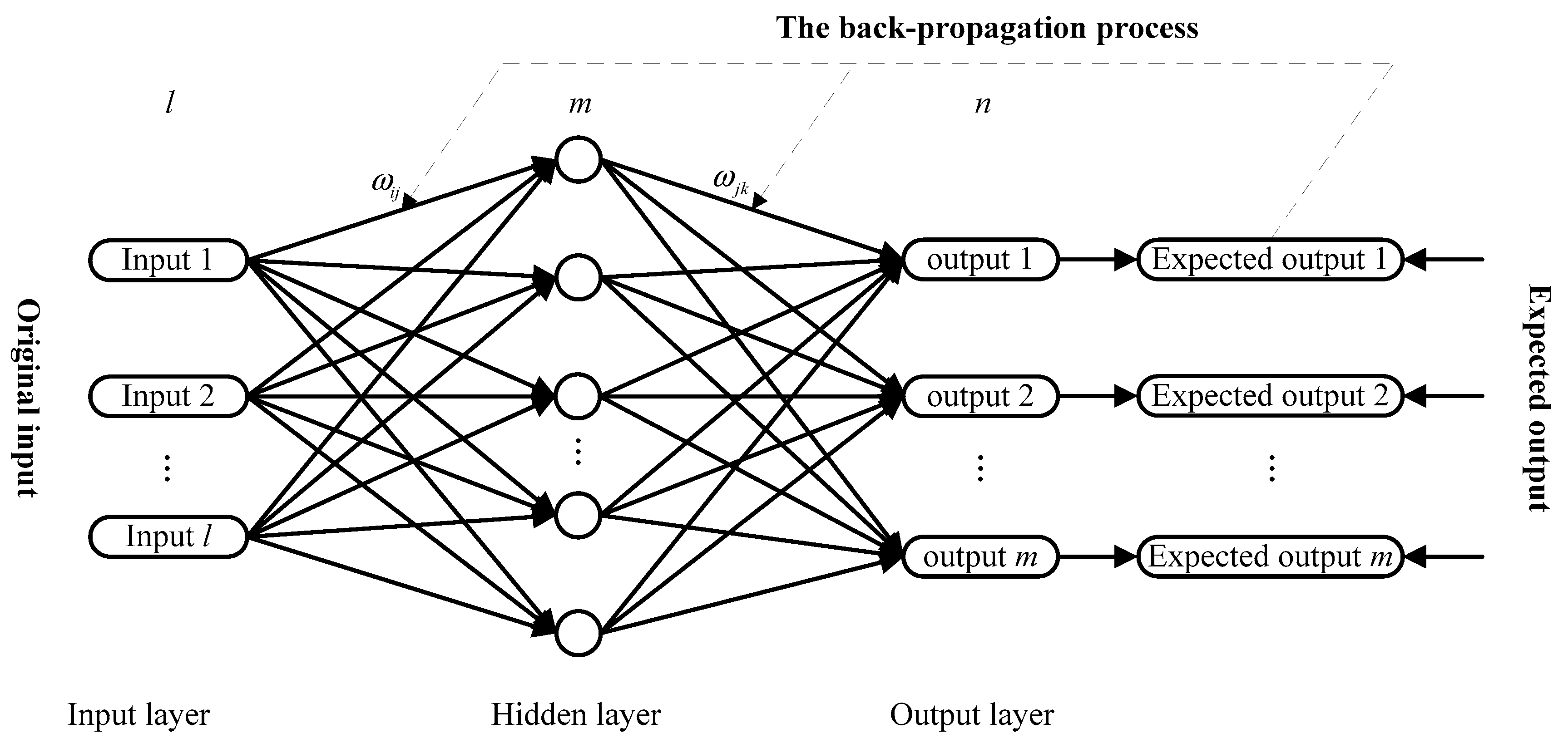
2.3.1. Back Propagation (BP) Neural Network
- Step 1:
- Calculate the output of the jth node in the hidden layer using the following equation.where is the index of neuron in the input layer, is the number of neurons in the input layer, is the connection weights between input layer and hidden layer, is the ith input value, is threshold value, and and represent the output of hidden layer and the incentive function of neurons, respectively.
- Step 2:
- Calculate the fitted value or forecasting value of the kth node in the output layer using the following equation.where is the connection weights between the output layer and hidden layer, is threshold value, and is the number of neurons in the output layer.
- Step 3:
- Calculate the fitting error based on the fitted value and expected output, and update the weight factor and threshold value by the following formula.where denotes the learning rate, is the ith input value.
2.3.2. Differential Evolution (DE) Algorithm
- Step 1:
- Population initialization. Initializing population of DE algorithm based on the following formula.where denotes the value of ith individual in the 0th generation and jth dimension.
- Step 2:
- Mutation. Based on the randomly selected three indices, and , , a mutant vector is generated based on the following formula.where , is a scaling factor and , is the base vector.
- Step 3:
- Crossover. Crossover operation is introduced into DE algorithm in order to improve the multiplicity of the perturbed parameter vectors. The trial point is established from its parents and by the following formula.where is crossover probability and , is a randomly selected index in the set of , which ensures that obtains at least one parameter from . The trial vector is formed of both current parameter vectors and mutant vector parameters (see formula (17)).
- Step 4:
- Selection. The trial vector can be obtained by comparing the fitness value of the vector obtained through mutation and crossover, and the process can be denoted as follows:
- Step 5:
- Iterative computing and stop the DE algorithm if the result satisfies the error requirement or the maximum number of iterations is reached. Otherwise, return to Step 2.
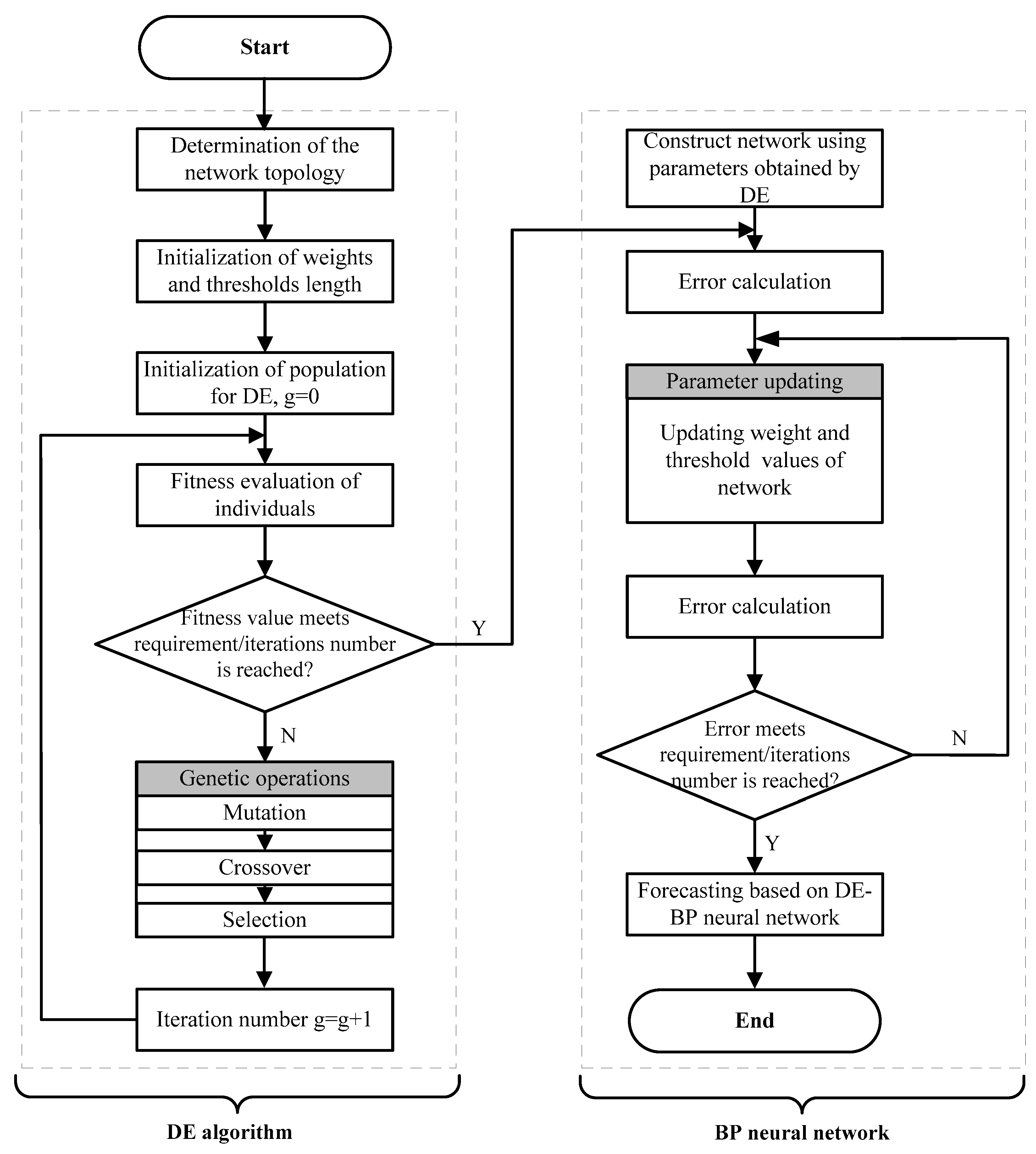
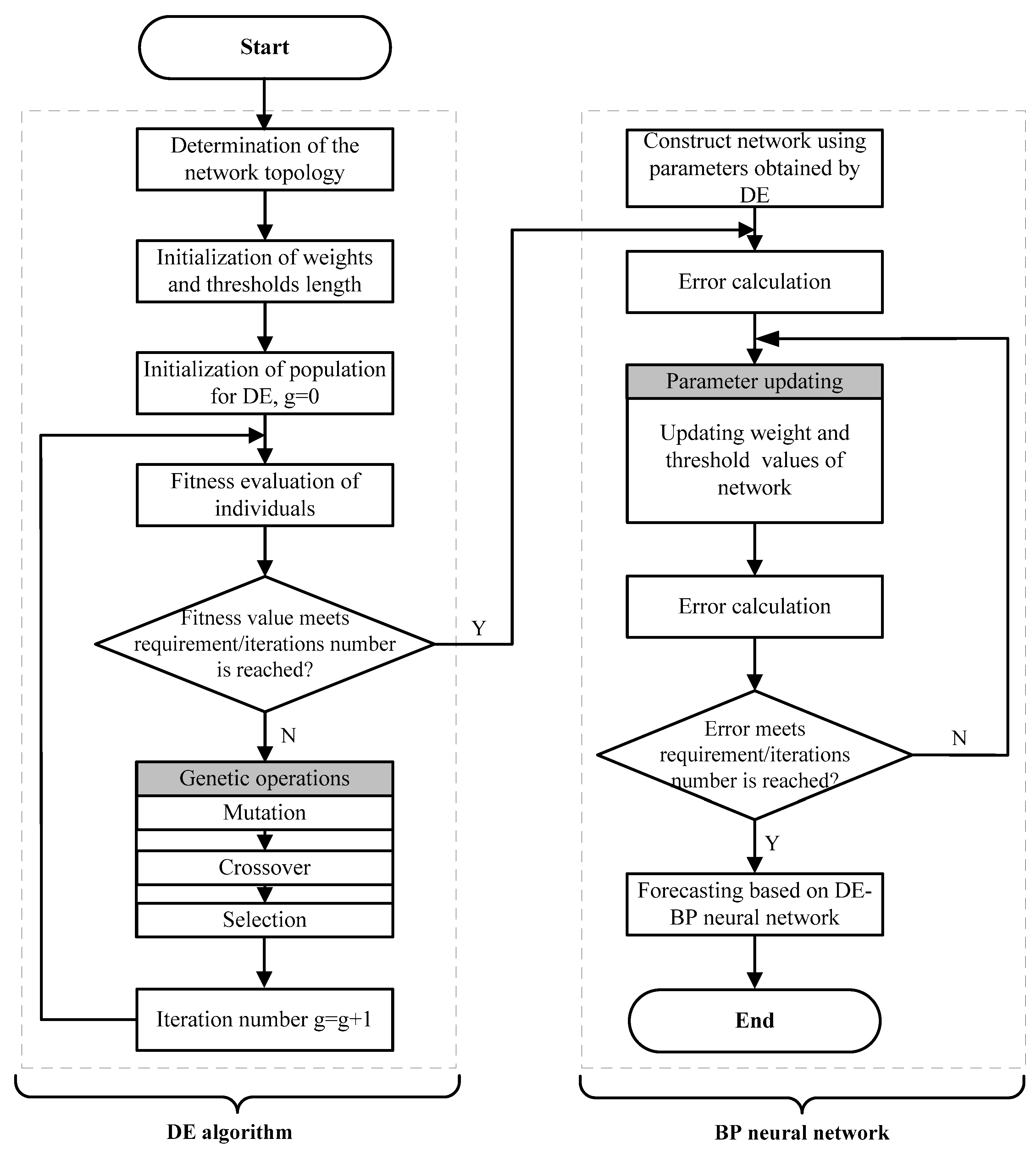
2.3.3. The DE-BP Model
- Step 1:
- Initialization. Determine the network topology of the network and initialize the parameters of DE algorithm including population size, maximum iteration number, probabilities of mutation and crossover operators. The initial population is generated using Equation (15).
- Step 2:
- Calculate the fitness value of each individual using Equation (19). The DE algorithm is stopped when the stop criterion is satisfied, and go to Step 4.
- Step 3:
- Update the population of DE algorithm based on mutation, crossover and selection operators. Go to Step 2.
- Step 4:
- The optimal individual obtained from DE algorithm is adopted as the initial connection weights and thresholds of the BP neural network.
- Step 5:
- Train and test the BP neural network based on the training and testing samples.
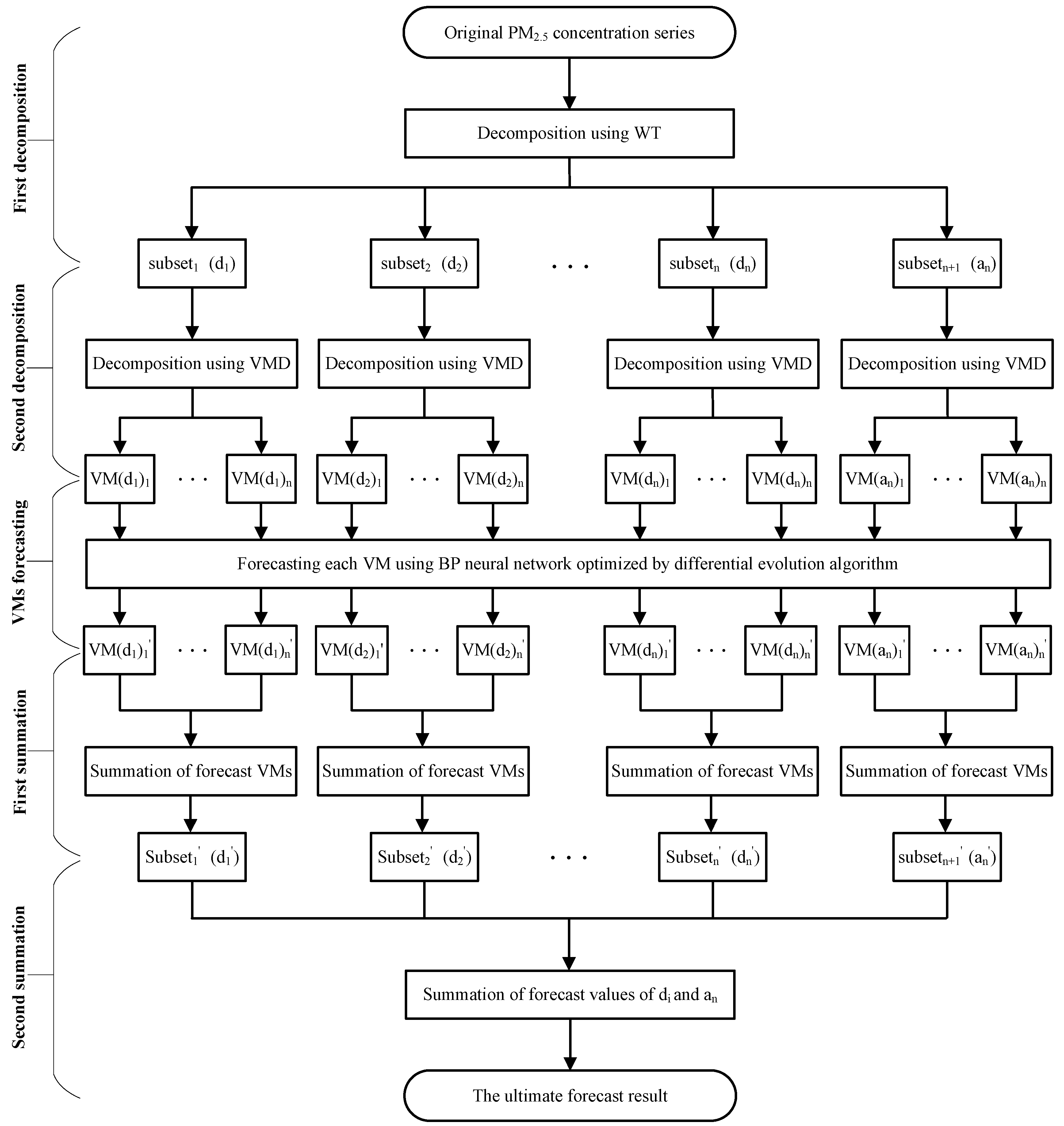
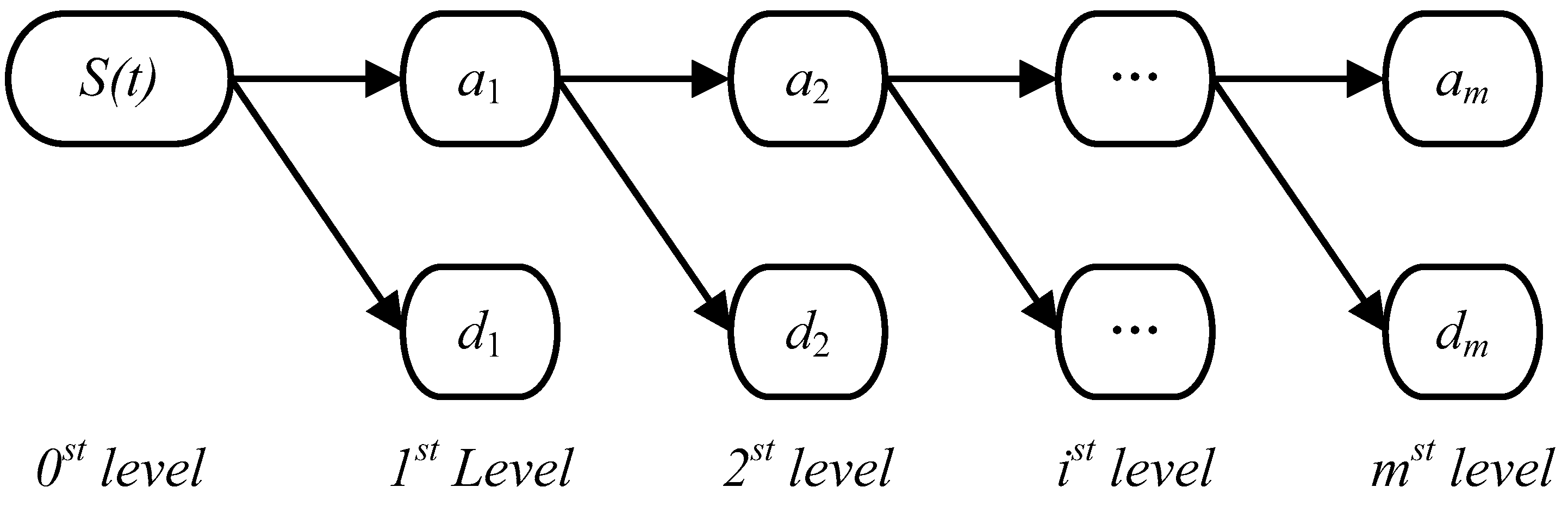
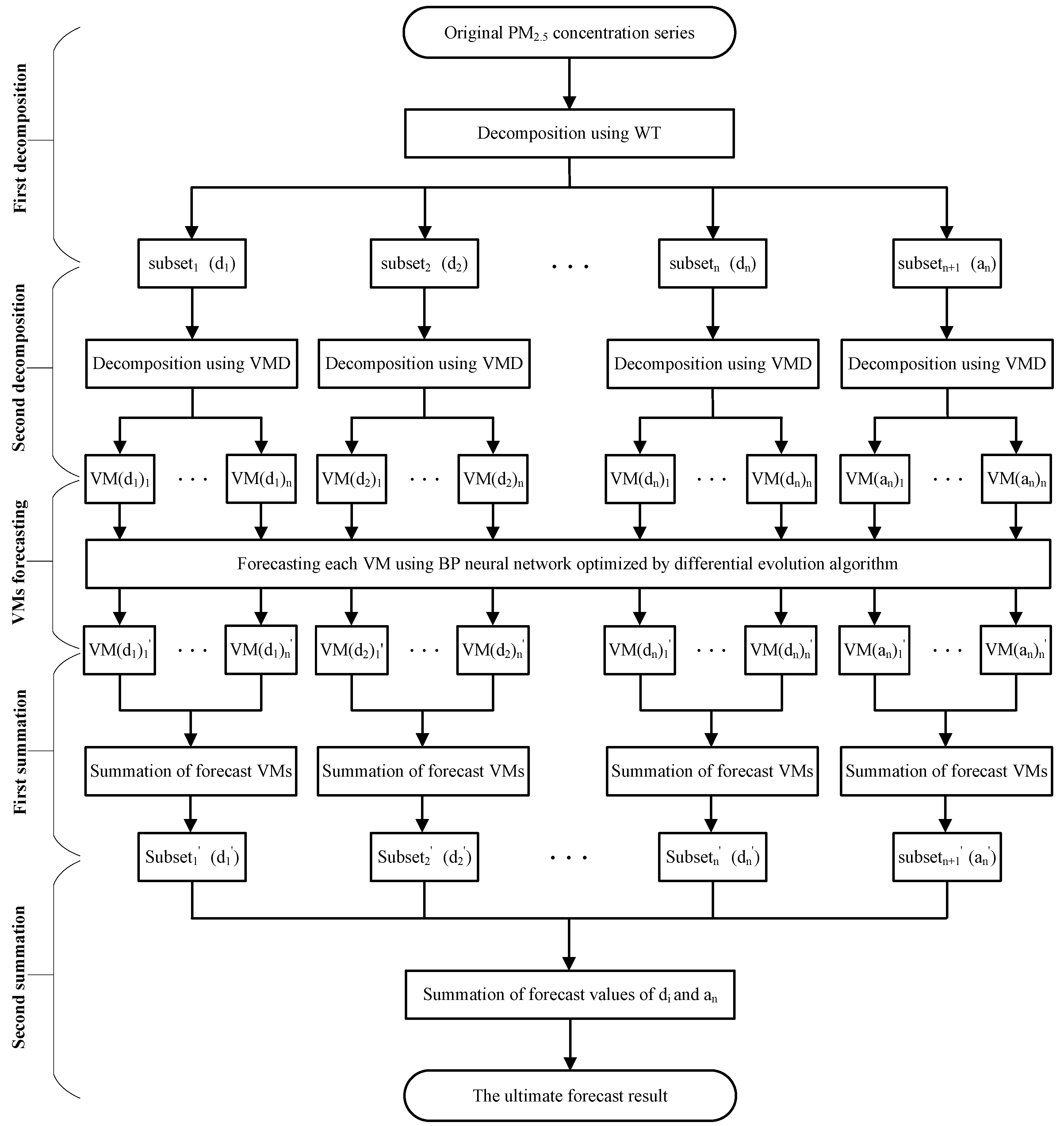
2.3.4. Hybrid WT-VMD-DE-BP Forecasting Model
- Step 1:
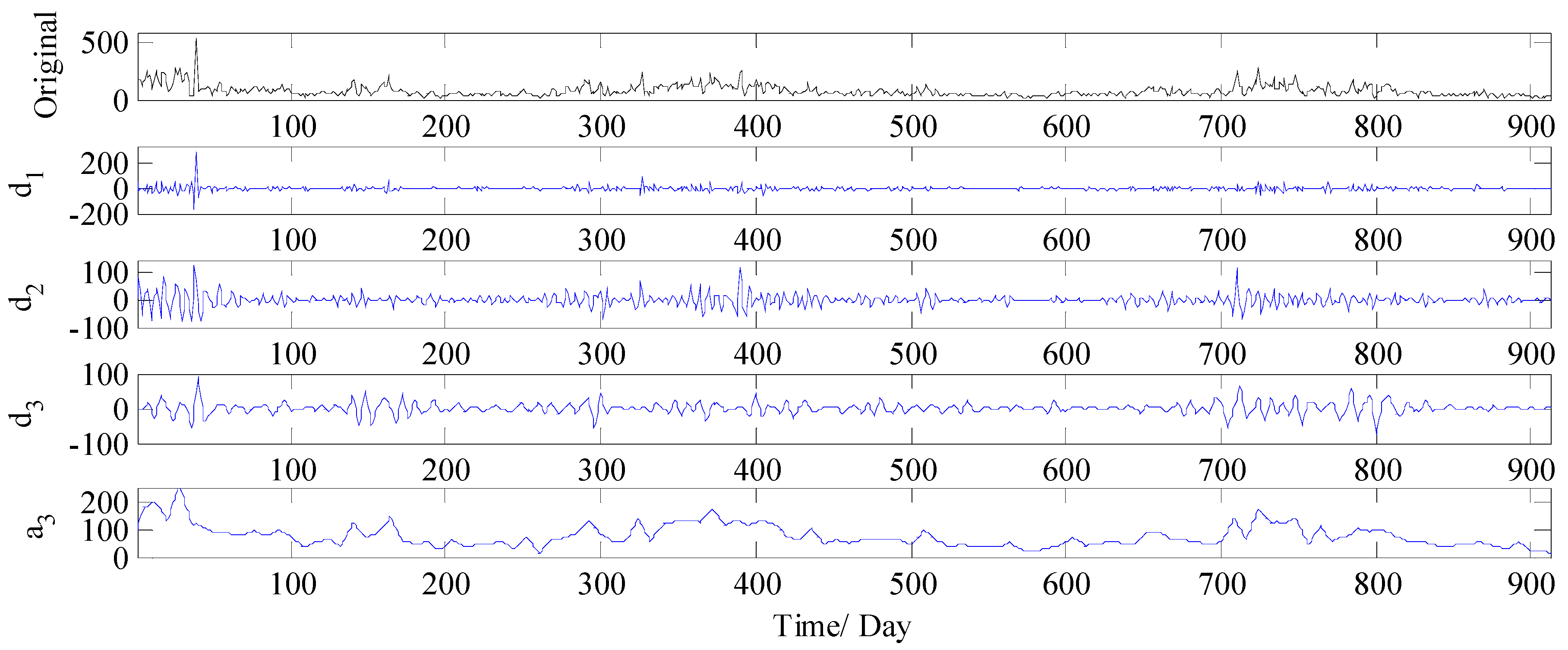
- First decomposition. The WT decomposition technique is utilized to decompose the PM2.5 concentration series into one low frequency approximation subset and several high frequency detail subsets.
- Step 2:
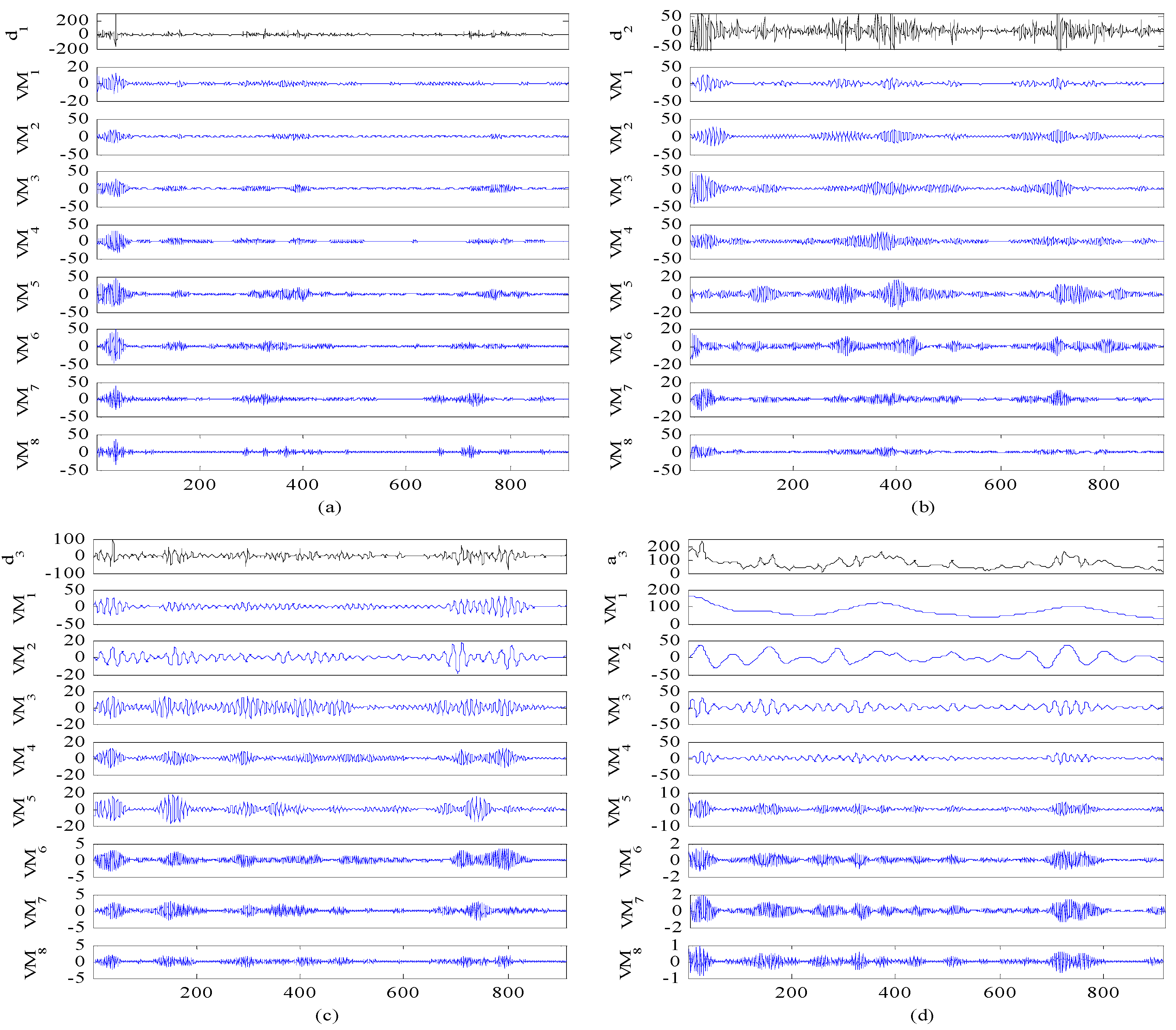
- Second decomposition. In order to increase the forecasting accuracy, the VMD technique is further employed to conduct the secondary decomposition of each subset generated by WT, and consequently a number of VMs are obtained.
- Step 3:
- Individual forecasting. Each VM generated by VMD is forecasted using DE-BP model.
- Step 4:
- First summation. The forecast value of each subset generated by WT is obtained by adding up all the forecast values of VMs generated by VMD decomposition of this subset.
- Step 5:
- Second summation. The forecast series of PM2.5 concentration is obtained by aggregating the forecast result of each subset.
3. Empirical Study
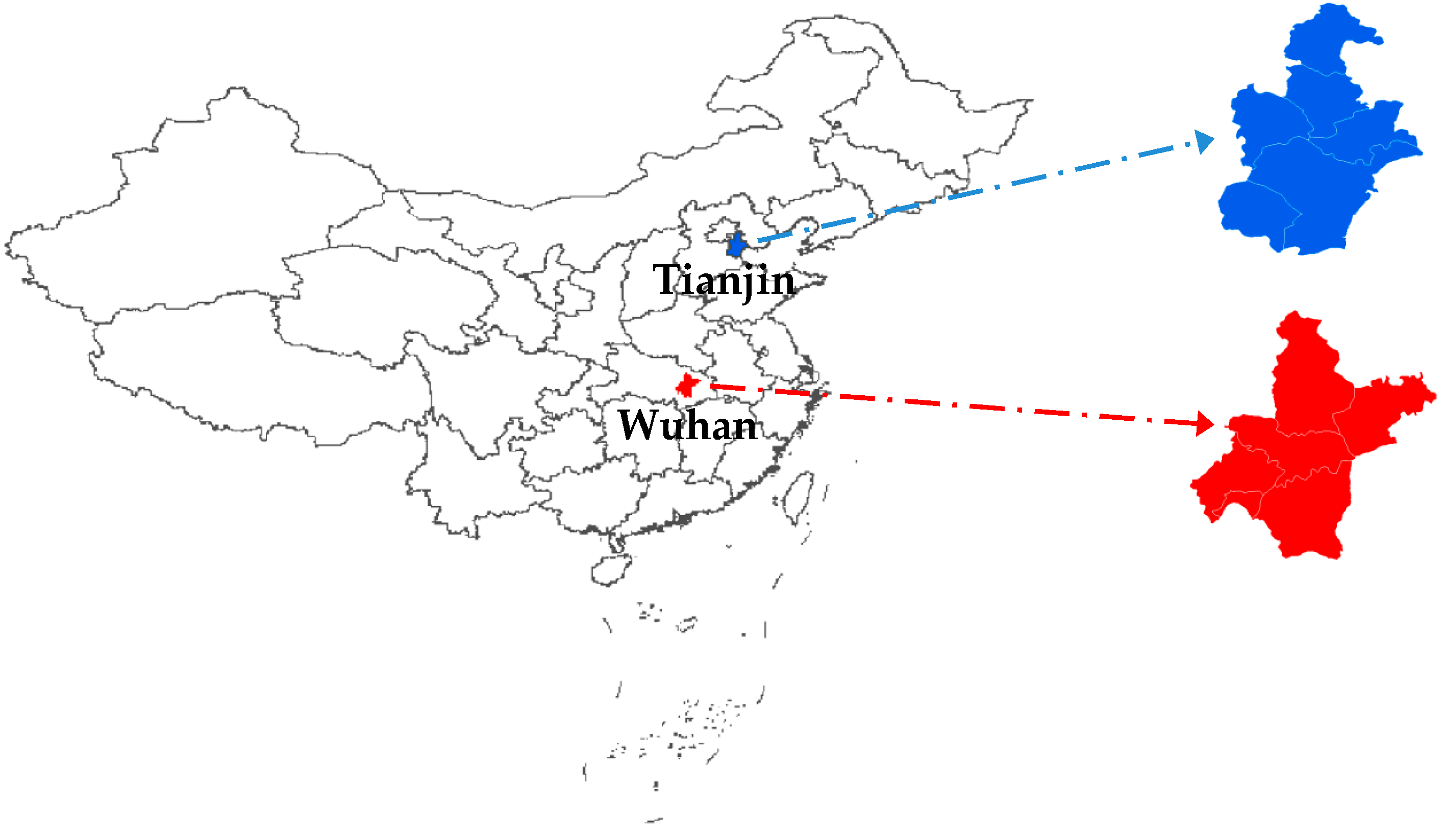
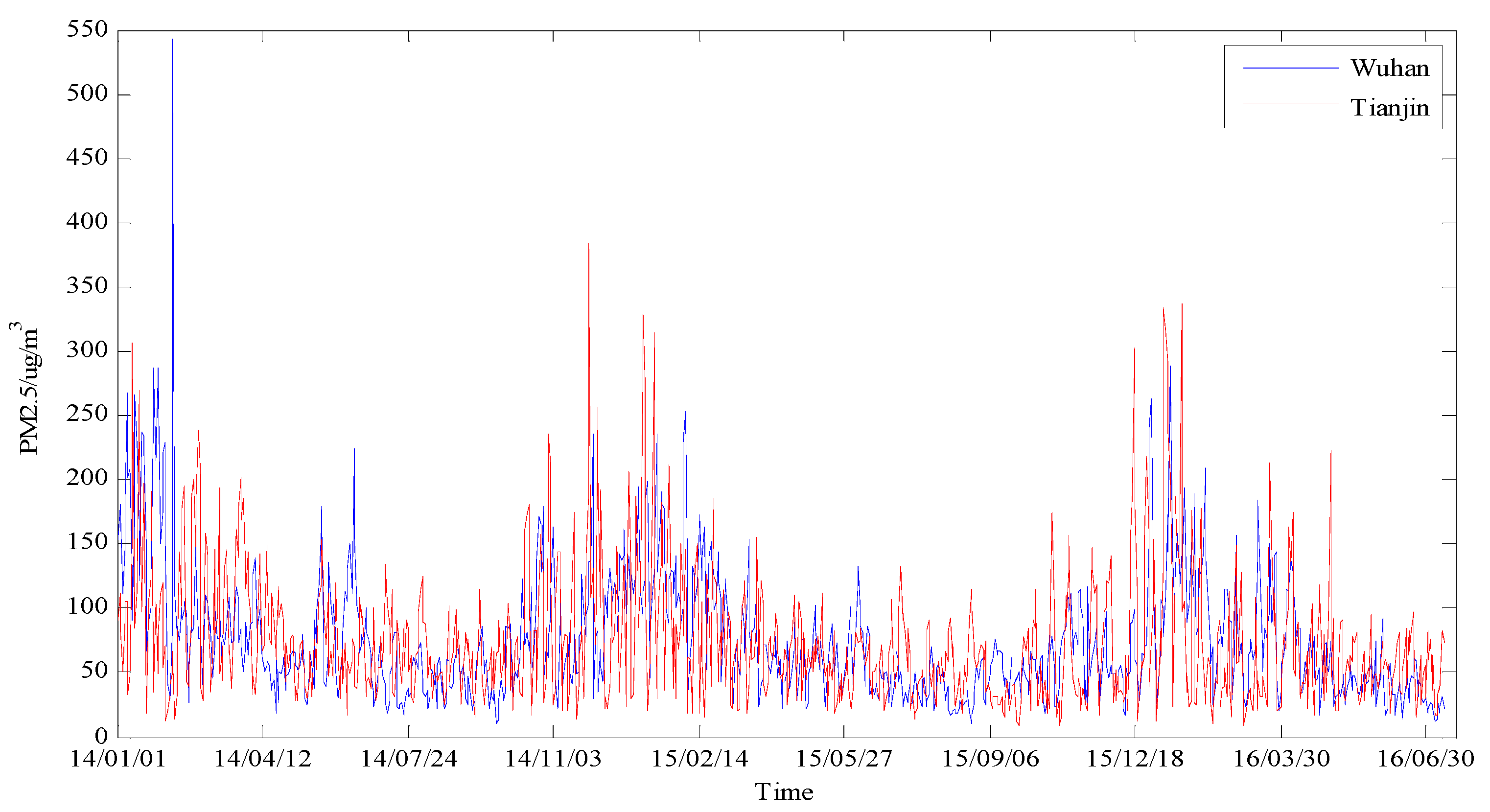
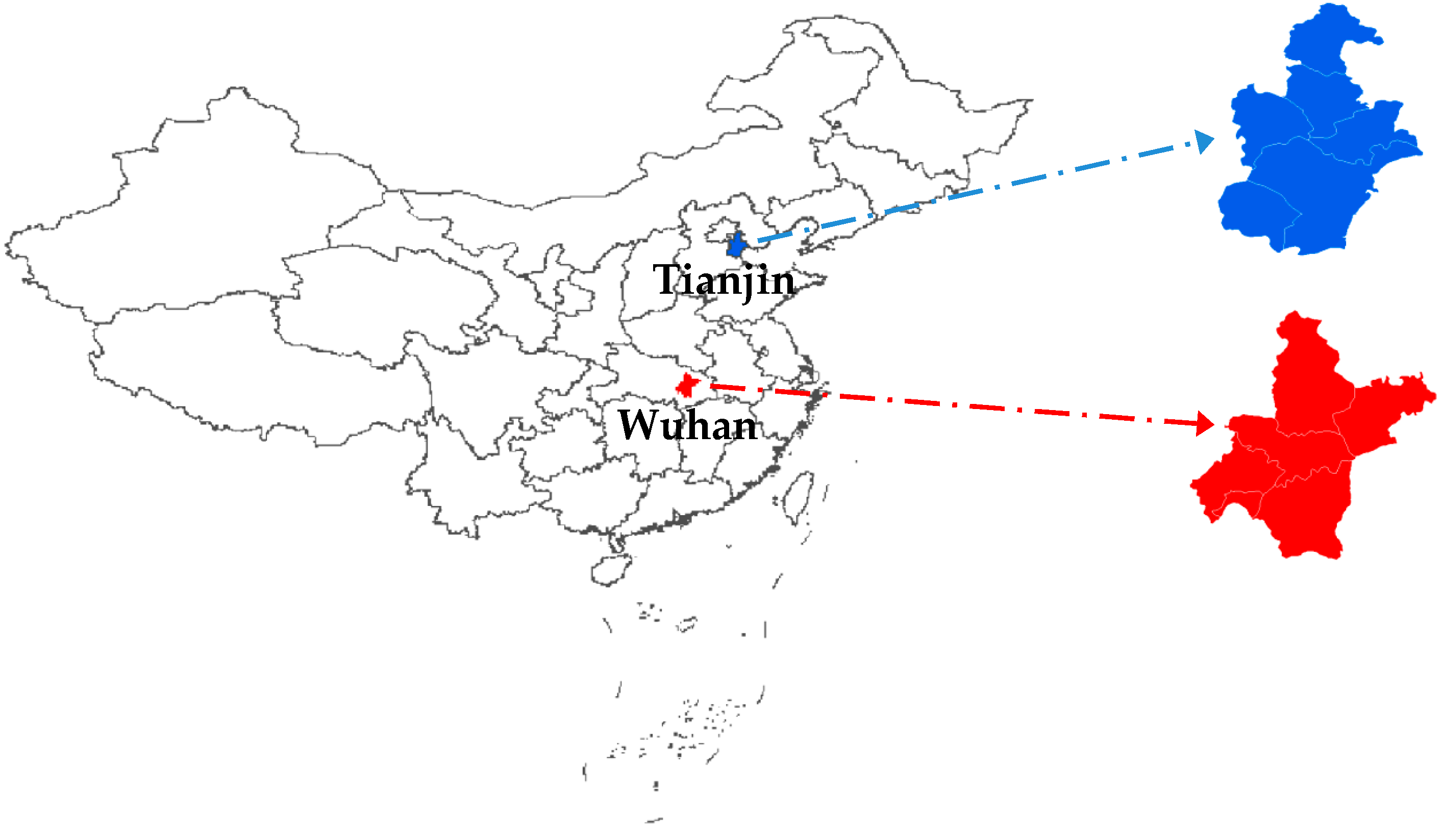
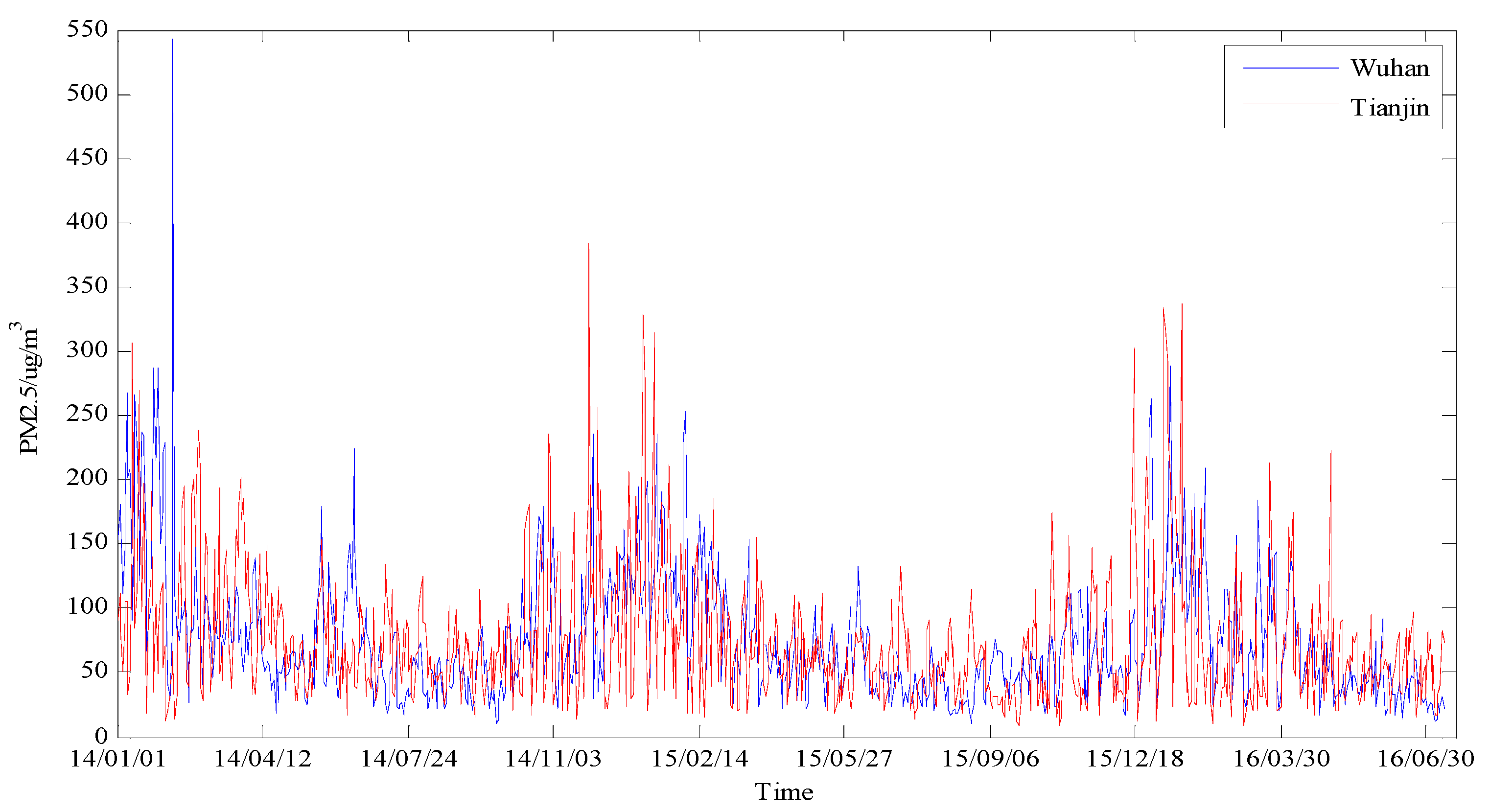
3.1. Study Area and Data Description
3.2. Performance Criteria of Forecasting Accuracy
3.3. PM2.5 Concentration Forecasting in Wuhan
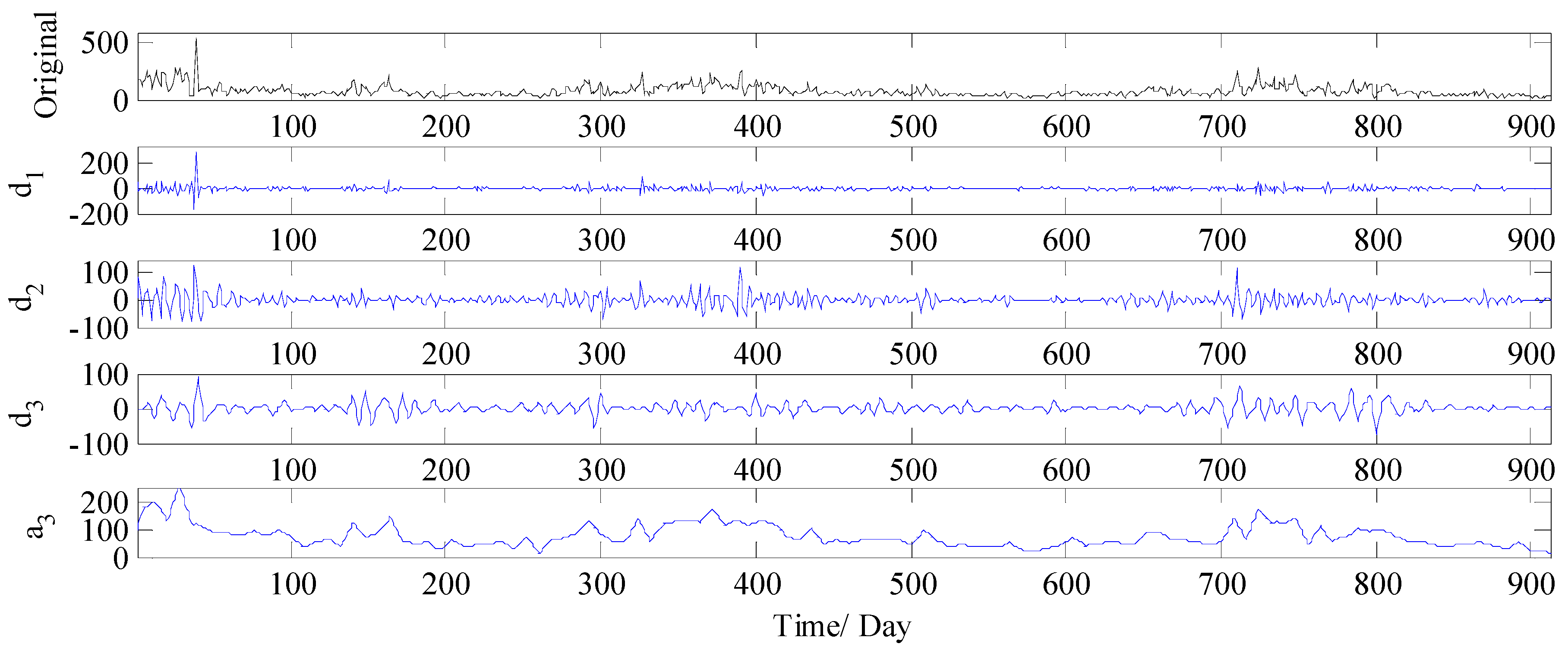
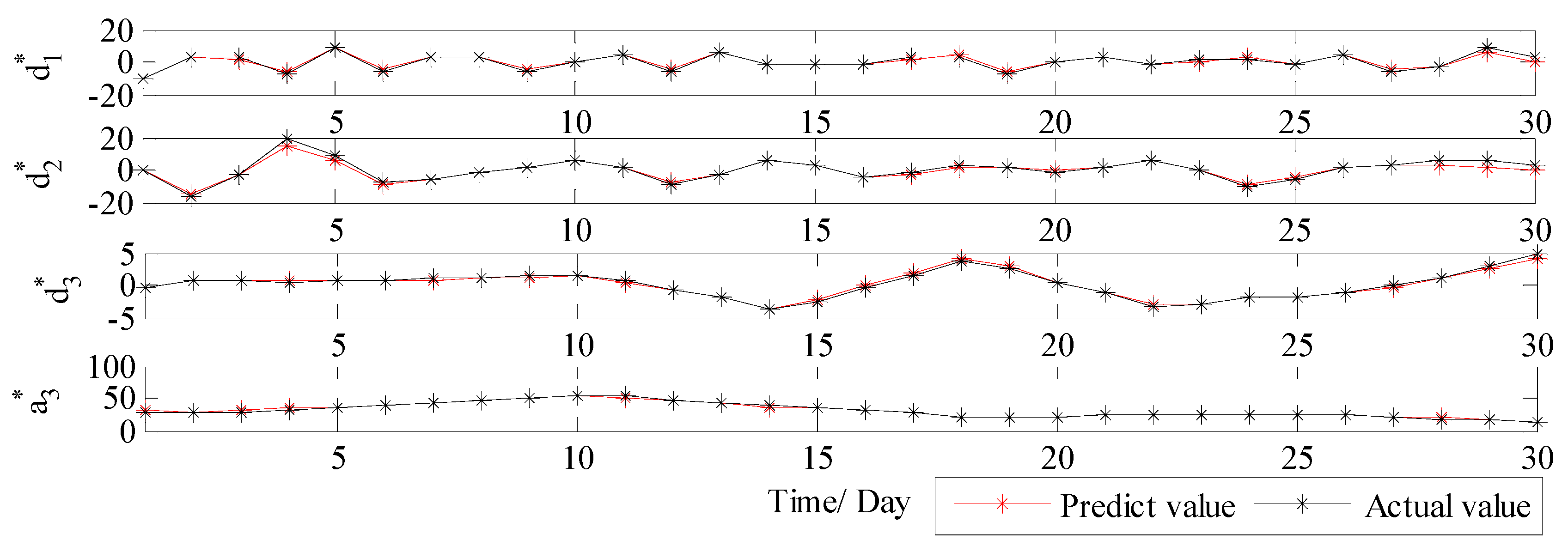
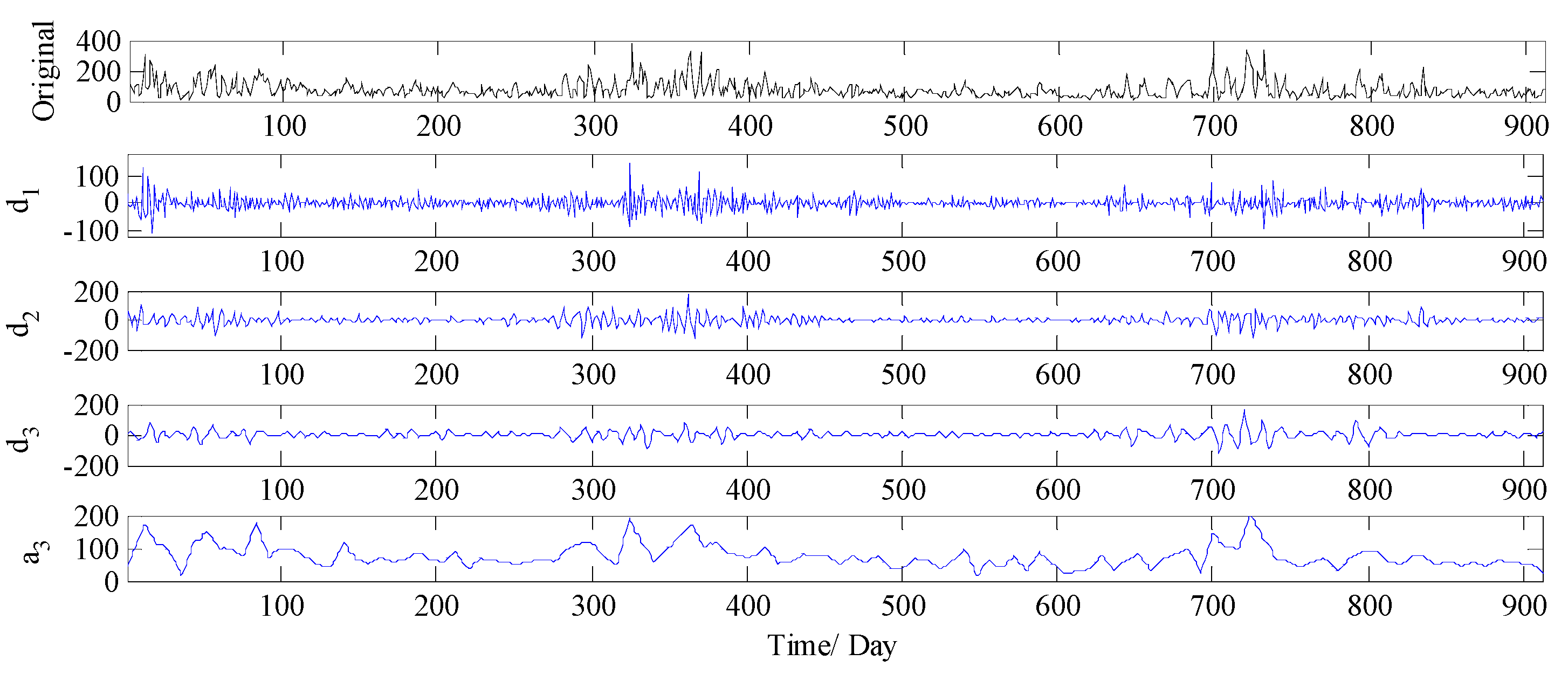
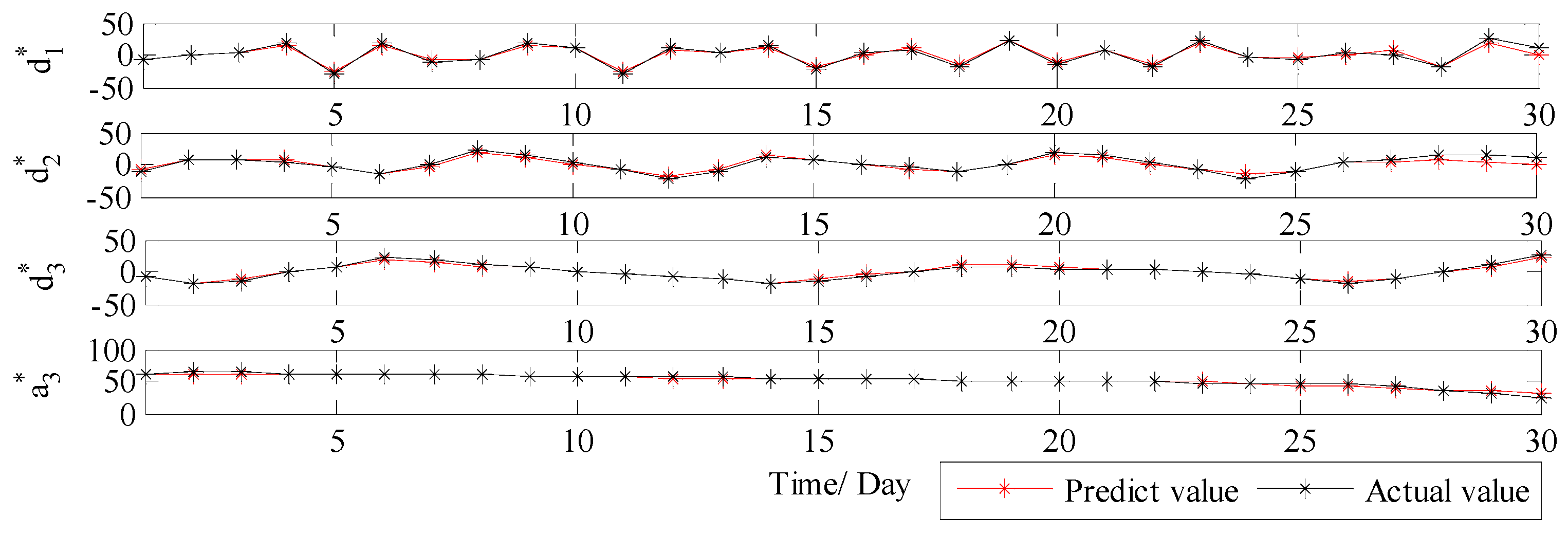
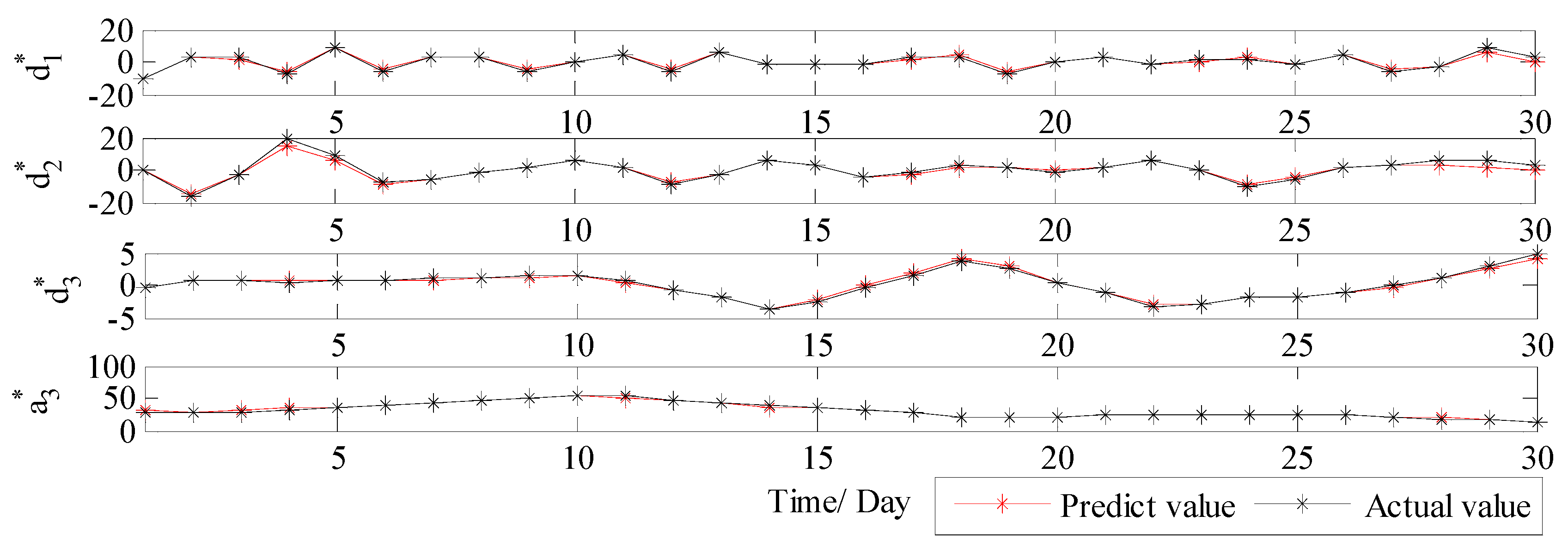
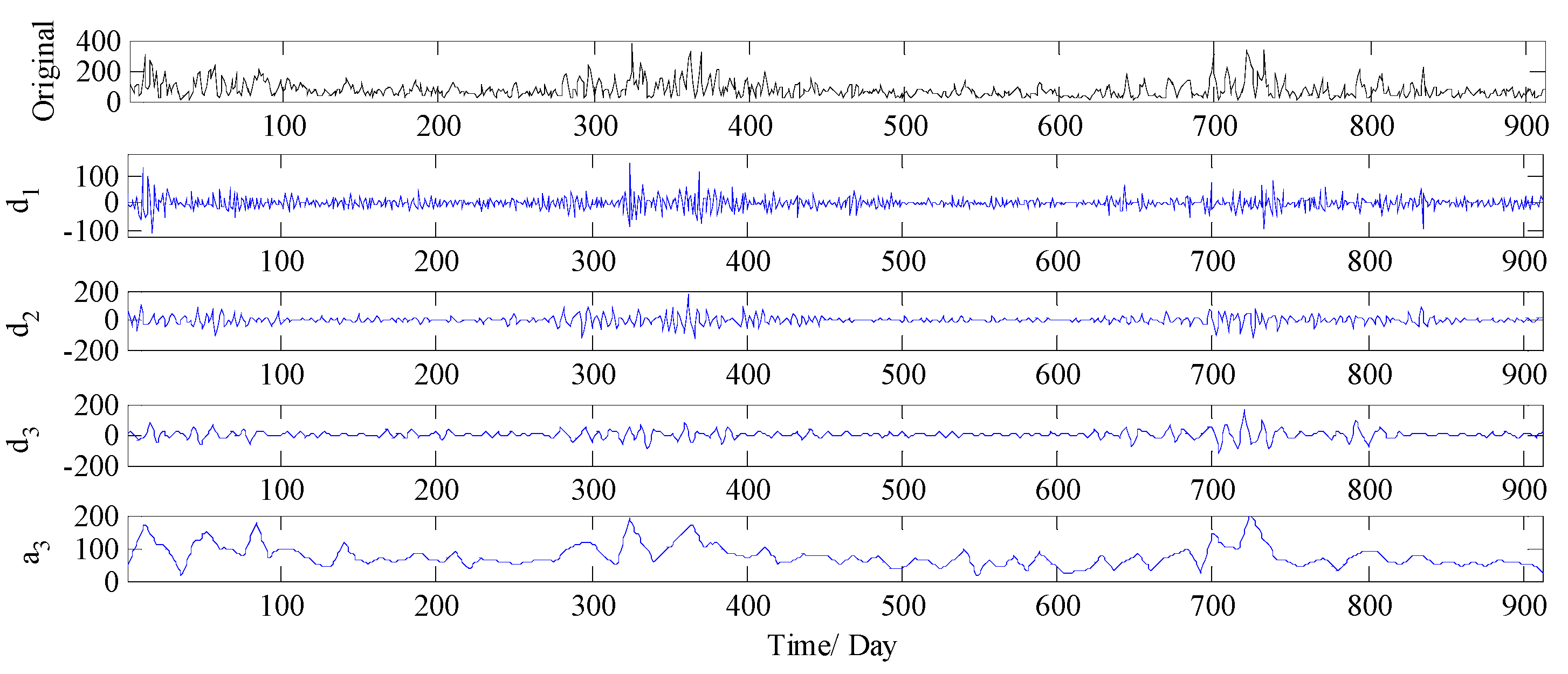
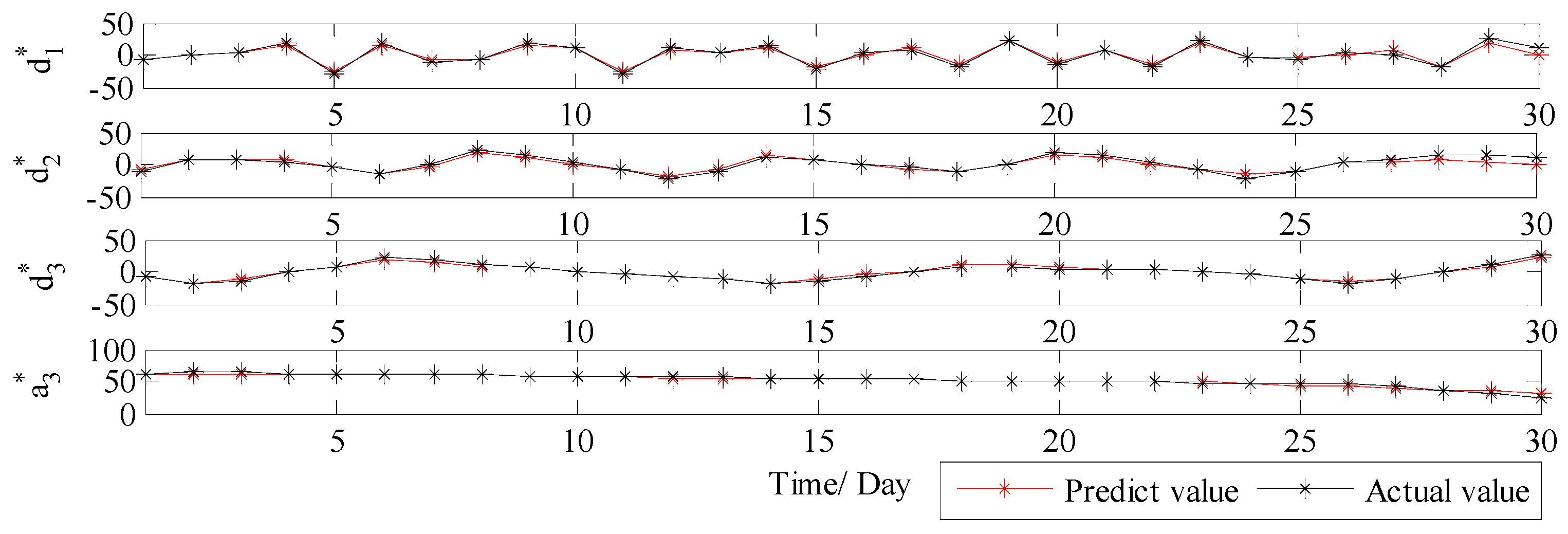
3.3.1. Analysis of Decomposition Results
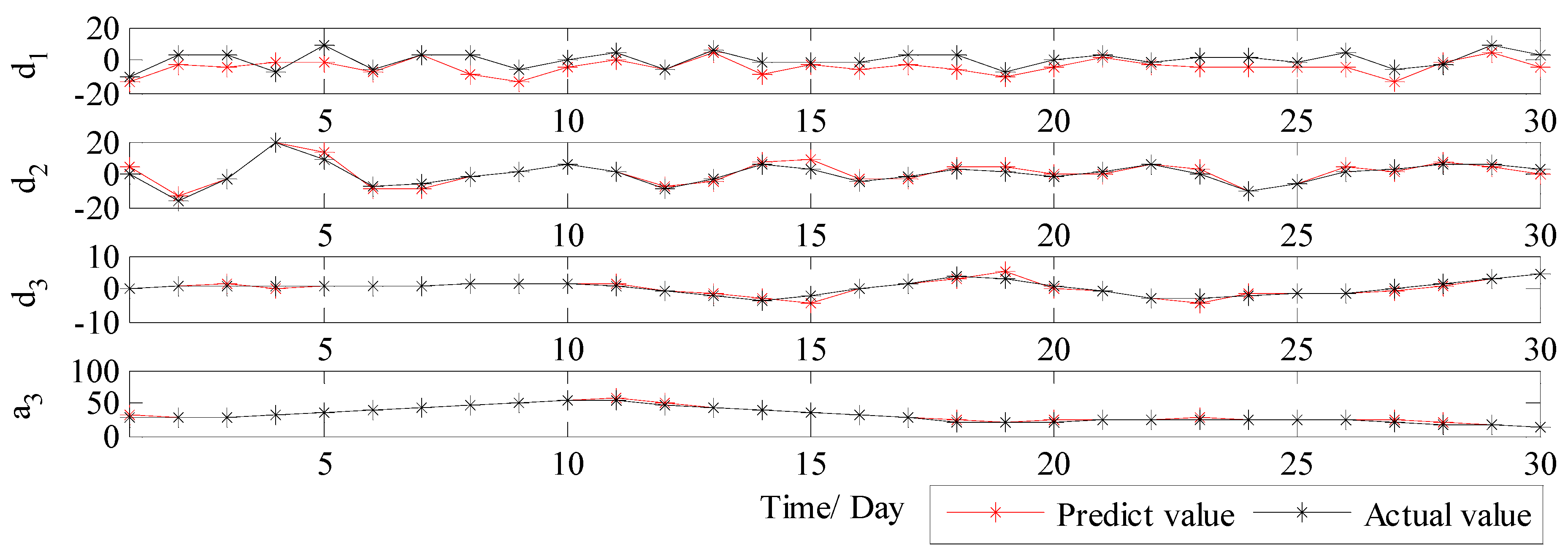
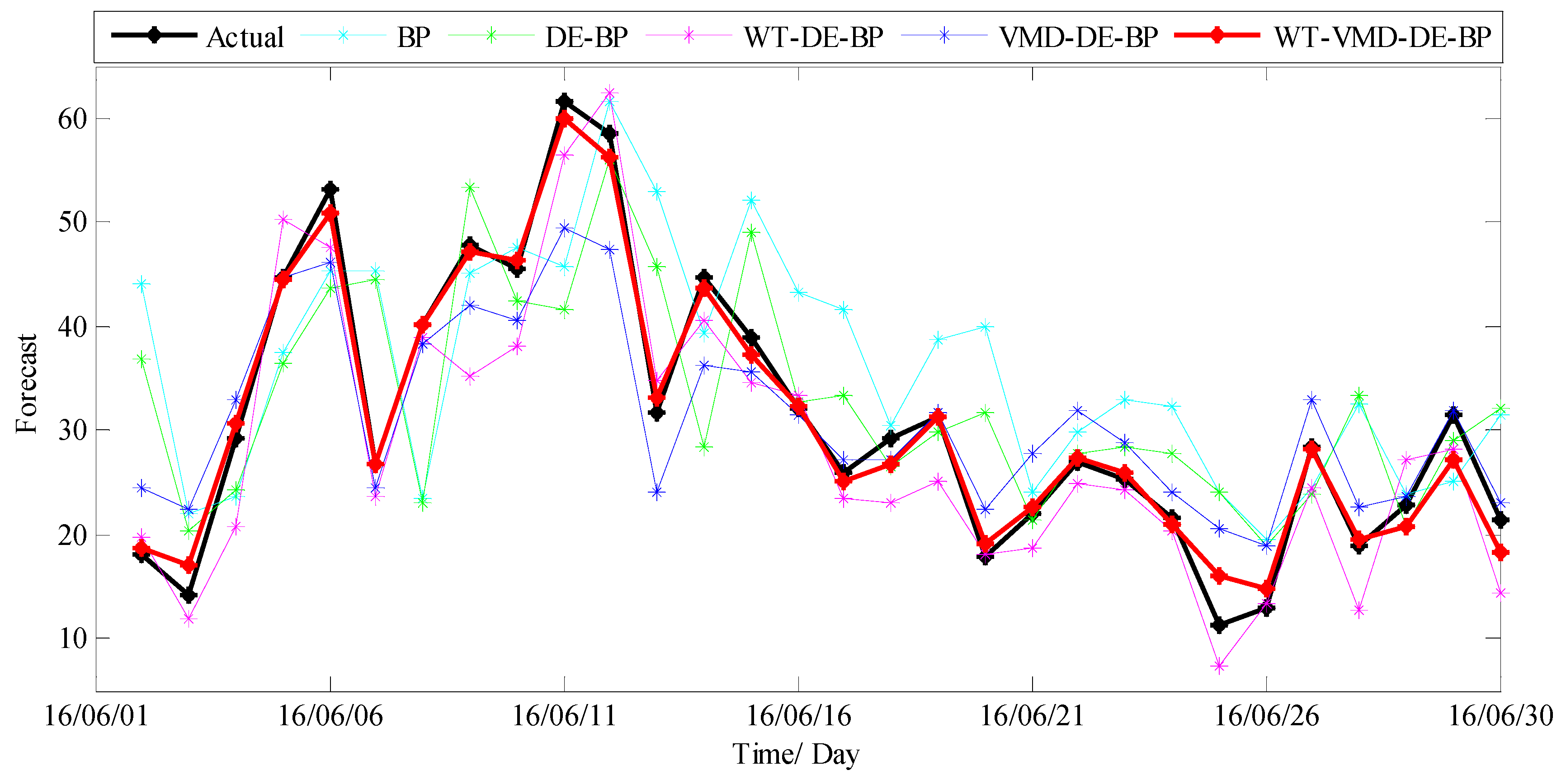
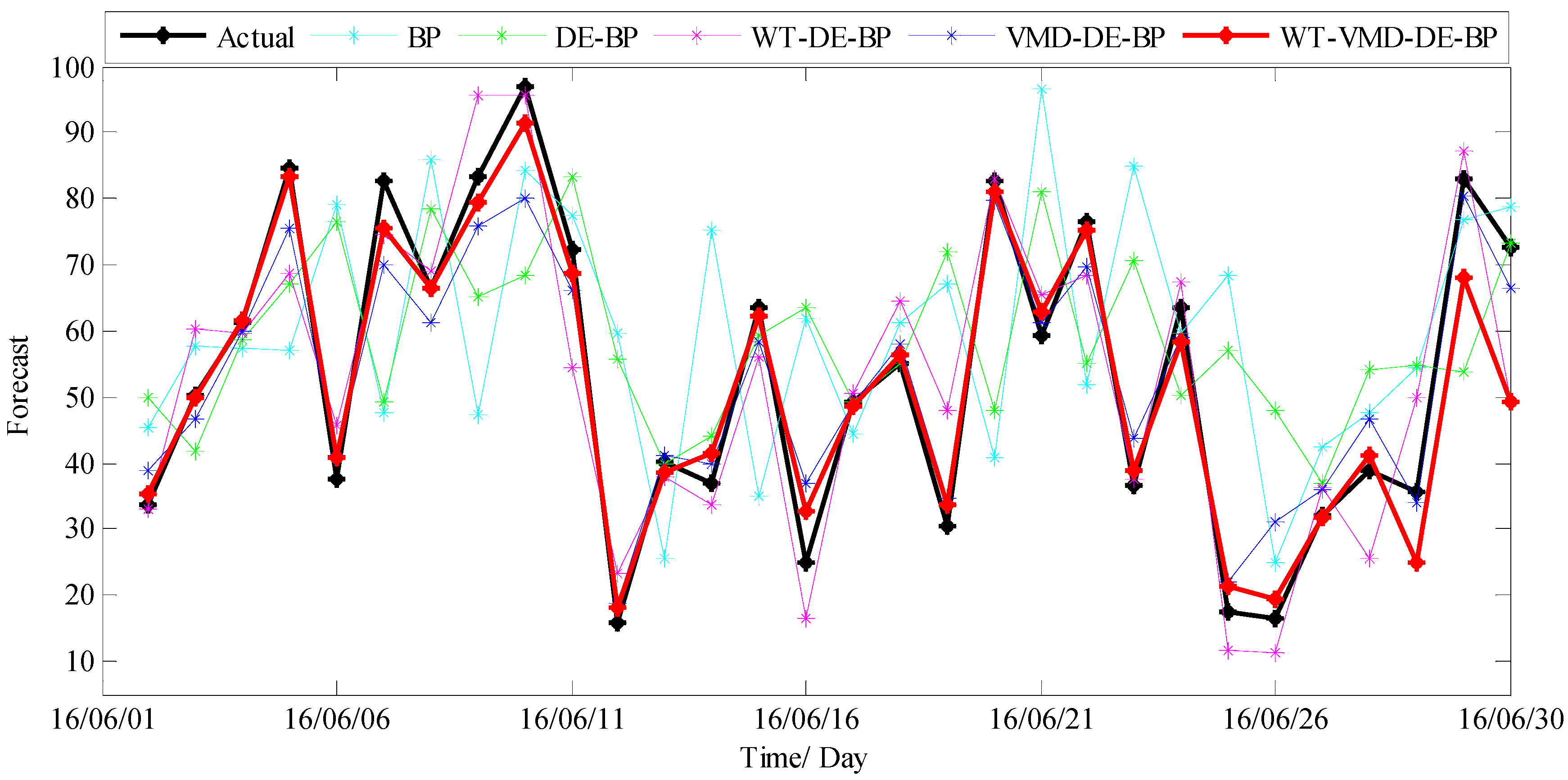
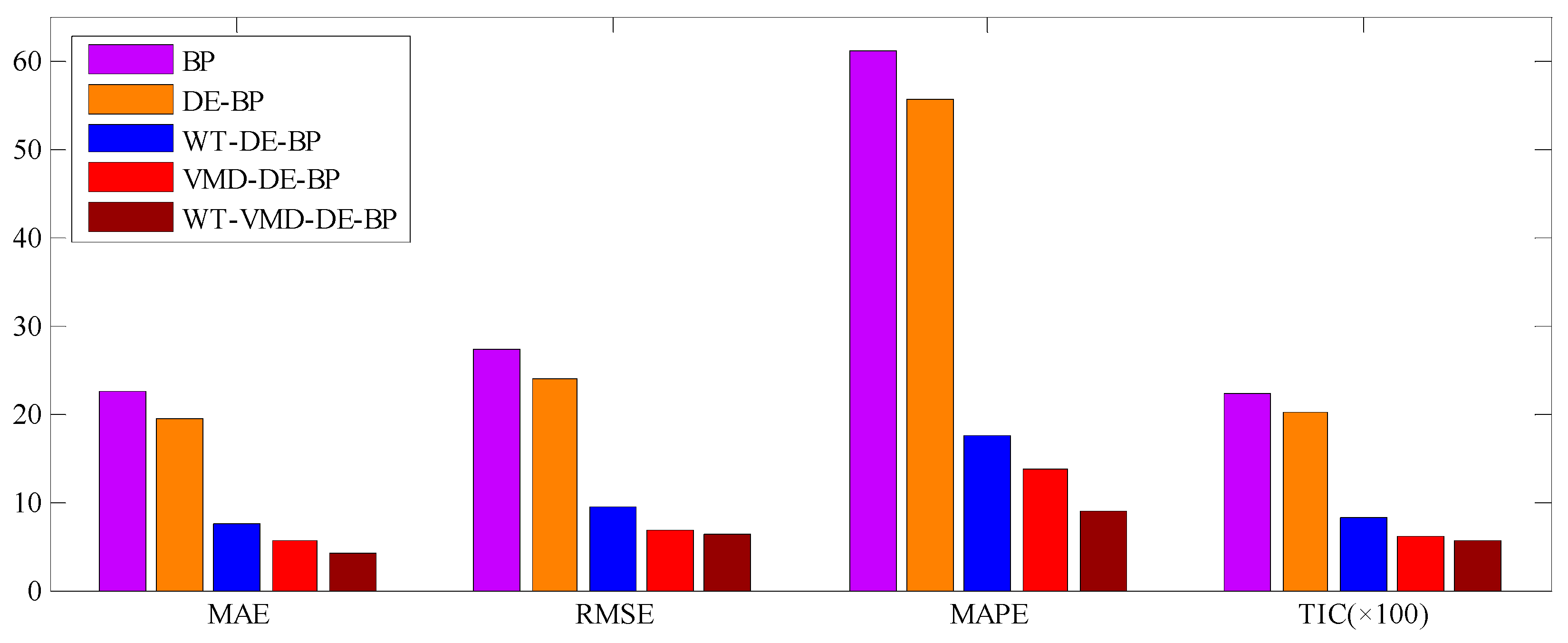
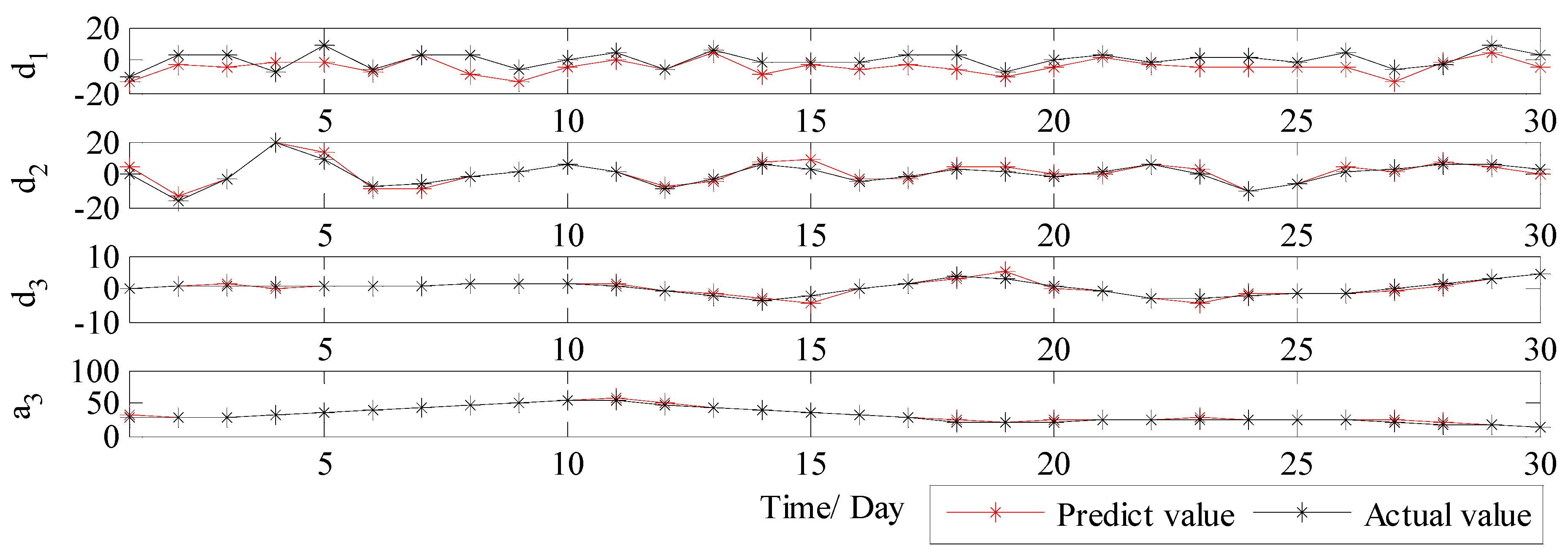
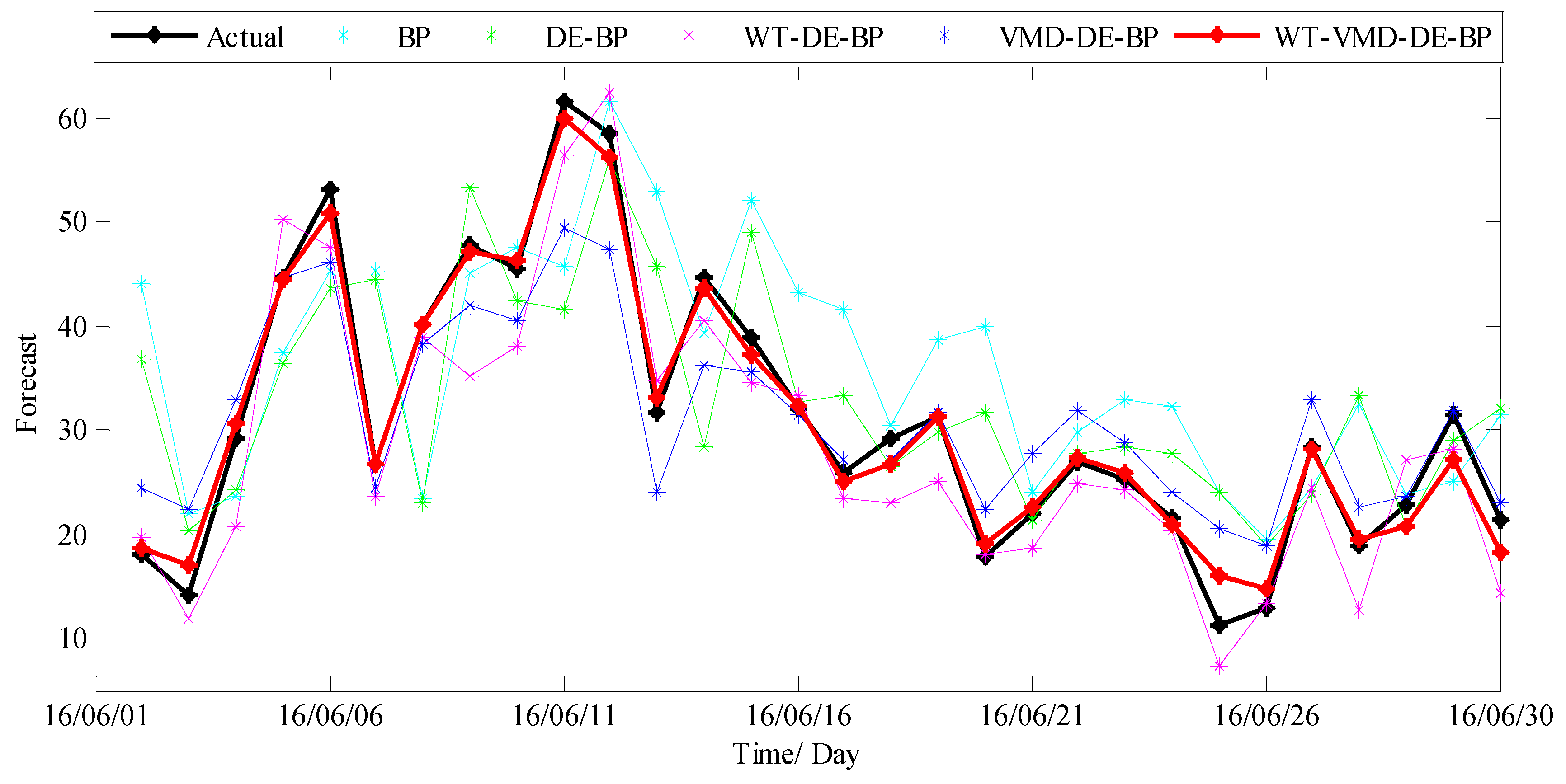
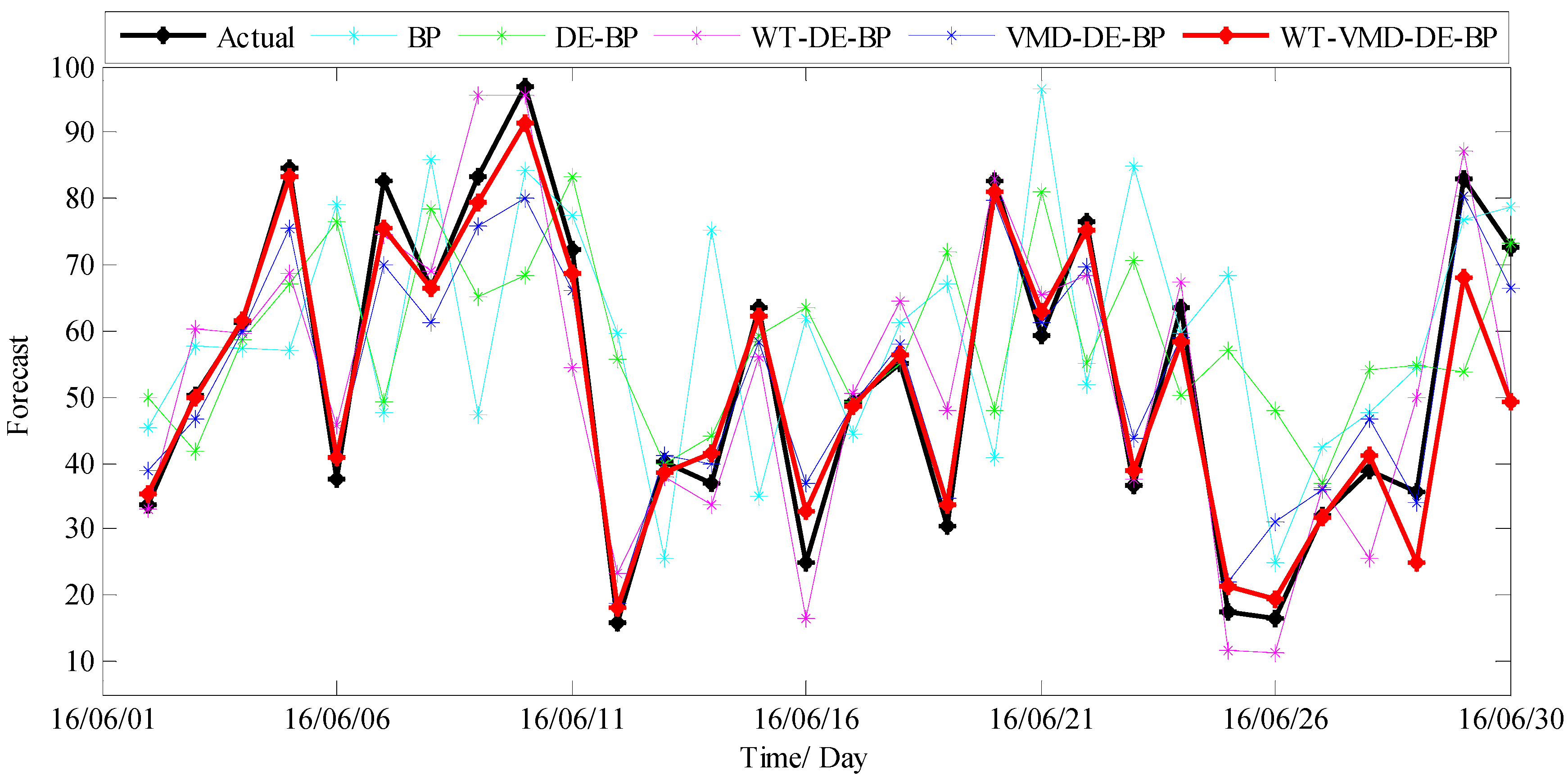
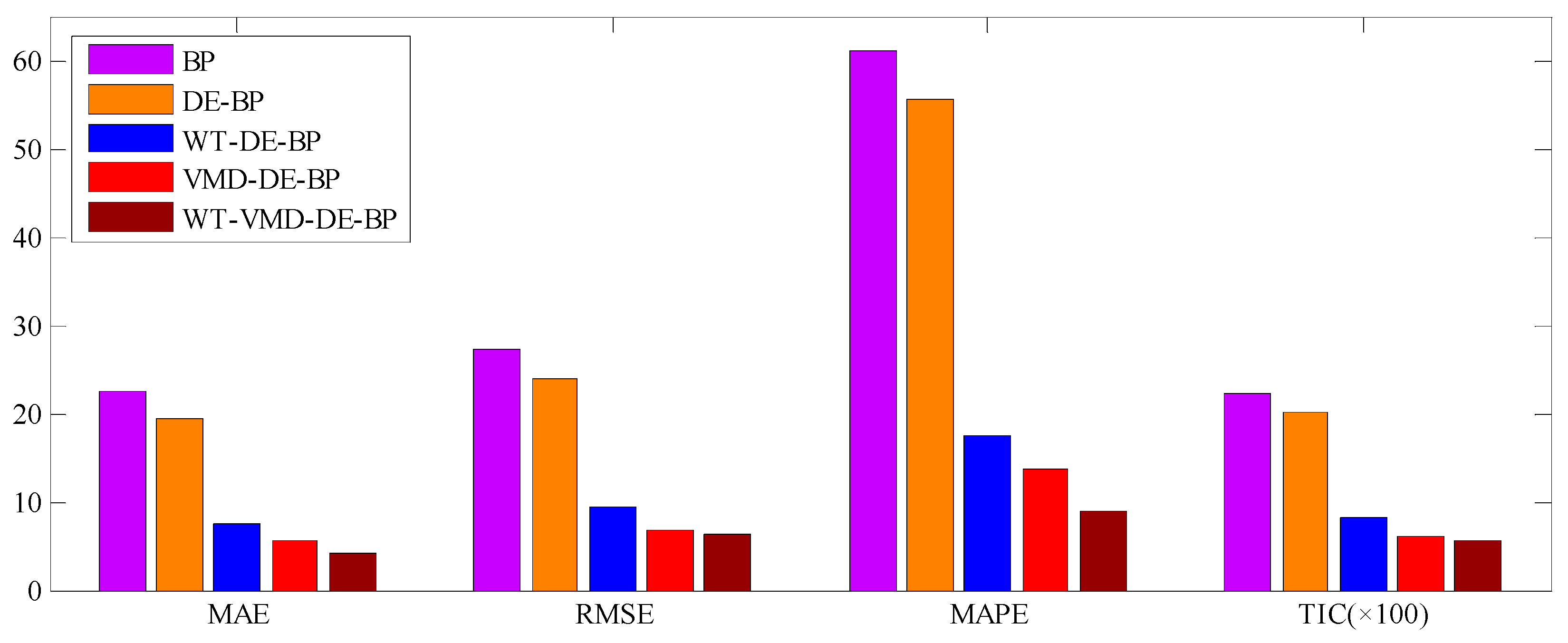
3.3.2. Results and Discussions
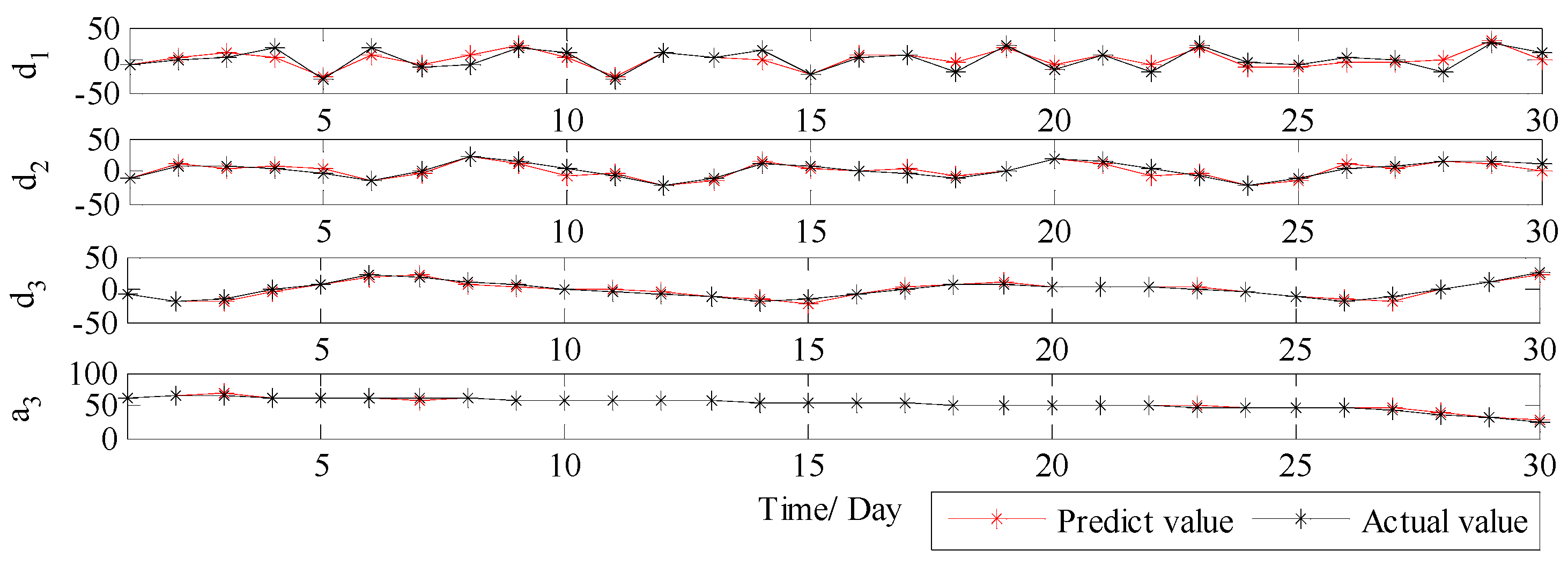
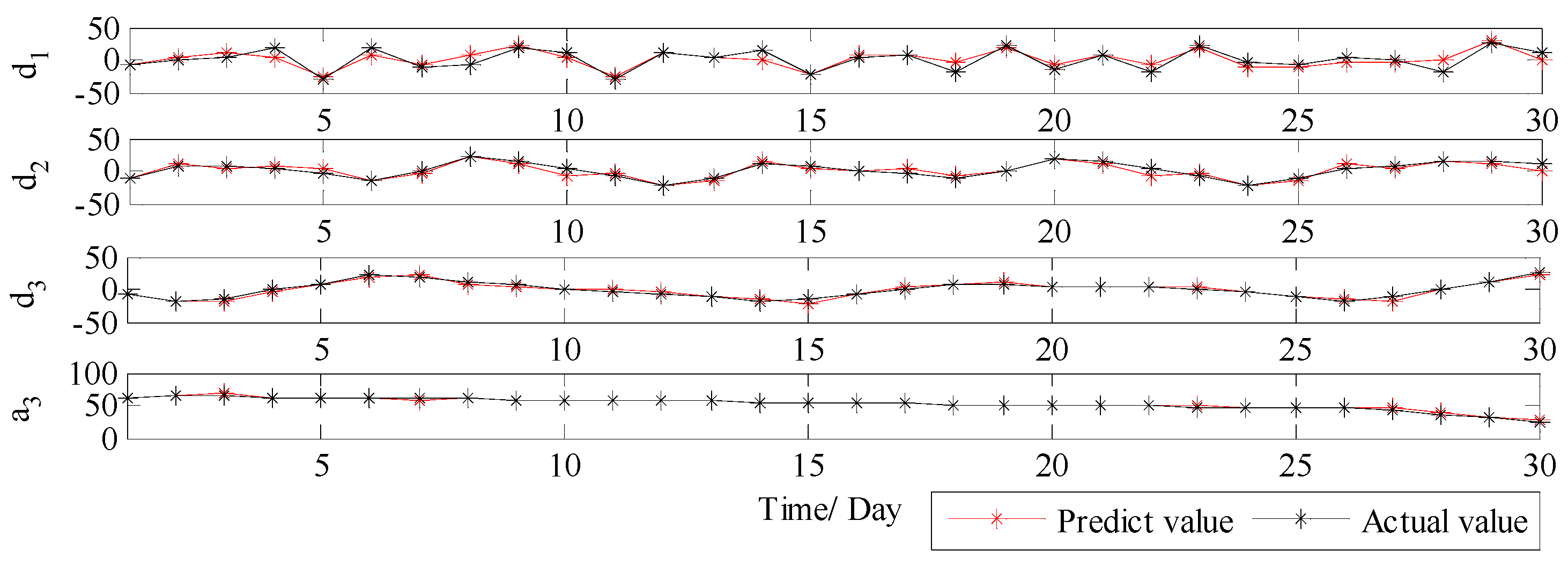
3.3.3. PM2.5 Concentration Forecasting in Tianjin
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Zhang, X.Y.; Wang, Y.Q.; Niu, T.; Zhang, X.C.; Gong, S.L.; Zhang, Y.M.; Sun, J.Y. Atmospheric aerosol compositions in China: Spatial/temporal variability, chemical signature, regional haze distribution and comparisons with global aerosols. Atmos. Chem. Phys. 2012, 12, 779–799. [Google Scholar] [CrossRef]
- Zhou, Q.P.; Jiang, H.Y.; Wang, J.Z.; Zhou, J.L. A hybrid model for PM2.5 forecasting based on ensemble empirical mode decomposition and a general regression neural network. Sci. Total Environ. 2014, 496, 264–274. [Google Scholar] [CrossRef] [PubMed]
- Mishra, D.; Goyal, P.; Upadhyay, A. Artificial intelligence based approach to forecast PM2.5 during haze episodes: A case study of Delhi, India. Atmos. Environ. 2015, 102, 239–248. [Google Scholar] [CrossRef]
- Qiao, T.; Zhao, M.; Xiu, G.; Yu, J.Z. Simultaneous monitoring and compositions analysis of PM1, and PM2.5 in Shanghai: Implications for characterization of haze pollution and source apportionment. Sci. Total Environ. 2016, 557, 286–394. [Google Scholar]
- Ye, X.N.; Ma, Z.; Zhang, J.C.; Du, H.H.; Chen, J.M.; Chen, H.; Yang, X.; Gao, W.; Geng, F.H. Important role of ammonia on haze formation in Shanghai. Environ. Res. Lett. 2011, 6, 1–5. [Google Scholar] [CrossRef]
- Donkelaar, A.; Martin, R.; Brauer, M.; Kahn, R.; Levy, R.; Verduzco, C.; Villeneuve, P.J. Global estimates of ambient fine particulate matter concentrations from satellite-based aerosol optical depth: Development and application. Environ. Health Perspect. 2010, 118, 847–855. [Google Scholar] [CrossRef] [PubMed]
- Lv, B.L.; Cobourn, W.G.; Bai, Y.Q. Development of nonlinear empirical models to forecast daily PM2.5 and ozone levels in three large Chinese cities. Atmos. Environ. 2016, 147, 209–223. [Google Scholar] [CrossRef]
- Liu, S.K.; Cai, S.; Chen, Y.; Xiao, B.; Chen, P.; Xiang, X.D. The effect of pollutional haze on pulmonary function. J. Thorac. Dis. 2016, 8, 41–56. [Google Scholar]
- World Health Organization (WHO). Health Risks of Particulate Matter from Long-Range Transboundary Air Pollution; WHO Regional Office for Europe: Copenhagen, Danmark, 2006. [Google Scholar]
- Li, H.; Wu, H.; Wang, Q.; Yang, M.; Li, F.; Sun, Y.X.; Qian, X.; Wanga, J.; Wanga, C. Chemical partitioning of fine particle-bound metals on haze-fog and non-haze-fog days in Nanjing, China and its contribution to human health risks. Atmos. Res. 2016, 183, 142–150. [Google Scholar] [CrossRef]
- Feng, X.; Li, Q.; Zhu, Y.; Hou, J.; Jin, L.; Wang, J. Artificial neural networks forecasting of PM2.5 pollution using air mass trajectory based geographic model and wavelet transformation. Atmos. Environ. 2015, 107, 118–128. [Google Scholar] [CrossRef]
- Liu, D.J.; Li, L. Application study of comprehensive forecasting model based on entropy weighting method on trend of PM2.5 concentration in Guangzhou, China. Int. J. Environ. Res. Public Health. 2015, 12, 7085–7099. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.Y.; Shi, R.H.; Shu, S.J.; Gao, W. Ensemble and enhanced PM10 concentration forecast model based on stepwise regression and wavelet analysis. Atmos. Environ. 2013, 74, 346–359. [Google Scholar] [CrossRef]
- Djalalova, I.; Monache, L.D.; Wilczak, J. PM2.5 analog forecast and Kalman filter post-processing for the Community Multi-scale Air Quality (CMAQ) model. Atmos. Environ. 2015, 108, 76–87. [Google Scholar] [CrossRef]
- Zhang, H.; Zhang, W.D.; Palazoglu, A.; Sun, W. Prediction of ozone levels using a hidden Markov model (HMM) with gamma distribution. Atmos. Environ. 2012, 62, 64–73. [Google Scholar] [CrossRef]
- Niu, M.; Wang, Y.; Sun, S.; Li, Y. A novel hybrid decomposition-and-ensemble model based on CEEMD and GWO for short-term PM2.5, concentration forecasting. Atmos. Environ. 2016, 134, 168–180. [Google Scholar] [CrossRef]
- Konovalov, I.B.; Beekmann, M.; Meleux, F.; Dutot, A.; Foret, G. Combining deterministic and statistical approaches for PM10 forecasting in Europe. Atmos. Environ. 2009, 43, 6425–6434. [Google Scholar] [CrossRef]
- Song, Y.; Qin, S.; Qu, J.; Liu, F. The forecasting research of early warning systems for atmospheric pollutants: A case in Yangtze River Delta region. Atmos. Environ. 2015, 118, 58–69. [Google Scholar] [CrossRef]
- Sun, W.; Sun, J.Y. Daily PM2.5 concentration prediction based on principal component analysis and LSSVM optimized by cuckoo search algorithm. J. Environ. Manag. 2017, 188, 144–152. [Google Scholar] [CrossRef] [PubMed]
- Jian, L.; Zhao, Y.; Zhu, Y.P.; Zhang, M.B.; Bertolatti, D. An application of ARIMA model to predict submicron particle concentrations from meteorological factors at a busy roadside in Hangzhou, China. Sci. Total Environ. 2012, 426, 336–345. [Google Scholar] [CrossRef] [PubMed]
- Stadlober, E.; Hörmann, S.; Pfeiler, B. Quality and performance of a PM10 daily forecasting model. Atmos. Environ. 2008, 42, 1098–1109. [Google Scholar] [CrossRef]
- Kumar, U.; Ridder, K.D. GARCH modeling in association with FFT-ARIMA to forecast ozone episodes. Atmos. Environ. 2010, 44, 4252–4265. [Google Scholar] [CrossRef]
- Pai, T.Y.; Ho, C.L.; Chen, S.W.; Lo, H.M.; Sung, P.J.; Lin, S.W.; Lai, W.-J.; Tseng, S.-C.; Ciou, S.-P.; Kuo, J.-L.; et al. Using seven types of GM (1.1) model to forecast hourly particulate matter concentration in Banciao City of Taiwan. Water Air Soil Pollut. 2011, 217, 25–33. [Google Scholar] [CrossRef]
- Sun, W.; Zhang, H.; Palazoglu, A.; Singh, A.; Zhang, W.D.; Liu, S.W. Prediction of 24-hour-average PM2.5 concentrations using a hidden Markov model with different emission distributions in Northern California. Sci. Total Environ. 2013, 443, 93–103. [Google Scholar] [CrossRef] [PubMed]
- Ordieres, J.B.; Vergara, E.P.; Capuz, R.S.; Salazar, R.E. Neural network prediction model for fine particulate matter (PM2.5) on the US-Mexico border in El Paso (Texas) and Ciudad Juárez (Chihuahua). Environ. Modell. Softw. 2005, 20, 547–559. [Google Scholar] [CrossRef]
- Voukantsis, D.; Karatzas, K.; Kukkonen, J.; Räsänen, T.; Karppinen, A.; Kolehmainen, M. Inter comparison of air quality data using principal component analysis, and forecasting of PM10 and PM2.5 concentrations using artificial neural networks, in Thessaloniki and Helsinki. Sci. Total Environ. 2011, 409, 1266–1276. [Google Scholar] [CrossRef] [PubMed]
- Lin, K.P.; Pai, P.F.; Yang, S.L. Forecasting concentrations of air pollutants by logarithm support vector regression with immune algorithms. Appl. Math. Comput. 2011, 217, 5318–5327. [Google Scholar] [CrossRef]
- Perez, P. Combined model for PM10 forecasting in a large city. Atmos. Environ. 2012, 60, 271–276. [Google Scholar] [CrossRef]
- Antanasijević, D.Z.; Pocajt, V.V.; Povrenović, D.S.; Ristić, M.D.; Perić-Grujić, A.A. PM10 emission forecasting using artificial neural networks and genetic algorithm input variable optimization. Sci. Total Environ. 2013, 443, 511–519. [Google Scholar] [CrossRef] [PubMed]
- Bai, Y.; Li, Y.; Wang, X.X.; Xie, J.J.; Li, C. Air pollutants concentrations forecasting using back propagation neural network based on wavelet decomposition with meteorological conditions. Atmos. Pollut. Res. 2016, 7, 557–566. [Google Scholar] [CrossRef]
- Liu, H.; Tian, H.Q.; Li, Y.F. Four wind speed multi-step forecasting models using extreme learning machines and signal decomposing algorithms. Energy Convers. Manag. 2015, 100, 16–22. [Google Scholar] [CrossRef]
- Wang, D.Y.; Luo, H.Y.; Grunder, O.; Lin, Y.B.; Guo, H.X. Multi-step ahead electricity price forecasting using a hybrid model based on two-layer decomposition technique and BP neural network optimized by firefly algorithm. Appl. Energy 2017, 190, 390–407. [Google Scholar] [CrossRef]
- Bilgin, S.; Çolak, O.H.; Koklukaya, E.; Niyazi, A. Efficient solution for frequency band decomposition problem using wavelet packet in HRV. Digit. Signal Process. 2008, 18, 892–899. [Google Scholar] [CrossRef]
- Tascikaraoglu, A.; Sanandaji, B.M.; Poolla, K.; Varaiya, P. Exploiting sparsity of interconnections in spatio-temporal wind speed forecasting using Wavelet Transform. Appl. Energy 2016, 165, 735–747. [Google Scholar] [CrossRef]
- Amjady, N.; Keynia, F. Short-term load forecasting of power systems by combination of wavelet transform and neuro-evolutionary algorithm. Energy. 2009, 34, 46–57. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational Mode Decomposition. IEEE T. Signal. Proces. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Wang, S.; Zhang, N.; Wu, L.; Wang, Y. Wind speed forecasting based on the hybrid ensemble empirical mode decomposition and GA-BP neural network method. Renew. Energy 2016, 94, 629–636. [Google Scholar] [CrossRef]
- Wang, H.S.; Wang, Y.N.; Wang, Y.C. Cost estimation of plastic injection molding parts through integration of PSO and BP neural network. Expert Syst. Appl. 2013, 40, 418–428. [Google Scholar] [CrossRef]
- Yu, F.; Xu, X. A short-term load forecasting model of natural gas based on optimized genetic algorithm and improved BP neural network. Appl. Energy 2014, 134, 102–113. [Google Scholar] [CrossRef]
- Storn, R.; Price, K. Differential evolution—A simple and efficient heuristic for global optimization over continuous spaces. J. Global Optim. 1997, 11, 341–359. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Index | Forecast Errors of WT-DE-BP | Forecast Errors of WT-VMD-DE-BP | ||||||
|---|---|---|---|---|---|---|---|---|
| MAE | 4.97 | 1.83 | 0.45 | 1.38 | 0.85 | 1.08 | 0.17 | 0.95 |
| RMSE | 5.79 | 2.31 | 0.75 | 1.89 | 1.05 | 1.58 | 0.21 | 1.20 |
| MAPE (%) | 222.38 | 357.01 | 56.56 | 5.42 | 33.75 | 36.04 | 22.83 | 3.80 |
| TIC | 0.52 | 0.17 | 0.18 | 0.03 | 0.12 | 0.13 | 0.05 | 0.02 |
| Index | BP | DE-BP | WT-DE-BP | VMD-DE-BP | WT-VMD-DE-BP |
|---|---|---|---|---|---|
| MAE | 9.61 | 8.12 | 4.05 | 4.53 | 1.34 |
| RMSE | 11.68 | 10.08 | 4.83 | 5.54 | 1.79 |
| MAPE (%) | 39.50 | 31.94 | 13.84 | 17.88 | 5.95 |
| TIC | 0.16 | 0.14 | 0.07 | 0.08 | 0.03 |
| Index | The Proportion of Reduction | ||||
|---|---|---|---|---|---|
| WT-VMD-DE-BP | WT-VMD-DE-BP | WT-DE-BP | VMD-DE-BP | DE-BP | |
| vs. | vs. | vs. | vs. | vs. | |
| WT-DE-BP | VMD-DE-BP | DE-BP | DE-BP | BP | |
| MAE (%) | 66.91 | 70.42 | 50.12 | 44.21 | 15.50 |
| RMSE (%) | 62.94 | 67.69 | 51.08 | 45.04 | 13.69 |
| MAPE (%) | 57.01 | 66.72 | 56.67 | 44.02 | 19.14 |
| TIC (%) | 57.14 | 62.50 | 50.00 | 42.86 | 14.29 |
| Index | BP | DE-BP | WT-DE-BP | VMD-DE-BP | WT-VMD-DE-BP |
|---|---|---|---|---|---|
| MAE | 22.52 | 19.45 | 7.53 | 5.54 | 4.05 |
| RMSE | 27.28 | 23.81 | 9.50 | 6.79 | 6.25 |
| MAPE(%) | 61.03 | 55.51 | 17.49 | 13.66 | 8.88 |
| TIC | 0.22 | 0.20 | 0.08 | 0.06 | 0.05 |
| Index | The Proportion of Reduction | ||||
|---|---|---|---|---|---|
| WT-VMD-DE-BP | WT-VMD-DE-BP | WT-DE-BP | VMD-DE-BP | DE-BP | |
| vs. | vs. | vs. | vs. | vs. | |
| WT-DE-BP | VMD-DE-BP | DE-BP | DE-BP | BP | |
| MAE (%) | 46.22 | 26.89 | 61.13 | 71.51 | 11.43 |
| RMSE (%) | 34.21 | 7.95 | 60.10 | 71.48 | 10.55 |
| MAPE (%) | 49.19 | 34.99 | 68.51 | 75.39 | 9.10 |
| TIC (%) | 37.50 | 16.67 | 60.00 | 70.00 | 9.09 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Liu, Y.; Luo, H.; Yue, C.; Cheng, S. Day-Ahead PM2.5 Concentration Forecasting Using WT-VMD Based Decomposition Method and Back Propagation Neural Network Improved by Differential Evolution. Int. J. Environ. Res. Public Health 2017, 14, 764. https://doi.org/10.3390/ijerph14070764
Wang D, Liu Y, Luo H, Yue C, Cheng S. Day-Ahead PM2.5 Concentration Forecasting Using WT-VMD Based Decomposition Method and Back Propagation Neural Network Improved by Differential Evolution. International Journal of Environmental Research and Public Health. 2017; 14(7):764. https://doi.org/10.3390/ijerph14070764
Chicago/Turabian StyleWang, Deyun, Yanling Liu, Hongyuan Luo, Chenqiang Yue, and Sheng Cheng. 2017. "Day-Ahead PM2.5 Concentration Forecasting Using WT-VMD Based Decomposition Method and Back Propagation Neural Network Improved by Differential Evolution" International Journal of Environmental Research and Public Health 14, no. 7: 764. https://doi.org/10.3390/ijerph14070764