Assessment of the Eutrophication-Related Environmental Parameters in Two Mediterranean Lakes by Integrating Statistical Techniques and Self-Organizing Maps

 ,
,  ,
, 
Abstract
:1. Introduction
2. Materials and Methods
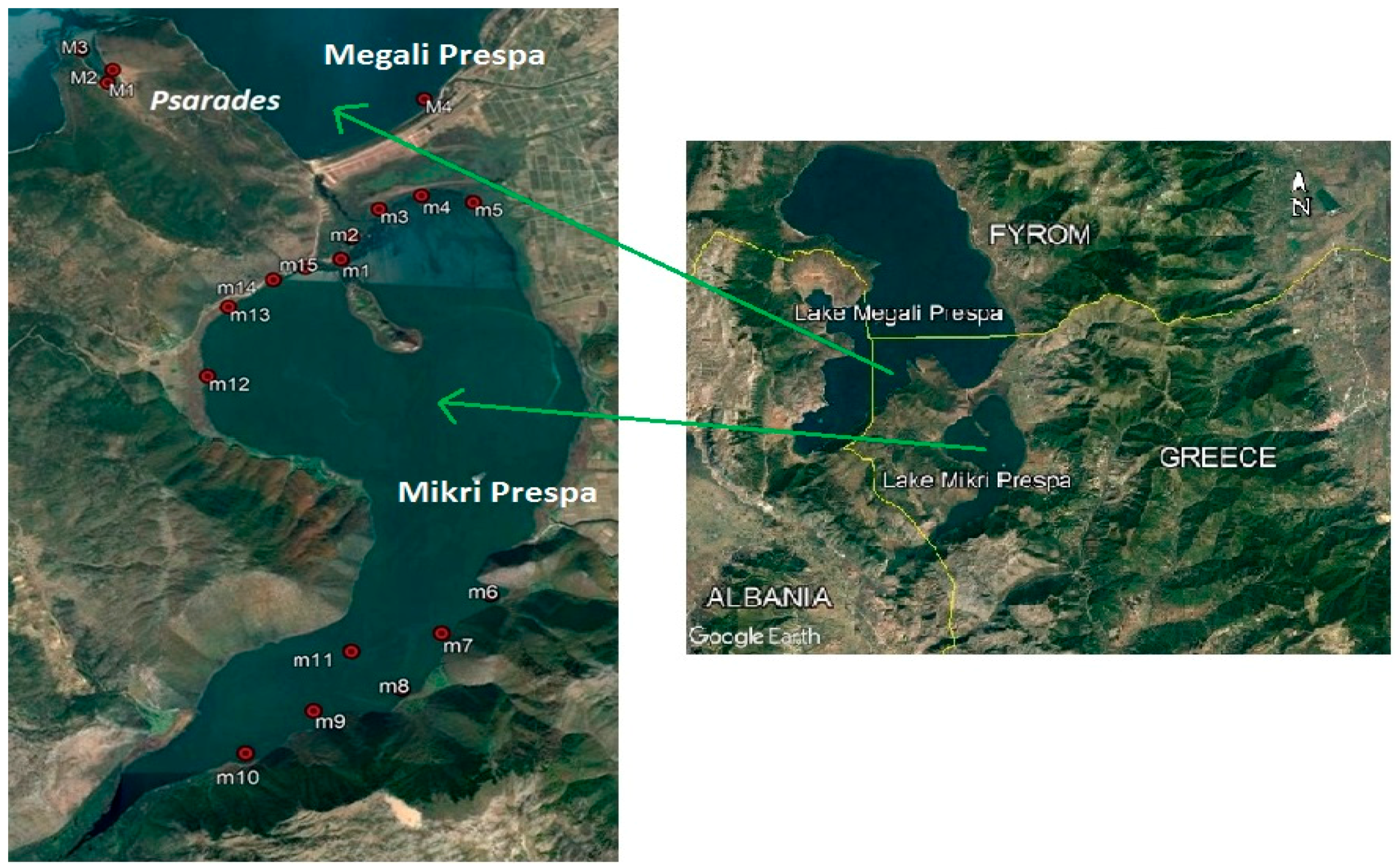
2.1. Study Area and Data Collection
2.2. Statistical Methods and Theoretical Background
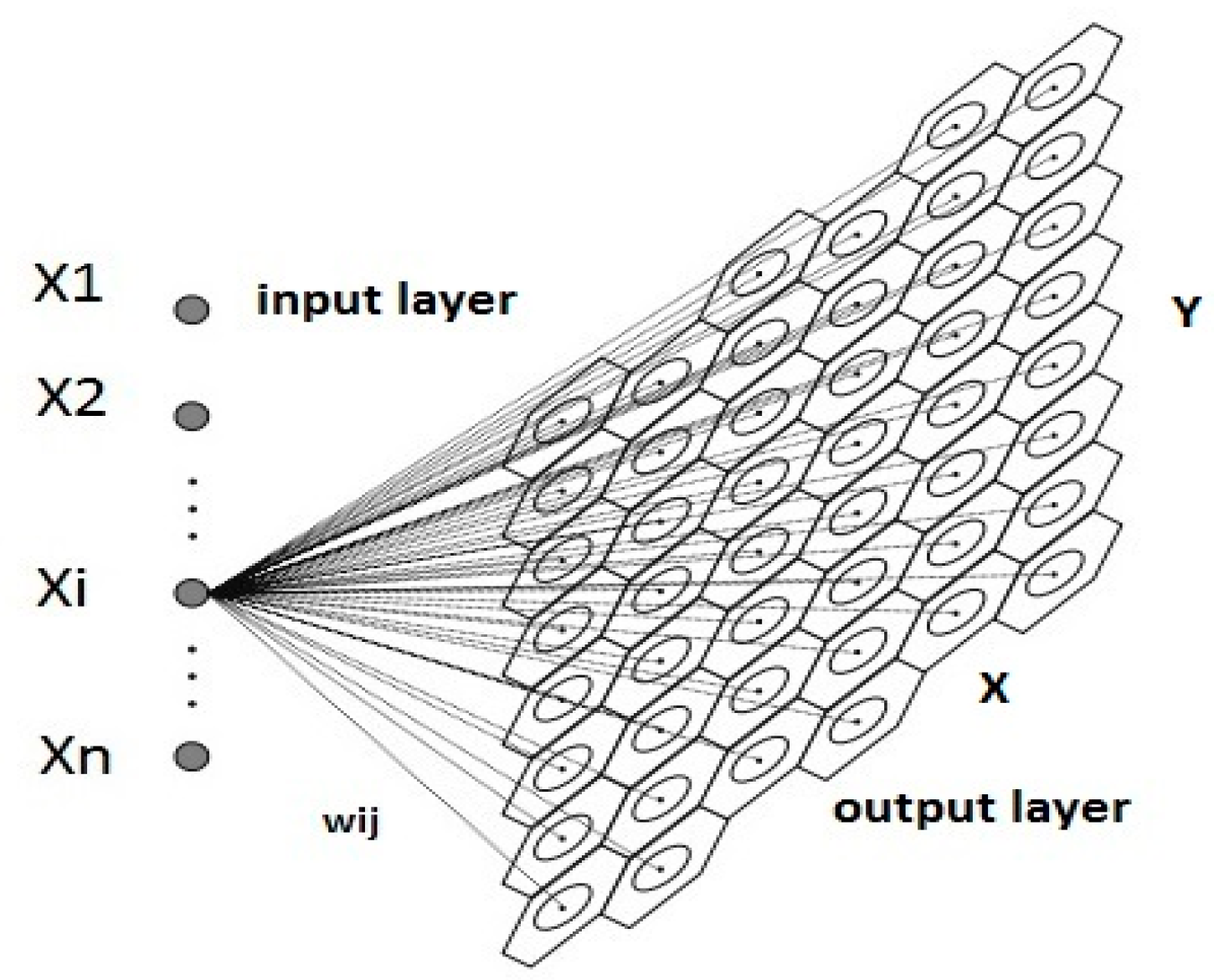
2.3. Self Organizing Map Theory
- Weight vector initialization with random values.
- Use of a distance measure, usually the Euclidean distance, to find the best-matching unit (BMU).
- Movement closer to the input vector by updating the weight vector of the BMU and the neighboring neurons.
3. Results
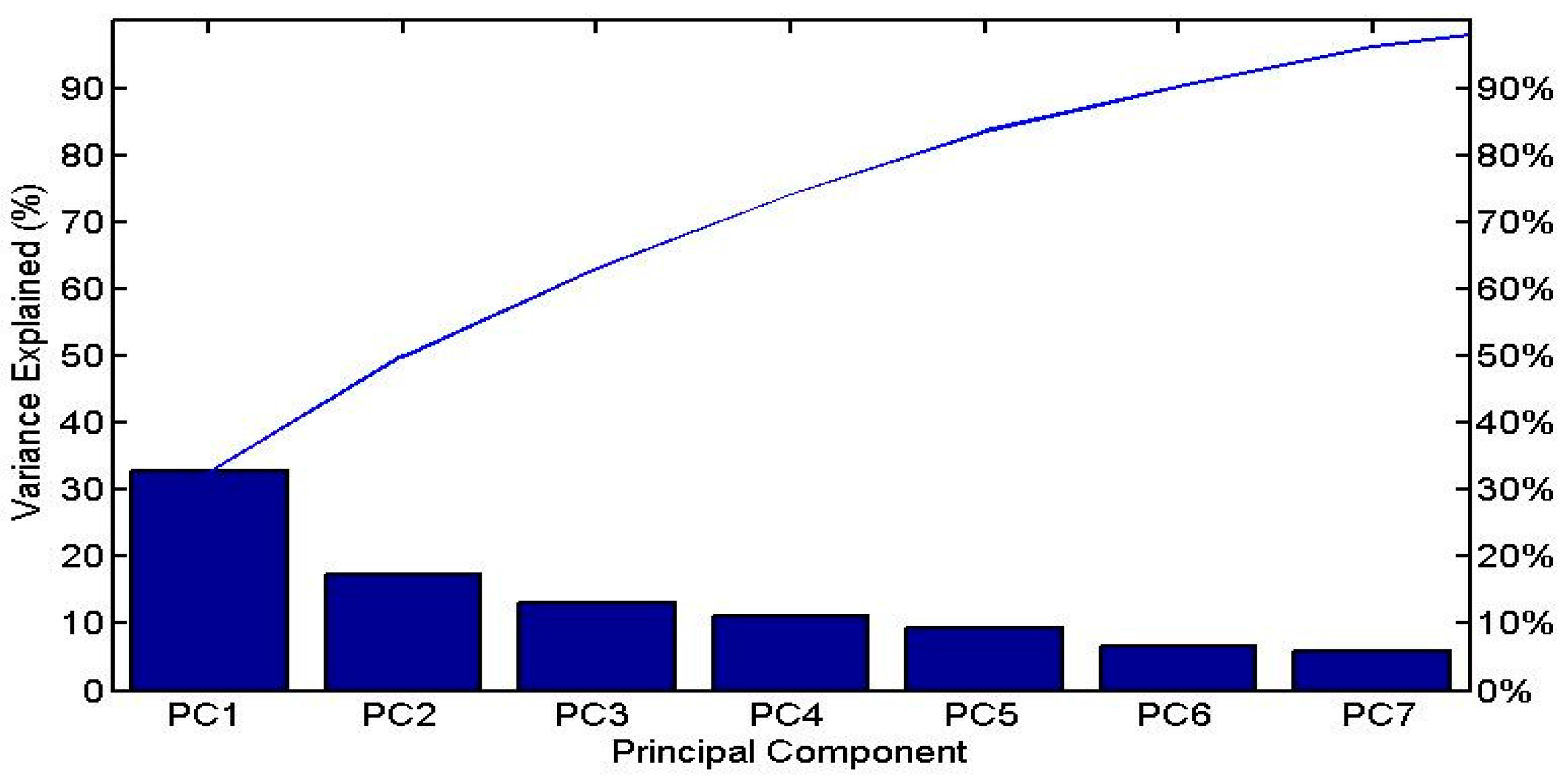
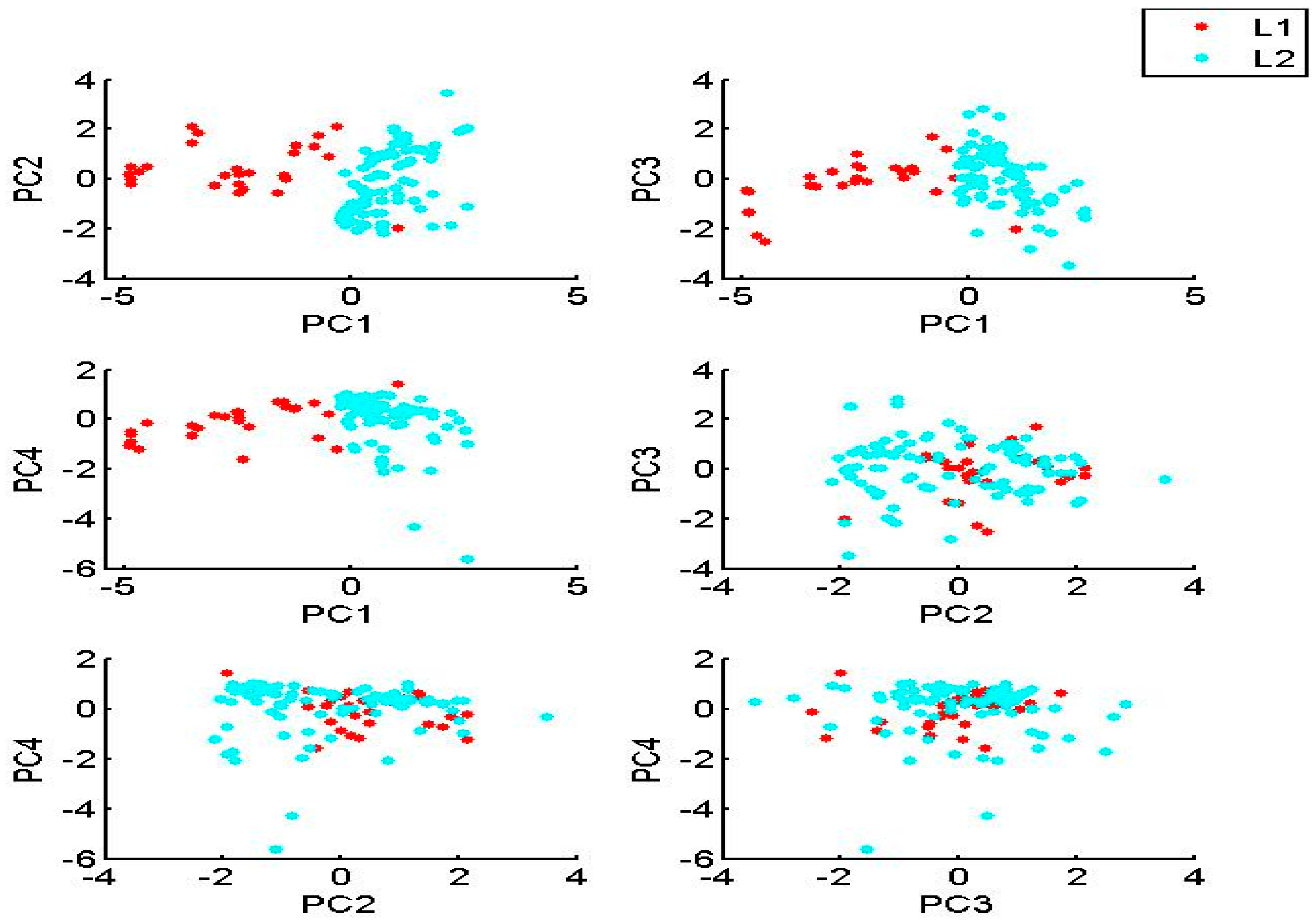
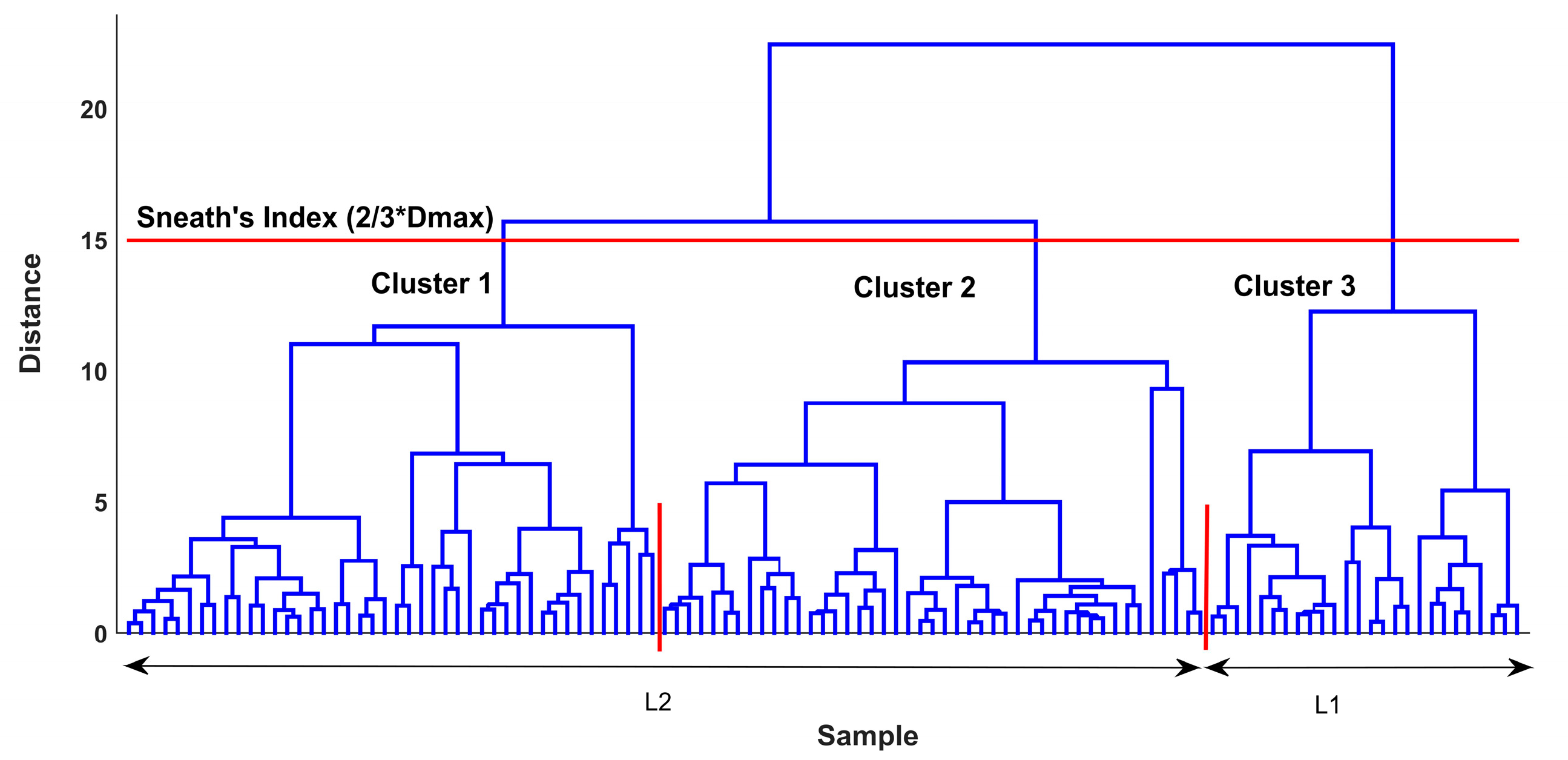
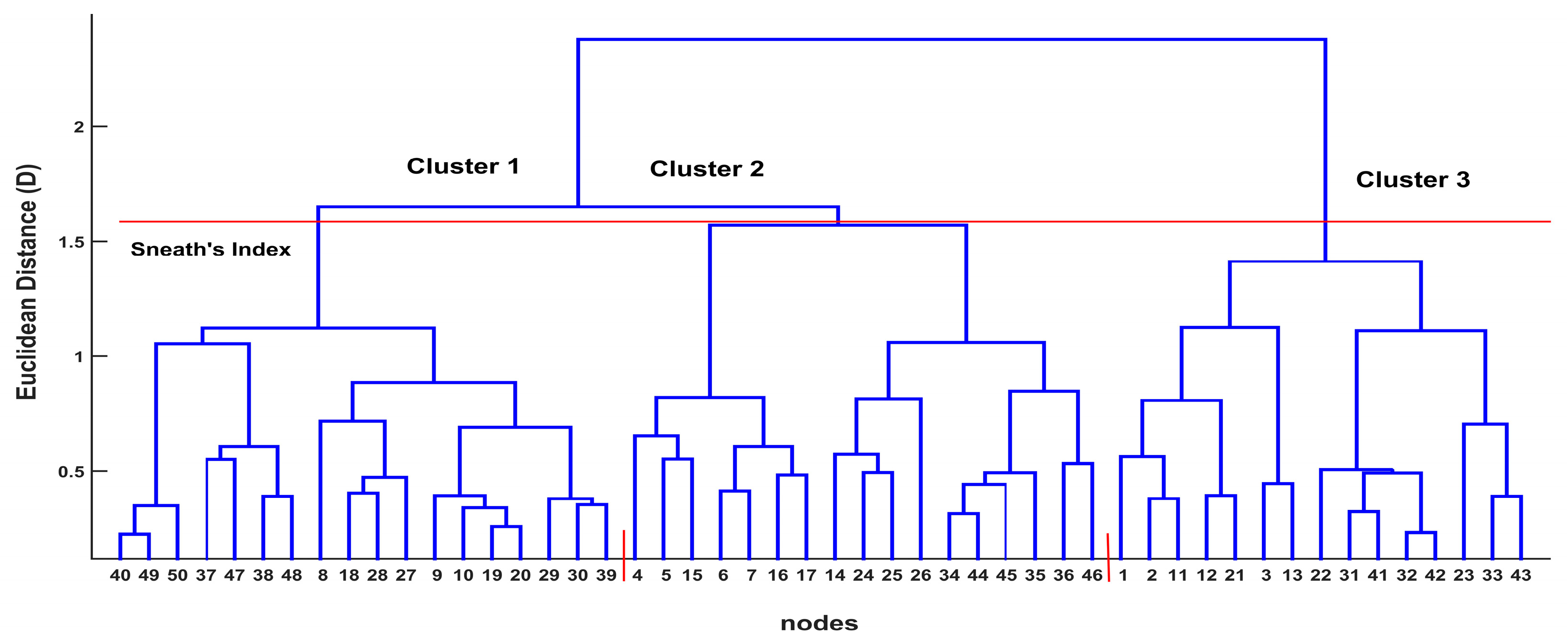
3.1. PCA and Cluster Analysis Results
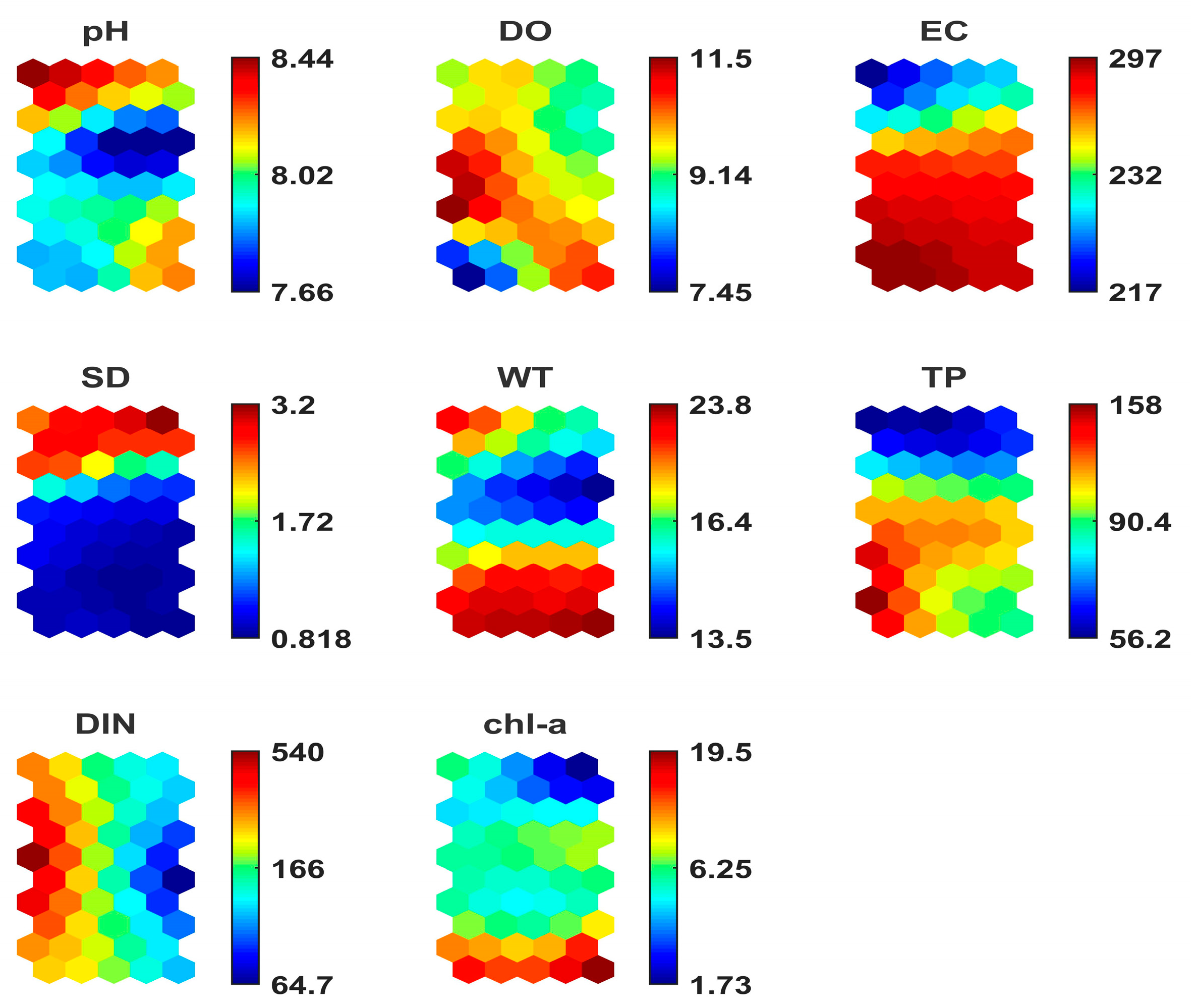
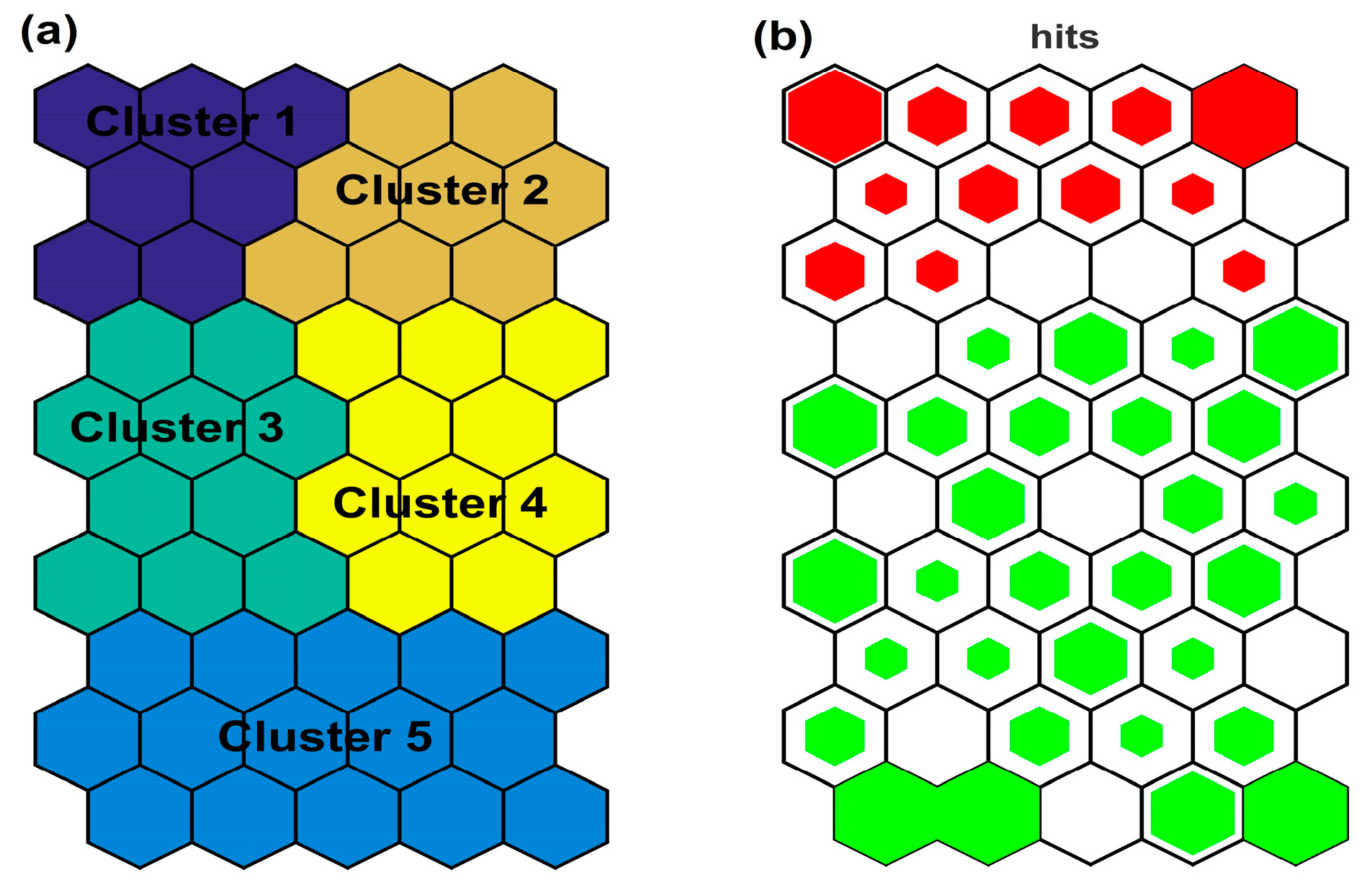
3.2. SOM Algorithm Results
4. Discussion
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Yang, X.; Wu, X.; Hao, H.; He, Z. Mechanisms and assessment of water eutrophication. J. Zhejiang Univ. Sci. B 2008, 9, 197–209. [Google Scholar] [CrossRef] [PubMed]
- Ignatiades, L.; Gotsis-Skretas, O. A review on Toxic and Harmful Algae in Greek Coastal Waters (E. Mediterranean Sea). Toxins 2010, 2, 1019–1037. [Google Scholar] [CrossRef] [PubMed]
- Hoeger, S.J.; Shaw, G.; Hitzfeld, B.C.; Dietrich, D.R. Occurrence and elimination of cyanobacterial toxins in two Australian drinking water treatment plants. Toxicon 2004, 43, 639–649. [Google Scholar] [CrossRef] [PubMed]
- Ferrente, M.; Oliver Conti, G.; Fiore, M.; Rapisarda, V. Harmful Algal Blooms in the Mediterranean Sea: Effects on Human Health. EMBJ 2013, 8, 25–34. [Google Scholar] [CrossRef]
- Maier, H.R.; Dandy, G.C. Neural Network Based Modelling of Environmental Variables: A Systematic Approach. Math. Comput. Model. 2001, 33, 669–682. [Google Scholar] [CrossRef]
- Odabas, M.S.; Leelaruban, N.; Simsek, H.; Padmanabhan, G. Quantifying impact of droughts on barley yield in North Dakota, USA using multiple linear regression and artificial neural network. Neural Netw. World 2014, 4, 343–355. [Google Scholar] [CrossRef]
- Moustris, K.; Larissi, I.; Nastos, P.; Paliatsos, A. Precipitation Forecast Using Artificial Neural Networks in Specific Regions of Greece. Water Resour. Manag. 2011, 25, 1979–1993. [Google Scholar] [CrossRef]
- Nastos, P.T.; Moustris, K.P.; Larissi, I.K.; Paliatsos, A.G. Rain intensity forecast using Artificial Neural Networks in Athens, Greece. Atmos. Res. 2013, 119, 153–160. [Google Scholar] [CrossRef]
- Simsek, H. Mathematical modeling of wastewater-derived biodegradable dissolved organic nitrogen. Environ. Technol. 2016, 37, 2879–2889. [Google Scholar] [CrossRef] [PubMed]
- Park, Y.-S.; Verdonschot, P.; Chon, T.-S.; Lek, S. Patterning and predicting aquatic macroinvertebrate diversities using artificial neural network. Water Res. 2003, 37, 1749–1758. [Google Scholar] [CrossRef]
- Peeters, L.; Bacao, F.; Lobo, V.; Dassargues, A. Exploratory data analysis and clustering of multivariate spatial hydrogeological data by means of GEO3DSOM, a variant of Kohonen’s Self-Organizing Map. Hydrol. Earth Syst. Sci. 2007, 11, 1309–1321. [Google Scholar] [CrossRef] [Green Version]
- Tsai, W.-P.; Huang, S.-P.; Cheng, S.-T.; Shao, K.-T.; Chang, F.-J. A data-mining framework for exploring the multi-relation between fish species and water quality through self-organizing map. Sci. Total Environ. 2017, 579, 474–483. [Google Scholar] [CrossRef] [PubMed]
- Ejarque-Gonzalez, E.; Butturini, A. Self-Organising Maps and Correlation Analysis as a Tool to Explore Patterns in Excitation-Emission Matrix Data Sets and to Discriminate Dissolved Organic Matter Fluorescence Components. PLoS ONE 2014, 9, e99618. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lee, B.-H.; Scholz, M. A comparative study: Prediction of constructed treatment wetland performance with k-nearest neighbors and neural networks. Water Air Soil Pollut. 2006, 174, 279–301. [Google Scholar] [CrossRef]
- Lee, B.-H.; Scholz, M. Application of the self-organizing map (SOM) to assess the heavy metal removal performance in experimental constructed wetlands. Water Res. 2006, 40, 3367–3374. [Google Scholar] [CrossRef] [PubMed]
- Recknagel, F.; Talib, A.; van der Molen, D. Phytoplankton community dynamics of two adjacent Dutch lakes in response to seasons and eutrophication control unravelled by non-supervised artificial neural networks. Ecol. Inform. 2006, 1, 277–285. [Google Scholar] [CrossRef]
- Oh, H.-M.; Ahn, C.-Y.; Lee, J.-W.; Chon, T.-S.; Choi, K.H.; Park, Y.-S. Community patterning and identification of predominant factors in algal bloom in Daechung Reservoir (Korea) using artificial neural networks. Ecol. Model. 2007, 203, 109–118. [Google Scholar] [CrossRef]
- Cheng, L.; Lek, S.; Lek-Ang, S.; Li, Z. Predicting fish assemblages and diversity in shallow lakes in the Yangtze River basin. Limnologica 2012, 42, 127–136. [Google Scholar] [CrossRef]
- Tota-Maharaj, K.; Scholz, M. Modeling of Permeable Pavements for Treatment of Urban Runoff using Self-Organizing Maps. Environ. Eng. Manag. J. 2013, 12, 2273–2287. [Google Scholar]
- Pyrovetsi, M. Integrated Mediterranean Programmes and the Natural Environment: A case study in Greece. Environmentalist 1989, 9, 201–211. [Google Scholar] [CrossRef]
- Panagiotopoulos, K.; Aufgebauer, A.; Schäbitz, F.; Wagner, B. Vegetation and climate history of the Lake Prespa region since the Lateglacial. Quat. Int. 2013, 293, 157–169. [Google Scholar] [CrossRef]
- Koussouris, T.S.; Diapoulis, A.C.; Balopoulos, E.T. Assessing the trophic status of Lake MikriPrespa, Greece. Ann. Limnol. 1989, 25, 17–24. [Google Scholar] [CrossRef]
- Cvetkoska, A.; Jovanovska, E.; Francke, A.; Tofilovska, S.; Vogel, H.; Levkov, Z.; Donders, T.H.; Wagner, B.; Wagner-Cremer, F. Ecosystems regimes and responses in a coupled ancient lake system from MIS 5b to present: The diatom record of lakes Ohrid and Prespa. Biogeosciences 2016, 13, 3147–3162. [Google Scholar] [CrossRef] [Green Version]
- Kagalou, I.; Leonardos, I. Typology, classification and management issues of Greek lakes: Implication of the Water Framework Directive (2000/60/EC). Environ. Monit. Assess. 2009, 150, 469–484. [Google Scholar] [CrossRef] [PubMed]
- Loffler, H.; Schiller, E.; Kusel, E.; Kraill, H. Lake Prespa, a European natural monument, endangered by irrigation and eutrophication? Hydrobiologia 1998, 384, 69–74. [Google Scholar] [CrossRef]
- Albrecht, C.; Hauffe, T.; Schreiber, K.; Wilke, T. Mollusc biodiversity in a European ancient lake system: Lakes Prespa and MikriPrespa in the Balkans. Hydrobiologia 2012, 682, 47–59. [Google Scholar] [CrossRef]
- Stefanidis, K.; Papastergiadou, E. Influence of hydrophyte abundance on the spatial distribution of zooplankton in selected lakes in Greece. Hydrobiologia 2010, 656, 55–65. [Google Scholar] [CrossRef]
- Leng, M.; Wagner, B.; Boehm, A.; Panagiotopoulos, K.; Vane, C.H.; Snelling, A.; Haidon, C.; Woodley, E.; Vogel, H.; Zanchetta, G.; et al. Understanding past climatic and hydrological variability in the Mediterranean from lake Prespa sediment isotope and geochemical record over the Last Glacial cycle. Quat. Sci. Rev. 2013, 66, 123–166. [Google Scholar] [CrossRef] [Green Version]
- Aufgebauer, A.; Panagiotopoulos, K.; Wagner, B.; Schaebitz, F.; Viehberg, F.; Vogel, H.; Zanchetta, G.; Sulpizio, R.; Leng, M.J.; Damaschke, M. Climate and environmental change in the Balkans over the 17 ka recorded in sediments from Lake Prespa (Albania/F.Y.R. of Macedonia/Greece). Quat. Int. 2012, 274, 122–135. [Google Scholar] [CrossRef]
- Vardaka, E.; Moustaka-Gouni, M.; Cook, C.; Lanaras, T. Cyanobacterial Blooms and water quality in Greek waterbodies. J. Appl. Phycol. 2005, 17, 391–401. [Google Scholar] [CrossRef]
- Hardle, W.; Simar, L. Applied Multivariate Statistical Analysis; Springer: Berlin/Heidelberg, Germany, 2003. [Google Scholar]
- Birks, J.B.H. Overview of Numerical Methods in Paleolimnology. In Tracking Environmental Change Using Lake Sediments: Data Handling and Numerical Techniques; Birks, J.B.H., Lotter, A.F., Juggins, S., Smol, J.P., Eds.; Springer: London, UK, 2012; Volume 5, pp. 35–86. [Google Scholar]
- Mueller, U.A.; Grunsky, E.C. Multivariate spatial analysis of lake sediment geochemical data; Melville Peninsula, Nuvanut, Canada. Appl. Geochem. 2016, 75, 247–262. [Google Scholar] [CrossRef]
- Reimann, C.; Filzmoser, P.; Garrett, R.; Dutter, R. Statistical Data Analysis Explained: Applied Environmental Statistics with R; Wiley: West Sussex, UK, 2008. [Google Scholar]
- Gore, P.A. Cluster Analysis. In Handbook of Multivariate Statistics and Mathematical Modeling; Tinsley, H.E.A., Brown, S.D., Eds.; Academic Press: San Diego, CA, USA, 2000; pp. 297–322. [Google Scholar]
- Sneath, P.H.A.; Sokal, R.R. Numerical Taxonomy; Freeman: San Fransisco, CA, USA, 1973. [Google Scholar]
- Rub, G.; Kruse, R.; Schneider, M.; Wagner, M. Visualization of Agriculture Data Using Self-Organizing Maps. In Applications and Innovations in Intelligent Systems; Allen, T., Ellis, R., Petridis, M., Eds.; Springer: London, UK, 2009; Volume XVI, pp. 47–60. [Google Scholar]
- Barreto-Sanz, M.A.; Perez-Uribe, A. Improving the correlation hunting in a large quantity of SOM Component planes. In Lecture Notes in Computer Science: Artificial Neural-Networks–ICANN 2007; de Sá, J.M., Alexandre, L.A., Duch, W., Mandic, D., Eds.; Springer: Berlin, Germany, 2007; Volume 4669, pp. 379–388. [Google Scholar]
- Kohonen, T. Self-Organizing Maps, 3rd ed.; Springer: Heidelberg/Berlin, Germany, 2001. [Google Scholar]
- Aguilera, P.A.; GarridoFrenich, A.; Torres, J.A.; Castro, H.; Martinez Vidal, J.L.; Canton, M. Application of the Kohonen Neural Network in Coastal Water Management: Methodological Development for the Assessment and Prediction of Water Quality. Water Resour. 2001, 17, 4053–4062. [Google Scholar] [CrossRef]
- Vesanto, J.; Alhoniemi, E. Clustering of the Self-Organizing Map. IEEE Trans. Neural Netw. 2000, 11, 586–600. [Google Scholar] [CrossRef] [PubMed]
- Choi, B.Y.; Yun, S.T.; Kim, K.H.; Kim, J.W.; Kim, H.M.; Koh, Y.K. Hydrochemical interpretation of South Korea groundwater monitoring data using Self-Organizing Maps. J. Geochem. Explor. 2014, 137, 73–84. [Google Scholar] [CrossRef]
- Park, Y.-S.; Lek, S.; Scardi, M.; Verdonschot, P.; Jorgensen, S.E. Patterning exergy of benthic macroinvertebrate communities using self-organizing maps. Ecol. Model. 2006, 195, 105–113. [Google Scholar] [CrossRef] [Green Version]
- An, Y.; Zou, Z.; Li, R. Descriptive Characteristics of Surface Water Quality in Hong Kong by a Self-Organising Map. Int. J. Environ. Res. Public Health 2016, 13, 115. [Google Scholar] [CrossRef] [PubMed]
- Zhang, L.; Scholz, M.; Mustafa, A.; Harrington, R. Assessment of the nutrient removal performance in integrated constructed wetlands with the self-organizing map. Water Res. 2008, 42, 3519–3527. [Google Scholar] [CrossRef] [PubMed]
- Vesanto, J.; Alhoniemi, E.; Himberg, J.; Parhankangas, J. SOM Toolbox for Matlab. 2000. Available online: http://www.cis.hut.fi/projects/somtoolbox/ (accessed on 2 May 2016).
- Wang, B.; Li, H.; Sun, D. Social-Ecological Patterns of Soil Heavy Metals Based on a Self-Organizing Map (SOM): A Case Study in Beijing, China. Int. J. Environ. Res. Public Health 2014, 11, 3618–3638. [Google Scholar] [CrossRef] [PubMed]
- Stefanidis, K.; Papastergiadou, E. Relationships between lake morphometry, water quality, and aquatic macrophytes, in Greek Lakes. Fresen. Environ. Bull. 2012, 21, 3018–3026. [Google Scholar]
- Hadjisolomou, E.; Stefanidis, K.; Papatheodorou, G.; Papastergiadou, E. Evaluating the contributing environmental parameters associated with eutrophication in a shallow lake by applying artificial neural networks techniques. Fresen. Environ. Bull. 2017, 26, 3200–3208. [Google Scholar]
- Atoui, A.; Hafez, H.; Slim, K. Occurrence of toxic cyanobacterial blooms for the first time in Lake Karaoun, Lebanon. Water Environ. J. 2013, 27, 42–49. [Google Scholar] [CrossRef]
- Kagalou, I.; Papastergiadou, E.; Leonardos, I. Long term changes in the eutrophication process in a shallow Mediterranean lake ecosystem of W. Greece: Response after the reduction of external load. J. Environ. Manag. 2008, 87, 497–506. [Google Scholar] [CrossRef] [PubMed]
- Muttil, N.; Chau, K.-W. Machine-learning paradigms for selecting ecologically significant input variables. Eng. Appl. Artif. Intell. 2007, 20, 735–744. [Google Scholar] [CrossRef] [Green Version]
- Cinar, O.; Merdun, H. Application of an unsupervised artificial neural network technique to multivariant surface water quality data. Ecol. Res. 2009, 24, 163–173. [Google Scholar] [CrossRef]
- Goncalves, M.L.; Netto, M.L.A.; Costa, J.A.F.; Zullo Junior, J. An unsupervised method of classifying remotely sensed images using Kohonen self-organizing maps and agglomerative hierarchical clustering methods. Int. J. Remote Sens. 2008, 29, 3171–3207. [Google Scholar] [CrossRef]
- Astel, A.; Tsakovski, S.; Barbieri, P.; Simeonov, V. Comparison of self-organizing maps classification approach with cluster and principal components analysis for large environmental data sets. Water Res. 2007, 41, 4566–4578. [Google Scholar] [CrossRef] [PubMed]
- Brosse, S.; Giraudel, J.L.; Lek, S. Utilisation of non-supervised neural networks and principal component analysis to study fish assemblages. Ecol. Model. 2001, 146, 159–166. [Google Scholar] [CrossRef]
- Tryfon, E.; Moustaka-Gouni, M. Species composition and seasonal cycles of phytoplankton with special reference to the nanoplankton of Lake MikriPrespa. Hydrobiologia 1997, 351, 61–75. [Google Scholar] [CrossRef]
- Jeppesen, E.; Sondergaard, M.; Lauridsen, T.L.; Kronvang, B.; Beklioglu, M.; Lammens, E.; Jensen, H.S.; Köhler, J.; Ventelä, A.M.; Tarvainen, M.; et al. Danish and other European experiences in managing shallow lakes. Lakes Reserv. Manag. 2007, 23, 439–451. [Google Scholar] [CrossRef]
- Scavia, D.; Allan, D.; Arend, K.K.; Bartell, S.; Beletsky, D.; Bosch, N.S.; Brandt, S.B.; Briland, R.D.; Daloğlu, I.; DePinto, J.V.; et al. Assessing and addressing the re-eutrophication of Lake Erie: Central basin hypoxia. J. Great Lakes Res. 2014, 40, 226–246. [Google Scholar] [CrossRef]
- Hadjisolomou, E.; Stefanidis, K.; Papatheodorou, G.; Papastergiadou, E. Assessing the Contribution of the Environmental Parameters to Eutrophication with the Use of the “PaD” and “PaD2” Methods in a Hypereutrophic Lake. Int. J. Environ. Res. Public Health 2016, 13, 764. [Google Scholar] [CrossRef] [PubMed]
- Zacharias, I.; Bertachas, I.; Skoulikidis, N.; Koussouris, T. Greek Lakes: Limnological overview. Lakes Reserv. Res. Manag. 2002, 7, 55–62. [Google Scholar] [CrossRef]
- Stefanidis, K.; Kostara, A.; Papastergiadou, E. Implications of Human Activities, Land Use Changes and Climate Variability in Mediterranean Lakes of Greece. Water 2016, 8, 483. [Google Scholar] [CrossRef]
- Jeppesen, E.; Sondergaard, M.; Liu, Z. Lake Restoration and Management in a Climate Change Perspective: An Introduction. Water 2017, 9, 122. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Variable | Mikri Prespa (n = 79) | Megali Prespa (n = 26) | ||||
|---|---|---|---|---|---|---|
| Mean | Minimum | Maximum | Mean | Minimum | Maximum | |
| pH | 7.93 | 7.00 | 8.60 | 8.32 | 8 | 8.90 |
| Dissolved oxygen (mg/L) | 9.96 | 4.50 | 18.00 | 9.75 | 5.90 | 13.00 |
| Electricalconductivity (μS/cm) | 281.94 | 245.00 | 310.00 | 221.61 | 214 | 227.00 |
| Secchi depth (m) | 0.92 | 0.40 | 2.00 | 3.35 | 1.00 | 6.00 |
| Water depth (m) | 1.39 | 0.70 | 2.50 | 6.33 | 1.50 | 12.00 |
| Water temperature (°C) | 19.20 | 12.60 | 26.1 | 18.54 | 13.80 | 24.00 |
| Total phosphorus (μg/L) | 123.47 | 17.00 | 463.00 | 77.43 | 21.90 | 249.10 |
| Dissolved inorganic nitrogen (mg/L) | 319.07 | 28.40 | 2486.00 | 249.07 | 79.50 | 808.30 |
| Chlorophyll-a (mg/m3) | 10.76 | 1.10 | 42.70 | 4.01 | 0.40 | 14.50 |
| Variable | PC1 | PC2 | PC3 | PC4 |
|---|---|---|---|---|
| pH | −0.1609 | 0.6158 | 0.1653 | −0.0569 |
| DO | −0.0350 | −0.0237 | 0.7513 | −0.1349 |
| EC | 0.4908 | −0.0198 | −0.0993 | −0.0736 |
| SD | −0.5300 | 0.0511 | −0.2700 | −0.1709 |
| Depth | −0.5171 | 0.1026 | −0.2527 | −0.1701 |
| WT | 0.2051 | 0.6144 | −0.1386 | 0.0279 |
| TP | 0.1613 | −0.2545 | −0.4452 | 0.1072 |
| DIN | 0.1248 | −0.1500 | −0.0275 | −0.9302 |
| Chl-a | 0.3230 | 0.3766 | −0.2085 | −0.1936 |
| Eigenvalue | 2.94 | 1.55 | 1.18 | 1.01 |
| Variance explained (%) | 32.68 | 17.29 | 13.08 | 11.12 |
| Cumulative variance (%) | 32.68 | 49.97 | 63.05 | 74.17 |
| Variable | Cluster 1 | Cluster 2 | Cluster 3 | Cluster 4 | Cluster 5 | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | Mean | SD | Mean | SD | |
| pH | 8.4 | 0.22 | 8.18 | 0.15 | 7.91 | 0.35 | 7.76 | 0.33 | 8.06 | 0.39 |
| DO | 10.19 | 2.05 | 9 | 1.34 | 11.54 | 2.74 | 9.82 | 2.65 | 9.55 | 1.99 |
| EC | 220.06 | 3.65 | 229.45 | 19.89 | 276.13 | 15.31 | 265.14 | 16.95 | 290.21 | 12.24 |
| SD | 3.23 | 1.78 | 3.33 | 1.78 | 0.98 | 0.34 | 0.96 | 0.28 | 0.85 | 0.33 |
| WT | 20.38 | 3.6 | 16.25 | 1.73 | 15.73 | 0.35 | 15.54 | 3.74 | 23.36 | 2.19 |
| TP | 77.38 | 41.46 | 73.61 | 57.9 | 145.5 | 2.74 | 112.89 | 43.98 | 122.6 | 80.34 |
| DIN | 331.76 | 232.62 | 135.12 | 36.23 | 481.37 | 15.31 | 101.75 | 36.62 | 195.54 | 83.21 |
| Chl-a | 5.64 | 3.7 | 1.9 | 0.72 | 6.37 | 0.34 | 7.22 | 3.36 | 15.4 | 9.74 |
| Variable | Cluster 1 | Cluster 2 | Cluster 3 | |||
|---|---|---|---|---|---|---|
| Mean | SD | Mean | SD | Mean | SD | |
| pH | 8.07 | 0.37 | 7.77 | 0.33 | 8.30 | 0.22 |
| DO | 9.62 | 2.37 | 10.78 | 2.54 | 9.66 | 1.84 |
| EC | 289 | 11.89 | 267.69 | 17.17 | 224.24 | 14.04 |
| SD | 0.89 | 0.38 | 0.94 | 0.22 | 3.27 | 1.75 |
| WT | 22.82 | 2.66 | 14.68 | 2.16 | 18.30 | 3.55 |
| TP | 126.64 | 81.25 | 124.46 | 55.43 | 75.71 | 48.45 |
| DIN | 183.44 | 82.82 | 316.05 | 326.88 | 244.36 | 199.01 |
| Chl-a | 13.41 | 9.96 | 7.35 | 3.2 | 3.98 | 3.34 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hadjisolomou, E.; Stefanidis, K.; Papatheodorou, G.; Papastergiadou, E. Assessment of the Eutrophication-Related Environmental Parameters in Two Mediterranean Lakes by Integrating Statistical Techniques and Self-Organizing Maps. Int. J. Environ. Res. Public Health 2018, 15, 547. https://doi.org/10.3390/ijerph15030547
Hadjisolomou E, Stefanidis K, Papatheodorou G, Papastergiadou E. Assessment of the Eutrophication-Related Environmental Parameters in Two Mediterranean Lakes by Integrating Statistical Techniques and Self-Organizing Maps. International Journal of Environmental Research and Public Health. 2018; 15(3):547. https://doi.org/10.3390/ijerph15030547
Chicago/Turabian StyleHadjisolomou, Ekaterini, Konstantinos Stefanidis, George Papatheodorou, and Evanthia Papastergiadou. 2018. "Assessment of the Eutrophication-Related Environmental Parameters in Two Mediterranean Lakes by Integrating Statistical Techniques and Self-Organizing Maps" International Journal of Environmental Research and Public Health 15, no. 3: 547. https://doi.org/10.3390/ijerph15030547