PIYAS-Proceeding to Intelligent Service Oriented Memory Allocation for Flash Based Data Centric Sensor Devices in Wireless Sensor Networks


Abstract
:1. Introduction
- First, when flash space becomes exhausted and there is no space remaining for further data storage, the system selects the victim block for garbage collection and the data in the victim block is simply erased and then the future queries cannot access this data as in [6–10]. This generates a data failure for user applications. Therefore, to address this issue, an effective data organization policy is required to provide long term in-network data availability.
- Second, the system initialization time and size of mapping structure increases with the size of stored data and flash media as in [7,10], but size of SRAM does not follow the trend of increasing size of flash memory. Thus, for instant mounting, a reliable and small size mapping structure is necessary with consideration of limited SRAM constraints of sensor nodes.
- Third, to entertain the read intensive conditions, reading of the entire media at the time of query responses becomes a big overhead with the increasing size of data and flash capacity as in [10]. Hence, an efficient query processing framework is desired to effectively satisfy the business needs.
- Minimize reads, writes and erases to secure energy,
- Effective garbage collection, and
- Reliable wear-leveling scheme.
2. Background
2.1. System Architecture of Sensor Node
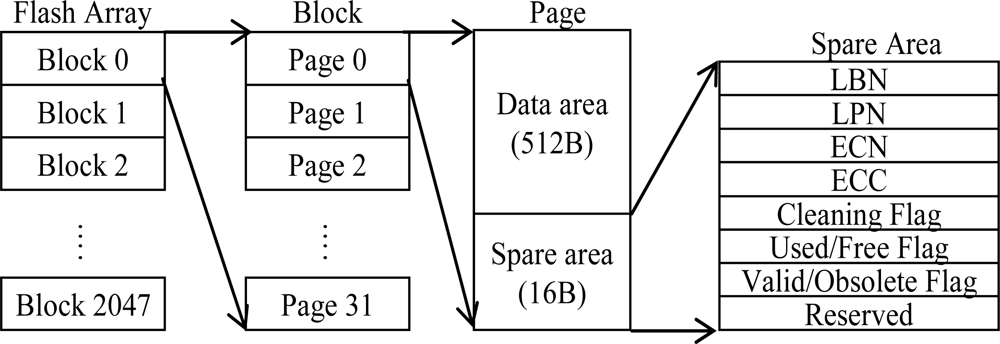
2.2. Overview of Flash Memory
- First Drawback: An inefficiency of in-place-update operation. When we modify data, we cannot update data directly at the same address due to the physical erase-before-write characteristics of flash memory. Therefore, updating even one byte data in any page requires an expensive erase operation on the corresponding block before the new data can be rewritten. To address this problem, the system software called flash translation layer (FTL) was introduced, as in [16–18]. FTL uses a non-in-place-update mechanism to avoid having to erase on every data update by using logical-to-physical address mapping table maintained in main memory. Under this mechanism, the FTL remaps each update request to different empty location and then the mapping table updates due to newly changed logical-to-physical addresses. This protects one block from being erased per overwrite. The obsolete data flagged as garbage which a software cleaning process later reclaims. This process is called garbage collection, as in [19–21].
- Second Drawback: The number of erase operations allowed to each block is limited like10,000 to 1,000,000 times and the single worn-out block affects the usefulness of the entire flash memory device. Therefore, data must be written evenly to all blocks. This operation is named as wear-leveling, as in [22,23]. These drawbacks represent hurdles for developing a reliable flash memory based sensor storage systems.
3. PIYAS: Proposed Memory Management Scheme
3.1. Data Organization Framework
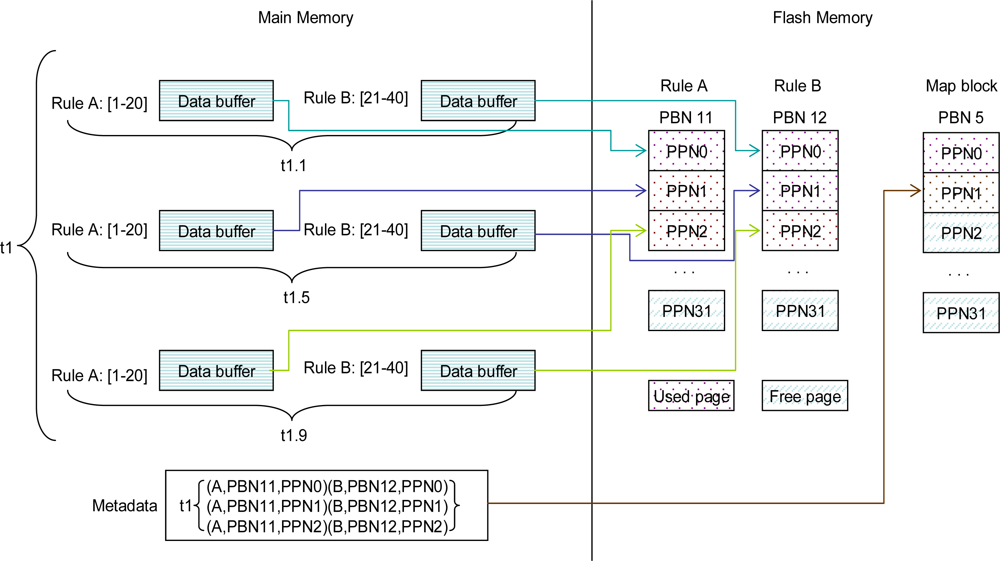
3.1.1. Data Buffers Management
3.1.2. Memory Block Organization
3.2. Mapping Structures Management
3.3. Query Processing Framework
3.3.1. Query on Raw Data Blocks
3.3.2. Queries on Aggregate Data Blocks
3.4. Garbage Collection
- Step 1: Select rule(s) with long chain of raw and aggregate data blocks. Every time, for cleaning the system evaluates two blocks from the long chain of blocks, one from RDBs and other from ADBs. The system selects the blocks by a first-in-first-out policy. It means the block with the oldest timestamp is always selected for erasure. RDB and ADB can be selected by the same or different rules, depending on the long chain of blocks in any rule.
- Step 2: Evaluate selected ADB. The system evaluates the timestamp of the last written page of the oldest ADB. If the data is dead, meaning the timestamp crossed the threshold of allowed in-network data sustainability, then the system marks the whole block as obsolete. As the last written page of every block represents the latest data within the block, if the last written page data becomes dead, then by default the data in all the previous pages become dead too. Then the block is erased and made available for new data. In the other case, if a block is still alive then the system goes to step three.
- Step 3: Evaluate selected RDB. The system evaluates the timestamp of the last written page of the oldest RDB. If the data exceeds the life limit then the system erases the block and provides it for new data. In the other case, the system evaluates the timestamps recorded in the spare areas of every page according to the time threshold of in-network data sustainability. The pages from the block under observation that are still alive aggregate on the user provided aggregation parameters. The system aggregates the data from the block size to page size and rewrites the aggregated data in the first available free page of ADB dedicated to the corresponding rule. Finally, the victim block is erased and becomes available for new data.
- Step 4: Perform cross checking for data sustainability periodically. The system evaluates the last written pages of the oldest blocks from the rules those have not participated in cleaning operations for a long time because they may not have long chains of blocks. The system considers both raw and aggregate data blocks. If the data is still alive, the system retains them or else blocks are marked obsolete and considered part of the dirty blocks pool. The system erases such blocks when idle.
3.5. Wear Leveling
4. Performance Evaluation
4.1. Simulation Methodology
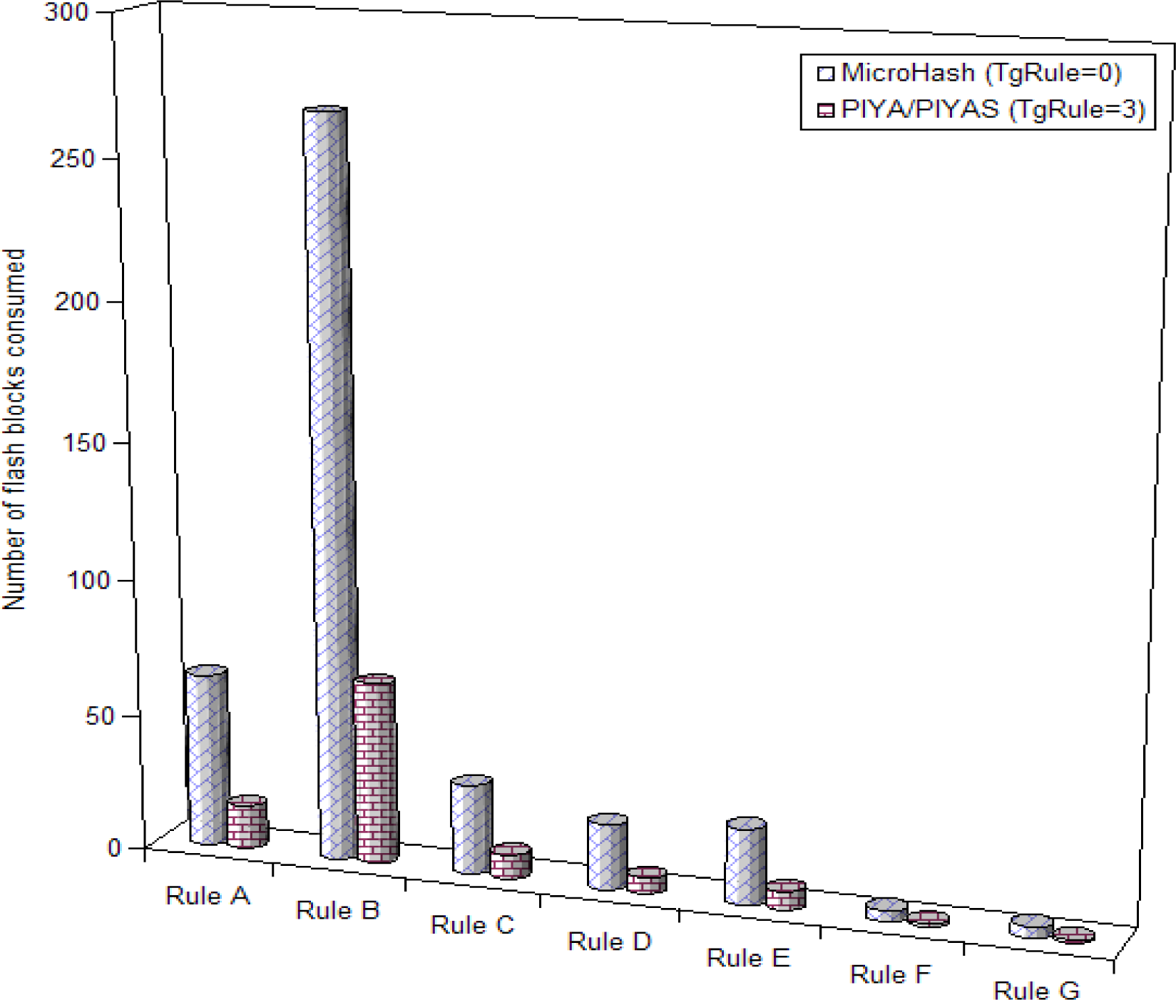
- Space Management: This shows the flash memory allocation against the thousands of continuous sensor readings and main memory consumption for maintaining the data buffers and metadata.
- Search Performance: This shows the number of pages required to be read for responding to a query.
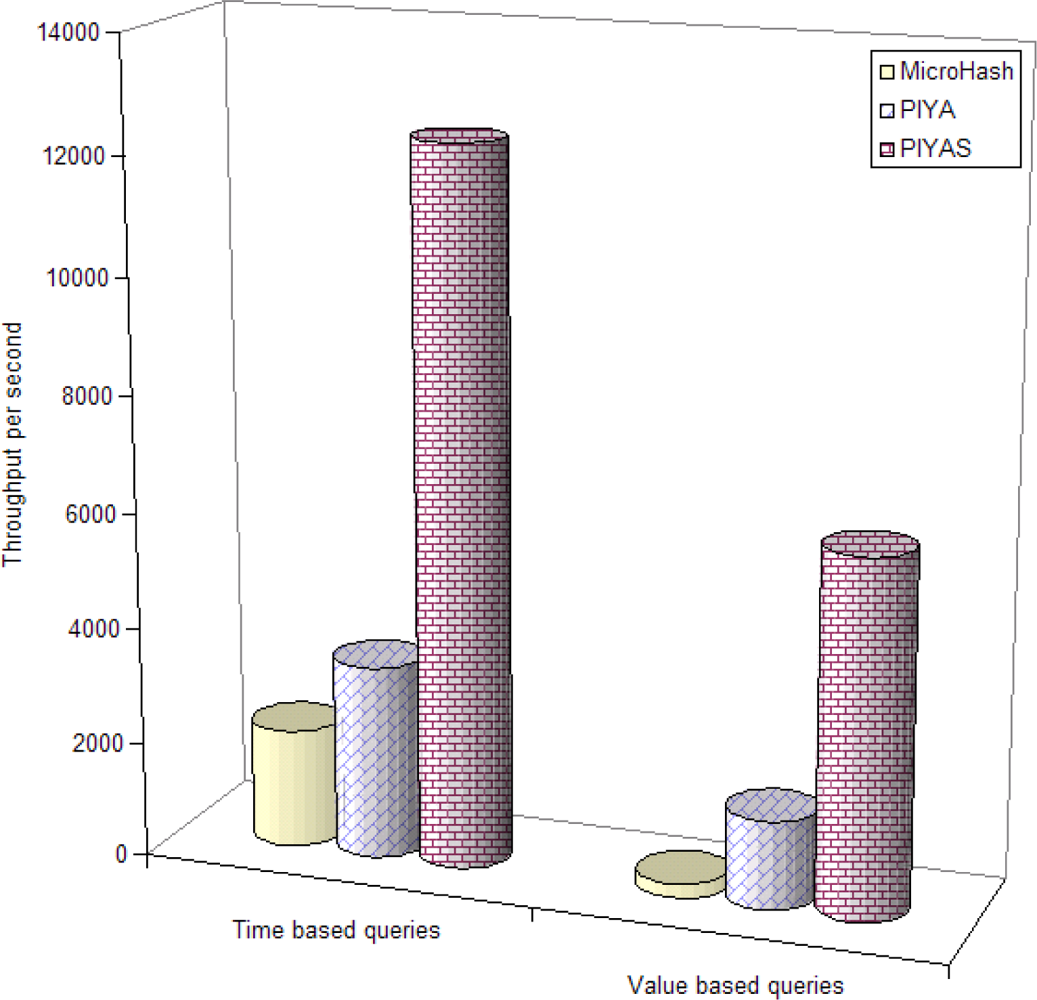
- Throughput Performance: This shows the response of number of queries in a unit of time.
- Energy Consumption: This shows the energy consumption while data writes to and data is read from sensor local flash memory.
4.2. Experimental Results
5. Conclusions
Acknowledgments
References and Notes
- Rizvi, S.S.; Chung, T.S. PIYA–Proceeding to Intelligent Service Oriented Memory Allocation for Flash Based Sensor Devices in Wireless Sensor Networks. Proceedings of the International Conference on Convergence and Hybrid Information Technology, Busan, Korea; 2008; pp. 625–630. [Google Scholar]
- Considine, J.; Li, F.; Kollios, G.; Byers, J. Approximate Aggregation Techniques for Sensor Databases. Proceedings of the International Conference on Data Engineering, Boston, MA, USA; 2004; pp. 449–460. [Google Scholar]
- Madden, S.; Franklin, M.J.; Hellerstein, J.; Hong, W. TAG: a Tiny AGgregation Service for Ad-Hoc Sensor Networks. Proceedings of the Symposium on Operating Systems Design and implementation, Boston, MA, USA; 2002; pp. 131–146. [Google Scholar]
- Zeinalipour-Yazti, D.; Neema, S.; Kalogeraki, V.; Gunopulos, D.; Najjar, W. Data Acquisition in Sensor Networks with Large Memories. Proceedings of the International Conference on Data Engineering, Tokyo, Japan; 2005; pp. 1188–1192. [Google Scholar]
- Lymberopoulos, D.; Savvides, A. XYZ: A Motion Enabled, Power Aware Sensor Node Platform for Distributed Sensor Network Applications. Proceedings of the International Symposium on Information Processing in Sensor Networks, Los Angeles, CA, USA; 2005; pp. 449–454. [Google Scholar]
- Banerjee, A.; Mitra, A.; Najjar, W.; Zeinalipour-Yazti, D.; Kalogeraki, V.; Gunopulos, D. RISE Co-S: High Performance Sensor Storage and Co-Processing Architecture. Proceedings of the IEEE Communications Society Conference on Sensor and Ad Hoc Communication and Networks, Santa Clara, CA, USA, 2005; pp. 1–12.
- Gay, D. Design of Matchbox: The simple Filing System for Motes. In TinyOS 1.x distribution, 2003. Available online: http://www.tinyos.net/ (accessed on 16 August 2009).
- Dai, H.; Neufeld, M.; Han, R. ELF: An Efficient Log-Structured Flash File System for Micro Sensor Nodes. Proceedings of the International Conference on Embedded Networked Sensor Systems, Baltimore, MD, USA; 2004; pp. 176–187. [Google Scholar]
- Mathur, Gaurav; Desnoyers, P.; Ganesan, D.; Shenoy, P.J. Capsule: An Energy-Optimized Object Storage System for Memory-Constrained Sensor Devices. Proceedings of the International Conference on Embedded Networked Sensor Systems, Boulder, CO, USA; 2006; pp. 195–208. [Google Scholar]
- Zeinalipour-Yazti, D.; Lin, S.; Kalogeraki, V.; Gunopulos, D.; Najjar, W.A. MicroHash: An Efficient Index Structure for Flash-Based Sensor Devices. Proceedings of the USENIX Conference on File and Storage Technology, San Francisco, CA, USA; 2005; pp. 31–44. [Google Scholar]
- Mathur, G.; Desnoyers, P.; Ganesan, D.; Shenoy, P. Ultra-low Power Data Storage for Sensor Networks. Proceedings of the International Conference on Information Processing in Sensor Networks, Nashville, TN, USA; 2006; pp. 374–381. [Google Scholar]
- Gal, E.; Sivan, T. Algorithms and Data Structures for Flash Memories. ACM Comput. Surv 2005, 37, 138–163. [Google Scholar]
- Zhang, P.; Sadler, C.M.; Lyon, A.S.; Martonosi, M. Hardware Design Experiences in ZebraNet. Proceedings of the ACM International Conference on Embedded Networked Sensor Systems, Baltimore, MD, USA; 2004; pp. 227–238. [Google Scholar]
- Dipert, B.; Levy, M. Designing with Flash Memory; Annabooks Publisher: Poway, CA, USA, 1993. [Google Scholar]
- Samsung Electronics, NAND Flash Memory, K9F5608U0D data book; Samsung Electronics Co., Ltd.: Jung-gu Seoul, South Korea, 2009.
- Chung, T.S.; Park, H.S. STAFF: A Flash Driver Algorithm Minimizing Block Erasures. J. Syst. Architect 2007, 53, 889–901. [Google Scholar]
- Chung, T.S.; Park, D.J; Park, S.; Lee, D.H.; Lee, S.W.; Song, H.J. A survey of Flash Translation Layer. J. Syst. Architect 2009, 55, 332–343. [Google Scholar]
- Kwon, S.J.; Chung, T.S. An Efficient and Advanced Space-management Technique for Flash Memory Using Reallocation Blocks. IEEE Trans. Consum. Electron 2008, 54, 631–638. [Google Scholar]
- Chung, T.S.; Lee, M.; Ryu, Y.; Lee, K. PORCE: An Efficient Power off Recovery Scheme for Flash Memory. J. Syst. Architect 2008, 54, 935–943. [Google Scholar]
- Han, L.Z.; Ryu, Y.; Chung, T.S.; Lee, M.; Hong, S. An Intelligent Garbage Collection Algorithm for Flash Memory Storages. Proceedings of the Computer Science and Its Applications, Lecture Notes in Computer Science, Glasgow, UK; 2006; pp. 1019–1027. [Google Scholar]
- Han, L.; Ryu, Y.; Yim, K. CATA: A Garbage Collection Scheme for Flash Memory File Systems. Proceedings of the Ubiquitous Intelligence and Computing, Lecture Notes in Computer Science, Wuhan, China; 2006; pp. 103–112. [Google Scholar]
- Chang, L.P. On Efficient Wear Leveling for Large Scale Flash Memory Storage Systems. Proceedings of the ACM Symposium on Applied computing, Seoul, Korea; 2007; pp. 1126–1130. [Google Scholar]
- Chang, Y.H.; Hsieh, J.W.; Kuo, T.W. Endurance Enhancement of Flash-Memory Storage Systems: An Efficient Static Wear Leveling Design. Proceedings of the ACM IEEE Design Automation Conference, San Diego, CA, USA, 2007; pp. 212–217.
- COAGMET. Available online: http://ccc.atmos.colostate.edu/~coagmet/index.php/ (accessed on 16 August 2009).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technique | Storage Device | Storage Location | Data Life Efficient | Device Life Efficient | Energy Efficient | Storage Efficient |
|---|---|---|---|---|---|---|
| Matchbox | NOR | Internal | No | No | No | No |
| ELF | NOR | Internal | No | Yes | No | No |
| Capsule | NOR/NAND | Internal | No | Yes | Yes | No |
| MicroHash | NAND | External | No | Yes | Yes | No |
| PIYA | NAND | External | Yes | Yes | Yes | Yes |
| PIYAS | NAND | External | Yes | Yes | Yes | Yes |
| Operation | Time (μsec) | Energy (mA) (Current 3.3 V) |
|---|---|---|
| Page Read (512 + 16) B | 15 | 20 |
| Page Write (512 + 16) B | 500 | 25 |
| Block Erase (16K + 512) B | 3,000 | 25 |
| Rule Description | PBN (PPN) |
|---|---|
| A: [1–20] | 14(1) |
| B: [21–40] | 15(2) |
| C: [41–60] | 16(3) |
| D: [61–80] | 17(4) |
| Rule Description | PBN (Raw Data) | PBN (Aggregate Data) |
|---|---|---|
| A: [1–20] | 1,5,9,14 | 13 |
| B: [21–40] | 2,6,10,15 | - |
| C: [41–60] | 3,7,11,16 | 18 |
| D: [61–80] | 4,8,12,17 | - |
| Rule Description | A: [1–20] | A: [21–40] | A: [41–60] | A: [61–80] |
|---|---|---|---|---|
| Timestamp | PBN (PPN) | PBN (PPN) | PBN (PPN) | PBN (PPN) |
| t1 | 11 (0,1,2) | 12 (0,1,2) | - | - |
| t2 | - | 12 (3,4,5) | 13 (0,1,2) | - |
| t3 | - | - | 13 (3,4,5) | 14 (0,1,2) |
| t4 | 11 (3,4,5) | - | - | 14 (3,4,5) |
| t5 | 11 (6,7,8) | 12 (6,7,8) | - | - |
| t6 | - | 12 (9,10,11) | 13 (6,7,8) | - |
| Aggregate Data Blocks | 21 | - | 22 | 23 |
| Rule Symbol | Rule Range (Temperature) |
|---|---|
| A | −99–0 |
| B | 1–100 |
| C | 101–200 |
| D | 201–300 |
| E | 301–400 |
| F | 401–500 |
| G | 501–600 |
| PIYA | MicroHash | |||
|---|---|---|---|---|
| RDBs | Time based queries | Time Energy | 216.4 μs 0.95 J | 406 μs 1.79 J |
| Value based queries | Time Energy | 487.2 μs 2.14 J | 3897.6 μs 17.15 J | |
| ADBs | Time based queries | Time Energy | 120.9 μs 0.53 J | N/A N/A |
| Value based queries | Time Energy | 150.5 μs 0.66 J | N/A N/A | |
| PIYA | MicroHash | ||
|---|---|---|---|
| RDBs | Time based queries Value based queries | 72.7% 75% | 83.3% 96% |
| ADBs | Time based queries Value based queries | 68.7% 74.6% | N/A N/A |
©2010 by the authors; licensee Molecular Diversity Preservation International, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/)
Share and Cite
Rizvi, S.S.; Chung, T.-S. PIYAS-Proceeding to Intelligent Service Oriented Memory Allocation for Flash Based Data Centric Sensor Devices in Wireless Sensor Networks. Sensors 2010, 10, 292-312. https://doi.org/10.3390/s100100292
Rizvi SS, Chung T-S. PIYAS-Proceeding to Intelligent Service Oriented Memory Allocation for Flash Based Data Centric Sensor Devices in Wireless Sensor Networks. Sensors. 2010; 10(1):292-312. https://doi.org/10.3390/s100100292
Chicago/Turabian StyleRizvi, Sanam Shahla, and Tae-Sun Chung. 2010. "PIYAS-Proceeding to Intelligent Service Oriented Memory Allocation for Flash Based Data Centric Sensor Devices in Wireless Sensor Networks" Sensors 10, no. 1: 292-312. https://doi.org/10.3390/s100100292
APA StyleRizvi, S. S., & Chung, T. -S. (2010). PIYAS-Proceeding to Intelligent Service Oriented Memory Allocation for Flash Based Data Centric Sensor Devices in Wireless Sensor Networks. Sensors, 10(1), 292-312. https://doi.org/10.3390/s100100292