1. Introduction
The Internet of Things (IoT) has been defined as communication between and integration of smart objects (things) [
1]. Nowadays, the rapid development of IoT has aroused increasing interest in a variety of fields [
2]. In the industrial field especially, more and more sensors are being incorporated into smart products, manufacturing equipment, and production monitoring. Smart manufacturing, which has become a vital component of manufacturing in the Industry 4.0 era, is currently facing challenges related mainly to the following three issues:
To solve the above issues, a heterogeneous device data ingestion model is urgently needed. Unfortunately, existing models do not properly address these issues. Therefore, we propose a heterogeneous device data ingestion model for our Industrial Big Data Platform (IBDP). IBDP is an industrial big data platform based on a series of open source softwares for ingestion, analysis and visualization of multi-source data [
9]. The model includes device templates and four strategies for data synchronization, data slicing, data splitting and data indexing, respectively. We can ingest device data from multiple sources using this heterogeneous device data ingestion model, which is verified on our IBDP. In addition, we report on a case study for a device data-based scenario analysis on the IBDP. The main contributions of our paper are the following:
We propose a heterogeneous device data ingestion model, which facilitates the ingestion and fusion of heterogeneous data from multiple sources.
We provide four data processing strategies for data synchronization, data slicing, data splitting and data indexing, respectively.
We implement the model on our IBDP and present a case study of data analysis after data ingestion.
The rest of the paper is structured as follows: first, a brief overview of related work is given in
Section 2. The heterogeneous device data ingestion model is proposed in
Section 3. Thereafter, heterogeneous sensor data ingestion methods for multiple data sources are explored in
Section 4. In
Section 5, the entire platform and some case studies are discussed, and finally, our conclusions are given in
Section 6.
2. Related Work
In recent years, we’ve been witnessing explosive growth in the variety, speed, and volume of data [
4]. The most fundamental challenge for the big data platform is how to explore the large volumes and analyze the data to get the useful information or knowledge for future actions [
10]. The traditional data platforms are not sufficient in dealing with these challenges. Hadoop is now widely used due to its cost effective, high scalability and fault-tolerance, and now it has become the basic technology for big data [
11]. Currently, many big data platform-based HDFS have been developed such as CDH, HDP, Hive, Cascade,
etc. In our platform, HDFS is also used to store data. Liu
et al. have summarized some of the big data platforms which have been widely used for achieving real-time availability [
11]. These platforms are Hadoop Online, Storm, Flume, Spark and Spark Streaming, Kafka, Scribe, S4, HStreaming, Impala,
etc. They are leveraged in one or more situations. They are suitable for different situations so the best effect can be achieved by integrating them.
Much research on sensor data and smart data ingestion and fusion has already been reported. Llinas
et al. provided a tutorial on data ingestion and a basis for sensor ingestion and fusion for further study and research [
12]. Regarding sensor data ingestion, various researchers have proposed frameworks; for example, Lee
et al. presented a peer-to-peer collaboration framework for multi-sensor data fusion in resource-rich radar networks [
13]. In most of these frameworks, data can be exchanged among different sensors. This is different from simple sensors, where data cannot be exchanged among the different devices. Dolui
et al. discussed two types of sensor data processing architectures, namely, on-device and on-server data processing architectures [
14]. Smart devices and products in the industrial field employ the second architecture.
For unstructured data, Sawant
et al. summarized the common data ingestion and streaming patterns, namely, the multi-source extractor pattern, protocol converter pattern, multi-destination pattern, just-in-time transformation pattern, and real-time streaming pattern [
15]. At LinkedIn, Lin Qiao
et al. proposed the far more general and extensible Gobblin, which enables an organization to use a single framework for different types of data ingestion [
16]. The structure of the data they collected is unknown, but for smart devices, the structure can be obtained if we have templates for the devices.
There are also a few specialized open-source tools for data ingestion, such as Apache Flume, Aegisthus, Morphlines, and so on, but these are generally used to ingest a single type of data. For heterogeneous device data from multiple sources, we need to ingest different types of data. Thus, we created the IBDP with a heterogeneous device data ingestion model for data from multiple sources. Using this model, we can ingest various device data and store them in a unified format.
This paper is a substantial extension of [
9] in some important aspects. First, we propose a heterogeneous device data ingestion model, which facilitates the ingestion and fusing of heterogeneous data from multiple sources. Second, we provide four data processing strategies for data synchronization, data slicing, data splitting and data indexing, respectively. Third, we re-implemented the ingestion layer of IBDP which proposed in [
9] with the heterogeneous device data ingestion model and the data processing strategies. Last, we provide more case study details.
3. Heterogeneous Device Data Ingestion Model
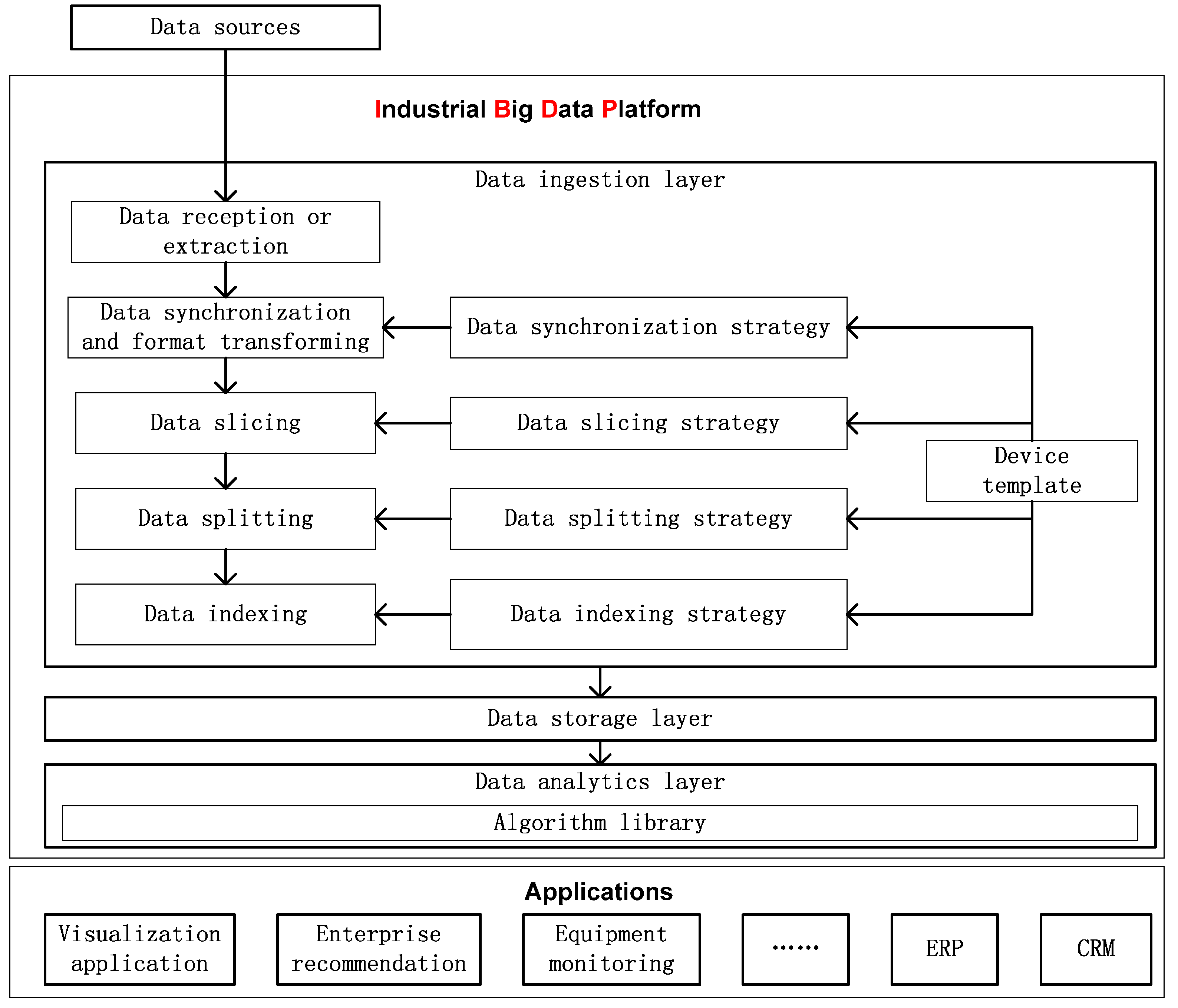
Device data include not only streaming data, but also data stored in relational databases and files. We propose a heterogeneous device data ingestion model as outlined in
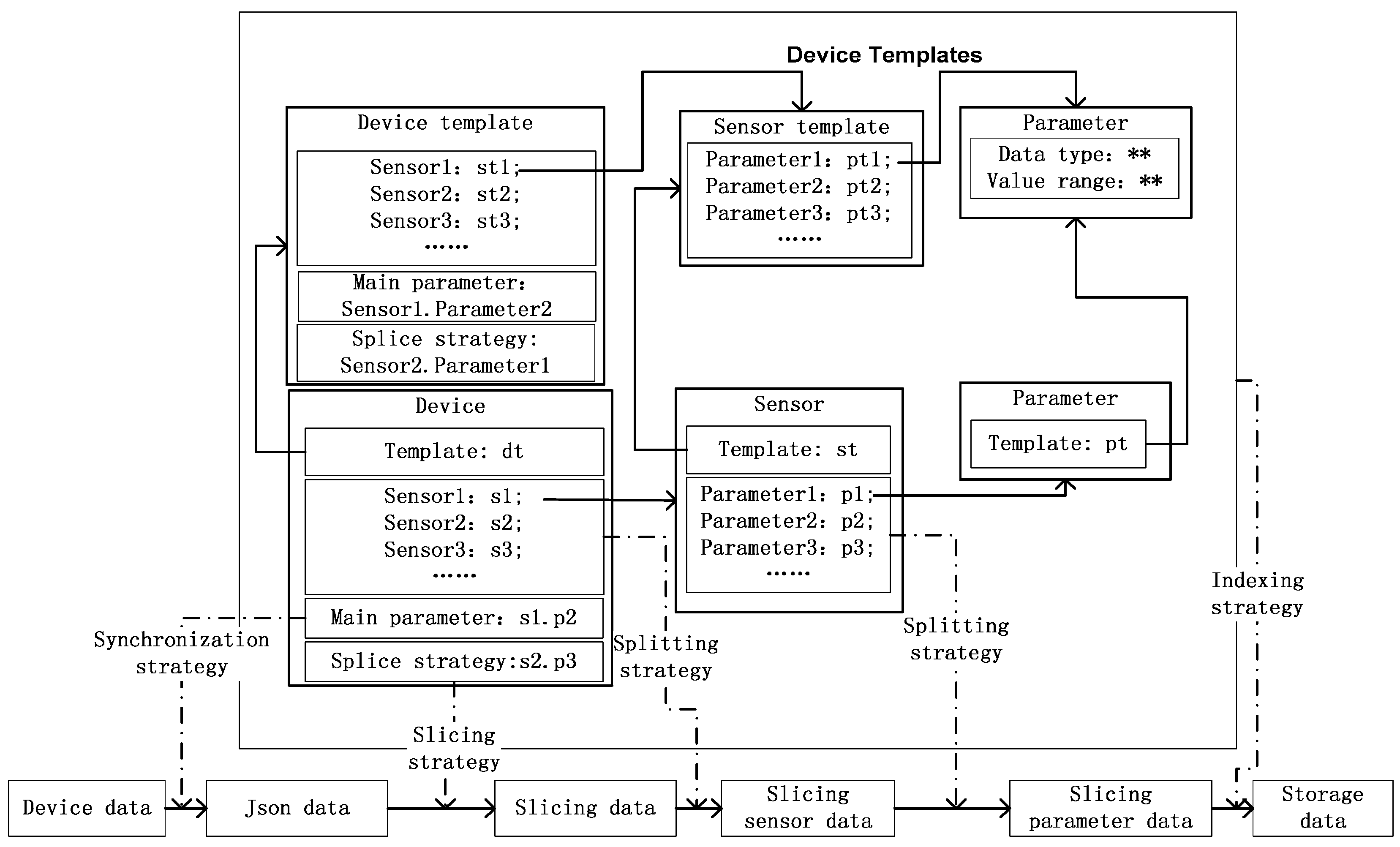
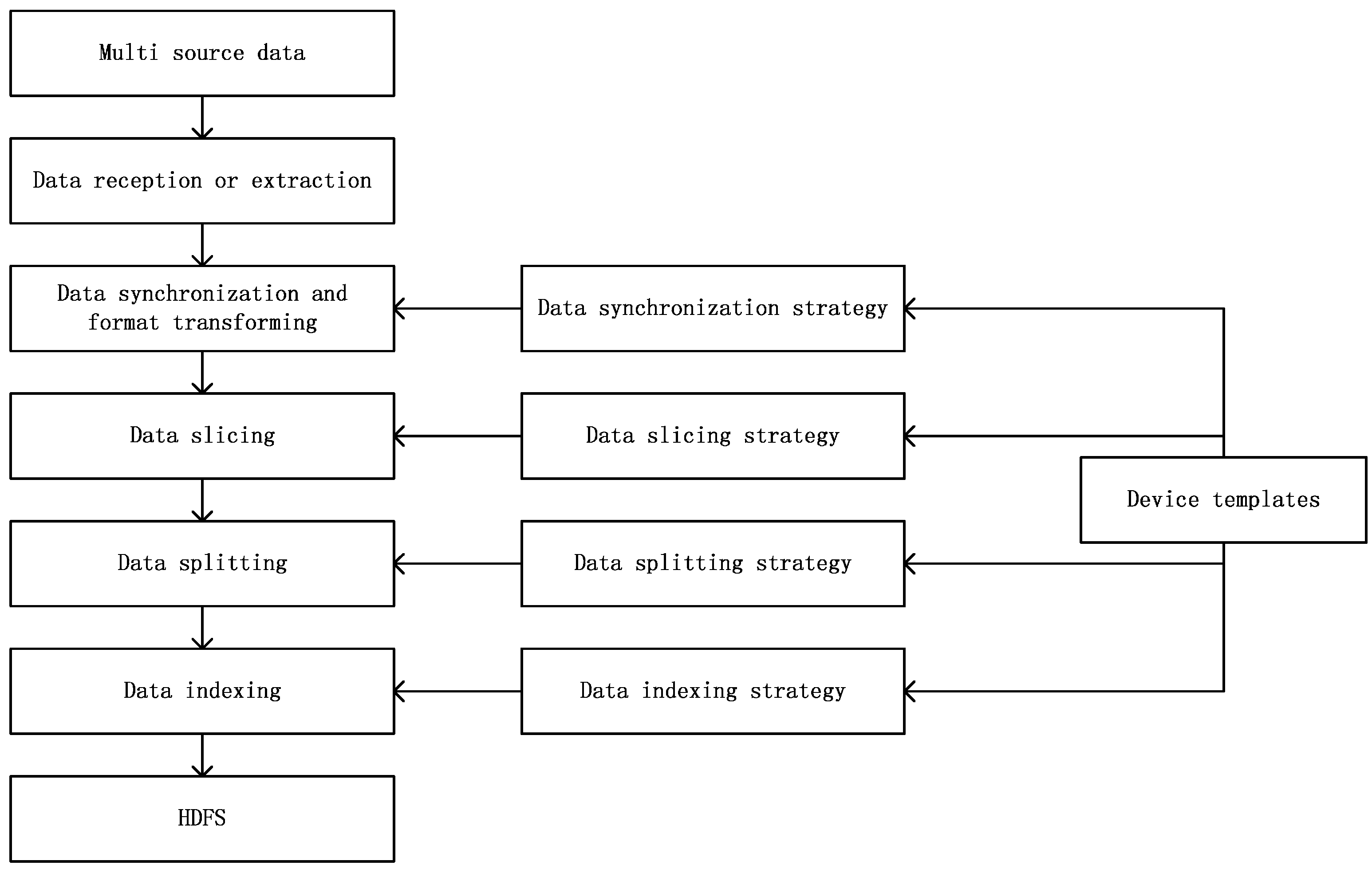
Figure 2. The model can receive or extract heterogeneous device from multiple sources and save them in a unified format. Included in our heterogeneous device data ingestion model are device templates and four strategies based on the device templates. The strategies cover data synchronization, data slicing, data splitting and data indexing.
3.1. Device Templates
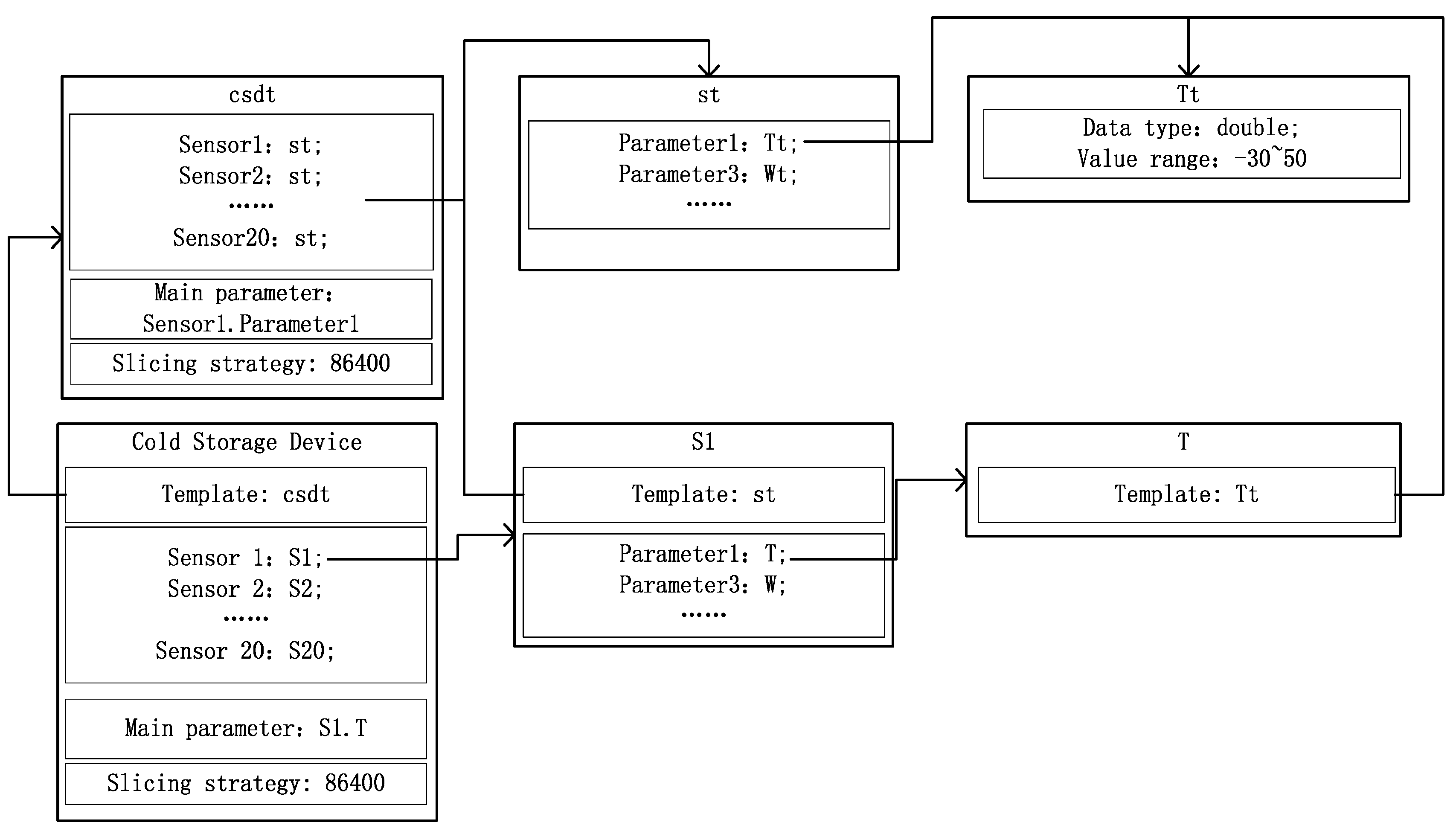
Each device has sensors and each sensor has parameters. Since for a single type of device the sensors and parameters are the same, we can manage each device with templates. As shown in
Figure 2, there are several sensor templates in each device template and there are several parameter templates in each sensor template. For each device, sensor, or parameter template, there may be several corresponding devices, sensors, or parameters, respectively. A device in different templates may contain the same sensor, while a sensor in different sensor templates may contain the same template parameter. In device templates, we need to set the main parameter, which is used for data synchronization. A splice strategy is also needed. Since devices may be logical, we can combine some related sensors to create a virtual device, which is also supported by the device templates.
3.2. Data Synchronization Strategy
Different sensor data in a device may be asynchronously transferred, especially in a virtual device. Besides, data stored in a relational database or files need to be merged, if they have been split on the basis of parameter or sensor. Thus, device data need to be synchronized. We propose a data synchronization strategy based on the main parameter in a device template. The synchronization strategy is given in Algorithm 1.
| Algorithm 1 Data Synchronization Strategy |
1. Receive data.
2. If the data are asynchronously transferred
3. If the data contain the main parameter
4. Create a new JSONObject.
5. Store the data in the JSONObject according to device template.
6. Else
7. Store the data in the JSONObject, whose time is the closest to the time of the data.
8. End If.
9. Else
10. Transform data into JSONObject according to device template.
11. End If
12. Output JSONObjects once a certain number of these objects have been created.
|
The main functions of the data synchronization strategy are data synchronization and data format conversion. To use the data synchronization strategy, we need to set the main parameter when creating the device template. When a device is added to the platform, the main parameter is automatically generated according to the templates.
For data format conversion, we need to set the data mapping relationship from the data received to the device format. For example, the format of data stored in relational databases is {
deviceId,
sensorId,
time,
p1,
p2,
p3}. In the process of data ingestion, each parameter value in the data item is placed in the corresponding position of the JSONObject. The format of a JSONObject is shown in
Table 1.
3.3. Data Slicing Strategy
Since the device data are continuously updated, they should not be placed in a file. We propose a data slicing strategy for the device templates. There are three slicing methods in this strategy, the first of which is timing slicing. This method requires setting a string in the device templates, the format of which and the included parameters are given in
Table 2.
For example, the string 0 4 −1 −1 −1 means that the data need to be sliced at 4:00 am every day. The second method is periodic slicing, which requires setting an integer in the device templates, denoting the length in seconds of the slicing interval. The third method involves slicing according to a specific parameter, which needs to be set in the device templates. When the parameter changes, the data are sliced. For instance, some devices need to slice data based on the value of a switch sensor. The data slicing strategy is set in the device template. When a device is added to the IBDP, it is automatically equipped with a slicing strategy. The algorithm for the data slicing strategy is given below (Algorithm 2).
| Algorithm 2 Data Slicing Strategy |
1. Obtain the data slicing strategy by deviceId in JSONObject.
2. If slicing strategy is timing slicing,
create a timer.
When the timer reaches the specified time, create a new file and transmit the old file;
Add data to the new file when the timer is sleeping.
End If.
3. If slicing strategy is periodic slicing,
create a timer.
At periodic intervals according to the timer, create a new file and transmit the old file;
add data to the new file when the timer is sleeping.
End If.
4. If slicing strategy is slicing according to specific parameter,
When the value of the specific parameter changes, create a new file and transmit the old file;
add data to the new file.
End If.
|
3.4. Data Splitting Strategy
In the slicing device sensor file, each data item is a JSONObject. Since the device data are heterogeneous, it is difficult to get specific parameters to analyze despite the fact that the parameters can only contain integer, float, Boolean or binary data. The device data could be used and analyzed more easily if they were split into parameters. We propose a splitting strategy based on the templates. Splitting involves two steps, the first of which is to split the file into sensor data items. Each data item in the sensor data files is listed in
Table 3. The second step is to split the sensor data files into parameter data files. Each data item in the parameter data file is listed in
Table 4.
3.5. Data Indexing Strategy
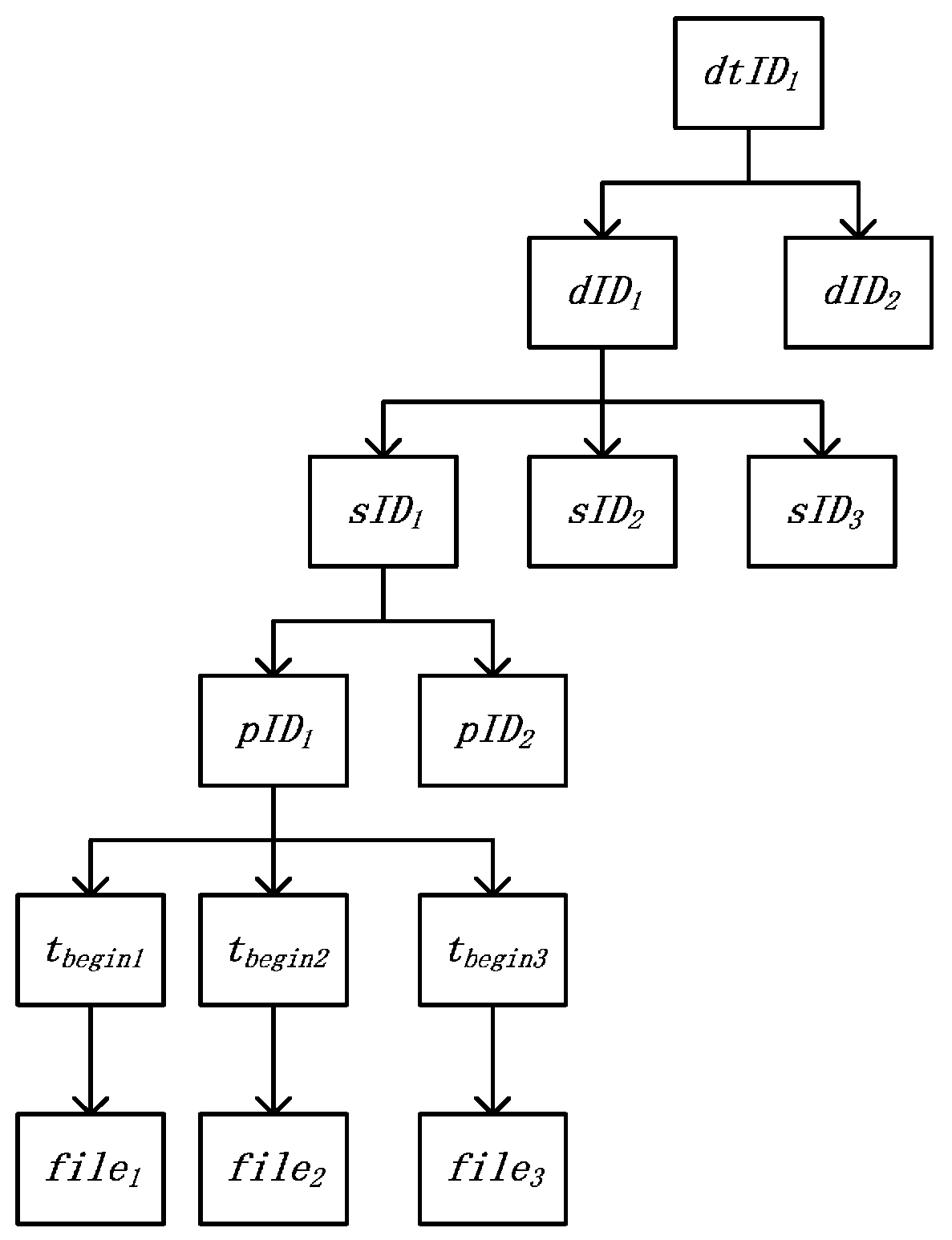
To speed up data ingestion, we propose a data indexing strategy for data saved in the Hadoop Distributed File System (hereafter, HDFS). In each file, the format of a data item is <
t,
v>, where
t is the time of data generation and
v is the value of the datum. When the files are created, they are indexed using the data indexing strategy described in
Figure 3, where
dtID is the unique identity of the device template,
dID is the unique identity of the device,
sID is the unique identity of the sensor,
pID is the unique identity of the parameter, and
tbegin is the start time in the file.
dtID,
dID,
sID,
pID, and
tbegin can be obtained from the parameter data files. To save space, we use the directories of HDFS to implement the index structure. Now, we give an example to show how to use the index. Suppose that we want to get the data of one parameter whose identity is
pID1 from
tbegin (
tbegin is earlier than
tbegin2 and is later than
tbegin1) to
tend (
end is earlier than
tbegin3 and is later than
tbegin2) which is shown in
Figure 3. First, we search the identities of the sensor and device which contain the parameter
pID1. The identities are
sID1 and
dID1, respectively. Second, we get the device template
dtID1 corresponding to device
dID1. Third, we use directory
/the_root_directory_to_store_device_data/stID1/dID1/sID1/pID1 to get data of parameter
pID1. Next, we get the files
file1 and
file2 (Note that the files not only contain data items between
tbegin and
tend, but also contain some data items earlier than
tbegin or later than
tend). Finally, we read data items from the files, align the data items <
t,
v > by
t and eliminate the data item which
t is earlier than
tbegin or later than
tend. After getting the data items, we can analyze the data of
Section 4.4.
4. Heterogeneous Sensor Data Ingestion Methods
The heterogeneous device data ingestion model includes five processes to ingest device data as shown in
Figure 4. These processes are data reception or extraction, data synchronization and format transformation, data slicing, data splitting, and data indexing. The data synchronization and format transformation process corresponds to the data synchronization strategy, the data slicing process to the data slicing strategy, the data splitting process to the data splitting strategy, and the data indexing process to the data indexing strategy. The four processes for different types of data sources are the same. The data reception or extraction process differs for different types of data sources.
4.1. Ingestion of Device Streaming Data
Most device data comprise streaming data, which is the basic form to ingest. We do not need to extract streaming data; instead, they are received through Flume, which is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. The ingestion algorithm for streaming data is given in Alogrithm 3.
| Algorithm 3 Streaming data ingestion algorithm |
|
4.2. Ingestion Files of Device Data
Some device data are saved in the form of files after real-time analysis or original application processing. If so, we first obtain the files through Flume and process these into pseudo streaming data. Thereafter, we can view and handle the data as streaming data. The ingestion algorithm for files is given in Algorithm 4.
| Algorithm 4 Files data ingestion algorithm |
| 1. Receive files from monitoring directories of Flume. |
| 2. Read the data and send the data to the monitoring port of Flume. |
| 3. Process the pseudo streaming data using streaming data ingestion algorithm (described in Section 4.1, Alogrithm 3). |
4.3. Ingestion of Device Data from Relational Database
Some device data are stored in relational databases after real-time analysis or original application processing. To ingest the data, we first need to extract them from the relational database using JDBC and Crontab.
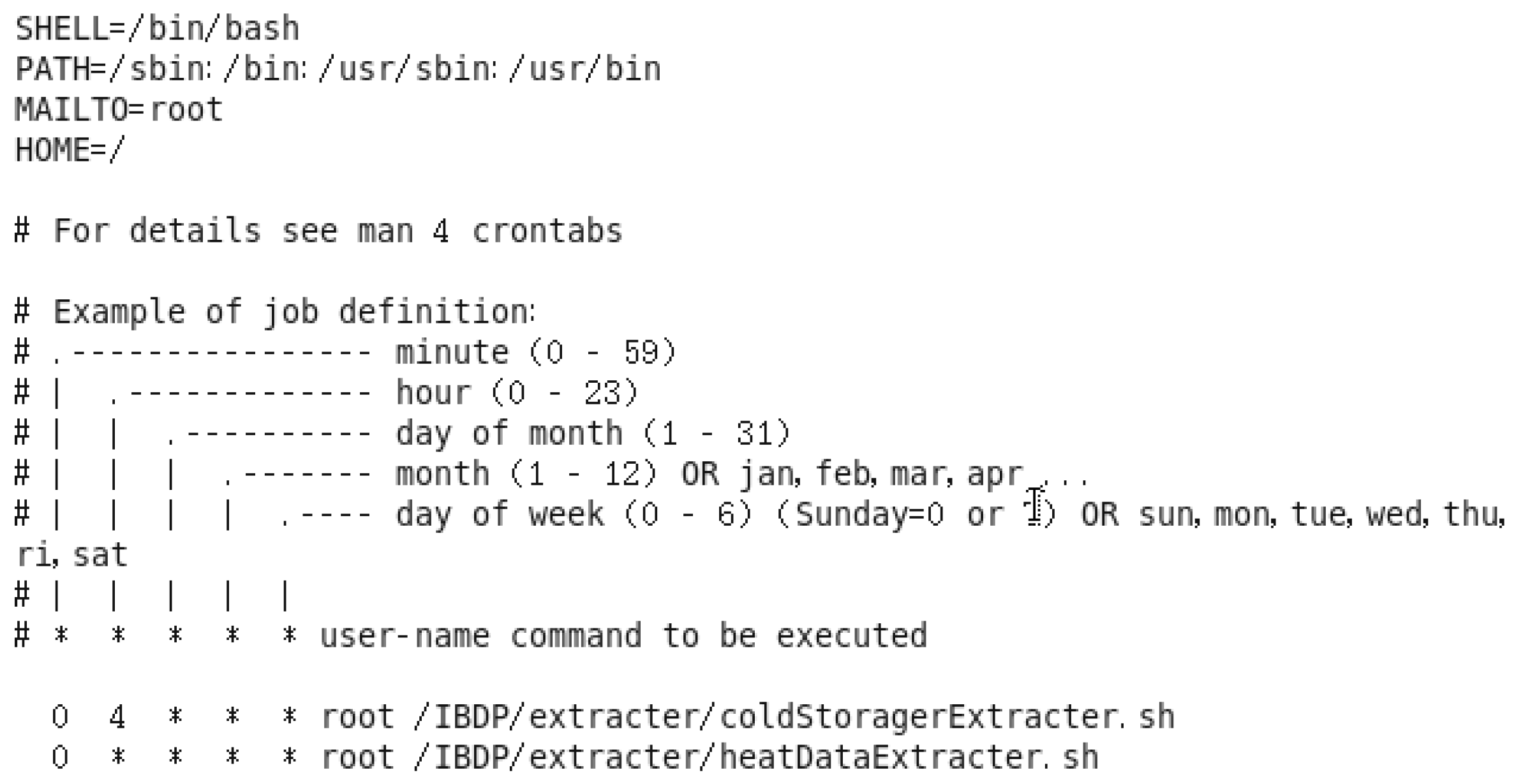
The extractor reads data from a relational database through JDBC and sends every line of data to the monitoring port of Flume. When to start the extraction is controlled by Crontab. Crontab, the configuration file for which is shown in
Figure 5, is a command provided by the operating system. When we create a timing job, a new line is added to the end of the file. Each line in Crontab, the description of which is shown towards the middle of
Figure 5, is a command to start an extractor. Two command examples are given at the bottom of
Figure 5. The first command,
0 4 * * * root /IBDP/extracter/coldStoragerExtracter.sh means that the system will start an extractor as described in file
coldStoragerExtracter.sh at 4:00 am.
The data after ingestion by the extractor take the form of pseudo streaming data, which can be viewed and handled as streaming data. The ingestion algorithm for relational data is given in Algorithm 5.
| Algorithm 5 Relational data ingestion algorithm |
|
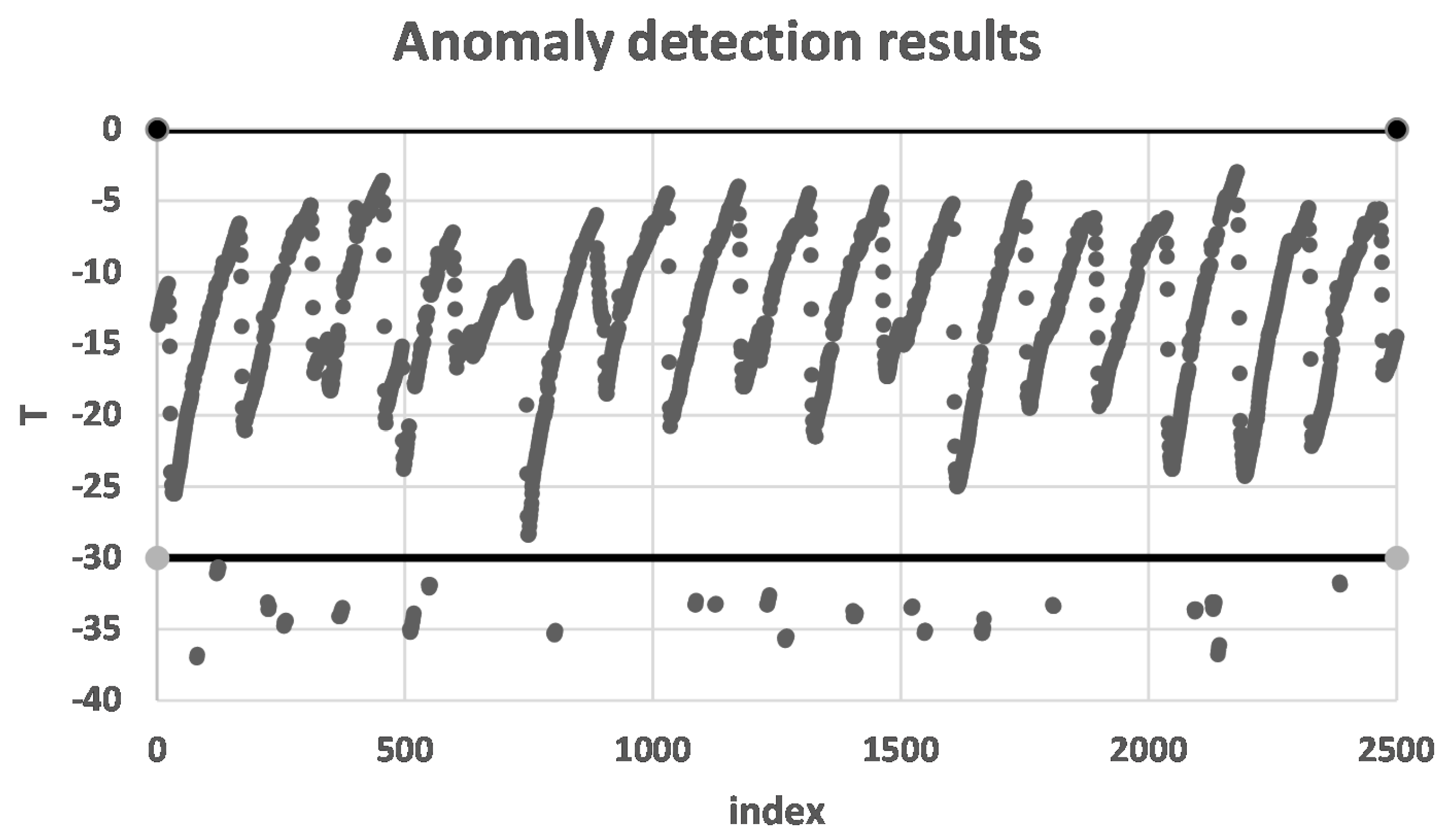
4.4. Analysis of Device Data
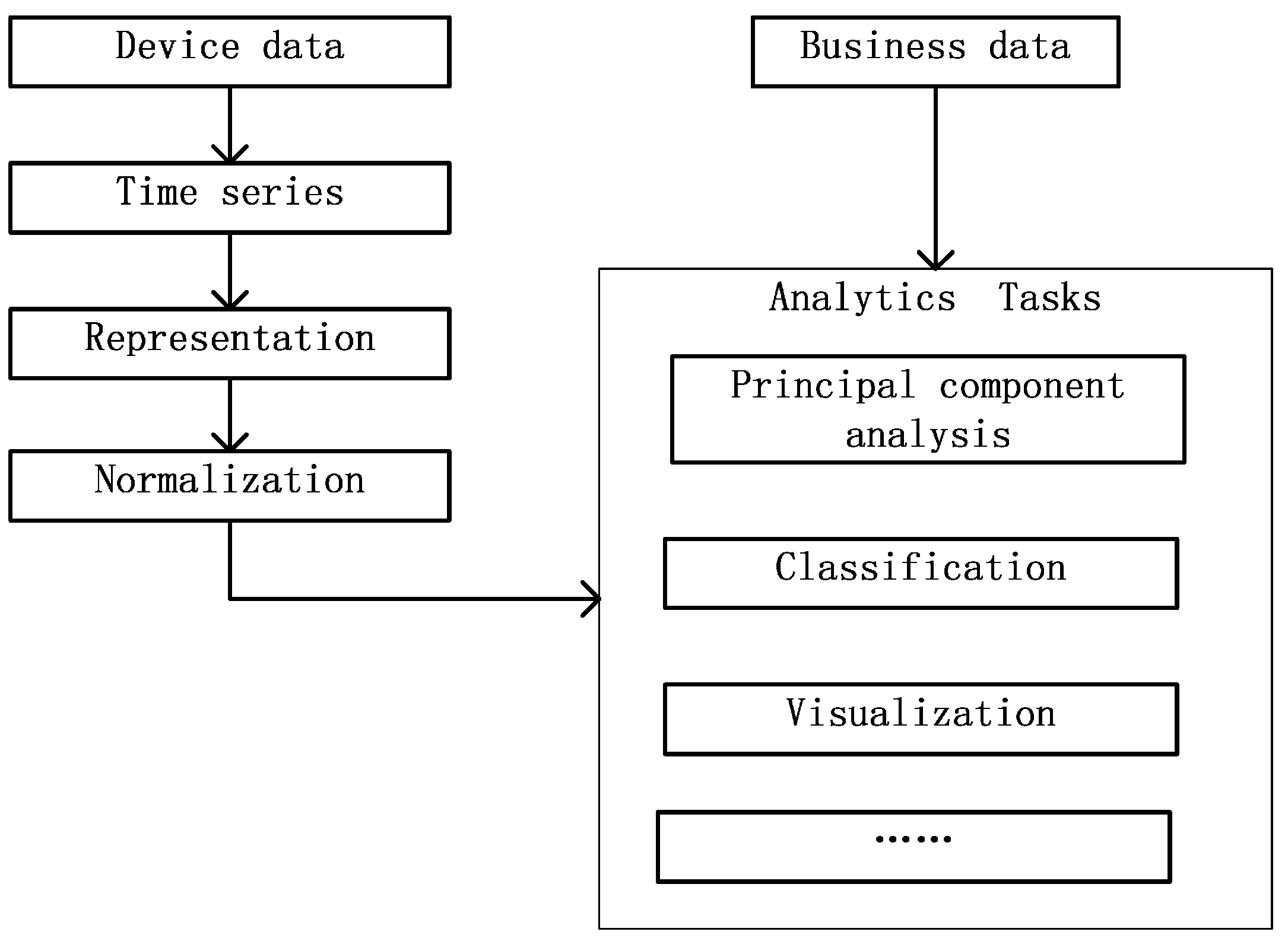
The device data are stored in a unified format after ingestion. However, in most cases, at least one item of the device data is meaningless. Recent empirical evidence strongly suggests that we should analyze the data as a time series. Moreover, the device data need to be fused with business data. In most cases, we analyze the data according to the process outlined in
Figure 6.
Though the device data are in a unified format after ingestion, there are still some difficulties in analyzing them, for example, the data frequency may not be consistent. Time series with different time intervals should not be compared directly. To support data for enterprise analysis, we provide a library of algorithms on IBDP, containing various common algorithms for time series including:
- (1)
Representation algorithms. In IBDP, there are several time series representation algorithms, such as sampling, piecewise aggregate approximation [
17], discrete Fourier transforms [
18], discrete wavelet transforms [
19], piecewise linear representation [
20] and piecewise linear representation based on series importance point [
21]. After choosing a representation, the time series can be compared with each other.
- (2)
Normalization algorithms. The time series obtained are generally accompanied by much noise. The IBDP contains the min-max and Z-score normalization algorithms. After normalization, the impact of noise is greatly reduced.
- (3)
Principal component analysis algorithms. We do not need to analyze all the parameters of each type of device; instead, only key parameters are extracted for analysis. The IBDP includes a principal component analysis [
22] algorithm to analyze the principal components of a time series.
- (4)
Visualization algorithms. To better display the features to enterprises, there are line chart [
23] and ThemeRiver [
24] algorithms for time series visualization. Using these visualization algorithms, enterprises can see the features directly.
- (5)
Classification algorithms. The IBDP includes some classification (as well as early classification) algorithms. The main classification algorithms are shapelets (perfectly accurate shapelets from [
25], and fast shapelets from [
26]), 1NN, and early classification of time series [
27]. Using the classification algorithms, enterprises can classify time series for different analytical tasks.
In the analytical tasks, we use not only device data, but also business data. By fusing the data, the analytical result is more accurate and more useful.
6. Conclusions
With the development of digitized manufacturing, data ingestion and analysis have become more and more important. In this paper, we presented a data ingestion model for heterogeneous devices, which consists of device templates and four strategies for data synchronization, data slicing, data splitting, and data indexing, respectively. Next, we introduced heterogeneous sensor data ingestion methods to ingest device data from multiple sources. Finally, we presented a case study describing a scenario in which device data were analyzed on the IBDP. We showed that the heterogeneous device data ingestion model can be used to ingest, analyze, and store data. It also makes it easier and more efficient for enterprises to analyze data.


 ,
, 











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}