
Optimal Parameter Exploration for Online Change-Point Detection in Activity Monitoring Using Genetic Algorithms



Abstract
:1. Introduction
2. Background
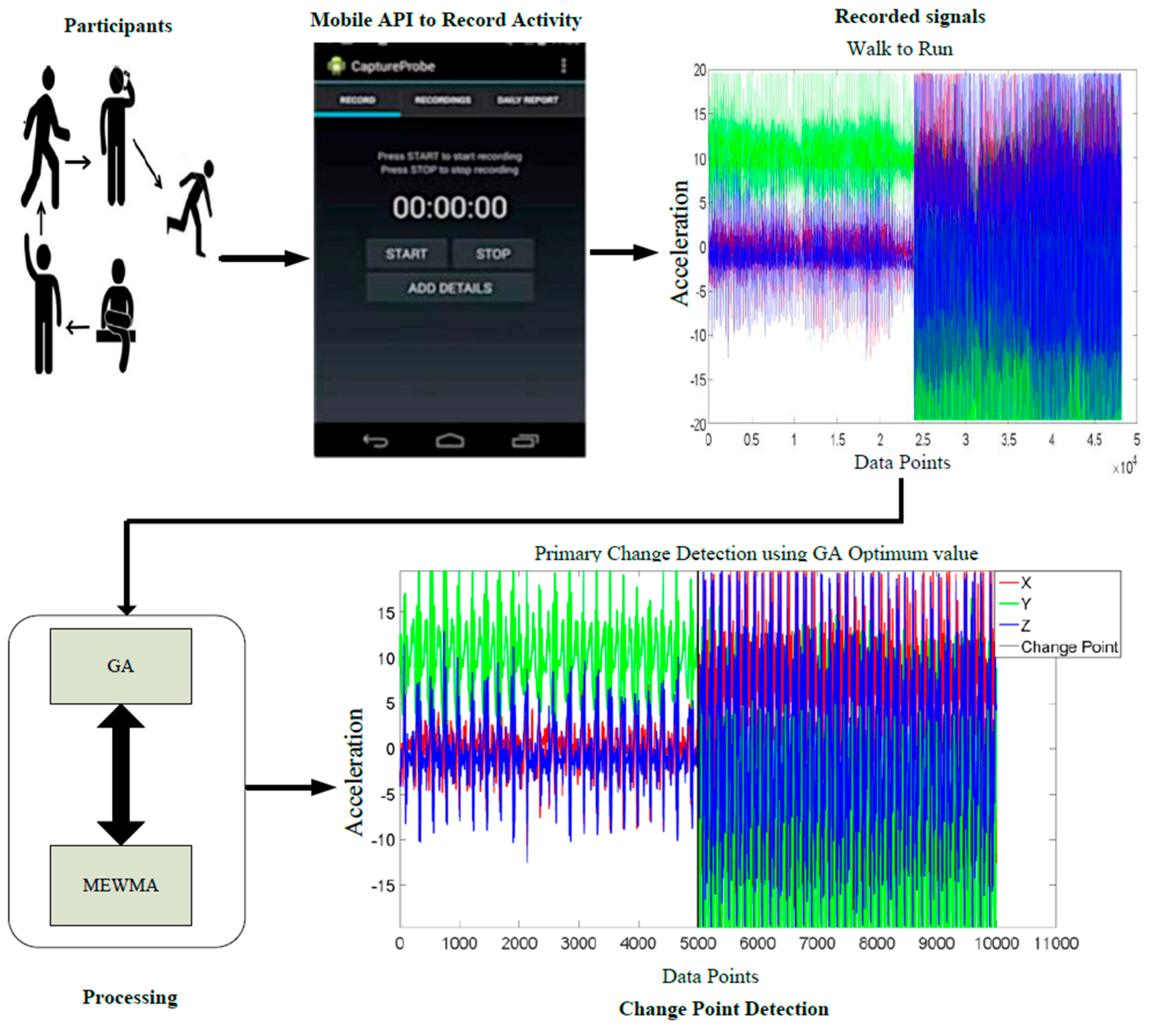
3. The Proposed Model
The Multivariate Exponentially Weighted Moving Average (MEWMA) Change-Point Detection Algorithm
- The population size is initialized with the number 50, which specifies how many individuals there are in each of the iterations. Usually, the number 50 is used for a problem with five or fewer variables, and the number of 200 is used otherwise.
- Check the termination condition of the algorithm on if the number of generations has exceeded the maximum value. If so, the GA algorithm is terminated, otherwise, continue with the following steps.
- Calculate the maximum value of the fitness function using Equation (3).
- The individuals are selected from the current population applying a stochastic uniform function. Each parent corresponds to a section proportional to its expectation. The algorithm moves along in steps of equal size. At each step, a parent is allocated from the section uniformly.
- The individuals are then reproduced randomly with a fraction using the crossover operation. The scatter function is used to select the genes where the vector is 1 from the first parent and 0 from the second parent before combining them to form a child.
- is then applied with the adaptive feasible method to randomly generate individuals in the population.
- Finally, a new generation is updated and the GA algorithm loops back to check the termination condition. The default value for the generations is 100 multiplied by the number of variables used, but we choose the best value for generation by experimentation with different values.
4. Evaluation
4.1. Experimental Results
4.2. Walking in the Wild
5. Conclusions
Author Contributions
Conflicts of Interest
References
- Subramaniam, S.; Palpanas, T.; Papadopoulos, D.; Kalogeraki, V.; Gunopulos, D. Online outlier detection in sensor data using non-parametric models. In Proceedings of the 32nd International Conference on very Large Data Bases, Seoul, Korea, 12–15 September 2006; pp. 187–198.
- Warneke, B.; Last, M.; Liebowitz, B.; Pister, K.S. Smart dust: Communicating with a cubic-millimeter computer. Computer 2001, 34, 44–51. [Google Scholar] [CrossRef]
- Behera, A.; Hogg, D.C.; Cohn, A.G. Egocentric activity monitoring and recovery. In Computer Vision–ACCV 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 519–532. [Google Scholar]
- Sánchez, D.; Tentori, M.; Favela, J. Activity recognition for the smart hospital. IEEE Intell. Syst. 2008, 23, 50–57. [Google Scholar] [CrossRef]
- Holzinger, A.; Schaupp, K.; Eder-Halbedl, W. An Investigation on Acceptance of Ubiquitous Devices for the Elderly in a Geriatric Hospital Environment: Using the Example of Person Tracking. In Proceedings of the International Conference on Computers for Handicapped Persons, Linz, Austria, 9–11 July 2008; pp. 22–29.
- Cleland, I.; Han, M.; Nugent, C.; Lee, H.; Zhang, S.; McClean, S.; Lee, S. Mobile based prompted labeling of large scale activity data. In Ambient Assisted Living and Active Aging; Nugent, C., Coronato, A., Bravo, J., Eds.; Springer: Carrillo, Costa Rica, 2013; Volume 8277, pp. 9–17. [Google Scholar]
- Basseville, M.; Nikiforov, I.V. Detection of Abrupt Changes: Theory and Application; Prentice Hall: Englewood Cliffs, NJ, USA, 1993; Volume 104. [Google Scholar]
- Stikic, M.; Larlus, D.; Ebert, S.; Schiele, B. Weakly supervised recognition of daily life activities with wearable sensors. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 2521–2537. [Google Scholar] [CrossRef] [PubMed]
- Darkhovski, B.S. Nonparametric methods in change-point problems: A general approach and some concrete algorithms. In Change-Point Problems; Carlstein, E., Muller, H.-G., Siegmund, D., Eds.; Institute of Mathematical Statistics: Hayward, CA, USA, 1994; Volume 23, pp. 99–107. [Google Scholar]
- Wechsler, S.S.H.A.H. Online Change Detection. Available online: http://www.Ntu.Edu.Sg/home/ssho/cpbook/chapter5.Pdf (accessed on 1 March 2016).
- Khan, N.; McClean, S.; Zhang, S.; Nugent, C. Parameter optimization for online change detection in activity monitoring using multivariate exponentially weighted moving average (MEWMA). In Proceedings of the Ubiquitous Computing and Ambient Intelligence. Sensing, Processing, and Using Environmental Information, Puerto Varas, Chile, 1–4 December 2015; pp. 50–59.
- Malhotra, R.; Singh, N.; Singh, Y. Genetic algorithms: Concepts, design for optimization of process controllers. Comput. Inf. Sci. 2011, 4, 39. [Google Scholar] [CrossRef]
- Macias, E.; Suarez, A.; Lloret, J. Mobile sensing systems. Sensors 2013, 13, 17292–17321. [Google Scholar] [CrossRef] [PubMed]
- Zeng, Y.; Li, D. A self-adaptive behavior-aware recruitment scheme for participatory sensing. Sensors 2015, 15, 23361–23375. [Google Scholar] [CrossRef] [PubMed]
- Hao, F.; Jiao, M.; Min, G.; Yang, L.T. Launching an efficient participatory sensing campaign: A smart mobile device-based approach. ACM Trans. Multimed. Comput. Commun. Appl. 2015, 12, 18. [Google Scholar] [CrossRef] [Green Version]
- Chang, Y.-J.; Paruthi, G.; Newman, M.W. A field study comparing approaches to collecting annotated activity data in real-world settings. In Proceedings of the 2015 ACM International Joint Conference on Pervasive and Ubiquitous Computing, Osaka, Japan, 7–11 September 2015; pp. 671–682.
- Zhang, S.; McClean, S.; Scotney, B.; Galway, L.; Nugent, C. A Framework for Context-Aware Online Physiological Monitoring. In Proceedings of the 2011 24th International Symposium on Computer-Based Medical Systems (CBMS), Bristol, UK, 27–30 June 2011; pp. 1–6.
- Xi, C.; Chen, K.S.; Boriah, S.; Chatterjee, S.; Kumar, V. Contextual Time Series Change Detection. Available online: http://www-users.Cs.Umn.Edu/~sboriah/pdfs/chencsbck2013.Pdf (accessed on 20 March 2016).
- D’Angelo, M.F.S.; Palhares, R.M.; Takahashi, R.H.; Loschi, R.H. A fuzzy/bayesian approach for the time series change point detection problem. Pesqui. Oper. 2011, 31, 217–234. [Google Scholar] [CrossRef]
- Vlasveld, R. Temporal Segmentation Using Support Vector Machines in the Context of Human Activity Recognition. Master’s Thesis, Thompson Rivers University, Vancouver, BC, Canada, 2014; pp. 1–85. [Google Scholar]
- Brusey, J.; Rednic, R.; Gaura, E. Classifying transition behaviour in postural activity monitoring. Sens. Transducers 2009, 7, 213–223. [Google Scholar]
- Kawahara, Y.; Sugiyama, M. Change-point detection in time-series data by direct density-ratio estimation. In Proceedings of the 2009 SIAM International Conference on Data Mining, Sparks, NV, USA, 30 April–2 May 2009; pp. 389–400.
- Sugiyama, M.; Nakajima, S.; Kashima, H.; Buenau, P.V.; Kawanabe, M. Direct importance estimation with model selection and its application to covariate shift adaptation. In Advances in Neural Information Processing Systems; Springer: Vancouver, BC, Canada, 2008; pp. 1433–1440. [Google Scholar]
- Lowry, C.A.; Woodall, W.H.; Champ, C.W.; Rigdon, S.E. A multivariate exponentially weighted moving average control chart. Technometrics 1992, 34, 46–53. [Google Scholar] [CrossRef]
- Khoo, M.B. An extension for the univariate exponentially weighted moving average control chart. Matematika 2004, 20, 43–48. [Google Scholar]
- Critical Values and p Values. Available online: http://www.itl.nist.gov/div898/handbook/prc/section1/prc131.htm (accessed on 8 August 2016).
- Holzinger, K.; Palade, V.; Rabadan, R.; Holzinger, A. Darwin or lamarck? Future challenges in evolutionary algorithms for knowledge discovery and data mining. In Interactive Knowledge Discovery and Data Mining in Biomedical Informatics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 35–56. [Google Scholar]
- Goldberg, D.E.; Holland, J.H. Genetic algorithms and machine learning. Mach. Learn. 1988, 3, 95–99. [Google Scholar] [CrossRef]
- Mitchell, T.M. Machine Learning; WCB/McGraw-Hill: Boston, MA, USA, 1997. [Google Scholar]
- McCall, J. Genetic algorithms for modelling and optimisation. J. Comput. Appl. Math. 2005, 184, 205–222. [Google Scholar] [CrossRef]
- Algosnap. Available online: http://algosnap.com/ (accessed on 1 February 2016).
- Han, M.; Bang, J.H.; Nugent, C.; McClean, S.; Lee, S. A lightweight hierarchical activity recognition framework using smartphone sensors. Sensors 2014, 14, 16181–16195. [Google Scholar] [CrossRef] [PubMed]
- Ziefle, M.; Klack, L.; Wilkowska, W.; Holzinger, A. Acceptance of telemedical treatments—A medical professional point of view. In Proceedings of the International Conference on Human Interface and the Management of Information, San Francisco, CA, USA, 21–26 July 2013; pp. 325–334.
- Khan, N.; McClean, S.; Zhang, S.; Nugent, C. Using genetic algorithms for optimal change point detection in activity monitoring. In Proceedings of the IEEE 29th International Symposium on Computer-Based Medical Systems, Dublin-Belfast, UK, 21–23 June 2016; pp. 318–323.
- Ni, Q.; García Hernando, A.; de la Cruz, I. The elderly’s independent living in smart homes: A characterization of activities and sensing infrastructure survey to facilitate services development. Sensors 2015, 15, 11312–11362. [Google Scholar] [CrossRef] [PubMed]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. Man Cybern. C 2012, 42, 463–484. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameters | GA |
|---|---|
| Population Size | 50 |
| Selection | Stochastic uniform |
| Reproduction | 0.8 |
| Crossover | Scattered |
| Mutation | Adaptive feasible |
| Generations | 100 |
| Change | Sig Value | Non-Optimized | Optimized with GA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| λ | Win Size | F_Measure | Accuracy | λ | Win Size | F_Measure | Accuracy | ||
| Walk to Sit | 0.05 | 0.3 | 2 s | 50% | 99.4% | 0.4 | 1.5 s | 66.7% | 99.8% |
| Walk to Stand | 2 s | 50% | 99.4% | 0.4 | 1.5 s | 66.7% | 99.8% | ||
| Walk to wash hands | 2.5 s | 50% | 99.4% | 0.5 | 2 s | 66.7% | 99.8% | ||
| Walk to Driving | 3 s | 40% | 98.5% | 0.6 | 2.5 s | 50% | 99.4% | ||
| Walk to Running | 3 s | 40% | 98.5% | 0.7 | 3 s | 50% | 99.4% | ||
| Activity | λ | Win Size | Sig Value | F_Measure | Accuracy |
|---|---|---|---|---|---|
| Walk to Wild | 0.7 | 3 s | 0.05 | 66.7% | 99.8% |
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, N.; McClean, S.; Zhang, S.; Nugent, C. Optimal Parameter Exploration for Online Change-Point Detection in Activity Monitoring Using Genetic Algorithms. Sensors 2016, 16, 1784. https://doi.org/10.3390/s16111784
Khan N, McClean S, Zhang S, Nugent C. Optimal Parameter Exploration for Online Change-Point Detection in Activity Monitoring Using Genetic Algorithms. Sensors. 2016; 16(11):1784. https://doi.org/10.3390/s16111784
Chicago/Turabian StyleKhan, Naveed, Sally McClean, Shuai Zhang, and Chris Nugent. 2016. "Optimal Parameter Exploration for Online Change-Point Detection in Activity Monitoring Using Genetic Algorithms" Sensors 16, no. 11: 1784. https://doi.org/10.3390/s16111784
APA StyleKhan, N., McClean, S., Zhang, S., & Nugent, C. (2016). Optimal Parameter Exploration for Online Change-Point Detection in Activity Monitoring Using Genetic Algorithms. Sensors, 16(11), 1784. https://doi.org/10.3390/s16111784