Abstract
This paper presents a novel class of self-organizing sensing agents that adaptively learn an anisotropic, spatio-temporal Gaussian process using noisy measurements and move in order to improve the quality of the estimated covariance function. This approach is based on a class of anisotropic covariance functions of Gaussian processes introduced to model a broad range of spatio-temporal physical phenomena. The covariance function is assumed to be unknown a priori. Hence, it is estimated by the maximum a posteriori probability (MAP) estimator. The prediction of the field of interest is then obtained based on the MAP estimate of the covariance function. An optimal sampling strategy is proposed to minimize the information-theoretic cost function of the Fisher Information Matrix. Simulation results demonstrate the effectiveness and the adaptability of the proposed scheme.1. Introduction
In recent years, due to global climate changes, more environmental scientists are interested in the change of ecosystems over vast regions in lands, oceans, and lakes. For instance, for certain environmental conditions, rapidly reproducing harmful algal blooms in the Great Lakes can produce cyanotoxins. Besides such natural disasters, there exist growing ubiquitous possibilities of the release of toxic chemicals and contaminants in the air, lakes, and public water systems. This resulted in the rising demands to utilize autonomous robotic systems that can perform a series of tasks such as estimation, prediction, monitoring, tracking and removal of a scalar field of interest undergoing often complex transport phenomena (Common examples are diffusion, convection, and advection).
Significant enhancements have been made in the areas of mobile sensor networks and mobile sensing vehicles such as unmanned ground vehicles, autonomous underwater vehicles, and unmanned aerial vehicles. Emerging technologies have been reported on the coordination of mobile sensing agents [1–6]. Mobile sensing agents form an ad-hoc wireless communication network in which each agent usually operates under a short communication range, with limited memory and computational power. Mobile sensing agents are often spatially distributed in an uncertain surveillance environment.
The mobility of mobile agents can be designed in order to perform the optimal sampling of the field of interest. Recently in [5], Leonard et al. developed mobile sensor networks that optimize ocean sampling performance defined in terms of uncertainty in a model estimate of a sampled field. In [6], distributed learning and cooperative control were developed for multi-agent systems to discover peaks of the unknown field based on the recursive estimation of an unknown field. In general, we design the mobility of sensing agents to find the most informative locations to make observations for a spatio-temporal phenomenon. To find these locations that predict the phenomena best, one needs a model of the spatio-temporal phenomenon itself. In our approach, we focus on Gaussian processes to model fields undergoing transport phenomena. A Gaussian process (or kriging in geostatistics) has been widely used as a nonlinear regression technique to estimate and predict geostatistical data [7–11]. A Gaussian process is a natural generalization of the Gaussian probability distribution. It generalizes the Gaussian distribution with a finite number of random variables to a Gaussian process with an infinite number of random variables in the surveillance region. Gaussian process modeling enables us to predict physical values, such as temperature and plume concentration, at any of spatial points with a predicted uncertainty level efficiently. For instance, near-optimal static sensor placements with a mutual information criterion in Gaussian processes were proposed by [12,13]. Distributed kriged Kalman filter for spatial estimation based on mobile sensor networks are developed by [14]. A distributed adaptive sampling approach was proposed by [15] for sensor networks to find locations that maximize the information contents by assuming that the covariance function is known up to a scaling parameter. Multi-agent systems that are versatile for various tasks by exploiting predictive posterior statistics of Gaussian processes were developed by [16,17].
The motivation of our work is as follows. Even though there have been efforts to utilize Gaussian processes to model and predict the spatio-temporal field of interest, most of recent papers assume that Gaussian processes are isotropic, implying that the covariance function only depends on the distance between locations. Many studies also assume that the corresponding covariance functions are known a priori for simplicity. However, this is not the case in general as pointed out in literature [12,13,18], in which they treat the non-stationary process by fusing a collection of isotropic spatial Gaussian processes associated with a set of local regions. Hence our motivation is to develop theoretically-sound algorithms for mobile sensor networks to learn the anisotropic covariance function of a spatio-temporal Gaussian process. Mobile sensing agents can then predict the Gaussian process based on the estimated covariance function in a nonparametric manner.
The contribution of this paper is to develop covariance function learning algorithms for the sensing agents to perform nonparametric prediction based on a properly adapted Gaussian process for a given spatio-temporal phenomenon. By introducing a generalized covariance function, we expand the class of Gaussian processes to include the anisotropic spatio-temporal phenomena. The maximum a posteriori probability (MAP) estimator is used to find hyperparameters for the associated covariance function. The proposed optimal navigation strategy for autonomous vehicles minimizes the information-theoretic cost function such as D-or A-optimality criterion using the Fisher Information Matrix (or Cramér-Rao lower bound (CRLB)[19], improving the quality of the estimated covariance function. A Gaussian process with a time-varying covariance function has been proposed to demonstrate the adaptability of the proposed scheme.
This paper is organized as follows. In Section 2, we briefly review the mobile sensing network model and the notation related to a graph. A nonparametric approach to predict a field of interest based on measurements is presented in Section 3. Section 4 introduces a covariance function learning algorithm for an anisotropic, spatio-temporal Gaussian process. An optimal navigation strategy is described in Section 5. In Section 6, simulation results illustrate the usefulness of our approach and its adaptability for unknown and/or time-varying covariance functions.
The standard notation will be used in the paper. Let ℝ, ℝ≥0, ℤ denote, respectively, the set of real, non-negative real, and integer numbers. The positive semi-definiteness of a matrix A is denoted by A ≽ 0. Let |B| denotes the determinant of a matrix B. 𝔼 denote the expectation operator.
2. Mobile Sensor Networks
First, we explain the mobile sensing network and the measurement model used in this paper. Let Ns be the number of sensing agents distributed over the surveillance region ∈ ℝ2. Assume that is a compact set. The identity of each agent is indexed by := {1, 2,⋯, Ns}. Let qi(t) ∈ be the location of the i-th sensing agent at time t ∈ ℝ≥0. We assume that the measurement y(qi(t), t) of agent i is the sum of the scalar value of the Gaussian process z(qi(t), t) and sensor noise wi(t), at its position qi(t) and some measurement time t,
The communication network of mobile agents can be represented by a graph with edges. Let G(t) = (, (t)) be an undirected communication graph such that an edge (i, j) ∈ (t) if and only if agent i can communicate with agent j ≠ i. We define the neighborhood of agent i at time t by Ni(t) := {j | (i, j) ∈ (t), i ∈ }. We also define the closed neighborhood of agent i at time t by the union of its index and its neighbors, i.e., N̄i (t) := {i} ∪ Ni(t).
3. The Nonparametric Approach
With the spatially distributed sampling capability, agents need to estimate and predict the field of interest by fusing the collective samples from different space and time indices. We show a nonparametric approach to predict a field of interest based on measurements. We assume that a field undergoing a physical transport phenomenon can be modeled by a spatio-temporal Gaussian process, which can be used for nonparametric prediction.
Consider a spatio-temporal Gaussian process:
In the case that the global coordinates are different from the local model coordinates, a similarity transformation can be used to address this issue. For instance, a rotational relationship between the model basis {e⃗x, e⃗y} and the global basis {E⃗x, E⃗y} is:
Up to time tk, agent i has noisy collective data {y(qj(tm), tm) | m ∈ ℤ, j ∈ N̄i(tm), 1 ≤ m ≤ k}, where N̄i(tm) denotes the closed neighborhood of agent i at time tm. The measurements y(qj(tm), tm) = z(qj(tm), tm) + wj(tm) are taken at different positions qj(tm) ∈ and different times tm ∈ ℝ≥0. The measurements are corrupted by the sensor and communication noises represented by Gaussian white noise . For the case in which the noise level σw is not known and needs to be estimated, the hyperparameter vector can be expanded to include σw, i.e., . The column-vectorized measurements collected by agent i is denoted by
If the covariance function is known a priori, the prediction of the random field z(s, t) at location s and time t is then obtained by
4. The MAP Estimate of the Hyperparameter Vector
Without loss of generality, we use a zero mean Gaussian process z(s, t) ∼ (0, (s, t, s′, t′)) for modeling the field undergoing a physical transport phenomenon. This is not a strong limitation since the mean of the posterior process is not confined to zero [11].
If the covariance function of a Gaussian process is not known a priori, mobile agents need to estimate parameters of the covariance function (Ψ) based on the observed samples. Using Bayes’ rule, the posterior p(Ψ|Y≤k) is proportional to the likelihood p(Y≤k|Ψ) times the prior p(Ψ), i.e.,
A gradient ascent algorithm is used to find a MAP estimate of Ψ:
After finding a MAP estimate of Ψ, agents can proceed the prediction of the field of interest using Equation (3).
5. An Adaptive Sampling Strategy
Agents should find new sampling positions to improve the quality of the estimated covariance function in the next iteration at time tk+1. For instance, to precisely estimate the anisotropic phenomenon, i.e., processes with different correlations along x-axis and y-axis directions, sensing agents need to explore and sample measurements along different directions.
To this end, we consider a centralized scheme. Suppose that a leader agent (or a central station) knows the communication graph at the next iteration time tk+1 and also has access to all measurements collected by agents. Let Yk+1 and Y≤k be the measurements at time tk+1 and the collective measurements up to time tk, respectively, i.e.,
To derive the optimal navigation strategy, we compute the log likelihood function of observations of Y≤k+1:
Since the locations of observations in Y≤k were already fixed, we represent the log likelihood function in terms of a vector of future sampling points q̃ at time tk+1 only and the hyperparameter vector Ψ:
Now consider the Fisher Information Matrix (FIM) that measures the information produced by measurements Y≤k+1 for estimating the hyperparameter vector at time tk+1. The Cramér-Rao lower bound (CRLB) theorem states that the inverse of the FIM is a lower bound of the estimation error covariance matrix [19,21]:
We can expect that minimizing the CRLB results in a decrease of uncertainty in estimating Ψ [22]. Using the D-optimality criterion [24,25], the objective function J is given by
However, optimization on ln p(Y≤k+1|Ψ) in Equation (6) and J(q̃, Ψ̂k) in Equation (8) or (9) can be numerically costly due to the increasing size of ΣY≤k. One way to deal with this problem is to use a truncated date set
The overall protocol for the sensor network is summarized as in Table 1.

6. Simulation Results
In this section, we evaluate the proposed approach for a spatio-temporal Gaussian process (Section 6.1) and an advection-diffusion process (Section 6.3). For both cases, we compare the simulation results using the proposed optimal sampling strategy with results using a benchmark random sampling strategy. In this random sampling strategy, each agent was initially randomly deployed in the surveillance region. At each time step, the next sampling position for agent i is generated randomly with the same mobility constraint, viz. a random position within a square region with length 2 centered at the current position qi. For fair comparison, the same values were used for all other conditions. In Section 6.2, our approach based on truncated observations has been applied to a Gaussian process with a time-varying covariance function to demonstrate the adaptability of the proposed scheme.
6.1. A Spatio-Temporal Gaussian Process
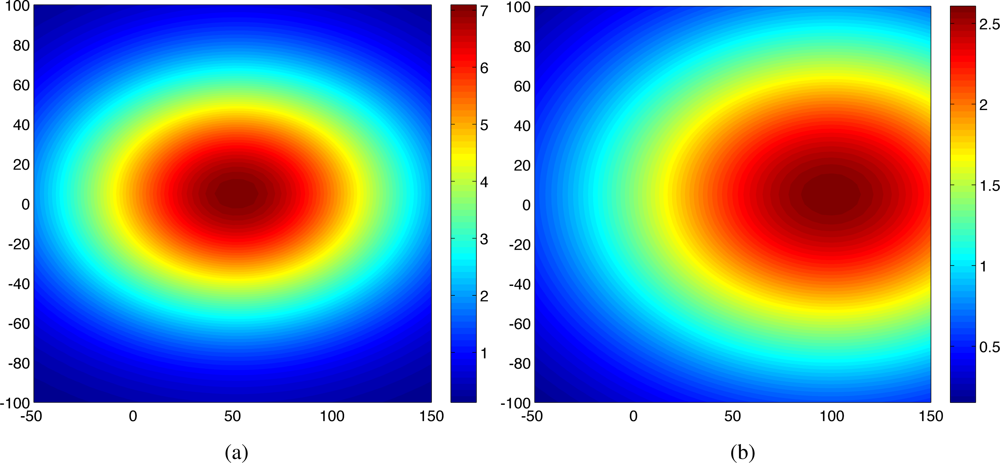
We apply our approach to a spatio-temporal Gaussian process. The Gaussian process was numerically generated for the simulation [11]. The hyperparameters used in the simulation were chosen such that . Two snap shots of the realized Gaussian random field at time t = 1 and t = 20 are shown in Figure 1. In this case, Ns = 5 mobile sensing agents were initialized at random positions in a surveillance region . The initial values for the algorithm were given to be . A prior of the hyperparameter vector has been selected as
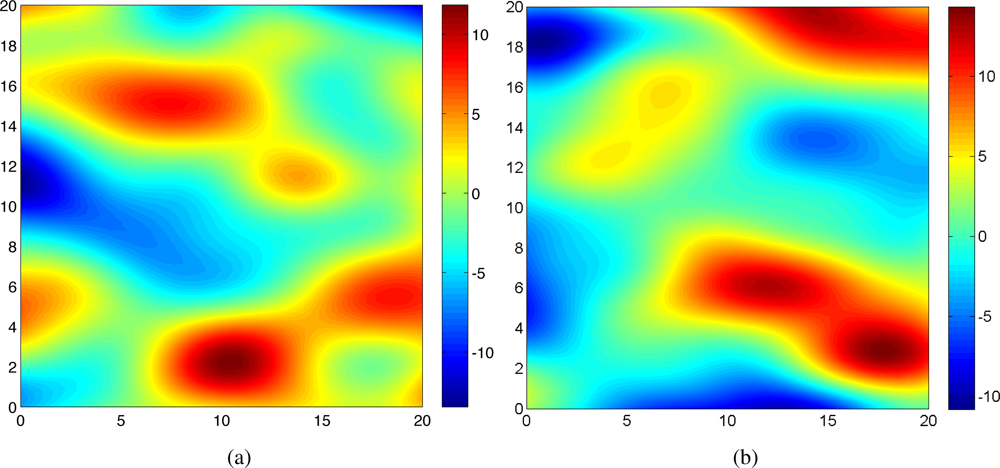
For simplicity, we assumed that the global basis is the same as the model basis. We considered a situation where at each time, measurements of agents are transmitted to a leader (or a central station) that uses our Gaussian learning algorithm and sends optimal control back to individual agents for next iteration to improve the quality of the estimated covariance function. The maximum distance for agents to move in one time step was chosen to be 1 for both x and y directions. The A-optimality criterion was used for optimal sampling.
For both proposed and random strategies, Monte Carlo simulations were run for 100 times and the statistical results are shown in Figure 2. The estimates of the hyperparameters (shown in circles and error bars) tend to converge to the true values (shown in dotted lines) for both strategies. As can be seen, the proposed scheme (Figure 2(a)) outperforms the random strategy (Figure 2(b)) in terms of the A-optimality criterion.
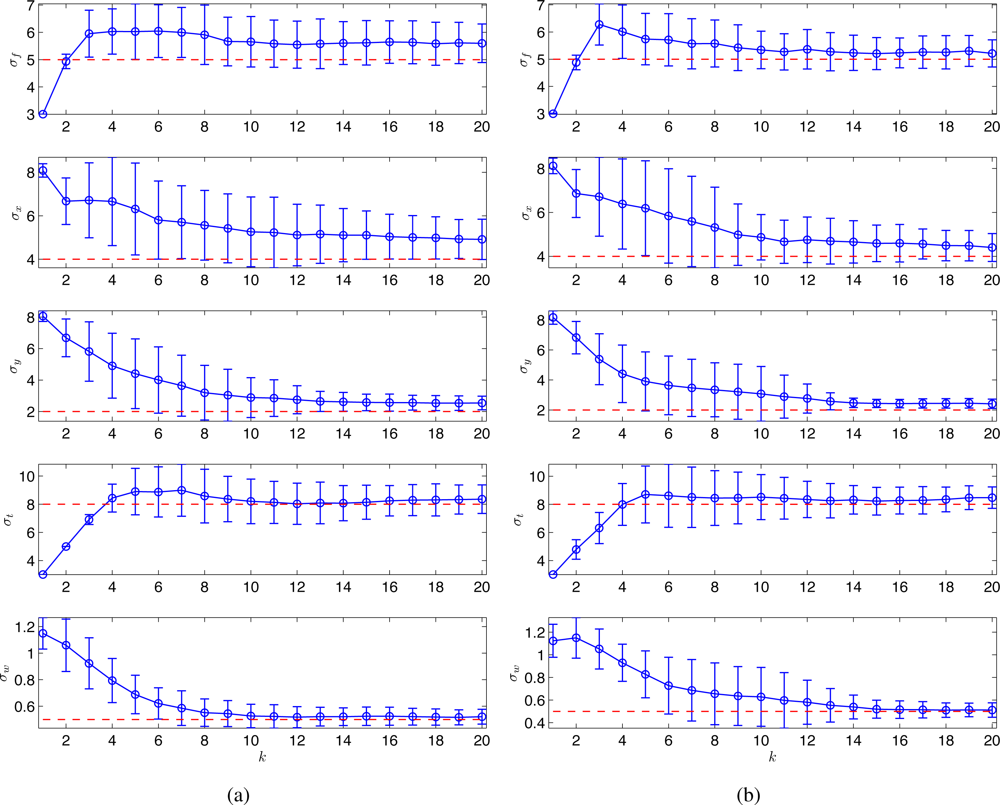
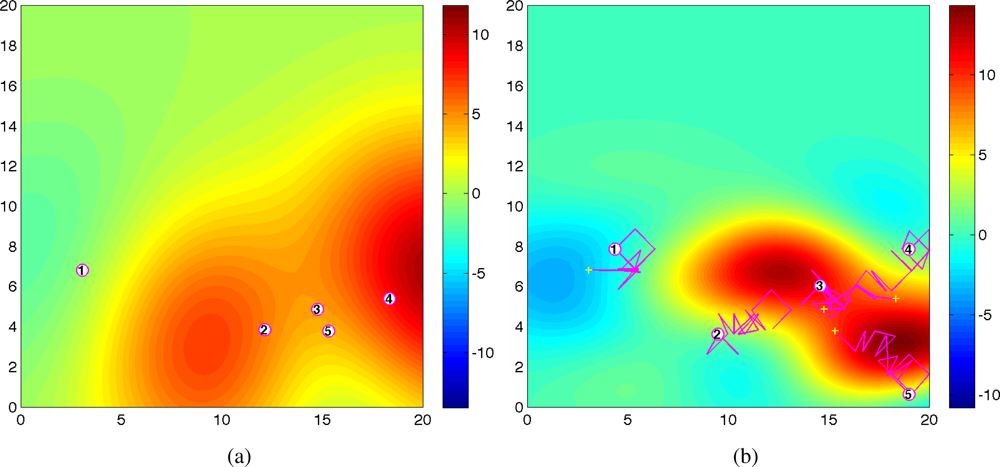
Figure 3 shows the predicted field along with agents’ trajectories at time t = 1 and t = 20 for one trial. As shown in Figure 1(a) and Figure 3(a), at time t = 1, the predicted field is far from the true field due to the inaccurate hyperparameters estimation and small number of observations. As time increases, the predicted field will be closer to the true field due to the improved quality of the estimated the covariance function and the cumulative observations. As expected, at time t = 20, the quality of the predicted field is very well near the sampled positions as shown in Figure 3(b). With 100 observations, the running time is around 30s using Matlab, R2008a (MathWorks) in a PC (2.4 GHz Dual-Core Processor). No attempt has been made to optimize the code. After converging to a good estimate of Ψ, agents can switch to a decentralized configuration and collect samples for other goals such as peak tracking and prediction of the process [6,16,17].
6.2. Time-Varying Covariance Functions
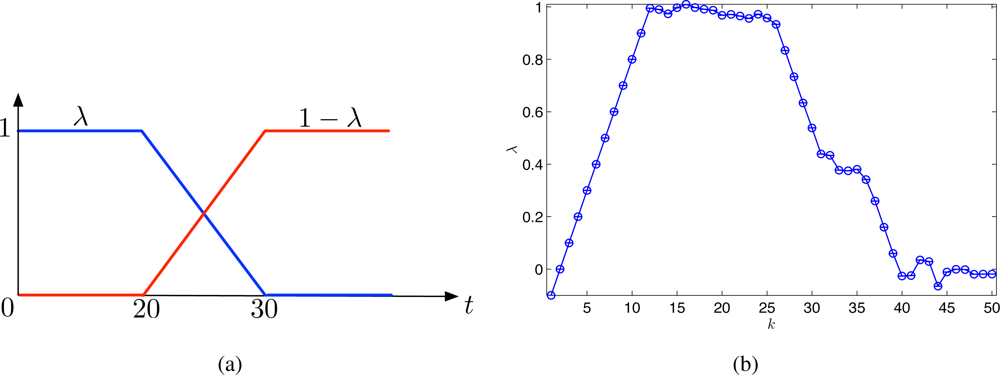
To illustrate the adaptability of the proposed strategy to time-varying covariance functions, we introduce a Gaussian process defined by the following covariance function. The time-varying covariance function is modeled by a time-varying weighted sum of two known covariance functions 1(·) and 2(·) such as
To improve the adaptability, the mobile sensor network uses only observations sampled during the last 20 iterations for estimating λ(t) online. The true λ(t) and the estimated λ(t) are shown in Figure 4(a,b), respectively. From Figure 4, it is clear that the weighting factor λ(t) can be estimated accurately after some delay about 5–8 iterations. The delay is due to using the truncated observations that contain past observations since the time-varying covariance function changes continuously in time.
6.3. Fitting a Gaussian Process to an Advection-Diffusion Process
We apply our approach to a spatio-temporal process generated by physical phenomena (advection and diffusion). This work can be viewed as a statistical modeling of a physical process, i.e., as an effort to fit a Gaussian process to a physical advection-diffusion process in practice. The advection-diffusion model developed in [26] was used to generate the experimental data numerically. An instantaneous release of Qkg of gas occurs at a location (x0, y0, z0). This is then spread by the wind with mean velocity Assuming that all measurements are recorded at a level z = 0, and the release occurs at a ground level (i.e., z0 = 0), the concentration C at an arbitrary location (x, y, 0) and time t is described by the following analytical solution [27]:
The initial values for the algorithm was chosen to be where we assumed σf = 1 and σw = 0.1. For this application, we did not assume any prior knowledge about the covariance function. Hence, the MAP estimator was the same as the ML estimator. The gradient method was used to find the ML estimate.
We again assumed that the global basis is the same as the model basis and assumed all agents have the same level of measurement noises for simplicity. In our simulation study, agents start sampling at t0 = 100min and take measurements at time tk with a sampling time of ts = 5min as in Table 2.
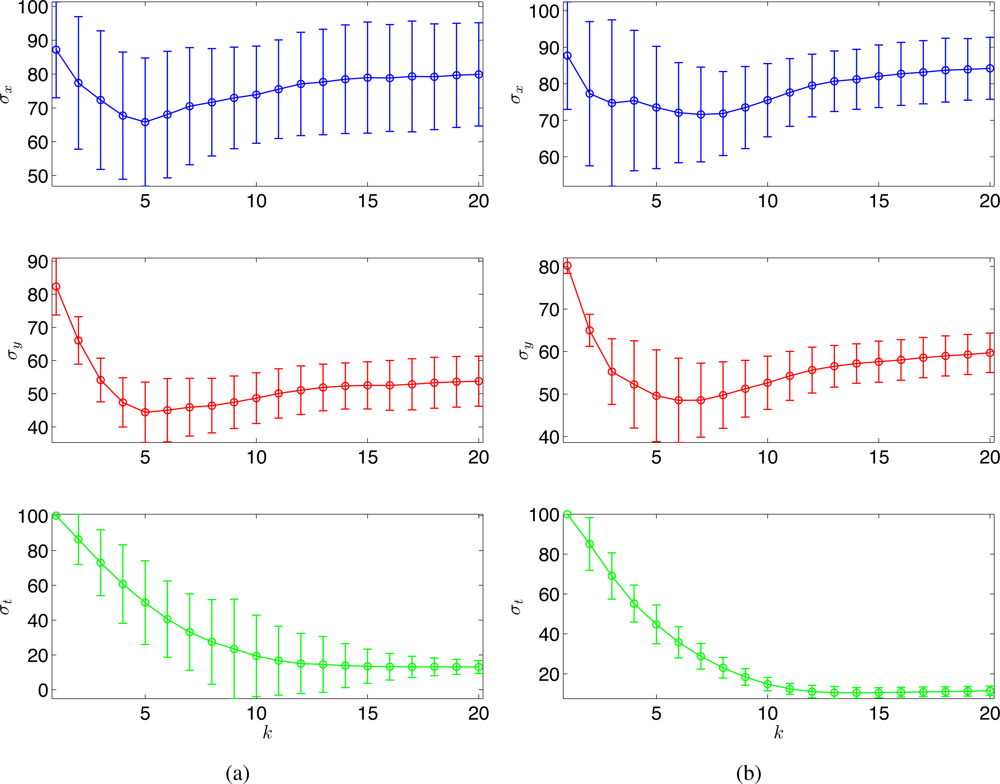
Monte Carlo simulations were run for 100 times, and Figure 6 shows the estimated σx, σy, and σt with (a) the random sampling strategy and (b) the optimal sampling strategy, respectively. With 100 observations, the running time at each time step is around 20s using Matlab, R2008a (MathWorks) in a PC (2.4 GHz Dual-Core Processor). No attempt has been made to optimize the code. As can be seen in Figure 6, the estimates of the hyperparameters tend to converge to similar values for both strategies. Clearly, the proposed strategy outperforms the random sampling strategy in terms of the estimation error variance.
7. Summary
In this paper, we presented a novel class of self-organizing sensing agents that learn an anisotropic, spatio-temporal Gaussian process using noisy measurements and move in order to improve the quality of the estimated covariance function. The MAP estimator was used to estimate the hyperparameters in the unknown covariance function and the prediction of the field of interest was obtained based on the MAP estimates. An optimal navigation strategy was proposed to minimize the information-theoretic cost function of the Fisher Information Matrix for the estimated hyperparameters. The proposed scheme was applied to both a spatio-temporal Gaussian process and a true advection-diffusion field. Simulation study indicated the effectiveness of the proposed scheme and the adaptability to time-varying covariance functions. The trade-off between a precise estimation and computational efficiency using truncated observations will be studied in the future work.
Acknowledgments
This work has been supported by the National Science Foundation through CAREER Award CMMI-0846547. This support is gratefully acknowledged.
References
- Lynch, KM; Schwartz, IB; Yang, P; Freeman, RA. Decentralized environmental modeling by mobile sensor networks. IEEE Trans. Robot 2008, 24, 710–724. [Google Scholar]
- Tanner, HG; Jadbabaie, A; Pappas, GJ. Stability of Flocking Motion; Technical Report MS-CIS-03-03,; The GRASP Laboratory, University Pennsylvania: Philadelphia, PA, USA; May; 2003. [Google Scholar]
- Olfati-Saber, R. Flocking for multi-agent dynamic systems: Algorithms and theory. IEEE Trans. Automat. Contr 2006, 51, 401–420. [Google Scholar]
- Ren, W; Beard, RW. Consensus seeking in multiagent systems under dynamically changing interaction topologies. IEEE Trans. Automat. Contr 2005, 50, 655–661. [Google Scholar]
- Leonard, NE; Paley, DA; Lekien, F; Sepulchre, R; Fratantoni, DM; Davis, RE. Collective motion, sensor networks, and ocean sampling. Proc. IEEE 2007, 95, 48–74. [Google Scholar]
- Choi, J; Oh, S; Horowitz, R. Distributed learning and cooperative control for multi-agent systems. Automatica 2009, 45, 2802–2814. [Google Scholar]
- Cressie, N. Kriging nonstationary data. J. Ame. Statist. Assn 1986, 81, 625–634. [Google Scholar]
- Cressie, N. Statistics for Spatial Data; A Wiley-Interscience Publication, John Wiley and Sons, Inc: Chichester, West Sussex, UK, 1991. [Google Scholar]
- Gibbs, M; MacKay, DJC. Efficient implementation of Gaussian processes. Available online: http://www.cs.toronto.edu/mackay/gpros.ps.gz.Preprint/ (accessed on 3 March 2011).
- Mackay, DJC. Introduction to Gaussian Processes. In NATO ASI Series Series F: Computer and System Sciences; Springer-Verlag: Heidelberg, Germany, 1998; pp. 133–165. [Google Scholar]
- Rasmussen, CE; Williams, CKI. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Krause, A; Guestrin, C; Gupta, A; Kleinberg, J. Near-optimal sensor placements: Maximizing information while minimizing communication cost. Proceedings of the 5th International Symposium on Information Processing in Sensor Networks (IPSN), Nashville, TN, USA, April 2006.
- Krause, A; Singh, A; Guestrin, C. Near-optimal sensor placements in Gaussian processes: Theory, efficient algorithms and empirical studies. J. Mach. Learn. Res 2008, 9, 235–284. [Google Scholar]
- Cortés, J. Distributed Kriged Kalman filter for spatial estimation. IEEE Trans. Automat. Contr 2010, 54, 2816–2827. [Google Scholar]
- Graham, R; Cortés, J. Cooperative adaptive sampling of random fields with partially known covariance. Int. J. Robust Nonlinear Contr 2009, 1, 1–2. [Google Scholar]
- Choi, J; Lee, J; Oh, S. Swarm intelligence for achieving the global maximum using spatio-temporal Gaussian processes. Proceedings of the 27th American Control Conference (ACC), Seattle, WA, USA, June 2008.
- Choi, J; Lee, J; Oh, S. Biologically-inspired navigation strategies for swarm intelligence using spatial Gaussian processes. Proceedings of the 17th International Federation of Automatic Control (IFAC) World Congress, Seoul, South Korea, July 2008.
- Nott, DJ; Dunsmuir, WTM. Estimation of nonstationary spatial covariance structure. Biometrika 2002, 89, 819–829. [Google Scholar]
- Kay, SM. Fundamentals of Statistical Signal Processing: Estimation Theory; Prentice Hall, Inc: Upper Saddle River, NJ, USA, 1993. [Google Scholar]
- Lagarias, J; Reeds, J; Wright, M; Wright, P. Convergence properties of the Nelder-Mead simplex method in low dimensions. SIAM J. Optimization 1999, 9, 112–147. [Google Scholar]
- Mandic, M; Franzzoli, E. Efficient sensor coverage for acoustic localization. Proceedings of the 46th IEEE Conference on Decision and Control, New Orleans, LA, USA, December 2007.
- Martínez, S; Bullo, F. Optimal sensor placement and motion coordination for target tracking. Automatica 2006, 42, 661–668. [Google Scholar]
- Nagamune, R; Choi, J. Parameter reduction in estimated model sets for robust control. J. Dynam. Syst. Meas. Contr 2010, 132, 021002. [Google Scholar]
- Pukelsheimi, F. Optimal Design of Experiments; Wiley: New York, NY, USA, 1993. [Google Scholar]
- Emery, AF; Nenarokomov, AV. Optimal experiment design. Meas. Sci. Technol 1998, 9, 864–76. [Google Scholar]
- Kathirgamanathan, P; McKibbin, R. Source term estimation of pollution from an instantaneous point source. Res. Lett. Infor. Math. Sci 2002, 3, 59–67. [Google Scholar]
- Christopoulos, VN; Roumeliotis, S. Adaptive sensing for instantaneous gas release parameter estimation. Proceedings of the 2005 IEEE International Conference on Robotics and Automation, Barcelona, Spain; 2005. [Google Scholar]
© 2011 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).