2. Related Works
Previous research on road lane detection used visible light and night-vision cameras, or combinations of the two, to enhance the accuracy. Previous studies on camera-based lane detection can be classified into model-based and feature-based methods. The first approach uses the structure of the road to create a mathematical model to detect and track road lane named model-based methods. A popular mathematical model is B-splines [
4,
8,
9,
10,
11]; this model can form any arbitrary shape using a set of control points. Xu et al. detected road lanes based on an open uniform B-spline curve model and maximum deviation of position shift (MDPS) method to search control points, but the method resulted in a large deviation, and, consequently, it could not fit the road model for the case when the road surface was not level [
8]. Li et al. adopted an extended Kalman filter with a B-spline curves model for continuous lane detection [
9]. Truong et al. [
4] combined the vector-lane-concept and non-uniform B-splines (NUBS) interpolation method to construct the left and right boundaries of road lanes. On the other hand, Jung et al. used the linear model to fit the near vision field, while the parabolic model was used to fit the far field to approximate lane boundaries in video sequences [
12]. Zhou et al. presented a lane detection algorithm based on a geometrical model and the Gabor filter [
13]. However, they assumed the road in front of the vehicle was approximately planar and marked, which is often correct on the highway and freeway; and the geometrical model built in this research required four parameters: starting position, lane orientation, lane width, and lane curvature. In previous research [
14], Yoo et al. proposed a lane detection method based on gradient-enhancing conversion to guarantee an illuminating-robust performance. In addition, an adaptive Canny edge detector, a Hough transformation (HT), and a quadratic curve model are used in their method. Li et al. adopted an inverse perspective mapping (IPM) model to locate a straight line in an image [
15]. The IPM model was also used in [
5,
15,
16,
17,
18]. Chiu et al. proposed a lane detection method based on color segmentation, thresholding, and fitting the model of a quadratic function [
19].
These methods start with the hypothesis of the road model, and then match the edge with the road structure model. They only use a few parameters to model the road structure. Therefore, the performance of lane marking detection is affected by the accurate definition of mathematical model, and the key problem is how to choose and fit the road model. That is why these methods work well only when they are fed with complete initial parameters of the camera or the structure of the road.
As the second category, feature-based methods or handcrafted feature-based methods have been researched to address this issue. These methods extract features such as edges, gradient, histogram and frequency domain features to locate lane markings [
6,
20,
21,
22,
23,
24,
25,
26,
27]. The main advantages are that this approach is not sensitive to the structure of road, model, or camera parameters. However, these feature-based methods require a noticeable color contrast between lane markings and road surface, as well as good illumination conditions. Therefore, some works perform a variety of color-space transformations to hue, saturation, and lightness (HSL), and luminance, chroma blue, and chroma red (YCbCr) to address this issue. In addition, others use the original red, green, and blue (RGB) image. In previous research, Wang et al. [
25] combined the self-clustering algorithm (SCA), fuzzy C-mean, and fuzzy rules to enhance lane boundary information and to make it suitable for various light conditions. At the beginning of their process, they converted the RGB image into that in YCbCr space so that the illumination component can be maintained, because they only required monochromatic information of each frame for processing. Sun et al. [
28] introduced the method that converts the RGB image into that in the HSI color model, and applied fuzzy C-mean for intensity difference segmentation. These methods worked well when road and lane markings produced separate clusters; however, the intensity values of the road surface and road lanes are often classified into the same cluster, and, consequently, the fundamental issue of the color lane and road lanes being converted into the same value is not resolved. Although it belongs to the model-based approach, a linear discriminant analysis (LDA)-based gradient-enhancing method was introduced in the research of Yoo et al. [
14] to dynamically generate a conversion vector that can be adapted for range illumination and different road conditions. Next, they achieved optimal RGB weights that maximize gradients at lane boundaries. However, their conversion method cannot work well in a case of extremely different multi-illumination conditions. This is because they assumed that multiple illuminations are not included in one scene. Wang et al. [
18] simply used the Canny edge detector and HT to obtain the line data, then created the filter conditions according to the vanishing point and other location features. First, their algorithm saved the detected lane and vanishing points in near history, then clustered and integrated to determine the detection output based on the historical data; and finally, a new vanishing point was updated for the next circuit. Convolutional neural network (CNN)-based lane detection with the image captured by camera (laterally-mounted camera) at the side mirror of the vehicle was proposed [
22]. In previous research [
6], the authors proposed a method for road lane detection that distinguishes between dashed and solid lanes. However, they used the predetermined region-of-interest (ROI) without the detection of the vanishing point, and used the line segment detector whose parameters were not adaptively changed according to the shadows on the road image. Therefore, their performances of road lane detection were affected by the shadows on the images.
As previously mentioned, these feature-based methods or handcrafted features-based methods work well only under visible and clear road conditions where the road lane markings can be easily separated from the ground by enhancing the contrast and brightness of the image. However, they have the limitations of detecting correct road lane in case of severe shadows from objects, trees or buildings. To address this issue, we propose a method to overcome poor illumination problems to get better results of detecting a road lane. In the following four ways, our research is novel compared to previous research.
- -
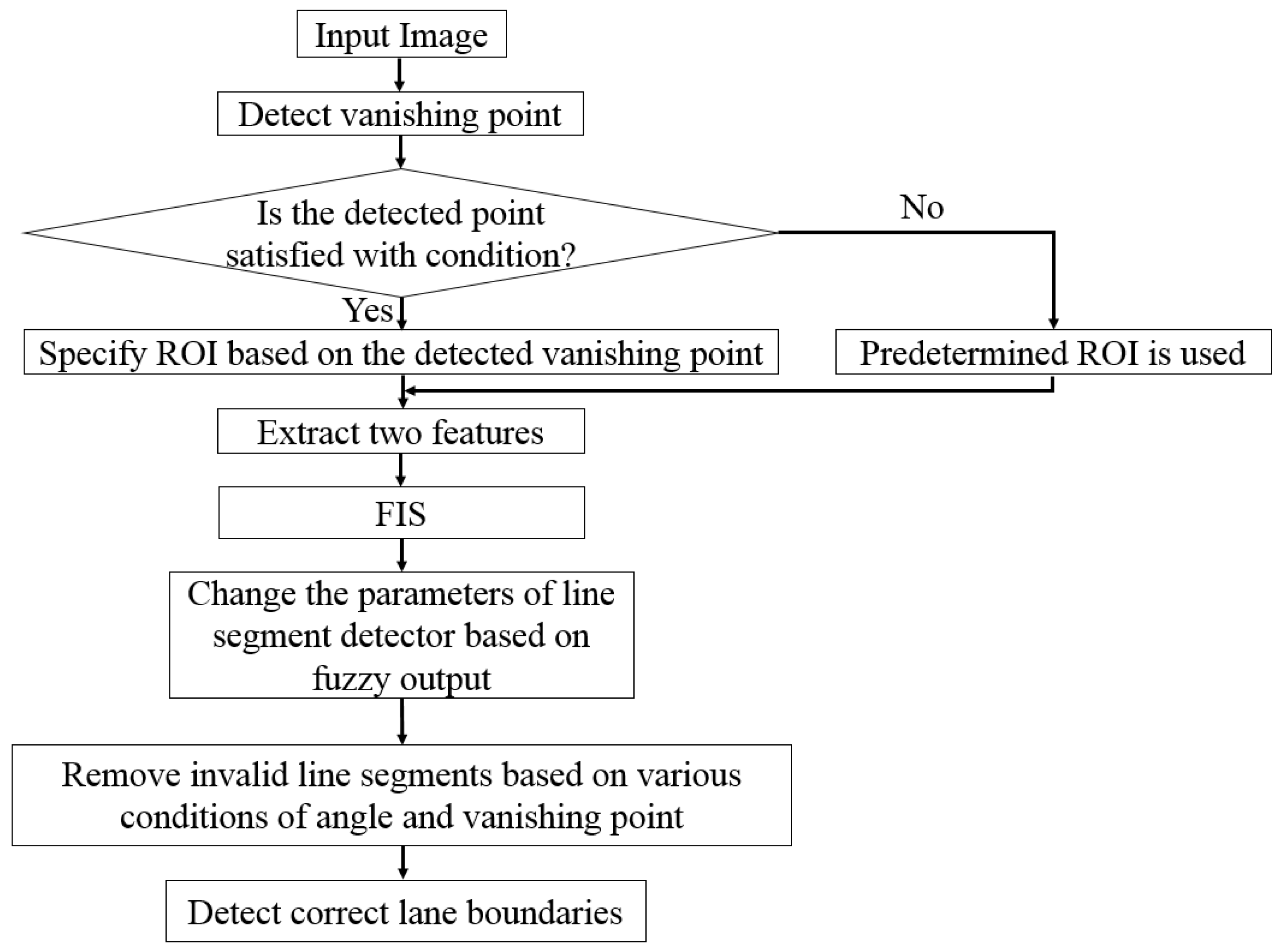
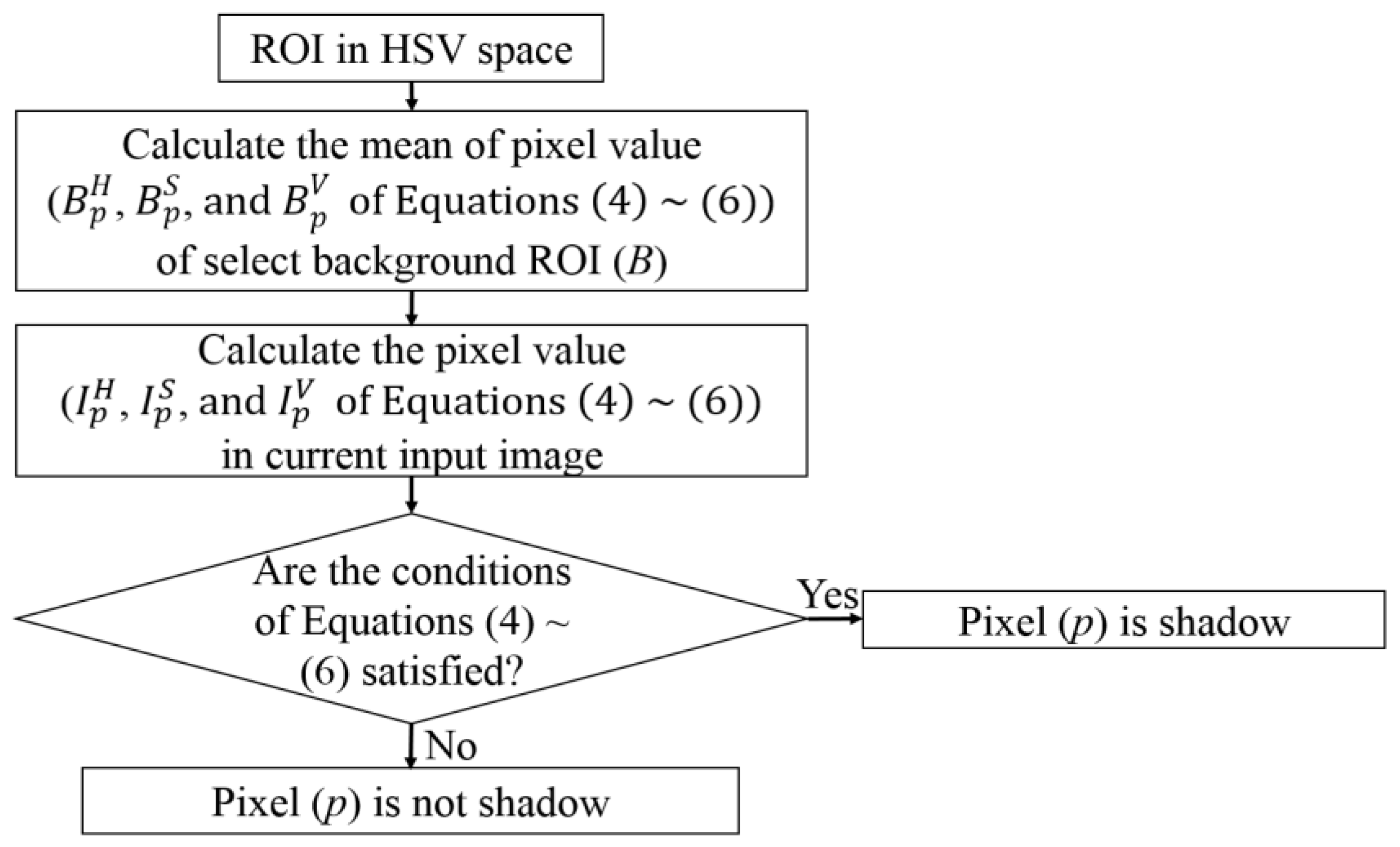
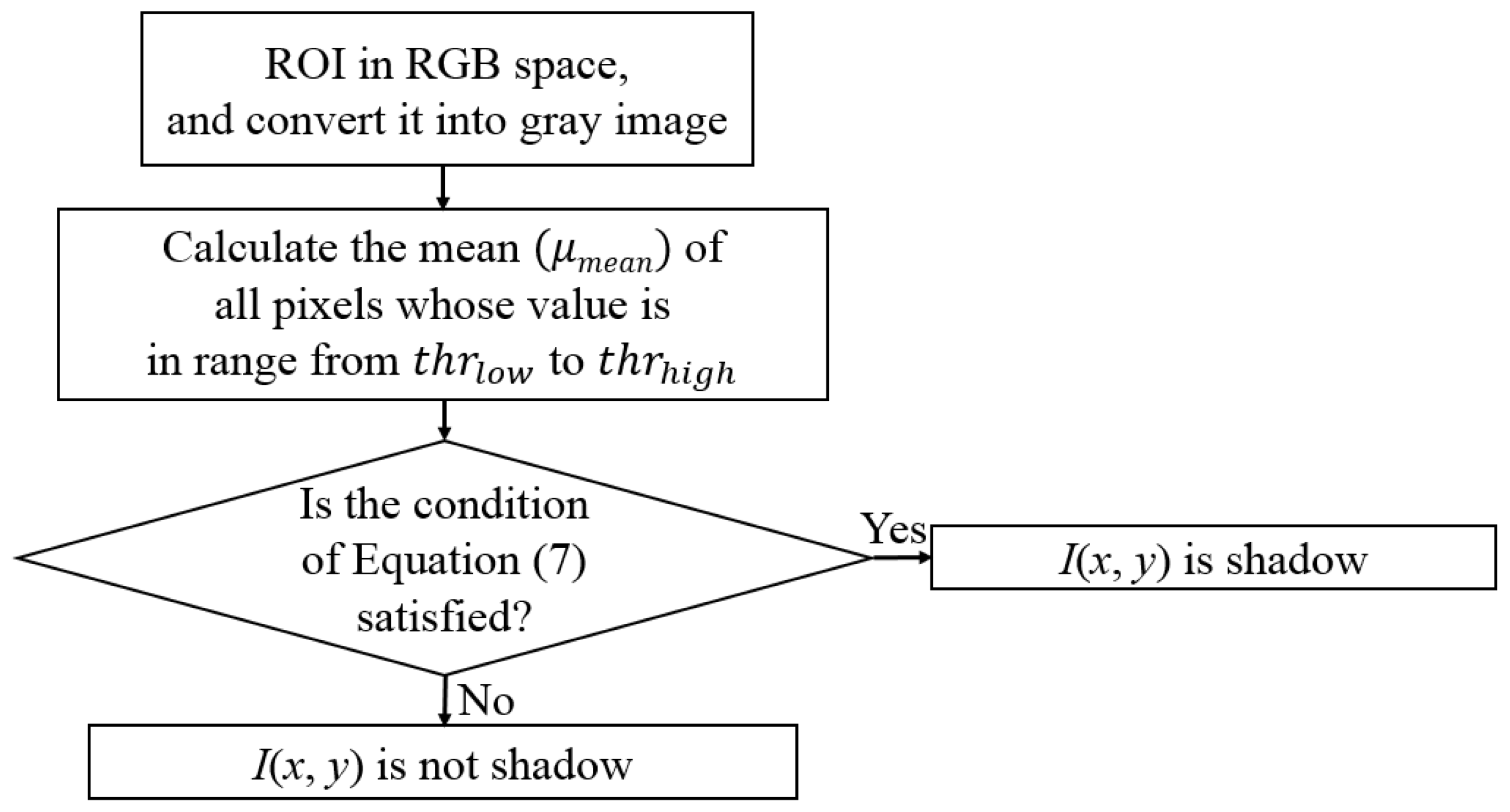
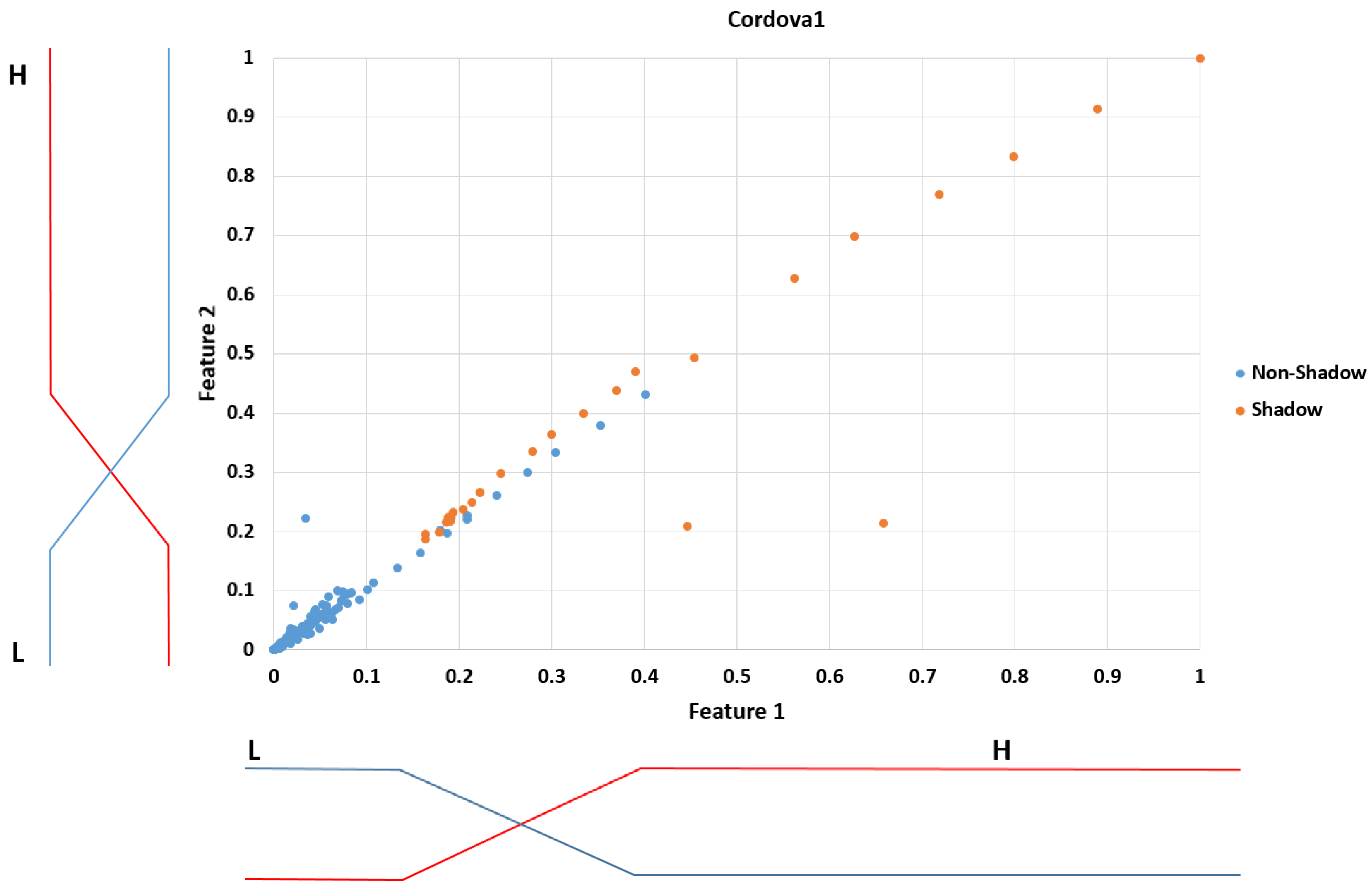
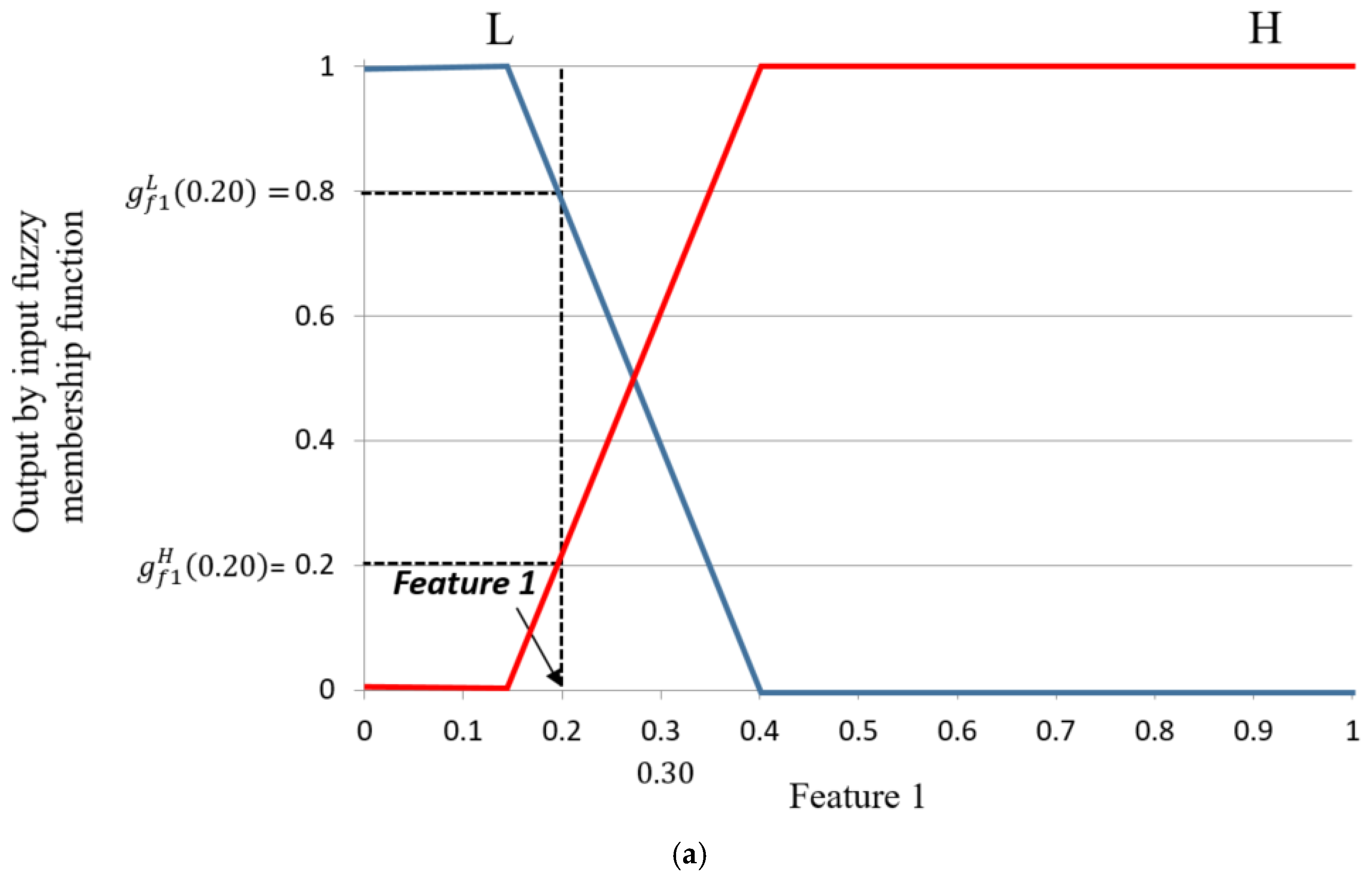
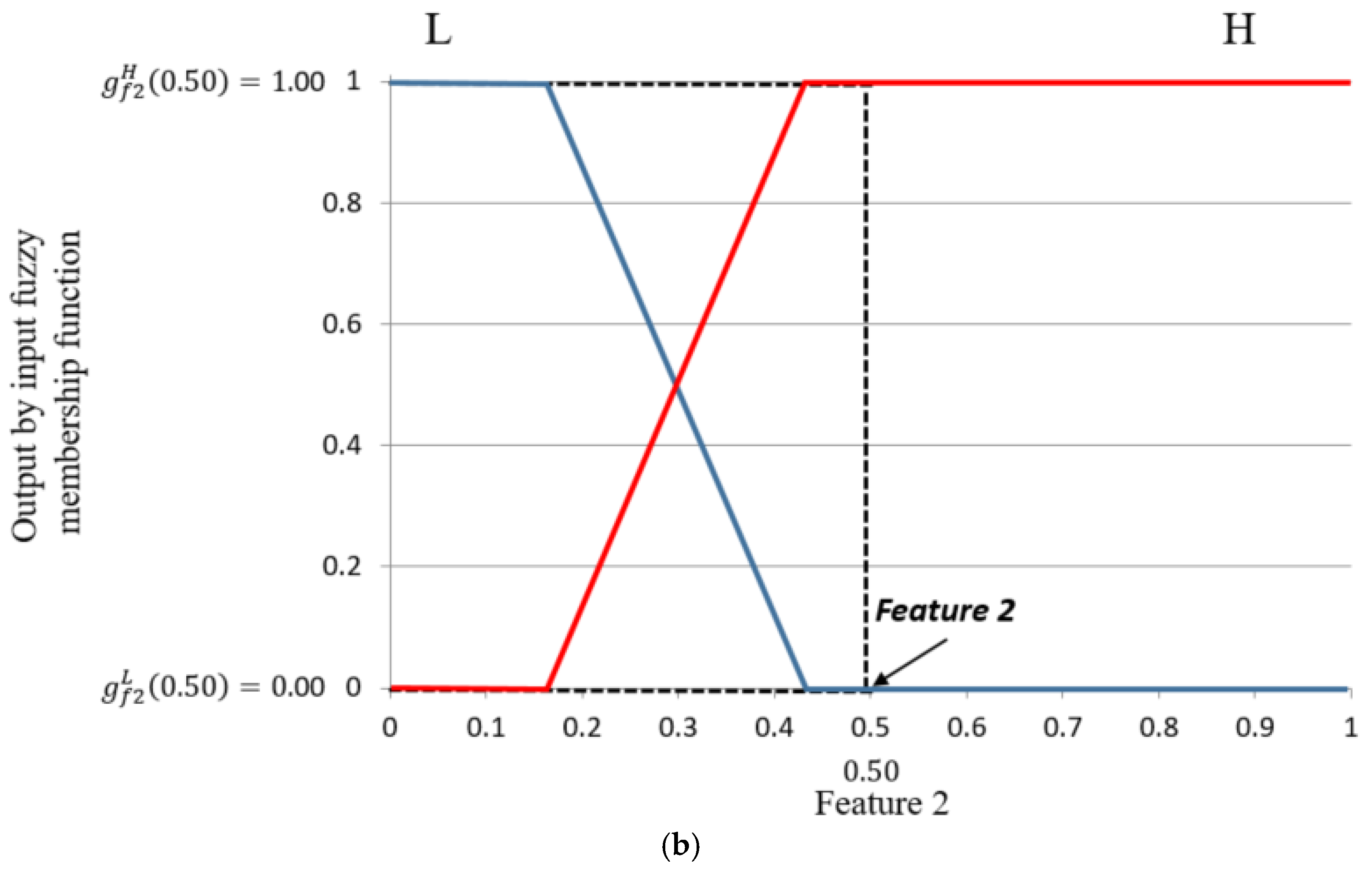
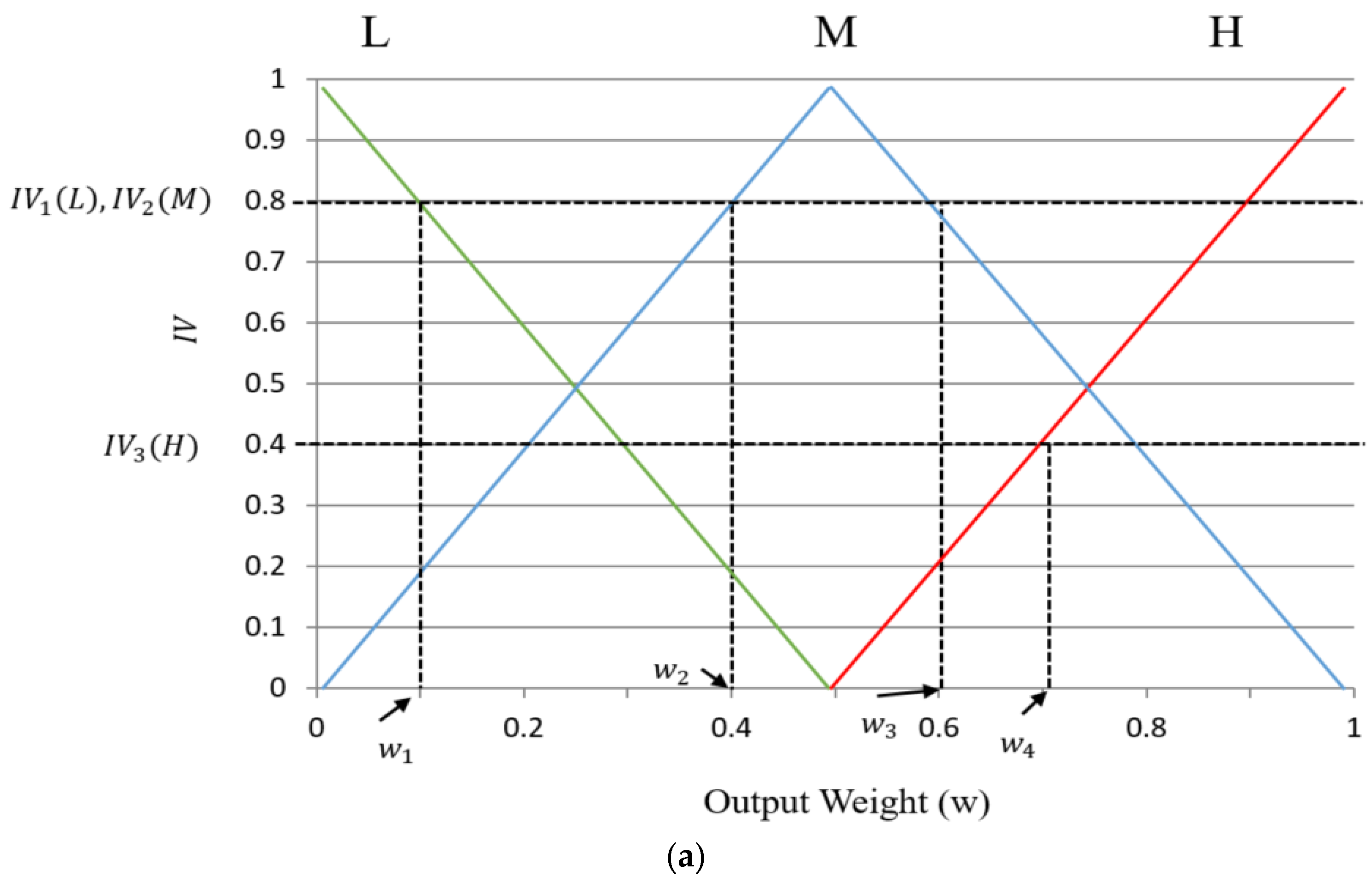
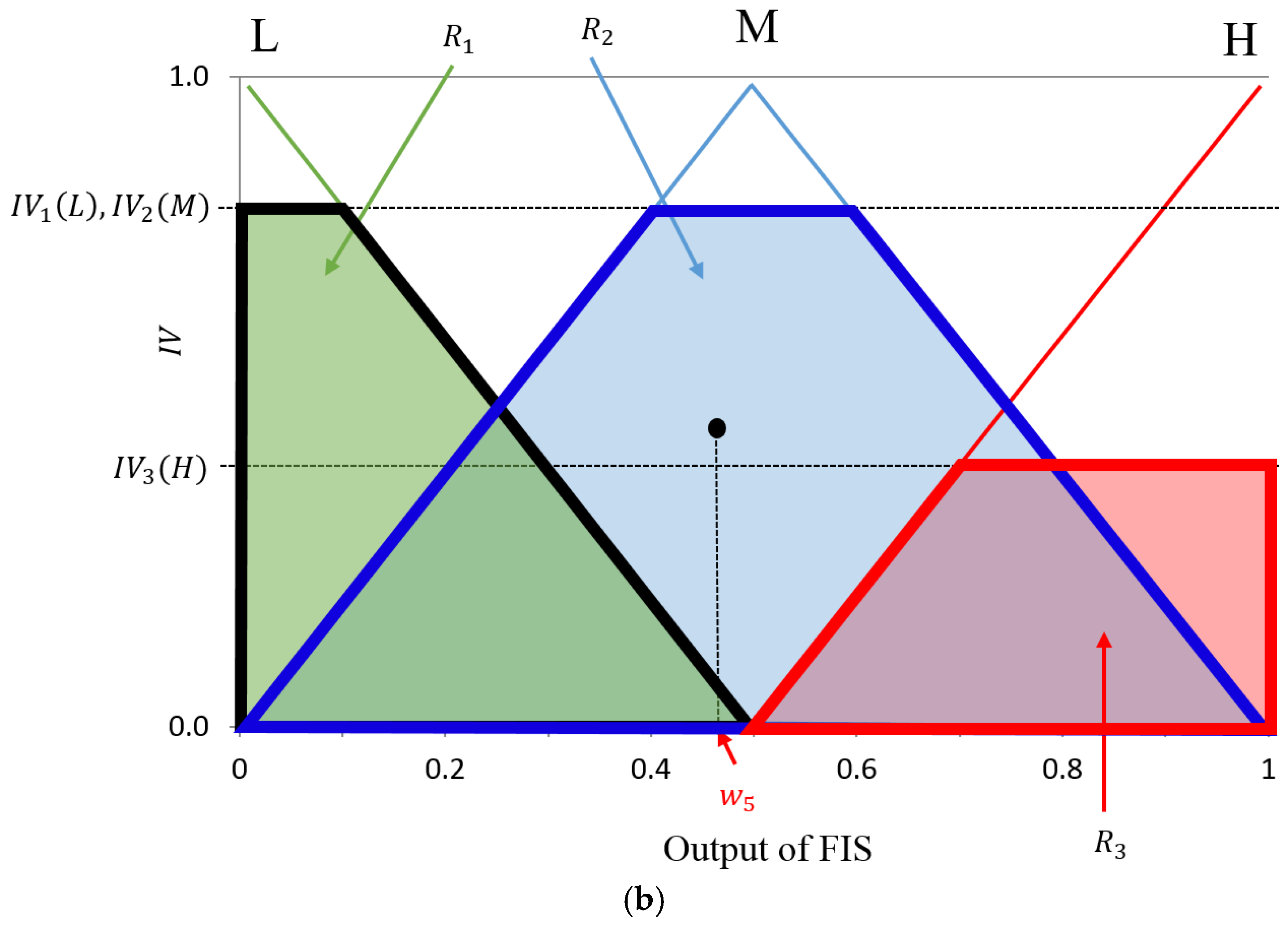
First, to evaluate the level of shadows in the ROI of the road image, we use two features as the inputs for FIS: hue, saturation, and value (HSV) color difference based on local background area (feature 1) and gray difference based on global background area (feature 2). Two features from different color and gray space are used for FIS to consider the characteristics of shadow in various color and gray spaces.
- -
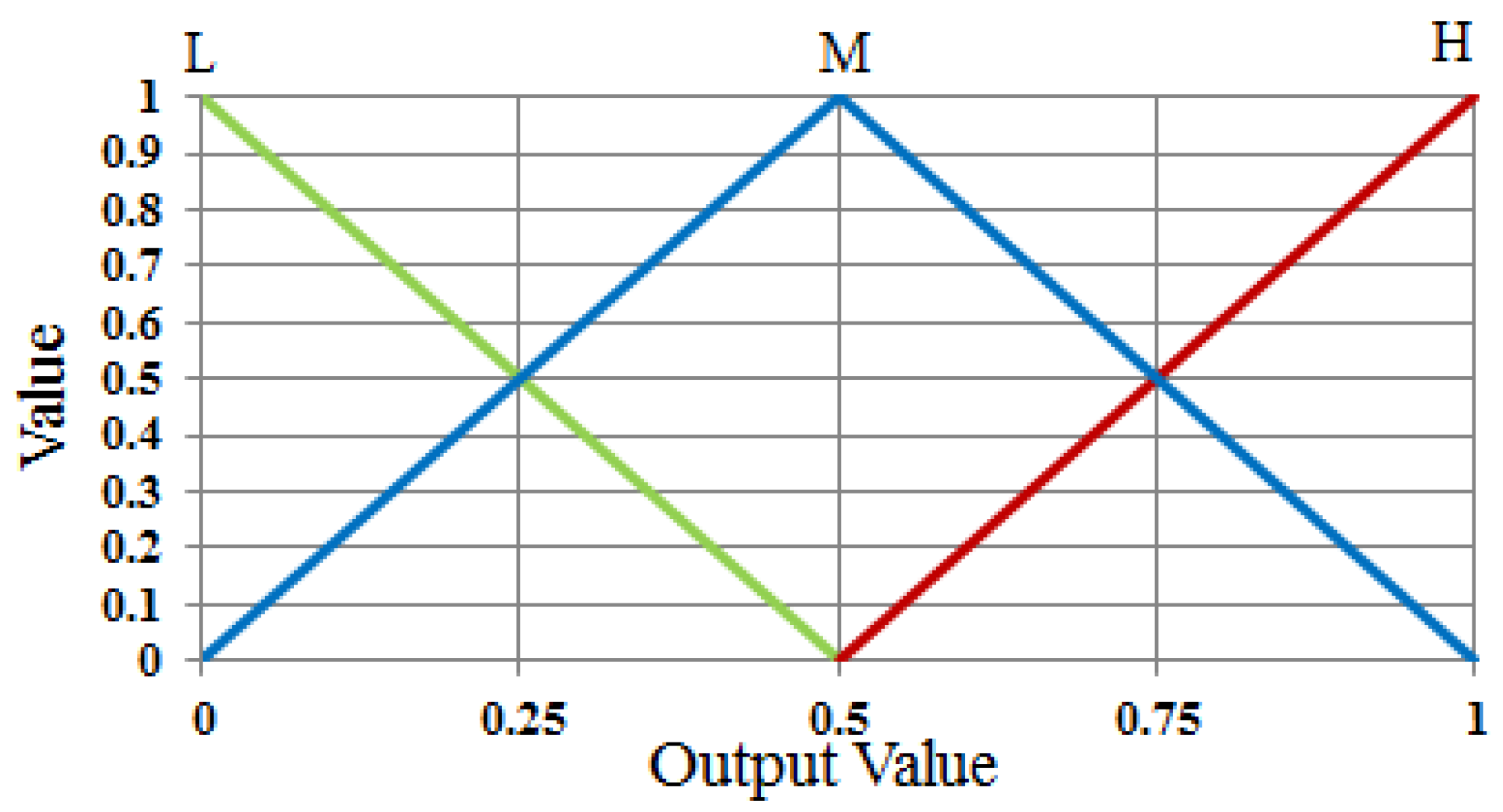
Second, using FIS based on these two features, we can estimate the level of shadows depending on the output of FIS after the defuzzification process. We modeled the input membership functions based on the training data of two features and maximum entropy criterion to enhance the accuracy of FIS. The procedure of intensive training which is required in training-based method such as neural network, support vector machine, and deep learning is not necessary for using FIS.
- -
Third, by adaptively changing the parameters of the line segment detector (LSD) and CannyLines detector algorithms based on the output of FIS, more accurate line detection can be possible based on the fusion of the detection results by LSD and CannyLines detector algorithms, irrespective of severe shadows on the road image.
- -
Previous researches did not discriminate the solid and dashed lanes in the detected road lanes although it is necessary for autonomous vehicle. However, even the solid and dashed lanes are discriminated (including the detection of starting and ending positions of dashed lanes) in the detected road lanes by our method.
In
Table 1, we show the summarized comparisons of the proposed and existing methods.
The remainder of this paper is organized as follows: in
Section 3, our proposed system and methodology are introduced. In
Section 4, the experimental setup is explained and the results are presented.
Section 5 presents both our conclusions and discussions on ideas for future work.
4. Experimental Results
We tested our proposed method with various datasets as shown in
Figure 17,
Figure 18 and
Figure 19. For the Caltech dataset, 1016 images were used, and the size of the image was 640 × 480 pixels [
5]. For the Santiago Lanes Dataset (SLD), 1201 images with the size of 640 × 480 pixels were used [
46]. In addition, the Road Marking dataset consists of various subsidiary dataset with more than 3000 frames captured under various illumination conditions, and the image size is 800 × 600 pixels [
47,
48]. These databases were collected at different times along the day. We performed the experiments on a desktop computer with Intel Core
TM i7 3.47 GHz, 12 GB memory of RAM, and the algorithm was implemented by Visual C++ 2015 and OpenCV library (version 3.1).
The ground-truth (starting and ending) positions of road lane markings were manually marked in the images to measure the accuracy of lane detection. Because our goal is to discriminate dashed and solid lanes in addition to lane detection, we manually detect the ground-truth point, and then compare it with detected starting and ending points with a certain interdistance threshold value to determine whether the detected line is correct or not.
In our method, we only consider whether the detected line segment is a lane mark or not, so negative data do not occur (i.e., ground-truth data of a non-lane), and true negative (TN) errors are 0% in our experiments. Other kinds of errors such as true positive (TP), false positive (FP), and false negative (FN) are defined and calculated to obtain precision, recall, and F-measure as shown in Equations (16)–(18) [
49,
50]. The number of TP, FP, and FN are represented as #TP, #FP and #FN, respectively:
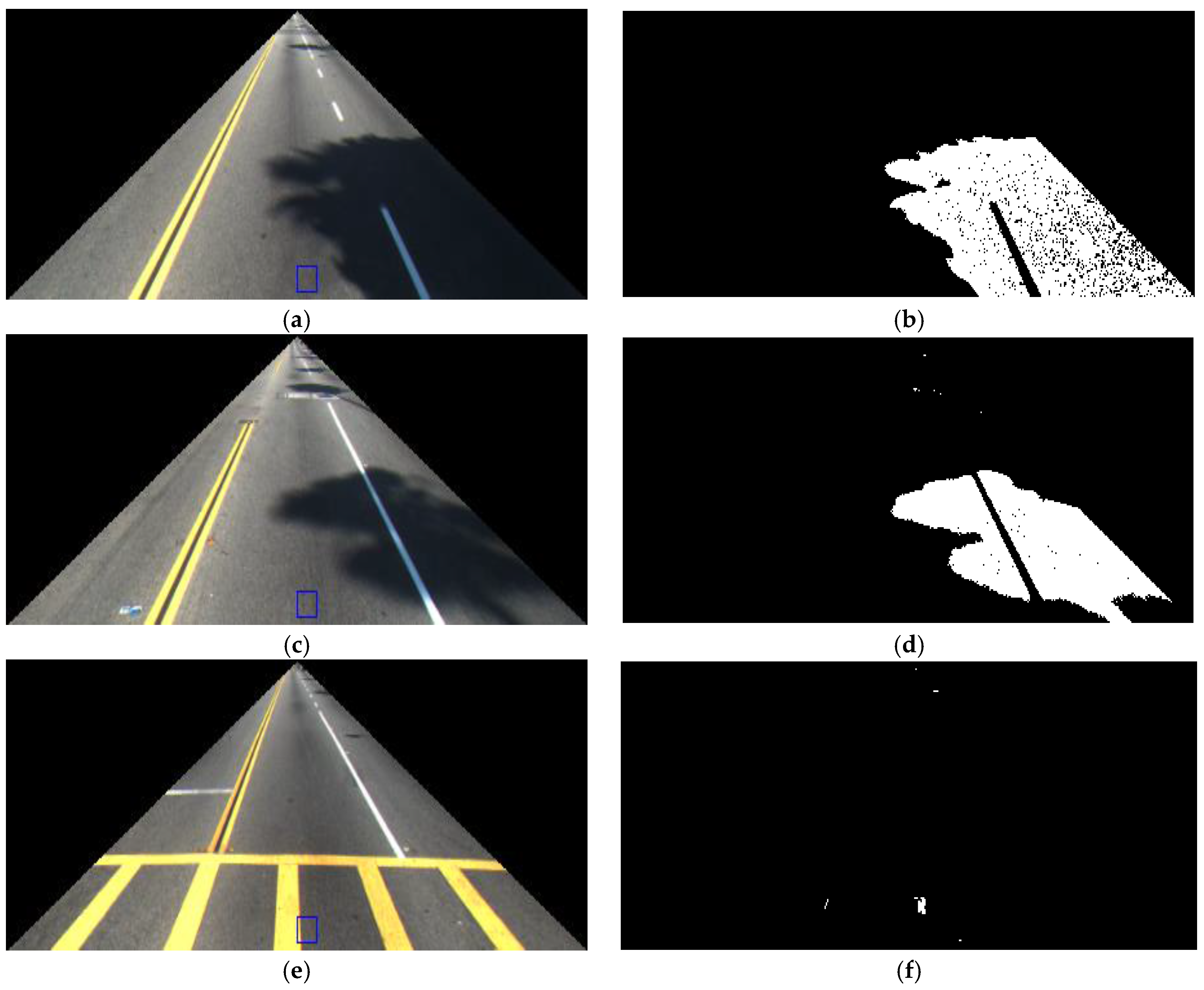
Figure 20 shows correct lane detection using our method with various datasets. In addition,
Figure 21 shows some examples of incorrect detection results. In
Figure 21a, our method incorrectly recognized non-road lane objects such as crosswalks, road-signs, text symbols, and pavement as lane markings. In those cases, there are no dynamic conditions to distinguish which one belongs to a road lane and which one belongs to non-road lane objects. In addition,
Figure 21b shows the effect of shadows on our method. Although our method uses the fuzzy rule to determine the amount of shadow in the image to automatically change the lane detector parameter, it still fails in some cases where extreme illumination occurs.
In the next experiment, we compare the performance of our method with some other methods: the Hoang et al. method [
6], Aly method [
5], Truong method [
4], Kylesf method [
7] and Nan method [
1]. In [
6], the line segment was detected by the LSD algorithm to detect the road lane. However, in [
6], the lane detection was performed within the smaller ROI compared to the ROI in our research, and the number of images including shadows is smaller than that in our research. Therefore, the accuracies of lane detection, even with the same database using the methods [
6] in
Table 7, are lower than those reported in [
6]. Owing to the same reasons, the accuracies by the methods [
4,
5] reported in [
6] are different from those in
Table 7. In other methods, they converted the input image by IPM with HT [
5,
7] to detect a straight line, and the random sample consensus (RANSAC) algorithm [
5] to fit lane makers. We empirically found the optimal thresholds for these methods [
1,
4,
5,
6,
7]. As shown in
Table 7 and
Figure 22, our method outperforms previous methods. The reason why the accuracies by [
1,
4,
5,
7] are too low is that they did not detect the left and right boundaries of road lane, and did not discriminate the dashed and solid lanes. That is, their method did not detect the starting point and ending point of road marking as well as the left and right boundaries of road lane. Although the method [
6] has these two functionalities, their method is more affected by the shadows in the image, and the accuracies by [
6] are lower than ours. Moreover, this method [
6] uses fixed ROI for detecting road lane and does not detect the vanishing point; thus, it generates more irrelevant line segments. That is why precision by this method is lower than that by our method. As shown in
Figure 22a, we included the examples with the presence of vehicles on the same road lane of the detection vehicle. These cases were already included in our experimental databases. As shown in
Figure 22a and
Table 7, the presence of cars on the same road lane does not affect our detection results.
As the next experiment, we measured the processing time per frame by our method as shown in
Table 8. As shown in
Table 8, we can confirm that our method can be operated at a fast speed (about 40.4 frames/s (1000/24.77)).
In other previous researches [
51,
52,
53,
54], they showed the high performance of road lane detection irrespective of various weather conditions, traffic, and curved lanes, etc. However, they did not discriminate the solid and dashed lanes in the detected road lanes although it is necessary for autonomous vehicle. Different from them, even the solid and dashed lanes are discriminated in the detected road lanes by our method. In addition, more severe shadows are considered in our research compared to the examples of three results in [
51,
52,
53,
54]. In other methods [
55,
56], they can detect the road lane in difficult environments, but the method [
55] did not discriminate the solid and dashed lanes in the detected road lanes either. The method [
56] discriminated the solid and dashed lanes in the detected road lanes. However, they did not detect the exact starting and ending positions of all the dashed lanes although the accurate detection of these positions are necessary for the prompt or predictive decision of the moment of crossing road lane by fast moving autonomous vehicle. Different from them, in addition to the discrimination of the solid and dashed lanes, the accurate starting and ending positions of dashed lane are also detected by our method.
5. Conclusions
In this study, we proposed a method to overcome severe shadows in the image, for obtaining better road lane detection results. We used two features as the inputs for FIS: HSV color difference based on local background area (feature 1) and gray difference based on global background area (feature 2) for evaluating the level of shadow in the ROI of a road image. Two features from different color and gray spaces were used for FIS for considering the characteristics of shadow in various color and gray spaces. Using FIS based on these two features, we estimated the level of shadows based on the output of FIS after the defuzzification process. We modeled the input membership functions based on the training data of two features and maximum entropy criterion for enhancing the accuracy of FIS. By adaptively changing the parameters of LSD and CannyLines detector algorithms based on the output of FIS, more accurate line detection was possible based on the fusion of the detection results by LSD and CannyLines detector algorithms, irrespective of severe shadows on the road image. Experiments with three open databases showed that our method outperformed previous methods, irrespective of severe shadows in the images. Because tracking information in successive image frames was not used in our method, the detection of lanes by our method was not affected by the speed of the car.
However, complex traffic with the presence of cars can affect our performance when detecting vanishing points and line segments, determining shadow levels, and locating final road lanes, which is the limitation of our system. Nevertheless, our three experimental databases do not include these cases, and we could not measure the effect of the presence of cars on the performance of our system.
In future, we would collect our own database including the complex traffic with the presence of cars, and measure the effect of these cases on our performance. In addition, we plan to solve this limitation by deep learning-based lane detection. Also, we plan to use a deep neural network for discriminating dashed and solid lane markings under various illumination conditions, as well as for detecting both straight and curved lanes. In addition, we would research to combine our method with a model-based method to enhance the performance of lane detection.































{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}