1. Introduction
Node localization is an essential technique in order to guarantee high-effectiveness of Wireless Sensors Network (WSN). In the indoor space, when the wirelessly propagated Line-of-Sight (LOS) paths between the target node and the anchor node are obstructed by obstacles (like people, table, wall, etc.), the radio waves must be propagated via the indirect paths such as refraction and reflection, which are referred to as Non-Line of Sight (NLOS) paths. Comparing with the LOS scenario, the NLOS scenario contains a positive excess distance measurements delay, which is called NLOS error. Unfortunately, traditional methods of node localization in LOS environment are hard to yield accurate Maximum Likelihood (ML) and often generate very noisy and unreliable final estimation results due to NLOS error. Therefore, we believe a new method is necessary to improve the accuracy and usability of NLOS node localization. In this paper, we present an efficient, accurate and scalable method for indoor mixed LOS/NLOS node localization that aim to reduce the NLOS error within NLOS propagation in the real environment.
In recent years, several attempts have been made to reduce the NLOS error in node localization. The general process of these attempts of NLOS localization mainly includes NLOS error identification and NLOS error elimination two steps. By NLOS error identification, one refers to find nodes that are in an NLOS environment or rebuild a LOS propagation model in NLOS scenario [
1]. Kalman filtering was also used to reconstruct NLOS signals [
2]. Residual test was used to identify NLOS error, and then localization can be realized simply via LOS measurements [
3]. The above algorithms need the acquisition of signal statistical properties, but such prior knowledge is hard to access in the real environment.
As for NLOS error elimination, the weighted least squares estimation based on Taylor series expansion (TS-LS) is widely used, but TS-LS needs pre-defined weights, which are usually obtained by a complex statistic model [
4]. Another method is a residual weighting approach, which is used to alleviate the NLOS error when it is very unmeasurable within the measurement range [
5]. The select residual weighting (SRwgh) localization algorithm based on classical NLOS error suppression algorithms aims to reduce the computation complexity and simplify the interference in NLOS [
6]. An ML function was used to elicit a ML estimation algorithm that contained the closed-form solution [
7]. Mcguir considers an NLOS scenario and proposed a non-parametric and highly efficient approximate localization algorithm based on a time difference of arrival [
8]. A hidden Markov model was applied to localization [
9]. The filtering method is proposed in [
10,
11] to reduce the NLOS error. Kalman or extended Kalman filtering was used in localization, and its main principle is to add new information and reduce error along with time prolonging [
12]. This precise algorithm can be applied to track a moving target in non-stationary random processes, but it requires a specific localization parameter at varying time points, and become non-convergent in some situations [
12]. The scattering of wave beam in an NLOS scenario is used to build a propagation model [
13]. In a co-localization algorithm, the neighbor node cooperates to reduce the interference of NLOS [
14]. A NLOS error-reducing localization algorithm based on constraint conditions was proposed, including some more accurate criteria compared with CRLB [
15]. An interactive multi-model (IMM) is built for NLOS localization, but it requires
priori information [
16].
In recent years, a lot of novel ideas and solutions have emerged for WSN localization. The localization technique based on multidimensional scaling (MDS), which first proposed by Shang
et al. [
17], offers a new solution of node localization. The MDS method that concerns dimension reduction and feature extraction is widely used to do data analysis and data visualization in fields of physics, biology and psychological phenomenon research, as well as pattern recognition, machine learning and so forth [
18,
19,
20]. Comparing with previous localization algorithms, the MDS-based localization algorithms can simultaneously locate multiple nodes by utilizing the associated information among all nodes within the network. The advantages of MDS are that, one can obtain actual positions between nodes by setting only a few anchor nodes, besides, the anchor nodes’ deployment has no strict restriction. Moreover, when anchor nodes are unavailable, one can still get relative positions between nodes. Recently, a variety of localization methods based on classical MDS method have been applied to sensor network [
21,
22] as well as cellular network [
23].
Existing algorithms in wireless sensor network localization can be broadly divided into two classes: range-based and range-free. The class of range-based algorithms is required to provide the accurate distance estimation between the target node and anchor node. Moreover, range-based algorithms require each sensor node to be equipped with a more powerful CPU. There are several approaches to get the distance estimation: received signal strength indicator (RSSI) [
24], time of arrival (TOA), and time different of arrival (TDOA) [
25]. The class of range-free algorithms can reduce the energy consumption and the demands for special hardware, but their accuracy is lower than the former one, such as Approximate Point-in-Triangulation Test (APIT) [
26] and Distance Vector-Hop (DV-Hop) algorithms. The existing NLOS localization algorithms are generally based on the distance measurements from some known nodes and localize an unknown node according to the distances relations between them. A common localization mechanism used by these algorithms is RSSI due to its low-cost, no extra hardware consumption, and simple computation, so RSSI gets wide application in node distance measurement. Based on the signal intensity measured from a base station, a localization system first computes the distance between a node and the base station by a signal propagation model, and then computes the position of that node by a localization algorithm. In the indoor space, however, RSSI is easy to be disturbed by shadow fading, multipath effect and NLOS, therefore, RSSI-based distance measurements often contain large errors and leads to final result inconsistency. Hence, RSSI-based distance-measurement and localization algorithms do not perform well in practical indoor NLOS applications. Moreover, it is computation-consuming for statistical data transformation when the parameters of wireless signal propagation model change as the environment dynamically changes. To solve these shortcomings, in this paper, we present an indoor Gaussian mixed model based non-metric Multidimensional (GMDS) localization algorithm. First, we model the RSSI measurement data for estimating RSSI actual value that is closest to that of the LOS scenario based on the NLOS error’s features by using a Gaussian mixed model (GMM). Second, we apply an improved MDS to indoor NLOS localization. In MDS, we use estimated wireless signal intensity values to localize position directly, which alleviates the errors and reduces the computation in transforming RSSI data to distances that happened in traditional signal propagation model. Simulation and practical application results demonstrate that GMDS is feasible and effective to indoor NLOS scenario with high robustness and precision, satisfying most indoor localization applications.
This paper is organized as follows.
Section 2 briefly describes the distance measurement models.
Section 3 presents the GMM and its application in RSSI estimation.
Section 4 describes the RSSI based GMDS method.
Section 5 shows the experimental results highlighting the performance of our algorithms.
Section 6 concludes this paper.
3. GMM and Its Application in RSSI Estimation
Observing that RSSI measurement contains bias in NLOS compares to LOS (namely, NLOS error) due to obstacle’s impact, one shall not expect a direct computation model as LOS does. From the technical perspective, we believe that RSSI measurements in both LOS and NLOS scenarios follow Gaussian distribution [
19,
20]. Thus, we used GMM as underlying distribution of RSSI measurements. The estimated values of RSSI in LOS and NLOS scenarios can be expressed as Gaussian submodels by different probability distributions in GMM.
3.1. About GMM
In this subsection, we start with a brief review of GMM. Let
denotes the vector of the
N-dimension of RSSI estimated values both in LOS and NLOS scenarios. The probability density function of RSSI estimated values in the LOS scenario satisfies
, where
is the RSSI value in LOS scenario;
is the fixed value under stable indoor environment, this value can be set to 0 if there is no large deviation;
is the variance in LOS scenario. The RSSI estimated values in NLOS scenario follow Gaussian distribution:
, where
. Thereby, we obtained the following K-order GMM probability density function:
where
is the
N-dimension joint Gaussian probability distribution of each sub-distribution;
is a mixed weight and satisfies the constraint
;
is the covariance matrix;
is the mean vector of each GMM, it denotes the RSSI values between the target node and the anchor node. Generally, a complete GMM involves covariance matrix, parameter mean vector, and the mixed weights, and it can be expressed as
, where
K denotes the total number of different error distributions, including LOS error, and varying intensity of NLOS error. With the number of data increasing, the probability density function of NLOS error trend to be smooth, and thus a limited number of Gaussian density functions are enough to smoothly approach the density function of measurements. Usually, a probability density function can be built by properly choosing GMM components and appropriately setting the means, covariances and mixed weights.
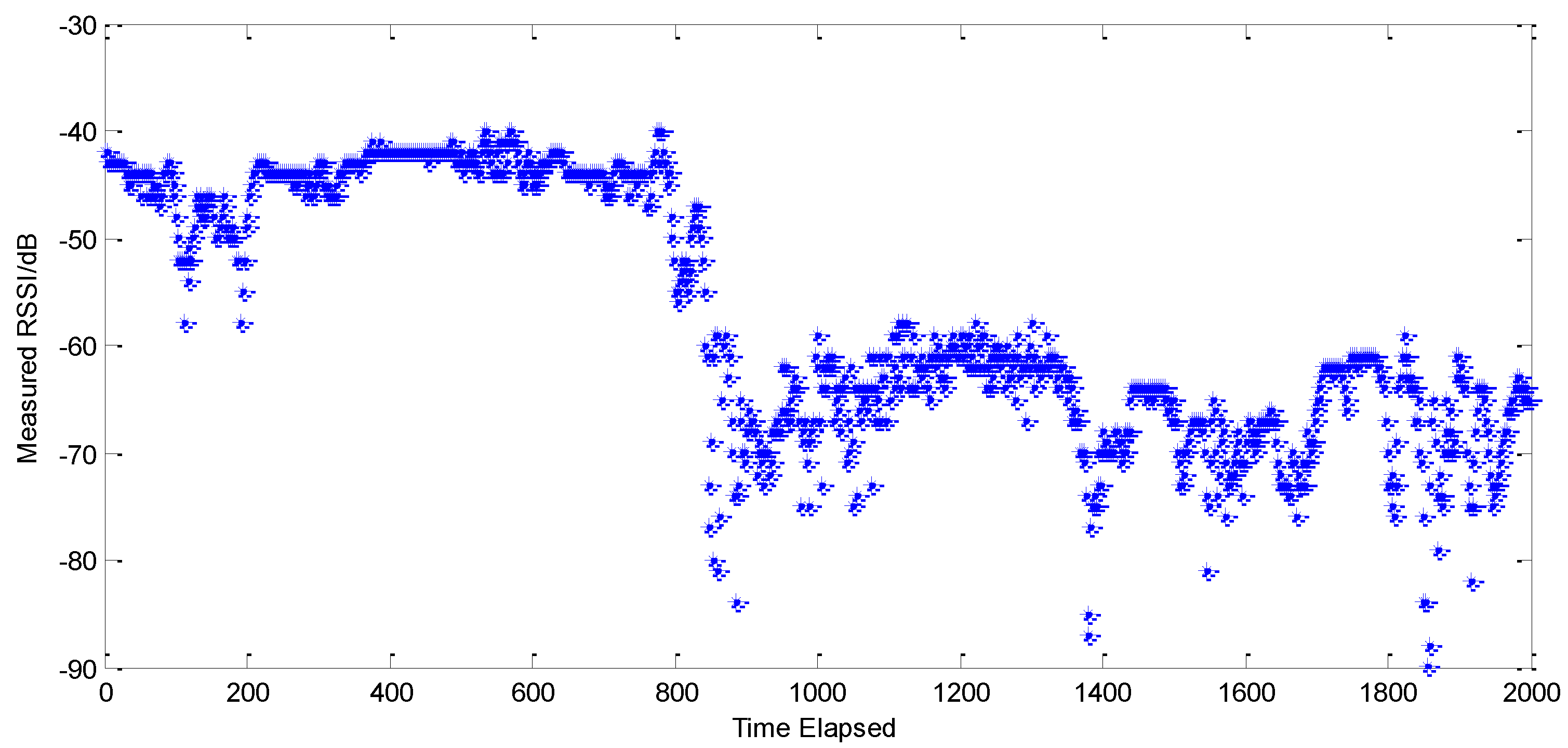
As the above section suggested, NLOS error is a positive value according to distance, and based on the signal fading model, the real RSSI value between receiver and transmitter can be approximated to the maximum among all RSSI estimated values.
3.2. Estimation of GMM Parameters
To express the RSSI measurements vector by GMM, one shall classifies the eigenvectors, the probability density function of each category can be regarded as an instance of Gaussian distribution, and the centers of each category are the mean value of corresponding Gaussian distribution instance, and sets the covariance matrix as its discrete degree.
The process of estimating GMM’s parameters is computing model parameters by a given set of measurements along with certain criteria, and thereby making evaluated probability distribution optimally satisfies the estimated RSSI values. A common parameter estimation method is maximum likelihood estimation (MLE), which sets a group of training vector series of estimated RSSI values: .
The likelihood of GMM is expressed as:
The goal of training is to find a group of parameter
that maximize
:
Equation (6) is a nonlinear function about θ, so exhaustively computes θ that maximizes
is ineffective. The expectation maximization (EM) algorithm is often used to perform effective parameter estimation as a substitute of MLE algorithm in practice. EM is a recurring ML algorithm and used to train data series to estimate model parameters. The computation of EM starts from a predefined initial value of θ, then iteratively updates the next new parameter based on the equation, that makes likelihood of the new parameter satisfies
. The new parameter of current round is regarded as initial value for next round training, and continuously running iterative operation until converging. The re-estimated mixed weights, means and variances at round
k as follows:
- (1)
The re-estimated probability weight is:
- (2)
The re-estimated mean is:
- (3)
The re-estimated variance is:
where
is posteriori probability and can be expressed as:
In the above equation, the computation of expectation (step E) and maximization (step M) in EM algorithm run synchronously and iteratively update steps E and M by computing the equation. The iteration ends when the likelihood function is maximized. EM algorithm performs well on solving the problem of GMM parameters estimation using MLE.
3.3. Clustering and Initialization
The above analyses show that GMM parameters can be estimated using EM algorithm. Since the EM algorithm is easy to fall into a local maximum, so the initialization of parameter becomes an important issue. The initial parameters of GMM include mixed coefficient, mean vector, covariance matrix, and the number of categories. The number of components K is usually set by user’s experience, in this paper, K value is set by the following steps: firstly, we carry out simulation analysis in MATLAB by setting 10 kinds of non-line-of-sight error, that is, K = 1, 2, ..., 10; then, in each kind of non-line-of-sight situation, we run GMM 10 times and analyze the deviation between the estimated RSSI value and true value under such situations. The experiment result shows that we can obtain an acceptable result which close to the optimal results if we set K = 2. Even though we can get a better result when setting a larger K value, however, the computational complexity increases drastically with the increasing value of K. Finally, we choose K = 2 from the view of trade-off between computational complexity and a better result.
Usually, EM parameters can be initialized in two ways: (1) randomly select several vectors from the training data as the initial parameters; (2) approximately estimate the sample distribution by using clustering, and based on this, set the mean as the initial value to get a better initial value. We simply set the covariance matrix as a diagonal matrix.
The clustering is grouping eigenvectors to specific categories, and then the means and covariance of each category are computed and used as the initial values. A weight is defined as the proportion of eigenvectors in total eigenvectors of a category. In practice, K-means clustering is commonly used. It aims to group n samples into K categories, so that the samples in the same category have maximal similarity. In other words, it minimizes the mean’s squared error sum between each sample in a category. The number of categories here is defined as the number of Gaussian components in GMM. We initialize EM by K-means clustering.
The objective function of K-means clustering is defined as:
The objective function of category
i is expressed as:
where
dij is the distance between category
i’s cluster center
mi and
j-th value
xj. It is expressed by Euclidean distance. µ
ij is defined as:
xj belongs to category
i when µ
ij = 1, and otherwise, µ
ij = 0. µ
ij satisfies the following constraint:
The general process of running K-means clustering is moving in the direction of where it decreases the objective function’s value, and finally minimizes objective function to get an optimized clustering result. One observation is that the setting of initial values plays an important role in increasing the precision of EM. Thus, in this paper, we first use K-means clustering to get the initial values, and then combine particle swarm optimization (PSO) and K-means clustering to optimize the initial values for getting better estimated results. PSO is one of the evolutionary algorithms. It starts from a random solution and seeks the approximate optimal solution via continual iteration. In each round of iteration, it evaluates the quality of a solution by a fitness function, and finds the global optimal solution by following the current optimal value. PSO has the advantages of easy implementation, rapid convergence, and high precision, so we use PSO to optimize the initial values that obtained from K-means clustering. The parameters need to be optimized including three initial values: mixed coefficient, mean vector and covariance matrix. Thus, we set a three-dimensions solution space in particle swarm, and set the number of particle swarms to
m, and the fitness function is:
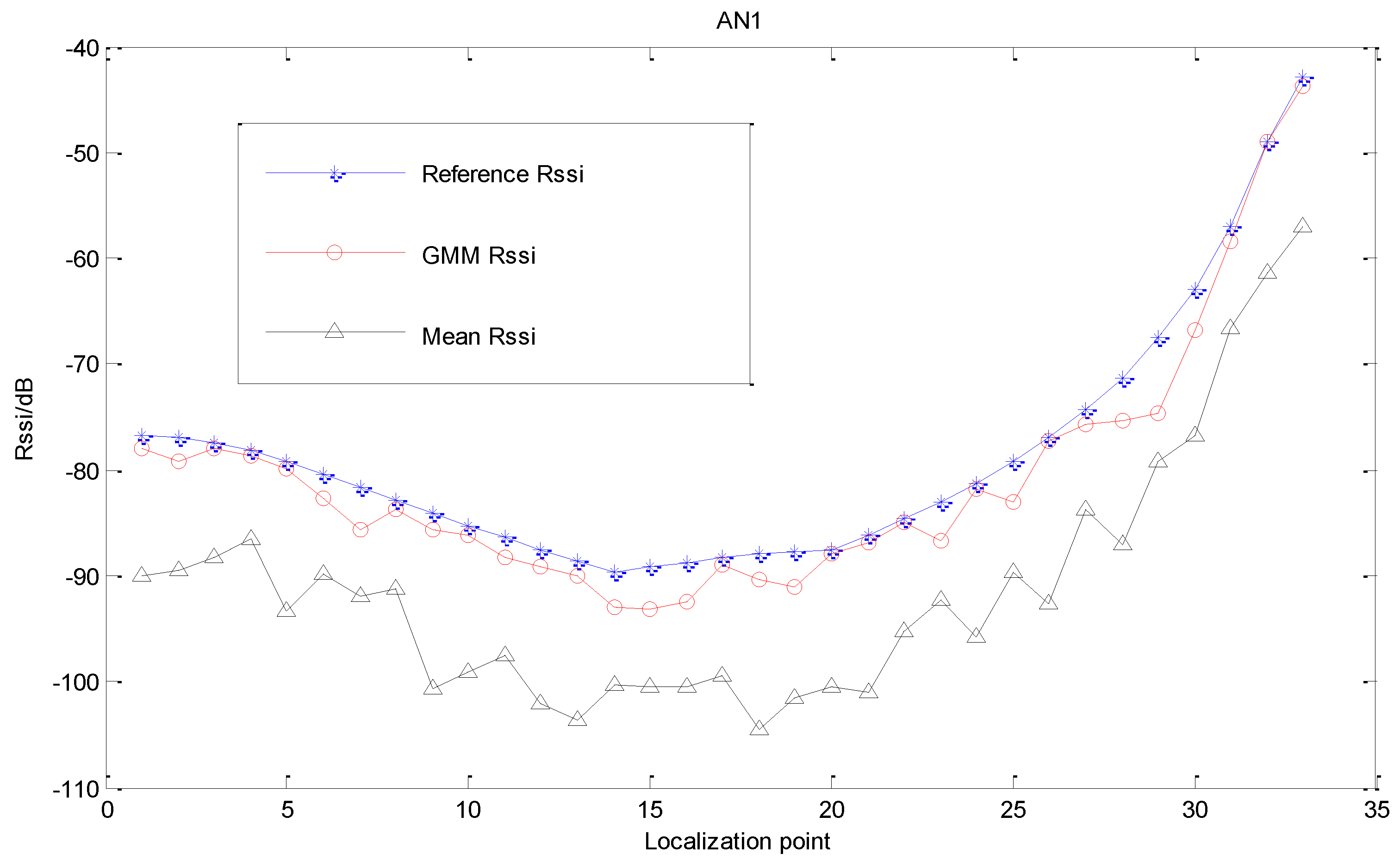
The combination of PSO and K-means clustering performs well on the issue of optimizing initial parameters of GMM. Moreover, via K-means clustering and PSO, we can distinguish the LOS estimated values and the varying intensity of erroneous NLOS measurements. The RSSI-based distance measurement model indicates that comparing to the signal intensity in LOS scenario, the RSSI measurement in NLOS scenario contains negative deviation. Thus, we select the RSSI signal with the highest intensity as the estimated result.
4. Design of RSSI-Based GMDS
Previous metric MDS localization algorithms for WSNs’ localization mostly rely on distance information to obtain their relative coordinates between nodes within a low-dimensions space. However, training a transformation model from RSSI value to distance needs large a priori data sets, meanwhile, the static transformation model cannot adapt to dynamic wireless signal propagation models due to continuous parameter change. Therefore, if we directly use estimated signal intensity values for localization instead of transforming it to distance, a complex transformation process be avoided, while at the same time preventing the involvement of transformation error caused by inaccurate parameters in the wireless signal propagation model. Hence, in this paper, we use a non-metric MDS technique for localization. Non-metric MDS does not require strict relationships of the dissimilarity and distance between entities, it only needs to satisfy monotonous sequence hierarchy without quantitative expressions.
4.1. Classical MDS (CMDS)
Let
pij be the dissimilarity between node
i and node
j (can also be expressed as distance information between nodes, or closeness). We can construct a dissimilarity matrix
P, whose single element is dissimilarity
pij. If there are
n objects, then the dimension of a dissimilarity matrix
P is
n ×
n. In the
m-dimension space, the Euclidean distance between two points
and
is expressed as:
The classical MDS constructs a nodes’ relative coordinates map in a multi-dimensional space, and making the dissimilarity
pij between objects close to the relative distance
dij between nodes. The closeness is expressed by
Stress:
The MDS aims to minimize
Stress. It finds the relative coordinates in a multi-dimension space as follows:
- (1)
Square-centralize the
n × n dissimilarity matrix
P of the
n objects:
- (2)
Perform SVD (Singular Value Decomposition) on matrix B, or B = AVA, and then the relative coordinates of all points in a multi-dimension space are ;
- (3)
Top r(r ≤ m) columns in X are the solution of MDS in a low-dimension space. For example, if r = 2, we can obtain the relative coordinates of all points in a 2D space. In this paper, we only focus on 2-Dimensional space, but the advantage of our algorithm is it can be easily extended to 3D environment by simply set r = 3.
4.2. GMM-Based MDS (GMDS)
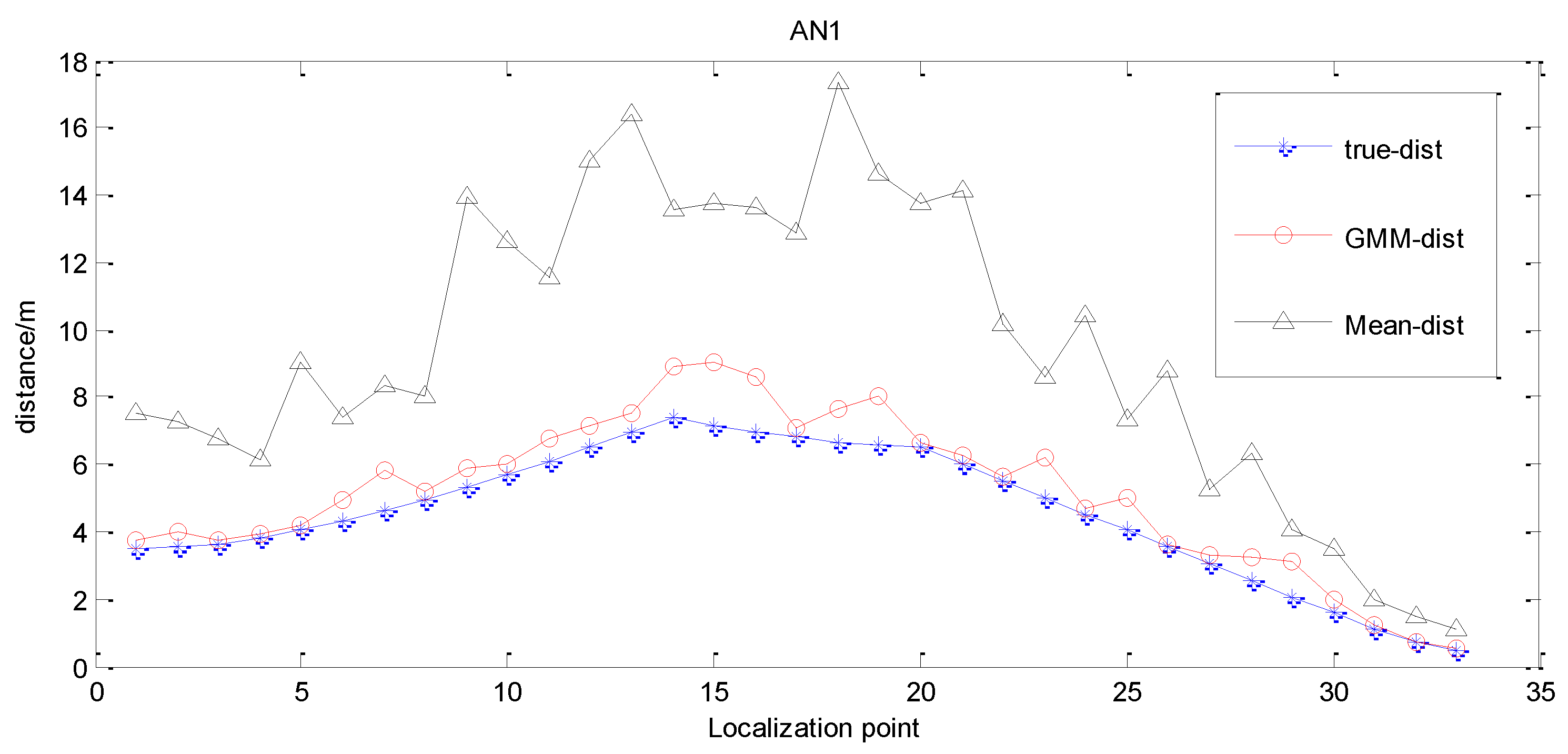
In practice, it is very hard to draw an ideal distribution of from limited data, because the propagation of wireless signals is susceptible to affect by reflection, obstacles and multipath propagation, which impair the consistency of conversion between RSSI and distance. One of the observations is that the RSSI at the same distance fluctuates largely in indoor space. Therefore, when the RSSI-based localization algorithms transform the signal intensity to distance value, it inevitably involves errors, which will reduce the precision and stability.
The relationship between RSSI and distance is a monotonous function. A smaller distance means a larger RSSI value, and vice versa. This monotonous relationship satisfies the requirement of non-metric MDS’s constrain about dissimilarity data. In this paper, by combining GMM estimated RSSI values with the MDS method, we propose an algorithm for localization of indoor targets: GMDS. This algorithm includes three parts: (1) estimate RSSI values based on GMM, and construct a dissimilarity matrix P in MDS; (2) use MDS to compute a node’s relative coordinates; (3) transform the relative coordinates to actual coordinates.
GMDS proceeds as follows:
Step l. Construct a sparse matrix based on the RSSI estimated values of GMM, where is the RSSI value between nodes i and j.
Step 2. Invert the sign of every element in matrix to yield a dissimilarity matrix , namely, . Traditional MDS localization algorithm use distance to build the dissimilarity matrix, in our algorithm, we use RSSI to build the dissimilarity matrix. However, RSSI and distance have an inversely proportional relation, or in other words, a smaller distance means a larger RSSI value, and vice versa. So we invert this inversely proportional relation by simply invert the sign of the values.
Step 3. Run non-metric MDS on dissimilarity matrix to form a relative coordinates map for each network’s nodes.
Non-metric MDS is an iterative process and can be described as follows:
- (1)
Use classical MDS to initialize all nodes’ coordinates and assign initial estimated coordinates to all nodes.
- (2)
Compute the Euclidean distance for each node pair.
- (3)
Perform Pair Adjacent Violator (PAV) stepwise monotonic regression on dissimilarity matrices and to get matrix .
For any i, j, u and v, if , , then ; if , then and .
- (4)
k increases by 1, the new coordinates
are updated as follows:
where
n is the total number of nodes to be localized; α is the step length of each iteration, we set α = 0.2 after carrying out simulations in Matlab, the detailed process for selecting a better α is as follows: firstly, build a dissimilarity matrix of RSSI and list 10 candidate values of α: {0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0}; then by running the GMDS algorithm, the average positioning error under each α value can be obtained; finally, according to the results of experimental simulation, we find that the appropriate α value interval is [0.2, 0.5]. We simply select 0.2 as α value in our paper.
- (5)
Update Euclidean distance of each node pair.
- (6)
Compute Stress on the basis of Equation (17).
- (7)
If Stress below the threshold, then the algorithm ends; otherwise, go to (3).
Step 4. Based on the known anchor nodes, transform the relative coordinates map to an absolute coordinate map.
It is implemented by matrix transformation. To obtain the actual position, we adopt a plane four-parameter model to transform coordinates from the actual coordinates of anchor node to that of the target node. The four-parameter coordinate transformation model is:
where
is the true coordinates after transformation;
is the relative coordinates in 2D space;
m, β, Δ
x, Δ
y are parameters. We first estimate the optimal parameters that can transform the anchor node’s relative coordinates to its actual coordinates, and then transform all nodes’ relative coordinates to actual coordinates by using the above equation.






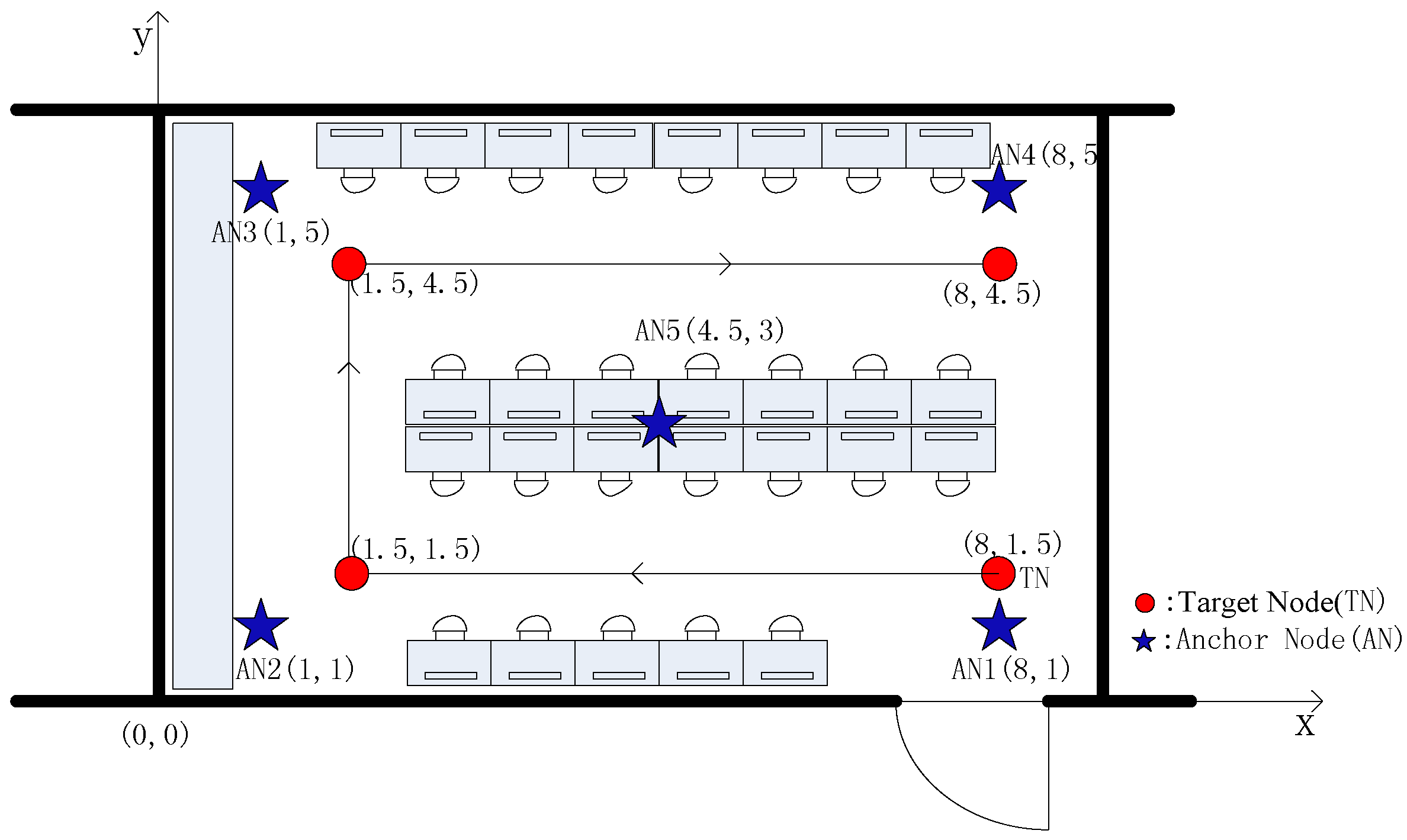{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
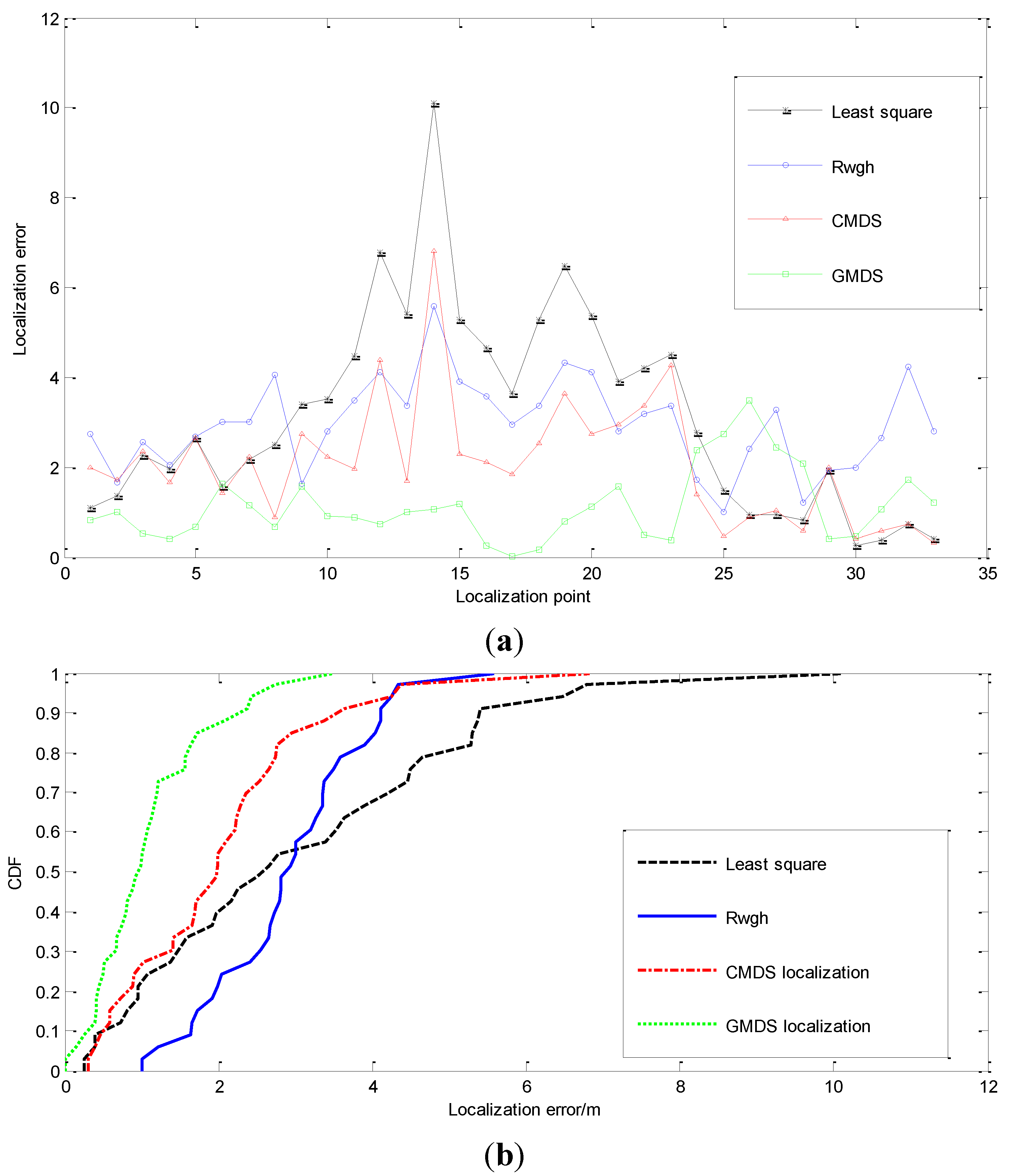{kind=link}
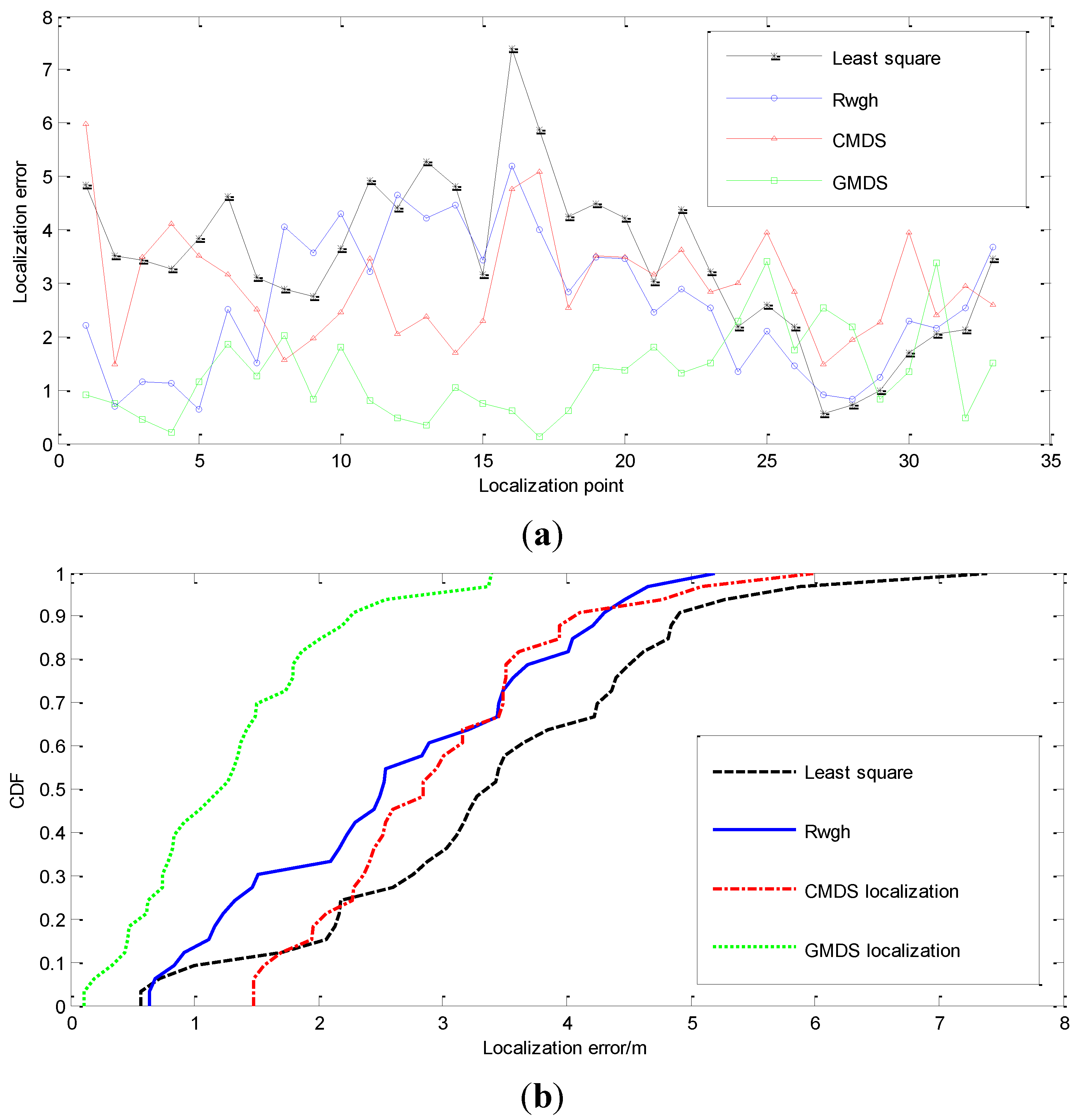{kind=link}
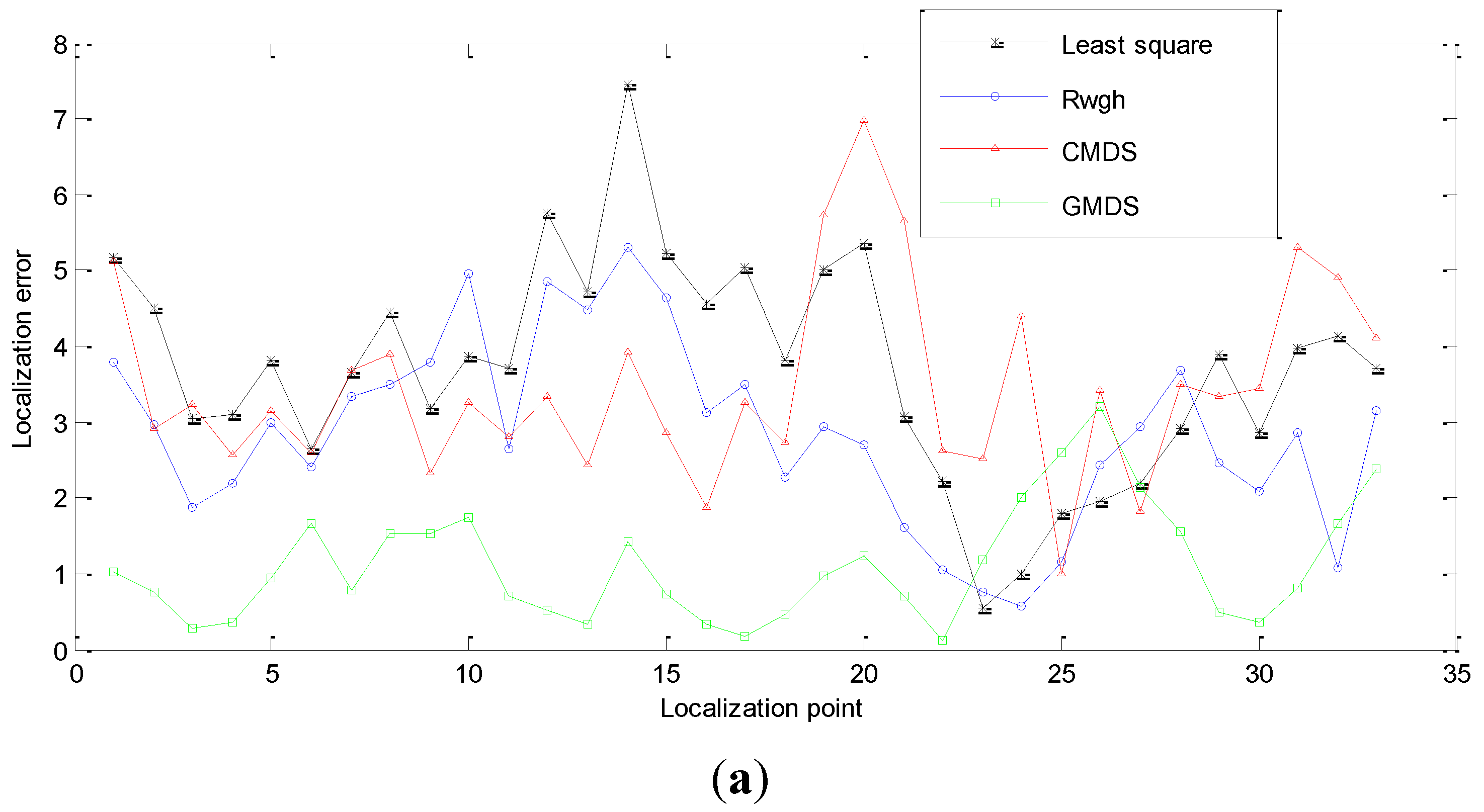{kind=link}
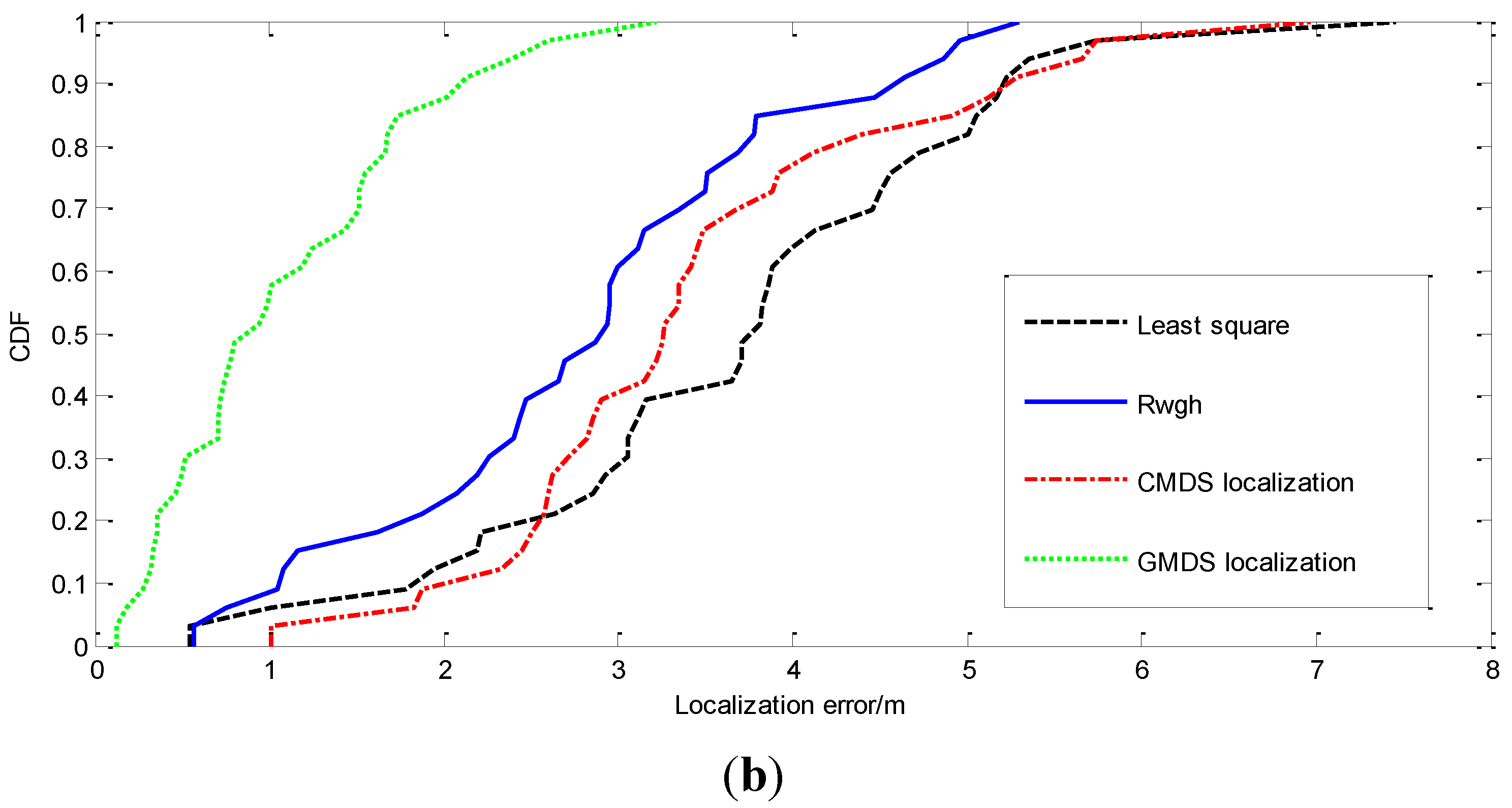{kind=link}





