Enhanced Monocular Visual Odometry Integrated with Laser Distance Meter for Astronaut Navigation

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
: Visual odometry provides astronauts with accurate knowledge of their position and orientation. Wearable astronaut navigation systems should be simple and compact. Therefore, monocular vision methods are preferred over stereo vision systems, commonly used in mobile robots. However, the projective nature of monocular visual odometry causes a scale ambiguity problem. In this paper, we focus on the integration of a monocular camera with a laser distance meter to solve this problem. The most remarkable advantage of the system is its ability to recover a global trajectory for monocular image sequences by incorporating direct distance measurements. First, we propose a robust and easy-to-use extrinsic calibration method between camera and laser distance meter. Second, we present a navigation scheme that fuses distance measurements with monocular sequences to correct the scale drift. In particular, we explain in detail how to match the projection of the invisible laser pointer on other frames. Our proposed integration architecture is examined using a live dataset collected in a simulated lunar surface environment. The experimental results demonstrate the feasibility and effectiveness of the proposed method.1. Introduction
The astronaut navigation system is one of the most important systems for manned missions on the lunar surface, as it keeps astronauts safe while exploring previously unknown environments and provides accurate positions for scientific targets. Although the principle of the lunar astronaut navigation system is much the same as that of a pedestrian navigation system, the global positioning system (GPS)-denied environment, and the absence of a dipolar magnetic field and an atmosphere limits the application of several traditional sensors that have been successfully used for pedestrian navigation on Earth, such as GPS, magnetometers and barometers [1]. Furthermore, unlike lunar or Mars exploration rovers, the size, weight, and power of on-suit astronaut navigation sensors are strictly limited. Therefore, vision sensors are well suited for this type of navigation system, as they are light and power-saving. They can work effectively as long as there are enough textures that can be extracted.
Visual odometry (VO) is the process of incrementally estimating the pose of an agent from the apparent motion induced on the images of its onboard cameras. Early research into VO was devoted to solving the wheel slippage problem in uneven and rough terrains for planetary rovers; its implementation was finally successfully applied onboard the Mars rovers [2–4]. It is fascinating to see that it provides the rover with more accurate positioning compared to wheel odometry. Later Nister [5] proposed the first long-run VO implementation with a robust outlier rejection scheme. This capability makes it vitally important, especially in GPS-denied environments such as the lunar surface. However, most of the research in VO has been performed using a stereo vision scheme, which is certainly not an optimal vision configuration for an ideal wearable astronaut navigation system, because it is less compact and less power-saving compared to monocular vision. In this case, the stereo vision scheme becomes ineffective and should be substituted by monocular VO. More compact navigation systems [6] and successful results have been demonstrated using both omnidirectional and perspective cameras [7,8]. Closely related to VO is the parallel research undertaken on visual simultaneous localization and mapping (V-SLAM). This aims to estimate both the motion of an agent and the surrounding map. Most V-SLAM work has been limited to small or indoor workspaces [9,10] and also involved stereo cameras. This approach is generally not appropriate for large-scale displacements because of algorithmic complexity and growing complexity [11]. Recently, great developments have been made by Strasdat [12] using only monocular image input after adopting the key-frame and Bundle Adjustment (BA) [13] optimization approaches of the state-of-the-art VO systems.
Due to the nature of monocular systems, with bearing information only available in a single frame, geometry must be inferred over time and 3D landmarks cannot be fully constrained before observations from multiple viewpoints can be made. Furthermore, there is the difficulty that the absolute scale cannot be obtained in a single frame and motion can only be recovered up to a scale factor. This absolute scale cannot be determined unless absolute scale information about the real world is introduced into the system. Without extra measurements, the scale is less constrained and error accumulates over time while motion is integrated from frame-to-frame estimation. This is the scale ambiguity problem for monocular VO. Special attention has been paid to this issue recently and a number of solutions have been proposed to solve the undetermined scale factor. Scaramuzza [14] used the height of the camera from the ground plane to obtain the global scale factor. Additionally, an observation of the average speed of the vehicle is also proposed to constrain the displacement of the camera [15]. While these techniques may become popularly used in monocular VO for vehicles, the motion constraints of a steady state may not work out for astronaut navigation. Also, by including additional carefully measured objects in the scene during the initialization stage, such as a calibration object, a metric scale can be fixed [9]. However, this metric scale is liable to drift over time. The pose-graph optimization technique presented by Strasdat [12] resolves the scale drift only at loop closures. A commonly used approach called sliding window bundle adjustment has been demonstrated to decrease the scale drift [16]. In some other work, extra metric sensors, such as inertial measurement units (IMU) and range sensors were also introduced to compensate for scale drift [17,18].
The integration of a camera and a laser distance meter (LDM) was first proposed by Ordonez [19] and was applied for 2D measurement of façade window apertures. In that work, Ordonez presented in detail the extrinsic calibration method of a digital camera and a LDM. Later, this low-cost 2D measurement system was extended to reconstruct scaled 3D models of buildings [20].
The issues mentioned above motivated us to use a monocular camera as the main sensor, aided by LDM for scaled navigation. However, as was admitted by the author in [20], there is a limitation that the shots must obey a plane constraint and the laser spot of the distance meter must fall in contact with a planar surface. Meanwhile, the process of the extrinsic calibration method of the camera and the laser distance meter proposed above is not simple and robust, as it requires careful intervention from the user, such as manual selection of the laser pointer's projection center.
In this paper, we focus on the integration of a laser distance meter and a monocular camera for applications such as astronaut navigation. We solve the scale ambiguity problem using metric measurements from a laser distance meter. Nevertheless, unlike 2D laser range finders and 3D laser scanners, which are widely used in the robotics community and provide both range and angular information on a series of laser points, LDM provides only the distance of a single laser dot. Therefore, compared with 2D laser range finders or 3D laser scanners, LDM consumes less power and simplifies the algorithm pipeline when integrated with a camera, as only one pixel of the image contains depth information. Besides, LDM has a more distant range to work in. So far most research concerning integration of a LDM and a camera has been for 3D model measurement or reconstruction, but not for scalable monocular VO. The main contribution of this work is the proposal of a novel enhanced monocular VO scheme by imposing an absolute scale constraint through integrating measurements from the LDM.
First, to obtain more accurate metric scaled navigation results, a flexible and robust extrinsic calibration method between the camera and the LDM is presented. This whole calibration process requires almost no manual intervention and is robust to gross errors. As soon as extrinsic calibration of the system is completed and geometrical parameters are ready, a global scaled monocular VO pipeline is proposed. We particularly describe how to match the invisible laser spot on other frames in detail and how to correct the scale drift using distance measurement and calibration parameters.
In principle, this enhanced monocular VO method is certainly applicable for a mobile robot (e.g., a rover). However, stereo vision systems are commonly used in mobile robots due to its less limitation of the size of the navigation payload. In addition to navigation, stereo vision also offers stereo images, which are very valuable for understanding of the surrounding environment and investigation of the interested targets. Thus, in general stereo VO is more favorable than monocular VO for mobile robots.
This paper is organized as follows: Section 2 gives a general description of the system's device components and the working principle of our global scaled monocular VO scheme. Section 3 and Section 4 present extrinsic calibration and robust motion estimation with LDM and a monocular camera. Section 5 gives expanded results with real outdoor data in a simulated lunar surface environment. Finally, conclusions are given in Section 6.
2. Proposed Approach for Monocular Visual Odometry
The hardware of the astronaut navigation system consists of five components: an industrial camera (MV-VE141SC/SM, Microvision, Xi'an, China; image dimension: 1392 pixels × 1040 pixels, focal length: 12 mm, max. frequency: 10 Hz), a LDM (CLD-A with RS232 port, Chenglide, Beijing, China; accuracy: ±2 mm, max. frequency: 4 Hz), a specially designed platform for holding these two devices rigidly and provision of power from the on-suit batteries, an industrial computer (CPU: Intel core i5) to control the acquisition of images and laser readings, and an iPad to control the computer triggering the signal to the camera and the distance meter through a local Wi-Fi network. Figure 1 shows the hardware components of our navigation system and the right-hand part of the figure shows the screen of the iPad while taking images.
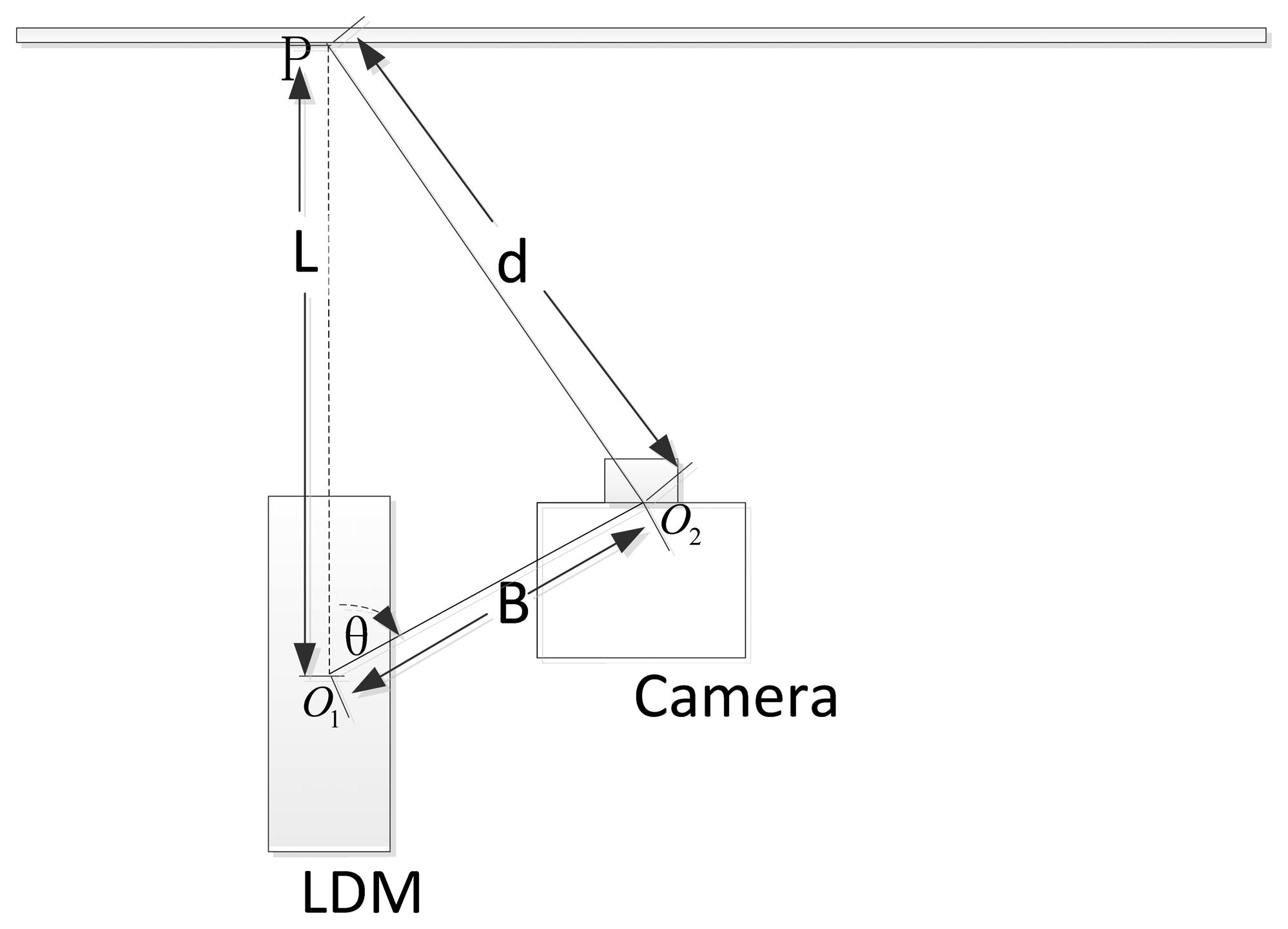
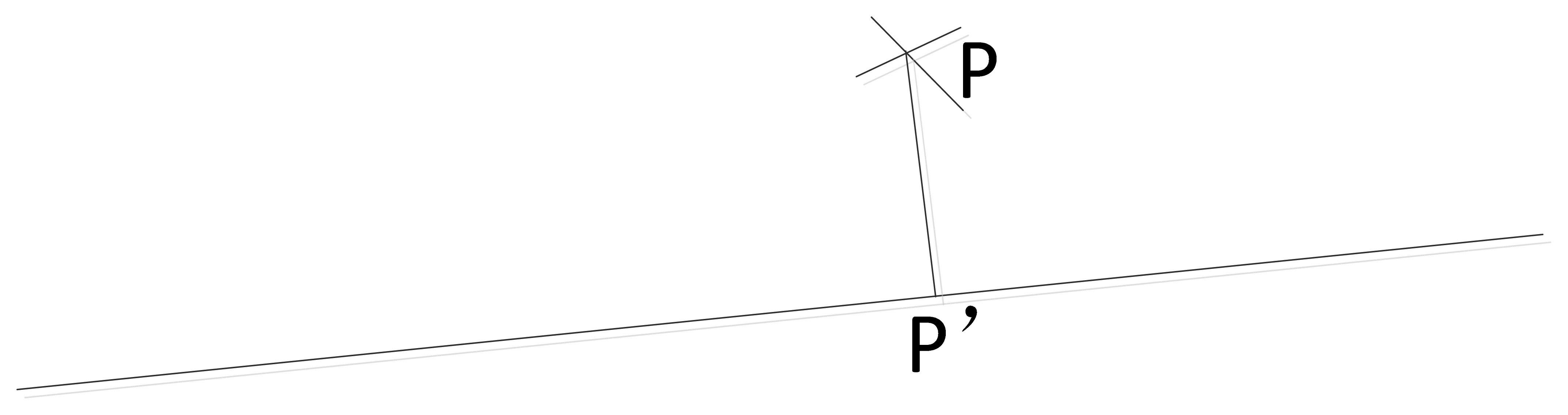
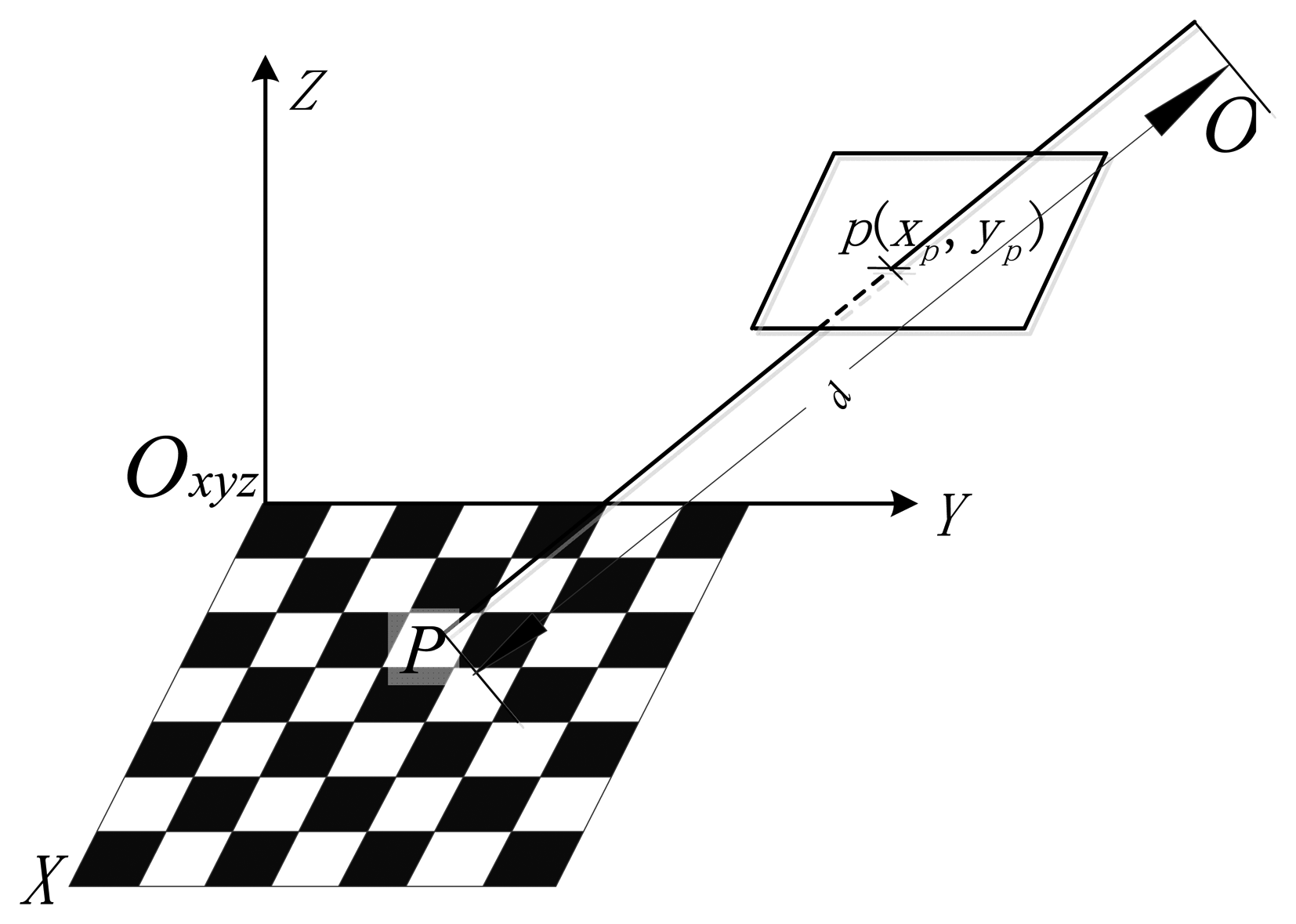
The laser beam is collinear, so it can be modeled by a straight line. In Figure 2, a view of the navigation system with its mathematical model is shown for clarity. The system calculates the distance d between the optical center O2 and the laser pointer P by knowing the distance L from P to the LDM's origin O1 measured with the LDM, and the geometrical relationship between the camera and the LDM. As we are only interested in the distance d, in this paper, the geometrical relationship between the distance meter and the camera is modeled by just two parameters:
The distance B from the LDM's origin to the optical center of the camera
The direction angle θ between the laser beam and the direction from O1 to O2.
As illustrated in Figure 2, the following expression can be deduced based on the triangulation principle:
These two parameters, B and θ, are known after extrinsic calibration that will be described in detail in the following section.
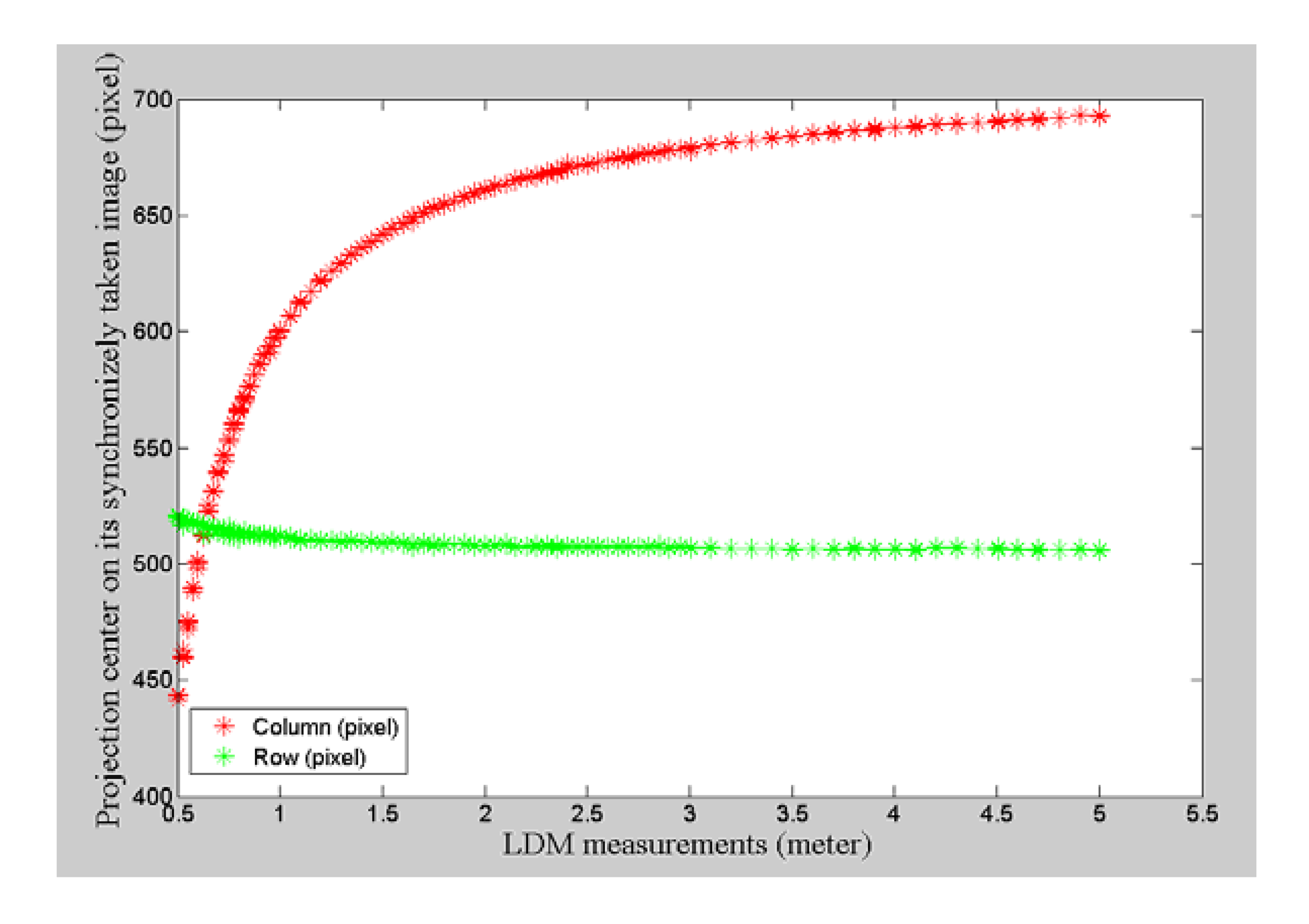
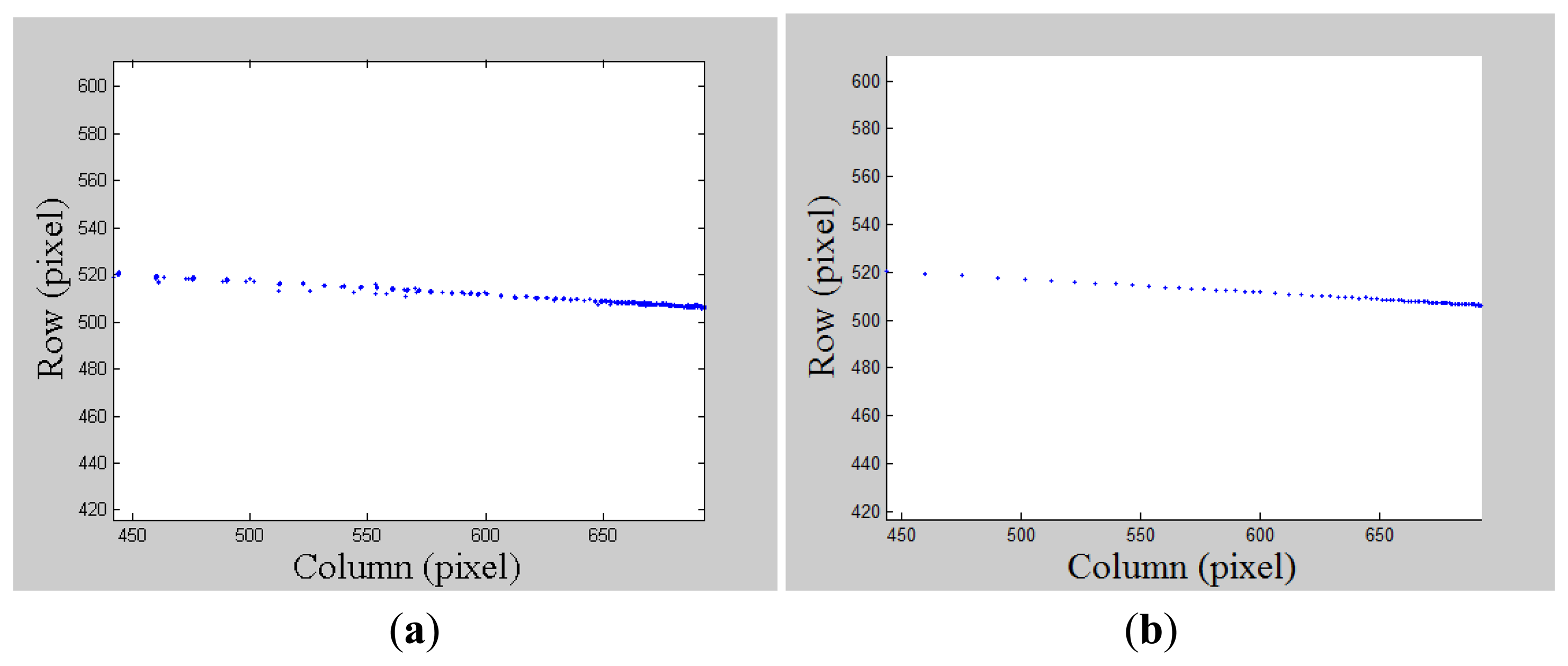
Meanwhile, for each laser pointer reading taken, the point has its projection on its synchronized image which is difficult to detect, as it is mostly invisible on daytime images because the contrast with the environment is too low. Its position can be determined by searching in an index table, which can be created at night by taking a series of images with varying distances and detecting the laser pointer projection center. This index table describes the one-to-one relationship between the distance measured by the LDM and the image position projected on the image. In other words, once we know the distance of the laser pointer measured by the LDM, we can calculate its distance to the camera center and its projection position on the synchronized image taken at the same time. This extra global scale information can be incorporated into monocular VO to restrict scale drift effectively.
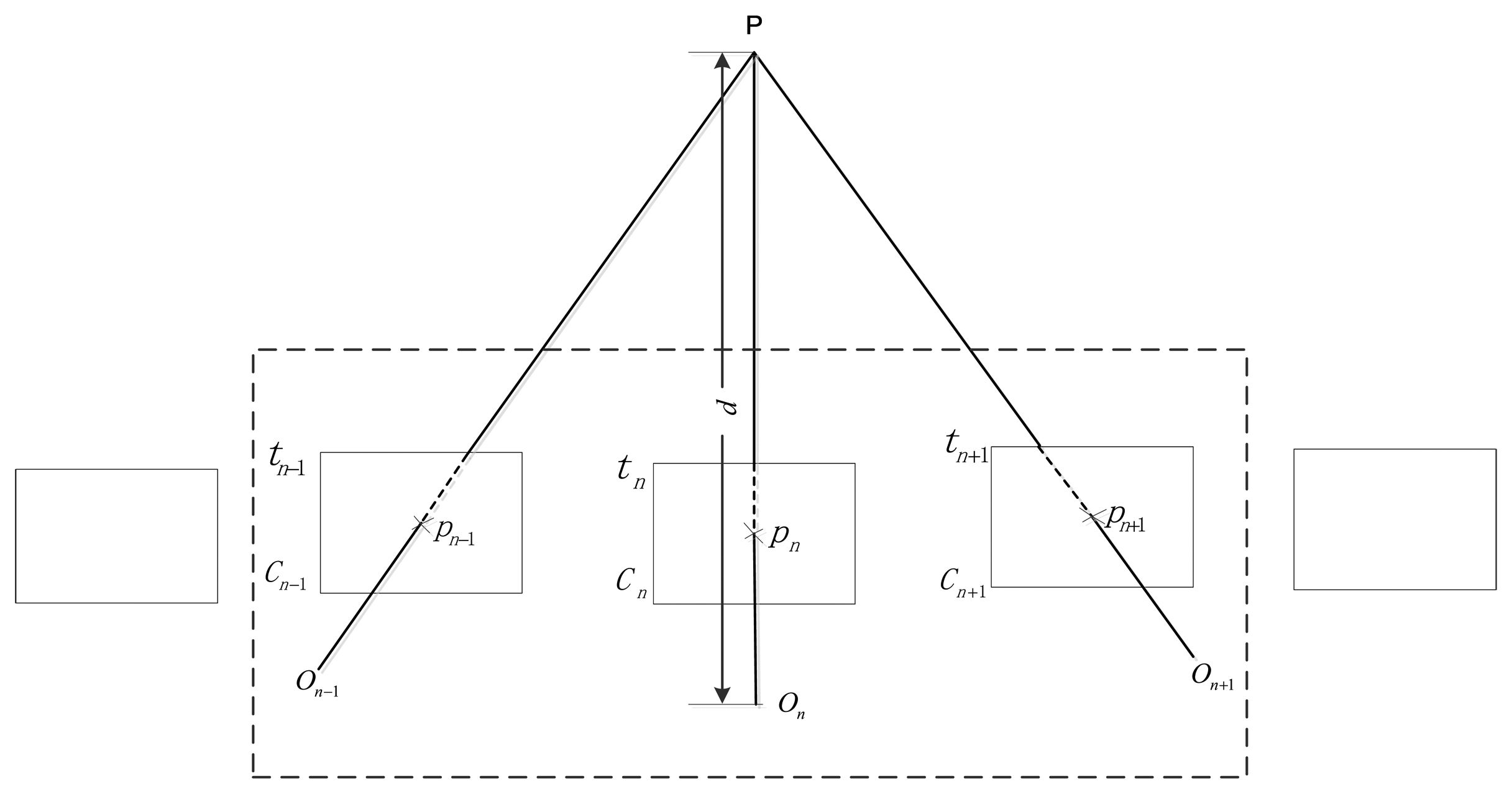
Figure 3 illustrates the nature of the scale ambiguity of the monocular system and the principle of our enhanced monocular system. The camera position can slide an unknown amount along the translation direction and estimation of the camera pose is intrinsically scale free. However, if we can track the laser pointer P on frame Cn−1 and Cn+1 successfully, we can obtain its depth at time tn in this stereo model by triangulation. As we can calculate its global scale depth d with Equation (1) at time tn using the distance measured, we can scale this stereo model with no drift. In this way, the scale drift is corrected whenever tracking along nearby key-frames is successful.
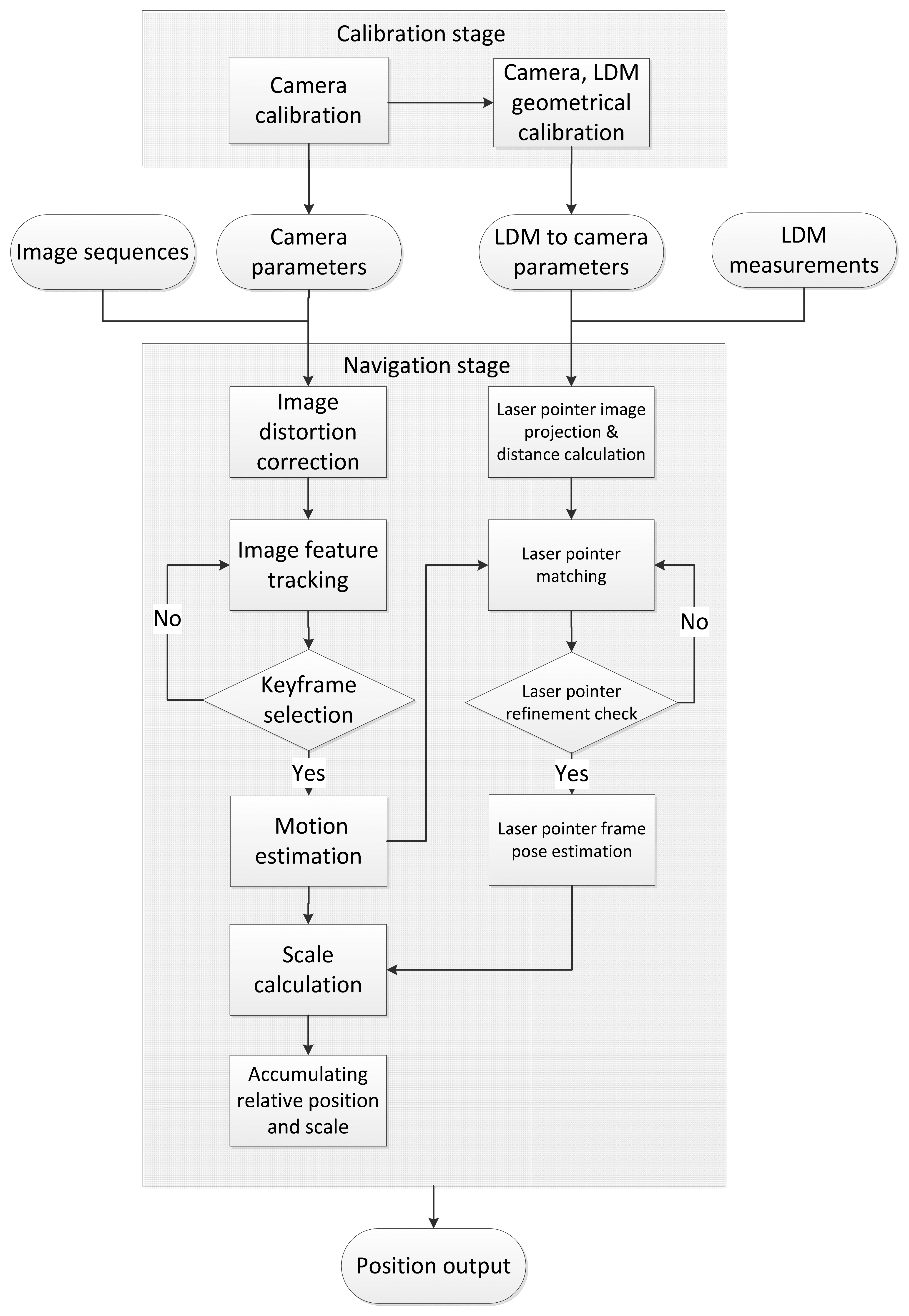
In this paper, this astronaut navigation system can be divided into two parts: the calibration stage and the navigation stage, as illustrated in Figure 4. As quality of calibration is crucial to ensure accurate estimation of motion displacement, we propose a robust method to implement extrinsic calibration of the camera and the LDM. In particular, we create an index table to establish directly the relationship between the distance measurements from the LDM and its projection position on the synchronized image, further simplifying the calibration process and reducing the systematic error.
After finishing this preparation stage, the navigation stage is begun using our enhanced VO method. As the quality of image tracking is important for obtaining a robust and accurate estimate [5,15], we use the principle that key-points should cover the image as evenly as possible. Image features are tracked along image sequences and only a subset of them, called key-frames, are selected for motion estimation. In previous work, a key-frame selection scheme was proposed and only frames in good state for triangulation were selected [11]. Our proposal follows this scheme and key-frames are selected for a further core computation step, named motion estimation, and the relative geometrical relationship of the image pair can be constructed. In the meantime, the laser pointer projection is matched on nearby key-frames for triangulation to obtain its relative distance to the camera. In this way, scale drift is corrected when this laser pointer is constrained by the global scale distance calculated from Equation (1).
Most laser pointers are projected on some image position with a weak feature response, thus it is difficult to find its correspondence directly on other images, a coarse-to-fine matching technique is proposed using local disparity constraints followed by dense matching, reducing the possibility of false matches in these local feature-less regions. When the laser pointer is matched successfully, the global scale can be recovered, as illustrated in Figure 3. Otherwise, a relative scale is calculated by exploiting the distance constraints between two image pairs [21]. By incorporating global scale constraints on monocular VO, we can effectively reduce the scale drift which accumulates quickly over a certain number of frames.
5. Experiments and Results
In this section, field tests using the proposed enhanced monocular VO algorithm are carried out in simulated lunar environments. These tests are designed to validate the feasibility and effectiveness of the proposed enhanced monocular VO method. The camera we used has a field of view of 30° and is rigidly attached to a LDM while facing forward during walking. The laser frequency was set at 1 Hz and the camera was set at 10 Hz, meaning that we have the distance measurements with synchronized captured images every second. The person carrying the system walked at a velocity of about 1.0 m/s. Here we report two typical experiments on outdoor and simulated lunar environments.
For the first dataset (see Figure 12a), 1108 frames and 89 laser pointer measurements (when the distance signal does not return in a valid time, this measurement is dropped in our system) were taken at a construction site covering a total distance of approximately 110 m. Finally, 173 key-frames were selected automatically and 41 key-frame pairs were successfully matched with the laser pointer projection. We can see from Figure 12a that the soil hardness is not as soft as that of the lunar surface and rocks of various sizes are spread across the terrain surface, which make features quite easy to detect among the two datasets. Therefore the first dataset can be taken as an ideal dataset to evaluate the performance of proposed VO method compared to traditional one. The second dataset was taken in a desert which seems to be more similar to the lunar surface. For the second dataset, there are 3840 frames and 368 laser pointer measurements covering a total distance of 300 m, of which 402 key-frames were selected and 154 key-frame pairs found laser pointer's projection. We can see from Figure 12b that the sandy surface in this dataset is more similar to the type of the lunar surface than the former dataset, with footprints clearly seen on this soft sandy terrain. Therefore, we can take it as a large-scale outdoor test field to simulate the real lunar terrain.
We walked a loop with the origin set at [0,0]. The same image was used for the first and last positions to ensure that the true last camera pose was exactly the same as where the first image was recorded. The commonly used approach called sliding window bundle adjustment is not involved in our current monocular VO scheme, nor is the loop closure correction.
Given that the loop is closed, we can use it to measure the navigation accuracy. Figure 13 shows the final result of our enhanced monocular VO scheme compared with the traditional scheme. The motion estimates of the first key-frame pair are both globally scaled with the LDM to facilitate comparison. From Figure 13a, obvious improvement can be seen with the relative error decreased from 5.91% to 0.54% for the first dataset when the LDM is added. In Figure 13b, the relative error decreased from 12.02% to 1.71% for the 300 m route in the desert. Considering the second dataset's high similarity to the lunar surface, it can be inferred that this enhanced monocular VO scheme should also work well when dealing with real lunar environment. Moreover, it can be inferred from Figure 13b the longer we walked, the higher the improvement is as scale drift accumulates severely for a single camera. As we emphasize the scale drift issue, the relative transformation relationships of key-frames are kept the same for the enhanced VO and the traditional VO except for the difference in scale selection during the whole trajectory, which shows that the accuracy is improved significantly by a better scale selection scheme.
We also compared the distance errors of laser points between LDM-aided monocular VO and the traditional one with the distance travelled. By taking the distance calculated from Equation (1) as a reference, we triangulate the laser pointer's projections in key-frame pairs in both VO schemes, as illustrated in Figure 14. As the distance constraints of the first laser pointer are used in both VO schemes, this error is set as zero in the beginning. It is clear from Figure 14 that the gradually accumulated scale drift is corrected effectively with our VO scheme.
6. Summary and Conclusions
In this paper, we have presented an enhanced monocular VO scheme to resolve the scale drift with the aid of LDM. We concentrated on the integration of LDM with monocular camera mounted on a walking person modeling astronaut navigation on a simulated lunar surface. A robust and simple extrinsic calibration method has been proposed. Based on this method, for every laser point measured, its projected image position and the distance to synchronized camera center is also precisely known. Later, an enhanced monocular VO scheme was proposed by integrating measurements from LDM. Accurate results for approximately 110 m of walking at a construction site were demonstrated by correcting the scale drift, outperforming the traditional monocular scheme by almost a factor of ten. Further experiments were taken in a desert to validate our method's feasibility and robustness on simulated lunar terrain compared to traditional one.
One of the most remarkable differences between our monocular VO scheme and previous methods is the introduction of LDM to correct the scale drift. Scale error propagation over time is avoided effectively, demonstrating the strength of LDM in the field of monocular VO. In our current system, the commonly used BA technique is not used. In the future, the sliding window BA with measurements using LDM will be integrated into our system, further improving the pose drift and being more practicable for astronaut long term navigation.
Acknowledgments
This research is funded by the National Natural Science Foundation of China (41171355) and National Basic Research Program of China (2012CB719902).
Author Contributions
Kaichang Di conceived the research and designed the overall methodology. Kai Wu designed and developed the algorithms and performed the experiments. Xun Sun constructed the hardware components. Wenhui Wan and Zhaoqin Liu participated in field data collection and processing.
Conflicts of Interest
The authors declare no conflict of interest.
References
- He, S. Integration of Multiple Sensors for Astronaut Navigation on The Lunar Surface. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2012; pp. 1–8. [Google Scholar]
- Maimone, M.W.; Cheng, Y.; Matthies, L. Two years of visual odometry on the mars exploration rovers. J. Field. Rob. 2007, 24, 169–186. [Google Scholar]
- Cheng, Y.; Maimone, M.W.; Matthies, L. Visual odometry on the Mars exploration rovers—A tool to ensure accurate driving and science imaging. IEEE Rob. Autom. Mag. 2006, 13, 54–62. [Google Scholar]
- Cheng, Y.; Maimone, M.W.; Matthies, L. Visual odometry on the Mars exploration rovers. Proceedings of the 2005 IEEE International Conference on Systems, Man and Cybernetics, Hawaii, HI, USA, 10–12 October 2005; pp. 903–910.
- Nistér, D.; Naroditsky, O.; Bergen, J. Visual Odometry. Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognitio, Washington, DC, USA, 27 June–2 July 2004; pp. 652–659.
- Scaramuzza, D.; Fraundorfer, F. Visual odometry [tutorial]. IEEE Rob. Autom. Mag. 2011, 18, 80–92. [Google Scholar]
- Nistér, D.; Naroditsky, O.; Bergen, J. Visual odometry for ground vehicle applications. J. Field. Rob. 2006, 23, 3–20. [Google Scholar]
- Scaramuzza, D. 1-point-ransac structure from motion for vehicle-mounted cameras by exploiting non-holonomic constraints. Int. J. Comput. Vision 2011, 95, 74–85. [Google Scholar]
- Davison, A. Real-Time Simultaneous Localisation and Mapping with a Single Camera. Proceedings of the 9th IEEE International Conference on Computer Vision, Nice, France, 14–17 October 2003; pp. 1403–1410.
- Klein, G.; Murray, D. Parallel Tracking and Mapping for Small AR Workspaces. Proceedings of the 6th IEEE and ACM International Symposium on Mixed and Augmented Reality, Nara, Japan, 13–16 November 2007; pp. 225–234.
- Mouragnon, E.; Lhuillier, M.; Dhome, M.; Dekeyser, F.; Sayd, P. Real time localization and 3D reconstruction. Proceedings of 2006IEEE Computer Society Conference on Computer Vision and Pattern Recognition, New York, NY, USA, 17–22 June 2006; pp. 363–370.
- Strasdat, H.; Montiel, J.M.M.; Davison, A. Scale Drift-Aware Large Scale Monocular SLAM. Rob. Sci. Syst. 2010, 2, 5–8. [Google Scholar]
- Triggs, B.; McLauchlan, P.F.; Hartley, R.; Fitzgibbon, A.W. Bundle Adjustment—A Modern Synthesis. Vision Algorithms: Theory and Practice; Springer-Verlag: Berlin/Heidelberg, Germany, 2000; pp. 298–372. [Google Scholar]
- Scaramuzza, D.; Siegwart, R. Appearance-guided monocular omnidirectional visual odometry for outdoor ground vehicles. IEEE Trans. Rob. 2008, 24, 1015–1026. [Google Scholar]
- Scaramuzza, D.; Fraundorfer, F.; Siegwart, R. Real-time monocular visual odometry for on-road vehicles with 1-point RANSAC. Proceedings of the 2009 IEEE Computer Society Conference on Robotics and Automation, Kobe, Japan, 12–17 May 2009; pp. 4293–4299.
- Konolige, K.; Agrawal, M.; Sola, J. Large-scale visual odometry for rough terrain. In Robotics Research; Kaneko, M., Nakamura, Y., Eds.; Springer-Verlag: Berlin/Heidelberg, Germany, 2011; pp. 201–212. [Google Scholar]
- Chu, T.; Guo, N.; Backén, S.; Akos, D. Monocular camera/IMU/GNSS integration for ground vehicle navigation in challenging GNSS environments. Sensors 2012, 12, 3162–3185. [Google Scholar]
- Zhang, X.; Rad, A.; Wong, Y. Sensor fusion of monocular cameras and laser rangefinders for line-based simultaneous localization and mapping (SLAM) tasks in autonomous mobile robots. Sensors 2012, 12, 429–452. [Google Scholar]
- Ordonez, C.; Arias, P.; Herráez, J.; Rodriguez, J.; Martín, M.T. A combined single range and single image device for low—Cost measurement of building façade features. Photogramm. Rec. 2008, 23, 228–240. [Google Scholar]
- Martínez, J.; Ordonez, C.; Arias, P.; Armesto, J. Non-contact 3D Measurement of Buildings through Close Range Photogrammetry and a Laser Distance Meter. Photogramm. Eng. Remote Sens. 2011, 77, 805–811. [Google Scholar]
- Fraundorfer, F.; Scaramuzza, D. Visual Odometry: Part II: Matching, Robustness, Optimization, and Applications. IEEE Rob. Autom. Mag. 2012, 19, 78–90. [Google Scholar]
- Bouguet, J. Camera Calibration Toolbox for Matlab. 2008. Available online http://www.vision.caltech.edu/bouguetj/calib doc/ (accessed on 20 October 2013). [Google Scholar]
- Otsu, N. A threshold selection method from gray-level histograms. Automatica 1979, 11, 23–27. [Google Scholar]
- Corke, P. Robotics, Vision and Control: Fundamental Algorithms in MATLAB; Springer-Verlag: Berlin/Heidelberg, Germany, 2011; pp. 351–355. [Google Scholar]
- Torr, P.H.S.; Zisserman, A. MLESAC: A new robust estimator with application to estimating image geometry. Comput. Vision Image Underst. 2000, 78, 138–156. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision, 2nd ed.; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Chum, O.; Matas, J. Matching with PROSAC-progressive sample consensus. Proceedings of the 2005IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR 2005, San Diego, CA, USA, 20–25 June 2005; pp. pp: 220–226.
- Shi, J.; Tomasi, C. Good Features to Track. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 21–23 June 1994; pp. 593–600.
- Bradski, G.; Kaehler, A. Learning OpenCV: Computer Vision with the OpenCV Library; O'Reilly Media: Sebastopol, CA, USA, 2008. [Google Scholar]
- Lucchese, L.; Mitra, S.K. Using saddle points for sub-pixel feature detection in camera calibration targets. Proceedings of the 2002 Asia Pacific Conference on Circuits and Systems, Kaohsiung, Taiwan, 2–5 December 2012; pp. 191–195.
- Lucas, B.D.; Kanade, T. An iterative image registration technique with an application to stereo vision. Proceedings of the 7th International Joint Conference on Artificial Intelligence, Vancouver, BC, Canada, 24–28 August 1981; pp. 674–679.
- Szeliski, R. Computer Vision: Algorithms and Applications; Springer-Verlag: Berlin/Heidelberg, Germany, 2011; pp. 232–234. [Google Scholar]
- Nistér, D. An efficient solution to the five-point relative pose problem. IEEE Trans. Pattern Anal. Mach. Intell. 2004, 26, 756–770. [Google Scholar]
- Horn, B.K. Recovering baseline and orientation from essential matrix. J. Opt. Soc. Am. A. 1990, 1, 1–10. [Google Scholar]
- Horn, B.K.; Schunck, B.G. Determining optical flow. Artif. Intell. 1981, 17, 185–203. [Google Scholar]
- Esteban, I.; Dorst, L.; Dijk, J. Closed form Solution for the Scale Ambiguity Problem in Monocular Visual Odometry. In Intelligent Robotics and Application; Liu, H., Ding, H., Xiong, Z., Zhu, X., Eds.; Springer-Verlag: Berlin/Heidelberg, Germany, 2010; pp. 665–679. [Google Scholar]
- Hansen, J.E. Exact and approximate solutions for multiple scattering by cloudy and hazy planetary atmospheres. J. Atmos. Sci. 1969, 26, 478–487. [Google Scholar]














© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license ( http://creativecommons.org/licenses/by/3.0/.
Share and Cite
Wu, K.; Di, K.; Sun, X.; Wan, W.; Liu, Z. Enhanced Monocular Visual Odometry Integrated with Laser Distance Meter for Astronaut Navigation. Sensors 2014, 14, 4981-5003. https://doi.org/10.3390/s140304981
Wu K, Di K, Sun X, Wan W, Liu Z. Enhanced Monocular Visual Odometry Integrated with Laser Distance Meter for Astronaut Navigation. Sensors. 2014; 14(3):4981-5003. https://doi.org/10.3390/s140304981
Chicago/Turabian StyleWu, Kai, Kaichang Di, Xun Sun, Wenhui Wan, and Zhaoqin Liu. 2014. "Enhanced Monocular Visual Odometry Integrated with Laser Distance Meter for Astronaut Navigation" Sensors 14, no. 3: 4981-5003. https://doi.org/10.3390/s140304981