
Vision Sensor-Based Road Detection for Field Robot Navigation


Abstract
:
1. Introduction
- (1)
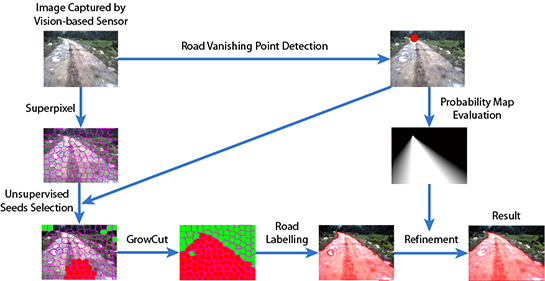
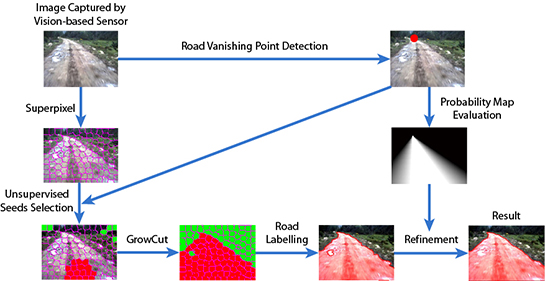
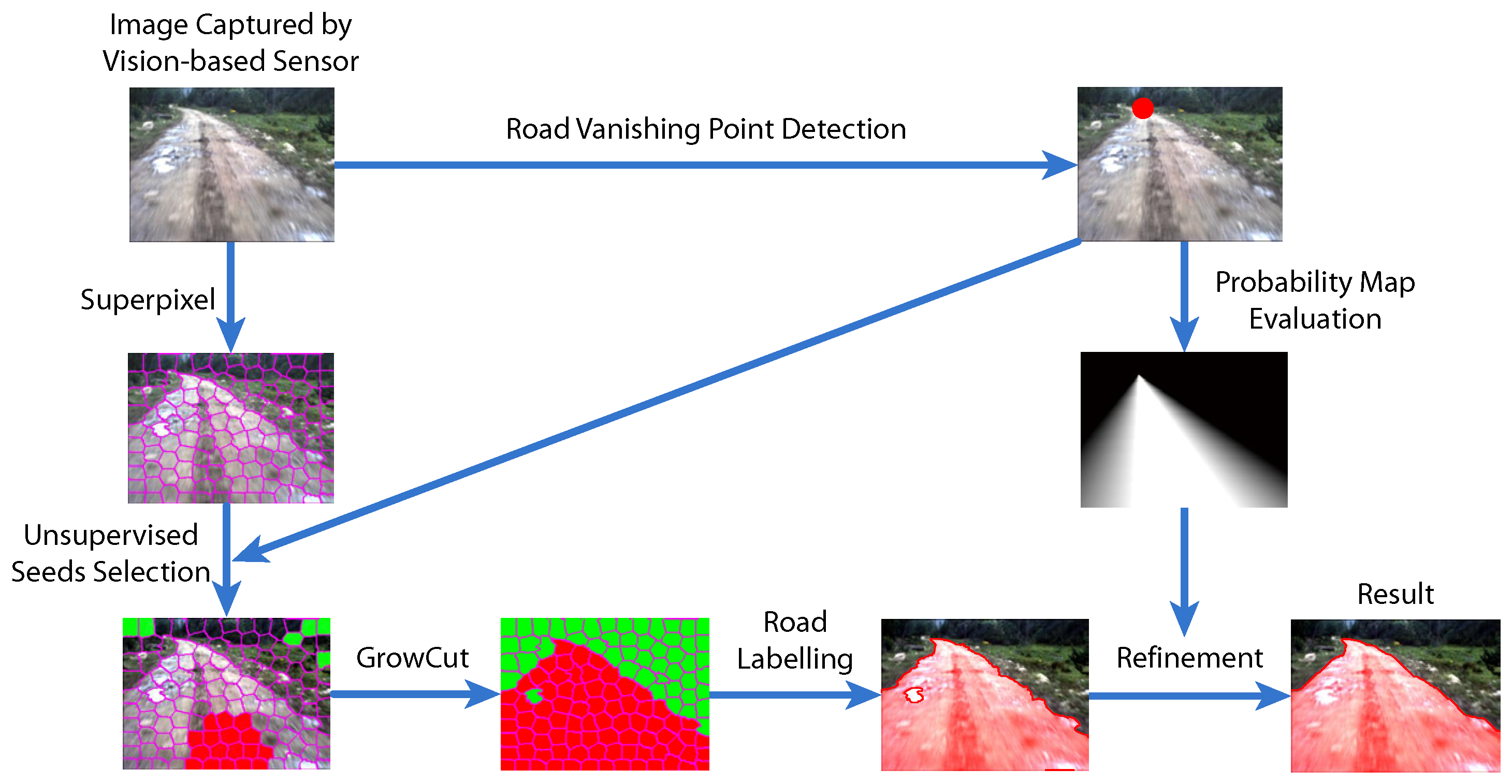
- Road vanishing point detection based on MPGA: We propose an efficient and effective road vanishing point detection method, which employed the multiple population genetic algorithm (MPGA) to search for vanishing point candidates heuristically. The value of the fitness function of MPGA is obtained by a locally-tangent-based voting scheme. In this way, we only need to estimate the local dominant texture orientations and calculate voting values at the positions of vanishing point candidate. Thus, the proposed method is highly efficient compared to traditional vanishing point detection methods. In this paper, the road vanishing point is a key element of subsequent image processing tasks.
- (2)
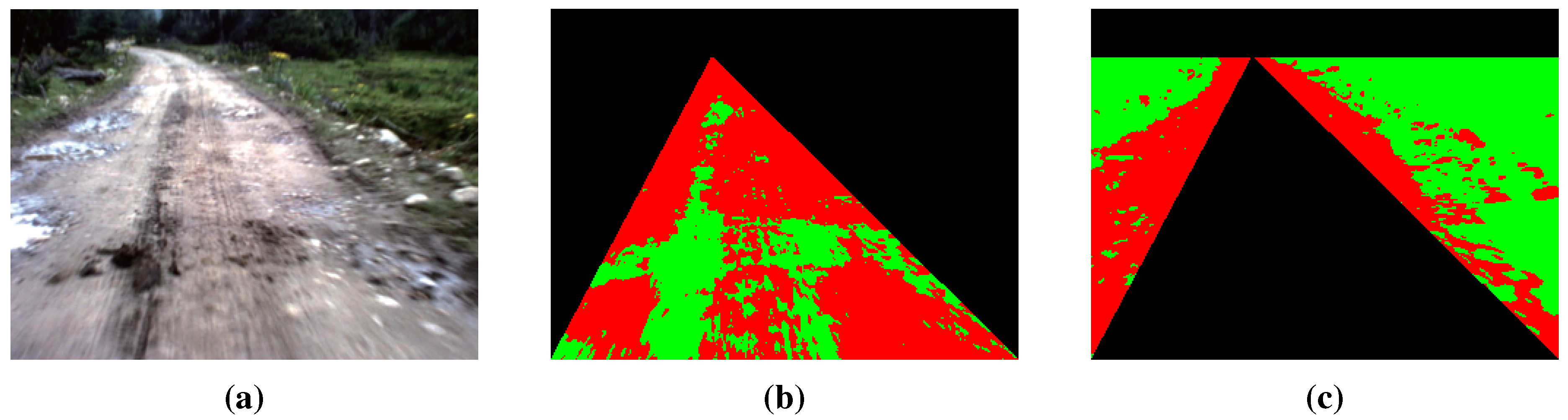
- GrowCut-based road segmentation: The initial road segments are obtained using GrowCut [13], which is an interactive segmentation framework based on cellular automaton (CA) theory [14]. The seed points of GrowCut are selected automatically by using the information of the road vanishing point, which makes GrowCut become an unsupervised process without an interactive property. Seed selection and GrowCut are performed at the superpixel level. Each superpixel is regarded as a cell with a label (road or background), the initial road segment is obtained when the proliferation of cells stops.
- (3)
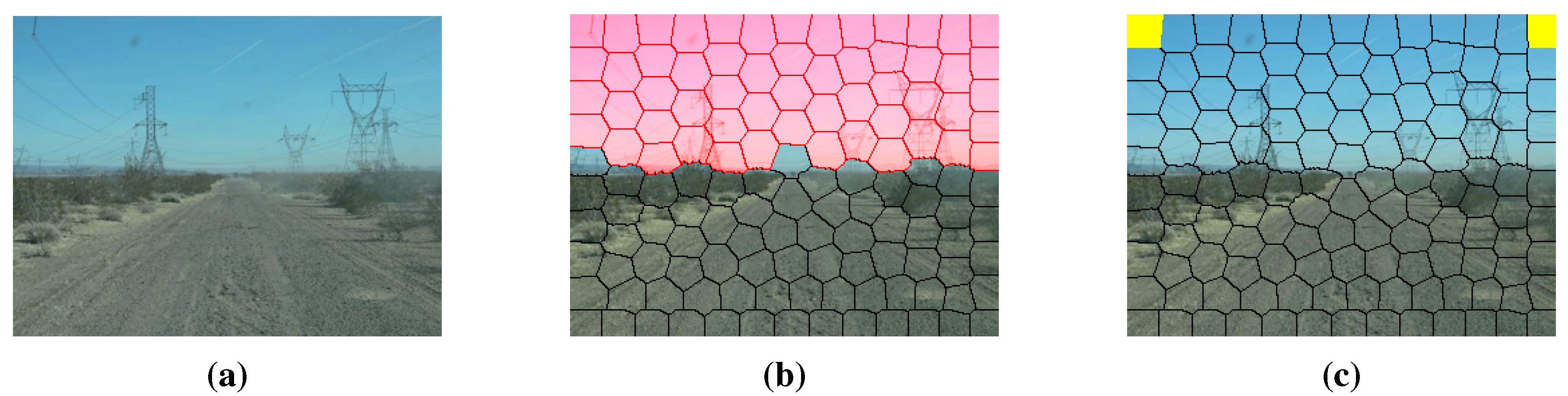
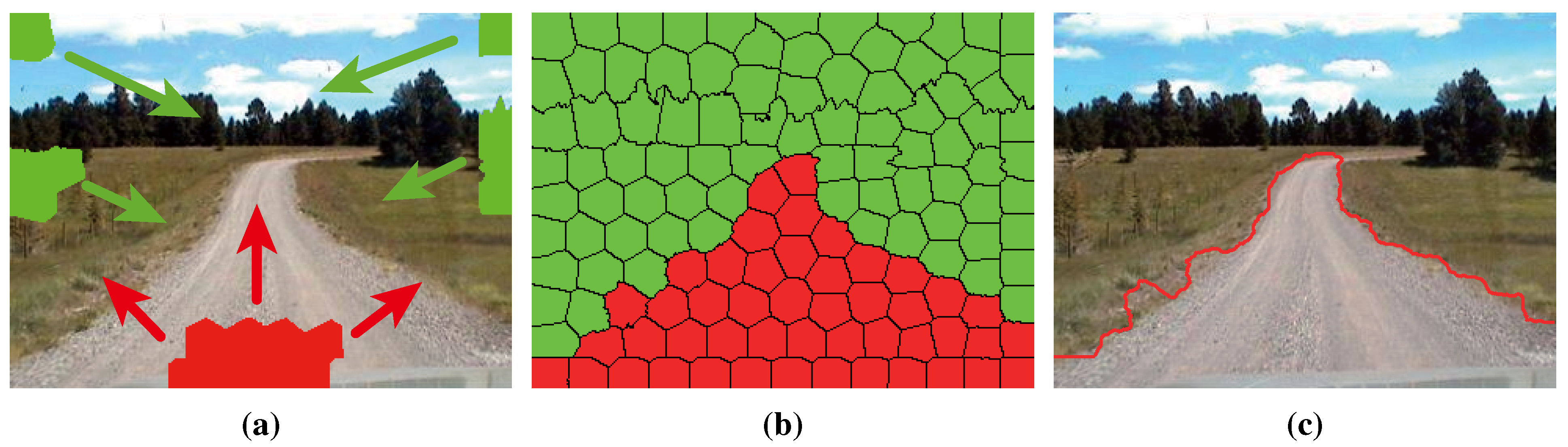
- Refinement using high-level information: In order to get rid of the shortcomings of the illuminant invariance-based method [11] and to ensure that the road segments are globally consistent, inspired by [5], we employ a conditional random field (CRF) [15] to integrate some high-level information into the road segments.

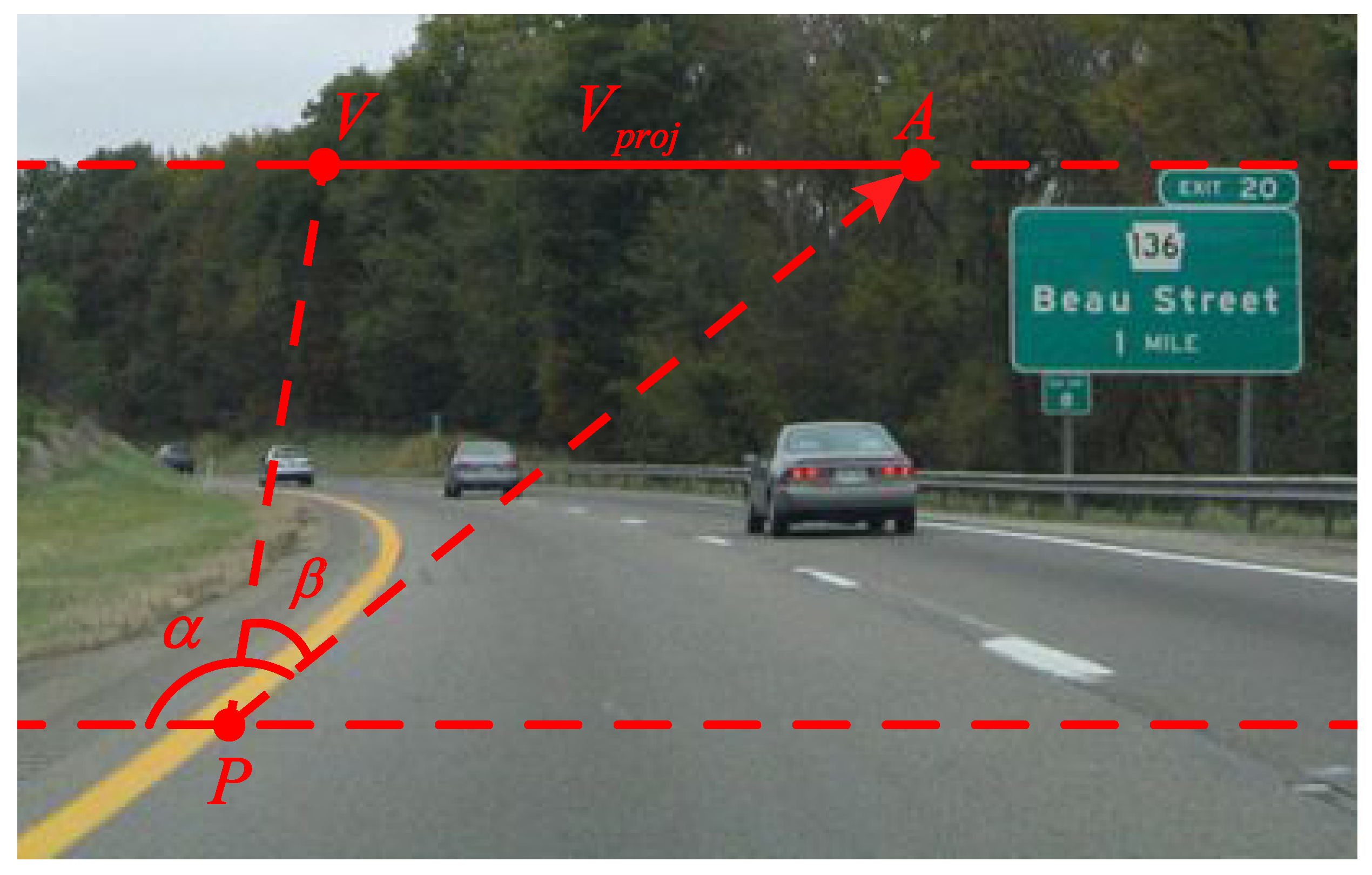
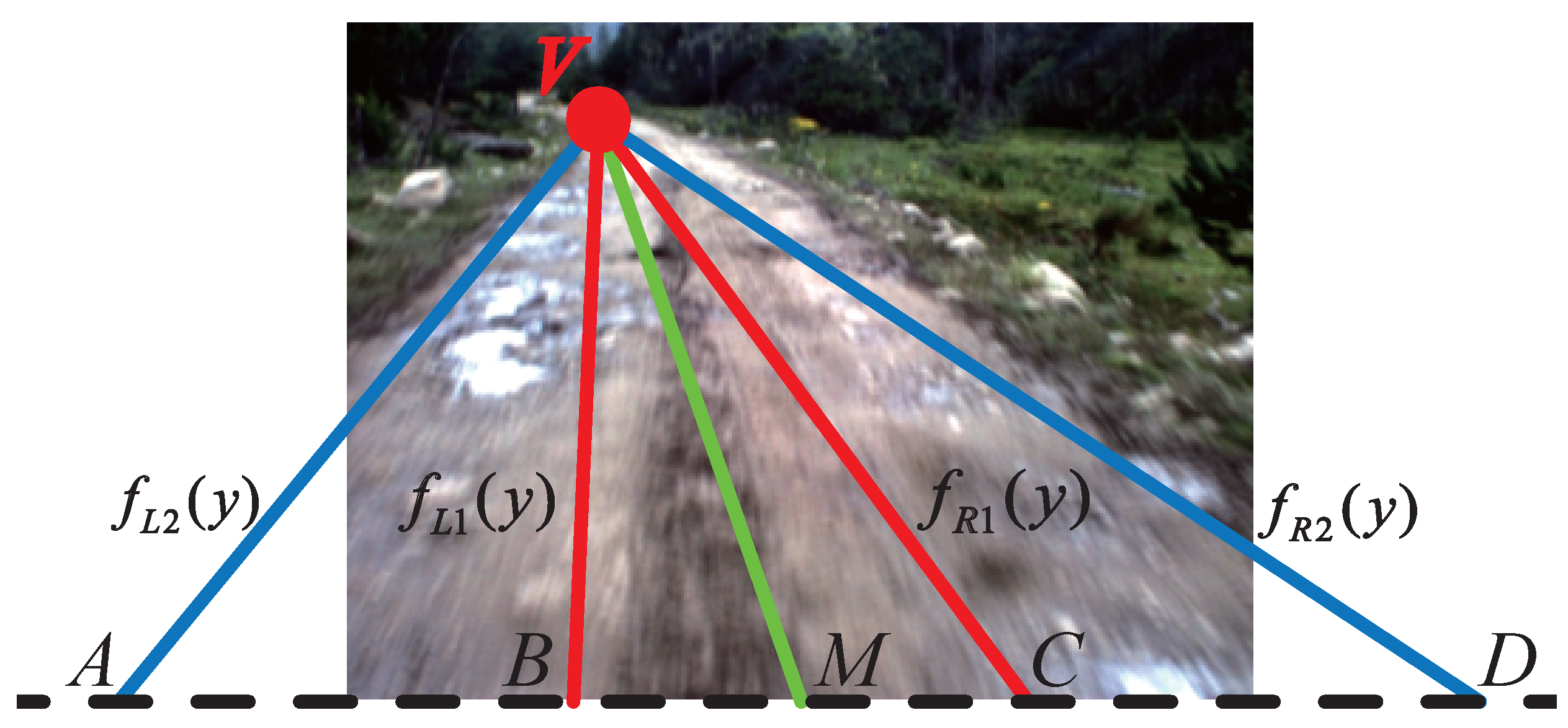
2. Road Vanishing Point Detection Based on MPGA
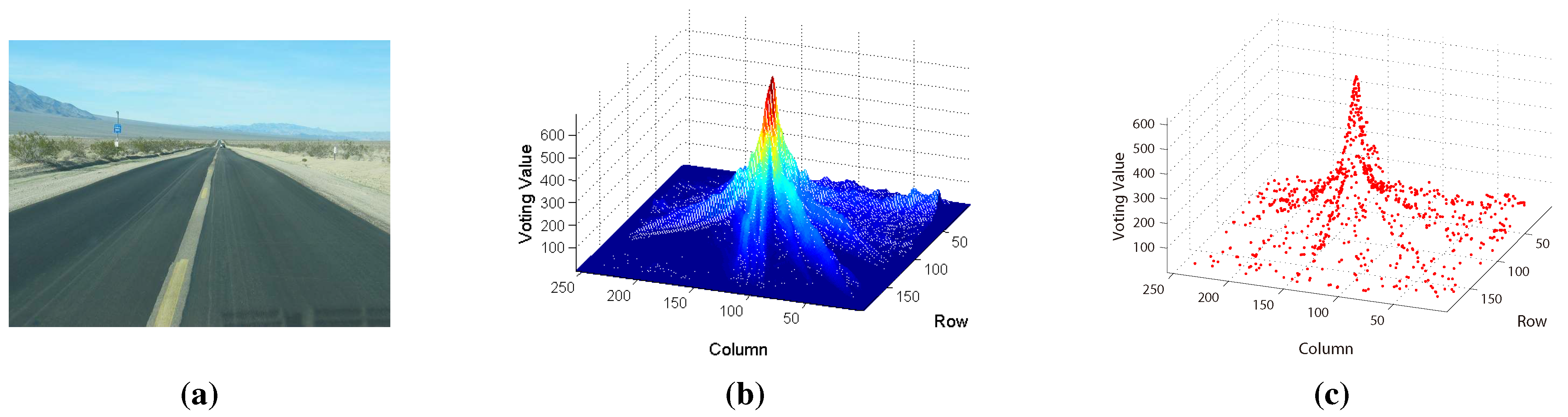
2.1. Searching Based on MPGA
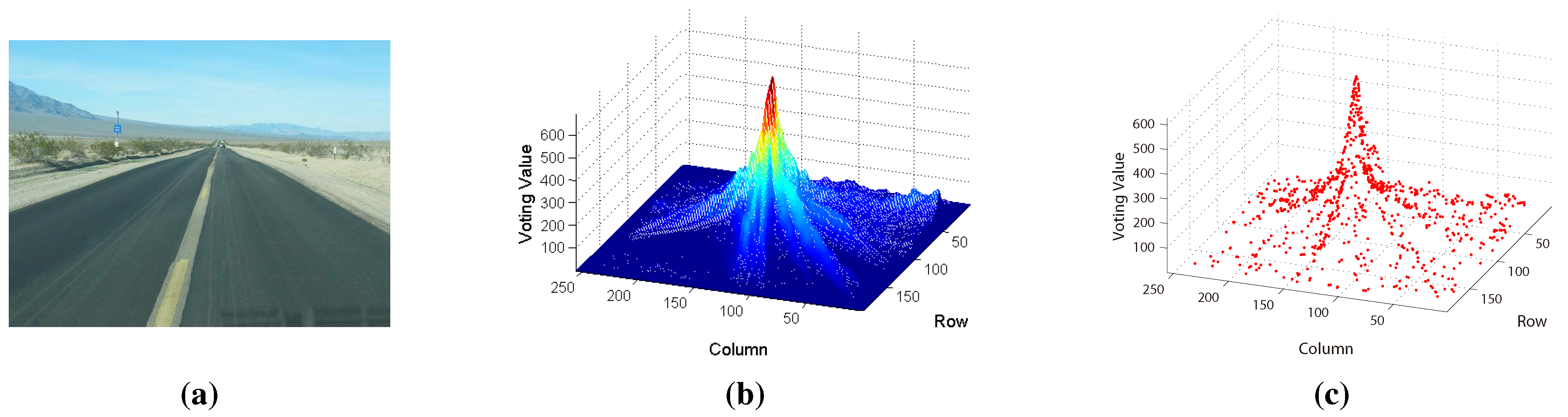
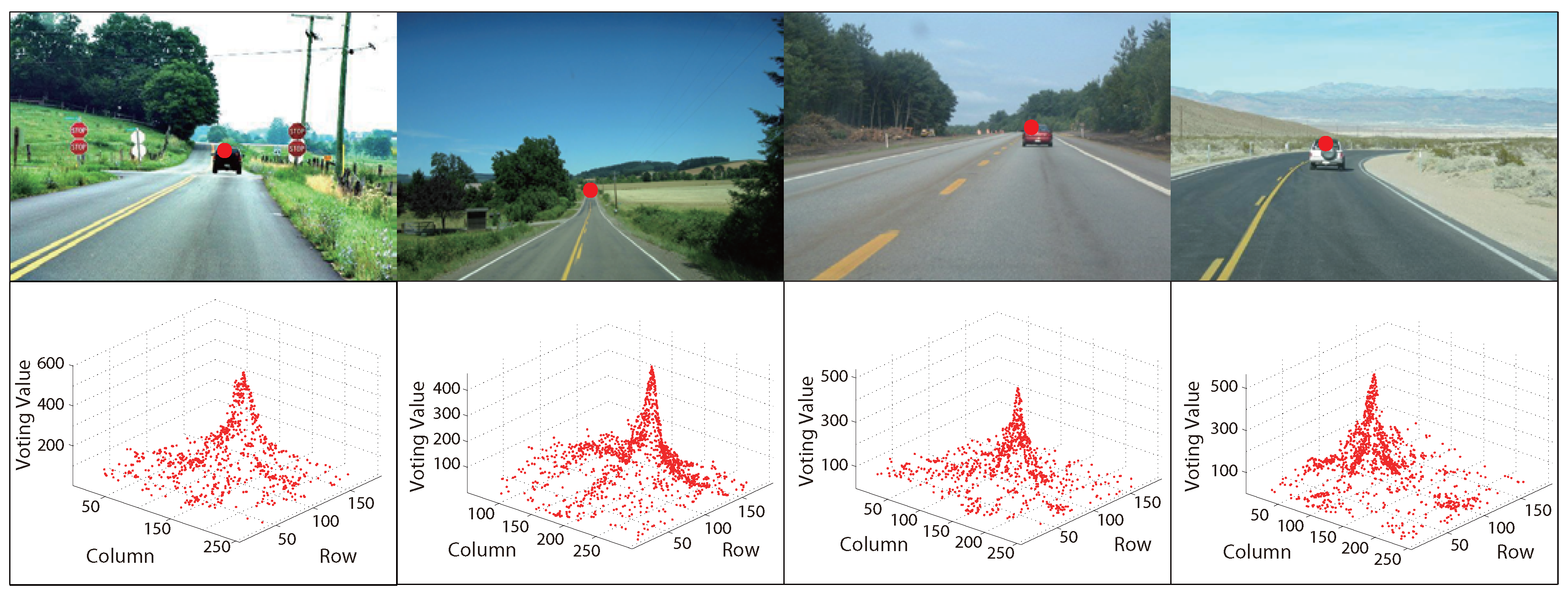
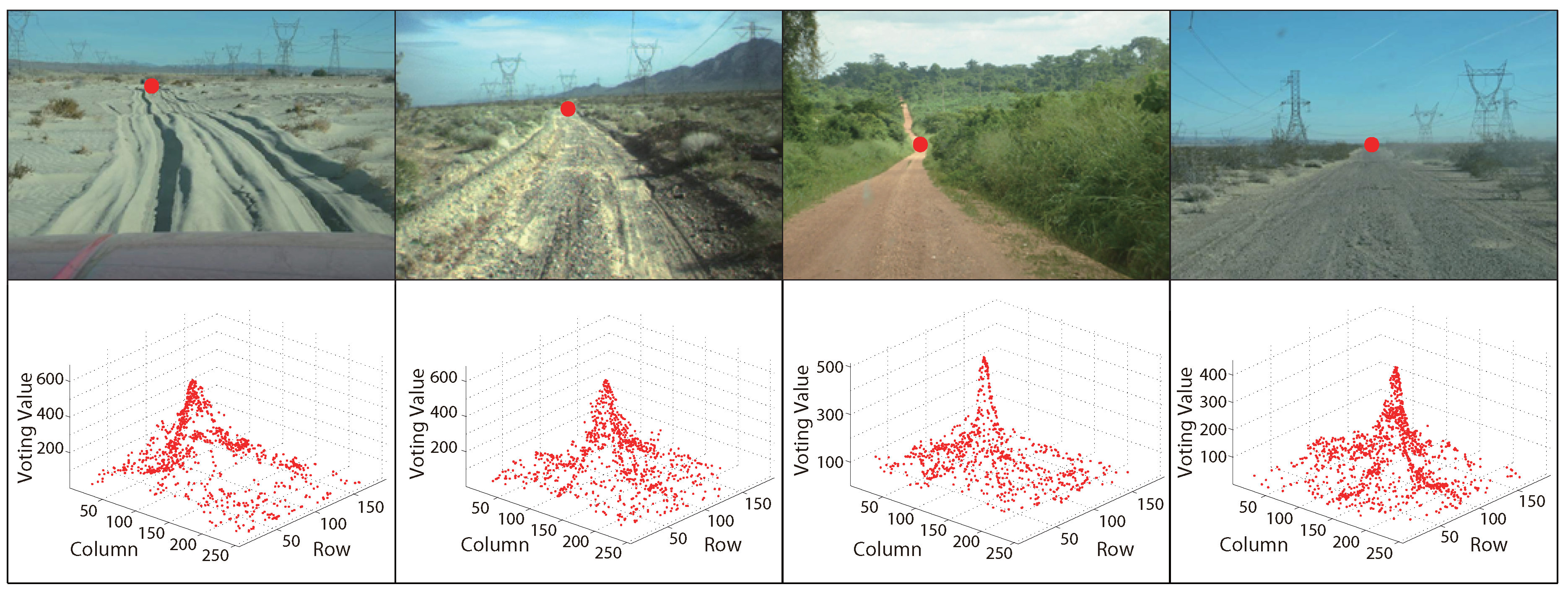
2.2. Voting Scheme


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| NI | 10 | 20 | 30 | 40 | 50 | ||
| NV | |||||||
| MP | |||||||
| 10 | 418 | 1009 | 1553 | 2139 | 2674 | ||
| 20 | 731 | 1767 | 2716 | 3738 | 4594 | ||
| 30 | 1004 | 2439 | 3761 | 5132 | 6313 | ||
| 40 | 1290 | 3098 | 4717 | 6427 | 7797 | ||
| 50 | 1537 | 3681 | 5597 | 7571 | 9177 | ||


3. GrowCut-Based Road Segmentation
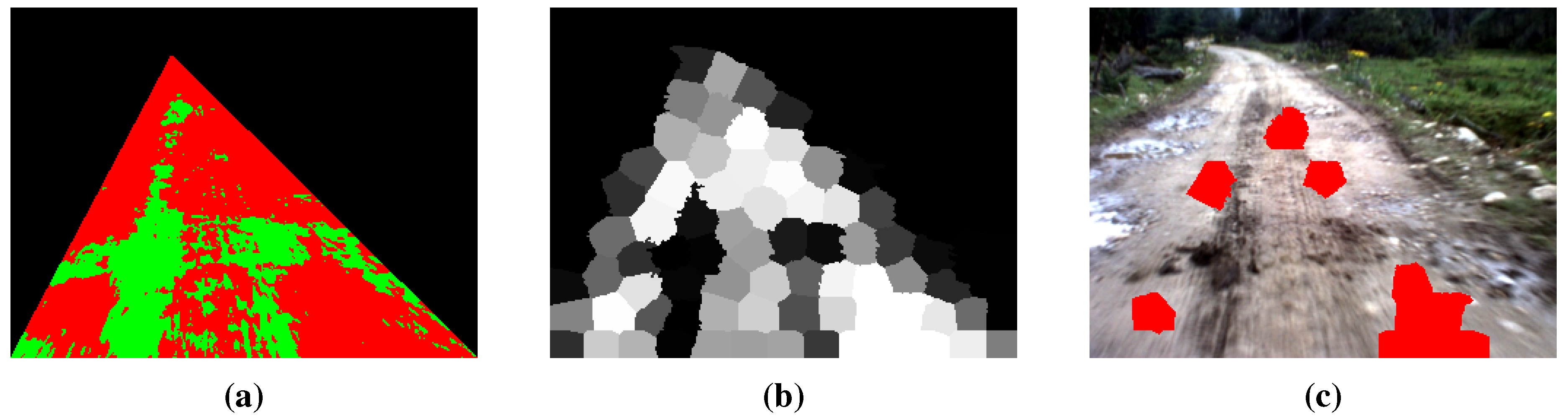
3.1. Seed Selection at the Superpixel Level






3.2. Segmentation Using the GrowCut Framework

4. Refinement Using High-Level Information

- There exist no isolated area in the road segments nor background segments;
- In on-board road images, road segments are shrinking from bottom to top;
- The direction of the road is relevant to the position of the road vanishing point.




5. Results and Discussion
5.1. Common Performance

| Pixel-Wise Measure | Definition |
|---|---|
| Precision | |
| Accuracy | |
| False Positive Rate | |
| Recall |
5.2. Scale Sensitivity


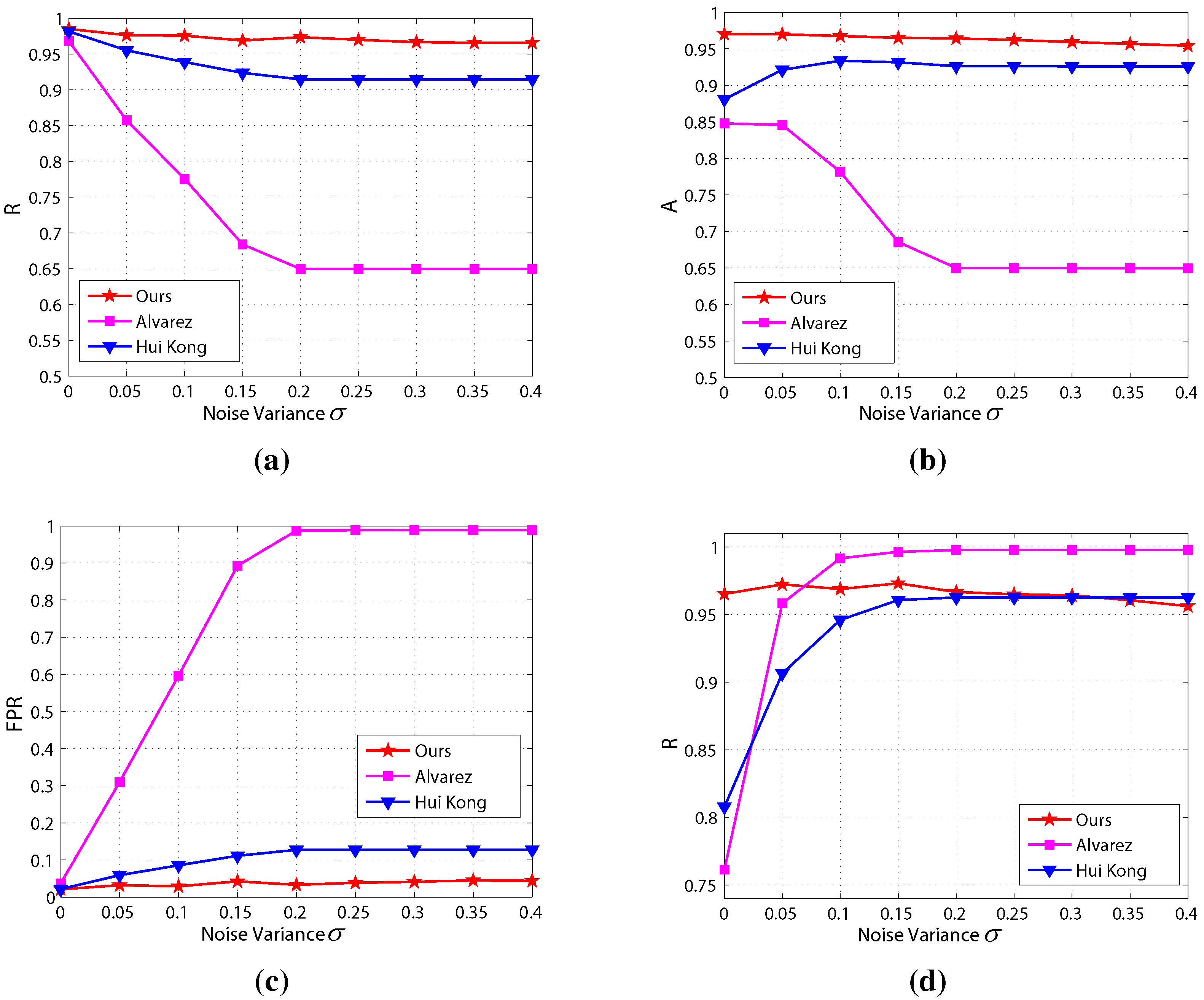
5.3. Noise Sensitivity


5.4. Discussion

6. Conclusions and Future Works
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Llorca, D.F.; Sánchez, S. Vision-Based Traffic Data Collection Sensor for Automotive Applications. Sensors 2010, 10, 860–875. [Google Scholar] [CrossRef] [PubMed]
- Tan, J.; Li, J.; An, X.; He, H. Robust Curb Detection with Fusion of 3D-Lidar and Camera Data. Sensors 2014, 14, 9046–9073. [Google Scholar] [CrossRef] [PubMed]
- Xu, W.; Zhuang, Y.; Hu, H.; Zhao, Y. Real-Time Road Detection and Description for Robot Navigation in an Unstructured Campus Environment. In Proceeding of the 11th World Congress on Intelligent Control and Automation, Shenyang, China, 27–30 June 2014; pp. 928–933.
- Rasmussen, C. RoadCompass: Following rural roads with vision + ladar using vanishing point tracking. Auton Robot 2008, 25, 205–229. [Google Scholar] [CrossRef]
- He, Z.; Wu, T.; Xiao, Z.; He, H. Robust road detection from a single image using road shape prior. In Proceedings of the 2013 IEEE International Conference on Image Processing (ICIP 2013), Melbourne, Australia, 15–18 September 2013; pp. 2757–2761.
- Rotaru, C.; Graf, T.; Zhang, J. Color image segmentation in HSI space for automotive applications. J. Real Time Image Proc. 2008, 3, 311–322. [Google Scholar] [CrossRef]
- Christopher, R. Combining laser range, color, and texture cues for autonomous road following. In Proceedings of the 2002 IEEE International Conference on Robotics and Automation (ICRA 2002), Washington, DC, USA, 11–15 May 2002; pp. 4320–4325.
- He, Y.; Wang, H.; Zhang, B. Color-based road detection in urban traffic scenes. IEEE Trans. Intell. Transp. Syst. 2004, 5, 309–318. [Google Scholar] [CrossRef]
- Kong, H.; Audibert, J.Y.; Ponce, J. General road detection from a single image. IEEE Trans. Image Proc. 2010, 19, 2211–2220. [Google Scholar] [CrossRef] [PubMed]
- Álvarez, J.M.; Ĺopez, A.M. Road detection based on illuminant invariance. IEEE Trans. Intell. Transp. Syst. 2011, 12, 184–193. [Google Scholar] [CrossRef]
- Álvarez, J.M.; Ĺopez, A.M.; Gevers, T.; Lumbreras, F. Combining Priors, Appearance, and Context for Road Detection. IEEE Trans. Intell. Transp. Syst. 2014, 15, 1168–1178. [Google Scholar] [CrossRef]
- Sotelo, M.A.; Rodriguez, F.J.; Magdalena, L. VIRTUOUS: Vision-Based Road Transportation for Unmanned Operation on Urban-Like Scenarios. IEEE Trans. Intell. Transp. Syst. 2004, 5, 69–83. [Google Scholar] [CrossRef]
- Vezhnevets, V.; Konouchine, V. “GrowCut”—Interactive multi-label n-d image segmentation by cellular automata. In Proceedings of the Fifteenth International Conference (GraphiCon’2005), Novosibirsk Akademgorodok, Russia, 20–24 June 2005; pp. 150–156.
- Neumann, J.V.; Burks, A.W. Theory of Self-Reproducing Automata; University of Illinois Press: Champaign, IL, USA, 1966. [Google Scholar]
- He, X.; Zemel, R.; Carreira-Perpinan, M. Multiscale conditional random fields for image labeling. In Proceedings of the 2004 IEEE International Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; pp. 1953–1959.
- Rasmussen, C. Following rural roads with vision + ladar using vanishing point tracking. Auton Robot 2008, 25, 205–229. [Google Scholar] [CrossRef]
- Moghadam, P.; Starzyk, J.A.; Wijesoma, W.S. Fast vanishing-point detection in unstructured environments. IEEE Trans. Image Proc. 2012, 21, 425–430. [Google Scholar] [CrossRef] [PubMed]
- Si-qi, H.; Hui, C. Studies on Three Modern Optimization Algorithms. Value Eng. 2014, 27, 301–302. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Zhang, X.; Zhang, Y.; Maybank, S.J.; Liang, J. A multi-modal moving object detection method based on GrowCut segmentation. In Proceedings of the 2014 IEEE Symposium on Computational Intelligence for Multimedia, Signal and Vision Processing, Orlando, FL, USA, 9–12 December 2014; pp. 1–6.
- Zhang, C.; Xiao, X.; Li, X. White Blood Cell Segmentation by Color-Space-Based K-Means Clustering. Sensors 2014, 14, 16128–16147. [Google Scholar] [CrossRef] [PubMed]
- Veksler, O.; Boykov, Y.; Mehrani, P. Superpixels and Supervoxels in an Energy Optimization Framework. In Proceedings of the 11th European Conference on Computer Vision, Crete, Greece, 5–11 September 2010; pp. 211–224.
- Achanta, R.; Shaji, A.; Smith, K.; Lucchi, A.; Fua, P.; Süsstrunk, S. SLIC Superpixels Compared to State-of-the-Art Superpixel Methods. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 2274–2282. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, T.V.; Tran, T.; Vo, P.; Le, B. Efficient Image Segmentation Incorporating Photometric and Geometric Information. In Proceedings of the International MultiConference of Engineers and Computer Scientists, Hong Kong, China, 6–18 March 2011; pp. 529–533.
- Ara., N.; Gary, B. Detection of Drivable Corridors for Off-road Autonomous Navigation. In Proceedings of the IEEE International Conference on Image Processing (ICIP 2006), Atlanta, GA, USA, 8–11 October 2006; pp. 3025–3028.
- Veksler, O. Star shape prior for graph-cut image segmentation. In Proceedings of the 10th European Conference on Computer Vision (ECCV 2008), Marseille, France, 12–18 October 2008; pp. 454–467.
- Szummer, M.; Kohli, P.; Hoiem, D. Learning CRFs Using Graph Cuts. In Proceedings of the 10th European Conference on Computer Vision (ECCV 2008), Marseille, France, 12–18 October 2008; pp. 582–595.
- Shang, E.; Zhao, H.; Li, J.; An, X.; Wu, T. Centre for Intelligent Machines. Available online: http://www.cim.mcgill.ca/lijian/roaddatabase.htm (accessed on 15 April 2014).
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, K.; Li, J.; An, X.; He, H. Vision Sensor-Based Road Detection for Field Robot Navigation. Sensors 2015, 15, 29594-29617. https://doi.org/10.3390/s151129594
Lu K, Li J, An X, He H. Vision Sensor-Based Road Detection for Field Robot Navigation. Sensors. 2015; 15(11):29594-29617. https://doi.org/10.3390/s151129594
Chicago/Turabian StyleLu, Keyu, Jian Li, Xiangjing An, and Hangen He. 2015. "Vision Sensor-Based Road Detection for Field Robot Navigation" Sensors 15, no. 11: 29594-29617. https://doi.org/10.3390/s151129594
APA StyleLu, K., Li, J., An, X., & He, H. (2015). Vision Sensor-Based Road Detection for Field Robot Navigation. Sensors, 15(11), 29594-29617. https://doi.org/10.3390/s151129594