1. Introduction
Vehicular ad hoc networks (VANETs) [
1] are a special case of mobile ad hoc networks (MANETs), where nodes are vehicles that interchange data to establish and maintain communication. Vehicular applications can be divided into safety, vehicular traffic efficiency and infotainment applications [
2]. Traffic flow control or environmental conditions monitoring are some aims of such applications. The efficiency-oriented applications require a continuous monitoring phase of the streets and city conditions. Vehicles can gather this information and feed the monitoring centers through the VANET. Vehicles can reach the watching center using Vehicle-to-Infrastructure (V2I) or Vehicle-to-Vehicle (V2V) communications, in a direct or multi-hop fashion, respectively. Challenges in VANETs, such as fast topology changes, low link lifetime or a potentially high number of nodes taking part in the network, have encouraged researches to propose geographical routing protocols for multi-hop communication in VANETs as an alternative to the classical topology-based routing approach. Geographical protocols, also known as position-based protocols, make their routing decision using local information, mainly nodes’ positions.
Two procedures can be recognized in the operation of geographical routing protocols: the forwarding mechanism, which defines the rules that a node follows to choose the next forwarding hop; and the recovery strategy, used by a node when it does not find any neighbor that meets the forwarding criteria.
One of the first and widely used classifications of VANET routing protocols presented in [
3] distinguishes two types of recovery strategy: the so-called “carry and forwarding” that consists of storing a packet until the node finds a suitable next forwarding node. This “carry and forwarding” strategy introduces in general high delay in data transmission. Hence, it is adequate for applications for Delay-Tolerant Networks (DTN), which are the target applications in this paper. The second recovery method is for Non-DTN protocols. There are two most common alternatives: (1) the use of the right hand rule; and (2) the construction of a recovery path through request/reply signaling messages. As the DTN recovery approach has increased its use in VANET routing protocols, a recent classification [
4] of VDTN (Vehicular Delay-Tolerant Network) uses geographical knowledge needed by the routing protocols to differentiate them. This information can range from only the necessity of get the geographic location of nodes, to use road maps or even to use on-line information.
Regarding the forwarding mechanisms in geographical routing, there are some classifications depending on the factor used to differentiate them. According to [
3], geographical protocols can be classified in non-overlay, in which all of the nodes of the network make routing decisions; and overlay, if only some nodes of the network are allowed to change the routing decision of a packet. A recent classification of geographical routing protocols that consider traffic and network status in their routing metrics [
5] identifies protocols that construct the full path using information like distance between nodes and vehicles’ density, among others, which is not the common approach. Other protocols make routing decisions in junctions or the anchor or in each node.
Updated surveys of geographical routing protocols [
5,
6,
7] show that the forwarding criteria of these protocols have evolved from considering only the geographical distance between nodes as in Greedy Perimeter Stateless Routing (GPSR) [
8] to other routing proposals that require detailed geographical information and include other additional metrics, like the speed and direction of the vehicle. Nevertheless, despite the enhancements in the routing decisions, the selection of the best node as the next hop maintains as predominant in the routing criterion among most of the geographical routing protocols.
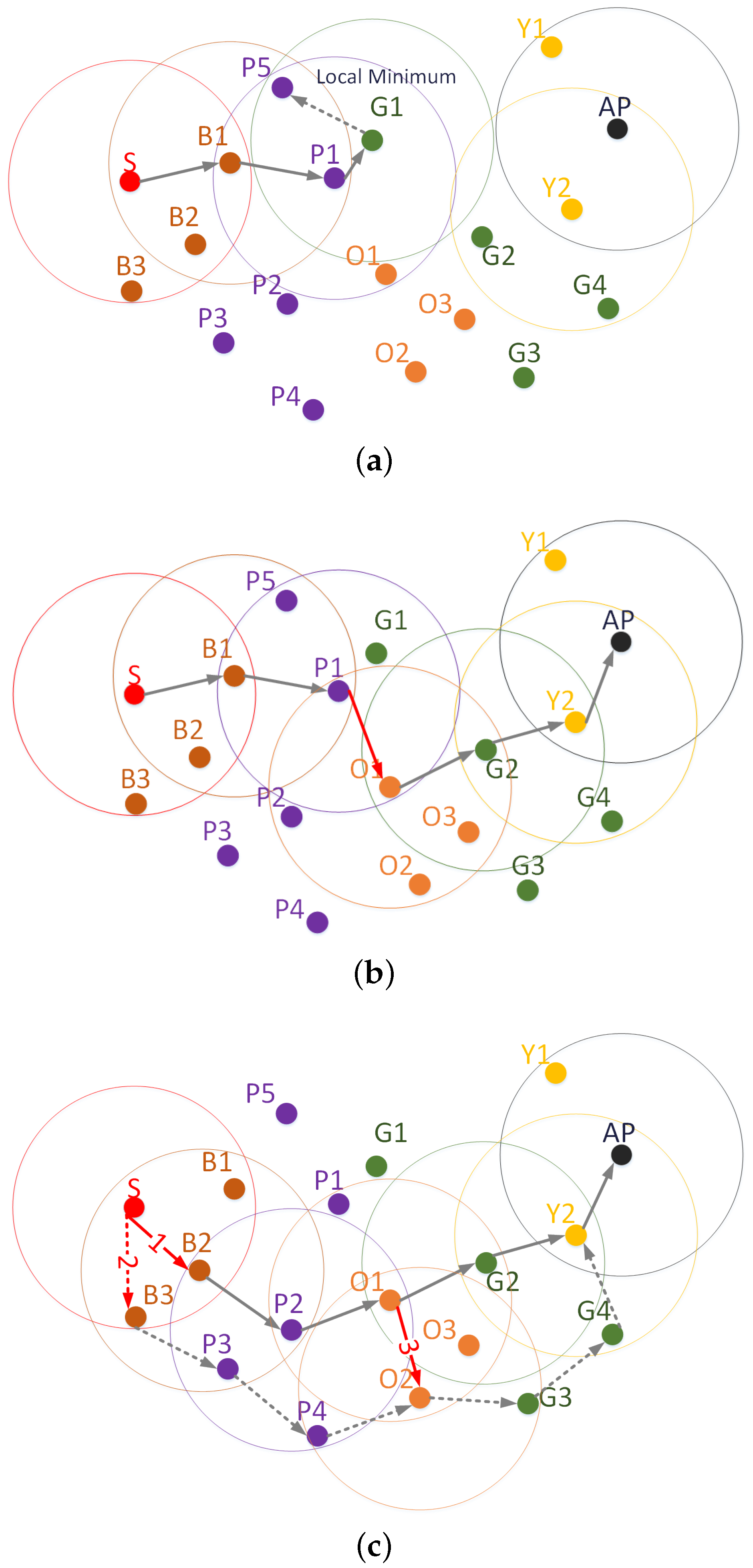
In [
9], the authors show that any geographical routing protocol that operates under a hop-by-hop forwarding strategy can be understood as a direct application of the general “local search” algorithm of discrete optimization. Furthermore, they propose to adapt some other heuristic to geographical routing protocols for VANETs in order to improve the results obtained with local-search algorithms.
In this work, we propose a generic Geographical Heuristic Routing (GHR) protocol that can be applied to any DTN geographical routing protocol that makes forwarding decisions at each hop. Our proposal combines all of the adaptations presented in [
9] for the forwarding and recovery phases of the protocol, which are based on Tabu search and simulated annealing.
Our paper offers a thorough performance evaluation of GHR with MMMR, a traffic-aware routing protocol suitable for delay-tolerant applications. Our study analyzes all of the meaningful combinations that our generic algorithm provides. Finally, to provide a complete analysis of our findings, we assess MANOVA and paired statistical t-tests to identify which performance differences are significant. This analysis takes into account the effect of the vehicle density in the appearance of differences. We found that some features of GHRbehave better than others depending on the vehicle densities or the applications’ requirements.
The rest of the paper is organized as follows:
Section 2 summarizes some other works that use optimization techniques in wireless networks. Then,
Section 3 present the Tabu search implementation used in our proposal, in addition to the simulated annealing strategy and a generic routing procedure.
Section 4 describes the algorithm of our heuristic routing protocol proposal. Next,
Section 5 is devoted to the performance evaluation of our contribution, which includes the description of the simulation scenario and the statistical analysis of the simulation results. Finally, conclusions and future work are drawn in
Section 6.
4. Geographical Heuristic Routing Protocol
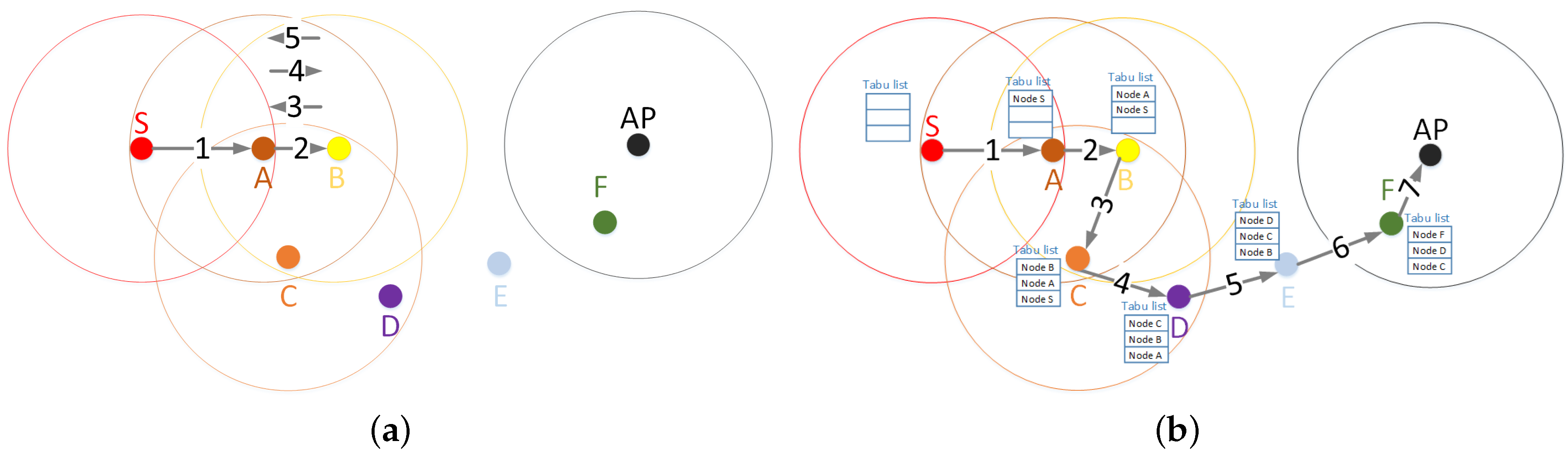
In this section, we present our proposal of the geographical routing protocol named the Geographical Heuristic Routing (GHR) protocol. GHR follows the DTN approach of carrying the packet when there is not a suitable next forwarding node. Moreover, our routing protocol can use any routing criteria to select the next forwarding node to make forwarding decisions at each hop.
The GHR protocol combines Tabu search and the Simulated Annealing (SA) adaptation summarized in the previous
Section 3 to avoid loops and select the next node with a certain degree of randomness, respectively. GHR does not need to add any information to the hello messages. Algorithm 2 shows the procedure of our proposed GHR. First, it needs five input parameters:
The packet p to extract its Tabu list τ.
The set of possible destination nodes, , according to the anycast address of the destination.
The Boolean variable that indicates if Tabu routing has to be used. This means that a node cannot forward packets to the nodes in the Tabu list τ.
The Boolean variable to select the first neighbor that meets the routing conditions.
The forwarding factor
α affects the probability of selecting a random legal neighbor, which is closer to the destination than the current node
v to forward the packet. The factor
α plays the role of
γ in Equation (1) for the forwarding Simulated Annealing (SA) explained in previous
Section 3.2.2. If
, then the next forwarding node will be selected randomly among the legal neighbors (i.e., random forwarding). On the contrary, if this factor
, then the best neighbor closer to the destination than the current node will always be selected (i.e., best forwarding). For
, we obtain probabilities
p between zero and one, which provides randomness to the forwarding decision.
The recovery factor β tunes the probability of avoiding the “carry and forwarding” approach in favor of forwarding a packet to a legal neighbor that is farther from the destination than the current node. The factor β plays the role of γ in the Equation (1). When , the routing protocol will always select a legal neighbor, if there is any, as the next forwarding node. On the other hand, when , carry and forwarding is always applied. Similar to the forwarding factor, if , then the GHR protocol uses the recovery simulated annealing, which forwards the packet to a farther node to the destination with a probability , computed according to Equation (1).
The first operations performed by the GHR are the following:
Extraction of the Tabu list τ from the packet P and
Set the initial value of the decision variables and to the current node ID (Lines 1 and 2 of Algorithm 2).
| Algorithm 2 Our proposed Geographical Heuristic Routing (GHR) protocol. |
| GeographicalHeuristicRouting () |
| Require: a packet P, destination set , use of , use of node, forwarding factor α, recovery factor β, current veh v |
| Ensure: Select the best neighbor vnh to reach a member of the destination set vdst. |
- 1:
GetTabuList() {if then } - 2:
{Initializing next hop variables} - 3:
- 4:
d0, d0, d0, d0 {Initializing distance variables for SA procedures} - 5:
U[0, 1] - 6:
L(N(v),v) {Initial empty set of legal neighbors of v closer to } - 7:
for all do - 8:
d D() - 9:
for all N(v) do - 10:
if then - 11:
if IsLegal then - 12:
d d - D() - 13:
ComputeMetric(n) - 14:
if d0 then {Forwarding phase} - 15:
L(N(v),v) ← L(N(v),v) - 16:
if then - 17:
v, d d d d {Set the current best vehicle as forwarding vehicle} - 18:
if First= then - 19:
- 20:
goto End - 21:
else {Revocery phase: To use a farther vehicle to dest. than v: d0} - 22:
if then - 23:
, d d d d {Set the best legal vehicle is not closer to as recovery vehicle} - 24:
end for - 25:
end for - 26:
if L(N(v),v) then {Forwarding phase: d0} - 27:
- 28:
if p then - 29:
:= S(L(N(v),v)) {Set a random legal neighbor as forwarding vehicle} - 30:
= - 31:
else {Recovery phase: d} - 32:
if then - 33:
- 34:
if p then - 35:
= - 36:
End: - 37:
if v then {The packet will be forwarded} - 38:
UpdateTabuList () - 39:
return
|
The Tabu list will be empty if the option is not enabled, and therefore, there will not be any forbidden neighbor as the next hop. Regarding , it stores the next forwarding node. It can be equal to the selected node of the forwarding phase, to the selected backup node in the recovery phase or it can store the initial value v because no neighbor was chosen to forward the packet P.
Secondly, GHR initializes to a very low value the best scores and of the selected node in the forwarding and recovery phases, respectively (line 3). Then, the variables , , and are initialized to zero (Line 4 of Algorithm 2). The two former variables, i.e., , , store the difference of distances to destination from the current node v and the best forwarding and recovery candidate neighbors, respectively. The distance of the current node to the destination member for which the best forwarding and candidate nodes got their score are kept in and , respectively. These four variables related to distances or the difference of distance to the destination are used in the computation of a probability p of using a random forwarding node or a recovery node, depending on the operation phase of GHR.
After that, a random uniform value between zero and one is stored in the variable θ (Line 5). The probability of random or recovery forwarding is compared to the value θ to decide if any of these options is performed. Next, in Line 6 of Algorithm 2, the set of legal neighbors L(N(v), v) is initialized as an empty set. L(N(v), v) stores the legal neighbors n, which are closer to some destination member than the current node v.
GHR searches the best forwarding and recovery nodes considering all of the members of the destination set . The GHR algorithm goes through the list of destination members (see the “for” loop from Lines 7 to 25 of Algorithm 2), seeking the forwarding and recovery nodes with the highest scores among legal neighbors. Hence, GHR makes an exhaustive search and chooses the neighbor with the best metric over all of the other neighbors and members of the destination set.
More specifically, for each destination member , GHR searches among the neighbors of current node (see the “for” loop from Lines 9 to 24) if any of them improves the current scores and of and , respectively. In the selection process, the first step is to obtain the distance from the current node to the destination member , which will be stored in d (Line 8). Then, GHR checks if the neighbor n under evaluation is not in the Tabu list τ (Line 10) and that it is legal (Line 11). Only if node n is not in the Tabu list and it is legal, the algorithm considers neighbor n as a possible next forwarding node. Otherwise, the node is discarded by the selection process.
After verifying the eligibility of a neighbor n, the GHR protocol calculates the difference of distances, called d, between the current node v to the destination member (i.e., ) and the candidate node n to the destination member , i.e., (see Line 12). In addition, the algorithm computes the routing metric score of the neighbor n (Line 13). If d in Line 14, this means that n is closer to than the current node v; therefore, n is a candidate to be the next forwarding node , and the neighbor n is added to the set of legal neighbors L(N(v), v) (Line 15). Otherwise (i.e., d in Line 21), the neighbor n is considered as a possible recovery node. We would like to highlight that, if a neighbor n is a legal forwarding node for more than one destination member, then that neighbor n will be included in the set of legal neighbors as many times as it was considered legal in the selection process. Hence, the probability of that node n being chosen in a random selection (Line 29) will be higher than for a node that is legal only for one destination member.
If the neighbor is closer to the destination (d), the score of neighbor n is compared with the current best forwarding score (Line 16). If it is higher than the current best score, then the neighbor n becomes the best forwarding node and the best forwarding score , and the difference of distance d between current node v and best candidate to the destination is updated to d and , respectively (Line 16). When the option is set to true, the first legal forwarding node is selected as the next forwarding node (Lines 18 and 19), and the searching stops and goes to the final step of the algorithm.
When the neighbor n is considered to be in the recovery phase (Line 21 of Algorithm 2), if the neighbor score is higher than the current best recovery score (Line 22), then n is the new best recovery node , and the corresponding score and distance variables are updated (Line 23).
After that, the GHR protocol searches for the best forwarding node considering all of the members of the destination set; it checks whether the set L(N(
v),
v) is empty or not (Line 26 of Algorithm 2). If it is not empty, which means that there are neighbors closer to the destination, then a probability
p is obtained as a function of the forwarding factor
α, the difference of distances d
and the distance from the current node to destination d
following Equation (1). The purpose of these factors was explained in the simulated annealing of
Section 3.2. If
, then the next forwarding node is chosen randomly from the set of legal neighbors (Line 29); otherwise, the next forwarding node is the best neighbor previously stored in
.
When there is no legal neighbor closer to the destination (i.e., L(N(v),v) = ∅), the algorithm checks if there is a legal recovery node different from the initial value of it, which was set to node v ( in Line 32). If there is some recovery node , then it will be farther from the destination (i.e., ). A probability p, computed as in the forwarding case (Line 33), decides if the packet P is forwarded to ( in Line 34) or if on the contrary, the packet is stored in a buffer. Notice that there is no negative sign in the equation of Line 33 because .
It is worth pointing out that we employ the random uniform number θ to decide if the probability computed with Equation (1) becomes true in the routing process. Since θ changes its value at each forwarding operation, the routing decision depends on the probability of randomness p and on the current value of . This makes random the decision of selecting a random node or a recovery node, which is the idea of simulated annealing. For instance, in the forwarding phase, even for high values of p, there is a chance of not randomly routing a packet because the current value of θ is higher than p. If were a fixed value, then the algorithm would use random routing or a recovery node only depending on the value of p computed through Equation (1). This would make decisions not random at all, contrary to the simulated annealing principle.
Finally, if
routing is being used (i.e.,
) and the packet will be forwarded to some neighbor (i.e.,
), then the current node
v is added to the top of the Tabu list
τ according to the procedure described in
Section 3.2.1.
5. Performance Evaluation
In this section, we present the performance evaluation of our routing proposal GHR. First, we study the forwarding options and the recovery setup of GHR in order to find the most suitable configuration for this protocol. After that, we compare the best configurations of GHR using different scoring algorithms against an adaptation for VANETs of the classical topological routing protocol Ad-hoc On demand Distance Vector (AODV) routing protocol [
21].
5.1. Simulation Settings
To carry out our performance evaluation, we use a simulation scenario for a reporting service, like traffic and/or environmental measurements, in a multi-hop VANET. These kinds of applications are not delay sensitive and can tolerate a moderate percentage of packet losses because reports coming from close enough positions may contain redundant information.
We carried out the simulations using the Estinet Network Simulator [
22]. Estinet is a simulator that includes the standard IEEE 802.11p and a simple and accurate way to design VANET realistic scenarios.
We considered three different amounts of vehicles: 100, 150 and 250 vehicles, which correspond to densities of 67, 100 and 166 vehicles per km, respectively.
For the evaluation of our proposals, we run 20 simulations per each vehicle density using different movement traces to present the figures with confidence intervals of 95%.
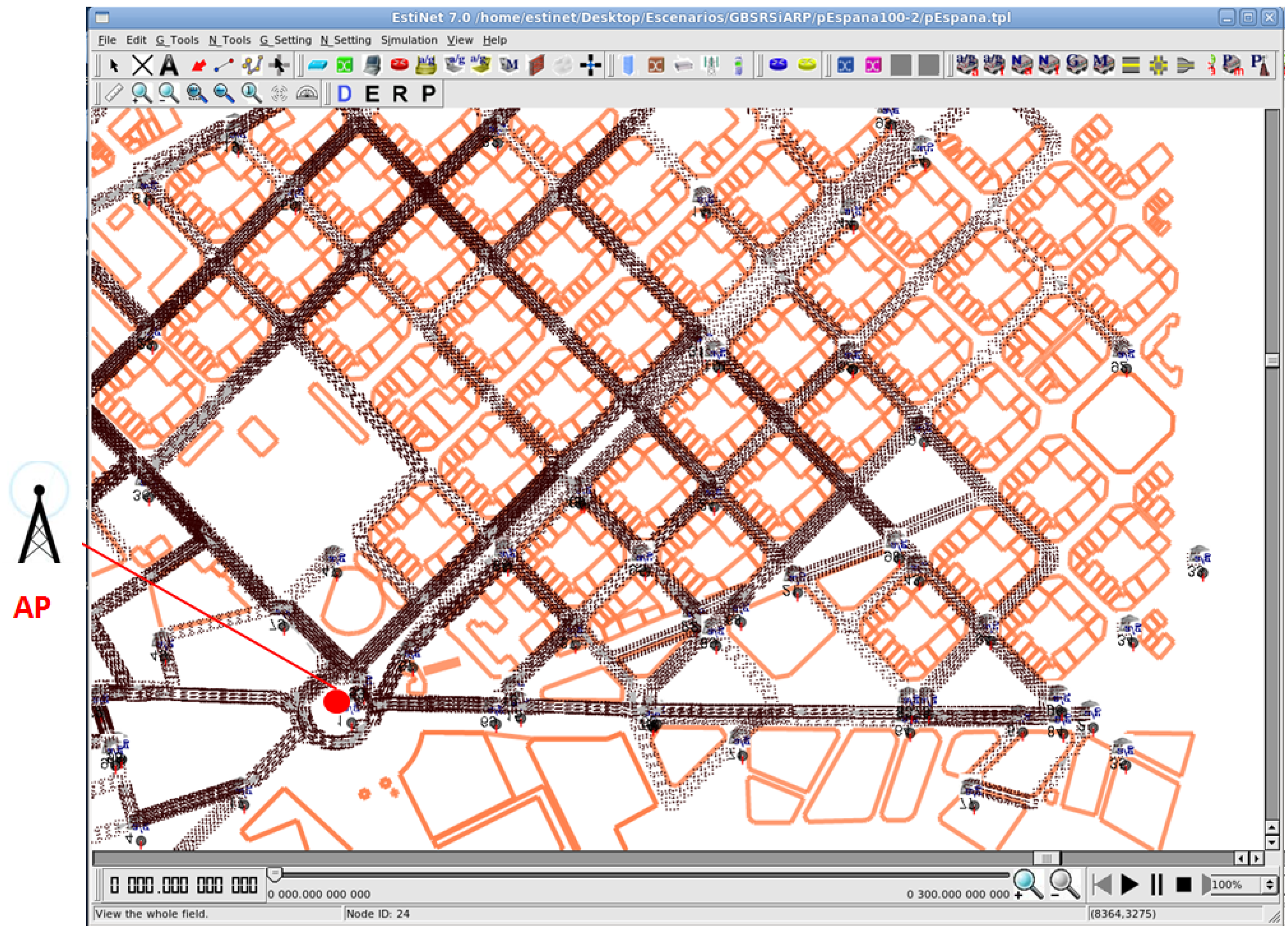
We used a real scenario of 1.5 km
from the Eixample district of Barcelona (see
Figure 3). In our realistic scenario, the mobility model was obtained with CityMob for Roadmaps (C4R) [
23], a mobility generator that uses the SUMO engine [
24]. C4R is able to import maps directly from the OpenStreetMap [
25] and to generate NS-2 mobility traces. C4R considers random origins and destinations for each vehicle’s trip in the simulation area. These points can be located with a higher probability in areas specified by the user. In addition, the path between the start and end points of a vehicle’s trip is computed through Dijkstra’s algorithm in a directed graph formed by the streets and their directions in the map (as a GPS-based navigation system computes a route). We exported the NS-2 traces to be compatible with Estinet and the buildings information using our own translating software, available at [
26]. Furthermore, the scenarios have building information (orange lines in
Figure 3) extracted from the OpenStreetMap using the SUMO tools.
There was one fixed destination, the Access Point (AP) in
Figure 3, that receives the vehicles’ traffic information (e.g., traffic reports, infraction notifications, event of an accident, etc.). We used a single AP in the scenario because in this way, we obtained a long range of route lengths, which depend on the position of the source vehicles in the scenario. All nodes sent 1000-byte packets every
T seconds to the unique destination during 300 s.
T follows a uniform distribution from 2 to 6 s. We point out that these two settings (i.e., a single AP and all vehicles generating traffic) are adverse for successful multi-hop transmissions because they make medium access contention very challenging, and therefore, collisions and the associated packet losses are more likely to happen. Moreover, packet transmissions from long paths due to the single AP in the scenario increase the chances of packet losses. For these reason, we consider the results presented in our paper a “worst case scenario” in the evaluation of the performance of our routing proposal.
Simulations were carried out using the IEEE 802.11p standard on physical and MAC layers. Moreover, we performed the simulations using the adaptation of the Contention Window (CW) mechanism proposed in [
27] to adapt the CW in a smoother way especially designed for VANETs for congestion control. We incorporated the Coherent Automatic Address Resolution (CAAR) explained in [
28]. CAAR adds the MAC address of a node into its hello messages of the routing protocol. In this way, CAAR avoids the address resolution handshake between nodes of paths to the destination because the couple MAC/IP addresses are received at the same time. Additionally, we enabled a packet filtering based on packet ID in the ad hoc routing protocols proposed in [
29]. This filter works in a similar manner as the duplicate frame filter of the MAC layer. The routing filter mitigates the propagation of unintentional copies generated by the local recovery procedures of routing protocols when a frame transmission fails because of the loss of an ACK frame.
All of the figures are presented with Confidence Intervals (CI) of 95%, obtained from 20 simulations per each density value, a GHR setup combination and using different movement traces per each simulation.
Table 1 summarizes the main simulation settings.
In the first step, we employed MMMR [
20] in the core of our routing proposal GHR to evaluate the different configurations that GHR can provide. Multi-Metric Map-aware Routing (MMMR) is a position-based, traffic-aware and delay-tolerant protocol based on the Greedy Perimeter Stateless Routing (GPSR) [
8]. MMMR considers four metrics instead of only one as GPSR to select the next forwarding hop among its neighbors. These four metrics evaluate the distance to the destination, the vehicle trajectory, the vehicle density and the available bandwidth. MMMR will be in charge of scoring the neighbors and choosing the best one among them.
As the second step, we used the best configurations of GHR, found with MMMR as the score algorithm, to test these configurations with a classical DTN routing protocol, named Greedy-DTN in [
4], in the scoring procedure of GHR. The greedy-DTN protocol is a variation of GPSR that replaces the perimeter mode by the carry and forwarding approach. The greedy-DTN protocol uses only distance to destination to select the next forwarding node. We present this comparison to provide an idea of the role of the scoring algorithm. Even more, this shows how GHR can be easily used for any DTN position-based routing protocol that makes routing decisions in a hop by hop fashion. In addition, we have compared these two protocols, i.e., GHR-MMMR, GHR-greedy-DTN, against a modified version of AODV for VANETs called irresponsible AODV [
33], which was especially adapted for VANETs because it reduces the number of route request signaling messages to establish an end-to-end path.
Notice that the Euclidean distances used by the three protocols, i.e., MMMR, greedy-DTN and iAODV , are computed through the positions provided by the GPS on-board units of the vehicles. Every node includes its own position in the hello messages received by its neighbors. It is known that the GPS positions have an error, whose radius typically ranges from zero to 10 meters [
34]. In our simulations, every time a node queries its position from the GPS unit, the simulator adds a uniform random error with a radius from zero to 10 meters to the exact position. This way, we mimic what happens in realistic GPS devices.
5.2. Statistical Procedure
The performance analysis of our heuristic protocol GHR is based on four different metrics. These metrics are:
Packet Delivery Ratio (PDR): This is the total percentage of packets (sent from the vehicles) that reach the AP. PDR does not increase due to the reception of copies of a packet. Hence, this metric measures the effectiveness of the routing protocol in terms of different delivered packets.
Average end-to-end delay: This is the average time elapsed from the transmission of a packet until it arrives at the destination (computed either for the original packet or for a copy).
Average number of hops: This is the average number of hops that a packet needs to reach the AP. This average includes the hops performed by the original packet and by its copies.
Percentage of idle time: This is the average of the idle time sensed by a node measured in 1 s. A node senses the channel as idle when it is not transmitting nor receiving a packet and given that the interference level is below the antenna sensitivity. Notice that a higher idle time sensed by the nodes leads to more bandwidth available in the channel to transmit more information. An estimation of the available bandwidth derived from the idle time measure could be done using the models proposed by [
35] or [
36].
We are interested in knowing if the differences in the performance metrics listed above are statistically significant or not. Furthermore, we want to determine if the presence of differences depends on the vehicle density and/or on other factor, for instance the use of the Tabu list in routing operations. To do this, we carry out MANOVA [
37] (Multivariate Analysis of Variance ) tests over the data using the statistical software SPSS [
38]. We use MANOVA to consider the inherent correlation among the performance metrics when they are not independent from each other.
For the MANOVA tests, we report the value of the statistics Wilk’s Λ and F, which allow us to obtain a probability called the
p-value. A
p-value is compared with a threshold named the significance level to determine if the simulation findings are statistically relevant (i.e., the
p-value is lower than the significance level). We use for our test a
p-value = 0.05 for the significance level. We divided the statistical procedure analysis into three steps:
- Step 1
Tests to determinate interactions among the identified factors for each analysis over the four performance metrics. If an interaction is detected, then the performance differences in a factor will depend on the combination of the factors involved.
- Step 2
Tests to determine if there is statistical difference in metrics for each one of the groups in which the dataset was divided because of the presence of interactions. If there is not a statistical difference in a metric, then this means that this metric behaves similarly under the different levels of the studied factor (i.e., heuristic technique). Otherwise, the test tells us that there is a difference, but it does not indicate between which levels of a factor this difference is present.
- Step 3
Pairwise comparisons for a metric. If the previous tests determine a significant difference in a metric with a certain factor, then we run a t-test pairwise comparison among the different levels of the factor under analysis. The objective of this step is to establish the performance relation between levels.
By following the above test order, we are able to provide a detailed and accurate analysis of the advantages and costs of our proposals. Next, we present our analyses and statistical results for each routing protocol separately.
5.3. Evaluation of the Forwarding Phase in GHR
To evaluate the forwarding phase of our Geographical Heuristic Routing (GHR) protocol, we distinguish three factors that could affect the performance of the GHR. These factors are:
The vehicle density of the scenario ().
The use of a Tabu list in the routing (T).
The forwarding technique ().
We compare the four different ways that GHR uses to select the next forwarding node: the best legal neighbor (
), a random legal neighbor (
), randomly according to Simulated Annealing (SA) (
) or the use of the first legal neighbor. Following the three-step procedure described in previous
Section 5.2, we have to analyze the results for each density separately because there is a significant three-way interaction
(Step 1) with a
p-value = 0.001 (Wilk’s Λ = 0.377 and F (24,92) = 2.41).
Table 2 shows the results of the further interaction test between the use of Tabu
T and
for the GHR protocol (Step 1). First, we perform the so-called “all together” test in which we evaluate the interaction between the two factors considering the correlation among the six performance metrics. If the
p-value < 0.05 for this test, we further carry separate interaction tests for each metric. In
Table 2, we can see that for the medium and the high density scenarios, the “all together” test has a
p-value under the threshold, so independent interaction tests per metric need to be performed in those cases. The results of the interaction tests for each metric indicate that the seeking of performance differences in the forwarding technique has to differentiate if tabu were used or not in the routing in the medium and high density scenarios (150 and 250 vehicles, respectively) to compare the average number of hops. There is also this significant interaction (i.e.,
) for the evaluation of the percentage of idle time in the scenario of 250 nodes.
The test results to determine if there are differences in the performance metrics, according to Step 2 of the statistical procedure of
Section 5.2, are shown in
Table 3. For this analysis, the data of the metrics were grouped according to the results of the interaction tests analyzed previously. This means that in most of the cases, we performed only one test per metric in each density without differentiating whether Tabu is enabled during the simulation. We labeled these cases as “together” in the Tabu column. All of the
p-values in this table are lower than 0.05, excluding the percentage of packet losses in the medium density scenario (150 vehicles) and the average end-to-end delay for the three vehicle densities. Hence, the use of different forwarding techniques (i.e.,
,
,
or
) produces a statistically-significant change among them in all performance metrics, and therefore, they require pairwise comparisons to analyze the differences. These pairwise comparisons are not needed for the average delay metric in all densities and for the percentage of packet losses in the medium density scenario, because there are no differences among the forwarding techniques in these cases.
Following Step 3 of the statistical analysis,
Table 4 shows the results of the pairwise comparisons among the forwarding techniques (i.e., (
,
), (
,
), (
,
), (
,
), (
,
) and (
,
)) in which there is no statistical significance for a particular metric (i.e.,
p-value ≥ 0.05). In these cases, the average values of the metrics are very similar and can be considered statistically the same.
The rest of the results of the pairwise comparison tests (not included in
Table 4), e.g., the percentage of packet losses for the high density scenario when Tabu is not enabled, obtained
p-values < 0.05. Those
p-values indicate that the forwarding technique (i.e., best node, SA, random or first) has an impact on the values of the metrics.
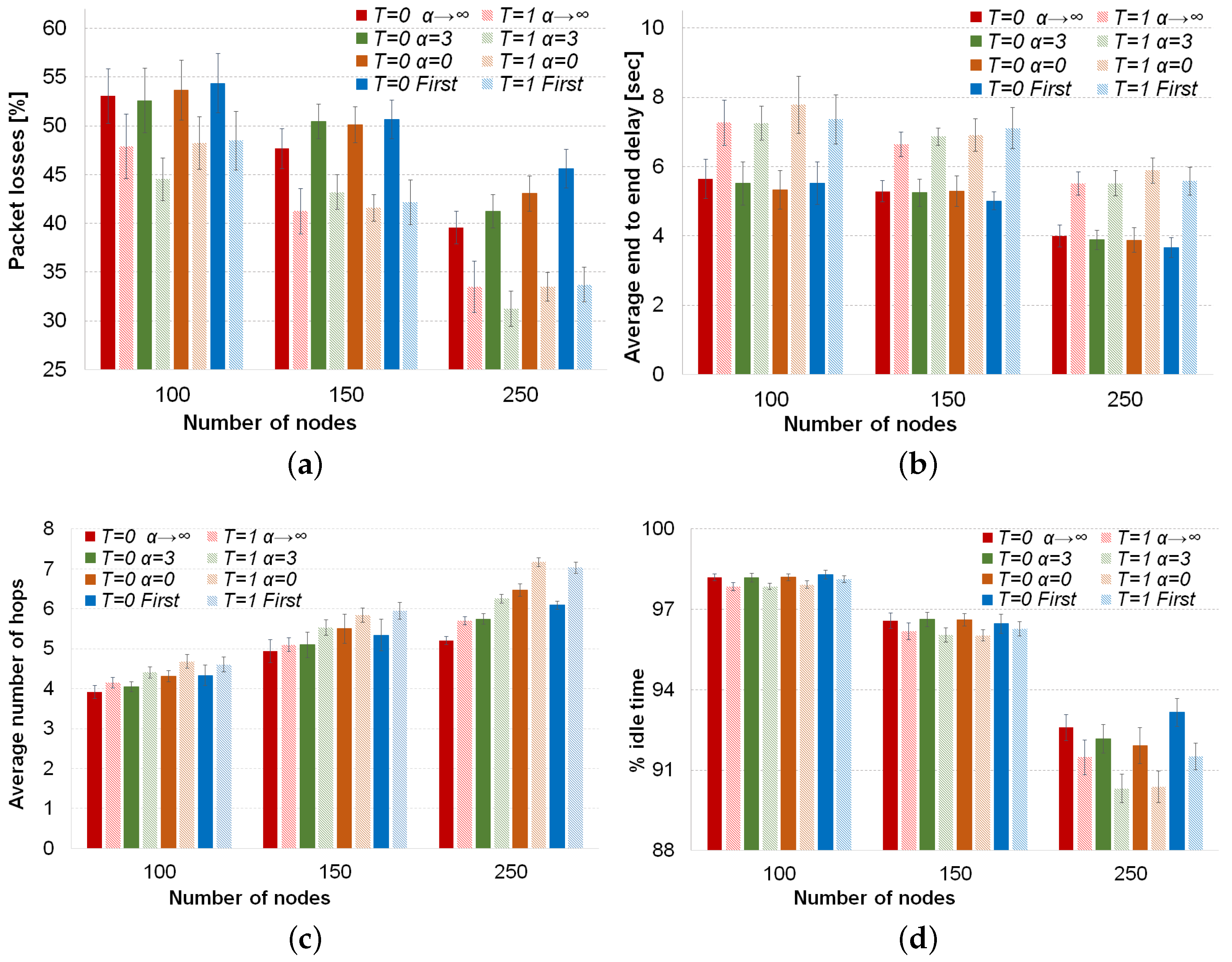
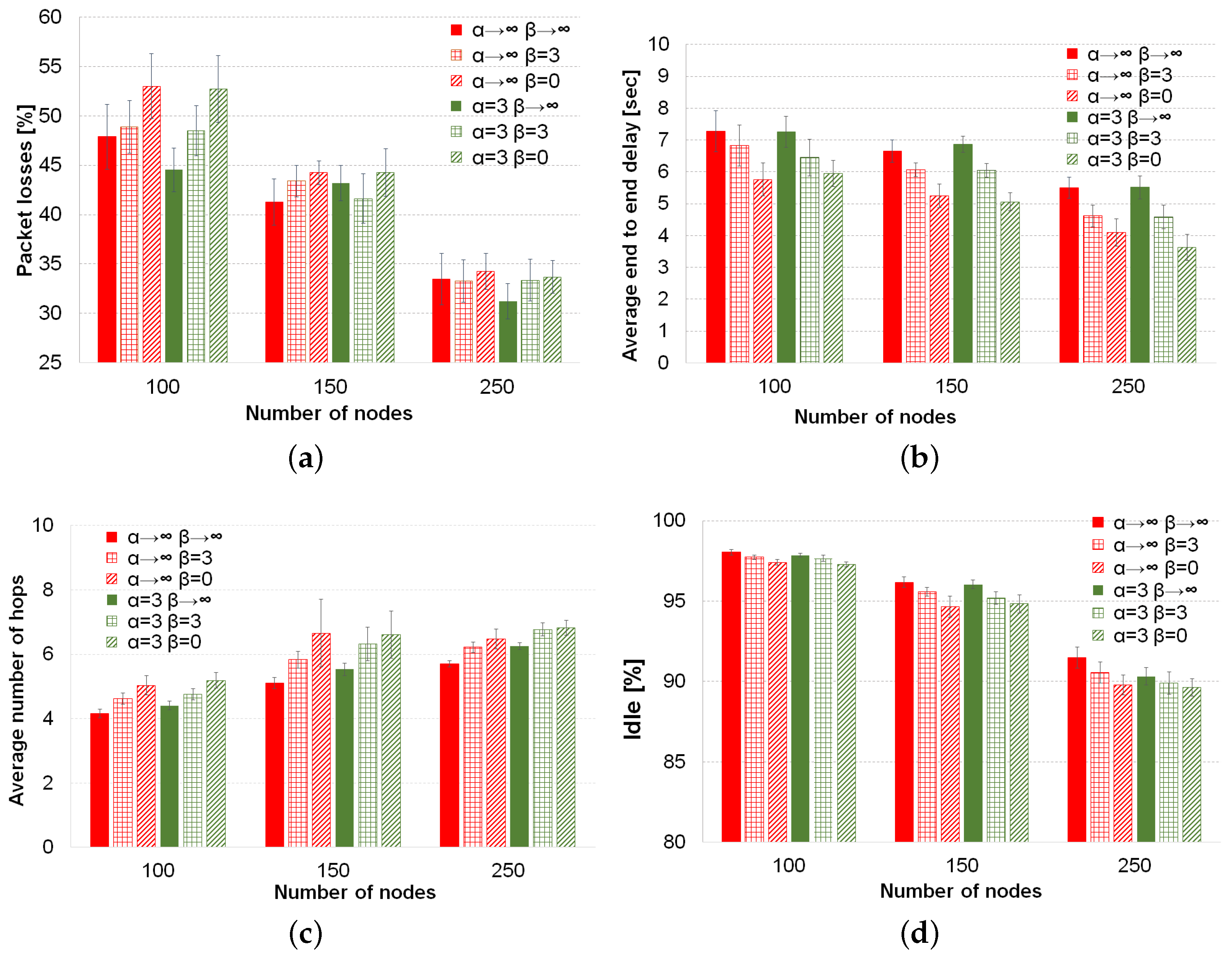
The comparisons of average values of the four performance metrics with the different forwarding techniques are depicted in
Figure 4. Considering the previous statistical analysis, we continue analyzing the behavior of forwarding techniques in the metrics.
Firstly, the use of our Tabu list, which consists of the three last nodes in the packet path, decreases the percentage of packet losses considerably. This descent in the packet losses goes from 6% in low density scenario till around 10% with high vehicle density, as can be seen in
Figure 4a. The reason for this improvement is that our Tabu list provides memory to the routing decision. This memory helps to avoid neighbors of the current node already visited by the packet that otherwise could be selected again to forward the packet. Therefore, the Tabu list avoids loops and helps to consider other possible next forwarding nodes. On the other hand, the use of our Tabu routing proposal increases the average number of hops (see
Figure 4c) by around 0.6 hops on average. Forbidding nodes as next hops forces nodes to search other path that might be longer. Moreover, the average end-to-end delay increases around 2 s for the low vehicle density scenario and 1.5 s for the high density scenario. The higher delay is because of the longer paths. In addition, since the amount of possible next forwarding nodes decreases due to the list of prohibited nodes (i.e., Tabu list), the carry and forwarding procedure is used more often, increasing the average delay of packets. Finally, the % of idle time sensed by a node decreases when our Tabu routing is enabled. In
Figure 4d, it can be seen that as the vehicle density increases, the difference between using or not using Tabu in the percentage of idle time increases, as well, reaching 2% in the scenario with 250 vehicles. There are two reasons for the decrease of the percentage of idle time; first, the higher number of hops needed by Tabu to reach the destination; second, it is important to notice that the use of a Tabu list is overhead to be carried by each packet until reaching the destination. This means more bandwidth utilization for a packet transmission at each hop in longer paths than when Tabu is disabled.
Nevertheless, the slightly higher delay and lower idle time are not so important compared to the noticeable lower losses achieved when the Tabu list is used. Thus, this trade-off clearly shows benefits in favor of the Tabu list.
Regarding the behavior of the forwarding techniques, as can be seen from
Figure 4a, in low vehicle density, the forwarding inspired in simulated annealing (
) has a slightly and statistically significant improvement (around 2%), compared to the other three approaches. Indeed, these three forwarding approaches, i.e., best node, random and first legal, behave similarly according to our statistical analysis (see
p-values > 0.05 for packet losses and 100 vehicles in
Table 4). For the medium density, there is not a statistically-significant difference among the forwarding techniques, neither when the Tabu is used, nor when this option is disabled (see second row in
Table 3). In the high density scenario, the behavior is different and depends on if Tabu routing is being used or not. When Tabu is not used, it is clear from
Figure 4a that the selection of the best neighbor gets the lowest percentage of packet losses. On the other hand, a complete random selection or the selection of the first legal neighbor as the next forwarding node has the worst % of packet losses. The reason lies in the high number of hops that these two forwarding techniques use to reach the destination. When Tabu routing is used in the high density scenario, the behavior of the routing techniques changes completely. The degree of randomness given by the SA forwarding (
,
in
Figure 4a) gets the best results. The advantage of this approach is based on not always selecting the best node, which could avoid collisions or link saturation, and on avoiding already visited nodes by using the Tabu list. The other three approaches (i.e.,
,
and
) have statistically the same results thanks to the use of Tabu.
As can be seen from
Figure 4b, the delay among the four different techniques is the same regardless of the use of Tabu routing for the three vehicle densities. This was confirmed by our statistical analysis, whose results (
p-values ≥ 0.05) are shown in the average delay section of
Table 3. From
Figure 4c, we can realize that applying a forwarding factor
, the average number of hops increases as is expected because the randomness in the forwarding increases, as well. Therefore, the highest number of hops is always obtained by a complete random selection (
), and the lowest hop count takes place for the best selection (
). When Tabu is used or in a low vehicle density, the selection of the first legal node needs as many hops as a random selection (see the
p-value ≥0.05 of the pairs (
,
) in the average number of hops in
Table 3).
The percentage of idle time depicted in
Figure 4d depends on the forwarding mechanism. The selection of the first legal neighbor has a high percentage of idle time for the three densities. This reveals a better use of the available bandwidth of this forwarding mechanism in spite of the high number of hops that the
strategy needs to operate. The reason is that the
strategy prefers to use recent updated neighbors, which have the most stable links, and therefore, will have a higher number of successful transmissions at the first attempt than other approaches, like best node or random selection. In fact, this technique reaches the highest value for the medium density scenario (150 nodes), while the other techniques obtain
p-values ≥ 0.05 in the pairwise comparisons of idle time; see
Table 4. In the high density scenario, the
strategy has the same high level of idle time as the best node selection (
), while random (
) and SA (
) have the lowest level of idle time because they perform more hops than the classical selection of the best node. However, it is worth noting that simulated annealing forwarding obtains the lowest percentage of packet losses with Tabu for this high vehicle density.
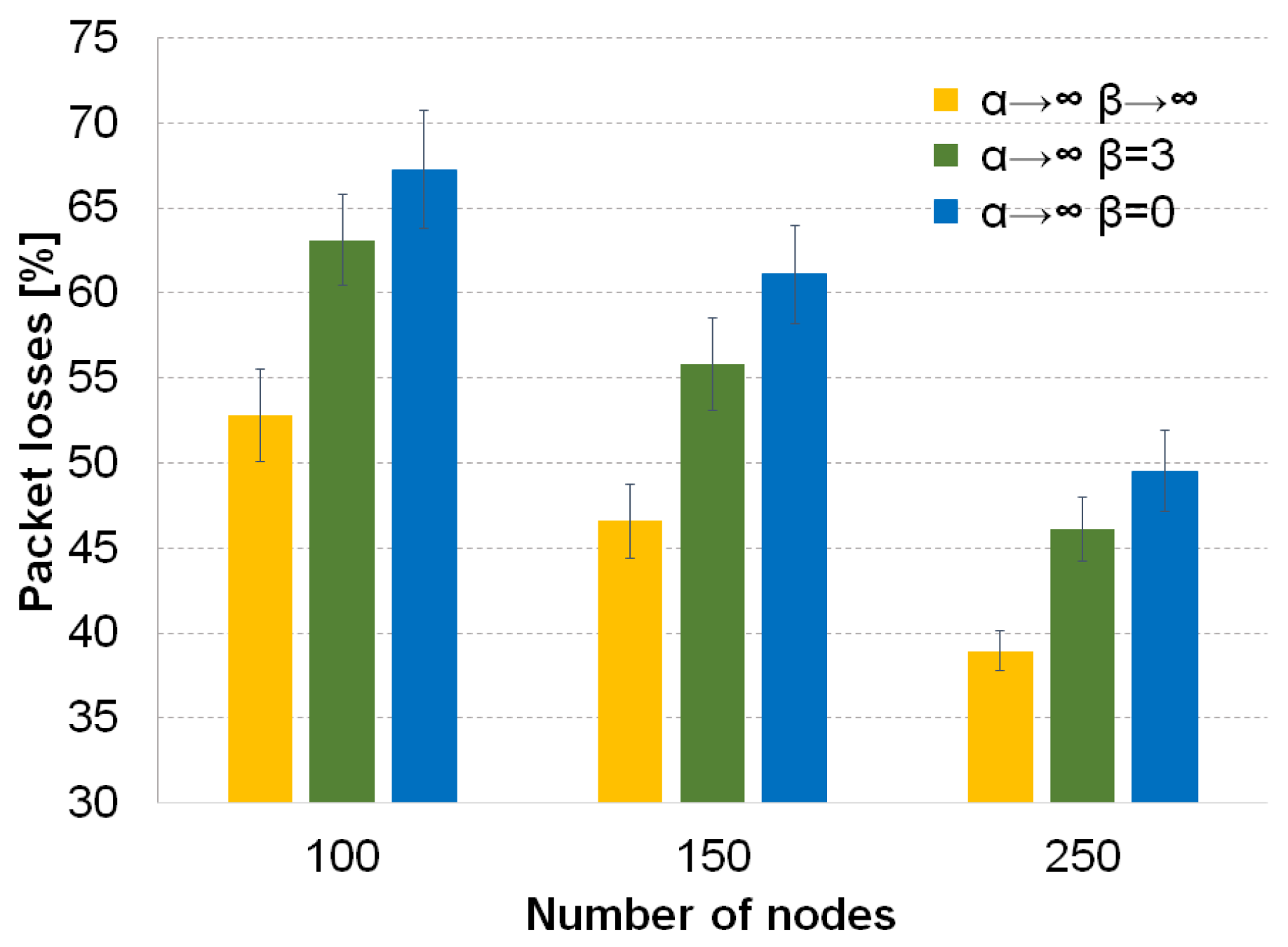
5.4. Evaluation of the Recovery Phase in GHR
In this section, we evaluate the performance of the recovery factor β. This factor allows the routing protocol to forward a packet to a node farther from the destination than the current node instead of keeping the packet in the buffer until a better next forwarding node appears. For this evaluation, we consider only the forwarding techniques best neighbor () and the simulated annealing forwarding (), both with Tabu routing enabled. The reason for using only these two strategies in the tests of the recovery phase is that SA forwarding has the lowest percentage of packet losses in the three densities of vehicles, and the selection based on the best neighbor is the classical approach in geographical routing. Moreover, the other two techniques, i.e., random forwarding () and first legal neighbor, behave similarly to the best node selection. They do not outperform the criterion of the best node in terms of packet losses and delay.
For this part of our study, we work with three factors that could affect the performance of the recovery phase of GHR. These factors are:
The vehicle density of the scenario ().
The forwarding technique ().
The recovery technique (), which depends on the β factor. We consider three different values for β. They are: , which is the default carry and forwarding approach; to use a recovery SA; and , which always selects a next forwarding node if the current node has some legal neighbor.
We do not evaluate the use of the recovery factor
β for the forwarding techniques without Tabu because the packet losses increase significantly for those cases, as can be seen in
Figure 5 for the forwarding technique based on the selection of the best neighbor (
). The values of
or
perform poorly because the recovery mechanism creates loops without Tabu. The recovery mechanism selects in most of the cases the previous neighbor that forwarded the packet to the current node. This creates loops, and nodes cannot avoid those nodes because they do not have a track of the previous path followed by the packet.
We have to analyze the results for each density separately because there is a significant three-way interaction (Step 1) with a p-value = 0.0001 (Wilk’s Λ = 3.41 and F (16,100) = 4.47).
Table 5 shows the results of the further interaction test between the
and
for GHR protocol (Step 1). We can see that for the medium and the high density scenarios, the “all together” tests have a
p-value under the threshold, so an independent interaction test per metric needs to be performed in those cases. The
p-value < 0.05 in the interaction tests for each metric indicates that the seeking of performance differences in the recovery technique should be done for each forwarding technique (i.e., best neighbor and SA forwarding) separately.
The test results to determine if there are differences in the performance metrics, according to Step 2 of the statistical procedure, are shown in
Table 6. All of the
p-values in this table are lower than 0.05, excluding the percentage of packet losses in the high density scenario (250 vehicles) for the forwarding factor
(select the best neighbor). Hence, the use of different values for the recovery factor
β produces a statistical significant change among them in all performance metrics, and therefore, they require pairwise comparisons to analyze the differences.
Table 7 shows the results of the pairwise comparisons among the recovery techniques (i.e., (
,
), (
,
), (
,
)) following Step 3 of the analysis, in which differences between
β values are not statistical significant for a particular metric (i.e.,
p-value ≥ 0.05). In these cases, the average values of the metrics are very similar and can be considered statistically the same.
The rest of the results of the pairwise comparison tests, e.g., the average end-to-end delay in the three vehicle densities, obtained
p-values <0.05, and we do not include them in
Table 4. Those
p-values indicate that the value of the recovery factor
β has an impact on the values of the metrics.
The comparisons of average values of the four performance metrics with the different forwarding techniques are depicted in
Figure 6.
The behavior of the recovery techniques in terms of packet losses can be seen in
Figure 6a. The carry and forwarding strategy (
) is the best option for the low vehicle density. As the value of
β increases, the percentage of packet losses becomes significantly higher in this density. In the intermediate density, for the classical forwarding to the best node (
), SA recovery and the aggressive recovery (
) reach the same level of packet losses (see the first row in
Table 7) between them, but they do not improve the default carry and forwarding (
). Only the SA recovery (
) has a better performance than the default carry and forwarding for SA annealing forwarding (
) in the intermediate density. Moreover, in this scenario (150 vehicles), this approach (
,
) has the same packet losses as the default selection of the best node with carry and forwarding (
,
). In the high vehicle density, the three recovery mechanisms behave very similarly as the classical forwarding (
). On the other hand, for the SA forwarding process (
), carry and forwarding (
) is again the best strategy when SA is used. However, contrary to the low density scenario, the other two recovery values of
β, which are similar between them (see the third row in
Table 7), are close to the percentage of packet losses of SA forwarding with
.
The average end-to-end delay is related with the value of the recovery factor
β. As can be seen from
Figure 6b, when the
β value decreases, the average end-to-end delay decreases, as well, for the two forwarding techniques. The reason is that the low
β values produced use the buffer less often than carry and forwarding, which is the main cause of high delays.
has the lowest delay because it uses the buffer only when there is not any legal neighbor. This aggressive recovery leads to a decrease around two seconds with respect to the carry and forwarding technique in the three vehicle densities. More importantly, this decrement comes with none or very little degradation in the percentage of packet losses for intermediate and high densities, respectively.
From
Figure 6c, we can realize that applying a recovery factor
, the average number of hops increases because the packets are forwarded more times than with carry and forwarding. When
β decreases, the increment in the average of hops is statistically significant (see the
p-values <0.05 in the average number of hops section in
Table 6). In fact, the are only two
β values that reach the same number of hops, the SA recovery (
) and the aggressive recovery (
) for classical forwarding (
) in the intermediate density. Notice that the differences in the average number of hops between the classical approach (
) and the other
β values examined in this section is up to 1.5 hops at maximum.
Regarding the percentage of idle time depicted in
Figure 6d, it follows exactly the same behavior described for the average number of hops. That is, while the probability to forward a packet instead of keeping it in the buffer (low
β values) increases, the percentage of idle time decreases. Only in the high density scenario and for SA forwarding (
), the idle times sensed by SA recovery (
) and aggressive recovery (
) are the same. Nevertheless, the maximum difference between the conservative carry and forwarding and the other mechanisms is at maximum 2% for the three vehicle densities.
To summarize the performance evaluation of our Geographical Heuristic Routing (GHR) protocol, we have found that SA forwarding with carry and forwarding (, ) is the best option for low density areas, because it shows the best percentage of packet losses in this vehicle density. In the intermediate density, SA forwarding and recovery (, ) obtains the same level of packet losses as traditional forwarding (, ) with a lower delay. For this reason, we choose this configuration for medium vehicle density. Finally, we consider that SA forwarding with aggressive recovery (, ) is appropriate for high vehicle density scenarios. This GHR setup gets the lowest average delay and only decrements around 2% the best packet delivery ratio in this density, achieved by SA forwarding (, ). We will use these specific configurations, which depend on the vehicle density, to compare GHR with MMMR, greedy-DTN and iAODV in the next section.
5.5. Performance Comparison
In this section, we show how an adequate configuration of GHR can enhance the performance of geographical routing protocols. In addition to using the MMMR routing procedure to score the neighbors of a node, a case widely studied in the two previous sections, in this section, we employ a basic routing criterion, which is based only on the distance to the destination to choose the next forwarding node. This approach is generally called greedy-DTN [
4], and it is widely used as a reference for comparison with more sophisticated DTN protocols [
4].
Moreover, we compare our proposed GHR with these two routing algorithms, i.e., GHR-MMMR, GHR-greedy-DTN, against a modified version of AODV called irresponsible AODV (iAODV) [
33], which was especially adapted for VANETs because it reduces the number of route request signaling messages to establish an end-to-end path. iAODV is a representative example of topology-based routing protocols.
Figure 7 shows the results of the four metrics used in this paper for the three protocols that we have compared, GHR-MMMR, GHR-greedy-DTN and iAODV, with red, blue and green bars, respectively. The default operations of MMMR, greedy-DTN and iAODV are the bars with solid fill (first, second and fifth bars). The results for MMMR and greedy-DTN when they are assisted with the best configuration of GHR, which depends on the vehicle density, are represented in red and blue bars with different filling patterns for each vehicle density.
The percentage of packet losses in
Figure 7a lets us see that the default MMMR operation (solid red bar), without GHR assistance, outperforms the default operation of greedy-DTN and iAODV in the three vehicle densities. The reason is the more elaborate scoring metric that considers, in addition to the distance, the trajectory of the neighbor, the vehicle density and the available bandwidth. If the trajectory of a neighbor approaches the destination, then it would be useful if the node implements “carry and forwarding”. A high vehicle density increases the probability of finding a suitable next forwarding hop. Finally, it is important that a neighbor has enough available bandwidth for a packet transmission. However, the reader can notice that the importance of the three additional parameters of MMMR with respect to greedy-DTN decreases when the vehicle density increases because it is easier for greedy-DTN to find good forwarding candidates. Regarding iAODV, we can see that it only reaches the greedy-DTN marks with low vehicle density. In this vehicle density, nodes can build and maintain end-to-end routes without mutual interference due to the low signaling traffic. For the intermediate vehicle density, iAODV is able to decrease the percentage of packet losses with respect to its low density results because it can find more routes and maintain a reasonable signaling overhead since it does not use the aggressive flooding of the route request message of the original AODV. However, iAODV is not able to follow the results obtained by default greedy-DTN nor MMMR, because these two protocols use a simple and effective routing strategy. More importantly, greedy-DTN and MMMR need very few signaling messages to operate compared to iAODV, which turns into idler communication channels for data transmissions. Despite the more efficient route construction mechanism of iAODV, broadcast storms of route request/reply messages arise when the number of vehicles is high. As a consequence, the performance of iAODV decreases considerable contrary to the behavior of the geographical routing protocols, which decreases the percentage of packet losses.
When greedy-DTN and MMMR work with GHR, with tailored configurations according to the vehicle density, both protocols decrease their percentage of packet losses. Nonetheless, the behavior between greedy-DTN and MMMR remains the same. That is, GHR-MMMR outperforms GHR-greedy-DTN in the three vehicle densities, and the difference in the packet losses decrease as the vehicle density increases. It is important to notice that GHR-greedy-DTN improves the default operation of MMMR, i.e., it always selects the best neighbor () and it always applies “carry and forwarding” when there is not a closer node to the destination (). This means that the use of Tabu and simulated annealing is able to improve the straightforward routing criterion of greedy-DTN to improve the MMMR’s results reached by using a combination of four parameters instead of only the distance to the destination.
Figure 7b shows the average end-to-end delay for the received packets. iAODV is the routing protocol with the lowest delay because it establishes end-to-end routes to reach destination. MMMR is able to reduce the delay compared to greedy-DTN because MMMR takes into account the congestion in the path through the available bandwidth metric, the vehicle density to avoid void areas and the trajectory to select nodes that approach the destination. The use of GHR with the routing protocols increases notably the delay with low vehicle density because Tabu is used with carry and forwarding (
). As we explained in previous sections, when Tabu forbids nodes, the set of possible next forwarding nodes is reduced. Consequently, nodes have to apply “carry and forwarding” more often. The delay of GHR configurations in intermediate vehicle density is closer to the default operations of MMMR and greedy-DTN than in low density, because the recovery simulated annealing (
) is applied by GHR in intermediate density; hence, “recovery and forwarding” (which introduces high delay) is used less often. Finally, the GHR configuration for high vehicle density decreases the delay compared with the default protocol operation, because this configuration does not apply “carry and forwarding” (
).
The average number of hops is depicted in
Figure 7c. iAODV needs the smallest number of hops to reach the destination because its algorithm builds a shortest path between the source and destination. On the other hand, MMMR needs more hops than greedy-DTN since the latter only selects the closest node to destination while MMMR considers other parameters and prefers more stable nodes, but requiring more hops to reach the destination. Regarding the GHR configuration, there are two reasons for the increment in the average number of hops. First the use of Tabu forces routing protocols to search alternative routes, typically longer than the ones obtained by the default operations of greedy-DTN and MMMR. The second reason for the increment in the number of hops for GHR configurations in intermediate and high vehicle densities is the use of recovery simulated annealing and aggressive recovery, respectively.
The difference in the percentage of idle time, shown in
Figure 7d, is related to the number of hops and the signaling traffic. AODV (green bar) is the most demanding protocol in terms of bandwidth compared to the default operation of greedy-DTN and MMMR (blue and red bars, respectively) because of the high number of signaling messages that AODV needs to operate. This fact is evident in the scenario with high vehicle density in which there is a broadcast storm of signaling messages. Greedy-DTN requires less bandwidth than MMMR because MMMR needs more hops than greedy-DTN. Furthermore, the signaling messages of greedy-DTN are shorter than the ones of MMMR because MMMR needs to transmit information about speed, direction, vehicle density and idle time into the hello messages. Regarding GHR configurations, they have less idle time than default protocol configurations because GHR employs a higher number of hops to reach the destination, and a Tabu list is added to each data packet.
In this section, we have compared the performance of two geographical routing protocols, i.e., MMMR and greedy-DTN, with and without the assistance of the heuristic implemented by our proposal Geographical Heuristic Routing (GHR). The results show that GHR contributes to the improvement in the performance of the geographical protocols. Furthermore, we have shown that geographical routing proposals can reach better results than classical topological routing protocols like iAODV with a reasonable bandwidth consumption.
6. Conclusions and Future Work
In this paper, we have proposed a generic Geographical Heuristic Routing (GHR) protocol. GHR is inspired by simulated annealing and Tabu search meta-heuristics [
39]. We divide the GHR operation according to the operation in forwarding and recovery. The forwarding heuristics are used when an improvement to reach the destination is feasible. The recovery heuristics are thought to be used with the carry and forwarding approach. GHR can adapt its forwarding criterion depending on the application requirements. We use the traffic-aware MMMR [
20] protocol in the core of our proposed GHR to validate and score the neighbors of the current node in the forwarding process. Nonetheless, GHR could use any other routing protocol for the validation and scoring tasks.
An extensive performance evaluation of our proposed GHR indicates that the use of a Tabu list contributes to improving the packet delivery ratio by around 5% to 10%. However, this better performance comes at the price of an additional delay (2 s) because of the more restrictive selection process of the next forwarding node. Nonetheless, the non-real-time applications, which are objective of our work (e.g., report of traffic notifications), could cope with this delay. On the other hand, we show that the classical selection of the best node to forward a packet (i.e., the node with the best metric) and the carry and forwarding recovery are only adequate when the use of Tabu is not possible. On the contrary, if the routing process enables a Tabu list, then a forwarding strategy selection based on simulated annealing and a recovery procedure that does not use the buffer frequently are preferred.
There are some interesting variants of the heuristics presented in this work that we believe are worth testing. Among these variants we highlight the possibility to redefine the numerator of the simulated annealing probability function by considering some function of the distances among candidate nodes. In this way, when candidates are close to each other, random selection would be preferred. Another variant in simulated annealing is not to select, with probability p, a random node to forward the packet. Instead, a node will prefer, with probability p, a backup node (chosen by some function) rather than the best candidate in the forwarding process.
In our performance evaluation, we have used a single AP, which makes multi-hop communications more challenging. We could achieve a more efficient reporting service through anycast communications. Some of them constitute part of our future work, including: an optimal placement of access points, an efficient procedure to select the member of the anycast group to which the packets will be forwarded and the use of summarizing messages to reduce the rate of reports. Currently, we are developing some algorithms to select the anycast member in the routing protocol based on some of the ideas presented in this work.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}