Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks


Abstract
:1. Introduction
1.1. Motivation
1.2. Related Work
1.3. Our Contributions
- We obtain an upper bound for throughput performance of the RR policies under average throughput criterion for quite general (Markov, i.i.d., nonuniform, uniform, etc.) EH processes. Furthermore, we show that all RR policies including the myopic policy achieve almost the same throughput performance under an average throughput criterion.
1.4. Organization of the Paper
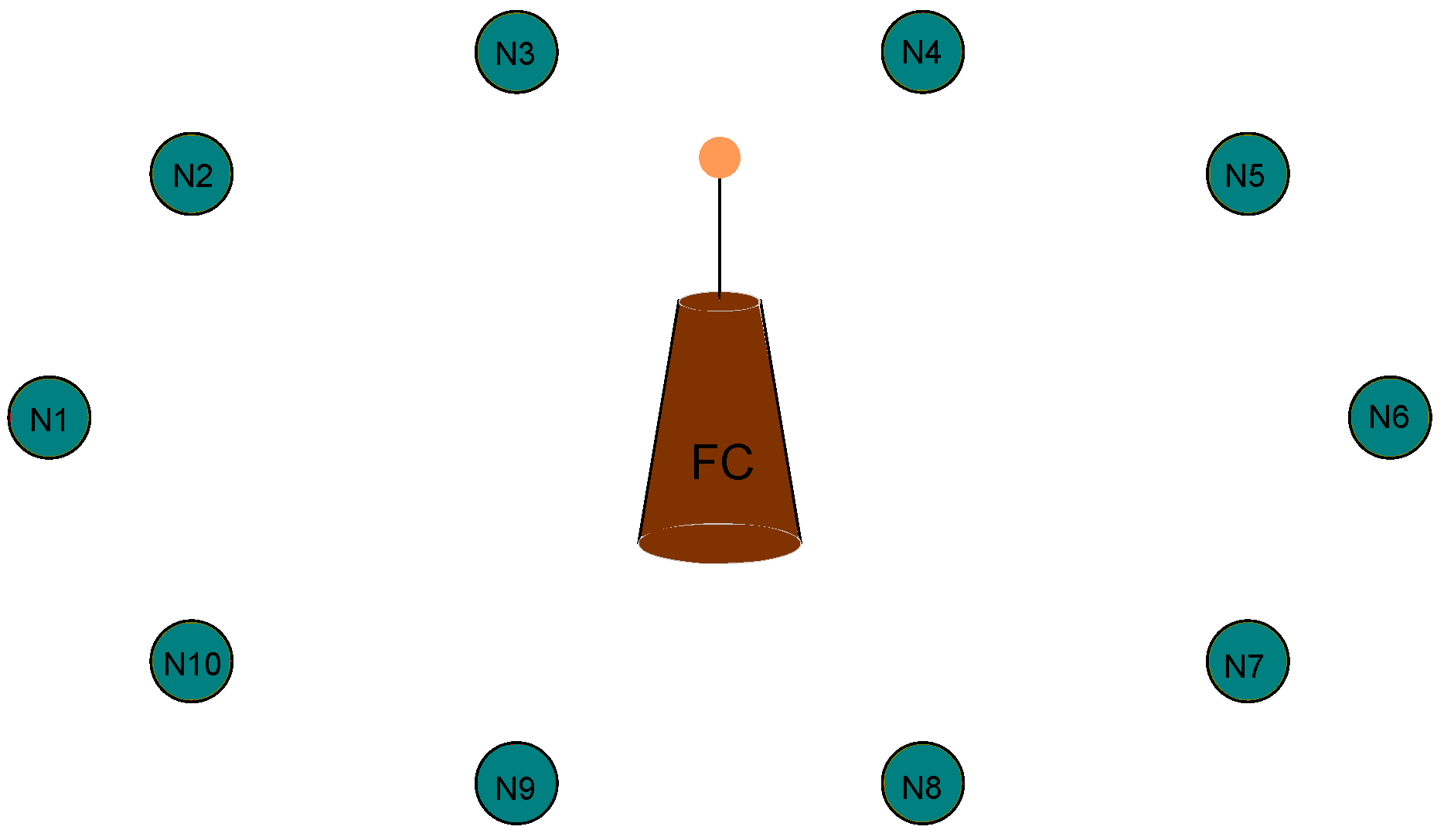
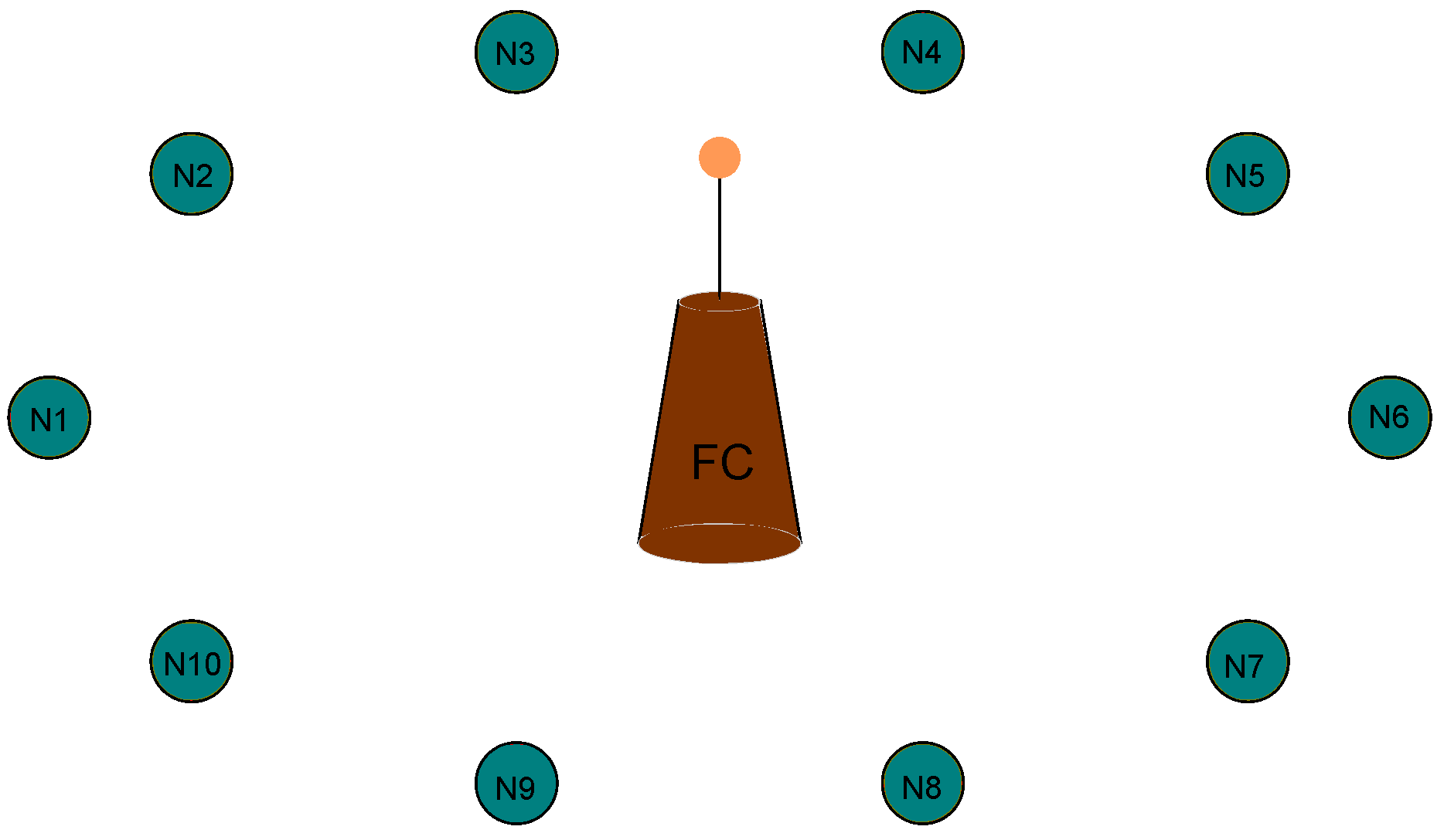
2. System Model and Problem Formulation
3. Efficiency of Myopic and Round Robin Policies
3.1. Efficiency Bounds of RR Policies with Quantum = 1 TS
- (i)
- If , efficiency of an RR policy with quantum=1 TS satisfies
- (ii)
- If , efficiency of an RR policy with quantum=1 TS satisfies
- (i)
- If , then .
- (ii)
- If , and , , then where .
3.2. Throughput Difference of RR Policies with Quantum = 1 TS
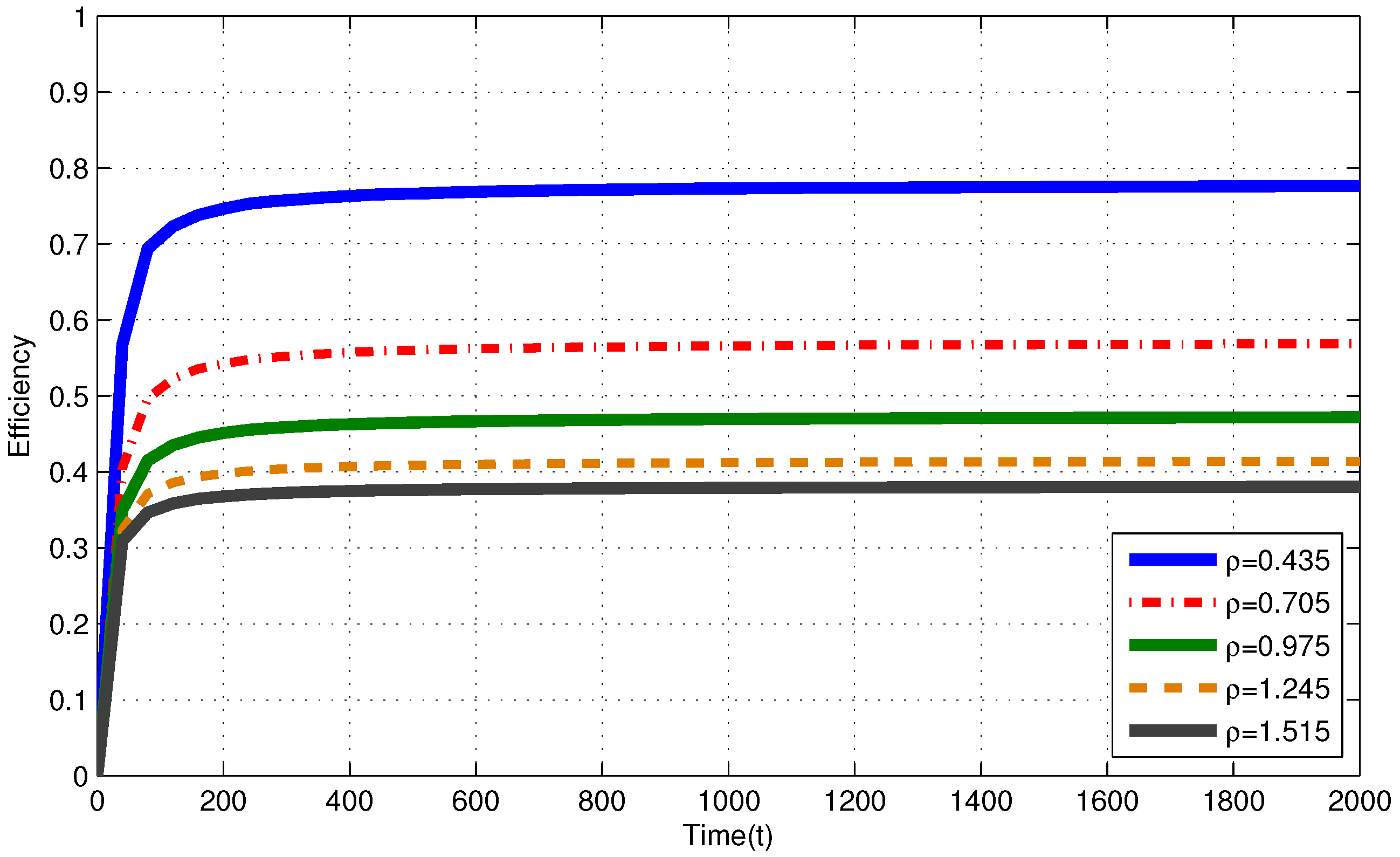
4. Numerical Results
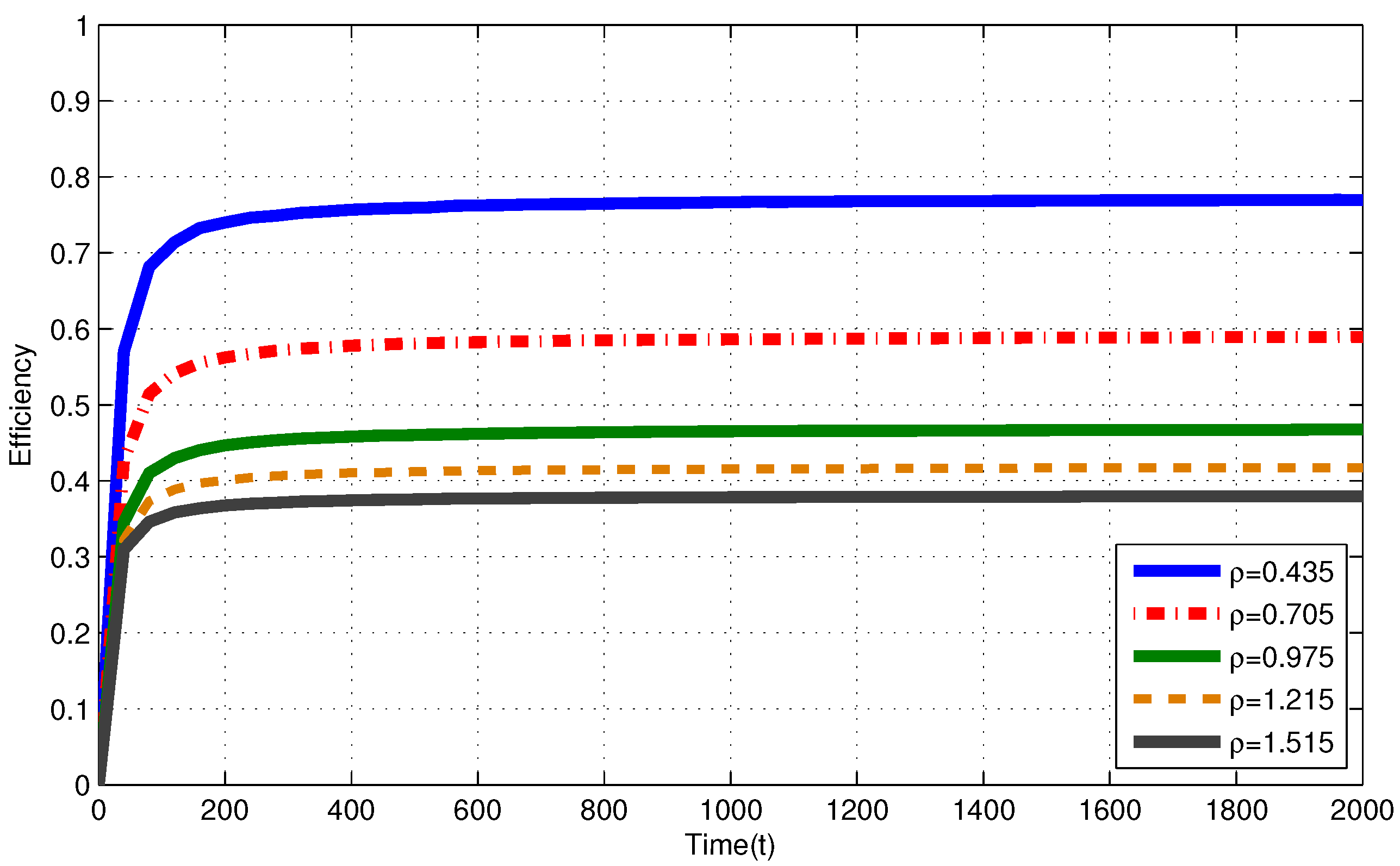
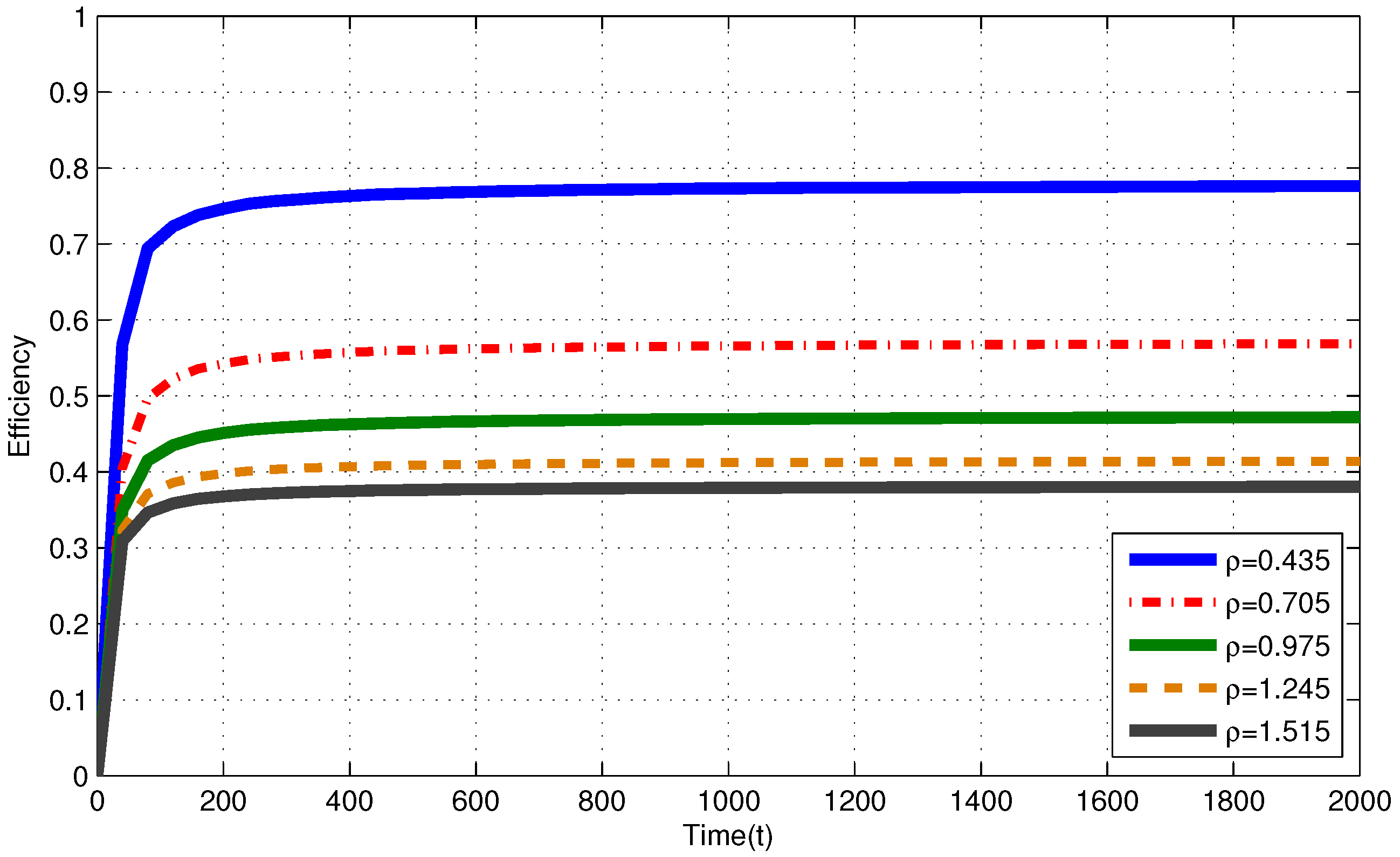
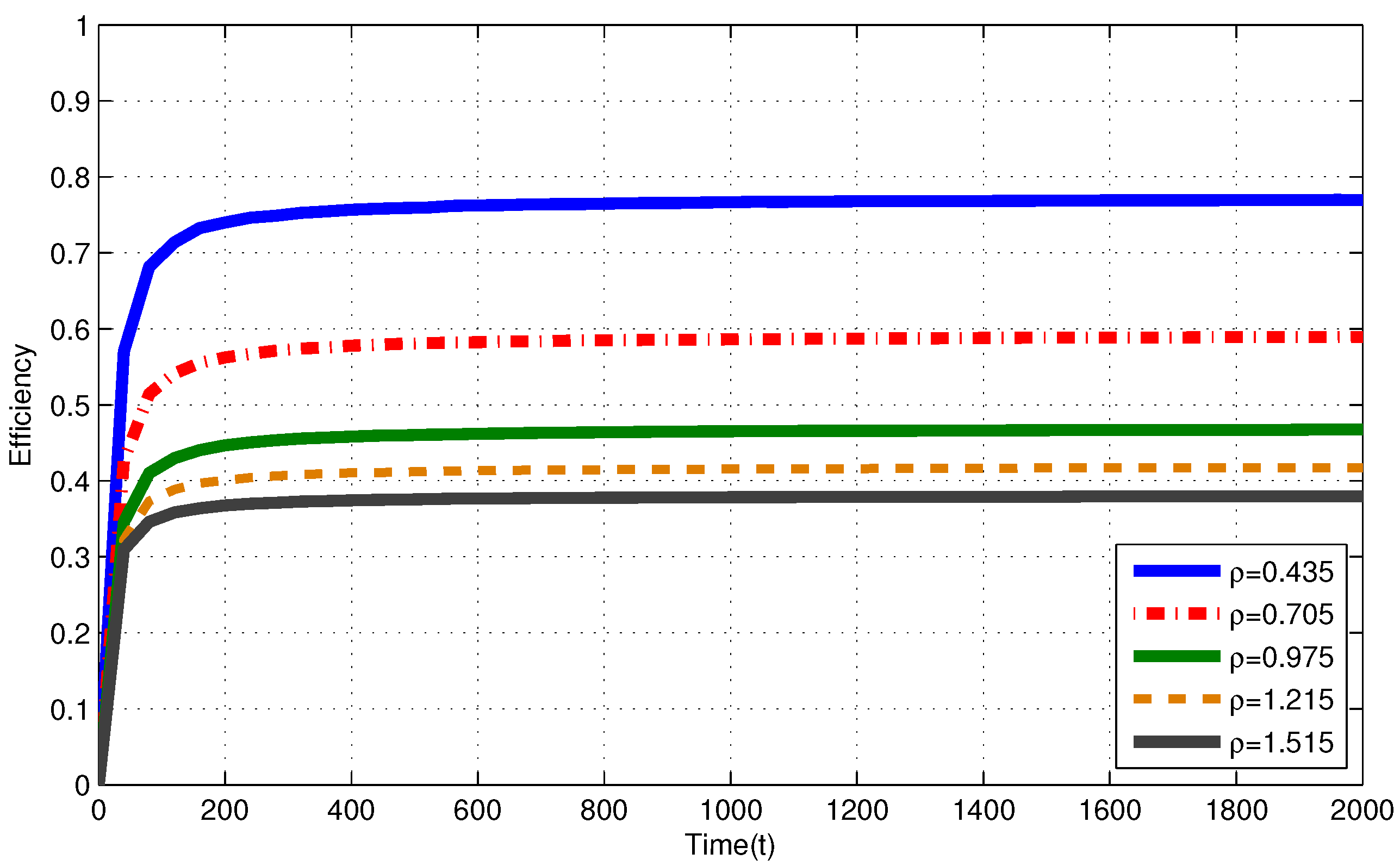
4.1. Infinite Capacity Battery
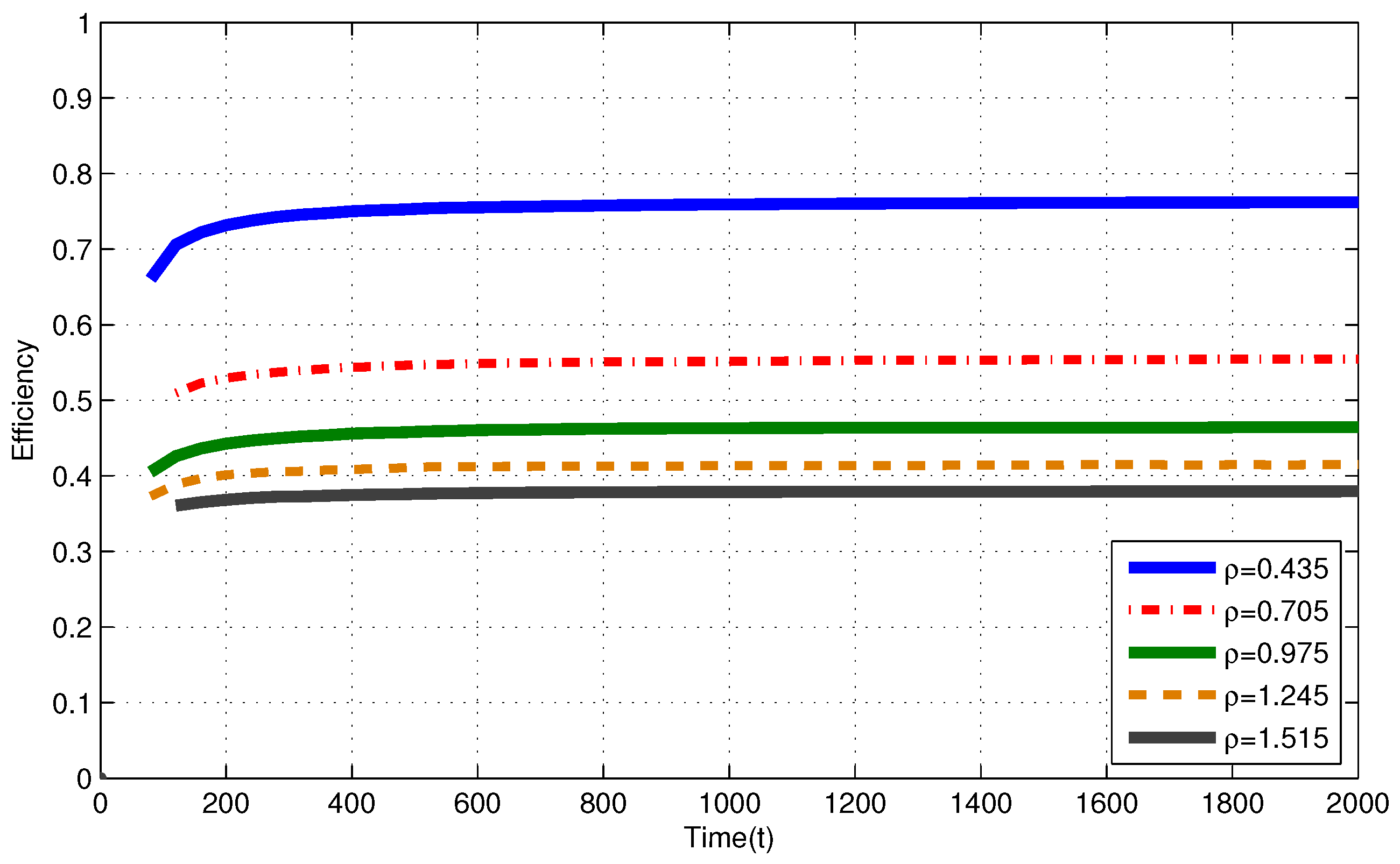
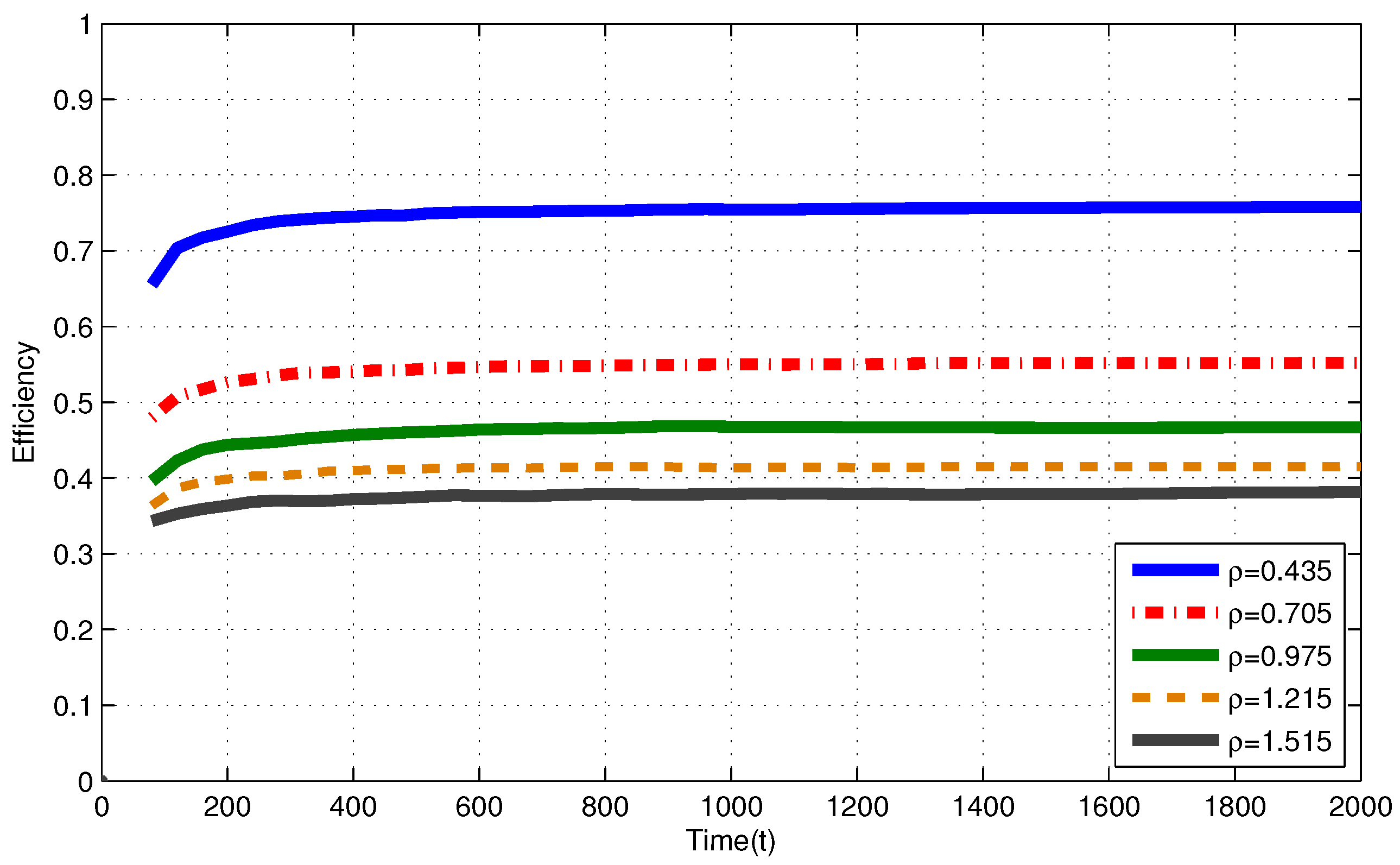
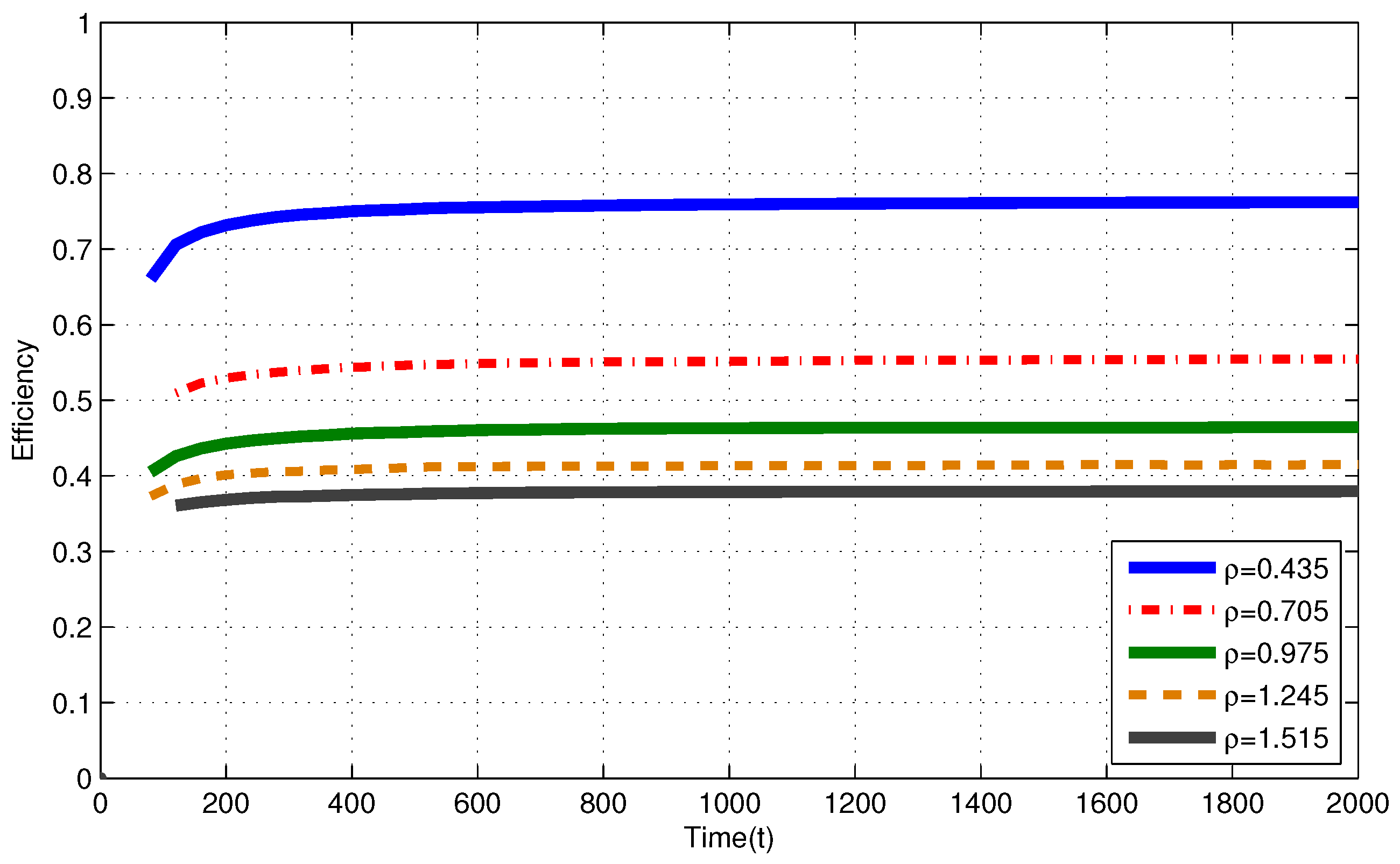
4.2. Finite Capacity Battery
4.3. Discussion
5. Conclusions
Author Contributions
Conflicts of Interest
Abbreviations
| IoT | Internet of Things |
| WSN | Wireless sensor network |
| EH | Energy harvesting |
| FC | Fusion center |
| TS | time slot |
| SNR | Signal to Noise Ratio |
| RF | Radio frequency |
| POMDP | Partially Observable Markov Decision Processes |
| DP | Dynamic Programming |
| RMAB | Restless Multi Armed Bandit |
| PSPACE | Polynomial Space |
| MP | Myopic policy |
| RR | Round-Robin |
| IID | independent and identically distributed |
Appendix A. Proof of Lemma 1
Appendix B. Proof of Theorem 2
Appendix C. Proof of Lemma 2
References
- Sheng, Z.; Yang, S.; Yu, Y.; Vasilakos, A.; Mccann, J.; Leung, K. Survey on the IETF Protocol Suite for the Internet of Things: Standards, Challenges, and Opportunities. IEEE Wirel. Commun. 2013, 20, 91–98. [Google Scholar] [CrossRef]
- Kamalinejad, P.; Mahapatra, C.; Sheng, Z.; Mirabbasi, S.; Leung, V.C.M.; Guan, Y.L. Wireless Energy Harvesting for the Internet of Things. IEEE Commun. Mag. 2015, 53, 102–108. [Google Scholar] [CrossRef]
- Tsai, C.W.; Hong, T.P.; Shiu, G.N. Metaheuristics for the lifetime of WSN: A review. IEEE Sens. J. 2016, 16, 2812–2831. [Google Scholar] [CrossRef]
- Wark, T.; Corke, P.; Sikka, P.; Klingbeil, L.; Guo, Y.; Crossman, C.; Valencia, P.; Swain, D.; Bishop-Hurley, G. Transforming Agriculture through Pervasive Wireless Sensor Networks. IEEE Pervasive Comput. 2007, 6. [Google Scholar] [CrossRef] [Green Version]
- Chaiwatpongsakorn, C.; Lu, M.; Keener, T.C.; Khang, S.-J. The deployment of carbon monoxide wireless sensor network (CO-WSN) for ambient air monitoring. Int. J. Environ. Res. Public Health 2014, 11, 6246–6264. [Google Scholar] [CrossRef] [PubMed]
- Liu, X.-Y.; Zhu, Y.; Kong, L.; Liu, C.; Gu, Y.; Vasilakos, A.V.; Wu, M.-Y. CDC: Compressive data collection for wireless sensor networks. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 2188–2197. [Google Scholar] [CrossRef]
- Valente, J.; Sanz, D.; Barrientos, A.; del Cerro, J.; Ribeiro, A.; Rossi, C. An Air-Ground Wireless Sensor Network for Crop Monitoring. Sensors 2011, 11, 6088–6108. [Google Scholar] [CrossRef]
- Fu, T.; Ghosh, A.; Johnson, E.A.; Krishnamachari, B. Energy-Efficient Deployment Strategies in Structural Health Monitoring using Wireless Sensor Networks. J. Struct. Control Health Monit. 2012, 20, 971–986. [Google Scholar] [CrossRef]
- Aderohunmu, F.; Balsamo, D.; Paci, G.; Brunelli, D. Long Term WSN Monitoring for Energy Efficiency in EU Cultural Heritage Buildings. Lect. Notes Electr. Eng. 2013, 281, 253–261. [Google Scholar]
- Balsamo, D.; Paci, G.; Benini, L.; Davide, B. Long Term, Low Cost, Passive Environmental Monitoring of Heritage Buildings for Energy Efficiency Retrofitting. In Proceedings of the 2013 IEEE Workshop on Environmental Energy and Structural Monitoring Systems (EESMS), Trento, Italy, 11–12 September 2013; pp. 1–6. [Google Scholar]
- Suryadevara, N.K.; Mukhopadhyay, S.C. Wireless sensor network based home monitoring system for wellness determination of elderly. IEEE Sens. J. 2012, 12, 1965–1972. [Google Scholar] [CrossRef]
- Yetgin, H.; Cheung, K.T.K.; El-Hajjar, M.; Hanzo, L. Network lifetime maximization of wireless sensor networks. IEEE Access 2015, 3, 2191–2226. [Google Scholar] [CrossRef]
- Zhou, F.; Chen, Z.; Guo, S.; Li, J. Maximizing Lifetime of Data-Gathering Trees With Different Aggregation Modes in WSNs. IEEE Sens. J. 2016, 16, 8167–8177. [Google Scholar] [CrossRef]
- Hancke, G.P.; de Carvalho e Silva, B.; Hancke, G.P., Jr. The role of advanced sensing in smart cities. Sensors 2013, 13, 393–425. [Google Scholar] [CrossRef] [PubMed]
- Gomez, C.; Paradells, J. Urban Automation Networks: Current and Emerging Solutions for Sensed Data Collection and Actuation in Smart Cities. Sensors 2015, 15, 22874–22898. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Paradiso, J.A.; Starner, T. Energy scavenging for mobile and wireless electronics. IEEE Pervasive Comput. 2005, 4, 18–27. [Google Scholar] [CrossRef]
- Sudevalayam, S.; Kulkarni, P. Energy Harvesting Sensor Nodes: Survey and Implications. IEEE Commun. Surv. Tutor. 2011, 13, 443–461. [Google Scholar] [CrossRef]
- Akyildiz, I.F.; Su, W.; Sankarasubramaniam, Y.; Cayirci, E. A survey on sensor networks. IEEE Commun. Mag. 2002, 40, 102–114. [Google Scholar] [CrossRef]
- Kansal, A.; Hsu, J.; Zahedi, S.; Srivastava, M.B. Power management in energy harvesting sensor networks. ACM Trans. Embed. Comput. Syst. 2007, 6, 32. [Google Scholar] [CrossRef]
- Garcia-Hernandez, C.F.; Ibargengoytia-Gonzalez, P.H.; Garcia-Hernandez, J.; Perez-Diaz, J.A. Wireless Sensor Networks and Applications: A Survey. IJCSNS Int. J. Comput. Sci. Netw. Secur. 2007, 7, 264–273. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Bell Syst. Technol. J. 1948, 27, 379–426. [Google Scholar] [CrossRef]
- Alsheikh, M.A.; Hoang, D.T.; Niyato, D.; Tan, H.; Lin, S. Markov Decision Processes With Applications in Wireless Sensor Networks: A Survey. IEEE Commun. Surv. Tutor. 2015, 17, 1239–1267. [Google Scholar] [CrossRef]
- Battery University (Cadex Electronics). BU-802b: What Does Elevated Self-discharge Do? Available online: http://batteryuniversity.com/learn/article/elevatingselfdischarge (accessed on 4 April 2017).
- Arapostathis, A.; Borkar, V.S.; Fernández-gaucherand, E.; Ghosh, M.K.; Marcus, S.I. Discrete-time controlled Markov processes with average cost criterion: A survey. SIAM J. Control Optim. 1993, 31, 282–334. [Google Scholar] [CrossRef]
- Monahan, G.E. State of the art-A survey of partially observable Markov decision processes: Theory, models, and algorithms. Manag. Sci. 1982, 28, 1–16. [Google Scholar] [CrossRef]
- Bellman, R.E. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Littman, M.L.; Dean, T.L.; Kaelbling, L.P. In the complexity of solving Markov decision problems. In Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–20 August 1995; pp. 394–402. [Google Scholar]
- Watkins, C.J. Learning from Delayed Rewards. Ph.D. Thesis, University of Cambridge, Cambridge, UK, 1989. [Google Scholar]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar]
- Mahadevan, S. Average reward reinforcement learning: Foundations, algorithms, and empirical results. Mach. Learn. Spec. Issue Reinf. Learn. 1996, 22, 159–196. [Google Scholar]
- Whittle, P. Restless bandits: Activity allocation in a changing world. J. Appl. Probab. 1988, 25, 287–298. [Google Scholar] [CrossRef]
- Papadimitriou, C.H.; Tsitsiklis, J.N. The complexity of optimal queueing network control. Math. Oper. Res. 1999, 24, 293–305. [Google Scholar] [CrossRef]
- Hero, A.; Castanon, D.; Cochran, D.; Kastella, K. Foundations and Applications of Sensor Management; Springer: New York, NY, USA, 2007. [Google Scholar]
- Blasco, P.; Gunduz, D.; Dohler, M. Low-Complexity Scheduling Policies for Energy Harvesting Communication Networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Istanbul, Turkey, 7–12 July 2013; pp. 1601–1605. [Google Scholar]
- Iannello, F.; Simeone, O.; Spagnolini, U. Optimality of myopic scheduling and whittle indexability for energy harvesting sensors. In Proceedings of the 46th Annual Conference on Information Sciences and Systems(CISS), Princeton, NJ, USA, 21–23 March 2012; pp. 1–6. [Google Scholar]
- Gittins, J.; Glazerbrook, K.; Weber, R. Multi-Armed Bandit Allocation Indices; Wiley: West Sussex, UK, 2011. [Google Scholar]
- Gul, O.M.; Uysal-Biyikoglu, E. A randomized scheduling algorithm for energy harvesting wireless sensor networks achieving nearly 100% throughput. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Istanbul, Turkey, 6–9 April 2014; pp. 2456–2461. [Google Scholar]
- Gul, O.M.; Uysal-Biyikoglu, E. Achieving nearly 100% throughput without feedback in energy harvesting wireless networks. In Proceedings of the IEEE International Symposium on Information Theory (ISIT), Honolulu, HI, USA, 29 June–4 July 2014; pp. 1171–1175. [Google Scholar]
- Gul, O.M.; Uysal-Biyikoglu, E. UROP: A Simple, Near-Optimal Scheduling Policy for Energy Harvesting Sensors. arXiv, 2014; arXiv:1401.0437. [Google Scholar]
- Durmaz Incel, O. A survey on multi-channel communication in wireless sensor networks. Comput. Netw. 2011, 55, 3081–3099. [Google Scholar] [CrossRef]
- Beckwith, R.; Teibel, D.; Bowen, P. Unwired Wine: Sensor Networks in Vineyards. In Proceedings of the 2014 IEEE Sensors, Vienna, Austria, 24–27 October 2004; pp. 1–4. [Google Scholar]
- Chaudhary, D.D.; Nayse, S.P.; Waghmare, L.M. Application of Wireless Sensor Networks for Greenhouse Parameter Control in Precision Agriculture. Int. J. Wirel. Mob. Netw. IJWMN 2011, 3, 140–149. [Google Scholar]
- Srbinovska, M.; Gavrovski, C.; Dimcev, V.; Krkoleva, A.; Borozan, V. Environmental parameters monitoring in precision agriculture using wireless sensor networks. J. Clean. Prod. 2015, 88, 297–307. [Google Scholar] [CrossRef]
- Project RHEA. Robot Fleets For Highly Effective Agriculture And Forestry Management. From 2010-08-01 to 2014-07-31, Closed Project. Available online: http://cordis.europa.eu/project/rcn/95055en.html (accessed on 29 May 2017).
- Project CROPS. Intelligent Sensing and Manipulation for Sustainable Production and Harvesting of High Value Crops, Clever Robots for Crops. From 2010-10-01 to 2014-09-30, Closed Project. Available online: http://cordis.europa.eu/project/rcn/96216_en.html (accessed on 25 May 2017).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| M | The number of energy harvesting nodes |
| K | The number of mutually orthogonal channels of FC |
| S | The index set of all nodes |
| T | The time horizon |
| Throughput of all nodes in TSs 1 through t under a policy | |
| Throughput of node i in TSs 1 through t under a policy | |
| Efficiency of a policy | |
| The number of packets which can be sent by node i in | |
| Intensity of node i | |
| Intensity |
| W | 95 | 85 | 75 | 65 | 55 |
| L | 5 | 15 | 25 | 35 | 45 |
| Efficiency of MP for Markov EH process, | |||||
| Efficiency of MP for Markov EH process, | |||||
| Efficiency of MP for IID EH process, | |||||
| Efficiency of MP for IID EH process, | |||||
| Max. efficiency difference between and | |||||
| Max. efficiency difference (%) btw. and | |||||
| Upper bound for efficiency of MP | |||||
| Max. deviation between the bound and efficiency of MP |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gul, O.M.; Demirekler, M. Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks. Sensors 2017, 17, 2206. https://doi.org/10.3390/s17102206
Gul OM, Demirekler M. Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks. Sensors. 2017; 17(10):2206. https://doi.org/10.3390/s17102206
Chicago/Turabian StyleGul, Omer Melih, and Mubeccel Demirekler. 2017. "Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks" Sensors 17, no. 10: 2206. https://doi.org/10.3390/s17102206
APA StyleGul, O. M., & Demirekler, M. (2017). Average Throughput Performance of Myopic Policy in Energy Harvesting Wireless Sensor Networks. Sensors, 17(10), 2206. https://doi.org/10.3390/s17102206