1. Introduction
Traffic detection is an important component of intelligent transportation systems. The collected traffic flow information provides the basis for urban traffic planning and management. However, the current traffic flow collection and analysis face two major issues. One issue is missing data, which result from equipment failure and processing errors. Almost 50% of road permanent traffic counts (PTCs) feature missing data [
1]. This issue becomes more serious for remote microwave sensor data in China [
2]. Another issue corresponds to data sparseness, which results from the low coverage of detectors and requires additional efforts to estimate intermediate traffic conditions between adjacent traffic sensors. These two issues are summarized as incompleteness of traffic flow data. The Texas Transportation Research Institute has reported that the completeness ratio of the data that is archived in transportation management systems increased from 16% to 93% with a data cleansing procedure [
3]. Traffic flow can be utilized to calculate traffic parameters such as annual average daily traffic (AADT) and road capacity. Therefore, missing traffic flow must be recovered for use by transportation planners and operators.
The integrity of traffic data is an important theme that has been discussed for nearly two decades. The principle of
Highway Traffic Monitoring Standards [
4] from the American Society for Testing and Materials Standard Practice and the American Association of State Highway and Transportation Officials Guidelines [
5] state that traffic measurements must be raw before they are saved as base data. However, the imputation of traffic data is not necessarily prohibited during analysis. Traffic data with missing values may be the only data available for certain purposes [
1]; thus, imputation of traffic flow is necessary for further analysis. For traffic flow data with missing values, traffic management agencies usually retake or impute based on incomplete observed data. Albright [
6] emphasized the use of excessive manpower and time to retake data collection from detectors with missing data and mentioned the imputation of missing traffic data as a common countermeasure by many traffic agencies in the United States.
A series of methods have been proposed to impute missing traffic data. The autoregressive integrated moving average (ARIMA) model [
7,
8] is often adopted in studies of time-series traffic prediction, where long-term trends, such as regular daily recurrent congestions, can be observed from traffic flow fluctuation. However, ARIMA is more suitable for short-term traffic prediction with stable traffic patterns and may not be applicable for scenarios with large portions of missing data. Gazis and Liu [
9] considered the sharing error at two adjacent road links and developed an extended Kalman filter approach for traffic flow estimation. The Bayesian and Markov models rely on prior knowledge to obtain estimated parameters [
10,
11,
12]; these models require substantial historical data as prior knowledge. In the context of big data, machine-learning-based methods have emerged. Neural networks and their variants are proposed by a number of scholars for traffic prediction [
13,
14,
15] and have presented promising prediction results. As representative statistical models, multi-variable-based methods are also widely used in traffic prediction. Multiple or weighted regression models [
16,
17] are based on kernel functions, which assign different weight values to independent variables. Common independent variables include historical traffic flow, weather information, and land use. Collecting external variables is time consuming and expensive for model construction of large-scale transportation networks. Lam and Xu [
18] compared two models, namely, regression and neural networks, to estimate AADT based on short-period counts in Hong Kong, suggesting that neural networks outperform regression methods.
The review of the above literature presented a common feature of treating data collection sites as isolated. This feature cannot easily expand to road networks with high numbers of malfunctioning sensors. Huang et al. [
19] pointed out that methods based on historical data will no longer apply when the missing data ratio is high. Missing traffic data can be ideally imputed by using only small valid samples collected from observed sensors. Implementation of this data imputation method can not only reduce economic expenditure of PTC deployment, but can also provide convenience for traffic operators. To achieve this goal, the spatial dependency of traffic flow from adjacent traffic sensors should be incorporated. Spatial interpolation of imputed missing traffic flow data initially captures the spatial dependence of other data collection sites at the same timestamp. Then, missing values are remedied by observed traffic flow data based on spatial dependence. The function that describes spatial dependence is a covariance function based on spatial distance. Kriging is the mainstream spatial interpolation approach based on covariance functions. The fundamental theory of kriging can be found in the works of Cressie [
20] and Stein [
21]. In the transportation domain, a number of successful studies used Kriging for traffic flow imputation. Wang and Kockelman [
22] utilized the Texas highway count data as model input in the Euclidean distance scale and observed that kriging is a promising method and can be applied to a variety of data sets for regression kriging [
23]. Zou et al. [
24] compared the Euclidean distance and road net distance and demonstrated that the use of distance from road net can perform better in traffic speed interpolation. Shamo et al. [
25] compared simple kriging (SK), ordinary kriging (OK), and universal kriging (UK) and discovered that combined with different correlation functions, the same kriging method consistently received suboptimal performance for AADT for 2008. The same researchers also demonstrated that the lack of optimal results for AADT for 2009 and 2010 was caused by data that undermined the assumption of the Gaussian stationary process when using kriging-based methods. The proposed kriging methods are not applicable when spatial correlation is relatively weak, thus coinciding with the results of Zhang et al. [
26]. Compared with AADT data, hourly traffic flow data fluctuates more significantly and therefore require a much more advanced method to relax the constraints of the stationary assumption.
This paper therefore proposes copula-based methods for their adaptability to data with high variability or extreme values [
27,
28]. Copula theory is commonly used in finance time series between stock markets for correlation analysis [
29,
30,
31], and has been recently applied to transportation. For example, Bhat et al. [
32] adopted the concept of copula to analyze the relationship between the daily miles of travel of household vehicles and residential neighborhood selection. Sener and Reeder [
33] explored the effects of the intense activity of workers on active travel behavior. Zou and Zhang [
34] examined the application of copula in a joint model of speed, headway, and vehicle length and proved dependency among these variables. Copula theory combines fitted marginal distribution functions from traffic flow data as a joint distribution function. However, we must firstly analyze spatial dependence to provide the required parameters for the joint distribution function. Finally, we accumulate the probability of the joint distribution function to estimate the missing traffic flow data. With additional support of the marginal distribution function, the copula-based model can more accurately describe spatial dependency than kriging methods [
35]. Copula also features variants that adapt to different roads with varying traffic patterns.
In view of the required data conversion in the interpolation process, we currently use Gaussian copula and non-Gaussian methods, such as Chi-square and Student’s t, to construct models and apply them to two expressways in Beijing. According to Kazianka’s work [
36], the spatial copula is designed to address the need for researchers to analyze spatial data which are markedly non-Gaussian. They also find Gaussian copula is applied in most applications for computational reasons. Gaussian copula has radial symmetry, implying that either the high or low tail of any distribution has an equal dependence [
37]. This assumption may not be applicable for modeling extreme events. To tackle the shortcoming of Gaussian copula, the property of radial asymmetry should be introduced. For example, high values of data generate a stronger spatial dependency than low values. Kazianka and Pliz [
38] have proposed to use non-central chi-squared copula to interpolate spatial data. In the transportation domain, non-recurrent congestion (e.g., accidents and adverse weather conditions) may produce heavy traffic flows. Therefore, the non-Gaussian copula is particularly suitable to spatially impute traffic flow data under extreme traffic conditions. This study aims to examine the applicability of different spatial copula methods in dealing with both stationary and extreme traffic data. In addition, kriging methods, such as classical spatial interpolation approaches, are also carried out for comparison. The main contribution of this study is to propose a copula-based spatial interpolation model for imputing missing traffic flow data from remote microwave sensors.
The remaining sections of this paper are organized as follows. In the next section, the interpolation model is constructed based on basic copula theory.
Section 3 describes the traffic flow data from remote microwave sensors in Beijing.
Section 4 lists parameters from copula-based models and analyzes the interpolation results in comparison with kriging. The final section summarizes conclusions and future work.
3. Data Source
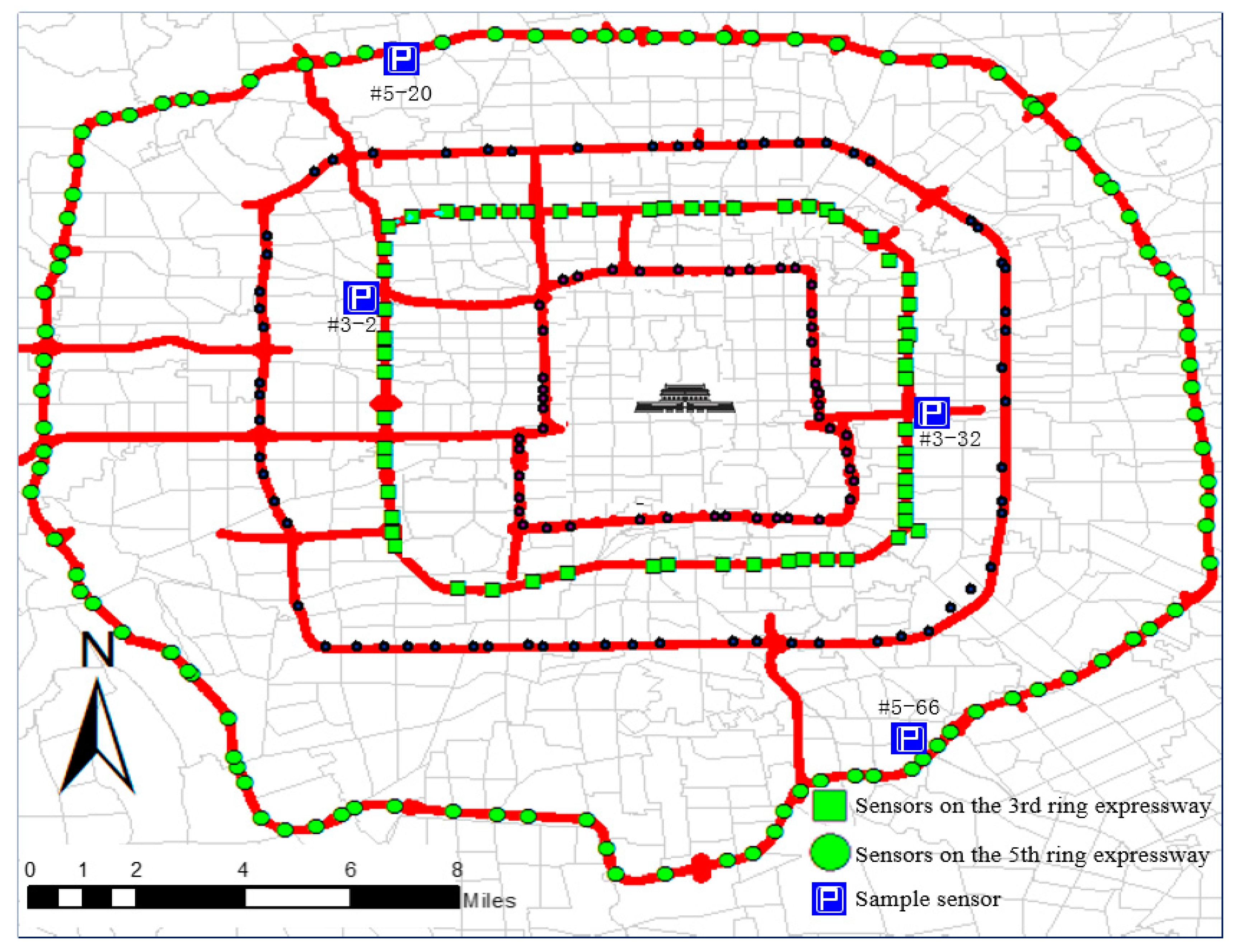
The data used in this study were collected from 454 remote microwave sensors deployed at two ring expressways in Beijing on June 1 (Children’s day), June 4 (a typical weekday), and June 7 (a typical weekend), 2015. The key information mainly includes the detector locations in latitude and longitude, timestamp, traffic flow, speed, and occupancy. The frequency of data updating spanned 2 min. The microwave sensors shown in
Figure 1 are deployed almost evenly on the ring expressway, but several detectors are sparsely deployed in certain areas. Although microwave sensors are more efficient and reliable than traditional loop detectors, they still feature erroneous and missing data issues.
Table 2 summarizes the data quality for all sensors located in the 3rd and 5th ring expressways at three timestamps. The “difference” field represents the positive difference between the number of valid sensors and the total number of deployed sensors. The “missing percentage” field indicates the missing data ratio, which ranges from 27% to 82%. The average missing percentage totals 48.2%, accounting for half of the malfunctioning sensors.
The images in
Figure 2 correspond to the four sample sensors marked in
Figure 1, and
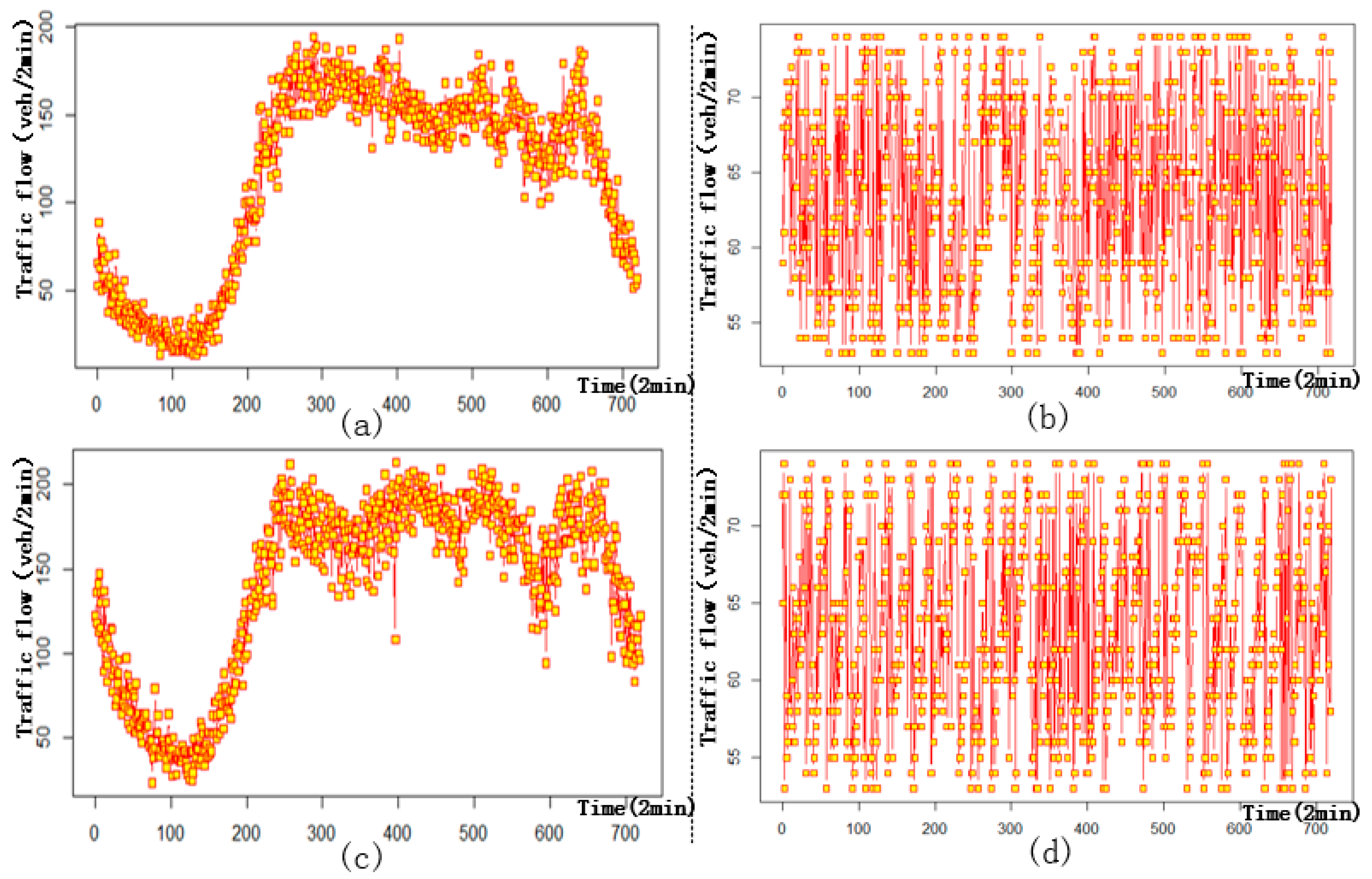
Figure 2a,b displays time series of traffic flow at two random places located on the 3rd and 5th ring expressway, respectively. We only present the time series from June 1 because the daily trends are similar on each weekday or weekend.
Figure 2a shows irregular fluctuations of traffic flow on the 3rd ring expressway. Traffic flow from 8:00 (timestamp equal to 240) to 22:00 (timestamp equal to 660) increases, then gradually decreases from 22:00 to 4:00 (timestamp equal to 120) on the next day, before finally increasing until 8:00. As shown in
Figure 2b, traffic flow on the 5th ring expressway remains between 50 and 80 vehicles every 2 min throughout the entire day.
Similar traffic flow patterns can be observed at the two sensors located on the same expressway.
Figure 2 shows the number of similarities between two random detectors on the 3rd and 5th ring expressways, indicating strong spatial similarities. This factor lays the foundation for the following spatial interpolation.
To test the effectiveness of the proposed algorithm, we randomly extract 50% of the observed data as the training data set, and the remaining 50% is used as the test data set. The coordinates and corresponding traffic flow data derived from discrete sample detectors served as inputs for modeling. In addition, in order to fully validate the proposed model, we added the data sets from the sensors on the 3rd ring expressway at 8:00 (timestamp equal to 240) on 4 June 2015 and 17:00 (timestamp equal to 510) on 7 June 2015. Each data set has two missing types, including missing at random (MR), and missing completely at random (MCR) according to Qu et al. [
45].
Figure 3 shows a schematic diagram of the MR and MCR types.
5. Conclusions
This paper proposes three copula-based models for the interpolation of missing traffic flow data from remote microwave sensors. This spatial interpolation method analyzes the spatial dependency of traffic flow from a spatial perspective and predicts missing values based on observed traffic flow at other spatial locations. The entire model can be divided into two parts, namely, spatial analysis and spatial interpolation. In the first part, a correlation function was employed to describe the spatial structure of traffic flow, and marginal distribution was used to fit the trend of traffic flow. In the second part, a connection was established between the predictor and the adjacent referenced points using copula functions. This connection provided the basis for spatial interpolation. To evaluate the performance of the proposed copula-based models, SK, OK, and UK were implemented for comparison. Comparison was carried out on two data sets with different timestamps at a 50% missing rate from the ring expressway in Beijing. The results from the two approaches indicate that the copula-based models are more effective than kriging methods, especially on roads, such as the 3rd ring expressway, with complex traffic conditions. The results for the data sets observed from different timestamps showed no significant difference, indicating that copula-based models are insensitive to the effects of temporal changes. Experiments for different missing data types proved that the copula-based models are significantly superior to kriging methods for the MR type, and is a robust way to deal with continuously missing data.
The proposed model can be further conducted using several approaches in future work. Although the model is applicable to different times of day, the effect of temporal covariance was still not considered. Thus, using traffic flow from different timestamps to model a spatial–temporal structure presents an interesting work proposal [
46]. In this way, Yang et al. [
47] proposed a sparse representation-based method for spatial–temporal correlation mining to predict city-scale traffic flows. They found that the spatial context can spread out very far. Similarly, Ermagun et al. [
48] developed a data de-trending algorithm to evaluate the spatial correlation between both competitive and complementary links in a grid-like traffic network in Minneapolis, USA. They found that a strong negative correlation happens in rush hours, while a positive correlation occurs between upstream and downstream links. The model is currently applied to only one-dimensional road segments instead of entire road networks with freeways and arterial roads. Potential research should enhance the model architecture for a two-dimensional, network-wide spatial interpolation of missing traffic data. In view of the interpolation ability of copula-based models, identifying optimal sensor deployment locations would be another meaningful study.







{kind=link}
{kind=link}
{kind=link}