
Multi-Task Joint Sparse and Low-Rank Representation for the Scene Classification of High-Resolution Remote Sensing Image




Abstract
:1. Introduction
2. Related Work
2.1. Sparse Representation Classification
2.2. Multi-Task Joint Sparse Representation Classification
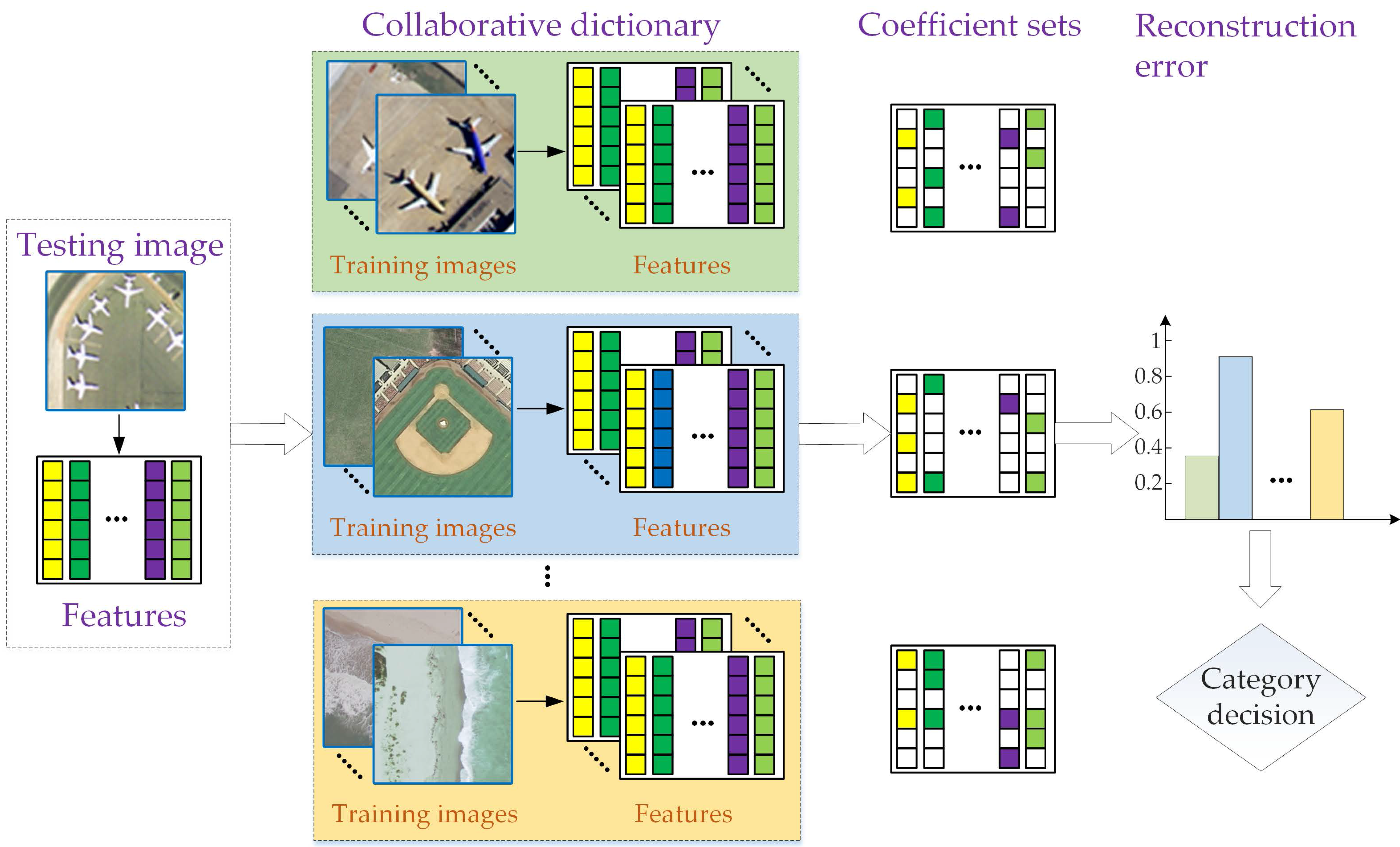
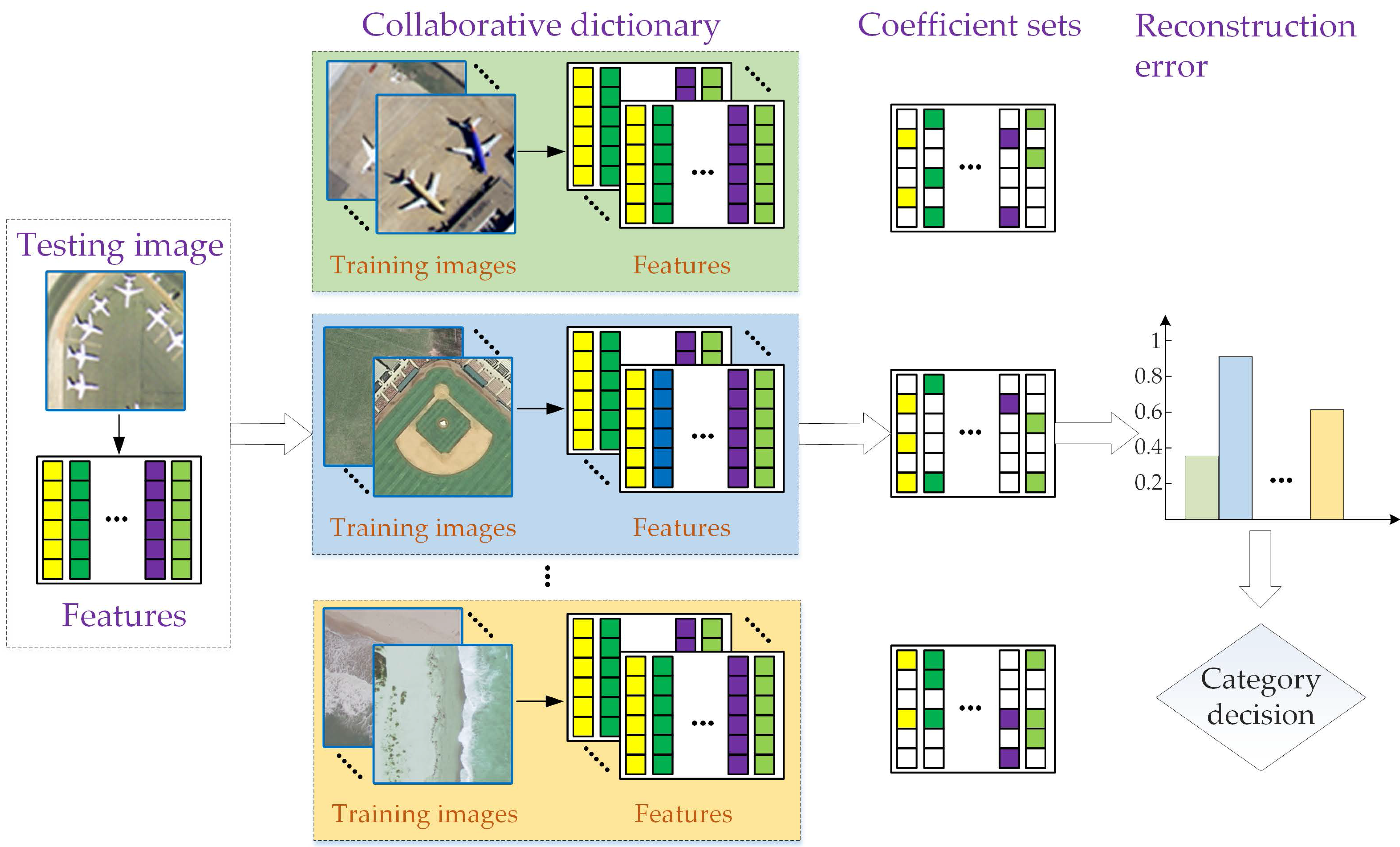
3. The Proposed Method
3.1. Sparse and Low-Rank Representation
3.2. Class-Level Joint Sparse and Low-Rank Regularization
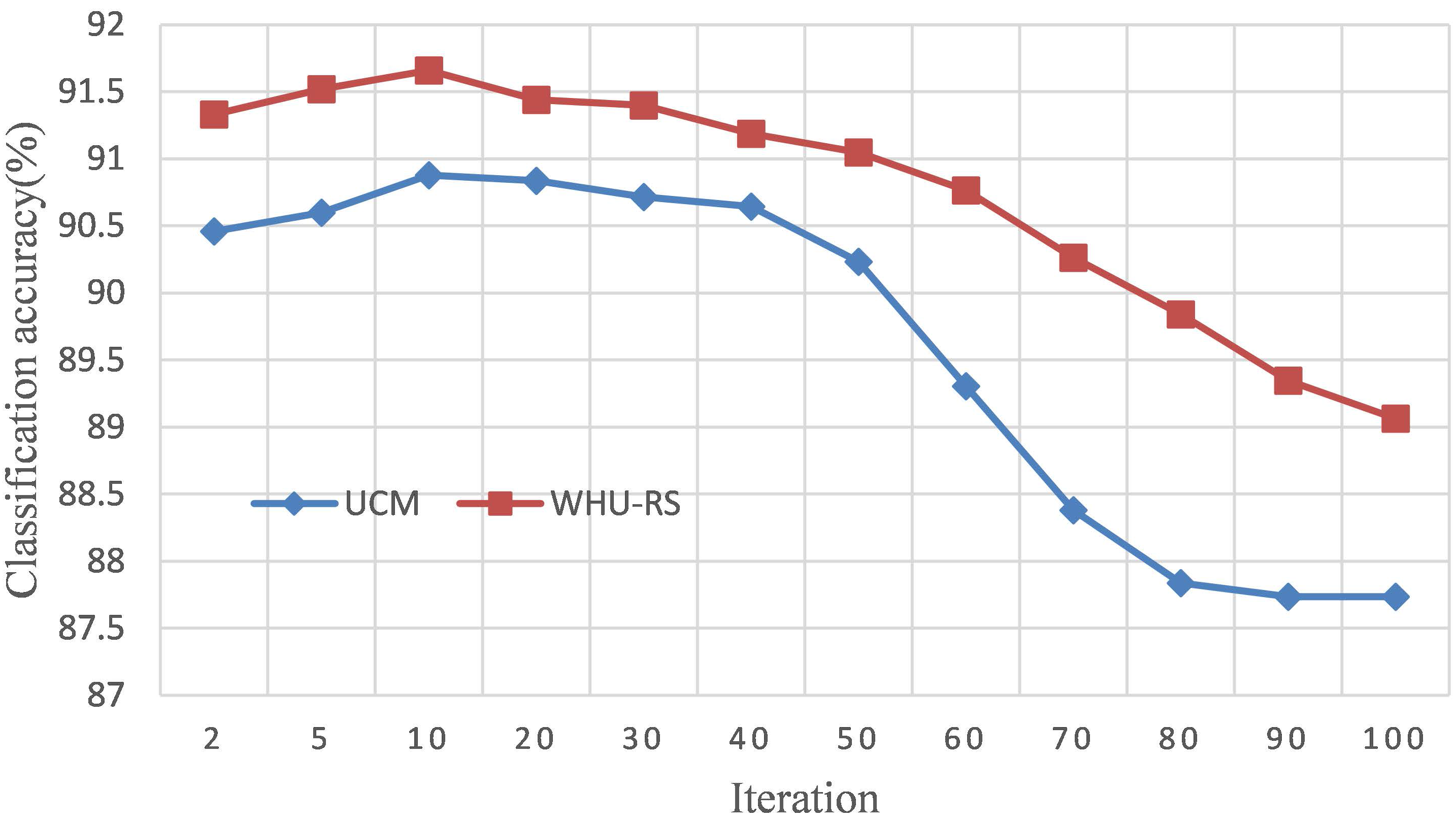
3.3. Optimization Algorithm
| Algorithm 1: MTJSLRC Algorithm |
| Inputs: The training image feature matrices, ; All testing image features, ; The regularization parameters, , ; The step-size parameter, ; The maximum number of iteration, ; Output: The representation coefficients, ; The predicted labels for testing image scenes, ; Initialization: , , 1: repeat: 2: Calculate , in which is given by 3: Calculate as , 4: Set 5: Update 6: Set 7: until converges or ; 8: Calculate |
3.4. Time Complexity Analysis
4. Experiments and Analysis
4.1. Experimental Setup
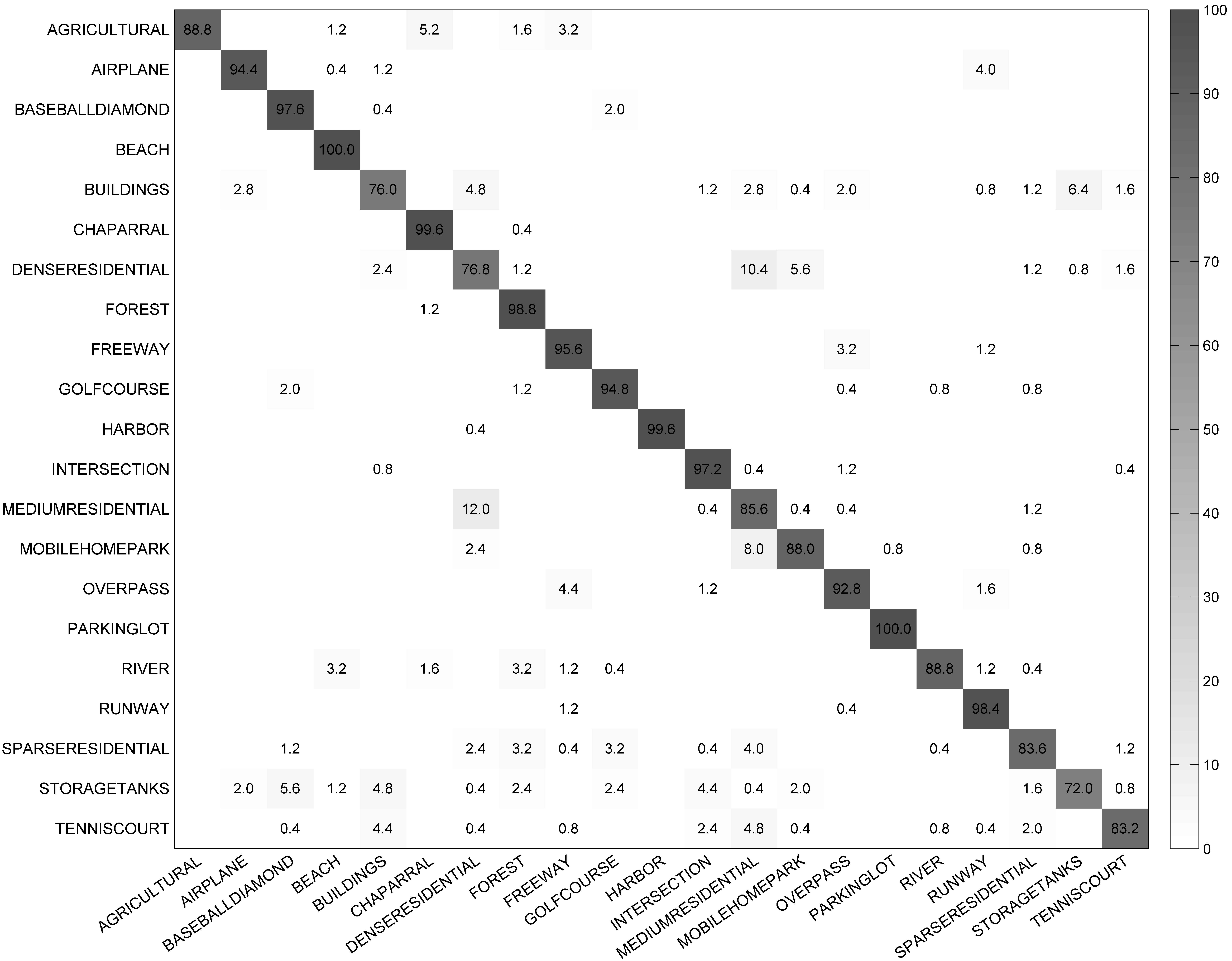
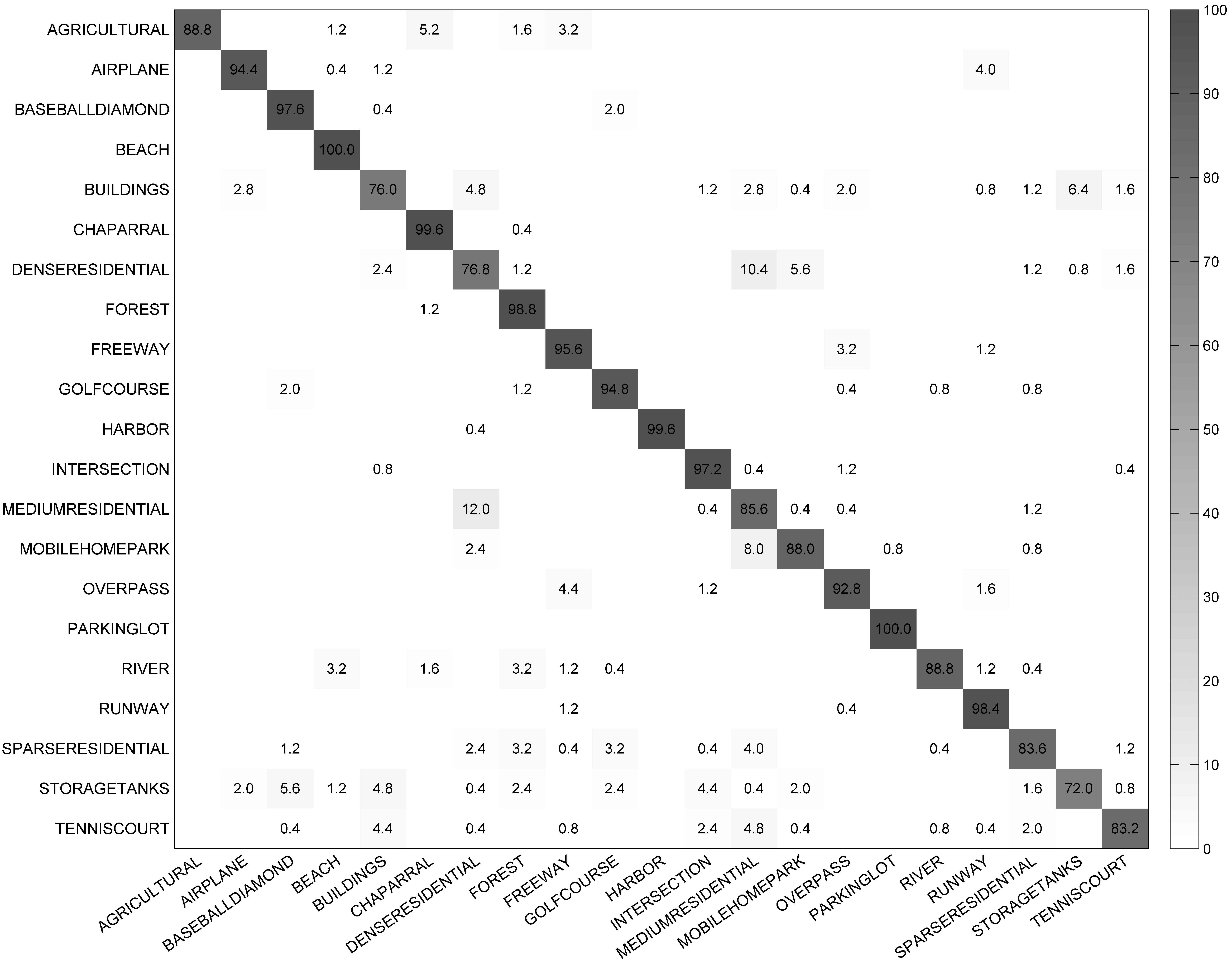
- UC Merced Land Use Dataset. The UC Merced dataset (UCM) [10] is one of the first ground truth datasets derived from a publicly available high resolution overhead image; it was manually extracted from aerial orthoimagery and downloaded from the United States Geological Survey (USGS) National Map. This dataset contains 21 typical land-use scene categories, each of which consists of 100 images measuring pixels with a pixel resolution of 30 cm in the red-green-blue color space. Figure 3 shows two examples of ground truth images from each class in this dataset. The classification of UCM dataset is challenging because of the high inter-class similarity among categories such as medium residential and dense residential areas.
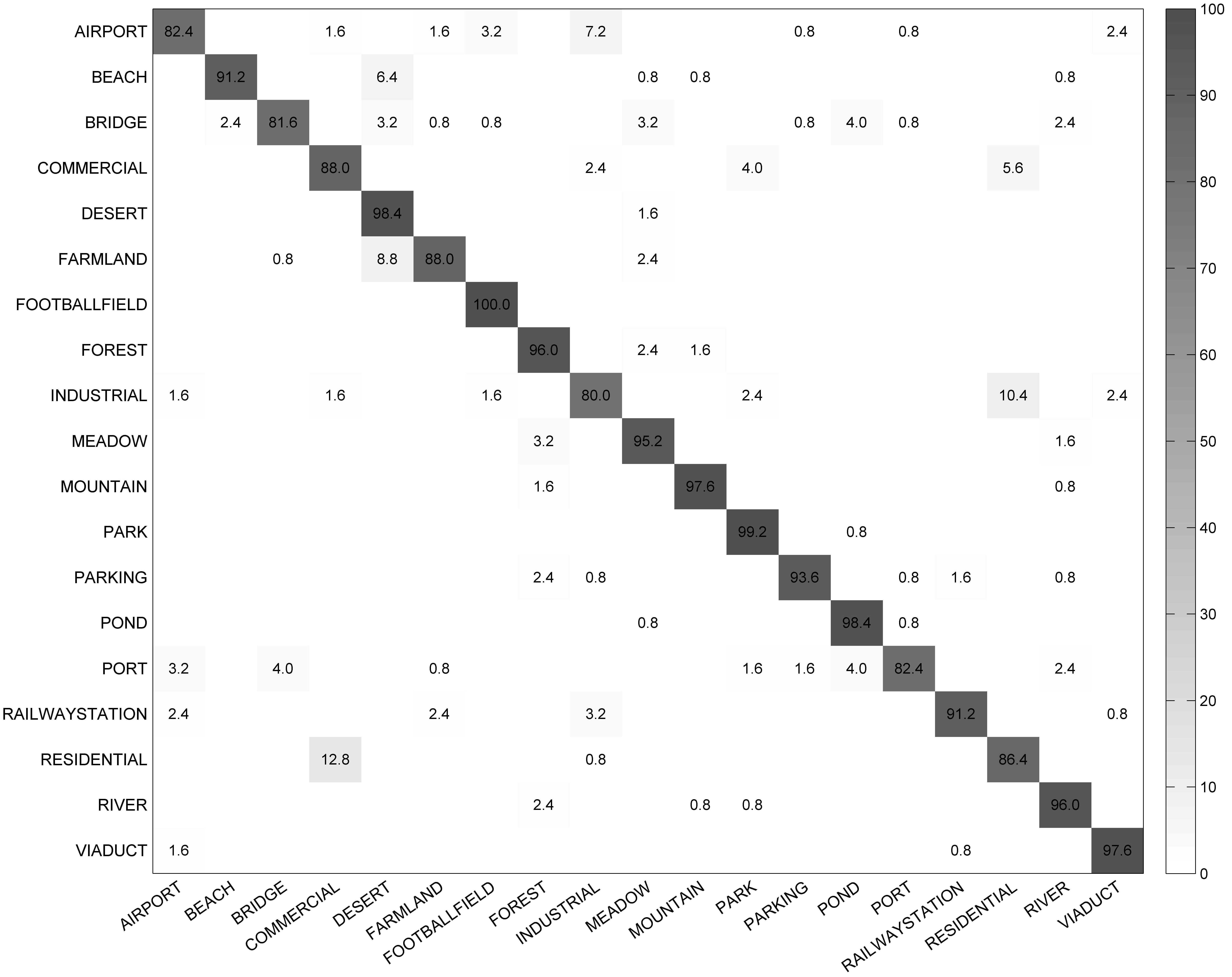
- WHU-RS Dataset. The WHU-RS dataset [52] is a new publicly available dataset wherein all the images are collected from Google Earth (Google Inc. Mountain View, CA, USA). This dataset consists of 950 images with a size of pixels distributed among 19 scene classes. Examples of ground truth images are shown in Figure 4. It can be seen that, as compared to the UCM dataset, the scene categories in the WHU-RS dataset are more complicated due to variations in scale, resolution, and viewpoint-dependent appearance.
- Bag of Visual Words (BoVW). We extracted Scale-Invariant Feature Transform (SIFT) descriptors [18] using a dense regular grid on the image with image patches at a pixel size over a grid with spacing of eight pixels [22]. The visual vocabulary containing 600 entries was formed by k-means clustering of a random subset of patches from the training set.
- Multi-Segmentation-based correlaton (MS-based correlaton) [8]. SIFT descriptors were extracted on a regular grid with a spacing of eight pixels and at pixel grid size. The segmentation size was set at six and the number of segments were . The MS-based correlograms were quantized in 300 MS-based correlatons using k-means.
- Dense words (including PhowGray, PhowColor) [11]. The PhowGray was modeled using rotationally invariant SIFT descriptors computed on a regular grid with the step of five pixels at four multiple scales (5, 7, 9, 12 pixel radii), zeroing the low contrast pixels. Then the descriptors were subsequently quantized into a vocabulary of 600 visual words that were generated by k-means clustering. The PhowColor is the color version of PhowGray that stacks SIFT descriptors for each HSV color channel.
- Self-SIMilarity features (SSIM). SSIM descriptors [12] were extracted on a regular grid at steps of five pixels. We acquired each descriptor by computing the correlation map of a pixels patch in a window of radius 40 pixels, quantizing it in 3 radial bins and 10 angular bins. This way, we obtained a pack of 30 dimensional descriptor vectors. These descriptors were then quantized into 600 visual words.
4.2. Experimental Results
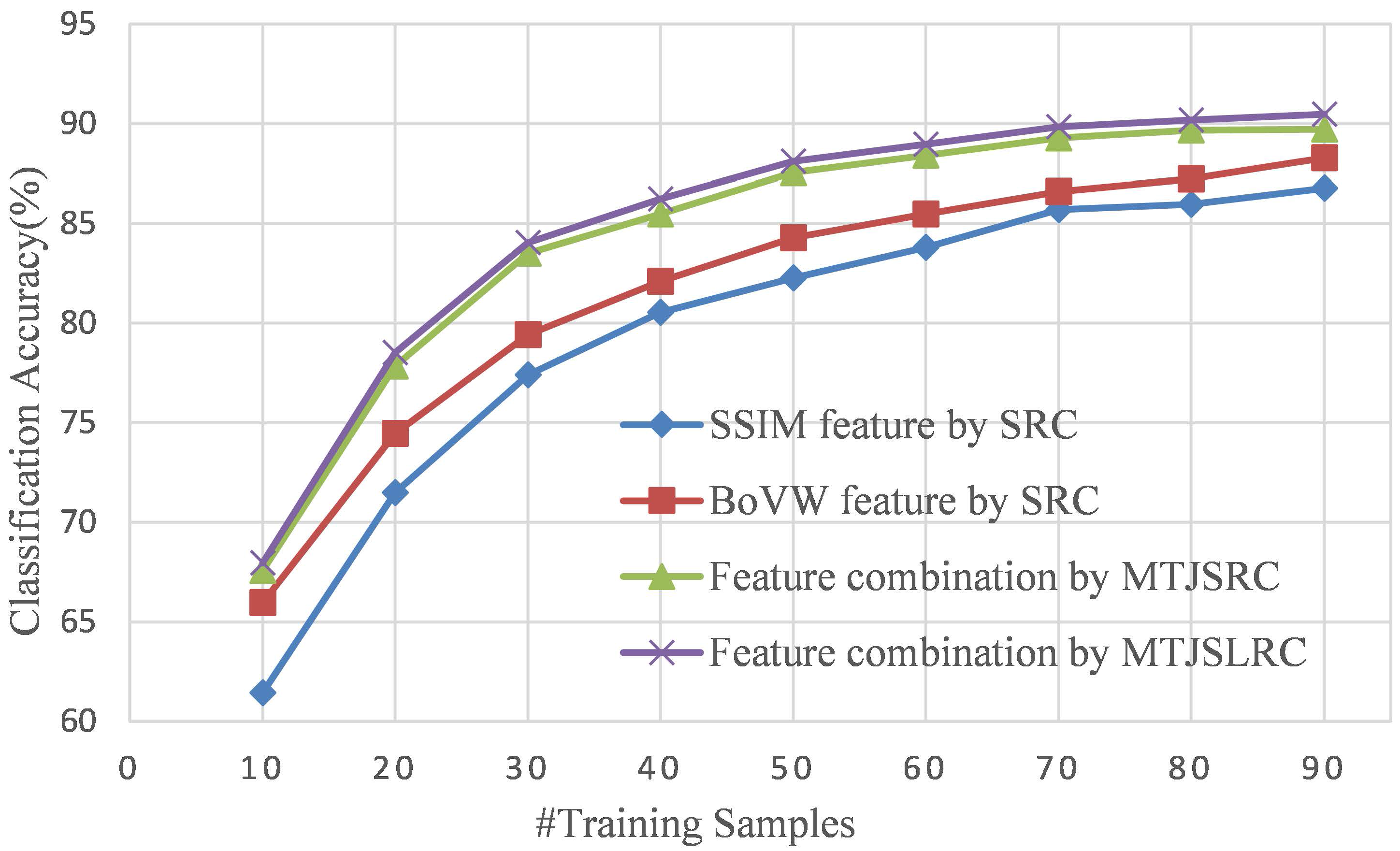
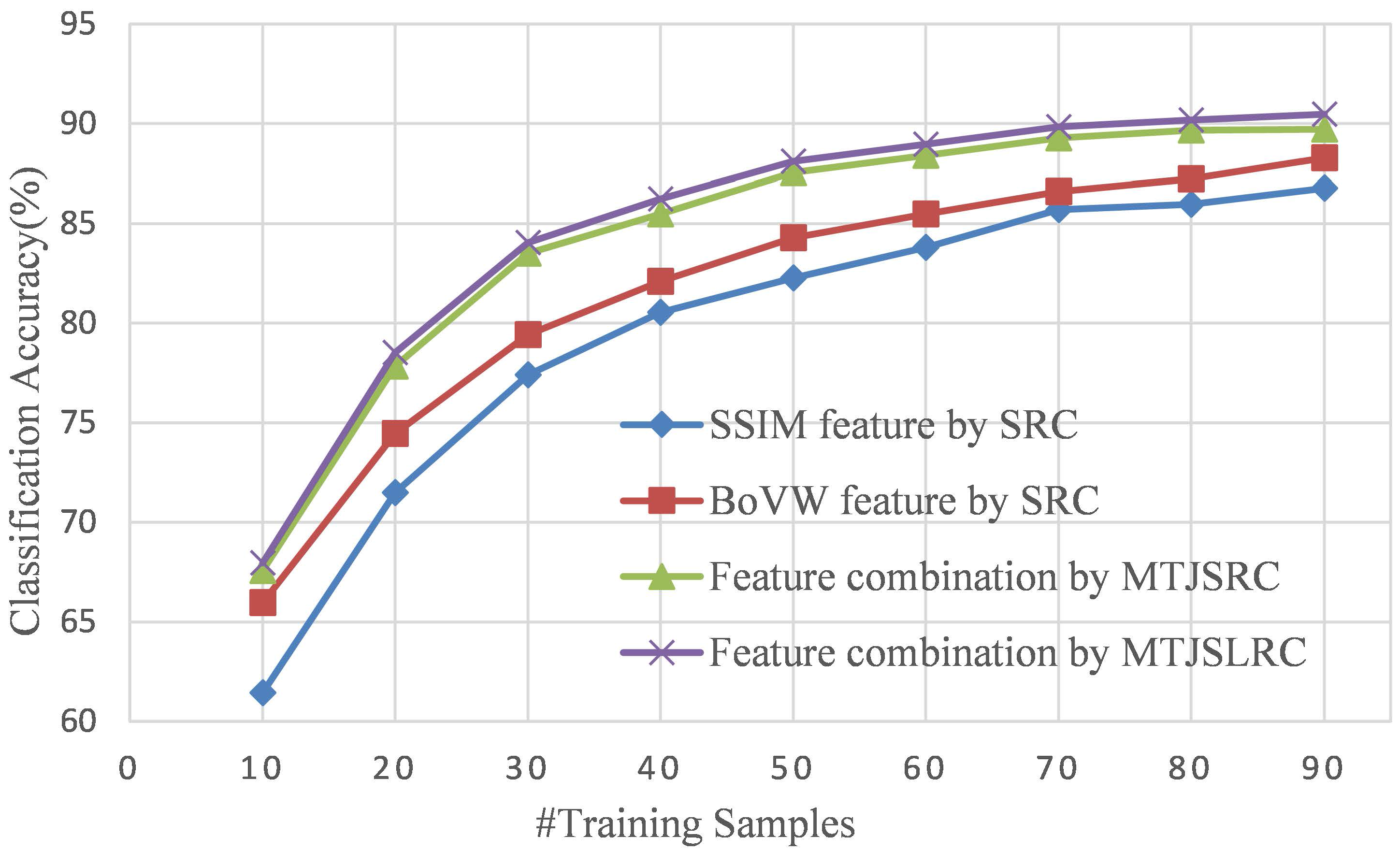
4.2.1. Explanation of Feature Combination
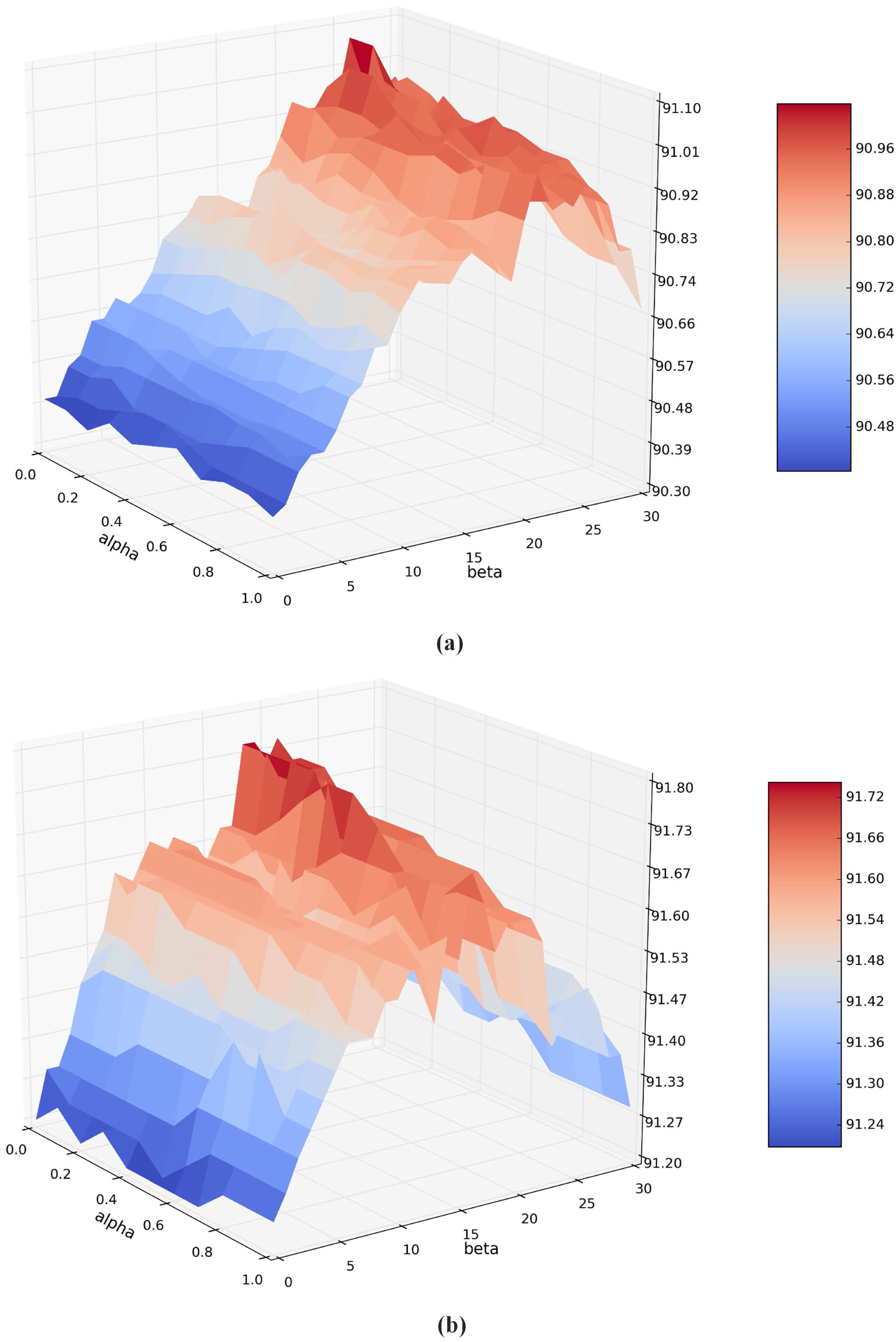
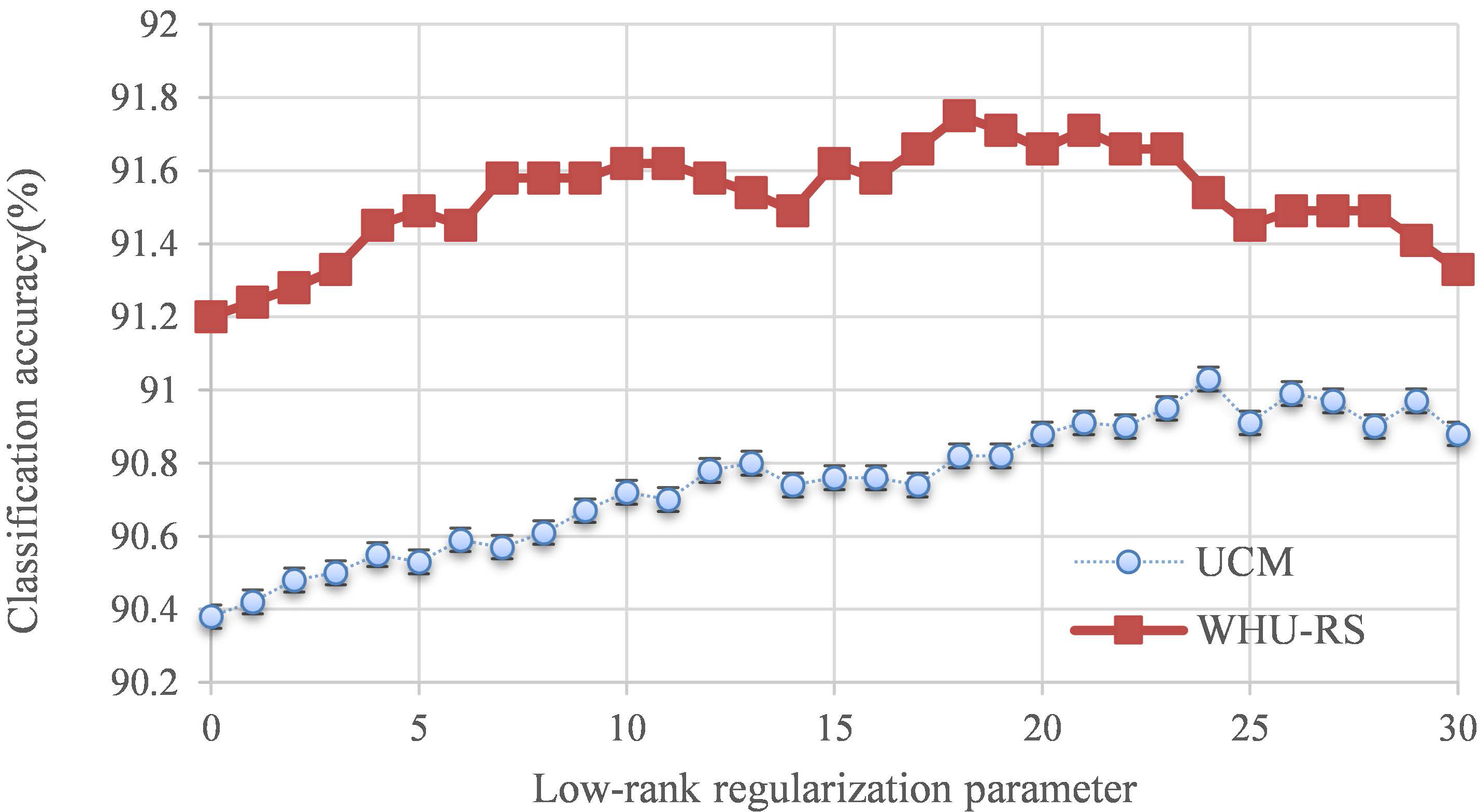
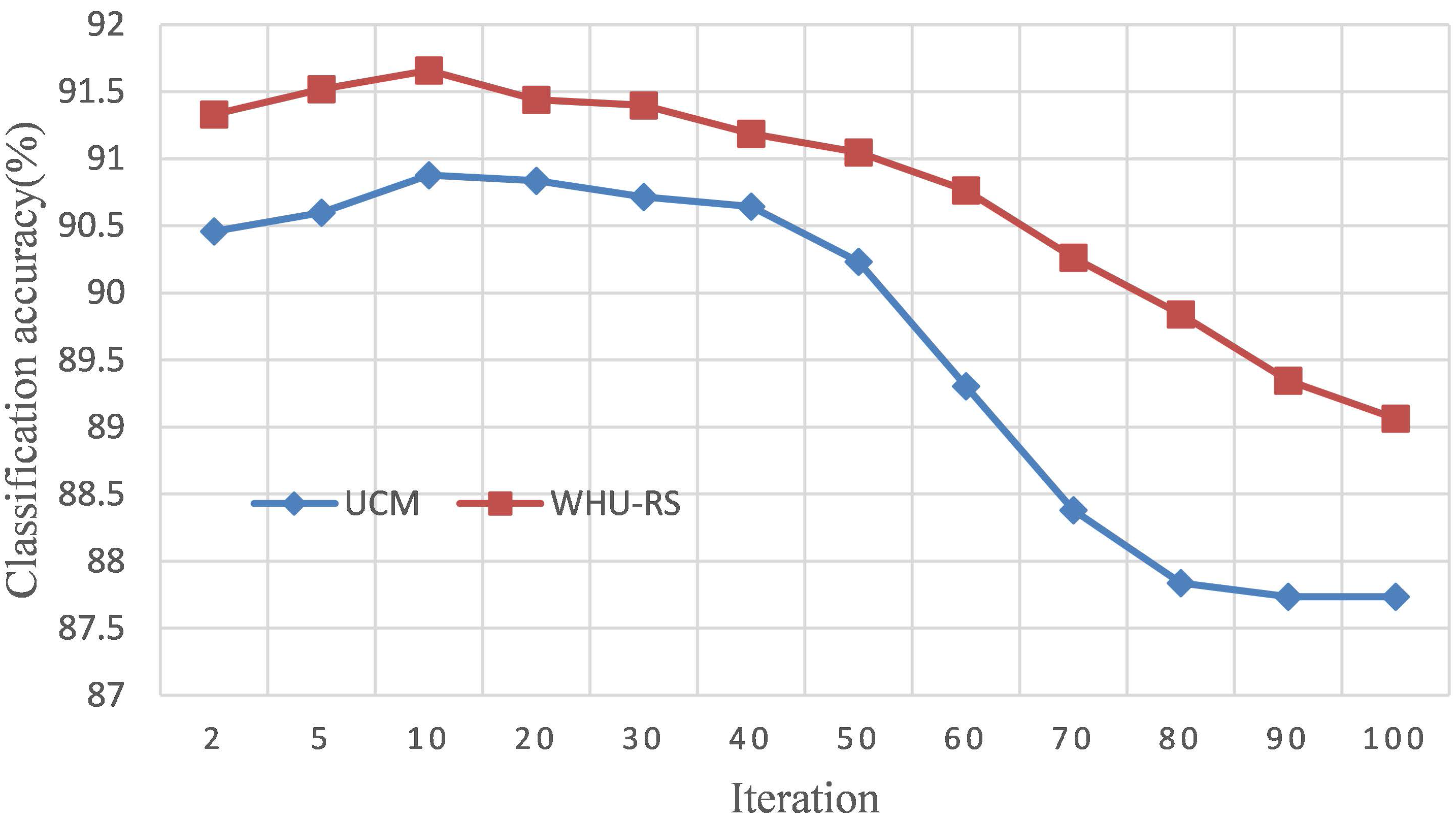
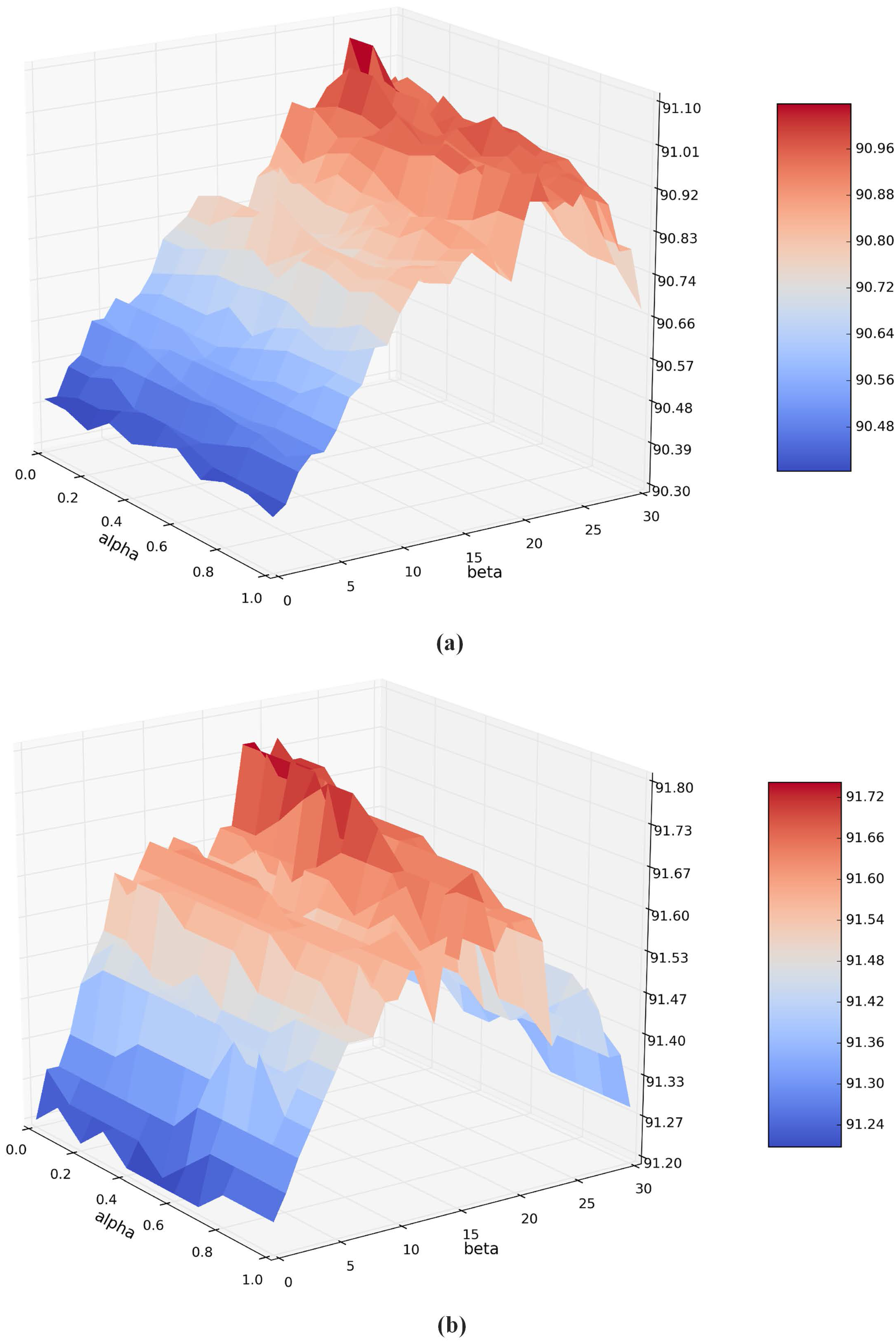
4.2.2. Parameter Effect
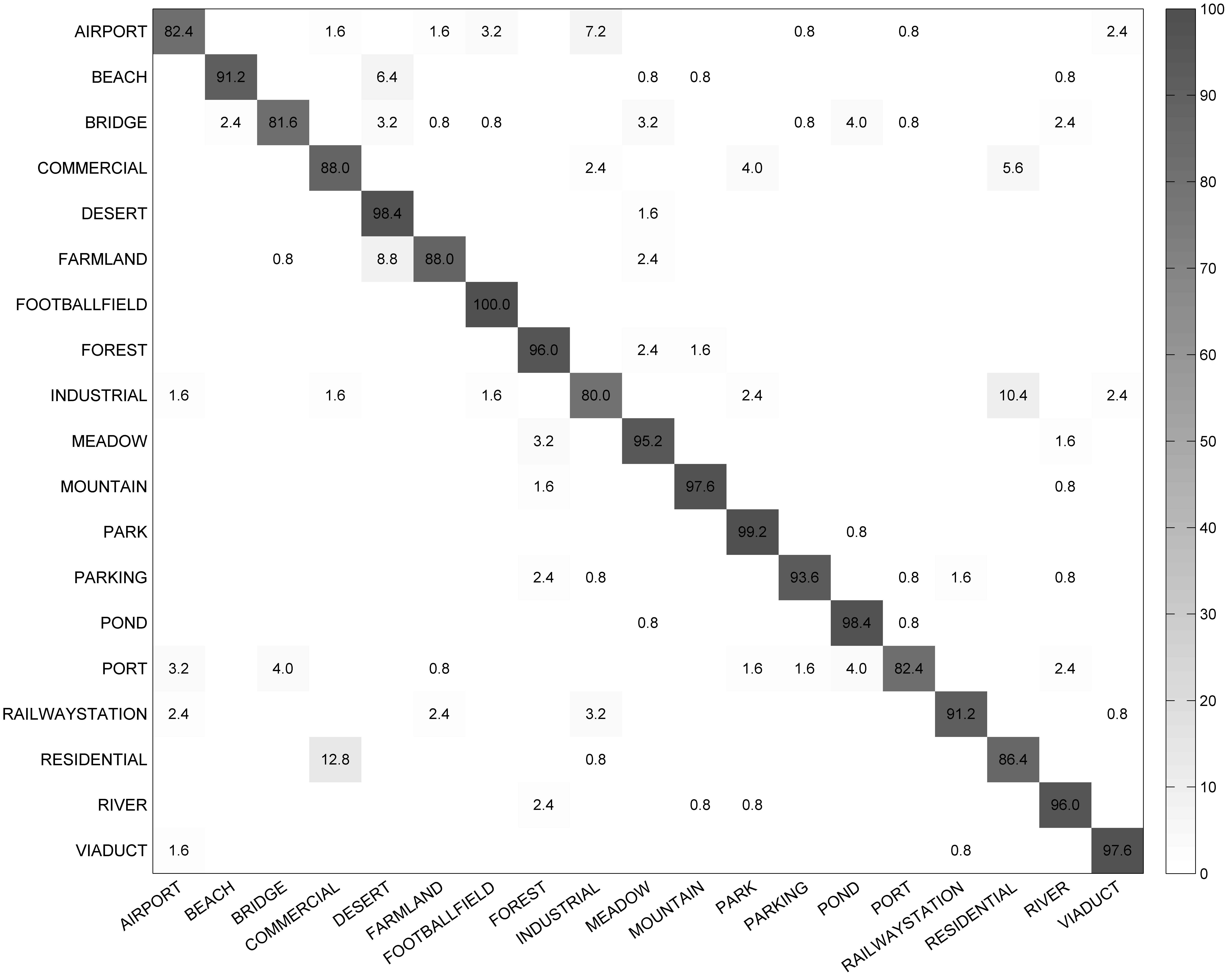
4.2.3. Classification Results
- Feature combination based on independent SRC. This method can be seen as a simplification of the MTJSLRC method without the joint sparsity and low-rank structure across tasks. Thus, the coefficients are independently learned by SRC.
- Feature combination based on MTJSRC. This method enforces the joint sparsity across tasks but ignore the low-rank structure in the multiple feature space.
- The representative multiple kernel learning method. The kernel matrices are computed as , where is set to be the mean value of the pairwise distance on the training set.
4.2.4. Running Time
5. Discussion
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Abbreviations
| HRS | high resolution satellite |
| MKL | multiple kernel learning |
| MTJSRC | multi-task joint sparse representation and classification |
| MTL | multi-task learning |
| SRC | sparse representation classification |
| MTJCS | multi-task joint covariate selection |
| LASSO | least absolute shrinkage and selection operator |
| MTJSLRC | multi-task joint sparse and low-rank representation and classification |
| APG | accelerated proximal gradient |
| Flops | floating-point operations |
| BoVW | bag of visual word |
| SIFT | scale-invariant feature transform |
| MS-based correlaton | multi-segmentation-based correlaton |
| SSIM | self-similarity features |
References
- Prasad, S.; Bruce, L.M. Decision fusion with confidence-based weight assignment for hyperspectral target recognition. IEEE Trans. Geosci. Remote Sens. 2008, 46, 1448–1456. [Google Scholar] [CrossRef]
- Bruzzone, L.; Carlin, L. A multilevel context-based system for classification of very high spatial resolution images. IEEE Trans. Geosci. Remote Sens. 2006, 44, 2587–2600. [Google Scholar] [CrossRef]
- Rizvi, I.A.; Mohan, B.K. Object-based image analysis of high-resolution satellite images using modified cloud basis function neural net-work and probabilistic relaxation labeling process. IEEE Trans. Geosci. Remote Sens. 2011, 49, 4815–4820. [Google Scholar] [CrossRef]
- Bellens, R.; Gautama, S.; Martinezfonte, L.; Philips, W.; Chan, J.C.; Canters, F. Improved classification of VHR images of urban areas using directional morphological profiles. IEEE Trans. Geosci. Remote Sens. 2008, 46, 2803–2813. [Google Scholar] [CrossRef]
- Blaschke, T. Object based image analysis for remote sensing. ISPRS J. Photogramm. Remote Sens. 2010, 65, 2–16. [Google Scholar] [CrossRef]
- Yu, H.; Yang, W.; Xia, G.; Liu, G. A color-texture-structure descriptor for high-resolution satellite image classification. Remote Sens. 2016, 8, 30259–30292. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.S.; Hu, J.; Zhang, L. Transferring deep convolutional neural networks for the scene classification of high-resolution remote sensing imagery. Remote Sens. 2015, 7, 14680–14707. [Google Scholar] [CrossRef]
- Qi, K.; Wu, H.; Shen, C.; Gong, J. Land-use scene classification in high-resolution remote sensing images using improved correlatons. IEEE Geosci. Remote Sens. Lett. 2015, 12, 2403–2407. [Google Scholar]
- Xia, G.S.; Wang, Z.; Xiong, C.; Zhang, L. Accurate annotation of remote sensing images via active spectral clustering with little expert knowledge. Remote Sens. 2015, 7, 15014–15045. [Google Scholar] [CrossRef]
- Yang, Y.; Newsam, S. Bag-of-visual-words and spatial extensions for land-use classification. In Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems, San Jose, CA, USA, 3–5 November 2010; pp. 270–279.
- Bosch, A.; Zisserman, A.; Muñoz, X. Scene classification via PLSA. In Proceedings of the 9th European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 517–530.
- Shechtman, E.; Irani, M. Matching Local Self-Similarities across Images and Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 19–21 June 2007; pp. 1–8.
- Bosch, A.; Munoz, X.; Marti, R. Which is the best way to organize/classify images by content? Image Vis. Comput. 2007, 25, 778–791. [Google Scholar] [CrossRef]
- Liénou, M.; Maître, H.; Datcu, M. Semantic annotation of satellite images using latent Dirichlet allocation. IEEE Geosci. Remote Sens. Lett. 2010, 7, 28–32. [Google Scholar] [CrossRef]
- Sheng, G.; Yang, W.; Xu, T.; Sun, H. High-resolution satellite scene classification using a sparse coding based multiple feature combination. Int. J. Remote Sens. 2012, 33, 2395–2412. [Google Scholar] [CrossRef]
- Dai, D.; Yang, W. Satellite image classification via two-layer sparse coding with biased image representation. IEEE Geosci. Remote Sens. Lett. 2011, 8, 173–176. [Google Scholar] [CrossRef]
- Hu, F.; Xia, G.; Hu, J.; Zhong, Y.; Xu, K. Fast Binary Coding for the Scene Classification of High-Resolution Remote Sensing Imagery. Remote Sens. 2016, 8, 70555–70578. [Google Scholar] [CrossRef]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Van DeWeijer, J.; Schmid, C. Coloring local feature extraction. In Proceedings of the 9th European Conference on Computer Vision (ECCV), Graz, Austria, 7–13 May 2006; pp. 334–348.
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Zhao, L.; Tang, P.; Huo, L. A 2-D wavelet decomposition-based bag-of-visual-words model for land-use scene classification. Int. J. Remote Sens. 2014, 35, 2296–2310. [Google Scholar]
- Lazebnik, S.; Schmid, C.; Ponce, J. Beyond bags of features: Spatial pyramid matching for recognizing natural scene categories. In Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR), New York, NY, USA, 17–22 June 2006; pp. 2169–2178.
- Qi, K.; Zhang, X.; Wu, B.; Wu, H. Sparse coding-based correlaton model for land-use scene classification in high-resolution remote-sensing images. J. Appl. Remote Sens. 2016, 10, 042005. [Google Scholar]
- Van De Sande, K.E.; Gevers, T.; Snoek, C.G. Evaluating color descriptors for object and scene recognition. IEEE Trans. Pattern Anal. 2010, 32, 1582–1596. [Google Scholar] [CrossRef] [PubMed]
- Gehler, P.; Nowozin, S. On feature combination for multiclass object classification. In Proceedings of the IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009; pp. 221–228.
- Fernando, B.; Fromont, E.; Muselet, D.; Sebban, M. Discriminative feature fusion for image classification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012; pp. 3434–3441.
- Van de Weijer, J.; Khan, F.S. Fusing color and shape for bag-of-words based object recognition. In Proceedings of the 2013 Computational Color Imaging Workshop, Chiba, Japan, 3–5 March 2013; pp. 25–34.
- Varma, M.; Ray, D. Learning the Discriminative Power-Invariance Trade-Off. In Proceedings of the 11th International Conference on Computer Vision (ICCV), Rio de Janeiro, Brazil, 14–20 October 2007.
- Lin, Y.; Liu, T.; Fuh, C. Local ensemble kernel learning for object category recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Minneapolis, MN, USA, 19–21 June 2007.
- Luo, W.; Yang, J.; Xu, W.; Li, J.; Zhang, J. Higher-level feature combination via multiple kernel learning for image classification. Neurocomputing 2015, 167, 209–217. [Google Scholar] [CrossRef]
- Vedaldi, A.; Gulshan, V.; Varma, M.; Zisserman, A. Multiple kernels for object detection. In Proceedings of the 10th International Conference on Computer Vision (ICCV), Kyoto, Japan, 27 September–4 October 2009.
- Yuan, X.; Liu, X.; Yan, S. Visual Classification with Multitask Joint Sparse Representation. IEEE Trans. Image Process. 2012, 21, 4349–4360. [Google Scholar] [CrossRef] [PubMed]
- Caruana, R. Multi-task learning. Mach. Learn. 1997, 28, 41–75. [Google Scholar] [CrossRef]
- Evgeniou, T.; Pontil, M. Regularized multi-task learning. In Proceedings of the Knowledge Discovery and Data Mining, Sydney, Australia, 26–28 May 2004; pp. 109–117.
- Wright, J.; Yang, A.Y.; Ganesh, A.; Sastry, S.S.; Ma, Y. Robust face recognition via sparse representation. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 210–227. [Google Scholar] [CrossRef] [PubMed]
- Li, J.; Zhang, H.; Zhang, L.; Huang, X.; Zhang, L. Joint collaborative representation with multitask learning for hyperspectral image classification. IEEE Trans. Geosci. Remote Sens. 2014, 52, 5923–5936. [Google Scholar] [CrossRef]
- Zhang, H.; Li, J.; Huang, Y.; Zhang, L. A nonlocal weighted joint sparse representation classification method for hyperspectral imagery. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2014, 7, 2056–2065. [Google Scholar] [CrossRef]
- Argyriou, A.; Evgeniou, T.; Pontil, M. Convex multi-task feature learning. Mach. Learn. 2008, 73, 243–272. [Google Scholar] [CrossRef]
- Zhang, L.; Yang, M.; Feng, X.; Ma, Y.; Zhang, D. Collaborative representation based classification for face recognition. arXiv, 2012; arXiv:1204.2358. [Google Scholar]
- Obozinski, G.; Taskar, B.; Jordan, M. Joint covariate selection and joint subspace selection for multiple classification problems. J. Stat. Comput. 2009, 20, 231–252. [Google Scholar] [CrossRef]
- Yuan, M.; Lin, Y. Model selection and estimation in regression with grouped variables. J. R. Stat. Soc. Ser. B 2006, 68, 49–67. [Google Scholar] [CrossRef]
- Liu, H.; Palatucci, M.; Zhang, J. Blockwise coordinate descent procedures for the multi-task lasso, with applications to neural semantic basis discovery. In Proceedings of the International Conference on Machine Learning (ICML), Montreal, QC, Canada, 14–18 June 2009; pp. 649–656.
- Ando, R.K.; Zhang, T. A framework for learning predictive structures from multiple tasks and unlabeled data. J. Mach. Learn. Res. 2005, 6, 1817–1853. [Google Scholar]
- Chen, J.; Liu, J.; Ye, J. Learning Incoherent Sparse and Low-Rank Patterns from Multiple Tasks. ACM Trans. Knowl. Discov. Data 2012, 5, 22–30. [Google Scholar] [CrossRef] [PubMed]
- Abernethy, J.; Bach, F.; Evgeniou, T.; Vert, J. A new approach to collaborative filtering: Operator estimation with spectral regularization. J. Mach. Learn. Res. 2009, 10, 803–826. [Google Scholar]
- Ji, S.; Ye, J. An accelerated gradient method for trace norm minimization. In Proceedings of the International Conference on Machine Learning (ICML), Montreal, QC, Canada, 14–18 June 2009.
- Nesterov, Y. Gradient methods for minimizing composite functions. Math. Program. 2013, 140, 125–161. [Google Scholar] [CrossRef]
- Candés, E.; Romberg, J.; Tao, T. Stable signal recovery from incomplete and inaccurate measurements. Commun. Pure Appl. Math. 2006, 59, 1207–1223. [Google Scholar]
- Chen, X.; Pan, W.; Kwok, J.; Garbonell, J. Accelerated gradient method for multi-task sparse learning problem. In Proceedings of the IEEE 5th International Conference on Data Mining (DMIN), Las Vegas, NV, USA, 13–16 July 2009; pp. 746–751.
- Mei, S.; Cao, B.; Sun, J. Encoding Low-Rank and Sparse Structures Simultaneously in Multi-Task Learning. Available online: http://research.microsoft.com/pubs/179139/LSS.pdf (accessed on 25 December 2016).
- Schmidt, M.; Berg, E.; Friedlander, M.; Murphy, K. Optimizing costly functions with simple constraints: A limited-memory projected quasi-Newton algorithm. In Proceedings of the 12th International Conference on Artificial Intelligence and Statistics, Clearwater Beach, FL, USA, 16–18 April 2009; pp. 456–463.
- Xia, G.S.; Yang, W.; Delon, J.; Gousseau, Y.; Sun, H.; Maitre, H. Structrual High-Resolution Satellite Image Indexing. In Proceedings of the ISPRS, TC VII Symposium (Part A): 100 Years ISPRS—Advancing Remote Sensing Science, Vienna, Austria, 5–7 July 2010.
- Vedaldi, A.; Fulkerson, B. VLFeat: An Open and Portable Library of Computer Vision Algorithms. Available online: http://www.vlfeat.org/ (accessed on 16 November 2015).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Single Features | ||
| Features | SVM | SRC |
| BoVW | 80.21 1.6 | 79.92 0.83 |
| PhowColor | 87.46 1.7 | 86.99 0.85 |
| PhowGray | 85.87 1.75 | 86.35 0.59 |
| SSIM | 80.95 1.26 | 80.38 1.27 |
| MS-based Correlaton | 81.73 1.15 | 81.12 0.86 |
| (b) Feature Combination Methods | ||
| Methods | Accuracy | |
| SRC | 90.03 0.78 | |
| MKL | 90.15 0.96 | |
| MTJSRC | 90.45 0.53 | |
| MTJSLRC | 91.07 0.67 | |
| (a) Single Features | ||
| Features | SVM | SRC |
| BoVW | 85.68 1.07 | 85.85 0.95 |
| PhowColor | 86.84 1.39 | 88.04 1.32 |
| PhowGray | 85.05 1.48 | 84.04 0.96 |
| SSIM | 84.9 2.18 | 82.32 1.02 |
| MS-based Correlaton | 87.72 1.42 | 87.12 1.7 |
| (b) Feature Combination Methods | ||
| Methods | Accuracy | |
| SRC | 91.2 1.03 | |
| MKL | 91.67 0.95 | |
| MTJSRC | 91.45 0.98 | |
| MTJSLRC | 91.74 1.14 | |
| Methods | UCM | WHU-RS | ||
|---|---|---|---|---|
| Training | Testing | Training | Testing | |
| SRC | 0 | 94.27/0.09 | 0 | 45.42/0.096 |
| MKL | 992.18/0.945 | 1.07/0.001 | 345.24/0.727 | 0.64/0.001 |
| MTJSRC | 0 | 124.98/0.119 | 0 | 58.17/0.122 |
| MTJSLRC | 0 | 389.2/0.37 | 0 | 179.57/0.378 |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qi, K.; Liu, W.; Yang, C.; Guan, Q.; Wu, H. Multi-Task Joint Sparse and Low-Rank Representation for the Scene Classification of High-Resolution Remote Sensing Image. Remote Sens. 2017, 9, 10. https://doi.org/10.3390/rs9010010
Qi K, Liu W, Yang C, Guan Q, Wu H. Multi-Task Joint Sparse and Low-Rank Representation for the Scene Classification of High-Resolution Remote Sensing Image. Remote Sensing. 2017; 9(1):10. https://doi.org/10.3390/rs9010010
Chicago/Turabian StyleQi, Kunlun, Wenxuan Liu, Chao Yang, Qingfeng Guan, and Huayi Wu. 2017. "Multi-Task Joint Sparse and Low-Rank Representation for the Scene Classification of High-Resolution Remote Sensing Image" Remote Sensing 9, no. 1: 10. https://doi.org/10.3390/rs9010010