In many SINS/GPS integrated navigation systems, common system models cannot conform to the use conditions of classical Kalman filter due to the “colored noise”. To still be able to use the optimal estimation method, it is necessary to expand the system state model [
1,
2]. However, as the state dimensions increase, filtering computation will rapidly become expensive and unstable, and the so-called “dimension disaster” could even break out. In order to address this problem, scholars have reported various optimization algorithms which can lower the computational costs and/or enhance the numerical robustness. The typical optimization algorithms contain square-root information filtering SRIF [
3], U-D decomposition filtering [
4], singular value decomposition filtering [
5] and their improved versions [
6,
7,
8]. These modified filters, besides greatly reducing the time consumption, theoretically guarantee the positive definiteness of covariance and effectively avoid the numerical divergence, thus they are widely applied in the theoretical design of higher-order systems. Nevertheless, they require the support of relatively complex matrix theory in derivation and may pose certain difficulty in engineering. On the other hand, although these algorithms have decreased computational costs, their complexity is still
O(
n3). With further expansion of the state dimensions, the above decomposition algorithms, as a kind of general method, are also being challenged on their real-time capability. Recently, researchers have paid much attention to non-commonality methods, which are designed for some specific applications or based on specific models. For instance, aiming at integrated navigation applications, a kind of reduced-order Kalman filter (RDKF) [
9,
10,
11,
12] was promoted to ease the computational load. The idea of these filters is to reduce the model dimension by theoretical/engineering methods. As the filter dimension
n is vital to computation time, the reduction of the state order will produce a direct benefit in terms of real time. However, the decrease of the state order will also bring partial accuracy damage, therefore, these methods may not be suitable for some high accuracy-demanding applications. Another kind of effective algorithm optimizes the float-point operations mainly by taking advantage of the sparse matrices (e.g., the transition matrix
Φn in SINS/GPS) during the filtering computation [
13,
14,
15]. In these algorithms, the so-called matrix accumulative method (MAM) or other online methods are used and the algorithm complexity can be simplified to
O(
s2 – u2) (
s/u represents the numbers of nonzero/1 elements in
Φn). As the matrices in the high order model normally contain substantial numbers of zero elements, the computational time can be curtailed to an ideal level by usage of this sparse-matrix-based method. Meanwhile, being different from RDKF, the sparse-matrix-based methods do not change the system model and need little engineering approximation, thus they perform better in the accuracy-control aspect. But these methods also have their own limitations:
- (1)
Though they avoid massive unnecessary multiplying-zero operations, the methods still need extra O(n3) times estimation of zero elements in each matrix multiplication;
- (2)
Methods based on MAM, a kind of online method, could not seek any deeper optimization online and their efficiency is totally dependent on the number of zeros in the real-time matrix. To enhance the optimization efficiency, the usual way is to set more zero elements by approximation methods, but this comes at the cost of a certain accuracy loss.
In response to the above problems, we present here a new highly-efficient, accuracy-lossless, and engineering-tractable optimization algorithm based on offline derivation and a parallel method exploiting the numerical characteristics of SINS/GPS. In comparison with other algorithms, the proposed method offers numerous advantages: (i) in comparison with the general algorithms, our proposed method requires little complex deduction and is easily understandable; (ii) in comparison with the RDKF optimization method, the proposed method needs little engineering approximation and would be more accurate; and (iii) in comparison with the filter based on MAM, it is free of zero-estimation operations and can deduce some stronger conclusions, thus it is more efficient. Emphasizing on the engineering simplicity, we will introduce our optimization method revolving around the classical Kalman filter and a loosely-coupled model of SINS/GPS. It is apprised here that the chosen model does not imply any constraints on the application scope of our method. Actually, the offline and parallel method, as a pure numerical optimization method, is equally applicable to the extended filter and other complex SINS/GPS models if some similar research on the special model is done. On the other hand, since there is no transformation on any models or equations in our method (the two distinct differences with the normal filtering computations are: (i) unnecessary floating-point operations are directly avoided; and (ii) de-coupled operations are processed in parallel), the precision and robustness of our method would be equal to the classical Kalman filter in theory. Owing to this fact, the efficiency rather than robustness or accuracy is focused on in our discussion later.
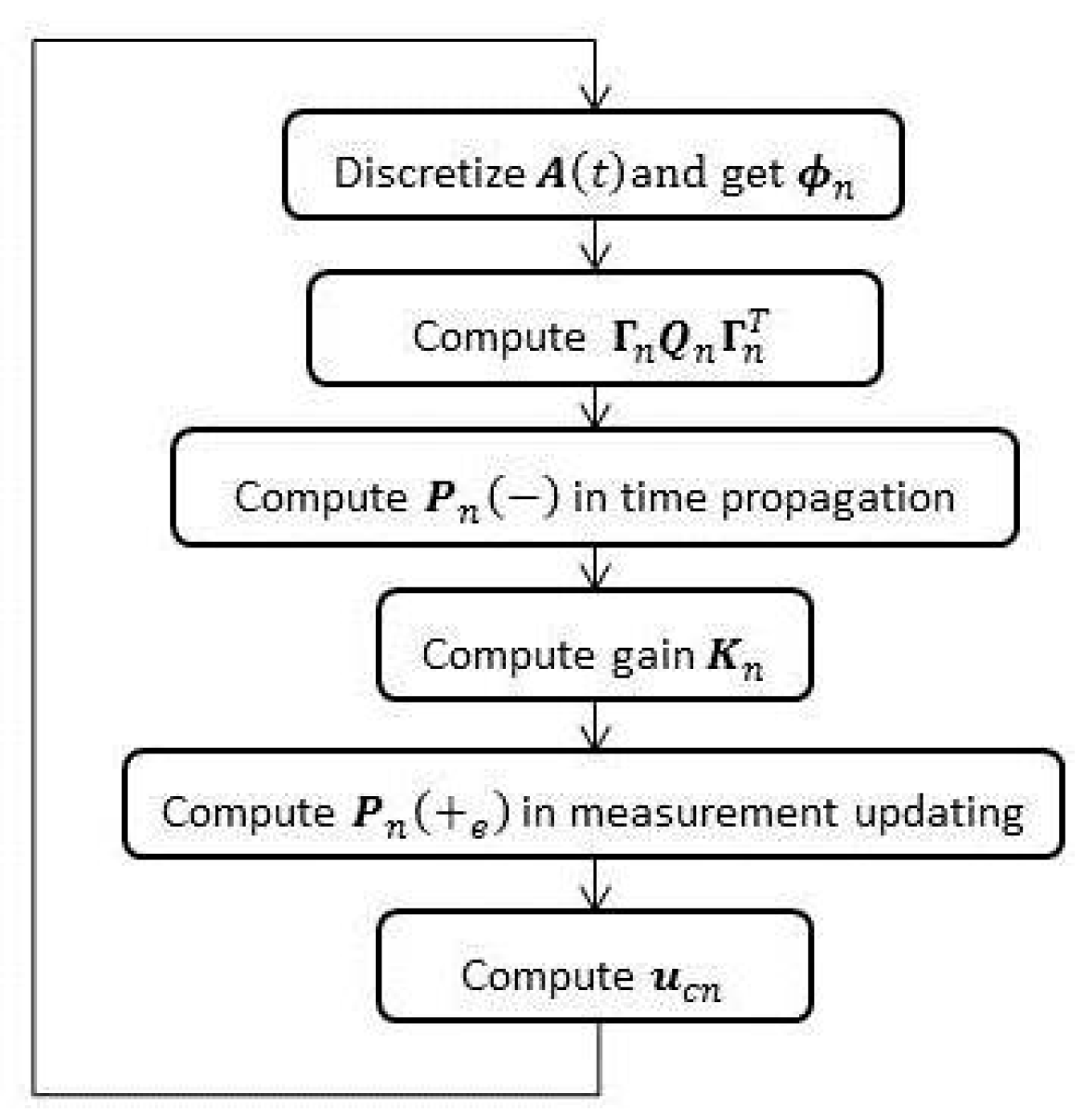
Section 2 gives a brief account of closed-loop Kalman filtering and a widely-used loosely-coupled model in SINS/GPS. In
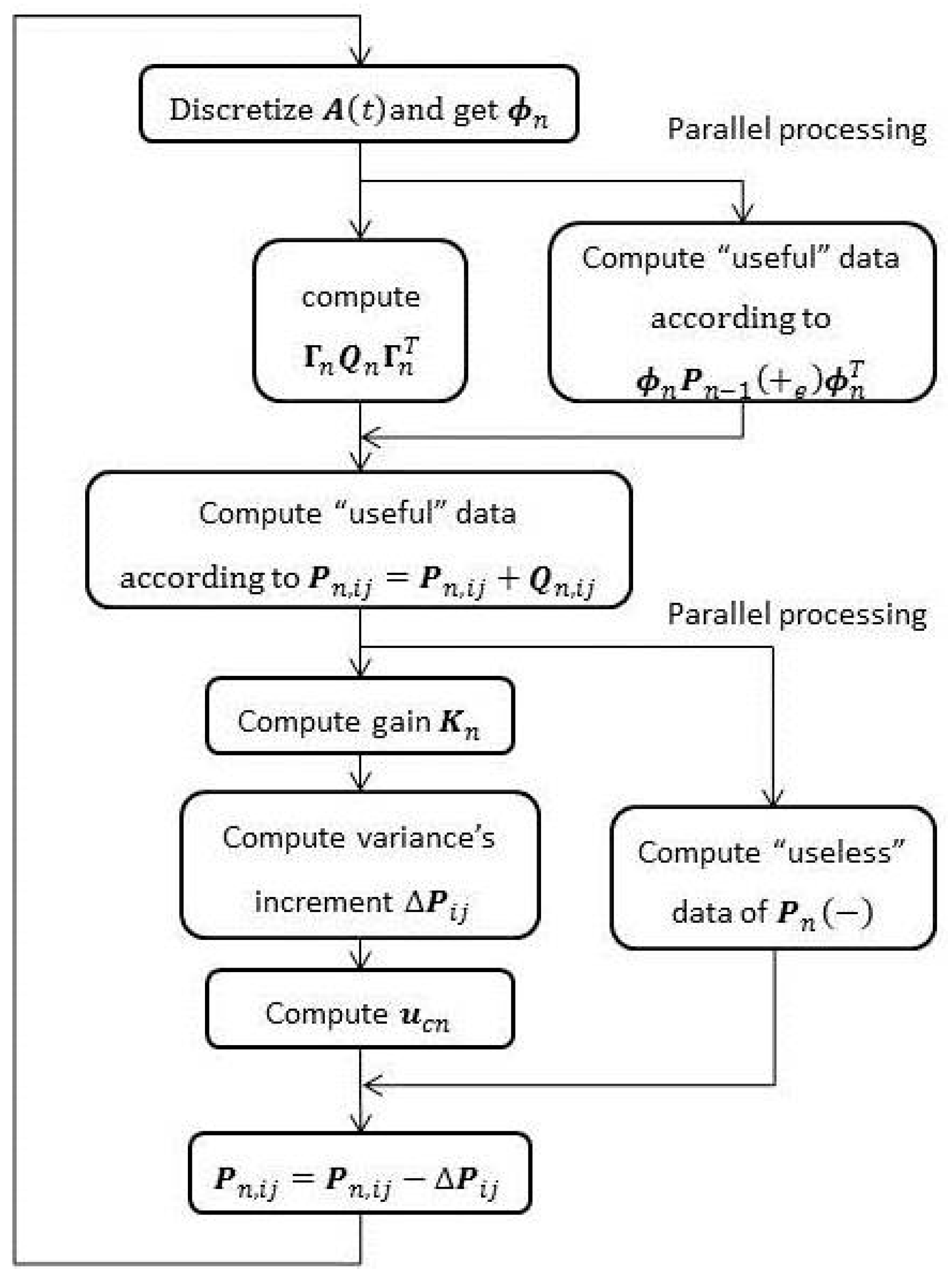
Section 3, the details of offline derivation and the parallel method based on a block-matrix technique are described.
Section 4 and
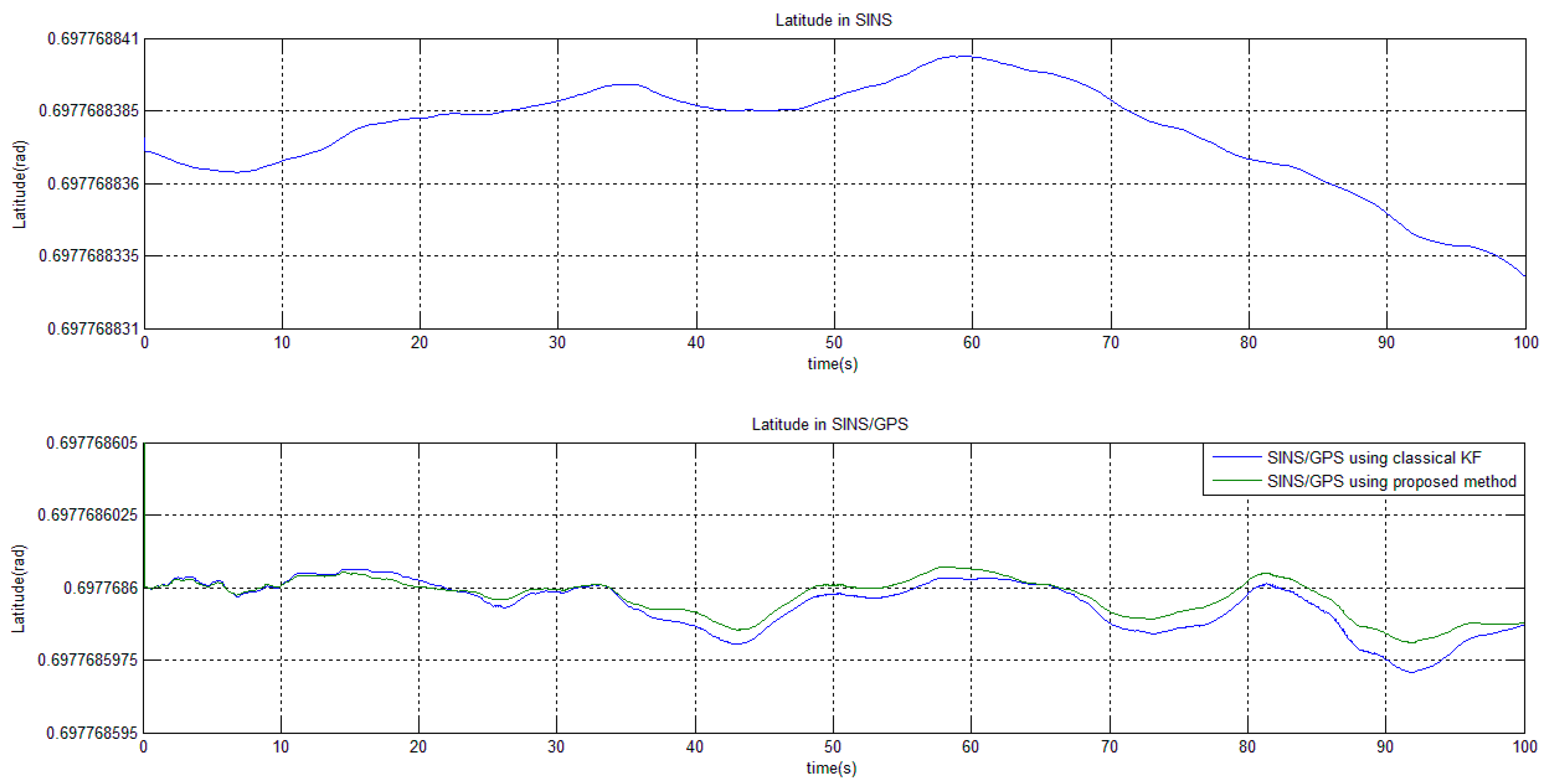
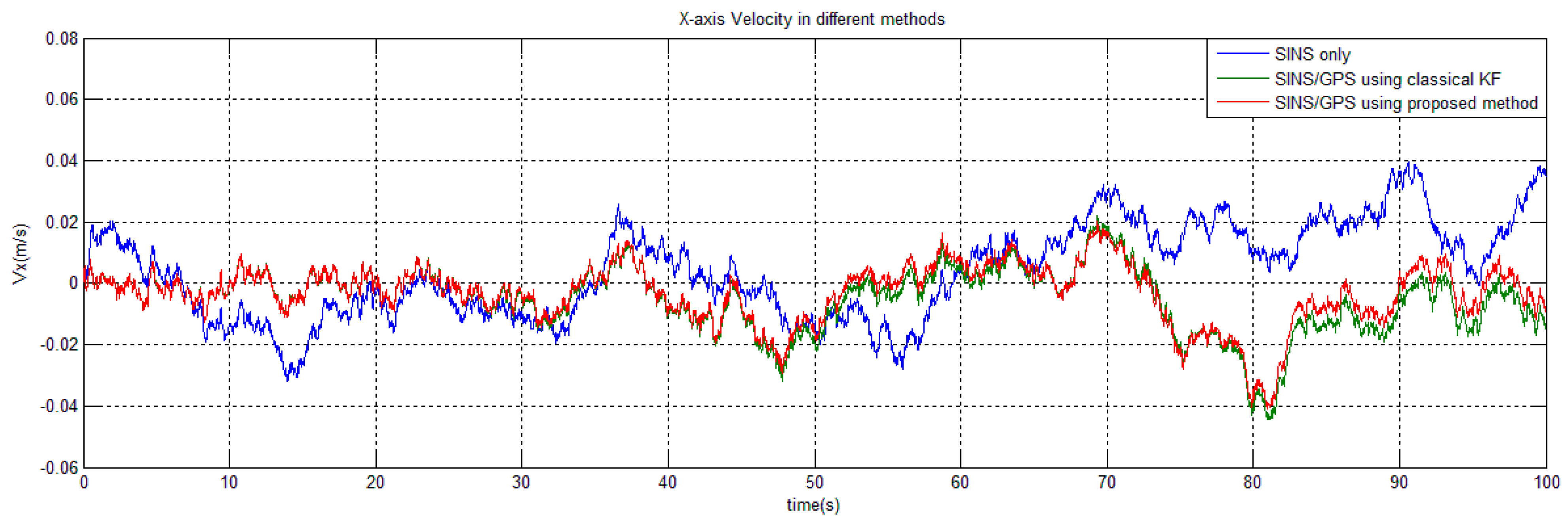
Section 5 deal with the statistics on computational costs and the filter performance on error estimation.




{kind=link}
{kind=link}
{kind=link}
{kind=link}


