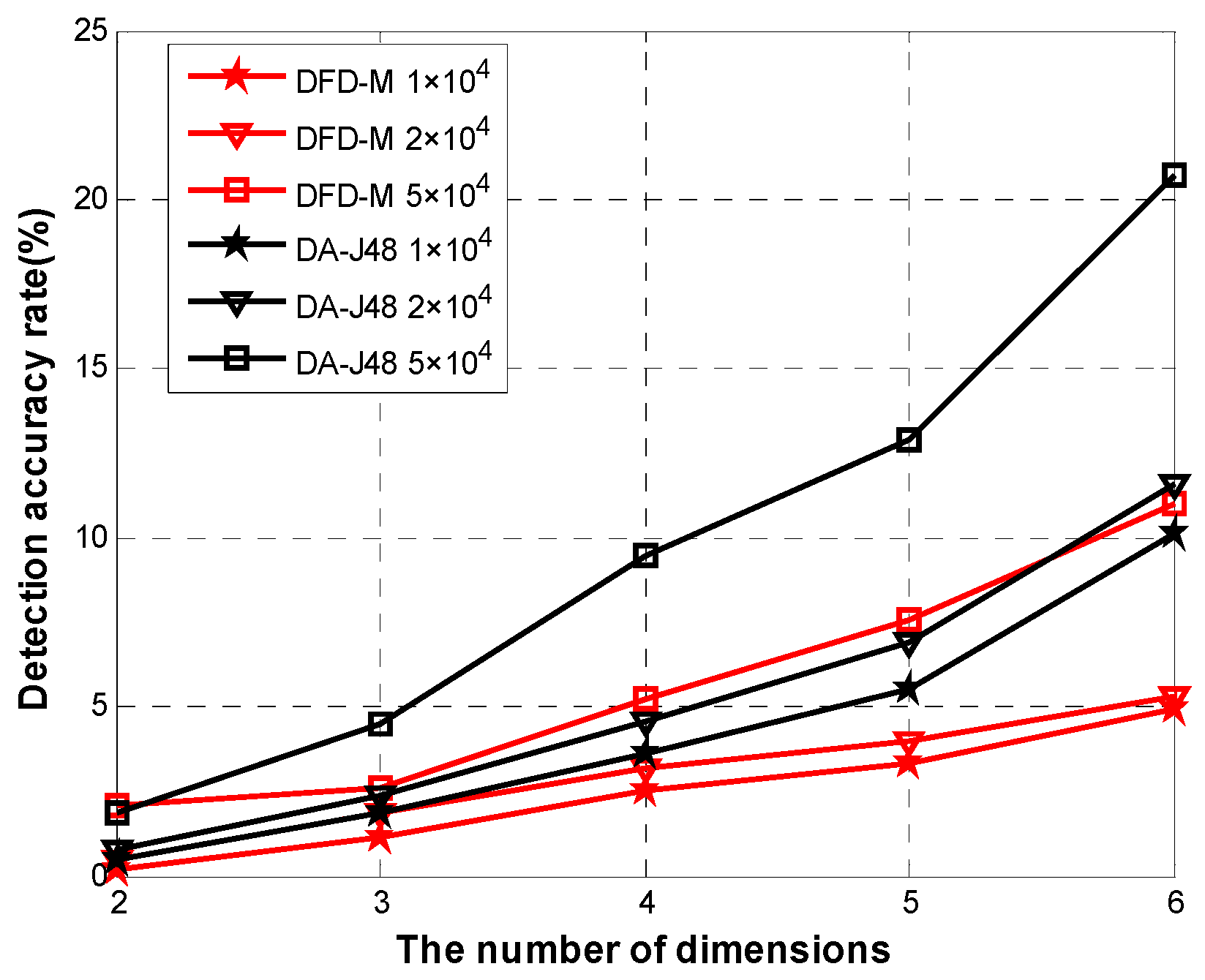
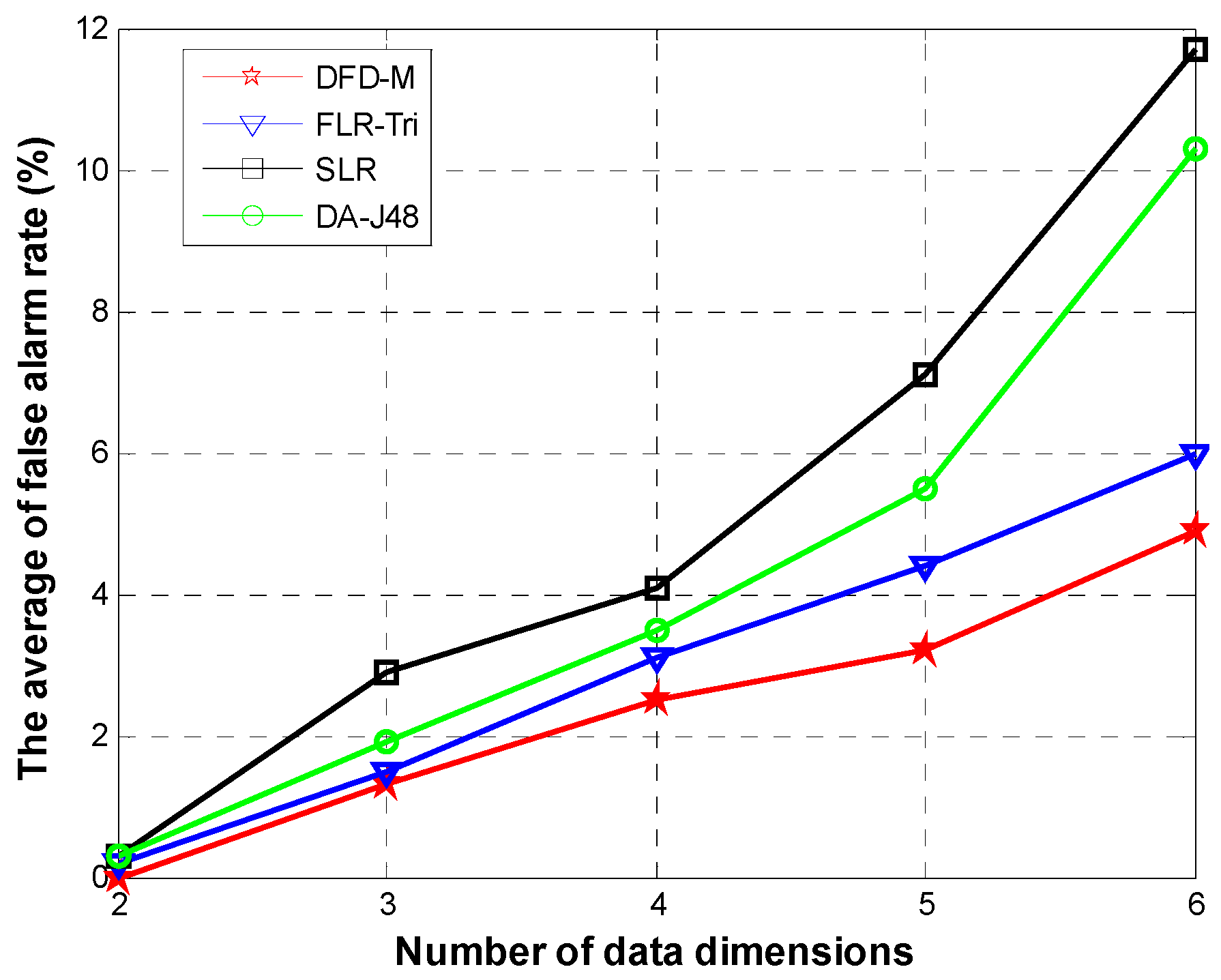
Physiological parameters are correlated in time and space, and the correlation must be exploited to identify and isolate faulty measurements, in order to ensure reliable operation and accuracy diagnosis results. Usually, there is no spatial and temporal correlation among monitored attributes for faulty measurements. Based on the above theory, we introduce the data fault detection of body sensors, and focus on detecting faulty medical sensors so as to determine and judge the fault readings.
We firstly give some definitions. Physiological readings are described as a matrix X = (Xji), in which j represents measuring time, and i is sensor i. The sequence Xi = (X1i, X2i, X3i, …, Xti) represents measured values of sensor i from time T1 to Tt. The vector Xj = (Xj1, Xj2, …, Xjn) represents all of physiological parameters on time Tj.
3.1. Dynamic-LOF Algorithm
An exact definition of an outlier depends on the data structure and detection methods. A data object is either an outlier or not. Breunig
et al. proposed an outlier detection method based on density and assign to each object a local outlier factor (LOF), which is the degree to which the object is outlying [
15]. It is local in that the degree depends on how isolated the object is with respect to the surrounding neighborhood, so the key idea of LOF is to compare the local density of an object’s neighborhood with that of its neighbors.
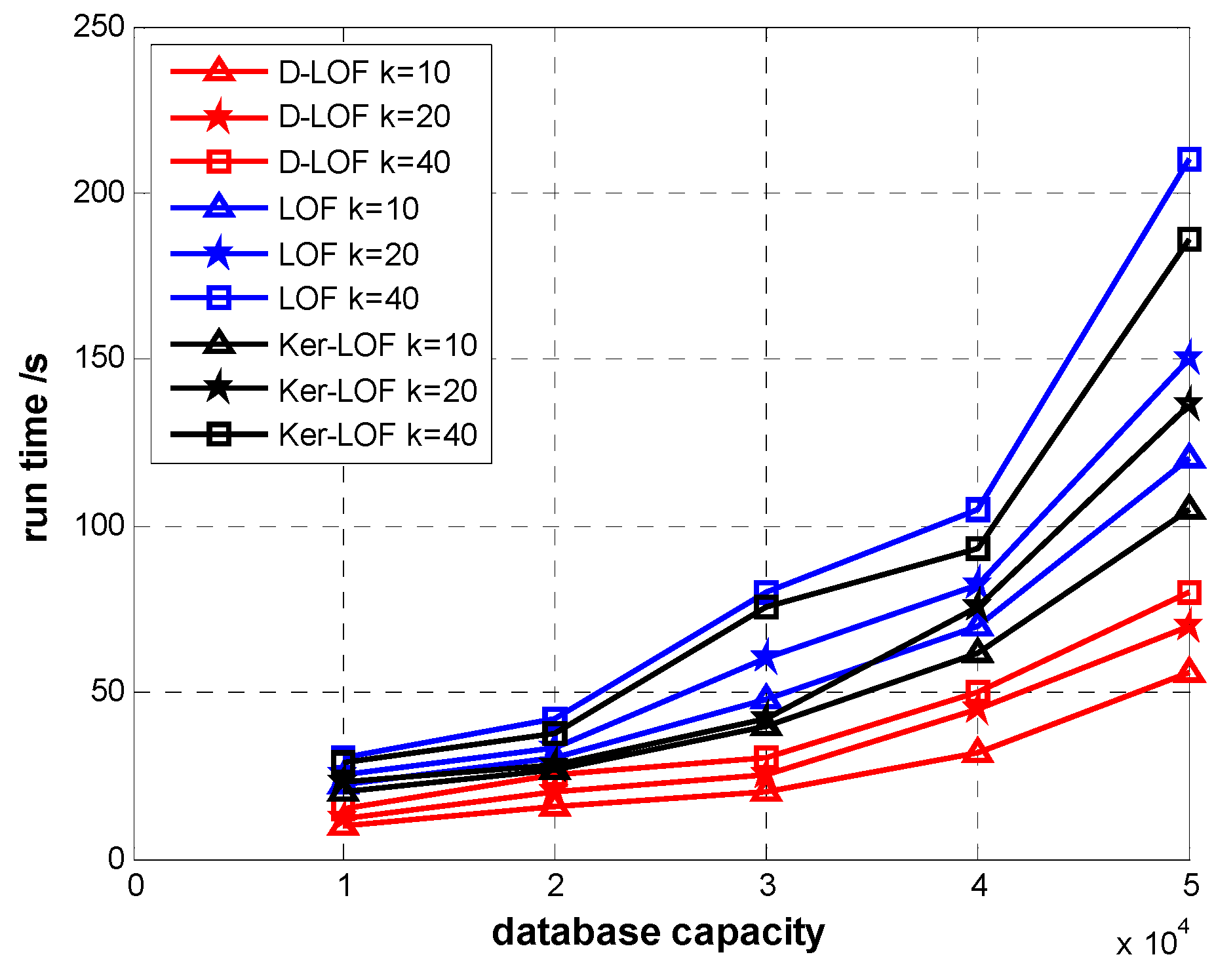
Our detection targets are dynamic time-series readings which are dynamic and constantly updated. Since the density-based LOF algorithm cannot detect contextual anomalies, the LOF values of all objects will be recalculated once the dataset changes. When the size of dataset increases, it will take a lot of time to frequently update the LOF values of all the objects in dataset, so the density-based LOF algorithm may not be suitable for the dynamic increment dataset. We find that newly added objects can only influence parts of objects’ LOF values in the original dataset. We only need to find out these related objects whose LOF values have changed, and recalculate their LOF values. Thus the efforts in recalculating LOF values of all the objects can be reduced, so in this paper, we propose a dynamic-LOF algorithm to identify outlying data vectors. We find out the three levels of influenced objects and recalculate these nodes’ new LOF values. Besides, a small modification is made to narrow down the scope of the detected objects’ nearest neighborhood, which can increase the detection accuracy, and then more outliers are detected.
The core idea of dynamic-LOF algorithm is, on the one hand, a small modification in k-distance, which makes our algorithm achieve higher detection average accuracy. On the other hand, finding out three levels of influenced objects and narrowing the range of updating LOF values to improve the outlier detection efficiency. The vector Xj = (Xj1, Xj2, …, Xjn) are all of sensed physiological readings at time Tj is regarded as an object in multidimensional space. The size of dataset D continually increases over time. Firstly we obtain LOF values of all objects in dataset D, and then establish an initial knowledge base. All the objects in the initial knowledge base are considered normal. The dynamic-LOF algorithm only needs to update the LOF values of the newly added object and other objects which are influenced by the new one.
Assume o, o', p, q, s, x, y, z to denote objects in a dataset D. Each object in dataset is assigned a local outlier factor. The larger the LOF is, the greater the chance is of an object being an outlier. We use the notation d(s, o) to denote the distance between objects s and o. s is an object in D. We take mean distance of object s, denoted as mk-distance to replace k-distance in the original LOF algorithm. It indicates the mean distance from s to its k-nearest objects.
Definition 1. k-distance and k-distance neighborhood of an object s.
For any positive integer
k, the
k-distance of object
s, denoted as
k-distance(
s) is defined as the distance
d(
s,
o) between
s and an object
o ϵ
D such that:
- (1)
For at least k objects o' ϵ D{s} it holds that d(s, o') ≤ d(s, o), and
- (2)
For at most k − 1 objects o' ϵ D{s} it holds that d(s, o') < d(s, o).
Then the k-distance neighborhood of s is Nk(s) = {q ϵ D\{s}|d(s, q) ≤ k-distance(s)}. These objects q are called the k-nearest neighbors of s.
Definition 2. mk-distance of an object s.
For any positive integer
k, the
mk-distance of object
s is:
Definition 3. mk-distance neighborhood of an object s.
Given mk-distance of s, the mk-distance neighborhood of s contains every object whose distance from s is not greater than mk-distance, i.e., Nmk(s) = {q ϵ D\{s}|d(s, q) ≤ mk-distance(s)}. Each object q in Nmk(s) is also in Nk(s).
Definition 4. Reachability distance of an object
s with respect to object
o is:
Definition 5. Local reachability density of an object s is:
Definition 6. Local outlier factor of an object s is:
The outlier factor of object s captures the degree to which we call s an outlier. It is the average of the ratio of the local reachability density of s and those of its mk-distance neighbors. It is easy to see that the lower local reachability density is, and the higher the local reachability densities of its mk-distance neighbors are, the higher is the LOF value of s.
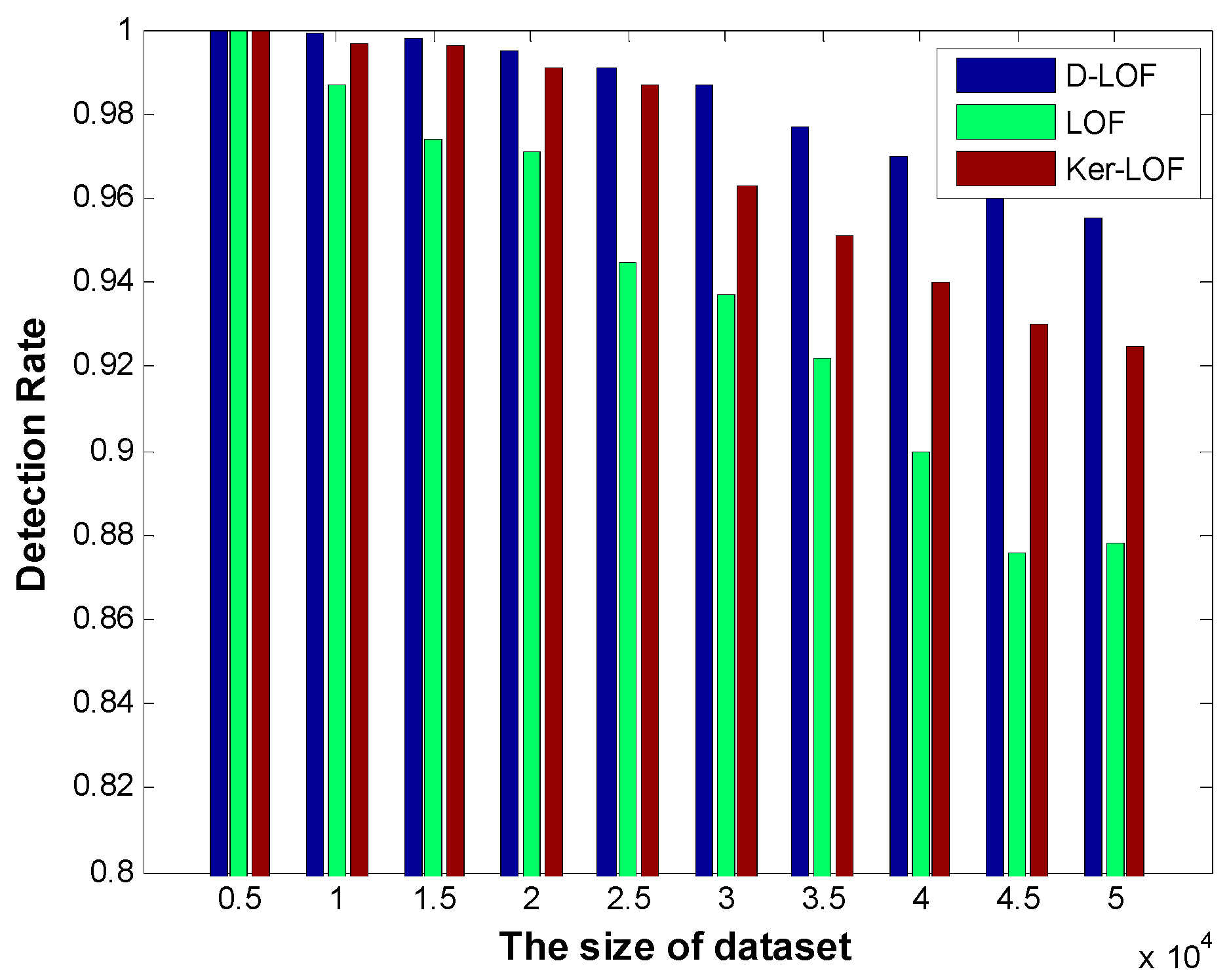
By using the above formulas to calculate the LOFmk values of all objects in the dataset, the scope of nearest neighborhood of each object can be narrowed down, so our improved algorithm is more sensitive to outliers, and can achieve higher detection average accuracy.
According to the steps above, it’s clear that the LOF value of each object depends on the local reachability density and its
k-nearest neighbors. When there are any newly added, deleted, or updated objects, the LOF values of partially related objects would be influenced. In the environment of dynamic increment dataset, updating the LOF values of all the objects in dataset frequently will cost a great deal of temporal and spatial resources, but we note that only part of the related objects will be influenced by the changes of dataset, so we only need to find out these related objects whose LOF values have changed, and recalculate LOF values of these objects. Assume that an added object is
p. According to Definition 1 to Definition 6, we also have the following definitions to find the three levels of influenced objects:
Definition 7. The first-level influenced objects. Given a new added object
p, the first-level influenced objects of
p contains every object
x whose distance from
p is not greater than
k-
distance(
x), and the first-level influenced objects can be defined as:
The new object p makes Nk(x) change, and then leads to the subsequent change of Nmk(x), lrdmk(x) and LOFmk(x).
Definition 8. The second-level influenced objects. The second-level influenced objects of
p contains every object
y whose distance from
x (object in
F1(
p)) is not greater than
mk-
distance(
y), and the second-level influenced objects can be defined as:
These second-level influenced objects remain Nmk(y) unchanged, but should recalculate lrdmk(y) and LOFmk(y) due to the change of mk-distance(x).
Definition 9. The third-level influenced objects. The third-level influenced objects of
p contains every object
z whose distance from
y (object in
F2(
p)) is not greater than
mk-
distance(
z), and the third-level influenced objects is:
The third-level influenced objects only LOFmk(z) changed. Based on the abovementioned analysis, we find that because of the addition of object p, there are only three levels influenced objects need to recalculate their LOFmk values. Other objects’ LOFmk values remain unchanged.
Definition 10. The set of influenced objects whose
LOFmk values to be recalculated is
F.
In the Dynamic LOF, we firstly obtain the k-distance neighborhood Nk, mk-distance neighborhood Nmk, local reachability density lrdmk and local outlier factor LOFmk of all the objects in dataset D. We put the new objects into the knowledge base, and find in turn the three level influenced objects based on the new knowledge base. Finally, we update Nk, Nmk, lrdmk and LOFmk of these objects, while the LOFmk values of other objects remain unchanged. Finally, the LOFmk value of each incoming new object will be calculated according to the unceasing updating of the knowledge base. If the LOFmk value of a new object is smaller than a given threshold (an empirical value, equal to 2.0), it is normal. Otherwise it is outlying. Algorithm 1 describes the process of finding the first-level influenced objects after adding a new object p into dataset D.
| Algorithm 1. Find First Level Objects (D, F1(p), p). |
0: Initialize
1: for do // The new object p is in the k-distance neighborhood of object x
2: input x into ; // Construct the set of the first-level influenced objects
3: end for
4: input p into D
5: input p into // p is also contained in |
F1(p) indicates the set of the first-level influenced objects (including p). If p is in the k-distance neighborhood of object x, then the object x is a first-level influenced object, and should be put into F1(p). In the end, all of objects in F1(p) should be recalculated the values of Nk, Nmk, lrdmk and LOFmk, so does object p, so we also put object p into F1(p). Algorithms 2 and 3 describe the process of constructing the sets of F2(p) and F3(p).
| Algorithm 2. Find Second Level Objects (D, F2(p), F1(p)) |
0: Initialize
1: for all objects x in \{p} do
2: for all objects y in D\ && x is in do
3: input y into ; // Construct the set of the second-level influenced objects
4: end for
5: end for |
| Algorithm 3. Find Third Level Objects (D, , ). |
0: Initialize
1: for all objects y in do
2: for all objects z in D\{} && y is in do
3: input z into ; // Construct the set of the third-level influenced objects
4: end for
5: end for |
Algorithm 4 describes the update process of and , where x is a first-level influenced object.
| Algorithm 4. Update K-Distance (). |
0: for all objects x in \{p} do
1: if then
2: input p into ;
3: else if ( && there are less than (k-1) objects in then
4: input p into ;
5: else if && there are (k-1) objects in then
6: remove the farthest neighbor in ;
7: input p into ;
8: recalculate ;
9: recalculate ;
10: recalculate ;
11: else break;
12: end if
13: end for |
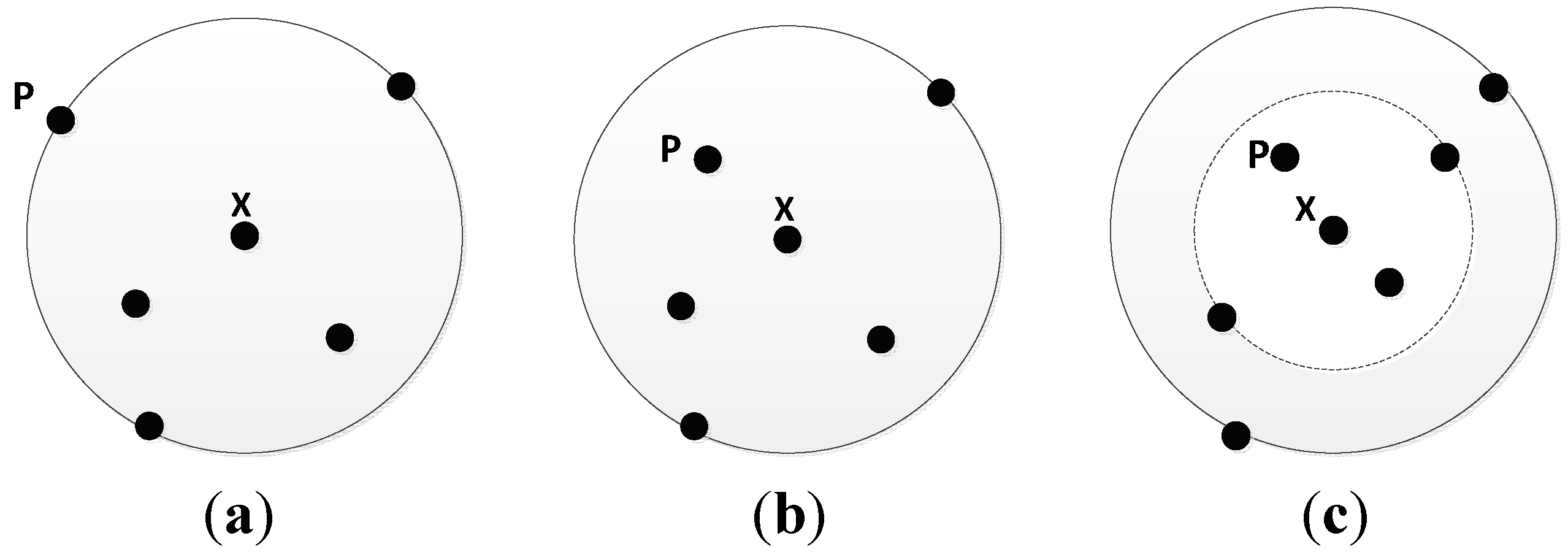
According to the different positions which p inserts into, the influence of Nk(x) differs. There are three different cases as follows:
Situation 1. In
Figure 1a,
d(
x,
p) =
k-distance(
x), that is
p falls on the circle of the
k-distance neighborhood of object
x. Put
p into
Nk(
x) directly.
Situation 2. In
Figure 1b,
d(
x,
p) <
k-distance(
x), that is
p falls within the circle of the
k-distance neighborhood of
x. If there are less than (
k-1) objects within the circle, then put
p into
Nk(
x).
Situation 3. In
Figure 1c,
d(
x,
p) <
k-distance(
x),
p falls within the circle of the
k-distance neighborhood of
x. If there are exactly (
k − 1) objects within the circle, firstly remove the farthest neighbor in
Nk(
x), then put
p into
Nk(
x) and recalculate
k-distance(
x).
After updating of Nk(x) and k-distance(x), and mk-distance(x) can also be recalculated.
Figure 1.
(a) Situation 1; (b) Situation 2; (c) Situation 3.
Figure 1.
(a) Situation 1; (b) Situation 2; (c) Situation 3.
Algorithm 5 describes the updating process of and , where x is a first-level influenced object and y is a second-level influenced object. Algorithm 6 describes the updating process of , , and , where x is a first-level influenced object, y is the second-level influenced object and z is the third-level influenced object.
| Algorithm 5. Update LRD (, ) |
0: for all objects x in do
1: recalculate ;
2: end for
3: for all objects y in do
4: recalculate ;
5: end for |
| Algorithm 6. Update LOF (, , ) |
0: for all objects x in do
1: recalculate ;
2: end for
3: for all objects y in do
4: recalculate ;
5: end for
6: for all objects z in do
7: recalculate ;
8: end for |
3.2. The Fuzzy Linear Regression Process
Considering the possible anomalies of sensed readings, and the uncertain relationships among them, it’s quite hard to reflect the fuzzy relationships by the simple linear regression which may cause prediction errors between the regression values and the actual sensed values. It’s better to characterize the output variable and regression coefficients by fuzzy numbers.
For medical sensor readings, we consider that the normal sensor readings from several days ago always show similarities, whereas abnormal sensor readings of adjacent times may deviate from each other, so the physiological parameters of a patient at a given time are closely associated with the historical data of adjacent times (which may be within several hours) instead of readings from several days ago. It also means that the impacts of historical data on the estimated outputs are more important at nearer monitoring times.
Based on the limitation mentioned above, we propose a linear regression model based on trapezoidal fuzzy number to predict a more appropriate fuzzy value for the suspected reading. In this regression model, we regard the minimum sum of regression error as a new objective function, and propose a method to obscure the sensor data using the expected value of trapezoidal fuzzy number. In addition, our proposed regression model has given adequate consideration to the different impacts of historical sensor data. By constructing the minimum sum of regression error and fuzzifying readings, we achieve more precise estimated outputs.
Construct the following fuzzy linear function:
where
n is the number of independent variables,
j is
j-th data vector on time
Tj which is involved in regression modeling. In Equation (9), the prediction value
and regression coefficient
are fuzzy values, and
is
i-th measured real number of
j-th vector. Define
and
are trapezoidal fuzzy numbers, so
,
, the membership function of
is defined as follows:
where:
These historical sensed readings are real numbers, and must be fuzzified for calculating the corresponding fuzzy regression coefficients
. We construct an optimized prediction model of trapezoidal fuzzy numbers so the prediction value is closer to the true value. To resolve the problem of fuzzifying historical values, we introduce a fuzzy number expectation which is a real number with reflecting the values of fuzzy number in average meaning. The expectation of trapezoidal fuzzy number [
16] is:
We construct
u sets of data to calculate the fuzzy coefficients using measured data. As physiological readings are cyclical, the value of
u is the total number of readings that pick out faulty data in a period. Assume that there are totally
m groups of measured samples. The following formula represents the
m-th sample group in one period:
where
u is the number of samples in one group,
n is the number of independent variables. For independent variables
in the
m-th group, we keep the precise real values unchanged and use them to calculate the fuzzy coefficients. For output variables
, regard the historical measured data at the same instant but in different groups as multi-measured results. Let
and
be the maximum and minimum of
respectively:
The highest and lowest dependent variables in the samples are viewed as parameters of
a and
b, so only parameters of
and
corresponding to
are changing, and thus, the output variables
have been fuzzified:
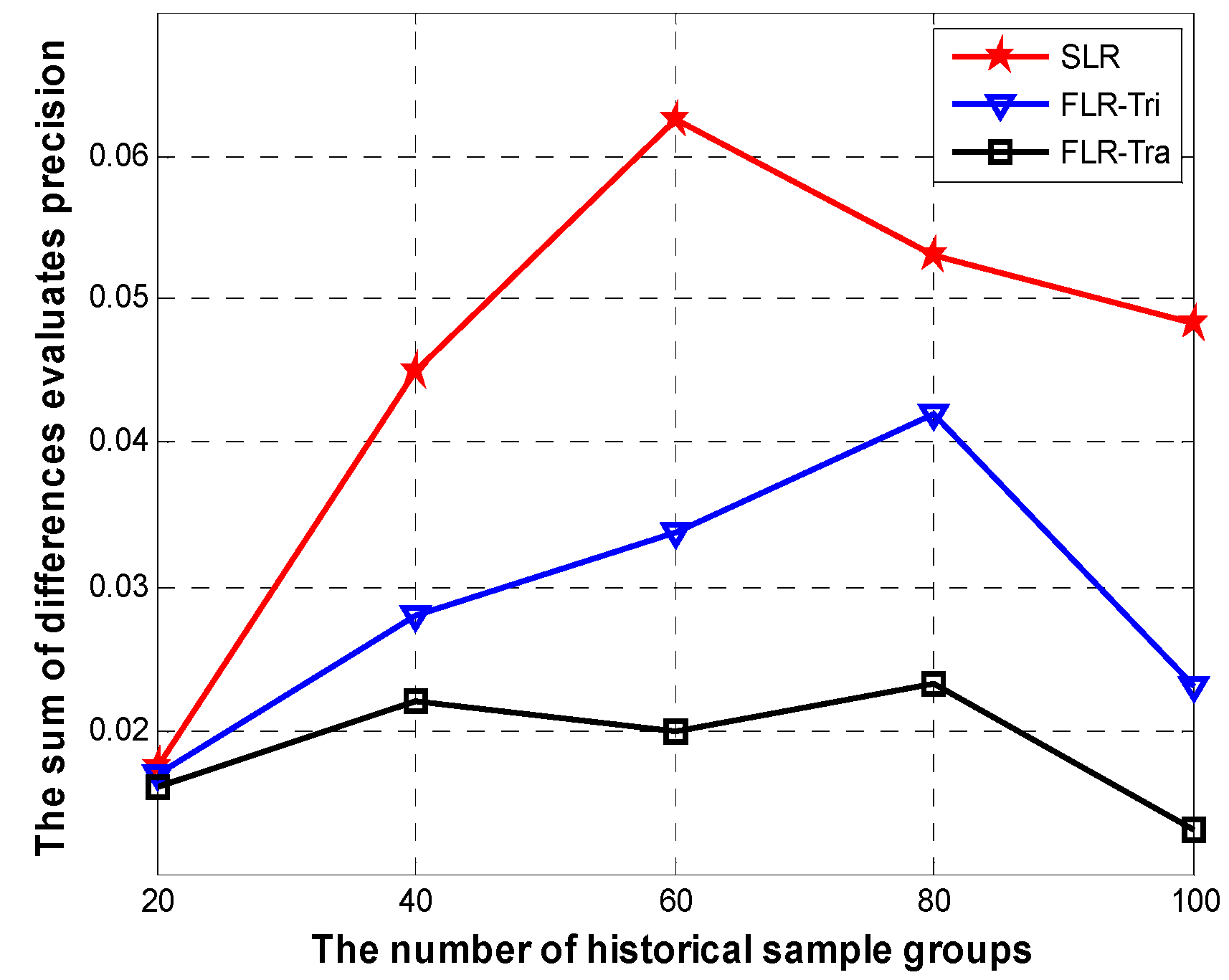
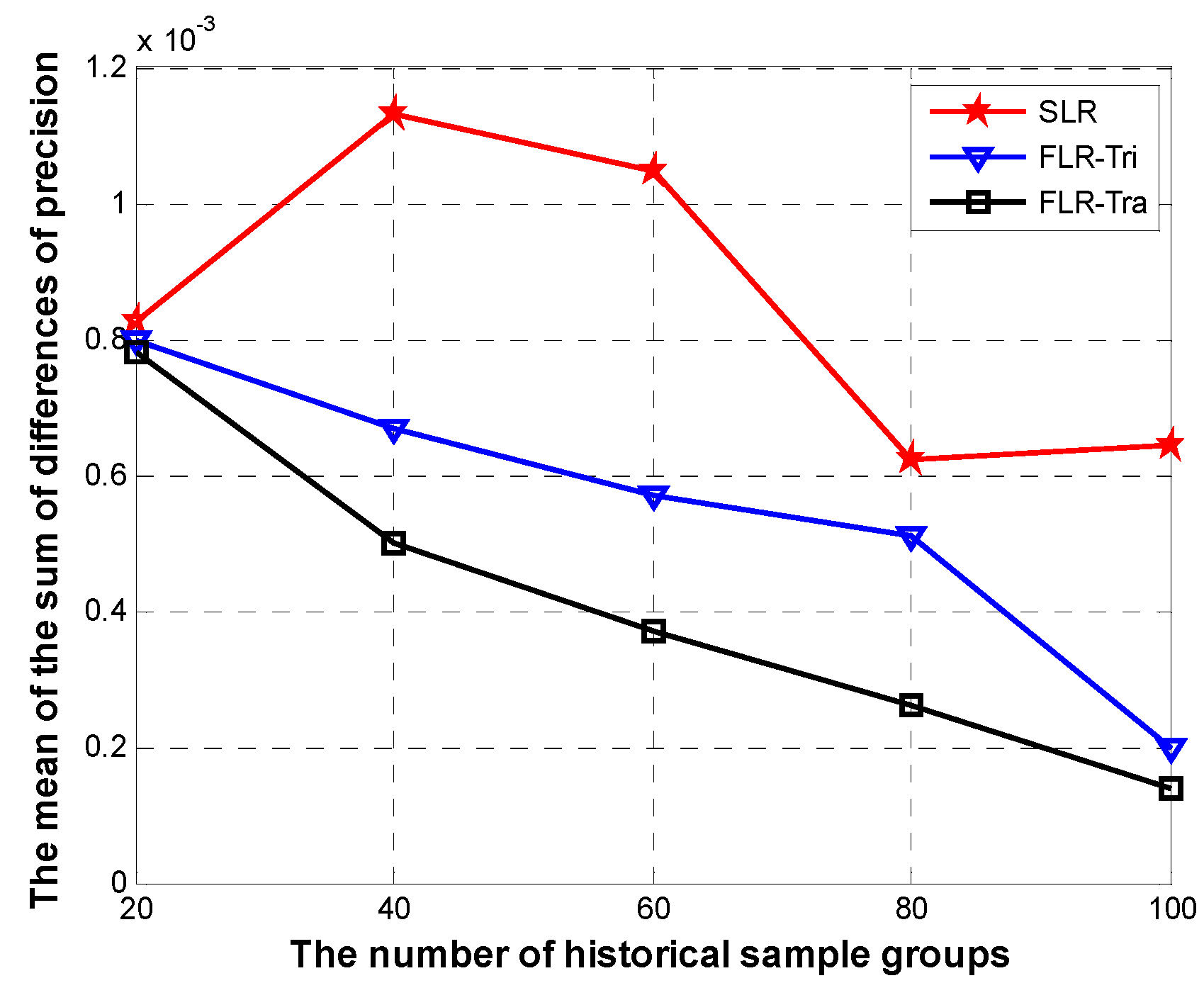
The least square method is a mathematical procedure for finding the best-fitting curve to a given set of points by minimizing the sum of the squares of the residuals of the points from the curve, so we borrow the ideas from the least square method to ensure the minimal sum of differences of evaluation precision R, it can be defined as follows:
where
is a precise prediction value on
m-th sample group. Then
is calculated as follows:
Besides, for each tuple of sensor data, the fuzzy linear regression requires the estimated fuzzy number to contain the observed data with more than the degree of fitting
which is a constant chosen by the decision-maker:
For different readings,
is designed as different membership. In general, the closer to the prediction instant, the more important the readings are, and the higher the corresponding membership is. The parameters to be solved are:
Expectation can be linearly described by and . The object function R is a quadratic function and all of restriction conditions are linear. Obviously, this is a nonlinear programming problem with one single objective function and several linear restrictions. In order to find the optimal solution to this problem and reduce the computation cost, we firstly transfer this constrained nonlinear programming problem into unconstrained nonlinear programming problem.
Consider the restrictions in this nonlinear programming model, Equations (28)–(33) can be rewritten as follows:
Then we construct the following unconstrained nonlinear programming model which is equivalent to the original constrained nonlinear programming model:
To find the optimal solution for this model, many traditional solutions have been proposed, such as the Lagrange multiplier method or Conjugate Gradient method. Meanwhile, several heuristic algorithms such as Genetic Algorithms (GA) [
17,
18,
19] also play an important role in solving this problem, because it is an efficient method to deal with the nonlinear programming problem with high-complexity and multi-parameters.
We use a genetic algorithm to get the optimal solution to Equation (42), so as to ensure the minimal sum of differences R when each membership of prediction variable is not lower than . Then we get the fuzzy representation of historical sensed readings and the least square estimation that is related to the fuzzy regression coefficients . The normal data will be involved in the prediction after getting the fuzzy coefficients. Finally, we get the fuzzy prediction value of the given sensor.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



























