DEEP-SEE: Joint Object Detection, Tracking and Recognition with Application to Visually Impaired Navigational Assistance

Abstract
:1. Introduction
2. Related Work
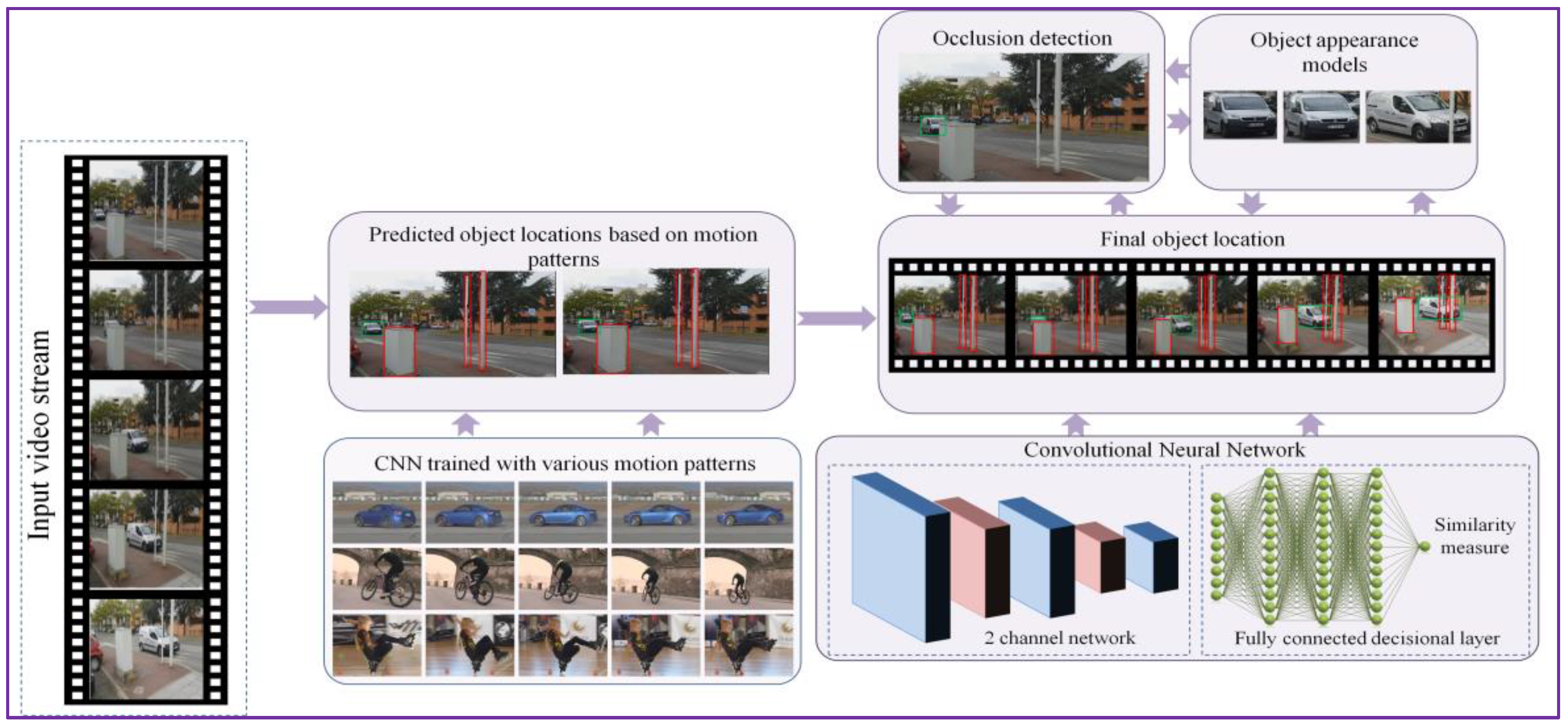
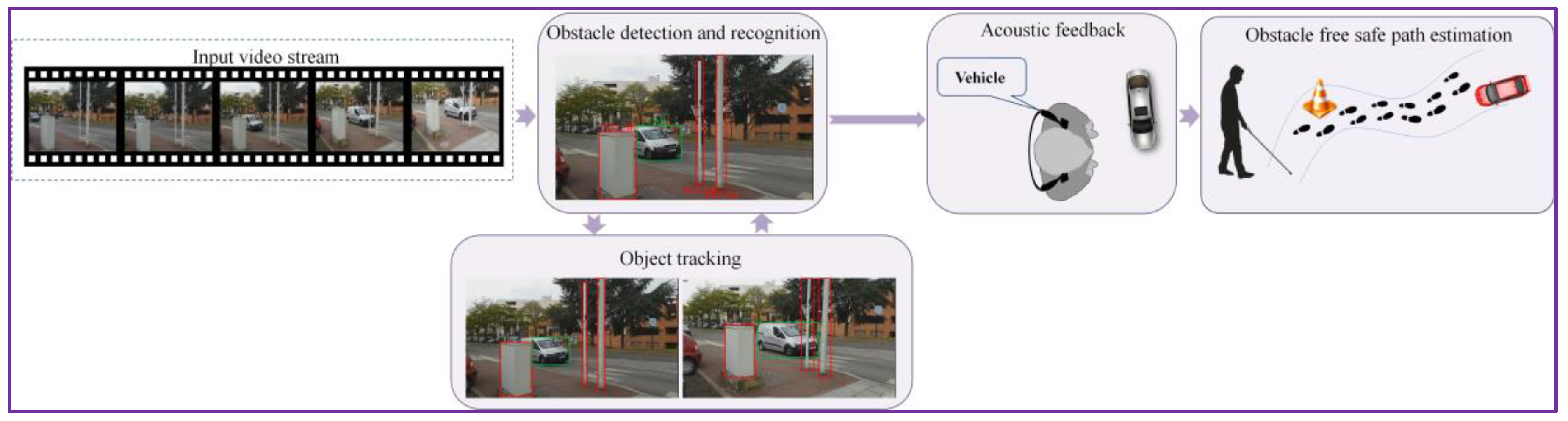
3. DEEP-SEE: Joint Object Detection, Recognition and Tracking
3.1. Object Detection and Recognition
3.2. Object Tracking
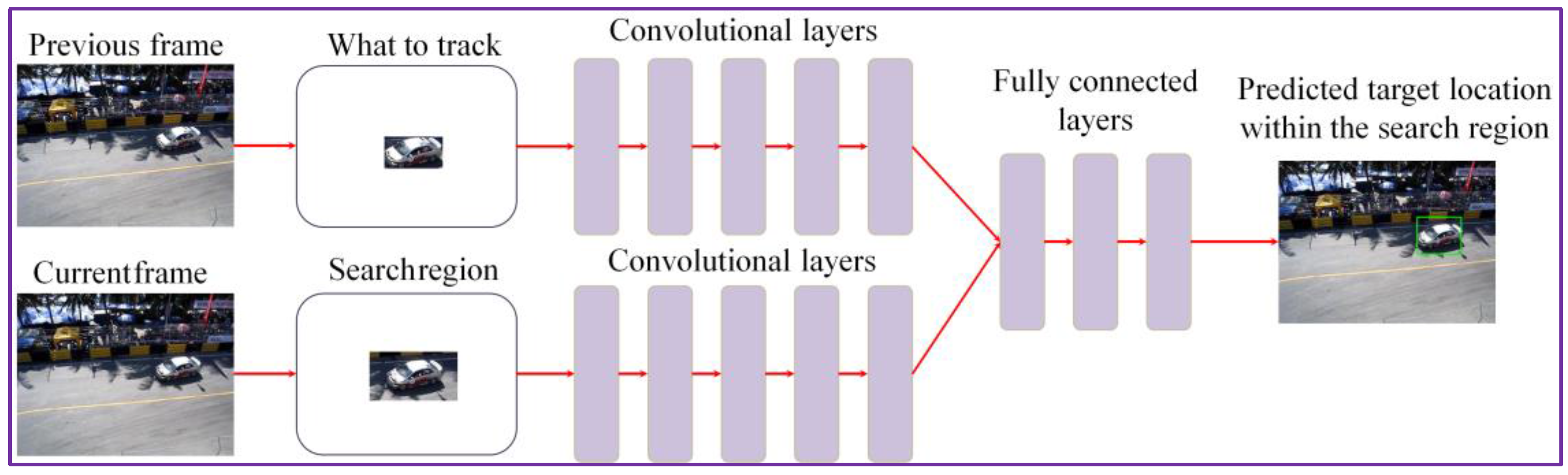
3.2.1. Initial Object Position Estimation: CNN Trained with Motion Patterns
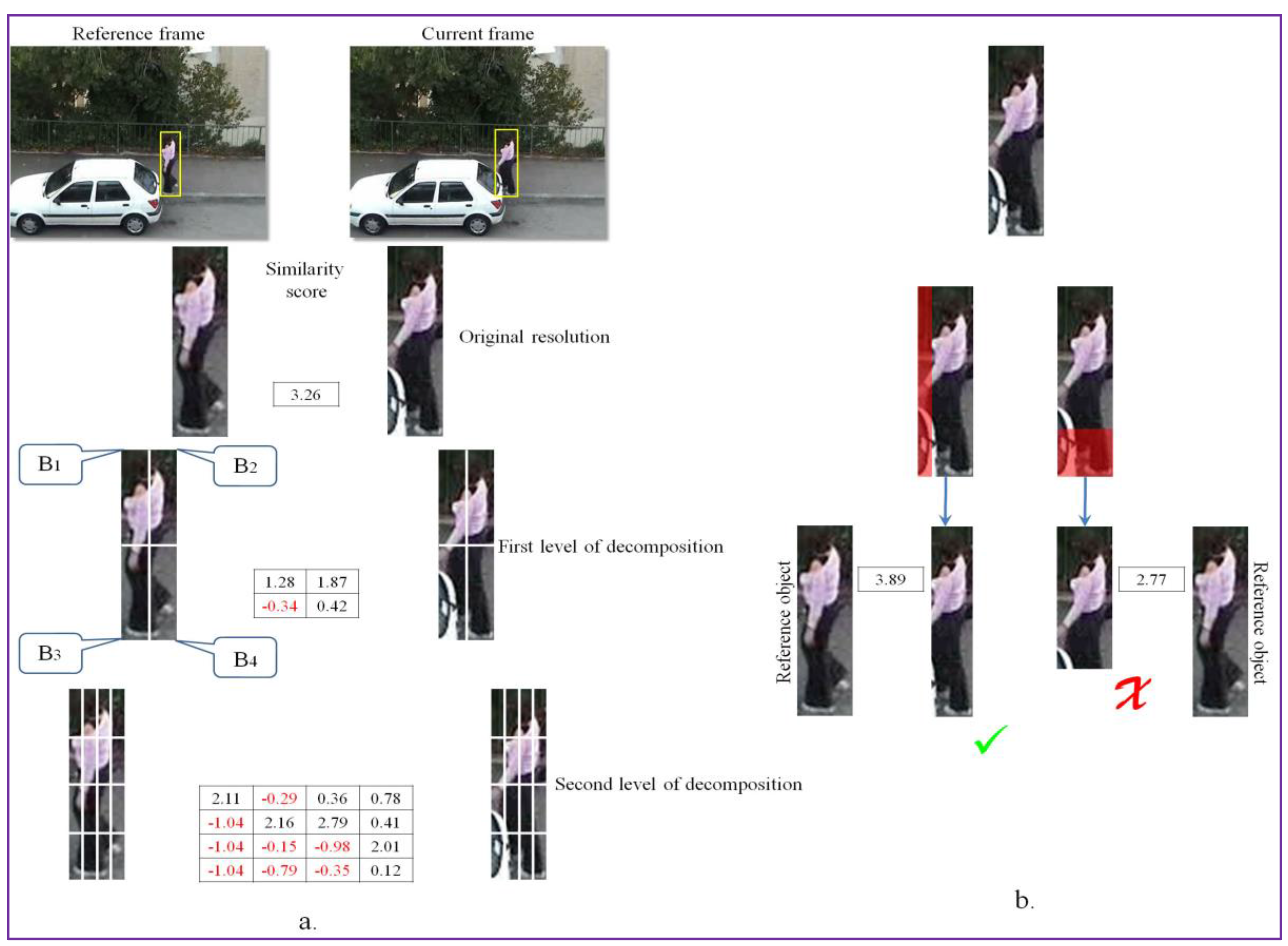
3.2.2. Occlusion Detection and Handling
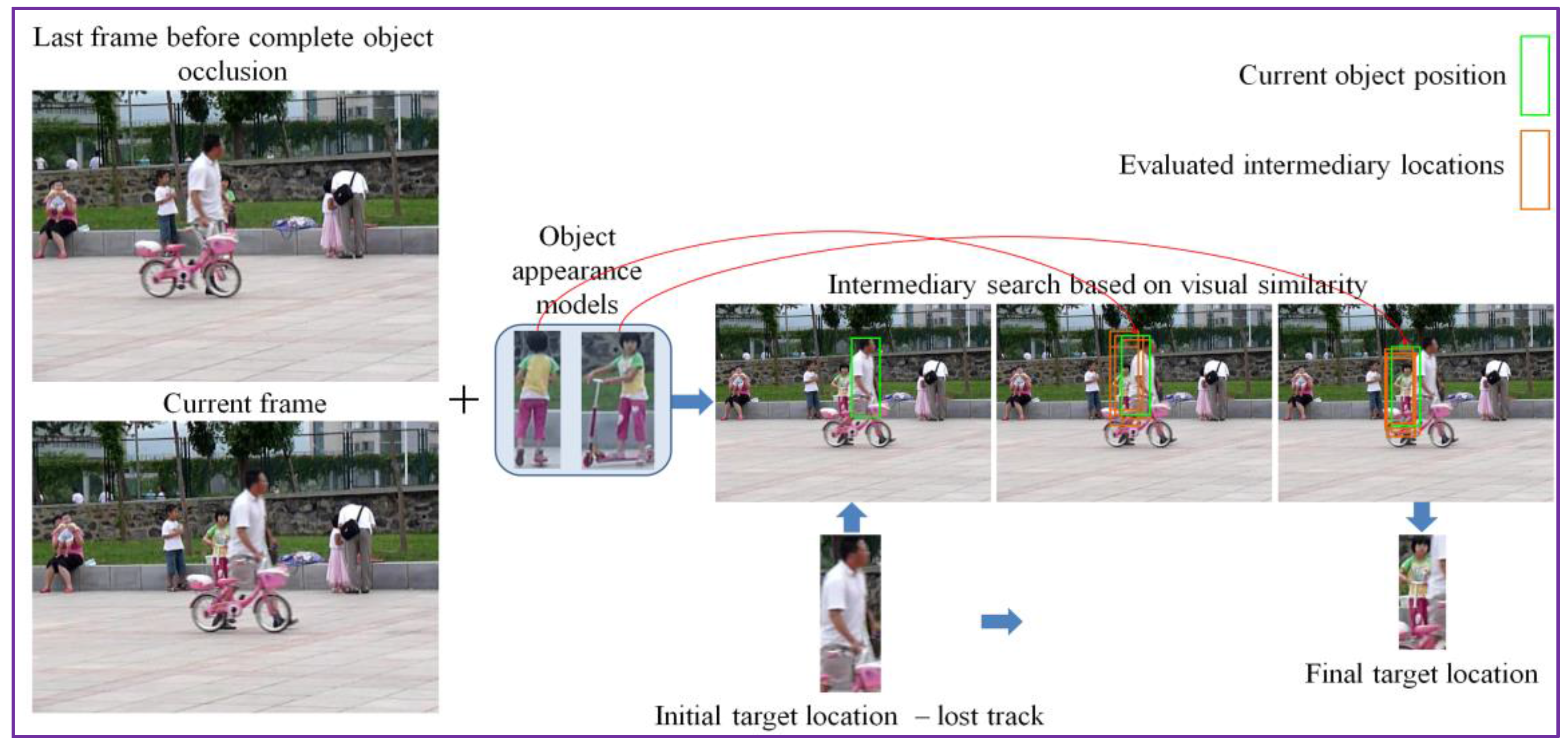
3.2.3. Object Appearance Model
4. Object Detection and Tracking: Experimental Evaluation
4.1. The Benchmark
- -
- unsupervised, where the tracking system receives as input the object bounding box from the first frame of the video sequence (the object bounding box can be provided by a human annotator or by an obstacle detection system) and then no human intervention is allowed; and
- -
- supervised, where the tracker is locally re-initialized with the object bounding box (from the ground truth) if the target element is lost (tracking failure).
4.2. Evaluation Metrics
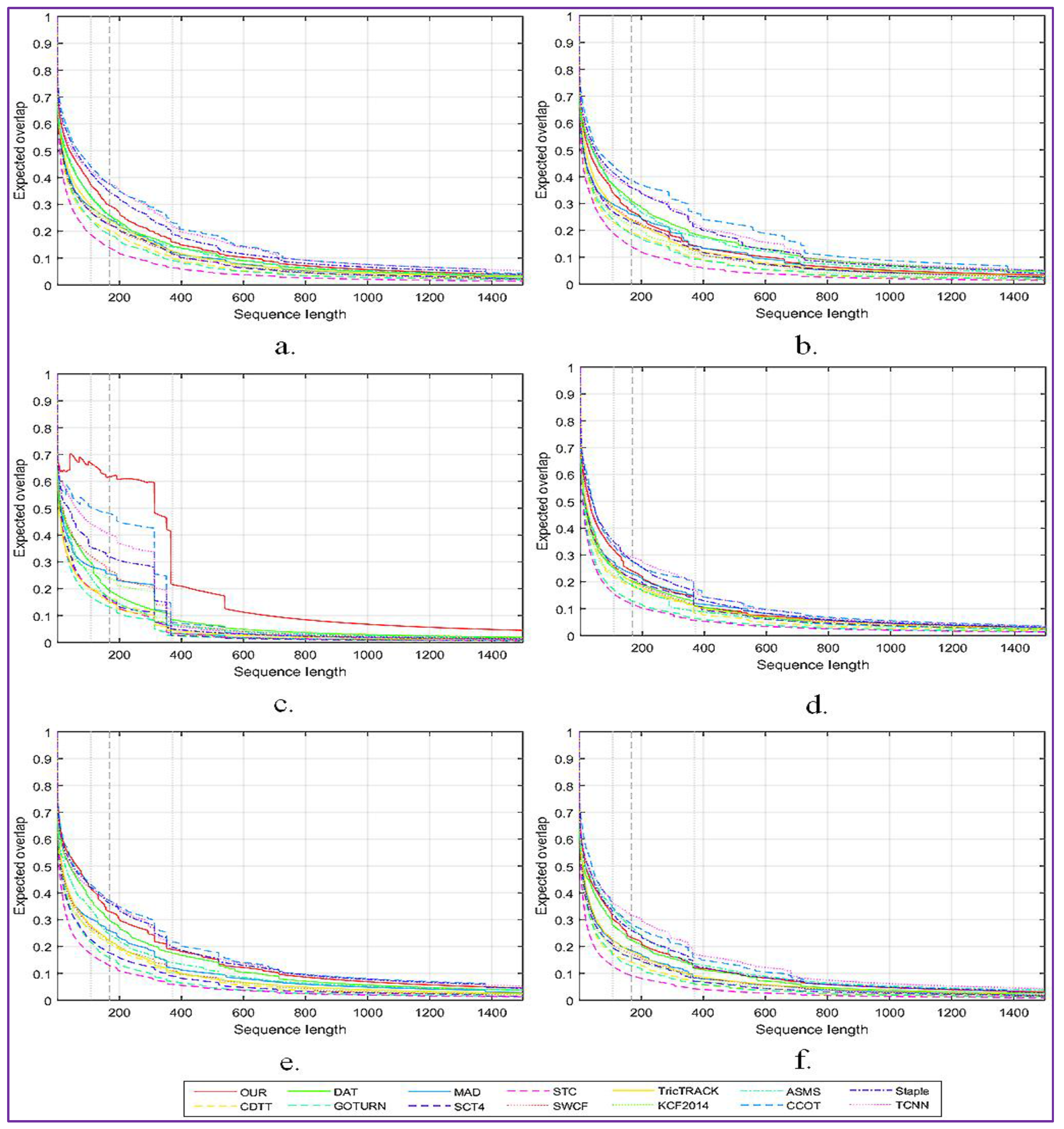
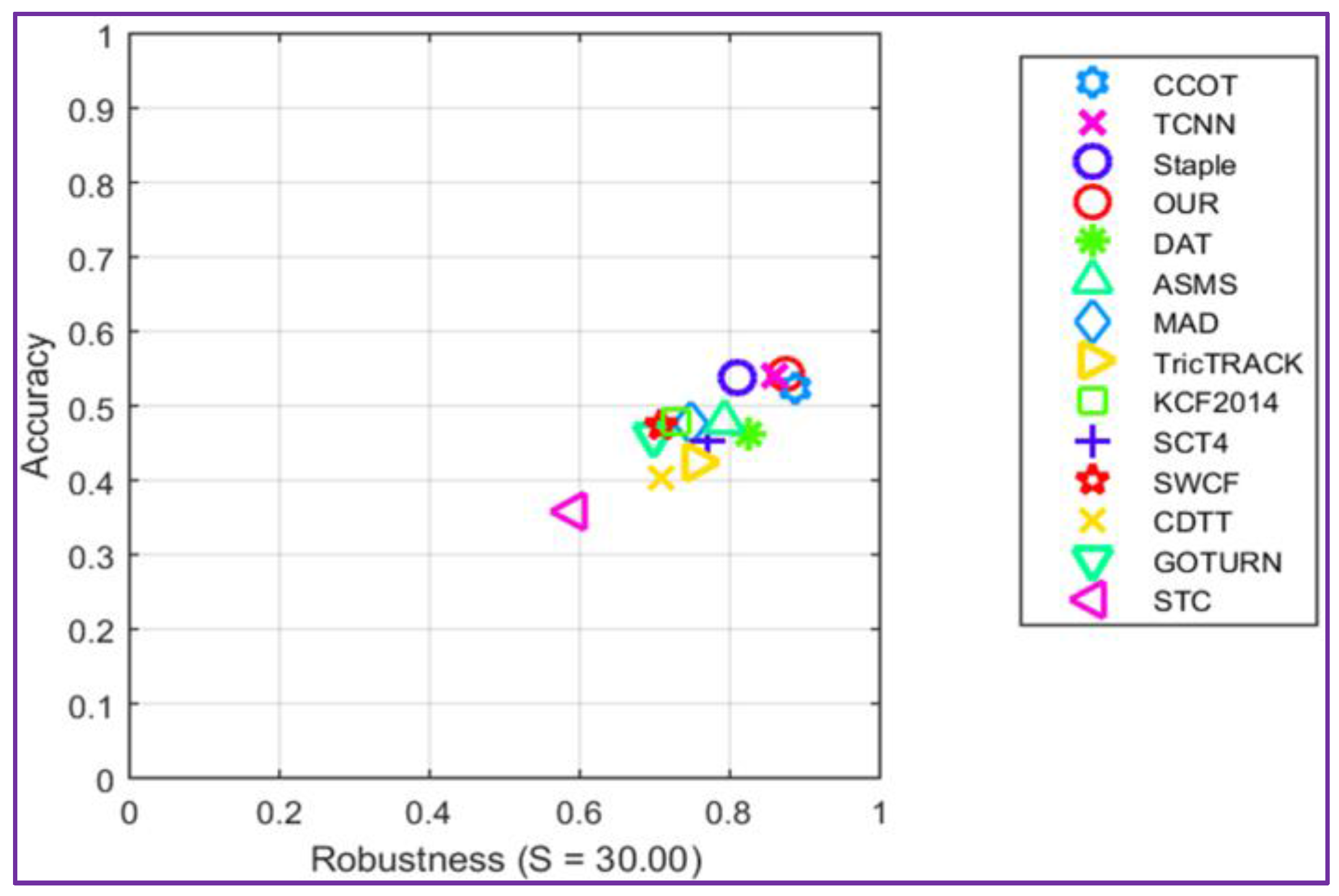
4.3. Quantitative Evaluation
4.4. Qualitative Evaluation
5. The DEEP-SEE Navigational Assistant
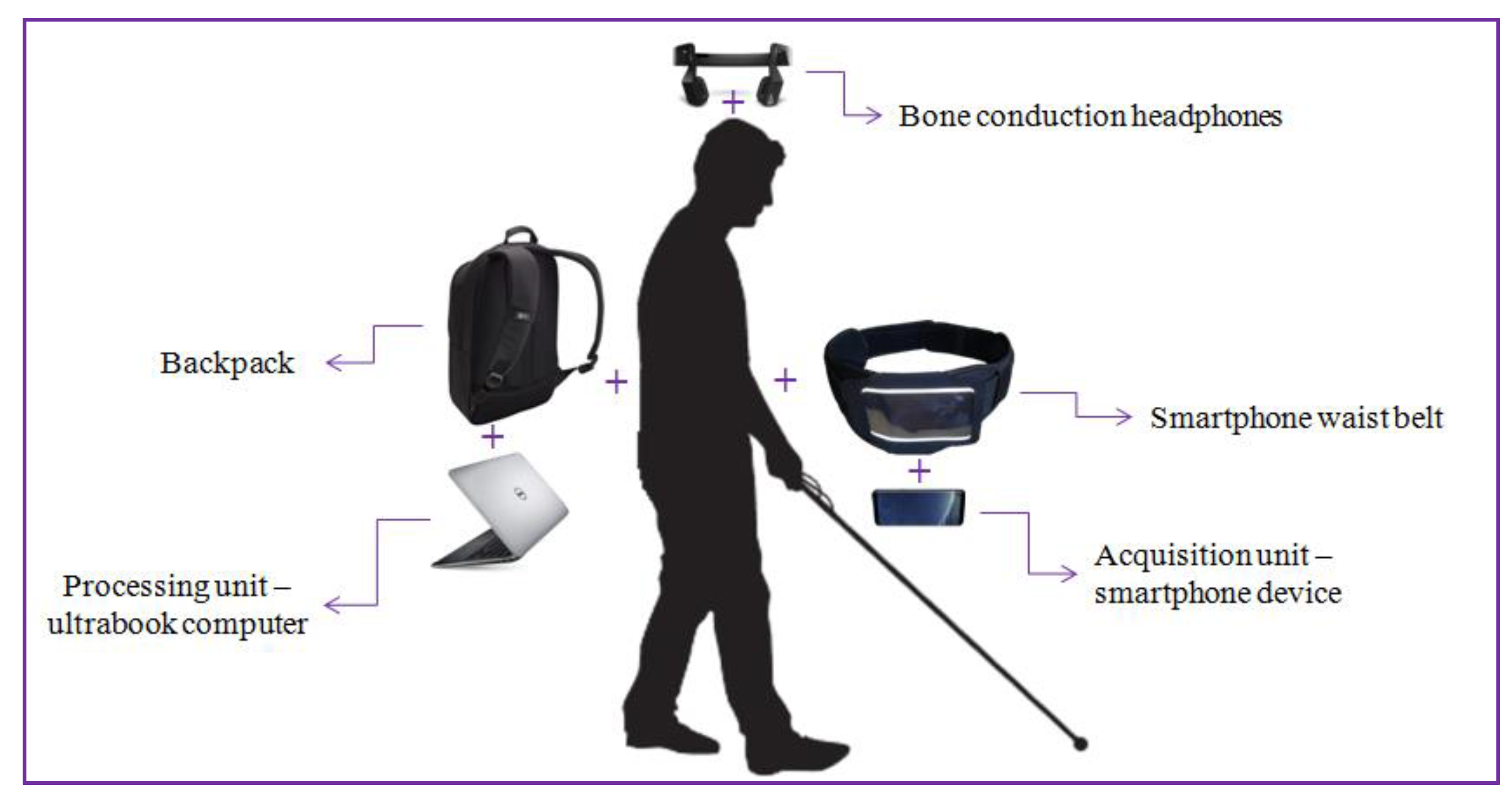
5.1. System Architecture
5.1.1. Acoustic Feedback
5.1.2. Estimation of the Degree of Dangerousness and Prioritization of Messages
5.2. VI Navigational Assistance: Experimental Evaluation
6. Conclusions and Perspectives
Author Contributions
Conflicts of Interest
References
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Vojir, T.; Noskova, J.; Matas, J. Robust scale-adaptive mean-shift for tracking. Pattern Recognit. Lett. 2014, 49, 250–258. [Google Scholar] [CrossRef]
- Becker, S.; Krah, S.; Hubner, W.; Arens, M. Mad for visual tracker fusion. In Proceedings of the Optics and Photonics for Counterterrorism, Crime Fighting, and Defence XIII, Edinburgh, UK, 26–29 September 2016. [Google Scholar]
- Wang, X.; Valstar, M.; Martinez, B.; Khan, H.; Pridmore, T. Tric-track: Tracking by regression with incrementally learned cascades. In Proceedings of the International Conference on Computer Vision, Santiago, Chile, 11–18 December 2015. [Google Scholar]
- Henriques, J.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 583–596. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Ouyang, W.; Wang, X.; Lu, H. Stct: Sequentially training convolutional networks for visual tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Gundogdu, E.; Alatan, A. Spatial windowing for correlation filter based visual tracking. In Proceedings of the International Conference on Image Processing, Phoenix, AZ, USA, 25–28 September 2016. [Google Scholar]
- Xiao, J.; Stolkin, R.; Leonardis, A. Single target tracking using adaptive clustered decision trees and dynamic multi-level appearance models. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Possegger, H.; Mauthner, T.; Bischof, H. In defense of color-based model-free tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Zhang, K.; Zhang, L.; Liu, Q.; Zhang, D.; Yang, M. Fast visual tracking via dense spatio-temporal context learning. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 127–141. [Google Scholar]
- Nam, H.; Baek, M.; Han, B. Modeling and propagating CNNs in a tree structure for visual tracking. arXiv, 2016; arXiv:1608.07242. [Google Scholar]
- Cehovin, L.; Leonardis, A.; Kristan, M. Visual object tracking performance measures revisited. arXiv, 2015; arXiv:1502.05803. [Google Scholar]
- Bertinetto, L.; Valmadre, J.; Golodetz, S.; Miksik, O.; Torr, P.H.S. Staple: Complementary learners for real-time tracking. In Proceedings of the IEEE International Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 1401–1409. [Google Scholar]
- Danelljan, M.; Robinson, A.; Khan, F.K.S.; Felsberg, M. Beyond correlation filters: Learning continuous convolution operators for visual tracking. In Proceedings of the European Conference on Computer Vision, Amsterdam, Netherlands, 8–16 October 2016; pp. 472–488. [Google Scholar]
- Held, D.; Thrun, S.; Savarese, S. Learning to track at 100 fps with deep regression net-works. In Proceedings of the European Conference on Computer Vision, Amsterdam, Netherlands, 8–16 October 2016; pp. 749–765. [Google Scholar]
- Tapu, R.; Mocanu, B.; Bursuc, A.; Zaharia, T. A Smartphone-Based Obstacle Detection and Classification System for Assisting Visually Impaired People. In Proceedings of the 2013 IEEE International Conference on Computer Vision Workshops, Sydney, Australia, 2–8 December 2013; pp. 444–451. [Google Scholar]
- Smeulders, A.; Chu, D.; Cucchiara, R.; Calderara, S.; Dehghan, A.; Shah, A. Visual Tracking: An Experimental Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 36, 1442–1468. [Google Scholar]
- Jia, Y. Caffe: An Open Source Convolutional Architecture for Fast Feature Embedding. Available online: http://caffe.berkeleyvision.org/ (accessed on 25 October2017).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. Imagenet large scale visual recognition challenge. Int. J. Comput. Vis. 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Zagoruyko, S.; Komodakis, N. Learning to compare image patches via convolutional neural networks. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4353–4361. [Google Scholar]
- Nie, Y.; Ma, K.K. Adaptive rood pattern search for fast block-matching motion estimation. IEEE Trans. Image Process. 2002, 11, 1442–1449. [Google Scholar] [CrossRef] [PubMed]
- A World Health Organization (WHO)—Visual Impairment and Blindness. Available online: http://www.who.int/mediacentre/factsheets/fs282/en/ (accessed on 25 October 2017).
- Rodríguez, A.; Yebes, J.J.; Alcantarilla, P.F.; Bergasa, L.M.; Almazán, J.; Cela, A. Assisting the Visually Impaired: Obstacle Detection and Warning System by Acoustic Feedback. Sensors 2012, 12, 17476–17496. [Google Scholar] [CrossRef] [PubMed]
- Tapu, R.; Mocanu, B.; Tapu, E. A survey on wearable devices used to assist the visual impaired user navigation in outdoor environments. In Proceedings of the 11th International Symposium on Electronics and Telecommunications (ISETC), Timisoara, Romania, 14–15 November 2014; pp. 1–4. [Google Scholar]
- Croce, D.; Giarré, L.; Rosa, F.G.L.; Montana, E.; Tinnirello, I. Enhancing tracking performance in a smartphone-based navigation system for visually impaired people. In Proceedings of the 24th Mediterranean Conference on Control and Automation (MED), Athens, Greece, 21–24 June 2016; pp. 1355–1360. [Google Scholar]
- Manduchi, R. Vision as assistive technology for the blind: An experimental study. In Proceedings of the 13th International Conference on Computers Helping People with Special Needs, Linz, Austria, 11–13 July 2012; pp. 9–16. [Google Scholar]
- Everding, L.; Walger, L.; Ghaderi, V.S.; Conradt, J. A mobility device for the blind with improved vertical resolution using dynamic vision sensors. In Proceedings of the IEEE 18th International Conference on E-Health Networking, Applications and Services (Healthcom), Munich, Germany, 14–16 September 2016; pp. 1–5. [Google Scholar]
- Cloix, S.; Weiss, V.; Bologna, G.; Pun, T.; Hasler, D. Obstacle and planar object detection using sparse 3D information for a smart walker. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; pp. 292–298. [Google Scholar]
- Buf, J.M.H.; Barroso, J.; Rodrigues, J.M.F.; Paredes, H.; Farrajota, M.; Fernandes, H.; Jose, J.; Teixeira, V.; Saleiro, T. The SmartVision navigation prototype for blind users. Int. J. Digital Content Technol. Appl. 2011, 5, 361–372. [Google Scholar]
- Mocanu, B.; Tapu, R.; Zaharia, T. When Ultrasonic Sensors and Computer Vision Join Forces for Efficient Obstacle Detection and Recognition. Sensors 2016, 16, 1807. [Google Scholar] [CrossRef] [PubMed]
- Lucas, B.; Kanade, T. An iterative technique of image registration and its application to stereo. In Proceedings of the 7th International Joint Conference on Artificial Intelligence (IJCAI’81), Vancouver, BC, Canada, 24–28 August 1981; Volume 2, pp. 674–679. [Google Scholar]
- Lee, J.J.; Kim, G. Robust estimation of camera homography using fuzzy RANSAC. In Proceedings of the International Conference on Computational Science and Its Applications, Kuala Lumpur, Malaysia, 26–29 August 2007; pp. 992–1002. [Google Scholar]
- Pradeep, V.; Medioni, G.; Weiland, J. Robot vision for the visually impaired. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition—Workshops, San Francisco, CA, USA, 13–18 June 2010; pp. 15–22. [Google Scholar]
- Neto, L.B.; Grijalva, F.; Maike, V.R.M.L.; Martini, L.C.; Florencio, D.; Baranauskas, M.C.C.; Rocha, A.; Goldenstein, S. A Kinect-Based Wearable Face Recognition System to Aid Visually Impaired Users. IEEE Trans. Hum. Mach. Syst. 2017, 47, 52–64. [Google Scholar] [CrossRef]
- Li, B.; Mũnoz, J.P.; Rong, X.; Xiao, J.; Tian, Y.; Arditi, A. ISANA: Wearable Context-Aware Indoor Assistive Navigation with Obstacle Avoidance for the Blind. In Proceedings of the Computer Vision—European Conference on Computer Vision 2016 Workshops, Amsterdam, Netherlands, 8–10 October and 15–16 October 2016; pp. 448–462. [Google Scholar]
- Elmannai, W.; Elleithy, K. Sensor-Based Assistive Devices for Visually-Impaired People: Current Status, Challenges, and Future Directions. Sensors 2017, 17, 565. [Google Scholar] [CrossRef] [PubMed]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
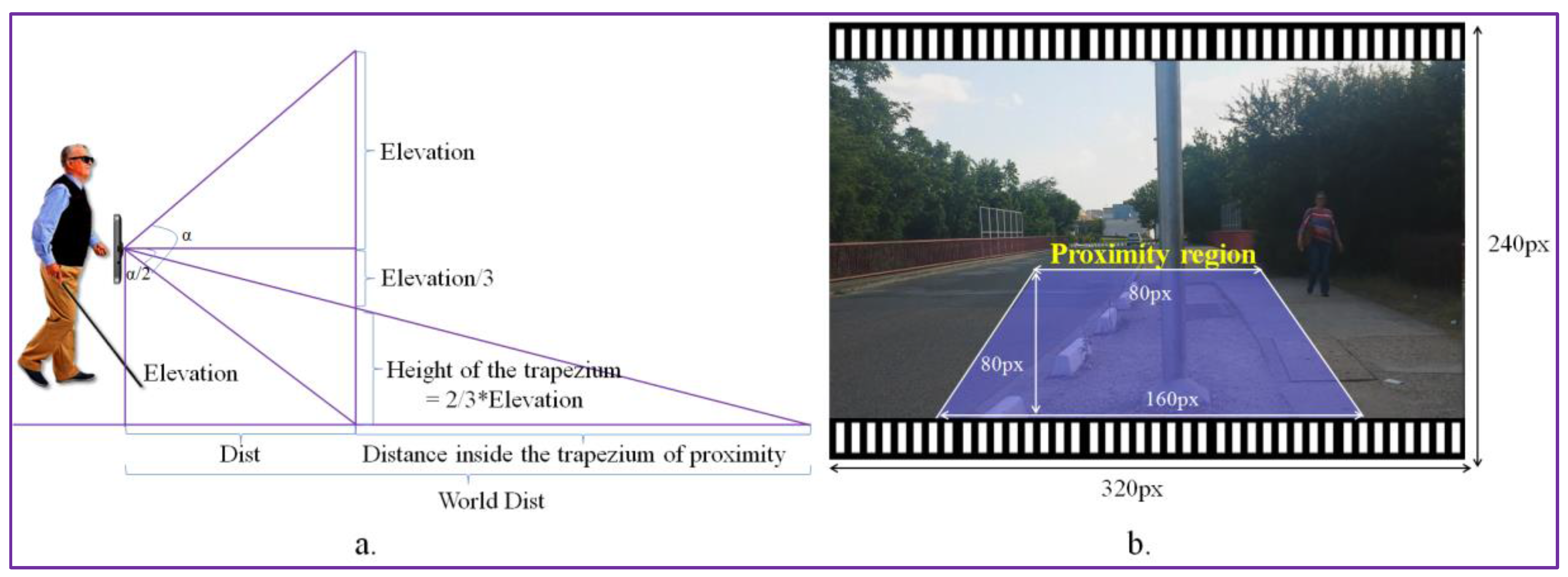{kind=link}
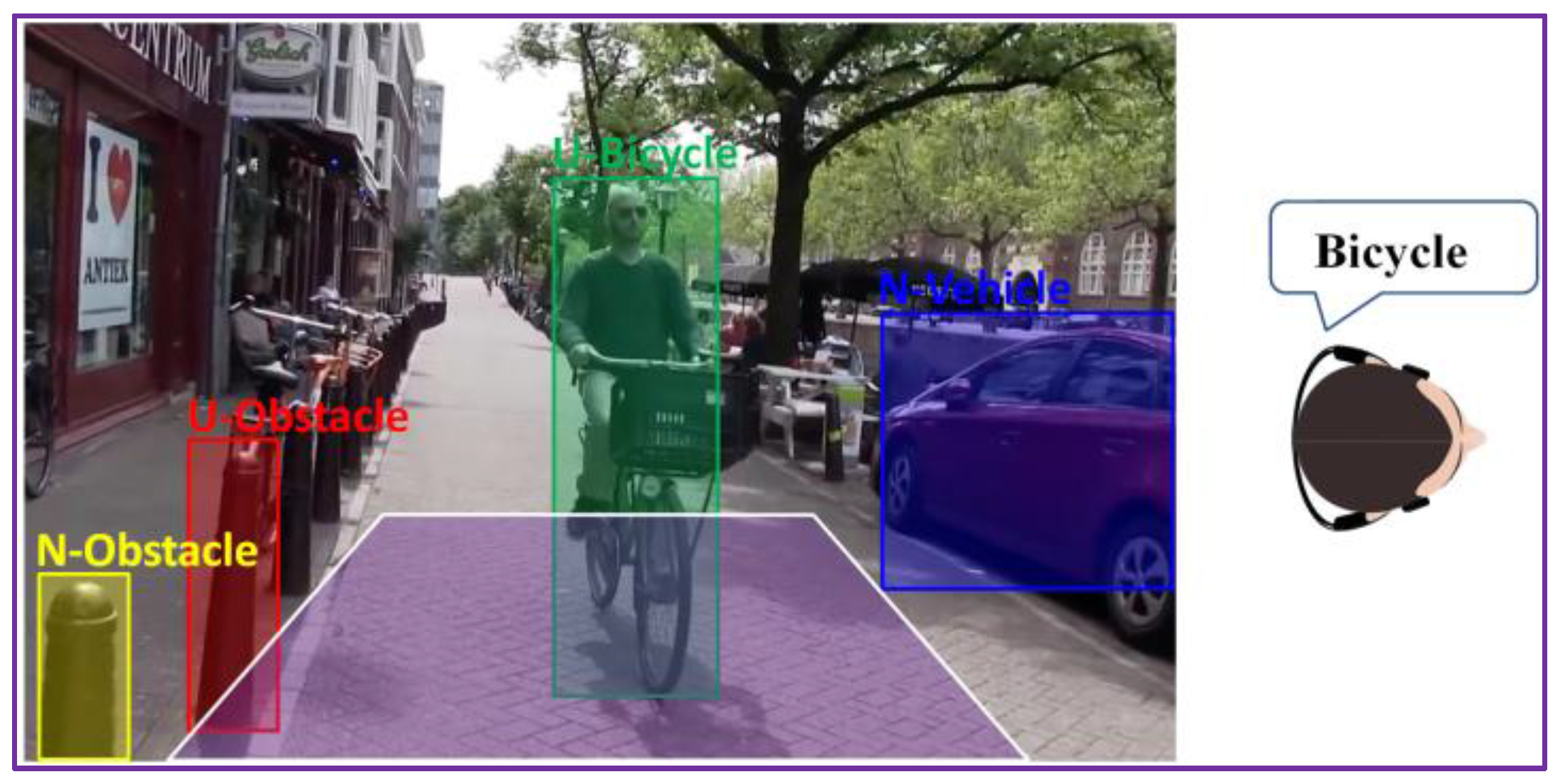{kind=link}
{kind=link}
{kind=link}
| Tracker | Year | Where | Accuracy | Failure Rate |
|---|---|---|---|---|
| Our | - | - | 0.54 | 1.17 |
| GOTURN | 2016 | ECCV | 0.42 | 2.46 |
| Staple | 2016 | CVPR | 0.54 | 1.15 |
| C-COT | 2016 | ECCV | 0.52 | 0.85 |
| TCNN | 2016 | CVPR | 0.53 | 0.96 |
| DAT | 2014 | CVPR | 0.46 | 1.72 |
| ASMS | 2015 | PRL | 0.48 | 1.87 |
| MAD | 2016 | SPIE | 0.48 | 1.81 |
| TricTRACK | 2015 | ICCV | 0.43 | 2.08 |
| STC | 2016 | ECCV | 0.36 | 3.61 |
| KCF2014 | 2015 | PAMI | 0.48 | 2.03 |
| STC4 | 2016 | CVPR | 0.45 | 1.95 |
| SWCF | 2016 | ICIP | 0.47 | 2.37 |
| CDTT | 2015 | CVPR | 0.41 | 2.08 |
| Order of Relevance | Recognized Object | Acoustic Warning |
|---|---|---|
| 1 | Vehicle | Urgent vehicle |
| 2 | Motorcycle | Urgent motorcycle |
| 3 | Bicycle | Urgent bicycle |
| 4 | Vehicle | Normal vehicle |
| 5 | Motorcycle | Normal motorcycle |
| 6 | Pedestrian | Urgent pedestrian |
| 7 | Obstruction | Urgent static obstacle |
| 8 | Bicycle | Normal bicycle |
| Obstacle Type | Ground Truth | Precision | Recall | F1-Score | |||
|---|---|---|---|---|---|---|---|
| DEEP-SEE | [16] | DEEP-SEE | [16] | DEEP-SEE | [16] | ||
| Vehicle | 431 | 0.94 | 0.94 | 0.92 | 0.92 | 0.93 | 0.92 |
| Bicycle | 120 | 0.91 | 0.87 | 0.90 | 0.69 | 0.90 | 0.77 |
| Pedestrian | 374 | 0.95 | 0.89 | 0.95 | 0.91 | 0.95 | 0.90 |
| Static obstruction | 478 | 0.90 | 0.90 | 0.87 | 0.79 | 0.88 | 0.84 |
| TOTAL | 1403 | 0.92 | 0.90 | 0.91 | 0.83 | 0.91 | 0.86 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tapu, R.; Mocanu, B.; Zaharia, T. DEEP-SEE: Joint Object Detection, Tracking and Recognition with Application to Visually Impaired Navigational Assistance. Sensors 2017, 17, 2473. https://doi.org/10.3390/s17112473
Tapu R, Mocanu B, Zaharia T. DEEP-SEE: Joint Object Detection, Tracking and Recognition with Application to Visually Impaired Navigational Assistance. Sensors. 2017; 17(11):2473. https://doi.org/10.3390/s17112473
Chicago/Turabian StyleTapu, Ruxandra, Bogdan Mocanu, and Titus Zaharia. 2017. "DEEP-SEE: Joint Object Detection, Tracking and Recognition with Application to Visually Impaired Navigational Assistance" Sensors 17, no. 11: 2473. https://doi.org/10.3390/s17112473
APA StyleTapu, R., Mocanu, B., & Zaharia, T. (2017). DEEP-SEE: Joint Object Detection, Tracking and Recognition with Application to Visually Impaired Navigational Assistance. Sensors, 17(11), 2473. https://doi.org/10.3390/s17112473