

Data 2024, 9(5), 73; https://doi.org/10.3390/data9050073 - 19 May 2024
Abstract
►
Show Figures
To solve the problem of environmental pollution caused by road traffic, alternatives to vehicles with internal combustion engines are often proposed. As such, eco-mobility microvehicles have significant potential in the fight against environmental pollution, but only on the condition that they are widely
[...] Read more.
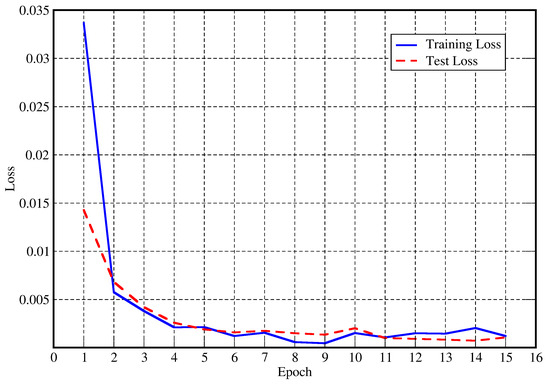
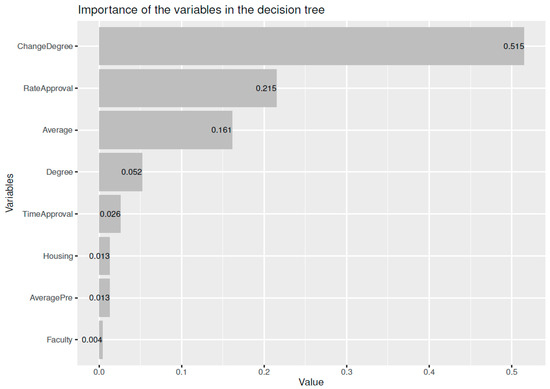
To solve the problem of environmental pollution caused by road traffic, alternatives to vehicles with internal combustion engines are often proposed. As such, eco-mobility microvehicles have significant potential in the fight against environmental pollution, but only on the condition that they are widely accepted and that they replace the vehicles that predominantly pollute the environment. With this in mind, this study aims to elucidate the main variables that influence the acceptability of these vehicles, using prediction models based on binary logistic regression and a multilayer artificial neural network—a multilayer perceptron (ANN). The data of a random sample obtained via an online questionnaire, answered by 503 inhabitants of Belgrade (Serbia), were used for training and testing the model. A multilayer perceptron with 9 and 7 neurons in two hidden layers, a hyperbolic tangent activation function in the hidden layer, and an identity function in the output layer performed slightly better than the binary logistic regression model. With an accuracy of 85%, a precision of 79%, a recall of 81%, and an area under the ROC curve of 0.9, the multilayer perceptron model recognized the influential variables in predicting acceptability. The results of the model indicate that a respondent’s relationship to their current environmental pollution, the frequency of their use of modes of transport such as bicycles and motorcycles, their mileage for commuting, and their personal income have the greatest influence on the acceptability of using eco-mobility vehicles.
Full article

Figure 1












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}