1. Introduction
Household trip data are of crucial importance for managing present transportation infrastructure as well as to plan and design future facilities. They also provide basis for new policies implemented under Transportation Demand Management (TDM). The methods used for household trip data collection have changed with passage of time, starting with the conventional face-to-face interviews or paper-and-pencil interviews in the 1950s. High cost and safety issues proved to be the major problems in this approach. To overcome such disadvantages, computer assisted surveys were introduced in the 1980s. These surveys included computer-assisted telephone interview (CATI) and computer-assisted self-interview (CASI) [
1,
2]. The computer assisted surveys proved to be an improvement from the previous face-to-face interviews [
3] but the underlying shortcomings in person trip (PT) data collection methods still remained. These included inaccuracies in recording the starting and ending times, underreporting due to missing short trips and non-response [
4,
5]. The source of all these problems was the enormous burden on the respondents to answer a huge number of questions based on their memories. To address this issue, GPS technology was employed during the late 1990s, providing the starting point for a generation of smart travel survey methods [
6].
Initially, GPS surveys were carried out as supplementary surveys to assess the accuracy of traditional methods, but later total replacement was experimented with [
7,
8,
9]. At the beginning, GPS devices were installed in vehicles. Consequently, only the travel behavior of people using vehicles was monitored. In the early 2000s, rapid advancement in technology paved way for the development of wearable GPS data loggers [
10]. With the introduction of lightweight, portable and handy GPS data loggers, all modes of transportation could be monitored. Although GPS devices can very accurately record the locations and time-stamps, important information like travel mode and trip purpose are not recorded. These details are inferred from the GPS data by appropriate data processing [
11].
Recently, the explosive spread of smartphones has provided the transportation community with a new potential and a lot of research is being carried out to utilize smartphones for travel data collection. This interest is because of GPS sensors being embedded into modern smartphones, making it possible to replace the GPS data loggers being used previously. Smartphones have an added advantage of being a necessary travel companion, hence being able to monitor the travel patterns over extended periods of time. Recently, GPS enabled smartphones are also utilized for indoor positioning and pedestrian navigation [
12,
13,
14]. On the other hand, GPS loggers are considered a burden to carry around. The inclusion of accelerometer in smartphones has dramatically enhanced its capability to accurately detect the travel mode and trip purpose. Accelerometer can detect accelerations along three axes (x, y and z) with respect to the gravitational force. It means that at rest, the accelerometer will register an acceleration of 9.8 m/s
2 along the downward direction. Orientation augments the accelerometer data by providing the information regarding angular motion. Orientation sensor is software-based and drives its data from the accelerometer and the geomagnetic field sensor. The current study focuses on the development of data-processing methodology for travel mode detection using accelerometer and orientation data collected by smartphones.
GPS devices have been used by many researchers for the purpose of mode detection, whether employing rule-based algorithms [
15,
16,
17,
18], or machine learning algorithms [
19,
20,
21].
Before smartphones came to the spotlight, the possibility of utilizing mobile phones for data collection using GSM technology was explored [
22]. Rather than employing GPS, locations were derived from mobile communication towers to be used for reconstructing travel patterns [
23]. Soon, more technology solutions were explored including Bluetooth, WiFi, RFID and smart-cards [
1]. Personal handy phone systems (PHS) became very popular in Japan for recording geographical locations. These systems located the device with the help of base stations [
24,
25]. Over 20 case studies have been conducted in Japan using PHS since 2003 [
26,
27,
28].
The tremendous popularity and increasing penetration of smartphones has attracted much research attention on their role in identifying the mode of transportation [
29,
30,
31,
32,
33]. Most of the studies have a similar methodology where suitable features were extracted from the raw sensor data, a training dataset was used to train a classification algorithm and then the algorithm was used to predict the test data based on the heuristics learned during the training phase. Transportation mode identification accuracy increased when GPS data were linked to GIS platform [
34]. The accuracy was further improved by combining GPS and accelerometer data for mode detection [
35].
A study by Tsui and Shalaby [
36] collected GPS data from Toronto. Accelerations, average and maximum speeds extracted from the GPS data along with public transportation route information, was used to predict the transportation modes, achieving a prediction accuracy of more than 90%. Another study performed in the same area used one participant to replicate 60 trips recorded during the ‘Toronto Transportation Tomorrow Survey’, carrying a GPS device [
37]. After collecting the GPS data and combining it with the GIS information available, a mode prediction accuracy of 92% was achieved. Another study extracted features like average accuracy of the GPS coordinates, average speed, average heading change, average acceleration, bus location proximity, rail line trajectory proximity, bus stop proximity rate and zip code, using collected GPS data accompanied by ground conditions [
30]. Five different classification algorithms were tested, with results suggesting that random forest outperforms others. A study named Future Mobility Survey (FMS) by Pereira [
38] compared the traditional survey results with survey by smartphones. It is part of a research project initiated by an alliance between Singapore and Massachusetts Institute of Technology (MIT). The study validated that participants tend to over-estimate the travel time in traditional surveys.
Smartphones are equipped with a range of sensors, many of which are not favored by or simply overlooked by majority of researchers. However, there are some studies that incorporate these sensors as well. Frendberg [
39] utilized data collected from GPS, accelerometer, orientation sensor and magnetic sensor to detect the travel mode using a smartphone application, similar to Su and Caceres [
40].
A number of studies have utilized the accelerometer data alone for classification purposes [
41,
42,
43,
44,
45,
46]. In one study [
29], the training and testing datasets were formed by taking 70% of the collected data as training data and rest as test data; a similar study divided the collected data as 90% for training and 10% for testing [
47]; and yet another study used almost 50% of the collected data for training and rest for testing the classification algorithms [
48]. Some studies (e.g., [
49]) also collected GPS data but for data validation only. Mode detection was still managed by accelerometer data.
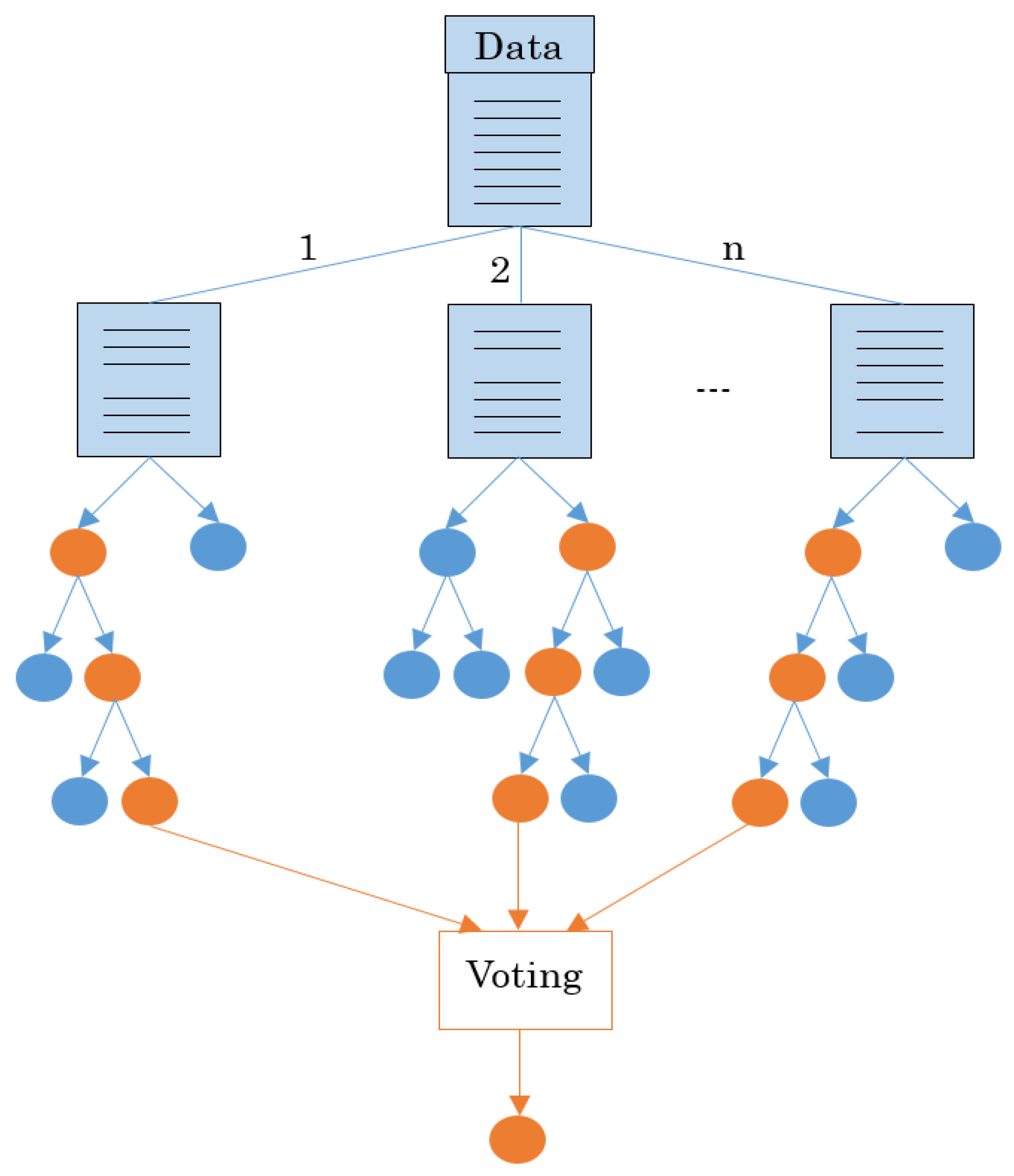
Various studies have compared random forest with other algorithms for the purpose of mode detection, while reaching the same conclusion that random forest is a superior algorithm for the intended purpose. For instance, one study made a comparison among random forest, naïve Bayes, Bayesian network, decision trees and multilayer perceptron [
30]; another incorporated neural network and support vector machines along with random forest [
32]; one more studied random forest, k-nearest neighbor, support vector machines, naïve Bayes and decision trees [
21]; and further a study reported a comparison among support vector machines, adaptive boosting, decision trees and random forest [
50]. These studies demonstrated that random forest yields higher travel mode prediction accuracies.
In our previous studies [
50,
51], acceleration data were collected by a purpose-built wearable device named as BCALs (Behavioral Context Addressable Loggers in the Shell). Mode detection was successfully done among four modes: walk, bicycle, car and train. Developing a methodology for data collected by smartphones and also to add some other modes for classification was required. Therefore, our current work proposes a methodology for identification among six different travel modes namely walk, bicycle, car, bus, train and subway, using data from accelerometer and orientation sensors embedded in smartphones. Further, it investigates the effect of various data collection frequencies on the classification accuracy of the used algorithm as well as the computational costs incurred.
3. Results and Discussion
Using 10 min moving window to extract the features and 10% data to train the algorithm, classification results were computed for datasets with varying recording frequencies. Additionally, the computation times were also recorded for each dataset, in order to aid in the comparison.
Table 7 gives the overall results along with the computation times and
Table 8 provides the detailed results in the form of confusion matrices. It is evident from
Table 7 that the overall classification accuracy decreases with decrease in data frequency.
It is already established from
Table 6 that the accuracy increases with increase in amount of training data. The trend observed in
Table 8 might also have the same reason. With increase in frequency, the amount of data also increased, which in turn increased the training data. Moreover, moving window concept seems to extract better feature values for high frequencies, as the outliers are averaged over a wider range, hence reducing their impacts. The other criterion observed is the time spent in computation. The computation time depends on the amount of data and as the data decreases with the decreased frequency, even though the recorded total time remains the same, the time required for computing decreases. Thus, if the required classification accuracy is more than 99%, then 1 Hz frequency will meet that condition with a 94% decrease in computation time compared to 10 Hz, while the difference in accuracy would be only 0.8%. Furthermore, as mentioned in
Section 3, the power consumption will also be reduced.
Hence, selection of data collection frequency is very crucial, as it not only controls the classification accuracy but also the efficiency of the methodology. Nevertheless, there is a tradeoff between the accuracy and efficiency of the methodology. Therefore, researchers should select the frequency according to their specific needs.
Table 9 provides an insight into the prediction accuracy for 0.2 Hz frequency data, with respect to entire trips. One thing to note here is the slightly larger number of trips (625) than reported in
Table 3 (559). This is due to breaking up of larger trips into multiple smaller ones when 60 s dwell time was used for trip segregation.
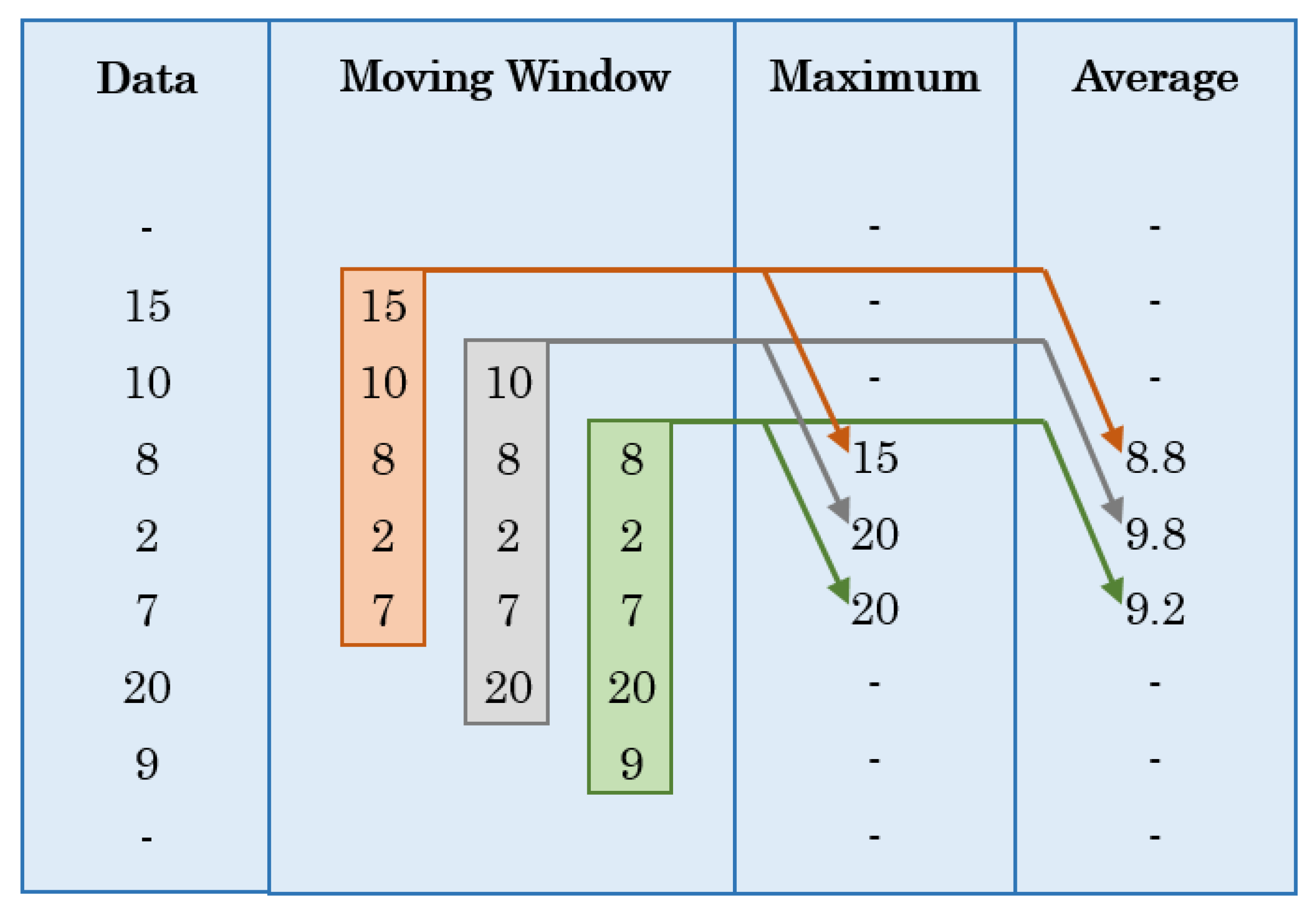
A valid question arises as to the reason for the remarkably high detection accuracy by this methodology. The secret lies in the moving window concept used to extract the various features.
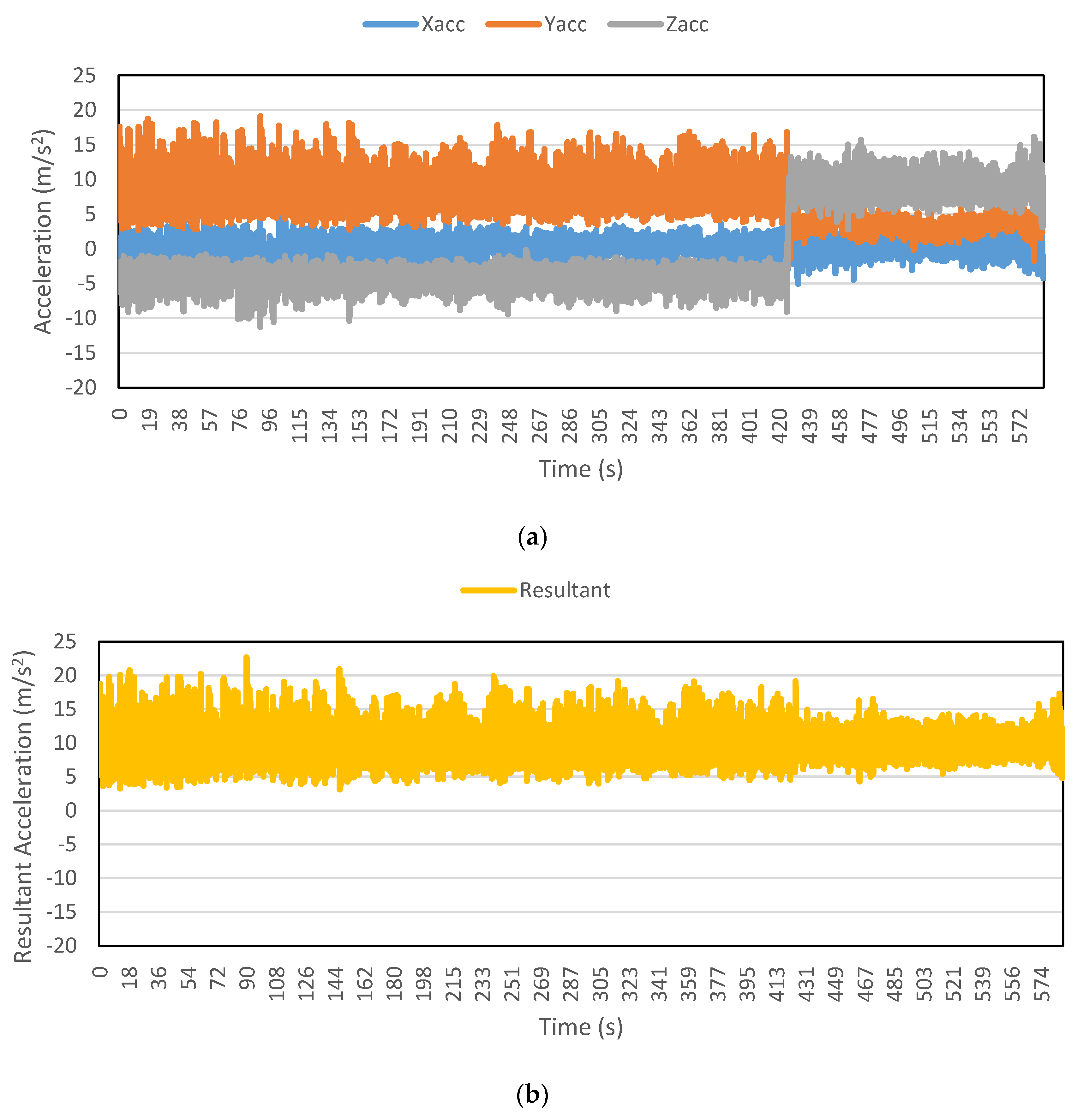
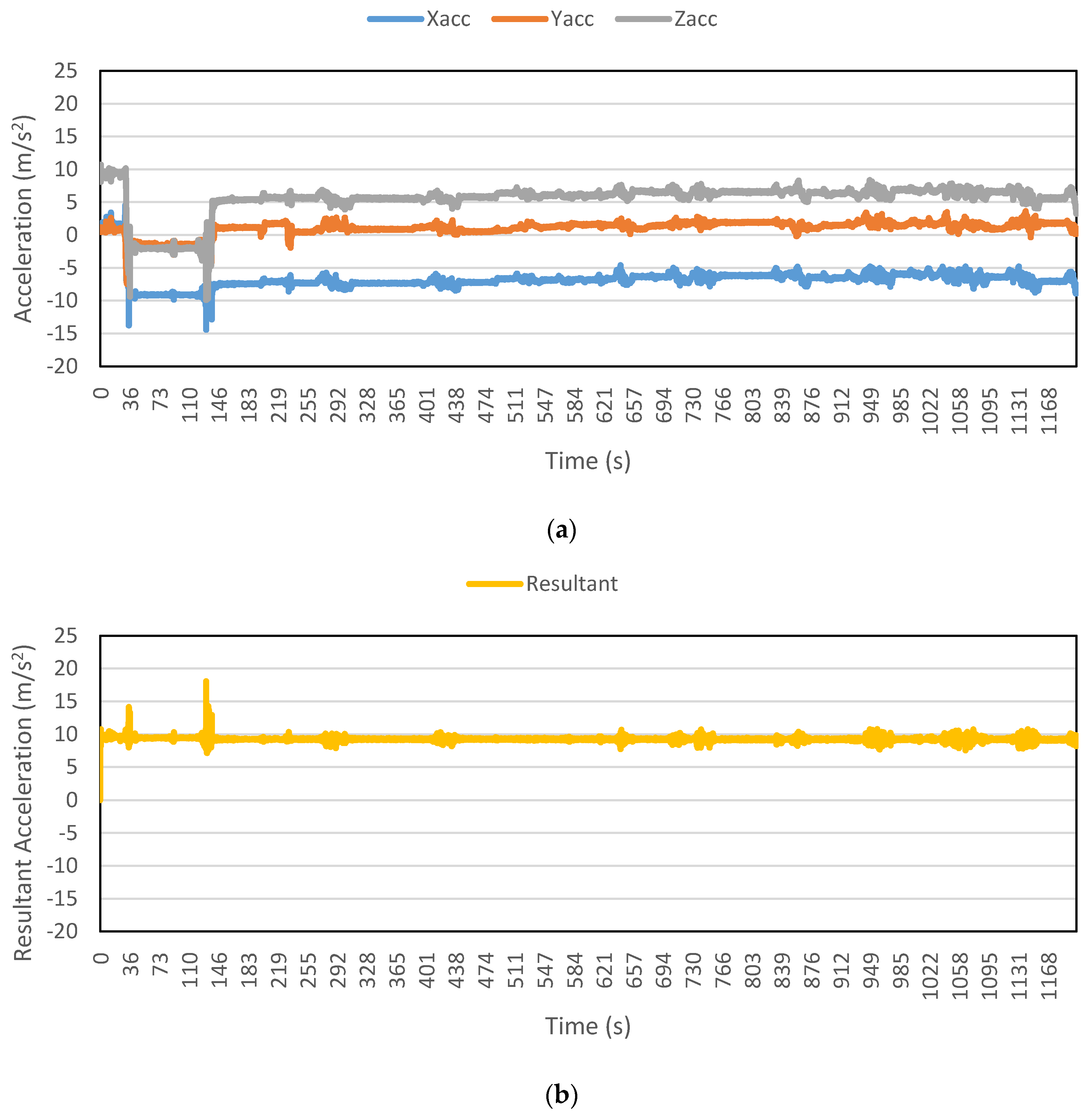
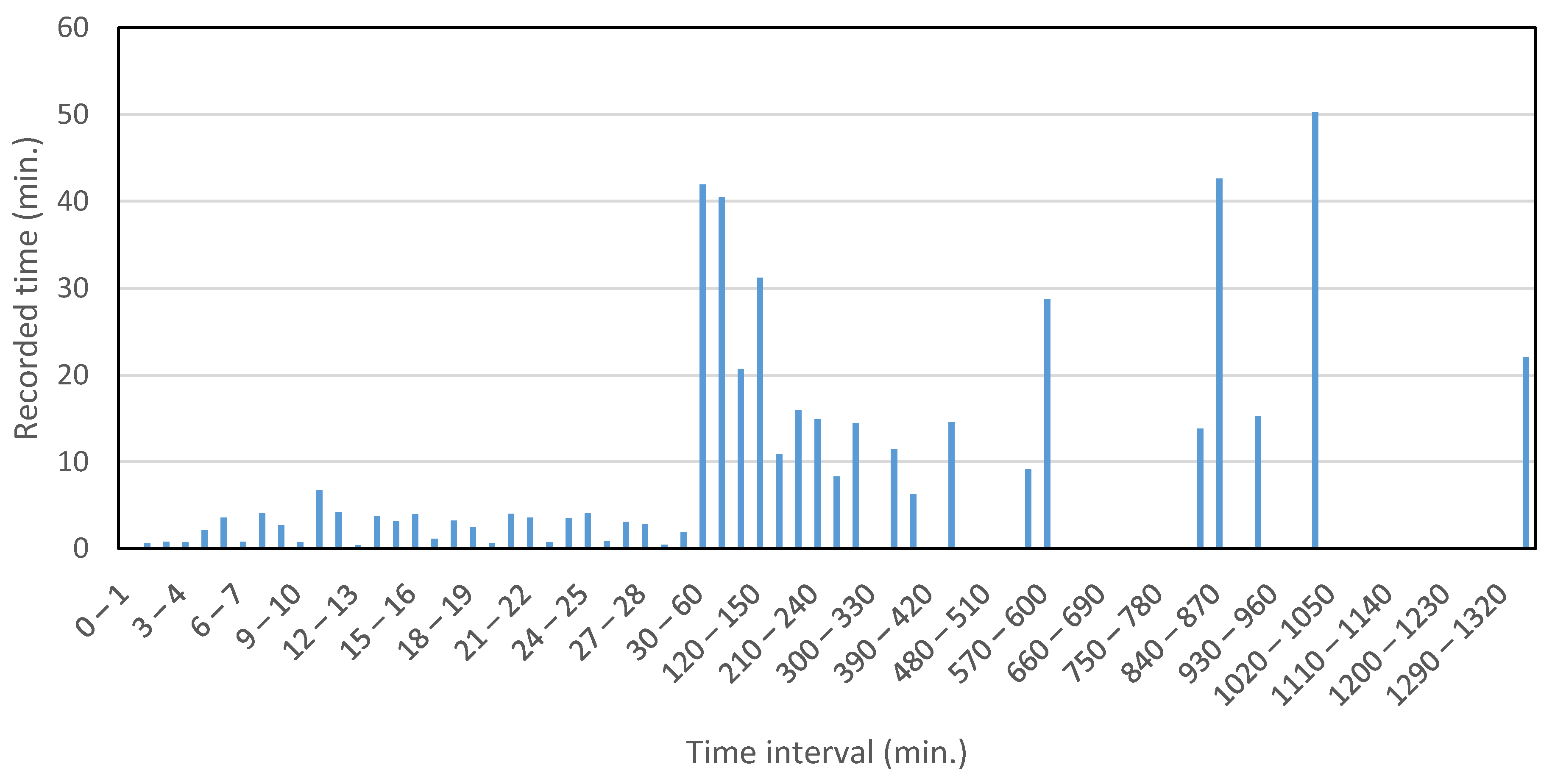
Figure 12 shows the resultant acceleration data collected for a part of a walking trip. The average resultant acceleration calculated by moving window is also shown in the figure. It is evident that the average values approximately remain constant, hence providing a very useful feature for the algorithm. If the algorithm is trained using only a few average values, then the algorithm will very easily identify the remaining values against the values from other modes. Moreover, additional features like maximum resultant acceleration, standard deviation, skewness and kurtosis refine the classification process and decrease the number of misclassifications. Conventionally, researchers use specific time windows, mostly having 50% overlap, to extract various features [
21,
29,
47,
54,
62]. One of the problems with this kind of approach is the loss of data points. For example, for data collected at one reading per second (1 Hz) and a time window of 10 s with 50% overlap, the extracted features will have a frequency of one reading per 5 s (0.2 Hz).
This explains why moving window was used but does not justify the large window size selected, which might result in excessive overlapping and consequently high prediction accuracies. The reason for using this approach lies in the real world application design of the developed methodology. Generally, people have unique walking and driving patterns, even if they usually stick to a distinctive routine while commuting daily via public transportation. To predict the mode of transportation of a person by studying a completely different person might not yield better results. However, if the prediction is done by studying limited data yielded from the same person, the accuracy will certainly be much better. As the algorithm requires training data, the application design is such that the participants will be asked to at least annotate one day’s data (encouraged by providing some incentive like free cinema tickets, gift vouchers,
etc.), all of which will be regarded as the training data. After that, the participants just need to keep the application running in the background for the intended period of the survey. In such a design, the big window size does not pose a problem; in fact, it helps to achieve higher prediction accuracy by smoothening the data and bringing it near to the training data. To explain this,
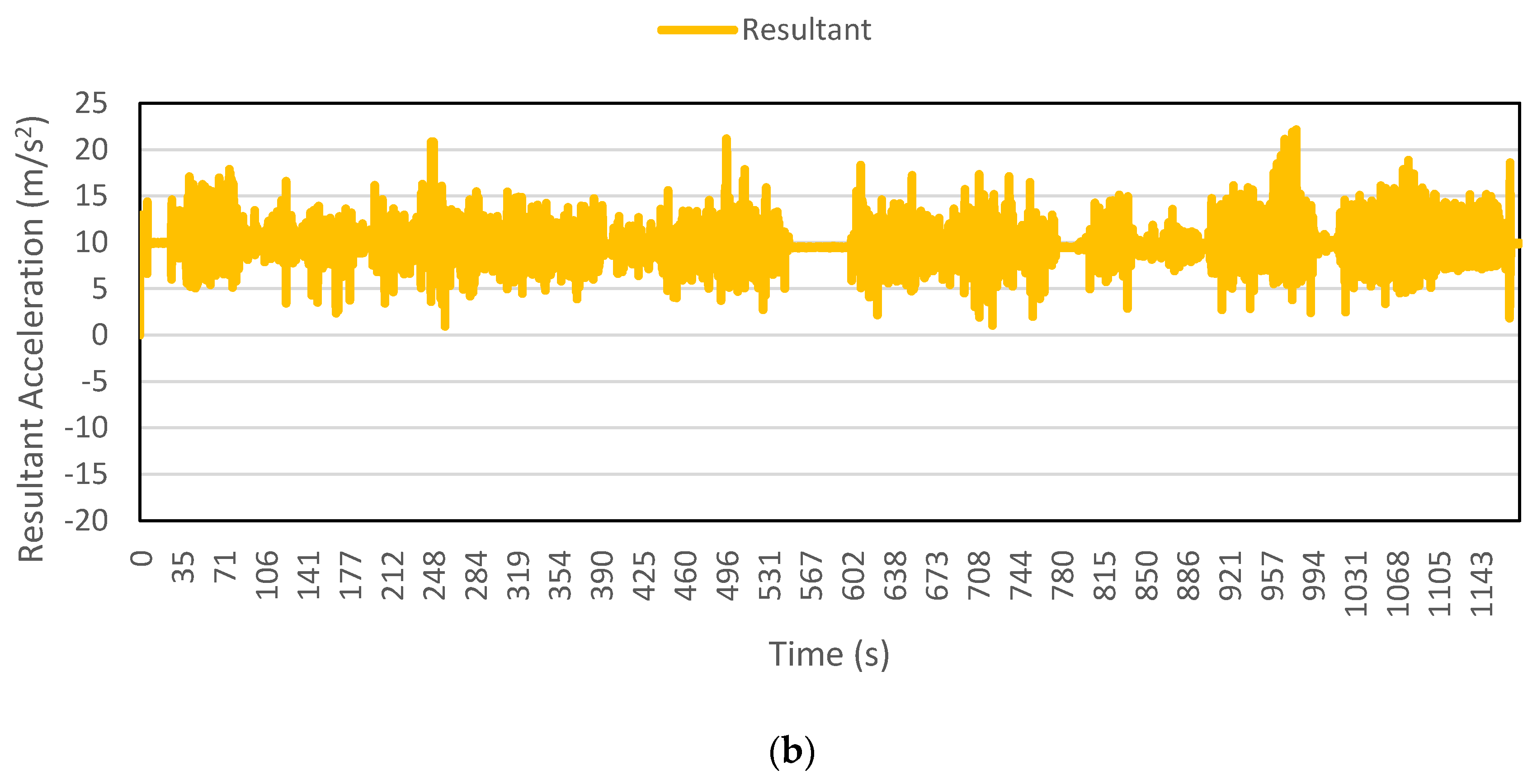
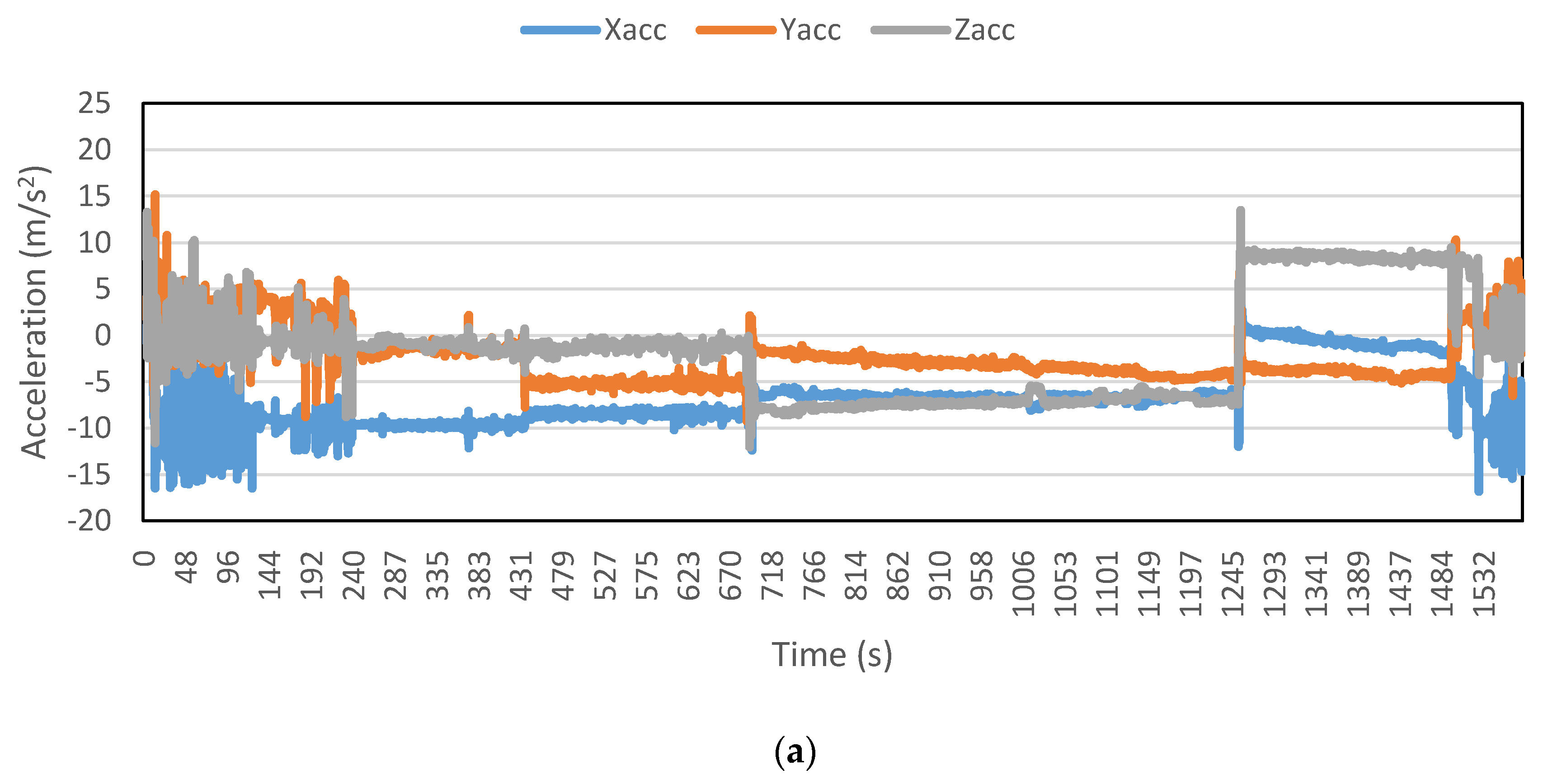
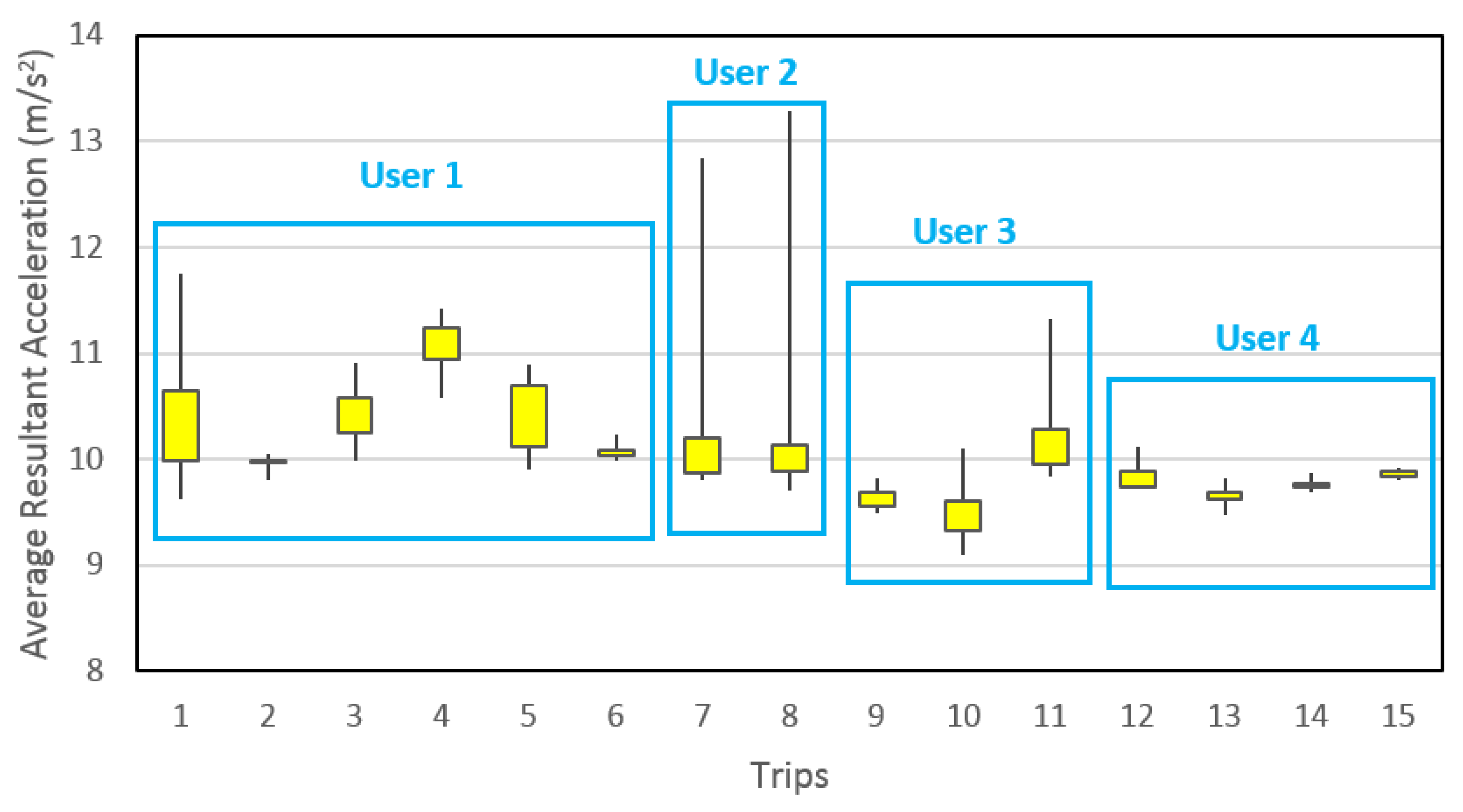
Figure 13 demonstrates the average resultant acceleration values, calculated by a 10 min moving window, for first day walking trips made by four participants only. It is evident from the figure that large window size brings the average resultant acceleration data for each trip, by a particular participant, closer to an average value. Hence, it allows the correct prediction within each participant’s data. Note that the figure shows only one feature. When assisted with a number of other features, the prediction process becomes efficient. This is the probable reason behind the extraordinarily high detection accuracies achieved in this study. To include randomness into the present analysis, the training data were randomly selected rather than taking entire trips. The aim is to assist the travel data collection survey; therefore, the predictions need not to be in real-time. Needless to say, it can be used for real-time prediction but then the window size should be decreased so as to abstain from unnecessarily long lag. The grouping of data in
Figure 13 should not be confused with window size, which remained constant throughout the entire data for the calculation of all features. This grouping is merely to assist in understanding the advantage of using the large window size of 10 min. Furthermore, each trip demonstrates the spread of average resultant acceleration values calculated using 10-min window size.
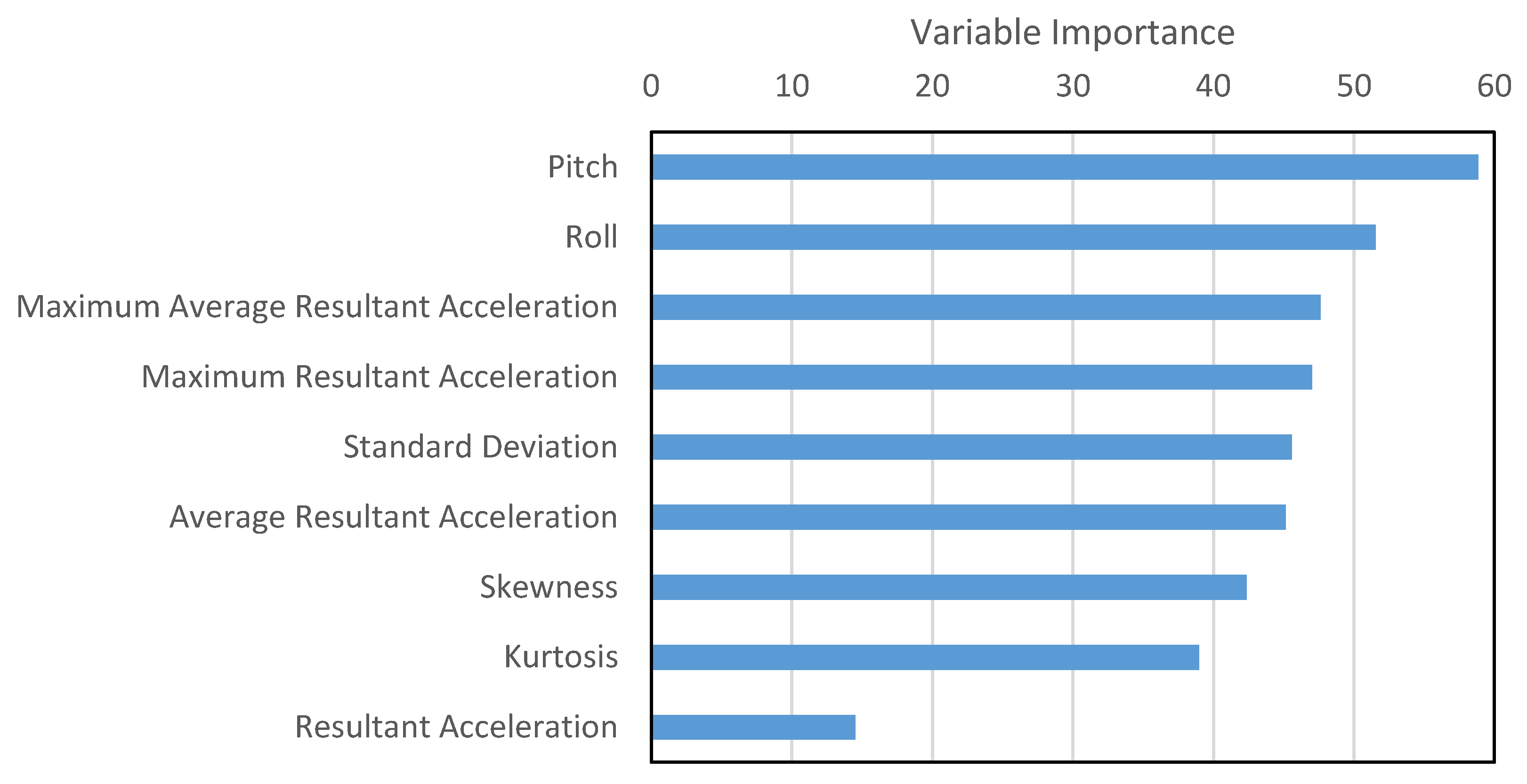
The variable importance, calculated by random forest, is shown in
Figure 14. It is evident that all features, including orientation readings, are important and add to the predictive power of the algorithm. Resultant acceleration is least important, possibly because all other features are extracted from it and within the extracted features the distinguishable information is magnified. Resultant acceleration can therefore be eliminated from the list of features.
4. Conclusions and Future Work
Smartphones are opening up a new horizon for introduction of technology to solve problems in the transportation sector. Travel data collection method can be revolutionized by employing smartphones for passive data recording. This vast possibility is identified by researchers all over the world and much research is being undertaken. The present study is expected to contribute to the ongoing research. The developed methodology takes the data from smartphone sensors as the input information. All this input data can be passively recorded without any effort required on the part of the smartphone carriers.
The current study demonstrated that data recording frequency has huge impacts on the accuracy and efficiency of the methodology. The frequency should be selected with care, as the accuracy decreases with decrease in frequency but simultaneously, the time required for computation also drops. As computation cost will play a decisive role for huge amounts of data, when data collection by smartphones will be applied on a large extent, selection of suitable frequency value will become all the more important. The researcher has to settle for a compromise between accuracy and computational cost. The results showed that an impressive overall classification accuracy of 99.96% can be achieved, with identification level of no mode less than 99.8%. The main sensor value used to extract further features was the magnitude of resultant acceleration. As individual accelerations are affected by activities performed on the smartphones, it is likely that the calculated magnitude will be slightly different for the same mode among smartphones in use and not in use. This in turn will influence the extracted features. It is therefore necessary to investigate this variability and its effect on mode detection.
Initially, automatic mode detection will complement the traditional travel data collection methods by providing accurate and detailed travel information. The participants will no longer need to keep a mental note of where and when they took a trip. All this information will be provided by their smartphones, and the accuracy will obviously be higher. The final form of smart data collection would be making the traditional methods redundant. In future, the smartphone will not only be able to determine the mode of transportation used but will also be able to identify the family, thereby extracting the family data from governmental records like number of family members, their ages, salaries, etc. Moreover, by interacting with nearby smartphones, the identity of the accompanying persons will also be ascertained. We are moving briskly towards that era, with ever increasing smartphone penetration as well as tremendous increase in Internet access.
The sharp decrease in accuracy below 10% learning data, as mentioned in
Section 2.7 might also be the result of small amount of collected data. As the amount of training data are increased, the algorithm becomes more and more intelligent towards predicting unknown examples correctly, until a certain amount is achieved, after which additional training examples do not add substantial detection power to the algorithm. In other words, the algorithm is fully trained and can predict huge amounts of unknown examples. Future studies should keep this aspect in mind and, while using large dataset, report the training data in terms of data points or number of trips rather than percentage of total data. Furthermore, the saturation point should be determined to decide the amount of training data.
One of the major limitations of this study is trip segmentation. Trip segmentation is implicitly added to the data by deleting sensor data during stay or periods of non-activity. It is then coupled with 60 s dwell time to divide the data into trips. In reality, the analyst will be unaware of breaks in the data; therefore, an efficient trip segmentation methodology should be developed. Another major constraint is the unequal representation of various modes in the collected data. Although the data provide a realistic picture of typical Japanese lifestyle, where walking has a major share in daily travelling, this may overshadow other modes. It can be witnessed from the mode-wise classification results, where walk showed outstanding accuracy as compared to other modes. Moreover, due to the massive amount of walk data used for training the algorithm, other modes are predominantly misclassified as walk. Applying the developed methodology for data with comparable representation from all modes might yield different results and should therefore be tested. Another limitation is the small amount of data used in the study. More data should be tested so that the developed methodology may obtain wider acceptance. Effort should be made in order to further decrease the percentage of data used to train the algorithm while attaining similar accuracy levels. This will ensure accurate data interpretation for a large amount of data collected, even when using a small percentage for training purpose. Moreover, variation in data and classification accuracy among different users should be explored to understand the role of users. This may provide new ideas to tackle the issue at hand.



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}