Optimal Deterministic Investment Strategies for Insurers

1
Department of Mathematics, Karlsruhe Institute of Technology, Karlsruhe D-76128, Germany
2
Department of Optimization and Operations Research, University of Ulm, Ulm D-89069, Germany
*
Author to whom correspondence should be addressed.
Risks 2013, 1(3), 101-118; https://doi.org/10.3390/risks1030101
Submission received: 30 September 2013
/
Revised: 28 October 2013
/
Accepted: 2 November 2013
/
Published: 7 November 2013
(This article belongs to the Special Issue Application of Stochastic Processes in Insurance)
{kind=link}
Abstract
:We consider an insurance company whose risk reserve is given by a Brownian motion with drift and which is able to invest the money into a Black–Scholes financial market. As optimization criteria, we treat mean-variance problems, problems with other risk measures, exponential utility and the probability of ruin. Following recent research, we assume that investment strategies have to be deterministic. This leads to deterministic control problems, which are quite easy to solve. Moreover, it turns out that there are some interesting links between the optimal investment strategies of these problems. Finally, we also show that this approach works in the Lévy process framework.
1. Introduction
Inspired by [1], we first consider a mean-variance problem for an insurance company, where the investment strategy has to be deterministic or, in other words, pre-determined at time zero. Mathematically, the strategy has to be -measurable. We assume that the risk reserve is given by a Brownian motion with drift and allow investments into a Black–Scholes market with one bond and d risky assets. Investment strategies are determined by the amount of money that is invested in the assets. Such a model has been considered in [2] with one stock, but different optimization criteria, and in [3] with the emphasis towards time-consistency. Here, we present, first, the solution of the classical mean-variance problem, where we optimize over adapted wealth-dependent investment strategies. The solution procedure uses a standard Hamilton–Jacobi–Bellman (HJB) approach and follows along established lines, like in [4,5]. More interestingly, in the second part, we consider the same problem with deterministic investment strategies. The authors in [1] motivate this approach by remarking that such a kind of investment strategy is easier to implement, communicate and compare to alternatives. These kinds of strategies are also partly used in defined contribution pension plans. We refer the reader to [6], where, among others, the performance of deterministic and dynamic investment strategies is compared. In [1], the authors consider a mean-variance problem with additional consumption, and their investment strategies are given in terms of the fraction of wealth invested in the single risky asset. We would like to add that our deterministic investment strategies are mathematically easier to obtain and that there are some interesting and surprising links to optimal investment strategies for other optimization criteria, as we will explain below. Although, when we compare the densities for the final wealth, which are obtained under the optimal deterministic and dynamic investment strategies for the mean-variance problem, we will see that there is quite some difference.
Mathematically, the mean-variance problem for the restricted class of strategies leads to a deterministic control problem directly, without the problem of facing the non-separability of the target function. In the classical adapted case, it is necessary to link the mean-variance problem to an auxiliary linear-quadratic problem first (see, e.g., [5,7,8]) denoted by in Section 3. This step is not necessary in the deterministic case. Moreover, we will also show that in this special model with deterministic strategies, the mean-variance optimal strategy is also optimal for an arbitrary mean-risk problem, where the variance is replaced by an arbitrary law-invariant and positive homogeneous risk measure for the deviation of the terminal wealth from the mean. This is mainly due to the fact that the terminal wealth under a deterministic investment strategy has a normal distribution with mean and variance depending on the strategy. This observation can also be used to solve the control problem for other optimization criteria, like, e.g., expected exponential utility or the probability of ruin. Surprisingly, it will turn out that the classical optimal investment strategy for a company with exponential utility (within the class of adapted strategies) is deterministic and coincides with the optimal deterministic strategy for the mean-variance problem. Finally, we also show that this approach works when the involved processes are Lévy processes. In order to explain our procedure, we restrict the presentation to the most important case, where the risk reserve process is given as in the Cramér–Lundberg model, i.e., the risk reserve process is a compound Poisson process. Since the jumps vanish under expectation, we can proceed in almost the same way. In the classical setting with adapted strategies, it is also possible to deal with Lévy processes; see, e.g., [9,10] for LQ- and mean-variance problems, [11] for the exponential utility or [12] for more general information. In [13], a reinsurance problem with a Lévy market has been considered, and it turned out that the optimal reinsurance strategy is deterministic in the larger class of adapted strategies already. For a recent interesting comparison of different approaches to solve continuous-time mean-variance problems, see [14]. The authors there also consider non-negativity constraints on terminal wealth.
In this paper, we do not deal with questions of the time-consistency of the optimal investment strategy. This seems to be a key point in recent research. We just point to the recent papers [3,15,16], where time-consistency is discussed. The deterministic investment strategies depend on time only and are consistent for the deterministic control problem.
The paper is organized as follows: In the next section, we introduce the insurance model and the mean-variance problem along with some standing assumptions. Then, we explain how to reduce the problem in general to a stochastic linear-quadratic problem. Next, we solve the problem within the classical framework of adapted, i.e., wealth-dependent investment strategies. In Section 5, we consider the mean-variance problem with deterministic investment strategies. We show how the problem is turned into a deterministic control problem and solve it. In a special case, we study the form of the densities of the optimal terminal wealth for the mean-variance problem under deterministic and adapted investment strategies. The next section is dedicated to more general mean-risk problems and other optimization criteria. We show that for deterministic investment strategies, the optimal one is insensitive to the choice of the risk measure, as long as it is law-invariant and positive homogeneous. Finally, in the last section, we deal with the Lévy process framework. We assume that the risk reserve process follows a compound Poisson process, like in the Cramér–Lundberg model.
2. The Model
We suppose that the risk reserve process, , of the insurance company is given by the following stochastic differential equation:
where is a Brownian motion and are arbitrary real constants with , and it is reasonable, but not mathematically necessary to assume that . The initial capital is given by . The risk reserve can be invested into a financial market, which is given by a riskless bond with price process , where
and denotes the deterministic interest rate. Further, there are d risky assets, and the price process of asset i is given by the stochastic differential equation:
with . The process is a k-dimensional Brownian motion, which may be correlated with the driving Brownian motion of the risk reserve process. More precisely, we assume that for and . In what follows, we set and . We assume that all processes are defined on a common probability space , that is the filtration generated by all Brownian motions and that there is a final time horizon .
The insurance company is now allowed to invest the risk reserve into the financial market. A classical trading strategy is an -adapted stochastic process, where and is the amount of money invested in stock i at time t. Note that short-selling is allowed and that the bond investment is given by the self-financing condition. Adaptedness means that we assume that the decision maker is able to observe all Brownian motions, and, thus, the risk reserve and the evolution of the financial market, and is able to react to it. Given a trading strategy, π, and the notation , the corresponding wealth process of the insurance company follows the stochastic differential equation:
In what follows, let us denote , which we assume to be positive definite. Since the quadratic variation of is given by:
the process is in a distribution equal to:
for a generic Brownian motion, . The generator of the controlled Markov process is for given by:
We call an investment strategy, π, admissible if all integrals in Equation (4) exist and . At first, we are interested in the dynamic mean-variance problem of the form (for )
In the next section, we explain the standard way to transform this problem into a classical stochastic control problem, which will then be solved in the subsequent sections. In order to obtain non-trivial problems, we assume that:
We will discuss this condition later in a remark at the end of Section 5.
3. Transformation of MV to an Ordinary Stochastic Control Problem
Problem (MV) can be solved via the well-known Lagrange multiplier technique. The discussion in this section follows [17], chapter 4.6. Let be the Lagrange-function, i.e.:
for π is an admissible investment strategy and As usual, with is called a saddle-point of the Lagrange-function, , if:
Lemma 1
Let be a saddle-point of Then, the value of (MV) is given by
and is optimal for (MV).
Proof:
Obviously, the value of (MV) is equal to and:
For the reverse inequality, we obtain:
and the first statement follows. Further, from the definition of a saddle-point, we obtain for all
and, hence, . Then, we conclude , and is optimal for (MV).☐
From Lemma 1, we see that it is sufficient to look for a saddle point of . It is not difficult to see that the pair is a saddle-point if and satisfy:
Here, denotes the so-called Lagrange-problem for the parameter
Note that the problem is not a standard stochastic control problem. We embed the problem, , into a tractable auxiliary problem, , that turns out to be a stochastic LQ-problem. For , define
The following result shows the relationship between the problems and .
Lemma 2
If is optimal for , then is optimal for with .
Proof:
Suppose is not optimal for with . Then, there exists an admissible π, such that:
Define the function by
Then, U is concave and for and Moreover, we set and The concavity of U implies:
where the last inequality is due to our assumption Hence, is not optimal for , leading to a contradiction. ☐
The implication of Lemma 2 is that any optimal solution of (as long as it exists) can be found by solving problem . Indeed, if has an optimal solution and if the optimal solution of is unique, it must be the optimal solution of .
4. Solution of MV for a Classical Adapted Investor
We will first solve problem , which is a classical stochastic control problem with no running cost and terminal cost . Let us denote
where, as usual, is the conditional expectation given . In view of the generator of the wealth process, the corresponding Hamilton–Jacobi–Bellman (HJB) equation reads (note that with a slight abuse of notation, we name the action again π):
where we denote by and the partial derivatives. Since this is a standard LQ-problem, a solution of the HJB equation can easily be found by using the Ansatz . Plugging this form into the HJB equation yields:
where denotes the derivative w.r.t. time. The minimum point of this equation is given by:
Inserting the minimum point into the HJB equation and collecting the terms without x, the terms with x and the terms with yields the following ordinary differential equations for , and :
with boundary condition . The differential equation for involves only and on the right-hand side. Since we are only interested in the optimal investment strategy, , the interesting quantity is . For , we obtain the differential equation
with and boundary condition . A solution is given by
Plugging this expression into Equation (10) yields:
Altogether, we obtain the following result with a standard verification argument (cf., for example, [4,18]):
Theorem 3
Finally, we want to solve problem (MV). Thus, we have to compute , the expected terminal wealth under the optimal strategy, , for . We obtain:
with . Thus, follows from solving the ordinary differential equation:
and we get:
From , and we conclude:
which is positive, due to Equation (7). Hence, we obtain the following result:
5. MV Problem for an Investor with Deterministic Investment Strategies
In this section, we assume now that the investment strategy has to be pre-determined, i.e., that the process, π is -measurable, which means it is deterministic and only a function of time. Thus, the fund manager of the insurance company has to explain at the investment strategy for the time horizon without using further knowledge about the evolution of the processes. This seems at least sometimes to be more realistic than the adaptive strategy Equation (15). A similar situation has been considered in [1], where the authors motivate such a strategy by pension funds often being managed by time-dependent investment strategies only. Hence, we consider
This is now the same problem over a smaller class of investment strategies. We consider the first problem :
Here, it is not necessary to consider the artificial problem, . can be transformed into a deterministic control problem as follows. To this end, note that the stochastic differential Equation (5) for the wealth can easily be solved. When we denote by the discounted wealth process, then we obtain:
For a deterministic process, π, the second integral is obviously a true martingale, and we obtain:
Note that and both depend on π. Thus, the target function of can be written as:
The deterministic control problem is then:
The value function of this problem is:
Obviously, the related HJB equation is:
In order to find a solution, we now consider the Ansatz
with . Thus, we obtain:
The minimizer of Equation (18) is determined by:
Plugging this into the HJB Equation (18) yields:
Note that this equation is satisfied when and ; thus:
Note that under the control and corresponding state trajectories , it holds that and for all . We summarize our results in the following theorem. A verification is straightforward.
Theorem 5
The value function of problem is given by
with being solutions of Equations (21) and (22), respectively. The optimal investment strategy is given by Equation (20).
Finally, we solve problem (MVD). First note that:
From , we obtain:
which is positive, due to condition Equation (7). Thus, we obtain the following result:
Theorem 6
Remark: In this setting, it is also easy to determine the strategy with the minimum achievable variance. In case the financial market is not perfectly correlated with the risk reserve, this minimal variance is not zero. For an arbitrary deterministic investment strategy, we obtain:
Minimizing this expression in yields the minimum variance investment strategy: with corresponding minimal variance
and expectation:
Thus, in case , problem (MVD) is trivial, because then, satisfies the constraint and yields the minimal possible variance. As a result, condition Equation (7) is reasonable.
Remark: Of course, for a given expected return of μ, when we minimize the variance over the smaller set of deterministic investment strategies, the variance will be not smaller than in the classical stochastic case. Indeed, when we suppose that , i.e., no additional insurance business and , we obtain the density of the optimal terminal wealth for (MVD), as well as for (MV). From Section 5, we conclude that for (MVD), the optimal terminal wealth satisfies:
For problem (MV), an optimal terminal wealth can be derived from the Lagrangian approach and is given by (cp.Theorem 3.3 in [14]):
where is the risk neutral density given by:
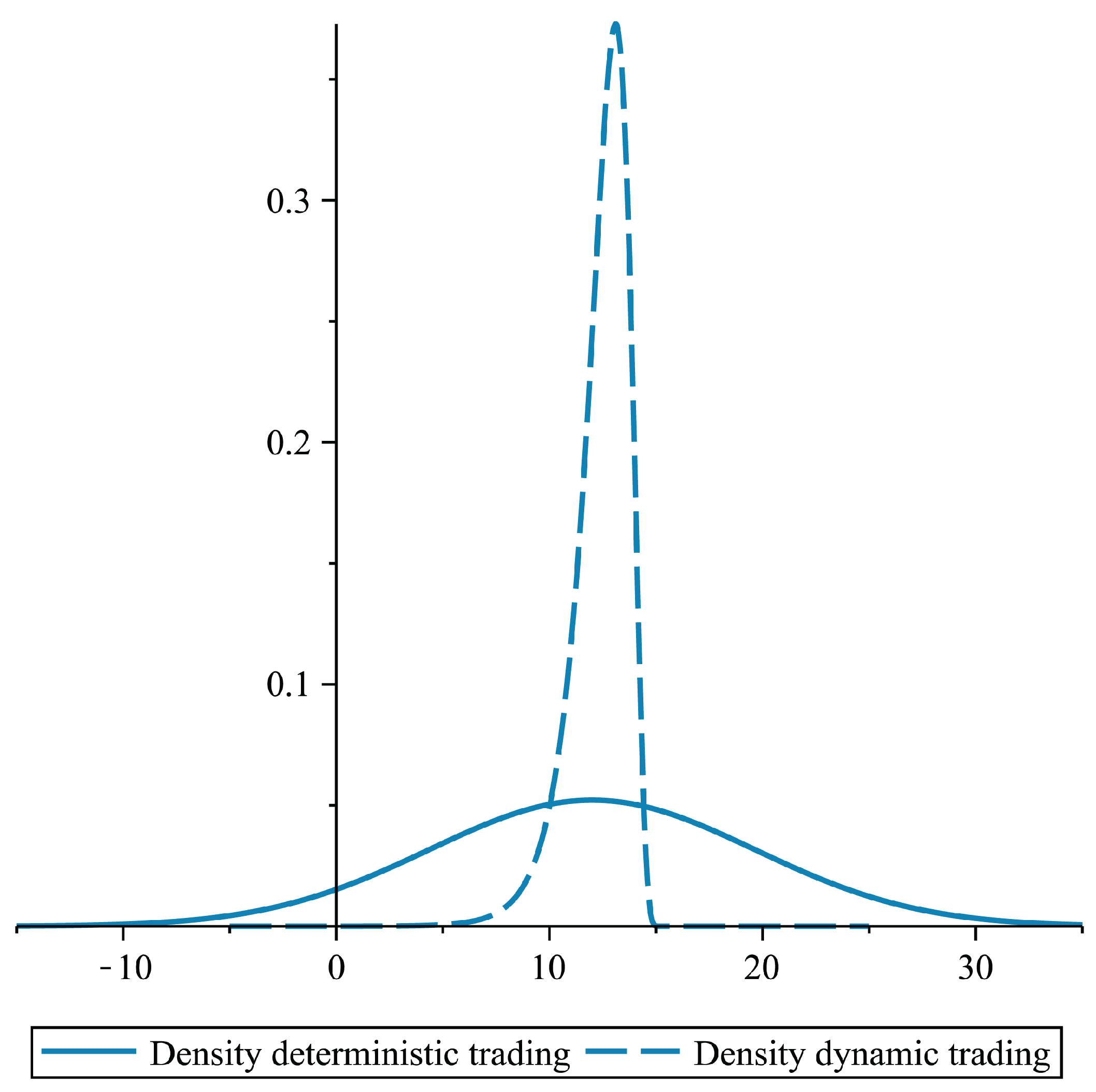
In Figure 1, we plotted the two densities of the optimal terminal wealth for (MVD) and (MV) for the parameters and .
Figure 1.
Densities of the optimal terminal wealth for (MVD) and (MV).

Obviously, for this time horizon (), there is a great difference in the performance of the two strategies. It seems that deterministic strategies here only make sense for small time horizons.
6. More General Mean-Risk Problems and Other Optimization Criteria
In this section, we will briefly discuss some other optimality criteria for the investment problem with deterministic investment strategies. Of course, when the solution of the classical stochastic control problem with adapted investment strategies yields an optimal strategy, which is itself deterministic, then this strategy is also optimal in the smaller class of deterministic strategies. A situation like this can occur when we consider the probability of ruin or the expected exponential utility as a target function. We discuss these cases below. However, we start this section with the observation that in the mean-variance framework, our optimal deterministic investment strategy is not only optimal w.r.t. to minimizing the variance.
6.1. More General Mean-Risk Problems
The variance or standard deviation is, of course, just one way to measure risk. Suppose now that ϱ is an arbitrary, law invariant and positive homogeneous risk measure, i.e., for all . We claim now that the problem
has the same solution as (MVD), which is obtained when we use the standard deviation .
Theorem 7
The optimal investment strategy for (MRD) coincides with the optimal investment strategy for (MVD).
Proof:
First note that in both cases, because of and the fact that , we can minimize the target function with replaced by and the side constraint, Now, due to Equation (17), we see that for deterministic investment strategies, has a normal distribution, , with parameters:
Hence, in distribution , where Z is a standard normal random variable. The optimization problem (MRD) can thus be written as:
Since ϱ is positive homogeneous, we obtain , which means that we have to minimize the standard deviation of . Hence, the statement follows. ☐
As a consequence, the optimal investment strategy we obtained is very robust w.r.t. the choice of risk measure. Indeed, it does not depend on the precise risk measure, as long as we agree to take a law invariant and positive homogeneous one. Indeed, the result is also valid for a function, ϱ, which is positive homogeneous of any order.
6.2. Maximizing Exponential Utility of Terminal Wealth
In this subsection, we consider the problem of maximizing with . For the classical stochastic case and only one stock, this has been done in [2]. We now directly consider the multi-asset model in the framework of deterministic strategies, i.e., we consider:
It turns out that the solution of this problem is very easy. We know already for deterministic π that has a normal distribution with parameters:
Hence, we can write , and the target function thus reduces to:
Obviously, the problem is equivalent to minimizing , and we end up with the following deterministic control problem:
However, this is equivalent to problem with , and we know from Equation (20) that the optimal investment strategy is given by:
Thus, due to Equation (23), there is a one-to-one relation between optimal mean-variance strategies and optimal strategies for the problem with the exponential utility function. For an early discussion about the relation of expected utility and mean-variance, see, e.g., [19,20]. Note that it can be shown that the optimal investment strategy we have computed here is also optimal within the larger class of adapted strategies.
6.3. Minimizing the Probability of Ruin
Another popular ‘risk measure’ in the actuarial sciences is the probability of ruin of a controlled risk reserve. When we consider the classical situation of -adapted investment strategies, it is very easy to find the one which minimizes the probability of ruin of process Equation (5). According to [21], the optimal feedback function, , is obtained by maximizing the ratio of mean over variance of the process, i.e.:
Obviously, when , then the maximizer, , is independent of x and deterministic. If further and , then .
7. Problems with Lévy Processes
The standard model for the risk reserve process of an insurance company is the so-called Cramér–Lundberg model. It assumes that the risk reserve process follows a Lévy process given as the difference of the premium income process and the claims that have been paid out so far. More precisely, it is usually assumed that:
where is the premium income rate, is a Poisson process with parameter , which counts the number of claims, and are independent and identically distributed random variables, representing the claim sizes. We denote and . The process in Equation (1) can be seen as a diffusion approximation of process Equation (24) when claims are small and frequent. The mean-variance problems we have considered in Section 4 and Section 5 can be dealt with in a Lévy framework along the same lines. The solution of the classical problem (MV) may be derived from [10]. Here, we concentrate on the problem (MVD) with deterministic investment strategies. We assume that:
In order to have an elegant notation, we write with the help of its Poisson random measure, , which is the sum of all claims taking values in the set B up to time t. Hence, we can write:
For simplicity, we leave the financial market as in the sections before, though one might also allow for jumps there. We again assume here that admissible trading strategies are -measurable. The corresponding wealth of the insurance company follows the stochastic differential equation:
We consider again the deterministic mean-variance problem (MVD) of Section 5. As in Section 5, we start with problem : Next, we compute . To this end, note that is a martingale. Thus, we obtain:
This is an ordinary differential equation for of the form:
with boundary condition . The solution is given by:
In order to compute the variance, we need the second moment of . Using partial integration, we get:
Taking the expectation yields:
which is an ordinary differential equation for of the form
with the boundary condition given by . When we define the variance as a function of time , it follows:
with boundary condition . Thus, we get:
The target function of can be written as:
and we obtain the deterministic control problem:
which is the same as in Section 5, where we have to set and replace α by and by . We use, again, the Ansatz:
The minimizer of the HJB Equation (18) is determined by:
and the value function is given by Equation (28) with:
We summarize our results in the following theorem. A verification is straightforward.
Theorem 8
The value function of problem is given by
with being solutions of Equations (30) and (31), respectively. The optimal investment strategy is given by Equation (29).
Finally, we solve the problem (MVD). Note that:
From , we obtain:
which is positive, due to condition Equation (25). Thus, we obtain the following result:
Theorem 9
As a result, we see that the optimal control depends only on the drift of the risk reserve (here, ), and it is not important whether the process has jumps or not.
8. Conclusions
We have shown that stochastic control problems with deterministic investment strategies lead to deterministic control problems that are, in general, easier to solve. In particular, in the case of a Brownian setting, the terminal wealth has a normal distribution under any admissible deterministic investment strategy. This leads to some very favorable properties, like the insensitivity of the optimal control w.r.t. to a class of target functions. Moreover, there are some interesting links between these problems. Optimal deterministic investment strategies for mean-variance problems, for example, correspond to optimal investment strategies for an insurance company with exponential utility. Finally, we also show that the current approach works in the setting of Lévy processes.
Conflicts of Interest
The authors declare no conflict of interest.
References
- M. Christiansen, and M. Steffensen. “Deterministic mean-variance-optimal consumption and investment.” Stochastics 85 (2013): 620–636. [Google Scholar] [CrossRef]
- S. Browne. “Optimal investment policies for a firm with a random risk process: Exponential utility and minimizing the probability of ruin.” Math. Oper. Res. 20 (1995): 937–958. [Google Scholar] [CrossRef]
- Y. Zeng, and Z. Li. “Optimal time-consistent investment and reinsurance policies for mean-variance insurers.” Insur. Math. Econom. 49 (2011): 145–154. [Google Scholar] [CrossRef]
- W.H. Fleming, and H.M. Soner. Controlled Markov Processes and Viscosity Solutions. New York, NY, USA: Springer, 2006. [Google Scholar]
- X.Y. Zhou, and D. Li. “Continuous-time mean-variance portfolio selection: A stochastic LQ framework.” Appl. Math. Optim. 42 (2000): 19–33. [Google Scholar] [CrossRef]
- P. Antolin, S. Payet, and J. Yermo. “Assessing default investment strategies in defined contribution pension plans.” OECD J.: Financ. Mark. Trends 1 (2010): 1–29. [Google Scholar]
- R. Korn, and S. Trautmann. “Continuous-time portfolio optimization under terminal wealth constraints.” ZOR—Math. Methods Oper. Res. 42 (1995): 69–92. [Google Scholar] [CrossRef]
- D. Li, and W.L. Ng. “Optimal dynamic portfolio selection: Multiperiod mean-variance formulation.” Math. Financ. 10 (2000): 387–406. [Google Scholar] [CrossRef]
- Ł. Delong, and R. Gerrard. “Mean-variance portfolio selection for a non-life insurance company.” Math. Methods Oper. Res. 66 (2007): 339–367. [Google Scholar]
- W. Guo, and C. Xu. “Optimal portfolio selection when stock prices follow a jump-diffusion process.” Math. Methods Oper. Res. 60 (2004): 485–496. [Google Scholar] [CrossRef]
- N. Bäuerle, and A. Blatter. “Optimal control and dependence modeling of insurance portfolios with Lévy dynamics.” Insur. Math. Econom. 48 (2011): 398–405. [Google Scholar] [CrossRef]
- B. Øksendal, and A. Sulem. Applied Stochastic Control of Jump Diffusions. Berlin, Germany: Springer, 2007. [Google Scholar]
- N. Bäuerle. “Benchmark and mean-variance problems for insurers.” Math. Methods Oper. Res. 62 (2005): 159–165. [Google Scholar] [CrossRef]
- O.S. Alp, and R. Korn. “Continuous-time mean-variance portfolios: A comparison.” Optimization 62 (2013): 961–973. [Google Scholar] [CrossRef]
- S. Basak, and G. Chabakauri. “Dynamic mean-variance asset allocation.” Rev. Financ. 23 (2010): 2970–3016. [Google Scholar] [CrossRef]
- E.M. Kryger, and M. Stefensen. “Some Solvable Portfolio Problems With Quadratic and Collective Objectives.” 2010. Available online at http://ssrn.com/abstract=1577265 (accessed on 1 October 2013).
- N. Bäuerle, and U. Rieder. Markov Decision Processes With Applications to Finance. Heidelberg, Germany: Springer, 2011. [Google Scholar]
- J. Yong, and X.Y. Zhou. Stochastic Controls. New York, NY, USA: Springer, 1999. [Google Scholar]
- G. Chamberlain. “A characterization of the distributions that imply mean variance utility functions.” JET 29 (1983): 185–201. [Google Scholar] [CrossRef]
- H. Levy, and H.M. Markowitz. “Approximating expected utility by a function of mean and variance.” Am. Econ. Rev. 69 (1979): 308–317. [Google Scholar]
- N. Bäuerle, and E. Bayraktar. “A note on applications of stochastic ordering to control problems in insurance and finance.” Stochastics, 2013. [Google Scholar] [CrossRef]
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Bäuerle, N.; Rieder, U. Optimal Deterministic Investment Strategies for Insurers. Risks 2013, 1, 101-118. https://doi.org/10.3390/risks1030101
AMA Style
Bäuerle N, Rieder U. Optimal Deterministic Investment Strategies for Insurers. Risks. 2013; 1(3):101-118. https://doi.org/10.3390/risks1030101
Chicago/Turabian StyleBäuerle, Nicole, and Ulrich Rieder. 2013. "Optimal Deterministic Investment Strategies for Insurers" Risks 1, no. 3: 101-118. https://doi.org/10.3390/risks1030101